OVirt HCI Setup Wizard - Drive specification Ignored

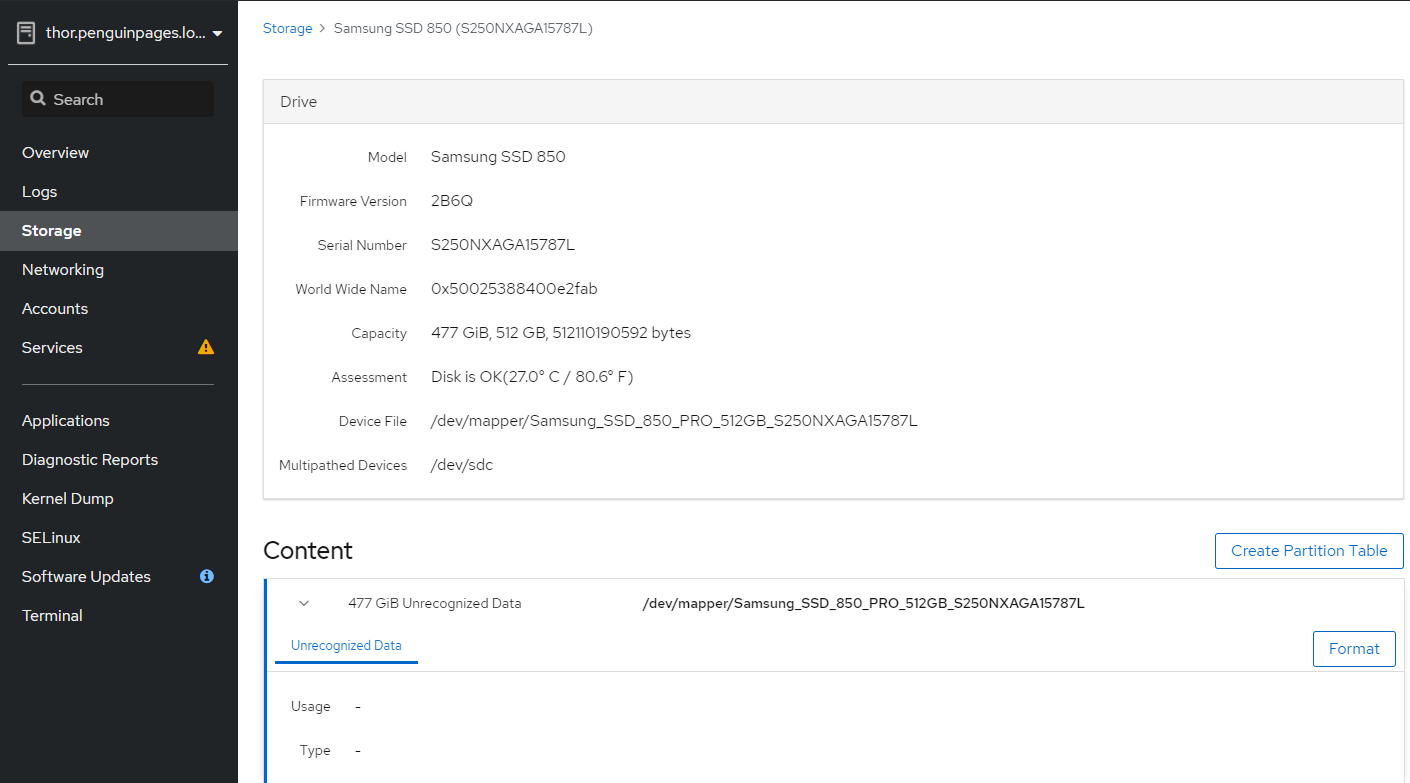
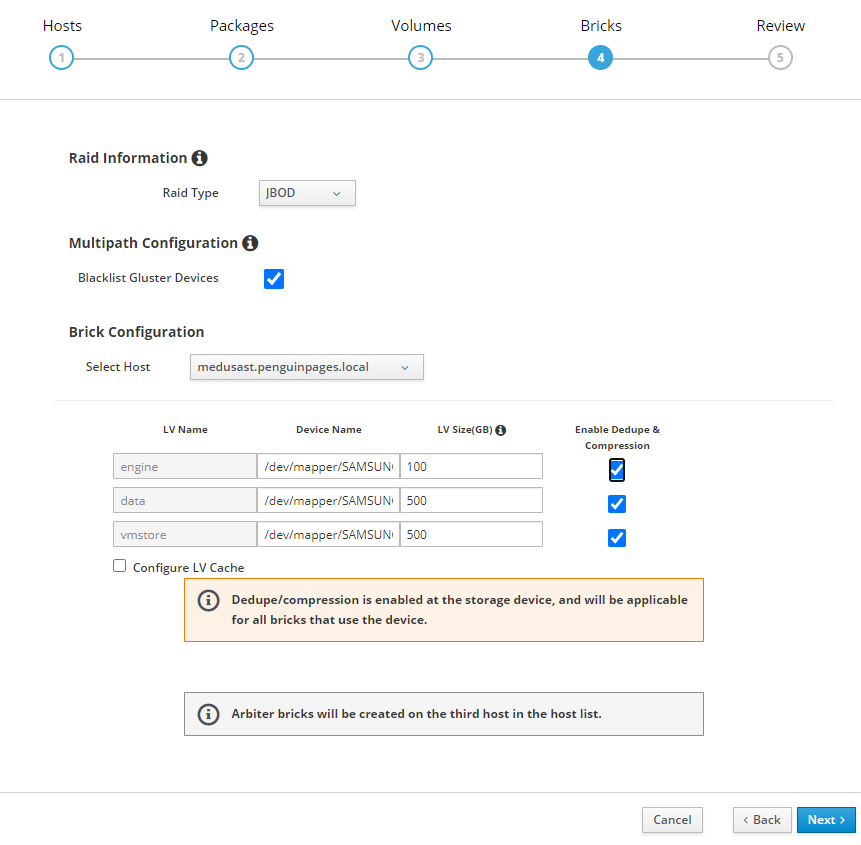
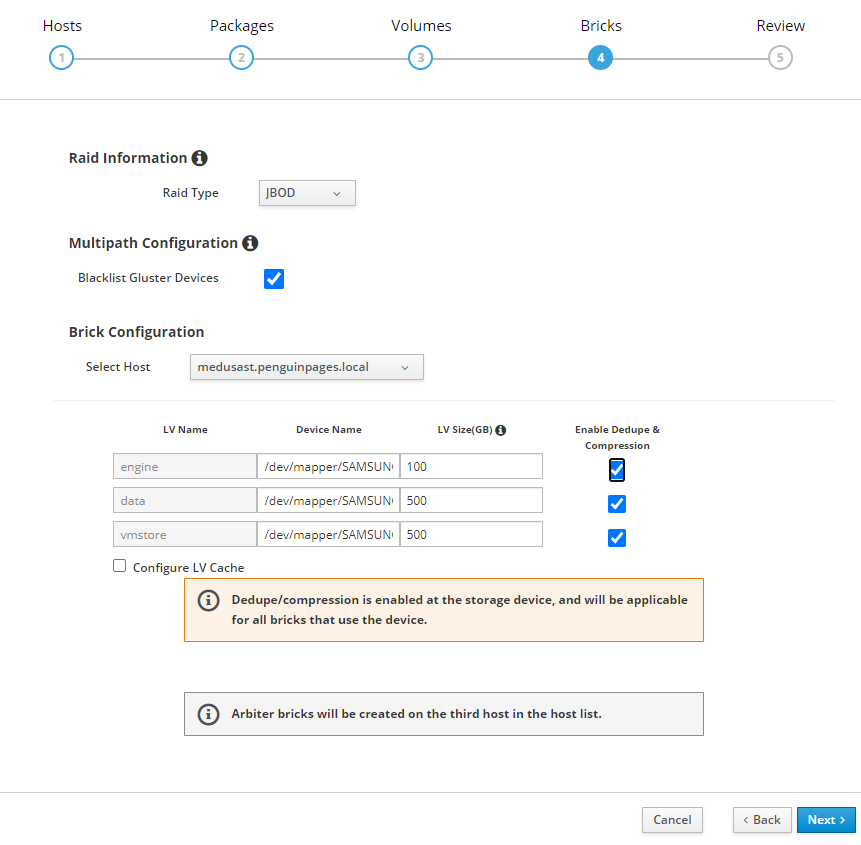
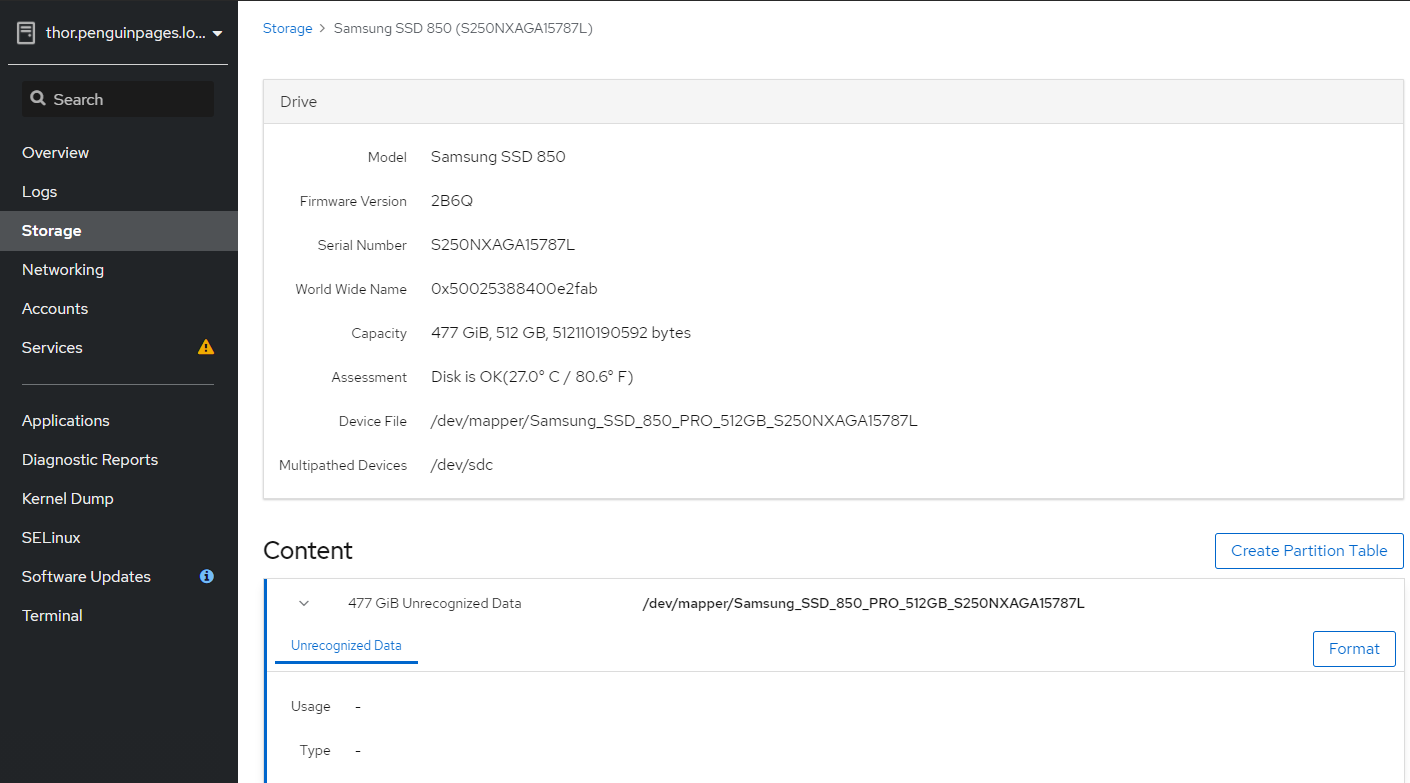
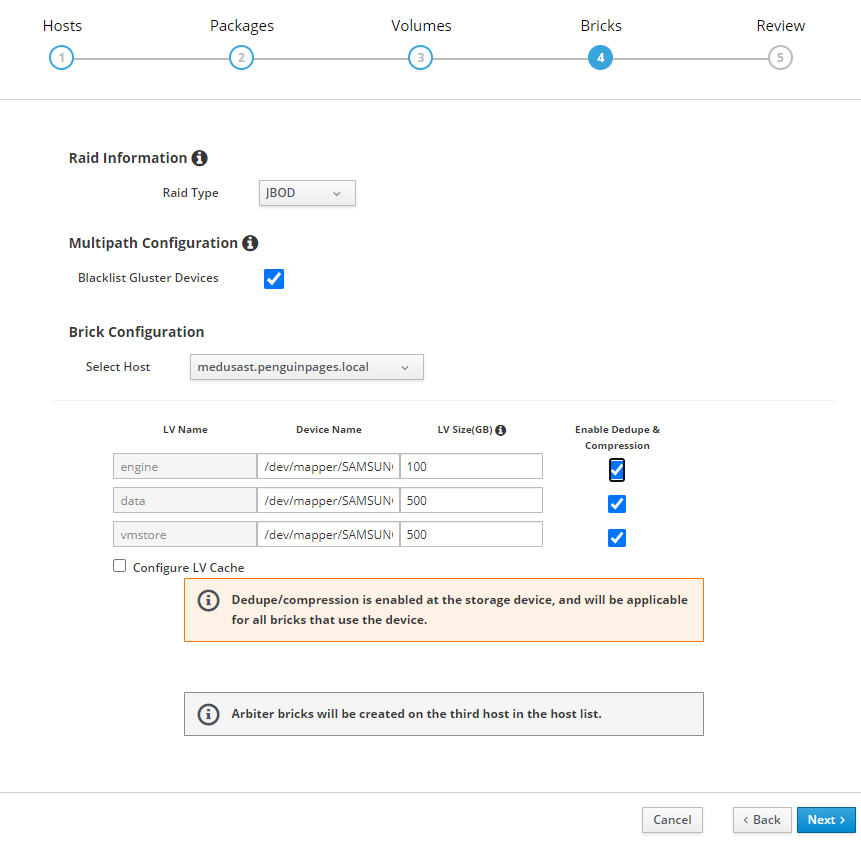
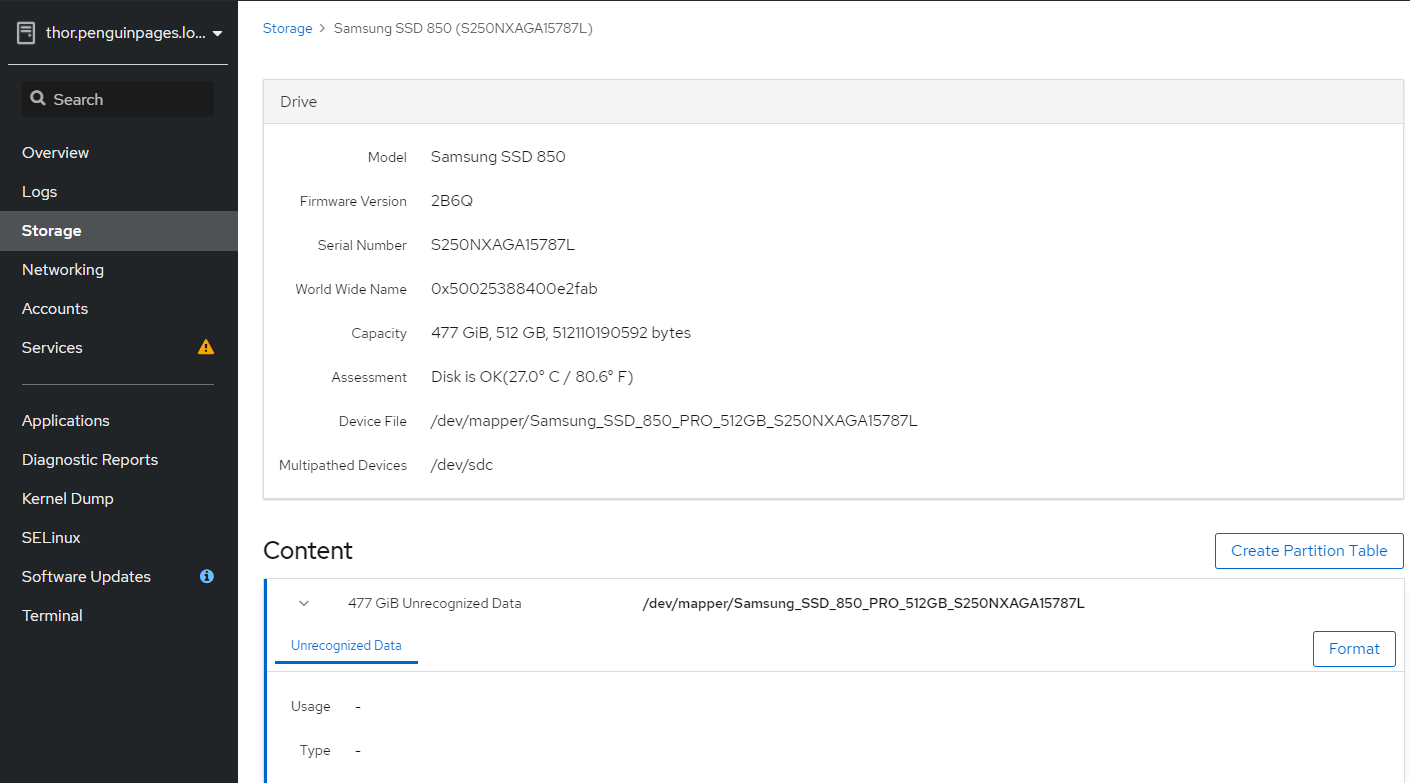
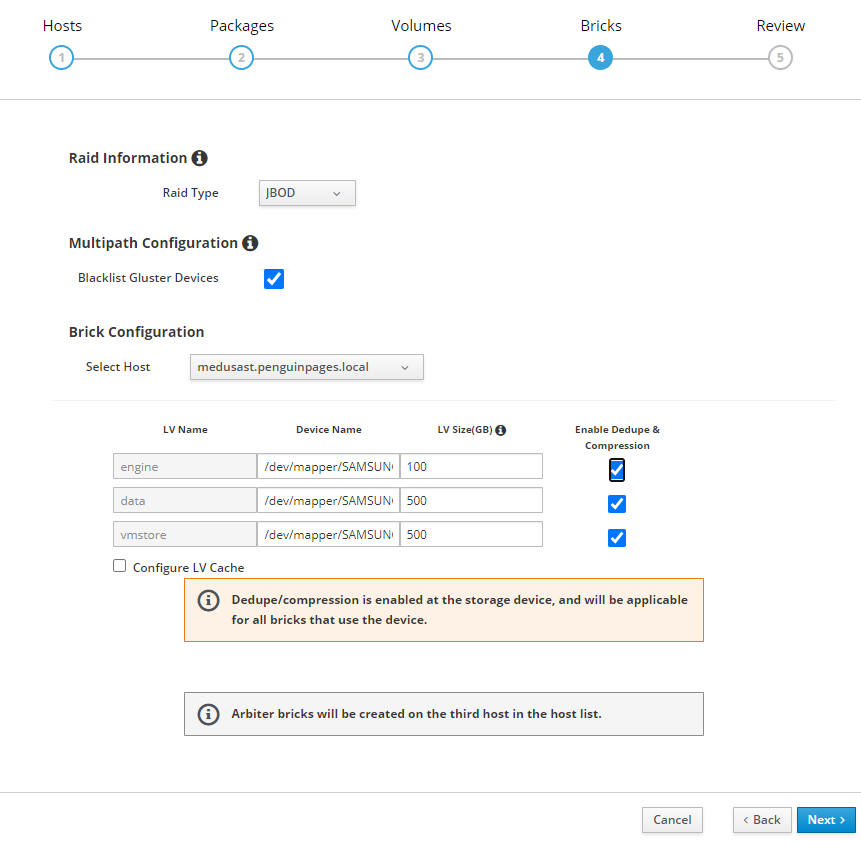
Greetings: 3 x servers each server has 1 x 512GB ssd 2 x 1TB SSD JBOD Goal: use HCI disk setup wizard to deploy initial structure Each server has disk scanning in as different /dev/sd# and so trying to use more clear /dev/mapper/<disk ID> As such I set this per table below: # Select each server and set each drive <<<<<<<<<<Double Check drive device ID as they do NOT match up per host # I transitioned to /dev/mapper object to avoid unclearness of /dev/sd# thor /dev/sdc /dev/mapper/Samsung_SSD_850_PRO_512GB_S250NXAGA15787L odin /dev/sdb /dev/mapper/Micron_1100_MTFDDAV512TBN_17401F699137 medusa /dev/sdb /dev/mapper/SAMSUNG_SSD_PM851_mSATA_512GB_S1EWNYAF609306 # Note that drives need to be completely clear of any partition or file system [root@thor /]# gdisk /dev/sdc GPT fdisk (gdisk) version 1.0.3 Partition table scan: MBR: protective BSD: not present APM: not present GPT: present Found valid GPT with protective MBR; using GPT. Command (? for help): x Expert command (? for help): z About to wipe out GPT on /dev/sdc. Proceed? (Y/N): y GPT data structures destroyed! You may now partition the disk using fdisk or other utilities. Blank out MBR? (Y/N): y [image: image.png] [image: image.png] But deployment fails with Error: <snip> TASK [gluster.infra/roles/backend_setup : Filter none-existing devices] ******** task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/get_vg_groupings.yml:38 ok: [thorst.penguinpages.local] => {"ansible_facts": {"gluster_volumes_by_groupname": {}}, "changed": false} ok: [odinst.penguinpages.local] => {"ansible_facts": {"gluster_volumes_by_groupname": {}}, "changed": false} ok: [medusast.penguinpages.local] => {"ansible_facts": {"gluster_volumes_by_groupname": {}}, "changed": false} TASK [gluster.infra/roles/backend_setup : Make sure thick pvs exists in volume group] *** task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/thick_lv_create.yml:37 TASK [gluster.infra/roles/backend_setup : update LVM