Fwd: Fwd: Issues with Gluster Domain

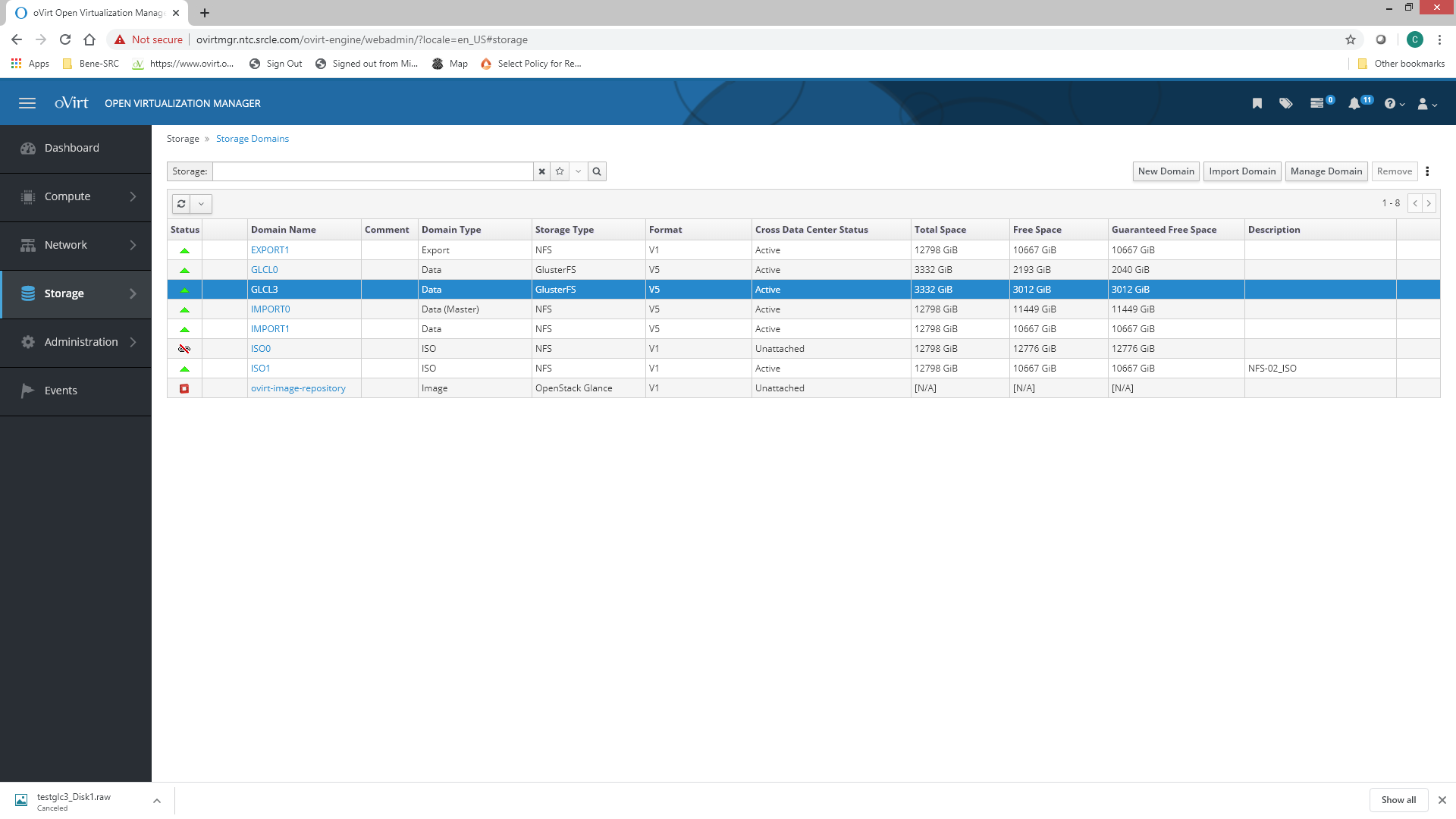
Resending to eliminate email issues ---------- Forwarded message --------- From: C Williams <cwilliams3320@gmail.com> Date: Thu, Jun 18, 2020 at 4:01 PM Subject: Re: [ovirt-users] Fwd: Issues with Gluster Domain To: Strahil Nikolov <hunter86_bg@yahoo.com> Here is output from mount 192.168.24.12:/stor/import0 on /rhev/data-center/mnt/192.168.24.12:_stor_import0 type nfs4 (rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12) 192.168.24.13:/stor/import1 on /rhev/data-center/mnt/192.168.24.13:_stor_import1 type nfs4 (rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) 192.168.24.13:/stor/iso1 on /rhev/data-center/mnt/192.168.24.13:_stor_iso1 type nfs4 (rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) 192.168.24.13:/stor/export0 on /rhev/data-center/mnt/192.168.24.13:_stor_export0 type nfs4 (rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) 192.168.24.15:/images on /rhev/data-center/mnt/glusterSD/192.168.24.15:_images type fuse.glusterfs (rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) 192.168.24.18:/images3 on /rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 type fuse.glusterfs (rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) tmpfs on /run/user/0 type tmpfs (rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) [root@ov06 glusterfs]# Also here is a screenshot of the console [image: image.png] The other domains are up Import0 and Import1 are NFS . GLCL0 is gluster. They all are running VMs Thank You For Your Help ! On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
I don't see '/rhev/data-center/mnt/192.168.24.13:_stor_import1' mounted at all . What is the status of all storage domains ?
Best Regards, Strahil Nikolov
На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Resending to deal with possible email issues
---------- Forwarded message --------- From: C Williams <cwilliams3320@gmail.com> Date: Thu, Jun 18, 2020 at 2:07 PM Subject: Re: [ovirt-users] Issues with Gluster Domain To: Strahil Nikolov <hunter86_bg@yahoo.com>
More
[root@ov06 ~]# for i in $(gluster volume list); do echo $i;echo; gluster volume info $i; echo;echo;gluster volume status $i;echo;echo;echo;done images3
Volume Name: images3 Type: Replicate Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b Status: Started Snapshot Count: 0 Number of Bricks: 1 x 3 = 3 Transport-type: tcp Bricks: Brick1: 192.168.24.18:/bricks/brick04/images3 Brick2: 192.168.24.19:/bricks/brick05/images3 Brick3: 192.168.24.20:/bricks/brick06/images3 Options Reconfigured: performance.client-io-threads: on nfs.disable: on transport.address-family: inet user.cifs: off auth.allow: * performance.quick-read: off performance.read-ahead: off performance.io-cache: off performance.low-prio-threads: 32 network.remote-dio: off cluster.eager-lock: enable cluster.quorum-type: auto cluster.server-quorum-type: server cluster.data-self-heal-algorithm: full cluster.locking-scheme: granular cluster.shd-max-threads: 8 cluster.shd-wait-qlength: 10000 features.shard: on cluster.choose-local: off client.event-threads: 4 server.event-threads: 4 storage.owner-uid: 36 storage.owner-gid: 36 performance.strict-o-direct: on network.ping-timeout: 30 cluster.granular-entry-heal: enable
Status of volume: images3 Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------ Brick 192.168.24.18:/bricks/brick04/images3 49152 0 Y 6666 Brick 192.168.24.19:/bricks/brick05/images3 49152 0 Y 6779 Brick 192.168.24.20:/bricks/brick06/images3 49152 0 Y 7227 Self-heal Daemon on localhost N/A N/A Y 6689 Self-heal Daemon on ov07.ntc.srcle.com N/A N/A Y 6802 Self-heal Daemon on ov08.ntc.srcle.com N/A N/A Y 7250
Task Status of Volume images3
------------------------------------------------------------------------------ There are no active volume tasks
[root@ov06 ~]# ls -l /rhev/data-center/mnt/glusterSD/ total 16 drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 192.168.24.15:_images drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 192.168.24.18:_images3 [root@ov06 ~]#
On Thu, Jun 18, 2020 at 2:03 PM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
Here you go -- Thank You For Your Help !
BTW -- I can write a test file to gluster and it replicates properly. Thinking something about the oVirt Storage Domain ?
[root@ov08 ~]# gluster pool list UUID Hostname State 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06 Connected 36ce5a00-6f65-4926-8438-696944ebadb5 ov07.ntc.srcle.com Connected c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost Connected [root@ov08 ~]# gluster volume list images3
On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Log to the oVirt cluster and provide the output of: gluster pool list gluster volume list for i in $(gluster volume list); do echo $i;echo; gluster volume info $i; echo;echo;gluster volume status $i;echo;echo;echo;done
ls -l /rhev/data-center/mnt/glusterSD/
Best Regards, Strahil Nikolov
Hello,
I recently added 6 hosts to an existing oVirt compute/gluster cluster.
Prior to this attempted addition, my cluster had 3 Hypervisor hosts and 3 gluster bricks which made up a single gluster volume (replica 3 volume) . I added the additional hosts and made a brick on 3 of the new hosts and attempted to make a new replica 3 volume. I had difficulty creating the new volume. So, I decided that I would make a new compute/gluster cluster for each set of 3 new hosts.
I removed the 6 new hosts from the existing oVirt Compute/Gluster Cluster leaving the 3 original hosts in place with their bricks. At that
my original bricks went down and came back up . The volume showed entries that needed healing. At that point I ran gluster volume heal images3 full, etc. The volume shows no unhealed entries. I also corrected some peer errors.
However, I am unable to copy disks, move disks to another domain, export disks, etc. It appears that the engine cannot locate disks properly and I get storage I/O errors.
I have detached and removed the oVirt Storage Domain. I reimported
На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: point the
domain and imported 2 VMs, But the VM disks exhibit the same behaviour and won't run from the hard disk.
I get errors such as this
VDSM ov05 command HSMGetAllTasksStatusesVDS failed: low level Image copy failed: ("Command ['/usr/bin/qemu-img', 'convert', '-p', '-t', 'none', '-T', 'none', '-f', 'raw', u'/rhev/data-center/mnt/glusterSD/192.168.24.18:
_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510',
'-O', 'raw', u'/rhev/data-center/mnt/192.168.24.13:
_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5']
failed with rc=1 out='' err=bytearray(b'qemu-img: error while reading sector 135168: Transport endpoint is not connected\\nqemu-img: error while reading sector 131072: Transport endpoint is not connected\\nqemu-img: error while reading sector 139264: Transport endpoint is not connected\\nqemu-img: error while reading sector 143360: Transport endpoint is not connected\\nqemu-img: error while reading sector 147456: Transport endpoint is not connected\\nqemu-img: error while reading sector 155648: Transport endpoint is not connected\\nqemu-img: error while reading sector 151552: Transport endpoint is not connected\\nqemu-img: error while reading sector 159744: Transport endpoint is not connected\\n')",)
oVirt version is 4.3.82-1.el7 OS CentOS Linux release 7.7.1908 (Core)
The Gluster Cluster has been working very well until this incident.
Please help.
Thank You
Charles Williams
{kind=link}

Check on the hosts tab , which is your current SPM (last column in Admin UI). Then open the /var/log/vdsm/vdsm.log and repeat the operation. Then provide the log from that host and the engine's log (on the HostedEngine VM or on your standalone engine). Best Regards, Strahil Nikolov На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Resending to eliminate email issues
---------- Forwarded message --------- From: C Williams <cwilliams3320@gmail.com> Date: Thu, Jun 18, 2020 at 4:01 PM Subject: Re: [ovirt-users] Fwd: Issues with Gluster Domain To: Strahil Nikolov <hunter86_bg@yahoo.com>
Here is output from mount
192.168.24.12:/stor/import0 on /rhev/data-center/mnt/192.168.24.12:_stor_import0 type nfs4 (rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12) 192.168.24.13:/stor/import1 on /rhev/data-center/mnt/192.168.24.13:_stor_import1 type nfs4 (rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) 192.168.24.13:/stor/iso1 on /rhev/data-center/mnt/192.168.24.13:_stor_iso1 type nfs4 (rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) 192.168.24.13:/stor/export0 on /rhev/data-center/mnt/192.168.24.13:_stor_export0 type nfs4 (rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) 192.168.24.15:/images on /rhev/data-center/mnt/glusterSD/192.168.24.15:_images type fuse.glusterfs (rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) 192.168.24.18:/images3 on /rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 type fuse.glusterfs (rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) tmpfs on /run/user/0 type tmpfs (rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) [root@ov06 glusterfs]#
Also here is a screenshot of the console
[image: image.png] The other domains are up
Import0 and Import1 are NFS . GLCL0 is gluster. They all are running VMs
Thank You For Your Help !
On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
I don't see '/rhev/data-center/mnt/192.168.24.13:_stor_import1' mounted at all . What is the status of all storage domains ?
Best Regards, Strahil Nikolov
На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Resending to deal with possible email issues
---------- Forwarded message --------- From: C Williams <cwilliams3320@gmail.com> Date: Thu, Jun 18, 2020 at 2:07 PM Subject: Re: [ovirt-users] Issues with Gluster Domain To: Strahil Nikolov <hunter86_bg@yahoo.com>
More
[root@ov06 ~]# for i in $(gluster volume list); do echo $i;echo; gluster volume info $i; echo;echo;gluster volume status $i;echo;echo;echo;done images3
Volume Name: images3 Type: Replicate Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b Status: Started Snapshot Count: 0 Number of Bricks: 1 x 3 = 3 Transport-type: tcp Bricks: Brick1: 192.168.24.18:/bricks/brick04/images3 Brick2: 192.168.24.19:/bricks/brick05/images3 Brick3: 192.168.24.20:/bricks/brick06/images3 Options Reconfigured: performance.client-io-threads: on nfs.disable: on transport.address-family: inet user.cifs: off auth.allow: * performance.quick-read: off performance.read-ahead: off performance.io-cache: off performance.low-prio-threads: 32 network.remote-dio: off cluster.eager-lock: enable cluster.quorum-type: auto cluster.server-quorum-type: server cluster.data-self-heal-algorithm: full cluster.locking-scheme: granular cluster.shd-max-threads: 8 cluster.shd-wait-qlength: 10000 features.shard: on cluster.choose-local: off client.event-threads: 4 server.event-threads: 4 storage.owner-uid: 36 storage.owner-gid: 36 performance.strict-o-direct: on network.ping-timeout: 30 cluster.granular-entry-heal: enable
Status of volume: images3 Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick 192.168.24.18:/bricks/brick04/images3 49152 0 Y 6666 Brick 192.168.24.19:/bricks/brick05/images3 49152 0 Y 6779 Brick 192.168.24.20:/bricks/brick06/images3 49152 0 Y 7227 Self-heal Daemon on localhost N/A N/A Y 6689 Self-heal Daemon on ov07.ntc.srcle.com N/A N/A Y 6802 Self-heal Daemon on ov08.ntc.srcle.com N/A N/A Y 7250
Task Status of Volume images3
There are no active volume tasks
[root@ov06 ~]# ls -l /rhev/data-center/mnt/glusterSD/ total 16 drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 192.168.24.15:_images drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 192.168.24.18:_images3 [root@ov06 ~]#
On Thu, Jun 18, 2020 at 2:03 PM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
Here you go -- Thank You For Your Help !
BTW -- I can write a test file to gluster and it replicates
Thinking something about the oVirt Storage Domain ?
[root@ov08 ~]# gluster pool list UUID Hostname State 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06 Connected 36ce5a00-6f65-4926-8438-696944ebadb5 ov07.ntc.srcle.com Connected c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost Connected [root@ov08 ~]# gluster volume list images3
On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Log to the oVirt cluster and provide the output of: gluster pool list gluster volume list for i in $(gluster volume list); do echo $i;echo; gluster volume info $i; echo;echo;gluster volume status $i;echo;echo;echo;done
ls -l /rhev/data-center/mnt/glusterSD/
Best Regards, Strahil Nikolov
Hello,
I recently added 6 hosts to an existing oVirt compute/gluster cluster.
Prior to this attempted addition, my cluster had 3 Hypervisor hosts and 3 gluster bricks which made up a single gluster volume (replica 3 volume) . I added the additional hosts and made a brick on 3 of the new hosts and attempted to make a new replica 3 volume. I had difficulty creating the new volume. So, I decided that I would make a new compute/gluster cluster for each set of 3 new hosts.
I removed the 6 new hosts from the existing oVirt Compute/Gluster Cluster leaving the 3 original hosts in place with their bricks. At that
На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: point
my original bricks went down and came back up . The volume showed entries that needed healing. At that point I ran gluster volume heal images3 full, etc. The volume shows no unhealed entries. I also corrected some peer errors.
However, I am unable to copy disks, move disks to another domain, export disks, etc. It appears that the engine cannot locate disks
------------------------------------------------------------------------------ properly. properly
I get storage I/O errors.
I have detached and removed the oVirt Storage Domain. I reimported
and the
domain and imported 2 VMs, But the VM disks exhibit the same behaviour and won't run from the hard disk.
I get errors such as this
VDSM ov05 command HSMGetAllTasksStatusesVDS failed: low level Image copy failed: ("Command ['/usr/bin/qemu-img', 'convert', '-p', '-t', 'none', '-T', 'none', '-f', 'raw', u'/rhev/data-center/mnt/glusterSD/192.168.24.18:
_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510',
'-O', 'raw', u'/rhev/data-center/mnt/192.168.24.13:
_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5']
failed with rc=1 out='' err=bytearray(b'qemu-img: error while reading sector 135168: Transport endpoint is not connected\\nqemu-img: error while reading sector 131072: Transport endpoint is not connected\\nqemu-img: error while reading sector 139264: Transport endpoint is not connected\\nqemu-img: error while reading sector 143360: Transport endpoint is not connected\\nqemu-img: error while reading sector 147456: Transport endpoint is not connected\\nqemu-img: error while reading sector 155648: Transport endpoint is not connected\\nqemu-img: error while reading sector 151552: Transport endpoint is not connected\\nqemu-img: error while reading sector 159744: Transport endpoint is not connected\\n')",)
oVirt version is 4.3.82-1.el7 OS CentOS Linux release 7.7.1908 (Core)
The Gluster Cluster has been working very well until this incident.
Please help.
Thank You
Charles Williams
Hello, Here are the logs (some IPs are changed ) ov05 is the SPM Thank You For Your Help ! On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Check on the hosts tab , which is your current SPM (last column in Admin UI). Then open the /var/log/vdsm/vdsm.log and repeat the operation. Then provide the log from that host and the engine's log (on the HostedEngine VM or on your standalone engine).
Best Regards, Strahil Nikolov
На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Resending to eliminate email issues
---------- Forwarded message --------- From: C Williams <cwilliams3320@gmail.com> Date: Thu, Jun 18, 2020 at 4:01 PM Subject: Re: [ovirt-users] Fwd: Issues with Gluster Domain To: Strahil Nikolov <hunter86_bg@yahoo.com>
Here is output from mount
192.168.24.12:/stor/import0 on /rhev/data-center/mnt/192.168.24.12:_stor_import0 type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12) 192.168.24.13:/stor/import1 on /rhev/data-center/mnt/192.168.24.13:_stor_import1 type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) 192.168.24.13:/stor/iso1 on /rhev/data-center/mnt/192.168.24.13:_stor_iso1 type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) 192.168.24.13:/stor/export0 on /rhev/data-center/mnt/192.168.24.13:_stor_export0 type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) 192.168.24.15:/images on /rhev/data-center/mnt/glusterSD/192.168.24.15:_images type fuse.glusterfs
(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) 192.168.24.18:/images3 on /rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 type fuse.glusterfs
(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) tmpfs on /run/user/0 type tmpfs (rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) [root@ov06 glusterfs]#
Also here is a screenshot of the console
[image: image.png] The other domains are up
Import0 and Import1 are NFS . GLCL0 is gluster. They all are running VMs
Thank You For Your Help !
On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
I don't see '/rhev/data-center/mnt/192.168.24.13:_stor_import1' mounted at all . What is the status of all storage domains ?
Best Regards, Strahil Nikolov
На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Resending to deal with possible email issues
---------- Forwarded message --------- From: C Williams <cwilliams3320@gmail.com> Date: Thu, Jun 18, 2020 at 2:07 PM Subject: Re: [ovirt-users] Issues with Gluster Domain To: Strahil Nikolov <hunter86_bg@yahoo.com>
More
[root@ov06 ~]# for i in $(gluster volume list); do echo $i;echo; gluster volume info $i; echo;echo;gluster volume status $i;echo;echo;echo;done images3
Volume Name: images3 Type: Replicate Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b Status: Started Snapshot Count: 0 Number of Bricks: 1 x 3 = 3 Transport-type: tcp Bricks: Brick1: 192.168.24.18:/bricks/brick04/images3 Brick2: 192.168.24.19:/bricks/brick05/images3 Brick3: 192.168.24.20:/bricks/brick06/images3 Options Reconfigured: performance.client-io-threads: on nfs.disable: on transport.address-family: inet user.cifs: off auth.allow: * performance.quick-read: off performance.read-ahead: off performance.io-cache: off performance.low-prio-threads: 32 network.remote-dio: off cluster.eager-lock: enable cluster.quorum-type: auto cluster.server-quorum-type: server cluster.data-self-heal-algorithm: full cluster.locking-scheme: granular cluster.shd-max-threads: 8 cluster.shd-wait-qlength: 10000 features.shard: on cluster.choose-local: off client.event-threads: 4 server.event-threads: 4 storage.owner-uid: 36 storage.owner-gid: 36 performance.strict-o-direct: on network.ping-timeout: 30 cluster.granular-entry-heal: enable
Status of volume: images3 Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick 192.168.24.18:/bricks/brick04/images3 49152 0 Y 6666 Brick 192.168.24.19:/bricks/brick05/images3 49152 0 Y 6779 Brick 192.168.24.20:/bricks/brick06/images3 49152 0 Y 7227 Self-heal Daemon on localhost N/A N/A Y 6689 Self-heal Daemon on ov07.ntc.srcle.com N/A N/A Y 6802 Self-heal Daemon on ov08.ntc.srcle.com N/A N/A Y 7250
Task Status of Volume images3
There are no active volume tasks
[root@ov06 ~]# ls -l /rhev/data-center/mnt/glusterSD/ total 16 drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 192.168.24.15:_images drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 192.168.24.18:_images3 [root@ov06 ~]#
On Thu, Jun 18, 2020 at 2:03 PM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
Here you go -- Thank You For Your Help !
BTW -- I can write a test file to gluster and it replicates
Thinking something about the oVirt Storage Domain ?
[root@ov08 ~]# gluster pool list UUID Hostname State 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06 Connected 36ce5a00-6f65-4926-8438-696944ebadb5 ov07.ntc.srcle.com Connected c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost Connected [root@ov08 ~]# gluster volume list images3
On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Log to the oVirt cluster and provide the output of: gluster pool list gluster volume list for i in $(gluster volume list); do echo $i;echo; gluster volume info $i; echo;echo;gluster volume status $i;echo;echo;echo;done
ls -l /rhev/data-center/mnt/glusterSD/
Best Regards, Strahil Nikolov
На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: >Hello, > >I recently added 6 hosts to an existing oVirt compute/gluster cluster. > >Prior to this attempted addition, my cluster had 3 Hypervisor hosts and >3 >gluster bricks which made up a single gluster volume (replica 3 volume) >. I >added the additional hosts and made a brick on 3 of the new hosts and >attempted to make a new replica 3 volume. I had difficulty creating >the >new volume. So, I decided that I would make a new compute/gluster >cluster >for each set of 3 new hosts. > >I removed the 6 new hosts from the existing oVirt Compute/Gluster >Cluster >leaving the 3 original hosts in place with their bricks. At that point >my >original bricks went down and came back up . The volume showed entries >that >needed healing. At that point I ran gluster volume heal images3 full, >etc. >The volume shows no unhealed entries. I also corrected some peer >errors. > >However, I am unable to copy disks, move disks to another domain, >export >disks, etc. It appears that the engine cannot locate disks
------------------------------------------------------------------------------ properly. properly
>I >get storage I/O errors. > >I have detached and removed the oVirt Storage Domain. I reimported
and the
>domain and imported 2 VMs, But the VM disks exhibit the same behaviour >and >won't run from the hard disk. > > >I get errors such as this > >VDSM ov05 command HSMGetAllTasksStatusesVDS failed: low level Image >copy >failed: ("Command ['/usr/bin/qemu-img', 'convert', '-p', '-t', 'none', >'-T', 'none', '-f', 'raw', >u'/rhev/data-center/mnt/glusterSD/192.168.24.18:
_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510',
>'-O', 'raw', >u'/rhev/data-center/mnt/192.168.24.13:
_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5']
>failed with rc=1 out='' err=bytearray(b'qemu-img: error while reading >sector 135168: Transport endpoint is not connected\\nqemu-img: error >while >reading sector 131072: Transport endpoint is not connected\\nqemu-img: >error while reading sector 139264: Transport endpoint is not >connected\\nqemu-img: error while reading sector 143360: Transport >endpoint >is not connected\\nqemu-img: error while reading sector 147456: >Transport >endpoint is not connected\\nqemu-img: error while reading sector >155648: >Transport endpoint is not connected\\nqemu-img: error while reading >sector >151552: Transport endpoint is not connected\\nqemu-img: error while >reading >sector 159744: Transport endpoint is not connected\\n')",) > >oVirt version is 4.3.82-1.el7 >OS CentOS Linux release 7.7.1908 (Core) > >The Gluster Cluster has been working very well until this incident. > >Please help. > >Thank You > >Charles Williams
Hello, Was wanting to follow up on this issue. Users are impacted. Thank You On Fri, Jun 19, 2020 at 9:20 AM C Williams <cwilliams3320@gmail.com> wrote:
Hello,
Here are the logs (some IPs are changed )
ov05 is the SPM
Thank You For Your Help !
On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Check on the hosts tab , which is your current SPM (last column in Admin UI). Then open the /var/log/vdsm/vdsm.log and repeat the operation. Then provide the log from that host and the engine's log (on the HostedEngine VM or on your standalone engine).
Best Regards, Strahil Nikolov
На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Resending to eliminate email issues
---------- Forwarded message --------- From: C Williams <cwilliams3320@gmail.com> Date: Thu, Jun 18, 2020 at 4:01 PM Subject: Re: [ovirt-users] Fwd: Issues with Gluster Domain To: Strahil Nikolov <hunter86_bg@yahoo.com>
Here is output from mount
192.168.24.12:/stor/import0 on /rhev/data-center/mnt/192.168.24.12:_stor_import0 type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12) 192.168.24.13:/stor/import1 on /rhev/data-center/mnt/192.168.24.13:_stor_import1 type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) 192.168.24.13:/stor/iso1 on /rhev/data-center/mnt/192.168.24.13:_stor_iso1 type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) 192.168.24.13:/stor/export0 on /rhev/data-center/mnt/192.168.24.13:_stor_export0 type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) 192.168.24.15:/images on /rhev/data-center/mnt/glusterSD/192.168.24.15:_images type fuse.glusterfs
(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) 192.168.24.18:/images3 on /rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 type fuse.glusterfs
(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) tmpfs on /run/user/0 type tmpfs (rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) [root@ov06 glusterfs]#
Also here is a screenshot of the console
[image: image.png] The other domains are up
Import0 and Import1 are NFS . GLCL0 is gluster. They all are running VMs
Thank You For Your Help !
On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
I don't see '/rhev/data-center/mnt/192.168.24.13:_stor_import1' mounted at all . What is the status of all storage domains ?
Best Regards, Strahil Nikolov
На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Resending to deal with possible email issues
---------- Forwarded message --------- From: C Williams <cwilliams3320@gmail.com> Date: Thu, Jun 18, 2020 at 2:07 PM Subject: Re: [ovirt-users] Issues with Gluster Domain To: Strahil Nikolov <hunter86_bg@yahoo.com>
More
[root@ov06 ~]# for i in $(gluster volume list); do echo $i;echo; gluster volume info $i; echo;echo;gluster volume status $i;echo;echo;echo;done images3
Volume Name: images3 Type: Replicate Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b Status: Started Snapshot Count: 0 Number of Bricks: 1 x 3 = 3 Transport-type: tcp Bricks: Brick1: 192.168.24.18:/bricks/brick04/images3 Brick2: 192.168.24.19:/bricks/brick05/images3 Brick3: 192.168.24.20:/bricks/brick06/images3 Options Reconfigured: performance.client-io-threads: on nfs.disable: on transport.address-family: inet user.cifs: off auth.allow: * performance.quick-read: off performance.read-ahead: off performance.io-cache: off performance.low-prio-threads: 32 network.remote-dio: off cluster.eager-lock: enable cluster.quorum-type: auto cluster.server-quorum-type: server cluster.data-self-heal-algorithm: full cluster.locking-scheme: granular cluster.shd-max-threads: 8 cluster.shd-wait-qlength: 10000 features.shard: on cluster.choose-local: off client.event-threads: 4 server.event-threads: 4 storage.owner-uid: 36 storage.owner-gid: 36 performance.strict-o-direct: on network.ping-timeout: 30 cluster.granular-entry-heal: enable
Status of volume: images3 Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick 192.168.24.18:/bricks/brick04/images3 49152 0 Y 6666 Brick 192.168.24.19:/bricks/brick05/images3 49152 0 Y 6779 Brick 192.168.24.20:/bricks/brick06/images3 49152 0 Y 7227 Self-heal Daemon on localhost N/A N/A Y 6689 Self-heal Daemon on ov07.ntc.srcle.com N/A N/A Y 6802 Self-heal Daemon on ov08.ntc.srcle.com N/A N/A Y 7250
Task Status of Volume images3
There are no active volume tasks
[root@ov06 ~]# ls -l /rhev/data-center/mnt/glusterSD/ total 16 drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 192.168.24.15:_images drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 192.168.24.18:_images3 [root@ov06 ~]#
On Thu, Jun 18, 2020 at 2:03 PM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
Here you go -- Thank You For Your Help !
BTW -- I can write a test file to gluster and it replicates
Thinking something about the oVirt Storage Domain ?
[root@ov08 ~]# gluster pool list UUID Hostname State 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06 Connected 36ce5a00-6f65-4926-8438-696944ebadb5 ov07.ntc.srcle.com Connected c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost Connected [root@ov08 ~]# gluster volume list images3
On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
> Log to the oVirt cluster and provide the output of: > gluster pool list > gluster volume list > for i in $(gluster volume list); do echo $i;echo; gluster volume info > $i; echo;echo;gluster volume status $i;echo;echo;echo;done > > ls -l /rhev/data-center/mnt/glusterSD/ > > Best Regards, > Strahil Nikolov > > > На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams <cwilliams3320@gmail.com> > написа: > >Hello, > > > >I recently added 6 hosts to an existing oVirt compute/gluster cluster. > > > >Prior to this attempted addition, my cluster had 3 Hypervisor hosts and > >3 > >gluster bricks which made up a single gluster volume (replica 3 volume) > >. I > >added the additional hosts and made a brick on 3 of the new hosts and > >attempted to make a new replica 3 volume. I had difficulty creating > >the > >new volume. So, I decided that I would make a new compute/gluster > >cluster > >for each set of 3 new hosts. > > > >I removed the 6 new hosts from the existing oVirt Compute/Gluster > >Cluster > >leaving the 3 original hosts in place with their bricks. At that point > >my > >original bricks went down and came back up . The volume showed entries > >that > >needed healing. At that point I ran gluster volume heal images3 full, > >etc. > >The volume shows no unhealed entries. I also corrected some peer > >errors. > > > >However, I am unable to copy disks, move disks to another domain, > >export > >disks, etc. It appears that the engine cannot locate disks
------------------------------------------------------------------------------ properly. properly
> >I > >get storage I/O errors. > > > >I have detached and removed the oVirt Storage Domain. I reimported
and the
> >domain and imported 2 VMs, But the VM disks exhibit the same behaviour > >and > >won't run from the hard disk. > > > > > >I get errors such as this > > > >VDSM ov05 command HSMGetAllTasksStatusesVDS failed: low level Image > >copy > >failed: ("Command ['/usr/bin/qemu-img', 'convert', '-p', '-t', 'none', > >'-T', 'none', '-f', 'raw', > >u'/rhev/data-center/mnt/glusterSD/192.168.24.18: >
_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510',
> >'-O', 'raw', > >u'/rhev/data-center/mnt/192.168.24.13: >
_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5']
> >failed with rc=1 out='' err=bytearray(b'qemu-img: error while reading > >sector 135168: Transport endpoint is not connected\\nqemu-img: error > >while > >reading sector 131072: Transport endpoint is not connected\\nqemu-img: > >error while reading sector 139264: Transport endpoint is not > >connected\\nqemu-img: error while reading sector 143360: Transport > >endpoint > >is not connected\\nqemu-img: error while reading sector 147456: > >Transport > >endpoint is not connected\\nqemu-img: error while reading sector > >155648: > >Transport endpoint is not connected\\nqemu-img: error while reading > >sector > >151552: Transport endpoint is not connected\\nqemu-img: error while > >reading > >sector 159744: Transport endpoint is not connected\\n')",) > > > >oVirt version is 4.3.82-1.el7 > >OS CentOS Linux release 7.7.1908 (Core) > > > >The Gluster Cluster has been working very well until this incident. > > > >Please help. > > > >Thank You > > > >Charles Williams >
Hey C Williams, sorry for the delay, but I couldn't get somw time to check your logs. Will try a little bit later. Best Regards, Strahil Nikolov На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Hello,
Was wanting to follow up on this issue. Users are impacted.
Thank You
On Fri, Jun 19, 2020 at 9:20 AM C Williams <cwilliams3320@gmail.com> wrote:
Hello,
Here are the logs (some IPs are changed )
ov05 is the SPM
Thank You For Your Help !
On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Check on the hosts tab , which is your current SPM (last column in Admin UI). Then open the /var/log/vdsm/vdsm.log and repeat the operation. Then provide the log from that host and the engine's log (on the HostedEngine VM or on your standalone engine).
Best Regards, Strahil Nikolov
На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Resending to eliminate email issues
---------- Forwarded message --------- From: C Williams <cwilliams3320@gmail.com> Date: Thu, Jun 18, 2020 at 4:01 PM Subject: Re: [ovirt-users] Fwd: Issues with Gluster Domain To: Strahil Nikolov <hunter86_bg@yahoo.com>
Here is output from mount
192.168.24.12:/stor/import0 on /rhev/data-center/mnt/192.168.24.12:_stor_import0 type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12)
192.168.24.13:/stor/import1 on /rhev/data-center/mnt/192.168.24.13:_stor_import1 type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
192.168.24.13:/stor/iso1 on /rhev/data-center/mnt/192.168.24.13:_stor_iso1 type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
192.168.24.13:/stor/export0 on /rhev/data-center/mnt/192.168.24.13:_stor_export0 type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
192.168.24.15:/images on /rhev/data-center/mnt/glusterSD/192.168.24.15:_images type fuse.glusterfs
(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
192.168.24.18:/images3 on /rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 type fuse.glusterfs
tmpfs on /run/user/0 type tmpfs (rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) [root@ov06 glusterfs]#
Also here is a screenshot of the console
[image: image.png] The other domains are up
Import0 and Import1 are NFS . GLCL0 is gluster. They all are running VMs
Thank You For Your Help !
On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
I don't see '/rhev/data-center/mnt/192.168.24.13:_stor_import1' mounted at all . What is the status of all storage domains ?
Best Regards, Strahil Nikolov
На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Resending to deal with possible email issues
---------- Forwarded message --------- From: C Williams <cwilliams3320@gmail.com> Date: Thu, Jun 18, 2020 at 2:07 PM Subject: Re: [ovirt-users] Issues with Gluster Domain To: Strahil Nikolov <hunter86_bg@yahoo.com>
More
[root@ov06 ~]# for i in $(gluster volume list); do echo $i;echo; gluster volume info $i; echo;echo;gluster volume status $i;echo;echo;echo;done images3
Volume Name: images3 Type: Replicate Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b Status: Started Snapshot Count: 0 Number of Bricks: 1 x 3 = 3 Transport-type: tcp Bricks: Brick1: 192.168.24.18:/bricks/brick04/images3 Brick2: 192.168.24.19:/bricks/brick05/images3 Brick3: 192.168.24.20:/bricks/brick06/images3 Options Reconfigured: performance.client-io-threads: on nfs.disable: on transport.address-family: inet user.cifs: off auth.allow: * performance.quick-read: off performance.read-ahead: off performance.io-cache: off performance.low-prio-threads: 32 network.remote-dio: off cluster.eager-lock: enable cluster.quorum-type: auto cluster.server-quorum-type: server cluster.data-self-heal-algorithm: full cluster.locking-scheme: granular cluster.shd-max-threads: 8 cluster.shd-wait-qlength: 10000 features.shard: on cluster.choose-local: off client.event-threads: 4 server.event-threads: 4 storage.owner-uid: 36 storage.owner-gid: 36 performance.strict-o-direct: on network.ping-timeout: 30 cluster.granular-entry-heal: enable
Status of volume: images3 Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick 192.168.24.18:/bricks/brick04/images3 49152 0 Y 6666 Brick 192.168.24.19:/bricks/brick05/images3 49152 0 Y 6779 Brick 192.168.24.20:/bricks/brick06/images3 49152 0 Y 7227 Self-heal Daemon on localhost N/A N/A Y 6689 Self-heal Daemon on ov07.ntc.srcle.com N/A N/A Y 6802 Self-heal Daemon on ov08.ntc.srcle.com N/A N/A Y 7250
Task Status of Volume images3
------------------------------------------------------------------------------
There are no active volume tasks
[root@ov06 ~]# ls -l /rhev/data-center/mnt/glusterSD/ total 16 drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 192.168.24.15:_images drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 192.168.24.18:_images3 [root@ov06 ~]#
On Thu, Jun 18, 2020 at 2:03 PM C Williams <cwilliams3320@gmail.com> wrote:
> Strahil, > > Here you go -- Thank You For Your Help ! > > BTW -- I can write a test file to gluster and it replicates properly. > Thinking something about the oVirt Storage Domain ? > > [root@ov08 ~]# gluster pool list > UUID Hostname State > 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06 Connected > 36ce5a00-6f65-4926-8438-696944ebadb5 ov07.ntc.srcle.com Connected > c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost Connected > [root@ov08 ~]# gluster volume list > images3 > > On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov <hunter86_bg@yahoo.com> > wrote: > >> Log to the oVirt cluster and provide the output of: >> gluster pool list >> gluster volume list >> for i in $(gluster volume list); do echo $i;echo; gluster volume info >> $i; echo;echo;gluster volume status $i;echo;echo;echo;done >> >> ls -l /rhev/data-center/mnt/glusterSD/ >> >> Best Regards, >> Strahil Nikolov >> >> >> На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams <cwilliams3320@gmail.com> >> написа: >> >Hello, >> > >> >I recently added 6 hosts to an existing oVirt compute/gluster cluster. >> > >> >Prior to this attempted addition, my cluster had 3 Hypervisor hosts and >> >3 >> >gluster bricks which made up a single gluster volume (replica 3 volume) >> >. I >> >added the additional hosts and made a brick on 3 of the new hosts and >> >attempted to make a new replica 3 volume. I had difficulty creating >> >the >> >new volume. So, I decided that I would make a new compute/gluster >> >cluster >> >for each set of 3 new hosts. >> > >> >I removed the 6 new hosts from the existing oVirt Compute/Gluster >> >Cluster >> >leaving the 3 original hosts in place with their bricks. At
point >> >my >> >original bricks went down and came back up . The volume showed entries >> >that >> >needed healing. At that point I ran gluster volume heal images3 full, >> >etc. >> >The volume shows no unhealed entries. I also corrected some
(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) that peer
>> >errors. >> > >> >However, I am unable to copy disks, move disks to another domain, >> >export >> >disks, etc. It appears that the engine cannot locate disks properly and >> >I >> >get storage I/O errors. >> > >> >I have detached and removed the oVirt Storage Domain. I reimported the >> >domain and imported 2 VMs, But the VM disks exhibit the same behaviour >> >and >> >won't run from the hard disk. >> > >> > >> >I get errors such as this >> > >> >VDSM ov05 command HSMGetAllTasksStatusesVDS failed: low level Image >> >copy >> >failed: ("Command ['/usr/bin/qemu-img', 'convert', '-p', '-t', 'none', >> >'-T', 'none', '-f', 'raw', >> >u'/rhev/data-center/mnt/glusterSD/192.168.24.18: >>
_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510',
>> >'-O', 'raw', >> >u'/rhev/data-center/mnt/192.168.24.13: >>
_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5']
>> >failed with rc=1 out='' err=bytearray(b'qemu-img: error while reading >> >sector 135168: Transport endpoint is not connected\\nqemu-img: error >> >while >> >reading sector 131072: Transport endpoint is not connected\\nqemu-img: >> >error while reading sector 139264: Transport endpoint is not >> >connected\\nqemu-img: error while reading sector 143360: Transport >> >endpoint >> >is not connected\\nqemu-img: error while reading sector 147456: >> >Transport >> >endpoint is not connected\\nqemu-img: error while reading sector >> >155648: >> >Transport endpoint is not connected\\nqemu-img: error while reading >> >sector >> >151552: Transport endpoint is not connected\\nqemu-img: error while >> >reading >> >sector 159744: Transport endpoint is not connected\\n')",) >> > >> >oVirt version is 4.3.82-1.el7 >> >OS CentOS Linux release 7.7.1908 (Core) >> > >> >The Gluster Cluster has been working very well until this incident. >> > >> >Please help. >> > >> >Thank You >> > >> >Charles Williams >> >
Strahil, I understand. Please keep me posted. Thanks For The Help ! On Sat, Jun 20, 2020 at 4:36 AM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Hey C Williams,
sorry for the delay, but I couldn't get somw time to check your logs. Will try a little bit later.
Best Regards, Strahil Nikolov
На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Hello,
Was wanting to follow up on this issue. Users are impacted.
Thank You
On Fri, Jun 19, 2020 at 9:20 AM C Williams <cwilliams3320@gmail.com> wrote:
Hello,
Here are the logs (some IPs are changed )
ov05 is the SPM
Thank You For Your Help !
On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Check on the hosts tab , which is your current SPM (last column in Admin UI). Then open the /var/log/vdsm/vdsm.log and repeat the operation. Then provide the log from that host and the engine's log (on the HostedEngine VM or on your standalone engine).
Best Regards, Strahil Nikolov
На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Resending to eliminate email issues
---------- Forwarded message --------- From: C Williams <cwilliams3320@gmail.com> Date: Thu, Jun 18, 2020 at 4:01 PM Subject: Re: [ovirt-users] Fwd: Issues with Gluster Domain To: Strahil Nikolov <hunter86_bg@yahoo.com>
Here is output from mount
192.168.24.12:/stor/import0 on /rhev/data-center/mnt/192.168.24.12:_stor_import0 type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12)
192.168.24.13:/stor/import1 on /rhev/data-center/mnt/192.168.24.13:_stor_import1 type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
192.168.24.13:/stor/iso1 on /rhev/data-center/mnt/192.168.24.13:_stor_iso1 type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
192.168.24.13:/stor/export0 on /rhev/data-center/mnt/192.168.24.13:_stor_export0 type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
192.168.24.15:/images on /rhev/data-center/mnt/glusterSD/192.168.24.15:_images type fuse.glusterfs
(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
192.168.24.18:/images3 on /rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 type fuse.glusterfs
(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
tmpfs on /run/user/0 type tmpfs (rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) [root@ov06 glusterfs]#
Also here is a screenshot of the console
[image: image.png] The other domains are up
Import0 and Import1 are NFS . GLCL0 is gluster. They all are running VMs
Thank You For Your Help !
On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
I don't see '/rhev/data-center/mnt/192.168.24.13:_stor_import1' mounted at all . What is the status of all storage domains ?
Best Regards, Strahil Nikolov
На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: > Resending to deal with possible email issues > >---------- Forwarded message --------- >From: C Williams <cwilliams3320@gmail.com> >Date: Thu, Jun 18, 2020 at 2:07 PM >Subject: Re: [ovirt-users] Issues with Gluster Domain >To: Strahil Nikolov <hunter86_bg@yahoo.com> > > >More > >[root@ov06 ~]# for i in $(gluster volume list); do echo $i;echo; >gluster >volume info $i; echo;echo;gluster volume status $i;echo;echo;echo;done >images3 > > >Volume Name: images3 >Type: Replicate >Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b >Status: Started >Snapshot Count: 0 >Number of Bricks: 1 x 3 = 3 >Transport-type: tcp >Bricks: >Brick1: 192.168.24.18:/bricks/brick04/images3 >Brick2: 192.168.24.19:/bricks/brick05/images3 >Brick3: 192.168.24.20:/bricks/brick06/images3 >Options Reconfigured: >performance.client-io-threads: on >nfs.disable: on >transport.address-family: inet >user.cifs: off >auth.allow: * >performance.quick-read: off >performance.read-ahead: off >performance.io-cache: off >performance.low-prio-threads: 32 >network.remote-dio: off >cluster.eager-lock: enable >cluster.quorum-type: auto >cluster.server-quorum-type: server >cluster.data-self-heal-algorithm: full >cluster.locking-scheme: granular >cluster.shd-max-threads: 8 >cluster.shd-wait-qlength: 10000 >features.shard: on >cluster.choose-local: off >client.event-threads: 4 >server.event-threads: 4 >storage.owner-uid: 36 >storage.owner-gid: 36 >performance.strict-o-direct: on >network.ping-timeout: 30 >cluster.granular-entry-heal: enable > > >Status of volume: images3 >Gluster process TCP Port RDMA Port Online > Pid
------------------------------------------------------------------------------
>Brick 192.168.24.18:/bricks/brick04/images3 49152 0 Y >6666 >Brick 192.168.24.19:/bricks/brick05/images3 49152 0 Y >6779 >Brick 192.168.24.20:/bricks/brick06/images3 49152 0 Y >7227 >Self-heal Daemon on localhost N/A N/A Y >6689 >Self-heal Daemon on ov07.ntc.srcle.com N/A N/A Y >6802 >Self-heal Daemon on ov08.ntc.srcle.com N/A N/A Y >7250 > >Task Status of Volume images3
>There are no active volume tasks > > > > >[root@ov06 ~]# ls -l /rhev/data-center/mnt/glusterSD/ >total 16 >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 192.168.24.15:_images >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 192.168.24.18:_images3 >[root@ov06 ~]# > >On Thu, Jun 18, 2020 at 2:03 PM C Williams <cwilliams3320@gmail.com> >wrote: > >> Strahil, >> >> Here you go -- Thank You For Your Help ! >> >> BTW -- I can write a test file to gluster and it replicates properly. >> Thinking something about the oVirt Storage Domain ? >> >> [root@ov08 ~]# gluster pool list >> UUID Hostname State >> 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06 >Connected >> 36ce5a00-6f65-4926-8438-696944ebadb5 ov07.ntc.srcle.com >Connected >> c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost >Connected >> [root@ov08 ~]# gluster volume list >> images3 >> >> On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov ><hunter86_bg@yahoo.com> >> wrote: >> >>> Log to the oVirt cluster and provide the output of: >>> gluster pool list >>> gluster volume list >>> for i in $(gluster volume list); do echo $i;echo; gluster volume >info >>> $i; echo;echo;gluster volume status $i;echo;echo;echo;done >>> >>> ls -l /rhev/data-center/mnt/glusterSD/ >>> >>> Best Regards, >>> Strahil Nikolov >>> >>> >>> На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams ><cwilliams3320@gmail.com> >>> написа: >>> >Hello, >>> > >>> >I recently added 6 hosts to an existing oVirt compute/gluster >cluster. >>> > >>> >Prior to this attempted addition, my cluster had 3 Hypervisor hosts >and >>> >3 >>> >gluster bricks which made up a single gluster volume (replica 3 >volume) >>> >. I >>> >added the additional hosts and made a brick on 3 of the new hosts >and >>> >attempted to make a new replica 3 volume. I had difficulty >creating >>> >the >>> >new volume. So, I decided that I would make a new compute/gluster >>> >cluster >>> >for each set of 3 new hosts. >>> > >>> >I removed the 6 new hosts from the existing oVirt Compute/Gluster >>> >Cluster >>> >leaving the 3 original hosts in place with their bricks. At
>point >>> >my >>> >original bricks went down and came back up . The volume showed >entries >>> >that >>> >needed healing. At that point I ran gluster volume heal images3 >full, >>> >etc. >>> >The volume shows no unhealed entries. I also corrected some
------------------------------------------------------------------------------ that peer
>>> >errors. >>> > >>> >However, I am unable to copy disks, move disks to another domain, >>> >export >>> >disks, etc. It appears that the engine cannot locate disks properly >and >>> >I >>> >get storage I/O errors. >>> > >>> >I have detached and removed the oVirt Storage Domain. I reimported >the >>> >domain and imported 2 VMs, But the VM disks exhibit the same >behaviour >>> >and >>> >won't run from the hard disk. >>> > >>> > >>> >I get errors such as this >>> > >>> >VDSM ov05 command HSMGetAllTasksStatusesVDS failed: low level Image >>> >copy >>> >failed: ("Command ['/usr/bin/qemu-img', 'convert', '-p', '-t', >'none', >>> >'-T', 'none', '-f', 'raw', >>> >u'/rhev/data-center/mnt/glusterSD/192.168.24.18: >>>
_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510',
>>> >'-O', 'raw', >>> >u'/rhev/data-center/mnt/192.168.24.13: >>>
_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5']
>>> >failed with rc=1 out='' err=bytearray(b'qemu-img: error while >reading >>> >sector 135168: Transport endpoint is not connected\\nqemu-img: >error >>> >while >>> >reading sector 131072: Transport endpoint is not >connected\\nqemu-img: >>> >error while reading sector 139264: Transport endpoint is not >>> >connected\\nqemu-img: error while reading sector 143360: Transport >>> >endpoint >>> >is not connected\\nqemu-img: error while reading sector 147456: >>> >Transport >>> >endpoint is not connected\\nqemu-img: error while reading sector >>> >155648: >>> >Transport endpoint is not connected\\nqemu-img: error while reading >>> >sector >>> >151552: Transport endpoint is not connected\\nqemu-img: error while >>> >reading >>> >sector 159744: Transport endpoint is not connected\\n')",) >>> > >>> >oVirt version is 4.3.82-1.el7 >>> >OS CentOS Linux release 7.7.1908 (Core) >>> > >>> >The Gluster Cluster has been working very well until this incident. >>> > >>> >Please help. >>> > >>> >Thank You >>> > >>> >Charles Williams >>> >>
Hello, Here are additional log tiles as well as a tree of the problematic Gluster storage domain. During this time I attempted to copy a virtual disk to another domain, move a virtual disk to another domain and run a VM where the virtual hard disk would be used. The copies/moves failed and the VM went into pause mode when the virtual HDD was involved. Please check these out. Thank You For Your Help ! On Sat, Jun 20, 2020 at 9:54 AM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
I understand. Please keep me posted.
Thanks For The Help !
On Sat, Jun 20, 2020 at 4:36 AM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Hey C Williams,
sorry for the delay, but I couldn't get somw time to check your logs. Will try a little bit later.
Best Regards, Strahil Nikolov
На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Hello,
Was wanting to follow up on this issue. Users are impacted.
Thank You
On Fri, Jun 19, 2020 at 9:20 AM C Williams <cwilliams3320@gmail.com> wrote:
Hello,
Here are the logs (some IPs are changed )
ov05 is the SPM
Thank You For Your Help !
On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Check on the hosts tab , which is your current SPM (last column in Admin UI). Then open the /var/log/vdsm/vdsm.log and repeat the operation. Then provide the log from that host and the engine's log (on the HostedEngine VM or on your standalone engine).
Best Regards, Strahil Nikolov
На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Resending to eliminate email issues
---------- Forwarded message --------- From: C Williams <cwilliams3320@gmail.com> Date: Thu, Jun 18, 2020 at 4:01 PM Subject: Re: [ovirt-users] Fwd: Issues with Gluster Domain To: Strahil Nikolov <hunter86_bg@yahoo.com>
Here is output from mount
192.168.24.12:/stor/import0 on /rhev/data-center/mnt/192.168.24.12:_stor_import0 type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12)
192.168.24.13:/stor/import1 on /rhev/data-center/mnt/192.168.24.13:_stor_import1 type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
192.168.24.13:/stor/iso1 on /rhev/data-center/mnt/192.168.24.13:_stor_iso1 type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
192.168.24.13:/stor/export0 on /rhev/data-center/mnt/192.168.24.13:_stor_export0 type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
192.168.24.15:/images on /rhev/data-center/mnt/glusterSD/192.168.24.15:_images type fuse.glusterfs
(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
192.168.24.18:/images3 on /rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 type fuse.glusterfs
(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
tmpfs on /run/user/0 type tmpfs (rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) [root@ov06 glusterfs]#
Also here is a screenshot of the console
[image: image.png] The other domains are up
Import0 and Import1 are NFS . GLCL0 is gluster. They all are running VMs
Thank You For Your Help !
On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
> I don't see '/rhev/data-center/mnt/192.168.24.13:_stor_import1' mounted > at all . > What is the status of all storage domains ? > > Best Regards, > Strahil Nikolov > > На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams <cwilliams3320@gmail.com> > написа: > > Resending to deal with possible email issues > > > >---------- Forwarded message --------- > >From: C Williams <cwilliams3320@gmail.com> > >Date: Thu, Jun 18, 2020 at 2:07 PM > >Subject: Re: [ovirt-users] Issues with Gluster Domain > >To: Strahil Nikolov <hunter86_bg@yahoo.com> > > > > > >More > > > >[root@ov06 ~]# for i in $(gluster volume list); do echo $i;echo; > >gluster > >volume info $i; echo;echo;gluster volume status $i;echo;echo;echo;done > >images3 > > > > > >Volume Name: images3 > >Type: Replicate > >Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b > >Status: Started > >Snapshot Count: 0 > >Number of Bricks: 1 x 3 = 3 > >Transport-type: tcp > >Bricks: > >Brick1: 192.168.24.18:/bricks/brick04/images3 > >Brick2: 192.168.24.19:/bricks/brick05/images3 > >Brick3: 192.168.24.20:/bricks/brick06/images3 > >Options Reconfigured: > >performance.client-io-threads: on > >nfs.disable: on > >transport.address-family: inet > >user.cifs: off > >auth.allow: * > >performance.quick-read: off > >performance.read-ahead: off > >performance.io-cache: off > >performance.low-prio-threads: 32 > >network.remote-dio: off > >cluster.eager-lock: enable > >cluster.quorum-type: auto > >cluster.server-quorum-type: server > >cluster.data-self-heal-algorithm: full > >cluster.locking-scheme: granular > >cluster.shd-max-threads: 8 > >cluster.shd-wait-qlength: 10000 > >features.shard: on > >cluster.choose-local: off > >client.event-threads: 4 > >server.event-threads: 4 > >storage.owner-uid: 36 > >storage.owner-gid: 36 > >performance.strict-o-direct: on > >network.ping-timeout: 30 > >cluster.granular-entry-heal: enable > > > > > >Status of volume: images3 > >Gluster process TCP Port RDMA Port Online > > Pid > >
------------------------------------------------------------------------------
> >Brick 192.168.24.18:/bricks/brick04/images3 49152 0 Y > >6666 > >Brick 192.168.24.19:/bricks/brick05/images3 49152 0 Y > >6779 > >Brick 192.168.24.20:/bricks/brick06/images3 49152 0 Y > >7227 > >Self-heal Daemon on localhost N/A N/A Y > >6689 > >Self-heal Daemon on ov07.ntc.srcle.com N/A N/A Y > >6802 > >Self-heal Daemon on ov08.ntc.srcle.com N/A N/A Y > >7250 > > > >Task Status of Volume images3 > >
> >There are no active volume tasks > > > > > > > > > >[root@ov06 ~]# ls -l /rhev/data-center/mnt/glusterSD/ > >total 16 > >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 192.168.24.15:_images > >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 192.168.24.18:_images3 > >[root@ov06 ~]# > > > >On Thu, Jun 18, 2020 at 2:03 PM C Williams <cwilliams3320@gmail.com> > >wrote: > > > >> Strahil, > >> > >> Here you go -- Thank You For Your Help ! > >> > >> BTW -- I can write a test file to gluster and it replicates properly. > >> Thinking something about the oVirt Storage Domain ? > >> > >> [root@ov08 ~]# gluster pool list > >> UUID Hostname State > >> 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06 > >Connected > >> 36ce5a00-6f65-4926-8438-696944ebadb5 ov07.ntc.srcle.com > >Connected > >> c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost > >Connected > >> [root@ov08 ~]# gluster volume list > >> images3 > >> > >> On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov > ><hunter86_bg@yahoo.com> > >> wrote: > >> > >>> Log to the oVirt cluster and provide the output of: > >>> gluster pool list > >>> gluster volume list > >>> for i in $(gluster volume list); do echo $i;echo; gluster volume > >info > >>> $i; echo;echo;gluster volume status $i;echo;echo;echo;done > >>> > >>> ls -l /rhev/data-center/mnt/glusterSD/ > >>> > >>> Best Regards, > >>> Strahil Nikolov > >>> > >>> > >>> На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams > ><cwilliams3320@gmail.com> > >>> написа: > >>> >Hello, > >>> > > >>> >I recently added 6 hosts to an existing oVirt compute/gluster > >cluster. > >>> > > >>> >Prior to this attempted addition, my cluster had 3 Hypervisor hosts > >and > >>> >3 > >>> >gluster bricks which made up a single gluster volume (replica 3 > >volume) > >>> >. I > >>> >added the additional hosts and made a brick on 3 of the new hosts > >and > >>> >attempted to make a new replica 3 volume. I had difficulty > >creating > >>> >the > >>> >new volume. So, I decided that I would make a new compute/gluster > >>> >cluster > >>> >for each set of 3 new hosts. > >>> > > >>> >I removed the 6 new hosts from the existing oVirt Compute/Gluster > >>> >Cluster > >>> >leaving the 3 original hosts in place with their bricks. At
> >point > >>> >my > >>> >original bricks went down and came back up . The volume showed > >entries > >>> >that > >>> >needed healing. At that point I ran gluster volume heal images3 > >full, > >>> >etc. > >>> >The volume shows no unhealed entries. I also corrected some
------------------------------------------------------------------------------ that peer
> >>> >errors. > >>> > > >>> >However, I am unable to copy disks, move disks to another domain, > >>> >export > >>> >disks, etc. It appears that the engine cannot locate disks properly > >and > >>> >I > >>> >get storage I/O errors. > >>> > > >>> >I have detached and removed the oVirt Storage Domain. I reimported > >the > >>> >domain and imported 2 VMs, But the VM disks exhibit the same > >behaviour > >>> >and > >>> >won't run from the hard disk. > >>> > > >>> > > >>> >I get errors such as this > >>> > > >>> >VDSM ov05 command HSMGetAllTasksStatusesVDS failed: low level Image > >>> >copy > >>> >failed: ("Command ['/usr/bin/qemu-img', 'convert', '-p', '-t', > >'none', > >>> >'-T', 'none', '-f', 'raw', > >>> >u'/rhev/data-center/mnt/glusterSD/192.168.24.18: > >>> > >
_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510',
> >>> >'-O', 'raw', > >>> >u'/rhev/data-center/mnt/192.168.24.13: > >>> > >
_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5']
> >>> >failed with rc=1 out='' err=bytearray(b'qemu-img: error while > >reading > >>> >sector 135168: Transport endpoint is not connected\\nqemu-img: > >error > >>> >while > >>> >reading sector 131072: Transport endpoint is not > >connected\\nqemu-img: > >>> >error while reading sector 139264: Transport endpoint is not > >>> >connected\\nqemu-img: error while reading sector 143360: Transport > >>> >endpoint > >>> >is not connected\\nqemu-img: error while reading sector 147456: > >>> >Transport > >>> >endpoint is not connected\\nqemu-img: error while reading sector > >>> >155648: > >>> >Transport endpoint is not connected\\nqemu-img: error while reading > >>> >sector > >>> >151552: Transport endpoint is not connected\\nqemu-img: error while > >>> >reading > >>> >sector 159744: Transport endpoint is not connected\\n')",) > >>> > > >>> >oVirt version is 4.3.82-1.el7 > >>> >OS CentOS Linux release 7.7.1908 (Core) > >>> > > >>> >The Gluster Cluster has been working very well until this incident. > >>> > > >>> >Please help. > >>> > > >>> >Thank You > >>> > > >>> >Charles Williams > >>> > >> >
Hi , This one really looks like the ACL bug I was hit with when I updated from Gluster v6.5 to 6.6 and later from 7.0 to 7.2. Did you update your setup recently ? Did you upgrade gluster also ? You have to check the gluster logs in order to verify that, so you can try: 1. Set Gluster logs to trace level (for details check: https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3/html... ) 2. Power up a VM that was already off , or retry the procedure from the logs you sent. 3. Stop the trace level of the logs 4. Check libvirt logs on the host that was supposed to power up the VM (in case a VM was powered on) 5. Check the gluster brick logs on all nodes for ACL errors. Here is a sample from my old logs: gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 13:19:41.489047] I [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- 4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:36,gid:36,perm:1,ngrps:3), ctx (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied] gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 13:22:51.818796] I [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- 4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:36,gid:36,perm:1,ngrps:3), ctx (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied] gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 13:24:43.732856] I [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- 4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:36,gid:36,perm:1,ngrps:3), ctx (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied] gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 13:26:50.758178] I [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- 4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:36,gid:36,perm:1,ngrps:3), ctx (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied] In my case , the workaround was to downgrade the gluster packages on all nodes (and reboot each node 1 by 1 ) if the major version is the same, but if you upgraded to v7.X - then you can try the v7.0 . Best Regards, Strahil Nikolov В събота, 20 юни 2020 г., 18:48:42 ч. Гринуич+3, C Williams <cwilliams3320@gmail.com> написа: Hello, Here are additional log tiles as well as a tree of the problematic Gluster storage domain. During this time I attempted to copy a virtual disk to another domain, move a virtual disk to another domain and run a VM where the virtual hard disk would be used. The copies/moves failed and the VM went into pause mode when the virtual HDD was involved. Please check these out. Thank You For Your Help ! On Sat, Jun 20, 2020 at 9:54 AM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
I understand. Please keep me posted.
Thanks For The Help !
On Sat, Jun 20, 2020 at 4:36 AM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Hey C Williams,
sorry for the delay, but I couldn't get somw time to check your logs. Will try a little bit later.
Best Regards, Strahil Nikolov
На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Hello,
Was wanting to follow up on this issue. Users are impacted.
Thank You
On Fri, Jun 19, 2020 at 9:20 AM C Williams <cwilliams3320@gmail.com> wrote:
Hello,
Here are the logs (some IPs are changed )
ov05 is the SPM
Thank You For Your Help !
On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Check on the hosts tab , which is your current SPM (last column in Admin UI). Then open the /var/log/vdsm/vdsm.log and repeat the operation. Then provide the log from that host and the engine's log (on the HostedEngine VM or on your standalone engine).
Best Regards, Strahil Nikolov
На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Resending to eliminate email issues
---------- Forwarded message --------- From: C Williams <cwilliams3320@gmail.com> Date: Thu, Jun 18, 2020 at 4:01 PM Subject: Re: [ovirt-users] Fwd: Issues with Gluster Domain To: Strahil Nikolov <hunter86_bg@yahoo.com>
Here is output from mount
192.168.24.12:/stor/import0 on /rhev/data-center/mnt/192.168.24.12:_stor_import0 type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12)
192.168.24.13:/stor/import1 on /rhev/data-center/mnt/192.168.24.13:_stor_import1 type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
192.168.24.13:/stor/iso1 on /rhev/data-center/mnt/192.168.24.13:_stor_iso1 type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
192.168.24.13:/stor/export0 on /rhev/data-center/mnt/192.168.24.13:_stor_export0 type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
192.168.24.15:/images on /rhev/data-center/mnt/glusterSD/192.168.24.15:_images type fuse.glusterfs
(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
192.168.24.18:/images3 on /rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 type fuse.glusterfs
tmpfs on /run/user/0 type tmpfs (rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) [root@ov06 glusterfs]#
Also here is a screenshot of the console
[image: image.png] The other domains are up
Import0 and Import1 are NFS . GLCL0 is gluster. They all are running VMs
Thank You For Your Help !
On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
> I don't see '/rhev/data-center/mnt/192.168.24.13:_stor_import1' mounted > at all . > What is the status of all storage domains ? > > Best Regards, > Strahil Nikolov > > На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams <cwilliams3320@gmail.com> > написа: > > Resending to deal with possible email issues > > > >---------- Forwarded message --------- > >From: C Williams <cwilliams3320@gmail.com> > >Date: Thu, Jun 18, 2020 at 2:07 PM > >Subject: Re: [ovirt-users] Issues with Gluster Domain > >To: Strahil Nikolov <hunter86_bg@yahoo.com> > > > > > >More > > > >[root@ov06 ~]# for i in $(gluster volume list); do echo $i;echo; > >gluster > >volume info $i; echo;echo;gluster volume status $i;echo;echo;echo;done > >images3 > > > > > >Volume Name: images3 > >Type: Replicate > >Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b > >Status: Started > >Snapshot Count: 0 > >Number of Bricks: 1 x 3 = 3 > >Transport-type: tcp > >Bricks: > >Brick1: 192.168.24.18:/bricks/brick04/images3 > >Brick2: 192.168.24.19:/bricks/brick05/images3 > >Brick3: 192.168.24.20:/bricks/brick06/images3 > >Options Reconfigured: > >performance.client-io-threads: on > >nfs.disable: on > >transport.address-family: inet > >user.cifs: off > >auth.allow: * > >performance.quick-read: off > >performance.read-ahead: off > >performance.io-cache: off > >performance.low-prio-threads: 32 > >network.remote-dio: off > >cluster.eager-lock: enable > >cluster.quorum-type: auto > >cluster.server-quorum-type: server > >cluster.data-self-heal-algorithm: full > >cluster.locking-scheme: granular > >cluster.shd-max-threads: 8 > >cluster.shd-wait-qlength: 10000 > >features.shard: on > >cluster.choose-local: off > >client.event-threads: 4 > >server.event-threads: 4 > >storage.owner-uid: 36 > >storage.owner-gid: 36 > >performance.strict-o-direct: on > >network.ping-timeout: 30 > >cluster.granular-entry-heal: enable > > > > > >Status of volume: images3 > >Gluster process TCP Port RDMA Port Online > > Pid > >
------------------------------------------------------------------------------
> >Brick 192.168.24.18:/bricks/brick04/images3 49152 0 Y > >6666 > >Brick 192.168.24.19:/bricks/brick05/images3 49152 0 Y > >6779 > >Brick 192.168.24.20:/bricks/brick06/images3 49152 0 Y > >7227 > >Self-heal Daemon on localhost N/A N/A Y > >6689 > >Self-heal Daemon on ov07.ntc.srcle.com N/A N/A Y > >6802 > >Self-heal Daemon on ov08.ntc.srcle.com N/A N/A Y > >7250 > > > >Task Status of Volume images3 > >
------------------------------------------------------------------------------
> >There are no active volume tasks > > > > > > > > > >[root@ov06 ~]# ls -l /rhev/data-center/mnt/glusterSD/ > >total 16 > >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 192.168.24.15:_images > >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 192.168.24.18:_images3 > >[root@ov06 ~]# > > > >On Thu, Jun 18, 2020 at 2:03 PM C Williams <cwilliams3320@gmail.com> > >wrote: > > > >> Strahil, > >> > >> Here you go -- Thank You For Your Help ! > >> > >> BTW -- I can write a test file to gluster and it replicates properly. > >> Thinking something about the oVirt Storage Domain ? > >> > >> [root@ov08 ~]# gluster pool list > >> UUID Hostname State > >> 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06 > >Connected > >> 36ce5a00-6f65-4926-8438-696944ebadb5 ov07.ntc.srcle.com > >Connected > >> c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost > >Connected > >> [root@ov08 ~]# gluster volume list > >> images3 > >> > >> On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov > ><hunter86_bg@yahoo.com> > >> wrote: > >> > >>> Log to the oVirt cluster and provide the output of: > >>> gluster pool list > >>> gluster volume list > >>> for i in $(gluster volume list); do echo $i;echo; gluster volume > >info > >>> $i; echo;echo;gluster volume status $i;echo;echo;echo;done > >>> > >>> ls -l /rhev/data-center/mnt/glusterSD/ > >>> > >>> Best Regards, > >>> Strahil Nikolov > >>> > >>> > >>> На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams > ><cwilliams3320@gmail.com> > >>> написа: > >>> >Hello, > >>> > > >>> >I recently added 6 hosts to an existing oVirt compute/gluster > >cluster. > >>> > > >>> >Prior to this attempted addition, my cluster had 3 Hypervisor hosts > >and > >>> >3 > >>> >gluster bricks which made up a single gluster volume (replica 3 > >volume) > >>> >. I > >>> >added the additional hosts and made a brick on 3 of the new hosts > >and > >>> >attempted to make a new replica 3 volume. I had difficulty > >creating > >>> >the > >>> >new volume. So, I decided that I would make a new compute/gluster > >>> >cluster > >>> >for each set of 3 new hosts. > >>> > > >>> >I removed the 6 new hosts from the existing oVirt Compute/Gluster > >>> >Cluster > >>> >leaving the 3 original hosts in place with their bricks. At
> >point > >>> >my > >>> >original bricks went down and came back up . The volume showed > >entries > >>> >that > >>> >needed healing. At that point I ran gluster volume heal images3 > >full, > >>> >etc. > >>> >The volume shows no unhealed entries. I also corrected some
(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) that peer
> >>> >errors. > >>> > > >>> >However, I am unable to copy disks, move disks to another domain, > >>> >export > >>> >disks, etc. It appears that the engine cannot locate disks properly > >and > >>> >I > >>> >get storage I/O errors. > >>> > > >>> >I have detached and removed the oVirt Storage Domain. I reimported > >the > >>> >domain and imported 2 VMs, But the VM disks exhibit the same > >behaviour > >>> >and > >>> >won't run from the hard disk. > >>> > > >>> > > >>> >I get errors such as this > >>> > > >>> >VDSM ov05 command HSMGetAllTasksStatusesVDS failed: low level Image > >>> >copy > >>> >failed: ("Command ['/usr/bin/qemu-img', 'convert', '-p', '-t', > >'none', > >>> >'-T', 'none', '-f', 'raw', > >>> >u'/rhev/data-center/mnt/glusterSD/192.168.24.18: > >>> > >
_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510',
> >>> >'-O', 'raw', > >>> >u'/rhev/data-center/mnt/192.168.24.13: > >>> > >
_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5']
> >>> >failed with rc=1 out='' err=bytearray(b'qemu-img: error while > >reading > >>> >sector 135168: Transport endpoint is not connected\\nqemu-img: > >error > >>> >while > >>> >reading sector 131072: Transport endpoint is not > >connected\\nqemu-img: > >>> >error while reading sector 139264: Transport endpoint is not > >>> >connected\\nqemu-img: error while reading sector 143360: Transport > >>> >endpoint > >>> >is not connected\\nqemu-img: error while reading sector 147456: > >>> >Transport > >>> >endpoint is not connected\\nqemu-img: error while reading sector > >>> >155648: > >>> >Transport endpoint is not connected\\nqemu-img: error while reading > >>> >sector > >>> >151552: Transport endpoint is not connected\\nqemu-img: error while > >>> >reading > >>> >sector 159744: Transport endpoint is not connected\\n')",) > >>> > > >>> >oVirt version is 4.3.82-1.el7 > >>> >OS CentOS Linux release 7.7.1908 (Core) > >>> > > >>> >The Gluster Cluster has been working very well until this incident. > >>> > > >>> >Please help. > >>> > > >>> >Thank You > >>> > > >>> >Charles Williams > >>> > >> >
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/YY3VUKEJLI7MRW...
Strahil, The gluster version on the current 3 gluster hosts is 6.7 (last update 2/26). These 3 hosts provide 1 brick each for the replica 3 volume. Earlier I had tried to add 6 additional hosts to the cluster. Those new hosts were 6.9 gluster. I attempted to make a new separate volume with 3 bricks provided by the 3 new gluster 6.9 hosts. After having many errors from the oVirt interface, I gave up and removed the 6 new hosts from the cluster. That is where the problems started. The intent was to expand the gluster cluster while making 2 new volumes for that cluster. The ovirt compute cluster would allow for efficient VM migration between 9 hosts -- while having separate gluster volumes for safety purposes. Looking at the brick logs, I see where there are acl errors starting from the time of the removal of the 6 new hosts. Please check out the attached brick log from 6/14-18. The events started on 6/17. I wish I had a downgrade path. Thank You For The Help !! On Sat, Jun 20, 2020 at 7:47 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Hi ,
This one really looks like the ACL bug I was hit with when I updated from Gluster v6.5 to 6.6 and later from 7.0 to 7.2.
Did you update your setup recently ? Did you upgrade gluster also ?
You have to check the gluster logs in order to verify that, so you can try:
1. Set Gluster logs to trace level (for details check: https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3/html... ) 2. Power up a VM that was already off , or retry the procedure from the logs you sent. 3. Stop the trace level of the logs 4. Check libvirt logs on the host that was supposed to power up the VM (in case a VM was powered on) 5. Check the gluster brick logs on all nodes for ACL errors. Here is a sample from my old logs:
gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 13:19:41.489047] I [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- 4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:36,gid:36,perm:1,ngrps:3), ctx (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied] gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 13:22:51.818796] I [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- 4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:36,gid:36,perm:1,ngrps:3), ctx (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied] gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 13:24:43.732856] I [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- 4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:36,gid:36,perm:1,ngrps:3), ctx (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied] gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 13:26:50.758178] I [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- 4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:36,gid:36,perm:1,ngrps:3), ctx (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied]
In my case , the workaround was to downgrade the gluster packages on all nodes (and reboot each node 1 by 1 ) if the major version is the same, but if you upgraded to v7.X - then you can try the v7.0 .
Best Regards, Strahil Nikolov
В събота, 20 юни 2020 г., 18:48:42 ч. Гринуич+3, C Williams < cwilliams3320@gmail.com> написа:
Hello,
Here are additional log tiles as well as a tree of the problematic Gluster storage domain. During this time I attempted to copy a virtual disk to another domain, move a virtual disk to another domain and run a VM where the virtual hard disk would be used.
The copies/moves failed and the VM went into pause mode when the virtual HDD was involved.
Please check these out.
Thank You For Your Help !
On Sat, Jun 20, 2020 at 9:54 AM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
I understand. Please keep me posted.
Thanks For The Help !
On Sat, Jun 20, 2020 at 4:36 AM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Hey C Williams,
sorry for the delay, but I couldn't get somw time to check your logs. Will try a little bit later.
Best Regards, Strahil Nikolov
На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams < cwilliams3320@gmail.com> написа:
Hello,
Was wanting to follow up on this issue. Users are impacted.
Thank You
On Fri, Jun 19, 2020 at 9:20 AM C Williams <cwilliams3320@gmail.com> wrote:
Hello,
Here are the logs (some IPs are changed )
ov05 is the SPM
Thank You For Your Help !
On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Check on the hosts tab , which is your current SPM (last column in Admin UI). Then open the /var/log/vdsm/vdsm.log and repeat the operation. Then provide the log from that host and the engine's log (on the HostedEngine VM or on your standalone engine).
Best Regards, Strahil Nikolov
На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: >Resending to eliminate email issues > >---------- Forwarded message --------- >From: C Williams <cwilliams3320@gmail.com> >Date: Thu, Jun 18, 2020 at 4:01 PM >Subject: Re: [ovirt-users] Fwd: Issues with Gluster Domain >To: Strahil Nikolov <hunter86_bg@yahoo.com> > > >Here is output from mount > >192.168.24.12:/stor/import0 on >/rhev/data-center/mnt/192.168.24.12:_stor_import0 >type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12)
>192.168.24.13:/stor/import1 on >/rhev/data-center/mnt/192.168.24.13:_stor_import1 >type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
>192.168.24.13:/stor/iso1 on >/rhev/data-center/mnt/192.168.24.13:_stor_iso1 >type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
>192.168.24.13:/stor/export0 on >/rhev/data-center/mnt/192.168.24.13:_stor_export0 >type nfs4
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
>192.168.24.15:/images on >/rhev/data-center/mnt/glusterSD/192.168.24.15:_images >type fuse.glusterfs
(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
>192.168.24.18:/images3 on >/rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 >type fuse.glusterfs
(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
>tmpfs on /run/user/0 type tmpfs >(rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) >[root@ov06 glusterfs]# > >Also here is a screenshot of the console > >[image: image.png] >The other domains are up > >Import0 and Import1 are NFS . GLCL0 is gluster. They all are running >VMs > >Thank You For Your Help ! > >On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov <hunter86_bg@yahoo.com> >wrote: > >> I don't see '/rhev/data-center/mnt/192.168.24.13:_stor_import1' >mounted >> at all . >> What is the status of all storage domains ? >> >> Best Regards, >> Strahil Nikolov >> >> На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams ><cwilliams3320@gmail.com> >> написа: >> > Resending to deal with possible email issues >> > >> >---------- Forwarded message --------- >> >From: C Williams <cwilliams3320@gmail.com> >> >Date: Thu, Jun 18, 2020 at 2:07 PM >> >Subject: Re: [ovirt-users] Issues with Gluster Domain >> >To: Strahil Nikolov <hunter86_bg@yahoo.com> >> > >> > >> >More >> > >> >[root@ov06 ~]# for i in $(gluster volume list); do echo $i;echo; >> >gluster >> >volume info $i; echo;echo;gluster volume status >$i;echo;echo;echo;done >> >images3 >> > >> > >> >Volume Name: images3 >> >Type: Replicate >> >Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b >> >Status: Started >> >Snapshot Count: 0 >> >Number of Bricks: 1 x 3 = 3 >> >Transport-type: tcp >> >Bricks: >> >Brick1: 192.168.24.18:/bricks/brick04/images3 >> >Brick2: 192.168.24.19:/bricks/brick05/images3 >> >Brick3: 192.168.24.20:/bricks/brick06/images3 >> >Options Reconfigured: >> >performance.client-io-threads: on >> >nfs.disable: on >> >transport.address-family: inet >> >user.cifs: off >> >auth.allow: * >> >performance.quick-read: off >> >performance.read-ahead: off >> >performance.io-cache: off >> >performance.low-prio-threads: 32 >> >network.remote-dio: off >> >cluster.eager-lock: enable >> >cluster.quorum-type: auto >> >cluster.server-quorum-type: server >> >cluster.data-self-heal-algorithm: full >> >cluster.locking-scheme: granular >> >cluster.shd-max-threads: 8 >> >cluster.shd-wait-qlength: 10000 >> >features.shard: on >> >cluster.choose-local: off >> >client.event-threads: 4 >> >server.event-threads: 4 >> >storage.owner-uid: 36 >> >storage.owner-gid: 36 >> >performance.strict-o-direct: on >> >network.ping-timeout: 30 >> >cluster.granular-entry-heal: enable >> > >> > >> >Status of volume: images3 >> >Gluster process TCP Port RDMA Port >Online >> > Pid >> >>
------------------------------------------------------------------------------ >> >Brick 192.168.24.18:/bricks/brick04/images3 49152 0 Y >> >6666 >> >Brick 192.168.24.19:/bricks/brick05/images3 49152 0 Y >> >6779 >> >Brick 192.168.24.20:/bricks/brick06/images3 49152 0 Y >> >7227 >> >Self-heal Daemon on localhost N/A N/A Y >> >6689 >> >Self-heal Daemon on ov07.ntc.srcle.com N/A N/A Y >> >6802 >> >Self-heal Daemon on ov08.ntc.srcle.com N/A N/A Y >> >7250 >> > >> >Task Status of Volume images3 >> >>
------------------------------------------------------------------------------ >> >There are no active volume tasks >> > >> > >> > >> > >> >[root@ov06 ~]# ls -l /rhev/data-center/mnt/glusterSD/ >> >total 16 >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 192.168.24.15:_images >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 192.168.24.18:_images3 >> >[root@ov06 ~]# >> > >> >On Thu, Jun 18, 2020 at 2:03 PM C Williams <cwilliams3320@gmail.com> >> >wrote: >> > >> >> Strahil, >> >> >> >> Here you go -- Thank You For Your Help ! >> >> >> >> BTW -- I can write a test file to gluster and it replicates >properly. >> >> Thinking something about the oVirt Storage Domain ? >> >> >> >> [root@ov08 ~]# gluster pool list >> >> UUID Hostname >State >> >> 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06 >> >Connected >> >> 36ce5a00-6f65-4926-8438-696944ebadb5 ov07.ntc.srcle.com >> >Connected >> >> c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost >> >Connected >> >> [root@ov08 ~]# gluster volume list >> >> images3 >> >> >> >> On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov >> ><hunter86_bg@yahoo.com> >> >> wrote: >> >> >> >>> Log to the oVirt cluster and provide the output of: >> >>> gluster pool list >> >>> gluster volume list >> >>> for i in $(gluster volume list); do echo $i;echo; gluster >volume >> >info >> >>> $i; echo;echo;gluster volume status $i;echo;echo;echo;done >> >>> >> >>> ls -l /rhev/data-center/mnt/glusterSD/ >> >>> >> >>> Best Regards, >> >>> Strahil Nikolov >> >>> >> >>> >> >>> На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams >> ><cwilliams3320@gmail.com> >> >>> написа: >> >>> >Hello, >> >>> > >> >>> >I recently added 6 hosts to an existing oVirt compute/gluster >> >cluster. >> >>> > >> >>> >Prior to this attempted addition, my cluster had 3 Hypervisor >hosts >> >and >> >>> >3 >> >>> >gluster bricks which made up a single gluster volume (replica 3 >> >volume) >> >>> >. I >> >>> >added the additional hosts and made a brick on 3 of the new >hosts >> >and >> >>> >attempted to make a new replica 3 volume. I had difficulty >> >creating >> >>> >the >> >>> >new volume. So, I decided that I would make a new >compute/gluster >> >>> >cluster >> >>> >for each set of 3 new hosts. >> >>> > >> >>> >I removed the 6 new hosts from the existing oVirt >Compute/Gluster >> >>> >Cluster >> >>> >leaving the 3 original hosts in place with their bricks. At that >> >point >> >>> >my >> >>> >original bricks went down and came back up . The volume showed >> >entries >> >>> >that >> >>> >needed healing. At that point I ran gluster volume heal images3 >> >full, >> >>> >etc. >> >>> >The volume shows no unhealed entries. I also corrected some peer >> >>> >errors. >> >>> > >> >>> >However, I am unable to copy disks, move disks to another >domain, >> >>> >export >> >>> >disks, etc. It appears that the engine cannot locate disks >properly >> >and >> >>> >I >> >>> >get storage I/O errors. >> >>> > >> >>> >I have detached and removed the oVirt Storage Domain. I >reimported >> >the >> >>> >domain and imported 2 VMs, But the VM disks exhibit the same >> >behaviour >> >>> >and >> >>> >won't run from the hard disk. >> >>> > >> >>> > >> >>> >I get errors such as this >> >>> > >> >>> >VDSM ov05 command HSMGetAllTasksStatusesVDS failed: low level >Image >> >>> >copy >> >>> >failed: ("Command ['/usr/bin/qemu-img', 'convert', '-p', '-t', >> >'none', >> >>> >'-T', 'none', '-f', 'raw', >> >>> >u'/rhev/data-center/mnt/glusterSD/192.168.24.18: >> >>> >> >>
_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510', >> >>> >'-O', 'raw', >> >>> >u'/rhev/data-center/mnt/192.168.24.13: >> >>> >> >>
_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5'] >> >>> >failed with rc=1 out='' err=bytearray(b'qemu-img: error while >> >reading >> >>> >sector 135168: Transport endpoint is not connected\\nqemu-img: >> >error >> >>> >while >> >>> >reading sector 131072: Transport endpoint is not >> >connected\\nqemu-img: >> >>> >error while reading sector 139264: Transport endpoint is not >> >>> >connected\\nqemu-img: error while reading sector 143360: >Transport >> >>> >endpoint >> >>> >is not connected\\nqemu-img: error while reading sector 147456: >> >>> >Transport >> >>> >endpoint is not connected\\nqemu-img: error while reading sector >> >>> >155648: >> >>> >Transport endpoint is not connected\\nqemu-img: error while >reading >> >>> >sector >> >>> >151552: Transport endpoint is not connected\\nqemu-img: error >while >> >>> >reading >> >>> >sector 159744: Transport endpoint is not connected\\n')",) >> >>> > >> >>> >oVirt version is 4.3.82-1.el7 >> >>> >OS CentOS Linux release 7.7.1908 (Core) >> >>> > >> >>> >The Gluster Cluster has been working very well until this >incident. >> >>> > >> >>> >Please help. >> >>> > >> >>> >Thank You >> >>> > >> >>> >Charles Williams >> >>> >> >> >>
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/YY3VUKEJLI7MRW...
Hello, Based on the situation, I am planning to upgrade the 3 affected hosts. My reasoning is that the hosts/bricks were attached to 6.9 at one time. Thanks For Your Help ! On Sat, Jun 20, 2020 at 8:38 PM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
The gluster version on the current 3 gluster hosts is 6.7 (last update 2/26). These 3 hosts provide 1 brick each for the replica 3 volume.
Earlier I had tried to add 6 additional hosts to the cluster. Those new hosts were 6.9 gluster.
I attempted to make a new separate volume with 3 bricks provided by the 3 new gluster 6.9 hosts. After having many errors from the oVirt interface, I gave up and removed the 6 new hosts from the cluster. That is where the problems started. The intent was to expand the gluster cluster while making 2 new volumes for that cluster. The ovirt compute cluster would allow for efficient VM migration between 9 hosts -- while having separate gluster volumes for safety purposes.
Looking at the brick logs, I see where there are acl errors starting from the time of the removal of the 6 new hosts.
Please check out the attached brick log from 6/14-18. The events started on 6/17.
I wish I had a downgrade path.
Thank You For The Help !!
On Sat, Jun 20, 2020 at 7:47 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Hi ,
This one really looks like the ACL bug I was hit with when I updated from Gluster v6.5 to 6.6 and later from 7.0 to 7.2.
Did you update your setup recently ? Did you upgrade gluster also ?
You have to check the gluster logs in order to verify that, so you can try:
1. Set Gluster logs to trace level (for details check: https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3/html... ) 2. Power up a VM that was already off , or retry the procedure from the logs you sent. 3. Stop the trace level of the logs 4. Check libvirt logs on the host that was supposed to power up the VM (in case a VM was powered on) 5. Check the gluster brick logs on all nodes for ACL errors. Here is a sample from my old logs:
gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 13:19:41.489047] I [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- 4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:36,gid:36,perm:1,ngrps:3), ctx (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied] gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 13:22:51.818796] I [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- 4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:36,gid:36,perm:1,ngrps:3), ctx (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied] gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 13:24:43.732856] I [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- 4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:36,gid:36,perm:1,ngrps:3), ctx (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied] gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 13:26:50.758178] I [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- 4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:36,gid:36,perm:1,ngrps:3), ctx (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied]
In my case , the workaround was to downgrade the gluster packages on all nodes (and reboot each node 1 by 1 ) if the major version is the same, but if you upgraded to v7.X - then you can try the v7.0 .
Best Regards, Strahil Nikolov
В събота, 20 юни 2020 г., 18:48:42 ч. Гринуич+3, C Williams < cwilliams3320@gmail.com> написа:
Hello,
Here are additional log tiles as well as a tree of the problematic Gluster storage domain. During this time I attempted to copy a virtual disk to another domain, move a virtual disk to another domain and run a VM where the virtual hard disk would be used.
The copies/moves failed and the VM went into pause mode when the virtual HDD was involved.
Please check these out.
Thank You For Your Help !
On Sat, Jun 20, 2020 at 9:54 AM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
I understand. Please keep me posted.
Thanks For The Help !
On Sat, Jun 20, 2020 at 4:36 AM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Hey C Williams,
sorry for the delay, but I couldn't get somw time to check your logs. Will try a little bit later.
