
17 Feb
2023
17 Feb
'23
1:14 p.m.
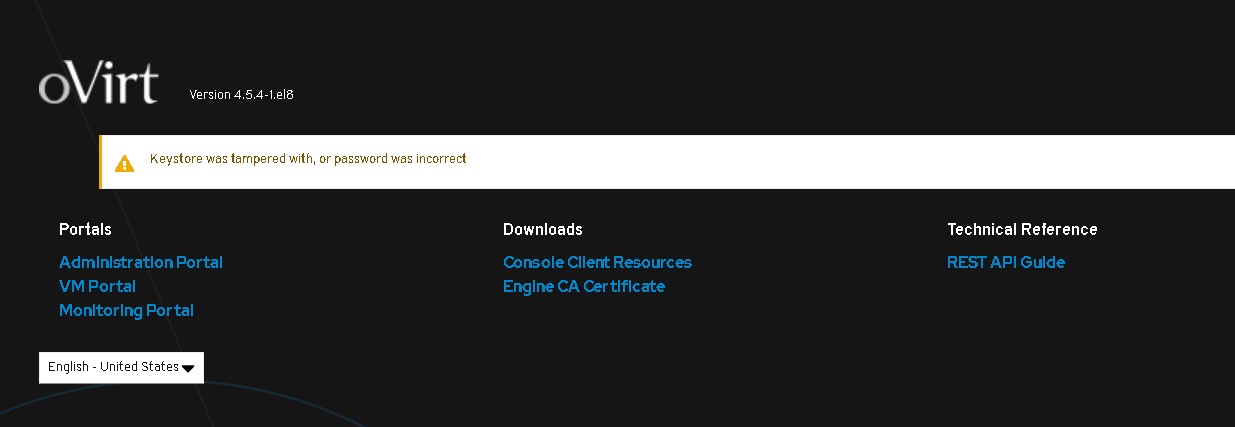
Hello all, I'm struggling with an issue with my oVirt environment and I seem not to be able to figure this one out on my own and am hoping you can point me in on the right track. My old oVirt 4.3 environment's certifcat went expired. I thought I could fix it by reading some tutorials but no luck so far. Now I have upgraded my engine already to 4.5 and now I get the message telling me this "Keystore was tampered with, or password is incorrect" Even before I can log on. I'm looking through the ovirtengine.log but so far I haven't find why exactly. Any help would be greatly appreciated. Kind regards.
{kind=link}