
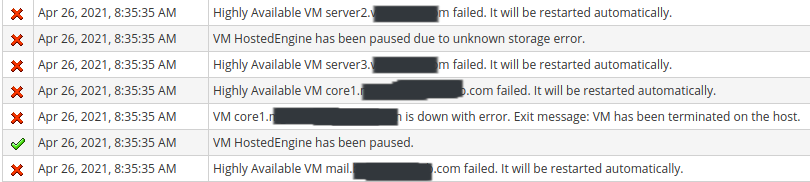
As the subject suggestions, something in oVirt HCI broke. I have no idea what, and it recovered on its own after about 20 minutes or so. I believe that the issue was limited to a single host (although I don't know that for sure), as we had two VMs go completely unresponsive, but a 3rd VM remained operational. For a while during the outage, I was able to log into the oVirt admin web portal, and I noticed at least 1-2 of my hosts (I have 3 hosts) showed the problematic VMs as being problematic inside of oVirt. Reviewing the oVirt Events, I see that this basically started right when the ETL Service Started. There were no events before that point since yesterday, but right when the ETL Service started, it seems like all hell broke loose. oVirt detected "No faulty multipaths" on any of the hosts, but then very quickly started indicating that hosts, vms, and storage targets were unavailable. See my screenshot below. Around 30 - 35 minutes later, it appears that the Hosted Engine terminated due to a storage issue, and auto recovered on a different host. There's a 2nd screenshot beneath the first. Everything came back up shortly before 9am, and has been stable since. In fact, the Volume replication issues that I saw in my environment after I performed maintenance on 1 of my hosts on Friday are no longer present. It appears that the Hosted Engine sees the storage as being perfectly healthy. How do I even begin to figure out what happened, and try to prevent it from happening again? [Screenshot from 2021-04-26 16-36-47.png] [Screenshot from 2021-04-26 16-44-08.png] Sent with ProtonMail Secure Email.
{kind=link}
{kind=link}