Best Regards, Strahil Nikolov
На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams < cwilliams3320@gmail.com> написа:
Hello,
Was wanting to follow up on this issue. Users are impacted.
Thank You
On Fri, Jun 19, 2020 at 9:20 AM C Williams <cwilliams3320@gmail.com> wrote:
Hello,
Here are the logs (some IPs are changed )
ov05 is the SPM
Thank You For Your Help !
On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
> Check on the hosts tab , which is your current SPM (last column in Admin > UI). > Then open the /var/log/vdsm/vdsm.log and repeat the operation. > Then provide the log from that host and the engine's log (on the > HostedEngine VM or on your standalone engine). > > Best Regards, > Strahil Nikolov > > На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams <cwilliams3320@gmail.com> > написа: > >Resending to eliminate email issues > > > >---------- Forwarded message --------- > >From: C Williams <cwilliams3320@gmail.com> > >Date: Thu, Jun 18, 2020 at 4:01 PM > >Subject: Re: [ovirt-users] Fwd: Issues with Gluster Domain > >To: Strahil Nikolov <hunter86_bg@yahoo.com> > > > > > >Here is output from mount > > > >192.168.24.12:/stor/import0 on > >/rhev/data-center/mnt/192.168.24.12:_stor_import0 > >type nfs4 > >
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12) > >192.168.24.13:/stor/import1 on > >/rhev/data-center/mnt/192.168.24.13:_stor_import1 > >type nfs4 > >
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) > >192.168.24.13:/stor/iso1 on > >/rhev/data-center/mnt/192.168.24.13:_stor_iso1 > >type nfs4 > >
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) > >192.168.24.13:/stor/export0 on > >/rhev/data-center/mnt/192.168.24.13:_stor_export0 > >type nfs4 > >
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) > >192.168.24.15:/images on > >/rhev/data-center/mnt/glusterSD/192.168.24.15:_images > >type fuse.glusterfs > >
(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) > >192.168.24.18:/images3 on > >/rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 > >type fuse.glusterfs > >
(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) > >tmpfs on /run/user/0 type tmpfs > >(rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) > >[root@ov06 glusterfs]# > > > >Also here is a screenshot of the console > > > >[image: image.png] > >The other domains are up > > > >Import0 and Import1 are NFS . GLCL0 is gluster. They all are running > >VMs > > > >Thank You For Your Help ! > > > >On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov <hunter86_bg@yahoo.com> > >wrote: > > > >> I don't see '/rhev/data-center/mnt/192.168.24.13:_stor_import1' > >mounted > >> at all . > >> What is the status of all storage domains ? > >> > >> Best Regards, > >> Strahil Nikolov > >> > >> На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams > ><cwilliams3320@gmail.com> > >> написа: > >> > Resending to deal with possible email issues > >> > > >> >---------- Forwarded message --------- > >> >From: C Williams <cwilliams3320@gmail.com> > >> >Date: Thu, Jun 18, 2020 at 2:07 PM > >> >Subject: Re: [ovirt-users] Issues with Gluster Domain > >> >To: Strahil Nikolov <hunter86_bg@yahoo.com> > >> > > >> > > >> >More > >> > > >> >[root@ov06 ~]# for i in $(gluster volume list); do echo $i;echo; > >> >gluster > >> >volume info $i; echo;echo;gluster volume status > >$i;echo;echo;echo;done > >> >images3 > >> > > >> > > >> >Volume Name: images3 > >> >Type: Replicate > >> >Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b > >> >Status: Started > >> >Snapshot Count: 0 > >> >Number of Bricks: 1 x 3 = 3 > >> >Transport-type: tcp > >> >Bricks: > >> >Brick1: 192.168.24.18:/bricks/brick04/images3 > >> >Brick2: 192.168.24.19:/bricks/brick05/images3 > >> >Brick3: 192.168.24.20:/bricks/brick06/images3 > >> >Options Reconfigured: > >> >performance.client-io-threads: on > >> >nfs.disable: on > >> >transport.address-family: inet > >> >user.cifs: off > >> >auth.allow: * > >> >performance.quick-read: off > >> >performance.read-ahead: off > >> >performance.io-cache: off > >> >performance.low-prio-threads: 32 > >> >network.remote-dio: off > >> >cluster.eager-lock: enable > >> >cluster.quorum-type: auto > >> >cluster.server-quorum-type: server > >> >cluster.data-self-heal-algorithm: full > >> >cluster.locking-scheme: granular > >> >cluster.shd-max-threads: 8 > >> >cluster.shd-wait-qlength: 10000 > >> >features.shard: on > >> >cluster.choose-local: off > >> >client.event-threads: 4 > >> >server.event-threads: 4 > >> >storage.owner-uid: 36 > >> >storage.owner-gid: 36 > >> >performance.strict-o-direct: on > >> >network.ping-timeout: 30 > >> >cluster.granular-entry-heal: enable > >> > > >> > > >> >Status of volume: images3 > >> >Gluster process TCP Port RDMA Port > >Online > >> > Pid > >> > >> > >
>------------------------------------------------------------------------------ > >> >Brick 192.168.24.18:/bricks/brick04/images3 49152 0
Y
> >> >6666 > >> >Brick 192.168.24.19:/bricks/brick05/images3 49152 0
Y
> >> >6779 > >> >Brick 192.168.24.20:/bricks/brick06/images3 49152 0
Y
> >> >7227 > >> >Self-heal Daemon on localhost N/A N/A Y > >> >6689 > >> >Self-heal Daemon on ov07.ntc.srcle.com N/A N/A
Y
> >> >6802 > >> >Self-heal Daemon on ov08.ntc.srcle.com N/A N/A
Y
> >> >7250 > >> > > >> >Task Status of Volume images3 > >> > >> > >
>------------------------------------------------------------------------------ > >> >There are no active volume tasks > >> > > >> > > >> > > >> > > >> >[root@ov06 ~]# ls -l /rhev/data-center/mnt/glusterSD/ > >> >total 16 > >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 192.168.24.15:_images > >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 192.168.24.18:_images3 > >> >[root@ov06 ~]# > >> > > >> >On Thu, Jun 18, 2020 at 2:03 PM C Williams <cwilliams3320@gmail.com> > >> >wrote: > >> > > >> >> Strahil, > >> >> > >> >> Here you go -- Thank You For Your Help ! > >> >> > >> >> BTW -- I can write a test file to gluster and it replicates > >properly. > >> >> Thinking something about the oVirt Storage Domain ? > >> >> > >> >> [root@ov08 ~]# gluster pool list > >> >> UUID Hostname > >State > >> >> 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06 > >> >Connected > >> >> 36ce5a00-6f65-4926-8438-696944ebadb5 ov07.ntc.srcle.com > >> >Connected > >> >> c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost > >> >Connected > >> >> [root@ov08 ~]# gluster volume list > >> >> images3 > >> >> > >> >> On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov > >> ><hunter86_bg@yahoo.com> > >> >> wrote: > >> >> > >> >>> Log to the oVirt cluster and provide the output of: > >> >>> gluster pool list > >> >>> gluster volume list > >> >>> for i in $(gluster volume list); do echo $i;echo; gluster > >volume > >> >info > >> >>> $i; echo;echo;gluster volume status $i;echo;echo;echo;done > >> >>> > >> >>> ls -l /rhev/data-center/mnt/glusterSD/ > >> >>> > >> >>> Best Regards, > >> >>> Strahil Nikolov > >> >>> > >> >>> > >> >>> На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams > >> ><cwilliams3320@gmail.com> > >> >>> написа: > >> >>> >Hello, > >> >>> > > >> >>> >I recently added 6 hosts to an existing oVirt compute/gluster > >> >cluster. > >> >>> > > >> >>> >Prior to this attempted addition, my cluster had 3 Hypervisor > >hosts > >> >and > >> >>> >3 > >> >>> >gluster bricks which made up a single gluster volume (replica 3 > >> >volume) > >> >>> >. I > >> >>> >added the additional hosts and made a brick on 3 of the new > >hosts > >> >and > >> >>> >attempted to make a new replica 3 volume. I had difficulty > >> >creating > >> >>> >the > >> >>> >new volume. So, I decided that I would make a new > >compute/gluster > >> >>> >cluster > >> >>> >for each set of 3 new hosts. > >> >>> > > >> >>> >I removed the 6 new hosts from the existing oVirt > >Compute/Gluster > >> >>> >Cluster > >> >>> >leaving the 3 original hosts in place with their bricks. At that > >> >point > >> >>> >my > >> >>> >original bricks went down and came back up . The volume showed > >> >entries > >> >>> >that > >> >>> >needed healing. At that point I ran gluster volume heal images3 > >> >full, > >> >>> >etc. > >> >>> >The volume shows no unhealed entries. I also corrected some peer > >> >>> >errors. > >> >>> > > >> >>> >However, I am unable to copy disks, move disks to another > >domain, > >> >>> >export > >> >>> >disks, etc. It appears that the engine cannot locate disks > >properly > >> >and > >> >>> >I > >> >>> >get storage I/O errors. > >> >>> > > >> >>> >I have detached and removed the oVirt Storage Domain. I > >reimported > >> >the > >> >>> >domain and imported 2 VMs, But the VM disks exhibit the same > >> >behaviour > >> >>> >and > >> >>> >won't run from the hard disk. > >> >>> > > >> >>> > > >> >>> >I get errors such as this > >> >>> > > >> >>> >VDSM ov05 command HSMGetAllTasksStatusesVDS failed: low level > >Image > >> >>> >copy > >> >>> >failed: ("Command ['/usr/bin/qemu-img', 'convert', '-p', '-t', > >> >'none', > >> >>> >'-T', 'none', '-f', 'raw', > >> >>> >u'/rhev/data-center/mnt/glusterSD/192.168.24.18: > >> >>> > >> > >> > >
>_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510', > >> >>> >'-O', 'raw', > >> >>> >u'/rhev/data-center/mnt/192.168.24.13: > >> >>> > >> > >> > >
>_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5'] > >> >>> >failed with rc=1 out='' err=bytearray(b'qemu-img: error while > >> >reading > >> >>> >sector 135168: Transport endpoint is not connected\\nqemu-img: > >> >error > >> >>> >while > >> >>> >reading sector 131072: Transport endpoint is not > >> >connected\\nqemu-img: > >> >>> >error while reading sector 139264: Transport endpoint is not > >> >>> >connected\\nqemu-img: error while reading sector 143360: > >Transport > >> >>> >endpoint > >> >>> >is not connected\\nqemu-img: error while reading sector 147456: > >> >>> >Transport > >> >>> >endpoint is not connected\\nqemu-img: error while reading sector > >> >>> >155648: > >> >>> >Transport endpoint is not connected\\nqemu-img: error while > >reading > >> >>> >sector > >> >>> >151552: Transport endpoint is not connected\\nqemu-img: error > >while > >> >>> >reading > >> >>> >sector 159744: Transport endpoint is not connected\\n')",) > >> >>> > > >> >>> >oVirt version is 4.3.82-1.el7 > >> >>> >OS CentOS Linux release 7.7.1908 (Core) > >> >>> > > >> >>> >The Gluster Cluster has been working very well until this > >incident. > >> >>> > > >> >>> >Please help. > >> >>> > > >> >>> >Thank You > >> >>> > > >> >>> >Charles Williams > >> >>> > >> >> > >> >
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/YY3VUKEJLI7MRW...
Hello, Upgrading diidn't help Still acl errors trying to use a Virtual Disk from a VM [root@ov06 bricks]# tail bricks-brick04-images3.log | grep acl [2020-06-21 01:33:45.665888] I [MSGID: 139001] [posix-acl.c:263:posix_acl_log_permit_denied] 0-images3-access-control: client: CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0, gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:107,gid:107,perm:1,ngrps:3), ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied] The message "I [MSGID: 139001] [posix-acl.c:263:posix_acl_log_permit_denied] 0-images3-access-control: client: CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0, gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:107,gid:107,perm:1,ngrps:3), ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied]" repeated 2 times between [2020-06-21 01:33:45.665888] and [2020-06-21 01:33:45.806779] Thank You For Your Help ! On Sat, Jun 20, 2020 at 8:59 PM C Williams <cwilliams3320@gmail.com> wrote:
Hello,
Based on the situation, I am planning to upgrade the 3 affected hosts.
My reasoning is that the hosts/bricks were attached to 6.9 at one time.
Thanks For Your Help !
On Sat, Jun 20, 2020 at 8:38 PM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
The gluster version on the current 3 gluster hosts is 6.7 (last update 2/26). These 3 hosts provide 1 brick each for the replica 3 volume.
Earlier I had tried to add 6 additional hosts to the cluster. Those new hosts were 6.9 gluster.
I attempted to make a new separate volume with 3 bricks provided by the 3 new gluster 6.9 hosts. After having many errors from the oVirt interface, I gave up and removed the 6 new hosts from the cluster. That is where the problems started. The intent was to expand the gluster cluster while making 2 new volumes for that cluster. The ovirt compute cluster would allow for efficient VM migration between 9 hosts -- while having separate gluster volumes for safety purposes.
Looking at the brick logs, I see where there are acl errors starting from the time of the removal of the 6 new hosts.
Please check out the attached brick log from 6/14-18. The events started on 6/17.
I wish I had a downgrade path.
Thank You For The Help !!
On Sat, Jun 20, 2020 at 7:47 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Hi ,
This one really looks like the ACL bug I was hit with when I updated from Gluster v6.5 to 6.6 and later from 7.0 to 7.2.
Did you update your setup recently ? Did you upgrade gluster also ?
You have to check the gluster logs in order to verify that, so you can try:
1. Set Gluster logs to trace level (for details check: https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3/html... ) 2. Power up a VM that was already off , or retry the procedure from the logs you sent. 3. Stop the trace level of the logs 4. Check libvirt logs on the host that was supposed to power up the VM (in case a VM was powered on) 5. Check the gluster brick logs on all nodes for ACL errors. Here is a sample from my old logs:
gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 13:19:41.489047] I [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- 4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:36,gid:36,perm:1,ngrps:3), ctx (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied] gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 13:22:51.818796] I [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- 4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:36,gid:36,perm:1,ngrps:3), ctx (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied] gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 13:24:43.732856] I [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- 4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:36,gid:36,perm:1,ngrps:3), ctx (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied] gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 13:26:50.758178] I [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- 4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:36,gid:36,perm:1,ngrps:3), ctx (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied]
In my case , the workaround was to downgrade the gluster packages on all nodes (and reboot each node 1 by 1 ) if the major version is the same, but if you upgraded to v7.X - then you can try the v7.0 .
Best Regards, Strahil Nikolov
В събота, 20 юни 2020 г., 18:48:42 ч. Гринуич+3, C Williams < cwilliams3320@gmail.com> написа:
Hello,
Here are additional log tiles as well as a tree of the problematic Gluster storage domain. During this time I attempted to copy a virtual disk to another domain, move a virtual disk to another domain and run a VM where the virtual hard disk would be used.
The copies/moves failed and the VM went into pause mode when the virtual HDD was involved.
Please check these out.
Thank You For Your Help !
On Sat, Jun 20, 2020 at 9:54 AM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
I understand. Please keep me posted.
Thanks For The Help !
On Sat, Jun 20, 2020 at 4:36 AM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Hey C Williams,
sorry for the delay, but I couldn't get somw time to check your logs. Will try a little bit later.
Best Regards, Strahil Nikolov
На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams < cwilliams3320@gmail.com> написа:
Hello,
Was wanting to follow up on this issue. Users are impacted.
Thank You
On Fri, Jun 19, 2020 at 9:20 AM C Williams <cwilliams3320@gmail.com> wrote:
> Hello, > > Here are the logs (some IPs are changed ) > > ov05 is the SPM > > Thank You For Your Help ! > > On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov <hunter86_bg@yahoo.com> > wrote: > >> Check on the hosts tab , which is your current SPM (last column in Admin >> UI). >> Then open the /var/log/vdsm/vdsm.log and repeat the operation. >> Then provide the log from that host and the engine's log (on the >> HostedEngine VM or on your standalone engine). >> >> Best Regards, >> Strahil Nikolov >> >> На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams <cwilliams3320@gmail.com> >> написа: >> >Resending to eliminate email issues >> > >> >---------- Forwarded message --------- >> >From: C Williams <cwilliams3320@gmail.com> >> >Date: Thu, Jun 18, 2020 at 4:01 PM >> >Subject: Re: [ovirt-users] Fwd: Issues with Gluster Domain >> >To: Strahil Nikolov <hunter86_bg@yahoo.com> >> > >> > >> >Here is output from mount >> > >> >192.168.24.12:/stor/import0 on >> >/rhev/data-center/mnt/192.168.24.12:_stor_import0 >> >type nfs4 >> >>
>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12) >> >192.168.24.13:/stor/import1 on >> >/rhev/data-center/mnt/192.168.24.13:_stor_import1 >> >type nfs4 >> >>
>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >> >192.168.24.13:/stor/iso1 on >> >/rhev/data-center/mnt/192.168.24.13:_stor_iso1 >> >type nfs4 >> >>
>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >> >192.168.24.13:/stor/export0 on >> >/rhev/data-center/mnt/192.168.24.13:_stor_export0 >> >type nfs4 >> >>
>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >> >192.168.24.15:/images on >> >/rhev/data-center/mnt/glusterSD/192.168.24.15:_images >> >type fuse.glusterfs >> >>
>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) >> >192.168.24.18:/images3 on >> >/rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 >> >type fuse.glusterfs >> >>
>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) >> >tmpfs on /run/user/0 type tmpfs >> >(rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) >> >[root@ov06 glusterfs]# >> > >> >Also here is a screenshot of the console >> > >> >[image: image.png] >> >The other domains are up >> > >> >Import0 and Import1 are NFS . GLCL0 is gluster. They all are running >> >VMs >> > >> >Thank You For Your Help ! >> > >> >On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov <hunter86_bg@yahoo.com> >> >wrote: >> > >> >> I don't see '/rhev/data-center/mnt/192.168.24.13:_stor_import1' >> >mounted >> >> at all . >> >> What is the status of all storage domains ? >> >> >> >> Best Regards, >> >> Strahil Nikolov >> >> >> >> На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams >> ><cwilliams3320@gmail.com> >> >> написа: >> >> > Resending to deal with possible email issues >> >> > >> >> >---------- Forwarded message --------- >> >> >From: C Williams <cwilliams3320@gmail.com> >> >> >Date: Thu, Jun 18, 2020 at 2:07 PM >> >> >Subject: Re: [ovirt-users] Issues with Gluster Domain >> >> >To: Strahil Nikolov <hunter86_bg@yahoo.com> >> >> > >> >> > >> >> >More >> >> > >> >> >[root@ov06 ~]# for i in $(gluster volume list); do echo $i;echo; >> >> >gluster >> >> >volume info $i; echo;echo;gluster volume status >> >$i;echo;echo;echo;done >> >> >images3 >> >> > >> >> > >> >> >Volume Name: images3 >> >> >Type: Replicate >> >> >Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b >> >> >Status: Started >> >> >Snapshot Count: 0 >> >> >Number of Bricks: 1 x 3 = 3 >> >> >Transport-type: tcp >> >> >Bricks: >> >> >Brick1: 192.168.24.18:/bricks/brick04/images3 >> >> >Brick2: 192.168.24.19:/bricks/brick05/images3 >> >> >Brick3: 192.168.24.20:/bricks/brick06/images3 >> >> >Options Reconfigured: >> >> >performance.client-io-threads: on >> >> >nfs.disable: on >> >> >transport.address-family: inet >> >> >user.cifs: off >> >> >auth.allow: * >> >> >performance.quick-read: off >> >> >performance.read-ahead: off >> >> >performance.io-cache: off >> >> >performance.low-prio-threads: 32 >> >> >network.remote-dio: off >> >> >cluster.eager-lock: enable >> >> >cluster.quorum-type: auto >> >> >cluster.server-quorum-type: server >> >> >cluster.data-self-heal-algorithm: full >> >> >cluster.locking-scheme: granular >> >> >cluster.shd-max-threads: 8 >> >> >cluster.shd-wait-qlength: 10000 >> >> >features.shard: on >> >> >cluster.choose-local: off >> >> >client.event-threads: 4 >> >> >server.event-threads: 4 >> >> >storage.owner-uid: 36 >> >> >storage.owner-gid: 36 >> >> >performance.strict-o-direct: on >> >> >network.ping-timeout: 30 >> >> >cluster.granular-entry-heal: enable >> >> > >> >> > >> >> >Status of volume: images3 >> >> >Gluster process TCP Port RDMA Port >> >Online >> >> > Pid >> >> >> >> >> >>
>>------------------------------------------------------------------------------ >> >> >Brick 192.168.24.18:/bricks/brick04/images3 49152 0
Y >> >> >6666 >> >> >Brick 192.168.24.19:/bricks/brick05/images3 49152 0
Y >> >> >6779 >> >> >Brick 192.168.24.20:/bricks/brick06/images3 49152 0
Y >> >> >7227 >> >> >Self-heal Daemon on localhost N/A N/A
Y >> >> >6689 >> >> >Self-heal Daemon on ov07.ntc.srcle.com N/A N/A
Y >> >> >6802 >> >> >Self-heal Daemon on ov08.ntc.srcle.com N/A N/A
Y >> >> >7250 >> >> > >> >> >Task Status of Volume images3 >> >> >> >> >> >>
>>------------------------------------------------------------------------------ >> >> >There are no active volume tasks >> >> > >> >> > >> >> > >> >> > >> >> >[root@ov06 ~]# ls -l /rhev/data-center/mnt/glusterSD/ >> >> >total 16 >> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 192.168.24.15:_images >> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 192.168.24.18: _images3 >> >> >[root@ov06 ~]# >> >> > >> >> >On Thu, Jun 18, 2020 at 2:03 PM C Williams <cwilliams3320@gmail.com> >> >> >wrote: >> >> > >> >> >> Strahil, >> >> >> >> >> >> Here you go -- Thank You For Your Help ! >> >> >> >> >> >> BTW -- I can write a test file to gluster and it replicates >> >properly. >> >> >> Thinking something about the oVirt Storage Domain ? >> >> >> >> >> >> [root@ov08 ~]# gluster pool list >> >> >> UUID Hostname >> >State >> >> >> 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06 >> >> >Connected >> >> >> 36ce5a00-6f65-4926-8438-696944ebadb5 ov07.ntc.srcle.com >> >> >Connected >> >> >> c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost >> >> >Connected >> >> >> [root@ov08 ~]# gluster volume list >> >> >> images3 >> >> >> >> >> >> On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov >> >> ><hunter86_bg@yahoo.com> >> >> >> wrote: >> >> >> >> >> >>> Log to the oVirt cluster and provide the output of: >> >> >>> gluster pool list >> >> >>> gluster volume list >> >> >>> for i in $(gluster volume list); do echo $i;echo; gluster >> >volume >> >> >info >> >> >>> $i; echo;echo;gluster volume status $i;echo;echo;echo;done >> >> >>> >> >> >>> ls -l /rhev/data-center/mnt/glusterSD/ >> >> >>> >> >> >>> Best Regards, >> >> >>> Strahil Nikolov >> >> >>> >> >> >>> >> >> >>> На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams >> >> ><cwilliams3320@gmail.com> >> >> >>> написа: >> >> >>> >Hello, >> >> >>> > >> >> >>> >I recently added 6 hosts to an existing oVirt compute/gluster >> >> >cluster. >> >> >>> > >> >> >>> >Prior to this attempted addition, my cluster had 3 Hypervisor >> >hosts >> >> >and >> >> >>> >3 >> >> >>> >gluster bricks which made up a single gluster volume (replica 3 >> >> >volume) >> >> >>> >. I >> >> >>> >added the additional hosts and made a brick on 3 of the new >> >hosts >> >> >and >> >> >>> >attempted to make a new replica 3 volume. I had difficulty >> >> >creating >> >> >>> >the >> >> >>> >new volume. So, I decided that I would make a new >> >compute/gluster >> >> >>> >cluster >> >> >>> >for each set of 3 new hosts. >> >> >>> > >> >> >>> >I removed the 6 new hosts from the existing oVirt >> >Compute/Gluster >> >> >>> >Cluster >> >> >>> >leaving the 3 original hosts in place with their bricks. At that >> >> >point >> >> >>> >my >> >> >>> >original bricks went down and came back up . The volume showed >> >> >entries >> >> >>> >that >> >> >>> >needed healing. At that point I ran gluster volume heal images3 >> >> >full, >> >> >>> >etc. >> >> >>> >The volume shows no unhealed entries. I also corrected some peer >> >> >>> >errors. >> >> >>> > >> >> >>> >However, I am unable to copy disks, move disks to another >> >domain, >> >> >>> >export >> >> >>> >disks, etc. It appears that the engine cannot locate disks >> >properly >> >> >and >> >> >>> >I >> >> >>> >get storage I/O errors. >> >> >>> > >> >> >>> >I have detached and removed the oVirt Storage Domain. I >> >reimported >> >> >the >> >> >>> >domain and imported 2 VMs, But the VM disks exhibit the same >> >> >behaviour >> >> >>> >and >> >> >>> >won't run from the hard disk. >> >> >>> > >> >> >>> > >> >> >>> >I get errors such as this >> >> >>> > >> >> >>> >VDSM ov05 command HSMGetAllTasksStatusesVDS failed: low level >> >Image >> >> >>> >copy >> >> >>> >failed: ("Command ['/usr/bin/qemu-img', 'convert', '-p', '-t', >> >> >'none', >> >> >>> >'-T', 'none', '-f', 'raw', >> >> >>> >u'/rhev/data-center/mnt/glusterSD/192.168.24.18: >> >> >>> >> >> >> >> >> >>
>>_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510', >> >> >>> >'-O', 'raw', >> >> >>> >u'/rhev/data-center/mnt/192.168.24.13: >> >> >>> >> >> >> >> >> >>
>>_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5'] >> >> >>> >failed with rc=1 out='' err=bytearray(b'qemu-img: error while >> >> >reading >> >> >>> >sector 135168: Transport endpoint is not connected\\nqemu-img: >> >> >error >> >> >>> >while >> >> >>> >reading sector 131072: Transport endpoint is not >> >> >connected\\nqemu-img: >> >> >>> >error while reading sector 139264: Transport endpoint is not >> >> >>> >connected\\nqemu-img: error while reading sector 143360: >> >Transport >> >> >>> >endpoint >> >> >>> >is not connected\\nqemu-img: error while reading sector 147456: >> >> >>> >Transport >> >> >>> >endpoint is not connected\\nqemu-img: error while reading sector >> >> >>> >155648: >> >> >>> >Transport endpoint is not connected\\nqemu-img: error while >> >reading >> >> >>> >sector >> >> >>> >151552: Transport endpoint is not connected\\nqemu-img: error >> >while >> >> >>> >reading >> >> >>> >sector 159744: Transport endpoint is not connected\\n')",) >> >> >>> > >> >> >>> >oVirt version is 4.3.82-1.el7 >> >> >>> >OS CentOS Linux release 7.7.1908 (Core) >> >> >>> > >> >> >>> >The Gluster Cluster has been working very well until this >> >incident. >> >> >>> > >> >> >>> >Please help. >> >> >>> > >> >> >>> >Thank You >> >> >>> > >> >> >>> >Charles Williams >> >> >>> >> >> >> >> >> >> >
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/YY3VUKEJLI7MRW...
Sorry to hear that. I can say that for me 6.5 was working, while 6.6 didn't and I upgraded to 7.0 . In the ended , I have ended with creating a new fresh volume and physically copying the data there, then I detached the storage domains and attached to the new ones (which holded the old data), but I could afford the downtime. Also, I can say that v7.0 ( but not 7.1 or anything later) also worked without the ACL issue, but it causes some trouble in oVirt - so avoid that unless you have no other options. Best Regards, Strahil Nikolov На 21 юни 2020 г. 4:39:46 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Hello,
Upgrading diidn't help
Still acl errors trying to use a Virtual Disk from a VM
[root@ov06 bricks]# tail bricks-brick04-images3.log | grep acl [2020-06-21 01:33:45.665888] I [MSGID: 139001] [posix-acl.c:263:posix_acl_log_permit_denied] 0-images3-access-control: client: CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0, gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:107,gid:107,perm:1,ngrps:3), ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied] The message "I [MSGID: 139001] [posix-acl.c:263:posix_acl_log_permit_denied] 0-images3-access-control: client: CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0, gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:107,gid:107,perm:1,ngrps:3), ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied]" repeated 2 times between [2020-06-21 01:33:45.665888] and [2020-06-21 01:33:45.806779]
Thank You For Your Help !
On Sat, Jun 20, 2020 at 8:59 PM C Williams <cwilliams3320@gmail.com> wrote:
Hello,
Based on the situation, I am planning to upgrade the 3 affected hosts.
My reasoning is that the hosts/bricks were attached to 6.9 at one time.
Thanks For Your Help !
On Sat, Jun 20, 2020 at 8:38 PM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
The gluster version on the current 3 gluster hosts is 6.7 (last update 2/26). These 3 hosts provide 1 brick each for the replica 3 volume.
Earlier I had tried to add 6 additional hosts to the cluster. Those new hosts were 6.9 gluster.
I attempted to make a new separate volume with 3 bricks provided by the 3 new gluster 6.9 hosts. After having many errors from the oVirt interface, I gave up and removed the 6 new hosts from the cluster. That is where the problems started. The intent was to expand the gluster cluster while making 2 new volumes for that cluster. The ovirt compute cluster would allow for efficient VM migration between 9 hosts -- while having separate gluster volumes for safety purposes.
Looking at the brick logs, I see where there are acl errors starting from the time of the removal of the 6 new hosts.
Please check out the attached brick log from 6/14-18. The events started on 6/17.
I wish I had a downgrade path.
Thank You For The Help !!
On Sat, Jun 20, 2020 at 7:47 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Hi ,
This one really looks like the ACL bug I was hit with when I updated from Gluster v6.5 to 6.6 and later from 7.0 to 7.2.
Did you update your setup recently ? Did you upgrade gluster also ?
You have to check the gluster logs in order to verify that, so you can try:
1. Set Gluster logs to trace level (for details check:
) 2. Power up a VM that was already off , or retry the procedure from
https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3/html... the
logs you sent. 3. Stop the trace level of the logs 4. Check libvirt logs on the host that was supposed to power up the VM (in case a VM was powered on) 5. Check the gluster brick logs on all nodes for ACL errors. Here is a sample from my old logs:
gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 13:19:41.489047] I [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:36,gid:36,perm:1,ngrps:3), ctx (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied] gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 13:22:51.818796] I [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:36,gid:36,perm:1,ngrps:3), ctx (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied] gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 13:24:43.732856] I [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:36,gid:36,perm:1,ngrps:3), ctx (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied] gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 13:26:50.758178] I [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:36,gid:36,perm:1,ngrps:3), ctx (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied]
In my case , the workaround was to downgrade the gluster packages on all nodes (and reboot each node 1 by 1 ) if the major version is the same, but if you upgraded to v7.X - then you can try the v7.0 .
Best Regards, Strahil Nikolov
В събота, 20 юни 2020 г., 18:48:42 ч. Гринуич+3, C Williams < cwilliams3320@gmail.com> написа:
Hello,
Here are additional log tiles as well as a tree of the problematic Gluster storage domain. During this time I attempted to copy a virtual disk to another domain, move a virtual disk to another domain and run a VM where the virtual hard disk would be used.
The copies/moves failed and the VM went into pause mode when the virtual HDD was involved.
Please check these out.
Thank You For Your Help !
On Sat, Jun 20, 2020 at 9:54 AM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
I understand. Please keep me posted.
Thanks For The Help !
On Sat, Jun 20, 2020 at 4:36 AM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Hey C Williams,
sorry for the delay, but I couldn't get somw time to check your logs. Will try a little bit later.
Best Regards, Strahil Nikolov
На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams < cwilliams3320@gmail.com> написа: >Hello, > >Was wanting to follow up on this issue. Users are impacted. > >Thank You > >On Fri, Jun 19, 2020 at 9:20 AM C Williams <cwilliams3320@gmail.com> >wrote: > >> Hello, >> >> Here are the logs (some IPs are changed ) >> >> ov05 is the SPM >> >> Thank You For Your Help ! >> >> On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov ><hunter86_bg@yahoo.com> >> wrote: >> >>> Check on the hosts tab , which is your current SPM (last
column in >>> >>>Admin >>> >>>>> UI). >>> >>>>> Then open the /var/log/vdsm/vdsm.log and repeat the operation. >>> >>>>> Then provide the log from that host and the engine's log (on the >>> >>>>> HostedEngine VM or on your standalone engine). >>> >>>>> >>> >>>>> Best Regards, >>> >>>>> Strahil Nikolov >>> >>>>> >>> >>>>> На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams >>> >>><cwilliams3320@gmail.com> >>> >>>>> написа: >>> >>>>> >Resending to eliminate email issues >>> >>>>> > >>> >>>>> >---------- Forwarded message --------- >>> >>>>> >From: C Williams <cwilliams3320@gmail.com> >>> >>>>> >Date: Thu, Jun 18, 2020 at 4:01 PM >>> >>>>> >Subject: Re: [ovirt-users] Fwd: Issues with Gluster Domain >>> >>>>> >To: Strahil Nikolov <hunter86_bg@yahoo.com> >>> >>>>> > >>> >>>>> > >>> >>>>> >Here is output from mount >>> >>>>> > >>> >>>>> >192.168.24.12:/stor/import0 on >>> >>>>> >/rhev/data-center/mnt/192.168.24.12:_stor_import0 >>> >>>>> >type nfs4 >>> >>>>> >>> >>>>> >>> >>> >>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12) >>> >>>>> >192.168.24.13:/stor/import1 on >>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_import1 >>> >>>>> >type nfs4 >>> >>>>> >>> >>>>> >>> >>> >>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >>> >>>>> >192.168.24.13:/stor/iso1 on >>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_iso1 >>> >>>>> >type nfs4 >>> >>>>> >>> >>>>> >>> >>> >>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >>> >>>>> >192.168.24.13:/stor/export0 on >>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_export0 >>> >>>>> >type nfs4 >>> >>>>> >>> >>>>> >>> >>> >>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >>> >>>>> >192.168.24.15:/images on >>> >>>>> >/rhev/data-center/mnt/glusterSD/192.168.24.15:_images >>> >>>>> >type fuse.glusterfs >>> >>>>> >>> >>>>> >>> >>> >>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) >>> >>>>> >192.168.24.18:/images3 on >>> >>>>> >/rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 >>> >>>>> >type fuse.glusterfs >>> >>>>> >>> >>>>> >>> >>> >>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) >>> >>>>> >tmpfs on /run/user/0 type tmpfs >>> >>>>> >(rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) >>> >>>>> >[root@ov06 glusterfs]# >>> >>>>> > >>> >>>>> >Also here is a screenshot of the console >>> >>>>> > >>> >>>>> >[image: image.png] >>> >>>>> >The other domains are up >>> >>>>> > >>> >>>>> >Import0 and Import1 are NFS . GLCL0 is gluster. They all are >>> >>>running >>> >>>>> >VMs >>> >>>>> > >>> >>>>> >Thank You For Your Help ! >>> >>>>> > >>> >>>>> >On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov >>> >>><hunter86_bg@yahoo.com> >>> >>>>> >wrote: >>> >>>>> > >>> >>>>> >> I don't see '/rhev/data-center/mnt/192.168.24.13:_stor_import1' >>> >>>>> >mounted >>> >>>>> >> at all . >>> >>>>> >> What is the status of all storage domains ? >>> >>>>> >> >>> >>>>> >> Best Regards, >>> >>>>> >> Strahil Nikolov >>> >>>>> >> >>> >>>>> >> На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams >>> >>>>> ><cwilliams3320@gmail.com> >>> >>>>> >> написа: >>> >>>>> >> > Resending to deal with possible email issues >>> >>>>> >> > >>> >>>>> >> >---------- Forwarded message --------- >>> >>>>> >> >From: C Williams <cwilliams3320@gmail.com> >>> >>>>> >> >Date: Thu, Jun 18, 2020 at 2:07 PM >>> >>>>> >> >Subject: Re: [ovirt-users] Issues with Gluster Domain >>> >>>>> >> >To: Strahil Nikolov <hunter86_bg@yahoo.com> >>> >>>>> >> > >>> >>>>> >> > >>> >>>>> >> >More >>> >>>>> >> > >>> >>>>> >> >[root@ov06 ~]# for i in $(gluster volume list); do echo >>> >>>$i;echo; >>> >>>>> >> >gluster >>> >>>>> >> >volume info $i; echo;echo;gluster volume status >>> >>>>> >$i;echo;echo;echo;done >>> >>>>> >> >images3 >>> >>>>> >> > >>> >>>>> >> > >>> >>>>> >> >Volume Name: images3 >>> >>>>> >> >Type: Replicate >>> >>>>> >> >Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b >>> >>>>> >> >Status: Started >>> >>>>> >> >Snapshot Count: 0 >>> >>>>> >> >Number of Bricks: 1 x 3 = 3 >>> >>>>> >> >Transport-type: tcp >>> >>>>> >> >Bricks: >>> >>>>> >> >Brick1: 192.168.24.18:/bricks/brick04/images3 >>> >>>>> >> >Brick2: 192.168.24.19:/bricks/brick05/images3 >>> >>>>> >> >Brick3: 192.168.24.20:/bricks/brick06/images3 >>> >>>>> >> >Options Reconfigured: >>> >>>>> >> >performance.client-io-threads: on >>> >>>>> >> >nfs.disable: on >>> >>>>> >> >transport.address-family: inet >>> >>>>> >> >user.cifs: off >>> >>>>> >> >auth.allow: * >>> >>>>> >> >performance.quick-read: off >>> >>>>> >> >performance.read-ahead: off >>> >>>>> >> >performance.io-cache: off >>> >>>>> >> >performance.low-prio-threads: 32 >>> >>>>> >> >network.remote-dio: off >>> >>>>> >> >cluster.eager-lock: enable >>> >>>>> >> >cluster.quorum-type: auto >>> >>>>> >> >cluster.server-quorum-type: server >>> >>>>> >> >cluster.data-self-heal-algorithm: full >>> >>>>> >> >cluster.locking-scheme: granular >>> >>>>> >> >cluster.shd-max-threads: 8 >>> >>>>> >> >cluster.shd-wait-qlength: 10000 >>> >>>>> >> >features.shard: on >>> >>>>> >> >cluster.choose-local: off >>> >>>>> >> >client.event-threads: 4 >>> >>>>> >> >server.event-threads: 4 >>> >>>>> >> >storage.owner-uid: 36 >>> >>>>> >> >storage.owner-gid: 36 >>> >>>>> >> >performance.strict-o-direct: on >>> >>>>> >> >network.ping-timeout: 30 >>> >>>>> >> >cluster.granular-entry-heal: enable >>> >>>>> >> > >>> >>>>> >> > >>> >>>>> >> >Status of volume: images3 >>> >>>>> >> >Gluster process TCP Port RDMA Port >>> >>>>> >Online >>> >>>>> >> > Pid >>> >>>>> >> >>> >>>>> >> >>> >>>>> >>> >>>>> >>> >>> >>>>>------------------------------------------------------------------------------ >>> >>>>> >> >Brick 192.168.24.18:/bricks/brick04/images3 49152 0 >>> >>> >>>Y >>> >>>>> >> >6666 >>> >>>>> >> >Brick 192.168.24.19:/bricks/brick05/images3 49152 0 >>> >>> >>>Y >>> >>>>> >> >6779 >>> >>>>> >> >Brick 192.168.24.20:/bricks/brick06/images3 49152 0 >>> >>> >>>Y >>> >>>>> >> >7227 >>> >>>>> >> >Self-heal Daemon on localhost N/A N/A >>> >>> >>>Y >>> >>>>> >> >6689 >>> >>>>> >> >Self-heal Daemon on ov07.ntc.srcle.com N/A N/A >>> >>> >>>Y >>> >>>>> >> >6802 >>> >>>>> >> >Self-heal Daemon on ov08.ntc.srcle.com N/A N/A >>> >>> >>>Y >>> >>>>> >> >7250 >>> >>>>> >> > >>> >>>>> >> >Task Status of Volume images3 >>> >>>>> >> >>> >>>>> >> >>> >>>>> >>> >>>>> >>> >>> >>>>>------------------------------------------------------------------------------ >>> >>>>> >> >There are no active volume tasks >>> >>>>> >> > >>> >>>>> >> > >>> >>>>> >> > >>> >>>>> >> > >>> >>>>> >> >[root@ov06 ~]# ls -l /rhev/data-center/mnt/glusterSD/ >>> >>>>> >> >total 16 >>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 192.168.24.15:_images >>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 192.168.24.18: >>> _images3 >>> >>>>> >> >[root@ov06 ~]# >>> >>>>> >> > >>> >>>>> >> >On Thu, Jun 18, 2020 at 2:03 PM C Williams >>> >>><cwilliams3320@gmail.com> >>> >>>>> >> >wrote: >>> >>>>> >> > >>> >>>>> >> >> Strahil, >>> >>>>> >> >> >>> >>>>> >> >> Here you go -- Thank You For Your Help ! >>> >>>>> >> >> >>> >>>>> >> >> BTW -- I can write a test file to gluster and it replicates >>> >>>>> >properly. >>> >>>>> >> >> Thinking something about the oVirt Storage Domain ? >>> >>>>> >> >> >>> >>>>> >> >> [root@ov08 ~]# gluster pool list >>> >>>>> >> >> UUID Hostname >>> >>>>> >State >>> >>>>> >> >> 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06 >>> >>>>> >> >Connected >>> >>>>> >> >> 36ce5a00-6f65-4926-8438-696944ebadb5 ov07.ntc.srcle.com >>> >>>>> >> >Connected >>> >>>>> >> >> c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost >>> >>>>> >> >Connected >>> >>>>> >> >> [root@ov08 ~]# gluster volume list >>> >>>>> >> >> images3 >>> >>>>> >> >> >>> >>>>> >> >> On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov >>> >>>>> >> ><hunter86_bg@yahoo.com> >>> >>>>> >> >> wrote: >>> >>>>> >> >> >>> >>>>> >> >>> Log to the oVirt cluster and provide the output of: >>> >>>>> >> >>> gluster pool list >>> >>>>> >> >>> gluster volume list >>> >>>>> >> >>> for i in $(gluster volume list); do echo $i;echo; gluster >>> >>>>> >volume >>> >>>>> >> >info >>> >>>>> >> >>> $i; echo;echo;gluster volume status $i;echo;echo;echo;done >>> >>>>> >> >>> >>> >>>>> >> >>> ls -l /rhev/data-center/mnt/glusterSD/ >>> >>>>> >> >>> >>> >>>>> >> >>> Best Regards, >>> >>>>> >> >>> Strahil Nikolov >>> >>>>> >> >>> >>> >>>>> >> >>> >>> >>>>> >> >>> На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams >>> >>>>> >> ><cwilliams3320@gmail.com> >>> >>>>> >> >>> написа: >>> >>>>> >> >>> >Hello, >>> >>>>> >> >>> > >>> >>>>> >> >>> >I recently added 6 hosts to an existing oVirt >>> >>>compute/gluster >>> >>>>> >> >cluster. >>> >>>>> >> >>> > >>> >>>>> >> >>> >Prior to this attempted addition, my cluster had 3 >>> >>>Hypervisor >>> >>>>> >hosts >>> >>>>> >> >and >>> >>>>> >> >>> >3 >>> >>>>> >> >>> >gluster bricks which made up a single gluster volume >>> >>>(replica 3 >>> >>>>> >> >volume) >>> >>>>> >> >>> >. I >>> >>>>> >> >>> >added the additional hosts and made a brick on 3 of the new >>> >>>>> >hosts >>> >>>>> >> >and >>> >>>>> >> >>> >attempted to make a new replica 3 volume. I had difficulty >>> >>>>> >> >creating >>> >>>>> >> >>> >the >>> >>>>> >> >>> >new volume. So, I decided that I would make a new >>> >>>>> >compute/gluster >>> >>>>> >> >>> >cluster >>> >>>>> >> >>> >for each set of 3 new hosts. >>> >>>>> >> >>> > >>> >>>>> >> >>> >I removed the 6 new hosts from the existing oVirt >>> >>>>> >Compute/Gluster >>> >>>>> >> >>> >Cluster >>> >>>>> >> >>> >leaving the 3 original hosts in place with their bricks. At >>> >>>that >>> >>>>> >> >point >>> >>>>> >> >>> >my >>> >>>>> >> >>> >original bricks went down and came back up . The volume >>> >>>showed >>> >>>>> >> >entries >>> >>>>> >> >>> >that >>> >>>>> >> >>> >needed healing. At that point I ran gluster volume heal >>> >>>images3 >>> >>>>> >> >full, >>> >>>>> >> >>> >etc. >>> >>>>> >> >>> >The volume shows no unhealed entries. I also corrected some >>> >>>peer >>> >>>>> >> >>> >errors. >>> >>>>> >> >>> > >>> >>>>> >> >>> >However, I am unable to copy disks, move disks to another >>> >>>>> >domain, >>> >>>>> >> >>> >export >>> >>>>> >> >>> >disks, etc. It appears that the engine cannot locate disks >>> >>>>> >properly >>> >>>>> >> >and >>> >>>>> >> >>> >I >>> >>>>> >> >>> >get storage I/O errors. >>> >>>>> >> >>> > >>> >>>>> >> >>> >I have detached and removed the oVirt Storage Domain. I >>> >>>>> >reimported >>> >>>>> >> >the >>> >>>>> >> >>> >domain and imported 2 VMs, But the VM disks exhibit the >>> same >>> >>>>> >> >behaviour >>> >>>>> >> >>> >and >>> >>>>> >> >>> >won't run from the hard disk. >>> >>>>> >> >>> > >>> >>>>> >> >>> > >>> >>>>> >> >>> >I get errors such as this >>> >>>>> >> >>> > >>> >>>>> >> >>> >VDSM ov05 command HSMGetAllTasksStatusesVDS failed: low >>> >>>level >>> >>>>> >Image >>> >>>>> >> >>> >copy >>> >>>>> >> >>> >failed: ("Command ['/usr/bin/qemu-img', 'convert', '-p', >>> >>>'-t', >>> >>>>> >> >'none', >>> >>>>> >> >>> >'-T', 'none', '-f', 'raw', >>> >>>>> >> >>> >u'/rhev/data-center/mnt/glusterSD/192.168.24.18: >>> >>>>> >> >>> >>> >>>>> >> >>> >>>>> >> >>> >>>>> >>> >>>>> >>> >>> >>>>>_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510', >>> >>>>> >> >>> >'-O', 'raw', >>> >>>>> >> >>> >u'/rhev/data-center/mnt/192.168.24.13: >>> >>>>> >> >>> >>> >>>>> >> >>> >>>>> >> >>> >>>>> >>> >>>>> >>> >>> >>>>>_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5'] >>> >>>>> >> >>> >failed with rc=1 out='' err=bytearray(b'qemu-img: error >>> >>>while >>> >>>>> >> >reading >>> >>>>> >> >>> >sector 135168: Transport endpoint is not >>> >>>connected\\nqemu-img: >>> >>>>> >> >error >>> >>>>> >> >>> >while >>> >>>>> >> >>> >reading sector 131072: Transport endpoint is not >>> >>>>> >> >connected\\nqemu-img: >>> >>>>> >> >>> >error while reading sector 139264: Transport endpoint is >>> not >>> >>>>> >> >>> >connected\\nqemu-img: error while reading sector 143360: >>> >>>>> >Transport >>> >>>>> >> >>> >endpoint >>> >>>>> >> >>> >is not connected\\nqemu-img: error while reading sector >>> >>>147456: >>> >>>>> >> >>> >Transport >>> >>>>> >> >>> >endpoint is not connected\\nqemu-img: error while reading >>> >>>sector >>> >>>>> >> >>> >155648: >>> >>>>> >> >>> >Transport endpoint is not connected\\nqemu-img: error while >>> >>>>> >reading >>> >>>>> >> >>> >sector >>> >>>>> >> >>> >151552: Transport endpoint is not connected\\nqemu-img: >>> >>>error >>> >>>>> >while >>> >>>>> >> >>> >reading >>> >>>>> >> >>> >sector 159744: Transport endpoint is not connected\\n')",) >>> >>>>> >> >>> > >>> >>>>> >> >>> >oVirt version is 4.3.82-1.el7 >>> >>>>> >> >>> >OS CentOS Linux release 7.7.1908 (Core) >>> >>>>> >> >>> > >>> >>>>> >> >>> >The Gluster Cluster has been working very well until this >>> >>>>> >incident. >>> >>>>> >> >>> > >>> >>>>> >> >>> >Please help. >>> >>>>> >> >>> > >>> >>>>> >> >>> >Thank You >>> >>>>> >> >>> > >>> >>>>> >> >>> >Charles Williams >>> >>>>> >> >>> >>> >>>>> >> >> >>> >>>>> >> >>> >>>>> >>> >>>> >>> >> >>> > >>> _______________________________________________ >>> Users mailing list -- users@ovirt.org >>> To unsubscribe send an email to users-leave@ovirt.org >>> Privacy Statement: https://www.ovirt.org/privacy-policy.html >>> oVirt Code of Conduct: >>> https://www.ovirt.org/community/about/community-guidelines/ >>> List Archives: >>> https://lists.ovirt.org/archives/list/users@ovirt.org/message/YY3VUKEJLI7MRWXF627EHQAMH36UJ5BQ/ >>> >>
Strahil, Thanks for the follow up ! How did you copy the data to another volume ? I have set up another storage domain GLCLNEW1 with a new volume imgnew1 . How would you copy all of the data from the problematic domain GLCL3 with volume images3 to GLCLNEW1 and volume imgnew1 and preserve all the VMs, VM disks, settings, etc. ? Remember all of the regular ovirt disk copy, disk move, VM export tools are failing and my VMs and disks are trapped on domain GLCL3 and volume images3 right now. Please let me know Thank You For Your Help ! On Sun, Jun 21, 2020 at 8:27 AM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Sorry to hear that. I can say that for me 6.5 was working, while 6.6 didn't and I upgraded to 7.0 . In the ended , I have ended with creating a new fresh volume and physically copying the data there, then I detached the storage domains and attached to the new ones (which holded the old data), but I could afford the downtime. Also, I can say that v7.0 ( but not 7.1 or anything later) also worked without the ACL issue, but it causes some trouble in oVirt - so avoid that unless you have no other options.
Best Regards, Strahil Nikolov
На 21 юни 2020 г. 4:39:46 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Hello,
Upgrading diidn't help
Still acl errors trying to use a Virtual Disk from a VM
[root@ov06 bricks]# tail bricks-brick04-images3.log | grep acl [2020-06-21 01:33:45.665888] I [MSGID: 139001] [posix-acl.c:263:posix_acl_log_permit_denied] 0-images3-access-control: client:
CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0, gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:107,gid:107,perm:1,ngrps:3), ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied] The message "I [MSGID: 139001] [posix-acl.c:263:posix_acl_log_permit_denied] 0-images3-access-control: client:
CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0, gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:107,gid:107,perm:1,ngrps:3), ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied]" repeated 2 times between [2020-06-21 01:33:45.665888] and [2020-06-21 01:33:45.806779]
Thank You For Your Help !
On Sat, Jun 20, 2020 at 8:59 PM C Williams <cwilliams3320@gmail.com> wrote:
Hello,
Based on the situation, I am planning to upgrade the 3 affected hosts.
My reasoning is that the hosts/bricks were attached to 6.9 at one time.
Thanks For Your Help !
On Sat, Jun 20, 2020 at 8:38 PM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
The gluster version on the current 3 gluster hosts is 6.7 (last update 2/26). These 3 hosts provide 1 brick each for the replica 3 volume.
Earlier I had tried to add 6 additional hosts to the cluster. Those new hosts were 6.9 gluster.
I attempted to make a new separate volume with 3 bricks provided by the 3 new gluster 6.9 hosts. After having many errors from the oVirt interface, I gave up and removed the 6 new hosts from the cluster. That is where the problems started. The intent was to expand the gluster cluster while making 2 new volumes for that cluster. The ovirt compute cluster would allow for efficient VM migration between 9 hosts -- while having separate gluster volumes for safety purposes.
Looking at the brick logs, I see where there are acl errors starting from the time of the removal of the 6 new hosts.
Please check out the attached brick log from 6/14-18. The events started on 6/17.
I wish I had a downgrade path.
Thank You For The Help !!
On Sat, Jun 20, 2020 at 7:47 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Hi ,
This one really looks like the ACL bug I was hit with when I updated from Gluster v6.5 to 6.6 and later from 7.0 to 7.2.
Did you update your setup recently ? Did you upgrade gluster also ?
You have to check the gluster logs in order to verify that, so you can try:
1. Set Gluster logs to trace level (for details check:
https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3/html...
) 2. Power up a VM that was already off , or retry the procedure from the logs you sent. 3. Stop the trace level of the logs 4. Check libvirt logs on the host that was supposed to power up the VM (in case a VM was powered on) 5. Check the gluster brick logs on all nodes for ACL errors. Here is a sample from my old logs:
gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 13:19:41.489047] I [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:36,gid:36,perm:1,ngrps:3), ctx (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied] gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 13:22:51.818796] I [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:36,gid:36,perm:1,ngrps:3), ctx (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied] gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 13:24:43.732856] I [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:36,gid:36,perm:1,ngrps:3), ctx (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied] gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 13:26:50.758178] I [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
gfid: be318638-e8a0-4c6d-977d-7a937aa84806, req(uid:36,gid:36,perm:1,ngrps:3), ctx (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) [Permission denied]
In my case , the workaround was to downgrade the gluster packages on all nodes (and reboot each node 1 by 1 ) if the major version is the same, but if you upgraded to v7.X - then you can try the v7.0 .
Best Regards, Strahil Nikolov
В събота, 20 юни 2020 г., 18:48:42 ч. Гринуич+3, C Williams < cwilliams3320@gmail.com> написа:
Hello,
Here are additional log tiles as well as a tree of the problematic Gluster storage domain. During this time I attempted to copy a virtual disk to another domain, move a virtual disk to another domain and run a VM where the virtual hard disk would be used.
The copies/moves failed and the VM went into pause mode when the virtual HDD was involved.
Please check these out.
Thank You For Your Help !
On Sat, Jun 20, 2020 at 9:54 AM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
I understand. Please keep me posted.
Thanks For The Help !
On Sat, Jun 20, 2020 at 4:36 AM Strahil Nikolov <hunter86_bg@yahoo.com> wrote: > Hey C Williams, > > sorry for the delay, but I couldn't get somw time to check your logs. Will try a little bit later. > > Best Regards, > Strahil Nikolov > > На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams < cwilliams3320@gmail.com> написа: >>Hello, >> >>Was wanting to follow up on this issue. Users are impacted. >> >>Thank You >> >>On Fri, Jun 19, 2020 at 9:20 AM C Williams <cwilliams3320@gmail.com> >>wrote: >> >>> Hello, >>> >>> Here are the logs (some IPs are changed ) >>> >>> ov05 is the SPM >>> >>> Thank You For Your Help ! >>> >>> On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov >><hunter86_bg@yahoo.com> >>> wrote: >>> >>>> Check on the hosts tab , which is your current SPM (last
column in >>> >>>Admin >>> >>>>> UI). >>> >>>>> Then open the /var/log/vdsm/vdsm.log and repeat the operation. >>> >>>>> Then provide the log from that host and the engine's log (on the >>> >>>>> HostedEngine VM or on your standalone engine). >>> >>>>> >>> >>>>> Best Regards, >>> >>>>> Strahil Nikolov >>> >>>>> >>> >>>>> На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams >>> >>><cwilliams3320@gmail.com> >>> >>>>> написа: >>> >>>>> >Resending to eliminate email issues >>> >>>>> > >>> >>>>> >---------- Forwarded message --------- >>> >>>>> >From: C Williams <cwilliams3320@gmail.com> >>> >>>>> >Date: Thu, Jun 18, 2020 at 4:01 PM >>> >>>>> >Subject: Re: [ovirt-users] Fwd: Issues with Gluster Domain >>> >>>>> >To: Strahil Nikolov <hunter86_bg@yahoo.com> >>> >>>>> > >>> >>>>> > >>> >>>>> >Here is output from mount >>> >>>>> > >>> >>>>> >192.168.24.12:/stor/import0 on >>> >>>>> >/rhev/data-center/mnt/192.168.24.12:_stor_import0 >>> >>>>> >type nfs4 >>> >>>>> >>> >>>>> >>> >>>
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12) >>>> >192.168.24.13:/stor/import1 on >>>> >/rhev/data-center/mnt/192.168.24.13:_stor_import1 >>>> >type nfs4 >>>> >>>>
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >>>> >192.168.24.13:/stor/iso1 on >>>> >/rhev/data-center/mnt/192.168.24.13:_stor_iso1 >>>> >type nfs4 >>>> >>>>
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >>>> >192.168.24.13:/stor/export0 on >>>> >/rhev/data-center/mnt/192.168.24.13:_stor_export0 >>>> >type nfs4 >>>> >>>>
(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >>>> >192.168.24.15:/images on >>>> >/rhev/data-center/mnt/glusterSD/192.168.24.15:_images >>>> >type fuse.glusterfs >>>> >>>>
(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) >>>> >192.168.24.18:/images3 on >>>> >/rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 >>>> >type fuse.glusterfs >>>> >>>>
(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) >>>> >tmpfs on /run/user/0 type tmpfs >>>> >(rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) >>>> >[root@ov06 glusterfs]# >>>> > >>>> >Also here is a screenshot of the console >>>> > >>>> >[image: image.png] >>>> >The other domains are up >>>> > >>>> >Import0 and Import1 are NFS . GLCL0 is gluster. They all are >>running >>>> >VMs >>>> > >>>> >Thank You For Your Help ! >>>> > >>>> >On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov >><hunter86_bg@yahoo.com> >>>> >wrote: >>>> > >>>> >> I don't see '/rhev/data-center/mnt/192.168.24.13:_stor_import1' >>>> >mounted >>>> >> at all . >>>> >> What is the status of all storage domains ? >>>> >> >>>> >> Best Regards, >>>> >> Strahil Nikolov >>>> >> >>>> >> На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams >>>> ><cwilliams3320@gmail.com> >>>> >> написа: >>>> >> > Resending to deal with possible email issues >>>> >> > >>>> >> >---------- Forwarded message --------- >>>> >> >From: C Williams <cwilliams3320@gmail.com> >>>> >> >Date: Thu, Jun 18, 2020 at 2:07 PM >>>> >> >Subject: Re: [ovirt-users] Issues with Gluster Domain >>>> >> >To: Strahil Nikolov <hunter86_bg@yahoo.com> >>>> >> > >>>> >> > >>>> >> >More >>>> >> > >>>> >> >[root@ov06 ~]# for i in $(gluster volume list); do echo >>$i;echo; >>>> >> >gluster >>>> >> >volume info $i; echo;echo;gluster volume status >>>> >$i;echo;echo;echo;done >>>> >> >images3 >>>> >> > >>>> >> > >>>> >> >Volume Name: images3 >>>> >> >Type: Replicate >>>> >> >Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b >>>> >> >Status: Started >>>> >> >Snapshot Count: 0 >>>> >> >Number of Bricks: 1 x 3 = 3 >>>> >> >Transport-type: tcp >>>> >> >Bricks: >>>> >> >Brick1: 192.168.24.18:/bricks/brick04/images3 >>>> >> >Brick2: 192.168.24.19:/bricks/brick05/images3 >>>> >> >Brick3: 192.168.24.20:/bricks/brick06/images3 >>>> >> >Options Reconfigured: >>>> >> >performance.client-io-threads: on >>>> >> >nfs.disable: on >>>> >> >transport.address-family: inet >>>> >> >user.cifs: off >>>> >> >auth.allow: * >>>> >> >performance.quick-read: off >>>> >> >performance.read-ahead: off >>>> >> >performance.io-cache: off >>>> >> >performance.low-prio-threads: 32 >>>> >> >network.remote-dio: off >>>> >> >cluster.eager-lock: enable >>>> >> >cluster.quorum-type: auto >>>> >> >cluster.server-quorum-type: server >>>> >> >cluster.data-self-heal-algorithm: full >>>> >> >cluster.locking-scheme: granular >>>> >> >cluster.shd-max-threads: 8 >>>> >> >cluster.shd-wait-qlength: 10000 >>>> >> >features.shard: on >>>> >> >cluster.choose-local: off >>>> >> >client.event-threads: 4 >>>> >> >server.event-threads: 4 >>>> >> >storage.owner-uid: 36 >>>> >> >storage.owner-gid: 36 >>>> >> >performance.strict-o-direct: on >>>> >> >network.ping-timeout: 30 >>>> >> >cluster.granular-entry-heal: enable >>>> >> > >>>> >> > >>>> >> >Status of volume: images3 >>>> >> >Gluster process TCP Port RDMA Port >>>> >Online >>>> >> > Pid >>>> >> >>>> >> >>>> >>>>
>------------------------------------------------------------------------------ >>>> >> >Brick 192.168.24.18:/bricks/brick04/images3 49152 0
>>Y >>>> >> >6666 >>>> >> >Brick 192.168.24.19:/bricks/brick05/images3 49152 0
>>Y >>>> >> >6779 >>>> >> >Brick 192.168.24.20:/bricks/brick06/images3 49152 0
>>Y >>>> >> >7227 >>>> >> >Self-heal Daemon on localhost N/A N/A
>>Y >>>> >> >6689 >>>> >> >Self-heal Daemon on ov07.ntc.srcle.com N/A N/A
>>Y >>>> >> >6802 >>>> >> >Self-heal Daemon on ov08.ntc.srcle.com N/A N/A
>>Y >>>> >> >7250 >>>> >> > >>>> >> >Task Status of Volume images3 >>>> >> >>>> >> >>>> >>>>
>------------------------------------------------------------------------------ >>>> >> >There are no active volume tasks >>>> >> > >>>> >> > >>>> >> > >>>> >> > >>>> >> >[root@ov06 ~]# ls -l /rhev/data-center/mnt/glusterSD/ >>>> >> >total 16 >>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 192.168.24.15:_images >>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 192.168.24.18: _images3 >>>> >> >[root@ov06 ~]# >>>> >> > >>>> >> >On Thu, Jun 18, 2020 at 2:03 PM C Williams >><cwilliams3320@gmail.com> >>>> >> >wrote: >>>> >> > >>>> >> >> Strahil, >>>> >> >> >>>> >> >> Here you go -- Thank You For Your Help ! >>>> >> >> >>>> >> >> BTW -- I can write a test file to gluster and it replicates >>>> >properly. >>>> >> >> Thinking something about the oVirt Storage Domain ? >>>> >> >> >>>> >> >> [root@ov08 ~]# gluster pool list >>>> >> >> UUID Hostname >>>> >State >>>> >> >> 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06 >>>> >> >Connected >>>> >> >> 36ce5a00-6f65-4926-8438-696944ebadb5 ov07.ntc.srcle.com >>>> >> >Connected >>>> >> >> c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost >>>> >> >Connected >>>> >> >> [root@ov08 ~]# gluster volume list >>>> >> >> images3 >>>> >> >> >>>> >> >> On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov >>>> >> ><hunter86_bg@yahoo.com> >>>> >> >> wrote: >>>> >> >> >>>> >> >>> Log to the oVirt cluster and provide the output of: >>>> >> >>> gluster pool list >>>> >> >>> gluster volume list >>>> >> >>> for i in $(gluster volume list); do echo $i;echo; gluster >>>> >volume >>>> >> >info >>>> >> >>> $i; echo;echo;gluster volume status $i;echo;echo;echo;done >>>> >> >>> >>>> >> >>> ls -l /rhev/data-center/mnt/glusterSD/ >>>> >> >>> >>>> >> >>> Best Regards, >>>> >> >>> Strahil Nikolov >>>> >> >>> >>>> >> >>> >>>> >> >>> На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams >>>> >> ><cwilliams3320@gmail.com> >>>> >> >>> написа: >>>> >> >>> >Hello, >>>> >> >>> > >>>> >> >>> >I recently added 6 hosts to an existing oVirt >>compute/gluster >>>> >> >cluster. >>>> >> >>> > >>>> >> >>> >Prior to this attempted addition, my cluster had 3 >>Hypervisor >>>> >hosts >>>> >> >and >>>> >> >>> >3 >>>> >> >>> >gluster bricks which made up a single gluster volume >>(replica 3 >>>> >> >volume) >>>> >> >>> >. I >>>> >> >>> >added the additional hosts and made a brick on 3 of the new >>>> >hosts >>>> >> >and >>>> >> >>> >attempted to make a new replica 3 volume. I had difficulty >>>> >> >creating >>>> >> >>> >the >>>> >> >>> >new volume. So, I decided that I would make a new >>>> >compute/gluster >>>> >> >>> >cluster >>>> >> >>> >for each set of 3 new hosts. >>>> >> >>> > >>>> >> >>> >I removed the 6 new hosts from the existing oVirt >>>> >Compute/Gluster >>>> >> >>> >Cluster >>>> >> >>> >leaving the 3 original hosts in place with their bricks. At >>that >>>> >> >point >>>> >> >>> >my >>>> >> >>> >original bricks went down and came back up . The volume >>showed >>>> >> >entries >>>> >> >>> >that >>>> >> >>> >needed healing. At that point I ran gluster volume heal >>images3 >>>> >> >full, >>>> >> >>> >etc. >>>> >> >>> >The volume shows no unhealed entries. I also corrected some >>peer >>>> >> >>> >errors. >>>> >> >>> > >>>> >> >>> >However, I am unable to copy disks, move disks to another >>>> >domain, >>>> >> >>> >export >>>> >> >>> >disks, etc. It appears that the engine cannot locate disks >>>> >properly >>>> >> >and >>>> >> >>> >I >>>> >> >>> >get storage I/O errors. >>>> >> >>> > >>>> >> >>> >I have detached and removed the oVirt Storage Domain. I >>>> >reimported >>>> >> >the >>>> >> >>> >domain and imported 2 VMs, But the VM disks exhibit the same >>>> >> >behaviour >>>> >> >>> >and >>>> >> >>> >won't run from the hard disk. >>>> >> >>> > >>>> >> >>> > >>>> >> >>> >I get errors such as this >>>> >> >>> > >>>> >> >>> >VDSM ov05 command HSMGetAllTasksStatusesVDS failed: low >>level >>>> >Image >>>> >> >>> >copy >>>> >> >>> >failed: ("Command ['/usr/bin/qemu-img', 'convert', '-p', >>'-t', >>>> >> >'none', >>>> >> >>> >'-T', 'none', '-f', 'raw', >>>> >> >>> >u'/rhev/data-center/mnt/glusterSD/192.168.24.18: >>>> >> >>> >>>> >> >>>> >> >>>> >>>>
>_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510', >>>> >> >>> >'-O', 'raw', >>>> >> >>> >u'/rhev/data-center/mnt/192.168.24.13: >>>> >> >>> >>>> >> >>>> >> >>>> >>>>
>_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5'] >>>> >> >>> >failed with rc=1 out='' err=bytearray(b'qemu-img: error >>while >>>> >> >reading >>>> >> >>> >sector 135168: Transport endpoint is not >>connected\\nqemu-img: >>>> >> >error >>>> >> >>> >while >>>> >> >>> >reading sector 131072: Transport endpoint is not >>>> >> >connected\\nqemu-img: >>>> >> >>> >error while reading sector 139264: Transport endpoint is not >>>> >> >>> >connected\\nqemu-img: error while reading sector 143360: >>>> >Transport >>>> >> >>> >endpoint >>>> >> >>> >is not connected\\nqemu-img: error while reading sector >>147456: >>>> >> >>> >Transport >>>> >> >>> >endpoint is not connected\\nqemu-img: error while reading >>sector >>>> >> >>> >155648: >>>> >> >>> >Transport endpoint is not connected\\nqemu-img: error while >>>> >reading >>>> >> >>> >sector >>>> >> >>> >151552: Transport endpoint is not connected\\nqemu-img: >>error >>>> >while >>>> >> >>> >reading >>>> >> >>> >sector 159744: Transport endpoint is not connected\\n')",) >>>> >> >>> > >>>> >> >>> >oVirt version is 4.3.82-1.el7 >>>> >> >>> >OS CentOS Linux release 7.7.1908 (Core) >>>> >> >>> > >>>> >> >>> >The Gluster Cluster has been working very well until this >>>> >incident. >>>> >> >>> > >>>> >> >>> >Please help. >>>> >> >>> > >>>> >> >>> >Thank You >>>> >> >>> > >>>> >> >>> >Charles Williams >>>> >> >>> >>>> >> >> >>>> >> >>>> >>> >
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives:
https://lists.ovirt.org/archives/list/users@ovirt.org/message/YY3VUKEJLI7MRW...
I created a fresh volume (which is not an ovirt sgorage domain), set the original storage domain in maintenance and detached it.
Then I 'cp -a ' the data from the old to the new volume. Next, I just added the new storage domain (the old one was a kind of a 'backup') - pointing to the new volume name.
If you observe issues , I would recommend you to downgrade gluster packages one node at a time . Then you might be able to restore your oVirt operations.
Best Regards,
Strahil Nikolov
На 21 юни 2020 г. 18:01:31 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
>Strahil,
>
>Thanks for the follow up !
>
>How did you copy the data to another volume ?
>
>I have set up another storage domain GLCLNEW1 with a new volume imgnew1
>.
>How would you copy all of the data from the problematic domain GLCL3
>with
>volume images3 to GLCLNEW1 and volume imgnew1 and preserve all the VMs,
>VM
>disks, settings, etc. ?
>
>Remember all of the regular ovirt disk copy, disk move, VM export
>tools
>are failing and my VMs and disks are trapped on domain GLCL3 and volume
>images3 right now.
>
>Please let me know
>
>Thank You For Your Help !
>
>
>
>
>
>On Sun, Jun 21, 2020 at 8:27 AM Strahil Nikolov <hunter86_bg@yahoo.com>
>wrote:
>
>> Sorry to hear that.
>> I can say that for me 6.5 was working, while 6.6 didn't and I
>upgraded
>> to 7.0 .
>> In the ended , I have ended with creating a new fresh volume and
>> physically copying the data there, then I detached the storage
>domains and
>> attached to the new ones (which holded the old data), but I
>could
>> afford the downtime.
>> Also, I can say that v7.0 ( but not 7.1 or anything later) also
>> worked without the ACL issue, but it causes some trouble in oVirt
>- so
>> avoid that unless you have no other options.
>>
>> Best Regards,
>> Strahil Nikolov
>>
>>
>>
>>
>> На 21 юни 2020 г. 4:39:46 GMT+03:00, C Williams
><cwilliams3320@gmail.com>
>> написа:
>> >Hello,
>> >
>> >Upgrading diidn't help
>> >
>> >Still acl errors trying to use a Virtual Disk from a VM
>> >
>> >[root@ov06 bricks]# tail bricks-brick04-images3.log | grep acl
>> >[2020-06-21 01:33:45.665888] I [MSGID: 139001]
>> >[posix-acl.c:263:posix_acl_log_permit_denied]
>0-images3-access-control:
>> >client:
>>
>>
>>CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0,
>> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
>> >req(uid:107,gid:107,perm:1,ngrps:3),
>> >ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
>> >[Permission denied]
>> >The message "I [MSGID: 139001]
>> >[posix-acl.c:263:posix_acl_log_permit_denied]
>0-images3-access-control:
>> >client:
>>
>>
>>CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0,
>> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
>> >req(uid:107,gid:107,perm:1,ngrps:3),
>> >ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
>> >[Permission denied]" repeated 2 times between [2020-06-21
>> >01:33:45.665888]
>> >and [2020-06-21 01:33:45.806779]
>> >
>> >Thank You For Your Help !
>> >
>> >On Sat, Jun 20, 2020 at 8:59 PM C Williams <cwilliams3320@gmail.com>
>> >wrote:
>> >
>> >> Hello,
>> >>
>> >> Based on the situation, I am planning to upgrade the 3 affected
>> >hosts.
>> >>
>> >> My reasoning is that the hosts/bricks were attached to 6.9 at one
>> >time.
>> >>
>> >> Thanks For Your Help !
>> >>
>> >> On Sat, Jun 20, 2020 at 8:38 PM C Williams
><cwilliams3320@gmail.com>
>> >> wrote:
>> >>
>> >>> Strahil,
>> >>>
>> >>> The gluster version on the current 3 gluster hosts is 6.7 (last
>> >update
>> >>> 2/26). These 3 hosts provide 1 brick each for the replica 3
>volume.
>> >>>
>> >>> Earlier I had tried to add 6 additional hosts to the cluster.
>Those
>> >new
>> >>> hosts were 6.9 gluster.
>> >>>
>> >>> I attempted to make a new separate volume with 3 bricks provided
>by
>> >the 3
>> >>> new gluster 6.9 hosts. After having many errors from the oVirt
>> >interface,
>> >>> I gave up and removed the 6 new hosts from the cluster. That is
>> >where the
>> >>> problems started. The intent was to expand the gluster cluster
>while
>> >making
>> >>> 2 new volumes for that cluster. The ovirt compute cluster would
>> >allow for
>> >>> efficient VM migration between 9 hosts -- while having separate
>> >gluster
>> >>> volumes for safety purposes.
>> >>>
>> >>> Looking at the brick logs, I see where there are acl errors
>starting
>> >from
>> >>> the time of the removal of the 6 new hosts.
>> >>>
>> >>> Please check out the attached brick log from 6/14-18. The events
>> >started
>> >>> on 6/17.
>> >>>
>> >>> I wish I had a downgrade path.
>> >>>
>> >>> Thank You For The Help !!
>> >>>
>> >>> On Sat, Jun 20, 2020 at 7:47 PM Strahil Nikolov
>> ><hunter86_bg@yahoo.com>
>> >>> wrote:
>> >>>
>> >>>> Hi ,
>> >>>>
>> >>>>
>> >>>> This one really looks like the ACL bug I was hit with when I
>> >updated
>> >>>> from Gluster v6.5 to 6.6 and later from 7.0 to 7.2.
>> >>>>
>> >>>> Did you update your setup recently ? Did you upgrade gluster
>also ?
>> >>>>
>> >>>> You have to check the gluster logs in order to verify that, so
>you
>> >can
>> >>>> try:
>> >>>>
>> >>>> 1. Set Gluster logs to trace level (for details check:
>> >>>>
>> >
>>
>https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3/html/administration_guide/configuring_the_log_level
>> >>>> )
>> >>>> 2. Power up a VM that was already off , or retry the procedure
>from
>> >the
>> >>>> logs you sent.
>> >>>> 3. Stop the trace level of the logs
>> >>>> 4. Check libvirt logs on the host that was supposed to power up
>the
>> >VM
>> >>>> (in case a VM was powered on)
>> >>>> 5. Check the gluster brick logs on all nodes for ACL errors.
>> >>>> Here is a sample from my old logs:
>> >>>>
>> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18
>> >13:19:41.489047] I
>> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied]
>> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
>> >>>>
>>
>>
>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
>> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
>> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx
>> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
>> >>>> [Permission denied]
>> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18
>> >13:22:51.818796] I
>> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied]
>> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
>> >>>>
>>
>>
>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
>> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
>> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx
>> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
>> >>>> [Permission denied]
>> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18
>> >13:24:43.732856] I
>> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied]
>> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
>> >>>>
>>
>>
>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
>> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
>> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx
>> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
>> >>>> [Permission denied]
>> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18
>> >13:26:50.758178] I
>> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied]
>> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
>> >>>>
>>
>>
>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
>> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
>> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx
>> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
>> >>>> [Permission denied]
>> >>>>
>> >>>>
>> >>>> In my case , the workaround was to downgrade the gluster
>packages
>> >on all
>> >>>> nodes (and reboot each node 1 by 1 ) if the major version is the
>> >same, but
>> >>>> if you upgraded to v7.X - then you can try the v7.0 .
>> >>>>
>> >>>> Best Regards,
>> >>>> Strahil Nikolov
>> >>>>
>> >>>>
>> >>>>
>> >>>>
>> >>>>
>> >>>>
>> >>>> В събота, 20 юни 2020 г., 18:48:42 ч. Гринуич+3, C Williams <
>> >>>> cwilliams3320@gmail.com> написа:
>> >>>>
>> >>>>
>> >>>>
>> >>>>
>> >>>>
>> >>>> Hello,
>> >>>>
>> >>>> Here are additional log tiles as well as a tree of the
>problematic
>> >>>> Gluster storage domain. During this time I attempted to copy a
>> >virtual disk
>> >>>> to another domain, move a virtual disk to another domain and run
>a
>> >VM where
>> >>>> the virtual hard disk would be used.
>> >>>>
>> >>>> The copies/moves failed and the VM went into pause mode when the
>> >virtual
>> >>>> HDD was involved.
>> >>>>
>> >>>> Please check these out.
>> >>>>
>> >>>> Thank You For Your Help !
>> >>>>
>> >>>> On Sat, Jun 20, 2020 at 9:54 AM C Williams
>> ><cwilliams3320@gmail.com>
>> >>>> wrote:
>> >>>> > Strahil,
>> >>>> >
>> >>>> > I understand. Please keep me posted.
>> >>>> >
>> >>>> > Thanks For The Help !
>> >>>> >
>> >>>> > On Sat, Jun 20, 2020 at 4:36 AM Strahil Nikolov
>> ><hunter86_bg@yahoo.com>
>> >>>> wrote:
>> >>>> >> Hey C Williams,
>> >>>> >>
>> >>>> >> sorry for the delay, but I couldn't get somw time to check
>your
>> >>>> logs. Will try a little bit later.
>> >>>> >>
>> >>>> >> Best Regards,
>> >>>> >> Strahil Nikolov
>> >>>> >>
>> >>>> >> На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams <
>> >>>> cwilliams3320@gmail.com> написа:
>> >>>> >>>Hello,
>> >>>> >>>
>> >>>> >>>Was wanting to follow up on this issue. Users are impacted.
>> >>>> >>>
>> >>>> >>>Thank You
>> >>>> >>>
>> >>>> >>>On Fri, Jun 19, 2020 at 9:20 AM C Williams
>> ><cwilliams3320@gmail.com>
>> >>>> >>>wrote:
>> >>>> >>>
>> >>>> >>>> Hello,
>> >>>> >>>>
>> >>>> >>>> Here are the logs (some IPs are changed )
>> >>>> >>>>
>> >>>> >>>> ov05 is the SPM
>> >>>> >>>>
>> >>>> >>>> Thank You For Your Help !
>> >>>> >>>>
>> >>>> >>>> On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov
>> >>>> >>><hunter86_bg@yahoo.com>
>> >>>> >>>> wrote:
>> >>>> >>>>
>> >>>> >>>>> Check on the hosts tab , which is your current SPM (last
>> >column in
>> >>>> >>>Admin
>> >>>> >>>>> UI).
>> >>>> >>>>> Then open the /var/log/vdsm/vdsm.log and repeat the
>> >operation.
>> >>>> >>>>> Then provide the log from that host and the engine's log
>(on
>> >the
>> >>>> >>>>> HostedEngine VM or on your standalone engine).
>> >>>> >>>>>
>> >>>> >>>>> Best Regards,
>> >>>> >>>>> Strahil Nikolov
>> >>>> >>>>>
>> >>>> >>>>> На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams
>> >>>> >>><cwilliams3320@gmail.com>
>> >>>> >>>>> написа:
>> >>>> >>>>> >Resending to eliminate email issues
>> >>>> >>>>> >
>> >>>> >>>>> >---------- Forwarded message ---------
>> >>>> >>>>> >From: C Williams <cwilliams3320@gmail.com>
>> >>>> >>>>> >Date: Thu, Jun 18, 2020 at 4:01 PM
>> >>>> >>>>> >Subject: Re: [ovirt-users] Fwd: Issues with Gluster
>Domain
>> >>>> >>>>> >To: Strahil Nikolov <hunter86_bg@yahoo.com>
>> >>>> >>>>> >
>> >>>> >>>>> >
>> >>>> >>>>> >Here is output from mount
>> >>>> >>>>> >
>> >>>> >>>>> >192.168.24.12:/stor/import0 on
>> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.12:_stor_import0
>> >>>> >>>>> >type nfs4
>> >>>> >>>>>
>> >>>> >>>>>
>> >>>>
>> >>>>
>>
>>
>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12)
>> >>>> >>>>> >192.168.24.13:/stor/import1 on
>> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_import1
>> >>>> >>>>> >type nfs4
>> >>>> >>>>>
>> >>>> >>>>>
>> >>>>
>> >>>>
>>
>>
>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
>> >>>> >>>>> >192.168.24.13:/stor/iso1 on
>> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_iso1
>> >>>> >>>>> >type nfs4
>> >>>> >>>>>
>> >>>> >>>>>
>> >>>>
>> >>>>
>>
>>
>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
>> >>>> >>>>> >192.168.24.13:/stor/export0 on
>> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_export0
>> >>>> >>>>> >type nfs4
>> >>>> >>>>>
>> >>>> >>>>>
>> >>>>
>> >>>>
>>
>>
>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
>> >>>> >>>>> >192.168.24.15:/images on
>> >>>> >>>>> >/rhev/data-center/mnt/glusterSD/192.168.24.15:_images
>> >>>> >>>>> >type fuse.glusterfs
>> >>>> >>>>>
>> >>>> >>>>>
>> >>>>
>> >>>>
>>
>>
>>>>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
>> >>>> >>>>> >192.168.24.18:/images3 on
>> >>>> >>>>> >/rhev/data-center/mnt/glusterSD/192.168.24.18:_images3
>> >>>> >>>>> >type fuse.glusterfs
>> >>>> >>>>>
>> >>>> >>>>>
>> >>>>
>> >>>>
>>
>>
>>>>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
>> >>>> >>>>> >tmpfs on /run/user/0 type tmpfs
>> >>>> >>>>>
>>(rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700)
>> >>>> >>>>> >[root@ov06 glusterfs]#
>> >>>> >>>>> >
>> >>>> >>>>> >Also here is a screenshot of the console
>> >>>> >>>>> >
>> >>>> >>>>> >[image: image.png]
>> >>>> >>>>> >The other domains are up
>> >>>> >>>>> >
>> >>>> >>>>> >Import0 and Import1 are NFS . GLCL0 is gluster. They all
>are
>> >>>> >>>running
>> >>>> >>>>> >VMs
>> >>>> >>>>> >
>> >>>> >>>>> >Thank You For Your Help !
>> >>>> >>>>> >
>> >>>> >>>>> >On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov
>> >>>> >>><hunter86_bg@yahoo.com>
>> >>>> >>>>> >wrote:
>> >>>> >>>>> >
>> >>>> >>>>> >> I don't see
>> >'/rhev/data-center/mnt/192.168.24.13:_stor_import1'
>> >>>> >>>>> >mounted
>> >>>> >>>>> >> at all .
>> >>>> >>>>> >> What is the status of all storage domains ?
>> >>>> >>>>> >>
>> >>>> >>>>> >> Best Regards,
>> >>>> >>>>> >> Strahil Nikolov
>> >>>> >>>>> >>
>> >>>> >>>>> >> На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams
>> >>>> >>>>> ><cwilliams3320@gmail.com>
>> >>>> >>>>> >> написа:
>> >>>> >>>>> >> > Resending to deal with possible email issues
>> >>>> >>>>> >> >
>> >>>> >>>>> >> >---------- Forwarded message ---------
>> >>>> >>>>> >> >From: C Williams <cwilliams3320@gmail.com>
>> >>>> >>>>> >> >Date: Thu, Jun 18, 2020 at 2:07 PM
>> >>>> >>>>> >> >Subject: Re: [ovirt-users] Issues with Gluster Domain
>> >>>> >>>>> >> >To: Strahil Nikolov <hunter86_bg@yahoo.com>
>> >>>> >>>>> >> >
>> >>>> >>>>> >> >
>> >>>> >>>>> >> >More
>> >>>> >>>>> >> >
>> >>>> >>>>> >> >[root@ov06 ~]# for i in $(gluster volume list); do
>echo
>> >>>> >>>$i;echo;
>> >>>> >>>>> >> >gluster
>> >>>> >>>>> >> >volume info $i; echo;echo;gluster volume status
>> >>>> >>>>> >$i;echo;echo;echo;done
>> >>>> >>>>> >> >images3
>> >>>> >>>>> >> >
>> >>>> >>>>> >> >
>> >>>> >>>>> >> >Volume Name: images3
>> >>>> >>>>> >> >Type: Replicate
>> >>>> >>>>> >> >Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b
>> >>>> >>>>> >> >Status: Started
>> >>>> >>>>> >> >Snapshot Count: 0
>> >>>> >>>>> >> >Number of Bricks: 1 x 3 = 3
>> >>>> >>>>> >> >Transport-type: tcp
>> >>>> >>>>> >> >Bricks:
>> >>>> >>>>> >> >Brick1: 192.168.24.18:/bricks/brick04/images3
>> >>>> >>>>> >> >Brick2: 192.168.24.19:/bricks/brick05/images3
>> >>>> >>>>> >> >Brick3: 192.168.24.20:/bricks/brick06/images3
>> >>>> >>>>> >> >Options Reconfigured:
>> >>>> >>>>> >> >performance.client-io-threads: on
>> >>>> >>>>> >> >nfs.disable: on
>> >>>> >>>>> >> >transport.address-family: inet
>> >>>> >>>>> >> >user.cifs: off
>> >>>> >>>>> >> >auth.allow: *
>> >>>> >>>>> >> >performance.quick-read: off
>> >>>> >>>>> >> >performance.read-ahead: off
>> >>>> >>>>> >> >performance.io-cache: off
>> >>>> >>>>> >> >performance.low-prio-threads: 32
>> >>>> >>>>> >> >network.remote-dio: off
>> >>>> >>>>> >> >cluster.eager-lock: enable
>> >>>> >>>>> >> >cluster.quorum-type: auto
>> >>>> >>>>> >> >cluster.server-quorum-type: server
>> >>>> >>>>> >> >cluster.data-self-heal-algorithm: full
>> >>>> >>>>> >> >cluster.locking-scheme: granular
>> >>>> >>>>> >> >cluster.shd-max-threads: 8
>> >>>> >>>>> >> >cluster.shd-wait-qlength: 10000
>> >>>> >>>>> >> >features.shard: on
>> >>>> >>>>> >> >cluster.choose-local: off
>> >>>> >>>>> >> >client.event-threads: 4
>> >>>> >>>>> >> >server.event-threads: 4
>> >>>> >>>>> >> >storage.owner-uid: 36
>> >>>> >>>>> >> >storage.owner-gid: 36
>> >>>> >>>>> >> >performance.strict-o-direct: on
>> >>>> >>>>> >> >network.ping-timeout: 30
>> >>>> >>>>> >> >cluster.granular-entry-heal: enable
>> >>>> >>>>> >> >
>> >>>> >>>>> >> >
>> >>>> >>>>> >> >Status of volume: images3
>> >>>> >>>>> >> >Gluster process TCP Port
>> >RDMA Port
>> >>>> >>>>> >Online
>> >>>> >>>>> >> > Pid
>> >>>> >>>>> >>
>> >>>> >>>>> >>
>> >>>> >>>>>
>> >>>> >>>>>
>> >>>>
>> >>>>
>>
>>
>>>>>>>------------------------------------------------------------------------------
>> >>>> >>>>> >> >Brick 192.168.24.18:/bricks/brick04/images3 49152
>0
>> >>>>
>> >>>> >>>Y
>> >>>> >>>>> >> >6666
>> >>>> >>>>> >> >Brick 192.168.24.19:/bricks/brick05/images3 49152
>0
>> >>>>
>> >>>> >>>Y
>> >>>> >>>>> >> >6779
>> >>>> >>>>> >> >Brick 192.168.24.20:/bricks/brick06/images3 49152
>0
>> >>>>
>> >>>> >>>Y
>> >>>> >>>>> >> >7227
>> >>>> >>>>> >> >Self-heal Daemon on localhost N/A
>N/A
>> >>>>
>> >>>> >>>Y
>> >>>> >>>>> >> >6689
>> >>>> >>>>> >> >Self-heal Daemon on ov07.ntc.srcle.com N/A
>N/A
>> >>>>
>> >>>> >>>Y
>> >>>> >>>>> >> >6802
>> >>>> >>>>> >> >Self-heal Daemon on ov08.ntc.srcle.com N/A
>N/A
>> >>>>
>> >>>> >>>Y
>> >>>> >>>>> >> >7250
>> >>>> >>>>> >> >
>> >>>> >>>>> >> >Task Status of Volume images3
>> >>>> >>>>> >>
>> >>>> >>>>> >>
>> >>>> >>>>>
>> >>>> >>>>>
>> >>>>
>> >>>>
>>
>>
>>>>>>>------------------------------------------------------------------------------
>> >>>> >>>>> >> >There are no active volume tasks
>> >>>> >>>>> >> >
>> >>>> >>>>> >> >
>> >>>> >>>>> >> >
>> >>>> >>>>> >> >
>> >>>> >>>>> >> >[root@ov06 ~]# ls -l /rhev/data-center/mnt/glusterSD/
>> >>>> >>>>> >> >total 16
>> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04
>> >192.168.24.15:_images
>> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05
>192.168.24.18:
>> >>>> _images3
>> >>>> >>>>> >> >[root@ov06 ~]#
>> >>>> >>>>> >> >
>> >>>> >>>>> >> >On Thu, Jun 18, 2020 at 2:03 PM C Williams
>> >>>> >>><cwilliams3320@gmail.com>
>> >>>> >>>>> >> >wrote:
>> >>>> >>>>> >> >
>> >>>> >>>>> >> >> Strahil,
>> >>>> >>>>> >> >>
>> >>>> >>>>> >> >> Here you go -- Thank You For Your Help !