fact's] ******************* task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/thick_lv_create.yml:83 skipping: [thorst.penguinpages.local] => {"changed": false, "skip_reason": "Conditional result was False"} skipping: [odinst.penguinpages.local] => {"changed": false, "skip_reason": "Conditional result was False"} skipping: [medusast.penguinpages.local] => {"changed": false, "skip_reason": "Conditional result was False"} TASK [gluster.infra/roles/backend_setup : Create thick logical volume] ********* task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/thick_lv_create.yml:90 failed: [medusast.penguinpages.local] (item={'vgname': ' gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L', 'lvname': 'gluster_lv_engine', 'size': '1000G'}) => {"ansible_index_var": "index", "ansible_loop_var": "item", "changed": false, "err": " Volume group \"gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L\" not found.\n Cannot process volume group gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L\n", "index": 0, "item": {"lvname": "gluster_lv_engine", "size": "1000G", "vgname": "gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L"}, "msg": "Volume group gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L does not exist.", "rc": 5} changed: [thorst.penguinpages.local] => (item={'vgname': ' gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L', 'lvname': 'gluster_lv_engine', 'size': '1000G'}) => {"ansible_index_var": "index", "ansible_loop_var": "item", "changed": true, "index": 0, "item": {"lvname": "gluster_lv_engine", "size": "1000G", "vgname": "gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L"}, "msg": ""} failed: [odinst.penguinpages.local] (item={'vgname': 'gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L', 'lvname': 'gluster_lv_engine', 'size': '1000G'}) => {"ansible_index_var": "index", "ansible_loop_var": "item", "changed": false, "err": " Volume group \"gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L\" not found.\n Cannot process volume group gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L\n", "index": 0, "item": {"lvname": "gluster_lv_engine", "size": "1000G", "vgname": "gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L"}, "msg": "Volume group gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L does not exist.", "rc": 5} NO MORE HOSTS LEFT ************************************************************* NO MORE HOSTS LEFT ************************************************************* PLAY RECAP ********************************************************************* medusast.penguinpages.local : ok=23 changed=5 unreachable=0 failed=1 skipped=34 rescued=0 ignored=0 odinst.penguinpages.local : ok=23 changed=5 unreachable=0 failed=1 skipped=34 rescued=0 ignored=0 thorst.penguinpages.local : ok=30 changed=9 unreachable=0 failed=0 skipped=29 rescued=0 ignored=0 Please check /var/log/cockpit/ovirt-dashboard/gluster-deployment.log for more informations. ############ Why is oVirt ignoring when I set (and double check explicite device call for deployment? Attached is the ansible file it creates and then one I had to edit to correct what wizard should have built it as. -- p <jeremey.wise@gmail.com>enguinpages
{kind=link}
{kind=link}

Hey! I am guessing that the deployment is failing due to the long lv name. Can you try to edit the ansible-playbook and shorten the lv name to 55 characters and try again? Regards Parth Dhanjal On Sun, Sep 13, 2020 at 11:16 AM Jeremey Wise <jeremey.wise@gmail.com> wrote:
Greetings:
3 x servers each server has 1 x 512GB ssd 2 x 1TB SSD JBOD
Goal: use HCI disk setup wizard to deploy initial structure
Each server has disk scanning in as different /dev/sd# and so trying to use more clear /dev/mapper/<disk ID>
As such I set this per table below:
# Select each server and set each drive <<<<<<<<<<Double Check drive device ID as they do NOT match up per host
# I transitioned to /dev/mapper object to avoid unclearness of /dev/sd#
thor
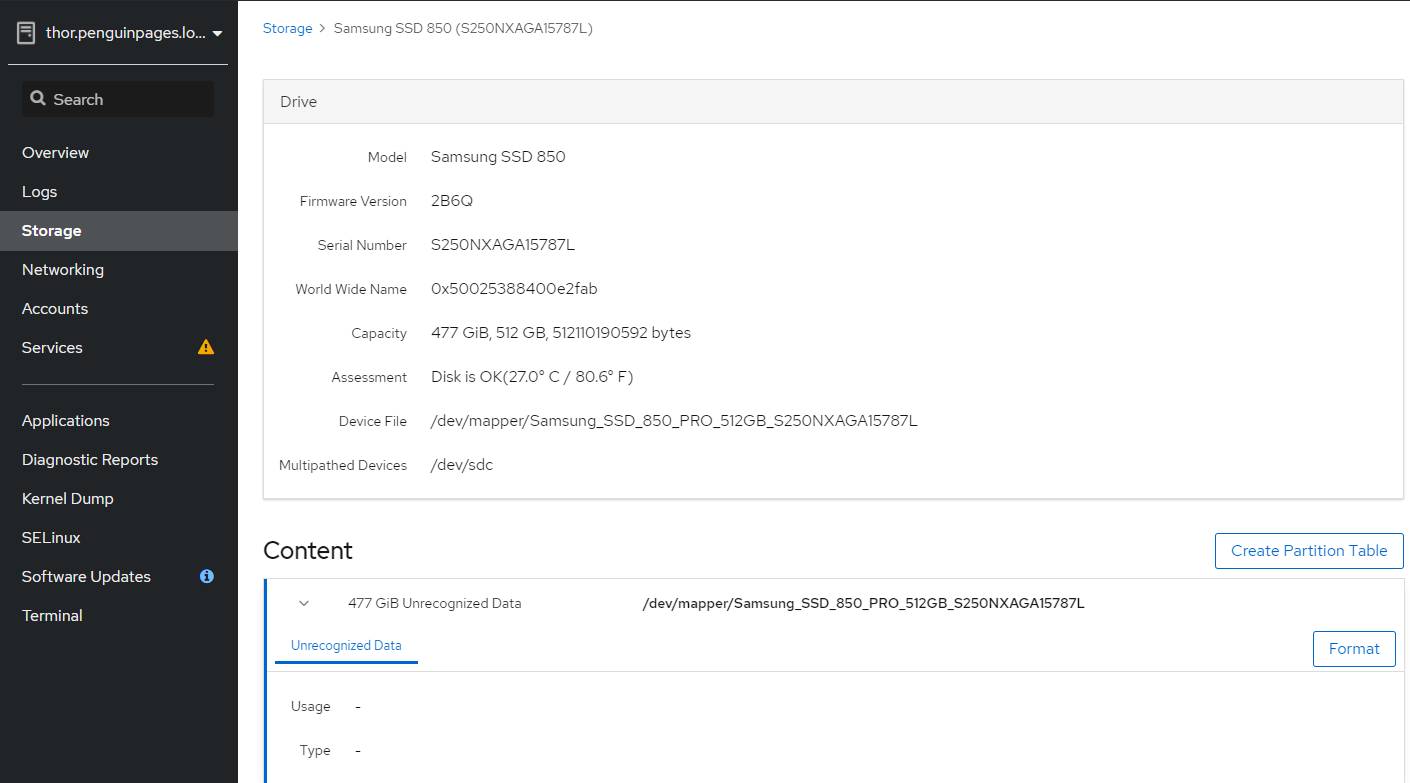
/dev/sdc
/dev/mapper/Samsung_SSD_850_PRO_512GB_S250NXAGA15787L
odin
/dev/sdb
/dev/mapper/Micron_1100_MTFDDAV512TBN_17401F699137
medusa
/dev/sdb
/dev/mapper/SAMSUNG_SSD_PM851_mSATA_512GB_S1EWNYAF609306
# Note that drives need to be completely clear of any partition or file system
[root@thor /]# gdisk /dev/sdc
GPT fdisk (gdisk) version 1.0.3
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: present
Found valid GPT with protective MBR; using GPT.
Command (? for help): x
Expert command (? for help): z
About to wipe out GPT on /dev/sdc. Proceed? (Y/N): y
GPT data structures destroyed! You may now partition the disk using fdisk or
other utilities.
