
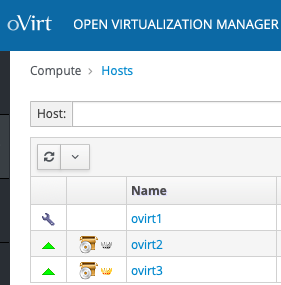
So, it's hard to follow the chain but so far I saw 'gluster volume heal info' showing '-' for 2 out of 3 hosts. Can you provide the following from all nodes: gluster pool listgluster peer statusgluster volume listfor i in $(gluster volume list); do gluster volume heal $i info summary; done Also, it's safe to restart the 'glusterd.service' via 'systemctl restart glusterd.service'. Note: restart glusterd one node at a time Best Regards,Strahil Nikolov On Wed, Nov 24, 2021 at 23:47, Staniforth, Paul<P.Staniforth@leedsbeckett.ac.uk> wrote: #yiv9281492485 P {margin-top:0;margin-bottom:0;} That's where the ! mark would show any detected issues.It's always safer to restart when in maintenance mode. the unsynched entries won't heal without the endpoints connected. Have you managed to get the vmstore mounted on ovirt1? Regard, Paul S. From: Gervais de Montbrun <gervais@demontbrun.com> Sent: 24 November 2021 21:06 To: Staniforth, Paul <P.Staniforth@leedsbeckett.ac.uk> Cc: users@ovirt.org <users@ovirt.org> Subject: Re: [ovirt-users] How to debug "Non Operational" host Caution External Mail: Do not click any links or open any attachments unless you trust the sender and know that the content is safe. Hi Paul (and anyone else who wants to chime in), By "host's section of webadmin," do you mean here? If so, then there is no indication that gluster is not working properly (even if I take it out of maintenance mode and it is showing non-operational). re: "gluster volume heal vmstore info summary"This is what I see:ovirt1: [root@ovirt1.dgi ~]# gluster volume heal vmstore info summary Brick ovirt1-storage.dgi:/gluster_bricks/vmstore/vmstore Status: Connected Total Number of entries: 27 Number of entries in heal pending: 27 Number of entries in split-brain: 0 Number of entries possibly healing: 0 Brick ovirt2-storage.dgi:/gluster_bricks/vmstore/vmstore Status: Transport endpoint is not connected Total Number of entries: - Number of entries in heal pending: - Number of entries in split-brain: - Number of entries possibly healing: - Brick ovirt3-storage.dgi:/gluster_bricks/vmstore/vmstore Status: Transport endpoint is not connected Total Number of entries: - Number of entries in heal pending: - Number of entries in split-brain: - Number of entries possibly healing: - ovirt2: [root@ovirt2.dgi ~]# gluster volume heal vmstore info summary Brick ovirt1-storage.dgi:/gluster_bricks/vmstore/vmstore Status: Connected Total Number of entries: 46 Number of entries in heal pending: 46 Number of entries in split-brain: 0 Number of entries possibly healing: 0 Brick ovirt2-storage.dgi:/gluster_bricks/vmstore/vmstore Status: Transport endpoint is not connected Total Number of entries: - Number of entries in heal pending: - Number of entries in split-brain: - Number of entries possibly healing: - Brick ovirt3-storage.dgi:/gluster_bricks/vmstore/vmstore Status: Transport endpoint is not connected Total Number of entries: - Number of entries in heal pending: - Number of entries in split-brain: - Number of entries possibly healing: - ovirt3: [root@ovirt3.dgi ~]# gluster volume heal vmstore info summary Brick ovirt1-storage.dgi:/gluster_bricks/vmstore/vmstore Status: Connected Total Number of entries: 46 Number of entries in heal pending: 46 Number of entries in split-brain: 0 Number of entries possibly healing: 0 Brick ovirt2-storage.dgi:/gluster_bricks/vmstore/vmstore Status: Transport endpoint is not connected Total Number of entries: - Number of entries in heal pending: - Number of entries in split-brain: - Number of entries possibly healing: - Brick ovirt3-storage.dgi:/gluster_bricks/vmstore/vmstore Status: Transport endpoint is not connected Total Number of entries: - Number of entries in heal pending: - Number of entries in split-brain: - Number of entries possibly healing: Forgive me for pasting all this in. My experience with gluster has been installing it as part of my hypervised ovirt install. It's generally just worked ok without any intervention. I see similar things for the engine brick also. Example:ovirt2: [root@ovirt2.dgi ~]# gluster volume heal engine info summary Brick ovirt1-storage.dgi:/gluster_bricks/engine/engine Status: Connected Total Number of entries: 1 Number of entries in heal pending: 1 Number of entries in split-brain: 0 Number of entries possibly healing: 