Seeking best performance on oVirt cluster

Good morning all, I am trying to get the best performance out of my cluster possible, Here are the details of what I have now: Ovirt version: 4.4.10.7-1.el8 Bare metal for the ovirt engine two hosts TrueNAS cluster storage 1 NFS share 3 vdevs, 6 drives in raidz2 in each vdev 2 nvme drives for silog Storage network is 10 GBit all static IP addresses Tonight, I built a new VM from a template. It had 5 attached disks totalling 100 GB. It took 30 minutes to deploy the new VM from the template. Global utilization was 9%. The SPM has 50% of its memory free and never showed more than 12% network utilization 62 out of 65 TB are available on the newly created NFS backing store (no fragmentation). The TureNAS system is probably overprovisioned for our use. There were peak throughputs of up to 4 GBytes/second (on a 10 GBit network), but overall throughput on the NAS and the network were low. ARC hits were 95 to 100% L2 hits were 0 to 70% Here's the NFS usage stats: [image: image.png] I believe the first peak is where the silog buffered the initial burst of instructions, followed by sustained IO as the VM volumes were built in parallel, and then finally tapering off to the one 50 GB volume that took 40 minutes to copy. The indications of the NFS stats graph are that the network performance is just fine. Here are the disk IO stats covering the same time frame, plus a bit before to show a spike IO: [image: image.png] The spike at 2250 (10 minutes before I started building my VM) shows that the spinners actually hit write speed of almost 20 MBytes per second briefly, then settled in at a sustained 3 to 4 MBytes per second. The silog absorbs several spikes, but remains mostly idle, with activity measured in kilobytes per second. The HGST HUS726060AL5210 drives boast a spike throughput of 12 GB/S, and sustained throughput of 227 Mbps. ------ Now to the questions: 1. Am I asking the on the right list? Does this look like something where tuning ovirt might make a difference, or is this more likely a configuration issue with my storage appliances? 2. Am I expecting too much? Is this well within the bounds of acceptable (expected) performance? 3. How would I go about identifying the bottleneck, should I need to dig deeper? Thanks, David Johnson
