
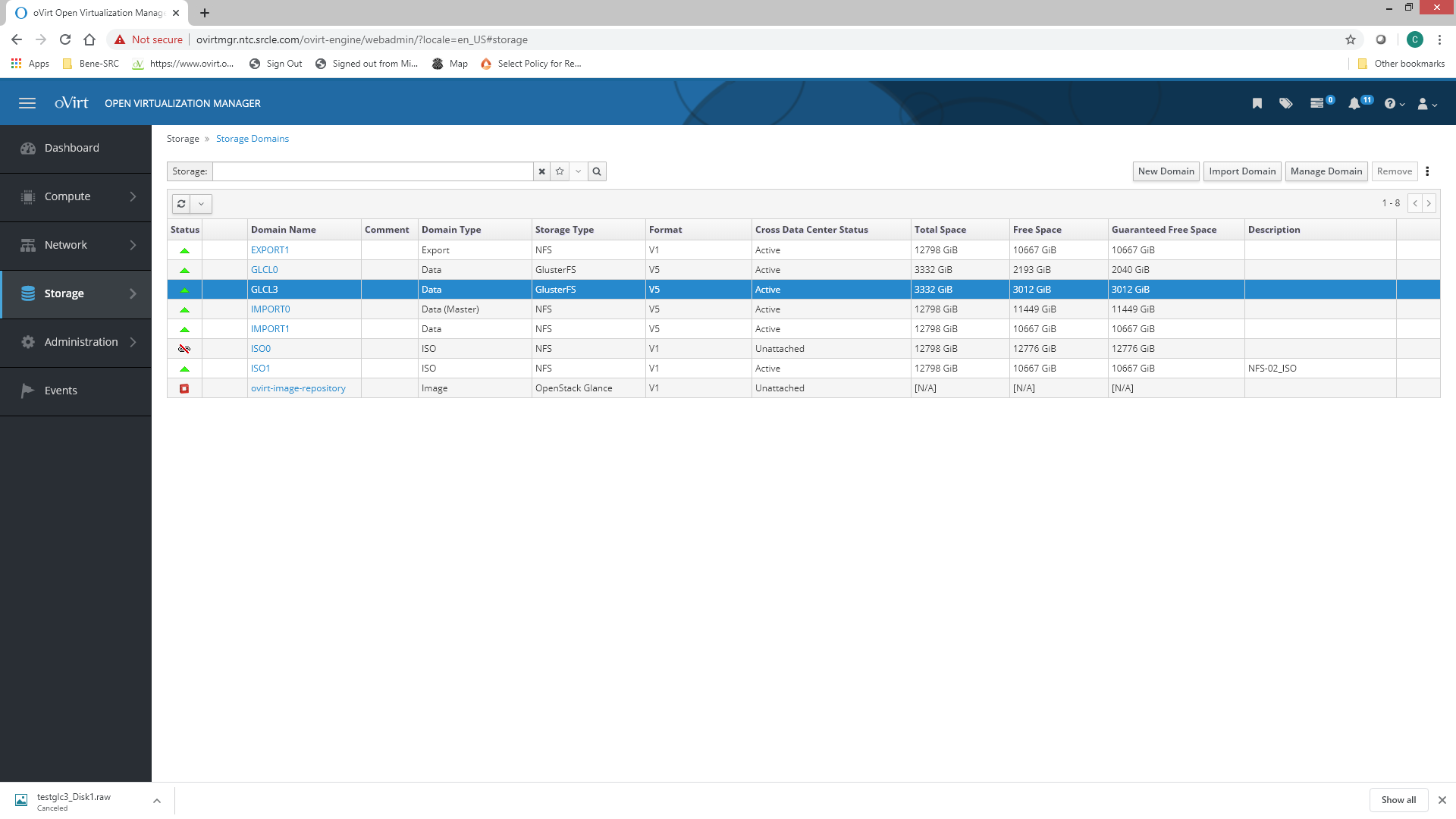
Resending to eliminate email issues ---------- Forwarded message --------- From: C Williams <cwilliams3320@gmail.com> Date: Thu, Jun 18, 2020 at 4:01 PM Subject: Re: [ovirt-users] Fwd: Issues with Gluster Domain To: Strahil Nikolov <hunter86_bg@yahoo.com> Here is output from mount 192.168.24.12:/stor/import0 on /rhev/data-center/mnt/192.168.24.12:_stor_import0 type nfs4 (rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12) 192.168.24.13:/stor/import1 on /rhev/data-center/mnt/192.168.24.13:_stor_import1 type nfs4 (rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) 192.168.24.13:/stor/iso1 on /rhev/data-center/mnt/192.168.24.13:_stor_iso1 type nfs4 (rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) 192.168.24.13:/stor/export0 on /rhev/data-center/mnt/192.168.24.13:_stor_export0 type nfs4 (rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) 192.168.24.15:/images on /rhev/data-center/mnt/glusterSD/192.168.24.15:_images type fuse.glusterfs (rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) 192.168.24.18:/images3 on /rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 type fuse.glusterfs (rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) tmpfs on /run/user/0 type tmpfs (rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) [root@ov06 glusterfs]# Also here is a screenshot of the console [image: image.png] The other domains are up Import0 and Import1 are NFS . GLCL0 is gluster. They all are running VMs Thank You For Your Help ! On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
I don't see '/rhev/data-center/mnt/192.168.24.13:_stor_import1' mounted at all . What is the status of all storage domains ?
Best Regards, Strahil Nikolov
На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Resending to deal with possible email issues
---------- Forwarded message --------- From: C Williams <cwilliams3320@gmail.com> Date: Thu, Jun 18, 2020 at 2:07 PM Subject: Re: [ovirt-users] Issues with Gluster Domain To: Strahil Nikolov <hunter86_bg@yahoo.com>
More
[root@ov06 ~]# for i in $(gluster volume list); do echo $i;echo; gluster volume info $i; echo;echo;gluster volume status $i;echo;echo;echo;done images3
Volume Name: images3 Type: Replicate Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b Status: Started Snapshot Count: 0 Number of Bricks: 1 x 3 = 3 Transport-type: tcp Bricks: Brick1: 192.168.24.18:/bricks/brick04/images3 Brick2: 192.168.24.19:/bricks/brick05/images3 Brick3: 192.168.24.20:/bricks/brick06/images3 Options Reconfigured: performance.client-io-threads: on nfs.disable: on transport.address-family: inet user.cifs: off auth.allow: * performance.quick-read: off performance.read-ahead: off performance.io-cache: off performance.low-prio-threads: 32 network.remote-dio: off cluster.eager-lock: enable cluster.quorum-type: auto cluster.server-quorum-type: server cluster.data-self-heal-algorithm: full cluster.locking-scheme: granular cluster.shd-max-threads: 8 cluster.shd-wait-qlength: 10000 features.shard: on cluster.choose-local: off client.event-threads: 4 server.event-threads: 4 storage.owner-uid: 36 storage.owner-gid: 36 performance.strict-o-direct: on network.ping-timeout: 30 cluster.granular-entry-heal: enable
Status of volume: images3 Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------ Brick 192.168.24.18:/bricks/brick04/images3 49152 0 Y 6666 Brick 192.168.24.19:/bricks/brick05/images3 49152 0 Y 6779 Brick 192.168.24.20:/bricks/brick06/images3 49152 0 Y 7227 Self-heal Daemon on localhost N/A N/A Y 6689 Self-heal Daemon on ov07.ntc.srcle.com N/A N/A Y 6802 Self-heal Daemon on ov08.ntc.srcle.com N/A N/A Y 7250
Task Status of Volume images3
------------------------------------------------------------------------------ There are no active volume tasks
[root@ov06 ~]# ls -l /rhev/data-center/mnt/glusterSD/ total 16 drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 192.168.24.15:_images drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 192.168.24.18:_images3 [root@ov06 ~]#
On Thu, Jun 18, 2020 at 2:03 PM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
Here you go -- Thank You For Your Help !
BTW -- I can write a test file to gluster and it replicates properly. Thinking something about the oVirt Storage Domain ?
[root@ov08 ~]# gluster pool list UUID Hostname State 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06 Connected 36ce5a00-6f65-4926-8438-696944ebadb5 ov07.ntc.srcle.com Connected c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost Connected [root@ov08 ~]# gluster volume list images3
On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Log to the oVirt cluster and provide the output of: gluster pool list gluster volume list for i in $(gluster volume list); do echo $i;echo; gluster volume info $i; echo;echo;gluster volume status $i;echo;echo;echo;done
ls -l /rhev/data-center/mnt/glusterSD/
Best Regards, Strahil Nikolov
Hello,
I recently added 6 hosts to an existing oVirt compute/gluster cluster.
Prior to this attempted addition, my cluster had 3 Hypervisor hosts and 3 gluster bricks which made up a single gluster volume (replica 3 volume) . I added the additional hosts and made a brick on 3 of the new hosts and attempted to make a new replica 3 volume. I had difficulty creating the new volume. So, I decided that I would make a new compute/gluster cluster for each set of 3 new hosts.
I removed the 6 new hosts from the existing oVirt Compute/Gluster Cluster leaving the 3 original hosts in place with their bricks. At that
my original bricks went down and came back up . The volume showed entries that needed healing. At that point I ran gluster volume heal images3 full, etc. The volume shows no unhealed entries. I also corrected some peer errors.
However, I am unable to copy disks, move disks to another domain, export disks, etc. It appears that the engine cannot locate disks properly and I get storage I/O errors.
I have detached and removed the oVirt Storage Domain. I reimported
На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: point the
domain and imported 2 VMs, But the VM disks exhibit the same behaviour and won't run from the hard disk.
I get errors such as this
VDSM ov05 command HSMGetAllTasksStatusesVDS failed: low level Image copy failed: ("Command ['/usr/bin/qemu-img', 'convert', '-p', '-t', 'none', '-T', 'none', '-f', 'raw', u'/rhev/data-center/mnt/glusterSD/192.168.24.18:
_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510',
'-O', 'raw', u'/rhev/data-center/mnt/192.168.24.13:
_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5']
failed with rc=1 out='' err=bytearray(b'qemu-img: error while reading sector 135168: Transport endpoint is not connected\\nqemu-img: error while reading sector 131072: Transport endpoint is not connected\\nqemu-img: error while reading sector 139264: Transport endpoint is not connected\\nqemu-img: error while reading sector 143360: Transport endpoint is not connected\\nqemu-img: error while reading sector 147456: Transport endpoint is not connected\\nqemu-img: error while reading sector 155648: Transport endpoint is not connected\\nqemu-img: error while reading sector 151552: Transport endpoint is not connected\\nqemu-img: error while reading sector 159744: Transport endpoint is not connected\\n')",)
oVirt version is 4.3.82-1.el7 OS CentOS Linux release 7.7.1908 (Core)
The Gluster Cluster has been working very well until this incident.
Please help.
Thank You
Charles Williams
{kind=link}