0 Brick ovirt2-storage.dgi:/gluster_bricks/engine/engine Status: Transport endpoint is not connected Total Number of entries: - Number of entries in heal pending: - Number of entries in split-brain: - Number of entries possibly healing: - Brick ovirt3-storage.dgi:/gluster_bricks/engine/engine Status: Connected Total Number of entries: 1 Number of entries in heal pending: 1 Number of entries in split-brain: 0 Number of entries possibly healing: 0 Is it safe to restart glusterd on all the servers? So far, I only did a restart on ovirt1 as it was in maintenance mode anyway. Cheers, Gervais On Nov 24, 2021, at 4:44 PM, Staniforth, Paul <P.Staniforth@leedsbeckett.ac.uk> wrote: Hi Gervais, The other mounts are the storage domains, as ovirt1 only has 1 storage domain mounted this is probably why the host is showing as non-operational. In the host's section of webadmin does it indicate any gluster issues? sometimes it detects these and gives you the option to restart gluster in the general tab of the host. Also, on any of the hosts to check all the gluster nodes are connected you can run "gluster volume heal vmstore info summary" then you can manually restart the glusterd service. e.g. "systemctl restart glusterd.service" Regards, Paul S. From: Gervais de Montbrun <gervais@demontbrun.com> Sent: 24 November 2021 18:15 To: Staniforth, Paul <P.Staniforth@leedsbeckett.ac.uk> Cc: users@ovirt.org <users@ovirt.org> Subject: Re: [ovirt-users] How to debug "Non Operational" host Caution External Mail: Do not click any links or open any attachments unless you trust the sender and know that the content is safe.Hi Paul. I've updated the /etc/hosts file on the engine and restarted the hosted-engine. It seems that the "Could not associate brick" errors have stopped. Thank you!No change in my issue though ☹️. It looks like Glusterd is starting up OK. I did force start the bricks on ovirt1. [root@ovirt1.dgi ~]# systemctl status glusterd● glusterd.service - GlusterFS, a clustered file-system server Loaded: loaded (/usr/lib/systemd/system/glusterd.service; enabled; vendor preset: disabled) Drop-In: /etc/systemd/system/glusterd.service.d └─99-cpu.conf Active: active (running) since Wed 2021-11-24 16:19:25 UTC; 1h 42min ago Docs: man:glusterd(8) Process: 2321 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS) Main PID: 2354 (glusterd) Tasks: 92 (limit: 1648201) Memory: 63.7G CPU: 1h 17min 42.666s CGroup: /glusterfs.slice/glusterd.service ├─2354 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO ├─3247 /usr/sbin/glusterfsd -s ovirt1-storage.dgi --volfile-id vmstore.ovirt1-storage.dgi.gluster_bricks-vmstore-vmstore -p /var/run/gluster/vols/vmstore/ovirt1-storage.dgi-gluster_bricks-vmstore-vmstore.pid -S /var/run/gluster/fb93ffff591764c8.socket --brick-name /gluster_bricks/vmstore/vmstore -l /var/log/glusterfs/bricks/gluster_b> ├─3275 /usr/sbin/glusterfsd -s ovirt1-storage.dgi --volfile-id engine.ovirt1-storage.dgi.gluster_bricks-engine-engine -p /var/run/gluster/vols/engine/ovirt1-storage.dgi-gluster_bricks-engine-engine.pid -S /var/run/gluster/66ebd47080b528d1.socket --brick-name /gluster_bricks/engine/engine -l /var/log/glusterfs/bricks/gluster_bricks-en> └─3287 /usr/sbin/glusterfs -s localhost --volfile-id shd/engine -p /var/run/gluster/shd/engine/engine-shd.pid -l /var/log/glusterfs/glustershd.log -S /var/run/gluster/c9b8692f3e532562.socket --xlator-option *replicate*.node-uuid=fdf2cf13-c2c5-4afa-8d73-76c50c69122a --process-name glustershd --client-pid=-6 Nov 24 16:19:22 ovirt1.dgi systemd[1]: Starting GlusterFS, a clustered file-system server...Nov 24 16:19:25 ovirt1.dgi systemd[1]: Started GlusterFS, a clustered file-system server.Nov 24 16:19:28 ovirt1.dgi glusterd[2354]: [2021-11-24 16:19:28.909836] C [MSGID: 106002] [glusterd-server-quorum.c:355:glusterd_do_volume_quorum_action] 0-management: Server quorum lost for volume engine. Stopping local bricks.Nov 24 16:19:28 ovirt1.dgi glusterd[2354]: [2021-11-24 16:19:28.910745] C [MSGID: 106002] [glusterd-server-quorum.c:355:glusterd_do_volume_quorum_action] 0-management: Server quorum lost for volume vmstore. Stopping local bricks.Nov 24 16:19:31 ovirt1.dgi glusterd[2354]: [2021-11-24 16:19:31.925206] C [MSGID: 106003] [glusterd-server-quorum.c:348:glusterd_do_volume_quorum_action] 0-management: Server quorum regained for volume engine. Starting local bricks.Nov 24 16:19:31 ovirt1.dgi glusterd[2354]: [2021-11-24 16:19:31.938507] C [MSGID: 106003] [glusterd-server-quorum.c:348:glusterd_do_volume_quorum_action] 0-management: Server quorum regained for volume vmstore. Starting local bricks. The bricks are showing all green at least in the UI, but they never seem to catch up and not show any unsynced entries:<PastedGraphic-5.png> As for mounting the bricks, they are mounting based on what is in /etc/fstab.