{kind=link}
{kind=link}

David, I’m curious what your tests would look like if you mounted nfs with async On Tue, Jul 12, 2022 at 3:02 AM David Johnson <djohnson@maxistechnology.com> wrote:
Good morning all,
I am trying to get the best performance out of my cluster possible,
Here are the details of what I have now:
Ovirt version: 4.4.10.7-1.el8 Bare metal for the ovirt engine two hosts TrueNAS cluster storage 1 NFS share 3 vdevs, 6 drives in raidz2 in each vdev 2 nvme drives for silog Storage network is 10 GBit all static IP addresses
Tonight, I built a new VM from a template. It had 5 attached disks totalling 100 GB. It took 30 minutes to deploy the new VM from the template.
Global utilization was 9%. The SPM has 50% of its memory free and never showed more than 12% network utilization
62 out of 65 TB are available on the newly created NFS backing store (no fragmentation). The TureNAS system is probably overprovisioned for our use.
There were peak throughputs of up to 4 GBytes/second (on a 10 GBit network), but overall throughput on the NAS and the network were low. ARC hits were 95 to 100% L2 hits were 0 to 70%
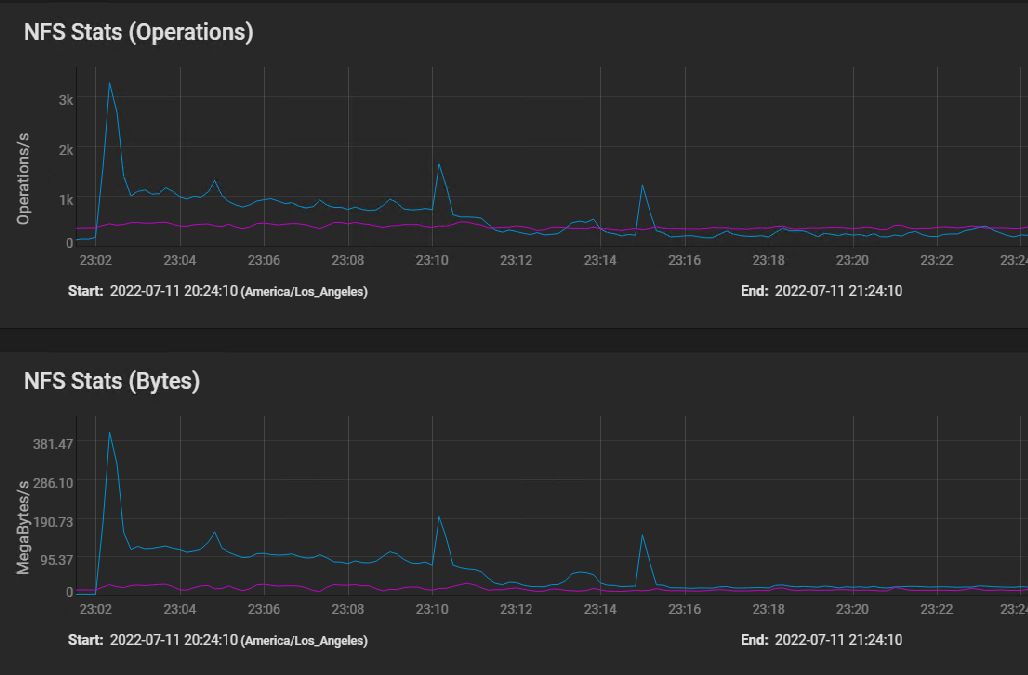
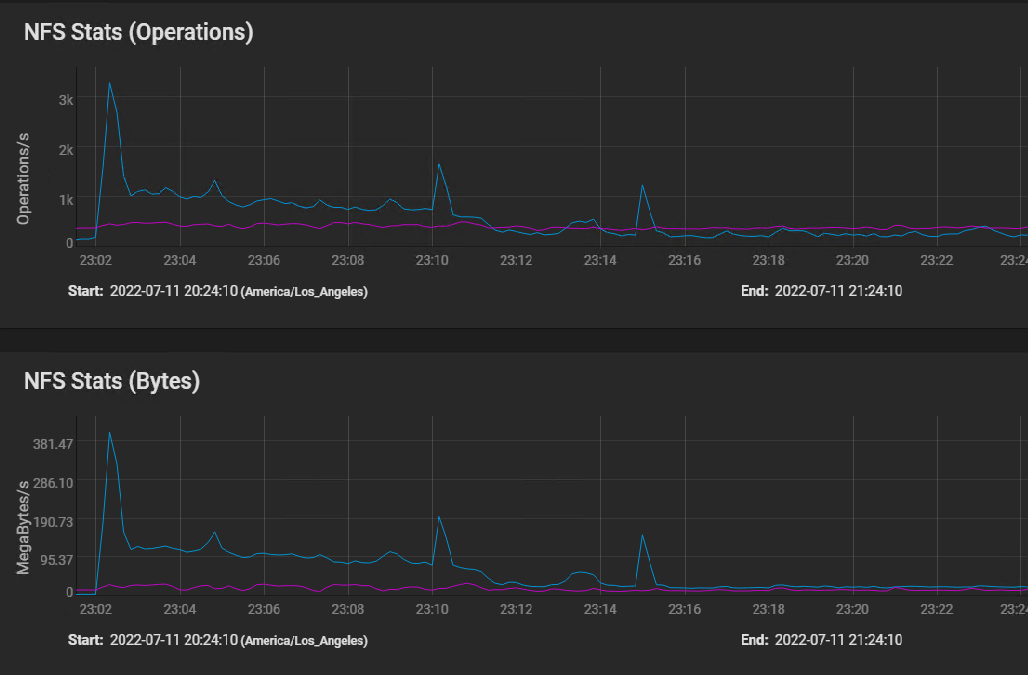
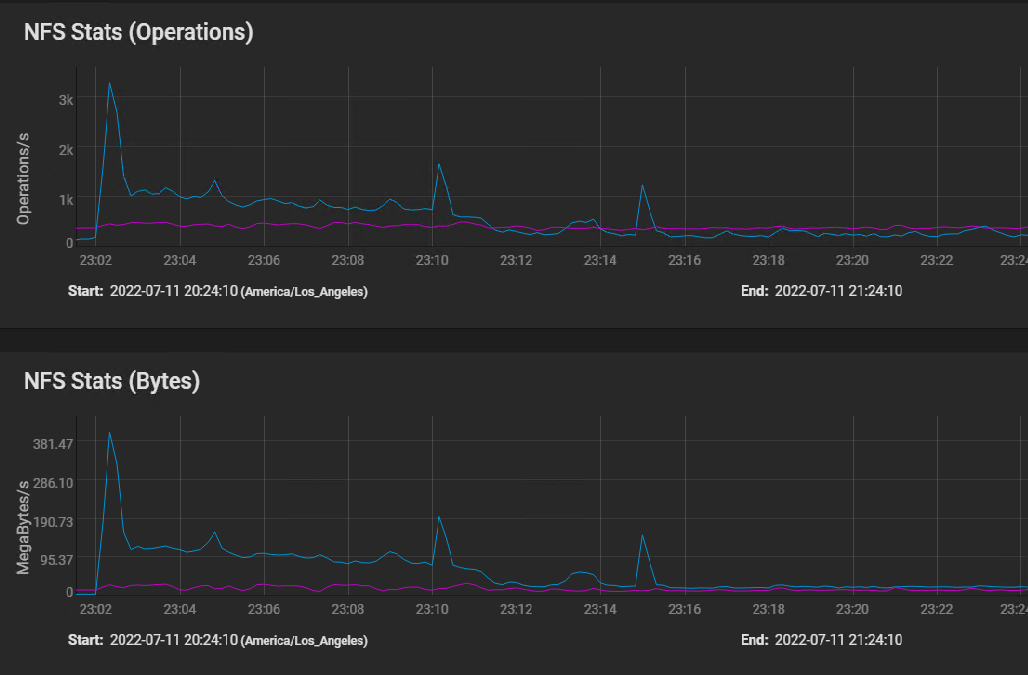
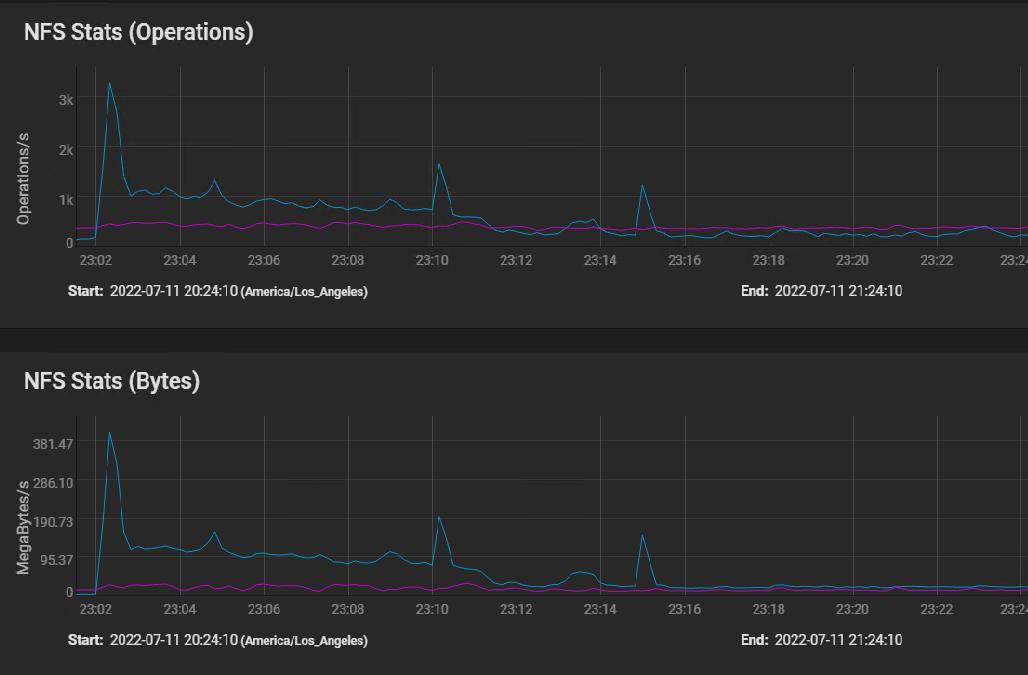
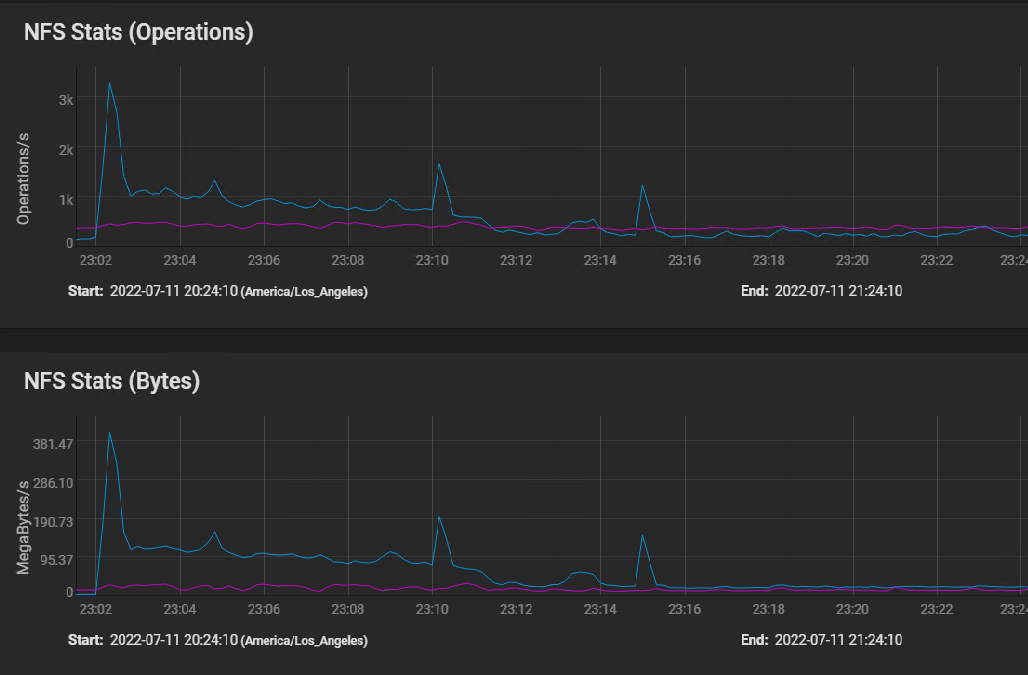
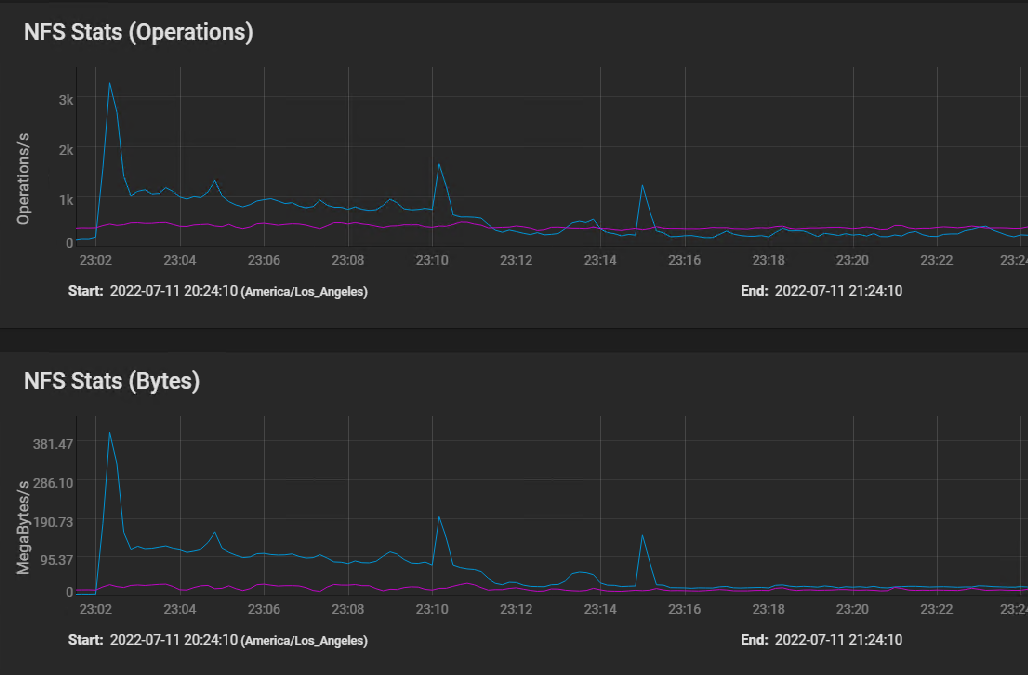
Here's the NFS usage stats: [image: image.png]
I believe the first peak is where the silog buffered the initial burst of instructions, followed by sustained IO as the VM volumes were built in parallel, and then finally tapering off to the one 50 GB volume that took 40 minutes to copy.
The indications of the NFS stats graph are that the network performance is just fine.
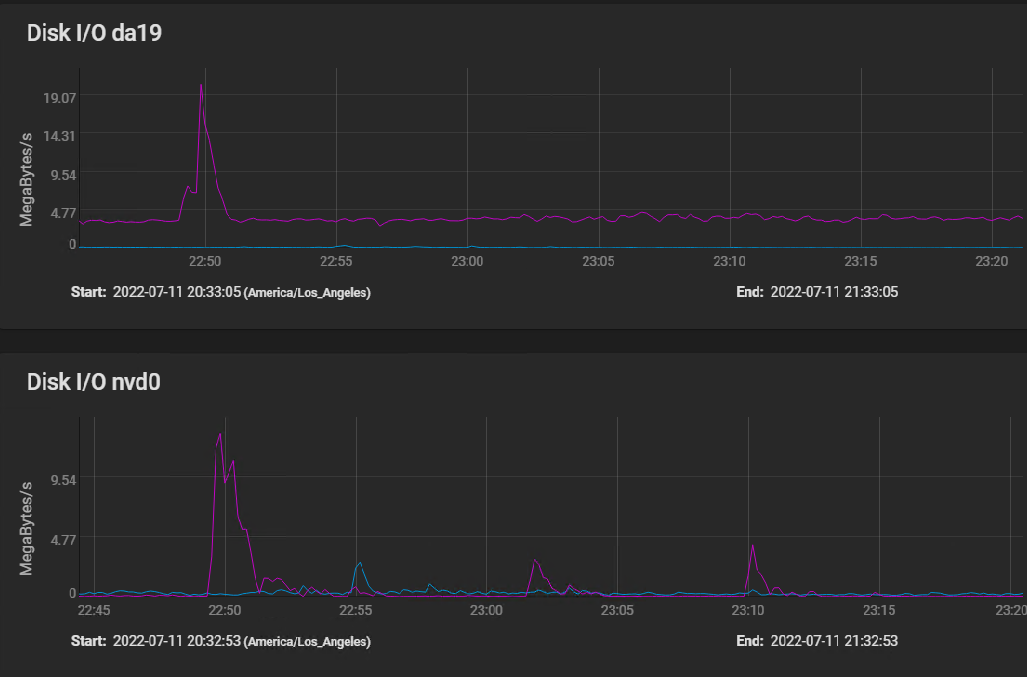
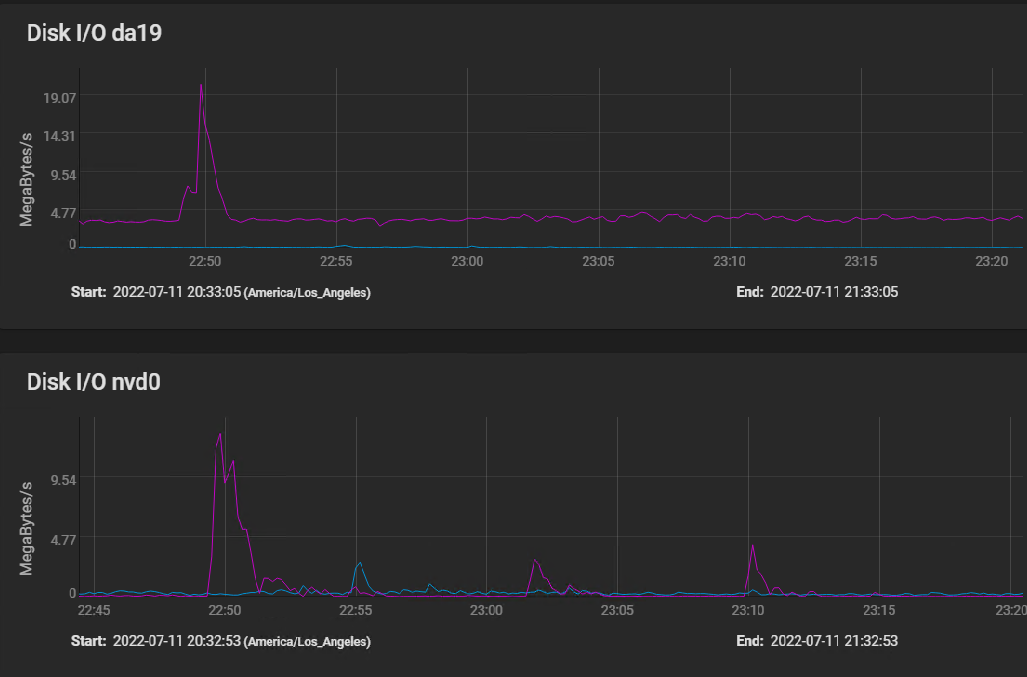
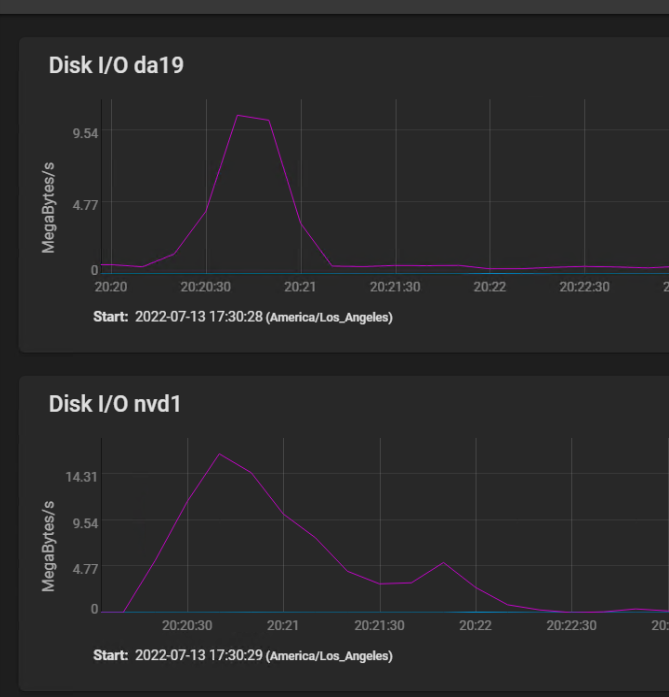
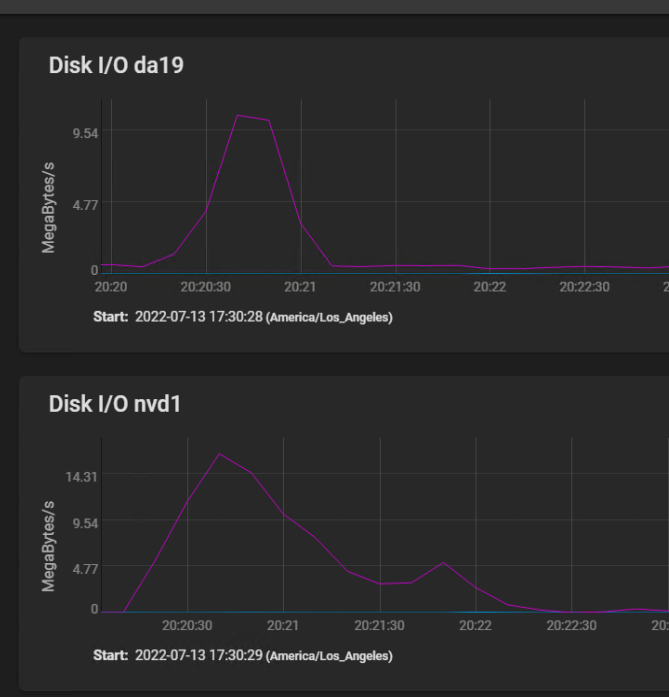
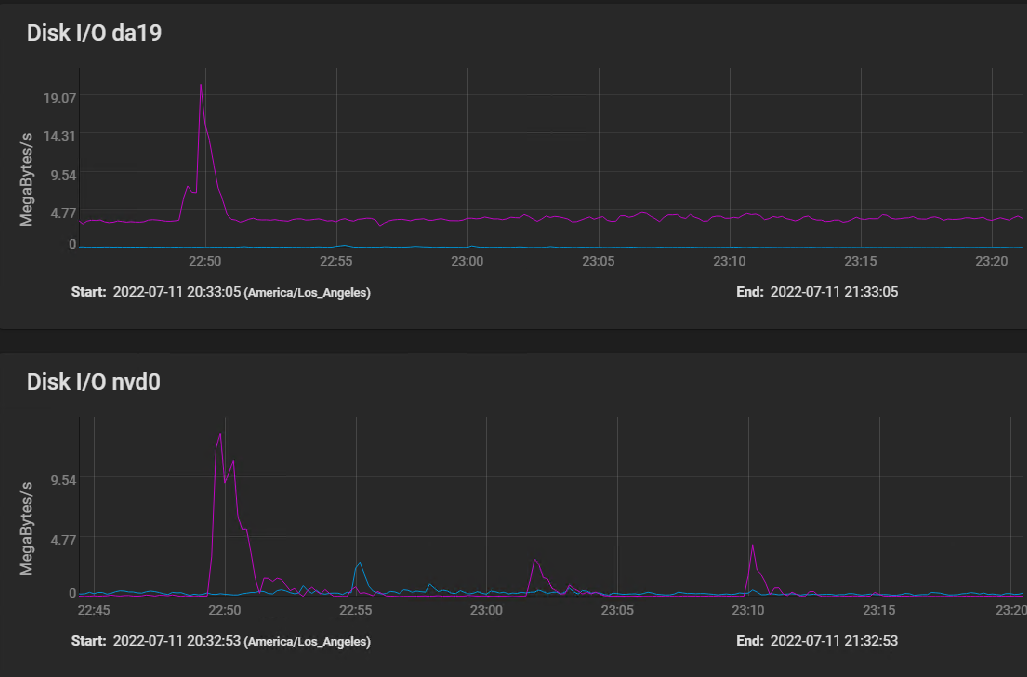
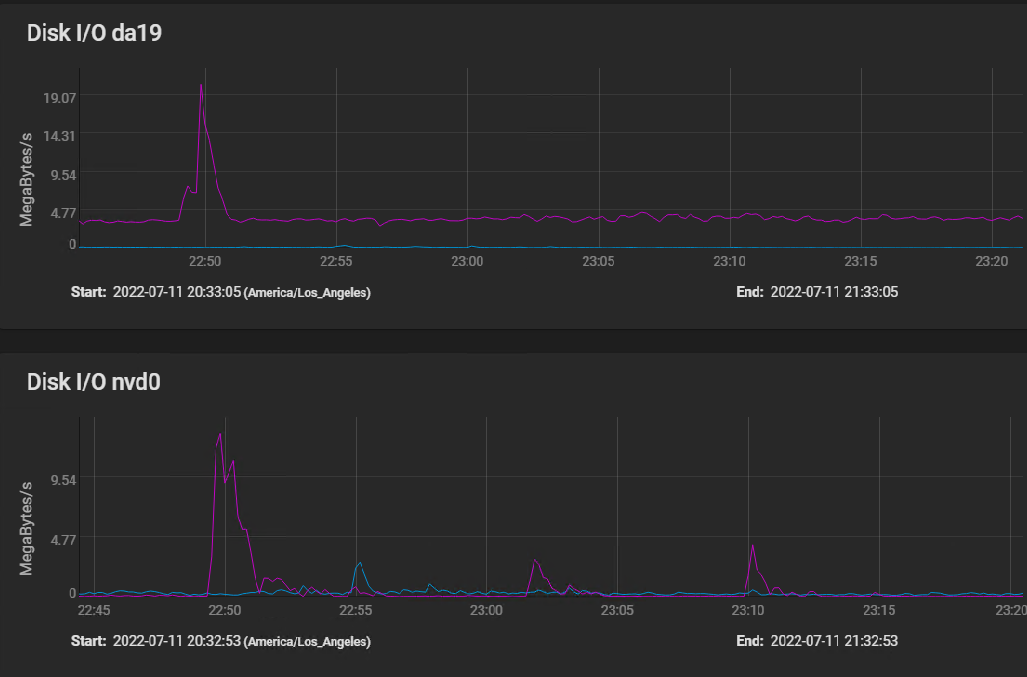