Blank out MBR? (Y/N): y [image: image.png]
[image: image.png]
But deployment fails with Error: <snip>
TASK [gluster.infra/roles/backend_setup : Filter none-existing devices] ******** task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/get_vg_groupings.yml:38 ok: [thorst.penguinpages.local] => {"ansible_facts": {"gluster_volumes_by_groupname": {}}, "changed": false} ok: [odinst.penguinpages.local] => {"ansible_facts": {"gluster_volumes_by_groupname": {}}, "changed": false} ok: [medusast.penguinpages.local] => {"ansible_facts": {"gluster_volumes_by_groupname": {}}, "changed": false}
TASK [gluster.infra/roles/backend_setup : Make sure thick pvs exists in volume group] *** task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/thick_lv_create.yml:37
TASK [gluster.infra/roles/backend_setup : update LVM fact's] ******************* task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/thick_lv_create.yml:83 skipping: [thorst.penguinpages.local] => {"changed": false, "skip_reason": "Conditional result was False"} skipping: [odinst.penguinpages.local] => {"changed": false, "skip_reason": "Conditional result was False"} skipping: [medusast.penguinpages.local] => {"changed": false, "skip_reason": "Conditional result was False"}
TASK [gluster.infra/roles/backend_setup : Create thick logical volume] ********* task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/thick_lv_create.yml:90 failed: [medusast.penguinpages.local] (item={'vgname': ' gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L', 'lvname': 'gluster_lv_engine', 'size': '1000G'}) => {"ansible_index_var": "index", "ansible_loop_var": "item", "changed": false, "err": " Volume group \"gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L\" not found.\n Cannot process volume group gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L\n", "index": 0, "item": {"lvname": "gluster_lv_engine", "size": "1000G", "vgname": "gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L"}, "msg": "Volume group gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L does not exist.", "rc": 5} changed: [thorst.penguinpages.local] => (item={'vgname': ' gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L', 'lvname': 'gluster_lv_engine', 'size': '1000G'}) => {"ansible_index_var": "index", "ansible_loop_var": "item", "changed": true, "index": 0, "item": {"lvname": "gluster_lv_engine", "size": "1000G", "vgname": "gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L"}, "msg": ""} failed: [odinst.penguinpages.local] (item={'vgname': 'gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L', 'lvname': 'gluster_lv_engine', 'size': '1000G'}) => {"ansible_index_var": "index", "ansible_loop_var": "item", "changed": false, "err": " Volume group \"gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L\" not found.\n Cannot process volume group gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L\n", "index": 0, "item": {"lvname": "gluster_lv_engine", "size": "1000G", "vgname": "gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L"}, "msg": "Volume group gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L does not exist.", "rc": 5}
NO MORE HOSTS LEFT *************************************************************
NO MORE HOSTS LEFT *************************************************************
PLAY RECAP ********************************************************************* medusast.penguinpages.local : ok=23 changed=5 unreachable=0 failed=1 skipped=34 rescued=0 ignored=0 odinst.penguinpages.local : ok=23 changed=5 unreachable=0 failed=1 skipped=34 rescued=0 ignored=0 thorst.penguinpages.local : ok=30 changed=9 unreachable=0 failed=0 skipped=29 rescued=0 ignored=0
Please check /var/log/cockpit/ovirt-dashboard/gluster-deployment.log for more informations.
############
Why is oVirt ignoring when I set (and double check explicite device call for deployment?
Attached is the ansible file it creates and then one I had to edit to correct what wizard should have built it as.
-- p <jeremey.wise@gmail.com>enguinpages _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives:
{kind=link}
{kind=link}
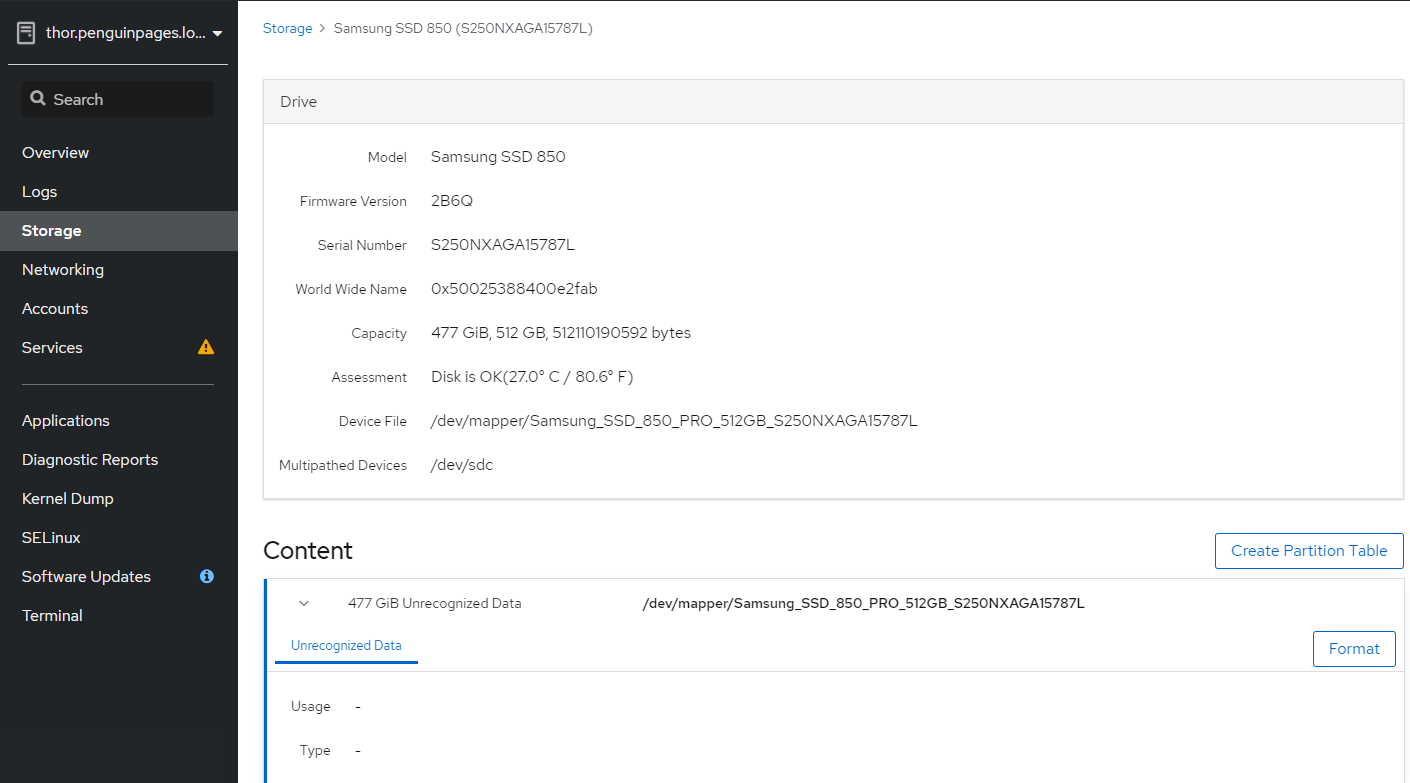
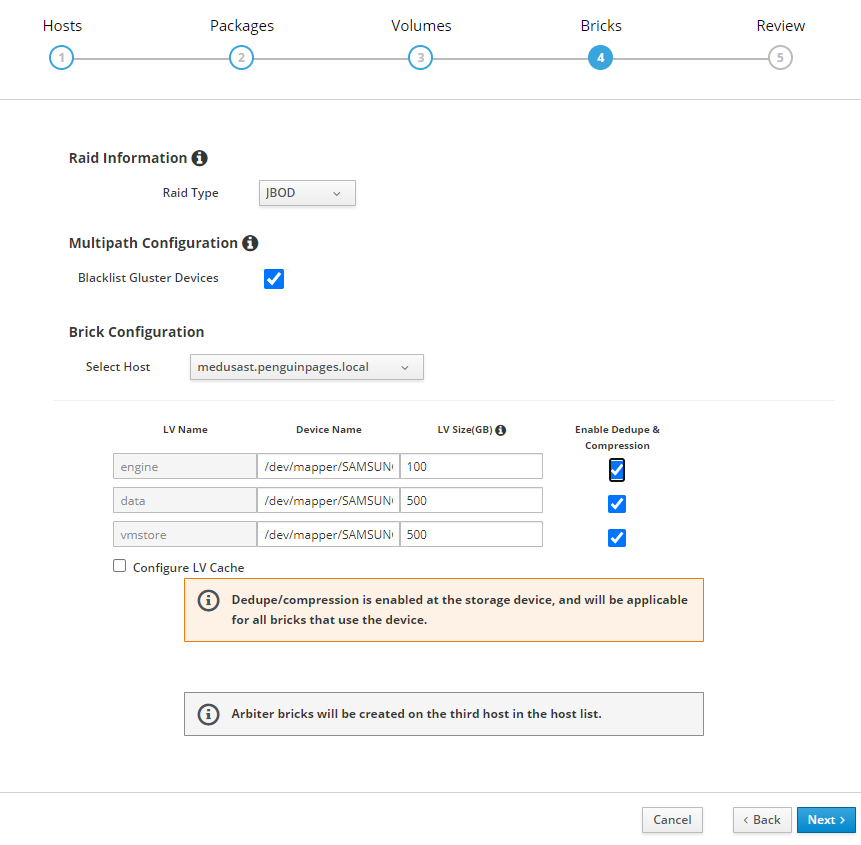
I noted this as an independent bug. Three separate issues here: 1) Wizard cannot take UUID names as names too long but does not note character limit that would guide one not to do that :) 2) Wizard , as it should, allows you to assign devices independently for each server, but does not retain this table on creation of ansible table. 3) Wizard, even when ansible file modified to reflect /dev/sd# for each server, ignores this and runs against drive NOT called for in ansible file. See attached Logs from where I took wizard output.. corrected first server which is to use /dev/sdc vs servers 2,3 to use /dev/sdb and deployment is against /dev/sdb on ALL THREE nodes. # Ansible file used per bug where it defines drives incorrectly to be just ID of first node hc_nodes: hosts: thorst.penguinpages.local: gluster_infra_volume_groups: - vgname: gluster_vg_sdc pvname: /dev/mapper/vdo_sdc gluster_infra_mount_devices: - path: /gluster_bricks/engine lvname: gluster_lv_engine vgname: gluster_vg_sdc - path: /gluster_bricks/data lvname: gluster_lv_data vgname: gluster_vg_sdc - path: /gluster_bricks/vmstore lvname: gluster_lv_vmstore vgname: gluster_vg_sdc gluster_infra_vdo: - name: vdo_sdc device: /dev/sdc slabsize: 32G logicalsize: 11000G blockmapcachesize: 128M emulate512: 'off' writepolicy: auto maxDiscardSize: 16M blacklist_mpath_devices: - sdc gluster_infra_thick_lvs: - vgname: gluster_vg_sdc lvname: gluster_lv_engine size: 1000G gluster_infra_thinpools: - vgname: gluster_vg_sdc thinpoolname: gluster_thinpool_gluster_vg_sdc poolmetadatasize: 3G gluster_infra_lv_logicalvols: - vgname: gluster_vg_sdc thinpool: gluster_thinpool_gluster_vg_sdc lvname: gluster_lv_data lvsize: 5000G - vgname: gluster_vg_sdc thinpool: gluster_thinpool_gluster_vg_sdc lvname: gluster_lv_vmstore lvsize: 5000G odinst.penguinpages.local: gluster_infra_volume_groups: - vgname: gluster_vg_sdb pvname: /dev/mapper/vdo_sdb gluster_infra_mount_devices: - path: /gluster_bricks/engine lvname: gluster_lv_engine vgname: gluster_vg_sdb - path: /gluster_bricks/data lvname: gluster_lv_data vgname: gluster_vg_sdb - path: /gluster_bricks/vmstore lvname: gluster_lv_vmstore vgname: gluster_vg_sdb gluster_infra_vdo: - name: vdo_sdb device: /dev/sdb slabsize: 32G logicalsize: 11000G blockmapcachesize: 128M emulate512: 'off' writepolicy: auto maxDiscardSize: 16M blacklist_mpath_devices: - sdb gluster_infra_thick_lvs: - vgname: gluster_vg_sdb lvname: gluster_lv_engine size: 1000G gluster_infra_thinpools: - vgname: gluster_vg_sdb thinpoolname: gluster_thinpool_gluster_vg_sdb poolmetadatasize: 3G gluster_infra_lv_logicalvols: - vgname: gluster_vg_sdb thinpool: gluster_thinpool_gluster_vg_sdb lvname: gluster_lv_data lvsize: 5000G - vgname: gluster_vg_sdb thinpool: gluster_thinpool_gluster_vg_sdb lvname: gluster_lv_vmstore lvsize: 5000G medusast.penguinpages.local: gluster_infra_volume_groups: - vgname: gluster_vg_sdb pvname: /dev/mapper/vdo_sdb gluster_infra_mount_devices: - path: /gluster_bricks/engine lvname: gluster_lv_engine vgname: gluster_vg_sdb - path: /gluster_bricks/data lvname: gluster_lv_data vgname: gluster_vg_sdb - path: /gluster_bricks/vmstore lvname: gluster_lv_vmstore vgname: gluster_vg_sdb gluster_infra_vdo: - name: vdo_sdb device: /dev/sdb slabsize: 32G logicalsize: 11000G blockmapcachesize: 128M emulate512: 'off' writepolicy: auto maxDiscardSize: 16M blacklist_mpath_devices: - sdb gluster_infra_thick_lvs: - vgname: gluster_vg_sdb lvname: gluster_lv_engine size: 1000G gluster_infra_thinpools: - vgname: gluster_vg_sdb thinpoolname: gluster_thinpool_gluster_vg_sdb poolmetadatasize: 3G gluster_infra_lv_logicalvols: - vgname: gluster_vg_sdb thinpool: gluster_thinpool_gluster_vg_sdb lvname: gluster_lv_data lvsize: 5000G - vgname: gluster_vg_sdb thinpool: gluster_thinpool_gluster_vg_sdb lvname: gluster_lv_vmstore lvsize: 5000G vars: gluster_infra_disktype: JBOD gluster_set_selinux_labels: true gluster_infra_fw_ports: - 2049/tcp - 54321/tcp - 5900/tcp - 5900-6923/tcp - 5666/tcp - 16514/tcp gluster_infra_fw_permanent: true gluster_infra_fw_state: enabled gluster_infra_fw_zone: public gluster_infra_fw_services: - glusterfs gluster_features_force_varlogsizecheck: false cluster_nodes: - thorst.penguinpages.local - odinst.penguinpages.local - medusast.penguinpages.local gluster_features_hci_cluster: '{{ cluster_nodes }}' gluster_features_hci_volumes: - volname: engine brick: /gluster_bricks/engine/engine arbiter: 0 - volname: data brick: /gluster_bricks/data/data arbiter: 0 - volname: vmstore brick: /gluster_bricks/vmstore/vmstore arbiter: 0 I have three drives in each server. The first is a 512GB SSD and this is how I want to do initial HCI setup. The other six are bricks with existing data VDO volumes from old Glutster volume. I wanted to import those. But lafter a few attempts it became apparent the HCI wizard just can't figure out how to stop VDO / Create partitions etc... and ignore drives not within its script. I have backups so I wiped all the data back to nakid drives..well.. then had other issues with CentOS that I am working out... so delay until I root cause that Hmmmm.. issue. Thanks for input/help On Sun, Sep 13, 2020 at 4:24 AM Parth Dhanjal <dparth@redhat.com> wrote:
Hey! I am guessing that the deployment is failing due to the long lv name. Can you try to edit the ansible-playbook and shorten the lv name to 55 characters and try again?
Regards Parth Dhanjal
On Sun, Sep 13, 2020 at 11:16 AM Jeremey Wise <jeremey.wise@gmail.com> wrote:
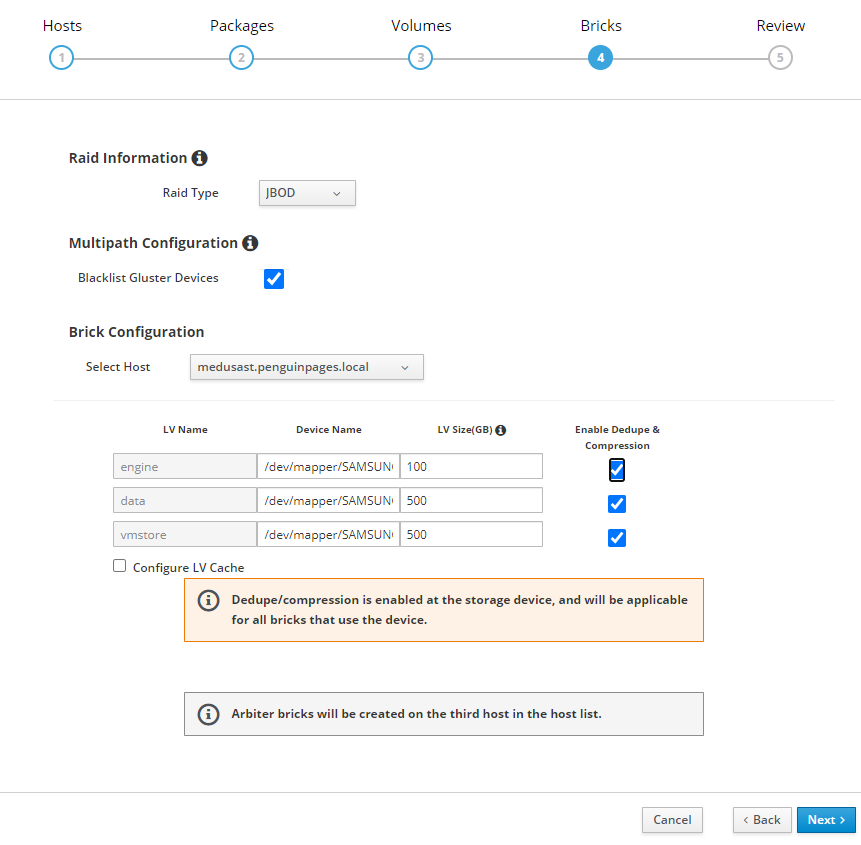
Greetings:
3 x servers each server has 1 x 512GB ssd 2 x 1TB SSD JBOD
Goal: use HCI disk setup wizard to deploy initial structure
Each server has disk scanning in as different /dev/sd# and so trying to use more clear /dev/mapper/<disk ID>
As such I set this per table below:
# Select each server and set each drive <<<<<<<<<<Double Check drive device ID as they do NOT match up per host
# I transitioned to /dev/mapper object to avoid unclearness of /dev/sd#
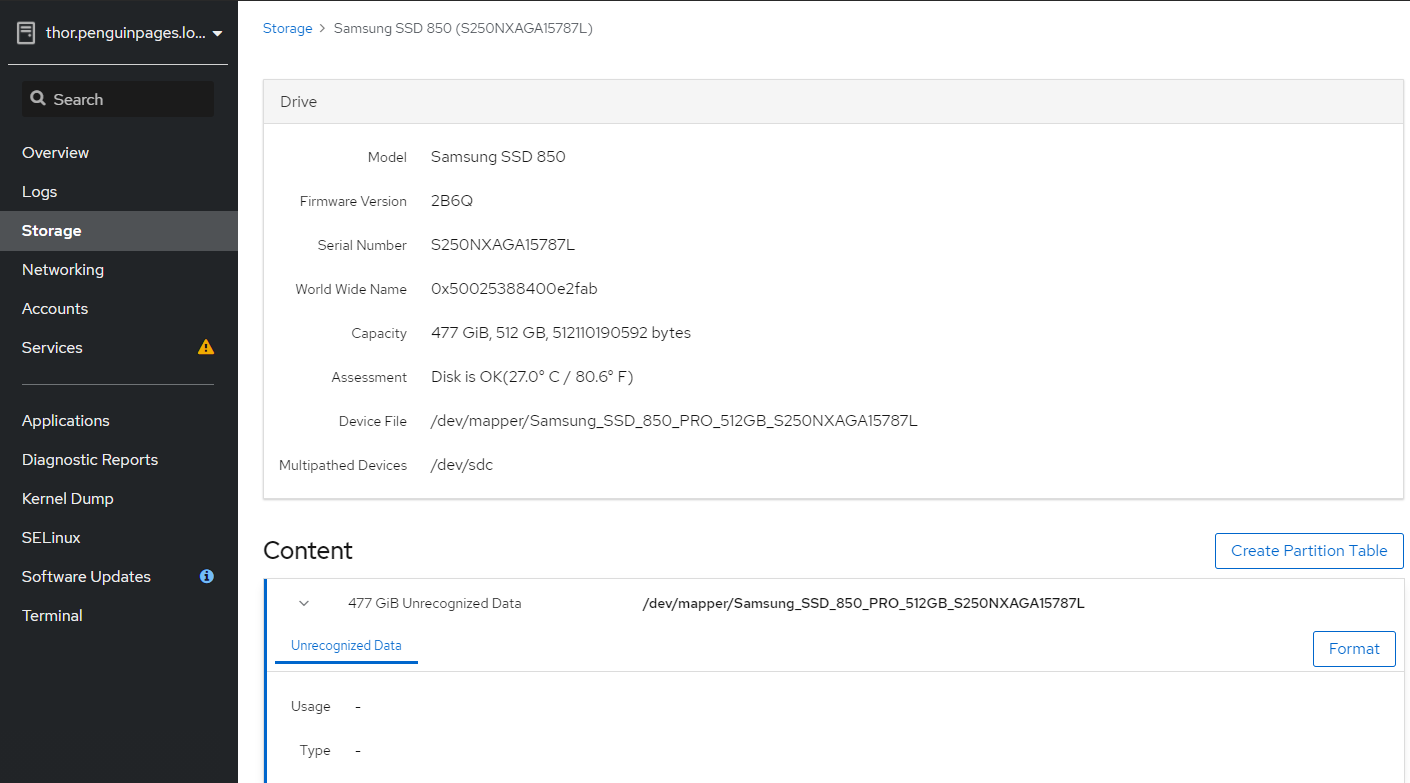
thor
/dev/sdc
/dev/mapper/Samsung_SSD_850_PRO_512GB_S250NXAGA15787L
odin
/dev/sdb
/dev/mapper/Micron_1100_MTFDDAV512TBN_17401F699137
medusa
/dev/sdb
/dev/mapper/SAMSUNG_SSD_PM851_mSATA_512GB_S1EWNYAF609306
# Note that drives need to be completely clear of any partition or file system
[root@thor /]# gdisk /dev/sdc
GPT fdisk (gdisk) version 1.0.3
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: present
Found valid GPT with protective MBR; using GPT.
