
On Wed, Sep 8, 2021 at 11:52 AM Gianluca Cecchi <gianluca.cecchi@gmail.com> wrote: ...
Right now what I see in the table is:
engine=# \x Expanded display is on.
Nice! I did know about that
engine=# select * from vm_backups; -[ RECORD 1 ]------+------------------------------------- backup_id | 68f83141-9d03-4cb0-84d4-e71fdd8753bb from_checkpoint_id | to_checkpoint_id | d31e35b6-bd16-46d2-a053-eabb26d283f5 vm_id | dc386237-1e98-40c8-9d3d-45658163d1e2 phase | Finalizing
In current code, this means that VM.stop_backup call was successful when you asked to finalize the backup.
_create_date | 2021-09-03 15:31:11.447+02 host_id | cc241ec7-64fc-4c93-8cec-9e0e7005a49d
engine=#
see below my doubts...
...
The VM is still running. The host (I see it in its events with relation to backup errors) is ov200. BTW: how can I see the mapping between host id and hostname (from the db and/or api)?
[root@ov200 ~]# vdsm-client VM stop_backup vmID=dc386237-1e98-40c8-9d3d-45658163d1e2 backup_id=68f83141-9d03-4cb0-84d4-e71fdd8753bb { "code": 0, "message": "Done" } [root@ov200 ~]#
If this succeeds, the backup is not running on vdsm side.
I preseum from the output above that the command succeeded, correct?
Yes, this is how a successful command looks like. If the command fails you will get a non-zero code and the message will explain the failure. If this fails, you may need stop the VM to end the backup.
If the backup was stopped, you may need to delete the scratch disks used in this backup. You can find the scratch disks ids in engine logs, and delete them from engine UI.
Any insight for finding the scratch disks ids in engine.log? See here my engine.log and timestamp of backup (as seen in database above) is 15:31 on 03 September:
https://drive.google.com/file/d/1Ao1CIA2wlFCqMMKeXbxKXrWZXUrnJN2h/view?usp=s...
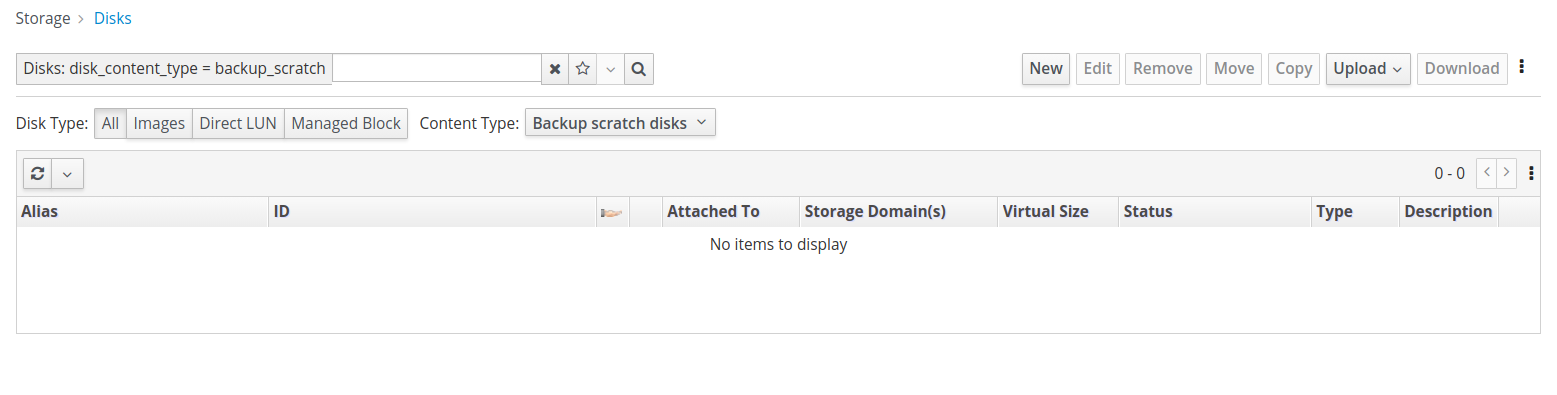
To find the scratch disks the best way is to use the UI - open the storage
disks tab and change the content type to "Backup scratch disks" (see attached screenshot)
The description and comment of the scratch disk should be enough to detect stale scratch disks that failed to be removed after a backup. You should be able to delete the disks from the UI/API.
Finally, after you cleaned up vdsm side, you can delete the backup from engine database, and unlock the disks.
Pavel, can you provide instructions on how to clean up engine db after stuck backup?
Can you please try manually updating the 'phase" of the problematic backup entry in the "vm_backups" DB table to 1 of the final phases, which are either "Succeeded" or "Failed"? This should allow creating a new backup. [image: image.png]
After vdsm and engine were cleaned, new backup should work normally.
OK, so I wait for Nir input about scratch disks removal and then I go with changing the phase column for the backup.
Once you stop the backup on vdsm side, you can fix the backup phase in the database. You don't need to delete the scratch disks before that, they can be deleted later. Backup stuck in the finalizing phase blocks future backups of the VM. Scratch disks only take logical space in your storage domain, and some physical space in your storage. Nir
{kind=link}
{kind=link}