Here are the disk IO stats covering the same time frame, plus a bit before to show a spike IO:
[image: image.png] The spike at 2250 (10 minutes before I started building my VM) shows that the spinners actually hit write speed of almost 20 MBytes per second briefly, then settled in at a sustained 3 to 4 MBytes per second. The silog absorbs several spikes, but remains mostly idle, with activity measured in kilobytes per second.
The HGST HUS726060AL5210 drives boast a spike throughput of 12 GB/S, and sustained throughput of 227 Mbps.
------ Now to the questions: 1. Am I asking the on the right list? Does this look like something where tuning ovirt might make a difference, or is this more likely a configuration issue with my storage appliances?
2. Am I expecting too much? Is this well within the bounds of acceptable (expected) performance?
3. How would I go about identifying the bottleneck, should I need to dig deeper?
Thanks, David Johnson _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/BDTES2D7V3KHAT...
{kind=link}
{kind=link}
Where and how do I make this change to test? Can I do it without interrupting the vms that are active? Thanks David Johnson On Tue, Jul 12, 2022, 5:25 AM Jayme <jaymef@gmail.com> wrote:
David,
I’m curious what your tests would look like if you mounted nfs with async
On Tue, Jul 12, 2022 at 3:02 AM David Johnson < djohnson@maxistechnology.com> wrote:
Good morning all,
I am trying to get the best performance out of my cluster possible,
Here are the details of what I have now:
Ovirt version: 4.4.10.7-1.el8 Bare metal for the ovirt engine two hosts TrueNAS cluster storage 1 NFS share 3 vdevs, 6 drives in raidz2 in each vdev 2 nvme drives for silog Storage network is 10 GBit all static IP addresses
Tonight, I built a new VM from a template. It had 5 attached disks totalling 100 GB. It took 30 minutes to deploy the new VM from the template.
Global utilization was 9%. The SPM has 50% of its memory free and never showed more than 12% network utilization
62 out of 65 TB are available on the newly created NFS backing store (no fragmentation). The TureNAS system is probably overprovisioned for our use.