Command (? for help): x
Expert command (? for help): z
About to wipe out GPT on /dev/sdc. Proceed? (Y/N): y
GPT data structures destroyed! You may now partition the disk using fdisk or
other utilities.
Blank out MBR? (Y/N): y [image: image.png]
[image: image.png]
But deployment fails with Error: <snip>
TASK [gluster.infra/roles/backend_setup : Filter none-existing devices] ******** task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/get_vg_groupings.yml:38 ok: [thorst.penguinpages.local] => {"ansible_facts": {"gluster_volumes_by_groupname": {}}, "changed": false} ok: [odinst.penguinpages.local] => {"ansible_facts": {"gluster_volumes_by_groupname": {}}, "changed": false} ok: [medusast.penguinpages.local] => {"ansible_facts": {"gluster_volumes_by_groupname": {}}, "changed": false}
TASK [gluster.infra/roles/backend_setup : Make sure thick pvs exists in volume group] *** task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/thick_lv_create.yml:37
TASK [gluster.infra/roles/backend_setup : update LVM fact's] ******************* task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/thick_lv_create.yml:83 skipping: [thorst.penguinpages.local] => {"changed": false, "skip_reason": "Conditional result was False"} skipping: [odinst.penguinpages.local] => {"changed": false, "skip_reason": "Conditional result was False"} skipping: [medusast.penguinpages.local] => {"changed": false, "skip_reason": "Conditional result was False"}
TASK [gluster.infra/roles/backend_setup : Create thick logical volume] ********* task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/thick_lv_create.yml:90 failed: [medusast.penguinpages.local] (item={'vgname': ' gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L', 'lvname': 'gluster_lv_engine', 'size': '1000G'}) => {"ansible_index_var": "index", "ansible_loop_var": "item", "changed": false, "err": " Volume group \"gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L\" not found.\n Cannot process volume group gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L\n", "index": 0, "item": {"lvname": "gluster_lv_engine", "size": "1000G", "vgname": "gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L"}, "msg": "Volume group gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L does not exist.", "rc": 5} changed: [thorst.penguinpages.local] => (item={'vgname': ' gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L', 'lvname': 'gluster_lv_engine', 'size': '1000G'}) => {"ansible_index_var": "index", "ansible_loop_var": "item", "changed": true, "index": 0, "item": {"lvname": "gluster_lv_engine", "size": "1000G", "vgname": "gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L"}, "msg": ""} failed: [odinst.penguinpages.local] (item={'vgname': 'gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L', 'lvname': 'gluster_lv_engine', 'size': '1000G'}) => {"ansible_index_var": "index", "ansible_loop_var": "item", "changed": false, "err": " Volume group \"gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L\" not found.\n Cannot process volume group gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L\n", "index": 0, "item": {"lvname": "gluster_lv_engine", "size": "1000G", "vgname": "gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L"}, "msg": "Volume group gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L does not exist.", "rc": 5}
NO MORE HOSTS LEFT *************************************************************
NO MORE HOSTS LEFT *************************************************************
PLAY RECAP ********************************************************************* medusast.penguinpages.local : ok=23 changed=5 unreachable=0 failed=1 skipped=34 rescued=0 ignored=0 odinst.penguinpages.local : ok=23 changed=5 unreachable=0 failed=1 skipped=34 rescued=0 ignored=0 thorst.penguinpages.local : ok=30 changed=9 unreachable=0 failed=0 skipped=29 rescued=0 ignored=0
Please check /var/log/cockpit/ovirt-dashboard/gluster-deployment.log for more informations.
############
Why is oVirt ignoring when I set (and double check explicite device call for deployment?
Attached is the ansible file it creates and then one I had to edit to correct what wizard should have built it as.
-- p <jeremey.wise@gmail.com>enguinpages _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives:
-- jeremey.wise@gmail.com
{kind=link}
{kind=link}
Update: 3) Wizard, even when ansible file modified to reflect /dev/sd# for each server, ignores this and runs against drive NOT called for in ansible file This is just an issue of unclarity on use of wizard. If you paste in corrected Ansible and click "reload" that does not do what I expected which is re-build ansible from wizard steps... but... seems to mean take what you pasted and load it for use by deployment wizard. AKA> Paste -> Reload button .. now it accepts modifications to ansible. On Sun, Sep 13, 2020 at 1:19 PM Jeremey Wise <jeremey.wise@gmail.com> wrote:
I noted this as an independent bug.
Three separate issues here: 1) Wizard cannot take UUID names as names too long but does not note character limit that would guide one not to do that :) 2) Wizard , as it should, allows you to assign devices independently for each server, but does not retain this table on creation of ansible table. 3) Wizard, even when ansible file modified to reflect /dev/sd# for each server, ignores this and runs against drive NOT called for in ansible file.
See attached Logs from where I took wizard output.. corrected first server which is to use /dev/sdc vs servers 2,3 to use /dev/sdb and deployment is against /dev/sdb on ALL THREE nodes.
# Ansible file used per bug where it defines drives incorrectly to be just ID of first node
hc_nodes:
hosts:
thorst.penguinpages.local:
gluster_infra_volume_groups:
- vgname: gluster_vg_sdc
pvname: /dev/mapper/vdo_sdc
gluster_infra_mount_devices:
- path: /gluster_bricks/engine
lvname: gluster_lv_engine
vgname: gluster_vg_sdc
- path: /gluster_bricks/data
lvname: gluster_lv_data
vgname: gluster_vg_sdc
- path: /gluster_bricks/vmstore
lvname: gluster_lv_vmstore
vgname: gluster_vg_sdc
gluster_infra_vdo:
- name: vdo_sdc
device: /dev/sdc
slabsize: 32G
logicalsize: 11000G
blockmapcachesize: 128M
emulate512: 'off'
writepolicy: auto
maxDiscardSize: 16M
blacklist_mpath_devices:
- sdc
gluster_infra_thick_lvs:
- vgname: gluster_vg_sdc
lvname: gluster_lv_engine
size: 1000G
gluster_infra_thinpools:
- vgname: gluster_vg_sdc
thinpoolname: gluster_thinpool_gluster_vg_sdc
poolmetadatasize: 3G
gluster_infra_lv_logicalvols:
- vgname: gluster_vg_sdc
thinpool: gluster_thinpool_gluster_vg_sdc
lvname: gluster_lv_data
lvsize: 5000G
- vgname: gluster_vg_sdc
thinpool: gluster_thinpool_gluster_vg_sdc
lvname: gluster_lv_vmstore
lvsize: 5000G
odinst.penguinpages.local:
gluster_infra_volume_groups:
- vgname: gluster_vg_sdb
pvname: /dev/mapper/vdo_sdb
gluster_infra_mount_devices:
- path: /gluster_bricks/engine
lvname: gluster_lv_engine
vgname: gluster_vg_sdb
- path: /gluster_bricks/data
lvname: gluster_lv_data
vgname: gluster_vg_sdb
- path: /gluster_bricks/vmstore
lvname: gluster_lv_vmstore
vgname: gluster_vg_sdb
gluster_infra_vdo:
- name: vdo_sdb
device: /dev/sdb
slabsize: 32G
logicalsize: 11000G
blockmapcachesize: 128M
emulate512: 'off'
writepolicy: auto
maxDiscardSize: 16M
blacklist_mpath_devices:
- sdb
gluster_infra_thick_lvs:
- vgname: gluster_vg_sdb
lvname: gluster_lv_engine
size: 1000G
gluster_infra_thinpools:
- vgname: gluster_vg_sdb
thinpoolname: gluster_thinpool_gluster_vg_sdb
poolmetadatasize: 3G
gluster_infra_lv_logicalvols:
- vgname: gluster_vg_sdb
thinpool: gluster_thinpool_gluster_vg_sdb
lvname: gluster_lv_data
lvsize: 5000G
- vgname: gluster_vg_sdb
thinpool: gluster_thinpool_gluster_vg_sdb
lvname: gluster_lv_vmstore
lvsize: 5000G
medusast.penguinpages.local:
gluster_infra_volume_groups:
- vgname: gluster_vg_sdb
pvname: /dev/mapper/vdo_sdb
gluster_infra_mount_devices:
- path: /gluster_bricks/engine
lvname: gluster_lv_engine
vgname: gluster_vg_sdb
- path: /gluster_bricks/data
lvname: gluster_lv_data
vgname: gluster_vg_sdb
- path: /gluster_bricks/vmstore
lvname: gluster_lv_vmstore
vgname: gluster_vg_sdb
gluster_infra_vdo:
- name: vdo_sdb
device: /dev/sdb
slabsize: 32G
logicalsize: 11000G
blockmapcachesize: 128M
emulate512: 'off'
writepolicy: auto
maxDiscardSize: 16M
blacklist_mpath_devices:
- sdb
gluster_infra_thick_lvs:
- vgname: gluster_vg_sdb
lvname: gluster_lv_engine
size: 1000G
gluster_infra_thinpools:
- vgname: gluster_vg_sdb
thinpoolname: gluster_thinpool_gluster_vg_sdb
poolmetadatasize: 3G
gluster_infra_lv_logicalvols:
- vgname: gluster_vg_sdb
thinpool: gluster_thinpool_gluster_vg_sdb
lvname: gluster_lv_data
lvsize: 5000G
- vgname: gluster_vg_sdb
thinpool: gluster_thinpool_gluster_vg_sdb
lvname: gluster_lv_vmstore
lvsize: 5000G
vars:
gluster_infra_disktype: JBOD
gluster_set_selinux_labels: true
gluster_infra_fw_ports:
- 2049/tcp
- 54321/tcp
- 5900/tcp
- 5900-6923/tcp
- 5666/tcp
- 16514/tcp
gluster_infra_fw_permanent: true
gluster_infra_fw_state: enabled
gluster_infra_fw_zone: public
gluster_infra_fw_services:
- glusterfs
gluster_features_force_varlogsizecheck: false
cluster_nodes:
- thorst.penguinpages.local
- odinst.penguinpages.local
- medusast.penguinpages.local
gluster_features_hci_cluster: '{{ cluster_nodes }}'
gluster_features_hci_volumes:
- volname: engine
brick: /gluster_bricks/engine/engine
arbiter: 0
- volname: data
brick: /gluster_bricks/data/data
arbiter: 0
- volname: vmstore
brick: /gluster_bricks/vmstore/vmstore
arbiter: 0
I have three drives in each server. The first is a 512GB SSD and this is how I want to do initial HCI setup. The other six are bricks with existing data VDO volumes from old Glutster volume. I wanted to import those. But lafter a few attempts it became apparent the HCI wizard just can't figure out how to stop VDO / Create partitions etc... and ignore drives not within its script. I have backups so I wiped all the data back to nakid drives..well.. then had other issues with CentOS that I am working out... so delay until I root cause that Hmmmm.. issue.