>> >>>> >>>>> >> >>
>> >>>> >>>>> >> >> BTW -- I can write a test file to gluster and it
>> >replicates
>> >>>> >>>>> >properly.
>> >>>> >>>>> >> >> Thinking something about the oVirt Storage Domain ?
>> >>>> >>>>> >> >>
>> >>>> >>>>> >> >> [root@ov08 ~]# gluster pool list
>> >>>> >>>>> >> >> UUID Hostname
>> >>>> >>>>> >State
>> >>>> >>>>> >> >> 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06
>> >>>> >>>>> >> >Connected
>> >>>> >>>>> >> >> 36ce5a00-6f65-4926-8438-696944ebadb5
>> >ov07.ntc.srcle.com
>> >>>> >>>>> >> >Connected
>> >>>> >>>>> >> >> c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost
>> >>>> >>>>> >> >Connected
>> >>>> >>>>> >> >> [root@ov08 ~]# gluster volume list
>> >>>> >>>>> >> >> images3
>> >>>> >>>>> >> >>
>> >>>> >>>>> >> >> On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov
>> >>>> >>>>> >> ><hunter86_bg@yahoo.com>
>> >>>> >>>>> >> >> wrote:
>> >>>> >>>>> >> >>
>> >>>> >>>>> >> >>> Log to the oVirt cluster and provide the output of:
>> >>>> >>>>> >> >>> gluster pool list
>> >>>> >>>>> >> >>> gluster volume list
>> >>>> >>>>> >> >>> for i in $(gluster volume list); do echo $i;echo;
>> >gluster
>> >>>> >>>>> >volume
>> >>>> >>>>> >> >info
>> >>>> >>>>> >> >>> $i; echo;echo;gluster volume status
>> >$i;echo;echo;echo;done
>> >>>> >>>>> >> >>>
>> >>>> >>>>> >> >>> ls -l /rhev/data-center/mnt/glusterSD/
>> >>>> >>>>> >> >>>
>> >>>> >>>>> >> >>> Best Regards,
>> >>>> >>>>> >> >>> Strahil Nikolov
>> >>>> >>>>> >> >>>
>> >>>> >>>>> >> >>>
>> >>>> >>>>> >> >>> На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams
>> >>>> >>>>> >> ><cwilliams3320@gmail.com>
>> >>>> >>>>> >> >>> написа:
>> >>>> >>>>> >> >>> >Hello,
>> >>>> >>>>> >> >>> >
>> >>>> >>>>> >> >>> >I recently added 6 hosts to an existing oVirt
>> >>>> >>>compute/gluster
>> >>>> >>>>> >> >cluster.
>> >>>> >>>>> >> >>> >
>> >>>> >>>>> >> >>> >Prior to this attempted addition, my cluster had 3
>> >>>> >>>Hypervisor
>> >>>> >>>>> >hosts
>> >>>> >>>>> >> >and
>> >>>> >>>>> >> >>> >3
>> >>>> >>>>> >> >>> >gluster bricks which made up a single gluster
>volume
>> >>>> >>>(replica 3
>> >>>> >>>>> >> >volume)
>> >>>> >>>>> >> >>> >. I
>> >>>> >>>>> >> >>> >added the additional hosts and made a brick on 3
>of
>> >the new
>> >>>> >>>>> >hosts
>> >>>> >>>>> >> >and
>> >>>> >>>>> >> >>> >attempted to make a new replica 3 volume. I had
>> >difficulty
>> >>>> >>>>> >> >creating
>> >>>> >>>>> >> >>> >the
>> >>>> >>>>> >> >>> >new volume. So, I decided that I would make a new
>> >>>> >>>>> >compute/gluster
>> >>>> >>>>> >> >>> >cluster
>> >>>> >>>>> >> >>> >for each set of 3 new hosts.
>> >>>> >>>>> >> >>> >
>> >>>> >>>>> >> >>> >I removed the 6 new hosts from the existing oVirt
>> >>>> >>>>> >Compute/Gluster
>> >>>> >>>>> >> >>> >Cluster
>> >>>> >>>>> >> >>> >leaving the 3 original hosts in place with their
>> >bricks. At
>> >>>> >>>that
>> >>>> >>>>> >> >point
>> >>>> >>>>> >> >>> >my
>> >>>> >>>>> >> >>> >original bricks went down and came back up . The
>> >volume
>> >>>> >>>showed
>> >>>> >>>>> >> >entries
>> >>>> >>>>> >> >>> >that
>> >>>> >>>>> >> >>> >needed healing. At that point I ran gluster volume
>> >heal
>> >>>> >>>images3
>> >>>> >>>>> >> >full,
>> >>>> >>>>> >> >>> >etc.
>> >>>> >>>>> >> >>> >The volume shows no unhealed entries. I also
>> >corrected some
>> >>>> >>>peer
>> >>>> >>>>> >> >>> >errors.
>> >>>> >>>>> >> >>> >
>> >>>> >>>>> >> >>> >However, I am unable to copy disks, move disks to
>> >another
>> >>>> >>>>> >domain,
>> >>>> >>>>> >> >>> >export
>> >>>> >>>>> >> >>> >disks, etc. It appears that the engine cannot
>locate
>> >disks
>> >>>> >>>>> >properly
>> >>>> >>>>> >> >and
>> >>>> >>>>> >> >>> >I
>> >>>> >>>>> >> >>> >get storage I/O errors.
>> >>>> >>>>> >> >>> >
>> >>>> >>>>> >> >>> >I have detached and removed the oVirt Storage
>Domain.
>> >I
>> >>>> >>>>> >reimported
>> >>>> >>>>> >> >the
>> >>>> >>>>> >> >>> >domain and imported 2 VMs, But the VM disks
>exhibit
>> >the
>> >>>> same
>> >>>> >>>>> >> >behaviour
>> >>>> >>>>> >> >>> >and
>> >>>> >>>>> >> >>> >won't run from the hard disk.
>> >>>> >>>>> >> >>> >
>> >>>> >>>>> >> >>> >
>> >>>> >>>>> >> >>> >I get errors such as this
>> >>>> >>>>> >> >>> >
>> >>>> >>>>> >> >>> >VDSM ov05 command HSMGetAllTasksStatusesVDS
>failed:
>> >low
>> >>>> >>>level
>> >>>> >>>>> >Image
>> >>>> >>>>> >> >>> >copy
>> >>>> >>>>> >> >>> >failed: ("Command ['/usr/bin/qemu-img', 'convert',
>> >'-p',
>> >>>> >>>'-t',
>> >>>> >>>>> >> >'none',
>> >>>> >>>>> >> >>> >'-T', 'none', '-f', 'raw',
>> >>>> >>>>> >> >>> >u'/rhev/data-center/mnt/glusterSD/192.168.24.18:
>> >>>> >>>>> >> >>>
>> >>>> >>>>> >>
>> >>>> >>>>> >>
>> >>>> >>>>>
>> >>>> >>>>>
>> >>>>
>> >>>>
>>
>>
>>>>>>>_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510',
>> >>>> >>>>> >> >>> >'-O', 'raw',
>> >>>> >>>>> >> >>> >u'/rhev/data-center/mnt/192.168.24.13:
>> >>>> >>>>> >> >>>
>> >>>> >>>>> >>
>> >>>> >>>>> >>
>> >>>> >>>>>
>> >>>> >>>>>
>> >>>>
>> >>>>
>>
>>
>>>>>>>_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5']
>> >>>> >>>>> >> >>> >failed with rc=1 out='' err=bytearray(b'qemu-img:
>> >error
>> >>>> >>>while
>> >>>> >>>>> >> >reading
>> >>>> >>>>> >> >>> >sector 135168: Transport endpoint is not
>> >>>> >>>connected\\nqemu-img:
>> >>>> >>>>> >> >error
>> >>>> >>>>> >> >>> >while
>> >>>> >>>>> >> >>> >reading sector 131072: Transport endpoint is not
>> >>>> >>>>> >> >connected\\nqemu-img:
>> >>>> >>>>> >> >>> >error while reading sector 139264: Transport
>endpoint
>> >is
>> >>>> not
>> >>>> >>>>> >> >>> >connected\\nqemu-img: error while reading sector
>> >143360:
>> >>>> >>>>> >Transport
>> >>>> >>>>> >> >>> >endpoint
>> >>>> >>>>> >> >>> >is not connected\\nqemu-img: error while reading
>> >sector
>> >>>> >>>147456:
>> >>>> >>>>> >> >>> >Transport
>> >>>> >>>>> >> >>> >endpoint is not connected\\nqemu-img: error while
>> >reading
>> >>>> >>>sector
>> >>>> >>>>> >> >>> >155648:
>> >>>> >>>>> >> >>> >Transport endpoint is not connected\\nqemu-img:
>error
>> >while
>> >>>> >>>>> >reading
>> >>>> >>>>> >> >>> >sector
>> >>>> >>>>> >> >>> >151552: Transport endpoint is not
>> >connected\\nqemu-img:
>> >>>> >>>error
>> >>>> >>>>> >while
>> >>>> >>>>> >> >>> >reading
>> >>>> >>>>> >> >>> >sector 159744: Transport endpoint is not
>> >connected\\n')",)
>> >>>> >>>>> >> >>> >
>> >>>> >>>>> >> >>> >oVirt version is 4.3.82-1.el7
>> >>>> >>>>> >> >>> >OS CentOS Linux release 7.7.1908 (Core)
>> >>>> >>>>> >> >>> >
>> >>>> >>>>> >> >>> >The Gluster Cluster has been working very well
>until
>> >this
>> >>>> >>>>> >incident.
>> >>>> >>>>> >> >>> >
>> >>>> >>>>> >> >>> >Please help.
>> >>>> >>>>> >> >>> >
>> >>>> >>>>> >> >>> >Thank You
>> >>>> >>>>> >> >>> >
>> >>>> >>>>> >> >>> >Charles Williams
>> >>>> >>>>> >> >>>
>> >>>> >>>>> >> >>
>> >>>> >>>>> >>
>> >>>> >>>>>
>> >>>> >>>>
>> >>>> >>
>> >>>> >
>> >>>> _______________________________________________
>> >>>> Users mailing list -- users@ovirt.org
>> >>>> To unsubscribe send an email to users-leave@ovirt.org
>> >>>> Privacy Statement: https://www.ovirt.org/privacy-policy.html
>> >>>> oVirt Code of Conduct:
>> >>>> https://www.ovirt.org/community/about/community-guidelines/
>> >>>> List Archives:
>> >>>>
>> >
>>
>https://lists.ovirt.org/archives/list/users@ovirt.org/message/YY3VUKEJLI7MRWXF627EHQAMH36UJ5BQ/
>> >>>>
>> >>>
>>
Strahil,
So should I make the target volume on 3 bricks which do not have ovirt --
just gluster ? In other words (3) Centos 7 hosts ?
Thank You For Your Help !
On Sun, Jun 21, 2020 at 3:08 PM Strahil Nikolov <hunter86_bg@yahoo.com>
wrote:
> I created a fresh volume (which is not an ovirt sgorage domain), set
> the original storage domain in maintenance and detached it.
> Then I 'cp -a ' the data from the old to the new volume. Next, I just
> added the new storage domain (the old one was a kind of a
> 'backup') - pointing to the new volume name.
>
> If you observe issues , I would recommend you to downgrade
> gluster packages one node at a time . Then you might be able to
> restore your oVirt operations.
>
> Best Regards,
> Strahil Nikolov
>
> На 21 юни 2020 г. 18:01:31 GMT+03:00, C Williams <cwilliams3320@gmail.com>
> написа:
> >Strahil,
> >
> >Thanks for the follow up !
> >
> >How did you copy the data to another volume ?
> >
> >I have set up another storage domain GLCLNEW1 with a new volume imgnew1
> >.
> >How would you copy all of the data from the problematic domain GLCL3
> >with
> >volume images3 to GLCLNEW1 and volume imgnew1 and preserve all the VMs,
> >VM
> >disks, settings, etc. ?
> >
> >Remember all of the regular ovirt disk copy, disk move, VM export
> >tools
> >are failing and my VMs and disks are trapped on domain GLCL3 and volume
> >images3 right now.
> >
> >Please let me know
> >
> >Thank You For Your Help !
> >
> >
> >
> >
> >
> >On Sun, Jun 21, 2020 at 8:27 AM Strahil Nikolov <hunter86_bg@yahoo.com>
> >wrote:
> >
> >> Sorry to hear that.
> >> I can say that for me 6.5 was working, while 6.6 didn't and I
> >upgraded
> >> to 7.0 .
> >> In the ended , I have ended with creating a new fresh volume and
> >> physically copying the data there, then I detached the storage
> >domains and
> >> attached to the new ones (which holded the old data), but I
> >could
> >> afford the downtime.
> >> Also, I can say that v7.0 ( but not 7.1 or anything later) also
> >> worked without the ACL issue, but it causes some trouble in oVirt
> >- so
> >> avoid that unless you have no other options.
> >>
> >> Best Regards,
> >> Strahil Nikolov
> >>
> >>
> >>
> >>
> >> На 21 юни 2020 г. 4:39:46 GMT+03:00, C Williams
> ><cwilliams3320@gmail.com>
> >> написа:
> >> >Hello,
> >> >
> >> >Upgrading diidn't help
> >> >
> >> >Still acl errors trying to use a Virtual Disk from a VM
> >> >
> >> >[root@ov06 bricks]# tail bricks-brick04-images3.log | grep acl
> >> >[2020-06-21 01:33:45.665888] I [MSGID: 139001]
> >> >[posix-acl.c:263:posix_acl_log_permit_denied]
> >0-images3-access-control:
> >> >client:
> >>
> >>
>
> >>CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0,
> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
> >> >req(uid:107,gid:107,perm:1,ngrps:3),
> >> >ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
> >> >[Permission denied]
> >> >The message "I [MSGID: 139001]
> >> >[posix-acl.c:263:posix_acl_log_permit_denied]
> >0-images3-access-control:
> >> >client:
> >>
> >>
>
> >>CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0,
> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
> >> >req(uid:107,gid:107,perm:1,ngrps:3),
> >> >ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
> >> >[Permission denied]" repeated 2 times between [2020-06-21
> >> >01:33:45.665888]
> >> >and [2020-06-21 01:33:45.806779]
> >> >
> >> >Thank You For Your Help !
> >> >
> >> >On Sat, Jun 20, 2020 at 8:59 PM C Williams <cwilliams3320@gmail.com>
> >> >wrote:
> >> >
> >> >> Hello,
> >> >>
> >> >> Based on the situation, I am planning to upgrade the 3 affected
> >> >hosts.
> >> >>
> >> >> My reasoning is that the hosts/bricks were attached to 6.9 at one
> >> >time.
> >> >>
> >> >> Thanks For Your Help !
> >> >>
> >> >> On Sat, Jun 20, 2020 at 8:38 PM C Williams
> ><cwilliams3320@gmail.com>
> >> >> wrote:
> >> >>
> >> >>> Strahil,
> >> >>>
> >> >>> The gluster version on the current 3 gluster hosts is 6.7 (last
> >> >update
> >> >>> 2/26). These 3 hosts provide 1 brick each for the replica 3
> >volume.
> >> >>>
> >> >>> Earlier I had tried to add 6 additional hosts to the cluster.
> >Those
> >> >new
> >> >>> hosts were 6.9 gluster.
> >> >>>
> >> >>> I attempted to make a new separate volume with 3 bricks provided
> >by
> >> >the 3
> >> >>> new gluster 6.9 hosts. After having many errors from the oVirt
> >> >interface,
> >> >>> I gave up and removed the 6 new hosts from the cluster. That is
> >> >where the
> >> >>> problems started. The intent was to expand the gluster cluster
> >while
> >> >making
> >> >>> 2 new volumes for that cluster. The ovirt compute cluster would
> >> >allow for
> >> >>> efficient VM migration between 9 hosts -- while having separate
> >> >gluster
> >> >>> volumes for safety purposes.
> >> >>>
> >> >>> Looking at the brick logs, I see where there are acl errors
> >starting
> >> >from
> >> >>> the time of the removal of the 6 new hosts.
> >> >>>
> >> >>> Please check out the attached brick log from 6/14-18. The events
> >> >started
> >> >>> on 6/17.
> >> >>>
> >> >>> I wish I had a downgrade path.
> >> >>>
> >> >>> Thank You For The Help !!
> >> >>>
> >> >>> On Sat, Jun 20, 2020 at 7:47 PM Strahil Nikolov
> >> ><hunter86_bg@yahoo.com>
> >> >>> wrote:
> >> >>>
> >> >>>> Hi ,
> >> >>>>
> >> >>>>
> >> >>>> This one really looks like the ACL bug I was hit with when I
> >> >updated
> >> >>>> from Gluster v6.5 to 6.6 and later from 7.0 to 7.2.
> >> >>>>
> >> >>>> Did you update your setup recently ? Did you upgrade gluster
> >also ?
> >> >>>>
> >> >>>> You have to check the gluster logs in order to verify that, so
> >you
> >> >can
> >> >>>> try:
> >> >>>>
> >> >>>> 1. Set Gluster logs to trace level (for details check:
> >> >>>>
> >> >
> >>
> >
> https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3/html/administration_guide/configuring_the_log_level
> >> >>>> )
> >> >>>> 2. Power up a VM that was already off , or retry the procedure
> >from
> >> >the
> >> >>>> logs you sent.
> >> >>>> 3. Stop the trace level of the logs
> >> >>>> 4. Check libvirt logs on the host that was supposed to power up
> >the
> >> >VM
> >> >>>> (in case a VM was powered on)
> >> >>>> 5. Check the gluster brick logs on all nodes for ACL errors.
> >> >>>> Here is a sample from my old logs:
> >> >>>>
> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18
> >> >13:19:41.489047] I
> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied]
> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
> >> >>>>
> >>
> >>
>
> >>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx
> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
> >> >>>> [Permission denied]
> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18
> >> >13:22:51.818796] I
> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied]
> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
> >> >>>>
> >>
> >>
>
> >>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx
> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
> >> >>>> [Permission denied]
> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18
> >> >13:24:43.732856] I
> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied]
> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
> >> >>>>
> >>
> >>
>
> >>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx
> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
> >> >>>> [Permission denied]
> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18
> >> >13:26:50.758178] I
> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied]
> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
> >> >>>>
> >>
> >>
>
> >>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx
> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
> >> >>>> [Permission denied]
> >> >>>>
> >> >>>>
> >> >>>> In my case , the workaround was to downgrade the gluster
> >packages
> >> >on all
> >> >>>> nodes (and reboot each node 1 by 1 ) if the major version is the
> >> >same, but
> >> >>>> if you upgraded to v7.X - then you can try the v7.0 .
> >> >>>>
> >> >>>> Best Regards,
> >> >>>> Strahil Nikolov
> >> >>>>
> >> >>>>
> >> >>>>
> >> >>>>
> >> >>>>
> >> >>>>
> >> >>>> В събота, 20 юни 2020 г., 18:48:42 ч. Гринуич+3, C Williams <
> >> >>>> cwilliams3320@gmail.com> написа:
> >> >>>>
> >> >>>>
> >> >>>>
> >> >>>>
> >> >>>>
> >> >>>> Hello,
> >> >>>>
> >> >>>> Here are additional log tiles as well as a tree of the
> >problematic
> >> >>>> Gluster storage domain. During this time I attempted to copy a
> >> >virtual disk
> >> >>>> to another domain, move a virtual disk to another domain and run
> >a
> >> >VM where
> >> >>>> the virtual hard disk would be used.
> >> >>>>
> >> >>>> The copies/moves failed and the VM went into pause mode when the
> >> >virtual
> >> >>>> HDD was involved.
> >> >>>>
> >> >>>> Please check these out.
> >> >>>>
> >> >>>> Thank You For Your Help !
> >> >>>>
> >> >>>> On Sat, Jun 20, 2020 at 9:54 AM C Williams
> >> ><cwilliams3320@gmail.com>
> >> >>>> wrote:
> >> >>>> > Strahil,
> >> >>>> >
> >> >>>> > I understand. Please keep me posted.
> >> >>>> >
> >> >>>> > Thanks For The Help !
> >> >>>> >
> >> >>>> > On Sat, Jun 20, 2020 at 4:36 AM Strahil Nikolov
> >> ><hunter86_bg@yahoo.com>
> >> >>>> wrote:
> >> >>>> >> Hey C Williams,
> >> >>>> >>
> >> >>>> >> sorry for the delay, but I couldn't get somw time to check
> >your
> >> >>>> logs. Will try a little bit later.
> >> >>>> >>
> >> >>>> >> Best Regards,
> >> >>>> >> Strahil Nikolov
> >> >>>> >>
> >> >>>> >> На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams <
> >> >>>> cwilliams3320@gmail.com> написа:
> >> >>>> >>>Hello,
> >> >>>> >>>
> >> >>>> >>>Was wanting to follow up on this issue. Users are impacted.
> >> >>>> >>>
> >> >>>> >>>Thank You
> >> >>>> >>>
> >> >>>> >>>On Fri, Jun 19, 2020 at 9:20 AM C Williams
> >> ><cwilliams3320@gmail.com>
> >> >>>> >>>wrote:
> >> >>>> >>>
> >> >>>> >>>> Hello,
> >> >>>> >>>>
> >> >>>> >>>> Here are the logs (some IPs are changed )
> >> >>>> >>>>
> >> >>>> >>>> ov05 is the SPM
> >> >>>> >>>>
> >> >>>> >>>> Thank You For Your Help !
> >> >>>> >>>>
> >> >>>> >>>> On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov
> >> >>>> >>><hunter86_bg@yahoo.com>
> >> >>>> >>>> wrote:
> >> >>>> >>>>
> >> >>>> >>>>> Check on the hosts tab , which is your current SPM (last
> >> >column in
> >> >>>> >>>Admin
> >> >>>> >>>>> UI).
> >> >>>> >>>>> Then open the /var/log/vdsm/vdsm.log and repeat the
> >> >operation.
> >> >>>> >>>>> Then provide the log from that host and the engine's log
> >(on
> >> >the
> >> >>>> >>>>> HostedEngine VM or on your standalone engine).
> >> >>>> >>>>>
> >> >>>> >>>>> Best Regards,
> >> >>>> >>>>> Strahil Nikolov
> >> >>>> >>>>>
> >> >>>> >>>>> На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams
> >> >>>> >>><cwilliams3320@gmail.com>
> >> >>>> >>>>> написа:
> >> >>>> >>>>> >Resending to eliminate email issues
> >> >>>> >>>>> >
> >> >>>> >>>>> >---------- Forwarded message ---------
> >> >>>> >>>>> >From: C Williams <cwilliams3320@gmail.com>
> >> >>>> >>>>> >Date: Thu, Jun 18, 2020 at 4:01 PM
> >> >>>> >>>>> >Subject: Re: [ovirt-users] Fwd: Issues with Gluster
> >Domain
> >> >>>> >>>>> >To: Strahil Nikolov <hunter86_bg@yahoo.com>
> >> >>>> >>>>> >
> >> >>>> >>>>> >
> >> >>>> >>>>> >Here is output from mount
> >> >>>> >>>>> >
> >> >>>> >>>>> >192.168.24.12:/stor/import0 on
> >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.12:_stor_import0
> >> >>>> >>>>> >type nfs4
> >> >>>> >>>>>
> >> >>>> >>>>>
> >> >>>>
> >> >>>>
> >>
> >>
>
> >>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12)
> >> >>>> >>>>> >192.168.24.13:/stor/import1 on
> >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_import1
> >> >>>> >>>>> >type nfs4
> >> >>>> >>>>>
> >> >>>> >>>>>
> >> >>>>
> >> >>>>
> >>
> >>
>
> >>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
> >> >>>> >>>>> >192.168.24.13:/stor/iso1 on
> >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_iso1
> >> >>>> >>>>> >type nfs4
> >> >>>> >>>>>
> >> >>>> >>>>>
> >> >>>>
> >> >>>>
> >>
> >>
>
> >>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
> >> >>>> >>>>> >192.168.24.13:/stor/export0 on
> >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_export0
> >> >>>> >>>>> >type nfs4
> >> >>>> >>>>>
> >> >>>> >>>>>
> >> >>>>
> >> >>>>
> >>
> >>
>
> >>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
> >> >>>> >>>>> >192.168.24.15:/images on
> >> >>>> >>>>> >/rhev/data-center/mnt/glusterSD/192.168.24.15:_images
> >> >>>> >>>>> >type fuse.glusterfs
> >> >>>> >>>>>
> >> >>>> >>>>>
> >> >>>>
> >> >>>>
> >>
> >>
>
> >>>>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
> >> >>>> >>>>> >192.168.24.18:/images3 on
> >> >>>> >>>>> >/rhev/data-center/mnt/glusterSD/192.168.24.18:_images3
> >> >>>> >>>>> >type fuse.glusterfs
> >> >>>> >>>>>
> >> >>>> >>>>>
> >> >>>>
> >> >>>>
> >>
> >>
>
> >>>>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
> >> >>>> >>>>> >tmpfs on /run/user/0 type tmpfs
> >> >>>> >>>>>
> >>(rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700)
> >> >>>> >>>>> >[root@ov06 glusterfs]#
> >> >>>> >>>>> >
> >> >>>> >>>>> >Also here is a screenshot of the console
> >> >>>> >>>>> >
> >> >>>> >>>>> >[image: image.png]
> >> >>>> >>>>> >The other domains are up
> >> >>>> >>>>> >
> >> >>>> >>>>> >Import0 and Import1 are NFS . GLCL0 is gluster. They all
> >are
> >> >>>> >>>running
> >> >>>> >>>>> >VMs
> >> >>>> >>>>> >
> >> >>>> >>>>> >Thank You For Your Help !
> >> >>>> >>>>> >
> >> >>>> >>>>> >On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov
> >> >>>> >>><hunter86_bg@yahoo.com>
> >> >>>> >>>>> >wrote:
> >> >>>> >>>>> >
> >> >>>> >>>>> >> I don't see
> >> >'/rhev/data-center/mnt/192.168.24.13:_stor_import1'
> >> >>>> >>>>> >mounted
> >> >>>> >>>>> >> at all .
> >> >>>> >>>>> >> What is the status of all storage domains ?
> >> >>>> >>>>> >>
> >> >>>> >>>>> >> Best Regards,
> >> >>>> >>>>> >> Strahil Nikolov
> >> >>>> >>>>> >>
> >> >>>> >>>>> >> На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams
> >> >>>> >>>>> ><cwilliams3320@gmail.com>
> >> >>>> >>>>> >> написа:
> >> >>>> >>>>> >> > Resending to deal with possible email issues
> >> >>>> >>>>> >> >
> >> >>>> >>>>> >> >---------- Forwarded message ---------
> >> >>>> >>>>> >> >From: C Williams <cwilliams3320@gmail.com>
> >> >>>> >>>>> >> >Date: Thu, Jun 18, 2020 at 2:07 PM
> >> >>>> >>>>> >> >Subject: Re: [ovirt-users] Issues with Gluster Domain
> >> >>>> >>>>> >> >To: Strahil Nikolov <hunter86_bg@yahoo.com>
> >> >>>> >>>>> >> >
> >> >>>> >>>>> >> >
> >> >>>> >>>>> >> >More
> >> >>>> >>>>> >> >
> >> >>>> >>>>> >> >[root@ov06 ~]# for i in $(gluster volume list); do
> >echo
> >> >>>> >>>$i;echo;
> >> >>>> >>>>> >> >gluster
> >> >>>> >>>>> >> >volume info $i; echo;echo;gluster volume status
> >> >>>> >>>>> >$i;echo;echo;echo;done
> >> >>>> >>>>> >> >images3
> >> >>>> >>>>> >> >
> >> >>>> >>>>> >> >
> >> >>>> >>>>> >> >Volume Name: images3
> >> >>>> >>>>> >> >Type: Replicate
> >> >>>> >>>>> >> >Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b
> >> >>>> >>>>> >> >Status: Started
> >> >>>> >>>>> >> >Snapshot Count: 0
> >> >>>> >>>>> >> >Number of Bricks: 1 x 3 = 3
> >> >>>> >>>>> >> >Transport-type: tcp
> >> >>>> >>>>> >> >Bricks:
> >> >>>> >>>>> >> >Brick1: 192.168.24.18:/bricks/brick04/images3
> >> >>>> >>>>> >> >Brick2: 192.168.24.19:/bricks/brick05/images3
> >> >>>> >>>>> >> >Brick3: 192.168.24.20:/bricks/brick06/images3
> >> >>>> >>>>> >> >Options Reconfigured:
> >> >>>> >>>>> >> >performance.client-io-threads: on
> >> >>>> >>>>> >> >nfs.disable: on
> >> >>>> >>>>> >> >transport.address-family: inet
> >> >>>> >>>>> >> >user.cifs: off
> >> >>>> >>>>> >> >auth.allow: *
> >> >>>> >>>>> >> >performance.quick-read: off
> >> >>>> >>>>> >> >performance.read-ahead: off
> >> >>>> >>>>> >> >performance.io-cache: off
> >> >>>> >>>>> >> >performance.low-prio-threads: 32
> >> >>>> >>>>> >> >network.remote-dio: off
> >> >>>> >>>>> >> >cluster.eager-lock: enable
> >> >>>> >>>>> >> >cluster.quorum-type: auto
> >> >>>> >>>>> >> >cluster.server-quorum-type: server
> >> >>>> >>>>> >> >cluster.data-self-heal-algorithm: full
> >> >>>> >>>>> >> >cluster.locking-scheme: granular
> >> >>>> >>>>> >> >cluster.shd-max-threads: 8
> >> >>>> >>>>> >> >cluster.shd-wait-qlength: 10000
> >> >>>> >>>>> >> >features.shard: on
> >> >>>> >>>>> >> >cluster.choose-local: off
> >> >>>> >>>>> >> >client.event-threads: 4
> >> >>>> >>>>> >> >server.event-threads: 4
> >> >>>> >>>>> >> >storage.owner-uid: 36
> >> >>>> >>>>> >> >storage.owner-gid: 36
> >> >>>> >>>>> >> >performance.strict-o-direct: on
> >> >>>> >>>>> >> >network.ping-timeout: 30
> >> >>>> >>>>> >> >cluster.granular-entry-heal: enable
> >> >>>> >>>>> >> >
> >> >>>> >>>>> >> >
> >> >>>> >>>>> >> >Status of volume: images3
> >> >>>> >>>>> >> >Gluster process TCP Port
> >> >RDMA Port
> >> >>>> >>>>> >Online
> >> >>>> >>>>> >> > Pid
> >> >>>> >>>>> >>
> >> >>>> >>>>> >>
> >> >>>> >>>>>
> >> >>>> >>>>>
> >> >>>>
> >> >>>>
> >>
> >>
>
> >>>>>>>------------------------------------------------------------------------------
> >> >>>> >>>>> >> >Brick 192.168.24.18:/bricks/brick04/images3 49152
> >0
> >> >>>>
> >> >>>> >>>Y
> >> >>>> >>>>> >> >6666
> >> >>>> >>>>> >> >Brick 192.168.24.19:/bricks/brick05/images3 49152
> >0
> >> >>>>
> >> >>>> >>>Y
> >> >>>> >>>>> >> >6779
> >> >>>> >>>>> >> >Brick 192.168.24.20:/bricks/brick06/images3 49152
> >0
> >> >>>>
> >> >>>> >>>Y
> >> >>>> >>>>> >> >7227
> >> >>>> >>>>> >> >Self-heal Daemon on localhost N/A
> >N/A
> >> >>>>
> >> >>>> >>>Y
> >> >>>> >>>>> >> >6689
> >> >>>> >>>>> >> >Self-heal Daemon on ov07.ntc.srcle.com N/A
> >N/A
> >> >>>>
> >> >>>> >>>Y
> >> >>>> >>>>> >> >6802
> >> >>>> >>>>> >> >Self-heal Daemon on ov08.ntc.srcle.com N/A
> >N/A
> >> >>>>
> >> >>>> >>>Y
> >> >>>> >>>>> >> >7250
> >> >>>> >>>>> >> >
> >> >>>> >>>>> >> >Task Status of Volume images3
> >> >>>> >>>>> >>
> >> >>>> >>>>> >>
> >> >>>> >>>>>
> >> >>>> >>>>>
> >> >>>>
> >> >>>>
> >>
> >>
>
> >>>>>>>------------------------------------------------------------------------------
> >> >>>> >>>>> >> >There are no active volume tasks
> >> >>>> >>>>> >> >
> >> >>>> >>>>> >> >
> >> >>>> >>>>> >> >
> >> >>>> >>>>> >> >
> >> >>>> >>>>> >> >[root@ov06 ~]# ls -l /rhev/data-center/mnt/glusterSD/
> >> >>>> >>>>> >> >total 16
> >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04
> >> >192.168.24.15:_images
> >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05
> >192.168.24.18:
> >> >>>> _images3
> >> >>>> >>>>> >> >[root@ov06 ~]#
> >> >>>> >>>>> >> >
> >> >>>> >>>>> >> >On Thu, Jun 18, 2020 at 2:03 PM C Williams
> >> >>>> >>><cwilliams3320@gmail.com>
> >> >>>> >>>>> >> >wrote:
> >> >>>> >>>>> >> >
> >> >>>> >>>>> >> >> Strahil,
> >> >>>> >>>>> >> >>
> >> >>>> >>>>> >> >> Here you go -- Thank You For Your Help !
> >> >>>> >>>>> >> >>
> >> >>>> >>>>> >> >> BTW -- I can write a test file to gluster and it
> >> >replicates
> >> >>>> >>>>> >properly.
> >> >>>> >>>>> >> >> Thinking something about the oVirt Storage Domain ?
> >> >>>> >>>>> >> >>
> >> >>>> >>>>> >> >> [root@ov08 ~]# gluster pool list
> >> >>>> >>>>> >> >> UUID Hostname
> >> >>>> >>>>> >State
> >> >>>> >>>>> >> >> 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06
> >> >>>> >>>>> >> >Connected
> >> >>>> >>>>> >> >> 36ce5a00-6f65-4926-8438-696944ebadb5
> >> >ov07.ntc.srcle.com
> >> >>>> >>>>> >> >Connected
> >> >>>> >>>>> >> >> c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost
> >> >>>> >>>>> >> >Connected
> >> >>>> >>>>> >> >> [root@ov08 ~]# gluster volume list
> >> >>>> >>>>> >> >> images3
> >> >>>> >>>>> >> >>
> >> >>>> >>>>> >> >> On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov
> >> >>>> >>>>> >> ><hunter86_bg@yahoo.com>
> >> >>>> >>>>> >> >> wrote:
> >> >>>> >>>>> >> >>
> >> >>>> >>>>> >> >>> Log to the oVirt cluster and provide the output of:
> >> >>>> >>>>> >> >>> gluster pool list
> >> >>>> >>>>> >> >>> gluster volume list
> >> >>>> >>>>> >> >>> for i in $(gluster volume list); do echo $i;echo;
> >> >gluster
> >> >>>> >>>>> >volume
> >> >>>> >>>>> >> >info
> >> >>>> >>>>> >> >>> $i; echo;echo;gluster volume status
> >> >$i;echo;echo;echo;done
> >> >>>> >>>>> >> >>>
> >> >>>> >>>>> >> >>> ls -l /rhev/data-center/mnt/glusterSD/
> >> >>>> >>>>> >> >>>
> >> >>>> >>>>> >> >>> Best Regards,
> >> >>>> >>>>> >> >>> Strahil Nikolov
> >> >>>> >>>>> >> >>>
> >> >>>> >>>>> >> >>>
> >> >>>> >>>>> >> >>> На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams
> >> >>>> >>>>> >> ><cwilliams3320@gmail.com>
> >> >>>> >>>>> >> >>> написа:
> >> >>>> >>>>> >> >>> >Hello,
> >> >>>> >>>>> >> >>> >
> >> >>>> >>>>> >> >>> >I recently added 6 hosts to an existing oVirt
> >> >>>> >>>compute/gluster
> >> >>>> >>>>> >> >cluster.
> >> >>>> >>>>> >> >>> >
> >> >>>> >>>>> >> >>> >Prior to this attempted addition, my cluster had 3
> >> >>>> >>>Hypervisor
> >> >>>> >>>>> >hosts
> >> >>>> >>>>> >> >and
> >> >>>> >>>>> >> >>> >3
> >> >>>> >>>>> >> >>> >gluster bricks which made up a single gluster
> >volume
> >> >>>> >>>(replica 3
> >> >>>> >>>>> >> >volume)
> >> >>>> >>>>> >> >>> >. I
> >> >>>> >>>>> >> >>> >added the additional hosts and made a brick on 3
> >of
> >> >the new
> >> >>>> >>>>> >hosts
> >> >>>> >>>>> >> >and
> >> >>>> >>>>> >> >>> >attempted to make a new replica 3 volume. I had
> >> >difficulty
> >> >>>> >>>>> >> >creating
> >> >>>> >>>>> >> >>> >the
> >> >>>> >>>>> >> >>> >new volume. So, I decided that I would make a new
> >> >>>> >>>>> >compute/gluster
> >> >>>> >>>>> >> >>> >cluster
> >> >>>> >>>>> >> >>> >for each set of 3 new hosts.
> >> >>>> >>>>> >> >>> >
> >> >>>> >>>>> >> >>> >I removed the 6 new hosts from the existing oVirt
> >> >>>> >>>>> >Compute/Gluster
> >> >>>> >>>>> >> >>> >Cluster
> >> >>>> >>>>> >> >>> >leaving the 3 original hosts in place with their
> >> >bricks. At
> >> >>>> >>>that
> >> >>>> >>>>> >> >point
> >> >>>> >>>>> >> >>> >my
> >> >>>> >>>>> >> >>> >original bricks went down and came back up . The
> >> >volume
> >> >>>> >>>showed
> >> >>>> >>>>> >> >entries
> >> >>>> >>>>> >> >>> >that
> >> >>>> >>>>> >> >>> >needed healing. At that point I ran gluster volume
> >> >heal
> >> >>>> >>>images3
> >> >>>> >>>>> >> >full,
> >> >>>> >>>>> >> >>> >etc.
> >> >>>> >>>>> >> >>> >The volume shows no unhealed entries. I also
> >> >corrected some
> >> >>>> >>>peer
> >> >>>> >>>>> >> >>> >errors.
> >> >>>> >>>>> >> >>> >
> >> >>>> >>>>> >> >>> >However, I am unable to copy disks, move disks to
> >> >another
> >> >>>> >>>>> >domain,
> >> >>>> >>>>> >> >>> >export
> >> >>>> >>>>> >> >>> >disks, etc. It appears that the engine cannot
> >locate
> >> >disks
> >> >>>> >>>>> >properly
> >> >>>> >>>>> >> >and
> >> >>>> >>>>> >> >>> >I
> >> >>>> >>>>> >> >>> >get storage I/O errors.
> >> >>>> >>>>> >> >>> >
> >> >>>> >>>>> >> >>> >I have detached and removed the oVirt Storage
> >Domain.
> >> >I
> >> >>>> >>>>> >reimported
> >> >>>> >>>>> >> >the
> >> >>>> >>>>> >> >>> >domain and imported 2 VMs, But the VM disks
> >exhibit
> >> >the
> >> >>>> same
> >> >>>> >>>>> >> >behaviour
> >> >>>> >>>>> >> >>> >and
> >> >>>> >>>>> >> >>> >won't run from the hard disk.
> >> >>>> >>>>> >> >>> >
> >> >>>> >>>>> >> >>> >
> >> >>>> >>>>> >> >>> >I get errors such as this
> >> >>>> >>>>> >> >>> >
> >> >>>> >>>>> >> >>> >VDSM ov05 command HSMGetAllTasksStatusesVDS
> >failed:
> >> >low
> >> >>>> >>>level
> >> >>>> >>>>> >Image
> >> >>>> >>>>> >> >>> >copy
> >> >>>> >>>>> >> >>> >failed: ("Command ['/usr/bin/qemu-img', 'convert',
> >> >'-p',
> >> >>>> >>>'-t',
> >> >>>> >>>>> >> >'none',
> >> >>>> >>>>> >> >>> >'-T', 'none', '-f', 'raw',
> >> >>>> >>>>> >> >>> >u'/rhev/data-center/mnt/glusterSD/192.168.24.18:
> >> >>>> >>>>> >> >>>
> >> >>>> >>>>> >>
> >> >>>> >>>>> >>
> >> >>>> >>>>>
> >> >>>> >>>>>
> >> >>>>
> >> >>>>
> >>
> >>
>
> >>>>>>>_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510',
> >> >>>> >>>>> >> >>> >'-O', 'raw',
> >> >>>> >>>>> >> >>> >u'/rhev/data-center/mnt/192.168.24.13:
> >> >>>> >>>>> >> >>>
> >> >>>> >>>>> >>
> >> >>>> >>>>> >>
> >> >>>> >>>>>
> >> >>>> >>>>>
> >> >>>>
> >> >>>>
> >>
> >>
>
> >>>>>>>_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5']
> >> >>>> >>>>> >> >>> >failed with rc=1 out='' err=bytearray(b'qemu-img:
> >> >error
> >> >>>> >>>while
> >> >>>> >>>>> >> >reading
> >> >>>> >>>>> >> >>> >sector 135168: Transport endpoint is not
> >> >>>> >>>connected\\nqemu-img:
> >> >>>> >>>>> >> >error
> >> >>>> >>>>> >> >>> >while
> >> >>>> >>>>> >> >>> >reading sector 131072: Transport endpoint is not
> >> >>>> >>>>> >> >connected\\nqemu-img:
> >> >>>> >>>>> >> >>> >error while reading sector 139264: Transport
> >endpoint
> >> >is
> >> >>>> not
> >> >>>> >>>>> >> >>> >connected\\nqemu-img: error while reading sector
> >> >143360:
> >> >>>> >>>>> >Transport
> >> >>>> >>>>> >> >>> >endpoint
> >> >>>> >>>>> >> >>> >is not connected\\nqemu-img: error while reading
> >> >sector
> >> >>>> >>>147456:
> >> >>>> >>>>> >> >>> >Transport
> >> >>>> >>>>> >> >>> >endpoint is not connected\\nqemu-img: error while
> >> >reading
> >> >>>> >>>sector
> >> >>>> >>>>> >> >>> >155648:
> >> >>>> >>>>> >> >>> >Transport endpoint is not connected\\nqemu-img:
> >error
> >> >while
> >> >>>> >>>>> >reading
> >> >>>> >>>>> >> >>> >sector
> >> >>>> >>>>> >> >>> >151552: Transport endpoint is not
> >> >connected\\nqemu-img:
> >> >>>> >>>error
> >> >>>> >>>>> >while
> >> >>>> >>>>> >> >>> >reading
> >> >>>> >>>>> >> >>> >sector 159744: Transport endpoint is not
> >> >connected\\n')",)
> >> >>>> >>>>> >> >>> >
> >> >>>> >>>>> >> >>> >oVirt version is 4.3.82-1.el7
> >> >>>> >>>>> >> >>> >OS CentOS Linux release 7.7.1908 (Core)
> >> >>>> >>>>> >> >>> >
> >> >>>> >>>>> >> >>> >The Gluster Cluster has been working very well
> >until
> >> >this
> >> >>>> >>>>> >incident.
> >> >>>> >>>>> >> >>> >
> >> >>>> >>>>> >> >>> >Please help.
> >> >>>> >>>>> >> >>> >
> >> >>>> >>>>> >> >>> >Thank You
> >> >>>> >>>>> >> >>> >
> >> >>>> >>>>> >> >>> >Charles Williams
> >> >>>> >>>>> >> >>>
> >> >>>> >>>>> >> >>
> >> >>>> >>>>> >>
> >> >>>> >>>>>
> >> >>>> >>>>
> >> >>>> >>
> >> >>>> >
> >> >>>> _______________________________________________
> >> >>>> Users mailing list -- users@ovirt.org
> >> >>>> To unsubscribe send an email to users-leave@ovirt.org
> >> >>>> Privacy Statement: https://www.ovirt.org/privacy-policy.html
> >> >>>> oVirt Code of Conduct:
> >> >>>> https://www.ovirt.org/community/about/community-guidelines/
> >> >>>> List Archives:
> >> >>>>
> >> >
> >>
> >
> https://lists.ovirt.org/archives/list/users@ovirt.org/message/YY3VUKEJLI7MRWXF627EHQAMH36UJ5BQ/
> >> >>>>
> >> >>>
> >>
>
In my situation I had only the ovirt nodes.
На 21 юни 2020 г. 22:43:04 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
>Strahil,
>
>So should I make the target volume on 3 bricks which do not have ovirt
>--
>just gluster ? In other words (3) Centos 7 hosts ?
>
>Thank You For Your Help !
>
>On Sun, Jun 21, 2020 at 3:08 PM Strahil Nikolov <hunter86_bg@yahoo.com>
>wrote:
>
>> I created a fresh volume (which is not an ovirt sgorage domain),
>set
>> the original storage domain in maintenance and detached it.
>> Then I 'cp -a ' the data from the old to the new volume. Next, I
>just
>> added the new storage domain (the old one was a kind of a
>> 'backup') - pointing to the new volume name.
>>
>> If you observe issues , I would recommend you to downgrade
>> gluster packages one node at a time . Then you might be able to
>> restore your oVirt operations.
>>
>> Best Regards,
>> Strahil Nikolov
>>
>> На 21 юни 2020 г. 18:01:31 GMT+03:00, C Williams
><cwilliams3320@gmail.com>
>> написа:
>> >Strahil,
>> >
>> >Thanks for the follow up !
>> >
>> >How did you copy the data to another volume ?
>> >
>> >I have set up another storage domain GLCLNEW1 with a new volume
>imgnew1
>> >.
>> >How would you copy all of the data from the problematic domain GLCL3
>> >with
>> >volume images3 to GLCLNEW1 and volume imgnew1 and preserve all the
>VMs,
>> >VM
>> >disks, settings, etc. ?
>> >
>> >Remember all of the regular ovirt disk copy, disk move, VM export
>> >tools
>> >are failing and my VMs and disks are trapped on domain GLCL3 and
>volume
>> >images3 right now.
>> >
>> >Please let me know
>> >
>> >Thank You For Your Help !
>> >
>> >
>> >
>> >
>> >
>> >On Sun, Jun 21, 2020 at 8:27 AM Strahil Nikolov
><hunter86_bg@yahoo.com>
>> >wrote:
>> >
>> >> Sorry to hear that.
>> >> I can say that for me 6.5 was working, while 6.6 didn't and I
>> >upgraded
>> >> to 7.0 .
>> >> In the ended , I have ended with creating a new fresh volume
>and
>> >> physically copying the data there, then I detached the storage
>> >domains and
>> >> attached to the new ones (which holded the old data), but I
>> >could
>> >> afford the downtime.
>> >> Also, I can say that v7.0 ( but not 7.1 or anything later)
>also
>> >> worked without the ACL issue, but it causes some trouble in
>oVirt
>> >- so
>> >> avoid that unless you have no other options.
>> >>
>> >> Best Regards,
>> >> Strahil Nikolov
>> >>
>> >>
>> >>
>> >>
>> >> На 21 юни 2020 г. 4:39:46 GMT+03:00, C Williams
>> ><cwilliams3320@gmail.com>
>> >> написа:
>> >> >Hello,
>> >> >
>> >> >Upgrading diidn't help
>> >> >
>> >> >Still acl errors trying to use a Virtual Disk from a VM
>> >> >
>> >> >[root@ov06 bricks]# tail bricks-brick04-images3.log | grep acl
>> >> >[2020-06-21 01:33:45.665888] I [MSGID: 139001]
>> >> >[posix-acl.c:263:posix_acl_log_permit_denied]
>> >0-images3-access-control:
>> >> >client:
>> >>
>> >>
>>
>>
>>>CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0,
>> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
>> >> >req(uid:107,gid:107,perm:1,ngrps:3),
>> >> >ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
>> >> >[Permission denied]
>> >> >The message "I [MSGID: 139001]
>> >> >[posix-acl.c:263:posix_acl_log_permit_denied]
>> >0-images3-access-control:
>> >> >client:
>> >>
>> >>
>>
>>
>>>CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0,
>> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
>> >> >req(uid:107,gid:107,perm:1,ngrps:3),
>> >> >ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
>> >> >[Permission denied]" repeated 2 times between [2020-06-21
>> >> >01:33:45.665888]
>> >> >and [2020-06-21 01:33:45.806779]
>> >> >
>> >> >Thank You For Your Help !
>> >> >
>> >> >On Sat, Jun 20, 2020 at 8:59 PM C Williams
><cwilliams3320@gmail.com>
>> >> >wrote:
>> >> >
>> >> >> Hello,
>> >> >>
>> >> >> Based on the situation, I am planning to upgrade the 3 affected
>> >> >hosts.
>> >> >>
>> >> >> My reasoning is that the hosts/bricks were attached to 6.9 at
>one
>> >> >time.
>> >> >>
>> >> >> Thanks For Your Help !
>> >> >>
>> >> >> On Sat, Jun 20, 2020 at 8:38 PM C Williams
>> ><cwilliams3320@gmail.com>
>> >> >> wrote:
>> >> >>
>> >> >>> Strahil,
>> >> >>>
>> >> >>> The gluster version on the current 3 gluster hosts is 6.7
>(last
>> >> >update
>> >> >>> 2/26). These 3 hosts provide 1 brick each for the replica 3
>> >volume.
>> >> >>>
>> >> >>> Earlier I had tried to add 6 additional hosts to the cluster.
>> >Those
>> >> >new
>> >> >>> hosts were 6.9 gluster.
>> >> >>>
>> >> >>> I attempted to make a new separate volume with 3 bricks
>provided
>> >by
>> >> >the 3
>> >> >>> new gluster 6.9 hosts. After having many errors from the
>oVirt
>> >> >interface,
>> >> >>> I gave up and removed the 6 new hosts from the cluster. That
>is
>> >> >where the
>> >> >>> problems started. The intent was to expand the gluster cluster
>> >while
>> >> >making
>> >> >>> 2 new volumes for that cluster. The ovirt compute cluster
>would
>> >> >allow for
>> >> >>> efficient VM migration between 9 hosts -- while having
>separate
>> >> >gluster
>> >> >>> volumes for safety purposes.
>> >> >>>
>> >> >>> Looking at the brick logs, I see where there are acl errors
>> >starting
>> >> >from
>> >> >>> the time of the removal of the 6 new hosts.
>> >> >>>
>> >> >>> Please check out the attached brick log from 6/14-18. The
>events
>> >> >started
>> >> >>> on 6/17.
>> >> >>>
>> >> >>> I wish I had a downgrade path.
>> >> >>>
>> >> >>> Thank You For The Help !!
>> >> >>>
>> >> >>> On Sat, Jun 20, 2020 at 7:47 PM Strahil Nikolov
>> >> ><hunter86_bg@yahoo.com>
>> >> >>> wrote:
>> >> >>>
>> >> >>>> Hi ,
>> >> >>>>
>> >> >>>>
>> >> >>>> This one really looks like the ACL bug I was hit with when I
>> >> >updated
>> >> >>>> from Gluster v6.5 to 6.6 and later from 7.0 to 7.2.
>> >> >>>>
>> >> >>>> Did you update your setup recently ? Did you upgrade gluster
>> >also ?
>> >> >>>>
>> >> >>>> You have to check the gluster logs in order to verify that,
>so
>> >you
>> >> >can
>> >> >>>> try:
>> >> >>>>
>> >> >>>> 1. Set Gluster logs to trace level (for details check:
>> >> >>>>
>> >> >
>> >>
>> >
>>
>https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3/html/administration_guide/configuring_the_log_level
>> >> >>>> )
>> >> >>>> 2. Power up a VM that was already off , or retry the
>procedure
>> >from
>> >> >the
>> >> >>>> logs you sent.
>> >> >>>> 3. Stop the trace level of the logs
>> >> >>>> 4. Check libvirt logs on the host that was supposed to power
>up
>> >the
>> >> >VM
>> >> >>>> (in case a VM was powered on)
>> >> >>>> 5. Check the gluster brick logs on all nodes for ACL errors.
>> >> >>>> Here is a sample from my old logs:
>> >> >>>>
>> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18
>> >> >13:19:41.489047] I
>> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied]
>> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
>> >> >>>>
>> >>
>> >>
>>
>>
>>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
>> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
>> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx
>> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
>> >> >>>> [Permission denied]
>> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18
>> >> >13:22:51.818796] I
>> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied]
>> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
>> >> >>>>
>> >>
>> >>
>>
>>
>>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
>> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
>> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx
>> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
>> >> >>>> [Permission denied]
>> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18
>> >> >13:24:43.732856] I
>> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied]
>> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
>> >> >>>>
>> >>
>> >>
>>
>>
>>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
>> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
>> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx
>> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
>> >> >>>> [Permission denied]
>> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18
>> >> >13:26:50.758178] I
>> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied]
>> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
>> >> >>>>
>> >>
>> >>
>>
>>
>>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
>> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
>> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx
>> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
>> >> >>>> [Permission denied]
>> >> >>>>
>> >> >>>>
>> >> >>>> In my case , the workaround was to downgrade the gluster
>> >packages
>> >> >on all
>> >> >>>> nodes (and reboot each node 1 by 1 ) if the major version is
>the
>> >> >same, but
>> >> >>>> if you upgraded to v7.X - then you can try the v7.0 .
>> >> >>>>
>> >> >>>> Best Regards,
>> >> >>>> Strahil Nikolov
>> >> >>>>
>> >> >>>>
>> >> >>>>
>> >> >>>>
>> >> >>>>
>> >> >>>>
>> >> >>>> В събота, 20 юни 2020 г., 18:48:42 ч. Гринуич+3, C Williams <
>> >> >>>> cwilliams3320@gmail.com> написа:
>> >> >>>>
>> >> >>>>
>> >> >>>>
>> >> >>>>
>> >> >>>>
>> >> >>>> Hello,
>> >> >>>>
>> >> >>>> Here are additional log tiles as well as a tree of the
>> >problematic
>> >> >>>> Gluster storage domain. During this time I attempted to copy
>a
>> >> >virtual disk
>> >> >>>> to another domain, move a virtual disk to another domain and
>run
>> >a
>> >> >VM where
>> >> >>>> the virtual hard disk would be used.
>> >> >>>>
>> >> >>>> The copies/moves failed and the VM went into pause mode when
>the
>> >> >virtual
>> >> >>>> HDD was involved.
>> >> >>>>
>> >> >>>> Please check these out.
>> >> >>>>
>> >> >>>> Thank You For Your Help !
>> >> >>>>
>> >> >>>> On Sat, Jun 20, 2020 at 9:54 AM C Williams
>> >> ><cwilliams3320@gmail.com>
>> >> >>>> wrote:
>> >> >>>> > Strahil,
>> >> >>>> >
>> >> >>>> > I understand. Please keep me posted.
>> >> >>>> >
>> >> >>>> > Thanks For The Help !
>> >> >>>> >
>> >> >>>> > On Sat, Jun 20, 2020 at 4:36 AM Strahil Nikolov
>> >> ><hunter86_bg@yahoo.com>
>> >> >>>> wrote:
>> >> >>>> >> Hey C Williams,
>> >> >>>> >>
>> >> >>>> >> sorry for the delay, but I couldn't get somw time to
>check
>> >your
>> >> >>>> logs. Will try a little bit later.
>> >> >>>> >>
>> >> >>>> >> Best Regards,
>> >> >>>> >> Strahil Nikolov
>> >> >>>> >>
>> >> >>>> >> На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams <
>> >> >>>> cwilliams3320@gmail.com> написа:
>> >> >>>> >>>Hello,
>> >> >>>> >>>
>> >> >>>> >>>Was wanting to follow up on this issue. Users are
>impacted.
>> >> >>>> >>>
>> >> >>>> >>>Thank You
>> >> >>>> >>>
>> >> >>>> >>>On Fri, Jun 19, 2020 at 9:20 AM C Williams
>> >> ><cwilliams3320@gmail.com>
>> >> >>>> >>>wrote:
>> >> >>>> >>>
>> >> >>>> >>>> Hello,
>> >> >>>> >>>>
>> >> >>>> >>>> Here are the logs (some IPs are changed )
>> >> >>>> >>>>
>> >> >>>> >>>> ov05 is the SPM
>> >> >>>> >>>>
>> >> >>>> >>>> Thank You For Your Help !
>> >> >>>> >>>>
>> >> >>>> >>>> On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov
>> >> >>>> >>><hunter86_bg@yahoo.com>
>> >> >>>> >>>> wrote:
>> >> >>>> >>>>
>> >> >>>> >>>>> Check on the hosts tab , which is your current SPM
>(last
>> >> >column in
>> >> >>>> >>>Admin
>> >> >>>> >>>>> UI).
>> >> >>>> >>>>> Then open the /var/log/vdsm/vdsm.log and repeat the
>> >> >operation.
>> >> >>>> >>>>> Then provide the log from that host and the engine's
>log
>> >(on
>> >> >the
>> >> >>>> >>>>> HostedEngine VM or on your standalone engine).
>> >> >>>> >>>>>
>> >> >>>> >>>>> Best Regards,
>> >> >>>> >>>>> Strahil Nikolov
>> >> >>>> >>>>>
>> >> >>>> >>>>> На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams
>> >> >>>> >>><cwilliams3320@gmail.com>
>> >> >>>> >>>>> написа:
>> >> >>>> >>>>> >Resending to eliminate email issues
>> >> >>>> >>>>> >
>> >> >>>> >>>>> >---------- Forwarded message ---------
>> >> >>>> >>>>> >From: C Williams <cwilliams3320@gmail.com>
>> >> >>>> >>>>> >Date: Thu, Jun 18, 2020 at 4:01 PM
>> >> >>>> >>>>> >Subject: Re: [ovirt-users] Fwd: Issues with Gluster
>> >Domain
>> >> >>>> >>>>> >To: Strahil Nikolov <hunter86_bg@yahoo.com>
>> >> >>>> >>>>> >
>> >> >>>> >>>>> >
>> >> >>>> >>>>> >Here is output from mount
>> >> >>>> >>>>> >
>> >> >>>> >>>>> >192.168.24.12:/stor/import0 on
>> >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.12:_stor_import0
>> >> >>>> >>>>> >type nfs4
>> >> >>>> >>>>>
>> >> >>>> >>>>>
>> >> >>>>
>> >> >>>>
>> >>
>> >>
>>
>>
>>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12)
>> >> >>>> >>>>> >192.168.24.13:/stor/import1 on
>> >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_import1
>> >> >>>> >>>>> >type nfs4
>> >> >>>> >>>>>
>> >> >>>> >>>>>
>> >> >>>>
>> >> >>>>
>> >>
>> >>
>>
>>
>>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
>> >> >>>> >>>>> >192.168.24.13:/stor/iso1 on
>> >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_iso1
>> >> >>>> >>>>> >type nfs4
>> >> >>>> >>>>>
>> >> >>>> >>>>>
>> >> >>>>
>> >> >>>>
>> >>
>> >>
>>
>>
>>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
>> >> >>>> >>>>> >192.168.24.13:/stor/export0 on
>> >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_export0
>> >> >>>> >>>>> >type nfs4
>> >> >>>> >>>>>
>> >> >>>> >>>>>
>> >> >>>>
>> >> >>>>
>> >>
>> >>
>>
>>
>>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
>> >> >>>> >>>>> >192.168.24.15:/images on
>> >> >>>> >>>>> >/rhev/data-center/mnt/glusterSD/192.168.24.15:_images
>> >> >>>> >>>>> >type fuse.glusterfs
>> >> >>>> >>>>>
>> >> >>>> >>>>>
>> >> >>>>
>> >> >>>>
>> >>
>> >>
>>
>>
>>>>>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
>> >> >>>> >>>>> >192.168.24.18:/images3 on
>> >> >>>> >>>>> >/rhev/data-center/mnt/glusterSD/192.168.24.18:_images3
>> >> >>>> >>>>> >type fuse.glusterfs
>> >> >>>> >>>>>
>> >> >>>> >>>>>
>> >> >>>>
>> >> >>>>
>> >>
>> >>
>>
>>
>>>>>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
>> >> >>>> >>>>> >tmpfs on /run/user/0 type tmpfs
>> >> >>>> >>>>>
>> >>(rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700)
>> >> >>>> >>>>> >[root@ov06 glusterfs]#
>> >> >>>> >>>>> >
>> >> >>>> >>>>> >Also here is a screenshot of the console
>> >> >>>> >>>>> >
>> >> >>>> >>>>> >[image: image.png]
>> >> >>>> >>>>> >The other domains are up
>> >> >>>> >>>>> >
>> >> >>>> >>>>> >Import0 and Import1 are NFS . GLCL0 is gluster. They
>all
>> >are
>> >> >>>> >>>running
>> >> >>>> >>>>> >VMs
>> >> >>>> >>>>> >
>> >> >>>> >>>>> >Thank You For Your Help !
>> >> >>>> >>>>> >
>> >> >>>> >>>>> >On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov
>> >> >>>> >>><hunter86_bg@yahoo.com>
>> >> >>>> >>>>> >wrote:
>> >> >>>> >>>>> >
>> >> >>>> >>>>> >> I don't see
>> >> >'/rhev/data-center/mnt/192.168.24.13:_stor_import1'
>> >> >>>> >>>>> >mounted
>> >> >>>> >>>>> >> at all .
>> >> >>>> >>>>> >> What is the status of all storage domains ?
>> >> >>>> >>>>> >>
>> >> >>>> >>>>> >> Best Regards,
>> >> >>>> >>>>> >> Strahil Nikolov
>> >> >>>> >>>>> >>
>> >> >>>> >>>>> >> На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams
>> >> >>>> >>>>> ><cwilliams3320@gmail.com>
>> >> >>>> >>>>> >> написа:
>> >> >>>> >>>>> >> > Resending to deal with possible email issues
>> >> >>>> >>>>> >> >
>> >> >>>> >>>>> >> >---------- Forwarded message ---------
>> >> >>>> >>>>> >> >From: C Williams <cwilliams3320@gmail.com>
>> >> >>>> >>>>> >> >Date: Thu, Jun 18, 2020 at 2:07 PM
>> >> >>>> >>>>> >> >Subject: Re: [ovirt-users] Issues with Gluster
>Domain
>> >> >>>> >>>>> >> >To: Strahil Nikolov <hunter86_bg@yahoo.com>
>> >> >>>> >>>>> >> >
>> >> >>>> >>>>> >> >
>> >> >>>> >>>>> >> >More
>> >> >>>> >>>>> >> >
>> >> >>>> >>>>> >> >[root@ov06 ~]# for i in $(gluster volume list); do
>> >echo
>> >> >>>> >>>$i;echo;
>> >> >>>> >>>>> >> >gluster
>> >> >>>> >>>>> >> >volume info $i; echo;echo;gluster volume status
>> >> >>>> >>>>> >$i;echo;echo;echo;done
>> >> >>>> >>>>> >> >images3
>> >> >>>> >>>>> >> >
>> >> >>>> >>>>> >> >
>> >> >>>> >>>>> >> >Volume Name: images3
>> >> >>>> >>>>> >> >Type: Replicate
>> >> >>>> >>>>> >> >Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b
>> >> >>>> >>>>> >> >Status: Started
>> >> >>>> >>>>> >> >Snapshot Count: 0
>> >> >>>> >>>>> >> >Number of Bricks: 1 x 3 = 3
>> >> >>>> >>>>> >> >Transport-type: tcp
>> >> >>>> >>>>> >> >Bricks:
>> >> >>>> >>>>> >> >Brick1: 192.168.24.18:/bricks/brick04/images3
>> >> >>>> >>>>> >> >Brick2: 192.168.24.19:/bricks/brick05/images3
>> >> >>>> >>>>> >> >Brick3: 192.168.24.20:/bricks/brick06/images3
>> >> >>>> >>>>> >> >Options Reconfigured:
>> >> >>>> >>>>> >> >performance.client-io-threads: on
>> >> >>>> >>>>> >> >nfs.disable: on
>> >> >>>> >>>>> >> >transport.address-family: inet
>> >> >>>> >>>>> >> >user.cifs: off
>> >> >>>> >>>>> >> >auth.allow: *
>> >> >>>> >>>>> >> >performance.quick-read: off
>> >> >>>> >>>>> >> >performance.read-ahead: off
>> >> >>>> >>>>> >> >performance.io-cache: off
>> >> >>>> >>>>> >> >performance.low-prio-threads: 32
>> >> >>>> >>>>> >> >network.remote-dio: off
>> >> >>>> >>>>> >> >cluster.eager-lock: enable
>> >> >>>> >>>>> >> >cluster.quorum-type: auto
>> >> >>>> >>>>> >> >cluster.server-quorum-type: server
>> >> >>>> >>>>> >> >cluster.data-self-heal-algorithm: full
>> >> >>>> >>>>> >> >cluster.locking-scheme: granular
>> >> >>>> >>>>> >> >cluster.shd-max-threads: 8
>> >> >>>> >>>>> >> >cluster.shd-wait-qlength: 10000
>> >> >>>> >>>>> >> >features.shard: on
>> >> >>>> >>>>> >> >cluster.choose-local: off
>> >> >>>> >>>>> >> >client.event-threads: 4
>> >> >>>> >>>>> >> >server.event-threads: 4
>> >> >>>> >>>>> >> >storage.owner-uid: 36
>> >> >>>> >>>>> >> >storage.owner-gid: 36
>> >> >>>> >>>>> >> >performance.strict-o-direct: on
>> >> >>>> >>>>> >> >network.ping-timeout: 30
>> >> >>>> >>>>> >> >cluster.granular-entry-heal: enable
>> >> >>>> >>>>> >> >
>> >> >>>> >>>>> >> >
>> >> >>>> >>>>> >> >Status of volume: images3
>> >> >>>> >>>>> >> >Gluster process TCP
>Port
>> >> >RDMA Port
>> >> >>>> >>>>> >Online
>> >> >>>> >>>>> >> > Pid
>> >> >>>> >>>>> >>
>> >> >>>> >>>>> >>
>> >> >>>> >>>>>
>> >> >>>> >>>>>
>> >> >>>>
>> >> >>>>
>> >>
>> >>
>>
>>
>>>>>>>>------------------------------------------------------------------------------
>> >> >>>> >>>>> >> >Brick 192.168.24.18:/bricks/brick04/images3 49152
>> >0
>> >> >>>>
>> >> >>>> >>>Y
>> >> >>>> >>>>> >> >6666
>> >> >>>> >>>>> >> >Brick 192.168.24.19:/bricks/brick05/images3 49152
>> >0
>> >> >>>>
>> >> >>>> >>>Y
>> >> >>>> >>>>> >> >6779
>> >> >>>> >>>>> >> >Brick 192.168.24.20:/bricks/brick06/images3 49152
>> >0
>> >> >>>>
>> >> >>>> >>>Y
>> >> >>>> >>>>> >> >7227
>> >> >>>> >>>>> >> >Self-heal Daemon on localhost N/A
>> >N/A
>> >> >>>>
>> >> >>>> >>>Y
>> >> >>>> >>>>> >> >6689
>> >> >>>> >>>>> >> >Self-heal Daemon on ov07.ntc.srcle.com N/A
>> >N/A
>> >> >>>>
>> >> >>>> >>>Y
>> >> >>>> >>>>> >> >6802
>> >> >>>> >>>>> >> >Self-heal Daemon on ov08.ntc.srcle.com N/A
>> >N/A
>> >> >>>>
>> >> >>>> >>>Y
>> >> >>>> >>>>> >> >7250
>> >> >>>> >>>>> >> >
>> >> >>>> >>>>> >> >Task Status of Volume images3
>> >> >>>> >>>>> >>
>> >> >>>> >>>>> >>
>> >> >>>> >>>>>
>> >> >>>> >>>>>
>> >> >>>>
>> >> >>>>
>> >>
>> >>
>>
>>
>>>>>>>>------------------------------------------------------------------------------
>> >> >>>> >>>>> >> >There are no active volume tasks
>> >> >>>> >>>>> >> >
>> >> >>>> >>>>> >> >
>> >> >>>> >>>>> >> >
>> >> >>>> >>>>> >> >
>> >> >>>> >>>>> >> >[root@ov06 ~]# ls -l
>/rhev/data-center/mnt/glusterSD/
>> >> >>>> >>>>> >> >total 16
>> >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04
>> >> >192.168.24.15:_images
>> >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05
>> >192.168.24.18:
>> >> >>>> _images3
>> >> >>>> >>>>> >> >[root@ov06 ~]#
>> >> >>>> >>>>> >> >
>> >> >>>> >>>>> >> >On Thu, Jun 18, 2020 at 2:03 PM C Williams
>> >> >>>> >>><cwilliams3320@gmail.com>
>> >> >>>> >>>>> >> >wrote:
>> >> >>>> >>>>> >> >
>> >> >>>> >>>>> >> >> Strahil,
>> >> >>>> >>>>> >> >>
>> >> >>>> >>>>> >> >> Here you go -- Thank You For Your Help !
>> >> >>>> >>>>> >> >>
>> >> >>>> >>>>> >> >> BTW -- I can write a test file to gluster and it
>> >> >replicates
>> >> >>>> >>>>> >properly.
>> >> >>>> >>>>> >> >> Thinking something about the oVirt Storage Domain
>?
>> >> >>>> >>>>> >> >>
>> >> >>>> >>>>> >> >> [root@ov08 ~]# gluster pool list
>> >> >>>> >>>>> >> >> UUID Hostname
>> >> >>>> >>>>> >State
>> >> >>>> >>>>> >> >> 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06
>> >> >>>> >>>>> >> >Connected
>> >> >>>> >>>>> >> >> 36ce5a00-6f65-4926-8438-696944ebadb5
>> >> >ov07.ntc.srcle.com
>> >> >>>> >>>>> >> >Connected
>> >> >>>> >>>>> >> >> c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost
>> >> >>>> >>>>> >> >Connected
>> >> >>>> >>>>> >> >> [root@ov08 ~]# gluster volume list
>> >> >>>> >>>>> >> >> images3
>> >> >>>> >>>>> >> >>
>> >> >>>> >>>>> >> >> On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov
>> >> >>>> >>>>> >> ><hunter86_bg@yahoo.com>
>> >> >>>> >>>>> >> >> wrote:
>> >> >>>> >>>>> >> >>
>> >> >>>> >>>>> >> >>> Log to the oVirt cluster and provide the output
>of:
>> >> >>>> >>>>> >> >>> gluster pool list
>> >> >>>> >>>>> >> >>> gluster volume list
>> >> >>>> >>>>> >> >>> for i in $(gluster volume list); do echo
>$i;echo;
>> >> >gluster
>> >> >>>> >>>>> >volume
>> >> >>>> >>>>> >> >info
>> >> >>>> >>>>> >> >>> $i; echo;echo;gluster volume status
>> >> >$i;echo;echo;echo;done
>> >> >>>> >>>>> >> >>>
>> >> >>>> >>>>> >> >>> ls -l /rhev/data-center/mnt/glusterSD/
>> >> >>>> >>>>> >> >>>
>> >> >>>> >>>>> >> >>> Best Regards,
>> >> >>>> >>>>> >> >>> Strahil Nikolov
>> >> >>>> >>>>> >> >>>
>> >> >>>> >>>>> >> >>>
>> >> >>>> >>>>> >> >>> На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams
>> >> >>>> >>>>> >> ><cwilliams3320@gmail.com>
>> >> >>>> >>>>> >> >>> написа:
>> >> >>>> >>>>> >> >>> >Hello,
>> >> >>>> >>>>> >> >>> >
>> >> >>>> >>>>> >> >>> >I recently added 6 hosts to an existing oVirt
>> >> >>>> >>>compute/gluster
>> >> >>>> >>>>> >> >cluster.
>> >> >>>> >>>>> >> >>> >
>> >> >>>> >>>>> >> >>> >Prior to this attempted addition, my cluster
>had 3
>> >> >>>> >>>Hypervisor
>> >> >>>> >>>>> >hosts
>> >> >>>> >>>>> >> >and
>> >> >>>> >>>>> >> >>> >3
>> >> >>>> >>>>> >> >>> >gluster bricks which made up a single gluster
>> >volume
>> >> >>>> >>>(replica 3
>> >> >>>> >>>>> >> >volume)
>> >> >>>> >>>>> >> >>> >. I
>> >> >>>> >>>>> >> >>> >added the additional hosts and made a brick on
>3
>> >of
>> >> >the new
>> >> >>>> >>>>> >hosts
>> >> >>>> >>>>> >> >and
>> >> >>>> >>>>> >> >>> >attempted to make a new replica 3 volume. I had
>> >> >difficulty
>> >> >>>> >>>>> >> >creating
>> >> >>>> >>>>> >> >>> >the
>> >> >>>> >>>>> >> >>> >new volume. So, I decided that I would make a
>new
>> >> >>>> >>>>> >compute/gluster
>> >> >>>> >>>>> >> >>> >cluster
>> >> >>>> >>>>> >> >>> >for each set of 3 new hosts.
>> >> >>>> >>>>> >> >>> >
>> >> >>>> >>>>> >> >>> >I removed the 6 new hosts from the existing
>oVirt
>> >> >>>> >>>>> >Compute/Gluster
>> >> >>>> >>>>> >> >>> >Cluster
>> >> >>>> >>>>> >> >>> >leaving the 3 original hosts in place with
>their
>> >> >bricks. At
>> >> >>>> >>>that
>> >> >>>> >>>>> >> >point
>> >> >>>> >>>>> >> >>> >my
>> >> >>>> >>>>> >> >>> >original bricks went down and came back up .
>The
>> >> >volume
>> >> >>>> >>>showed
>> >> >>>> >>>>> >> >entries
>> >> >>>> >>>>> >> >>> >that
>> >> >>>> >>>>> >> >>> >needed healing. At that point I ran gluster
>volume
>> >> >heal
>> >> >>>> >>>images3
>> >> >>>> >>>>> >> >full,
>> >> >>>> >>>>> >> >>> >etc.
>> >> >>>> >>>>> >> >>> >The volume shows no unhealed entries. I also
>> >> >corrected some
>> >> >>>> >>>peer
>> >> >>>> >>>>> >> >>> >errors.
>> >> >>>> >>>>> >> >>> >
>> >> >>>> >>>>> >> >>> >However, I am unable to copy disks, move disks
>to
>> >> >another
>> >> >>>> >>>>> >domain,
>> >> >>>> >>>>> >> >>> >export
>> >> >>>> >>>>> >> >>> >disks, etc. It appears that the engine cannot
>> >locate
>> >> >disks
>> >> >>>> >>>>> >properly
>> >> >>>> >>>>> >> >and
>> >> >>>> >>>>> >> >>> >I
>> >> >>>> >>>>> >> >>> >get storage I/O errors.
>> >> >>>> >>>>> >> >>> >
>> >> >>>> >>>>> >> >>> >I have detached and removed the oVirt Storage
>> >Domain.
>> >> >I
>> >> >>>> >>>>> >reimported
>> >> >>>> >>>>> >> >the
>> >> >>>> >>>>> >> >>> >domain and imported 2 VMs, But the VM disks
>> >exhibit
>> >> >the
>> >> >>>> same
>> >> >>>> >>>>> >> >behaviour
>> >> >>>> >>>>> >> >>> >and
>> >> >>>> >>>>> >> >>> >won't run from the hard disk.
>> >> >>>> >>>>> >> >>> >
>> >> >>>> >>>>> >> >>> >
>> >> >>>> >>>>> >> >>> >I get errors such as this
>> >> >>>> >>>>> >> >>> >
>> >> >>>> >>>>> >> >>> >VDSM ov05 command HSMGetAllTasksStatusesVDS
>> >failed:
>> >> >low
>> >> >>>> >>>level
>> >> >>>> >>>>> >Image
>> >> >>>> >>>>> >> >>> >copy
>> >> >>>> >>>>> >> >>> >failed: ("Command ['/usr/bin/qemu-img',
>'convert',
>> >> >'-p',
>> >> >>>> >>>'-t',
>> >> >>>> >>>>> >> >'none',
>> >> >>>> >>>>> >> >>> >'-T', 'none', '-f', 'raw',
>> >> >>>> >>>>> >> >>>
>>u'/rhev/data-center/mnt/glusterSD/192.168.24.18:
>> >> >>>> >>>>> >> >>>
>> >> >>>> >>>>> >>
>> >> >>>> >>>>> >>
>> >> >>>> >>>>>
>> >> >>>> >>>>>
>> >> >>>>
>> >> >>>>
>> >>
>> >>
>>
>>
>>>>>>>>_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510',
>> >> >>>> >>>>> >> >>> >'-O', 'raw',
>> >> >>>> >>>>> >> >>> >u'/rhev/data-center/mnt/192.168.24.13:
>> >> >>>> >>>>> >> >>>
>> >> >>>> >>>>> >>
>> >> >>>> >>>>> >>
>> >> >>>> >>>>>
>> >> >>>> >>>>>
>> >> >>>>
>> >> >>>>
>> >>
>> >>
>>
>>
>>>>>>>>_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5']
>> >> >>>> >>>>> >> >>> >failed with rc=1 out=''
>err=bytearray(b'qemu-img:
>> >> >error
>> >> >>>> >>>while
>> >> >>>> >>>>> >> >reading
>> >> >>>> >>>>> >> >>> >sector 135168: Transport endpoint is not
>> >> >>>> >>>connected\\nqemu-img:
>> >> >>>> >>>>> >> >error
>> >> >>>> >>>>> >> >>> >while
>> >> >>>> >>>>> >> >>> >reading sector 131072: Transport endpoint is
>not
>> >> >>>> >>>>> >> >connected\\nqemu-img:
>> >> >>>> >>>>> >> >>> >error while reading sector 139264: Transport
>> >endpoint
>> >> >is
>> >> >>>> not
>> >> >>>> >>>>> >> >>> >connected\\nqemu-img: error while reading
>sector
>> >> >143360:
>> >> >>>> >>>>> >Transport
>> >> >>>> >>>>> >> >>> >endpoint
>> >> >>>> >>>>> >> >>> >is not connected\\nqemu-img: error while
>reading
>> >> >sector
>> >> >>>> >>>147456:
>> >> >>>> >>>>> >> >>> >Transport
>> >> >>>> >>>>> >> >>> >endpoint is not connected\\nqemu-img: error
>while
>> >> >reading
>> >> >>>> >>>sector
>> >> >>>> >>>>> >> >>> >155648:
>> >> >>>> >>>>> >> >>> >Transport endpoint is not connected\\nqemu-img:
>> >error
>> >> >while
>> >> >>>> >>>>> >reading
>> >> >>>> >>>>> >> >>> >sector
>> >> >>>> >>>>> >> >>> >151552: Transport endpoint is not
>> >> >connected\\nqemu-img:
>> >> >>>> >>>error
>> >> >>>> >>>>> >while
>> >> >>>> >>>>> >> >>> >reading
>> >> >>>> >>>>> >> >>> >sector 159744: Transport endpoint is not
>> >> >connected\\n')",)
>> >> >>>> >>>>> >> >>> >
>> >> >>>> >>>>> >> >>> >oVirt version is 4.3.82-1.el7
>> >> >>>> >>>>> >> >>> >OS CentOS Linux release 7.7.1908 (Core)
>> >> >>>> >>>>> >> >>> >
>> >> >>>> >>>>> >> >>> >The Gluster Cluster has been working very well
>> >until
>> >> >this
>> >> >>>> >>>>> >incident.
>> >> >>>> >>>>> >> >>> >
>> >> >>>> >>>>> >> >>> >Please help.
>> >> >>>> >>>>> >> >>> >
>> >> >>>> >>>>> >> >>> >Thank You
>> >> >>>> >>>>> >> >>> >
>> >> >>>> >>>>> >> >>> >Charles Williams
>> >> >>>> >>>>> >> >>>
>> >> >>>> >>>>> >> >>
>> >> >>>> >>>>> >>
>> >> >>>> >>>>>
>> >> >>>> >>>>
>> >> >>>> >>
>> >> >>>> >
>> >> >>>> _______________________________________________
>> >> >>>> Users mailing list -- users@ovirt.org
>> >> >>>> To unsubscribe send an email to users-leave@ovirt.org
>> >> >>>> Privacy Statement: https://www.ovirt.org/privacy-policy.html
>> >> >>>> oVirt Code of Conduct:
>> >> >>>> https://www.ovirt.org/community/about/community-guidelines/
>> >> >>>> List Archives:
>> >> >>>>
>> >> >
>> >>
>> >
>>
>https://lists.ovirt.org/archives/list/users@ovirt.org/message/YY3VUKEJLI7MRWXF627EHQAMH36UJ5BQ/
>> >> >>>>
>> >> >>>
>> >>
>>
Strahil,
So you made another oVirt Storage Domain -- then copied the data with cp -a
from the failed volume to the new volume.
At the root of the volume there will be the old domain folder id ex
5fe3ad3f-2d21-404c-832e-4dc7318ca10d
in my case. Did that cause issues with making the new domain since it is
the same folder id as the old one ?
Thank You For Your Help !
On Sun, Jun 21, 2020 at 5:18 PM Strahil Nikolov <hunter86_bg@yahoo.com>
wrote:
> In my situation I had only the ovirt nodes.
>
> На 21 юни 2020 г. 22:43:04 GMT+03:00, C Williams <cwilliams3320@gmail.com>
> написа:
> >Strahil,
> >
> >So should I make the target volume on 3 bricks which do not have ovirt
> >--
> >just gluster ? In other words (3) Centos 7 hosts ?
> >
> >Thank You For Your Help !
> >
> >On Sun, Jun 21, 2020 at 3:08 PM Strahil Nikolov <hunter86_bg@yahoo.com>
> >wrote:
> >
> >> I created a fresh volume (which is not an ovirt sgorage domain),
> >set
> >> the original storage domain in maintenance and detached it.
> >> Then I 'cp -a ' the data from the old to the new volume. Next, I
> >just
> >> added the new storage domain (the old one was a kind of a
> >> 'backup') - pointing to the new volume name.
> >>
> >> If you observe issues , I would recommend you to downgrade
> >> gluster packages one node at a time . Then you might be able to
> >> restore your oVirt operations.
> >>
> >> Best Regards,
> >> Strahil Nikolov
> >>
> >> На 21 юни 2020 г. 18:01:31 GMT+03:00, C Williams
> ><cwilliams3320@gmail.com>
> >> написа:
> >> >Strahil,
> >> >
> >> >Thanks for the follow up !
> >> >
> >> >How did you copy the data to another volume ?
> >> >
> >> >I have set up another storage domain GLCLNEW1 with a new volume
> >imgnew1
> >> >.
> >> >How would you copy all of the data from the problematic domain GLCL3
> >> >with
> >> >volume images3 to GLCLNEW1 and volume imgnew1 and preserve all the
> >VMs,
> >> >VM
> >> >disks, settings, etc. ?
> >> >
> >> >Remember all of the regular ovirt disk copy, disk move, VM export
> >> >tools
> >> >are failing and my VMs and disks are trapped on domain GLCL3 and
> >volume
> >> >images3 right now.
> >> >
> >> >Please let me know
> >> >
> >> >Thank You For Your Help !
> >> >
> >> >
> >> >
> >> >
> >> >
> >> >On Sun, Jun 21, 2020 at 8:27 AM Strahil Nikolov
> ><hunter86_bg@yahoo.com>
> >> >wrote:
> >> >
> >> >> Sorry to hear that.
> >> >> I can say that for me 6.5 was working, while 6.6 didn't and I
> >> >upgraded
> >> >> to 7.0 .
> >> >> In the ended , I have ended with creating a new fresh volume
> >and
> >> >> physically copying the data there, then I detached the storage
> >> >domains and
> >> >> attached to the new ones (which holded the old data), but I
> >> >could
> >> >> afford the downtime.
> >> >> Also, I can say that v7.0 ( but not 7.1 or anything later)
> >also
> >> >> worked without the ACL issue, but it causes some trouble in
> >oVirt
> >> >- so
> >> >> avoid that unless you have no other options.
> >> >>
> >> >> Best Regards,
> >> >> Strahil Nikolov
> >> >>
> >> >>
> >> >>
> >> >>
> >> >> На 21 юни 2020 г. 4:39:46 GMT+03:00, C Williams
> >> ><cwilliams3320@gmail.com>
> >> >> написа:
> >> >> >Hello,
> >> >> >
> >> >> >Upgrading diidn't help
> >> >> >
> >> >> >Still acl errors trying to use a Virtual Disk from a VM
> >> >> >
> >> >> >[root@ov06 bricks]# tail bricks-brick04-images3.log | grep acl
> >> >> >[2020-06-21 01:33:45.665888] I [MSGID: 139001]
> >> >> >[posix-acl.c:263:posix_acl_log_permit_denied]
> >> >0-images3-access-control:
> >> >> >client:
> >> >>
> >> >>
> >>
> >>
>
> >>>CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0,
> >> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
> >> >> >req(uid:107,gid:107,perm:1,ngrps:3),
> >> >> >ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
> >> >> >[Permission denied]
> >> >> >The message "I [MSGID: 139001]
> >> >> >[posix-acl.c:263:posix_acl_log_permit_denied]
> >> >0-images3-access-control:
> >> >> >client:
> >> >>
> >> >>
> >>
> >>
>
> >>>CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0,
> >> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
> >> >> >req(uid:107,gid:107,perm:1,ngrps:3),
> >> >> >ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
> >> >> >[Permission denied]" repeated 2 times between [2020-06-21
> >> >> >01:33:45.665888]
> >> >> >and [2020-06-21 01:33:45.806779]
> >> >> >
> >> >> >Thank You For Your Help !
> >> >> >
> >> >> >On Sat, Jun 20, 2020 at 8:59 PM C Williams
> ><cwilliams3320@gmail.com>
> >> >> >wrote:
> >> >> >
> >> >> >> Hello,
> >> >> >>
> >> >> >> Based on the situation, I am planning to upgrade the 3 affected
> >> >> >hosts.
> >> >> >>
> >> >> >> My reasoning is that the hosts/bricks were attached to 6.9 at
> >one
> >> >> >time.
> >> >> >>
> >> >> >> Thanks For Your Help !