There were peak throughputs of up to 4 GBytes/second (on a 10 GBit network), but overall throughput on the NAS and the network were low. ARC hits were 95 to 100% L2 hits were 0 to 70%
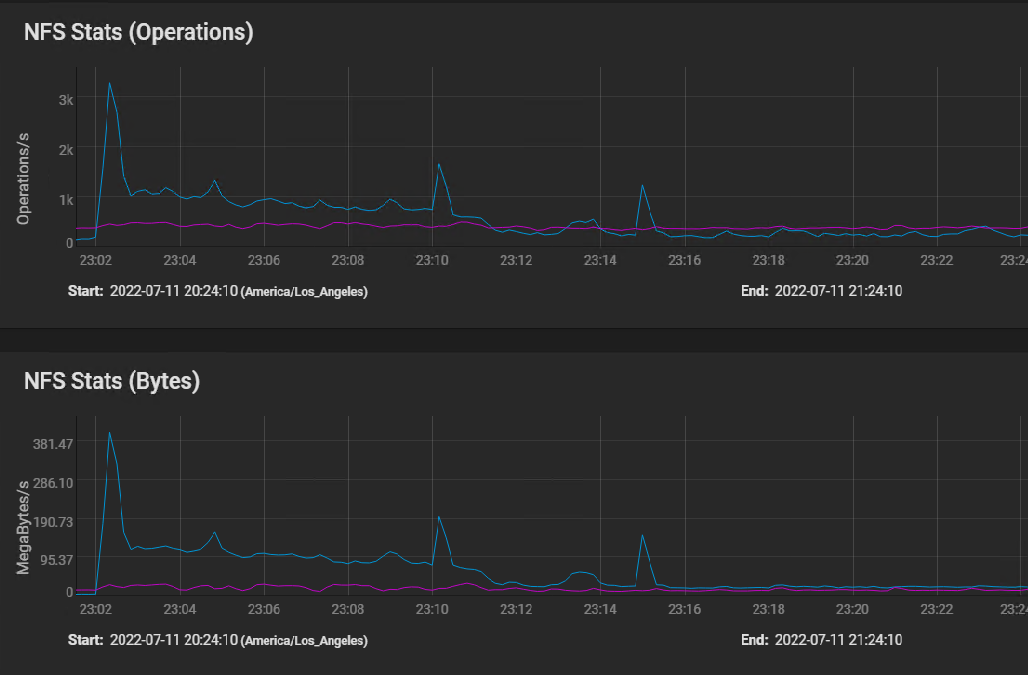
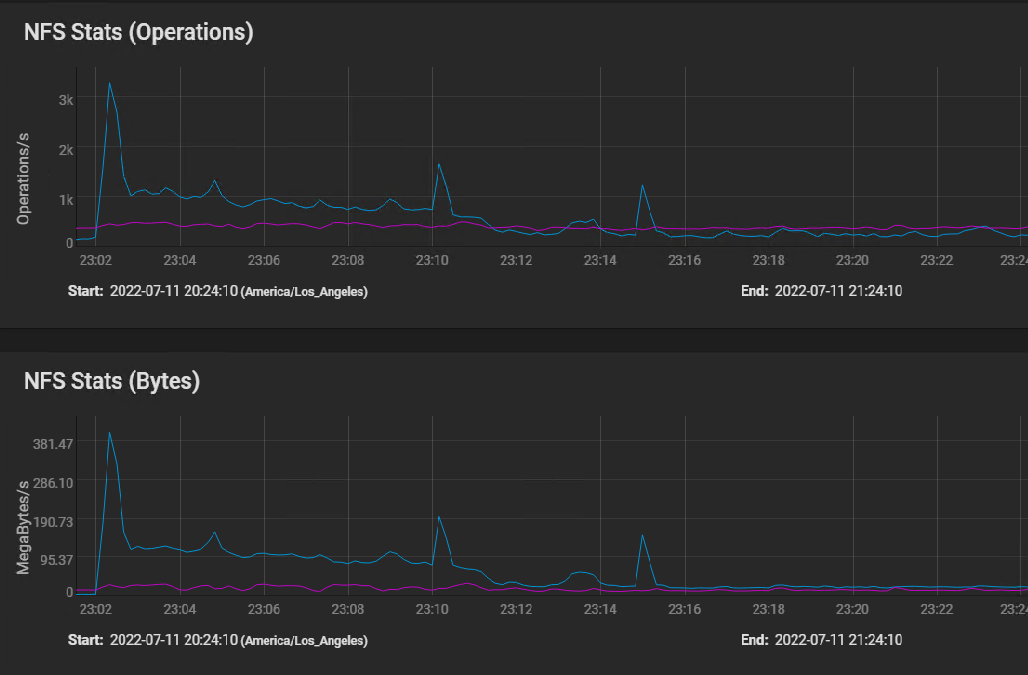
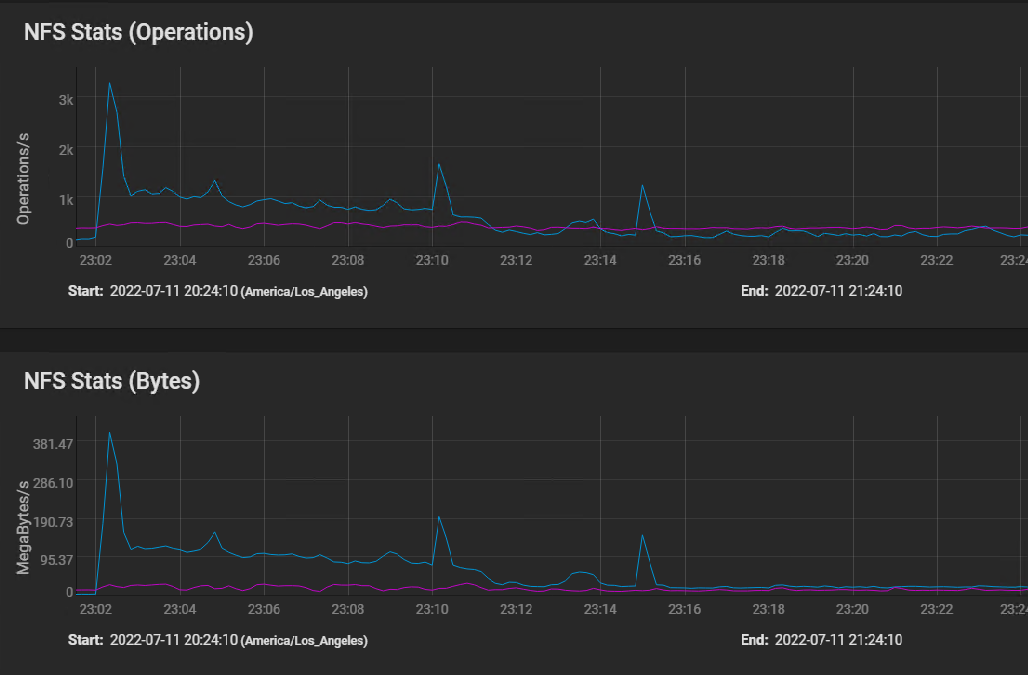
Here's the NFS usage stats: [image: image.png]
I believe the first peak is where the silog buffered the initial burst of instructions, followed by sustained IO as the VM volumes were built in parallel, and then finally tapering off to the one 50 GB volume that took 40 minutes to copy.
The indications of the NFS stats graph are that the network performance is just fine.
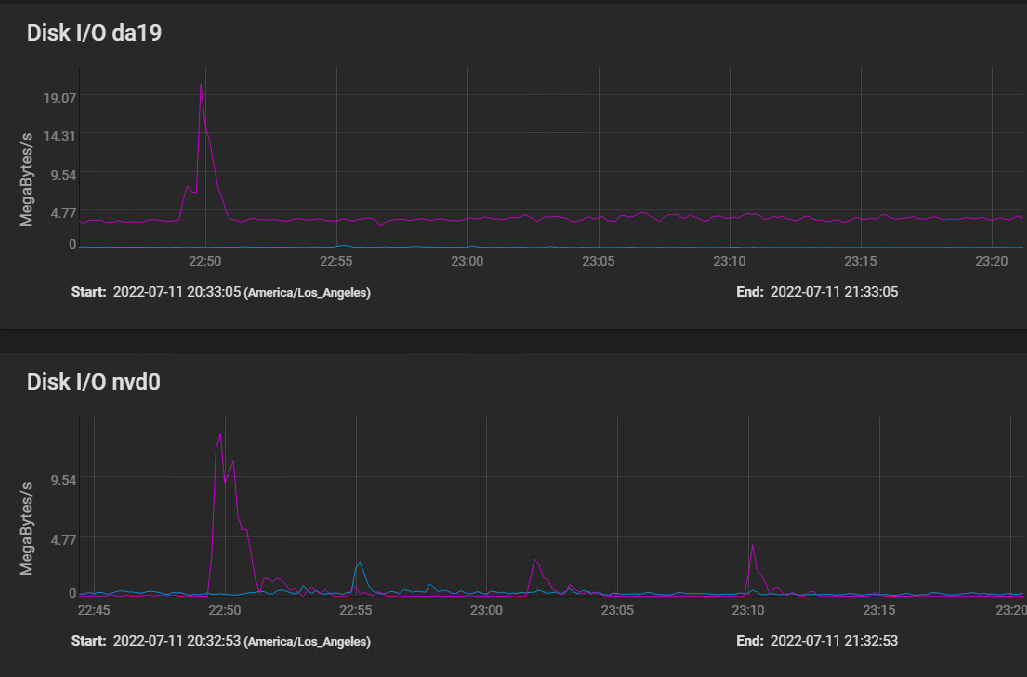
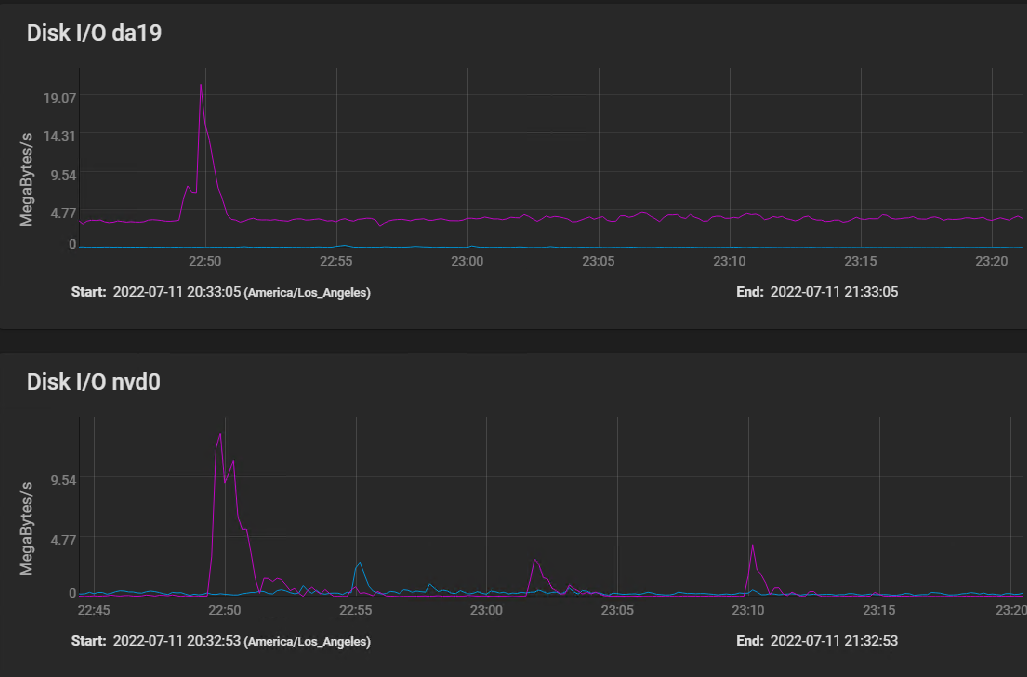
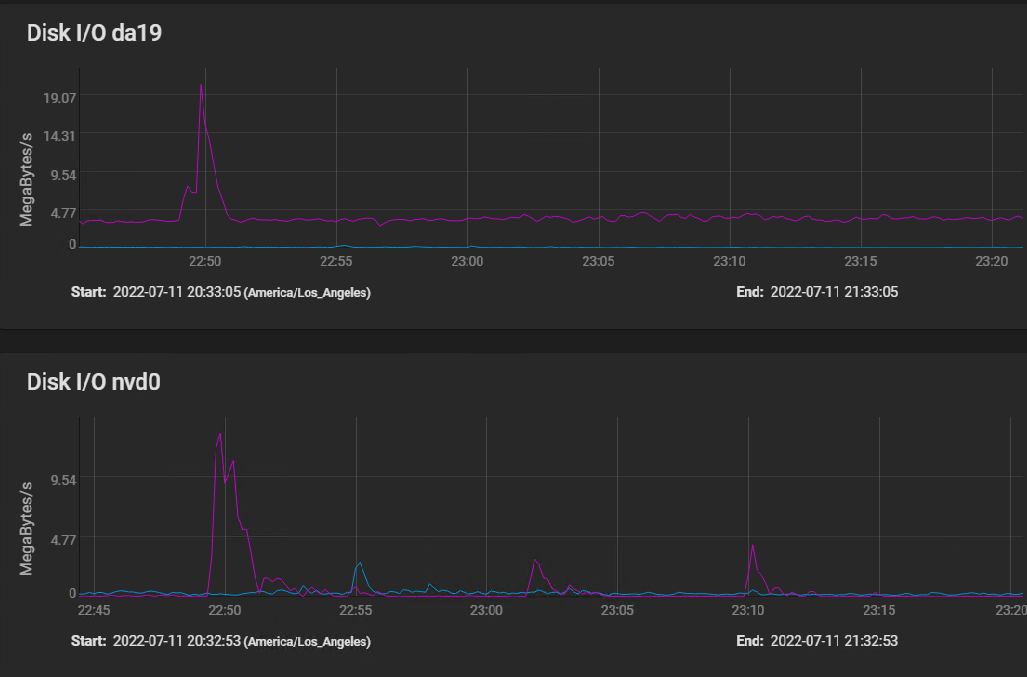
Here are the disk IO stats covering the same time frame, plus a bit before to show a spike IO:
[image: image.png] The spike at 2250 (10 minutes before I started building my VM) shows that the spinners actually hit write speed of almost 20 MBytes per second briefly, then settled in at a sustained 3 to 4 MBytes per second. The silog absorbs several spikes, but remains mostly idle, with activity measured in kilobytes per second.