Thanks for input/help
On Sun, Sep 13, 2020 at 4:24 AM Parth Dhanjal <dparth@redhat.com> wrote:
Hey! I am guessing that the deployment is failing due to the long lv name. Can you try to edit the ansible-playbook and shorten the lv name to 55 characters and try again?
Regards Parth Dhanjal
On Sun, Sep 13, 2020 at 11:16 AM Jeremey Wise <jeremey.wise@gmail.com> wrote:
Greetings:
3 x servers each server has 1 x 512GB ssd 2 x 1TB SSD JBOD
Goal: use HCI disk setup wizard to deploy initial structure
Each server has disk scanning in as different /dev/sd# and so trying to use more clear /dev/mapper/<disk ID>
As such I set this per table below:
# Select each server and set each drive <<<<<<<<<<Double Check drive device ID as they do NOT match up per host
# I transitioned to /dev/mapper object to avoid unclearness of /dev/sd#
thor
/dev/sdc
/dev/mapper/Samsung_SSD_850_PRO_512GB_S250NXAGA15787L
odin
/dev/sdb
/dev/mapper/Micron_1100_MTFDDAV512TBN_17401F699137
medusa
/dev/sdb
/dev/mapper/SAMSUNG_SSD_PM851_mSATA_512GB_S1EWNYAF609306
# Note that drives need to be completely clear of any partition or file system
[root@thor /]# gdisk /dev/sdc
GPT fdisk (gdisk) version 1.0.3
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: present
Found valid GPT with protective MBR; using GPT.
Command (? for help): x
Expert command (? for help): z
About to wipe out GPT on /dev/sdc. Proceed? (Y/N): y
GPT data structures destroyed! You may now partition the disk using fdisk or
other utilities.
Blank out MBR? (Y/N): y [image: image.png]
[image: image.png]
But deployment fails with Error: <snip>
TASK [gluster.infra/roles/backend_setup : Filter none-existing devices] ******** task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/get_vg_groupings.yml:38 ok: [thorst.penguinpages.local] => {"ansible_facts": {"gluster_volumes_by_groupname": {}}, "changed": false} ok: [odinst.penguinpages.local] => {"ansible_facts": {"gluster_volumes_by_groupname": {}}, "changed": false} ok: [medusast.penguinpages.local] => {"ansible_facts": {"gluster_volumes_by_groupname": {}}, "changed": false}
TASK [gluster.infra/roles/backend_setup : Make sure thick pvs exists in volume group] *** task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/thick_lv_create.yml:37
TASK [gluster.infra/roles/backend_setup : update LVM fact's] ******************* task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/thick_lv_create.yml:83 skipping: [thorst.penguinpages.local] => {"changed": false, "skip_reason": "Conditional result was False"} skipping: [odinst.penguinpages.local] => {"changed": false, "skip_reason": "Conditional result was False"} skipping: [medusast.penguinpages.local] => {"changed": false, "skip_reason": "Conditional result was False"}
TASK [gluster.infra/roles/backend_setup : Create thick logical volume] ********* task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/thick_lv_create.yml:90 failed: [medusast.penguinpages.local] (item={'vgname': ' gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L', 'lvname': 'gluster_lv_engine', 'size': '1000G'}) => {"ansible_index_var": "index", "ansible_loop_var": "item", "changed": false, "err": " Volume group \"gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L\" not found.\n Cannot process volume group gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L\n", "index": 0, "item": {"lvname": "gluster_lv_engine", "size": "1000G", "vgname": "gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L"}, "msg": "Volume group gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L does not exist.", "rc": 5} changed: [thorst.penguinpages.local] => (item={'vgname': ' gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L', 'lvname': 'gluster_lv_engine', 'size': '1000G'}) => {"ansible_index_var": "index", "ansible_loop_var": "item", "changed": true, "index": 0, "item": {"lvname": "gluster_lv_engine", "size": "1000G", "vgname": "gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L"}, "msg": ""} failed: [odinst.penguinpages.local] (item={'vgname': 'gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L', 'lvname': 'gluster_lv_engine', 'size': '1000G'}) => {"ansible_index_var": "index", "ansible_loop_var": "item", "changed": false, "err": " Volume group \"gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L\" not found.\n Cannot process volume group gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L\n", "index": 0, "item": {"lvname": "gluster_lv_engine", "size": "1000G", "vgname": "gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L"}, "msg": "Volume group gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L does not exist.", "rc": 5}
NO MORE HOSTS LEFT *************************************************************
NO MORE HOSTS LEFT *************************************************************
PLAY RECAP ********************************************************************* medusast.penguinpages.local : ok=23 changed=5 unreachable=0 failed=1 skipped=34 rescued=0 ignored=0 odinst.penguinpages.local : ok=23 changed=5 unreachable=0 failed=1 skipped=34 rescued=0 ignored=0 thorst.penguinpages.local : ok=30 changed=9 unreachable=0 failed=0 skipped=29 rescued=0 ignored=0
Please check /var/log/cockpit/ovirt-dashboard/gluster-deployment.log for more informations.
############
Why is oVirt ignoring when I set (and double check explicite device call for deployment?
Attached is the ansible file it creates and then one I had to edit to correct what wizard should have built it as.
-- p <jeremey.wise@gmail.com>enguinpages _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives:
-- jeremey.wise@gmail.com
-- jeremey.wise@gmail.com
{kind=link}
{kind=link}

On Sun, Sep 13, 2020 at 8:48 AM Jeremey Wise <jeremey.wise@gmail.com> wrote:
Greetings:
3 x servers each server has 1 x 512GB ssd 2 x 1TB SSD JBOD
Goal: use HCI disk setup wizard to deploy initial structure
Each server has disk scanning in as different /dev/sd# and so trying to use more clear /dev/mapper/<disk ID>
As such I set this per table below:
# Select each server and set each drive <<<<<<<<<<Double Check drive device ID as they do NOT match up per host
# I transitioned to /dev/mapper object to avoid unclearness of /dev/sd#
thor
/dev/sdc
/dev/mapper/Samsung_SSD_850_PRO_512GB_S250NXAGA15787L
odin
/dev/sdb
/dev/mapper/Micron_1100_MTFDDAV512TBN_17401F699137
medusa
/dev/sdb
/dev/mapper/SAMSUNG_SSD_PM851_mSATA_512GB_S1EWNYAF609306
What is /dev/mapper/Samsung_SSD_850_PRO_512GB_S250NXAGA15787L? It looks like you are using multipath for local disks, which is not a good idea. First the additional layer can harm performance, and second, these disks may be exposed to engine as FC storage, which can lead to disaster when you try to use the local disk as shared storage. If you want to use stable names instead of /dev/sd{X}, use /dev/disk/by-id/ symlinks, like: $ ls -lh /dev/disk/by-id/nvme-eui.5cd2e42a81a11f69 lrwxrwxrwx. 1 root root 13 Sep 7 01:21 /dev/disk/by-id/nvme-eui.5cd2e42a81a11f69 -> ../../nvme0n1 You can find the right stabe name of the device using udevadm: $ udevadm info --query symlink /dev/nvme0n1 disk/by-id/nvme-INTEL_SSDPEKKF256G8L_BTHH827507DP256B disk/by-path/pci-0000:3e:00.0-nvme-1 disk/by-id/nvme-eui.5cd2e42a81a11f69 Nir
# Note that drives need to be completely clear of any partition or file system
[root@thor /]# gdisk /dev/sdc
GPT fdisk (gdisk) version 1.0.3
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: present
Found valid GPT with protective MBR; using GPT.
Command (? for help): x
Expert command (? for help): z
About to wipe out GPT on /dev/sdc. Proceed? (Y/N): y
GPT data structures destroyed! You may now partition the disk using fdisk or
other utilities.