[root@ovirt1.dgi ~]# cat /etc/fstab ## /etc/fstab# Created by anaconda on Wed Feb 17 20:17:28 2021## Accessible filesystems, by reference, are maintained under '/dev/disk/'.# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info.## After editing this file, run 'systemctl daemon-reload' to update systemd# units generated from this file.#/dev/onn/ovirt-node-ng-4.4.9-0.20211026.0+1 / xfs defaults,discard 0 0UUID=07e9dfea-9710-483d-bc63-aea7dbb5801d /boot xfs defaults 0 0/dev/mapper/onn-home /home xfs defaults,discard 0 0/dev/mapper/onn-tmp /tmp xfs defaults,discard 0 0/dev/mapper/onn-var /var xfs defaults,discard 0 0/dev/mapper/onn-var_log /var/log xfs defaults,discard 0 0/dev/mapper/onn-var_log_audit /var/log/audit xfs defaults,discard 0 0/dev/mapper/onn-swap none swap defaults 0 0UUID=4e2c88e4-2bae-4b41-bb62-631820435845 /gluster_bricks/engine xfs inode64,noatime,nodiratime 0 0UUID=ad938b6e-44d2-492a-a313-c4d0c0608e09 /gluster_bricks/vmstore xfs inode64,noatime,nodiratime 0 0 [root@ovirt1.dgi ~]# mount |grep gluster_bricks/dev/mapper/gluster_vg_sdb-gluster_lv_engine on /gluster_bricks/engine type xfs (rw,noatime,nodiratime,seclabel,attr2,inode64,logbufs=8,logbsize=256k,sunit=512,swidth=3072,noquota)/dev/mapper/gluster_vg_sdb-gluster_lv_vmstore on /gluster_bricks/vmstore type xfs (rw,noatime,nodiratime,seclabel,attr2,inode64,logbufs=8,logbsize=256k,sunit=512,swidth=3072,noquota) What does this "extra" mount?[root@ovirt1.dgi ~]# mount | grep storageovirt1-storage.dgi:/engine on /rhev/data-center/mnt/glusterSD/ovirt1-storage.dgi:_engine type fuse.glusterfs (rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) I've noticed that on my working servers, I see this output:[root@ovirt2.dgi ~]# mount | grep storageovirt1-storage.dgi:/engine on /rhev/data-center/mnt/glusterSD/ovirt1-storage.dgi:_engine type fuse.glusterfs (rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)ovirt1-storage.dgi:/vmstore on /rhev/data-center/mnt/glusterSD/ovirt1-storage.dgi:_vmstore type fuse.glusterfs (rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) There is obviously something not mounting properly on ovirt1. I don't see how this can be a network issue as the storage for the hosted engine is working ok. I truly appreciate the help. Any other ideas or logs/places to check? Cheers, Gervais On Nov 24, 2021, at 4:03 AM, Staniforth, Paul <P.Staniforth@leedsbeckett.ac.uk> wrote: Hi Gervais, The engine doesn't need to be able to ping the IP address, just needs to know what it is so adding them to the /etc/hosts file should work. Also, I would check ovirt1, is it mounting the brick, what does "systemctl status glusterd" show, what are the logs in /var/log/gluster ? Regards, Paul S. From: Gervais de Montbrun <gervais@demontbrun.com> Sent: 24 November 2021 01:16 To: Staniforth, Paul <P.Staniforth@leedsbeckett.ac.uk> Cc: Vojtech Juranek <vjuranek@redhat.com>; users@ovirt.org <users@ovirt.org> Subject: Re: [ovirt-users] How to debug "Non Operational" host Caution External Mail: Do not click any links or open any attachments unless you trust the sender and know that the content is safe.Hi Paul, I don't quite get what you mean by this: assuming you have a storage network for the gluster nodes the engine needs to resolve be able to resolve the host addresses The storage network is on 10GB network cards and plugged into a stand-alone switch. The hosted-engine is not on the same network at all and can not ping the IP's associated with those cards. Are you saying that it needs access to that network, or that is needs to be able to resolve the IP's. I can add them to the /etc/hosts file on the ovirt-engine or do I need to reconfigure my setup? It was working as it currently configured before applying the update. I have no idea why the ovirt1 server is not showing up with the fqdn. I set up all the servers the same way. It's been like that since I set things up. I