The HGST HUS726060AL5210 drives boast a spike throughput of 12 GB/S, and sustained throughput of 227 Mbps.
------ Now to the questions: 1. Am I asking the on the right list? Does this look like something where tuning ovirt might make a difference, or is this more likely a configuration issue with my storage appliances?
2. Am I expecting too much? Is this well within the bounds of acceptable (expected) performance?
3. How would I go about identifying the bottleneck, should I need to dig deeper?
Thanks, David Johnson _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/BDTES2D7V3KHAT...
{kind=link}
{kind=link}

Are you using pNFS ? Best Regards,Strahil Nikolov On Tue, Jul 12, 2022 at 14:21, David Johnson<djohnson@maxistechnology.com> wrote: _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/JNN5CADTFTEZVA...
Short answer: No. Long answer: TrueNAS doesn't support pNFS yet (or at least does not advertise that support), and they are having stability issues with some of the other NFS enhancements they have brought in from BSD. On Tue, Jul 12, 2022 at 3:31 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Are you using pNFS ?
Best Regards, Strahil Nikolov
On Tue, Jul 12, 2022 at 14:21, David Johnson <djohnson@maxistechnology.com> wrote: _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/JNN5CADTFTEZVA...

I have experienced the same performance problem in creating new template or creating new stateful image from template. I have traced it to the use of qemu-img convert which is very very slow. Currently a template creation on my setup, takes around 29m for a 45G image when a simple copy over NFS takes 1m26s over a 10G network which is expected since there is roughly as many read as write over the network (4Gbps) Adding --cache writeback to qemu-img improves from 29m to around 8m but according to a prior comment on this mailing list might not work on all platform. Hope that helps
I would consider using smaller templates .Also, give it a try with iSCSI. Best Regards,Strahil Nikolov On Wed, Jul 13, 2022 at 3:10, Pascal D<pascal@butterflyit.com> wrote: I have experienced the same performance problem in creating new template or creating new stateful image from template. I have traced it to the use of qemu-img convert which is very very slow. Currently a template creation on my setup, takes around 29m for a 45G image when a simple copy over NFS takes 1m26s over a 10G network which is expected since there is roughly as many read as write over the network (4Gbps) Adding --cache writeback to qemu-img improves from 29m to around 8m but according to a prior comment on this mailing list might not work on all platform. Hope that helps _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/XWUDXA47L72FUH...
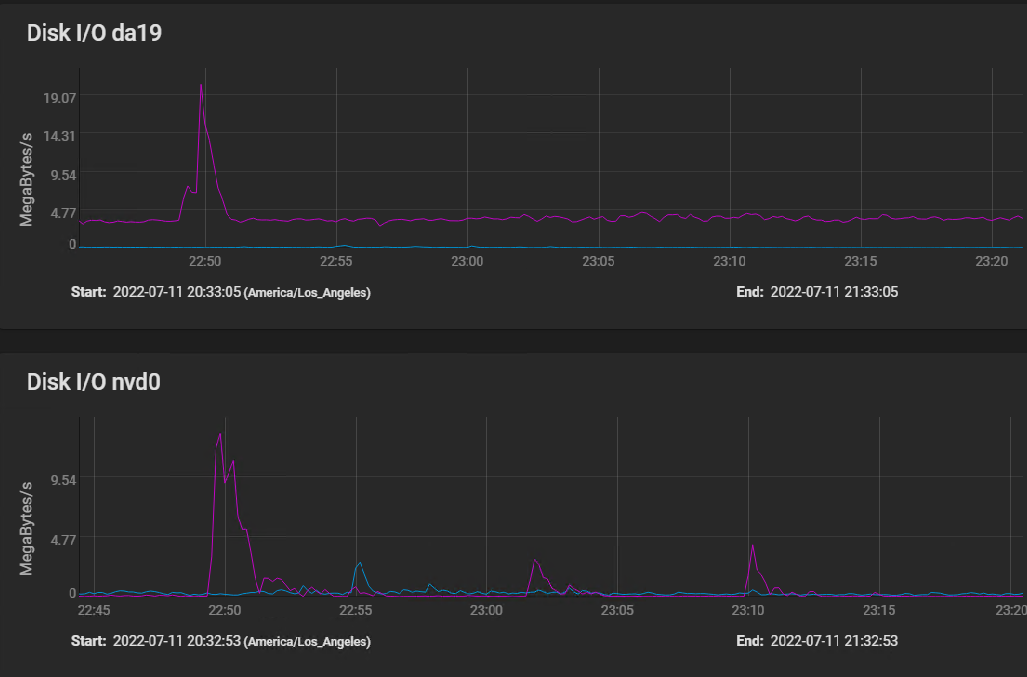
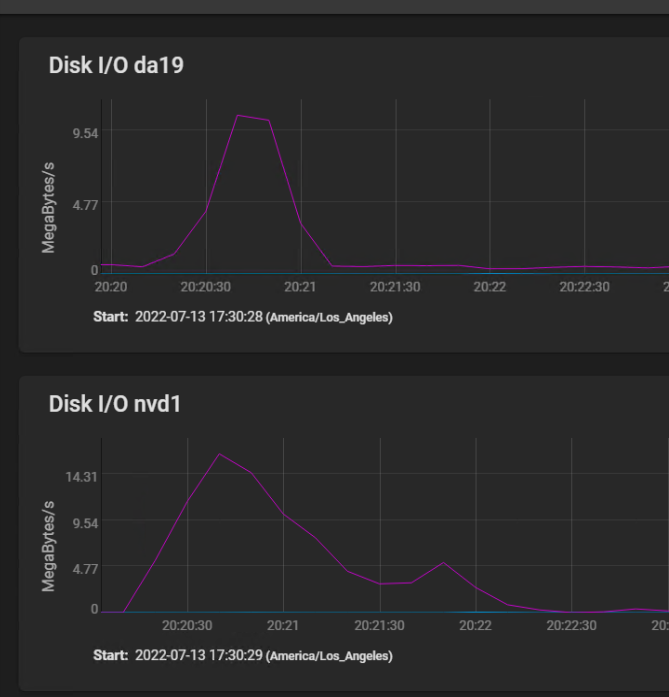
I have changed the TrueNAS pool setting to synchronous writes = disabled, and it improved throughput enormously. I have not been able to figure out how to set the NFS to async - TrueNAS and Ovirt both seem to hide the NFS settings, and I haven't found where either of them allows me to configure these. I am still not seeing anywhere near the throughput on the disks that I would expect. Here is what happened creating a VM from the same template. The VM was created in 2 minutes instead of 30. The graph doesn't show 10x the throughput, but that is what I see experientially. [image: image.png] This operation did peg the storage network at 10 gbits very briefly, but at no point did the hard drives hit as much as 10% of their rated sustained throughput. Do you see room for more tuning, or have I tuned this as far as is reasonable? Thank you On Tue, Jul 12, 2022 at 5:25 AM Jayme <jaymef@gmail.com> wrote:
David,
I’m curious what your tests would look like if you mounted nfs with async
On Tue, Jul 12, 2022 at 3:02 AM David Johnson < djohnson@maxistechnology.com> wrote:
Good morning all,
I am trying to get the best performance out of my cluster possible,
Here are the details of what I have now:
Ovirt version: 4.4.10.7-1.el8 Bare metal for the ovirt engine two hosts TrueNAS cluster storage 1 NFS share 3 vdevs, 6 drives in raidz2 in each vdev 2 nvme drives for silog Storage network is 10 GBit all static IP addresses
Tonight, I built a new VM from a template. It had 5 attached disks totalling 100 GB. It took 30 minutes to deploy the new VM from the template.
Global utilization was 9%. The SPM has 50% of its memory free and never showed more than 12% network utilization
62 out of 65 TB are available on the newly created NFS backing store (no fragmentation). The TureNAS system is probably overprovisioned for our use.