> >> >> >>
> >> >> >> On Sat, Jun 20, 2020 at 8:38 PM C Williams
> >> ><cwilliams3320@gmail.com>
> >> >> >> wrote:
> >> >> >>
> >> >> >>> Strahil,
> >> >> >>>
> >> >> >>> The gluster version on the current 3 gluster hosts is 6.7
> >(last
> >> >> >update
> >> >> >>> 2/26). These 3 hosts provide 1 brick each for the replica 3
> >> >volume.
> >> >> >>>
> >> >> >>> Earlier I had tried to add 6 additional hosts to the cluster.
> >> >Those
> >> >> >new
> >> >> >>> hosts were 6.9 gluster.
> >> >> >>>
> >> >> >>> I attempted to make a new separate volume with 3 bricks
> >provided
> >> >by
> >> >> >the 3
> >> >> >>> new gluster 6.9 hosts. After having many errors from the
> >oVirt
> >> >> >interface,
> >> >> >>> I gave up and removed the 6 new hosts from the cluster. That
> >is
> >> >> >where the
> >> >> >>> problems started. The intent was to expand the gluster cluster
> >> >while
> >> >> >making
> >> >> >>> 2 new volumes for that cluster. The ovirt compute cluster
> >would
> >> >> >allow for
> >> >> >>> efficient VM migration between 9 hosts -- while having
> >separate
> >> >> >gluster
> >> >> >>> volumes for safety purposes.
> >> >> >>>
> >> >> >>> Looking at the brick logs, I see where there are acl errors
> >> >starting
> >> >> >from
> >> >> >>> the time of the removal of the 6 new hosts.
> >> >> >>>
> >> >> >>> Please check out the attached brick log from 6/14-18. The
> >events
> >> >> >started
> >> >> >>> on 6/17.
> >> >> >>>
> >> >> >>> I wish I had a downgrade path.
> >> >> >>>
> >> >> >>> Thank You For The Help !!
> >> >> >>>
> >> >> >>> On Sat, Jun 20, 2020 at 7:47 PM Strahil Nikolov
> >> >> ><hunter86_bg@yahoo.com>
> >> >> >>> wrote:
> >> >> >>>
> >> >> >>>> Hi ,
> >> >> >>>>
> >> >> >>>>
> >> >> >>>> This one really looks like the ACL bug I was hit with when I
> >> >> >updated
> >> >> >>>> from Gluster v6.5 to 6.6 and later from 7.0 to 7.2.
> >> >> >>>>
> >> >> >>>> Did you update your setup recently ? Did you upgrade gluster
> >> >also ?
> >> >> >>>>
> >> >> >>>> You have to check the gluster logs in order to verify that,
> >so
> >> >you
> >> >> >can
> >> >> >>>> try:
> >> >> >>>>
> >> >> >>>> 1. Set Gluster logs to trace level (for details check:
> >> >> >>>>
> >> >> >
> >> >>
> >> >
> >>
> >
> https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3/html/administration_guide/configuring_the_log_level
> >> >> >>>> )
> >> >> >>>> 2. Power up a VM that was already off , or retry the
> >procedure
> >> >from
> >> >> >the
> >> >> >>>> logs you sent.
> >> >> >>>> 3. Stop the trace level of the logs
> >> >> >>>> 4. Check libvirt logs on the host that was supposed to power
> >up
> >> >the
> >> >> >VM
> >> >> >>>> (in case a VM was powered on)
> >> >> >>>> 5. Check the gluster brick logs on all nodes for ACL errors.
> >> >> >>>> Here is a sample from my old logs:
> >> >> >>>>
> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18
> >> >> >13:19:41.489047] I
> >> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied]
> >> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
> >> >> >>>>
> >> >>
> >> >>
> >>
> >>
>
> >>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx
> >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
> >> >> >>>> [Permission denied]
> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18
> >> >> >13:22:51.818796] I
> >> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied]
> >> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
> >> >> >>>>
> >> >>
> >> >>
> >>
> >>
>
> >>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx
> >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
> >> >> >>>> [Permission denied]
> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18
> >> >> >13:24:43.732856] I
> >> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied]
> >> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
> >> >> >>>>
> >> >>
> >> >>
> >>
> >>
>
> >>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx
> >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
> >> >> >>>> [Permission denied]
> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18
> >> >> >13:26:50.758178] I
> >> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied]
> >> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
> >> >> >>>>
> >> >>
> >> >>
> >>
> >>
>
> >>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx
> >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
> >> >> >>>> [Permission denied]
> >> >> >>>>
> >> >> >>>>
> >> >> >>>> In my case , the workaround was to downgrade the gluster
> >> >packages
> >> >> >on all
> >> >> >>>> nodes (and reboot each node 1 by 1 ) if the major version is
> >the
> >> >> >same, but
> >> >> >>>> if you upgraded to v7.X - then you can try the v7.0 .
> >> >> >>>>
> >> >> >>>> Best Regards,
> >> >> >>>> Strahil Nikolov
> >> >> >>>>
> >> >> >>>>
> >> >> >>>>
> >> >> >>>>
> >> >> >>>>
> >> >> >>>>
> >> >> >>>> В събота, 20 юни 2020 г., 18:48:42 ч. Гринуич+3, C Williams <
> >> >> >>>> cwilliams3320@gmail.com> написа:
> >> >> >>>>
> >> >> >>>>
> >> >> >>>>
> >> >> >>>>
> >> >> >>>>
> >> >> >>>> Hello,
> >> >> >>>>
> >> >> >>>> Here are additional log tiles as well as a tree of the
> >> >problematic
> >> >> >>>> Gluster storage domain. During this time I attempted to copy
> >a
> >> >> >virtual disk
> >> >> >>>> to another domain, move a virtual disk to another domain and
> >run
> >> >a
> >> >> >VM where
> >> >> >>>> the virtual hard disk would be used.
> >> >> >>>>
> >> >> >>>> The copies/moves failed and the VM went into pause mode when
> >the
> >> >> >virtual
> >> >> >>>> HDD was involved.
> >> >> >>>>
> >> >> >>>> Please check these out.
> >> >> >>>>
> >> >> >>>> Thank You For Your Help !
> >> >> >>>>
> >> >> >>>> On Sat, Jun 20, 2020 at 9:54 AM C Williams
> >> >> ><cwilliams3320@gmail.com>
> >> >> >>>> wrote:
> >> >> >>>> > Strahil,
> >> >> >>>> >
> >> >> >>>> > I understand. Please keep me posted.
> >> >> >>>> >
> >> >> >>>> > Thanks For The Help !
> >> >> >>>> >
> >> >> >>>> > On Sat, Jun 20, 2020 at 4:36 AM Strahil Nikolov
> >> >> ><hunter86_bg@yahoo.com>
> >> >> >>>> wrote:
> >> >> >>>> >> Hey C Williams,
> >> >> >>>> >>
> >> >> >>>> >> sorry for the delay, but I couldn't get somw time to
> >check
> >> >your
> >> >> >>>> logs. Will try a little bit later.
> >> >> >>>> >>
> >> >> >>>> >> Best Regards,
> >> >> >>>> >> Strahil Nikolov
> >> >> >>>> >>
> >> >> >>>> >> На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams <
> >> >> >>>> cwilliams3320@gmail.com> написа:
> >> >> >>>> >>>Hello,
> >> >> >>>> >>>
> >> >> >>>> >>>Was wanting to follow up on this issue. Users are
> >impacted.
> >> >> >>>> >>>
> >> >> >>>> >>>Thank You
> >> >> >>>> >>>
> >> >> >>>> >>>On Fri, Jun 19, 2020 at 9:20 AM C Williams
> >> >> ><cwilliams3320@gmail.com>
> >> >> >>>> >>>wrote:
> >> >> >>>> >>>
> >> >> >>>> >>>> Hello,
> >> >> >>>> >>>>
> >> >> >>>> >>>> Here are the logs (some IPs are changed )
> >> >> >>>> >>>>
> >> >> >>>> >>>> ov05 is the SPM
> >> >> >>>> >>>>
> >> >> >>>> >>>> Thank You For Your Help !
> >> >> >>>> >>>>
> >> >> >>>> >>>> On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov
> >> >> >>>> >>><hunter86_bg@yahoo.com>
> >> >> >>>> >>>> wrote:
> >> >> >>>> >>>>
> >> >> >>>> >>>>> Check on the hosts tab , which is your current SPM
> >(last
> >> >> >column in
> >> >> >>>> >>>Admin
> >> >> >>>> >>>>> UI).
> >> >> >>>> >>>>> Then open the /var/log/vdsm/vdsm.log and repeat the
> >> >> >operation.
> >> >> >>>> >>>>> Then provide the log from that host and the engine's
> >log
> >> >(on
> >> >> >the
> >> >> >>>> >>>>> HostedEngine VM or on your standalone engine).
> >> >> >>>> >>>>>
> >> >> >>>> >>>>> Best Regards,
> >> >> >>>> >>>>> Strahil Nikolov
> >> >> >>>> >>>>>
> >> >> >>>> >>>>> На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams
> >> >> >>>> >>><cwilliams3320@gmail.com>
> >> >> >>>> >>>>> написа:
> >> >> >>>> >>>>> >Resending to eliminate email issues
> >> >> >>>> >>>>> >
> >> >> >>>> >>>>> >---------- Forwarded message ---------
> >> >> >>>> >>>>> >From: C Williams <cwilliams3320@gmail.com>
> >> >> >>>> >>>>> >Date: Thu, Jun 18, 2020 at 4:01 PM
> >> >> >>>> >>>>> >Subject: Re: [ovirt-users] Fwd: Issues with Gluster
> >> >Domain
> >> >> >>>> >>>>> >To: Strahil Nikolov <hunter86_bg@yahoo.com>
> >> >> >>>> >>>>> >
> >> >> >>>> >>>>> >
> >> >> >>>> >>>>> >Here is output from mount
> >> >> >>>> >>>>> >
> >> >> >>>> >>>>> >192.168.24.12:/stor/import0 on
> >> >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.12:_stor_import0
> >> >> >>>> >>>>> >type nfs4
> >> >> >>>> >>>>>
> >> >> >>>> >>>>>
> >> >> >>>>
> >> >> >>>>
> >> >>
> >> >>
> >>
> >>
>
> >>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12)
> >> >> >>>> >>>>> >192.168.24.13:/stor/import1 on
> >> >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_import1
> >> >> >>>> >>>>> >type nfs4
> >> >> >>>> >>>>>
> >> >> >>>> >>>>>
> >> >> >>>>
> >> >> >>>>
> >> >>
> >> >>
> >>
> >>
>
> >>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
> >> >> >>>> >>>>> >192.168.24.13:/stor/iso1 on
> >> >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_iso1
> >> >> >>>> >>>>> >type nfs4
> >> >> >>>> >>>>>
> >> >> >>>> >>>>>
> >> >> >>>>
> >> >> >>>>
> >> >>
> >> >>
> >>
> >>
>
> >>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
> >> >> >>>> >>>>> >192.168.24.13:/stor/export0 on
> >> >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_export0
> >> >> >>>> >>>>> >type nfs4
> >> >> >>>> >>>>>
> >> >> >>>> >>>>>
> >> >> >>>>
> >> >> >>>>
> >> >>
> >> >>
> >>
> >>
>
> >>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
> >> >> >>>> >>>>> >192.168.24.15:/images on
> >> >> >>>> >>>>> >/rhev/data-center/mnt/glusterSD/192.168.24.15:_images
> >> >> >>>> >>>>> >type fuse.glusterfs
> >> >> >>>> >>>>>
> >> >> >>>> >>>>>
> >> >> >>>>
> >> >> >>>>
> >> >>
> >> >>
> >>
> >>
>
> >>>>>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
> >> >> >>>> >>>>> >192.168.24.18:/images3 on
> >> >> >>>> >>>>> >/rhev/data-center/mnt/glusterSD/192.168.24.18:_images3
> >> >> >>>> >>>>> >type fuse.glusterfs
> >> >> >>>> >>>>>
> >> >> >>>> >>>>>
> >> >> >>>>
> >> >> >>>>
> >> >>
> >> >>
> >>
> >>
>
> >>>>>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
> >> >> >>>> >>>>> >tmpfs on /run/user/0 type tmpfs
> >> >> >>>> >>>>>
> >> >>(rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700)
> >> >> >>>> >>>>> >[root@ov06 glusterfs]#
> >> >> >>>> >>>>> >
> >> >> >>>> >>>>> >Also here is a screenshot of the console
> >> >> >>>> >>>>> >
> >> >> >>>> >>>>> >[image: image.png]
> >> >> >>>> >>>>> >The other domains are up
> >> >> >>>> >>>>> >
> >> >> >>>> >>>>> >Import0 and Import1 are NFS . GLCL0 is gluster. They
> >all
> >> >are
> >> >> >>>> >>>running
> >> >> >>>> >>>>> >VMs
> >> >> >>>> >>>>> >
> >> >> >>>> >>>>> >Thank You For Your Help !
> >> >> >>>> >>>>> >
> >> >> >>>> >>>>> >On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov
> >> >> >>>> >>><hunter86_bg@yahoo.com>
> >> >> >>>> >>>>> >wrote:
> >> >> >>>> >>>>> >
> >> >> >>>> >>>>> >> I don't see
> >> >> >'/rhev/data-center/mnt/192.168.24.13:_stor_import1'
> >> >> >>>> >>>>> >mounted
> >> >> >>>> >>>>> >> at all .
> >> >> >>>> >>>>> >> What is the status of all storage domains ?
> >> >> >>>> >>>>> >>
> >> >> >>>> >>>>> >> Best Regards,
> >> >> >>>> >>>>> >> Strahil Nikolov
> >> >> >>>> >>>>> >>
> >> >> >>>> >>>>> >> На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams
> >> >> >>>> >>>>> ><cwilliams3320@gmail.com>
> >> >> >>>> >>>>> >> написа:
> >> >> >>>> >>>>> >> > Resending to deal with possible email issues
> >> >> >>>> >>>>> >> >
> >> >> >>>> >>>>> >> >---------- Forwarded message ---------
> >> >> >>>> >>>>> >> >From: C Williams <cwilliams3320@gmail.com>
> >> >> >>>> >>>>> >> >Date: Thu, Jun 18, 2020 at 2:07 PM
> >> >> >>>> >>>>> >> >Subject: Re: [ovirt-users] Issues with Gluster
> >Domain
> >> >> >>>> >>>>> >> >To: Strahil Nikolov <hunter86_bg@yahoo.com>
> >> >> >>>> >>>>> >> >
> >> >> >>>> >>>>> >> >
> >> >> >>>> >>>>> >> >More
> >> >> >>>> >>>>> >> >
> >> >> >>>> >>>>> >> >[root@ov06 ~]# for i in $(gluster volume list); do
> >> >echo
> >> >> >>>> >>>$i;echo;
> >> >> >>>> >>>>> >> >gluster
> >> >> >>>> >>>>> >> >volume info $i; echo;echo;gluster volume status
> >> >> >>>> >>>>> >$i;echo;echo;echo;done
> >> >> >>>> >>>>> >> >images3
> >> >> >>>> >>>>> >> >
> >> >> >>>> >>>>> >> >
> >> >> >>>> >>>>> >> >Volume Name: images3
> >> >> >>>> >>>>> >> >Type: Replicate
> >> >> >>>> >>>>> >> >Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b
> >> >> >>>> >>>>> >> >Status: Started
> >> >> >>>> >>>>> >> >Snapshot Count: 0
> >> >> >>>> >>>>> >> >Number of Bricks: 1 x 3 = 3
> >> >> >>>> >>>>> >> >Transport-type: tcp
> >> >> >>>> >>>>> >> >Bricks:
> >> >> >>>> >>>>> >> >Brick1: 192.168.24.18:/bricks/brick04/images3
> >> >> >>>> >>>>> >> >Brick2: 192.168.24.19:/bricks/brick05/images3
> >> >> >>>> >>>>> >> >Brick3: 192.168.24.20:/bricks/brick06/images3
> >> >> >>>> >>>>> >> >Options Reconfigured:
> >> >> >>>> >>>>> >> >performance.client-io-threads: on
> >> >> >>>> >>>>> >> >nfs.disable: on
> >> >> >>>> >>>>> >> >transport.address-family: inet
> >> >> >>>> >>>>> >> >user.cifs: off
> >> >> >>>> >>>>> >> >auth.allow: *
> >> >> >>>> >>>>> >> >performance.quick-read: off
> >> >> >>>> >>>>> >> >performance.read-ahead: off
> >> >> >>>> >>>>> >> >performance.io-cache: off
> >> >> >>>> >>>>> >> >performance.low-prio-threads: 32
> >> >> >>>> >>>>> >> >network.remote-dio: off
> >> >> >>>> >>>>> >> >cluster.eager-lock: enable
> >> >> >>>> >>>>> >> >cluster.quorum-type: auto
> >> >> >>>> >>>>> >> >cluster.server-quorum-type: server
> >> >> >>>> >>>>> >> >cluster.data-self-heal-algorithm: full
> >> >> >>>> >>>>> >> >cluster.locking-scheme: granular
> >> >> >>>> >>>>> >> >cluster.shd-max-threads: 8
> >> >> >>>> >>>>> >> >cluster.shd-wait-qlength: 10000
> >> >> >>>> >>>>> >> >features.shard: on
> >> >> >>>> >>>>> >> >cluster.choose-local: off
> >> >> >>>> >>>>> >> >client.event-threads: 4
> >> >> >>>> >>>>> >> >server.event-threads: 4
> >> >> >>>> >>>>> >> >storage.owner-uid: 36
> >> >> >>>> >>>>> >> >storage.owner-gid: 36
> >> >> >>>> >>>>> >> >performance.strict-o-direct: on
> >> >> >>>> >>>>> >> >network.ping-timeout: 30
> >> >> >>>> >>>>> >> >cluster.granular-entry-heal: enable
> >> >> >>>> >>>>> >> >
> >> >> >>>> >>>>> >> >
> >> >> >>>> >>>>> >> >Status of volume: images3
> >> >> >>>> >>>>> >> >Gluster process TCP
> >Port
> >> >> >RDMA Port
> >> >> >>>> >>>>> >Online
> >> >> >>>> >>>>> >> > Pid
> >> >> >>>> >>>>> >>
> >> >> >>>> >>>>> >>
> >> >> >>>> >>>>>
> >> >> >>>> >>>>>
> >> >> >>>>
> >> >> >>>>
> >> >>
> >> >>
> >>
> >>
>
> >>>>>>>>------------------------------------------------------------------------------
> >> >> >>>> >>>>> >> >Brick 192.168.24.18:/bricks/brick04/images3 49152
> >> >0
> >> >> >>>>
> >> >> >>>> >>>Y
> >> >> >>>> >>>>> >> >6666
> >> >> >>>> >>>>> >> >Brick 192.168.24.19:/bricks/brick05/images3 49152
> >> >0
> >> >> >>>>
> >> >> >>>> >>>Y
> >> >> >>>> >>>>> >> >6779
> >> >> >>>> >>>>> >> >Brick 192.168.24.20:/bricks/brick06/images3 49152
> >> >0
> >> >> >>>>
> >> >> >>>> >>>Y
> >> >> >>>> >>>>> >> >7227
> >> >> >>>> >>>>> >> >Self-heal Daemon on localhost N/A
> >> >N/A
> >> >> >>>>
> >> >> >>>> >>>Y
> >> >> >>>> >>>>> >> >6689
> >> >> >>>> >>>>> >> >Self-heal Daemon on ov07.ntc.srcle.com N/A
> >> >N/A
> >> >> >>>>
> >> >> >>>> >>>Y
> >> >> >>>> >>>>> >> >6802
> >> >> >>>> >>>>> >> >Self-heal Daemon on ov08.ntc.srcle.com N/A
> >> >N/A
> >> >> >>>>
> >> >> >>>> >>>Y
> >> >> >>>> >>>>> >> >7250
> >> >> >>>> >>>>> >> >
> >> >> >>>> >>>>> >> >Task Status of Volume images3
> >> >> >>>> >>>>> >>
> >> >> >>>> >>>>> >>
> >> >> >>>> >>>>>
> >> >> >>>> >>>>>
> >> >> >>>>
> >> >> >>>>
> >> >>
> >> >>
> >>
> >>
>
> >>>>>>>>------------------------------------------------------------------------------
> >> >> >>>> >>>>> >> >There are no active volume tasks
> >> >> >>>> >>>>> >> >
> >> >> >>>> >>>>> >> >
> >> >> >>>> >>>>> >> >
> >> >> >>>> >>>>> >> >
> >> >> >>>> >>>>> >> >[root@ov06 ~]# ls -l
> >/rhev/data-center/mnt/glusterSD/
> >> >> >>>> >>>>> >> >total 16
> >> >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04
> >> >> >192.168.24.15:_images
> >> >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05
> >> >192.168.24.18:
> >> >> >>>> _images3
> >> >> >>>> >>>>> >> >[root@ov06 ~]#
> >> >> >>>> >>>>> >> >
> >> >> >>>> >>>>> >> >On Thu, Jun 18, 2020 at 2:03 PM C Williams
> >> >> >>>> >>><cwilliams3320@gmail.com>
> >> >> >>>> >>>>> >> >wrote:
> >> >> >>>> >>>>> >> >
> >> >> >>>> >>>>> >> >> Strahil,
> >> >> >>>> >>>>> >> >>
> >> >> >>>> >>>>> >> >> Here you go -- Thank You For Your Help !
> >> >> >>>> >>>>> >> >>
> >> >> >>>> >>>>> >> >> BTW -- I can write a test file to gluster and it
> >> >> >replicates
> >> >> >>>> >>>>> >properly.
> >> >> >>>> >>>>> >> >> Thinking something about the oVirt Storage Domain
> >?
> >> >> >>>> >>>>> >> >>
> >> >> >>>> >>>>> >> >> [root@ov08 ~]# gluster pool list
> >> >> >>>> >>>>> >> >> UUID Hostname
> >> >> >>>> >>>>> >State
> >> >> >>>> >>>>> >> >> 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06
> >> >> >>>> >>>>> >> >Connected
> >> >> >>>> >>>>> >> >> 36ce5a00-6f65-4926-8438-696944ebadb5
> >> >> >ov07.ntc.srcle.com
> >> >> >>>> >>>>> >> >Connected
> >> >> >>>> >>>>> >> >> c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost
> >> >> >>>> >>>>> >> >Connected
> >> >> >>>> >>>>> >> >> [root@ov08 ~]# gluster volume list
> >> >> >>>> >>>>> >> >> images3
> >> >> >>>> >>>>> >> >>
> >> >> >>>> >>>>> >> >> On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov
> >> >> >>>> >>>>> >> ><hunter86_bg@yahoo.com>
> >> >> >>>> >>>>> >> >> wrote:
> >> >> >>>> >>>>> >> >>
> >> >> >>>> >>>>> >> >>> Log to the oVirt cluster and provide the output
> >of:
> >> >> >>>> >>>>> >> >>> gluster pool list
> >> >> >>>> >>>>> >> >>> gluster volume list
> >> >> >>>> >>>>> >> >>> for i in $(gluster volume list); do echo
> >$i;echo;
> >> >> >gluster
> >> >> >>>> >>>>> >volume
> >> >> >>>> >>>>> >> >info
> >> >> >>>> >>>>> >> >>> $i; echo;echo;gluster volume status
> >> >> >$i;echo;echo;echo;done
> >> >> >>>> >>>>> >> >>>
> >> >> >>>> >>>>> >> >>> ls -l /rhev/data-center/mnt/glusterSD/
> >> >> >>>> >>>>> >> >>>
> >> >> >>>> >>>>> >> >>> Best Regards,
> >> >> >>>> >>>>> >> >>> Strahil Nikolov
> >> >> >>>> >>>>> >> >>>
> >> >> >>>> >>>>> >> >>>
> >> >> >>>> >>>>> >> >>> На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams
> >> >> >>>> >>>>> >> ><cwilliams3320@gmail.com>
> >> >> >>>> >>>>> >> >>> написа:
> >> >> >>>> >>>>> >> >>> >Hello,
> >> >> >>>> >>>>> >> >>> >
> >> >> >>>> >>>>> >> >>> >I recently added 6 hosts to an existing oVirt
> >> >> >>>> >>>compute/gluster
> >> >> >>>> >>>>> >> >cluster.
> >> >> >>>> >>>>> >> >>> >
> >> >> >>>> >>>>> >> >>> >Prior to this attempted addition, my cluster
> >had 3
> >> >> >>>> >>>Hypervisor
> >> >> >>>> >>>>> >hosts
> >> >> >>>> >>>>> >> >and
> >> >> >>>> >>>>> >> >>> >3
> >> >> >>>> >>>>> >> >>> >gluster bricks which made up a single gluster
> >> >volume
> >> >> >>>> >>>(replica 3
> >> >> >>>> >>>>> >> >volume)
> >> >> >>>> >>>>> >> >>> >. I
> >> >> >>>> >>>>> >> >>> >added the additional hosts and made a brick on
> >3
> >> >of
> >> >> >the new
> >> >> >>>> >>>>> >hosts
> >> >> >>>> >>>>> >> >and
> >> >> >>>> >>>>> >> >>> >attempted to make a new replica 3 volume. I had
> >> >> >difficulty
> >> >> >>>> >>>>> >> >creating
> >> >> >>>> >>>>> >> >>> >the
> >> >> >>>> >>>>> >> >>> >new volume. So, I decided that I would make a
> >new
> >> >> >>>> >>>>> >compute/gluster
> >> >> >>>> >>>>> >> >>> >cluster
> >> >> >>>> >>>>> >> >>> >for each set of 3 new hosts.
> >> >> >>>> >>>>> >> >>> >
> >> >> >>>> >>>>> >> >>> >I removed the 6 new hosts from the existing
> >oVirt
> >> >> >>>> >>>>> >Compute/Gluster
> >> >> >>>> >>>>> >> >>> >Cluster
> >> >> >>>> >>>>> >> >>> >leaving the 3 original hosts in place with
> >their
> >> >> >bricks. At
> >> >> >>>> >>>that
> >> >> >>>> >>>>> >> >point
> >> >> >>>> >>>>> >> >>> >my
> >> >> >>>> >>>>> >> >>> >original bricks went down and came back up .
> >The
> >> >> >volume
> >> >> >>>> >>>showed
> >> >> >>>> >>>>> >> >entries
> >> >> >>>> >>>>> >> >>> >that
> >> >> >>>> >>>>> >> >>> >needed healing. At that point I ran gluster
> >volume
> >> >> >heal
> >> >> >>>> >>>images3
> >> >> >>>> >>>>> >> >full,
> >> >> >>>> >>>>> >> >>> >etc.
> >> >> >>>> >>>>> >> >>> >The volume shows no unhealed entries. I also
> >> >> >corrected some
> >> >> >>>> >>>peer
> >> >> >>>> >>>>> >> >>> >errors.
> >> >> >>>> >>>>> >> >>> >
> >> >> >>>> >>>>> >> >>> >However, I am unable to copy disks, move disks
> >to
> >> >> >another
> >> >> >>>> >>>>> >domain,
> >> >> >>>> >>>>> >> >>> >export
> >> >> >>>> >>>>> >> >>> >disks, etc. It appears that the engine cannot
> >> >locate
> >> >> >disks
> >> >> >>>> >>>>> >properly
> >> >> >>>> >>>>> >> >and
> >> >> >>>> >>>>> >> >>> >I
> >> >> >>>> >>>>> >> >>> >get storage I/O errors.
> >> >> >>>> >>>>> >> >>> >
> >> >> >>>> >>>>> >> >>> >I have detached and removed the oVirt Storage
> >> >Domain.
> >> >> >I
> >> >> >>>> >>>>> >reimported
> >> >> >>>> >>>>> >> >the
> >> >> >>>> >>>>> >> >>> >domain and imported 2 VMs, But the VM disks
> >> >exhibit
> >> >> >the
> >> >> >>>> same
> >> >> >>>> >>>>> >> >behaviour
> >> >> >>>> >>>>> >> >>> >and
> >> >> >>>> >>>>> >> >>> >won't run from the hard disk.
> >> >> >>>> >>>>> >> >>> >
> >> >> >>>> >>>>> >> >>> >
> >> >> >>>> >>>>> >> >>> >I get errors such as this
> >> >> >>>> >>>>> >> >>> >
> >> >> >>>> >>>>> >> >>> >VDSM ov05 command HSMGetAllTasksStatusesVDS
> >> >failed:
> >> >> >low
> >> >> >>>> >>>level
> >> >> >>>> >>>>> >Image
> >> >> >>>> >>>>> >> >>> >copy
> >> >> >>>> >>>>> >> >>> >failed: ("Command ['/usr/bin/qemu-img',
> >'convert',
> >> >> >'-p',
> >> >> >>>> >>>'-t',
> >> >> >>>> >>>>> >> >'none',
> >> >> >>>> >>>>> >> >>> >'-T', 'none', '-f', 'raw',
> >> >> >>>> >>>>> >> >>>
> >>u'/rhev/data-center/mnt/glusterSD/192.168.24.18:
> >> >> >>>> >>>>> >> >>>
> >> >> >>>> >>>>> >>
> >> >> >>>> >>>>> >>
> >> >> >>>> >>>>>
> >> >> >>>> >>>>>
> >> >> >>>>
> >> >> >>>>
> >> >>
> >> >>
> >>
> >>
>
> >>>>>>>>_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510',
> >> >> >>>> >>>>> >> >>> >'-O', 'raw',
> >> >> >>>> >>>>> >> >>> >u'/rhev/data-center/mnt/192.168.24.13:
> >> >> >>>> >>>>> >> >>>
> >> >> >>>> >>>>> >>
> >> >> >>>> >>>>> >>
> >> >> >>>> >>>>>
> >> >> >>>> >>>>>
> >> >> >>>>
> >> >> >>>>
> >> >>
> >> >>
> >>
> >>
>
> >>>>>>>>_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5']
> >> >> >>>> >>>>> >> >>> >failed with rc=1 out=''
> >err=bytearray(b'qemu-img:
> >> >> >error
> >> >> >>>> >>>while
> >> >> >>>> >>>>> >> >reading
> >> >> >>>> >>>>> >> >>> >sector 135168: Transport endpoint is not
> >> >> >>>> >>>connected\\nqemu-img:
> >> >> >>>> >>>>> >> >error
> >> >> >>>> >>>>> >> >>> >while
> >> >> >>>> >>>>> >> >>> >reading sector 131072: Transport endpoint is
> >not
> >> >> >>>> >>>>> >> >connected\\nqemu-img:
> >> >> >>>> >>>>> >> >>> >error while reading sector 139264: Transport
> >> >endpoint
> >> >> >is
> >> >> >>>> not
> >> >> >>>> >>>>> >> >>> >connected\\nqemu-img: error while reading
> >sector
> >> >> >143360:
> >> >> >>>> >>>>> >Transport
> >> >> >>>> >>>>> >> >>> >endpoint
> >> >> >>>> >>>>> >> >>> >is not connected\\nqemu-img: error while
> >reading
> >> >> >sector
> >> >> >>>> >>>147456:
> >> >> >>>> >>>>> >> >>> >Transport
> >> >> >>>> >>>>> >> >>> >endpoint is not connected\\nqemu-img: error
> >while
> >> >> >reading
> >> >> >>>> >>>sector
> >> >> >>>> >>>>> >> >>> >155648:
> >> >> >>>> >>>>> >> >>> >Transport endpoint is not connected\\nqemu-img:
> >> >error
> >> >> >while
> >> >> >>>> >>>>> >reading
> >> >> >>>> >>>>> >> >>> >sector
> >> >> >>>> >>>>> >> >>> >151552: Transport endpoint is not
> >> >> >connected\\nqemu-img:
> >> >> >>>> >>>error
> >> >> >>>> >>>>> >while
> >> >> >>>> >>>>> >> >>> >reading
> >> >> >>>> >>>>> >> >>> >sector 159744: Transport endpoint is not
> >> >> >connected\\n')",)
> >> >> >>>> >>>>> >> >>> >
> >> >> >>>> >>>>> >> >>> >oVirt version is 4.3.82-1.el7
> >> >> >>>> >>>>> >> >>> >OS CentOS Linux release 7.7.1908 (Core)
> >> >> >>>> >>>>> >> >>> >
> >> >> >>>> >>>>> >> >>> >The Gluster Cluster has been working very well
> >> >until
> >> >> >this
> >> >> >>>> >>>>> >incident.
> >> >> >>>> >>>>> >> >>> >
> >> >> >>>> >>>>> >> >>> >Please help.
> >> >> >>>> >>>>> >> >>> >
> >> >> >>>> >>>>> >> >>> >Thank You
> >> >> >>>> >>>>> >> >>> >
> >> >> >>>> >>>>> >> >>> >Charles Williams
> >> >> >>>> >>>>> >> >>>
> >> >> >>>> >>>>> >> >>
> >> >> >>>> >>>>> >>
> >> >> >>>> >>>>>
> >> >> >>>> >>>>
> >> >> >>>> >>
> >> >> >>>> >
> >> >> >>>> _______________________________________________
> >> >> >>>> Users mailing list -- users@ovirt.org
> >> >> >>>> To unsubscribe send an email to users-leave@ovirt.org
> >> >> >>>> Privacy Statement: https://www.ovirt.org/privacy-policy.html
> >> >> >>>> oVirt Code of Conduct:
> >> >> >>>> https://www.ovirt.org/community/about/community-guidelines/
> >> >> >>>> List Archives:
> >> >> >>>>
> >> >> >
> >> >>
> >> >
> >>
> >
> https://lists.ovirt.org/archives/list/users@ovirt.org/message/YY3VUKEJLI7MRWXF627EHQAMH36UJ5BQ/
> >> >> >>>>
> >> >> >>>
> >> >>
> >>
>
Strahil,
It sounds like you used a "System Managed Volume" for the new storage
domain,is that correct?
Thank You For Your Help !
On Sun, Jun 21, 2020 at 5:40 PM C Williams <cwilliams3320@gmail.com> wrote:
> Strahil,
>
> So you made another oVirt Storage Domain -- then copied the data with cp
> -a from the failed volume to the new volume.
>
> At the root of the volume there will be the old domain folder id ex
> 5fe3ad3f-2d21-404c-832e-4dc7318ca10d
> in my case. Did that cause issues with making the new domain since it is
> the same folder id as the old one ?
>
> Thank You For Your Help !
>
> On Sun, Jun 21, 2020 at 5:18 PM Strahil Nikolov <hunter86_bg@yahoo.com>
> wrote:
>
>> In my situation I had only the ovirt nodes.
>>
>> На 21 юни 2020 г. 22:43:04 GMT+03:00, C Williams <cwilliams3320@gmail.com>
>> написа:
>> >Strahil,
>> >
>> >So should I make the target volume on 3 bricks which do not have ovirt
>> >--
>> >just gluster ? In other words (3) Centos 7 hosts ?
>> >
>> >Thank You For Your Help !
>> >
>> >On Sun, Jun 21, 2020 at 3:08 PM Strahil Nikolov <hunter86_bg@yahoo.com>
>> >wrote:
>> >
>> >> I created a fresh volume (which is not an ovirt sgorage domain),
>> >set
>> >> the original storage domain in maintenance and detached it.
>> >> Then I 'cp -a ' the data from the old to the new volume. Next, I
>> >just
>> >> added the new storage domain (the old one was a kind of a
>> >> 'backup') - pointing to the new volume name.
>> >>
>> >> If you observe issues , I would recommend you to downgrade
>> >> gluster packages one node at a time . Then you might be able to
>> >> restore your oVirt operations.
>> >>
>> >> Best Regards,
>> >> Strahil Nikolov
>> >>
>> >> На 21 юни 2020 г. 18:01:31 GMT+03:00, C Williams
>> ><cwilliams3320@gmail.com>
>> >> написа:
>> >> >Strahil,
>> >> >
>> >> >Thanks for the follow up !
>> >> >
>> >> >How did you copy the data to another volume ?
>> >> >
>> >> >I have set up another storage domain GLCLNEW1 with a new volume
>> >imgnew1
>> >> >.
>> >> >How would you copy all of the data from the problematic domain GLCL3
>> >> >with
>> >> >volume images3 to GLCLNEW1 and volume imgnew1 and preserve all the
>> >VMs,
>> >> >VM
>> >> >disks, settings, etc. ?
>> >> >
>> >> >Remember all of the regular ovirt disk copy, disk move, VM export
>> >> >tools
>> >> >are failing and my VMs and disks are trapped on domain GLCL3 and
>> >volume
>> >> >images3 right now.
>> >> >
>> >> >Please let me know
>> >> >
>> >> >Thank You For Your Help !
>> >> >
>> >> >
>> >> >
>> >> >
>> >> >
>> >> >On Sun, Jun 21, 2020 at 8:27 AM Strahil Nikolov
>> ><hunter86_bg@yahoo.com>
>> >> >wrote:
>> >> >
>> >> >> Sorry to hear that.
>> >> >> I can say that for me 6.5 was working, while 6.6 didn't and I
>> >> >upgraded
>> >> >> to 7.0 .
>> >> >> In the ended , I have ended with creating a new fresh volume
>> >and
>> >> >> physically copying the data there, then I detached the storage
>> >> >domains and
>> >> >> attached to the new ones (which holded the old data), but I
>> >> >could
>> >> >> afford the downtime.
>> >> >> Also, I can say that v7.0 ( but not 7.1 or anything later)
>> >also
>> >> >> worked without the ACL issue, but it causes some trouble in
>> >oVirt
>> >> >- so
>> >> >> avoid that unless you have no other options.
>> >> >>
>> >> >> Best Regards,
>> >> >> Strahil Nikolov
>> >> >>
>> >> >>
>> >> >>
>> >> >>
>> >> >> На 21 юни 2020 г. 4:39:46 GMT+03:00, C Williams
>> >> ><cwilliams3320@gmail.com>
>> >> >> написа:
>> >> >> >Hello,
>> >> >> >
>> >> >> >Upgrading diidn't help
>> >> >> >
>> >> >> >Still acl errors trying to use a Virtual Disk from a VM
>> >> >> >
>> >> >> >[root@ov06 bricks]# tail bricks-brick04-images3.log | grep acl
>> >> >> >[2020-06-21 01:33:45.665888] I [MSGID: 139001]
>> >> >> >[posix-acl.c:263:posix_acl_log_permit_denied]
>> >> >0-images3-access-control:
>> >> >> >client:
>> >> >>
>> >> >>
>> >>
>> >>
>>
>> >>>CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0,
>> >> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
>> >> >> >req(uid:107,gid:107,perm:1,ngrps:3),
>> >> >> >ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
>> >> >> >[Permission denied]
>> >> >> >The message "I [MSGID: 139001]
>> >> >> >[posix-acl.c:263:posix_acl_log_permit_denied]
>> >> >0-images3-access-control:
>> >> >> >client:
>> >> >>
>> >> >>
>> >>
>> >>
>>
>> >>>CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0,
>> >> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
>> >> >> >req(uid:107,gid:107,perm:1,ngrps:3),
>> >> >> >ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
>> >> >> >[Permission denied]" repeated 2 times between [2020-06-21
>> >> >> >01:33:45.665888]
>> >> >> >and [2020-06-21 01:33:45.806779]
>> >> >> >
>> >> >> >Thank You For Your Help !
>> >> >> >
>> >> >> >On Sat, Jun 20, 2020 at 8:59 PM C Williams
>> ><cwilliams3320@gmail.com>
>> >> >> >wrote:
>> >> >> >
>> >> >> >> Hello,
>> >> >> >>
>> >> >> >> Based on the situation, I am planning to upgrade the 3 affected
>> >> >> >hosts.
>> >> >> >>
>> >> >> >> My reasoning is that the hosts/bricks were attached to 6.9 at
>> >one
>> >> >> >time.
>> >> >> >>
>> >> >> >> Thanks For Your Help !
>> >> >> >>
>> >> >> >> On Sat, Jun 20, 2020 at 8:38 PM C Williams
>> >> ><cwilliams3320@gmail.com>
>> >> >> >> wrote:
>> >> >> >>
>> >> >> >>> Strahil,
>> >> >> >>>
>> >> >> >>> The gluster version on the current 3 gluster hosts is 6.7
>> >(last
>> >> >> >update
>> >> >> >>> 2/26). These 3 hosts provide 1 brick each for the replica 3
>> >> >volume.
>> >> >> >>>
>> >> >> >>> Earlier I had tried to add 6 additional hosts to the cluster.
>> >> >Those
>> >> >> >new
>> >> >> >>> hosts were 6.9 gluster.
>> >> >> >>>
>> >> >> >>> I attempted to make a new separate volume with 3 bricks
>> >provided
>> >> >by
>> >> >> >the 3
>> >> >> >>> new gluster 6.9 hosts. After having many errors from the
>> >oVirt
>> >> >> >interface,
>> >> >> >>> I gave up and removed the 6 new hosts from the cluster. That
>> >is
>> >> >> >where the
>> >> >> >>> problems started. The intent was to expand the gluster cluster
>> >> >while
>> >> >> >making
>> >> >> >>> 2 new volumes for that cluster. The ovirt compute cluster
>> >would
>> >> >> >allow for
>> >> >> >>> efficient VM migration between 9 hosts -- while having
>> >separate
>> >> >> >gluster
>> >> >> >>> volumes for safety purposes.
>> >> >> >>>
>> >> >> >>> Looking at the brick logs, I see where there are acl errors
>> >> >starting
>> >> >> >from
>> >> >> >>> the time of the removal of the 6 new hosts.
>> >> >> >>>
>> >> >> >>> Please check out the attached brick log from 6/14-18. The
>> >events
>> >> >> >started
>> >> >> >>> on 6/17.
>> >> >> >>>
>> >> >> >>> I wish I had a downgrade path.
>> >> >> >>>
>> >> >> >>> Thank You For The Help !!
>> >> >> >>>
>> >> >> >>> On Sat, Jun 20, 2020 at 7:47 PM Strahil Nikolov
>> >> >> ><hunter86_bg@yahoo.com>
>> >> >> >>> wrote:
>> >> >> >>>
>> >> >> >>>> Hi ,
>> >> >> >>>>
>> >> >> >>>>
>> >> >> >>>> This one really looks like the ACL bug I was hit with when I
>> >> >> >updated
>> >> >> >>>> from Gluster v6.5 to 6.6 and later from 7.0 to 7.2.
>> >> >> >>>>
>> >> >> >>>> Did you update your setup recently ? Did you upgrade gluster
>> >> >also ?
>> >> >> >>>>
>> >> >> >>>> You have to check the gluster logs in order to verify that,
>> >so
>> >> >you
>> >> >> >can
>> >> >> >>>> try:
>> >> >> >>>>
>> >> >> >>>> 1. Set Gluster logs to trace level (for details check:
>> >> >> >>>>
>> >> >> >
>> >> >>
>> >> >
>> >>
>> >
>> https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3/html/administration_guide/configuring_the_log_level
>> >> >> >>>> )
>> >> >> >>>> 2. Power up a VM that was already off , or retry the
>> >procedure
>> >> >from
>> >> >> >the
>> >> >> >>>> logs you sent.
>> >> >> >>>> 3. Stop the trace level of the logs
>> >> >> >>>> 4. Check libvirt logs on the host that was supposed to power
>> >up
>> >> >the
>> >> >> >VM
>> >> >> >>>> (in case a VM was powered on)
>> >> >> >>>> 5. Check the gluster brick logs on all nodes for ACL errors.
>> >> >> >>>> Here is a sample from my old logs:
>> >> >> >>>>
>> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18
>> >> >> >13:19:41.489047] I
>> >> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied]
>> >> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
>> >> >> >>>>
>> >> >>
>> >> >>
>> >>
>> >>
>>
>> >>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
>> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
>> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx
>> >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
>> >> >> >>>> [Permission denied]
>> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18
>> >> >> >13:22:51.818796] I
>> >> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied]
>> >> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
>> >> >> >>>>
>> >> >>
>> >> >>
>> >>
>> >>
>>
>> >>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
>> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
>> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx
>> >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
>> >> >> >>>> [Permission denied]
>> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18
>> >> >> >13:24:43.732856] I
>> >> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied]
>> >> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
>> >> >> >>>>
>> >> >>
>> >> >>
>> >>
>> >>
>>
>> >>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
>> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
>> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx
>> >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
>> >> >> >>>> [Permission denied]
>> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18
>> >> >> >13:26:50.758178] I
>> >> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied]
>> >> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4-
>> >> >> >>>>
>> >> >>
>> >> >>
>> >>
>> >>
>>
>> >>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
>> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806,
>> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx
>> >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-)
>> >> >> >>>> [Permission denied]
>> >> >> >>>>
>> >> >> >>>>
>> >> >> >>>> In my case , the workaround was to downgrade the gluster
>> >> >packages
>> >> >> >on all
>> >> >> >>>> nodes (and reboot each node 1 by 1 ) if the major version is
>> >the
>> >> >> >same, but
>> >> >> >>>> if you upgraded to v7.X - then you can try the v7.0 .
>> >> >> >>>>
>> >> >> >>>> Best Regards,
>> >> >> >>>> Strahil Nikolov
>> >> >> >>>>
>> >> >> >>>>
>> >> >> >>>>
>> >> >> >>>>
>> >> >> >>>>
>> >> >> >>>>
>> >> >> >>>> В събота, 20 юни 2020 г., 18:48:42 ч. Гринуич+3, C Williams <
>> >> >> >>>> cwilliams3320@gmail.com> написа:
>> >> >> >>>>
>> >> >> >>>>
>> >> >> >>>>
>> >> >> >>>>
>> >> >> >>>>
>> >> >> >>>> Hello,
>> >> >> >>>>
>> >> >> >>>> Here are additional log tiles as well as a tree of the
>> >> >problematic
>> >> >> >>>> Gluster storage domain. During this time I attempted to copy
>> >a
>> >> >> >virtual disk
>> >> >> >>>> to another domain, move a virtual disk to another domain and
>> >run
>> >> >a
>> >> >> >VM where
>> >> >> >>>> the virtual hard disk would be used.
>> >> >> >>>>
>> >> >> >>>> The copies/moves failed and the VM went into pause mode when
>> >the
>> >> >> >virtual
>> >> >> >>>> HDD was involved.
>> >> >> >>>>
>> >> >> >>>> Please check these out.
>> >> >> >>>>
>> >> >> >>>> Thank You For Your Help !
>> >> >> >>>>
>> >> >> >>>> On Sat, Jun 20, 2020 at 9:54 AM C Williams
>> >> >> ><cwilliams3320@gmail.com>
>> >> >> >>>> wrote:
>> >> >> >>>> > Strahil,
>> >> >> >>>> >
>> >> >> >>>> > I understand. Please keep me posted.
>> >> >> >>>> >
>> >> >> >>>> > Thanks For The Help !
>> >> >> >>>> >
>> >> >> >>>> > On Sat, Jun 20, 2020 at 4:36 AM Strahil Nikolov
>> >> >> ><hunter86_bg@yahoo.com>
>> >> >> >>>> wrote:
>> >> >> >>>> >> Hey C Williams,
>> >> >> >>>> >>
>> >> >> >>>> >> sorry for the delay, but I couldn't get somw time to
>> >check
>> >> >your
>> >> >> >>>> logs. Will try a little bit later.
>> >> >> >>>> >>
>> >> >> >>>> >> Best Regards,
>> >> >> >>>> >> Strahil Nikolov
>> >> >> >>>> >>
>> >> >> >>>> >> На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams <
>> >> >> >>>> cwilliams3320@gmail.com> написа:
>> >> >> >>>> >>>Hello,
>> >> >> >>>> >>>
>> >> >> >>>> >>>Was wanting to follow up on this issue. Users are
>> >impacted.
>> >> >> >>>> >>>
>> >> >> >>>> >>>Thank You
>> >> >> >>>> >>>
>> >> >> >>>> >>>On Fri, Jun 19, 2020 at 9:20 AM C Williams
>> >> >> ><cwilliams3320@gmail.com>
>> >> >> >>>> >>>wrote:
>> >> >> >>>> >>>
>> >> >> >>>> >>>> Hello,
>> >> >> >>>> >>>>
>> >> >> >>>> >>>> Here are the logs (some IPs are changed )
>> >> >> >>>> >>>>
>> >> >> >>>> >>>> ov05 is the SPM
>> >> >> >>>> >>>>
>> >> >> >>>> >>>> Thank You For Your Help !
>> >> >> >>>> >>>>
>> >> >> >>>> >>>> On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov
>> >> >> >>>> >>><hunter86_bg@yahoo.com>
>> >> >> >>>> >>>> wrote:
>> >> >> >>>> >>>>
>> >> >> >>>> >>>>> Check on the hosts tab , which is your current SPM
>> >(last
>> >> >> >column in
>> >> >> >>>> >>>Admin
>> >> >> >>>> >>>>> UI).
>> >> >> >>>> >>>>> Then open the /var/log/vdsm/vdsm.log and repeat the
>> >> >> >operation.
>> >> >> >>>> >>>>> Then provide the log from that host and the engine's
>> >log
>> >> >(on
>> >> >> >the
>> >> >> >>>> >>>>> HostedEngine VM or on your standalone engine).
>> >> >> >>>> >>>>>
>> >> >> >>>> >>>>> Best Regards,
>> >> >> >>>> >>>>> Strahil Nikolov
>> >> >> >>>> >>>>>
>> >> >> >>>> >>>>> На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams
>> >> >> >>>> >>><cwilliams3320@gmail.com>
>> >> >> >>>> >>>>> написа:
>> >> >> >>>> >>>>> >Resending to eliminate email issues
>> >> >> >>>> >>>>> >
>> >> >> >>>> >>>>> >---------- Forwarded message ---------
>> >> >> >>>> >>>>> >From: C Williams <cwilliams3320@gmail.com>
>> >> >> >>>> >>>>> >Date: Thu, Jun 18, 2020 at 4:01 PM
>> >> >> >>>> >>>>> >Subject: Re: [ovirt-users] Fwd: Issues with Gluster
>> >> >Domain
>> >> >> >>>> >>>>> >To: Strahil Nikolov <hunter86_bg@yahoo.com>
>> >> >> >>>> >>>>> >
>> >> >> >>>> >>>>> >
>> >> >> >>>> >>>>> >Here is output from mount
>> >> >> >>>> >>>>> >
>> >> >> >>>> >>>>> >192.168.24.12:/stor/import0 on
>> >> >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.12:_stor_import0
>> >> >> >>>> >>>>> >type nfs4
>> >> >> >>>> >>>>>
>> >> >> >>>> >>>>>
>> >> >> >>>>
>> >> >> >>>>
>> >> >>
>> >> >>
>> >>
>> >>
>>
>> >>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12)
>> >> >> >>>> >>>>> >192.168.24.13:/stor/import1 on
>> >> >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_import1
>> >> >> >>>> >>>>> >type nfs4
>> >> >> >>>> >>>>>
>> >> >> >>>> >>>>>
>> >> >> >>>>
>> >> >> >>>>
>> >> >>
>> >> >>
>> >>
>> >>
>>
>> >>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
>> >> >> >>>> >>>>> >192.168.24.13:/stor/iso1 on
>> >> >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_iso1
>> >> >> >>>> >>>>> >type nfs4
>> >> >> >>>> >>>>>
>> >> >> >>>> >>>>>
>> >> >> >>>>
>> >> >> >>>>
>> >> >>
>> >> >>
>> >>
>> >>
>>
>> >>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
>> >> >> >>>> >>>>> >192.168.24.13:/stor/export0 on
>> >> >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_export0
>> >> >> >>>> >>>>> >type nfs4
>> >> >> >>>> >>>>>
>> >> >> >>>> >>>>>
>> >> >> >>>>
>> >> >> >>>>
>> >> >>
>> >> >>
>> >>
>> >>
>>
>> >>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13)
>> >> >> >>>> >>>>> >192.168.24.15:/images on
>> >> >> >>>> >>>>> >/rhev/data-center/mnt/glusterSD/192.168.24.15:_images
>> >> >> >>>> >>>>> >type fuse.glusterfs
>> >> >> >>>> >>>>>
>> >> >> >>>> >>>>>
>> >> >> >>>>
>> >> >> >>>>
>> >> >>
>> >> >>
>> >>
>> >>
>>
>> >>>>>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
>> >> >> >>>> >>>>> >192.168.24.18:/images3 on
>> >> >> >>>> >>>>> >/rhev/data-center/mnt/glusterSD/192.168.24.18:_images3
>> >> >> >>>> >>>>> >type fuse.glusterfs
>> >> >> >>>> >>>>>
>> >> >> >>>> >>>>>
>> >> >> >>>>
>> >> >> >>>>
>> >> >>
>> >> >>
>> >>
>> >>
>>
>> >>>>>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
>> >> >> >>>> >>>>> >tmpfs on /run/user/0 type tmpfs
>> >> >> >>>> >>>>>
>> >> >>(rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700)
>> >> >> >>>> >>>>> >[root@ov06 glusterfs]#
>> >> >> >>>> >>>>> >
>> >> >> >>>> >>>>> >Also here is a screenshot of the console
>> >> >> >>>> >>>>> >
>> >> >> >>>> >>>>> >[image: image.png]
>> >> >> >>>> >>>>> >The other domains are up
>> >> >> >>>> >>>>> >
>> >> >> >>>> >>>>> >Import0 and Import1 are NFS . GLCL0 is gluster. They
>> >all
>> >> >are
>> >> >> >>>> >>>running
>> >> >> >>>> >>>>> >VMs
>> >> >> >>>> >>>>> >
>> >> >> >>>> >>>>> >Thank You For Your Help !
>> >> >> >>>> >>>>> >
>> >> >> >>>> >>>>> >On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov
>> >> >> >>>> >>><hunter86_bg@yahoo.com>
>> >> >> >>>> >>>>> >wrote:
>> >> >> >>>> >>>>> >
>> >> >> >>>> >>>>> >> I don't see
>> >> >> >'/rhev/data-center/mnt/192.168.24.13:_stor_import1'
>> >> >> >>>> >>>>> >mounted
>> >> >> >>>> >>>>> >> at all .
>> >> >> >>>> >>>>> >> What is the status of all storage domains ?
>> >> >> >>>> >>>>> >>
>> >> >> >>>> >>>>> >> Best Regards,
>> >> >> >>>> >>>>> >> Strahil Nikolov
>> >> >> >>>> >>>>> >>
>> >> >> >>>> >>>>> >> На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams
>> >> >> >>>> >>>>> ><cwilliams3320@gmail.com>
>> >> >> >>>> >>>>> >> написа:
>> >> >> >>>> >>>>> >> > Resending to deal with possible email issues
>> >> >> >>>> >>>>> >> >
>> >> >> >>>> >>>>> >> >---------- Forwarded message ---------
>> >> >> >>>> >>>>> >> >From: C Williams <cwilliams3320@gmail.com>
>> >> >> >>>> >>>>> >> >Date: Thu, Jun 18, 2020 at 2:07 PM
>> >> >> >>>> >>>>> >> >Subject: Re: [ovirt-users] Issues with Gluster
>> >Domain
>> >> >> >>>> >>>>> >> >To: Strahil Nikolov <hunter86_bg@yahoo.com>
>> >> >> >>>> >>>>> >> >
>> >> >> >>>> >>>>> >> >
>> >> >> >>>> >>>>> >> >More
>> >> >> >>>> >>>>> >> >
>> >> >> >>>> >>>>> >> >[root@ov06 ~]# for i in $(gluster volume list); do
>> >> >echo
>> >> >> >>>> >>>$i;echo;
>> >> >> >>>> >>>>> >> >gluster
>> >> >> >>>> >>>>> >> >volume info $i; echo;echo;gluster volume status
>> >> >> >>>> >>>>> >$i;echo;echo;echo;done
>> >> >> >>>> >>>>> >> >images3
>> >> >> >>>> >>>>> >> >
>> >> >> >>>> >>>>> >> >
>> >> >> >>>> >>>>> >> >Volume Name: images3
>> >> >> >>>> >>>>> >> >Type: Replicate
>> >> >> >>>> >>>>> >> >Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b
>> >> >> >>>> >>>>> >> >Status: Started
>> >> >> >>>> >>>>> >> >Snapshot Count: 0
>> >> >> >>>> >>>>> >> >Number of Bricks: 1 x 3 = 3
>> >> >> >>>> >>>>> >> >Transport-type: tcp
>> >> >> >>>> >>>>> >> >Bricks:
>> >> >> >>>> >>>>> >> >Brick1: 192.168.24.18:/bricks/brick04/images3
>> >> >> >>>> >>>>> >> >Brick2: 192.168.24.19:/bricks/brick05/images3
>> >> >> >>>> >>>>> >> >Brick3: 192.168.24.20:/bricks/brick06/images3
>> >> >> >>>> >>>>> >> >Options Reconfigured:
>> >> >> >>>> >>>>> >> >performance.client-io-threads: on
>> >> >> >>>> >>>>> >> >nfs.disable: on
>> >> >> >>>> >>>>> >> >transport.address-family: inet
>> >> >> >>>> >>>>> >> >user.cifs: off
>> >> >> >>>> >>>>> >> >auth.allow: *
>> >> >> >>>> >>>>> >> >performance.quick-read: off
>> >> >> >>>> >>>>> >> >performance.read-ahead: off
>> >> >> >>>> >>>>> >> >performance.io-cache: off
>> >> >> >>>> >>>>> >> >performance.low-prio-threads: 32
>> >> >> >>>> >>>>> >> >network.remote-dio: off
>> >> >> >>>> >>>>> >> >cluster.eager-lock: enable
>> >> >> >>>> >>>>> >> >cluster.quorum-type: auto
>> >> >> >>>> >>>>> >> >cluster.server-quorum-type: server
>> >> >> >>>> >>>>> >> >cluster.data-self-heal-algorithm: full
>> >> >> >>>> >>>>> >> >cluster.locking-scheme: granular
>> >> >> >>>> >>>>> >> >cluster.shd-max-threads: 8
>> >> >> >>>> >>>>> >> >cluster.shd-wait-qlength: 10000
>> >> >> >>>> >>>>> >> >features.shard: on
>> >> >> >>>> >>>>> >> >cluster.choose-local: off
>> >> >> >>>> >>>>> >> >client.event-threads: 4
>> >> >> >>>> >>>>> >> >server.event-threads: 4
>> >> >> >>>> >>>>> >> >storage.owner-uid: 36
>> >> >> >>>> >>>>> >> >storage.owner-gid: 36
>> >> >> >>>> >>>>> >> >performance.strict-o-direct: on
>> >> >> >>>> >>>>> >> >network.ping-timeout: 30
>> >> >> >>>> >>>>> >> >cluster.granular-entry-heal: enable
>> >> >> >>>> >>>>> >> >
>> >> >> >>>> >>>>> >> >
>> >> >> >>>> >>>>> >> >Status of volume: images3
>> >> >> >>>> >>>>> >> >Gluster process TCP
>> >Port
>> >> >> >RDMA Port
>> >> >> >>>> >>>>> >Online
>> >> >> >>>> >>>>> >> > Pid
>> >> >> >>>> >>>>> >>
>> >> >> >>>> >>>>> >>
>> >> >> >>>> >>>>>
>> >> >> >>>> >>>>>
>> >> >> >>>>
>> >> >> >>>>
>> >> >>
>> >> >>
>> >>
>> >>
>>
>> >>>>>>>>------------------------------------------------------------------------------
>> >> >> >>>> >>>>> >> >Brick 192.168.24.18:/bricks/brick04/images3 49152
>> >> >0
>> >> >> >>>>
>> >> >> >>>> >>>Y
>> >> >> >>>> >>>>> >> >6666
>> >> >> >>>> >>>>> >> >Brick 192.168.24.19:/bricks/brick05/images3 49152
>> >> >0
>> >> >> >>>>
>> >> >> >>>> >>>Y
>> >> >> >>>> >>>>> >> >6779
>> >> >> >>>> >>>>> >> >Brick 192.168.24.20:/bricks/brick06/images3 49152
>> >> >0
>> >> >> >>>>
>> >> >> >>>> >>>Y
>> >> >> >>>> >>>>> >> >7227
>> >> >> >>>> >>>>> >> >Self-heal Daemon on localhost N/A
>> >> >N/A
>> >> >> >>>>
>> >> >> >>>> >>>Y
>> >> >> >>>> >>>>> >> >6689
>> >> >> >>>> >>>>> >> >Self-heal Daemon on ov07.ntc.srcle.com N/A
>> >> >N/A
>> >> >> >>>>
>> >> >> >>>> >>>Y
>> >> >> >>>> >>>>> >> >6802
>> >> >> >>>> >>>>> >> >Self-heal Daemon on ov08.ntc.srcle.com N/A
>> >> >N/A
>> >> >> >>>>
>> >> >> >>>> >>>Y
>> >> >> >>>> >>>>> >> >7250
>> >> >> >>>> >>>>> >> >
>> >> >> >>>> >>>>> >> >Task Status of Volume images3
>> >> >> >>>> >>>>> >>
>> >> >> >>>> >>>>> >>
>> >> >> >>>> >>>>>
>> >> >> >>>> >>>>>
>> >> >> >>>>
>> >> >> >>>>
>> >> >>
>> >> >>
>> >>
>> >>
>>
>> >>>>>>>>------------------------------------------------------------------------------
>> >> >> >>>> >>>>> >> >There are no active volume tasks
>> >> >> >>>> >>>>> >> >
>> >> >> >>>> >>>>> >> >
>> >> >> >>>> >>>>> >> >
>> >> >> >>>> >>>>> >> >
>> >> >> >>>> >>>>> >> >[root@ov06 ~]# ls -l
>> >/rhev/data-center/mnt/glusterSD/
>> >> >> >>>> >>>>> >> >total 16
>> >> >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04
>> >> >> >192.168.24.15:_images
>> >> >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05
>> >> >192.168.24.18:
>> >> >> >>>> _images3
>> >> >> >>>> >>>>> >> >[root@ov06 ~]#
>> >> >> >>>> >>>>> >> >
>> >> >> >>>> >>>>> >> >On Thu, Jun 18, 2020 at 2:03 PM C Williams
>> >> >> >>>> >>><cwilliams3320@gmail.com>
>> >> >> >>>> >>>>> >> >wrote:
>> >> >> >>>> >>>>> >> >
>> >> >> >>>> >>>>> >> >> Strahil,
>> >> >> >>>> >>>>> >> >>
>> >> >> >>>> >>>>> >> >> Here you go -- Thank You For Your Help !
>> >> >> >>>> >>>>> >> >>
>> >> >> >>>> >>>>> >> >> BTW -- I can write a test file to gluster and it
>> >> >> >replicates
>> >> >> >>>> >>>>> >properly.
>> >> >> >>>> >>>>> >> >> Thinking something about the oVirt Storage Domain
>> >?
>> >> >> >>>> >>>>> >> >>
>> >> >> >>>> >>>>> >> >> [root@ov08 ~]# gluster pool list
>> >> >> >>>> >>>>> >> >> UUID Hostname
>> >> >> >>>> >>>>> >State
>> >> >> >>>> >>>>> >> >> 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06
>> >> >> >>>> >>>>> >> >Connected
>> >> >> >>>> >>>>> >> >> 36ce5a00-6f65-4926-8438-696944ebadb5
>> >> >> >ov07.ntc.srcle.com
>> >> >> >>>> >>>>> >> >Connected
>> >> >> >>>> >>>>> >> >> c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost
>> >> >> >>>> >>>>> >> >Connected
>> >> >> >>>> >>>>> >> >> [root@ov08 ~]# gluster volume list
>> >> >> >>>> >>>>> >> >> images3
>> >> >> >>>> >>>>> >> >>
>> >> >> >>>> >>>>> >> >> On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov
>> >> >> >>>> >>>>> >> ><hunter86_bg@yahoo.com>
>> >> >> >>>> >>>>> >> >> wrote:
>> >> >> >>>> >>>>> >> >>
>> >> >> >>>> >>>>> >> >>> Log to the oVirt cluster and provide the output
>> >of:
>> >> >> >>>> >>>>> >> >>> gluster pool list
>> >> >> >>>> >>>>> >> >>> gluster volume list
>> >> >> >>>> >>>>> >> >>> for i in $(gluster volume list); do echo
>> >$i;echo;
>> >> >> >gluster
>> >> >> >>>> >>>>> >volume
>> >> >> >>>> >>>>> >> >info
>> >> >> >>>> >>>>> >> >>> $i; echo;echo;gluster volume status
>> >> >> >$i;echo;echo;echo;done
>> >> >> >>>> >>>>> >> >>>
>> >> >> >>>> >>>>> >> >>> ls -l /rhev/data-center/mnt/glusterSD/
>> >> >> >>>> >>>>> >> >>>
>> >> >> >>>> >>>>> >> >>> Best Regards,
>> >> >> >>>> >>>>> >> >>> Strahil Nikolov
>> >> >> >>>> >>>>> >> >>>
>> >> >> >>>> >>>>> >> >>>
>> >> >> >>>> >>>>> >> >>> На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams
>> >> >> >>>> >>>>> >> ><cwilliams3320@gmail.com>
>> >> >> >>>> >>>>> >> >>> написа:
>> >> >> >>>> >>>>> >> >>> >Hello,
>> >> >> >>>> >>>>> >> >>> >
>> >> >> >>>> >>>>> >> >>> >I recently added 6 hosts to an existing oVirt
>> >> >> >>>> >>>compute/gluster
>> >> >> >>>> >>>>> >> >cluster.
>> >> >> >>>> >>>>> >> >>> >
>> >> >> >>>> >>>>> >> >>> >Prior to this attempted addition, my cluster
>> >had 3
>> >> >> >>>> >>>Hypervisor
>> >> >> >>>> >>>>> >hosts
>> >> >> >>>> >>>>> >> >and
>> >> >> >>>> >>>>> >> >>> >3
>> >> >> >>>> >>>>> >> >>> >gluster bricks which made up a single gluster
>> >> >volume
>> >> >> >>>> >>>(replica 3
>> >> >> >>>> >>>>> >> >volume)
>> >> >> >>>> >>>>> >> >>> >. I
>> >> >> >>>> >>>>> >> >>> >added the additional hosts and made a brick on
>> >3
>> >> >of
>> >> >> >the new
>> >> >> >>>> >>>>> >hosts
>> >> >> >>>> >>>>> >> >and
>> >> >> >>>> >>>>> >> >>> >attempted to make a new replica 3 volume. I had
>> >> >> >difficulty
>> >> >> >>>> >>>>> >> >creating
>> >> >> >>>> >>>>> >> >>> >the
>> >> >> >>>> >>>>> >> >>> >new volume. So, I decided that I would make a
>> >new
>> >> >> >>>> >>>>> >compute/gluster
>> >> >> >>>> >>>>> >> >>> >cluster
>> >> >> >>>> >>>>> >> >>> >for each set of 3 new hosts.
>> >> >> >>>> >>>>> >> >>> >
>> >> >> >>>> >>>>> >> >>> >I removed the 6 new hosts from the existing
>> >oVirt
>> >> >> >>>> >>>>> >Compute/Gluster
>> >> >> >>>> >>>>> >> >>> >Cluster
>> >> >> >>>> >>>>> >> >>> >leaving the 3 original hosts in place with
>> >their
>> >> >> >bricks. At
>> >> >> >>>> >>>that
>> >> >> >>>> >>>>> >> >point
>> >> >> >>>> >>>>> >> >>> >my
>> >> >> >>>> >>>>> >> >>> >original bricks went down and came back up .
>> >The
>> >> >> >volume
>> >> >> >>>> >>>showed
>> >> >> >>>> >>>>> >> >entries
>> >> >> >>>> >>>>> >> >>> >that
>> >> >> >>>> >>>>> >> >>> >needed healing. At that point I ran gluster
>> >volume
>> >> >> >heal
>> >> >> >>>> >>>images3
>> >> >> >>>> >>>>> >> >full,
>> >> >> >>>> >>>>> >> >>> >etc.
>> >> >> >>>> >>>>> >> >>> >The volume shows no unhealed entries. I also
>> >> >> >corrected some
>> >> >> >>>> >>>peer
>> >> >> >>>> >>>>> >> >>> >errors.
>> >> >> >>>> >>>>> >> >>> >
>> >> >> >>>> >>>>> >> >>> >However, I am unable to copy disks, move disks
>> >to
>> >> >> >another
>> >> >> >>>> >>>>> >domain,
>> >> >> >>>> >>>>> >> >>> >export
>> >> >> >>>> >>>>> >> >>> >disks, etc. It appears that the engine cannot
>> >> >locate
>> >> >> >disks
>> >> >> >>>> >>>>> >properly
>> >> >> >>>> >>>>> >> >and
>> >> >> >>>> >>>>> >> >>> >I
>> >> >> >>>> >>>>> >> >>> >get storage I/O errors.
>> >> >> >>>> >>>>> >> >>> >
>> >> >> >>>> >>>>> >> >>> >I have detached and removed the oVirt Storage
>> >> >Domain.
>> >> >> >I
>> >> >> >>>> >>>>> >reimported
>> >> >> >>>> >>>>> >> >the
>> >> >> >>>> >>>>> >> >>> >domain and imported 2 VMs, But the VM disks
>> >> >exhibit
>> >> >> >the
>> >> >> >>>> same
>> >> >> >>>> >>>>> >> >behaviour
>> >> >> >>>> >>>>> >> >>> >and
>> >> >> >>>> >>>>> >> >>> >won't run from the hard disk.
>> >> >> >>>> >>>>> >> >>> >
>> >> >> >>>> >>>>> >> >>> >
>> >> >> >>>> >>>>> >> >>> >I get errors such as this
>> >> >> >>>> >>>>> >> >>> >
>> >> >> >>>> >>>>> >> >>> >VDSM ov05 command HSMGetAllTasksStatusesVDS
>> >> >failed:
>> >> >> >low
>> >> >> >>>> >>>level
>> >> >> >>>> >>>>> >Image
>> >> >> >>>> >>>>> >> >>> >copy
>> >> >> >>>> >>>>> >> >>> >failed: ("Command ['/usr/bin/qemu-img',
>> >'convert',
>> >> >> >'-p',
>> >> >> >>>> >>>'-t',
>> >> >> >>>> >>>>> >> >'none',
>> >> >> >>>> >>>>> >> >>> >'-T', 'none', '-f', 'raw',
>> >> >> >>>> >>>>> >> >>>
>> >>u'/rhev/data-center/mnt/glusterSD/192.168.24.18:
>> >> >> >>>> >>>>> >> >>>
>> >> >> >>>> >>>>> >>
>> >> >> >>>> >>>>> >>
>> >> >> >>>> >>>>>
>> >> >> >>>> >>>>>
>> >> >> >>>>
>> >> >> >>>>
>> >> >>
>> >> >>
>> >>
>> >>
>>
>> >>>>>>>>_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510',
>> >> >> >>>> >>>>> >> >>> >'-O', 'raw',
>> >> >> >>>> >>>>> >> >>> >u'/rhev/data-center/mnt/192.168.24.13:
>> >> >> >>>> >>>>> >> >>>
>> >> >> >>>> >>>>> >>
>> >> >> >>>> >>>>> >>
>> >> >> >>>> >>>>>
>> >> >> >>>> >>>>>
>> >> >> >>>>
>> >> >> >>>>
>> >> >>
>> >> >>
>> >>
>> >>
>>
>> >>>>>>>>_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5']
>> >> >> >>>> >>>>> >> >>> >failed with rc=1 out=''
>> >err=bytearray(b'qemu-img:
>> >> >> >error
>> >> >> >>>> >>>while
>> >> >> >>>> >>>>> >> >reading
>> >> >> >>>> >>>>> >> >>> >sector 135168: Transport endpoint is not
>> >> >> >>>> >>>connected\\nqemu-img:
>> >> >> >>>> >>>>> >> >error
>> >> >> >>>> >>>>> >> >>> >while
>> >> >> >>>> >>>>> >> >>> >reading sector 131072: Transport endpoint is
>> >not
>> >> >> >>>> >>>>> >> >connected\\nqemu-img:
>> >> >> >>>> >>>>> >> >>> >error while reading sector 139264: Transport
>> >> >endpoint
>> >> >> >is
>> >> >> >>>> not
>> >> >> >>>> >>>>> >> >>> >connected\\nqemu-img: error while reading
>> >sector
>> >> >> >143360:
>> >> >> >>>> >>>>> >Transport
>> >> >> >>>> >>>>> >> >>> >endpoint
>> >> >> >>>> >>>>> >> >>> >is not connected\\nqemu-img: error while
>> >reading
>> >> >> >sector
>> >> >> >>>> >>>147456:
>> >> >> >>>> >>>>> >> >>> >Transport
>> >> >> >>>> >>>>> >> >>> >endpoint is not connected\\nqemu-img: error
>> >while
>> >> >> >reading
>> >> >> >>>> >>>sector
>> >> >> >>>> >>>>> >> >>> >155648:
>> >> >> >>>> >>>>> >> >>> >Transport endpoint is not connected\\nqemu-img:
>> >> >error
>> >> >> >while
>> >> >> >>>> >>>>> >reading
>> >> >> >>>> >>>>> >> >>> >sector
>> >> >> >>>> >>>>> >> >>> >151552: Transport endpoint is not
>> >> >> >connected\\nqemu-img:
>> >> >> >>>> >>>error
>> >> >> >>>> >>>>> >while
>> >> >> >>>> >>>>> >> >>> >reading
>> >> >> >>>> >>>>> >> >>> >sector 159744: Transport endpoint is not
>> >> >> >connected\\n')",)
>> >> >> >>>> >>>>> >> >>> >
>> >> >> >>>> >>>>> >> >>> >oVirt version is 4.3.82-1.el7
>> >> >> >>>> >>>>> >> >>> >OS CentOS Linux release 7.7.1908 (Core)
>> >> >> >>>> >>>>> >> >>> >
>> >> >> >>>> >>>>> >> >>> >The Gluster Cluster has been working very well
>> >> >until
>> >> >> >this
>> >> >> >>>> >>>>> >incident.
>> >> >> >>>> >>>>> >> >>> >
>> >> >> >>>> >>>>> >> >>> >Please help.
>> >> >> >>>> >>>>> >> >>> >
>> >> >> >>>> >>>>> >> >>> >Thank You
>> >> >> >>>> >>>>> >> >>> >
>> >> >> >>>> >>>>> >> >>> >Charles Williams
>> >> >> >>>> >>>>> >> >>>
>> >> >> >>>> >>>>> >> >>
>> >> >> >>>> >>>>> >>
>> >> >> >>>> >>>>>
>> >> >> >>>> >>>>
>> >> >> >>>> >>
>> >> >> >>>> >
>> >> >> >>>> _______________________________________________
>> >> >> >>>> Users mailing list -- users@ovirt.org
>> >> >> >>>> To unsubscribe send an email to users-leave@ovirt.org
>> >> >> >>>> Privacy Statement: https://www.ovirt.org/privacy-policy.html
>> >> >> >>>> oVirt Code of Conduct:
>> >> >> >>>> https://www.ovirt.org/community/about/community-guidelines/
>> >> >> >>>> List Archives:
>> >> >> >>>>
>> >> >> >
>> >> >>
>> >> >
>> >>
>> >
>> https://lists.ovirt.org/archives/list/users@ovirt.org/message/YY3VUKEJLI7MRWXF627EHQAMH36UJ5BQ/
>> >> >> >>>>
>> >> >> >>>
>> >> >>
>> >>
>>
>
You are definitely reading it wrong. 1. I didn't create a new storage domain ontop this new volume. 2. I used cli Something like this (in your case it should be 'replica 3'): gluster volume create newvol replica 3 arbiter 1 ovirt1:/new/brick/path ovirt2:/new/brick/path ovirt3:/new/arbiter/brick/path gluster volume start newvol #Detach oldvol from ovirt mount -t glusterfs ovirt1:/oldvol /mnt/oldvol mount -t glusterfs ovirt1:/newvol /mnt/newvol cp -a /mnt/oldvol/* /mnt/newvol #Add only newvol as a storage domain in oVirt #Import VMs I still think that you should downgrade your gluster packages!!! Best Regards, Strahil Nikolov На 22 юни 2020 г. 0:43:46 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Strahil,
It sounds like you used a "System Managed Volume" for the new storage domain,is that correct?
Thank You For Your Help !
On Sun, Jun 21, 2020 at 5:40 PM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
So you made another oVirt Storage Domain -- then copied the data with cp -a from the failed volume to the new volume.
At the root of the volume there will be the old domain folder id ex 5fe3ad3f-2d21-404c-832e-4dc7318ca10d in my case. Did that cause issues with making the new domain since it is the same folder id as the old one ?
Thank You For Your Help !
On Sun, Jun 21, 2020 at 5:18 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
In my situation I had only the ovirt nodes.
Strahil,
So should I make the target volume on 3 bricks which do not have ovirt -- just gluster ? In other words (3) Centos 7 hosts ?
Thank You For Your Help !
On Sun, Jun 21, 2020 at 3:08 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
I created a fresh volume (which is not an ovirt sgorage domain), set the original storage domain in maintenance and detached it. Then I 'cp -a ' the data from the old to the new volume. Next, I just added the new storage domain (the old one was a kind of a 'backup') - pointing to the new volume name.
If you observe issues , I would recommend you to downgrade gluster packages one node at a time . Then you might be able to restore your oVirt operations.
Best Regards, Strahil Nikolov
На 21 юни 2020 г. 18:01:31 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Strahil,
Thanks for the follow up !
How did you copy the data to another volume ?
I have set up another storage domain GLCLNEW1 with a new volume imgnew1 . How would you copy all of the data from the problematic domain GLCL3 with volume images3 to GLCLNEW1 and volume imgnew1 and preserve all
На 21 юни 2020 г. 22:43:04 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: the
VMs,
VM disks, settings, etc. ?
Remember all of the regular ovirt disk copy, disk move, VM export tools are failing and my VMs and disks are trapped on domain GLCL3 and volume images3 right now.
Please let me know
Thank You For Your Help !