have looked for where this might be corrected, but can't find it. Ideas? The yellow bricks... I can force start them (and I have in the past), but now it turns green for a few minutes and then returns to red. Cheers, Gervais On Nov 23, 2021, at 12:57 PM, Staniforth, Paul <P.Staniforth@leedsbeckett.ac.uk> wrote: Hello Gervais, is the brick mounted on ovirt1 ? can you mount it using the settings in /etc/fstab ? The hostname is not using a FQDN for ovirt1 assuming you have a storage network for the gluster nodes the engine needs to resolve be able to resolve the host addressesovirt1-storage.dgi ovirt2-storage.dgi ovirt3-storage.dgi So that it can assign them to the correct network. When the volume is showing yellow you can force restart them again from the GUI. Regards, Paul S. From: Gervais de Montbrun <gervais@demontbrun.com> Sent: 23 November 2021 13:42 To: Vojtech Juranek <vjuranek@redhat.com> Cc: users@ovirt.org <users@ovirt.org> Subject: [ovirt-users] Re: How to debug "Non Operational" host Caution External Mail: Do not click any links or open any attachments unless you trust the sender and know that the content is safe. Hi Vojta, Thanks for the help. I tried to activate my server this morning and captured the logs from vdsm.log and engine.log. They are attached. Something went awry with my gluster (I think) as it is showing that the bricks on the affected server (ovirt1) are not mounted: <PastedGraphic-2.png> <PastedGraphic-3.png> <PastedGraphic-4.png> The networking looks fine. Cheers, Gervais
Hi Folks, I did a minor upgrade on the first host in my cluster and now it is reporting "Non Operational" This is what yum showed as updatable. However, I did the update through the ovirt-engine web interface. ovirt-node-ng-image-update.noarch 4.4.9-1.el8 ovirt-4.4 Obsoleting Packages ovirt-node-ng-image-update.noarch 4.4.9-1.el8 ovirt-4.4 ovirt-node-ng-image-update.noarch 4.4.8.3-1.el8 @System ovirt-node-ng-image-update.noarch 4.4.9-1.el8 ovirt-4.4 ovirt-node-ng-image-update-placeholder.noarch 4.4.8.3-1.el8 @System How do I start to debug this issue? Check engine log in /var/log/ovirt-engine/engine.log on the machine where engine runs Also, it looks like the vmstore brick is not mounting on that host. I only see the engine mounted. Could you also attach relevant part of vdsm log (/var/log/vdsm/vdsm.log) from
On Nov 23, 2021, at 3:37 AM, Vojtech Juranek <vjuranek@redhat.com> wrote: On Tuesday, 23 November 2021 03:36:07 CET Gervais de Montbrun wrote: the machine where mount failed? You should see some mount related error there. This could be also a reason why hosts become non-operational. Thanks Vojta
Broken server: root@ovirt1.dgi log]# mount | grep storage ovirt1-storage.dgi:/engine on /rhev/data-center/mnt/glusterSD/ovirt1-storage.dgi:_engine type fuse.glusterfs (rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read= 131072) Working server: [root@ovirt2.dgi ~]# mount | grep storage ovirt1-storage.dgi:/engine on /rhev/data-center/mnt/glusterSD/ovirt1-storage.dgi:_engine type fuse.glusterfs (rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read= 131072) ovirt1-storage.dgi:/vmstore on /rhev/data-center/mnt/glusterSD/ovirt1-storage.dgi:_vmstore type fuse.glusterfs (rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read= 131072) I tried putting the server into maintenance mode and running a reinstall on it. No change. I'de really appreciate some help sorting this our. Cheers, Gervais
Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/S6C7R6LUTJXFMG...
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/AWSWTXS6CEAYSA... To view the terms under which this email is distributed, please go to:- https://leedsbeckett.ac.uk/disclaimer/email _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/4YYEHIXZCSQCNR... To view the terms under which this email is distributed, please go to:- https://leedsbeckett.ac.uk/disclaimer/email _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/H7SLDPRW6FJ5S4... To view the terms under which this email is distributed, please go to:- https://leedsbeckett.ac.uk/disclaimer/email _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/FCXTUGI2G2GXNN... To view the terms under which this email is distributed, please go to:- https://leedsbeckett.ac.uk/disclaimer/email _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/OZSTLXDSHK6AWE...
{kind=link}