There were peak throughputs of up to 4 GBytes/second (on a 10 GBit network), but overall throughput on the NAS and the network were low. ARC hits were 95 to 100% L2 hits were 0 to 70%
Here's the NFS usage stats: [image: image.png]
I believe the first peak is where the silog buffered the initial burst of instructions, followed by sustained IO as the VM volumes were built in parallel, and then finally tapering off to the one 50 GB volume that took 40 minutes to copy.
The indications of the NFS stats graph are that the network performance is just fine.
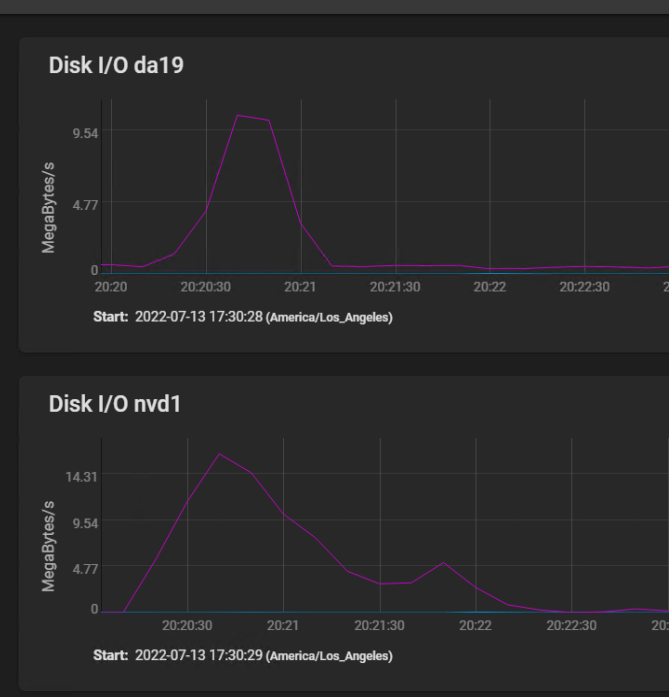
Here are the disk IO stats covering the same time frame, plus a bit before to show a spike IO:
[image: image.png] The spike at 2250 (10 minutes before I started building my VM) shows that the spinners actually hit write speed of almost 20 MBytes per second briefly, then settled in at a sustained 3 to 4 MBytes per second. The silog absorbs several spikes, but remains mostly idle, with activity measured in kilobytes per second.
The HGST HUS726060AL5210 drives boast a spike throughput of 12 GB/S, and sustained throughput of 227 Mbps.
------ Now to the questions: 1. Am I asking the on the right list? Does this look like something where tuning ovirt might make a difference, or is this more likely a configuration issue with my storage appliances?
2. Am I expecting too much? Is this well within the bounds of acceptable (expected) performance?
3. How would I go about identifying the bottleneck, should I need to dig deeper?
Thanks, David Johnson _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/BDTES2D7V3KHAT...
{kind=link}
{kind=link}
{kind=link}

for the ovirt side: you can set nfs mount options on the storage domain settings (Custom connection parameters) but it's recommended to keep them as is. Greetings Klaas On 7/14/22 03:38, David Johnson wrote:
I have changed the TrueNAS pool setting to synchronous writes = disabled, and it improved throughput enormously.
I have not been able to figure out how to set the NFS to async - TrueNAS and Ovirt both seem to hide the NFS settings, and I haven't found where either of them allows me to configure these.
I am still not seeing anywhere near the throughput on the disks that I would expect.
Here is what happened creating a VM from the same template. The VM was created in 2 minutes instead of 30. The graph doesn't show 10x the throughput, but that is what I see experientially.
image.png
This operation did peg the storage network at 10 gbits very briefly, but at no point did the hard drives hit as much as 10% of their rated sustained throughput.
Do you see room for more tuning, or have I tuned this as far as is reasonable?
Thank you
On Tue, Jul 12, 2022 at 5:25 AM Jayme <jaymef@gmail.com> wrote:
David,
I’m curious what your tests would look like if you mounted nfs with async
On Tue, Jul 12, 2022 at 3:02 AM David Johnson <djohnson@maxistechnology.com> wrote:
Good morning all,
I am trying to get the best performance out of my cluster possible,
Here are the details of what I have now:
Ovirt version: 4.4.10.7-1.el8 Bare metal for the ovirt engine two hosts TrueNAS cluster storage 1 NFS share 3 vdevs, 6 drives in raidz2 in each vdev 2 nvme drives for silog Storage network is 10 GBit all static IP addresses
Tonight, I built a new VM from a template. It had 5 attached disks totalling 100 GB. It took 30 minutes to deploy the new VM from the template.
Global utilization was 9%. The SPM has 50% of its memory free and never showed more than 12% network utilization
62 out of 65 TB are available on the newly created NFS backing store (no fragmentation). The TureNAS system is probably overprovisioned for our use.
There were peak throughputs of up to 4 GBytes/second (on a 10 GBit network), but overall throughput on the NAS and the network were low. ARC hits were 95 to 100% L2 hits were 0 to 70%
Here's the NFS usage stats: image.png
I believe the first peak is where the silog buffered the initial burst of instructions, followed by sustained IO as the VM volumes were built in parallel, and then finally tapering off to the one 50 GB volume that took 40 minutes to copy.
The indications of the NFS stats graph are that the network performance is just fine.
Here are the disk IO stats covering the same time frame, plus a bit before to show a spike IO:
image.png The spike at 2250 (10 minutes before I started building my VM) shows that the spinners actually hit write speed of almost 20 MBytes per second briefly, then settled in at a sustained 3 to 4 MBytes per second. The silog absorbs several spikes, but remains mostly idle, with activity measured in kilobytes per second.
The HGST HUS726060AL5210 drives boast a spike throughput of 12 GB/S, and sustained throughput of 227 Mbps.
------ Now to the questions: 1. Am I asking the on the right list? Does this look like something where tuning ovirt might make a difference, or is this more likely a configuration issue with my storage appliances?
2. Am I expecting too much? Is this well within the bounds of acceptable (expected) performance?
3. How would I go about identifying the bottleneck, should I need to dig deeper?
Thanks, David Johnson _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/BDTES2D7V3KHAT...
_______________________________________________ Users mailing list --users@ovirt.org To unsubscribe send an email tousers-leave@ovirt.org Privacy Statement:https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct:https://www.ovirt.org/community/about/community-guidelines/ List Archives:https://lists.ovirt.org/archives/list/users@ovirt.org/message/ORZWBQMFJT2JWG...
{kind=link}
{kind=link}
{kind=link}
David, You should keep in mind that disabling sync on NFS can be potentially dangerous. I suggested trying it to see if you'd see a difference in your tests but it may not be recommended for production use because it could lead to data corruption in certain cases, power loss etc. On Wed, Jul 13, 2022 at 10:39 PM David Johnson <djohnson@maxistechnology.com> wrote:
I have changed the TrueNAS pool setting to synchronous writes = disabled, and it improved throughput enormously.
I have not been able to figure out how to set the NFS to async - TrueNAS and Ovirt both seem to hide the NFS settings, and I haven't found where either of them allows me to configure these.
I am still not seeing anywhere near the throughput on the disks that I would expect.
Here is what happened creating a VM from the same template. The VM was created in 2 minutes instead of 30. The graph doesn't show 10x the throughput, but that is what I see experientially.
[image: image.png]
This operation did peg the storage network at 10 gbits very briefly, but at no point did the hard drives hit as much as 10% of their rated sustained throughput.
Do you see room for more tuning, or have I tuned this as far as is reasonable?
Thank you
On Tue, Jul 12, 2022 at 5:25 AM Jayme <jaymef@gmail.com> wrote:
David,
I’m curious what your tests would look like if you mounted nfs with async
On Tue, Jul 12, 2022 at 3:02 AM David Johnson < djohnson@maxistechnology.com> wrote:
Good morning all,
I am trying to get the best performance out of my cluster possible,
Here are the details of what I have now:
Ovirt version: 4.4.10.7-1.el8 Bare metal for the ovirt engine two hosts TrueNAS cluster storage 1 NFS share 3 vdevs, 6 drives in raidz2 in each vdev 2 nvme drives for silog Storage network is 10 GBit all static IP addresses
Tonight, I built a new VM from a template. It had 5 attached disks totalling 100 GB. It took 30 minutes to deploy the new VM from the template.
Global utilization was 9%. The SPM has 50% of its memory free and never showed more than 12% network utilization
62 out of 65 TB are available on the newly created NFS backing store (no fragmentation). The TureNAS system is probably overprovisioned for our use.
There were peak throughputs of up to 4 GBytes/second (on a 10 GBit network), but overall throughput on the NAS and the network were low. ARC hits were 95 to 100% L2 hits were 0 to 70%
Here's the NFS usage stats: [image: image.png]
I believe the first peak is where the silog buffered the initial burst of instructions, followed by sustained IO as the VM volumes were built in parallel, and then finally tapering off to the one 50 GB volume that took 40 minutes to copy.
The indications of the NFS stats graph are that the network performance is just fine.
Here are the disk IO stats covering the same time frame, plus a bit before to show a spike IO:
[image: image.png] The spike at 2250 (10 minutes before I started building my VM) shows that the spinners actually hit write speed of almost 20 MBytes per second briefly, then settled in at a sustained 3 to 4 MBytes per second. The silog absorbs several spikes, but remains mostly idle, with activity measured in kilobytes per second.
The HGST HUS726060AL5210 drives boast a spike throughput of 12 GB/S, and sustained throughput of 227 Mbps.
------ Now to the questions: 1. Am I asking the on the right list? Does this look like something where tuning ovirt might make a difference, or is this more likely a configuration issue with my storage appliances?
2. Am I expecting too much? Is this well within the bounds of acceptable (expected) performance?
3. How would I go about identifying the bottleneck, should I need to dig deeper?
Thanks, David Johnson _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/BDTES2D7V3KHAT...
{kind=link}
{kind=link}
{kind=link}
Yes, we did the analysis on this. The on-platter consistency of the underlying ZRAID file system is sufficiently robust to meet our production needs today. In this cluster, our workload is such that a loss of a few minutes of data is not a business issue. An event that could cause data loss would require re-execution of the jobs anyways. Since our cluster is colocated in the power company's data center, if we see power loss we have much bigger problems. The mishap that started this is that we had what looked like power loss, but was actually a failing motherboard. From bitter past experience, nothing protects from a failing motherboard or RAID controller except frequent backups, in which case you can lose up to a day's worth of data.. The long term plan is to move to a cinder system when we have resources for a dedicated platform administrator. NFS on TrueNASis a hold-me-over that we selected primarily because of its ease of administration. After consulting here and on the ixSystems lists, TrueNAS is not the right platform for iSCSI with write intensive virtual machines. Thank you! On Thu, Jul 14, 2022 at 8:30 AM Jayme <jaymef@gmail.com> wrote:
David,
You should keep in mind that disabling sync on NFS can be potentially dangerous. I suggested trying it to see if you'd see a difference in your tests but it may not be recommended for production use because it could lead to data corruption in certain cases, power loss etc.
On Wed, Jul 13, 2022 at 10:39 PM David Johnson < djohnson@maxistechnology.com> wrote:
I have changed the TrueNAS pool setting to synchronous writes = disabled, and it improved throughput enormously.
I have not been able to figure out how to set the NFS to async - TrueNAS and Ovirt both seem to hide the NFS settings, and I haven't found where either of them allows me to configure these.
I am still not seeing anywhere near the throughput on the disks that I would expect.
Here is what happened creating a VM from the same template. The VM was created in 2 minutes instead of 30. The graph doesn't show 10x the throughput, but that is what I see experientially.
[image: image.png]
This operation did peg the storage network at 10 gbits very briefly, but at no point did the hard drives hit as much as 10% of their rated sustained throughput.
Do you see room for more tuning, or have I tuned this as far as is reasonable?
Thank you
On Tue, Jul 12, 2022 at 5:25 AM Jayme <jaymef@gmail.com> wrote:
David,
I’m curious what your tests would look like if you mounted nfs with async
On Tue, Jul 12, 2022 at 3:02 AM David Johnson < djohnson@maxistechnology.com> wrote:
Good morning all,
I am trying to get the best performance out of my cluster possible,
Here are the details of what I have now:
Ovirt version: 4.4.10.7-1.el8 Bare metal for the ovirt engine two hosts TrueNAS cluster storage 1 NFS share 3 vdevs, 6 drives in raidz2 in each vdev 2 nvme drives for silog Storage network is 10 GBit all static IP addresses
Tonight, I built a new VM from a template. It had 5 attached disks totalling 100 GB. It took 30 minutes to deploy the new VM from the template.
Global utilization was 9%. The SPM has 50% of its memory free and never showed more than 12% network utilization
62 out of 65 TB are available on the newly created NFS backing store (no fragmentation). The TureNAS system is probably overprovisioned for our use.
There were peak throughputs of up to 4 GBytes/second (on a 10 GBit network), but overall throughput on the NAS and the network were low. ARC hits were 95 to 100% L2 hits were 0 to 70%
Here's the NFS usage stats: [image: image.png]
I believe the first peak is where the silog buffered the initial burst of instructions, followed by sustained IO as the VM volumes were built in parallel, and then finally tapering off to the one 50 GB volume that took 40 minutes to copy.
The indications of the NFS stats graph are that the network performance is just fine.
Here are the disk IO stats covering the same time frame, plus a bit before to show a spike IO:
[image: image.png] The spike at 2250 (10 minutes before I started building my VM) shows that the spinners actually hit write speed of almost 20 MBytes per second briefly, then settled in at a sustained 3 to 4 MBytes per second. The silog absorbs several spikes, but remains mostly idle, with activity measured in kilobytes per second.
The HGST HUS726060AL5210 drives boast a spike throughput of 12 GB/S, and sustained throughput of 227 Mbps.
------ Now to the questions: 1. Am I asking the on the right list? Does this look like something where tuning ovirt might make a difference, or is this more likely a configuration issue with my storage appliances?
2. Am I expecting too much? Is this well within the bounds of acceptable (expected) performance?
3. How would I go about identifying the bottleneck, should I need to dig deeper?
Thanks, David Johnson _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/BDTES2D7V3KHAT...
{kind=link}
{kind=link}
{kind=link}

Once upon a time, David Johnson <djohnson@maxistechnology.com> said:
Since our cluster is colocated in the power company's data center, if we see power loss we have much bigger problems.
Heh, you'd think that... but experience has taught me otherwise. -- Chris Adams <cma@cmadams.net>

On Tue, Jul 12, 2022 at 9:02 AM David Johnson <djohnson@maxistechnology.com> wrote:
Good morning all,
I am trying to get the best performance out of my cluster possible,
Here are the details of what I have now:
Ovirt version: 4.4.10.7-1.el8 Bare metal for the ovirt engine two hosts TrueNAS cluster storage 1 NFS share 3 vdevs, 6 drives in raidz2 in each vdev 2 nvme drives for silog Storage network is 10 GBit all static IP addresses
Tonight, I built a new VM from a template. It had 5 attached disks totalling 100 GB. It took 30 minutes to deploy the new VM from the template.
Global utilization was 9%. The SPM has 50% of its memory free and never showed more than 12% network utilization
62 out of 65 TB are available on the newly created NFS backing store (no fragmentation). The TureNAS system is probably overprovisioned for our use.
There were peak throughputs of up to 4 GBytes/second (on a 10 GBit network), but overall throughput on the NAS and the network were low. ARC hits were 95 to 100% L2 hits were 0 to 70%
Here's the NFS usage stats: [image: image.png]
I believe the first peak is where the silog buffered the initial burst of instructions, followed by sustained IO as the VM volumes were built in parallel, and then finally tapering off to the one 50 GB volume that took 40 minutes to copy.
The indications of the NFS stats graph are that the network performance is just fine.
Here are the disk IO stats covering the same time frame, plus a bit before to show a spike IO:
[image: image.png] The spike at 2250 (10 minutes before I started building my VM) shows that the spinners actually hit write speed of almost 20 MBytes per second briefly, then settled in at a sustained 3 to 4 MBytes per second. The silog absorbs several spikes, but remains mostly idle, with activity measured in kilobytes per second.
The HGST HUS726060AL5210 drives boast a spike throughput of 12 GB/S, and sustained throughput of 227 Mbps.
------ Now to the questions: 1. Am I asking the on the right list? Does this look like something where tuning ovirt might make a difference, or is this more likely a configuration issue with my storage appliances?
2. Am I expecting too much? Is this well within the bounds of acceptable (expected) performance?
3. How would I go about identifying the bottleneck, should I need to dig deeper?
One thing that can be interesting to try to to apply this patch for vdsm: diff --git a/lib/vdsm/storage/sd.py b/lib/vdsm/storage/sd.py index 36c393b5a..9cb7486c0 100644 --- a/lib/vdsm/storage/sd.py +++ b/lib/vdsm/storage/sd.py @@ -401,7 +401,7 @@ class StorageDomainManifest(object): Unordered writes improve copy performance but are recommended only for preallocated devices and raw format. """ - return format == sc.RAW_FORMAT and not self.supportsSparseness + return True @property def oop(self): This enables unordered writes for qemu-img convert, which can be up to 6 times faster on block storage. When we tested it with file storage it did not give lot of improvement, but this was tested a long time ago, and since then we use unordered writes everywhere else in the system. Another thing to try is NFS 4.2, which can be much faster when coping images, since it supports sparseness. But I don't think TrueNAS supports NFS 4.2 yet (in 12.x they did not). If you must work with older NFS, using qcow2 disks will be much faster when copying disks (e.g. create vm from template). The way to get qcow2 disks is to check "enable incremental backup" when creating disks. Nir
{kind=link}
{kind=link}
Thank you Nir, this is good information. On Thu, Jul 14, 2022 at 9:34 AM Nir Soffer <nsoffer@redhat.com> wrote:
On Tue, Jul 12, 2022 at 9:02 AM David Johnson < djohnson@maxistechnology.com> wrote:
Good morning all,
I am trying to get the best performance out of my cluster possible,
Here are the details of what I have now:
Ovirt version: 4.4.10.7-1.el8 Bare metal for the ovirt engine two hosts TrueNAS cluster storage 1 NFS share 3 vdevs, 6 drives in raidz2 in each vdev 2 nvme drives for silog Storage network is 10 GBit all static IP addresses
Tonight, I built a new VM from a template. It had 5 attached disks totalling 100 GB. It took 30 minutes to deploy the new VM from the template.
Global utilization was 9%. The SPM has 50% of its memory free and never showed more than 12% network utilization
62 out of 65 TB are available on the newly created NFS backing store (no fragmentation). The TureNAS system is probably overprovisioned for our use.
There were peak throughputs of up to 4 GBytes/second (on a 10 GBit network), but overall throughput on the NAS and the network were low. ARC hits were 95 to 100% L2 hits were 0 to 70%
Here's the NFS usage stats: [image: image.png]
I believe the first peak is where the silog buffered the initial burst of instructions, followed by sustained IO as the VM volumes were built in parallel, and then finally tapering off to the one 50 GB volume that took 40 minutes to copy.
The indications of the NFS stats graph are that the network performance is just fine.
Here are the disk IO stats covering the same time frame, plus a bit before to show a spike IO:
[image: image.png] The spike at 2250 (10 minutes before I started building my VM) shows that the spinners actually hit write speed of almost 20 MBytes per second briefly, then settled in at a sustained 3 to 4 MBytes per second. The silog absorbs several spikes, but remains mostly idle, with activity measured in kilobytes per second.
The HGST HUS726060AL5210 drives boast a spike throughput of 12 GB/S, and sustained throughput of 227 Mbps.
------ Now to the questions: 1. Am I asking the on the right list? Does this look like something where tuning ovirt might make a difference, or is this more likely a configuration issue with my storage appliances?
2. Am I expecting too much? Is this well within the bounds of acceptable (expected) performance?
3. How would I go about identifying the bottleneck, should I need to dig deeper?
One thing that can be interesting to try to to apply this patch for vdsm:
diff --git a/lib/vdsm/storage/sd.py b/lib/vdsm/storage/sd.py index 36c393b5a..9cb7486c0 100644 --- a/lib/vdsm/storage/sd.py +++ b/lib/vdsm/storage/sd.py @@ -401,7 +401,7 @@ class StorageDomainManifest(object): Unordered writes improve copy performance but are recommended only for preallocated devices and raw format. """ - return format == sc.RAW_FORMAT and not self.supportsSparseness + return True
@property def oop(self):
This enables unordered writes for qemu-img convert, which can be up to 6 times faster on block storage. When we tested it with file storage it did not give lot of improvement, but this was tested a long time ago, and since then we use unordered writes everywhere else in the system.
Another thing to try is NFS 4.2, which can be much faster when coping images, since it supports sparseness. But I don't think TrueNAS supports NFS 4.2 yet (in 12.x they did not).
If you must work with older NFS, using qcow2 disks will be much faster when copying disks (e.g. create vm from template). The way to get qcow2 disks is to check "enable incremental backup" when creating disks.
Nir
{kind=link}
{kind=link}

Hi David, as an advise. You should not set sync=disabled on TrueNAS. Doing that you’re considering every write as async, and if you have a powerless you’ll have data lost. There are some conservatives that state that you should do the opposite: sync=always, which bogs down the performance, but I particularly use sync=standard. I think you should look at the real issue on your pool. Is it with more than 80% occupation? Do you have an SLOG device (to offload the sync writes, so you can continue using sync=standard)? Another issue is that RAID-Z is not really recommended for latency scenarios (VMs). You should be using stripe of mirrors instead. RAID-Z2 would be a choice if you have lots of RAM and L2ARC devices to compensate the slow disk access. ZFS is not a performance beast, security is the first option in this filesystem. Regards. PS: I run FreeNAS (and now TrueNAS) since the 0.7 days and with VM storage since 8.2. It’s good if you know what you’re doing. On 14 Jul 2022, at 12:26, David Johnson <djohnson@maxistechnology.com<mailto:djohnson@maxistechnology.com>> wrote: Thank you Nir, this is good information. On Thu, Jul 14, 2022 at 9:34 AM Nir Soffer <nsoffer@redhat.com<mailto:nsoffer@redhat.com>> wrote: On Tue, Jul 12, 2022 at 9:02 AM David Johnson <djohnson@maxistechnology.com<mailto:djohnson@maxistechnology.com>> wrote: Good morning all, I am trying to get the best performance out of my cluster possible, Here are the details of what I have now: Ovirt version: 4.4.10.7-1.el8 Bare metal for the ovirt engine two hosts TrueNAS cluster storage 1 NFS share 3 vdevs, 6 drives in raidz2 in each vdev 2 nvme drives for silog Storage network is 10 GBit all static IP addresses Tonight, I built a new VM from a template. It had 5 attached disks totalling 100 GB. It took 30 minutes to deploy the new VM from the template. Global utilization was 9%. The SPM has 50% of its memory free and never showed more than 12% network utilization 62 out of 65 TB are available on the newly created NFS backing store (no fragmentation). The TureNAS system is probably overprovisioned for our use. There were peak throughputs of up to 4 GBytes/second (on a 10 GBit network), but overall throughput on the NAS and the network were low. ARC hits were 95 to 100% L2 hits were 0 to 70% Here's the NFS usage stats: <image.png> I believe the first peak is where the silog buffered the initial burst of instructions, followed by sustained IO as the VM volumes were built in parallel, and then finally tapering off to the one 50 GB volume that took 40 minutes to copy. The indications of the NFS stats graph are that the network performance is just fine. Here are the disk IO stats covering the same time frame, plus a bit before to show a spike IO: <image.png> The spike at 2250 (10 minutes before I started building my VM) shows that the spinners actually hit write speed of almost 20 MBytes per second briefly, then settled in at a sustained 3 to 4 MBytes per second. The silog absorbs several spikes, but remains mostly idle, with activity measured in kilobytes per second. The HGST HUS726060AL5210 drives boast a spike throughput of 12 GB/S, and sustained throughput of 227 Mbps. ------ Now to the questions: 1. Am I asking the on the right list? Does this look like something where tuning ovirt might make a difference, or is this more likely a configuration issue with my storage appliances? 2. Am I expecting too much? Is this well within the bounds of acceptable (expected) performance? 3. How would I go about identifying the bottleneck, should I need to dig deeper? One thing that can be interesting to try to to apply this patch for vdsm: diff --git a/lib/vdsm/storage/sd.py b/lib/vdsm/storage/sd.py index 36c393b5a..9cb7486c0 100644 --- a/lib/vdsm/storage/sd.py +++ b/lib/vdsm/storage/sd.py @@ -401,7 +401,7 @@ class StorageDomainManifest(object): Unordered writes improve copy performance but are recommended only for preallocated devices and raw format. """ - return format == sc.RAW_FORMAT and not self.supportsSparseness + return True @property def oop(self): This enables unordered writes for qemu-img convert, which can be up to 6 times faster on block storage. When we tested it with file storage it did not give lot of improvement, but this was tested a long time ago, and since then we use unordered writes everywhere else in the system. Another thing to try is NFS 4.2, which can be much faster when coping images, since it supports sparseness. But I don't think TrueNAS supports NFS 4.2 yet (in 12.x they did not). If you must work with older NFS, using qcow2 disks will be much faster when copying disks (e.g. create vm from template). The way to get qcow2 disks is to check "enable incremental backup" when creating disks. Nir _______________________________________________ Users mailing list -- users@ovirt.org<mailto:users@ovirt.org> To unsubscribe send an email to users-leave@ovirt.org<mailto:users-leave@ovirt.org> Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/US7ENNAE3F365B...
Hi Vicinius, Thank you for your kind analysis. Responses to your questions follow: - The setting was sync=standard in the original samples. - I have two 1TB NVME drives striped for the SLOG. You can see the utilization on NVD1 - The pool is 65 TB is nize, with 4 tb (6%) used today. - The pool uses lz4 compression - The disks never get above 5% of their rated sustained write usage in spikes, even with sync=false. In effect, we're barely touching the hard drives. With Sync-false, I hit sustained 100% utilization of the 10 gbit network for 2 minutes when creating a VM from a template. During that network spike, the drives were barely active, averaging 3% with a spike to 5% of rated sustained throughput. - Yes, we are running raidz2. - The system is heavily overspecced for the workload, with 256 GB RAM (196 GB zfs cache), 2x CPU E5-2683 v3 CPU (14 cores x 2). We have never seen more than 7 threads used, even under heavy loading. - Power loss is not a concern since we are colocated in the power utility's data center. If we lose power, we've got much bigger issues than a few minutes of lost data - we have a local cataclysm that affects everyone. - Out of 89 active processes, over the lifetime of this system, on average 87 processes have been sleeping, with the range of sleeping processes being 86 to 88. - From the analysis that has gone into addressing this question over the past couple of weeks, we understand that TrueNAS is not the best long term solution for us. Our particular usage hits every weakness of TrueNAS, and TrueNAS' iSCSI implementation is particularly wrong for our usage. The long term goal is to move to a cinder storage option when ease of management is less of a concern. Thank you again for taking the time to look at this with me. On Thu, Jul 14, 2022 at 11:25 AM Vinícius Ferrão <ferrao@versatushpc.com.br> wrote:
Hi David, as an advise. You should not set sync=disabled on TrueNAS. Doing that you’re considering every write as async, and if you have a powerless you’ll have data lost.
There are some conservatives that state that you should do the opposite: sync=always, which bogs down the performance, but I particularly use sync=standard.
I think you should look at the real issue on your pool. Is it with more than 80% occupation? Do you have an SLOG device (to offload the sync writes, so you can continue using sync=standard)?
Another issue is that RAID-Z is not really recommended for latency scenarios (VMs). You should be using stripe of mirrors instead. RAID-Z2 would be a choice if you have lots of RAM and L2ARC devices to compensate the slow disk access. ZFS is not a performance beast, security is the first option in this filesystem.
Regards.
PS: I run FreeNAS (and now TrueNAS) since the 0.7 days and with VM storage since 8.2. It’s good if you know what you’re doing.
On 14 Jul 2022, at 12:26, David Johnson <djohnson@maxistechnology.com> wrote:
Thank you Nir, this is good information.
On Thu, Jul 14, 2022 at 9:34 AM Nir Soffer <nsoffer@redhat.com> wrote:
On Tue, Jul 12, 2022 at 9:02 AM David Johnson < djohnson@maxistechnology.com> wrote:
Good morning all,
I am trying to get the best performance out of my cluster possible,
Here are the details of what I have now:
Ovirt version: 4.4.10.7-1.el8 Bare metal for the ovirt engine two hosts TrueNAS cluster storage 1 NFS share 3 vdevs, 6 drives in raidz2 in each vdev 2 nvme drives for silog Storage network is 10 GBit all static IP addresses
Tonight, I built a new VM from a template. It had 5 attached disks totalling 100 GB. It took 30 minutes to deploy the new VM from the template.
Global utilization was 9%. The SPM has 50% of its memory free and never showed more than 12% network utilization
62 out of 65 TB are available on the newly created NFS backing store (no fragmentation). The TureNAS system is probably overprovisioned for our use.
There were peak throughputs of up to 4 GBytes/second (on a 10 GBit network), but overall throughput on the NAS and the network were low. ARC hits were 95 to 100% L2 hits were 0 to 70%
Here's the NFS usage stats: <image.png>
I believe the first peak is where the silog buffered the initial burst of instructions, followed by sustained IO as the VM volumes were built in parallel, and then finally tapering off to the one 50 GB volume that took 40 minutes to copy.
The indications of the NFS stats graph are that the network performance is just fine.
Here are the disk IO stats covering the same time frame, plus a bit before to show a spike IO:
<image.png> The spike at 2250 (10 minutes before I started building my VM) shows that the spinners actually hit write speed of almost 20 MBytes per second briefly, then settled in at a sustained 3 to 4 MBytes per second. The silog absorbs several spikes, but remains mostly idle, with activity measured in kilobytes per second.
The HGST HUS726060AL5210 drives boast a spike throughput of 12 GB/S, and sustained throughput of 227 Mbps.
------ Now to the questions: 1. Am I asking the on the right list? Does this look like something where tuning ovirt might make a difference, or is this more likely a configuration issue with my storage appliances?
2. Am I expecting too much? Is this well within the bounds of acceptable (expected) performance?
3. How would I go about identifying the bottleneck, should I need to dig deeper?
One thing that can be interesting to try to to apply this patch for vdsm:
diff --git a/lib/vdsm/storage/sd.py b/lib/vdsm/storage/sd.py index 36c393b5a..9cb7486c0 100644 --- a/lib/vdsm/storage/sd.py +++ b/lib/vdsm/storage/sd.py @@ -401,7 +401,7 @@ class StorageDomainManifest(object): Unordered writes improve copy performance but are recommended only for preallocated devices and raw format. """ - return format == sc.RAW_FORMAT and not self.supportsSparseness + return True
@property def oop(self):
This enables unordered writes for qemu-img convert, which can be up to 6 times faster on block storage. When we tested it with file storage it did not give lot of improvement, but this was tested a long time ago, and since then we use unordered writes everywhere else in the system.
Another thing to try is NFS 4.2, which can be much faster when coping images, since it supports sparseness. But I don't think TrueNAS supports NFS 4.2 yet (in 12.x they did not).
If you must work with older NFS, using qcow2 disks will be much faster when copying disks (e.g. create vm from template). The way to get qcow2 disks is to check "enable incremental backup" when creating disks.
Nir
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/US7ENNAE3F365B...
participants (8)
-
 Chris Adams
Chris Adams -
 David Johnson
David Johnson -
 Jayme
Jayme -
 Klaas Demter
Klaas Demter -
 Nir Soffer
Nir Soffer -
 Pascal D
Pascal D -
 Strahil Nikolov
Strahil Nikolov -
 Vinícius Ferrão
Vinícius Ferrão