On Sun, Jun 21, 2020 at 8:27 AM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
> Sorry to hear that. > I can say that for me 6.5 was working, while 6.6 didn't and I upgraded > to 7.0 . > In the ended , I have ended with creating a new fresh volume and > physically copying the data there, then I detached the storage domains and > attached to the new ones (which holded the old data), but I could > afford the downtime. > Also, I can say that v7.0 ( but not 7.1 or anything later) also > worked without the ACL issue, but it causes some trouble in oVirt - so > avoid that unless you have no other options. > > Best Regards, > Strahil Nikolov > > > > > На 21 юни 2020 г. 4:39:46 GMT+03:00, C Williams <cwilliams3320@gmail.com> > написа: > >Hello, > > > >Upgrading diidn't help > > > >Still acl errors trying to use a Virtual Disk from a VM > > > >[root@ov06 bricks]# tail bricks-brick04-images3.log | grep acl > >[2020-06-21 01:33:45.665888] I [MSGID: 139001] > >[posix-acl.c:263:posix_acl_log_permit_denied] 0-images3-access-control: > >client: > >
CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0,
> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >req(uid:107,gid:107,perm:1,ngrps:3), > >ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) > >[Permission denied] > >The message "I [MSGID: 139001] > >[posix-acl.c:263:posix_acl_log_permit_denied] 0-images3-access-control: > >client: > >
> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >req(uid:107,gid:107,perm:1,ngrps:3), > >ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) > >[Permission denied]" repeated 2 times between [2020-06-21 > >01:33:45.665888] > >and [2020-06-21 01:33:45.806779] > > > >Thank You For Your Help ! > > > >On Sat, Jun 20, 2020 at 8:59 PM C Williams <cwilliams3320@gmail.com> > >wrote: > > > >> Hello, > >> > >> Based on the situation, I am planning to upgrade the 3 affected > >hosts. > >> > >> My reasoning is that the hosts/bricks were attached to 6.9 at one > >time. > >> > >> Thanks For Your Help ! > >> > >> On Sat, Jun 20, 2020 at 8:38 PM C Williams <cwilliams3320@gmail.com> > >> wrote: > >> > >>> Strahil, > >>> > >>> The gluster version on the current 3 gluster hosts is 6.7 (last > >update > >>> 2/26). These 3 hosts provide 1 brick each for the replica 3 volume. > >>> > >>> Earlier I had tried to add 6 additional hosts to the cluster. Those > >new > >>> hosts were 6.9 gluster. > >>> > >>> I attempted to make a new separate volume with 3 bricks
by > >the 3 > >>> new gluster 6.9 hosts. After having many errors from the oVirt > >interface, > >>> I gave up and removed the 6 new hosts from the cluster. That is > >where the > >>> problems started. The intent was to expand the gluster cluster while > >making > >>> 2 new volumes for that cluster. The ovirt compute cluster would > >allow for > >>> efficient VM migration between 9 hosts -- while having separate > >gluster > >>> volumes for safety purposes. > >>> > >>> Looking at the brick logs, I see where there are acl errors starting > >from > >>> the time of the removal of the 6 new hosts. > >>> > >>> Please check out the attached brick log from 6/14-18. The events > >started > >>> on 6/17. > >>> > >>> I wish I had a downgrade path. > >>> > >>> Thank You For The Help !! > >>> > >>> On Sat, Jun 20, 2020 at 7:47 PM Strahil Nikolov > ><hunter86_bg@yahoo.com> > >>> wrote: > >>> > >>>> Hi , > >>>> > >>>> > >>>> This one really looks like the ACL bug I was hit with when I > >updated > >>>> from Gluster v6.5 to 6.6 and later from 7.0 to 7.2. > >>>> > >>>> Did you update your setup recently ? Did you upgrade gluster also ? > >>>> > >>>> You have to check the gluster logs in order to verify
CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0, provided that, so
you > >can > >>>> try: > >>>> > >>>> 1. Set Gluster logs to trace level (for details check: > >>>> > > >
> >>>> ) > >>>> 2. Power up a VM that was already off , or retry the procedure from > >the > >>>> logs you sent. > >>>> 3. Stop the trace level of the logs > >>>> 4. Check libvirt logs on the host that was supposed to
up
the > >VM > >>>> (in case a VM was powered on) > >>>> 5. Check the gluster brick logs on all nodes for ACL errors. > >>>> Here is a sample from my old logs: > >>>> > >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 > >13:19:41.489047] I > >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] > >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- > >>>> > >
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx > >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) > >>>> [Permission denied] > >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 > >13:22:51.818796] I > >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] > >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- > >>>> > >
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx > >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) > >>>> [Permission denied] > >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 > >13:24:43.732856] I > >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] > >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- > >>>> > >
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx > >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) > >>>> [Permission denied] > >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 > >13:26:50.758178] I > >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] > >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- > >>>> > >
> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx > >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) > >>>> [Permission denied] > >>>> > >>>> > >>>> In my case , the workaround was to downgrade the gluster packages > >on all > >>>> nodes (and reboot each node 1 by 1 ) if the major version is
> >same, but > >>>> if you upgraded to v7.X - then you can try the v7.0 . > >>>> > >>>> Best Regards, > >>>> Strahil Nikolov > >>>> > >>>> > >>>> > >>>> > >>>> > >>>> > >>>> В събота, 20 юни 2020 г., 18:48:42 ч. Гринуич+3, C Williams < > >>>> cwilliams3320@gmail.com> написа: > >>>> > >>>> > >>>> > >>>> > >>>> > >>>> Hello, > >>>> > >>>> Here are additional log tiles as well as a tree of the problematic > >>>> Gluster storage domain. During this time I attempted to copy a > >virtual disk > >>>> to another domain, move a virtual disk to another domain and run a > >VM where > >>>> the virtual hard disk would be used. > >>>> > >>>> The copies/moves failed and the VM went into pause mode when
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, the the
> >virtual > >>>> HDD was involved. > >>>> > >>>> Please check these out. > >>>> > >>>> Thank You For Your Help ! > >>>> > >>>> On Sat, Jun 20, 2020 at 9:54 AM C Williams > ><cwilliams3320@gmail.com> > >>>> wrote: > >>>> > Strahil, > >>>> > > >>>> > I understand. Please keep me posted. > >>>> > > >>>> > Thanks For The Help ! > >>>> > > >>>> > On Sat, Jun 20, 2020 at 4:36 AM Strahil Nikolov > ><hunter86_bg@yahoo.com> > >>>> wrote: > >>>> >> Hey C Williams, > >>>> >> > >>>> >> sorry for the delay, but I couldn't get somw time to check your > >>>> logs. Will try a little bit later. > >>>> >> > >>>> >> Best Regards, > >>>> >> Strahil Nikolov > >>>> >> > >>>> >> На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams < > >>>> cwilliams3320@gmail.com> написа: > >>>> >>>Hello, > >>>> >>> > >>>> >>>Was wanting to follow up on this issue. Users are impacted. > >>>> >>> > >>>> >>>Thank You > >>>> >>> > >>>> >>>On Fri, Jun 19, 2020 at 9:20 AM C Williams > ><cwilliams3320@gmail.com> > >>>> >>>wrote: > >>>> >>> > >>>> >>>> Hello, > >>>> >>>> > >>>> >>>> Here are the logs (some IPs are changed ) > >>>> >>>> > >>>> >>>> ov05 is the SPM > >>>> >>>> > >>>> >>>> Thank You For Your Help ! > >>>> >>>> > >>>> >>>> On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov > >>>> >>><hunter86_bg@yahoo.com> > >>>> >>>> wrote: > >>>> >>>> > >>>> >>>>> Check on the hosts tab , which is your current SPM (last > >column in > >>>> >>>Admin > >>>> >>>>> UI). > >>>> >>>>> Then open the /var/log/vdsm/vdsm.log and repeat
https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3/html... power the
> >operation. > >>>> >>>>> Then provide the log from that host and the engine's log (on > >the > >>>> >>>>> HostedEngine VM or on your standalone engine). > >>>> >>>>> > >>>> >>>>> Best Regards, > >>>> >>>>> Strahil Nikolov > >>>> >>>>> > >>>> >>>>> На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams > >>>> >>><cwilliams3320@gmail.com> > >>>> >>>>> написа: > >>>> >>>>> >Resending to eliminate email issues > >>>> >>>>> > > >>>> >>>>> >---------- Forwarded message --------- > >>>> >>>>> >From: C Williams <cwilliams3320@gmail.com> > >>>> >>>>> >Date: Thu, Jun 18, 2020 at 4:01 PM > >>>> >>>>> >Subject: Re: [ovirt-users] Fwd: Issues with Gluster Domain > >>>> >>>>> >To: Strahil Nikolov <hunter86_bg@yahoo.com> > >>>> >>>>> > > >>>> >>>>> > > >>>> >>>>> >Here is output from mount > >>>> >>>>> > > >>>> >>>>> >192.168.24.12:/stor/import0 on > >>>> >>>>> >/rhev/data-center/mnt/192.168.24.12:_stor_import0 > >>>> >>>>> >type nfs4 > >>>> >>>>> > >>>> >>>>> > >>>> > >>>> > >
>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12) > >>>> >>>>> >192.168.24.13:/stor/import1 on > >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_import1 > >>>> >>>>> >type nfs4 > >>>> >>>>> > >>>> >>>>> > >>>> > >>>> > >
>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) > >>>> >>>>> >192.168.24.13:/stor/iso1 on > >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_iso1 > >>>> >>>>> >type nfs4 > >>>> >>>>> > >>>> >>>>> > >>>> > >>>> > >
>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) > >>>> >>>>> >192.168.24.13:/stor/export0 on > >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_export0 > >>>> >>>>> >type nfs4 > >>>> >>>>> > >>>> >>>>> > >>>> > >>>> > >
>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) > >>>> >>>>> >192.168.24.15:/images on > >>>> >>>>> /rhev/data-center/mnt/glusterSD/192.168.24.15:_images > >>>> >>>>> >type fuse.glusterfs > >>>> >>>>> > >>>> >>>>> > >>>> > >>>> > >
>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) > >>>> >>>>> >192.168.24.18:/images3 on > >>>> >>>>> /rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 > >>>> >>>>> >type fuse.glusterfs > >>>> >>>>> > >>>> >>>>> > >>>> > >>>> > >
>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) > >>>> >>>>> >tmpfs on /run/user/0 type tmpfs > >>>> >>>>> >(rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) > >>>> >>>>> >[root@ov06 glusterfs]# > >>>> >>>>> > > >>>> >>>>> >Also here is a screenshot of the console > >>>> >>>>> > > >>>> >>>>> >[image: image.png] > >>>> >>>>> >The other domains are up > >>>> >>>>> > > >>>> >>>>> >Import0 and Import1 are NFS . GLCL0 is gluster. They all are > >>>> >>>running > >>>> >>>>> >VMs > >>>> >>>>> > > >>>> >>>>> >Thank You For Your Help ! > >>>> >>>>> > > >>>> >>>>> >On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov > >>>> >>><hunter86_bg@yahoo.com> > >>>> >>>>> >wrote: > >>>> >>>>> > > >>>> >>>>> >> I don't see > >'/rhev/data-center/mnt/192.168.24.13:_stor_import1' > >>>> >>>>> >mounted > >>>> >>>>> >> at all . > >>>> >>>>> >> What is the status of all storage domains ? > >>>> >>>>> >> > >>>> >>>>> >> Best Regards, > >>>> >>>>> >> Strahil Nikolov > >>>> >>>>> >> > >>>> >>>>> >> На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams > >>>> >>>>> ><cwilliams3320@gmail.com> > >>>> >>>>> >> написа: > >>>> >>>>> >> > Resending to deal with possible email issues > >>>> >>>>> >> > > >>>> >>>>> >> >---------- Forwarded message --------- > >>>> >>>>> >> >From: C Williams <cwilliams3320@gmail.com> > >>>> >>>>> >> >Date: Thu, Jun 18, 2020 at 2:07 PM > >>>> >>>>> >> >Subject: Re: [ovirt-users] Issues with Gluster Domain > >>>> >>>>> >> >To: Strahil Nikolov <hunter86_bg@yahoo.com> > >>>> >>>>> >> > > >>>> >>>>> >> > > >>>> >>>>> >> >More > >>>> >>>>> >> > > >>>> >>>>> >> >[root@ov06 ~]# for i in $(gluster volume list); do echo > >>>> >>>$i;echo; > >>>> >>>>> >> >gluster > >>>> >>>>> >> >volume info $i; echo;echo;gluster volume status > >>>> >>>>> >$i;echo;echo;echo;done > >>>> >>>>> >> >images3 > >>>> >>>>> >> > > >>>> >>>>> >> > > >>>> >>>>> >> >Volume Name: images3 > >>>> >>>>> >> >Type: Replicate > >>>> >>>>> >> >Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b > >>>> >>>>> >> >Status: Started > >>>> >>>>> >> >Snapshot Count: 0 > >>>> >>>>> >> >Number of Bricks: 1 x 3 = 3 > >>>> >>>>> >> >Transport-type: tcp > >>>> >>>>> >> >Bricks: > >>>> >>>>> >> >Brick1: 192.168.24.18:/bricks/brick04/images3 > >>>> >>>>> >> >Brick2: 192.168.24.19:/bricks/brick05/images3 > >>>> >>>>> >> >Brick3: 192.168.24.20:/bricks/brick06/images3 > >>>> >>>>> >> >Options Reconfigured: > >>>> >>>>> >> >performance.client-io-threads: on > >>>> >>>>> >> >nfs.disable: on > >>>> >>>>> >> >transport.address-family: inet > >>>> >>>>> >> >user.cifs: off > >>>> >>>>> >> >auth.allow: * > >>>> >>>>> >> >performance.quick-read: off > >>>> >>>>> >> >performance.read-ahead: off > >>>> >>>>> >> >performance.io-cache: off > >>>> >>>>> >> >performance.low-prio-threads: 32 > >>>> >>>>> >> >network.remote-dio: off > >>>> >>>>> >> >cluster.eager-lock: enable > >>>> >>>>> >> >cluster.quorum-type: auto > >>>> >>>>> >> >cluster.server-quorum-type: server > >>>> >>>>> >> >cluster.data-self-heal-algorithm: full > >>>> >>>>> >> >cluster.locking-scheme: granular > >>>> >>>>> >> >cluster.shd-max-threads: 8 > >>>> >>>>> >> >cluster.shd-wait-qlength: 10000 > >>>> >>>>> >> >features.shard: on > >>>> >>>>> >> >cluster.choose-local: off > >>>> >>>>> >> >client.event-threads: 4 > >>>> >>>>> >> >server.event-threads: 4 > >>>> >>>>> >> >storage.owner-uid: 36 > >>>> >>>>> >> >storage.owner-gid: 36 > >>>> >>>>> >> >performance.strict-o-direct: on > >>>> >>>>> >> >network.ping-timeout: 30 > >>>> >>>>> >> >cluster.granular-entry-heal: enable > >>>> >>>>> >> > > >>>> >>>>> >> > > >>>> >>>>> >> >Status of volume: images3 > >>>> >>>>> >> >Gluster process TCP Port > >RDMA Port > >>>> >>>>> >Online > >>>> >>>>> >> > Pid > >>>> >>>>> >> > >>>> >>>>> >> > >>>> >>>>> > >>>> >>>>> > >>>> > >>>> > >
>>>------------------------------------------------------------------------------ > >>>> >>>>> >> >Brick 192.168.24.18:/bricks/brick04/images3 49152 0 > >>>> > >>>> >>>Y > >>>> >>>>> >> >6666 > >>>> >>>>> >> >Brick 192.168.24.19:/bricks/brick05/images3 49152 0 > >>>> > >>>> >>>Y > >>>> >>>>> >> >6779 > >>>> >>>>> >> >Brick 192.168.24.20:/bricks/brick06/images3 49152 0 > >>>> > >>>> >>>Y > >>>> >>>>> >> >7227 > >>>> >>>>> >> >Self-heal Daemon on localhost N/A N/A > >>>> > >>>> >>>Y > >>>> >>>>> >> >6689 > >>>> >>>>> >> >Self-heal Daemon on ov07.ntc.srcle.com N/A N/A > >>>> > >>>> >>>Y > >>>> >>>>> >> >6802 > >>>> >>>>> >> >Self-heal Daemon on ov08.ntc.srcle.com N/A N/A > >>>> > >>>> >>>Y > >>>> >>>>> >> >7250 > >>>> >>>>> >> > > >>>> >>>>> >> >Task Status of Volume images3 > >>>> >>>>> >> > >>>> >>>>> >> > >>>> >>>>> > >>>> >>>>> > >>>> > >>>> > >
>>>------------------------------------------------------------------------------ > >>>> >>>>> >> >There are no active volume tasks > >>>> >>>>> >> > > >>>> >>>>> >> > > >>>> >>>>> >> > > >>>> >>>>> >> > > >>>> >>>>> >> >[root@ov06 ~]# ls -l /rhev/data-center/mnt/glusterSD/ > >>>> >>>>> >> >total 16 > >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 > >192.168.24.15:_images > >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 192.168.24.18: > >>>> _images3 > >>>> >>>>> >> >[root@ov06 ~]# > >>>> >>>>> >> > > >>>> >>>>> >> >On Thu, Jun 18, 2020 at 2:03 PM C Williams > >>>> >>><cwilliams3320@gmail.com> > >>>> >>>>> >> >wrote: > >>>> >>>>> >> > > >>>> >>>>> >> >> Strahil, > >>>> >>>>> >> >> > >>>> >>>>> >> >> Here you go -- Thank You For Your Help ! > >>>> >>>>> >> >> > >>>> >>>>> >> >> BTW -- I can write a test file to gluster and it > >replicates > >>>> >>>>> >properly. > >>>> >>>>> >> >> Thinking something about the oVirt Storage Domain ? > >>>> >>>>> >> >> > >>>> >>>>> >> >> [root@ov08 ~]# gluster pool list > >>>> >>>>> >> >> UUID Hostname > >>>> >>>>> >State > >>>> >>>>> >> >> 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06 > >>>> >>>>> >> >Connected > >>>> >>>>> >> >> 36ce5a00-6f65-4926-8438-696944ebadb5 > >ov07.ntc.srcle.com > >>>> >>>>> >> >Connected > >>>> >>>>> >> >> c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost > >>>> >>>>> >> >Connected > >>>> >>>>> >> >> [root@ov08 ~]# gluster volume list > >>>> >>>>> >> >> images3 > >>>> >>>>> >> >> > >>>> >>>>> >> >> On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov > >>>> >>>>> >> ><hunter86_bg@yahoo.com> > >>>> >>>>> >> >> wrote: > >>>> >>>>> >> >> > >>>> >>>>> >> >>> Log to the oVirt cluster and provide the output of: > >>>> >>>>> >> >>> gluster pool list > >>>> >>>>> >> >>> gluster volume list > >>>> >>>>> >> >>> for i in $(gluster volume list); do echo $i;echo; > >gluster > >>>> >>>>> >volume > >>>> >>>>> >> >info > >>>> >>>>> >> >>> $i; echo;echo;gluster volume status > >$i;echo;echo;echo;done > >>>> >>>>> >> >>> > >>>> >>>>> >> >>> ls -l /rhev/data-center/mnt/glusterSD/ > >>>> >>>>> >> >>> > >>>> >>>>> >> >>> Best Regards, > >>>> >>>>> >> >>> Strahil Nikolov > >>>> >>>>> >> >>> > >>>> >>>>> >> >>> > >>>> >>>>> >> >>> На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams > >>>> >>>>> >> ><cwilliams3320@gmail.com> > >>>> >>>>> >> >>> написа: > >>>> >>>>> >> >>> >Hello, > >>>> >>>>> >> >>> > > >>>> >>>>> >> >>> >I recently added 6 hosts to an existing oVirt > >>>> >>>compute/gluster > >>>> >>>>> >> >cluster. > >>>> >>>>> >> >>> > > >>>> >>>>> >> >>> >Prior to this attempted addition, my cluster had 3 > >>>> >>>Hypervisor > >>>> >>>>> >hosts > >>>> >>>>> >> >and > >>>> >>>>> >> >>> >3 > >>>> >>>>> >> >>> >gluster bricks which made up a single gluster volume > >>>> >>>(replica 3 > >>>> >>>>> >> >volume) > >>>> >>>>> >> >>> >. I > >>>> >>>>> >> >>> >added the additional hosts and made a brick on 3 of > >the new > >>>> >>>>> >hosts > >>>> >>>>> >> >and > >>>> >>>>> >> >>> >attempted to make a new replica 3 volume. I had > >difficulty > >>>> >>>>> >> >creating > >>>> >>>>> >> >>> >the > >>>> >>>>> >> >>> >new volume. So, I decided that I would make a new > >>>> >>>>> >compute/gluster > >>>> >>>>> >> >>> >cluster > >>>> >>>>> >> >>> >for each set of 3 new hosts. > >>>> >>>>> >> >>> > > >>>> >>>>> >> >>> >I removed the 6 new hosts from the existing oVirt > >>>> >>>>> >Compute/Gluster > >>>> >>>>> >> >>> >Cluster > >>>> >>>>> >> >>> >leaving the 3 original hosts in place with their > >bricks. At > >>>> >>>that > >>>> >>>>> >> >point > >>>> >>>>> >> >>> >my > >>>> >>>>> >> >>> >original bricks went down and came back up . The > >volume > >>>> >>>showed > >>>> >>>>> >> >entries > >>>> >>>>> >> >>> >that > >>>> >>>>> >> >>> >needed healing. At that point I ran gluster volume > >heal > >>>> >>>images3 > >>>> >>>>> >> >full, > >>>> >>>>> >> >>> >etc. > >>>> >>>>> >> >>> >The volume shows no unhealed entries. I also > >corrected some > >>>> >>>peer > >>>> >>>>> >> >>> >errors. > >>>> >>>>> >> >>> > > >>>> >>>>> >> >>> >However, I am unable to copy disks, move disks to > >another > >>>> >>>>> >domain, > >>>> >>>>> >> >>> >export > >>>> >>>>> >> >>> >disks, etc. It appears that the engine cannot locate > >disks > >>>> >>>>> >properly > >>>> >>>>> >> >and > >>>> >>>>> >> >>> >I > >>>> >>>>> >> >>> >get storage I/O errors. > >>>> >>>>> >> >>> > > >>>> >>>>> >> >>> >I have detached and removed the oVirt Storage Domain. > >I > >>>> >>>>> >reimported > >>>> >>>>> >> >the > >>>> >>>>> >> >>> >domain and imported 2 VMs, But the VM disks exhibit > >the > >>>> same > >>>> >>>>> >> >behaviour > >>>> >>>>> >> >>> >and > >>>> >>>>> >> >>> >won't run from the hard disk. > >>>> >>>>> >> >>> > > >>>> >>>>> >> >>> > > >>>> >>>>> >> >>> >I get errors such as this > >>>> >>>>> >> >>> > > >>>> >>>>> >> >>> >VDSM ov05 command HSMGetAllTasksStatusesVDS failed: > >low > >>>> >>>level > >>>> >>>>> >Image > >>>> >>>>> >> >>> >copy > >>>> >>>>> >> >>> >failed: ("Command ['/usr/bin/qemu-img', 'convert', > >'-p', > >>>> >>>'-t', > >>>> >>>>> >> >'none', > >>>> >>>>> >> >>> >'-T', 'none', '-f', 'raw', > >>>> >>>>> >> >>> u'/rhev/data-center/mnt/glusterSD/192.168.24.18: > >>>> >>>>> >> >>> > >>>> >>>>> >> > >>>> >>>>> >> > >>>> >>>>> > >>>> >>>>> > >>>> > >>>> > >
>>>_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510', > >>>> >>>>> >> >>> >'-O', 'raw', > >>>> >>>>> >> >>> >u'/rhev/data-center/mnt/192.168.24.13: > >>>> >>>>> >> >>> > >>>> >>>>> >> > >>>> >>>>> >> > >>>> >>>>> > >>>> >>>>> > >>>> > >>>> > >
>>>_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5'] > >>>> >>>>> >> >>> >failed with rc=1 out='' err=bytearray(b'qemu-img: > >error > >>>> >>>while > >>>> >>>>> >> >reading > >>>> >>>>> >> >>> >sector 135168: Transport endpoint is not > >>>> >>>connected\\nqemu-img: > >>>> >>>>> >> >error > >>>> >>>>> >> >>> >while > >>>> >>>>> >> >>> >reading sector 131072: Transport endpoint is not > >>>> >>>>> >> >connected\\nqemu-img: > >>>> >>>>> >> >>> >error while reading sector 139264: Transport endpoint > >is > >>>> not > >>>> >>>>> >> >>> >connected\\nqemu-img: error while reading sector > >143360: > >>>> >>>>> >Transport > >>>> >>>>> >> >>> >endpoint > >>>> >>>>> >> >>> >is not connected\\nqemu-img: error while reading > >sector > >>>> >>>147456: > >>>> >>>>> >> >>> >Transport > >>>> >>>>> >> >>> >endpoint is not connected\\nqemu-img: error while > >reading > >>>> >>>sector > >>>> >>>>> >> >>> >155648: > >>>> >>>>> >> >>> >Transport endpoint is not connected\\nqemu-img: error > >while > >>>> >>>>> >reading > >>>> >>>>> >> >>> >sector > >>>> >>>>> >> >>> >151552: Transport endpoint is not > >connected\\nqemu-img: > >>>> >>>error > >>>> >>>>> >while > >>>> >>>>> >> >>> >reading > >>>> >>>>> >> >>> >sector 159744: Transport endpoint is not > >connected\\n')",) > >>>> >>>>> >> >>> > > >>>> >>>>> >> >>> >oVirt version is 4.3.82-1.el7 > >>>> >>>>> >> >>> >OS CentOS Linux release 7.7.1908 (Core) > >>>> >>>>> >> >>> > > >>>> >>>>> >> >>> >The Gluster Cluster has been working very well until > >this > >>>> >>>>> >incident. > >>>> >>>>> >> >>> > > >>>> >>>>> >> >>> >Please help. > >>>> >>>>> >> >>> > > >>>> >>>>> >> >>> >Thank You > >>>> >>>>> >> >>> > > >>>> >>>>> >> >>> >Charles Williams > >>>> >>>>> >> >>> > >>>> >>>>> >> >> > >>>> >>>>> >> > >>>> >>>>> > >>>> >>>> > >>>> >> > >>>> > > >>>> _______________________________________________ > >>>> Users mailing list -- users@ovirt.org > >>>> To unsubscribe send an email to users-leave@ovirt.org > >>>> Privacy Statement: https://www.ovirt.org/privacy-policy.html > >>>> oVirt Code of Conduct: > >>>> https://www.ovirt.org/community/about/community-guidelines/ > >>>> List Archives: > >>>> > > >
https://lists.ovirt.org/archives/list/users@ovirt.org/message/YY3VUKEJLI7MRW...
> >>>> > >>> >
Thanks Strahil I made a new gluster volume using only gluster CLI. Mounted the old volume and the new volume. Copied my data from the old volume to the new domain. Set the volume options like the old domain via the CLI. Tried to make a new storage domain using the paths to the new servers. However, oVirt complained that there was already a domain there and that I needed to clean it first. . What to do ? Thank You For Your Help !
Here is what I did to make my volume gluster volume create imgnew2a replica 3 transport tcp ov12.strg.srcle.com:/bricks/brick10/imgnew2a ov13.strg.srcle.com:/bricks/brick11/imgnew2a ov14.strg.srcle.com: /bricks/brick12/imgnew2a on a host with the old volume I did this mount -t glusterfs yy.yy.24.18:/images3/ /mnt/test/ -- Old defective volume 974 ls /mnt/test 975 mount 976 mkdir /mnt/test1trg 977 mount -t glusterfs yy.yy.24.24:/imgnew2a /mnt/test1trg ---- New volume 978 mount 979 ls /mnt/test 980 cp -a /mnt/test/* /mnt/test1trg/ When I tried to add the storage domain -- I got the errors described previously about needing to clean out the old domain. Thank You For Your Help ! On Mon, Jun 22, 2020 at 12:01 AM C Williams <cwilliams3320@gmail.com> wrote:
Thanks Strahil
I made a new gluster volume using only gluster CLI. Mounted the old volume and the new volume. Copied my data from the old volume to the new domain. Set the volume options like the old domain via the CLI. Tried to make a new storage domain using the paths to the new servers. However, oVirt complained that there was already a domain there and that I needed to clean it first. .
What to do ?
Thank You For Your Help !
Another question What version could I downgrade to safely ? I am at 6.9 . Thank You For Your Help !! On Sun, Jun 21, 2020 at 11:38 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
You are definitely reading it wrong. 1. I didn't create a new storage domain ontop this new volume. 2. I used cli
Something like this (in your case it should be 'replica 3'): gluster volume create newvol replica 3 arbiter 1 ovirt1:/new/brick/path ovirt2:/new/brick/path ovirt3:/new/arbiter/brick/path gluster volume start newvol
#Detach oldvol from ovirt
mount -t glusterfs ovirt1:/oldvol /mnt/oldvol mount -t glusterfs ovirt1:/newvol /mnt/newvol cp -a /mnt/oldvol/* /mnt/newvol
#Add only newvol as a storage domain in oVirt #Import VMs
I still think that you should downgrade your gluster packages!!!
Best Regards, Strahil Nikolov
На 22 юни 2020 г. 0:43:46 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Strahil,
It sounds like you used a "System Managed Volume" for the new storage domain,is that correct?
Thank You For Your Help !
On Sun, Jun 21, 2020 at 5:40 PM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
So you made another oVirt Storage Domain -- then copied the data with cp -a from the failed volume to the new volume.
At the root of the volume there will be the old domain folder id ex 5fe3ad3f-2d21-404c-832e-4dc7318ca10d in my case. Did that cause issues with making the new domain since it is the same folder id as the old one ?
Thank You For Your Help !
On Sun, Jun 21, 2020 at 5:18 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
In my situation I had only the ovirt nodes.
Strahil,
So should I make the target volume on 3 bricks which do not have ovirt -- just gluster ? In other words (3) Centos 7 hosts ?
Thank You For Your Help !
On Sun, Jun 21, 2020 at 3:08 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
I created a fresh volume (which is not an ovirt sgorage domain), set the original storage domain in maintenance and detached it. Then I 'cp -a ' the data from the old to the new volume. Next, I just added the new storage domain (the old one was a kind of a 'backup') - pointing to the new volume name.
If you observe issues , I would recommend you to downgrade gluster packages one node at a time . Then you might be able to restore your oVirt operations.
Best Regards, Strahil Nikolov
На 21 юни 2020 г. 18:01:31 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: >Strahil, > >Thanks for the follow up ! > >How did you copy the data to another volume ? > >I have set up another storage domain GLCLNEW1 with a new volume imgnew1 >. >How would you copy all of the data from the problematic domain GLCL3 >with >volume images3 to GLCLNEW1 and volume imgnew1 and preserve all
На 21 юни 2020 г. 22:43:04 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: the
VMs,
>VM >disks, settings, etc. ? > >Remember all of the regular ovirt disk copy, disk move, VM export >tools >are failing and my VMs and disks are trapped on domain GLCL3 and volume >images3 right now. > >Please let me know > >Thank You For Your Help ! > > > > > >On Sun, Jun 21, 2020 at 8:27 AM Strahil Nikolov <hunter86_bg@yahoo.com> >wrote: > >> Sorry to hear that. >> I can say that for me 6.5 was working, while 6.6 didn't and I >upgraded >> to 7.0 . >> In the ended , I have ended with creating a new fresh volume and >> physically copying the data there, then I detached the storage >domains and >> attached to the new ones (which holded the old data), but I >could >> afford the downtime. >> Also, I can say that v7.0 ( but not 7.1 or anything later) also >> worked without the ACL issue, but it causes some trouble in oVirt >- so >> avoid that unless you have no other options. >> >> Best Regards, >> Strahil Nikolov >> >> >> >> >> На 21 юни 2020 г. 4:39:46 GMT+03:00, C Williams ><cwilliams3320@gmail.com> >> написа: >> >Hello, >> > >> >Upgrading diidn't help >> > >> >Still acl errors trying to use a Virtual Disk from a VM >> > >> >[root@ov06 bricks]# tail bricks-brick04-images3.log | grep acl >> >[2020-06-21 01:33:45.665888] I [MSGID: 139001] >> >[posix-acl.c:263:posix_acl_log_permit_denied] >0-images3-access-control: >> >client: >> >>
CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0,
>> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >> >req(uid:107,gid:107,perm:1,ngrps:3), >> >ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) >> >[Permission denied] >> >The message "I [MSGID: 139001] >> >[posix-acl.c:263:posix_acl_log_permit_denied] >0-images3-access-control: >> >client: >> >>
>> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >> >req(uid:107,gid:107,perm:1,ngrps:3), >> >ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) >> >[Permission denied]" repeated 2 times between [2020-06-21 >> >01:33:45.665888] >> >and [2020-06-21 01:33:45.806779] >> > >> >Thank You For Your Help ! >> > >> >On Sat, Jun 20, 2020 at 8:59 PM C Williams <cwilliams3320@gmail.com> >> >wrote: >> > >> >> Hello, >> >> >> >> Based on the situation, I am planning to upgrade the 3 affected >> >hosts. >> >> >> >> My reasoning is that the hosts/bricks were attached to 6.9 at one >> >time. >> >> >> >> Thanks For Your Help ! >> >> >> >> On Sat, Jun 20, 2020 at 8:38 PM C Williams ><cwilliams3320@gmail.com> >> >> wrote: >> >> >> >>> Strahil, >> >>> >> >>> The gluster version on the current 3 gluster hosts is 6.7 (last >> >update >> >>> 2/26). These 3 hosts provide 1 brick each for the replica 3 >volume. >> >>> >> >>> Earlier I had tried to add 6 additional hosts to the cluster. >Those >> >new >> >>> hosts were 6.9 gluster. >> >>> >> >>> I attempted to make a new separate volume with 3 bricks
>by >> >the 3 >> >>> new gluster 6.9 hosts. After having many errors from the oVirt >> >interface, >> >>> I gave up and removed the 6 new hosts from the cluster. That is >> >where the >> >>> problems started. The intent was to expand the gluster cluster >while >> >making >> >>> 2 new volumes for that cluster. The ovirt compute cluster would >> >allow for >> >>> efficient VM migration between 9 hosts -- while having separate >> >gluster >> >>> volumes for safety purposes. >> >>> >> >>> Looking at the brick logs, I see where there are acl errors >starting >> >from >> >>> the time of the removal of the 6 new hosts. >> >>> >> >>> Please check out the attached brick log from 6/14-18. The events >> >started >> >>> on 6/17. >> >>> >> >>> I wish I had a downgrade path. >> >>> >> >>> Thank You For The Help !! >> >>> >> >>> On Sat, Jun 20, 2020 at 7:47 PM Strahil Nikolov >> ><hunter86_bg@yahoo.com> >> >>> wrote: >> >>> >> >>>> Hi , >> >>>> >> >>>> >> >>>> This one really looks like the ACL bug I was hit with when I >> >updated >> >>>> from Gluster v6.5 to 6.6 and later from 7.0 to 7.2. >> >>>> >> >>>> Did you update your setup recently ? Did you upgrade gluster >also ? >> >>>> >> >>>> You have to check the gluster logs in order to verify
CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0, provided that, so
>you >> >can >> >>>> try: >> >>>> >> >>>> 1. Set Gluster logs to trace level (for details check: >> >>>> >> > >> >
https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3/html...
>> >>>> ) >> >>>> 2. Power up a VM that was already off , or retry the procedure >from >> >the >> >>>> logs you sent. >> >>>> 3. Stop the trace level of the logs >> >>>> 4. Check libvirt logs on the host that was supposed to power up >the >> >VM >> >>>> (in case a VM was powered on) >> >>>> 5. Check the gluster brick logs on all nodes for ACL errors. >> >>>> Here is a sample from my old logs: >> >>>> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 >> >13:19:41.489047] I >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- >> >>>> >> >>
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
>> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) >> >>>> [Permission denied] >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 >> >13:22:51.818796] I >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- >> >>>> >> >>
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
>> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) >> >>>> [Permission denied] >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 >> >13:24:43.732856] I >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- >> >>>> >> >>
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
>> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) >> >>>> [Permission denied] >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 >> >13:26:50.758178] I >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- >> >>>> >> >>
>> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) >> >>>> [Permission denied] >> >>>> >> >>>> >> >>>> In my case , the workaround was to downgrade the gluster >packages >> >on all >> >>>> nodes (and reboot each node 1 by 1 ) if the major version is
>> >same, but >> >>>> if you upgraded to v7.X - then you can try the v7.0 . >> >>>> >> >>>> Best Regards, >> >>>> Strahil Nikolov >> >>>> >> >>>> >> >>>> >> >>>> >> >>>> >> >>>> >> >>>> В събота, 20 юни 2020 г., 18:48:42 ч. Гринуич+3, C Williams < >> >>>> cwilliams3320@gmail.com> написа: >> >>>> >> >>>> >> >>>> >> >>>> >> >>>> >> >>>> Hello, >> >>>> >> >>>> Here are additional log tiles as well as a tree of the >problematic >> >>>> Gluster storage domain. During this time I attempted to copy a >> >virtual disk >> >>>> to another domain, move a virtual disk to another domain and run >a >> >VM where >> >>>> the virtual hard disk would be used. >> >>>> >> >>>> The copies/moves failed and the VM went into pause mode when
>> >virtual >> >>>> HDD was involved. >> >>>> >> >>>> Please check these out. >> >>>> >> >>>> Thank You For Your Help ! >> >>>> >> >>>> On Sat, Jun 20, 2020 at 9:54 AM C Williams >> ><cwilliams3320@gmail.com> >> >>>> wrote: >> >>>> > Strahil, >> >>>> > >> >>>> > I understand. Please keep me posted. >> >>>> > >> >>>> > Thanks For The Help ! >> >>>> > >> >>>> > On Sat, Jun 20, 2020 at 4:36 AM Strahil Nikolov >> ><hunter86_bg@yahoo.com> >> >>>> wrote: >> >>>> >> Hey C Williams, >> >>>> >> >> >>>> >> sorry for the delay, but I couldn't get somw time to check >your >> >>>> logs. Will try a little bit later. >> >>>> >> >> >>>> >> Best Regards, >> >>>> >> Strahil Nikolov >> >>>> >> >> >>>> >> На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams < >> >>>> cwilliams3320@gmail.com> написа: >> >>>> >>>Hello, >> >>>> >>> >> >>>> >>>Was wanting to follow up on this issue. Users are impacted. >> >>>> >>> >> >>>> >>>Thank You >> >>>> >>> >> >>>> >>>On Fri, Jun 19, 2020 at 9:20 AM C Williams >> ><cwilliams3320@gmail.com> >> >>>> >>>wrote: >> >>>> >>> >> >>>> >>>> Hello, >> >>>> >>>> >> >>>> >>>> Here are the logs (some IPs are changed ) >> >>>> >>>> >> >>>> >>>> ov05 is the SPM >> >>>> >>>> >> >>>> >>>> Thank You For Your Help ! >> >>>> >>>> >> >>>> >>>> On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov >> >>>> >>><hunter86_bg@yahoo.com> >> >>>> >>>> wrote: >> >>>> >>>> >> >>>> >>>>> Check on the hosts tab , which is your current SPM (last >> >column in >> >>>> >>>Admin >> >>>> >>>>> UI). >> >>>> >>>>> Then open the /var/log/vdsm/vdsm.log and repeat
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, the the the
>> >operation. >> >>>> >>>>> Then provide the log from that host and the engine's log >(on >> >the >> >>>> >>>>> HostedEngine VM or on your standalone engine). >> >>>> >>>>> >> >>>> >>>>> Best Regards, >> >>>> >>>>> Strahil Nikolov >> >>>> >>>>> >> >>>> >>>>> На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams >> >>>> >>><cwilliams3320@gmail.com> >> >>>> >>>>> написа: >> >>>> >>>>> >Resending to eliminate email issues >> >>>> >>>>> > >> >>>> >>>>> >---------- Forwarded message --------- >> >>>> >>>>> >From: C Williams <cwilliams3320@gmail.com> >> >>>> >>>>> >Date: Thu, Jun 18, 2020 at 4:01 PM >> >>>> >>>>> >Subject: Re: [ovirt-users] Fwd: Issues with Gluster >Domain >> >>>> >>>>> >To: Strahil Nikolov <hunter86_bg@yahoo.com> >> >>>> >>>>> > >> >>>> >>>>> > >> >>>> >>>>> >Here is output from mount >> >>>> >>>>> > >> >>>> >>>>> >192.168.24.12:/stor/import0 on >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.12:_stor_import0 >> >>>> >>>>> >type nfs4 >> >>>> >>>>> >> >>>> >>>>> >> >>>> >> >>>> >> >>
>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12) >> >>>> >>>>> >192.168.24.13:/stor/import1 on >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_import1 >> >>>> >>>>> >type nfs4 >> >>>> >>>>> >> >>>> >>>>> >> >>>> >> >>>> >> >>
>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >> >>>> >>>>> >192.168.24.13:/stor/iso1 on >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_iso1 >> >>>> >>>>> >type nfs4 >> >>>> >>>>> >> >>>> >>>>> >> >>>> >> >>>> >> >>
>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >> >>>> >>>>> >192.168.24.13:/stor/export0 on >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_export0 >> >>>> >>>>> >type nfs4 >> >>>> >>>>> >> >>>> >>>>> >> >>>> >> >>>> >> >>
>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >> >>>> >>>>> >192.168.24.15:/images on >> >>>> >>>>> /rhev/data-center/mnt/glusterSD/192.168.24.15:_images >> >>>> >>>>> >type fuse.glusterfs >> >>>> >>>>> >> >>>> >>>>> >> >>>> >> >>>> >> >>
>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) >> >>>> >>>>> >192.168.24.18:/images3 on >> >>>> >>>>> /rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 >> >>>> >>>>> >type fuse.glusterfs >> >>>> >>>>> >> >>>> >>>>> >> >>>> >> >>>> >> >>
>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) >> >>>> >>>>> >tmpfs on /run/user/0 type tmpfs >> >>>> >>>>> >>(rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) >> >>>> >>>>> >[root@ov06 glusterfs]# >> >>>> >>>>> > >> >>>> >>>>> >Also here is a screenshot of the console >> >>>> >>>>> > >> >>>> >>>>> >[image: image.png] >> >>>> >>>>> >The other domains are up >> >>>> >>>>> > >> >>>> >>>>> >Import0 and Import1 are NFS . GLCL0 is gluster. They all >are >> >>>> >>>running >> >>>> >>>>> >VMs >> >>>> >>>>> > >> >>>> >>>>> >Thank You For Your Help ! >> >>>> >>>>> > >> >>>> >>>>> >On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov >> >>>> >>><hunter86_bg@yahoo.com> >> >>>> >>>>> >wrote: >> >>>> >>>>> > >> >>>> >>>>> >> I don't see >> >'/rhev/data-center/mnt/192.168.24.13:_stor_import1' >> >>>> >>>>> >mounted >> >>>> >>>>> >> at all . >> >>>> >>>>> >> What is the status of all storage domains ? >> >>>> >>>>> >> >> >>>> >>>>> >> Best Regards, >> >>>> >>>>> >> Strahil Nikolov >> >>>> >>>>> >> >> >>>> >>>>> >> На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams >> >>>> >>>>> ><cwilliams3320@gmail.com> >> >>>> >>>>> >> написа: >> >>>> >>>>> >> > Resending to deal with possible email issues >> >>>> >>>>> >> > >> >>>> >>>>> >> >---------- Forwarded message --------- >> >>>> >>>>> >> >From: C Williams <cwilliams3320@gmail.com> >> >>>> >>>>> >> >Date: Thu, Jun 18, 2020 at 2:07 PM >> >>>> >>>>> >> >Subject: Re: [ovirt-users] Issues with Gluster Domain >> >>>> >>>>> >> >To: Strahil Nikolov <hunter86_bg@yahoo.com> >> >>>> >>>>> >> > >> >>>> >>>>> >> > >> >>>> >>>>> >> >More >> >>>> >>>>> >> > >> >>>> >>>>> >> >[root@ov06 ~]# for i in $(gluster volume list); do >echo >> >>>> >>>$i;echo; >> >>>> >>>>> >> >gluster >> >>>> >>>>> >> >volume info $i; echo;echo;gluster volume status >> >>>> >>>>> >$i;echo;echo;echo;done >> >>>> >>>>> >> >images3 >> >>>> >>>>> >> > >> >>>> >>>>> >> > >> >>>> >>>>> >> >Volume Name: images3 >> >>>> >>>>> >> >Type: Replicate >> >>>> >>>>> >> >Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b >> >>>> >>>>> >> >Status: Started >> >>>> >>>>> >> >Snapshot Count: 0 >> >>>> >>>>> >> >Number of Bricks: 1 x 3 = 3 >> >>>> >>>>> >> >Transport-type: tcp >> >>>> >>>>> >> >Bricks: >> >>>> >>>>> >> >Brick1: 192.168.24.18:/bricks/brick04/images3 >> >>>> >>>>> >> >Brick2: 192.168.24.19:/bricks/brick05/images3 >> >>>> >>>>> >> >Brick3: 192.168.24.20:/bricks/brick06/images3 >> >>>> >>>>> >> >Options Reconfigured: >> >>>> >>>>> >> >performance.client-io-threads: on >> >>>> >>>>> >> >nfs.disable: on >> >>>> >>>>> >> >transport.address-family: inet >> >>>> >>>>> >> >user.cifs: off >> >>>> >>>>> >> >auth.allow: * >> >>>> >>>>> >> >performance.quick-read: off >> >>>> >>>>> >> >performance.read-ahead: off >> >>>> >>>>> >> >performance.io-cache: off >> >>>> >>>>> >> >performance.low-prio-threads: 32 >> >>>> >>>>> >> >network.remote-dio: off >> >>>> >>>>> >> >cluster.eager-lock: enable >> >>>> >>>>> >> >cluster.quorum-type: auto >> >>>> >>>>> >> >cluster.server-quorum-type: server >> >>>> >>>>> >> >cluster.data-self-heal-algorithm: full >> >>>> >>>>> >> >cluster.locking-scheme: granular >> >>>> >>>>> >> >cluster.shd-max-threads: 8 >> >>>> >>>>> >> >cluster.shd-wait-qlength: 10000 >> >>>> >>>>> >> >features.shard: on >> >>>> >>>>> >> >cluster.choose-local: off >> >>>> >>>>> >> >client.event-threads: 4 >> >>>> >>>>> >> >server.event-threads: 4 >> >>>> >>>>> >> >storage.owner-uid: 36 >> >>>> >>>>> >> >storage.owner-gid: 36 >> >>>> >>>>> >> >performance.strict-o-direct: on >> >>>> >>>>> >> >network.ping-timeout: 30 >> >>>> >>>>> >> >cluster.granular-entry-heal: enable >> >>>> >>>>> >> > >> >>>> >>>>> >> > >> >>>> >>>>> >> >Status of volume: images3 >> >>>> >>>>> >> >Gluster process TCP Port >> >RDMA Port >> >>>> >>>>> >Online >> >>>> >>>>> >> > Pid >> >>>> >>>>> >> >> >>>> >>>>> >> >> >>>> >>>>> >> >>>> >>>>> >> >>>> >> >>>> >> >>
>>>>------------------------------------------------------------------------------ >> >>>> >>>>> >> >Brick 192.168.24.18:/bricks/brick04/images3 49152 >0 >> >>>> >> >>>> >>>Y >> >>>> >>>>> >> >6666 >> >>>> >>>>> >> >Brick 192.168.24.19:/bricks/brick05/images3 49152 >0 >> >>>> >> >>>> >>>Y >> >>>> >>>>> >> >6779 >> >>>> >>>>> >> >Brick 192.168.24.20:/bricks/brick06/images3 49152 >0 >> >>>> >> >>>> >>>Y >> >>>> >>>>> >> >7227 >> >>>> >>>>> >> >Self-heal Daemon on localhost N/A >N/A >> >>>> >> >>>> >>>Y >> >>>> >>>>> >> >6689 >> >>>> >>>>> >> >Self-heal Daemon on ov07.ntc.srcle.com N/A >N/A >> >>>> >> >>>> >>>Y >> >>>> >>>>> >> >6802 >> >>>> >>>>> >> >Self-heal Daemon on ov08.ntc.srcle.com N/A >N/A >> >>>> >> >>>> >>>Y >> >>>> >>>>> >> >7250 >> >>>> >>>>> >> > >> >>>> >>>>> >> >Task Status of Volume images3 >> >>>> >>>>> >> >> >>>> >>>>> >> >> >>>> >>>>> >> >>>> >>>>> >> >>>> >> >>>> >> >>
>>>>------------------------------------------------------------------------------ >> >>>> >>>>> >> >There are no active volume tasks >> >>>> >>>>> >> > >> >>>> >>>>> >> > >> >>>> >>>>> >> > >> >>>> >>>>> >> > >> >>>> >>>>> >> >[root@ov06 ~]# ls -l /rhev/data-center/mnt/glusterSD/ >> >>>> >>>>> >> >total 16 >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 >> >192.168.24.15:_images >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 >192.168.24.18: >> >>>> _images3 >> >>>> >>>>> >> >[root@ov06 ~]# >> >>>> >>>>> >> > >> >>>> >>>>> >> >On Thu, Jun 18, 2020 at 2:03 PM C Williams >> >>>> >>><cwilliams3320@gmail.com> >> >>>> >>>>> >> >wrote: >> >>>> >>>>> >> > >> >>>> >>>>> >> >> Strahil, >> >>>> >>>>> >> >> >> >>>> >>>>> >> >> Here you go -- Thank You For Your Help ! >> >>>> >>>>> >> >> >> >>>> >>>>> >> >> BTW -- I can write a test file to gluster and it >> >replicates >> >>>> >>>>> >properly. >> >>>> >>>>> >> >> Thinking something about the oVirt Storage Domain ? >> >>>> >>>>> >> >> >> >>>> >>>>> >> >> [root@ov08 ~]# gluster pool list >> >>>> >>>>> >> >> UUID Hostname >> >>>> >>>>> >State >> >>>> >>>>> >> >> 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06 >> >>>> >>>>> >> >Connected >> >>>> >>>>> >> >> 36ce5a00-6f65-4926-8438-696944ebadb5 >> >ov07.ntc.srcle.com >> >>>> >>>>> >> >Connected >> >>>> >>>>> >> >> c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost >> >>>> >>>>> >> >Connected >> >>>> >>>>> >> >> [root@ov08 ~]# gluster volume list >> >>>> >>>>> >> >> images3 >> >>>> >>>>> >> >> >> >>>> >>>>> >> >> On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov >> >>>> >>>>> >> ><hunter86_bg@yahoo.com> >> >>>> >>>>> >> >> wrote: >> >>>> >>>>> >> >> >> >>>> >>>>> >> >>> Log to the oVirt cluster and provide the output of: >> >>>> >>>>> >> >>> gluster pool list >> >>>> >>>>> >> >>> gluster volume list >> >>>> >>>>> >> >>> for i in $(gluster volume list); do echo $i;echo; >> >gluster >> >>>> >>>>> >volume >> >>>> >>>>> >> >info >> >>>> >>>>> >> >>> $i; echo;echo;gluster volume status >> >$i;echo;echo;echo;done >> >>>> >>>>> >> >>> >> >>>> >>>>> >> >>> ls -l /rhev/data-center/mnt/glusterSD/ >> >>>> >>>>> >> >>> >> >>>> >>>>> >> >>> Best Regards, >> >>>> >>>>> >> >>> Strahil Nikolov >> >>>> >>>>> >> >>> >> >>>> >>>>> >> >>> >> >>>> >>>>> >> >>> На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams >> >>>> >>>>> >> ><cwilliams3320@gmail.com> >> >>>> >>>>> >> >>> написа: >> >>>> >>>>> >> >>> >Hello, >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> >>> >I recently added 6 hosts to an existing oVirt >> >>>> >>>compute/gluster >> >>>> >>>>> >> >cluster. >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> >>> >Prior to this attempted addition, my cluster had 3 >> >>>> >>>Hypervisor >> >>>> >>>>> >hosts >> >>>> >>>>> >> >and >> >>>> >>>>> >> >>> >3 >> >>>> >>>>> >> >>> >gluster bricks which made up a single gluster >volume >> >>>> >>>(replica 3 >> >>>> >>>>> >> >volume) >> >>>> >>>>> >> >>> >. I >> >>>> >>>>> >> >>> >added the additional hosts and made a brick on 3 >of >> >the new >> >>>> >>>>> >hosts >> >>>> >>>>> >> >and >> >>>> >>>>> >> >>> >attempted to make a new replica 3 volume. I had >> >difficulty >> >>>> >>>>> >> >creating >> >>>> >>>>> >> >>> >the >> >>>> >>>>> >> >>> >new volume. So, I decided that I would make a new >> >>>> >>>>> >compute/gluster >> >>>> >>>>> >> >>> >cluster >> >>>> >>>>> >> >>> >for each set of 3 new hosts. >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> >>> >I removed the 6 new hosts from the existing oVirt >> >>>> >>>>> >Compute/Gluster >> >>>> >>>>> >> >>> >Cluster >> >>>> >>>>> >> >>> >leaving the 3 original hosts in place with their >> >bricks. At >> >>>> >>>that >> >>>> >>>>> >> >point >> >>>> >>>>> >> >>> >my >> >>>> >>>>> >> >>> >original bricks went down and came back up . The >> >volume >> >>>> >>>showed >> >>>> >>>>> >> >entries >> >>>> >>>>> >> >>> >that >> >>>> >>>>> >> >>> >needed healing. At that point I ran gluster volume >> >heal >> >>>> >>>images3 >> >>>> >>>>> >> >full, >> >>>> >>>>> >> >>> >etc. >> >>>> >>>>> >> >>> >The volume shows no unhealed entries. I also >> >corrected some >> >>>> >>>peer >> >>>> >>>>> >> >>> >errors. >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> >>> >However, I am unable to copy disks, move disks to >> >another >> >>>> >>>>> >domain, >> >>>> >>>>> >> >>> >export >> >>>> >>>>> >> >>> >disks, etc. It appears that the engine cannot >locate >> >disks >> >>>> >>>>> >properly >> >>>> >>>>> >> >and >> >>>> >>>>> >> >>> >I >> >>>> >>>>> >> >>> >get storage I/O errors. >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> >>> >I have detached and removed the oVirt Storage >Domain. >> >I >> >>>> >>>>> >reimported >> >>>> >>>>> >> >the >> >>>> >>>>> >> >>> >domain and imported 2 VMs, But the VM disks >exhibit >> >the >> >>>> same >> >>>> >>>>> >> >behaviour >> >>>> >>>>> >> >>> >and >> >>>> >>>>> >> >>> >won't run from the hard disk. >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> >>> >I get errors such as this >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> >>> >VDSM ov05 command HSMGetAllTasksStatusesVDS >failed: >> >low >> >>>> >>>level >> >>>> >>>>> >Image >> >>>> >>>>> >> >>> >copy >> >>>> >>>>> >> >>> >failed: ("Command ['/usr/bin/qemu-img', 'convert', >> >'-p', >> >>>> >>>'-t', >> >>>> >>>>> >> >'none', >> >>>> >>>>> >> >>> >'-T', 'none', '-f', 'raw', >> >>>> >>>>> >> >>> u'/rhev/data-center/mnt/glusterSD/192.168.24.18: >> >>>> >>>>> >> >>> >> >>>> >>>>> >> >> >>>> >>>>> >> >> >>>> >>>>> >> >>>> >>>>> >> >>>> >> >>>> >> >>
>>>>_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510', >> >>>> >>>>> >> >>> >'-O', 'raw', >> >>>> >>>>> >> >>> >u'/rhev/data-center/mnt/192.168.24.13: >> >>>> >>>>> >> >>> >> >>>> >>>>> >> >> >>>> >>>>> >> >> >>>> >>>>> >> >>>> >>>>> >> >>>> >> >>>> >> >>
>>>>_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5'] >> >>>> >>>>> >> >>> >failed with rc=1 out='' err=bytearray(b'qemu-img: >> >error >> >>>> >>>while >> >>>> >>>>> >> >reading >> >>>> >>>>> >> >>> >sector 135168: Transport endpoint is not >> >>>> >>>connected\\nqemu-img: >> >>>> >>>>> >> >error >> >>>> >>>>> >> >>> >while >> >>>> >>>>> >> >>> >reading sector 131072: Transport endpoint is not >> >>>> >>>>> >> >connected\\nqemu-img: >> >>>> >>>>> >> >>> >error while reading sector 139264: Transport >endpoint >> >is >> >>>> not >> >>>> >>>>> >> >>> >connected\\nqemu-img: error while reading sector >> >143360: >> >>>> >>>>> >Transport >> >>>> >>>>> >> >>> >endpoint >> >>>> >>>>> >> >>> >is not connected\\nqemu-img: error while reading >> >sector >> >>>> >>>147456: >> >>>> >>>>> >> >>> >Transport >> >>>> >>>>> >> >>> >endpoint is not connected\\nqemu-img: error while >> >reading >> >>>> >>>sector >> >>>> >>>>> >> >>> >155648: >> >>>> >>>>> >> >>> >Transport endpoint is not connected\\nqemu-img: >error >> >while >> >>>> >>>>> >reading >> >>>> >>>>> >> >>> >sector >> >>>> >>>>> >> >>> >151552: Transport endpoint is not >> >connected\\nqemu-img: >> >>>> >>>error >> >>>> >>>>> >while >> >>>> >>>>> >> >>> >reading >> >>>> >>>>> >> >>> >sector 159744: Transport endpoint is not >> >connected\\n')",) >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> >>> >oVirt version is 4.3.82-1.el7 >> >>>> >>>>> >> >>> >OS CentOS Linux release 7.7.1908 (Core) >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> >>> >The Gluster Cluster has been working very well >until >> >this >> >>>> >>>>> >incident. >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> >>> >Please help. >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> >>> >Thank You >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> >>> >Charles Williams >> >>>> >>>>> >> >>> >> >>>> >>>>> >> >> >> >>>> >>>>> >> >> >>>> >>>>> >> >>>> >>>> >> >>>> >> >> >>>> > >> >>>> _______________________________________________ >> >>>> Users mailing list -- users@ovirt.org >> >>>> To unsubscribe send an email to users-leave@ovirt.org >> >>>> Privacy Statement: https://www.ovirt.org/privacy-policy.html >> >>>> oVirt Code of Conduct: >> >>>> https://www.ovirt.org/community/about/community-guidelines/ >> >>>> List Archives: >> >>>> >> > >> >
https://lists.ovirt.org/archives/list/users@ovirt.org/message/YY3VUKEJLI7MRW...
>> >>>> >> >>> >>
You can't add the new volume as it contains the same data (UUID) as the old one , thus you need to detach the old one before adding the new one - of course this means downtime for all VMs on that storage. As you see , downgrading is more simpler. For me v6.5 was working, while anything above (6.6+) was causing complete lockdown. Also v7.0 was working, but it's supported in oVirt 4.4. Best Regards, Strahil Nikolov На 22 юни 2020 г. 7:21:15 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Another question
What version could I downgrade to safely ? I am at 6.9 .
Thank You For Your Help !!
On Sun, Jun 21, 2020 at 11:38 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
You are definitely reading it wrong. 1. I didn't create a new storage domain ontop this new volume. 2. I used cli
Something like this (in your case it should be 'replica 3'): gluster volume create newvol replica 3 arbiter 1 ovirt1:/new/brick/path ovirt2:/new/brick/path ovirt3:/new/arbiter/brick/path gluster volume start newvol
#Detach oldvol from ovirt
mount -t glusterfs ovirt1:/oldvol /mnt/oldvol mount -t glusterfs ovirt1:/newvol /mnt/newvol cp -a /mnt/oldvol/* /mnt/newvol
#Add only newvol as a storage domain in oVirt #Import VMs
I still think that you should downgrade your gluster packages!!!
Best Regards, Strahil Nikolov
На 22 юни 2020 г. 0:43:46 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Strahil,
It sounds like you used a "System Managed Volume" for the new storage domain,is that correct?
Thank You For Your Help !
On Sun, Jun 21, 2020 at 5:40 PM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
So you made another oVirt Storage Domain -- then copied the data with cp -a from the failed volume to the new volume.
At the root of the volume there will be the old domain folder id ex 5fe3ad3f-2d21-404c-832e-4dc7318ca10d in my case. Did that cause issues with making the new domain since it is the same folder id as the old one ?
Thank You For Your Help !
On Sun, Jun 21, 2020 at 5:18 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
In my situation I had only the ovirt nodes.
Strahil,
So should I make the target volume on 3 bricks which do not have ovirt -- just gluster ? In other words (3) Centos 7 hosts ?
Thank You For Your Help !
On Sun, Jun 21, 2020 at 3:08 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
> I created a fresh volume (which is not an ovirt sgorage domain), set > the original storage domain in maintenance and detached it. > Then I 'cp -a ' the data from the old to the new volume. Next, I just > added the new storage domain (the old one was a kind of a > 'backup') - pointing to the new volume name. > > If you observe issues , I would recommend you to downgrade > gluster packages one node at a time . Then you might be able to > restore your oVirt operations. > > Best Regards, > Strahil Nikolov > > На 21 юни 2020 г. 18:01:31 GMT+03:00, C Williams <cwilliams3320@gmail.com> > написа: > >Strahil, > > > >Thanks for the follow up ! > > > >How did you copy the data to another volume ? > > > >I have set up another storage domain GLCLNEW1 with a new volume imgnew1 > >. > >How would you copy all of the data from the problematic domain GLCL3 > >with > >volume images3 to GLCLNEW1 and volume imgnew1 and preserve all
На 21 юни 2020 г. 22:43:04 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: the
VMs, > >VM > >disks, settings, etc. ? > > > >Remember all of the regular ovirt disk copy, disk move, VM export > >tools > >are failing and my VMs and disks are trapped on domain GLCL3 and volume > >images3 right now. > > > >Please let me know > > > >Thank You For Your Help ! > > > > > > > > > > > >On Sun, Jun 21, 2020 at 8:27 AM Strahil Nikolov <hunter86_bg@yahoo.com> > >wrote: > > > >> Sorry to hear that. > >> I can say that for me 6.5 was working, while 6.6 didn't and I > >upgraded > >> to 7.0 . > >> In the ended , I have ended with creating a new fresh volume and > >> physically copying the data there, then I detached the storage > >domains and > >> attached to the new ones (which holded the old data), but I > >could > >> afford the downtime. > >> Also, I can say that v7.0 ( but not 7.1 or anything later) also > >> worked without the ACL issue, but it causes some trouble in oVirt > >- so > >> avoid that unless you have no other options. > >> > >> Best Regards, > >> Strahil Nikolov > >> > >> > >> > >> > >> На 21 юни 2020 г. 4:39:46 GMT+03:00, C Williams > ><cwilliams3320@gmail.com> > >> написа: > >> >Hello, > >> > > >> >Upgrading diidn't help > >> > > >> >Still acl errors trying to use a Virtual Disk from a VM > >> > > >> >[root@ov06 bricks]# tail bricks-brick04-images3.log | grep acl > >> >[2020-06-21 01:33:45.665888] I [MSGID: 139001] > >> >[posix-acl.c:263:posix_acl_log_permit_denied] > >0-images3-access-control: > >> >client: > >> > >> > >
CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0,
> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >> >req(uid:107,gid:107,perm:1,ngrps:3), > >> >ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) > >> >[Permission denied] > >> >The message "I [MSGID: 139001] > >> >[posix-acl.c:263:posix_acl_log_permit_denied] > >0-images3-access-control: > >> >client: > >> > >> > >
> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >> >req(uid:107,gid:107,perm:1,ngrps:3), > >> >ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) > >> >[Permission denied]" repeated 2 times between [2020-06-21 > >> >01:33:45.665888] > >> >and [2020-06-21 01:33:45.806779] > >> > > >> >Thank You For Your Help ! > >> > > >> >On Sat, Jun 20, 2020 at 8:59 PM C Williams <cwilliams3320@gmail.com> > >> >wrote: > >> > > >> >> Hello, > >> >> > >> >> Based on the situation, I am planning to upgrade the 3 affected > >> >hosts. > >> >> > >> >> My reasoning is that the hosts/bricks were attached to 6.9 at one > >> >time. > >> >> > >> >> Thanks For Your Help ! > >> >> > >> >> On Sat, Jun 20, 2020 at 8:38 PM C Williams > ><cwilliams3320@gmail.com> > >> >> wrote: > >> >> > >> >>> Strahil, > >> >>> > >> >>> The gluster version on the current 3 gluster hosts is 6.7 (last > >> >update > >> >>> 2/26). These 3 hosts provide 1 brick each for the replica 3 > >volume. > >> >>> > >> >>> Earlier I had tried to add 6 additional hosts to the cluster. > >Those > >> >new > >> >>> hosts were 6.9 gluster. > >> >>> > >> >>> I attempted to make a new separate volume with 3 bricks provided > >by > >> >the 3 > >> >>> new gluster 6.9 hosts. After having many errors from
oVirt > >> >interface, > >> >>> I gave up and removed the 6 new hosts from the cluster. That is > >> >where the > >> >>> problems started. The intent was to expand the gluster cluster > >while > >> >making > >> >>> 2 new volumes for that cluster. The ovirt compute cluster would > >> >allow for > >> >>> efficient VM migration between 9 hosts -- while having separate > >> >gluster > >> >>> volumes for safety purposes. > >> >>> > >> >>> Looking at the brick logs, I see where there are acl errors > >starting > >> >from > >> >>> the time of the removal of the 6 new hosts. > >> >>> > >> >>> Please check out the attached brick log from 6/14-18. The events > >> >started > >> >>> on 6/17. > >> >>> > >> >>> I wish I had a downgrade path. > >> >>> > >> >>> Thank You For The Help !! > >> >>> > >> >>> On Sat, Jun 20, 2020 at 7:47 PM Strahil Nikolov > >> ><hunter86_bg@yahoo.com> > >> >>> wrote: > >> >>> > >> >>>> Hi , > >> >>>> > >> >>>> > >> >>>> This one really looks like the ACL bug I was hit with when I > >> >updated > >> >>>> from Gluster v6.5 to 6.6 and later from 7.0 to 7.2. > >> >>>> > >> >>>> Did you update your setup recently ? Did you upgrade gluster > >also ? > >> >>>> > >> >>>> You have to check the gluster logs in order to verify
CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0, the that,
so > >you > >> >can > >> >>>> try: > >> >>>> > >> >>>> 1. Set Gluster logs to trace level (for details check: > >> >>>> > >> > > >> > > >
> >> >>>> ) > >> >>>> 2. Power up a VM that was already off , or retry the procedure > >from > >> >the > >> >>>> logs you sent. > >> >>>> 3. Stop the trace level of the logs > >> >>>> 4. Check libvirt logs on the host that was supposed to power up > >the > >> >VM > >> >>>> (in case a VM was powered on) > >> >>>> 5. Check the gluster brick logs on all nodes for ACL errors. > >> >>>> Here is a sample from my old logs: > >> >>>> > >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 > >> >13:19:41.489047] I > >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] > >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- > >> >>>> > >> > >> > >
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx > >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) > >> >>>> [Permission denied] > >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 > >> >13:22:51.818796] I > >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] > >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- > >> >>>> > >> > >> > >
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx > >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) > >> >>>> [Permission denied] > >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 > >> >13:24:43.732856] I > >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] > >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- > >> >>>> > >> > >> > >
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx > >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) > >> >>>> [Permission denied] > >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 > >> >13:26:50.758178] I > >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] > >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- > >> >>>> > >> > >> > >
> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx > >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) > >> >>>> [Permission denied] > >> >>>> > >> >>>> > >> >>>> In my case , the workaround was to downgrade the gluster > >packages > >> >on all > >> >>>> nodes (and reboot each node 1 by 1 ) if the major version is the > >> >same, but > >> >>>> if you upgraded to v7.X - then you can try the v7.0 . > >> >>>> > >> >>>> Best Regards, > >> >>>> Strahil Nikolov > >> >>>> > >> >>>> > >> >>>> > >> >>>> > >> >>>> > >> >>>> > >> >>>> В събота, 20 юни 2020 г., 18:48:42 ч. Гринуич+3, C Williams < > >> >>>> cwilliams3320@gmail.com> написа: > >> >>>> > >> >>>> > >> >>>> > >> >>>> > >> >>>> > >> >>>> Hello, > >> >>>> > >> >>>> Here are additional log tiles as well as a tree of the > >problematic > >> >>>> Gluster storage domain. During this time I attempted to copy a > >> >virtual disk > >> >>>> to another domain, move a virtual disk to another domain and run > >a > >> >VM where > >> >>>> the virtual hard disk would be used. > >> >>>> > >> >>>> The copies/moves failed and the VM went into pause mode when the > >> >virtual > >> >>>> HDD was involved. > >> >>>> > >> >>>> Please check these out. > >> >>>> > >> >>>> Thank You For Your Help ! > >> >>>> > >> >>>> On Sat, Jun 20, 2020 at 9:54 AM C Williams > >> ><cwilliams3320@gmail.com> > >> >>>> wrote: > >> >>>> > Strahil, > >> >>>> > > >> >>>> > I understand. Please keep me posted. > >> >>>> > > >> >>>> > Thanks For The Help ! > >> >>>> > > >> >>>> > On Sat, Jun 20, 2020 at 4:36 AM Strahil Nikolov > >> ><hunter86_bg@yahoo.com> > >> >>>> wrote: > >> >>>> >> Hey C Williams, > >> >>>> >> > >> >>>> >> sorry for the delay, but I couldn't get somw time to check > >your > >> >>>> logs. Will try a little bit later. > >> >>>> >> > >> >>>> >> Best Regards, > >> >>>> >> Strahil Nikolov > >> >>>> >> > >> >>>> >> На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams < > >> >>>> cwilliams3320@gmail.com> написа: > >> >>>> >>>Hello, > >> >>>> >>> > >> >>>> >>>Was wanting to follow up on this issue. Users are impacted. > >> >>>> >>> > >> >>>> >>>Thank You > >> >>>> >>> > >> >>>> >>>On Fri, Jun 19, 2020 at 9:20 AM C Williams > >> ><cwilliams3320@gmail.com> > >> >>>> >>>wrote: > >> >>>> >>> > >> >>>> >>>> Hello, > >> >>>> >>>> > >> >>>> >>>> Here are the logs (some IPs are changed ) > >> >>>> >>>> > >> >>>> >>>> ov05 is the SPM > >> >>>> >>>> > >> >>>> >>>> Thank You For Your Help ! > >> >>>> >>>> > >> >>>> >>>> On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov > >> >>>> >>><hunter86_bg@yahoo.com> > >> >>>> >>>> wrote: > >> >>>> >>>> > >> >>>> >>>>> Check on the hosts tab , which is your current SPM (last > >> >column in > >> >>>> >>>Admin > >> >>>> >>>>> UI). > >> >>>> >>>>> Then open the /var/log/vdsm/vdsm.log and repeat
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, the
> >> >operation. > >> >>>> >>>>> Then provide the log from that host and the engine's log > >(on > >> >the > >> >>>> >>>>> HostedEngine VM or on your standalone engine). > >> >>>> >>>>> > >> >>>> >>>>> Best Regards, > >> >>>> >>>>> Strahil Nikolov > >> >>>> >>>>> > >> >>>> >>>>> На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams > >> >>>> >>><cwilliams3320@gmail.com> > >> >>>> >>>>> написа: > >> >>>> >>>>> >Resending to eliminate email issues > >> >>>> >>>>> > > >> >>>> >>>>> >---------- Forwarded message --------- > >> >>>> >>>>> >From: C Williams <cwilliams3320@gmail.com> > >> >>>> >>>>> >Date: Thu, Jun 18, 2020 at 4:01 PM > >> >>>> >>>>> >Subject: Re: [ovirt-users] Fwd: Issues with Gluster > >Domain > >> >>>> >>>>> >To: Strahil Nikolov <hunter86_bg@yahoo.com> > >> >>>> >>>>> > > >> >>>> >>>>> > > >> >>>> >>>>> >Here is output from mount > >> >>>> >>>>> > > >> >>>> >>>>> >192.168.24.12:/stor/import0 on > >> >>>> >>>>> /rhev/data-center/mnt/192.168.24.12:_stor_import0 > >> >>>> >>>>> >type nfs4 > >> >>>> >>>>> > >> >>>> >>>>> > >> >>>> > >> >>>> > >> > >> > >
>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12) > >> >>>> >>>>> >192.168.24.13:/stor/import1 on > >> >>>> >>>>> /rhev/data-center/mnt/192.168.24.13:_stor_import1 > >> >>>> >>>>> >type nfs4 > >> >>>> >>>>> > >> >>>> >>>>> > >> >>>> > >> >>>> > >> > >> > >
>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) > >> >>>> >>>>> >192.168.24.13:/stor/iso1 on > >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_iso1 > >> >>>> >>>>> >type nfs4 > >> >>>> >>>>> > >> >>>> >>>>> > >> >>>> > >> >>>> > >> > >> > >
>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) > >> >>>> >>>>> >192.168.24.13:/stor/export0 on > >> >>>> >>>>> /rhev/data-center/mnt/192.168.24.13:_stor_export0 > >> >>>> >>>>> >type nfs4 > >> >>>> >>>>> > >> >>>> >>>>> > >> >>>> > >> >>>> > >> > >> > >
>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) > >> >>>> >>>>> >192.168.24.15:/images on > >> >>>> >>>>> /rhev/data-center/mnt/glusterSD/192.168.24.15:_images > >> >>>> >>>>> >type fuse.glusterfs > >> >>>> >>>>> > >> >>>> >>>>> > >> >>>> > >> >>>> > >> > >> > >
>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) > >> >>>> >>>>> >192.168.24.18:/images3 on > >> >>>> >>>>> /rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 > >> >>>> >>>>> >type fuse.glusterfs > >> >>>> >>>>> > >> >>>> >>>>> > >> >>>> > >> >>>> > >> > >> > >
>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) > >> >>>> >>>>> >tmpfs on /run/user/0 type tmpfs > >> >>>> >>>>> > >>(rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) > >> >>>> >>>>> >[root@ov06 glusterfs]# > >> >>>> >>>>> > > >> >>>> >>>>> >Also here is a screenshot of the console > >> >>>> >>>>> > > >> >>>> >>>>> >[image: image.png] > >> >>>> >>>>> >The other domains are up > >> >>>> >>>>> > > >> >>>> >>>>> >Import0 and Import1 are NFS . GLCL0 is gluster. They all > >are > >> >>>> >>>running > >> >>>> >>>>> >VMs > >> >>>> >>>>> > > >> >>>> >>>>> >Thank You For Your Help ! > >> >>>> >>>>> > > >> >>>> >>>>> >On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov > >> >>>> >>><hunter86_bg@yahoo.com> > >> >>>> >>>>> >wrote: > >> >>>> >>>>> > > >> >>>> >>>>> >> I don't see > >> >'/rhev/data-center/mnt/192.168.24.13:_stor_import1' > >> >>>> >>>>> >mounted > >> >>>> >>>>> >> at all . > >> >>>> >>>>> >> What is the status of all storage domains ? > >> >>>> >>>>> >> > >> >>>> >>>>> >> Best Regards, > >> >>>> >>>>> >> Strahil Nikolov > >> >>>> >>>>> >> > >> >>>> >>>>> >> На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams > >> >>>> >>>>> ><cwilliams3320@gmail.com> > >> >>>> >>>>> >> написа: > >> >>>> >>>>> >> > Resending to deal with possible email issues > >> >>>> >>>>> >> > > >> >>>> >>>>> >> >---------- Forwarded message --------- > >> >>>> >>>>> >> >From: C Williams <cwilliams3320@gmail.com> > >> >>>> >>>>> >> >Date: Thu, Jun 18, 2020 at 2:07 PM > >> >>>> >>>>> >> >Subject: Re: [ovirt-users] Issues with Gluster Domain > >> >>>> >>>>> >> >To: Strahil Nikolov <hunter86_bg@yahoo.com> > >> >>>> >>>>> >> > > >> >>>> >>>>> >> > > >> >>>> >>>>> >> >More > >> >>>> >>>>> >> > > >> >>>> >>>>> >> >[root@ov06 ~]# for i in $(gluster volume
https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3/html... list);
do
> >echo > >> >>>> >>>$i;echo; > >> >>>> >>>>> >> >gluster > >> >>>> >>>>> >> >volume info $i; echo;echo;gluster volume status > >> >>>> >>>>> >$i;echo;echo;echo;done > >> >>>> >>>>> >> >images3 > >> >>>> >>>>> >> > > >> >>>> >>>>> >> > > >> >>>> >>>>> >> >Volume Name: images3 > >> >>>> >>>>> >> >Type: Replicate > >> >>>> >>>>> >> >Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b > >> >>>> >>>>> >> >Status: Started > >> >>>> >>>>> >> >Snapshot Count: 0 > >> >>>> >>>>> >> >Number of Bricks: 1 x 3 = 3 > >> >>>> >>>>> >> >Transport-type: tcp > >> >>>> >>>>> >> >Bricks: > >> >>>> >>>>> >> >Brick1: 192.168.24.18:/bricks/brick04/images3 > >> >>>> >>>>> >> >Brick2: 192.168.24.19:/bricks/brick05/images3 > >> >>>> >>>>> >> >Brick3: 192.168.24.20:/bricks/brick06/images3 > >> >>>> >>>>> >> >Options Reconfigured: > >> >>>> >>>>> >> >performance.client-io-threads: on > >> >>>> >>>>> >> >nfs.disable: on > >> >>>> >>>>> >> >transport.address-family: inet > >> >>>> >>>>> >> >user.cifs: off > >> >>>> >>>>> >> >auth.allow: * > >> >>>> >>>>> >> >performance.quick-read: off > >> >>>> >>>>> >> >performance.read-ahead: off > >> >>>> >>>>> >> >performance.io-cache: off > >> >>>> >>>>> >> >performance.low-prio-threads: 32 > >> >>>> >>>>> >> >network.remote-dio: off > >> >>>> >>>>> >> >cluster.eager-lock: enable > >> >>>> >>>>> >> >cluster.quorum-type: auto > >> >>>> >>>>> >> >cluster.server-quorum-type: server > >> >>>> >>>>> >> >cluster.data-self-heal-algorithm: full > >> >>>> >>>>> >> >cluster.locking-scheme: granular > >> >>>> >>>>> >> >cluster.shd-max-threads: 8 > >> >>>> >>>>> >> >cluster.shd-wait-qlength: 10000 > >> >>>> >>>>> >> >features.shard: on > >> >>>> >>>>> >> >cluster.choose-local: off > >> >>>> >>>>> >> >client.event-threads: 4 > >> >>>> >>>>> >> >server.event-threads: 4 > >> >>>> >>>>> >> >storage.owner-uid: 36 > >> >>>> >>>>> >> >storage.owner-gid: 36 > >> >>>> >>>>> >> >performance.strict-o-direct: on > >> >>>> >>>>> >> >network.ping-timeout: 30 > >> >>>> >>>>> >> >cluster.granular-entry-heal: enable > >> >>>> >>>>> >> > > >> >>>> >>>>> >> > > >> >>>> >>>>> >> >Status of volume: images3 > >> >>>> >>>>> >> >Gluster process TCP Port > >> >RDMA Port > >> >>>> >>>>> >Online > >> >>>> >>>>> >> > Pid > >> >>>> >>>>> >> > >> >>>> >>>>> >> > >> >>>> >>>>> > >> >>>> >>>>> > >> >>>> > >> >>>> > >> > >> > >
>>>>------------------------------------------------------------------------------ > >> >>>> >>>>> >> >Brick 192.168.24.18:/bricks/brick04/images3 49152 > >0 > >> >>>> > >> >>>> >>>Y > >> >>>> >>>>> >> >6666 > >> >>>> >>>>> >> >Brick 192.168.24.19:/bricks/brick05/images3 49152 > >0 > >> >>>> > >> >>>> >>>Y > >> >>>> >>>>> >> >6779 > >> >>>> >>>>> >> >Brick 192.168.24.20:/bricks/brick06/images3 49152 > >0 > >> >>>> > >> >>>> >>>Y > >> >>>> >>>>> >> >7227 > >> >>>> >>>>> >> >Self-heal Daemon on localhost N/A > >N/A > >> >>>> > >> >>>> >>>Y > >> >>>> >>>>> >> >6689 > >> >>>> >>>>> >> >Self-heal Daemon on ov07.ntc.srcle.com N/A > >N/A > >> >>>> > >> >>>> >>>Y > >> >>>> >>>>> >> >6802 > >> >>>> >>>>> >> >Self-heal Daemon on ov08.ntc.srcle.com N/A > >N/A > >> >>>> > >> >>>> >>>Y > >> >>>> >>>>> >> >7250 > >> >>>> >>>>> >> > > >> >>>> >>>>> >> >Task Status of Volume images3 > >> >>>> >>>>> >> > >> >>>> >>>>> >> > >> >>>> >>>>> > >> >>>> >>>>> > >> >>>> > >> >>>> > >> > >> > >
>>>>------------------------------------------------------------------------------ > >> >>>> >>>>> >> >There are no active volume tasks > >> >>>> >>>>> >> > > >> >>>> >>>>> >> > > >> >>>> >>>>> >> > > >> >>>> >>>>> >> > > >> >>>> >>>>> >> >[root@ov06 ~]# ls -l /rhev/data-center/mnt/glusterSD/ > >> >>>> >>>>> >> >total 16 > >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 > >> >192.168.24.15:_images > >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 > >192.168.24.18: > >> >>>> _images3 > >> >>>> >>>>> >> >[root@ov06 ~]# > >> >>>> >>>>> >> > > >> >>>> >>>>> >> >On Thu, Jun 18, 2020 at 2:03 PM C Williams > >> >>>> >>><cwilliams3320@gmail.com> > >> >>>> >>>>> >> >wrote: > >> >>>> >>>>> >> > > >> >>>> >>>>> >> >> Strahil, > >> >>>> >>>>> >> >> > >> >>>> >>>>> >> >> Here you go -- Thank You For Your Help ! > >> >>>> >>>>> >> >> > >> >>>> >>>>> >> >> BTW -- I can write a test file to gluster and it > >> >replicates > >> >>>> >>>>> >properly. > >> >>>> >>>>> >> >> Thinking something about the oVirt Storage Domain ? > >> >>>> >>>>> >> >> > >> >>>> >>>>> >> >> [root@ov08 ~]# gluster pool list > >> >>>> >>>>> >> >> UUID Hostname > >> >>>> >>>>> >State > >> >>>> >>>>> >> >> 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06 > >> >>>> >>>>> >> >Connected > >> >>>> >>>>> >> >> 36ce5a00-6f65-4926-8438-696944ebadb5 > >> >ov07.ntc.srcle.com > >> >>>> >>>>> >> >Connected > >> >>>> >>>>> >> >> c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost > >> >>>> >>>>> >> >Connected > >> >>>> >>>>> >> >> [root@ov08 ~]# gluster volume list > >> >>>> >>>>> >> >> images3 > >> >>>> >>>>> >> >> > >> >>>> >>>>> >> >> On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov > >> >>>> >>>>> >> ><hunter86_bg@yahoo.com> > >> >>>> >>>>> >> >> wrote: > >> >>>> >>>>> >> >> > >> >>>> >>>>> >> >>> Log to the oVirt cluster and provide the output of: > >> >>>> >>>>> >> >>> gluster pool list > >> >>>> >>>>> >> >>> gluster volume list > >> >>>> >>>>> >> >>> for i in $(gluster volume list); do echo $i;echo; > >> >gluster > >> >>>> >>>>> >volume > >> >>>> >>>>> >> >info > >> >>>> >>>>> >> >>> $i; echo;echo;gluster volume status > >> >$i;echo;echo;echo;done > >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> >>> ls -l /rhev/data-center/mnt/glusterSD/ > >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> >>> Best Regards, > >> >>>> >>>>> >> >>> Strahil Nikolov > >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> >>> На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams > >> >>>> >>>>> >> ><cwilliams3320@gmail.com> > >> >>>> >>>>> >> >>> написа: > >> >>>> >>>>> >> >>> >Hello, > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> >I recently added 6 hosts to an existing oVirt > >> >>>> >>>compute/gluster > >> >>>> >>>>> >> >cluster. > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> >Prior to this attempted addition, my cluster had 3 > >> >>>> >>>Hypervisor > >> >>>> >>>>> >hosts > >> >>>> >>>>> >> >and > >> >>>> >>>>> >> >>> >3 > >> >>>> >>>>> >> >>> >gluster bricks which made up a single gluster > >volume > >> >>>> >>>(replica 3 > >> >>>> >>>>> >> >volume) > >> >>>> >>>>> >> >>> >. I > >> >>>> >>>>> >> >>> >added the additional hosts and made a brick on 3 > >of > >> >the new > >> >>>> >>>>> >hosts > >> >>>> >>>>> >> >and > >> >>>> >>>>> >> >>> >attempted to make a new replica 3 volume. I had > >> >difficulty > >> >>>> >>>>> >> >creating > >> >>>> >>>>> >> >>> >the > >> >>>> >>>>> >> >>> >new volume. So, I decided that I would make a new > >> >>>> >>>>> >compute/gluster > >> >>>> >>>>> >> >>> >cluster > >> >>>> >>>>> >> >>> >for each set of 3 new hosts. > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> >I removed the 6 new hosts from the existing oVirt > >> >>>> >>>>> >Compute/Gluster > >> >>>> >>>>> >> >>> >Cluster > >> >>>> >>>>> >> >>> >leaving the 3 original hosts in place with their > >> >bricks. At > >> >>>> >>>that > >> >>>> >>>>> >> >point > >> >>>> >>>>> >> >>> >my > >> >>>> >>>>> >> >>> >original bricks went down and came back up . The > >> >volume > >> >>>> >>>showed > >> >>>> >>>>> >> >entries > >> >>>> >>>>> >> >>> >that > >> >>>> >>>>> >> >>> >needed healing. At that point I ran gluster volume > >> >heal > >> >>>> >>>images3 > >> >>>> >>>>> >> >full, > >> >>>> >>>>> >> >>> >etc. > >> >>>> >>>>> >> >>> >The volume shows no unhealed entries. I also > >> >corrected some > >> >>>> >>>peer > >> >>>> >>>>> >> >>> >errors. > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> >However, I am unable to copy disks, move disks to > >> >another > >> >>>> >>>>> >domain, > >> >>>> >>>>> >> >>> >export > >> >>>> >>>>> >> >>> >disks, etc. It appears that the engine cannot > >locate > >> >disks > >> >>>> >>>>> >properly > >> >>>> >>>>> >> >and > >> >>>> >>>>> >> >>> >I > >> >>>> >>>>> >> >>> >get storage I/O errors. > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> >I have detached and removed the oVirt Storage > >Domain. > >> >I > >> >>>> >>>>> >reimported > >> >>>> >>>>> >> >the > >> >>>> >>>>> >> >>> >domain and imported 2 VMs, But the VM disks > >exhibit > >> >the > >> >>>> same > >> >>>> >>>>> >> >behaviour > >> >>>> >>>>> >> >>> >and > >> >>>> >>>>> >> >>> >won't run from the hard disk. > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> >I get errors such as this > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> >VDSM ov05 command HSMGetAllTasksStatusesVDS > >failed: > >> >low > >> >>>> >>>level > >> >>>> >>>>> >Image > >> >>>> >>>>> >> >>> >copy > >> >>>> >>>>> >> >>> >failed: ("Command ['/usr/bin/qemu-img', 'convert', > >> >'-p', > >> >>>> >>>'-t', > >> >>>> >>>>> >> >'none', > >> >>>> >>>>> >> >>> >'-T', 'none', '-f', 'raw', > >> >>>> >>>>> >> >>> >u'/rhev/data-center/mnt/glusterSD/192.168.24.18: > >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> > >> >>>> >>>>> >> > >> >>>> >>>>> > >> >>>> >>>>> > >> >>>> > >> >>>> > >> > >> > >
>>>>_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510', > >> >>>> >>>>> >> >>> >'-O', 'raw', > >> >>>> >>>>> >> >>> >u'/rhev/data-center/mnt/192.168.24.13: > >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> > >> >>>> >>>>> >> > >> >>>> >>>>> > >> >>>> >>>>> > >> >>>> > >> >>>> > >> > >> > >
>>>>_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5'] > >> >>>> >>>>> >> >>> >failed with rc=1 out='' err=bytearray(b'qemu-img: > >> >error > >> >>>> >>>while > >> >>>> >>>>> >> >reading > >> >>>> >>>>> >> >>> >sector 135168: Transport endpoint is not > >> >>>> >>>connected\\nqemu-img: > >> >>>> >>>>> >> >error > >> >>>> >>>>> >> >>> >while > >> >>>> >>>>> >> >>> >reading sector 131072: Transport endpoint is not > >> >>>> >>>>> >> >connected\\nqemu-img: > >> >>>> >>>>> >> >>> >error while reading sector 139264: Transport > >endpoint > >> >is > >> >>>> not > >> >>>> >>>>> >> >>> >connected\\nqemu-img: error while reading sector > >> >143360: > >> >>>> >>>>> >Transport > >> >>>> >>>>> >> >>> >endpoint > >> >>>> >>>>> >> >>> >is not connected\\nqemu-img: error while reading > >> >sector > >> >>>> >>>147456: > >> >>>> >>>>> >> >>> >Transport > >> >>>> >>>>> >> >>> >endpoint is not connected\\nqemu-img: error while > >> >reading > >> >>>> >>>sector > >> >>>> >>>>> >> >>> >155648: > >> >>>> >>>>> >> >>> >Transport endpoint is not connected\\nqemu-img: > >error > >> >while > >> >>>> >>>>> >reading > >> >>>> >>>>> >> >>> >sector > >> >>>> >>>>> >> >>> >151552: Transport endpoint is not > >> >connected\\nqemu-img: > >> >>>> >>>error > >> >>>> >>>>> >while > >> >>>> >>>>> >> >>> >reading > >> >>>> >>>>> >> >>> >sector 159744: Transport endpoint is not > >> >connected\\n')",) > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> >oVirt version is 4.3.82-1.el7 > >> >>>> >>>>> >> >>> >OS CentOS Linux release 7.7.1908 (Core) > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> >The Gluster Cluster has been working very well > >until > >> >this > >> >>>> >>>>> >incident. > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> >Please help. > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> >Thank You > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> >Charles Williams > >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> >> > >> >>>> >>>>> >> > >> >>>> >>>>> > >> >>>> >>>> > >> >>>> >> > >> >>>> > > >> >>>> _______________________________________________ > >> >>>> Users mailing list -- users@ovirt.org > >> >>>> To unsubscribe send an email to users-leave@ovirt.org > >> >>>> Privacy Statement: https://www.ovirt.org/privacy-policy.html > >> >>>> oVirt Code of Conduct: > >> >>>> https://www.ovirt.org/community/about/community-guidelines/ > >> >>>> List Archives: > >> >>>> > >> > > >> > > >
https://lists.ovirt.org/archives/list/users@ovirt.org/message/YY3VUKEJLI7MRW...
> >> >>>> > >> >>> > >> >
Strahil, The GLCL3 storage domain was detached prior to attempting to add the new storage domain. Should I also "Remove" it ? Thank You For Your Help ! ---------- Forwarded message --------- From: Strahil Nikolov <hunter86_bg@yahoo.com> Date: Mon, Jun 22, 2020 at 12:50 AM Subject: Re: [ovirt-users] Re: Fwd: Fwd: Issues with Gluster Domain To: C Williams <cwilliams3320@gmail.com> Cc: users <Users@ovirt.org> You can't add the new volume as it contains the same data (UUID) as the old one , thus you need to detach the old one before adding the new one - of course this means downtime for all VMs on that storage. As you see , downgrading is more simpler. For me v6.5 was working, while anything above (6.6+) was causing complete lockdown. Also v7.0 was working, but it's supported in oVirt 4.4. Best Regards, Strahil Nikolov На 22 юни 2020 г. 7:21:15 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Another question
What version could I downgrade to safely ? I am at 6.9 .
Thank You For Your Help !!
On Sun, Jun 21, 2020 at 11:38 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
You are definitely reading it wrong. 1. I didn't create a new storage domain ontop this new volume. 2. I used cli
Something like this (in your case it should be 'replica 3'): gluster volume create newvol replica 3 arbiter 1 ovirt1:/new/brick/path ovirt2:/new/brick/path ovirt3:/new/arbiter/brick/path gluster volume start newvol
#Detach oldvol from ovirt
mount -t glusterfs ovirt1:/oldvol /mnt/oldvol mount -t glusterfs ovirt1:/newvol /mnt/newvol cp -a /mnt/oldvol/* /mnt/newvol
#Add only newvol as a storage domain in oVirt #Import VMs
I still think that you should downgrade your gluster packages!!!
Best Regards, Strahil Nikolov
На 22 юни 2020 г. 0:43:46 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Strahil,
It sounds like you used a "System Managed Volume" for the new storage domain,is that correct?
Thank You For Your Help !
On Sun, Jun 21, 2020 at 5:40 PM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
So you made another oVirt Storage Domain -- then copied the data with cp -a from the failed volume to the new volume.
At the root of the volume there will be the old domain folder id ex 5fe3ad3f-2d21-404c-832e-4dc7318ca10d in my case. Did that cause issues with making the new domain since it is the same folder id as the old one ?
Thank You For Your Help !
On Sun, Jun 21, 2020 at 5:18 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
In my situation I had only the ovirt nodes.
Strahil,
So should I make the target volume on 3 bricks which do not have ovirt -- just gluster ? In other words (3) Centos 7 hosts ?
Thank You For Your Help !
On Sun, Jun 21, 2020 at 3:08 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
> I created a fresh volume (which is not an ovirt sgorage domain), set > the original storage domain in maintenance and detached it. > Then I 'cp -a ' the data from the old to the new volume. Next, I just > added the new storage domain (the old one was a kind of a > 'backup') - pointing to the new volume name. > > If you observe issues , I would recommend you to downgrade > gluster packages one node at a time . Then you might be able to > restore your oVirt operations. > > Best Regards, > Strahil Nikolov > > На 21 юни 2020 г. 18:01:31 GMT+03:00, C Williams <cwilliams3320@gmail.com> > написа: > >Strahil, > > > >Thanks for the follow up ! > > > >How did you copy the data to another volume ? > > > >I have set up another storage domain GLCLNEW1 with a new volume imgnew1 > >. > >How would you copy all of the data from the problematic domain GLCL3 > >with > >volume images3 to GLCLNEW1 and volume imgnew1 and preserve all
На 21 юни 2020 г. 22:43:04 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: the
VMs, > >VM > >disks, settings, etc. ? > > > >Remember all of the regular ovirt disk copy, disk move, VM export > >tools > >are failing and my VMs and disks are trapped on domain GLCL3 and volume > >images3 right now. > > > >Please let me know > > > >Thank You For Your Help ! > > > > > > > > > > > >On Sun, Jun 21, 2020 at 8:27 AM Strahil Nikolov <hunter86_bg@yahoo.com> > >wrote: > > > >> Sorry to hear that. > >> I can say that for me 6.5 was working, while 6.6 didn't and I > >upgraded > >> to 7.0 . > >> In the ended , I have ended with creating a new fresh volume and > >> physically copying the data there, then I detached the storage > >domains and > >> attached to the new ones (which holded the old data), but I > >could > >> afford the downtime. > >> Also, I can say that v7.0 ( but not 7.1 or anything later) also > >> worked without the ACL issue, but it causes some trouble in oVirt > >- so > >> avoid that unless you have no other options. > >> > >> Best Regards, > >> Strahil Nikolov > >> > >> > >> > >> > >> На 21 юни 2020 г. 4:39:46 GMT+03:00, C Williams > ><cwilliams3320@gmail.com> > >> написа: > >> >Hello, > >> > > >> >Upgrading diidn't help > >> > > >> >Still acl errors trying to use a Virtual Disk from a VM > >> > > >> >[root@ov06 bricks]# tail bricks-brick04-images3.log | grep acl > >> >[2020-06-21 01:33:45.665888] I [MSGID: 139001] > >> >[posix-acl.c:263:posix_acl_log_permit_denied] > >0-images3-access-control: > >> >client: > >> > >> > >
CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0,
> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >> >req(uid:107,gid:107,perm:1,ngrps:3), > >> >ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) > >> >[Permission denied] > >> >The message "I [MSGID: 139001] > >> >[posix-acl.c:263:posix_acl_log_permit_denied] > >0-images3-access-control: > >> >client: > >> > >> > >
> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >> >req(uid:107,gid:107,perm:1,ngrps:3), > >> >ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) > >> >[Permission denied]" repeated 2 times between [2020-06-21 > >> >01:33:45.665888] > >> >and [2020-06-21 01:33:45.806779] > >> > > >> >Thank You For Your Help ! > >> > > >> >On Sat, Jun 20, 2020 at 8:59 PM C Williams <cwilliams3320@gmail.com> > >> >wrote: > >> > > >> >> Hello, > >> >> > >> >> Based on the situation, I am planning to upgrade the 3 affected > >> >hosts. > >> >> > >> >> My reasoning is that the hosts/bricks were attached to 6.9 at one > >> >time. > >> >> > >> >> Thanks For Your Help ! > >> >> > >> >> On Sat, Jun 20, 2020 at 8:38 PM C Williams > ><cwilliams3320@gmail.com> > >> >> wrote: > >> >> > >> >>> Strahil, > >> >>> > >> >>> The gluster version on the current 3 gluster hosts is 6.7 (last > >> >update > >> >>> 2/26). These 3 hosts provide 1 brick each for the replica 3 > >volume. > >> >>> > >> >>> Earlier I had tried to add 6 additional hosts to the cluster. > >Those > >> >new > >> >>> hosts were 6.9 gluster. > >> >>> > >> >>> I attempted to make a new separate volume with 3 bricks provided > >by > >> >the 3 > >> >>> new gluster 6.9 hosts. After having many errors from
oVirt > >> >interface, > >> >>> I gave up and removed the 6 new hosts from the cluster. That is > >> >where the > >> >>> problems started. The intent was to expand the gluster cluster > >while > >> >making > >> >>> 2 new volumes for that cluster. The ovirt compute cluster would > >> >allow for > >> >>> efficient VM migration between 9 hosts -- while having separate > >> >gluster > >> >>> volumes for safety purposes. > >> >>> > >> >>> Looking at the brick logs, I see where there are acl errors > >starting > >> >from > >> >>> the time of the removal of the 6 new hosts. > >> >>> > >> >>> Please check out the attached brick log from 6/14-18. The events > >> >started > >> >>> on 6/17. > >> >>> > >> >>> I wish I had a downgrade path. > >> >>> > >> >>> Thank You For The Help !! > >> >>> > >> >>> On Sat, Jun 20, 2020 at 7:47 PM Strahil Nikolov > >> ><hunter86_bg@yahoo.com> > >> >>> wrote: > >> >>> > >> >>>> Hi , > >> >>>> > >> >>>> > >> >>>> This one really looks like the ACL bug I was hit with when I > >> >updated > >> >>>> from Gluster v6.5 to 6.6 and later from 7.0 to 7.2. > >> >>>> > >> >>>> Did you update your setup recently ? Did you upgrade gluster > >also ? > >> >>>> > >> >>>> You have to check the gluster logs in order to verify
CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0, the that,
so > >you > >> >can > >> >>>> try: > >> >>>> > >> >>>> 1. Set Gluster logs to trace level (for details check: > >> >>>> > >> > > >> > > >
https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3/html...
> >> >>>> ) > >> >>>> 2. Power up a VM that was already off , or retry the procedure > >from > >> >the > >> >>>> logs you sent. > >> >>>> 3. Stop the trace level of the logs > >> >>>> 4. Check libvirt logs on the host that was supposed to power up > >the > >> >VM > >> >>>> (in case a VM was powered on) > >> >>>> 5. Check the gluster brick logs on all nodes for ACL errors. > >> >>>> Here is a sample from my old logs: > >> >>>> > >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 > >> >13:19:41.489047] I > >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] > >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- > >> >>>> > >> > >> > >
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx > >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) > >> >>>> [Permission denied] > >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 > >> >13:22:51.818796] I > >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] > >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- > >> >>>> > >> > >> > >
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx > >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) > >> >>>> [Permission denied] > >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 > >> >13:24:43.732856] I > >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] > >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- > >> >>>> > >> > >> > >
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19,
> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx > >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) > >> >>>> [Permission denied] > >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 > >> >13:26:50.758178] I > >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] > >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- > >> >>>> > >> > >> > >
> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx > >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) > >> >>>> [Permission denied] > >> >>>> > >> >>>> > >> >>>> In my case , the workaround was to downgrade the gluster > >packages > >> >on all > >> >>>> nodes (and reboot each node 1 by 1 ) if the major version is the > >> >same, but > >> >>>> if you upgraded to v7.X - then you can try the v7.0 . > >> >>>> > >> >>>> Best Regards, > >> >>>> Strahil Nikolov > >> >>>> > >> >>>> > >> >>>> > >> >>>> > >> >>>> > >> >>>> > >> >>>> В събота, 20 юни 2020 г., 18:48:42 ч. Гринуич+3, C Williams < > >> >>>> cwilliams3320@gmail.com> написа: > >> >>>> > >> >>>> > >> >>>> > >> >>>> > >> >>>> > >> >>>> Hello, > >> >>>> > >> >>>> Here are additional log tiles as well as a tree of the > >problematic > >> >>>> Gluster storage domain. During this time I attempted to copy a > >> >virtual disk > >> >>>> to another domain, move a virtual disk to another domain and run > >a > >> >VM where > >> >>>> the virtual hard disk would be used. > >> >>>> > >> >>>> The copies/moves failed and the VM went into pause mode when the > >> >virtual > >> >>>> HDD was involved. > >> >>>> > >> >>>> Please check these out. > >> >>>> > >> >>>> Thank You For Your Help ! > >> >>>> > >> >>>> On Sat, Jun 20, 2020 at 9:54 AM C Williams > >> ><cwilliams3320@gmail.com> > >> >>>> wrote: > >> >>>> > Strahil, > >> >>>> > > >> >>>> > I understand. Please keep me posted. > >> >>>> > > >> >>>> > Thanks For The Help ! > >> >>>> > > >> >>>> > On Sat, Jun 20, 2020 at 4:36 AM Strahil Nikolov > >> ><hunter86_bg@yahoo.com> > >> >>>> wrote: > >> >>>> >> Hey C Williams, > >> >>>> >> > >> >>>> >> sorry for the delay, but I couldn't get somw time to check > >your > >> >>>> logs. Will try a little bit later. > >> >>>> >> > >> >>>> >> Best Regards, > >> >>>> >> Strahil Nikolov > >> >>>> >> > >> >>>> >> На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams < > >> >>>> cwilliams3320@gmail.com> написа: > >> >>>> >>>Hello, > >> >>>> >>> > >> >>>> >>>Was wanting to follow up on this issue. Users are impacted. > >> >>>> >>> > >> >>>> >>>Thank You > >> >>>> >>> > >> >>>> >>>On Fri, Jun 19, 2020 at 9:20 AM C Williams > >> ><cwilliams3320@gmail.com> > >> >>>> >>>wrote: > >> >>>> >>> > >> >>>> >>>> Hello, > >> >>>> >>>> > >> >>>> >>>> Here are the logs (some IPs are changed ) > >> >>>> >>>> > >> >>>> >>>> ov05 is the SPM > >> >>>> >>>> > >> >>>> >>>> Thank You For Your Help ! > >> >>>> >>>> > >> >>>> >>>> On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov > >> >>>> >>><hunter86_bg@yahoo.com> > >> >>>> >>>> wrote: > >> >>>> >>>> > >> >>>> >>>>> Check on the hosts tab , which is your current SPM (last > >> >column in > >> >>>> >>>Admin > >> >>>> >>>>> UI). > >> >>>> >>>>> Then open the /var/log/vdsm/vdsm.log and repeat
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, the
> >> >operation. > >> >>>> >>>>> Then provide the log from that host and the engine's log > >(on > >> >the > >> >>>> >>>>> HostedEngine VM or on your standalone engine). > >> >>>> >>>>> > >> >>>> >>>>> Best Regards, > >> >>>> >>>>> Strahil Nikolov > >> >>>> >>>>> > >> >>>> >>>>> На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams > >> >>>> >>><cwilliams3320@gmail.com> > >> >>>> >>>>> написа: > >> >>>> >>>>> >Resending to eliminate email issues > >> >>>> >>>>> > > >> >>>> >>>>> >---------- Forwarded message --------- > >> >>>> >>>>> >From: C Williams <cwilliams3320@gmail.com> > >> >>>> >>>>> >Date: Thu, Jun 18, 2020 at 4:01 PM > >> >>>> >>>>> >Subject: Re: [ovirt-users] Fwd: Issues with Gluster > >Domain > >> >>>> >>>>> >To: Strahil Nikolov <hunter86_bg@yahoo.com> > >> >>>> >>>>> > > >> >>>> >>>>> > > >> >>>> >>>>> >Here is output from mount > >> >>>> >>>>> > > >> >>>> >>>>> >192.168.24.12:/stor/import0 on > >> >>>> >>>>> /rhev/data-center/mnt/192.168.24.12:_stor_import0 > >> >>>> >>>>> >type nfs4 > >> >>>> >>>>> > >> >>>> >>>>> > >> >>>> > >> >>>> > >> > >> > >
>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12) > >> >>>> >>>>> >192.168.24.13:/stor/import1 on > >> >>>> >>>>> /rhev/data-center/mnt/192.168.24.13:_stor_import1 > >> >>>> >>>>> >type nfs4 > >> >>>> >>>>> > >> >>>> >>>>> > >> >>>> > >> >>>> > >> > >> > >
>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) > >> >>>> >>>>> >192.168.24.13:/stor/iso1 on > >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_iso1 > >> >>>> >>>>> >type nfs4 > >> >>>> >>>>> > >> >>>> >>>>> > >> >>>> > >> >>>> > >> > >> > >
>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) > >> >>>> >>>>> >192.168.24.13:/stor/export0 on > >> >>>> >>>>> /rhev/data-center/mnt/192.168.24.13:_stor_export0 > >> >>>> >>>>> >type nfs4 > >> >>>> >>>>> > >> >>>> >>>>> > >> >>>> > >> >>>> > >> > >> > >
>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) > >> >>>> >>>>> >192.168.24.15:/images on > >> >>>> >>>>> /rhev/data-center/mnt/glusterSD/192.168.24.15:_images > >> >>>> >>>>> >type fuse.glusterfs > >> >>>> >>>>> > >> >>>> >>>>> > >> >>>> > >> >>>> > >> > >> > >
>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) > >> >>>> >>>>> >192.168.24.18:/images3 on > >> >>>> >>>>> /rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 > >> >>>> >>>>> >type fuse.glusterfs > >> >>>> >>>>> > >> >>>> >>>>> > >> >>>> > >> >>>> > >> > >> > >
>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) > >> >>>> >>>>> >tmpfs on /run/user/0 type tmpfs > >> >>>> >>>>> > >>(rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) > >> >>>> >>>>> >[root@ov06 glusterfs]# > >> >>>> >>>>> > > >> >>>> >>>>> >Also here is a screenshot of the console > >> >>>> >>>>> > > >> >>>> >>>>> >[image: image.png] > >> >>>> >>>>> >The other domains are up > >> >>>> >>>>> > > >> >>>> >>>>> >Import0 and Import1 are NFS . GLCL0 is gluster. They all > >are > >> >>>> >>>running > >> >>>> >>>>> >VMs > >> >>>> >>>>> > > >> >>>> >>>>> >Thank You For Your Help ! > >> >>>> >>>>> > > >> >>>> >>>>> >On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov > >> >>>> >>><hunter86_bg@yahoo.com> > >> >>>> >>>>> >wrote: > >> >>>> >>>>> > > >> >>>> >>>>> >> I don't see > >> >'/rhev/data-center/mnt/192.168.24.13:_stor_import1' > >> >>>> >>>>> >mounted > >> >>>> >>>>> >> at all . > >> >>>> >>>>> >> What is the status of all storage domains ? > >> >>>> >>>>> >> > >> >>>> >>>>> >> Best Regards, > >> >>>> >>>>> >> Strahil Nikolov > >> >>>> >>>>> >> > >> >>>> >>>>> >> На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams > >> >>>> >>>>> ><cwilliams3320@gmail.com> > >> >>>> >>>>> >> написа: > >> >>>> >>>>> >> > Resending to deal with possible email issues > >> >>>> >>>>> >> > > >> >>>> >>>>> >> >---------- Forwarded message --------- > >> >>>> >>>>> >> >From: C Williams <cwilliams3320@gmail.com> > >> >>>> >>>>> >> >Date: Thu, Jun 18, 2020 at 2:07 PM > >> >>>> >>>>> >> >Subject: Re: [ovirt-users] Issues with Gluster Domain > >> >>>> >>>>> >> >To: Strahil Nikolov <hunter86_bg@yahoo.com> > >> >>>> >>>>> >> > > >> >>>> >>>>> >> > > >> >>>> >>>>> >> >More > >> >>>> >>>>> >> > > >> >>>> >>>>> >> >[root@ov06 ~]# for i in $(gluster volume list); do > >echo > >> >>>> >>>$i;echo; > >> >>>> >>>>> >> >gluster > >> >>>> >>>>> >> >volume info $i; echo;echo;gluster volume status > >> >>>> >>>>> >$i;echo;echo;echo;done > >> >>>> >>>>> >> >images3 > >> >>>> >>>>> >> > > >> >>>> >>>>> >> > > >> >>>> >>>>> >> >Volume Name: images3 > >> >>>> >>>>> >> >Type: Replicate > >> >>>> >>>>> >> >Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b > >> >>>> >>>>> >> >Status: Started > >> >>>> >>>>> >> >Snapshot Count: 0 > >> >>>> >>>>> >> >Number of Bricks: 1 x 3 = 3 > >> >>>> >>>>> >> >Transport-type: tcp > >> >>>> >>>>> >> >Bricks: > >> >>>> >>>>> >> >Brick1: 192.168.24.18:/bricks/brick04/images3 > >> >>>> >>>>> >> >Brick2: 192.168.24.19:/bricks/brick05/images3 > >> >>>> >>>>> >> >Brick3: 192.168.24.20:/bricks/brick06/images3 > >> >>>> >>>>> >> >Options Reconfigured: > >> >>>> >>>>> >> >performance.client-io-threads: on > >> >>>> >>>>> >> >nfs.disable: on > >> >>>> >>>>> >> >transport.address-family: inet > >> >>>> >>>>> >> >user.cifs: off > >> >>>> >>>>> >> >auth.allow: * > >> >>>> >>>>> >> >performance.quick-read: off > >> >>>> >>>>> >> >performance.read-ahead: off > >> >>>> >>>>> >> >performance.io-cache: off > >> >>>> >>>>> >> >performance.low-prio-threads: 32 > >> >>>> >>>>> >> >network.remote-dio: off > >> >>>> >>>>> >> >cluster.eager-lock: enable > >> >>>> >>>>> >> >cluster.quorum-type: auto > >> >>>> >>>>> >> >cluster.server-quorum-type: server > >> >>>> >>>>> >> >cluster.data-self-heal-algorithm: full > >> >>>> >>>>> >> >cluster.locking-scheme: granular > >> >>>> >>>>> >> >cluster.shd-max-threads: 8 > >> >>>> >>>>> >> >cluster.shd-wait-qlength: 10000 > >> >>>> >>>>> >> >features.shard: on > >> >>>> >>>>> >> >cluster.choose-local: off > >> >>>> >>>>> >> >client.event-threads: 4 > >> >>>> >>>>> >> >server.event-threads: 4 > >> >>>> >>>>> >> >storage.owner-uid: 36 > >> >>>> >>>>> >> >storage.owner-gid: 36 > >> >>>> >>>>> >> >performance.strict-o-direct: on > >> >>>> >>>>> >> >network.ping-timeout: 30 > >> >>>> >>>>> >> >cluster.granular-entry-heal: enable > >> >>>> >>>>> >> > > >> >>>> >>>>> >> > > >> >>>> >>>>> >> >Status of volume: images3 > >> >>>> >>>>> >> >Gluster process TCP Port > >> >RDMA Port > >> >>>> >>>>> >Online > >> >>>> >>>>> >> > Pid > >> >>>> >>>>> >> > >> >>>> >>>>> >> > >> >>>> >>>>> > >> >>>> >>>>> > >> >>>> > >> >>>> > >> > >> > >
>>>>------------------------------------------------------------------------------ > >> >>>> >>>>> >> >Brick 192.168.24.18:/bricks/brick04/images3 49152 > >0 > >> >>>> > >> >>>> >>>Y > >> >>>> >>>>> >> >6666 > >> >>>> >>>>> >> >Brick 192.168.24.19:/bricks/brick05/images3 49152 > >0 > >> >>>> > >> >>>> >>>Y > >> >>>> >>>>> >> >6779 > >> >>>> >>>>> >> >Brick 192.168.24.20:/bricks/brick06/images3 49152 > >0 > >> >>>> > >> >>>> >>>Y > >> >>>> >>>>> >> >7227 > >> >>>> >>>>> >> >Self-heal Daemon on localhost N/A > >N/A > >> >>>> > >> >>>> >>>Y > >> >>>> >>>>> >> >6689 > >> >>>> >>>>> >> >Self-heal Daemon on ov07.ntc.srcle.com N/A > >N/A > >> >>>> > >> >>>> >>>Y > >> >>>> >>>>> >> >6802 > >> >>>> >>>>> >> >Self-heal Daemon on ov08.ntc.srcle.com N/A > >N/A > >> >>>> > >> >>>> >>>Y > >> >>>> >>>>> >> >7250 > >> >>>> >>>>> >> > > >> >>>> >>>>> >> >Task Status of Volume images3 > >> >>>> >>>>> >> > >> >>>> >>>>> >> > >> >>>> >>>>> > >> >>>> >>>>> > >> >>>> > >> >>>> > >> > >> > >
>>>>------------------------------------------------------------------------------ > >> >>>> >>>>> >> >There are no active volume tasks > >> >>>> >>>>> >> > > >> >>>> >>>>> >> > > >> >>>> >>>>> >> > > >> >>>> >>>>> >> > > >> >>>> >>>>> >> >[root@ov06 ~]# ls -l /rhev/data-center/mnt/glusterSD/ > >> >>>> >>>>> >> >total 16 > >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 > >> >192.168.24.15:_images > >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 > >192.168.24.18: > >> >>>> _images3 > >> >>>> >>>>> >> >[root@ov06 ~]# > >> >>>> >>>>> >> > > >> >>>> >>>>> >> >On Thu, Jun 18, 2020 at 2:03 PM C Williams > >> >>>> >>><cwilliams3320@gmail.com> > >> >>>> >>>>> >> >wrote: > >> >>>> >>>>> >> > > >> >>>> >>>>> >> >> Strahil, > >> >>>> >>>>> >> >> > >> >>>> >>>>> >> >> Here you go -- Thank You For Your Help ! > >> >>>> >>>>> >> >> > >> >>>> >>>>> >> >> BTW -- I can write a test file to gluster and it > >> >replicates > >> >>>> >>>>> >properly. > >> >>>> >>>>> >> >> Thinking something about the oVirt Storage Domain ? > >> >>>> >>>>> >> >> > >> >>>> >>>>> >> >> [root@ov08 ~]# gluster pool list > >> >>>> >>>>> >> >> UUID Hostname > >> >>>> >>>>> >State > >> >>>> >>>>> >> >> 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06 > >> >>>> >>>>> >> >Connected > >> >>>> >>>>> >> >> 36ce5a00-6f65-4926-8438-696944ebadb5 > >> >ov07.ntc.srcle.com > >> >>>> >>>>> >> >Connected > >> >>>> >>>>> >> >> c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost > >> >>>> >>>>> >> >Connected > >> >>>> >>>>> >> >> [root@ov08 ~]# gluster volume list > >> >>>> >>>>> >> >> images3 > >> >>>> >>>>> >> >> > >> >>>> >>>>> >> >> On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov > >> >>>> >>>>> >> ><hunter86_bg@yahoo.com> > >> >>>> >>>>> >> >> wrote: > >> >>>> >>>>> >> >> > >> >>>> >>>>> >> >>> Log to the oVirt cluster and provide the output of: > >> >>>> >>>>> >> >>> gluster pool list > >> >>>> >>>>> >> >>> gluster volume list > >> >>>> >>>>> >> >>> for i in $(gluster volume list); do echo $i;echo; > >> >gluster > >> >>>> >>>>> >volume > >> >>>> >>>>> >> >info > >> >>>> >>>>> >> >>> $i; echo;echo;gluster volume status > >> >$i;echo;echo;echo;done > >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> >>> ls -l /rhev/data-center/mnt/glusterSD/ > >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> >>> Best Regards, > >> >>>> >>>>> >> >>> Strahil Nikolov > >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> >>> На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams > >> >>>> >>>>> >> ><cwilliams3320@gmail.com> > >> >>>> >>>>> >> >>> написа: > >> >>>> >>>>> >> >>> >Hello, > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> >I recently added 6 hosts to an existing oVirt > >> >>>> >>>compute/gluster > >> >>>> >>>>> >> >cluster. > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> >Prior to this attempted addition, my cluster had 3 > >> >>>> >>>Hypervisor > >> >>>> >>>>> >hosts > >> >>>> >>>>> >> >and > >> >>>> >>>>> >> >>> >3 > >> >>>> >>>>> >> >>> >gluster bricks which made up a single gluster > >volume > >> >>>> >>>(replica 3 > >> >>>> >>>>> >> >volume) > >> >>>> >>>>> >> >>> >. I > >> >>>> >>>>> >> >>> >added the additional hosts and made a brick on 3 > >of > >> >the new > >> >>>> >>>>> >hosts > >> >>>> >>>>> >> >and > >> >>>> >>>>> >> >>> >attempted to make a new replica 3 volume. I had > >> >difficulty > >> >>>> >>>>> >> >creating > >> >>>> >>>>> >> >>> >the > >> >>>> >>>>> >> >>> >new volume. So, I decided that I would make a new > >> >>>> >>>>> >compute/gluster > >> >>>> >>>>> >> >>> >cluster > >> >>>> >>>>> >> >>> >for each set of 3 new hosts. > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> >I removed the 6 new hosts from the existing oVirt > >> >>>> >>>>> >Compute/Gluster > >> >>>> >>>>> >> >>> >Cluster > >> >>>> >>>>> >> >>> >leaving the 3 original hosts in place with their > >> >bricks. At > >> >>>> >>>that > >> >>>> >>>>> >> >point > >> >>>> >>>>> >> >>> >my > >> >>>> >>>>> >> >>> >original bricks went down and came back up . The > >> >volume > >> >>>> >>>showed > >> >>>> >>>>> >> >entries > >> >>>> >>>>> >> >>> >that > >> >>>> >>>>> >> >>> >needed healing. At that point I ran gluster volume > >> >heal > >> >>>> >>>images3 > >> >>>> >>>>> >> >full, > >> >>>> >>>>> >> >>> >etc. > >> >>>> >>>>> >> >>> >The volume shows no unhealed entries. I also > >> >corrected some > >> >>>> >>>peer > >> >>>> >>>>> >> >>> >errors. > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> >However, I am unable to copy disks, move disks to > >> >another > >> >>>> >>>>> >domain, > >> >>>> >>>>> >> >>> >export > >> >>>> >>>>> >> >>> >disks, etc. It appears that the engine cannot > >locate > >> >disks > >> >>>> >>>>> >properly > >> >>>> >>>>> >> >and > >> >>>> >>>>> >> >>> >I > >> >>>> >>>>> >> >>> >get storage I/O errors. > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> >I have detached and removed the oVirt Storage > >Domain. > >> >I > >> >>>> >>>>> >reimported > >> >>>> >>>>> >> >the > >> >>>> >>>>> >> >>> >domain and imported 2 VMs, But the VM disks > >exhibit > >> >the > >> >>>> same > >> >>>> >>>>> >> >behaviour > >> >>>> >>>>> >> >>> >and > >> >>>> >>>>> >> >>> >won't run from the hard disk. > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> >I get errors such as this > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> >VDSM ov05 command HSMGetAllTasksStatusesVDS > >failed: > >> >low > >> >>>> >>>level > >> >>>> >>>>> >Image > >> >>>> >>>>> >> >>> >copy > >> >>>> >>>>> >> >>> >failed: ("Command ['/usr/bin/qemu-img', 'convert', > >> >'-p', > >> >>>> >>>'-t', > >> >>>> >>>>> >> >'none', > >> >>>> >>>>> >> >>> >'-T', 'none', '-f', 'raw', > >> >>>> >>>>> >> >>> >u'/rhev/data-center/mnt/glusterSD/192.168.24.18: > >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> > >> >>>> >>>>> >> > >> >>>> >>>>> > >> >>>> >>>>> > >> >>>> > >> >>>> > >> > >> > >
>>>>_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510', > >> >>>> >>>>> >> >>> >'-O', 'raw', > >> >>>> >>>>> >> >>> >u'/rhev/data-center/mnt/192.168.24.13: > >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> > >> >>>> >>>>> >> > >> >>>> >>>>> > >> >>>> >>>>> > >> >>>> > >> >>>> > >> > >> > >
>>>>_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5'] > >> >>>> >>>>> >> >>> >failed with rc=1 out='' err=bytearray(b'qemu-img: > >> >error > >> >>>> >>>while > >> >>>> >>>>> >> >reading > >> >>>> >>>>> >> >>> >sector 135168: Transport endpoint is not > >> >>>> >>>connected\\nqemu-img: > >> >>>> >>>>> >> >error > >> >>>> >>>>> >> >>> >while > >> >>>> >>>>> >> >>> >reading sector 131072: Transport endpoint is not > >> >>>> >>>>> >> >connected\\nqemu-img: > >> >>>> >>>>> >> >>> >error while reading sector 139264: Transport > >endpoint > >> >is > >> >>>> not > >> >>>> >>>>> >> >>> >connected\\nqemu-img: error while reading sector > >> >143360: > >> >>>> >>>>> >Transport > >> >>>> >>>>> >> >>> >endpoint > >> >>>> >>>>> >> >>> >is not connected\\nqemu-img: error while reading > >> >sector > >> >>>> >>>147456: > >> >>>> >>>>> >> >>> >Transport > >> >>>> >>>>> >> >>> >endpoint is not connected\\nqemu-img: error while > >> >reading > >> >>>> >>>sector > >> >>>> >>>>> >> >>> >155648: > >> >>>> >>>>> >> >>> >Transport endpoint is not connected\\nqemu-img: > >error > >> >while > >> >>>> >>>>> >reading > >> >>>> >>>>> >> >>> >sector > >> >>>> >>>>> >> >>> >151552: Transport endpoint is not > >> >connected\\nqemu-img: > >> >>>> >>>error > >> >>>> >>>>> >while > >> >>>> >>>>> >> >>> >reading > >> >>>> >>>>> >> >>> >sector 159744: Transport endpoint is not > >> >connected\\n')",) > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> >oVirt version is 4.3.82-1.el7 > >> >>>> >>>>> >> >>> >OS CentOS Linux release 7.7.1908 (Core) > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> >The Gluster Cluster has been working very well > >until > >> >this > >> >>>> >>>>> >incident. > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> >Please help. > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> >Thank You > >> >>>> >>>>> >> >>> > > >> >>>> >>>>> >> >>> >Charles Williams > >> >>>> >>>>> >> >>> > >> >>>> >>>>> >> >> > >> >>>> >>>>> >> > >> >>>> >>>>> > >> >>>> >>>> > >> >>>> >> > >> >>>> > > >> >>>> _______________________________________________ > >> >>>> Users mailing list -- users@ovirt.org > >> >>>> To unsubscribe send an email to users-leave@ovirt.org > >> >>>> Privacy Statement: https://www.ovirt.org/privacy-policy.html > >> >>>> oVirt Code of Conduct: > >> >>>> https://www.ovirt.org/community/about/community-guidelines/ > >> >>>> List Archives: > >> >>>> > >> > > >> > > >
https://lists.ovirt.org/archives/list/users@ovirt.org/message/YY3VUKEJLI7MRW...
> >> >>>> > >> >>> > >> >
You should ensure that in the storage domain tab, the old storage is not visible. I still wander why yoiu didn't try to downgrade first. Best Regards, Strahil Nikolov На 22 юни 2020 г. 13:58:33 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Strahil,
The GLCL3 storage domain was detached prior to attempting to add the new storage domain.
Should I also "Remove" it ?
Thank You For Your Help !
---------- Forwarded message --------- From: Strahil Nikolov <hunter86_bg@yahoo.com> Date: Mon, Jun 22, 2020 at 12:50 AM Subject: Re: [ovirt-users] Re: Fwd: Fwd: Issues with Gluster Domain To: C Williams <cwilliams3320@gmail.com> Cc: users <Users@ovirt.org>
You can't add the new volume as it contains the same data (UUID) as the old one , thus you need to detach the old one before adding the new one - of course this means downtime for all VMs on that storage.
As you see , downgrading is more simpler. For me v6.5 was working, while anything above (6.6+) was causing complete lockdown. Also v7.0 was working, but it's supported in oVirt 4.4.
Best Regards, Strahil Nikolov
Another question
What version could I downgrade to safely ? I am at 6.9 .
Thank You For Your Help !!
On Sun, Jun 21, 2020 at 11:38 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
You are definitely reading it wrong. 1. I didn't create a new storage domain ontop this new volume. 2. I used cli
Something like this (in your case it should be 'replica 3'): gluster volume create newvol replica 3 arbiter 1 ovirt1:/new/brick/path ovirt2:/new/brick/path ovirt3:/new/arbiter/brick/path gluster volume start newvol
#Detach oldvol from ovirt
mount -t glusterfs ovirt1:/oldvol /mnt/oldvol mount -t glusterfs ovirt1:/newvol /mnt/newvol cp -a /mnt/oldvol/* /mnt/newvol
#Add only newvol as a storage domain in oVirt #Import VMs
I still think that you should downgrade your gluster packages!!!
Best Regards, Strahil Nikolov
На 22 юни 2020 г. 0:43:46 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Strahil,
It sounds like you used a "System Managed Volume" for the new storage domain,is that correct?
Thank You For Your Help !
On Sun, Jun 21, 2020 at 5:40 PM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
So you made another oVirt Storage Domain -- then copied the data with cp -a from the failed volume to the new volume.
At the root of the volume there will be the old domain folder id ex 5fe3ad3f-2d21-404c-832e-4dc7318ca10d in my case. Did that cause issues with making the new domain since it is the same folder id as the old one ?
Thank You For Your Help !
On Sun, Jun 21, 2020 at 5:18 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
In my situation I had only the ovirt nodes.
На 21 юни 2020 г. 22:43:04 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: >Strahil, > >So should I make the target volume on 3 bricks which do not have ovirt >-- >just gluster ? In other words (3) Centos 7 hosts ? > >Thank You For Your Help ! > >On Sun, Jun 21, 2020 at 3:08 PM Strahil Nikolov <hunter86_bg@yahoo.com> >wrote: > >> I created a fresh volume (which is not an ovirt sgorage domain), >set >> the original storage domain in maintenance and detached it. >> Then I 'cp -a ' the data from the old to the new volume. Next, I >just >> added the new storage domain (the old one was a kind of a >> 'backup') - pointing to the new volume name. >> >> If you observe issues , I would recommend you to downgrade >> gluster packages one node at a time . Then you might be able to >> restore your oVirt operations. >> >> Best Regards, >> Strahil Nikolov >> >> На 21 юни 2020 г. 18:01:31 GMT+03:00, C Williams ><cwilliams3320@gmail.com> >> написа: >> >Strahil, >> > >> >Thanks for the follow up ! >> > >> >How did you copy the data to another volume ? >> > >> >I have set up another storage domain GLCLNEW1 with a new volume >imgnew1 >> >. >> >How would you copy all of the data from the problematic domain GLCL3 >> >with >> >volume images3 to GLCLNEW1 and volume imgnew1 and preserve all the >VMs, >> >VM >> >disks, settings, etc. ? >> > >> >Remember all of the regular ovirt disk copy, disk move, VM export >> >tools >> >are failing and my VMs and disks are trapped on domain GLCL3 and >volume >> >images3 right now. >> > >> >Please let me know >> > >> >Thank You For Your Help ! >> > >> > >> > >> > >> > >> >On Sun, Jun 21, 2020 at 8:27 AM Strahil Nikolov ><hunter86_bg@yahoo.com> >> >wrote: >> > >> >> Sorry to hear that. >> >> I can say that for me 6.5 was working, while 6.6 didn't and I >> >upgraded >> >> to 7.0 . >> >> In the ended , I have ended with creating a new fresh volume >and >> >> physically copying the data there, then I detached the storage >> >domains and >> >> attached to the new ones (which holded the old data), but I >> >could >> >> afford the downtime. >> >> Also, I can say that v7.0 ( but not 7.1 or anything later) >also >> >> worked without the ACL issue, but it causes some
На 22 юни 2020 г. 7:21:15 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: trouble
in
>oVirt >> >- so >> >> avoid that unless you have no other options. >> >> >> >> Best Regards, >> >> Strahil Nikolov >> >> >> >> >> >> >> >> >> >> На 21 юни 2020 г. 4:39:46 GMT+03:00, C Williams >> ><cwilliams3320@gmail.com> >> >> написа: >> >> >Hello, >> >> > >> >> >Upgrading diidn't help >> >> > >> >> >Still acl errors trying to use a Virtual Disk from a VM >> >> > >> >> >[root@ov06 bricks]# tail bricks-brick04-images3.log | grep acl >> >> >[2020-06-21 01:33:45.665888] I [MSGID: 139001] >> >> >[posix-acl.c:263:posix_acl_log_permit_denied] >> >0-images3-access-control: >> >> >client: >> >> >> >> >> >>
CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0, >> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >> >> >req(uid:107,gid:107,perm:1,ngrps:3), >> >> >ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) >> >> >[Permission denied] >> >> >The message "I [MSGID: 139001] >> >> >[posix-acl.c:263:posix_acl_log_permit_denied] >> >0-images3-access-control: >> >> >client: >> >> >> >> >> >>
CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0, >> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >> >> >req(uid:107,gid:107,perm:1,ngrps:3), >> >> >ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) >> >> >[Permission denied]" repeated 2 times between [2020-06-21 >> >> >01:33:45.665888] >> >> >and [2020-06-21 01:33:45.806779] >> >> > >> >> >Thank You For Your Help ! >> >> > >> >> >On Sat, Jun 20, 2020 at 8:59 PM C Williams ><cwilliams3320@gmail.com> >> >> >wrote: >> >> > >> >> >> Hello, >> >> >> >> >> >> Based on the situation, I am planning to upgrade the 3 affected >> >> >hosts. >> >> >> >> >> >> My reasoning is that the hosts/bricks were attached to 6.9 at >one >> >> >time. >> >> >> >> >> >> Thanks For Your Help ! >> >> >> >> >> >> On Sat, Jun 20, 2020 at 8:38 PM C Williams >> ><cwilliams3320@gmail.com> >> >> >> wrote: >> >> >> >> >> >>> Strahil, >> >> >>> >> >> >>> The gluster version on the current 3 gluster hosts is 6.7 >(last >> >> >update >> >> >>> 2/26). These 3 hosts provide 1 brick each for the replica 3 >> >volume. >> >> >>> >> >> >>> Earlier I had tried to add 6 additional hosts to the cluster. >> >Those >> >> >new >> >> >>> hosts were 6.9 gluster. >> >> >>> >> >> >>> I attempted to make a new separate volume with 3 bricks >provided >> >by >> >> >the 3 >> >> >>> new gluster 6.9 hosts. After having many errors from the >oVirt >> >> >interface, >> >> >>> I gave up and removed the 6 new hosts from the cluster. That >is >> >> >where the >> >> >>> problems started. The intent was to expand the gluster cluster >> >while >> >> >making >> >> >>> 2 new volumes for that cluster. The ovirt compute cluster >would >> >> >allow for >> >> >>> efficient VM migration between 9 hosts -- while having >separate >> >> >gluster >> >> >>> volumes for safety purposes. >> >> >>> >> >> >>> Looking at the brick logs, I see where there are acl errors >> >starting >> >> >from >> >> >>> the time of the removal of the 6 new hosts. >> >> >>> >> >> >>> Please check out the attached brick log from 6/14-18. The >events >> >> >started >> >> >>> on 6/17. >> >> >>> >> >> >>> I wish I had a downgrade path. >> >> >>> >> >> >>> Thank You For The Help !! >> >> >>> >> >> >>> On Sat, Jun 20, 2020 at 7:47 PM Strahil Nikolov >> >> ><hunter86_bg@yahoo.com> >> >> >>> wrote: >> >> >>> >> >> >>>> Hi , >> >> >>>> >> >> >>>> >> >> >>>> This one really looks like the ACL bug I was hit with when I >> >> >updated >> >> >>>> from Gluster v6.5 to 6.6 and later from 7.0 to 7.2. >> >> >>>> >> >> >>>> Did you update your setup recently ? Did you upgrade gluster >> >also ? >> >> >>>> >> >> >>>> You have to check the gluster logs in order to verify that, >so >> >you >> >> >can >> >> >>>> try: >> >> >>>> >> >> >>>> 1. Set Gluster logs to trace level (for details check: >> >> >>>> >> >> > >> >> >> > >> >
>> >> >>>> ) >> >> >>>> 2. Power up a VM that was already off , or retry the >procedure >> >from >> >> >the >> >> >>>> logs you sent. >> >> >>>> 3. Stop the trace level of the logs >> >> >>>> 4. Check libvirt logs on the host that was supposed to power >up >> >the >> >> >VM >> >> >>>> (in case a VM was powered on) >> >> >>>> 5. Check the gluster brick logs on all nodes for ACL errors. >> >> >>>> Here is a sample from my old logs: >> >> >>>> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 >> >> >13:19:41.489047] I >> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] >> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- >> >> >>>> >> >> >> >> >> >>
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) >> >> >>>> [Permission denied] >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 >> >> >13:22:51.818796] I >> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] >> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- >> >> >>>> >> >> >> >> >> >>
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) >> >> >>>> [Permission denied] >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 >> >> >13:24:43.732856] I >> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] >> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- >> >> >>>> >> >> >> >> >> >>
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) >> >> >>>> [Permission denied] >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 >> >> >13:26:50.758178] I >> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] >> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- >> >> >>>> >> >> >> >> >> >>
4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) >> >> >>>> [Permission denied] >> >> >>>> >> >> >>>> >> >> >>>> In my case , the workaround was to downgrade the gluster >> >packages >> >> >on all >> >> >>>> nodes (and reboot each node 1 by 1 ) if the major version is >the >> >> >same, but >> >> >>>> if you upgraded to v7.X - then you can try the v7.0 . >> >> >>>> >> >> >>>> Best Regards, >> >> >>>> Strahil Nikolov >> >> >>>> >> >> >>>> >> >> >>>> >> >> >>>> >> >> >>>> >> >> >>>> >> >> >>>> В събота, 20 юни 2020 г., 18:48:42 ч. Гринуич+3, C Williams < >> >> >>>> cwilliams3320@gmail.com> написа: >> >> >>>> >> >> >>>> >> >> >>>> >> >> >>>> >> >> >>>> >> >> >>>> Hello, >> >> >>>> >> >> >>>> Here are additional log tiles as well as a tree of
https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3/html... the
>> >problematic >> >> >>>> Gluster storage domain. During this time I attempted to copy >a >> >> >virtual disk >> >> >>>> to another domain, move a virtual disk to another domain and >run >> >a >> >> >VM where >> >> >>>> the virtual hard disk would be used. >> >> >>>> >> >> >>>> The copies/moves failed and the VM went into pause mode when >the >> >> >virtual >> >> >>>> HDD was involved. >> >> >>>> >> >> >>>> Please check these out. >> >> >>>> >> >> >>>> Thank You For Your Help ! >> >> >>>> >> >> >>>> On Sat, Jun 20, 2020 at 9:54 AM C Williams >> >> ><cwilliams3320@gmail.com> >> >> >>>> wrote: >> >> >>>> > Strahil, >> >> >>>> > >> >> >>>> > I understand. Please keep me posted. >> >> >>>> > >> >> >>>> > Thanks For The Help ! >> >> >>>> > >> >> >>>> > On Sat, Jun 20, 2020 at 4:36 AM Strahil Nikolov >> >> ><hunter86_bg@yahoo.com> >> >> >>>> wrote: >> >> >>>> >> Hey C Williams, >> >> >>>> >> >> >> >>>> >> sorry for the delay, but I couldn't get somw time to >check >> >your >> >> >>>> logs. Will try a little bit later. >> >> >>>> >> >> >> >>>> >> Best Regards, >> >> >>>> >> Strahil Nikolov >> >> >>>> >> >> >> >>>> >> На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams < >> >> >>>> cwilliams3320@gmail.com> написа: >> >> >>>> >>>Hello, >> >> >>>> >>> >> >> >>>> >>>Was wanting to follow up on this issue. Users are >impacted. >> >> >>>> >>> >> >> >>>> >>>Thank You >> >> >>>> >>> >> >> >>>> >>>On Fri, Jun 19, 2020 at 9:20 AM C Williams >> >> ><cwilliams3320@gmail.com> >> >> >>>> >>>wrote: >> >> >>>> >>> >> >> >>>> >>>> Hello, >> >> >>>> >>>> >> >> >>>> >>>> Here are the logs (some IPs are changed ) >> >> >>>> >>>> >> >> >>>> >>>> ov05 is the SPM >> >> >>>> >>>> >> >> >>>> >>>> Thank You For Your Help ! >> >> >>>> >>>> >> >> >>>> >>>> On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov >> >> >>>> >>><hunter86_bg@yahoo.com> >> >> >>>> >>>> wrote: >> >> >>>> >>>> >> >> >>>> >>>>> Check on the hosts tab , which is your current SPM >(last >> >> >column in >> >> >>>> >>>Admin >> >> >>>> >>>>> UI). >> >> >>>> >>>>> Then open the /var/log/vdsm/vdsm.log and repeat the >> >> >operation. >> >> >>>> >>>>> Then provide the log from that host and the engine's >log >> >(on >> >> >the >> >> >>>> >>>>> HostedEngine VM or on your standalone engine). >> >> >>>> >>>>> >> >> >>>> >>>>> Best Regards, >> >> >>>> >>>>> Strahil Nikolov >> >> >>>> >>>>> >> >> >>>> >>>>> На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams >> >> >>>> >>><cwilliams3320@gmail.com> >> >> >>>> >>>>> написа: >> >> >>>> >>>>> >Resending to eliminate email issues >> >> >>>> >>>>> > >> >> >>>> >>>>> >---------- Forwarded message --------- >> >> >>>> >>>>> >From: C Williams <cwilliams3320@gmail.com> >> >> >>>> >>>>> >Date: Thu, Jun 18, 2020 at 4:01 PM >> >> >>>> >>>>> >Subject: Re: [ovirt-users] Fwd: Issues with Gluster >> >Domain >> >> >>>> >>>>> >To: Strahil Nikolov <hunter86_bg@yahoo.com> >> >> >>>> >>>>> > >> >> >>>> >>>>> > >> >> >>>> >>>>> >Here is output from mount >> >> >>>> >>>>> > >> >> >>>> >>>>> >192.168.24.12:/stor/import0 on >> >> >>>> >>>>> /rhev/data-center/mnt/192.168.24.12:_stor_import0 >> >> >>>> >>>>> >type nfs4 >> >> >>>> >>>>> >> >> >>>> >>>>> >> >> >>>> >> >> >>>> >> >> >> >> >> >>
>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12) >> >> >>>> >>>>> >192.168.24.13:/stor/import1 on >> >> >>>> >>>>> /rhev/data-center/mnt/192.168.24.13:_stor_import1 >> >> >>>> >>>>> >type nfs4 >> >> >>>> >>>>> >> >> >>>> >>>>> >> >> >>>> >> >> >>>> >> >> >> >> >> >>
>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >> >> >>>> >>>>> >192.168.24.13:/stor/iso1 on >> >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_iso1 >> >> >>>> >>>>> >type nfs4 >> >> >>>> >>>>> >> >> >>>> >>>>> >> >> >>>> >> >> >>>> >> >> >> >> >> >>
>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >> >> >>>> >>>>> >192.168.24.13:/stor/export0 on >> >> >>>> >>>>> /rhev/data-center/mnt/192.168.24.13:_stor_export0 >> >> >>>> >>>>> >type nfs4 >> >> >>>> >>>>> >> >> >>>> >>>>> >> >> >>>> >> >> >>>> >> >> >> >> >> >>
>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >> >> >>>> >>>>> >192.168.24.15:/images on >> >> >>>> >>>>> /rhev/data-center/mnt/glusterSD/192.168.24.15:_images >> >> >>>> >>>>> >type fuse.glusterfs >> >> >>>> >>>>> >> >> >>>> >>>>> >> >> >>>> >> >> >>>> >> >> >> >> >> >>
>>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) >> >> >>>> >>>>> >192.168.24.18:/images3 on >> >> >>>> >>>>> /rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 >> >> >>>> >>>>> >type fuse.glusterfs >> >> >>>> >>>>> >> >> >>>> >>>>> >> >> >>>> >> >> >>>> >> >> >> >> >> >>
>>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) >> >> >>>> >>>>> >tmpfs on /run/user/0 type tmpfs >> >> >>>> >>>>> >> >>(rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) >> >> >>>> >>>>> >[root@ov06 glusterfs]# >> >> >>>> >>>>> > >> >> >>>> >>>>> >Also here is a screenshot of the console >> >> >>>> >>>>> > >> >> >>>> >>>>> >[image: image.png] >> >> >>>> >>>>> >The other domains are up >> >> >>>> >>>>> > >> >> >>>> >>>>> >Import0 and Import1 are NFS . GLCL0 is gluster. They >all >> >are >> >> >>>> >>>running >> >> >>>> >>>>> >VMs >> >> >>>> >>>>> > >> >> >>>> >>>>> >Thank You For Your Help ! >> >> >>>> >>>>> > >> >> >>>> >>>>> >On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov >> >> >>>> >>><hunter86_bg@yahoo.com> >> >> >>>> >>>>> >wrote: >> >> >>>> >>>>> > >> >> >>>> >>>>> >> I don't see >> >> >'/rhev/data-center/mnt/192.168.24.13:_stor_import1' >> >> >>>> >>>>> >mounted >> >> >>>> >>>>> >> at all . >> >> >>>> >>>>> >> What is the status of all storage domains ? >> >> >>>> >>>>> >> >> >> >>>> >>>>> >> Best Regards, >> >> >>>> >>>>> >> Strahil Nikolov >> >> >>>> >>>>> >> >> >> >>>> >>>>> >> На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams >> >> >>>> >>>>> ><cwilliams3320@gmail.com> >> >> >>>> >>>>> >> написа: >> >> >>>> >>>>> >> > Resending to deal with possible email issues >> >> >>>> >>>>> >> > >> >> >>>> >>>>> >> >---------- Forwarded message --------- >> >> >>>> >>>>> >> >From: C Williams <cwilliams3320@gmail.com> >> >> >>>> >>>>> >> >Date: Thu, Jun 18, 2020 at 2:07 PM >> >> >>>> >>>>> >> >Subject: Re: [ovirt-users] Issues with Gluster >Domain >> >> >>>> >>>>> >> >To: Strahil Nikolov <hunter86_bg@yahoo.com> >> >> >>>> >>>>> >> > >> >> >>>> >>>>> >> > >> >> >>>> >>>>> >> >More >> >> >>>> >>>>> >> > >> >> >>>> >>>>> >> >[root@ov06 ~]# for i in $(gluster volume list); do >> >echo >> >> >>>> >>>$i;echo; >> >> >>>> >>>>> >> >gluster >> >> >>>> >>>>> >> >volume info $i; echo;echo;gluster volume status >> >> >>>> >>>>> >$i;echo;echo;echo;done >> >> >>>> >>>>> >> >images3 >> >> >>>> >>>>> >> > >> >> >>>> >>>>> >> > >> >> >>>> >>>>> >> >Volume Name: images3 >> >> >>>> >>>>> >> >Type: Replicate >> >> >>>> >>>>> >> >Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b >> >> >>>> >>>>> >> >Status: Started >> >> >>>> >>>>> >> >Snapshot Count: 0 >> >> >>>> >>>>> >> >Number of Bricks: 1 x 3 = 3 >> >> >>>> >>>>> >> >Transport-type: tcp >> >> >>>> >>>>> >> >Bricks: >> >> >>>> >>>>> >> >Brick1: 192.168.24.18:/bricks/brick04/images3 >> >> >>>> >>>>> >> >Brick2: 192.168.24.19:/bricks/brick05/images3 >> >> >>>> >>>>> >> >Brick3: 192.168.24.20:/bricks/brick06/images3 >> >> >>>> >>>>> >> >Options Reconfigured: >> >> >>>> >>>>> >> >performance.client-io-threads: on >> >> >>>> >>>>> >> >nfs.disable: on >> >> >>>> >>>>> >> >transport.address-family: inet >> >> >>>> >>>>> >> >user.cifs: off >> >> >>>> >>>>> >> >auth.allow: * >> >> >>>> >>>>> >> >performance.quick-read: off >> >> >>>> >>>>> >> >performance.read-ahead: off >> >> >>>> >>>>> >> >performance.io-cache: off >> >> >>>> >>>>> >> >performance.low-prio-threads: 32 >> >> >>>> >>>>> >> >network.remote-dio: off >> >> >>>> >>>>> >> >cluster.eager-lock: enable >> >> >>>> >>>>> >> >cluster.quorum-type: auto >> >> >>>> >>>>> >> >cluster.server-quorum-type: server >> >> >>>> >>>>> >> >cluster.data-self-heal-algorithm: full >> >> >>>> >>>>> >> >cluster.locking-scheme: granular >> >> >>>> >>>>> >> >cluster.shd-max-threads: 8 >> >> >>>> >>>>> >> >cluster.shd-wait-qlength: 10000 >> >> >>>> >>>>> >> >features.shard: on >> >> >>>> >>>>> >> >cluster.choose-local: off >> >> >>>> >>>>> >> >client.event-threads: 4 >> >> >>>> >>>>> >> >server.event-threads: 4 >> >> >>>> >>>>> >> >storage.owner-uid: 36 >> >> >>>> >>>>> >> >storage.owner-gid: 36 >> >> >>>> >>>>> >> >performance.strict-o-direct: on >> >> >>>> >>>>> >> >network.ping-timeout: 30 >> >> >>>> >>>>> >> >cluster.granular-entry-heal: enable >> >> >>>> >>>>> >> > >> >> >>>> >>>>> >> > >> >> >>>> >>>>> >> >Status of volume: images3 >> >> >>>> >>>>> >> >Gluster process TCP >Port >> >> >RDMA Port >> >> >>>> >>>>> >Online >> >> >>>> >>>>> >> > Pid >> >> >>>> >>>>> >> >> >> >>>> >>>>> >> >> >> >>>> >>>>> >> >> >>>> >>>>> >> >> >>>> >> >> >>>> >> >> >> >> >> >>
>>>>>------------------------------------------------------------------------------ >> >> >>>> >>>>> >> >Brick 192.168.24.18:/bricks/brick04/images3 49152 >> >0 >> >> >>>> >> >> >>>> >>>Y >> >> >>>> >>>>> >> >6666 >> >> >>>> >>>>> >> >Brick 192.168.24.19:/bricks/brick05/images3 49152 >> >0 >> >> >>>> >> >> >>>> >>>Y >> >> >>>> >>>>> >> >6779 >> >> >>>> >>>>> >> >Brick 192.168.24.20:/bricks/brick06/images3 49152 >> >0 >> >> >>>> >> >> >>>> >>>Y >> >> >>>> >>>>> >> >7227 >> >> >>>> >>>>> >> >Self-heal Daemon on localhost N/A >> >N/A >> >> >>>> >> >> >>>> >>>Y >> >> >>>> >>>>> >> >6689 >> >> >>>> >>>>> >> >Self-heal Daemon on ov07.ntc.srcle.com N/A >> >N/A >> >> >>>> >> >> >>>> >>>Y >> >> >>>> >>>>> >> >6802 >> >> >>>> >>>>> >> >Self-heal Daemon on ov08.ntc.srcle.com N/A >> >N/A >> >> >>>> >> >> >>>> >>>Y >> >> >>>> >>>>> >> >7250 >> >> >>>> >>>>> >> > >> >> >>>> >>>>> >> >Task Status of Volume images3 >> >> >>>> >>>>> >> >> >> >>>> >>>>> >> >> >> >>>> >>>>> >> >> >>>> >>>>> >> >> >>>> >> >> >>>> >> >> >> >> >> >>
>>>>>------------------------------------------------------------------------------ >> >> >>>> >>>>> >> >There are no active volume tasks >> >> >>>> >>>>> >> > >> >> >>>> >>>>> >> > >> >> >>>> >>>>> >> > >> >> >>>> >>>>> >> > >> >> >>>> >>>>> >> >[root@ov06 ~]# ls -l >/rhev/data-center/mnt/glusterSD/ >> >> >>>> >>>>> >> >total 16 >> >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 >> >> >192.168.24.15:_images >> >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 >> >192.168.24.18: >> >> >>>> _images3 >> >> >>>> >>>>> >> >[root@ov06 ~]# >> >> >>>> >>>>> >> > >> >> >>>> >>>>> >> >On Thu, Jun 18, 2020 at 2:03 PM C Williams >> >> >>>> >>><cwilliams3320@gmail.com> >> >> >>>> >>>>> >> >wrote: >> >> >>>> >>>>> >> > >> >> >>>> >>>>> >> >> Strahil, >> >> >>>> >>>>> >> >> >> >> >>>> >>>>> >> >> Here you go -- Thank You For Your Help ! >> >> >>>> >>>>> >> >> >> >> >>>> >>>>> >> >> BTW -- I can write a test file to gluster and it >> >> >replicates >> >> >>>> >>>>> >properly. >> >> >>>> >>>>> >> >> Thinking something about the oVirt Storage Domain >? >> >> >>>> >>>>> >> >> >> >> >>>> >>>>> >> >> [root@ov08 ~]# gluster pool list >> >> >>>> >>>>> >> >> UUID Hostname >> >> >>>> >>>>> >State >> >> >>>> >>>>> >> >> 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06 >> >> >>>> >>>>> >> >Connected >> >> >>>> >>>>> >> >> 36ce5a00-6f65-4926-8438-696944ebadb5 >> >> >ov07.ntc.srcle.com >> >> >>>> >>>>> >> >Connected >> >> >>>> >>>>> >> >> c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost >> >> >>>> >>>>> >> >Connected >> >> >>>> >>>>> >> >> [root@ov08 ~]# gluster volume list >> >> >>>> >>>>> >> >> images3 >> >> >>>> >>>>> >> >> >> >> >>>> >>>>> >> >> On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov >> >> >>>> >>>>> >> ><hunter86_bg@yahoo.com> >> >> >>>> >>>>> >> >> wrote: >> >> >>>> >>>>> >> >> >> >> >>>> >>>>> >> >>> Log to the oVirt cluster and provide the output >of: >> >> >>>> >>>>> >> >>> gluster pool list >> >> >>>> >>>>> >> >>> gluster volume list >> >> >>>> >>>>> >> >>> for i in $(gluster volume list); do echo >$i;echo; >> >> >gluster >> >> >>>> >>>>> >volume >> >> >>>> >>>>> >> >info >> >> >>>> >>>>> >> >>> $i; echo;echo;gluster volume status >> >> >$i;echo;echo;echo;done >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >> >>> ls -l /rhev/data-center/mnt/glusterSD/ >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >> >>> Best Regards, >> >> >>>> >>>>> >> >>> Strahil Nikolov >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >> >>> На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams >> >> >>>> >>>>> >> ><cwilliams3320@gmail.com> >> >> >>>> >>>>> >> >>> написа: >> >> >>>> >>>>> >> >>> >Hello, >> >> >>>> >>>>> >> >>> > >> >> >>>> >>>>> >> >>> >I recently added 6 hosts to an existing oVirt >> >> >>>> >>>compute/gluster >> >> >>>> >>>>> >> >cluster. >> >> >>>> >>>>> >> >>> > >> >> >>>> >>>>> >> >>> >Prior to this attempted addition, my cluster >had 3 >> >> >>>> >>>Hypervisor >> >> >>>> >>>>> >hosts >> >> >>>> >>>>> >> >and >> >> >>>> >>>>> >> >>> >3 >> >> >>>> >>>>> >> >>> >gluster bricks which made up a single gluster >> >volume >> >> >>>> >>>(replica 3 >> >> >>>> >>>>> >> >volume) >> >> >>>> >>>>> >> >>> >. I >> >> >>>> >>>>> >> >>> >added the additional hosts and made a brick on >3 >> >of >> >> >the new >> >> >>>> >>>>> >hosts >> >> >>>> >>>>> >> >and >> >> >>>> >>>>> >> >>> >attempted to make a new replica 3 volume. I had >> >> >difficulty >> >> >>>> >>>>> >> >creating >> >> >>>> >>>>> >> >>> >the >> >> >>>> >>>>> >> >>> >new volume. So, I decided that I would make a >new >> >> >>>> >>>>> >compute/gluster >> >> >>>> >>>>> >> >>> >cluster >> >> >>>> >>>>> >> >>> >for each set of 3 new hosts. >> >> >>>> >>>>> >> >>> > >> >> >>>> >>>>> >> >>> >I removed the 6 new hosts from the existing >oVirt >> >> >>>> >>>>> >Compute/Gluster >> >> >>>> >>>>> >> >>> >Cluster >> >> >>>> >>>>> >> >>> >leaving the 3 original hosts in place with >their >> >> >bricks. At >> >> >>>> >>>that >> >> >>>> >>>>> >> >point >> >> >>>> >>>>> >> >>> >my >> >> >>>> >>>>> >> >>> >original bricks went down and came back up . >The >> >> >volume >> >> >>>> >>>showed >> >> >>>> >>>>> >> >entries >> >> >>>> >>>>> >> >>> >that >> >> >>>> >>>>> >> >>> >needed healing. At that point I ran gluster >volume >> >> >heal >> >> >>>> >>>images3 >> >> >>>> >>>>> >> >full, >> >> >>>> >>>>> >> >>> >etc. >> >> >>>> >>>>> >> >>> >The volume shows no unhealed entries. I also >> >> >corrected some >> >> >>>> >>>peer >> >> >>>> >>>>> >> >>> >errors. >> >> >>>> >>>>> >> >>> > >> >> >>>> >>>>> >> >>> >However, I am unable to copy disks, move disks >to >> >> >another >> >> >>>> >>>>> >domain, >> >> >>>> >>>>> >> >>> >export >> >> >>>> >>>>> >> >>> >disks, etc. It appears that the engine cannot >> >locate >> >> >disks >> >> >>>> >>>>> >properly >> >> >>>> >>>>> >> >and >> >> >>>> >>>>> >> >>> >I >> >> >>>> >>>>> >> >>> >get storage I/O errors. >> >> >>>> >>>>> >> >>> > >> >> >>>> >>>>> >> >>> >I have detached and removed the oVirt Storage >> >Domain. >> >> >I >> >> >>>> >>>>> >reimported >> >> >>>> >>>>> >> >the >> >> >>>> >>>>> >> >>> >domain and imported 2 VMs, But the VM disks >> >exhibit >> >> >the >> >> >>>> same >> >> >>>> >>>>> >> >behaviour >> >> >>>> >>>>> >> >>> >and >> >> >>>> >>>>> >> >>> >won't run from the hard disk. >> >> >>>> >>>>> >> >>> > >> >> >>>> >>>>> >> >>> > >> >> >>>> >>>>> >> >>> >I get errors such as this >> >> >>>> >>>>> >> >>> > >> >> >>>> >>>>> >> >>> >VDSM ov05 command HSMGetAllTasksStatusesVDS >> >failed: >> >> >low >> >> >>>> >>>level >> >> >>>> >>>>> >Image >> >> >>>> >>>>> >> >>> >copy >> >> >>>> >>>>> >> >>> >failed: ("Command ['/usr/bin/qemu-img', >'convert', >> >> >'-p', >> >> >>>> >>>'-t', >> >> >>>> >>>>> >> >'none', >> >> >>>> >>>>> >> >>> >'-T', 'none', '-f', 'raw', >> >> >>>> >>>>> >> >>> >>u'/rhev/data-center/mnt/glusterSD/192.168.24.18: >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >> >> >> >>>> >>>>> >> >> >> >>>> >>>>> >> >> >>>> >>>>> >> >> >>>> >> >> >>>> >> >> >> >> >> >>
>>>>>_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510', >> >> >>>> >>>>> >> >>> >'-O', 'raw', >> >> >>>> >>>>> >> >>> >u'/rhev/data-center/mnt/192.168.24.13: >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >> >> >> >>>> >>>>> >> >> >> >>>> >>>>> >> >> >>>> >>>>> >> >> >>>> >> >> >>>> >> >> >> >> >> >>
>>>>>_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5'] >> >> >>>> >>>>> >> >>> >failed with rc=1 out='' >err=bytearray(b'qemu-img: >> >> >error >> >> >>>> >>>while >> >> >>>> >>>>> >> >reading >> >> >>>> >>>>> >> >>> >sector 135168: Transport endpoint is not >> >> >>>> >>>connected\\nqemu-img: >> >> >>>> >>>>> >> >error >> >> >>>> >>>>> >> >>> >while >> >> >>>> >>>>> >> >>> >reading sector 131072: Transport endpoint is >not >> >> >>>> >>>>> >> >connected\\nqemu-img: >> >> >>>> >>>>> >> >>> >error while reading sector 139264: Transport >> >endpoint >> >> >is >> >> >>>> not >> >> >>>> >>>>> >> >>> >connected\\nqemu-img: error while reading >sector >> >> >143360: >> >> >>>> >>>>> >Transport >> >> >>>> >>>>> >> >>> >endpoint >> >> >>>> >>>>> >> >>> >is not connected\\nqemu-img: error while >reading >> >> >sector >> >> >>>> >>>147456: >> >> >>>> >>>>> >> >>> >Transport >> >> >>>> >>>>> >> >>> >endpoint is not connected\\nqemu-img: error >while >> >> >reading >> >> >>>> >>>sector >> >> >>>> >>>>> >> >>> >155648: >> >> >>>> >>>>> >> >>> >Transport endpoint is not connected\\nqemu-img: >> >error >> >> >while >> >> >>>> >>>>> >reading >> >> >>>> >>>>> >> >>> >sector >> >> >>>> >>>>> >> >>> >151552: Transport endpoint is not >> >> >connected\\nqemu-img: >> >> >>>> >>>error >> >> >>>> >>>>> >while >> >> >>>> >>>>> >> >>> >reading >> >> >>>> >>>>> >> >>> >sector 159744: Transport endpoint is not >> >> >connected\\n')",) >> >> >>>> >>>>> >> >>> > >> >> >>>> >>>>> >> >>> >oVirt version is 4.3.82-1.el7 >> >> >>>> >>>>> >> >>> >OS CentOS Linux release 7.7.1908 (Core) >> >> >>>> >>>>> >> >>> > >> >> >>>> >>>>> >> >>> >The Gluster Cluster has been working very well >> >until >> >> >this >> >> >>>> >>>>> >incident. >> >> >>>> >>>>> >> >>> > >> >> >>>> >>>>> >> >>> >Please help. >> >> >>>> >>>>> >> >>> > >> >> >>>> >>>>> >> >>> >Thank You >> >> >>>> >>>>> >> >>> > >> >> >>>> >>>>> >> >>> >Charles Williams >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >> >> >> >> >>>> >>>>> >> >> >> >>>> >>>>> >> >> >>>> >>>> >> >> >>>> >> >> >> >>>> > >> >> >>>> _______________________________________________ >> >> >>>> Users mailing list -- users@ovirt.org >> >> >>>> To unsubscribe send an email to users-leave@ovirt.org >> >> >>>> Privacy Statement: https://www.ovirt.org/privacy-policy.html >> >> >>>> oVirt Code of Conduct: >> >> >>>> https://www.ovirt.org/community/about/community-guidelines/ >> >> >>>> List Archives: >> >> >>>> >> >> > >> >> >> > >> >
https://lists.ovirt.org/archives/list/users@ovirt.org/message/YY3VUKEJLI7MRW...
>> >> >>>> >> >> >>> >> >> >>
Strahil, I have downgraded the target. The copy from the problematic volume to the target is going on now. Once I have the data copied, I might downgrade the problematic volume's Gluster to 6.5. At that point I might reattach the original ovirt domain and see if it will work again. But the copy is going on right now. Thank You For Your Help ! On Mon, Jun 22, 2020 at 10:52 AM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
You should ensure that in the storage domain tab, the old storage is not visible.
I still wander why yoiu didn't try to downgrade first.
Best Regards, Strahil Nikolov
На 22 юни 2020 г. 13:58:33 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Strahil,
The GLCL3 storage domain was detached prior to attempting to add the new storage domain.
Should I also "Remove" it ?
Thank You For Your Help !
---------- Forwarded message --------- From: Strahil Nikolov <hunter86_bg@yahoo.com> Date: Mon, Jun 22, 2020 at 12:50 AM Subject: Re: [ovirt-users] Re: Fwd: Fwd: Issues with Gluster Domain To: C Williams <cwilliams3320@gmail.com> Cc: users <Users@ovirt.org>
You can't add the new volume as it contains the same data (UUID) as the old one , thus you need to detach the old one before adding the new one - of course this means downtime for all VMs on that storage.
As you see , downgrading is more simpler. For me v6.5 was working, while anything above (6.6+) was causing complete lockdown. Also v7.0 was working, but it's supported in oVirt 4.4.
Best Regards, Strahil Nikolov
Another question
What version could I downgrade to safely ? I am at 6.9 .
Thank You For Your Help !!
On Sun, Jun 21, 2020 at 11:38 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
You are definitely reading it wrong. 1. I didn't create a new storage domain ontop this new volume. 2. I used cli
Something like this (in your case it should be 'replica 3'): gluster volume create newvol replica 3 arbiter 1 ovirt1:/new/brick/path ovirt2:/new/brick/path ovirt3:/new/arbiter/brick/path gluster volume start newvol
#Detach oldvol from ovirt
mount -t glusterfs ovirt1:/oldvol /mnt/oldvol mount -t glusterfs ovirt1:/newvol /mnt/newvol cp -a /mnt/oldvol/* /mnt/newvol
#Add only newvol as a storage domain in oVirt #Import VMs
I still think that you should downgrade your gluster packages!!!
Best Regards, Strahil Nikolov
На 22 юни 2020 г. 0:43:46 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Strahil,
It sounds like you used a "System Managed Volume" for the new storage domain,is that correct?
Thank You For Your Help !
On Sun, Jun 21, 2020 at 5:40 PM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
So you made another oVirt Storage Domain -- then copied the data with cp -a from the failed volume to the new volume.
At the root of the volume there will be the old domain folder id ex 5fe3ad3f-2d21-404c-832e-4dc7318ca10d in my case. Did that cause issues with making the new domain since it is the same folder id as the old one ?
Thank You For Your Help !
On Sun, Jun 21, 2020 at 5:18 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
> In my situation I had only the ovirt nodes. > > На 21 юни 2020 г. 22:43:04 GMT+03:00, C Williams <cwilliams3320@gmail.com> > написа: > >Strahil, > > > >So should I make the target volume on 3 bricks which do not have ovirt > >-- > >just gluster ? In other words (3) Centos 7 hosts ? > > > >Thank You For Your Help ! > > > >On Sun, Jun 21, 2020 at 3:08 PM Strahil Nikolov <hunter86_bg@yahoo.com> > >wrote: > > > >> I created a fresh volume (which is not an ovirt sgorage domain), > >set > >> the original storage domain in maintenance and detached it. > >> Then I 'cp -a ' the data from the old to the new volume. Next, I > >just > >> added the new storage domain (the old one was a kind of a > >> 'backup') - pointing to the new volume name. > >> > >> If you observe issues , I would recommend you to downgrade > >> gluster packages one node at a time . Then you might be able to > >> restore your oVirt operations. > >> > >> Best Regards, > >> Strahil Nikolov > >> > >> На 21 юни 2020 г. 18:01:31 GMT+03:00, C Williams > ><cwilliams3320@gmail.com> > >> написа: > >> >Strahil, > >> > > >> >Thanks for the follow up ! > >> > > >> >How did you copy the data to another volume ? > >> > > >> >I have set up another storage domain GLCLNEW1 with a new volume > >imgnew1 > >> >. > >> >How would you copy all of the data from the problematic domain GLCL3 > >> >with > >> >volume images3 to GLCLNEW1 and volume imgnew1 and preserve all the > >VMs, > >> >VM > >> >disks, settings, etc. ? > >> > > >> >Remember all of the regular ovirt disk copy, disk move, VM export > >> >tools > >> >are failing and my VMs and disks are trapped on domain GLCL3 and > >volume > >> >images3 right now. > >> > > >> >Please let me know > >> > > >> >Thank You For Your Help ! > >> > > >> > > >> > > >> > > >> > > >> >On Sun, Jun 21, 2020 at 8:27 AM Strahil Nikolov > ><hunter86_bg@yahoo.com> > >> >wrote: > >> > > >> >> Sorry to hear that. > >> >> I can say that for me 6.5 was working, while 6.6 didn't and I > >> >upgraded > >> >> to 7.0 . > >> >> In the ended , I have ended with creating a new fresh volume > >and > >> >> physically copying the data there, then I detached the storage > >> >domains and > >> >> attached to the new ones (which holded the old data), but I > >> >could > >> >> afford the downtime. > >> >> Also, I can say that v7.0 ( but not 7.1 or anything later) > >also > >> >> worked without the ACL issue, but it causes some
На 22 юни 2020 г. 7:21:15 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: trouble
in
> >oVirt > >> >- so > >> >> avoid that unless you have no other options. > >> >> > >> >> Best Regards, > >> >> Strahil Nikolov > >> >> > >> >> > >> >> > >> >> > >> >> На 21 юни 2020 г. 4:39:46 GMT+03:00, C Williams > >> ><cwilliams3320@gmail.com> > >> >> написа: > >> >> >Hello, > >> >> > > >> >> >Upgrading diidn't help > >> >> > > >> >> >Still acl errors trying to use a Virtual Disk from a VM > >> >> > > >> >> >[root@ov06 bricks]# tail bricks-brick04-images3.log | grep acl > >> >> >[2020-06-21 01:33:45.665888] I [MSGID: 139001] > >> >> >[posix-acl.c:263:posix_acl_log_permit_denied] > >> >0-images3-access-control: > >> >> >client: > >> >> > >> >> > >> > >> > >
>CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0, > >> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >> >> >req(uid:107,gid:107,perm:1,ngrps:3), > >> >> >ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) > >> >> >[Permission denied] > >> >> >The message "I [MSGID: 139001] > >> >> >[posix-acl.c:263:posix_acl_log_permit_denied] > >> >0-images3-access-control: > >> >> >client: > >> >> > >> >> > >> > >> > >
>CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0, > >> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >> >> >req(uid:107,gid:107,perm:1,ngrps:3), > >> >> >ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) > >> >> >[Permission denied]" repeated 2 times between [2020-06-21 > >> >> >01:33:45.665888] > >> >> >and [2020-06-21 01:33:45.806779] > >> >> > > >> >> >Thank You For Your Help ! > >> >> > > >> >> >On Sat, Jun 20, 2020 at 8:59 PM C Williams > ><cwilliams3320@gmail.com> > >> >> >wrote: > >> >> > > >> >> >> Hello, > >> >> >> > >> >> >> Based on the situation, I am planning to upgrade the 3 affected > >> >> >hosts. > >> >> >> > >> >> >> My reasoning is that the hosts/bricks were attached to 6.9 at > >one > >> >> >time. > >> >> >> > >> >> >> Thanks For Your Help ! > >> >> >> > >> >> >> On Sat, Jun 20, 2020 at 8:38 PM C Williams > >> ><cwilliams3320@gmail.com> > >> >> >> wrote: > >> >> >> > >> >> >>> Strahil, > >> >> >>> > >> >> >>> The gluster version on the current 3 gluster hosts is 6.7 > >(last > >> >> >update > >> >> >>> 2/26). These 3 hosts provide 1 brick each for the replica 3 > >> >volume. > >> >> >>> > >> >> >>> Earlier I had tried to add 6 additional hosts to the cluster. > >> >Those > >> >> >new > >> >> >>> hosts were 6.9 gluster. > >> >> >>> > >> >> >>> I attempted to make a new separate volume with 3 bricks > >provided > >> >by > >> >> >the 3 > >> >> >>> new gluster 6.9 hosts. After having many errors from the > >oVirt > >> >> >interface, > >> >> >>> I gave up and removed the 6 new hosts from the cluster. That > >is > >> >> >where the > >> >> >>> problems started. The intent was to expand the gluster cluster > >> >while > >> >> >making > >> >> >>> 2 new volumes for that cluster. The ovirt compute cluster > >would > >> >> >allow for > >> >> >>> efficient VM migration between 9 hosts -- while having > >separate > >> >> >gluster > >> >> >>> volumes for safety purposes. > >> >> >>> > >> >> >>> Looking at the brick logs, I see where there are acl errors > >> >starting > >> >> >from > >> >> >>> the time of the removal of the 6 new hosts. > >> >> >>> > >> >> >>> Please check out the attached brick log from 6/14-18. The > >events > >> >> >started > >> >> >>> on 6/17. > >> >> >>> > >> >> >>> I wish I had a downgrade path. > >> >> >>> > >> >> >>> Thank You For The Help !! > >> >> >>> > >> >> >>> On Sat, Jun 20, 2020 at 7:47 PM Strahil Nikolov > >> >> ><hunter86_bg@yahoo.com> > >> >> >>> wrote: > >> >> >>> > >> >> >>>> Hi , > >> >> >>>> > >> >> >>>> > >> >> >>>> This one really looks like the ACL bug I was hit with when I > >> >> >updated > >> >> >>>> from Gluster v6.5 to 6.6 and later from 7.0 to 7.2. > >> >> >>>> > >> >> >>>> Did you update your setup recently ? Did you upgrade gluster > >> >also ? > >> >> >>>> > >> >> >>>> You have to check the gluster logs in order to verify that, > >so > >> >you > >> >> >can > >> >> >>>> try: > >> >> >>>> > >> >> >>>> 1. Set Gluster logs to trace level (for details check: > >> >> >>>> > >> >> > > >> >> > >> > > >> > > >
https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3/html...
> >> >> >>>> ) > >> >> >>>> 2. Power up a VM that was already off , or retry the > >procedure > >> >from > >> >> >the > >> >> >>>> logs you sent. > >> >> >>>> 3. Stop the trace level of the logs > >> >> >>>> 4. Check libvirt logs on the host that was supposed to power > >up > >> >the > >> >> >VM > >> >> >>>> (in case a VM was powered on) > >> >> >>>> 5. Check the gluster brick logs on all nodes for ACL errors. > >> >> >>>> Here is a sample from my old logs: > >> >> >>>> > >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 > >> >> >13:19:41.489047] I > >> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] > >> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- > >> >> >>>> > >> >> > >> >> > >> > >> > >
>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, > >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx > >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) > >> >> >>>> [Permission denied] > >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 > >> >> >13:22:51.818796] I > >> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] > >> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- > >> >> >>>> > >> >> > >> >> > >> > >> > >
>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, > >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx > >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) > >> >> >>>> [Permission denied] > >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 > >> >> >13:24:43.732856] I > >> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] > >> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- > >> >> >>>> > >> >> > >> >> > >> > >> > >
>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, > >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx > >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) > >> >> >>>> [Permission denied] > >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 > >> >> >13:26:50.758178] I > >> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] > >> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- > >> >> >>>> > >> >> > >> >> > >> > >> > >
>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, > >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx > >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) > >> >> >>>> [Permission denied] > >> >> >>>> > >> >> >>>> > >> >> >>>> In my case , the workaround was to downgrade the gluster > >> >packages > >> >> >on all > >> >> >>>> nodes (and reboot each node 1 by 1 ) if the major version is > >the > >> >> >same, but > >> >> >>>> if you upgraded to v7.X - then you can try the v7.0 . > >> >> >>>> > >> >> >>>> Best Regards, > >> >> >>>> Strahil Nikolov > >> >> >>>> > >> >> >>>> > >> >> >>>> > >> >> >>>> > >> >> >>>> > >> >> >>>> > >> >> >>>> В събота, 20 юни 2020 г., 18:48:42 ч. Гринуич+3, C Williams < > >> >> >>>> cwilliams3320@gmail.com> написа: > >> >> >>>> > >> >> >>>> > >> >> >>>> > >> >> >>>> > >> >> >>>> > >> >> >>>> Hello, > >> >> >>>> > >> >> >>>> Here are additional log tiles as well as a tree of the > >> >problematic > >> >> >>>> Gluster storage domain. During this time I attempted to copy > >a > >> >> >virtual disk > >> >> >>>> to another domain, move a virtual disk to another domain and > >run > >> >a > >> >> >VM where > >> >> >>>> the virtual hard disk would be used. > >> >> >>>> > >> >> >>>> The copies/moves failed and the VM went into pause mode when > >the > >> >> >virtual > >> >> >>>> HDD was involved. > >> >> >>>> > >> >> >>>> Please check these out. > >> >> >>>> > >> >> >>>> Thank You For Your Help ! > >> >> >>>> > >> >> >>>> On Sat, Jun 20, 2020 at 9:54 AM C Williams > >> >> ><cwilliams3320@gmail.com> > >> >> >>>> wrote: > >> >> >>>> > Strahil, > >> >> >>>> > > >> >> >>>> > I understand. Please keep me posted. > >> >> >>>> > > >> >> >>>> > Thanks For The Help ! > >> >> >>>> > > >> >> >>>> > On Sat, Jun 20, 2020 at 4:36 AM Strahil Nikolov > >> >> ><hunter86_bg@yahoo.com> > >> >> >>>> wrote: > >> >> >>>> >> Hey C Williams, > >> >> >>>> >> > >> >> >>>> >> sorry for the delay, but I couldn't get somw time to > >check > >> >your > >> >> >>>> logs. Will try a little bit later. > >> >> >>>> >> > >> >> >>>> >> Best Regards, > >> >> >>>> >> Strahil Nikolov > >> >> >>>> >> > >> >> >>>> >> На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams < > >> >> >>>> cwilliams3320@gmail.com> написа: > >> >> >>>> >>>Hello, > >> >> >>>> >>> > >> >> >>>> >>>Was wanting to follow up on this issue. Users are > >impacted. > >> >> >>>> >>> > >> >> >>>> >>>Thank You > >> >> >>>> >>> > >> >> >>>> >>>On Fri, Jun 19, 2020 at 9:20 AM C Williams > >> >> ><cwilliams3320@gmail.com> > >> >> >>>> >>>wrote: > >> >> >>>> >>> > >> >> >>>> >>>> Hello, > >> >> >>>> >>>> > >> >> >>>> >>>> Here are the logs (some IPs are changed ) > >> >> >>>> >>>> > >> >> >>>> >>>> ov05 is the SPM > >> >> >>>> >>>> > >> >> >>>> >>>> Thank You For Your Help ! > >> >> >>>> >>>> > >> >> >>>> >>>> On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov > >> >> >>>> >>><hunter86_bg@yahoo.com> > >> >> >>>> >>>> wrote: > >> >> >>>> >>>> > >> >> >>>> >>>>> Check on the hosts tab , which is your current SPM > >(last > >> >> >column in > >> >> >>>> >>>Admin > >> >> >>>> >>>>> UI). > >> >> >>>> >>>>> Then open the /var/log/vdsm/vdsm.log and repeat the > >> >> >operation. > >> >> >>>> >>>>> Then provide the log from that host and the engine's > >log > >> >(on > >> >> >the > >> >> >>>> >>>>> HostedEngine VM or on your standalone engine). > >> >> >>>> >>>>> > >> >> >>>> >>>>> Best Regards, > >> >> >>>> >>>>> Strahil Nikolov > >> >> >>>> >>>>> > >> >> >>>> >>>>> На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams > >> >> >>>> >>><cwilliams3320@gmail.com> > >> >> >>>> >>>>> написа: > >> >> >>>> >>>>> >Resending to eliminate email issues > >> >> >>>> >>>>> > > >> >> >>>> >>>>> >---------- Forwarded message --------- > >> >> >>>> >>>>> >From: C Williams <cwilliams3320@gmail.com> > >> >> >>>> >>>>> >Date: Thu, Jun 18, 2020 at 4:01 PM > >> >> >>>> >>>>> >Subject: Re: [ovirt-users] Fwd: Issues with Gluster > >> >Domain > >> >> >>>> >>>>> >To: Strahil Nikolov <hunter86_bg@yahoo.com> > >> >> >>>> >>>>> > > >> >> >>>> >>>>> > > >> >> >>>> >>>>> >Here is output from mount > >> >> >>>> >>>>> > > >> >> >>>> >>>>> >192.168.24.12:/stor/import0 on > >> >> >>>> >>>>> /rhev/data-center/mnt/192.168.24.12:_stor_import0 > >> >> >>>> >>>>> >type nfs4 > >> >> >>>> >>>>> > >> >> >>>> >>>>> > >> >> >>>> > >> >> >>>> > >> >> > >> >> > >> > >> > >
>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12) > >> >> >>>> >>>>> >192.168.24.13:/stor/import1 on > >> >> >>>> >>>>> /rhev/data-center/mnt/192.168.24.13:_stor_import1 > >> >> >>>> >>>>> >type nfs4 > >> >> >>>> >>>>> > >> >> >>>> >>>>> > >> >> >>>> > >> >> >>>> > >> >> > >> >> > >> > >> > >
>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) > >> >> >>>> >>>>> >192.168.24.13:/stor/iso1 on > >> >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_iso1 > >> >> >>>> >>>>> >type nfs4 > >> >> >>>> >>>>> > >> >> >>>> >>>>> > >> >> >>>> > >> >> >>>> > >> >> > >> >> > >> > >> > >
>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) > >> >> >>>> >>>>> >192.168.24.13:/stor/export0 on > >> >> >>>> >>>>> /rhev/data-center/mnt/192.168.24.13:_stor_export0 > >> >> >>>> >>>>> >type nfs4 > >> >> >>>> >>>>> > >> >> >>>> >>>>> > >> >> >>>> > >> >> >>>> > >> >> > >> >> > >> > >> > >
>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) > >> >> >>>> >>>>> >192.168.24.15:/images on > >> >> >>>> >>>>> /rhev/data-center/mnt/glusterSD/192.168.24.15:_images > >> >> >>>> >>>>> >type fuse.glusterfs > >> >> >>>> >>>>> > >> >> >>>> >>>>> > >> >> >>>> > >> >> >>>> > >> >> > >> >> > >> > >> > >
>>>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) > >> >> >>>> >>>>> >192.168.24.18:/images3 on > >> >> >>>> >>>>> /rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 > >> >> >>>> >>>>> >type fuse.glusterfs > >> >> >>>> >>>>> > >> >> >>>> >>>>> > >> >> >>>> > >> >> >>>> > >> >> > >> >> > >> > >> > >
>>>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) > >> >> >>>> >>>>> >tmpfs on /run/user/0 type tmpfs > >> >> >>>> >>>>> > >> >>(rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) > >> >> >>>> >>>>> >[root@ov06 glusterfs]# > >> >> >>>> >>>>> > > >> >> >>>> >>>>> >Also here is a screenshot of the console > >> >> >>>> >>>>> > > >> >> >>>> >>>>> >[image: image.png] > >> >> >>>> >>>>> >The other domains are up > >> >> >>>> >>>>> > > >> >> >>>> >>>>> >Import0 and Import1 are NFS . GLCL0 is gluster. They > >all > >> >are > >> >> >>>> >>>running > >> >> >>>> >>>>> >VMs > >> >> >>>> >>>>> > > >> >> >>>> >>>>> >Thank You For Your Help ! > >> >> >>>> >>>>> > > >> >> >>>> >>>>> >On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov > >> >> >>>> >>><hunter86_bg@yahoo.com> > >> >> >>>> >>>>> >wrote: > >> >> >>>> >>>>> > > >> >> >>>> >>>>> >> I don't see > >> >> >'/rhev/data-center/mnt/192.168.24.13:_stor_import1' > >> >> >>>> >>>>> >mounted > >> >> >>>> >>>>> >> at all . > >> >> >>>> >>>>> >> What is the status of all storage domains ? > >> >> >>>> >>>>> >> > >> >> >>>> >>>>> >> Best Regards, > >> >> >>>> >>>>> >> Strahil Nikolov > >> >> >>>> >>>>> >> > >> >> >>>> >>>>> >> На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams > >> >> >>>> >>>>> ><cwilliams3320@gmail.com> > >> >> >>>> >>>>> >> написа: > >> >> >>>> >>>>> >> > Resending to deal with possible email issues > >> >> >>>> >>>>> >> > > >> >> >>>> >>>>> >> >---------- Forwarded message --------- > >> >> >>>> >>>>> >> >From: C Williams <cwilliams3320@gmail.com> > >> >> >>>> >>>>> >> >Date: Thu, Jun 18, 2020 at 2:07 PM > >> >> >>>> >>>>> >> >Subject: Re: [ovirt-users] Issues with Gluster > >Domain > >> >> >>>> >>>>> >> >To: Strahil Nikolov <hunter86_bg@yahoo.com> > >> >> >>>> >>>>> >> > > >> >> >>>> >>>>> >> > > >> >> >>>> >>>>> >> >More > >> >> >>>> >>>>> >> > > >> >> >>>> >>>>> >> >[root@ov06 ~]# for i in $(gluster volume list); do > >> >echo > >> >> >>>> >>>$i;echo; > >> >> >>>> >>>>> >> >gluster > >> >> >>>> >>>>> >> >volume info $i; echo;echo;gluster volume status > >> >> >>>> >>>>> >$i;echo;echo;echo;done > >> >> >>>> >>>>> >> >images3 > >> >> >>>> >>>>> >> > > >> >> >>>> >>>>> >> > > >> >> >>>> >>>>> >> >Volume Name: images3 > >> >> >>>> >>>>> >> >Type: Replicate > >> >> >>>> >>>>> >> >Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b > >> >> >>>> >>>>> >> >Status: Started > >> >> >>>> >>>>> >> >Snapshot Count: 0 > >> >> >>>> >>>>> >> >Number of Bricks: 1 x 3 = 3 > >> >> >>>> >>>>> >> >Transport-type: tcp > >> >> >>>> >>>>> >> >Bricks: > >> >> >>>> >>>>> >> >Brick1: 192.168.24.18:/bricks/brick04/images3 > >> >> >>>> >>>>> >> >Brick2: 192.168.24.19:/bricks/brick05/images3 > >> >> >>>> >>>>> >> >Brick3: 192.168.24.20:/bricks/brick06/images3 > >> >> >>>> >>>>> >> >Options Reconfigured: > >> >> >>>> >>>>> >> >performance.client-io-threads: on > >> >> >>>> >>>>> >> >nfs.disable: on > >> >> >>>> >>>>> >> >transport.address-family: inet > >> >> >>>> >>>>> >> >user.cifs: off > >> >> >>>> >>>>> >> >auth.allow: * > >> >> >>>> >>>>> >> >performance.quick-read: off > >> >> >>>> >>>>> >> >performance.read-ahead: off > >> >> >>>> >>>>> >> >performance.io-cache: off > >> >> >>>> >>>>> >> >performance.low-prio-threads: 32 > >> >> >>>> >>>>> >> >network.remote-dio: off > >> >> >>>> >>>>> >> >cluster.eager-lock: enable > >> >> >>>> >>>>> >> >cluster.quorum-type: auto > >> >> >>>> >>>>> >> >cluster.server-quorum-type: server > >> >> >>>> >>>>> >> >cluster.data-self-heal-algorithm: full > >> >> >>>> >>>>> >> >cluster.locking-scheme: granular > >> >> >>>> >>>>> >> >cluster.shd-max-threads: 8 > >> >> >>>> >>>>> >> >cluster.shd-wait-qlength: 10000 > >> >> >>>> >>>>> >> >features.shard: on > >> >> >>>> >>>>> >> >cluster.choose-local: off > >> >> >>>> >>>>> >> >client.event-threads: 4 > >> >> >>>> >>>>> >> >server.event-threads: 4 > >> >> >>>> >>>>> >> >storage.owner-uid: 36 > >> >> >>>> >>>>> >> >storage.owner-gid: 36 > >> >> >>>> >>>>> >> >performance.strict-o-direct: on > >> >> >>>> >>>>> >> >network.ping-timeout: 30 > >> >> >>>> >>>>> >> >cluster.granular-entry-heal: enable > >> >> >>>> >>>>> >> > > >> >> >>>> >>>>> >> > > >> >> >>>> >>>>> >> >Status of volume: images3 > >> >> >>>> >>>>> >> >Gluster process TCP > >Port > >> >> >RDMA Port > >> >> >>>> >>>>> >Online > >> >> >>>> >>>>> >> > Pid > >> >> >>>> >>>>> >> > >> >> >>>> >>>>> >> > >> >> >>>> >>>>> > >> >> >>>> >>>>> > >> >> >>>> > >> >> >>>> > >> >> > >> >> > >> > >> > >
>>>>>>------------------------------------------------------------------------------ > >> >> >>>> >>>>> >> >Brick 192.168.24.18:/bricks/brick04/images3 49152 > >> >0 > >> >> >>>> > >> >> >>>> >>>Y > >> >> >>>> >>>>> >> >6666 > >> >> >>>> >>>>> >> >Brick 192.168.24.19:/bricks/brick05/images3 49152 > >> >0 > >> >> >>>> > >> >> >>>> >>>Y > >> >> >>>> >>>>> >> >6779 > >> >> >>>> >>>>> >> >Brick 192.168.24.20:/bricks/brick06/images3 49152 > >> >0 > >> >> >>>> > >> >> >>>> >>>Y > >> >> >>>> >>>>> >> >7227 > >> >> >>>> >>>>> >> >Self-heal Daemon on localhost N/A > >> >N/A > >> >> >>>> > >> >> >>>> >>>Y > >> >> >>>> >>>>> >> >6689 > >> >> >>>> >>>>> >> >Self-heal Daemon on ov07.ntc.srcle.com N/A > >> >N/A > >> >> >>>> > >> >> >>>> >>>Y > >> >> >>>> >>>>> >> >6802 > >> >> >>>> >>>>> >> >Self-heal Daemon on ov08.ntc.srcle.com N/A > >> >N/A > >> >> >>>> > >> >> >>>> >>>Y > >> >> >>>> >>>>> >> >7250 > >> >> >>>> >>>>> >> > > >> >> >>>> >>>>> >> >Task Status of Volume images3 > >> >> >>>> >>>>> >> > >> >> >>>> >>>>> >> > >> >> >>>> >>>>> > >> >> >>>> >>>>> > >> >> >>>> > >> >> >>>> > >> >> > >> >> > >> > >> > >
>>>>>>------------------------------------------------------------------------------ > >> >> >>>> >>>>> >> >There are no active volume tasks > >> >> >>>> >>>>> >> > > >> >> >>>> >>>>> >> > > >> >> >>>> >>>>> >> > > >> >> >>>> >>>>> >> > > >> >> >>>> >>>>> >> >[root@ov06 ~]# ls -l > >/rhev/data-center/mnt/glusterSD/ > >> >> >>>> >>>>> >> >total 16 > >> >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 > >> >> >192.168.24.15:_images > >> >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 > >> >192.168.24.18: > >> >> >>>> _images3 > >> >> >>>> >>>>> >> >[root@ov06 ~]# > >> >> >>>> >>>>> >> > > >> >> >>>> >>>>> >> >On Thu, Jun 18, 2020 at 2:03 PM C Williams > >> >> >>>> >>><cwilliams3320@gmail.com> > >> >> >>>> >>>>> >> >wrote: > >> >> >>>> >>>>> >> > > >> >> >>>> >>>>> >> >> Strahil, > >> >> >>>> >>>>> >> >> > >> >> >>>> >>>>> >> >> Here you go -- Thank You For Your Help ! > >> >> >>>> >>>>> >> >> > >> >> >>>> >>>>> >> >> BTW -- I can write a test file to gluster and it > >> >> >replicates > >> >> >>>> >>>>> >properly. > >> >> >>>> >>>>> >> >> Thinking something about the oVirt Storage Domain > >? > >> >> >>>> >>>>> >> >> > >> >> >>>> >>>>> >> >> [root@ov08 ~]# gluster pool list > >> >> >>>> >>>>> >> >> UUID Hostname > >> >> >>>> >>>>> >State > >> >> >>>> >>>>> >> >> 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06 > >> >> >>>> >>>>> >> >Connected > >> >> >>>> >>>>> >> >> 36ce5a00-6f65-4926-8438-696944ebadb5 > >> >> >ov07.ntc.srcle.com > >> >> >>>> >>>>> >> >Connected > >> >> >>>> >>>>> >> >> c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost > >> >> >>>> >>>>> >> >Connected > >> >> >>>> >>>>> >> >> [root@ov08 ~]# gluster volume list > >> >> >>>> >>>>> >> >> images3 > >> >> >>>> >>>>> >> >> > >> >> >>>> >>>>> >> >> On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov > >> >> >>>> >>>>> >> ><hunter86_bg@yahoo.com> > >> >> >>>> >>>>> >> >> wrote: > >> >> >>>> >>>>> >> >> > >> >> >>>> >>>>> >> >>> Log to the oVirt cluster and provide the output > >of: > >> >> >>>> >>>>> >> >>> gluster pool list > >> >> >>>> >>>>> >> >>> gluster volume list > >> >> >>>> >>>>> >> >>> for i in $(gluster volume list); do echo > >$i;echo; > >> >> >gluster > >> >> >>>> >>>>> >volume > >> >> >>>> >>>>> >> >info > >> >> >>>> >>>>> >> >>> $i; echo;echo;gluster volume status > >> >> >$i;echo;echo;echo;done > >> >> >>>> >>>>> >> >>> > >> >> >>>> >>>>> >> >>> ls -l /rhev/data-center/mnt/glusterSD/ > >> >> >>>> >>>>> >> >>> > >> >> >>>> >>>>> >> >>> Best Regards, > >> >> >>>> >>>>> >> >>> Strahil Nikolov > >> >> >>>> >>>>> >> >>> > >> >> >>>> >>>>> >> >>> > >> >> >>>> >>>>> >> >>> На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams > >> >> >>>> >>>>> >> ><cwilliams3320@gmail.com> > >> >> >>>> >>>>> >> >>> написа: > >> >> >>>> >>>>> >> >>> >Hello, > >> >> >>>> >>>>> >> >>> > > >> >> >>>> >>>>> >> >>> >I recently added 6 hosts to an existing oVirt > >> >> >>>> >>>compute/gluster > >> >> >>>> >>>>> >> >cluster. > >> >> >>>> >>>>> >> >>> > > >> >> >>>> >>>>> >> >>> >Prior to this attempted addition, my cluster > >had 3 > >> >> >>>> >>>Hypervisor > >> >> >>>> >>>>> >hosts > >> >> >>>> >>>>> >> >and > >> >> >>>> >>>>> >> >>> >3 > >> >> >>>> >>>>> >> >>> >gluster bricks which made up a single gluster > >> >volume > >> >> >>>> >>>(replica 3 > >> >> >>>> >>>>> >> >volume) > >> >> >>>> >>>>> >> >>> >. I > >> >> >>>> >>>>> >> >>> >added the additional hosts and made a brick on > >3 > >> >of > >> >> >the new > >> >> >>>> >>>>> >hosts > >> >> >>>> >>>>> >> >and > >> >> >>>> >>>>> >> >>> >attempted to make a new replica 3 volume. I had > >> >> >difficulty > >> >> >>>> >>>>> >> >creating > >> >> >>>> >>>>> >> >>> >the > >> >> >>>> >>>>> >> >>> >new volume. So, I decided that I would make a > >new > >> >> >>>> >>>>> >compute/gluster > >> >> >>>> >>>>> >> >>> >cluster > >> >> >>>> >>>>> >> >>> >for each set of 3 new hosts. > >> >> >>>> >>>>> >> >>> > > >> >> >>>> >>>>> >> >>> >I removed the 6 new hosts from the existing > >oVirt > >> >> >>>> >>>>> >Compute/Gluster > >> >> >>>> >>>>> >> >>> >Cluster > >> >> >>>> >>>>> >> >>> >leaving the 3 original hosts in place with > >their > >> >> >bricks. At > >> >> >>>> >>>that > >> >> >>>> >>>>> >> >point > >> >> >>>> >>>>> >> >>> >my > >> >> >>>> >>>>> >> >>> >original bricks went down and came back up . > >The > >> >> >volume > >> >> >>>> >>>showed > >> >> >>>> >>>>> >> >entries > >> >> >>>> >>>>> >> >>> >that > >> >> >>>> >>>>> >> >>> >needed healing. At that point I ran gluster > >volume > >> >> >heal > >> >> >>>> >>>images3 > >> >> >>>> >>>>> >> >full, > >> >> >>>> >>>>> >> >>> >etc. > >> >> >>>> >>>>> >> >>> >The volume shows no unhealed entries. I also > >> >> >corrected some > >> >> >>>> >>>peer > >> >> >>>> >>>>> >> >>> >errors. > >> >> >>>> >>>>> >> >>> > > >> >> >>>> >>>>> >> >>> >However, I am unable to copy disks, move disks > >to > >> >> >another > >> >> >>>> >>>>> >domain, > >> >> >>>> >>>>> >> >>> >export > >> >> >>>> >>>>> >> >>> >disks, etc. It appears that the engine cannot > >> >locate > >> >> >disks > >> >> >>>> >>>>> >properly > >> >> >>>> >>>>> >> >and > >> >> >>>> >>>>> >> >>> >I > >> >> >>>> >>>>> >> >>> >get storage I/O errors. > >> >> >>>> >>>>> >> >>> > > >> >> >>>> >>>>> >> >>> >I have detached and removed the oVirt Storage > >> >Domain. > >> >> >I > >> >> >>>> >>>>> >reimported > >> >> >>>> >>>>> >> >the > >> >> >>>> >>>>> >> >>> >domain and imported 2 VMs, But the VM disks > >> >exhibit > >> >> >the > >> >> >>>> same > >> >> >>>> >>>>> >> >behaviour > >> >> >>>> >>>>> >> >>> >and > >> >> >>>> >>>>> >> >>> >won't run from the hard disk. > >> >> >>>> >>>>> >> >>> > > >> >> >>>> >>>>> >> >>> > > >> >> >>>> >>>>> >> >>> >I get errors such as this > >> >> >>>> >>>>> >> >>> > > >> >> >>>> >>>>> >> >>> >VDSM ov05 command HSMGetAllTasksStatusesVDS > >> >failed: > >> >> >low > >> >> >>>> >>>level > >> >> >>>> >>>>> >Image > >> >> >>>> >>>>> >> >>> >copy > >> >> >>>> >>>>> >> >>> >failed: ("Command ['/usr/bin/qemu-img', > >'convert', > >> >> >'-p', > >> >> >>>> >>>'-t', > >> >> >>>> >>>>> >> >'none', > >> >> >>>> >>>>> >> >>> >'-T', 'none', '-f', 'raw', > >> >> >>>> >>>>> >> >>> > >>u'/rhev/data-center/mnt/glusterSD/192.168.24.18: > >> >> >>>> >>>>> >> >>> > >> >> >>>> >>>>> >> > >> >> >>>> >>>>> >> > >> >> >>>> >>>>> > >> >> >>>> >>>>> > >> >> >>>> > >> >> >>>> > >> >> > >> >> > >> > >> > >
>>>>>>_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510', > >> >> >>>> >>>>> >> >>> >'-O', 'raw', > >> >> >>>> >>>>> >> >>> >u'/rhev/data-center/mnt/192.168.24.13: > >> >> >>>> >>>>> >> >>> > >> >> >>>> >>>>> >> > >> >> >>>> >>>>> >> > >> >> >>>> >>>>> > >> >> >>>> >>>>> > >> >> >>>> > >> >> >>>> > >> >> > >> >> > >> > >> > >
>>>>>>_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5'] > >> >> >>>> >>>>> >> >>> >failed with rc=1 out='' > >err=bytearray(b'qemu-img: > >> >> >error > >> >> >>>> >>>while > >> >> >>>> >>>>> >> >reading > >> >> >>>> >>>>> >> >>> >sector 135168: Transport endpoint is not > >> >> >>>> >>>connected\\nqemu-img: > >> >> >>>> >>>>> >> >error > >> >> >>>> >>>>> >> >>> >while > >> >> >>>> >>>>> >> >>> >reading sector 131072: Transport endpoint is > >not > >> >> >>>> >>>>> >> >connected\\nqemu-img: > >> >> >>>> >>>>> >> >>> >error while reading sector 139264: Transport > >> >endpoint > >> >> >is > >> >> >>>> not > >> >> >>>> >>>>> >> >>> >connected\\nqemu-img: error while reading > >sector > >> >> >143360: > >> >> >>>> >>>>> >Transport > >> >> >>>> >>>>> >> >>> >endpoint > >> >> >>>> >>>>> >> >>> >is not connected\\nqemu-img: error while > >reading > >> >> >sector > >> >> >>>> >>>147456: > >> >> >>>> >>>>> >> >>> >Transport > >> >> >>>> >>>>> >> >>> >endpoint is not connected\\nqemu-img: error > >while > >> >> >reading > >> >> >>>> >>>sector > >> >> >>>> >>>>> >> >>> >155648: > >> >> >>>> >>>>> >> >>> >Transport endpoint is not connected\\nqemu-img: > >> >error > >> >> >while > >> >> >>>> >>>>> >reading > >> >> >>>> >>>>> >> >>> >sector > >> >> >>>> >>>>> >> >>> >151552: Transport endpoint is not > >> >> >connected\\nqemu-img: > >> >> >>>> >>>error > >> >> >>>> >>>>> >while > >> >> >>>> >>>>> >> >>> >reading > >> >> >>>> >>>>> >> >>> >sector 159744: Transport endpoint is not > >> >> >connected\\n')",) > >> >> >>>> >>>>> >> >>> > > >> >> >>>> >>>>> >> >>> >oVirt version is 4.3.82-1.el7 > >> >> >>>> >>>>> >> >>> >OS CentOS Linux release 7.7.1908 (Core) > >> >> >>>> >>>>> >> >>> > > >> >> >>>> >>>>> >> >>> >The Gluster Cluster has been working very well > >> >until > >> >> >this > >> >> >>>> >>>>> >incident. > >> >> >>>> >>>>> >> >>> > > >> >> >>>> >>>>> >> >>> >Please help. > >> >> >>>> >>>>> >> >>> > > >> >> >>>> >>>>> >> >>> >Thank You > >> >> >>>> >>>>> >> >>> > > >> >> >>>> >>>>> >> >>> >Charles Williams > >> >> >>>> >>>>> >> >>> > >> >> >>>> >>>>> >> >> > >> >> >>>> >>>>> >> > >> >> >>>> >>>>> > >> >> >>>> >>>> > >> >> >>>> >> > >> >> >>>> > > >> >> >>>> _______________________________________________ > >> >> >>>> Users mailing list -- users@ovirt.org > >> >> >>>> To unsubscribe send an email to users-leave@ovirt.org > >> >> >>>> Privacy Statement: https://www.ovirt.org/privacy-policy.html > >> >> >>>> oVirt Code of Conduct: > >> >> >>>> https://www.ovirt.org/community/about/community-guidelines/ > >> >> >>>> List Archives: > >> >> >>>> > >> >> > > >> >> > >> > > >> > > >
https://lists.ovirt.org/archives/list/users@ovirt.org/message/YY3VUKEJLI7MRW...
> >> >> >>>> > >> >> >>> > >> >> > >> >
Strahil, Thank You For Help ! Downgrading Gluster to 6.5 got the original storage domain working again ! After, I finished my copy of the contents of the problematic volume to a new volume, I did the following Unmounted the mount points Stopped the original problematic Gluster volume On each problematic peer, I downgraded Gluster to 6.5 (yum downgrade glusterfs-6.5-1.el7.x86_64 vdsm-gluster-4.30.46-1.el7.x86_64 python2-gluster-6.5-1.el7.x86_64 glusterfs-libs-6.5-1.el7.x86_64 glusterfs-cli-6.5-1.el7.x86_64 glusterfs-fuse-6.5-1.el7.x86_64 glusterfs-rdma-6.5-1.el7.x86_64 glusterfs-api-6.5-1.el7.x86_64 glusterfs-server-6.5-1.el7.x86_64 glusterfs-events-6.5-1.el7.x86_64 glusterfs-client-xlators-6.5-1.el7.x86_64 glusterfs-geo-replication-6.5-1.el7.x86_64) Restarted glusterd (systemctl restart glusterd) Restarted the problematic Gluster volume Reattached the problematic storage domain Started the problematic storage domain Things work now. I can now run VMs and write data, copy virtual disks, move virtual disks to other storage domains, etc. I am very thankful that the storage domain is working again ! How can I safely perform upgrades on Gluster ! When will it be safe to do so ? Thank You Again For Your Help ! On Mon, Jun 22, 2020 at 10:58 AM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
I have downgraded the target. The copy from the problematic volume to the target is going on now. Once I have the data copied, I might downgrade the problematic volume's Gluster to 6.5. At that point I might reattach the original ovirt domain and see if it will work again. But the copy is going on right now.
Thank You For Your Help !
On Mon, Jun 22, 2020 at 10:52 AM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
You should ensure that in the storage domain tab, the old storage is not visible.
I still wander why yoiu didn't try to downgrade first.
Best Regards, Strahil Nikolov
На 22 юни 2020 г. 13:58:33 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Strahil,
The GLCL3 storage domain was detached prior to attempting to add the new storage domain.
Should I also "Remove" it ?
Thank You For Your Help !
---------- Forwarded message --------- From: Strahil Nikolov <hunter86_bg@yahoo.com> Date: Mon, Jun 22, 2020 at 12:50 AM Subject: Re: [ovirt-users] Re: Fwd: Fwd: Issues with Gluster Domain To: C Williams <cwilliams3320@gmail.com> Cc: users <Users@ovirt.org>
You can't add the new volume as it contains the same data (UUID) as the old one , thus you need to detach the old one before adding the new one - of course this means downtime for all VMs on that storage.
As you see , downgrading is more simpler. For me v6.5 was working, while anything above (6.6+) was causing complete lockdown. Also v7.0 was working, but it's supported in oVirt 4.4.
Best Regards, Strahil Nikolov
Another question
What version could I downgrade to safely ? I am at 6.9 .
Thank You For Your Help !!
On Sun, Jun 21, 2020 at 11:38 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
You are definitely reading it wrong. 1. I didn't create a new storage domain ontop this new volume. 2. I used cli
Something like this (in your case it should be 'replica 3'): gluster volume create newvol replica 3 arbiter 1 ovirt1:/new/brick/path ovirt2:/new/brick/path ovirt3:/new/arbiter/brick/path gluster volume start newvol
#Detach oldvol from ovirt
mount -t glusterfs ovirt1:/oldvol /mnt/oldvol mount -t glusterfs ovirt1:/newvol /mnt/newvol cp -a /mnt/oldvol/* /mnt/newvol
#Add only newvol as a storage domain in oVirt #Import VMs
I still think that you should downgrade your gluster packages!!!
Best Regards, Strahil Nikolov
На 22 юни 2020 г. 0:43:46 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Strahil,
It sounds like you used a "System Managed Volume" for the new storage domain,is that correct?
Thank You For Your Help !
On Sun, Jun 21, 2020 at 5:40 PM C Williams <cwilliams3320@gmail.com> wrote:
> Strahil, > > So you made another oVirt Storage Domain -- then copied the data with cp > -a from the failed volume to the new volume. > > At the root of the volume there will be the old domain folder id ex > 5fe3ad3f-2d21-404c-832e-4dc7318ca10d > in my case. Did that cause issues with making the new domain since it is > the same folder id as the old one ? > > Thank You For Your Help ! > > On Sun, Jun 21, 2020 at 5:18 PM Strahil Nikolov <hunter86_bg@yahoo.com> > wrote: > >> In my situation I had only the ovirt nodes. >> >> На 21 юни 2020 г. 22:43:04 GMT+03:00, C Williams <cwilliams3320@gmail.com> >> написа: >> >Strahil, >> > >> >So should I make the target volume on 3 bricks which do not have ovirt >> >-- >> >just gluster ? In other words (3) Centos 7 hosts ? >> > >> >Thank You For Your Help ! >> > >> >On Sun, Jun 21, 2020 at 3:08 PM Strahil Nikolov <hunter86_bg@yahoo.com> >> >wrote: >> > >> >> I created a fresh volume (which is not an ovirt sgorage domain), >> >set >> >> the original storage domain in maintenance and detached it. >> >> Then I 'cp -a ' the data from the old to the new volume. Next, I >> >just >> >> added the new storage domain (the old one was a kind of a >> >> 'backup') - pointing to the new volume name. >> >> >> >> If you observe issues , I would recommend you to downgrade >> >> gluster packages one node at a time . Then you might be able to >> >> restore your oVirt operations. >> >> >> >> Best Regards, >> >> Strahil Nikolov >> >> >> >> На 21 юни 2020 г. 18:01:31 GMT+03:00, C Williams >> ><cwilliams3320@gmail.com> >> >> написа: >> >> >Strahil, >> >> > >> >> >Thanks for the follow up ! >> >> > >> >> >How did you copy the data to another volume ? >> >> > >> >> >I have set up another storage domain GLCLNEW1 with a new volume >> >imgnew1 >> >> >. >> >> >How would you copy all of the data from the problematic domain GLCL3 >> >> >with >> >> >volume images3 to GLCLNEW1 and volume imgnew1 and preserve all the >> >VMs, >> >> >VM >> >> >disks, settings, etc. ? >> >> > >> >> >Remember all of the regular ovirt disk copy, disk move, VM export >> >> >tools >> >> >are failing and my VMs and disks are trapped on domain GLCL3 and >> >volume >> >> >images3 right now. >> >> > >> >> >Please let me know >> >> > >> >> >Thank You For Your Help ! >> >> > >> >> > >> >> > >> >> > >> >> > >> >> >On Sun, Jun 21, 2020 at 8:27 AM Strahil Nikolov >> ><hunter86_bg@yahoo.com> >> >> >wrote: >> >> > >> >> >> Sorry to hear that. >> >> >> I can say that for me 6.5 was working, while 6.6 didn't and I >> >> >upgraded >> >> >> to 7.0 . >> >> >> In the ended , I have ended with creating a new fresh volume >> >and >> >> >> physically copying the data there, then I detached the storage >> >> >domains and >> >> >> attached to the new ones (which holded the old data), but I >> >> >could >> >> >> afford the downtime. >> >> >> Also, I can say that v7.0 ( but not 7.1 or anything later) >> >also >> >> >> worked without the ACL issue, but it causes some
На 22 юни 2020 г. 7:21:15 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: trouble
in >> >oVirt >> >> >- so >> >> >> avoid that unless you have no other options. >> >> >> >> >> >> Best Regards, >> >> >> Strahil Nikolov >> >> >> >> >> >> >> >> >> >> >> >> >> >> >> На 21 юни 2020 г. 4:39:46 GMT+03:00, C Williams >> >> ><cwilliams3320@gmail.com> >> >> >> написа: >> >> >> >Hello, >> >> >> > >> >> >> >Upgrading diidn't help >> >> >> > >> >> >> >Still acl errors trying to use a Virtual Disk from a VM >> >> >> > >> >> >> >[root@ov06 bricks]# tail bricks-brick04-images3.log | grep acl >> >> >> >[2020-06-21 01:33:45.665888] I [MSGID: 139001] >> >> >> >[posix-acl.c:263:posix_acl_log_permit_denied] >> >> >0-images3-access-control: >> >> >> >client: >> >> >> >> >> >> >> >> >> >> >> >>
>>CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0, >> >> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >> >> >> >req(uid:107,gid:107,perm:1,ngrps:3), >> >> >> >ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) >> >> >> >[Permission denied] >> >> >> >The message "I [MSGID: 139001] >> >> >> >[posix-acl.c:263:posix_acl_log_permit_denied] >> >> >0-images3-access-control: >> >> >> >client: >> >> >> >> >> >> >> >> >> >> >> >>
>>CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0, >> >> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >> >> >> >req(uid:107,gid:107,perm:1,ngrps:3), >> >> >> >ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) >> >> >> >[Permission denied]" repeated 2 times between [2020-06-21 >> >> >> >01:33:45.665888] >> >> >> >and [2020-06-21 01:33:45.806779] >> >> >> > >> >> >> >Thank You For Your Help ! >> >> >> > >> >> >> >On Sat, Jun 20, 2020 at 8:59 PM C Williams >> ><cwilliams3320@gmail.com> >> >> >> >wrote: >> >> >> > >> >> >> >> Hello, >> >> >> >> >> >> >> >> Based on the situation, I am planning to upgrade the 3 affected >> >> >> >hosts. >> >> >> >> >> >> >> >> My reasoning is that the hosts/bricks were attached to 6.9 at >> >one >> >> >> >time. >> >> >> >> >> >> >> >> Thanks For Your Help ! >> >> >> >> >> >> >> >> On Sat, Jun 20, 2020 at 8:38 PM C Williams >> >> ><cwilliams3320@gmail.com> >> >> >> >> wrote: >> >> >> >> >> >> >> >>> Strahil, >> >> >> >>> >> >> >> >>> The gluster version on the current 3 gluster hosts is 6.7 >> >(last >> >> >> >update >> >> >> >>> 2/26). These 3 hosts provide 1 brick each for the replica 3 >> >> >volume. >> >> >> >>> >> >> >> >>> Earlier I had tried to add 6 additional hosts to the cluster. >> >> >Those >> >> >> >new >> >> >> >>> hosts were 6.9 gluster. >> >> >> >>> >> >> >> >>> I attempted to make a new separate volume with 3 bricks >> >provided >> >> >by >> >> >> >the 3 >> >> >> >>> new gluster 6.9 hosts. After having many errors from the >> >oVirt >> >> >> >interface, >> >> >> >>> I gave up and removed the 6 new hosts from the cluster. That >> >is >> >> >> >where the >> >> >> >>> problems started. The intent was to expand the gluster cluster >> >> >while >> >> >> >making >> >> >> >>> 2 new volumes for that cluster. The ovirt compute cluster >> >would >> >> >> >allow for >> >> >> >>> efficient VM migration between 9 hosts -- while having >> >separate >> >> >> >gluster >> >> >> >>> volumes for safety purposes. >> >> >> >>> >> >> >> >>> Looking at the brick logs, I see where there are acl errors >> >> >starting >> >> >> >from >> >> >> >>> the time of the removal of the 6 new hosts. >> >> >> >>> >> >> >> >>> Please check out the attached brick log from 6/14-18. The >> >events >> >> >> >started >> >> >> >>> on 6/17. >> >> >> >>> >> >> >> >>> I wish I had a downgrade path. >> >> >> >>> >> >> >> >>> Thank You For The Help !! >> >> >> >>> >> >> >> >>> On Sat, Jun 20, 2020 at 7:47 PM Strahil Nikolov >> >> >> ><hunter86_bg@yahoo.com> >> >> >> >>> wrote: >> >> >> >>> >> >> >> >>>> Hi , >> >> >> >>>> >> >> >> >>>> >> >> >> >>>> This one really looks like the ACL bug I was hit with when I >> >> >> >updated >> >> >> >>>> from Gluster v6.5 to 6.6 and later from 7.0 to 7.2. >> >> >> >>>> >> >> >> >>>> Did you update your setup recently ? Did you upgrade gluster >> >> >also ? >> >> >> >>>> >> >> >> >>>> You have to check the gluster logs in order to verify that, >> >so >> >> >you >> >> >> >can >> >> >> >>>> try: >> >> >> >>>> >> >> >> >>>> 1. Set Gluster logs to trace level (for details check: >> >> >> >>>> >> >> >> > >> >> >> >> >> > >> >> >> > >>
https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3/html...
>> >> >> >>>> ) >> >> >> >>>> 2. Power up a VM that was already off , or retry the >> >procedure >> >> >from >> >> >> >the >> >> >> >>>> logs you sent. >> >> >> >>>> 3. Stop the trace level of the logs >> >> >> >>>> 4. Check libvirt logs on the host that was supposed to power >> >up >> >> >the >> >> >> >VM >> >> >> >>>> (in case a VM was powered on) >> >> >> >>>> 5. Check the gluster brick logs on all nodes for ACL errors. >> >> >> >>>> Here is a sample from my old logs: >> >> >> >>>> >> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 >> >> >> >13:19:41.489047] I >> >> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] >> >> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- >> >> >> >>>> >> >> >> >> >> >> >> >> >> >> >> >>
>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, >> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx >> >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) >> >> >> >>>> [Permission denied] >> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 >> >> >> >13:22:51.818796] I >> >> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] >> >> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- >> >> >> >>>> >> >> >> >> >> >> >> >> >> >> >> >>
>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, >> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx >> >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) >> >> >> >>>> [Permission denied] >> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 >> >> >> >13:24:43.732856] I >> >> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] >> >> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- >> >> >> >>>> >> >> >> >> >> >> >> >> >> >> >> >>
>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, >> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx >> >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) >> >> >> >>>> [Permission denied] >> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 >> >> >> >13:26:50.758178] I >> >> >> >>>> [MSGID: 139001] [posix-acl.c:262:posix_acl_log_permit_denied] >> >> >> >>>> 0-data_fast4-access-control: client: CTX_ID:4a654305-d2e4- >> >> >> >>>> >> >> >> >> >> >> >> >> >> >> >> >>
>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, >> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx >> >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, acl:-) >> >> >> >>>> [Permission denied] >> >> >> >>>> >> >> >> >>>> >> >> >> >>>> In my case , the workaround was to downgrade the gluster >> >> >packages >> >> >> >on all >> >> >> >>>> nodes (and reboot each node 1 by 1 ) if the major version is >> >the >> >> >> >same, but >> >> >> >>>> if you upgraded to v7.X - then you can try the v7.0 . >> >> >> >>>> >> >> >> >>>> Best Regards, >> >> >> >>>> Strahil Nikolov >> >> >> >>>> >> >> >> >>>> >> >> >> >>>> >> >> >> >>>> >> >> >> >>>> >> >> >> >>>> >> >> >> >>>> В събота, 20 юни 2020 г., 18:48:42 ч. Гринуич+3, C Williams < >> >> >> >>>> cwilliams3320@gmail.com> написа: >> >> >> >>>> >> >> >> >>>> >> >> >> >>>> >> >> >> >>>> >> >> >> >>>> >> >> >> >>>> Hello, >> >> >> >>>> >> >> >> >>>> Here are additional log tiles as well as a tree of the >> >> >problematic >> >> >> >>>> Gluster storage domain. During this time I attempted to copy >> >a >> >> >> >virtual disk >> >> >> >>>> to another domain, move a virtual disk to another domain and >> >run >> >> >a >> >> >> >VM where >> >> >> >>>> the virtual hard disk would be used. >> >> >> >>>> >> >> >> >>>> The copies/moves failed and the VM went into pause mode when >> >the >> >> >> >virtual >> >> >> >>>> HDD was involved. >> >> >> >>>> >> >> >> >>>> Please check these out. >> >> >> >>>> >> >> >> >>>> Thank You For Your Help ! >> >> >> >>>> >> >> >> >>>> On Sat, Jun 20, 2020 at 9:54 AM C Williams >> >> >> ><cwilliams3320@gmail.com> >> >> >> >>>> wrote: >> >> >> >>>> > Strahil, >> >> >> >>>> > >> >> >> >>>> > I understand. Please keep me posted. >> >> >> >>>> > >> >> >> >>>> > Thanks For The Help ! >> >> >> >>>> > >> >> >> >>>> > On Sat, Jun 20, 2020 at 4:36 AM Strahil Nikolov >> >> >> ><hunter86_bg@yahoo.com> >> >> >> >>>> wrote: >> >> >> >>>> >> Hey C Williams, >> >> >> >>>> >> >> >> >> >>>> >> sorry for the delay, but I couldn't get somw time to >> >check >> >> >your >> >> >> >>>> logs. Will try a little bit later. >> >> >> >>>> >> >> >> >> >>>> >> Best Regards, >> >> >> >>>> >> Strahil Nikolov >> >> >> >>>> >> >> >> >> >>>> >> На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams < >> >> >> >>>> cwilliams3320@gmail.com> написа: >> >> >> >>>> >>>Hello, >> >> >> >>>> >>> >> >> >> >>>> >>>Was wanting to follow up on this issue. Users are >> >impacted. >> >> >> >>>> >>> >> >> >> >>>> >>>Thank You >> >> >> >>>> >>> >> >> >> >>>> >>>On Fri, Jun 19, 2020 at 9:20 AM C Williams >> >> >> ><cwilliams3320@gmail.com> >> >> >> >>>> >>>wrote: >> >> >> >>>> >>> >> >> >> >>>> >>>> Hello, >> >> >> >>>> >>>> >> >> >> >>>> >>>> Here are the logs (some IPs are changed ) >> >> >> >>>> >>>> >> >> >> >>>> >>>> ov05 is the SPM >> >> >> >>>> >>>> >> >> >> >>>> >>>> Thank You For Your Help ! >> >> >> >>>> >>>> >> >> >> >>>> >>>> On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov >> >> >> >>>> >>><hunter86_bg@yahoo.com> >> >> >> >>>> >>>> wrote: >> >> >> >>>> >>>> >> >> >> >>>> >>>>> Check on the hosts tab , which is your current SPM >> >(last >> >> >> >column in >> >> >> >>>> >>>Admin >> >> >> >>>> >>>>> UI). >> >> >> >>>> >>>>> Then open the /var/log/vdsm/vdsm.log and repeat the >> >> >> >operation. >> >> >> >>>> >>>>> Then provide the log from that host and the engine's >> >log >> >> >(on >> >> >> >the >> >> >> >>>> >>>>> HostedEngine VM or on your standalone engine). >> >> >> >>>> >>>>> >> >> >> >>>> >>>>> Best Regards, >> >> >> >>>> >>>>> Strahil Nikolov >> >> >> >>>> >>>>> >> >> >> >>>> >>>>> На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams >> >> >> >>>> >>><cwilliams3320@gmail.com> >> >> >> >>>> >>>>> написа: >> >> >> >>>> >>>>> >Resending to eliminate email issues >> >> >> >>>> >>>>> > >> >> >> >>>> >>>>> >---------- Forwarded message --------- >> >> >> >>>> >>>>> >From: C Williams <cwilliams3320@gmail.com> >> >> >> >>>> >>>>> >Date: Thu, Jun 18, 2020 at 4:01 PM >> >> >> >>>> >>>>> >Subject: Re: [ovirt-users] Fwd: Issues with Gluster >> >> >Domain >> >> >> >>>> >>>>> >To: Strahil Nikolov <hunter86_bg@yahoo.com> >> >> >> >>>> >>>>> > >> >> >> >>>> >>>>> > >> >> >> >>>> >>>>> >Here is output from mount >> >> >> >>>> >>>>> > >> >> >> >>>> >>>>> >192.168.24.12:/stor/import0 on >> >> >> >>>> >>>>> /rhev/data-center/mnt/192.168.24.12:_stor_import0 >> >> >> >>>> >>>>> >type nfs4 >> >> >> >>>> >>>>> >> >> >> >>>> >>>>> >> >> >> >>>> >> >> >> >>>> >> >> >> >> >> >> >> >> >> >> >> >>
>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12) >> >> >> >>>> >>>>> >192.168.24.13:/stor/import1 on >> >> >> >>>> >>>>> /rhev/data-center/mnt/192.168.24.13:_stor_import1 >> >> >> >>>> >>>>> >type nfs4 >> >> >> >>>> >>>>> >> >> >> >>>> >>>>> >> >> >> >>>> >> >> >> >>>> >> >> >> >> >> >> >> >> >> >> >> >>
>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >> >> >> >>>> >>>>> >192.168.24.13:/stor/iso1 on >> >> >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_iso1 >> >> >> >>>> >>>>> >type nfs4 >> >> >> >>>> >>>>> >> >> >> >>>> >>>>> >> >> >> >>>> >> >> >> >>>> >> >> >> >> >> >> >> >> >> >> >> >>
>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >> >> >> >>>> >>>>> >192.168.24.13:/stor/export0 on >> >> >> >>>> >>>>> /rhev/data-center/mnt/192.168.24.13:_stor_export0 >> >> >> >>>> >>>>> >type nfs4 >> >> >> >>>> >>>>> >> >> >> >>>> >>>>> >> >> >> >>>> >> >> >> >>>> >> >> >> >> >> >> >> >> >> >> >> >>
>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >> >> >> >>>> >>>>> >192.168.24.15:/images on >> >> >> >>>> >>>>> >/rhev/data-center/mnt/glusterSD/192.168.24.15:_images >> >> >> >>>> >>>>> >type fuse.glusterfs >> >> >> >>>> >>>>> >> >> >> >>>> >>>>> >> >> >> >>>> >> >> >> >>>> >> >> >> >> >> >> >> >> >> >> >> >>
>>>>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) >> >> >> >>>> >>>>> >192.168.24.18:/images3 on >> >> >> >>>> >>>>> >/rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 >> >> >> >>>> >>>>> >type fuse.glusterfs >> >> >> >>>> >>>>> >> >> >> >>>> >>>>> >> >> >> >>>> >> >> >> >>>> >> >> >> >> >> >> >> >> >> >> >> >>
>>>>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) >> >> >> >>>> >>>>> >tmpfs on /run/user/0 type tmpfs >> >> >> >>>> >>>>> >> >> >>(rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) >> >> >> >>>> >>>>> >[root@ov06 glusterfs]# >> >> >> >>>> >>>>> > >> >> >> >>>> >>>>> >Also here is a screenshot of the console >> >> >> >>>> >>>>> > >> >> >> >>>> >>>>> >[image: image.png] >> >> >> >>>> >>>>> >The other domains are up >> >> >> >>>> >>>>> > >> >> >> >>>> >>>>> >Import0 and Import1 are NFS . GLCL0 is gluster. They >> >all >> >> >are >> >> >> >>>> >>>running >> >> >> >>>> >>>>> >VMs >> >> >> >>>> >>>>> > >> >> >> >>>> >>>>> >Thank You For Your Help ! >> >> >> >>>> >>>>> > >> >> >> >>>> >>>>> >On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov >> >> >> >>>> >>><hunter86_bg@yahoo.com> >> >> >> >>>> >>>>> >wrote: >> >> >> >>>> >>>>> > >> >> >> >>>> >>>>> >> I don't see >> >> >> >'/rhev/data-center/mnt/192.168.24.13:_stor_import1' >> >> >> >>>> >>>>> >mounted >> >> >> >>>> >>>>> >> at all . >> >> >> >>>> >>>>> >> What is the status of all storage domains ? >> >> >> >>>> >>>>> >> >> >> >> >>>> >>>>> >> Best Regards, >> >> >> >>>> >>>>> >> Strahil Nikolov >> >> >> >>>> >>>>> >> >> >> >> >>>> >>>>> >> На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams >> >> >> >>>> >>>>> ><cwilliams3320@gmail.com> >> >> >> >>>> >>>>> >> написа: >> >> >> >>>> >>>>> >> > Resending to deal with possible email issues >> >> >> >>>> >>>>> >> > >> >> >> >>>> >>>>> >> >---------- Forwarded message --------- >> >> >> >>>> >>>>> >> >From: C Williams <cwilliams3320@gmail.com> >> >> >> >>>> >>>>> >> >Date: Thu, Jun 18, 2020 at 2:07 PM >> >> >> >>>> >>>>> >> >Subject: Re: [ovirt-users] Issues with Gluster >> >Domain >> >> >> >>>> >>>>> >> >To: Strahil Nikolov <hunter86_bg@yahoo.com> >> >> >> >>>> >>>>> >> > >> >> >> >>>> >>>>> >> > >> >> >> >>>> >>>>> >> >More >> >> >> >>>> >>>>> >> > >> >> >> >>>> >>>>> >> >[root@ov06 ~]# for i in $(gluster volume list); do >> >> >echo >> >> >> >>>> >>>$i;echo; >> >> >> >>>> >>>>> >> >gluster >> >> >> >>>> >>>>> >> >volume info $i; echo;echo;gluster volume status >> >> >> >>>> >>>>> >$i;echo;echo;echo;done >> >> >> >>>> >>>>> >> >images3 >> >> >> >>>> >>>>> >> > >> >> >> >>>> >>>>> >> > >> >> >> >>>> >>>>> >> >Volume Name: images3 >> >> >> >>>> >>>>> >> >Type: Replicate >> >> >> >>>> >>>>> >> >Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b >> >> >> >>>> >>>>> >> >Status: Started >> >> >> >>>> >>>>> >> >Snapshot Count: 0 >> >> >> >>>> >>>>> >> >Number of Bricks: 1 x 3 = 3 >> >> >> >>>> >>>>> >> >Transport-type: tcp >> >> >> >>>> >>>>> >> >Bricks: >> >> >> >>>> >>>>> >> >Brick1: 192.168.24.18:/bricks/brick04/images3 >> >> >> >>>> >>>>> >> >Brick2: 192.168.24.19:/bricks/brick05/images3 >> >> >> >>>> >>>>> >> >Brick3: 192.168.24.20:/bricks/brick06/images3 >> >> >> >>>> >>>>> >> >Options Reconfigured: >> >> >> >>>> >>>>> >> >performance.client-io-threads: on >> >> >> >>>> >>>>> >> >nfs.disable: on >> >> >> >>>> >>>>> >> >transport.address-family: inet >> >> >> >>>> >>>>> >> >user.cifs: off >> >> >> >>>> >>>>> >> >auth.allow: * >> >> >> >>>> >>>>> >> >performance.quick-read: off >> >> >> >>>> >>>>> >> >performance.read-ahead: off >> >> >> >>>> >>>>> >> >performance.io-cache: off >> >> >> >>>> >>>>> >> >performance.low-prio-threads: 32 >> >> >> >>>> >>>>> >> >network.remote-dio: off >> >> >> >>>> >>>>> >> >cluster.eager-lock: enable >> >> >> >>>> >>>>> >> >cluster.quorum-type: auto >> >> >> >>>> >>>>> >> >cluster.server-quorum-type: server >> >> >> >>>> >>>>> >> >cluster.data-self-heal-algorithm: full >> >> >> >>>> >>>>> >> >cluster.locking-scheme: granular >> >> >> >>>> >>>>> >> >cluster.shd-max-threads: 8 >> >> >> >>>> >>>>> >> >cluster.shd-wait-qlength: 10000 >> >> >> >>>> >>>>> >> >features.shard: on >> >> >> >>>> >>>>> >> >cluster.choose-local: off >> >> >> >>>> >>>>> >> >client.event-threads: 4 >> >> >> >>>> >>>>> >> >server.event-threads: 4 >> >> >> >>>> >>>>> >> >storage.owner-uid: 36 >> >> >> >>>> >>>>> >> >storage.owner-gid: 36 >> >> >> >>>> >>>>> >> >performance.strict-o-direct: on >> >> >> >>>> >>>>> >> >network.ping-timeout: 30 >> >> >> >>>> >>>>> >> >cluster.granular-entry-heal: enable >> >> >> >>>> >>>>> >> > >> >> >> >>>> >>>>> >> > >> >> >> >>>> >>>>> >> >Status of volume: images3 >> >> >> >>>> >>>>> >> >Gluster process TCP >> >Port >> >> >> >RDMA Port >> >> >> >>>> >>>>> >Online >> >> >> >>>> >>>>> >> > Pid >> >> >> >>>> >>>>> >> >> >> >> >>>> >>>>> >> >> >> >> >>>> >>>>> >> >> >> >>>> >>>>> >> >> >> >>>> >> >> >> >>>> >> >> >> >> >> >> >> >> >> >> >> >>
>>>>>>>------------------------------------------------------------------------------ >> >> >> >>>> >>>>> >> >Brick 192.168.24.18:/bricks/brick04/images3 49152 >> >> >0 >> >> >> >>>> >> >> >> >>>> >>>Y >> >> >> >>>> >>>>> >> >6666 >> >> >> >>>> >>>>> >> >Brick 192.168.24.19:/bricks/brick05/images3 49152 >> >> >0 >> >> >> >>>> >> >> >> >>>> >>>Y >> >> >> >>>> >>>>> >> >6779 >> >> >> >>>> >>>>> >> >Brick 192.168.24.20:/bricks/brick06/images3 49152 >> >> >0 >> >> >> >>>> >> >> >> >>>> >>>Y >> >> >> >>>> >>>>> >> >7227 >> >> >> >>>> >>>>> >> >Self-heal Daemon on localhost N/A >> >> >N/A >> >> >> >>>> >> >> >> >>>> >>>Y >> >> >> >>>> >>>>> >> >6689 >> >> >> >>>> >>>>> >> >Self-heal Daemon on ov07.ntc.srcle.com N/A >> >> >N/A >> >> >> >>>> >> >> >> >>>> >>>Y >> >> >> >>>> >>>>> >> >6802 >> >> >> >>>> >>>>> >> >Self-heal Daemon on ov08.ntc.srcle.com N/A >> >> >N/A >> >> >> >>>> >> >> >> >>>> >>>Y >> >> >> >>>> >>>>> >> >7250 >> >> >> >>>> >>>>> >> > >> >> >> >>>> >>>>> >> >Task Status of Volume images3 >> >> >> >>>> >>>>> >> >> >> >> >>>> >>>>> >> >> >> >> >>>> >>>>> >> >> >> >>>> >>>>> >> >> >> >>>> >> >> >> >>>> >> >> >> >> >> >> >> >> >> >> >> >>
>>>>>>>------------------------------------------------------------------------------ >> >> >> >>>> >>>>> >> >There are no active volume tasks >> >> >> >>>> >>>>> >> > >> >> >> >>>> >>>>> >> > >> >> >> >>>> >>>>> >> > >> >> >> >>>> >>>>> >> > >> >> >> >>>> >>>>> >> >[root@ov06 ~]# ls -l >> >/rhev/data-center/mnt/glusterSD/ >> >> >> >>>> >>>>> >> >total 16 >> >> >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 >> >> >> >192.168.24.15:_images >> >> >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 >> >> >192.168.24.18: >> >> >> >>>> _images3 >> >> >> >>>> >>>>> >> >[root@ov06 ~]# >> >> >> >>>> >>>>> >> > >> >> >> >>>> >>>>> >> >On Thu, Jun 18, 2020 at 2:03 PM C Williams >> >> >> >>>> >>><cwilliams3320@gmail.com> >> >> >> >>>> >>>>> >> >wrote: >> >> >> >>>> >>>>> >> > >> >> >> >>>> >>>>> >> >> Strahil, >> >> >> >>>> >>>>> >> >> >> >> >> >>>> >>>>> >> >> Here you go -- Thank You For Your Help ! >> >> >> >>>> >>>>> >> >> >> >> >> >>>> >>>>> >> >> BTW -- I can write a test file to gluster and it >> >> >> >replicates >> >> >> >>>> >>>>> >properly. >> >> >> >>>> >>>>> >> >> Thinking something about the oVirt Storage Domain >> >? >> >> >> >>>> >>>>> >> >> >> >> >> >>>> >>>>> >> >> [root@ov08 ~]# gluster pool list >> >> >> >>>> >>>>> >> >> UUID Hostname >> >> >> >>>> >>>>> >State >> >> >> >>>> >>>>> >> >> 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06 >> >> >> >>>> >>>>> >> >Connected >> >> >> >>>> >>>>> >> >> 36ce5a00-6f65-4926-8438-696944ebadb5 >> >> >> >ov07.ntc.srcle.com >> >> >> >>>> >>>>> >> >Connected >> >> >> >>>> >>>>> >> >> c7e7abdb-a8f4-4842-924c-e227f0db1b29 localhost >> >> >> >>>> >>>>> >> >Connected >> >> >> >>>> >>>>> >> >> [root@ov08 ~]# gluster volume list >> >> >> >>>> >>>>> >> >> images3 >> >> >> >>>> >>>>> >> >> >> >> >> >>>> >>>>> >> >> On Thu, Jun 18, 2020 at 1:13 PM Strahil Nikolov >> >> >> >>>> >>>>> >> ><hunter86_bg@yahoo.com> >> >> >> >>>> >>>>> >> >> wrote: >> >> >> >>>> >>>>> >> >> >> >> >> >>>> >>>>> >> >>> Log to the oVirt cluster and provide the output >> >of: >> >> >> >>>> >>>>> >> >>> gluster pool list >> >> >> >>>> >>>>> >> >>> gluster volume list >> >> >> >>>> >>>>> >> >>> for i in $(gluster volume list); do echo >> >$i;echo; >> >> >> >gluster >> >> >> >>>> >>>>> >volume >> >> >> >>>> >>>>> >> >info >> >> >> >>>> >>>>> >> >>> $i; echo;echo;gluster volume status >> >> >> >$i;echo;echo;echo;done >> >> >> >>>> >>>>> >> >>> >> >> >> >>>> >>>>> >> >>> ls -l /rhev/data-center/mnt/glusterSD/ >> >> >> >>>> >>>>> >> >>> >> >> >> >>>> >>>>> >> >>> Best Regards, >> >> >> >>>> >>>>> >> >>> Strahil Nikolov >> >> >> >>>> >>>>> >> >>> >> >> >> >>>> >>>>> >> >>> >> >> >> >>>> >>>>> >> >>> На 18 юни 2020 г. 19:17:46 GMT+03:00, C Williams >> >> >> >>>> >>>>> >> ><cwilliams3320@gmail.com> >> >> >> >>>> >>>>> >> >>> написа: >> >> >> >>>> >>>>> >> >>> >Hello, >> >> >> >>>> >>>>> >> >>> > >> >> >> >>>> >>>>> >> >>> >I recently added 6 hosts to an existing oVirt >> >> >> >>>> >>>compute/gluster >> >> >> >>>> >>>>> >> >cluster. >> >> >> >>>> >>>>> >> >>> > >> >> >> >>>> >>>>> >> >>> >Prior to this attempted addition, my cluster >> >had 3 >> >> >> >>>> >>>Hypervisor >> >> >> >>>> >>>>> >hosts >> >> >> >>>> >>>>> >> >and >> >> >> >>>> >>>>> >> >>> >3 >> >> >> >>>> >>>>> >> >>> >gluster bricks which made up a single gluster >> >> >volume >> >> >> >>>> >>>(replica 3 >> >> >> >>>> >>>>> >> >volume) >> >> >> >>>> >>>>> >> >>> >. I >> >> >> >>>> >>>>> >> >>> >added the additional hosts and made a brick on >> >3 >> >> >of >> >> >> >the new >> >> >> >>>> >>>>> >hosts >> >> >> >>>> >>>>> >> >and >> >> >> >>>> >>>>> >> >>> >attempted to make a new replica 3 volume. I had >> >> >> >difficulty >> >> >> >>>> >>>>> >> >creating >> >> >> >>>> >>>>> >> >>> >the >> >> >> >>>> >>>>> >> >>> >new volume. So, I decided that I would make a >> >new >> >> >> >>>> >>>>> >compute/gluster >> >> >> >>>> >>>>> >> >>> >cluster >> >> >> >>>> >>>>> >> >>> >for each set of 3 new hosts. >> >> >> >>>> >>>>> >> >>> > >> >> >> >>>> >>>>> >> >>> >I removed the 6 new hosts from the existing >> >oVirt >> >> >> >>>> >>>>> >Compute/Gluster >> >> >> >>>> >>>>> >> >>> >Cluster >> >> >> >>>> >>>>> >> >>> >leaving the 3 original hosts in place with >> >their >> >> >> >bricks. At >> >> >> >>>> >>>that >> >> >> >>>> >>>>> >> >point >> >> >> >>>> >>>>> >> >>> >my >> >> >> >>>> >>>>> >> >>> >original bricks went down and came back up . >> >The >> >> >> >volume >> >> >> >>>> >>>showed >> >> >> >>>> >>>>> >> >entries >> >> >> >>>> >>>>> >> >>> >that >> >> >> >>>> >>>>> >> >>> >needed healing. At that point I ran gluster >> >volume >> >> >> >heal >> >> >> >>>> >>>images3 >> >> >> >>>> >>>>> >> >full, >> >> >> >>>> >>>>> >> >>> >etc. >> >> >> >>>> >>>>> >> >>> >The volume shows no unhealed entries. I also >> >> >> >corrected some >> >> >> >>>> >>>peer >> >> >> >>>> >>>>> >> >>> >errors. >> >> >> >>>> >>>>> >> >>> > >> >> >> >>>> >>>>> >> >>> >However, I am unable to copy disks, move disks >> >to >> >> >> >another >> >> >> >>>> >>>>> >domain, >> >> >> >>>> >>>>> >> >>> >export >> >> >> >>>> >>>>> >> >>> >disks, etc. It appears that the engine cannot >> >> >locate >> >> >> >disks >> >> >> >>>> >>>>> >properly >> >> >> >>>> >>>>> >> >and >> >> >> >>>> >>>>> >> >>> >I >> >> >> >>>> >>>>> >> >>> >get storage I/O errors. >> >> >> >>>> >>>>> >> >>> > >> >> >> >>>> >>>>> >> >>> >I have detached and removed the oVirt Storage >> >> >Domain. >> >> >> >I >> >> >> >>>> >>>>> >reimported >> >> >> >>>> >>>>> >> >the >> >> >> >>>> >>>>> >> >>> >domain and imported 2 VMs, But the VM disks >> >> >exhibit >> >> >> >the >> >> >> >>>> same >> >> >> >>>> >>>>> >> >behaviour >> >> >> >>>> >>>>> >> >>> >and >> >> >> >>>> >>>>> >> >>> >won't run from the hard disk. >> >> >> >>>> >>>>> >> >>> > >> >> >> >>>> >>>>> >> >>> > >> >> >> >>>> >>>>> >> >>> >I get errors such as this >> >> >> >>>> >>>>> >> >>> > >> >> >> >>>> >>>>> >> >>> >VDSM ov05 command HSMGetAllTasksStatusesVDS >> >> >failed: >> >> >> >low >> >> >> >>>> >>>level >> >> >> >>>> >>>>> >Image >> >> >> >>>> >>>>> >> >>> >copy >> >> >> >>>> >>>>> >> >>> >failed: ("Command ['/usr/bin/qemu-img', >> >'convert', >> >> >> >'-p', >> >> >> >>>> >>>'-t', >> >> >> >>>> >>>>> >> >'none', >> >> >> >>>> >>>>> >> >>> >'-T', 'none', '-f', 'raw', >> >> >> >>>> >>>>> >> >>> >> >>u'/rhev/data-center/mnt/glusterSD/192.168.24.18: >> >> >> >>>> >>>>> >> >>> >> >> >> >>>> >>>>> >> >> >> >> >>>> >>>>> >> >> >> >> >>>> >>>>> >> >> >> >>>> >>>>> >> >> >> >>>> >> >> >> >>>> >> >> >> >> >> >> >> >> >> >> >> >>
>>>>>>>_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510', >> >> >> >>>> >>>>> >> >>> >'-O', 'raw', >> >> >> >>>> >>>>> >> >>> >u'/rhev/data-center/mnt/192.168.24.13: >> >> >> >>>> >>>>> >> >>> >> >> >> >>>> >>>>> >> >> >> >> >>>> >>>>> >> >> >> >> >>>> >>>>> >> >> >> >>>> >>>>> >> >> >> >>>> >> >> >> >>>> >> >> >> >> >> >> >> >> >> >> >> >>
>>>>>>>_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5'] >> >> >> >>>> >>>>> >> >>> >failed with rc=1 out='' >> >err=bytearray(b'qemu-img: >> >> >> >error >> >> >> >>>> >>>while >> >> >> >>>> >>>>> >> >reading >> >> >> >>>> >>>>> >> >>> >sector 135168: Transport endpoint is not >> >> >> >>>> >>>connected\\nqemu-img: >> >> >> >>>> >>>>> >> >error >> >> >> >>>> >>>>> >> >>> >while >> >> >> >>>> >>>>> >> >>> >reading sector 131072: Transport endpoint is >> >not >> >> >> >>>> >>>>> >> >connected\\nqemu-img: >> >> >> >>>> >>>>> >> >>> >error while reading sector 139264: Transport >> >> >endpoint >> >> >> >is >> >> >> >>>> not >> >> >> >>>> >>>>> >> >>> >connected\\nqemu-img: error while reading >> >sector >> >> >> >143360: >> >> >> >>>> >>>>> >Transport >> >> >> >>>> >>>>> >> >>> >endpoint >> >> >> >>>> >>>>> >> >>> >is not connected\\nqemu-img: error while >> >reading >> >> >> >sector >> >> >> >>>> >>>147456: >> >> >> >>>> >>>>> >> >>> >Transport >> >> >> >>>> >>>>> >> >>> >endpoint is not connected\\nqemu-img: error >> >while >> >> >> >reading >> >> >> >>>> >>>sector >> >> >> >>>> >>>>> >> >>> >155648: >> >> >> >>>> >>>>> >> >>> >Transport endpoint is not connected\\nqemu-img: >> >> >error >> >> >> >while >> >> >> >>>> >>>>> >reading >> >> >> >>>> >>>>> >> >>> >sector >> >> >> >>>> >>>>> >> >>> >151552: Transport endpoint is not >> >> >> >connected\\nqemu-img: >> >> >> >>>> >>>error >> >> >> >>>> >>>>> >while >> >> >> >>>> >>>>> >> >>> >reading >> >> >> >>>> >>>>> >> >>> >sector 159744: Transport endpoint is not >> >> >> >connected\\n')",) >> >> >> >>>> >>>>> >> >>> > >> >> >> >>>> >>>>> >> >>> >oVirt version is 4.3.82-1.el7 >> >> >> >>>> >>>>> >> >>> >OS CentOS Linux release 7.7.1908 (Core) >> >> >> >>>> >>>>> >> >>> > >> >> >> >>>> >>>>> >> >>> >The Gluster Cluster has been working very well >> >> >until >> >> >> >this >> >> >> >>>> >>>>> >incident. >> >> >> >>>> >>>>> >> >>> > >> >> >> >>>> >>>>> >> >>> >Please help. >> >> >> >>>> >>>>> >> >>> > >> >> >> >>>> >>>>> >> >>> >Thank You >> >> >> >>>> >>>>> >> >>> > >> >> >> >>>> >>>>> >> >>> >Charles Williams >> >> >> >>>> >>>>> >> >>> >> >> >> >>>> >>>>> >> >> >> >> >> >>>> >>>>> >> >> >> >> >>>> >>>>> >> >> >> >>>> >>>> >> >> >> >>>> >> >> >> >> >>>> > >> >> >> >>>> _______________________________________________ >> >> >> >>>> Users mailing list -- users@ovirt.org >> >> >> >>>> To unsubscribe send an email to users-leave@ovirt.org >> >> >> >>>> Privacy Statement: https://www.ovirt.org/privacy-policy.html >> >> >> >>>> oVirt Code of Conduct: >> >> >> >>>> https://www.ovirt.org/community/about/community-guidelines/ >> >> >> >>>> List Archives: >> >> >> >>>> >> >> >> > >> >> >> >> >> > >> >> >> > >>
https://lists.ovirt.org/archives/list/users@ovirt.org/message/YY3VUKEJLI7MRW...
>> >> >> >>>> >> >> >> >>> >> >> >> >> >> >> >
As I told you, you could just downgrade gluster on all nodes and later plan to live migrate the VM disks. I had to copy my data to the new volume, so I can avoid the ACL bug , when I use newer versions of gluster. Let's clarify some details: 1. Which version of oVirt and Gluster are you using ? 2. You now have your old gluster volume attached to oVirt and the new volume unused, right ? 3. Did you copy the contents of the old volume to the new one ? Best Regards, Strahil Nikolov На 23 юни 2020 г. 4:34:19 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Strahil,
Thank You For Help !
Downgrading Gluster to 6.5 got the original storage domain working again !
After, I finished my copy of the contents of the problematic volume to a new volume, I did the following
Unmounted the mount points Stopped the original problematic Gluster volume On each problematic peer, I downgraded Gluster to 6.5 (yum downgrade glusterfs-6.5-1.el7.x86_64 vdsm-gluster-4.30.46-1.el7.x86_64 python2-gluster-6.5-1.el7.x86_64 glusterfs-libs-6.5-1.el7.x86_64 glusterfs-cli-6.5-1.el7.x86_64 glusterfs-fuse-6.5-1.el7.x86_64 glusterfs-rdma-6.5-1.el7.x86_64 glusterfs-api-6.5-1.el7.x86_64 glusterfs-server-6.5-1.el7.x86_64 glusterfs-events-6.5-1.el7.x86_64 glusterfs-client-xlators-6.5-1.el7.x86_64 glusterfs-geo-replication-6.5-1.el7.x86_64) Restarted glusterd (systemctl restart glusterd) Restarted the problematic Gluster volume Reattached the problematic storage domain Started the problematic storage domain
Things work now. I can now run VMs and write data, copy virtual disks, move virtual disks to other storage domains, etc.
I am very thankful that the storage domain is working again !
How can I safely perform upgrades on Gluster ! When will it be safe to do so ?
Thank You Again For Your Help !
On Mon, Jun 22, 2020 at 10:58 AM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
I have downgraded the target. The copy from the problematic volume to the target is going on now. Once I have the data copied, I might downgrade the problematic volume's Gluster to 6.5. At that point I might reattach the original ovirt domain and see if it will work again. But the copy is going on right now.
Thank You For Your Help !
On Mon, Jun 22, 2020 at 10:52 AM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
You should ensure that in the storage domain tab, the old storage is not visible.
I still wander why yoiu didn't try to downgrade first.
Best Regards, Strahil Nikolov
Strahil,
The GLCL3 storage domain was detached prior to attempting to add
new storage domain.
Should I also "Remove" it ?
Thank You For Your Help !
---------- Forwarded message --------- From: Strahil Nikolov <hunter86_bg@yahoo.com> Date: Mon, Jun 22, 2020 at 12:50 AM Subject: Re: [ovirt-users] Re: Fwd: Fwd: Issues with Gluster Domain To: C Williams <cwilliams3320@gmail.com> Cc: users <Users@ovirt.org>
You can't add the new volume as it contains the same data (UUID) as
На 22 юни 2020 г. 13:58:33 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: the the
old one , thus you need to detach the old one before adding the new one
of course this means downtime for all VMs on that storage.
As you see , downgrading is more simpler. For me v6.5 was working, while anything above (6.6+) was causing complete lockdown. Also v7.0 was working, but it's supported in oVirt 4.4.
Best Regards, Strahil Nikolov
Another question
What version could I downgrade to safely ? I am at 6.9 .
Thank You For Your Help !!
On Sun, Jun 21, 2020 at 11:38 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
You are definitely reading it wrong. 1. I didn't create a new storage domain ontop this new volume. 2. I used cli
Something like this (in your case it should be 'replica 3'): gluster volume create newvol replica 3 arbiter 1 ovirt1:/new/brick/path ovirt2:/new/brick/path ovirt3:/new/arbiter/brick/path gluster volume start newvol
#Detach oldvol from ovirt
mount -t glusterfs ovirt1:/oldvol /mnt/oldvol mount -t glusterfs ovirt1:/newvol /mnt/newvol cp -a /mnt/oldvol/* /mnt/newvol
#Add only newvol as a storage domain in oVirt #Import VMs
I still think that you should downgrade your gluster packages!!!
Best Regards, Strahil Nikolov
На 22 юни 2020 г. 0:43:46 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: >Strahil, > >It sounds like you used a "System Managed Volume" for the new storage >domain,is that correct? > >Thank You For Your Help ! > >On Sun, Jun 21, 2020 at 5:40 PM C Williams <cwilliams3320@gmail.com> >wrote: > >> Strahil, >> >> So you made another oVirt Storage Domain -- then copied the data with >cp >> -a from the failed volume to the new volume. >> >> At the root of the volume there will be the old domain folder id ex >> 5fe3ad3f-2d21-404c-832e-4dc7318ca10d >> in my case. Did that cause issues with making the new domain since >it is >> the same folder id as the old one ? >> >> Thank You For Your Help ! >> >> On Sun, Jun 21, 2020 at 5:18 PM Strahil Nikolov ><hunter86_bg@yahoo.com> >> wrote: >> >>> In my situation I had only the ovirt nodes. >>> >>> На 21 юни 2020 г. 22:43:04 GMT+03:00, C Williams ><cwilliams3320@gmail.com> >>> написа: >>> >Strahil, >>> > >>> >So should I make the target volume on 3 bricks which do not have >ovirt >>> >-- >>> >just gluster ? In other words (3) Centos 7 hosts ? >>> > >>> >Thank You For Your Help ! >>> > >>> >On Sun, Jun 21, 2020 at 3:08 PM Strahil Nikolov ><hunter86_bg@yahoo.com> >>> >wrote: >>> > >>> >> I created a fresh volume (which is not an ovirt sgorage >domain), >>> >set >>> >> the original storage domain in maintenance and detached it. >>> >> Then I 'cp -a ' the data from the old to the new volume. Next, >I >>> >just >>> >> added the new storage domain (the old one was a kind of a >>> >> 'backup') - pointing to the new volume name. >>> >> >>> >> If you observe issues , I would recommend you to downgrade >>> >> gluster packages one node at a time . Then you might be able >to >>> >> restore your oVirt operations. >>> >> >>> >> Best Regards, >>> >> Strahil Nikolov >>> >> >>> >> На 21 юни 2020 г. 18:01:31 GMT+03:00, C Williams >>> ><cwilliams3320@gmail.com> >>> >> написа: >>> >> >Strahil, >>> >> > >>> >> >Thanks for the follow up ! >>> >> > >>> >> >How did you copy the data to another volume ? >>> >> > >>> >> >I have set up another storage domain GLCLNEW1 with a new volume >>> >imgnew1 >>> >> >. >>> >> >How would you copy all of the data from the problematic domain >GLCL3 >>> >> >with >>> >> >volume images3 to GLCLNEW1 and volume imgnew1 and
all
>the >>> >VMs, >>> >> >VM >>> >> >disks, settings, etc. ? >>> >> > >>> >> >Remember all of the regular ovirt disk copy, disk move, VM >export >>> >> >tools >>> >> >are failing and my VMs and disks are trapped on domain GLCL3 and >>> >volume >>> >> >images3 right now. >>> >> > >>> >> >Please let me know >>> >> > >>> >> >Thank You For Your Help ! >>> >> > >>> >> > >>> >> > >>> >> > >>> >> > >>> >> >On Sun, Jun 21, 2020 at 8:27 AM Strahil Nikolov >>> ><hunter86_bg@yahoo.com> >>> >> >wrote: >>> >> > >>> >> >> Sorry to hear that. >>> >> >> I can say that for me 6.5 was working, while 6.6 didn't >and I >>> >> >upgraded >>> >> >> to 7.0 . >>> >> >> In the ended , I have ended with creating a new fresh >volume >>> >and >>> >> >> physically copying the data there, then I detached
>storage >>> >> >domains and >>> >> >> attached to the new ones (which holded the old data), but >I >>> >> >could >>> >> >> afford the downtime. >>> >> >> Also, I can say that v7.0 ( but not 7.1 or anything later) >>> >also >>> >> >> worked without the ACL issue, but it causes some
На 22 юни 2020 г. 7:21:15 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: preserve the trouble
>in >>> >oVirt >>> >> >- so >>> >> >> avoid that unless you have no other options. >>> >> >> >>> >> >> Best Regards, >>> >> >> Strahil Nikolov >>> >> >> >>> >> >> >>> >> >> >>> >> >> >>> >> >> На 21 юни 2020 г. 4:39:46 GMT+03:00, C Williams >>> >> ><cwilliams3320@gmail.com> >>> >> >> написа: >>> >> >> >Hello, >>> >> >> > >>> >> >> >Upgrading diidn't help >>> >> >> > >>> >> >> >Still acl errors trying to use a Virtual Disk from a VM >>> >> >> > >>> >> >> >[root@ov06 bricks]# tail bricks-brick04-images3.log | grep >acl >>> >> >> >[2020-06-21 01:33:45.665888] I [MSGID: 139001] >>> >> >> >[posix-acl.c:263:posix_acl_log_permit_denied] >>> >> >0-images3-access-control: >>> >> >> >client: >>> >> >> >>> >> >> >>> >> >>> >> >>> >>>
>CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0, >>> >> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >>> >> >> >req(uid:107,gid:107,perm:1,ngrps:3), >>> >> >> ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, >acl:-) >>> >> >> >[Permission denied] >>> >> >> >The message "I [MSGID: 139001] >>> >> >> >[posix-acl.c:263:posix_acl_log_permit_denied] >>> >> >0-images3-access-control: >>> >> >> >client: >>> >> >> >>> >> >> >>> >> >>> >> >>> >>>
>CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0, >>> >> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >>> >> >> >req(uid:107,gid:107,perm:1,ngrps:3), >>> >> >> ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, >acl:-) >>> >> >> >[Permission denied]" repeated 2 times between [2020-06-21 >>> >> >> >01:33:45.665888] >>> >> >> >and [2020-06-21 01:33:45.806779] >>> >> >> > >>> >> >> >Thank You For Your Help ! >>> >> >> > >>> >> >> >On Sat, Jun 20, 2020 at 8:59 PM C Williams >>> ><cwilliams3320@gmail.com> >>> >> >> >wrote: >>> >> >> > >>> >> >> >> Hello, >>> >> >> >> >>> >> >> >> Based on the situation, I am planning to upgrade the 3 >affected >>> >> >> >hosts. >>> >> >> >> >>> >> >> >> My reasoning is that the hosts/bricks were attached to 6.9 >at >>> >one >>> >> >> >time. >>> >> >> >> >>> >> >> >> Thanks For Your Help ! >>> >> >> >> >>> >> >> >> On Sat, Jun 20, 2020 at 8:38 PM C Williams >>> >> ><cwilliams3320@gmail.com> >>> >> >> >> wrote: >>> >> >> >> >>> >> >> >>> Strahil, >>> >> >> >>> >>> >> >> >>> The gluster version on the current 3 gluster hosts is 6.7 >>> >(last >>> >> >> >update >>> >> >> >>> 2/26). These 3 hosts provide 1 brick each for the replica >3 >>> >> >volume. >>> >> >> >>> >>> >> >> >>> Earlier I had tried to add 6 additional hosts to the >cluster. >>> >> >Those >>> >> >> >new >>> >> >> >>> hosts were 6.9 gluster. >>> >> >> >>> >>> >> >> >>> I attempted to make a new separate volume with 3 bricks >>> >provided >>> >> >by >>> >> >> >the 3 >>> >> >> >>> new gluster 6.9 hosts. After having many errors from the >>> >oVirt >>> >> >> >interface, >>> >> >> >>> I gave up and removed the 6 new hosts from the cluster. >That >>> >is >>> >> >> >where the >>> >> >> >>> problems started. The intent was to expand the gluster >cluster >>> >> >while >>> >> >> >making >>> >> >> >>> 2 new volumes for that cluster. The ovirt compute cluster >>> >would >>> >> >> >allow for >>> >> >> >>> efficient VM migration between 9 hosts -- while having >>> >separate >>> >> >> >gluster >>> >> >> >>> volumes for safety purposes. >>> >> >> >>> >>> >> >> >>> Looking at the brick logs, I see where there are acl >errors >>> >> >starting >>> >> >> >from >>> >> >> >>> the time of the removal of the 6 new hosts. >>> >> >> >>> >>> >> >> >>> Please check out the attached brick log from 6/14-18. The >>> >events >>> >> >> >started >>> >> >> >>> on 6/17. >>> >> >> >>> >>> >> >> >>> I wish I had a downgrade path. >>> >> >> >>> >>> >> >> >>> Thank You For The Help !! >>> >> >> >>> >>> >> >> >>> On Sat, Jun 20, 2020 at 7:47 PM Strahil Nikolov >>> >> >> ><hunter86_bg@yahoo.com> >>> >> >> >>> wrote: >>> >> >> >>> >>> >> >> >>>> Hi , >>> >> >> >>>> >>> >> >> >>>> >>> >> >> >>>> This one really looks like the ACL bug I was hit with >when I >>> >> >> >updated >>> >> >> >>>> from Gluster v6.5 to 6.6 and later from 7.0 to 7.2. >>> >> >> >>>> >>> >> >> >>>> Did you update your setup recently ? Did you upgrade >gluster >>> >> >also ? >>> >> >> >>>> >>> >> >> >>>> You have to check the gluster logs in order to verify >that, >>> >so >>> >> >you >>> >> >> >can >>> >> >> >>>> try: >>> >> >> >>>> >>> >> >> >>>> 1. Set Gluster logs to trace level (for details check: >>> >> >> >>>> >>> >> >> > >>> >> >> >>> >> > >>> >> >>> > >>> >
>>> >> >> >>>> ) >>> >> >> >>>> 2. Power up a VM that was already off , or retry
>>> >procedure >>> >> >from >>> >> >> >the >>> >> >> >>>> logs you sent. >>> >> >> >>>> 3. Stop the trace level of the logs >>> >> >> >>>> 4. Check libvirt logs on the host that was supposed to >power >>> >up >>> >> >the >>> >> >> >VM >>> >> >> >>>> (in case a VM was powered on) >>> >> >> >>>> 5. Check the gluster brick logs on all nodes for ACL >errors. >>> >> >> >>>> Here is a sample from my old logs: >>> >> >> >>>> >>> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 >>> >> >> >13:19:41.489047] I >>> >> >> >>>> [MSGID: 139001] >[posix-acl.c:262:posix_acl_log_permit_denied] >>> >> >> >>>> 0-data_fast4-access-control: client: >CTX_ID:4a654305-d2e4- >>> >> >> >>>> >>> >> >> >>> >> >> >>> >> >>> >> >>> >>>
>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, >>> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >>> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx >>> >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, >acl:-) >>> >> >> >>>> [Permission denied] >>> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 >>> >> >> >13:22:51.818796] I >>> >> >> >>>> [MSGID: 139001] >[posix-acl.c:262:posix_acl_log_permit_denied] >>> >> >> >>>> 0-data_fast4-access-control: client: >CTX_ID:4a654305-d2e4- >>> >> >> >>>> >>> >> >> >>> >> >> >>> >> >>> >> >>> >>>
>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, >>> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >>> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx >>> >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, >acl:-) >>> >> >> >>>> [Permission denied] >>> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 >>> >> >> >13:24:43.732856] I >>> >> >> >>>> [MSGID: 139001] >[posix-acl.c:262:posix_acl_log_permit_denied] >>> >> >> >>>> 0-data_fast4-access-control: client: >CTX_ID:4a654305-d2e4- >>> >> >> >>>> >>> >> >> >>> >> >> >>> >> >>> >> >>> >>>
>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, >>> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >>> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx >>> >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, >acl:-) >>> >> >> >>>> [Permission denied] >>> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 >>> >> >> >13:26:50.758178] I >>> >> >> >>>> [MSGID: 139001] >[posix-acl.c:262:posix_acl_log_permit_denied] >>> >> >> >>>> 0-data_fast4-access-control: client: >CTX_ID:4a654305-d2e4- >>> >> >> >>>> >>> >> >> >>> >> >> >>> >> >>> >> >>> >>>
>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, >>> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >>> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx >>> >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, >acl:-) >>> >> >> >>>> [Permission denied] >>> >> >> >>>> >>> >> >> >>>> >>> >> >> >>>> In my case , the workaround was to downgrade the gluster >>> >> >packages >>> >> >> >on all >>> >> >> >>>> nodes (and reboot each node 1 by 1 ) if the major version >is >>> >the >>> >> >> >same, but >>> >> >> >>>> if you upgraded to v7.X - then you can try the v7.0 . >>> >> >> >>>> >>> >> >> >>>> Best Regards, >>> >> >> >>>> Strahil Nikolov >>> >> >> >>>> >>> >> >> >>>> >>> >> >> >>>> >>> >> >> >>>> >>> >> >> >>>> >>> >> >> >>>> >>> >> >> >>>> В събота, 20 юни 2020 г., 18:48:42 ч. Гринуич+3, C >Williams < >>> >> >> >>>> cwilliams3320@gmail.com> написа: >>> >> >> >>>> >>> >> >> >>>> >>> >> >> >>>> >>> >> >> >>>> >>> >> >> >>>> >>> >> >> >>>> Hello, >>> >> >> >>>> >>> >> >> >>>> Here are additional log tiles as well as a tree of the >>> >> >problematic >>> >> >> >>>> Gluster storage domain. During this time I attempted to >copy >>> >a >>> >> >> >virtual disk >>> >> >> >>>> to another domain, move a virtual disk to another domain >and >>> >run >>> >> >a >>> >> >> >VM where >>> >> >> >>>> the virtual hard disk would be used. >>> >> >> >>>> >>> >> >> >>>> The copies/moves failed and the VM went into
mode
>when >>> >the >>> >> >> >virtual >>> >> >> >>>> HDD was involved. >>> >> >> >>>> >>> >> >> >>>> Please check these out. >>> >> >> >>>> >>> >> >> >>>> Thank You For Your Help ! >>> >> >> >>>> >>> >> >> >>>> On Sat, Jun 20, 2020 at 9:54 AM C Williams >>> >> >> ><cwilliams3320@gmail.com> >>> >> >> >>>> wrote: >>> >> >> >>>> > Strahil, >>> >> >> >>>> > >>> >> >> >>>> > I understand. Please keep me posted. >>> >> >> >>>> > >>> >> >> >>>> > Thanks For The Help ! >>> >> >> >>>> > >>> >> >> >>>> > On Sat, Jun 20, 2020 at 4:36 AM Strahil Nikolov >>> >> >> ><hunter86_bg@yahoo.com> >>> >> >> >>>> wrote: >>> >> >> >>>> >> Hey C Williams, >>> >> >> >>>> >> >>> >> >> >>>> >> sorry for the delay, but I couldn't get somw time to >>> >check >>> >> >your >>> >> >> >>>> logs. Will try a little bit later. >>> >> >> >>>> >> >>> >> >> >>>> >> Best Regards, >>> >> >> >>>> >> Strahil Nikolov >>> >> >> >>>> >> >>> >> >> >>>> >> На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams < >>> >> >> >>>> cwilliams3320@gmail.com> написа: >>> >> >> >>>> >>>Hello, >>> >> >> >>>> >>> >>> >> >> >>>> >>>Was wanting to follow up on this issue. Users are >>> >impacted. >>> >> >> >>>> >>> >>> >> >> >>>> >>>Thank You >>> >> >> >>>> >>> >>> >> >> >>>> >>>On Fri, Jun 19, 2020 at 9:20 AM C Williams >>> >> >> ><cwilliams3320@gmail.com> >>> >> >> >>>> >>>wrote: >>> >> >> >>>> >>> >>> >> >> >>>> >>>> Hello, >>> >> >> >>>> >>>> >>> >> >> >>>> >>>> Here are the logs (some IPs are changed ) >>> >> >> >>>> >>>> >>> >> >> >>>> >>>> ov05 is the SPM >>> >> >> >>>> >>>> >>> >> >> >>>> >>>> Thank You For Your Help ! >>> >> >> >>>> >>>> >>> >> >> >>>> >>>> On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov >>> >> >> >>>> >>><hunter86_bg@yahoo.com> >>> >> >> >>>> >>>> wrote: >>> >> >> >>>> >>>> >>> >> >> >>>> >>>>> Check on the hosts tab , which is your current SPM >>> >(last >>> >> >> >column in >>> >> >> >>>> >>>Admin >>> >> >> >>>> >>>>> UI). >>> >> >> >>>> >>>>> Then open the /var/log/vdsm/vdsm.log and repeat >the >>> >> >> >operation. >>> >> >> >>>> >>>>> Then provide the log from that host and the >engine's >>> >log >>> >> >(on >>> >> >> >the >>> >> >> >>>> >>>>> HostedEngine VM or on your standalone engine). >>> >> >> >>>> >>>>> >>> >> >> >>>> >>>>> Best Regards, >>> >> >> >>>> >>>>> Strahil Nikolov >>> >> >> >>>> >>>>> >>> >> >> >>>> >>>>> На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams >>> >> >> >>>> >>><cwilliams3320@gmail.com> >>> >> >> >>>> >>>>> написа: >>> >> >> >>>> >>>>> >Resending to eliminate email issues >>> >> >> >>>> >>>>> > >>> >> >> >>>> >>>>> >---------- Forwarded message --------- >>> >> >> >>>> >>>>> >From: C Williams <cwilliams3320@gmail.com> >>> >> >> >>>> >>>>> >Date: Thu, Jun 18, 2020 at 4:01 PM >>> >> >> >>>> >>>>> >Subject: Re: [ovirt-users] Fwd: Issues with >Gluster >>> >> >Domain >>> >> >> >>>> >>>>> >To: Strahil Nikolov <hunter86_bg@yahoo.com> >>> >> >> >>>> >>>>> > >>> >> >> >>>> >>>>> > >>> >> >> >>>> >>>>> >Here is output from mount >>> >> >> >>>> >>>>> > >>> >> >> >>>> >>>>> >192.168.24.12:/stor/import0 on >>> >> >> >>>> >>>>> /rhev/data-center/mnt/192.168.24.12:_stor_import0 >>> >> >> >>>> >>>>> >type nfs4 >>> >> >> >>>> >>>>> >>> >> >> >>>> >>>>> >>> >> >> >>>> >>> >> >> >>>> >>> >> >> >>> >> >> >>> >> >>> >> >>> >>>
>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12) >>> >> >> >>>> >>>>> >192.168.24.13:/stor/import1 on >>> >> >> >>>> >>>>> /rhev/data-center/mnt/192.168.24.13:_stor_import1 >>> >> >> >>>> >>>>> >type nfs4 >>> >> >> >>>> >>>>> >>> >> >> >>>> >>>>> >>> >> >> >>>> >>> >> >> >>>> >>> >> >> >>> >> >> >>> >> >>> >> >>> >>>
>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >>> >> >> >>>> >>>>> >192.168.24.13:/stor/iso1 on >>> >> >> >>>> >>>>> /rhev/data-center/mnt/192.168.24.13:_stor_iso1 >>> >> >> >>>> >>>>> >type nfs4 >>> >> >> >>>> >>>>> >>> >> >> >>>> >>>>> >>> >> >> >>>> >>> >> >> >>>> >>> >> >> >>> >> >> >>> >> >>> >> >>> >>>
>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >>> >> >> >>>> >>>>> >192.168.24.13:/stor/export0 on >>> >> >> >>>> >>>>> /rhev/data-center/mnt/192.168.24.13:_stor_export0 >>> >> >> >>>> >>>>> >type nfs4 >>> >> >> >>>> >>>>> >>> >> >> >>>> >>>>> >>> >> >> >>>> >>> >> >> >>>> >>> >> >> >>> >> >> >>> >> >>> >> >>> >>>
>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >>> >> >> >>>> >>>>> >192.168.24.15:/images on >>> >> >> >>>> >>>>> >>/rhev/data-center/mnt/glusterSD/192.168.24.15:_images >>> >> >> >>>> >>>>> >type fuse.glusterfs >>> >> >> >>>> >>>>> >>> >> >> >>>> >>>>> >>> >> >> >>>> >>> >> >> >>>> >>> >> >> >>> >> >> >>> >> >>> >> >>> >>>
>>>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) >>> >> >> >>>> >>>>> >192.168.24.18:/images3 on >>> >> >> >>>> >>>>> >>/rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 >>> >> >> >>>> >>>>> >type fuse.glusterfs >>> >> >> >>>> >>>>> >>> >> >> >>>> >>>>> >>> >> >> >>>> >>> >> >> >>>> >>> >> >> >>> >> >> >>> >> >>> >> >>> >>>
>>>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) >>> >> >> >>>> >>>>> >tmpfs on /run/user/0 type tmpfs >>> >> >> >>>> >>>>> >>> >> (rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) >>> >> >> >>>> >>>>> >[root@ov06 glusterfs]# >>> >> >> >>>> >>>>> > >>> >> >> >>>> >>>>> >Also here is a screenshot of the console >>> >> >> >>>> >>>>> > >>> >> >> >>>> >>>>> >[image: image.png] >>> >> >> >>>> >>>>> >The other domains are up >>> >> >> >>>> >>>>> > >>> >> >> >>>> >>>>> >Import0 and Import1 are NFS . GLCL0 is gluster. >They >>> >all >>> >> >are >>> >> >> >>>> >>>running >>> >> >> >>>> >>>>> >VMs >>> >> >> >>>> >>>>> > >>> >> >> >>>> >>>>> >Thank You For Your Help ! >>> >> >> >>>> >>>>> > >>> >> >> >>>> >>>>> >On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov >>> >> >> >>>> >>><hunter86_bg@yahoo.com> >>> >> >> >>>> >>>>> >wrote: >>> >> >> >>>> >>>>> > >>> >> >> >>>> >>>>> >> I don't see >>> >> >> >'/rhev/data-center/mnt/192.168.24.13:_stor_import1' >>> >> >> >>>> >>>>> >mounted >>> >> >> >>>> >>>>> >> at all . >>> >> >> >>>> >>>>> >> What is the status of all storage domains ? >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >> Best Regards, >>> >> >> >>>> >>>>> >> Strahil Nikolov >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >> На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams >>> >> >> >>>> >>>>> ><cwilliams3320@gmail.com> >>> >> >> >>>> >>>>> >> написа: >>> >> >> >>>> >>>>> >> > Resending to deal with possible email issues >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> >> >---------- Forwarded message --------- >>> >> >> >>>> >>>>> >> >From: C Williams <cwilliams3320@gmail.com> >>> >> >> >>>> >>>>> >> >Date: Thu, Jun 18, 2020 at 2:07 PM >>> >> >> >>>> >>>>> >> >Subject: Re: [ovirt-users] Issues with Gluster >>> >Domain >>> >> >> >>>> >>>>> >> >To: Strahil Nikolov <hunter86_bg@yahoo.com> >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> >> >More >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> >> >[root@ov06 ~]# for i in $(gluster volume list); > do >>> >> >echo >>> >> >> >>>> >>>$i;echo; >>> >> >> >>>> >>>>> >> >gluster >>> >> >> >>>> >>>>> >> >volume info $i; echo;echo;gluster volume status >>> >> >> >>>> >>>>> >$i;echo;echo;echo;done >>> >> >> >>>> >>>>> >> >images3 >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> >> >Volume Name: images3 >>> >> >> >>>> >>>>> >> >Type: Replicate >>> >> >> >>>> >>>>> >> >Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b >>> >> >> >>>> >>>>> >> >Status: Started >>> >> >> >>>> >>>>> >> >Snapshot Count: 0 >>> >> >> >>>> >>>>> >> >Number of Bricks: 1 x 3 = 3 >>> >> >> >>>> >>>>> >> >Transport-type: tcp >>> >> >> >>>> >>>>> >> >Bricks: >>> >> >> >>>> >>>>> >> >Brick1: 192.168.24.18:/bricks/brick04/images3 >>> >> >> >>>> >>>>> >> >Brick2: 192.168.24.19:/bricks/brick05/images3 >>> >> >> >>>> >>>>> >> >Brick3: 192.168.24.20:/bricks/brick06/images3 >>> >> >> >>>> >>>>> >> >Options Reconfigured: >>> >> >> >>>> >>>>> >> >performance.client-io-threads: on >>> >> >> >>>> >>>>> >> >nfs.disable: on >>> >> >> >>>> >>>>> >> >transport.address-family: inet >>> >> >> >>>> >>>>> >> >user.cifs: off >>> >> >> >>>> >>>>> >> >auth.allow: * >>> >> >> >>>> >>>>> >> >performance.quick-read: off >>> >> >> >>>> >>>>> >> >performance.read-ahead: off >>> >> >> >>>> >>>>> >> >performance.io-cache: off >>> >> >> >>>> >>>>> >> >performance.low-prio-threads: 32 >>> >> >> >>>> >>>>> >> >network.remote-dio: off >>> >> >> >>>> >>>>> >> >cluster.eager-lock: enable >>> >> >> >>>> >>>>> >> >cluster.quorum-type: auto >>> >> >> >>>> >>>>> >> >cluster.server-quorum-type: server >>> >> >> >>>> >>>>> >> >cluster.data-self-heal-algorithm: full >>> >> >> >>>> >>>>> >> >cluster.locking-scheme: granular >>> >> >> >>>> >>>>> >> >cluster.shd-max-threads: 8 >>> >> >> >>>> >>>>> >> >cluster.shd-wait-qlength: 10000 >>> >> >> >>>> >>>>> >> >features.shard: on >>> >> >> >>>> >>>>> >> >cluster.choose-local: off >>> >> >> >>>> >>>>> >> >client.event-threads: 4 >>> >> >> >>>> >>>>> >> >server.event-threads: 4 >>> >> >> >>>> >>>>> >> >storage.owner-uid: 36 >>> >> >> >>>> >>>>> >> >storage.owner-gid: 36 >>> >> >> >>>> >>>>> >> >performance.strict-o-direct: on >>> >> >> >>>> >>>>> >> >network.ping-timeout: 30 >>> >> >> >>>> >>>>> >> >cluster.granular-entry-heal: enable >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> >> >Status of volume: images3 >>> >> >> >>>> >>>>> >> >Gluster process TCP >>> >Port >>> >> >> >RDMA Port >>> >> >> >>>> >>>>> >Online >>> >> >> >>>> >>>>> >> > Pid >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >>> >> >> >>>> >>>>> >>> >> >> >>>> >>> >> >> >>>> >>> >> >> >>> >> >> >>> >> >>> >> >>> >>>
>>>>>>------------------------------------------------------------------------------ >>> >> >> >>>> >>>>> >> >Brick 192.168.24.18:/bricks/brick04/images3 >49152 >>> >> >0 >>> >> >> >>>> >>> >> >> >>>> >>>Y >>> >> >> >>>> >>>>> >> >6666 >>> >> >> >>>> >>>>> >> >Brick 192.168.24.19:/bricks/brick05/images3 >49152 >>> >> >0 >>> >> >> >>>> >>> >> >> >>>> >>>Y >>> >> >> >>>> >>>>> >> >6779 >>> >> >> >>>> >>>>> >> >Brick 192.168.24.20:/bricks/brick06/images3 >49152 >>> >> >0 >>> >> >> >>>> >>> >> >> >>>> >>>Y >>> >> >> >>>> >>>>> >> >7227 >>> >> >> >>>> >>>>> >> >Self-heal Daemon on localhost N/A >>> >> >N/A >>> >> >> >>>> >>> >> >> >>>> >>>Y >>> >> >> >>>> >>>>> >> >6689 >>> >> >> >>>> >>>>> >> >Self-heal Daemon on ov07.ntc.srcle.com N/A >>> >> >N/A >>> >> >> >>>> >>> >> >> >>>> >>>Y >>> >> >> >>>> >>>>> >> >6802 >>> >> >> >>>> >>>>> >> >Self-heal Daemon on ov08.ntc.srcle.com N/A >>> >> >N/A >>> >> >> >>>> >>> >> >> >>>> >>>Y >>> >> >> >>>> >>>>> >> >7250 >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> >> >Task Status of Volume images3 >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >>> >> >> >>>> >>>>> >>> >> >> >>>> >>> >> >> >>>> >>> >> >> >>> >> >> >>> >> >>> >> >>> >>>
>>>>>>------------------------------------------------------------------------------ >>> >> >> >>>> >>>>> >> >There are no active volume tasks >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> >> >[root@ov06 ~]# ls -l >>> >/rhev/data-center/mnt/glusterSD/ >>> >> >> >>>> >>>>> >> >total 16 >>> >> >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 >>> >> >> >192.168.24.15:_images >>> >> >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 >>> >> >192.168.24.18: >>> >> >> >>>> _images3 >>> >> >> >>>> >>>>> >> >[root@ov06 ~]# >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> >> >On Thu, Jun 18, 2020 at 2:03 PM C Williams >>> >> >> >>>> >>><cwilliams3320@gmail.com> >>> >> >> >>>> >>>>> >> >wrote: >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> >> >> Strahil, >>> >> >> >>>> >>>>> >> >> >>> >> >> >>>> >>>>> >> >> Here you go -- Thank You For Your Help ! >>> >> >> >>>> >>>>> >> >> >>> >> >> >>>> >>>>> >> >> BTW -- I can write a test file to gluster and >it >>> >> >> >replicates >>> >> >> >>>> >>>>> >properly. >>> >> >> >>>> >>>>> >> >> Thinking something about the oVirt Storage >Domain >>> >? >>> >> >> >>>> >>>>> >> >> >>> >> >> >>>> >>>>> >> >> [root@ov08 ~]# gluster pool list >>> >> >> >>>> >>>>> >> >> UUID >Hostname >>> >> >> >>>> >>>>> >State >>> >> >> >>>> >>>>> >> >> 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06 >>> >> >> >>>> >>>>> >> >Connected >>> >> >> >>>> >>>>> >> >> 36ce5a00-6f65-4926-8438-696944ebadb5 >>> >> >> >ov07.ntc.srcle.com >>> >> >> >>>> >>>>> >> >Connected >>> >> >> >>>> >>>>> >> >> c7e7abdb-a8f4-4842-924c-e227f0db1b29 >localhost >>> >> >> >>>> >>>>> >> >Connected >>> >> >> >>>> >>>>> >> >> [root@ov08 ~]# gluster volume list >>> >> >> >>>> >>>>> >> >> images3 >>> >> >> >>>> >>>>> >> >> >>> >> >> >>>> >>>>> >> >> On Thu, Jun 18, 2020 at 1:13 PM Strahil >Nikolov >>> >> >> >>>> >>>>> >> ><hunter86_bg@yahoo.com> >>> >> >> >>>> >>>>> >> >> wrote: >>> >> >> >>>> >>>>> >> >> >>> >> >> >>>> >>>>> >> >>> Log to the oVirt cluster and provide
>output >>> >of: >>> >> >> >>>> >>>>> >> >>> gluster pool list >>> >> >> >>>> >>>>> >> >>> gluster volume list >>> >> >> >>>> >>>>> >> >>> for i in $(gluster volume list); do echo >>> >$i;echo; >>> >> >> >gluster >>> >> >> >>>> >>>>> >volume >>> >> >> >>>> >>>>> >> >info >>> >> >> >>>> >>>>> >> >>> $i; echo;echo;gluster volume status >>> >> >> >$i;echo;echo;echo;done >>> >> >> >>>> >>>>> >> >>> >>> >> >> >>>> >>>>> >> >>> ls -l /rhev/data-center/mnt/glusterSD/ >>> >> >> >>>> >>>>> >> >>> >>> >> >> >>>> >>>>> >> >>> Best Regards, >>> >> >> >>>> >>>>> >> >>> Strahil Nikolov >>> >> >> >>>> >>>>> >> >>> >>> >> >> >>>> >>>>> >> >>> >>> >> >> >>>> >>>>> >> >>> На 18 юни 2020 г. 19:17:46 GMT+03:00, C >Williams >>> >> >> >>>> >>>>> >> ><cwilliams3320@gmail.com> >>> >> >> >>>> >>>>> >> >>> написа: >>> >> >> >>>> >>>>> >> >>> >Hello, >>> >> >> >>>> >>>>> >> >>> > >>> >> >> >>>> >>>>> >> >>> >I recently added 6 hosts to an existing >oVirt >>> >> >> >>>> >>>compute/gluster >>> >> >> >>>> >>>>> >> >cluster. >>> >> >> >>>> >>>>> >> >>> > >>> >> >> >>>> >>>>> >> >>> >Prior to this attempted addition, my >cluster >>> >had 3 >>> >> >> >>>> >>>Hypervisor >>> >> >> >>>> >>>>> >hosts >>> >> >> >>>> >>>>> >> >and >>> >> >> >>>> >>>>> >> >>> >3 >>> >> >> >>>> >>>>> >> >>> >gluster bricks which made up a single >gluster >>> >> >volume >>> >> >> >>>> >>>(replica 3 >>> >> >> >>>> >>>>> >> >volume) >>> >> >> >>>> >>>>> >> >>> >. I >>> >> >> >>>> >>>>> >> >>> >added the additional hosts and made a brick >on >>> >3 >>> >> >of >>> >> >> >the new >>> >> >> >>>> >>>>> >hosts >>> >> >> >>>> >>>>> >> >and >>> >> >> >>>> >>>>> >> >>> >attempted to make a new replica 3 volume. I >had >>> >> >> >difficulty >>> >> >> >>>> >>>>> >> >creating >>> >> >> >>>> >>>>> >> >>> >the >>> >> >> >>>> >>>>> >> >>> >new volume. So, I decided that I would make >a >>> >new >>> >> >> >>>> >>>>> >compute/gluster >>> >> >> >>>> >>>>> >> >>> >cluster >>> >> >> >>>> >>>>> >> >>> >for each set of 3 new hosts. >>> >> >> >>>> >>>>> >> >>> > >>> >> >> >>>> >>>>> >> >>> >I removed the 6 new hosts from the existing >>> >oVirt >>> >> >> >>>> >>>>> >Compute/Gluster >>> >> >> >>>> >>>>> >> >>> >Cluster >>> >> >> >>>> >>>>> >> >>> >leaving the 3 original hosts in
https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3/html... the pause the place
with
>>> >their >>> >> >> >bricks. At >>> >> >> >>>> >>>that >>> >> >> >>>> >>>>> >> >point >>> >> >> >>>> >>>>> >> >>> >my >>> >> >> >>>> >>>>> >> >>> >original bricks went down and came back up >. >>> >The >>> >> >> >volume >>> >> >> >>>> >>>showed >>> >> >> >>>> >>>>> >> >entries >>> >> >> >>>> >>>>> >> >>> >that >>> >> >> >>>> >>>>> >> >>> >needed healing. At that point I ran gluster >>> >volume >>> >> >> >heal >>> >> >> >>>> >>>images3 >>> >> >> >>>> >>>>> >> >full, >>> >> >> >>>> >>>>> >> >>> >etc. >>> >> >> >>>> >>>>> >> >>> >The volume shows no unhealed entries. I >also >>> >> >> >corrected some >>> >> >> >>>> >>>peer >>> >> >> >>>> >>>>> >> >>> >errors. >>> >> >> >>>> >>>>> >> >>> > >>> >> >> >>>> >>>>> >> >>> >However, I am unable to copy disks, move >disks >>> >to >>> >> >> >another >>> >> >> >>>> >>>>> >domain, >>> >> >> >>>> >>>>> >> >>> >export >>> >> >> >>>> >>>>> >> >>> >disks, etc. It appears that the engine >cannot >>> >> >locate >>> >> >> >disks >>> >> >> >>>> >>>>> >properly >>> >> >> >>>> >>>>> >> >and >>> >> >> >>>> >>>>> >> >>> >I >>> >> >> >>>> >>>>> >> >>> >get storage I/O errors. >>> >> >> >>>> >>>>> >> >>> > >>> >> >> >>>> >>>>> >> >>> >I have detached and removed the oVirt >Storage >>> >> >Domain. >>> >> >> >I >>> >> >> >>>> >>>>> >reimported >>> >> >> >>>> >>>>> >> >the >>> >> >> >>>> >>>>> >> >>> >domain and imported 2 VMs, But the VM disks >>> >> >exhibit >>> >> >> >the >>> >> >> >>>> same >>> >> >> >>>> >>>>> >> >behaviour >>> >> >> >>>> >>>>> >> >>> >and >>> >> >> >>>> >>>>> >> >>> >won't run from the hard disk. >>> >> >> >>>> >>>>> >> >>> > >>> >> >> >>>> >>>>> >> >>> > >>> >> >> >>>> >>>>> >> >>> >I get errors such as this >>> >> >> >>>> >>>>> >> >>> > >>> >> >> >>>> >>>>> >> >>> >VDSM ov05 command HSMGetAllTasksStatusesVDS >>> >> >failed: >>> >> >> >low >>> >> >> >>>> >>>level >>> >> >> >>>> >>>>> >Image >>> >> >> >>>> >>>>> >> >>> >copy >>> >> >> >>>> >>>>> >> >>> >failed: ("Command ['/usr/bin/qemu-img', >>> >'convert', >>> >> >> >'-p', >>> >> >> >>>> >>>'-t', >>> >> >> >>>> >>>>> >> >'none', >>> >> >> >>>> >>>>> >> >>> >'-T', 'none', '-f', 'raw', >>> >> >> >>>> >>>>> >> >>> >>> >>u'/rhev/data-center/mnt/glusterSD/192.168.24.18: >>> >> >> >>>> >>>>> >> >>> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >>> >> >> >>>> >>>>> >>> >> >> >>>> >>> >> >> >>>> >>> >> >> >>> >> >> >>> >> >>> >> >>> >>>
>>>>>>_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510', >>> >> >> >>>> >>>>> >> >>> >'-O', 'raw', >>> >> >> >>>> >>>>> >> >>> u'/rhev/data-center/mnt/192.168.24.13: >>> >> >> >>>> >>>>> >> >>> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >>> >> >> >>>> >>>>> >>> >> >> >>>> >>> >> >> >>>> >>> >> >> >>> >> >> >>> >> >>> >> >>> >>>
>>>>>>_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5'] >>> >> >> >>>> >>>>> >> >>> >failed with rc=1 out='' >>> >err=bytearray(b'qemu-img: >>> >> >> >error >>> >> >> >>>> >>>while >>> >> >> >>>> >>>>> >> >reading >>> >> >> >>>> >>>>> >> >>> >sector 135168: Transport endpoint is not >>> >> >> >>>> >>>connected\\nqemu-img: >>> >> >> >>>> >>>>> >> >error >>> >> >> >>>> >>>>> >> >>> >while >>> >> >> >>>> >>>>> >> >>> >reading sector 131072: Transport endpoint >is >>> >not >>> >> >> >>>> >>>>> >> >connected\\nqemu-img: >>> >> >> >>>> >>>>> >> >>> >error while reading sector 139264: >Transport >>> >> >endpoint >>> >> >> >is >>> >> >> >>>> not >>> >> >> >>>> >>>>> >> >>> >connected\\nqemu-img: error while reading >>> >sector >>> >> >> >143360: >>> >> >> >>>> >>>>> >Transport >>> >> >> >>>> >>>>> >> >>> >endpoint >>> >> >> >>>> >>>>> >> >>> >is not connected\\nqemu-img: error while >>> >reading >>> >> >> >sector >>> >> >> >>>> >>>147456: >>> >> >> >>>> >>>>> >> >>> >Transport >>> >> >> >>>> >>>>> >> >>> >endpoint is not connected\\nqemu-img: error >>> >while >>> >> >> >reading >>> >> >> >>>> >>>sector >>> >> >> >>>> >>>>> >> >>> >155648: >>> >> >> >>>> >>>>> >> >>> >Transport endpoint is not >connected\\nqemu-img: >>> >> >error >>> >> >> >while >>> >> >> >>>> >>>>> >reading >>> >> >> >>>> >>>>> >> >>> >sector >>> >> >> >>>> >>>>> >> >>> >151552: Transport endpoint is not >>> >> >> >connected\\nqemu-img: >>> >> >> >>>> >>>error >>> >> >> >>>> >>>>> >while >>> >> >> >>>> >>>>> >> >>> >reading >>> >> >> >>>> >>>>> >> >>> >sector 159744: Transport endpoint is not >>> >> >> >connected\\n')",) >>> >> >> >>>> >>>>> >> >>> > >>> >> >> >>>> >>>>> >> >>> >oVirt version is 4.3.82-1.el7 >>> >> >> >>>> >>>>> >> >>> >OS CentOS Linux release 7.7.1908 (Core) >>> >> >> >>>> >>>>> >> >>> > >>> >> >> >>>> >>>>> >> >>> >The Gluster Cluster has been working very >well >>> >> >until >>> >> >> >this >>> >> >> >>>> >>>>> >incident. >>> >> >> >>>> >>>>> >> >>> > >>> >> >> >>>> >>>>> >> >>> >Please help. >>> >> >> >>>> >>>>> >> >>> > >>> >> >> >>>> >>>>> >> >>> >Thank You >>> >> >> >>>> >>>>> >> >>> > >>> >> >> >>>> >>>>> >> >>> >Charles Williams >>> >> >> >>>> >>>>> >> >>> >>> >> >> >>>> >>>>> >> >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >>> >> >> >>>> >>>> >>> >> >> >>>> >> >>> >> >> >>>> > >>> >> >> >>>> _______________________________________________ >>> >> >> >>>> Users mailing list -- users@ovirt.org >>> >> >> >>>> To unsubscribe send an email to users-leave@ovirt.org >>> >> >> >>>> Privacy Statement: >https://www.ovirt.org/privacy-policy.html >>> >> >> >>>> oVirt Code of Conduct: >>> >> >> >>>> >https://www.ovirt.org/community/about/community-guidelines/ >>> >> >> >>>> List Archives: >>> >> >> >>>> >>> >> >> > >>> >> >> >>> >> > >>> >> >>> > >>> >
https://lists.ovirt.org/archives/list/users@ovirt.org/message/YY3VUKEJLI7MRW...
>>> >> >> >>>> >>> >> >> >>> >>> >> >> >>> >> >>> >>
Strahil, Thanks for getting back with me ! Sounds like it is best to evacuate VM disks to another storage domain -- if possible from a Gluster storage domain -- prior to an upgrade . Per your questions ... 1. Which version of oVirt and Gluster are you using ? oVirt 4.3.8.2-1 Gluster 6.5 , 6.7, 6.9 (depends on the cluster) 2. You now have your old gluster volume attached to oVirt and the new volume unused, right ? Correct -- intending to dispose of data on the new volume since the old one is now working 3. Did you copy the contents of the old volume to the new one ? I did prior to trying to downgrade the Gluster version on the hosts for the old volume. I am planning to delete the data now that the old volume is working. Thanks Again For Your Help !! On Mon, Jun 22, 2020 at 11:34 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
As I told you, you could just downgrade gluster on all nodes and later plan to live migrate the VM disks. I had to copy my data to the new volume, so I can avoid the ACL bug , when I use newer versions of gluster.
Let's clarify some details: 1. Which version of oVirt and Gluster are you using ? 2. You now have your old gluster volume attached to oVirt and the new volume unused, right ? 3. Did you copy the contents of the old volume to the new one ?
Best Regards, Strahil Nikolov
На 23 юни 2020 г. 4:34:19 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Strahil,
Thank You For Help !
Downgrading Gluster to 6.5 got the original storage domain working again !
After, I finished my copy of the contents of the problematic volume to a new volume, I did the following
Unmounted the mount points Stopped the original problematic Gluster volume On each problematic peer, I downgraded Gluster to 6.5 (yum downgrade glusterfs-6.5-1.el7.x86_64 vdsm-gluster-4.30.46-1.el7.x86_64 python2-gluster-6.5-1.el7.x86_64 glusterfs-libs-6.5-1.el7.x86_64 glusterfs-cli-6.5-1.el7.x86_64 glusterfs-fuse-6.5-1.el7.x86_64 glusterfs-rdma-6.5-1.el7.x86_64 glusterfs-api-6.5-1.el7.x86_64 glusterfs-server-6.5-1.el7.x86_64 glusterfs-events-6.5-1.el7.x86_64 glusterfs-client-xlators-6.5-1.el7.x86_64 glusterfs-geo-replication-6.5-1.el7.x86_64) Restarted glusterd (systemctl restart glusterd) Restarted the problematic Gluster volume Reattached the problematic storage domain Started the problematic storage domain
Things work now. I can now run VMs and write data, copy virtual disks, move virtual disks to other storage domains, etc.
I am very thankful that the storage domain is working again !
How can I safely perform upgrades on Gluster ! When will it be safe to do so ?
Thank You Again For Your Help !
On Mon, Jun 22, 2020 at 10:58 AM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
I have downgraded the target. The copy from the problematic volume to the target is going on now. Once I have the data copied, I might downgrade the problematic volume's Gluster to 6.5. At that point I might reattach the original ovirt domain and see if it will work again. But the copy is going on right now.
Thank You For Your Help !
On Mon, Jun 22, 2020 at 10:52 AM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
You should ensure that in the storage domain tab, the old storage is not visible.
I still wander why yoiu didn't try to downgrade first.
Best Regards, Strahil Nikolov
Strahil,
The GLCL3 storage domain was detached prior to attempting to add
new storage domain.
Should I also "Remove" it ?
Thank You For Your Help !
---------- Forwarded message --------- From: Strahil Nikolov <hunter86_bg@yahoo.com> Date: Mon, Jun 22, 2020 at 12:50 AM Subject: Re: [ovirt-users] Re: Fwd: Fwd: Issues with Gluster Domain To: C Williams <cwilliams3320@gmail.com> Cc: users <Users@ovirt.org>
You can't add the new volume as it contains the same data (UUID) as
На 22 юни 2020 г. 13:58:33 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: the the
old one , thus you need to detach the old one before adding the new one
of course this means downtime for all VMs on that storage.
As you see , downgrading is more simpler. For me v6.5 was working, while anything above (6.6+) was causing complete lockdown. Also v7.0 was working, but it's supported in oVirt 4.4.
Best Regards, Strahil Nikolov
Another question
What version could I downgrade to safely ? I am at 6.9 .
Thank You For Your Help !!
On Sun, Jun 21, 2020 at 11:38 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
> You are definitely reading it wrong. > 1. I didn't create a new storage domain ontop this new volume. > 2. I used cli > > Something like this (in your case it should be 'replica 3'): > gluster volume create newvol replica 3 arbiter 1 ovirt1:/new/brick/path > ovirt2:/new/brick/path ovirt3:/new/arbiter/brick/path > gluster volume start newvol > > #Detach oldvol from ovirt > > mount -t glusterfs ovirt1:/oldvol /mnt/oldvol > mount -t glusterfs ovirt1:/newvol /mnt/newvol > cp -a /mnt/oldvol/* /mnt/newvol > > #Add only newvol as a storage domain in oVirt > #Import VMs > > I still think that you should downgrade your gluster packages!!! > > Best Regards, > Strahil Nikolov > > На 22 юни 2020 г. 0:43:46 GMT+03:00, C Williams <cwilliams3320@gmail.com> > написа: > >Strahil, > > > >It sounds like you used a "System Managed Volume" for the new storage > >domain,is that correct? > > > >Thank You For Your Help ! > > > >On Sun, Jun 21, 2020 at 5:40 PM C Williams <cwilliams3320@gmail.com> > >wrote: > > > >> Strahil, > >> > >> So you made another oVirt Storage Domain -- then copied the data with > >cp > >> -a from the failed volume to the new volume. > >> > >> At the root of the volume there will be the old domain folder id ex > >> 5fe3ad3f-2d21-404c-832e-4dc7318ca10d > >> in my case. Did that cause issues with making the new domain since > >it is > >> the same folder id as the old one ? > >> > >> Thank You For Your Help ! > >> > >> On Sun, Jun 21, 2020 at 5:18 PM Strahil Nikolov > ><hunter86_bg@yahoo.com> > >> wrote: > >> > >>> In my situation I had only the ovirt nodes. > >>> > >>> На 21 юни 2020 г. 22:43:04 GMT+03:00, C Williams > ><cwilliams3320@gmail.com> > >>> написа: > >>> >Strahil, > >>> > > >>> >So should I make the target volume on 3 bricks which do not have > >ovirt > >>> >-- > >>> >just gluster ? In other words (3) Centos 7 hosts ? > >>> > > >>> >Thank You For Your Help ! > >>> > > >>> >On Sun, Jun 21, 2020 at 3:08 PM Strahil Nikolov > ><hunter86_bg@yahoo.com> > >>> >wrote: > >>> > > >>> >> I created a fresh volume (which is not an ovirt sgorage > >domain), > >>> >set > >>> >> the original storage domain in maintenance and detached it. > >>> >> Then I 'cp -a ' the data from the old to the new volume. Next, > >I > >>> >just > >>> >> added the new storage domain (the old one was a kind of a > >>> >> 'backup') - pointing to the new volume name. > >>> >> > >>> >> If you observe issues , I would recommend you to downgrade > >>> >> gluster packages one node at a time . Then you might be able > >to > >>> >> restore your oVirt operations. > >>> >> > >>> >> Best Regards, > >>> >> Strahil Nikolov > >>> >> > >>> >> На 21 юни 2020 г. 18:01:31 GMT+03:00, C Williams > >>> ><cwilliams3320@gmail.com> > >>> >> написа: > >>> >> >Strahil, > >>> >> > > >>> >> >Thanks for the follow up ! > >>> >> > > >>> >> >How did you copy the data to another volume ? > >>> >> > > >>> >> >I have set up another storage domain GLCLNEW1 with a new volume > >>> >imgnew1 > >>> >> >. > >>> >> >How would you copy all of the data from the problematic domain > >GLCL3 > >>> >> >with > >>> >> >volume images3 to GLCLNEW1 and volume imgnew1 and
all > >the > >>> >VMs, > >>> >> >VM > >>> >> >disks, settings, etc. ? > >>> >> > > >>> >> >Remember all of the regular ovirt disk copy, disk move, VM > >export > >>> >> >tools > >>> >> >are failing and my VMs and disks are trapped on domain GLCL3 and > >>> >volume > >>> >> >images3 right now. > >>> >> > > >>> >> >Please let me know > >>> >> > > >>> >> >Thank You For Your Help ! > >>> >> > > >>> >> > > >>> >> > > >>> >> > > >>> >> > > >>> >> >On Sun, Jun 21, 2020 at 8:27 AM Strahil Nikolov > >>> ><hunter86_bg@yahoo.com> > >>> >> >wrote: > >>> >> > > >>> >> >> Sorry to hear that. > >>> >> >> I can say that for me 6.5 was working, while 6.6 didn't > >and I > >>> >> >upgraded > >>> >> >> to 7.0 . > >>> >> >> In the ended , I have ended with creating a new fresh > >volume > >>> >and > >>> >> >> physically copying the data there, then I detached
> >storage > >>> >> >domains and > >>> >> >> attached to the new ones (which holded the old data), but > >I > >>> >> >could > >>> >> >> afford the downtime. > >>> >> >> Also, I can say that v7.0 ( but not 7.1 or anything later) > >>> >also > >>> >> >> worked without the ACL issue, but it causes some
На 22 юни 2020 г. 7:21:15 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: preserve the trouble
> >in > >>> >oVirt > >>> >> >- so > >>> >> >> avoid that unless you have no other options. > >>> >> >> > >>> >> >> Best Regards, > >>> >> >> Strahil Nikolov > >>> >> >> > >>> >> >> > >>> >> >> > >>> >> >> > >>> >> >> На 21 юни 2020 г. 4:39:46 GMT+03:00, C Williams > >>> >> ><cwilliams3320@gmail.com> > >>> >> >> написа: > >>> >> >> >Hello, > >>> >> >> > > >>> >> >> >Upgrading diidn't help > >>> >> >> > > >>> >> >> >Still acl errors trying to use a Virtual Disk from a VM > >>> >> >> > > >>> >> >> >[root@ov06 bricks]# tail bricks-brick04-images3.log | grep > >acl > >>> >> >> >[2020-06-21 01:33:45.665888] I [MSGID: 139001] > >>> >> >> >[posix-acl.c:263:posix_acl_log_permit_denied] > >>> >> >0-images3-access-control: > >>> >> >> >client: > >>> >> >> > >>> >> >> > >>> >> > >>> >> > >>> > >>> > >
>>CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0, > >>> >> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >>> >> >> >req(uid:107,gid:107,perm:1,ngrps:3), > >>> >> >> ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, > >acl:-) > >>> >> >> >[Permission denied] > >>> >> >> >The message "I [MSGID: 139001] > >>> >> >> >[posix-acl.c:263:posix_acl_log_permit_denied] > >>> >> >0-images3-access-control: > >>> >> >> >client: > >>> >> >> > >>> >> >> > >>> >> > >>> >> > >>> > >>> > >
>>CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0, > >>> >> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >>> >> >> >req(uid:107,gid:107,perm:1,ngrps:3), > >>> >> >> ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, > >acl:-) > >>> >> >> >[Permission denied]" repeated 2 times between [2020-06-21 > >>> >> >> >01:33:45.665888] > >>> >> >> >and [2020-06-21 01:33:45.806779] > >>> >> >> > > >>> >> >> >Thank You For Your Help ! > >>> >> >> > > >>> >> >> >On Sat, Jun 20, 2020 at 8:59 PM C Williams > >>> ><cwilliams3320@gmail.com> > >>> >> >> >wrote: > >>> >> >> > > >>> >> >> >> Hello, > >>> >> >> >> > >>> >> >> >> Based on the situation, I am planning to upgrade the 3 > >affected > >>> >> >> >hosts. > >>> >> >> >> > >>> >> >> >> My reasoning is that the hosts/bricks were attached to 6.9 > >at > >>> >one > >>> >> >> >time. > >>> >> >> >> > >>> >> >> >> Thanks For Your Help ! > >>> >> >> >> > >>> >> >> >> On Sat, Jun 20, 2020 at 8:38 PM C Williams > >>> >> ><cwilliams3320@gmail.com> > >>> >> >> >> wrote: > >>> >> >> >> > >>> >> >> >>> Strahil, > >>> >> >> >>> > >>> >> >> >>> The gluster version on the current 3 gluster hosts is 6.7 > >>> >(last > >>> >> >> >update > >>> >> >> >>> 2/26). These 3 hosts provide 1 brick each for the replica > >3 > >>> >> >volume. > >>> >> >> >>> > >>> >> >> >>> Earlier I had tried to add 6 additional hosts to the > >cluster. > >>> >> >Those > >>> >> >> >new > >>> >> >> >>> hosts were 6.9 gluster. > >>> >> >> >>> > >>> >> >> >>> I attempted to make a new separate volume with 3 bricks > >>> >provided > >>> >> >by > >>> >> >> >the 3 > >>> >> >> >>> new gluster 6.9 hosts. After having many errors from the > >>> >oVirt > >>> >> >> >interface, > >>> >> >> >>> I gave up and removed the 6 new hosts from the cluster. > >That > >>> >is > >>> >> >> >where the > >>> >> >> >>> problems started. The intent was to expand the gluster > >cluster > >>> >> >while > >>> >> >> >making > >>> >> >> >>> 2 new volumes for that cluster. The ovirt compute cluster > >>> >would > >>> >> >> >allow for > >>> >> >> >>> efficient VM migration between 9 hosts -- while having > >>> >separate > >>> >> >> >gluster > >>> >> >> >>> volumes for safety purposes. > >>> >> >> >>> > >>> >> >> >>> Looking at the brick logs, I see where there are acl > >errors > >>> >> >starting > >>> >> >> >from > >>> >> >> >>> the time of the removal of the 6 new hosts. > >>> >> >> >>> > >>> >> >> >>> Please check out the attached brick log from 6/14-18. The > >>> >events > >>> >> >> >started > >>> >> >> >>> on 6/17. > >>> >> >> >>> > >>> >> >> >>> I wish I had a downgrade path. > >>> >> >> >>> > >>> >> >> >>> Thank You For The Help !! > >>> >> >> >>> > >>> >> >> >>> On Sat, Jun 20, 2020 at 7:47 PM Strahil Nikolov > >>> >> >> ><hunter86_bg@yahoo.com> > >>> >> >> >>> wrote: > >>> >> >> >>> > >>> >> >> >>>> Hi , > >>> >> >> >>>> > >>> >> >> >>>> > >>> >> >> >>>> This one really looks like the ACL bug I was hit with > >when I > >>> >> >> >updated > >>> >> >> >>>> from Gluster v6.5 to 6.6 and later from 7.0 to 7.2. > >>> >> >> >>>> > >>> >> >> >>>> Did you update your setup recently ? Did you upgrade > >gluster > >>> >> >also ? > >>> >> >> >>>> > >>> >> >> >>>> You have to check the gluster logs in order to verify > >that, > >>> >so > >>> >> >you > >>> >> >> >can > >>> >> >> >>>> try: > >>> >> >> >>>> > >>> >> >> >>>> 1. Set Gluster logs to trace level (for details check: > >>> >> >> >>>> > >>> >> >> > > >>> >> >> > >>> >> > > >>> >> > >>> > > >>> > > >
https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3/html...
> >>> >> >> >>>> ) > >>> >> >> >>>> 2. Power up a VM that was already off , or retry the > >>> >procedure > >>> >> >from > >>> >> >> >the > >>> >> >> >>>> logs you sent. > >>> >> >> >>>> 3. Stop the trace level of the logs > >>> >> >> >>>> 4. Check libvirt logs on the host that was supposed to > >power > >>> >up > >>> >> >the > >>> >> >> >VM > >>> >> >> >>>> (in case a VM was powered on) > >>> >> >> >>>> 5. Check the gluster brick logs on all nodes for ACL > >errors. > >>> >> >> >>>> Here is a sample from my old logs: > >>> >> >> >>>> > >>> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 > >>> >> >> >13:19:41.489047] I > >>> >> >> >>>> [MSGID: 139001] > >[posix-acl.c:262:posix_acl_log_permit_denied] > >>> >> >> >>>> 0-data_fast4-access-control: client: > >CTX_ID:4a654305-d2e4- > >>> >> >> >>>> > >>> >> >> > >>> >> >> > >>> >> > >>> >> > >>> > >>> > >
>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, > >>> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >>> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx > >>> >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, > >acl:-) > >>> >> >> >>>> [Permission denied] > >>> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 > >>> >> >> >13:22:51.818796] I > >>> >> >> >>>> [MSGID: 139001] > >[posix-acl.c:262:posix_acl_log_permit_denied] > >>> >> >> >>>> 0-data_fast4-access-control: client: > >CTX_ID:4a654305-d2e4- > >>> >> >> >>>> > >>> >> >> > >>> >> >> > >>> >> > >>> >> > >>> > >>> > >
>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, > >>> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >>> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx > >>> >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, > >acl:-) > >>> >> >> >>>> [Permission denied] > >>> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 > >>> >> >> >13:24:43.732856] I > >>> >> >> >>>> [MSGID: 139001] > >[posix-acl.c:262:posix_acl_log_permit_denied] > >>> >> >> >>>> 0-data_fast4-access-control: client: > >CTX_ID:4a654305-d2e4- > >>> >> >> >>>> > >>> >> >> > >>> >> >> > >>> >> > >>> >> > >>> > >>> > >
>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, > >>> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >>> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx > >>> >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, > >acl:-) > >>> >> >> >>>> [Permission denied] > >>> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 > >>> >> >> >13:26:50.758178] I > >>> >> >> >>>> [MSGID: 139001] > >[posix-acl.c:262:posix_acl_log_permit_denied] > >>> >> >> >>>> 0-data_fast4-access-control: client: > >CTX_ID:4a654305-d2e4- > >>> >> >> >>>> > >>> >> >> > >>> >> >> > >>> >> > >>> >> > >>> > >>> > >
>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, > >>> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, > >>> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx > >>> >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, > >acl:-) > >>> >> >> >>>> [Permission denied] > >>> >> >> >>>> > >>> >> >> >>>> > >>> >> >> >>>> In my case , the workaround was to downgrade the gluster > >>> >> >packages > >>> >> >> >on all > >>> >> >> >>>> nodes (and reboot each node 1 by 1 ) if the major version > >is > >>> >the > >>> >> >> >same, but > >>> >> >> >>>> if you upgraded to v7.X - then you can try the v7.0 . > >>> >> >> >>>> > >>> >> >> >>>> Best Regards, > >>> >> >> >>>> Strahil Nikolov > >>> >> >> >>>> > >>> >> >> >>>> > >>> >> >> >>>> > >>> >> >> >>>> > >>> >> >> >>>> > >>> >> >> >>>> > >>> >> >> >>>> В събота, 20 юни 2020 г., 18:48:42 ч. Гринуич+3, C > >Williams < > >>> >> >> >>>> cwilliams3320@gmail.com> написа: > >>> >> >> >>>> > >>> >> >> >>>> > >>> >> >> >>>> > >>> >> >> >>>> > >>> >> >> >>>> > >>> >> >> >>>> Hello, > >>> >> >> >>>> > >>> >> >> >>>> Here are additional log tiles as well as a tree of the > >>> >> >problematic > >>> >> >> >>>> Gluster storage domain. During this time I attempted to > >copy > >>> >a > >>> >> >> >virtual disk > >>> >> >> >>>> to another domain, move a virtual disk to another domain > >and > >>> >run > >>> >> >a > >>> >> >> >VM where > >>> >> >> >>>> the virtual hard disk would be used. > >>> >> >> >>>> > >>> >> >> >>>> The copies/moves failed and the VM went into pause mode > >when > >>> >the > >>> >> >> >virtual > >>> >> >> >>>> HDD was involved. > >>> >> >> >>>> > >>> >> >> >>>> Please check these out. > >>> >> >> >>>> > >>> >> >> >>>> Thank You For Your Help ! > >>> >> >> >>>> > >>> >> >> >>>> On Sat, Jun 20, 2020 at 9:54 AM C Williams > >>> >> >> ><cwilliams3320@gmail.com> > >>> >> >> >>>> wrote: > >>> >> >> >>>> > Strahil, > >>> >> >> >>>> > > >>> >> >> >>>> > I understand. Please keep me posted. > >>> >> >> >>>> > > >>> >> >> >>>> > Thanks For The Help ! > >>> >> >> >>>> > > >>> >> >> >>>> > On Sat, Jun 20, 2020 at 4:36 AM Strahil Nikolov > >>> >> >> ><hunter86_bg@yahoo.com> > >>> >> >> >>>> wrote: > >>> >> >> >>>> >> Hey C Williams, > >>> >> >> >>>> >> > >>> >> >> >>>> >> sorry for the delay, but I couldn't get somw time to > >>> >check > >>> >> >your > >>> >> >> >>>> logs. Will try a little bit later. > >>> >> >> >>>> >> > >>> >> >> >>>> >> Best Regards, > >>> >> >> >>>> >> Strahil Nikolov > >>> >> >> >>>> >> > >>> >> >> >>>> >> На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams < > >>> >> >> >>>> cwilliams3320@gmail.com> написа: > >>> >> >> >>>> >>>Hello, > >>> >> >> >>>> >>> > >>> >> >> >>>> >>>Was wanting to follow up on this issue. Users are > >>> >impacted. > >>> >> >> >>>> >>> > >>> >> >> >>>> >>>Thank You > >>> >> >> >>>> >>> > >>> >> >> >>>> >>>On Fri, Jun 19, 2020 at 9:20 AM C Williams > >>> >> >> ><cwilliams3320@gmail.com> > >>> >> >> >>>> >>>wrote: > >>> >> >> >>>> >>> > >>> >> >> >>>> >>>> Hello, > >>> >> >> >>>> >>>> > >>> >> >> >>>> >>>> Here are the logs (some IPs are changed ) > >>> >> >> >>>> >>>> > >>> >> >> >>>> >>>> ov05 is the SPM > >>> >> >> >>>> >>>> > >>> >> >> >>>> >>>> Thank You For Your Help ! > >>> >> >> >>>> >>>> > >>> >> >> >>>> >>>> On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov > >>> >> >> >>>> >>><hunter86_bg@yahoo.com> > >>> >> >> >>>> >>>> wrote: > >>> >> >> >>>> >>>> > >>> >> >> >>>> >>>>> Check on the hosts tab , which is your current SPM > >>> >(last > >>> >> >> >column in > >>> >> >> >>>> >>>Admin > >>> >> >> >>>> >>>>> UI). > >>> >> >> >>>> >>>>> Then open the /var/log/vdsm/vdsm.log and repeat > >the > >>> >> >> >operation. > >>> >> >> >>>> >>>>> Then provide the log from that host and the > >engine's > >>> >log > >>> >> >(on > >>> >> >> >the > >>> >> >> >>>> >>>>> HostedEngine VM or on your standalone engine). > >>> >> >> >>>> >>>>> > >>> >> >> >>>> >>>>> Best Regards, > >>> >> >> >>>> >>>>> Strahil Nikolov > >>> >> >> >>>> >>>>> > >>> >> >> >>>> >>>>> На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams > >>> >> >> >>>> >>><cwilliams3320@gmail.com> > >>> >> >> >>>> >>>>> написа: > >>> >> >> >>>> >>>>> >Resending to eliminate email issues > >>> >> >> >>>> >>>>> > > >>> >> >> >>>> >>>>> >---------- Forwarded message --------- > >>> >> >> >>>> >>>>> >From: C Williams <cwilliams3320@gmail.com> > >>> >> >> >>>> >>>>> >Date: Thu, Jun 18, 2020 at 4:01 PM > >>> >> >> >>>> >>>>> >Subject: Re: [ovirt-users] Fwd: Issues with > >Gluster > >>> >> >Domain > >>> >> >> >>>> >>>>> >To: Strahil Nikolov <hunter86_bg@yahoo.com> > >>> >> >> >>>> >>>>> > > >>> >> >> >>>> >>>>> > > >>> >> >> >>>> >>>>> >Here is output from mount > >>> >> >> >>>> >>>>> > > >>> >> >> >>>> >>>>> >192.168.24.12:/stor/import0 on > >>> >> >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.12:_stor_import0 > >>> >> >> >>>> >>>>> >type nfs4 > >>> >> >> >>>> >>>>> > >>> >> >> >>>> >>>>> > >>> >> >> >>>> > >>> >> >> >>>> > >>> >> >> > >>> >> >> > >>> >> > >>> >> > >>> > >>> > >
>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12) > >>> >> >> >>>> >>>>> >192.168.24.13:/stor/import1 on > >>> >> >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_import1 > >>> >> >> >>>> >>>>> >type nfs4 > >>> >> >> >>>> >>>>> > >>> >> >> >>>> >>>>> > >>> >> >> >>>> > >>> >> >> >>>> > >>> >> >> > >>> >> >> > >>> >> > >>> >> > >>> > >>> > >
>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) > >>> >> >> >>>> >>>>> >192.168.24.13:/stor/iso1 on > >>> >> >> >>>> >>>>> /rhev/data-center/mnt/192.168.24.13:_stor_iso1 > >>> >> >> >>>> >>>>> >type nfs4 > >>> >> >> >>>> >>>>> > >>> >> >> >>>> >>>>> > >>> >> >> >>>> > >>> >> >> >>>> > >>> >> >> > >>> >> >> > >>> >> > >>> >> > >>> > >>> > >
>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) > >>> >> >> >>>> >>>>> >192.168.24.13:/stor/export0 on > >>> >> >> >>>> >>>>> >/rhev/data-center/mnt/192.168.24.13:_stor_export0 > >>> >> >> >>>> >>>>> >type nfs4 > >>> >> >> >>>> >>>>> > >>> >> >> >>>> >>>>> > >>> >> >> >>>> > >>> >> >> >>>> > >>> >> >> > >>> >> >> > >>> >> > >>> >> > >>> > >>> > >
>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) > >>> >> >> >>>> >>>>> >192.168.24.15:/images on > >>> >> >> >>>> >>>>> > >>/rhev/data-center/mnt/glusterSD/192.168.24.15:_images > >>> >> >> >>>> >>>>> >type fuse.glusterfs > >>> >> >> >>>> >>>>> > >>> >> >> >>>> >>>>> > >>> >> >> >>>> > >>> >> >> >>>> > >>> >> >> > >>> >> >> > >>> >> > >>> >> > >>> > >>> > >
>>>>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) > >>> >> >> >>>> >>>>> >192.168.24.18:/images3 on > >>> >> >> >>>> >>>>> > >>/rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 > >>> >> >> >>>> >>>>> >type fuse.glusterfs > >>> >> >> >>>> >>>>> > >>> >> >> >>>> >>>>> > >>> >> >> >>>> > >>> >> >> >>>> > >>> >> >> > >>> >> >> > >>> >> > >>> >> > >>> > >>> > >
>>>>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) > >>> >> >> >>>> >>>>> >tmpfs on /run/user/0 type tmpfs > >>> >> >> >>>> >>>>> > >>> >> (rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) > >>> >> >> >>>> >>>>> >[root@ov06 glusterfs]# > >>> >> >> >>>> >>>>> > > >>> >> >> >>>> >>>>> >Also here is a screenshot of the console > >>> >> >> >>>> >>>>> > > >>> >> >> >>>> >>>>> >[image: image.png] > >>> >> >> >>>> >>>>> >The other domains are up > >>> >> >> >>>> >>>>> > > >>> >> >> >>>> >>>>> >Import0 and Import1 are NFS . GLCL0 is gluster. > >They > >>> >all > >>> >> >are > >>> >> >> >>>> >>>running > >>> >> >> >>>> >>>>> >VMs > >>> >> >> >>>> >>>>> > > >>> >> >> >>>> >>>>> >Thank You For Your Help ! > >>> >> >> >>>> >>>>> > > >>> >> >> >>>> >>>>> >On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov > >>> >> >> >>>> >>><hunter86_bg@yahoo.com> > >>> >> >> >>>> >>>>> >wrote: > >>> >> >> >>>> >>>>> > > >>> >> >> >>>> >>>>> >> I don't see > >>> >> >> >'/rhev/data-center/mnt/192.168.24.13:_stor_import1' > >>> >> >> >>>> >>>>> >mounted > >>> >> >> >>>> >>>>> >> at all . > >>> >> >> >>>> >>>>> >> What is the status of all storage domains ? > >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> >> Best Regards, > >>> >> >> >>>> >>>>> >> Strahil Nikolov > >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> >> На 18 юни 2020 г. 21:43:44 GMT+03:00, C Williams > >>> >> >> >>>> >>>>> ><cwilliams3320@gmail.com> > >>> >> >> >>>> >>>>> >> написа: > >>> >> >> >>>> >>>>> >> > Resending to deal with possible email issues > >>> >> >> >>>> >>>>> >> > > >>> >> >> >>>> >>>>> >> >---------- Forwarded message --------- > >>> >> >> >>>> >>>>> >> >From: C Williams <cwilliams3320@gmail.com> > >>> >> >> >>>> >>>>> >> >Date: Thu, Jun 18, 2020 at 2:07 PM > >>> >> >> >>>> >>>>> >> >Subject: Re: [ovirt-users] Issues with Gluster > >>> >Domain > >>> >> >> >>>> >>>>> >> >To: Strahil Nikolov <hunter86_bg@yahoo.com> > >>> >> >> >>>> >>>>> >> > > >>> >> >> >>>> >>>>> >> > > >>> >> >> >>>> >>>>> >> >More > >>> >> >> >>>> >>>>> >> > > >>> >> >> >>>> >>>>> >> >[root@ov06 ~]# for i in $(gluster volume list); > > do > >>> >> >echo > >>> >> >> >>>> >>>$i;echo; > >>> >> >> >>>> >>>>> >> >gluster > >>> >> >> >>>> >>>>> >> >volume info $i; echo;echo;gluster volume status > >>> >> >> >>>> >>>>> >$i;echo;echo;echo;done > >>> >> >> >>>> >>>>> >> >images3 > >>> >> >> >>>> >>>>> >> > > >>> >> >> >>>> >>>>> >> > > >>> >> >> >>>> >>>>> >> >Volume Name: images3 > >>> >> >> >>>> >>>>> >> >Type: Replicate > >>> >> >> >>>> >>>>> >> >Volume ID: 0243d439-1b29-47d0-ab39-d61c2f15ae8b > >>> >> >> >>>> >>>>> >> >Status: Started > >>> >> >> >>>> >>>>> >> >Snapshot Count: 0 > >>> >> >> >>>> >>>>> >> >Number of Bricks: 1 x 3 = 3 > >>> >> >> >>>> >>>>> >> >Transport-type: tcp > >>> >> >> >>>> >>>>> >> >Bricks: > >>> >> >> >>>> >>>>> >> >Brick1: 192.168.24.18:/bricks/brick04/images3 > >>> >> >> >>>> >>>>> >> >Brick2: 192.168.24.19:/bricks/brick05/images3 > >>> >> >> >>>> >>>>> >> >Brick3: 192.168.24.20:/bricks/brick06/images3 > >>> >> >> >>>> >>>>> >> >Options Reconfigured: > >>> >> >> >>>> >>>>> >> >performance.client-io-threads: on > >>> >> >> >>>> >>>>> >> >nfs.disable: on > >>> >> >> >>>> >>>>> >> >transport.address-family: inet > >>> >> >> >>>> >>>>> >> >user.cifs: off > >>> >> >> >>>> >>>>> >> >auth.allow: * > >>> >> >> >>>> >>>>> >> >performance.quick-read: off > >>> >> >> >>>> >>>>> >> >performance.read-ahead: off > >>> >> >> >>>> >>>>> >> >performance.io-cache: off > >>> >> >> >>>> >>>>> >> >performance.low-prio-threads: 32 > >>> >> >> >>>> >>>>> >> >network.remote-dio: off > >>> >> >> >>>> >>>>> >> >cluster.eager-lock: enable > >>> >> >> >>>> >>>>> >> >cluster.quorum-type: auto > >>> >> >> >>>> >>>>> >> >cluster.server-quorum-type: server > >>> >> >> >>>> >>>>> >> >cluster.data-self-heal-algorithm: full > >>> >> >> >>>> >>>>> >> >cluster.locking-scheme: granular > >>> >> >> >>>> >>>>> >> >cluster.shd-max-threads: 8 > >>> >> >> >>>> >>>>> >> >cluster.shd-wait-qlength: 10000 > >>> >> >> >>>> >>>>> >> >features.shard: on > >>> >> >> >>>> >>>>> >> >cluster.choose-local: off > >>> >> >> >>>> >>>>> >> >client.event-threads: 4 > >>> >> >> >>>> >>>>> >> >server.event-threads: 4 > >>> >> >> >>>> >>>>> >> >storage.owner-uid: 36 > >>> >> >> >>>> >>>>> >> >storage.owner-gid: 36 > >>> >> >> >>>> >>>>> >> >performance.strict-o-direct: on > >>> >> >> >>>> >>>>> >> >network.ping-timeout: 30 > >>> >> >> >>>> >>>>> >> >cluster.granular-entry-heal: enable > >>> >> >> >>>> >>>>> >> > > >>> >> >> >>>> >>>>> >> > > >>> >> >> >>>> >>>>> >> >Status of volume: images3 > >>> >> >> >>>> >>>>> >> >Gluster process TCP > >>> >Port > >>> >> >> >RDMA Port > >>> >> >> >>>> >>>>> >Online > >>> >> >> >>>> >>>>> >> > Pid > >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> > >>> >> >> >>>> >>>>> > >>> >> >> >>>> > >>> >> >> >>>> > >>> >> >> > >>> >> >> > >>> >> > >>> >> > >>> > >>> > >
>>>>>>>------------------------------------------------------------------------------ > >>> >> >> >>>> >>>>> >> >Brick 192.168.24.18:/bricks/brick04/images3 > >49152 > >>> >> >0 > >>> >> >> >>>> > >>> >> >> >>>> >>>Y > >>> >> >> >>>> >>>>> >> >6666 > >>> >> >> >>>> >>>>> >> >Brick 192.168.24.19:/bricks/brick05/images3 > >49152 > >>> >> >0 > >>> >> >> >>>> > >>> >> >> >>>> >>>Y > >>> >> >> >>>> >>>>> >> >6779 > >>> >> >> >>>> >>>>> >> >Brick 192.168.24.20:/bricks/brick06/images3 > >49152 > >>> >> >0 > >>> >> >> >>>> > >>> >> >> >>>> >>>Y > >>> >> >> >>>> >>>>> >> >7227 > >>> >> >> >>>> >>>>> >> >Self-heal Daemon on localhost N/A > >>> >> >N/A > >>> >> >> >>>> > >>> >> >> >>>> >>>Y > >>> >> >> >>>> >>>>> >> >6689 > >>> >> >> >>>> >>>>> >> >Self-heal Daemon on ov07.ntc.srcle.com N/A > >>> >> >N/A > >>> >> >> >>>> > >>> >> >> >>>> >>>Y > >>> >> >> >>>> >>>>> >> >6802 > >>> >> >> >>>> >>>>> >> >Self-heal Daemon on ov08.ntc.srcle.com N/A > >>> >> >N/A > >>> >> >> >>>> > >>> >> >> >>>> >>>Y > >>> >> >> >>>> >>>>> >> >7250 > >>> >> >> >>>> >>>>> >> > > >>> >> >> >>>> >>>>> >> >Task Status of Volume images3 > >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> > >>> >> >> >>>> >>>>> > >>> >> >> >>>> > >>> >> >> >>>> > >>> >> >> > >>> >> >> > >>> >> > >>> >> > >>> > >>> > >
>>>>>>>------------------------------------------------------------------------------ > >>> >> >> >>>> >>>>> >> >There are no active volume tasks > >>> >> >> >>>> >>>>> >> > > >>> >> >> >>>> >>>>> >> > > >>> >> >> >>>> >>>>> >> > > >>> >> >> >>>> >>>>> >> > > >>> >> >> >>>> >>>>> >> >[root@ov06 ~]# ls -l > >>> >/rhev/data-center/mnt/glusterSD/ > >>> >> >> >>>> >>>>> >> >total 16 > >>> >> >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 > >>> >> >> >192.168.24.15:_images > >>> >> >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 > >>> >> >192.168.24.18: > >>> >> >> >>>> _images3 > >>> >> >> >>>> >>>>> >> >[root@ov06 ~]# > >>> >> >> >>>> >>>>> >> > > >>> >> >> >>>> >>>>> >> >On Thu, Jun 18, 2020 at 2:03 PM C Williams > >>> >> >> >>>> >>><cwilliams3320@gmail.com> > >>> >> >> >>>> >>>>> >> >wrote: > >>> >> >> >>>> >>>>> >> > > >>> >> >> >>>> >>>>> >> >> Strahil, > >>> >> >> >>>> >>>>> >> >> > >>> >> >> >>>> >>>>> >> >> Here you go -- Thank You For Your Help ! > >>> >> >> >>>> >>>>> >> >> > >>> >> >> >>>> >>>>> >> >> BTW -- I can write a test file to gluster and > >it > >>> >> >> >replicates > >>> >> >> >>>> >>>>> >properly. > >>> >> >> >>>> >>>>> >> >> Thinking something about the oVirt Storage > >Domain > >>> >? > >>> >> >> >>>> >>>>> >> >> > >>> >> >> >>>> >>>>> >> >> [root@ov08 ~]# gluster pool list > >>> >> >> >>>> >>>>> >> >> UUID > >Hostname > >>> >> >> >>>> >>>>> >State > >>> >> >> >>>> >>>>> >> >> 5b40c659-d9ab-43c3-9af8-18b074ea0b83 ov06 > >>> >> >> >>>> >>>>> >> >Connected > >>> >> >> >>>> >>>>> >> >> 36ce5a00-6f65-4926-8438-696944ebadb5 > >>> >> >> >ov07.ntc.srcle.com > >>> >> >> >>>> >>>>> >> >Connected > >>> >> >> >>>> >>>>> >> >> c7e7abdb-a8f4-4842-924c-e227f0db1b29 > >localhost > >>> >> >> >>>> >>>>> >> >Connected > >>> >> >> >>>> >>>>> >> >> [root@ov08 ~]# gluster volume list > >>> >> >> >>>> >>>>> >> >> images3 > >>> >> >> >>>> >>>>> >> >> > >>> >> >> >>>> >>>>> >> >> On Thu, Jun 18, 2020 at 1:13 PM Strahil > >Nikolov > >>> >> >> >>>> >>>>> >> ><hunter86_bg@yahoo.com> > >>> >> >> >>>> >>>>> >> >> wrote: > >>> >> >> >>>> >>>>> >> >> > >>> >> >> >>>> >>>>> >> >>> Log to the oVirt cluster and provide the > >output > >>> >of: > >>> >> >> >>>> >>>>> >> >>> gluster pool list > >>> >> >> >>>> >>>>> >> >>> gluster volume list > >>> >> >> >>>> >>>>> >> >>> for i in $(gluster volume list); do echo > >>> >$i;echo; > >>> >> >> >gluster > >>> >> >> >>>> >>>>> >volume > >>> >> >> >>>> >>>>> >> >info > >>> >> >> >>>> >>>>> >> >>> $i; echo;echo;gluster volume status > >>> >> >> >$i;echo;echo;echo;done > >>> >> >> >>>> >>>>> >> >>> > >>> >> >> >>>> >>>>> >> >>> ls -l /rhev/data-center/mnt/glusterSD/ > >>> >> >> >>>> >>>>> >> >>> > >>> >> >> >>>> >>>>> >> >>> Best Regards, > >>> >> >> >>>> >>>>> >> >>> Strahil Nikolov > >>> >> >> >>>> >>>>> >> >>> > >>> >> >> >>>> >>>>> >> >>> > >>> >> >> >>>> >>>>> >> >>> На 18 юни 2020 г. 19:17:46 GMT+03:00, C > >Williams > >>> >> >> >>>> >>>>> >> ><cwilliams3320@gmail.com> > >>> >> >> >>>> >>>>> >> >>> написа: > >>> >> >> >>>> >>>>> >> >>> >Hello, > >>> >> >> >>>> >>>>> >> >>> > > >>> >> >> >>>> >>>>> >> >>> >I recently added 6 hosts to an existing > >oVirt > >>> >> >> >>>> >>>compute/gluster > >>> >> >> >>>> >>>>> >> >cluster. > >>> >> >> >>>> >>>>> >> >>> > > >>> >> >> >>>> >>>>> >> >>> >Prior to this attempted addition, my > >cluster > >>> >had 3 > >>> >> >> >>>> >>>Hypervisor > >>> >> >> >>>> >>>>> >hosts > >>> >> >> >>>> >>>>> >> >and > >>> >> >> >>>> >>>>> >> >>> >3 > >>> >> >> >>>> >>>>> >> >>> >gluster bricks which made up a single > >gluster > >>> >> >volume > >>> >> >> >>>> >>>(replica 3 > >>> >> >> >>>> >>>>> >> >volume) > >>> >> >> >>>> >>>>> >> >>> >. I > >>> >> >> >>>> >>>>> >> >>> >added the additional hosts and made a brick > >on > >>> >3 > >>> >> >of > >>> >> >> >the new > >>> >> >> >>>> >>>>> >hosts > >>> >> >> >>>> >>>>> >> >and > >>> >> >> >>>> >>>>> >> >>> >attempted to make a new replica 3 volume. I > >had > >>> >> >> >difficulty > >>> >> >> >>>> >>>>> >> >creating > >>> >> >> >>>> >>>>> >> >>> >the > >>> >> >> >>>> >>>>> >> >>> >new volume. So, I decided that I would make > >a > >>> >new > >>> >> >> >>>> >>>>> >compute/gluster > >>> >> >> >>>> >>>>> >> >>> >cluster > >>> >> >> >>>> >>>>> >> >>> >for each set of 3 new hosts. > >>> >> >> >>>> >>>>> >> >>> > > >>> >> >> >>>> >>>>> >> >>> >I removed the 6 new hosts from the existing > >>> >oVirt > >>> >> >> >>>> >>>>> >Compute/Gluster > >>> >> >> >>>> >>>>> >> >>> >Cluster > >>> >> >> >>>> >>>>> >> >>> >leaving the 3 original hosts in place with > >>> >their > >>> >> >> >bricks. At > >>> >> >> >>>> >>>that > >>> >> >> >>>> >>>>> >> >point > >>> >> >> >>>> >>>>> >> >>> >my > >>> >> >> >>>> >>>>> >> >>> >original bricks went down and came back up > >. > >>> >The > >>> >> >> >volume > >>> >> >> >>>> >>>showed > >>> >> >> >>>> >>>>> >> >entries > >>> >> >> >>>> >>>>> >> >>> >that > >>> >> >> >>>> >>>>> >> >>> >needed healing. At that point I ran gluster > >>> >volume > >>> >> >> >heal > >>> >> >> >>>> >>>images3 > >>> >> >> >>>> >>>>> >> >full, > >>> >> >> >>>> >>>>> >> >>> >etc. > >>> >> >> >>>> >>>>> >> >>> >The volume shows no unhealed entries. I > >also > >>> >> >> >corrected some > >>> >> >> >>>> >>>peer > >>> >> >> >>>> >>>>> >> >>> >errors. > >>> >> >> >>>> >>>>> >> >>> > > >>> >> >> >>>> >>>>> >> >>> >However, I am unable to copy disks, move > >disks > >>> >to > >>> >> >> >another > >>> >> >> >>>> >>>>> >domain, > >>> >> >> >>>> >>>>> >> >>> >export > >>> >> >> >>>> >>>>> >> >>> >disks, etc. It appears that the engine > >cannot > >>> >> >locate > >>> >> >> >disks > >>> >> >> >>>> >>>>> >properly > >>> >> >> >>>> >>>>> >> >and > >>> >> >> >>>> >>>>> >> >>> >I > >>> >> >> >>>> >>>>> >> >>> >get storage I/O errors. > >>> >> >> >>>> >>>>> >> >>> > > >>> >> >> >>>> >>>>> >> >>> >I have detached and removed the oVirt > >Storage > >>> >> >Domain. > >>> >> >> >I > >>> >> >> >>>> >>>>> >reimported > >>> >> >> >>>> >>>>> >> >the > >>> >> >> >>>> >>>>> >> >>> >domain and imported 2 VMs, But the VM disks > >>> >> >exhibit > >>> >> >> >the > >>> >> >> >>>> same > >>> >> >> >>>> >>>>> >> >behaviour > >>> >> >> >>>> >>>>> >> >>> >and > >>> >> >> >>>> >>>>> >> >>> >won't run from the hard disk. > >>> >> >> >>>> >>>>> >> >>> > > >>> >> >> >>>> >>>>> >> >>> > > >>> >> >> >>>> >>>>> >> >>> >I get errors such as this > >>> >> >> >>>> >>>>> >> >>> > > >>> >> >> >>>> >>>>> >> >>> >VDSM ov05 command HSMGetAllTasksStatusesVDS > >>> >> >failed: > >>> >> >> >low > >>> >> >> >>>> >>>level > >>> >> >> >>>> >>>>> >Image > >>> >> >> >>>> >>>>> >> >>> >copy > >>> >> >> >>>> >>>>> >> >>> >failed: ("Command ['/usr/bin/qemu-img', > >>> >'convert', > >>> >> >> >'-p', > >>> >> >> >>>> >>>'-t', > >>> >> >> >>>> >>>>> >> >'none', > >>> >> >> >>>> >>>>> >> >>> >'-T', 'none', '-f', 'raw', > >>> >> >> >>>> >>>>> >> >>> > >>> >>u'/rhev/data-center/mnt/glusterSD/192.168.24.18: > >>> >> >> >>>> >>>>> >> >>> > >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> > >>> >> >> >>>> >>>>> > >>> >> >> >>>> > >>> >> >> >>>> > >>> >> >> > >>> >> >> > >>> >> > >>> >> > >>> > >>> > >
>>>>>>>_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510', > >>> >> >> >>>> >>>>> >> >>> >'-O', 'raw', > >>> >> >> >>>> >>>>> >> >>> u'/rhev/data-center/mnt/192.168.24.13: > >>> >> >> >>>> >>>>> >> >>> > >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> > >>> >> >> >>>> >>>>> > >>> >> >> >>>> > >>> >> >> >>>> > >>> >> >> > >>> >> >> > >>> >> > >>> >> > >>> > >>> > >
>>>>>>>_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5'] > >>> >> >> >>>> >>>>> >> >>> >failed with rc=1 out='' > >>> >err=bytearray(b'qemu-img: > >>> >> >> >error > >>> >> >> >>>> >>>while > >>> >> >> >>>> >>>>> >> >reading > >>> >> >> >>>> >>>>> >> >>> >sector 135168: Transport endpoint is not > >>> >> >> >>>> >>>connected\\nqemu-img: > >>> >> >> >>>> >>>>> >> >error > >>> >> >> >>>> >>>>> >> >>> >while > >>> >> >> >>>> >>>>> >> >>> >reading sector 131072: Transport endpoint > >is > >>> >not > >>> >> >> >>>> >>>>> >> >connected\\nqemu-img: > >>> >> >> >>>> >>>>> >> >>> >error while reading sector 139264: > >Transport > >>> >> >endpoint > >>> >> >> >is > >>> >> >> >>>> not > >>> >> >> >>>> >>>>> >> >>> >connected\\nqemu-img: error while reading > >>> >sector > >>> >> >> >143360: > >>> >> >> >>>> >>>>> >Transport > >>> >> >> >>>> >>>>> >> >>> >endpoint > >>> >> >> >>>> >>>>> >> >>> >is not connected\\nqemu-img: error while > >>> >reading > >>> >> >> >sector > >>> >> >> >>>> >>>147456: > >>> >> >> >>>> >>>>> >> >>> >Transport > >>> >> >> >>>> >>>>> >> >>> >endpoint is not connected\\nqemu-img: error > >>> >while > >>> >> >> >reading > >>> >> >> >>>> >>>sector > >>> >> >> >>>> >>>>> >> >>> >155648: > >>> >> >> >>>> >>>>> >> >>> >Transport endpoint is not > >connected\\nqemu-img: > >>> >> >error > >>> >> >> >while > >>> >> >> >>>> >>>>> >reading > >>> >> >> >>>> >>>>> >> >>> >sector > >>> >> >> >>>> >>>>> >> >>> >151552: Transport endpoint is not > >>> >> >> >connected\\nqemu-img: > >>> >> >> >>>> >>>error > >>> >> >> >>>> >>>>> >while > >>> >> >> >>>> >>>>> >> >>> >reading > >>> >> >> >>>> >>>>> >> >>> >sector 159744: Transport endpoint is not > >>> >> >> >connected\\n')",) > >>> >> >> >>>> >>>>> >> >>> > > >>> >> >> >>>> >>>>> >> >>> >oVirt version is 4.3.82-1.el7 > >>> >> >> >>>> >>>>> >> >>> >OS CentOS Linux release 7.7.1908 (Core) > >>> >> >> >>>> >>>>> >> >>> > > >>> >> >> >>>> >>>>> >> >>> >The Gluster Cluster has been working very > >well > >>> >> >until > >>> >> >> >this > >>> >> >> >>>> >>>>> >incident. > >>> >> >> >>>> >>>>> >> >>> > > >>> >> >> >>>> >>>>> >> >>> >Please help. > >>> >> >> >>>> >>>>> >> >>> > > >>> >> >> >>>> >>>>> >> >>> >Thank You > >>> >> >> >>>> >>>>> >> >>> > > >>> >> >> >>>> >>>>> >> >>> >Charles Williams > >>> >> >> >>>> >>>>> >> >>> > >>> >> >> >>>> >>>>> >> >> > >>> >> >> >>>> >>>>> >> > >>> >> >> >>>> >>>>> > >>> >> >> >>>> >>>> > >>> >> >> >>>> >> > >>> >> >> >>>> > > >>> >> >> >>>> _______________________________________________ > >>> >> >> >>>> Users mailing list -- users@ovirt.org > >>> >> >> >>>> To unsubscribe send an email to users-leave@ovirt.org > >>> >> >> >>>> Privacy Statement: > >https://www.ovirt.org/privacy-policy.html > >>> >> >> >>>> oVirt Code of Conduct: > >>> >> >> >>>> > >https://www.ovirt.org/community/about/community-guidelines/ > >>> >> >> >>>> List Archives: > >>> >> >> >>>> > >>> >> >> > > >>> >> >> > >>> >> > > >>> >> > >>> > > >>> > > >
https://lists.ovirt.org/archives/list/users@ovirt.org/message/YY3VUKEJLI7MRW...
> >>> >> >> >>>> > >>> >> >> >>> > >>> >> >> > >>> >> > >>> > >> >
As far as I know, oVirt 4.4 uses gluster v7.X , so you will eventually have to upgrade the version. As I mentioned, I have created my new volume while I was running a higher version and copied the data to it, which prevented the acl bug hitting me again. I can recommend you to: 1. Mount the new gluster volume via FUSE 2. Wipe the data, as you don't need it 3. Attach the new gluster volume as a fresh storage domain in ovirt 4. Live migrate the VM disks to the new volume prior to upgrading gluster I cannot guarantee that the issue will be avoided , but it's worth trying . Best Regards, Strahil Nikolov На 23 юни 2020 г. 23:42:13 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Strahil,
Thanks for getting back with me !
Sounds like it is best to evacuate VM disks to another storage domain -- if possible from a Gluster storage domain -- prior to an upgrade .
Per your questions ...
1. Which version of oVirt and Gluster are you using ? oVirt 4.3.8.2-1 Gluster 6.5 , 6.7, 6.9 (depends on the cluster)
2. You now have your old gluster volume attached to oVirt and the new volume unused, right ? Correct -- intending to dispose of data on the new volume since the old one is now working
3. Did you copy the contents of the old volume to the new one ? I did prior to trying to downgrade the Gluster version on the hosts for the old volume. I am planning to delete the data now that the old volume is working.
Thanks Again For Your Help !!
On Mon, Jun 22, 2020 at 11:34 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
As I told you, you could just downgrade gluster on all nodes and later plan to live migrate the VM disks. I had to copy my data to the new volume, so I can avoid the ACL bug , when I use newer versions of gluster.
Let's clarify some details: 1. Which version of oVirt and Gluster are you using ? 2. You now have your old gluster volume attached to oVirt and the new volume unused, right ? 3. Did you copy the contents of the old volume to the new one ?
Best Regards, Strahil Nikolov
Strahil,
Thank You For Help !
Downgrading Gluster to 6.5 got the original storage domain working again !
After, I finished my copy of the contents of the problematic volume to a new volume, I did the following
Unmounted the mount points Stopped the original problematic Gluster volume On each problematic peer, I downgraded Gluster to 6.5 (yum downgrade glusterfs-6.5-1.el7.x86_64 vdsm-gluster-4.30.46-1.el7.x86_64 python2-gluster-6.5-1.el7.x86_64 glusterfs-libs-6.5-1.el7.x86_64 glusterfs-cli-6.5-1.el7.x86_64 glusterfs-fuse-6.5-1.el7.x86_64 glusterfs-rdma-6.5-1.el7.x86_64 glusterfs-api-6.5-1.el7.x86_64 glusterfs-server-6.5-1.el7.x86_64 glusterfs-events-6.5-1.el7.x86_64 glusterfs-client-xlators-6.5-1.el7.x86_64 glusterfs-geo-replication-6.5-1.el7.x86_64) Restarted glusterd (systemctl restart glusterd) Restarted the problematic Gluster volume Reattached the problematic storage domain Started the problematic storage domain
Things work now. I can now run VMs and write data, copy virtual disks, move virtual disks to other storage domains, etc.
I am very thankful that the storage domain is working again !
How can I safely perform upgrades on Gluster ! When will it be safe to do so ?
Thank You Again For Your Help !
On Mon, Jun 22, 2020 at 10:58 AM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
I have downgraded the target. The copy from the problematic volume to the target is going on now. Once I have the data copied, I might downgrade the problematic volume's Gluster to 6.5. At that point I might reattach the original ovirt domain and see if it will work again. But the copy is going on right now.
Thank You For Your Help !
On Mon, Jun 22, 2020 at 10:52 AM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
You should ensure that in the storage domain tab, the old storage is not visible.
I still wander why yoiu didn't try to downgrade first.
Best Regards, Strahil Nikolov
Strahil,
The GLCL3 storage domain was detached prior to attempting to add
new storage domain.
Should I also "Remove" it ?
Thank You For Your Help !
---------- Forwarded message --------- From: Strahil Nikolov <hunter86_bg@yahoo.com> Date: Mon, Jun 22, 2020 at 12:50 AM Subject: Re: [ovirt-users] Re: Fwd: Fwd: Issues with Gluster Domain To: C Williams <cwilliams3320@gmail.com> Cc: users <Users@ovirt.org>
You can't add the new volume as it contains the same data (UUID) as
На 22 юни 2020 г. 13:58:33 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: the the
old one , thus you need to detach the old one before adding the new one
of course this means downtime for all VMs on that storage.
As you see , downgrading is more simpler. For me v6.5 was working, while anything above (6.6+) was causing complete lockdown. Also v7.0 was working, but it's supported in oVirt 4.4.
Best Regards, Strahil Nikolov
На 22 юни 2020 г. 7:21:15 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: >Another question > >What version could I downgrade to safely ? I am at 6.9 . > >Thank You For Your Help !! > >On Sun, Jun 21, 2020 at 11:38 PM Strahil Nikolov ><hunter86_bg@yahoo.com> >wrote: > >> You are definitely reading it wrong. >> 1. I didn't create a new storage domain ontop this new volume. >> 2. I used cli >> >> Something like this (in your case it should be 'replica 3'): >> gluster volume create newvol replica 3 arbiter 1 >ovirt1:/new/brick/path >> ovirt2:/new/brick/path ovirt3:/new/arbiter/brick/path >> gluster volume start newvol >> >> #Detach oldvol from ovirt >> >> mount -t glusterfs ovirt1:/oldvol /mnt/oldvol >> mount -t glusterfs ovirt1:/newvol /mnt/newvol >> cp -a /mnt/oldvol/* /mnt/newvol >> >> #Add only newvol as a storage domain in oVirt >> #Import VMs >> >> I still think that you should downgrade your gluster
>> >> Best Regards, >> Strahil Nikolov >> >> На 22 юни 2020 г. 0:43:46 GMT+03:00, C Williams ><cwilliams3320@gmail.com> >> написа: >> >Strahil, >> > >> >It sounds like you used a "System Managed Volume" for the new >storage >> >domain,is that correct? >> > >> >Thank You For Your Help ! >> > >> >On Sun, Jun 21, 2020 at 5:40 PM C Williams <cwilliams3320@gmail.com> >> >wrote: >> > >> >> Strahil, >> >> >> >> So you made another oVirt Storage Domain -- then copied
data
>with >> >cp >> >> -a from the failed volume to the new volume. >> >> >> >> At the root of the volume there will be the old domain folder id >ex >> >> 5fe3ad3f-2d21-404c-832e-4dc7318ca10d >> >> in my case. Did that cause issues with making the new domain >since >> >it is >> >> the same folder id as the old one ? >> >> >> >> Thank You For Your Help ! >> >> >> >> On Sun, Jun 21, 2020 at 5:18 PM Strahil Nikolov >> ><hunter86_bg@yahoo.com> >> >> wrote: >> >> >> >>> In my situation I had only the ovirt nodes. >> >>> >> >>> На 21 юни 2020 г. 22:43:04 GMT+03:00, C Williams >> ><cwilliams3320@gmail.com> >> >>> написа: >> >>> >Strahil, >> >>> > >> >>> >So should I make the target volume on 3 bricks which do not have >> >ovirt >> >>> >-- >> >>> >just gluster ? In other words (3) Centos 7 hosts ? >> >>> > >> >>> >Thank You For Your Help ! >> >>> > >> >>> >On Sun, Jun 21, 2020 at 3:08 PM Strahil Nikolov >> ><hunter86_bg@yahoo.com> >> >>> >wrote: >> >>> > >> >>> >> I created a fresh volume (which is not an ovirt sgorage >> >domain), >> >>> >set >> >>> >> the original storage domain in maintenance and detached >it. >> >>> >> Then I 'cp -a ' the data from the old to the new volume. >Next, >> >I >> >>> >just >> >>> >> added the new storage domain (the old one was a kind >of a >> >>> >> 'backup') - pointing to the new volume name. >> >>> >> >> >>> >> If you observe issues , I would recommend you to >downgrade >> >>> >> gluster packages one node at a time . Then you might be >able >> >to >> >>> >> restore your oVirt operations. >> >>> >> >> >>> >> Best Regards, >> >>> >> Strahil Nikolov >> >>> >> >> >>> >> На 21 юни 2020 г. 18:01:31 GMT+03:00, C Williams >> >>> ><cwilliams3320@gmail.com> >> >>> >> написа: >> >>> >> >Strahil, >> >>> >> > >> >>> >> >Thanks for the follow up ! >> >>> >> > >> >>> >> >How did you copy the data to another volume ? >> >>> >> > >> >>> >> >I have set up another storage domain GLCLNEW1 with a new >volume >> >>> >imgnew1 >> >>> >> >. >> >>> >> >How would you copy all of the data from the
На 23 юни 2020 г. 4:34:19 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: packages!!! the problematic
>domain >> >GLCL3 >> >>> >> >with >> >>> >> >volume images3 to GLCLNEW1 and volume imgnew1 and preserve >all >> >the >> >>> >VMs, >> >>> >> >VM >> >>> >> >disks, settings, etc. ? >> >>> >> > >> >>> >> >Remember all of the regular ovirt disk copy, disk move, VM >> >export >> >>> >> >tools >> >>> >> >are failing and my VMs and disks are trapped on domain GLCL3 >and >> >>> >volume >> >>> >> >images3 right now. >> >>> >> > >> >>> >> >Please let me know >> >>> >> > >> >>> >> >Thank You For Your Help ! >> >>> >> > >> >>> >> > >> >>> >> > >> >>> >> > >> >>> >> > >> >>> >> >On Sun, Jun 21, 2020 at 8:27 AM Strahil Nikolov >> >>> ><hunter86_bg@yahoo.com> >> >>> >> >wrote: >> >>> >> > >> >>> >> >> Sorry to hear that. >> >>> >> >> I can say that for me 6.5 was working, while 6.6 didn't >> >and I >> >>> >> >upgraded >> >>> >> >> to 7.0 . >> >>> >> >> In the ended , I have ended with creating a new fresh >> >volume >> >>> >and >> >>> >> >> physically copying the data there, then I detached the >> >storage >> >>> >> >domains and >> >>> >> >> attached to the new ones (which holded the old data), >but >> >I >> >>> >> >could >> >>> >> >> afford the downtime. >> >>> >> >> Also, I can say that v7.0 ( but not 7.1 or anything >later) >> >>> >also >> >>> >> >> worked without the ACL issue, but it causes some trouble >> >in >> >>> >oVirt >> >>> >> >- so >> >>> >> >> avoid that unless you have no other options. >> >>> >> >> >> >>> >> >> Best Regards, >> >>> >> >> Strahil Nikolov >> >>> >> >> >> >>> >> >> >> >>> >> >> >> >>> >> >> >> >>> >> >> На 21 юни 2020 г. 4:39:46 GMT+03:00, C Williams >> >>> >> ><cwilliams3320@gmail.com> >> >>> >> >> написа: >> >>> >> >> >Hello, >> >>> >> >> > >> >>> >> >> >Upgrading diidn't help >> >>> >> >> > >> >>> >> >> >Still acl errors trying to use a Virtual Disk from a VM >> >>> >> >> > >> >>> >> >> >[root@ov06 bricks]# tail bricks-brick04-images3.log | grep >> >acl >> >>> >> >> >[2020-06-21 01:33:45.665888] I [MSGID: 139001] >> >>> >> >> >[posix-acl.c:263:posix_acl_log_permit_denied] >> >>> >> >0-images3-access-control: >> >>> >> >> >client: >> >>> >> >> >> >>> >> >> >> >>> >> >> >>> >> >> >>> >> >>> >> >>
>>CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0, >> >>> >> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >> >>> >> >> >req(uid:107,gid:107,perm:1,ngrps:3), >> >>> >> >> ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, >> >acl:-) >> >>> >> >> >[Permission denied] >> >>> >> >> >The message "I [MSGID: 139001] >> >>> >> >> >[posix-acl.c:263:posix_acl_log_permit_denied] >> >>> >> >0-images3-access-control: >> >>> >> >> >client: >> >>> >> >> >> >>> >> >> >> >>> >> >> >>> >> >> >>> >> >>> >> >>
>>CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0, >> >>> >> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >> >>> >> >> >req(uid:107,gid:107,perm:1,ngrps:3), >> >>> >> >> ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, >> >acl:-) >> >>> >> >> >[Permission denied]" repeated 2 times between [2020-06-21 >> >>> >> >> >01:33:45.665888] >> >>> >> >> >and [2020-06-21 01:33:45.806779] >> >>> >> >> > >> >>> >> >> >Thank You For Your Help ! >> >>> >> >> > >> >>> >> >> >On Sat, Jun 20, 2020 at 8:59 PM C Williams >> >>> ><cwilliams3320@gmail.com> >> >>> >> >> >wrote: >> >>> >> >> > >> >>> >> >> >> Hello, >> >>> >> >> >> >> >>> >> >> >> Based on the situation, I am planning to upgrade the 3 >> >affected >> >>> >> >> >hosts. >> >>> >> >> >> >> >>> >> >> >> My reasoning is that the hosts/bricks were attached to >6.9 >> >at >> >>> >one >> >>> >> >> >time. >> >>> >> >> >> >> >>> >> >> >> Thanks For Your Help ! >> >>> >> >> >> >> >>> >> >> >> On Sat, Jun 20, 2020 at 8:38 PM C Williams >> >>> >> ><cwilliams3320@gmail.com> >> >>> >> >> >> wrote: >> >>> >> >> >> >> >>> >> >> >>> Strahil, >> >>> >> >> >>> >> >>> >> >> >>> The gluster version on the current 3 gluster hosts is >6.7 >> >>> >(last >> >>> >> >> >update >> >>> >> >> >>> 2/26). These 3 hosts provide 1 brick each for the >replica >> >3 >> >>> >> >volume. >> >>> >> >> >>> >> >>> >> >> >>> Earlier I had tried to add 6 additional hosts to the >> >cluster. >> >>> >> >Those >> >>> >> >> >new >> >>> >> >> >>> hosts were 6.9 gluster. >> >>> >> >> >>> >> >>> >> >> >>> I attempted to make a new separate volume with 3 bricks >> >>> >provided >> >>> >> >by >> >>> >> >> >the 3 >> >>> >> >> >>> new gluster 6.9 hosts. After having many errors from >the >> >>> >oVirt >> >>> >> >> >interface, >> >>> >> >> >>> I gave up and removed the 6 new hosts from the cluster. >> >That >> >>> >is >> >>> >> >> >where the >> >>> >> >> >>> problems started. The intent was to expand the gluster >> >cluster >> >>> >> >while >> >>> >> >> >making >> >>> >> >> >>> 2 new volumes for that cluster. The ovirt compute >cluster >> >>> >would >> >>> >> >> >allow for >> >>> >> >> >>> efficient VM migration between 9 hosts -- while having >> >>> >separate >> >>> >> >> >gluster >> >>> >> >> >>> volumes for safety purposes. >> >>> >> >> >>> >> >>> >> >> >>> Looking at the brick logs, I see where there are acl >> >errors >> >>> >> >starting >> >>> >> >> >from >> >>> >> >> >>> the time of the removal of the 6 new hosts. >> >>> >> >> >>> >> >>> >> >> >>> Please check out the attached brick log from 6/14-18. >The >> >>> >events >> >>> >> >> >started >> >>> >> >> >>> on 6/17. >> >>> >> >> >>> >> >>> >> >> >>> I wish I had a downgrade path. >> >>> >> >> >>> >> >>> >> >> >>> Thank You For The Help !! >> >>> >> >> >>> >> >>> >> >> >>> On Sat, Jun 20, 2020 at 7:47 PM Strahil Nikolov >> >>> >> >> ><hunter86_bg@yahoo.com> >> >>> >> >> >>> wrote: >> >>> >> >> >>> >> >>> >> >> >>>> Hi , >> >>> >> >> >>>> >> >>> >> >> >>>> >> >>> >> >> >>>> This one really looks like the ACL bug I was hit with >> >when I >> >>> >> >> >updated >> >>> >> >> >>>> from Gluster v6.5 to 6.6 and later from 7.0 to 7.2. >> >>> >> >> >>>> >> >>> >> >> >>>> Did you update your setup recently ? Did you upgrade >> >gluster >> >>> >> >also ? >> >>> >> >> >>>> >> >>> >> >> >>>> You have to check the gluster logs in order to verify >> >that, >> >>> >so >> >>> >> >you >> >>> >> >> >can >> >>> >> >> >>>> try: >> >>> >> >> >>>> >> >>> >> >> >>>> 1. Set Gluster logs to trace level (for details check: >> >>> >> >> >>>> >> >>> >> >> > >> >>> >> >> >> >>> >> > >> >>> >> >> >>> > >> >>> >> > >> >
>> >>> >> >> >>>> ) >> >>> >> >> >>>> 2. Power up a VM that was already off , or retry the >> >>> >procedure >> >>> >> >from >> >>> >> >> >the >> >>> >> >> >>>> logs you sent. >> >>> >> >> >>>> 3. Stop the trace level of the logs >> >>> >> >> >>>> 4. Check libvirt logs on the host that was supposed to >> >power >> >>> >up >> >>> >> >the >> >>> >> >> >VM >> >>> >> >> >>>> (in case a VM was powered on) >> >>> >> >> >>>> 5. Check the gluster brick logs on all nodes for ACL >> >errors. >> >>> >> >> >>>> Here is a sample from my old logs: >> >>> >> >> >>>> >> >>> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 >> >>> >> >> >13:19:41.489047] I >> >>> >> >> >>>> [MSGID: 139001] >> >[posix-acl.c:262:posix_acl_log_permit_denied] >> >>> >> >> >>>> 0-data_fast4-access-control: client: >> >CTX_ID:4a654305-d2e4- >> >>> >> >> >>>> >> >>> >> >> >> >>> >> >> >> >>> >> >> >>> >> >> >>> >> >>> >> >>
>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, >> >>> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >> >>> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx >> >>> >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, >> >acl:-) >> >>> >> >> >>>> [Permission denied] >> >>> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 >> >>> >> >> >13:22:51.818796] I >> >>> >> >> >>>> [MSGID: 139001] >> >[posix-acl.c:262:posix_acl_log_permit_denied] >> >>> >> >> >>>> 0-data_fast4-access-control: client: >> >CTX_ID:4a654305-d2e4- >> >>> >> >> >>>> >> >>> >> >> >> >>> >> >> >> >>> >> >> >>> >> >> >>> >> >>> >> >>
>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, >> >>> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >> >>> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx >> >>> >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, >> >acl:-) >> >>> >> >> >>>> [Permission denied] >> >>> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 >> >>> >> >> >13:24:43.732856] I >> >>> >> >> >>>> [MSGID: 139001] >> >[posix-acl.c:262:posix_acl_log_permit_denied] >> >>> >> >> >>>> 0-data_fast4-access-control: client: >> >CTX_ID:4a654305-d2e4- >> >>> >> >> >>>> >> >>> >> >> >> >>> >> >> >> >>> >> >> >>> >> >> >>> >> >>> >> >>
>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, >> >>> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >> >>> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx >> >>> >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, >> >acl:-) >> >>> >> >> >>>> [Permission denied] >> >>> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 >> >>> >> >> >13:26:50.758178] I >> >>> >> >> >>>> [MSGID: 139001] >> >[posix-acl.c:262:posix_acl_log_permit_denied] >> >>> >> >> >>>> 0-data_fast4-access-control: client: >> >CTX_ID:4a654305-d2e4- >> >>> >> >> >>>> >> >>> >> >> >> >>> >> >> >> >>> >> >> >>> >> >> >>> >> >>> >> >>
>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, >> >>> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >> >>> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx >> >>> >> >> >>>> (uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, >> >acl:-) >> >>> >> >> >>>> [Permission denied] >> >>> >> >> >>>> >> >>> >> >> >>>> >> >>> >> >> >>>> In my case , the workaround was to downgrade
>gluster >> >>> >> >packages >> >>> >> >> >on all >> >>> >> >> >>>> nodes (and reboot each node 1 by 1 ) if the major >version >> >is >> >>> >the >> >>> >> >> >same, but >> >>> >> >> >>>> if you upgraded to v7.X - then you can try the v7.0 . >> >>> >> >> >>>> >> >>> >> >> >>>> Best Regards, >> >>> >> >> >>>> Strahil Nikolov >> >>> >> >> >>>> >> >>> >> >> >>>> >> >>> >> >> >>>> >> >>> >> >> >>>> >> >>> >> >> >>>> >> >>> >> >> >>>> >> >>> >> >> >>>> В събота, 20 юни 2020 г., 18:48:42 ч. Гринуич+3, C >> >Williams < >> >>> >> >> >>>> cwilliams3320@gmail.com> написа: >> >>> >> >> >>>> >> >>> >> >> >>>> >> >>> >> >> >>>> >> >>> >> >> >>>> >> >>> >> >> >>>> >> >>> >> >> >>>> Hello, >> >>> >> >> >>>> >> >>> >> >> >>>> Here are additional log tiles as well as a
the >> >>> >> >problematic >> >>> >> >> >>>> Gluster storage domain. During this time I attempted >to >> >copy >> >>> >a >> >>> >> >> >virtual disk >> >>> >> >> >>>> to another domain, move a virtual disk to another >domain >> >and >> >>> >run >> >>> >> >a >> >>> >> >> >VM where >> >>> >> >> >>>> the virtual hard disk would be used. >> >>> >> >> >>>> >> >>> >> >> >>>> The copies/moves failed and the VM went into
of pause
>mode >> >when >> >>> >the >> >>> >> >> >virtual >> >>> >> >> >>>> HDD was involved. >> >>> >> >> >>>> >> >>> >> >> >>>> Please check these out. >> >>> >> >> >>>> >> >>> >> >> >>>> Thank You For Your Help ! >> >>> >> >> >>>> >> >>> >> >> >>>> On Sat, Jun 20, 2020 at 9:54 AM C Williams >> >>> >> >> ><cwilliams3320@gmail.com> >> >>> >> >> >>>> wrote: >> >>> >> >> >>>> > