
9 Apr
2018
9 Apr
'18
5:48 p.m.
Does anyone have any clues about these errors? On Sat, Apr 7, 2018 at 9:02 PM, Vincent Royer <vincent@epicenergy.ca> wrote:
Suffered a long power outage that outlasted our huge UPS, so both my nodes went down.
Upon return, the nodes came back up but engine did not start because the storage server takes longer to boot than the nodes do, so the NFS mounts didn't reconnect.
I manually re-entered the mounts using cockpit, rebooted the nodes and the engine came back up along with all VMs.
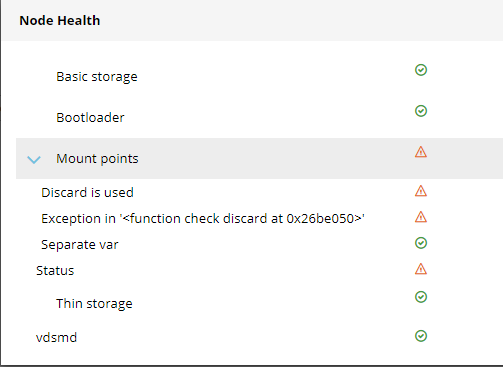
Now in cockpit under Node Status, It says Health: bad, and these messages:
Everything seems to be working fine though.
{kind=link}