Blank out MBR? (Y/N): y [image: image.png]
[image: image.png]
But deployment fails with Error: <snip>
TASK [gluster.infra/roles/backend_setup : Filter none-existing devices] ******** task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/get_vg_groupings.yml:38 ok: [thorst.penguinpages.local] => {"ansible_facts": {"gluster_volumes_by_groupname": {}}, "changed": false} ok: [odinst.penguinpages.local] => {"ansible_facts": {"gluster_volumes_by_groupname": {}}, "changed": false} ok: [medusast.penguinpages.local] => {"ansible_facts": {"gluster_volumes_by_groupname": {}}, "changed": false}
TASK [gluster.infra/roles/backend_setup : Make sure thick pvs exists in volume group] *** task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/thick_lv_create.yml:37
TASK [gluster.infra/roles/backend_setup : update LVM fact's] ******************* task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/thick_lv_create.yml:83 skipping: [thorst.penguinpages.local] => {"changed": false, "skip_reason": "Conditional result was False"} skipping: [odinst.penguinpages.local] => {"changed": false, "skip_reason": "Conditional result was False"} skipping: [medusast.penguinpages.local] => {"changed": false, "skip_reason": "Conditional result was False"}
TASK [gluster.infra/roles/backend_setup : Create thick logical volume] ********* task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/thick_lv_create.yml:90 failed: [medusast.penguinpages.local] (item={'vgname': ' gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L', 'lvname': 'gluster_lv_engine', 'size': '1000G'}) => {"ansible_index_var": "index", "ansible_loop_var": "item", "changed": false, "err": " Volume group \"gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L\" not found.\n Cannot process volume group gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L\n", "index": 0, "item": {"lvname": "gluster_lv_engine", "size": "1000G", "vgname": "gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L"}, "msg": "Volume group gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L does not exist.", "rc": 5} changed: [thorst.penguinpages.local] => (item={'vgname': ' gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L', 'lvname': 'gluster_lv_engine', 'size': '1000G'}) => {"ansible_index_var": "index", "ansible_loop_var": "item", "changed": true, "index": 0, "item": {"lvname": "gluster_lv_engine", "size": "1000G", "vgname": "gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L"}, "msg": ""} failed: [odinst.penguinpages.local] (item={'vgname': 'gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L', 'lvname': 'gluster_lv_engine', 'size': '1000G'}) => {"ansible_index_var": "index", "ansible_loop_var": "item", "changed": false, "err": " Volume group \"gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L\" not found.\n Cannot process volume group gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L\n", "index": 0, "item": {"lvname": "gluster_lv_engine", "size": "1000G", "vgname": "gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L"}, "msg": "Volume group gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L does not exist.", "rc": 5}
NO MORE HOSTS LEFT *************************************************************
NO MORE HOSTS LEFT *************************************************************
PLAY RECAP ********************************************************************* medusast.penguinpages.local : ok=23 changed=5 unreachable=0 failed=1 skipped=34 rescued=0 ignored=0 odinst.penguinpages.local : ok=23 changed=5 unreachable=0 failed=1 skipped=34 rescued=0 ignored=0 thorst.penguinpages.local : ok=30 changed=9 unreachable=0 failed=0 skipped=29 rescued=0 ignored=0
Please check /var/log/cockpit/ovirt-dashboard/gluster-deployment.log for more informations.
############
Why is oVirt ignoring when I set (and double check explicite device call for deployment?
Attached is the ansible file it creates and then one I had to edit to correct what wizard should have built it as.
-- p <jeremey.wise@gmail.com>enguinpages _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives:
{kind=link}
{kind=link}
I am kind of ignoring it as that is disk #3 in each server.. so first is get oVirt up.. import VMs ... and get use to new environment. Then create gluster stack with NVMe and RDMA :) I was able to deploy cluster. But issue is back. But I don't want to take this thread down that This post is about a bug in the HCI wizard that needs review. I posted ansible file generated.. it is 100% repeatable that when you set /dev/sda or so for one server and /dev/sdc etc.. for another.. the wizard ignores this during ansible build. You can fix it with edit / manual change / paste back.. and reload.... but it should get cleaned up. It is an invaluable feature.. but is broken atm. On Sun, Sep 13, 2020 at 9:45 AM Nir Soffer <nsoffer@redhat.com> wrote:
On Sun, Sep 13, 2020 at 8:48 AM Jeremey Wise <jeremey.wise@gmail.com> wrote:
Greetings:
3 x servers each server has 1 x 512GB ssd 2 x 1TB SSD JBOD
Goal: use HCI disk setup wizard to deploy initial structure
Each server has disk scanning in as different /dev/sd# and so trying to use more clear /dev/mapper/<disk ID>
As such I set this per table below:
# Select each server and set each drive <<<<<<<<<<Double Check drive device ID as they do NOT match up per host
# I transitioned to /dev/mapper object to avoid unclearness of /dev/sd#
thor
/dev/sdc
/dev/mapper/Samsung_SSD_850_PRO_512GB_S250NXAGA15787L
odin
/dev/sdb
/dev/mapper/Micron_1100_MTFDDAV512TBN_17401F699137
medusa
/dev/sdb
/dev/mapper/SAMSUNG_SSD_PM851_mSATA_512GB_S1EWNYAF609306
What is /dev/mapper/Samsung_SSD_850_PRO_512GB_S250NXAGA15787L?
It looks like you are using multipath for local disks, which is not a good idea. First the additional layer can harm performance, and second, these disks may be exposed to engine as FC storage, which can lead to disaster when you try to use the local disk as shared storage.
If you want to use stable names instead of /dev/sd{X}, use /dev/disk/by-id/ symlinks, like:
$ ls -lh /dev/disk/by-id/nvme-eui.5cd2e42a81a11f69 lrwxrwxrwx. 1 root root 13 Sep 7 01:21 /dev/disk/by-id/nvme-eui.5cd2e42a81a11f69 -> ../../nvme0n1
You can find the right stabe name of the device using udevadm:
$ udevadm info --query symlink /dev/nvme0n1 disk/by-id/nvme-INTEL_SSDPEKKF256G8L_BTHH827507DP256B disk/by-path/pci-0000:3e:00.0-nvme-1 disk/by-id/nvme-eui.5cd2e42a81a11f69
Nir
# Note that drives need to be completely clear of any partition or file system
[root@thor /]# gdisk /dev/sdc
GPT fdisk (gdisk) version 1.0.3
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: present
Found valid GPT with protective MBR; using GPT.
Command (? for help): x
Expert command (? for help): z
About to wipe out GPT on /dev/sdc. Proceed? (Y/N): y
GPT data structures destroyed! You may now partition the disk using fdisk or
other utilities.
Blank out MBR? (Y/N): y [image: image.png]
[image: image.png]
But deployment fails with Error: <snip>
TASK [gluster.infra/roles/backend_setup : Filter none-existing devices] ******** task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/get_vg_groupings.yml:38 ok: [thorst.penguinpages.local] => {"ansible_facts": {"gluster_volumes_by_groupname": {}}, "changed": false} ok: [odinst.penguinpages.local] => {"ansible_facts": {"gluster_volumes_by_groupname": {}}, "changed": false} ok: [medusast.penguinpages.local] => {"ansible_facts": {"gluster_volumes_by_groupname": {}}, "changed": false}
TASK [gluster.infra/roles/backend_setup : Make sure thick pvs exists in volume group] *** task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/thick_lv_create.yml:37
TASK [gluster.infra/roles/backend_setup : update LVM fact's] ******************* task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/thick_lv_create.yml:83 skipping: [thorst.penguinpages.local] => {"changed": false, "skip_reason": "Conditional result was False"} skipping: [odinst.penguinpages.local] => {"changed": false, "skip_reason": "Conditional result was False"} skipping: [medusast.penguinpages.local] => {"changed": false, "skip_reason": "Conditional result was False"}
TASK [gluster.infra/roles/backend_setup : Create thick logical volume] ********* task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/thick_lv_create.yml:90 failed: [medusast.penguinpages.local] (item={'vgname': ' gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L', 'lvname': 'gluster_lv_engine', 'size': '1000G'}) => {"ansible_index_var": "index", "ansible_loop_var": "item", "changed": false, "err": " Volume group \"gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L\" not found.\n Cannot process volume group gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L\n", "index": 0, "item": {"lvname": "gluster_lv_engine", "size": "1000G", "vgname": "gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L"}, "msg": "Volume group gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L does not exist.", "rc": 5} changed: [thorst.penguinpages.local] => (item={'vgname': ' gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L', 'lvname': 'gluster_lv_engine', 'size': '1000G'}) => {"ansible_index_var": "index", "ansible_loop_var": "item", "changed": true, "index": 0, "item": {"lvname": "gluster_lv_engine", "size": "1000G", "vgname": "gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L"}, "msg": ""} failed: [odinst.penguinpages.local] (item={'vgname': 'gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L', 'lvname': 'gluster_lv_engine', 'size': '1000G'}) => {"ansible_index_var": "index", "ansible_loop_var": "item", "changed": false, "err": " Volume group \"gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L\" not found.\n Cannot process volume group gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L\n", "index": 0, "item": {"lvname": "gluster_lv_engine", "size": "1000G", "vgname": "gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L"}, "msg": "Volume group gluster_vg_Samsung_SSD_850_PRO_512GB_S250NXAGA15787L does not exist.", "rc": 5}
NO MORE HOSTS LEFT *************************************************************
NO MORE HOSTS LEFT *************************************************************
PLAY RECAP ********************************************************************* medusast.penguinpages.local : ok=23 changed=5 unreachable=0 failed=1 skipped=34 rescued=0 ignored=0 odinst.penguinpages.local : ok=23 changed=5 unreachable=0 failed=1 skipped=34 rescued=0 ignored=0 thorst.penguinpages.local : ok=30 changed=9 unreachable=0 failed=0 skipped=29 rescued=0 ignored=0
Please check /var/log/cockpit/ovirt-dashboard/gluster-deployment.log for more informations.
############
Why is oVirt ignoring when I set (and double check explicite device call for deployment?
Attached is the ansible file it creates and then one I had to edit to correct what wizard should have built it as.
-- p <jeremey.wise@gmail.com>enguinpages _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives:
-- jeremey.wise@gmail.com
{kind=link}
{kind=link}
participants (3)
-
 Jeremey Wise
Jeremey Wise -
 Nir Soffer
Nir Soffer -
 Parth Dhanjal
Parth Dhanjal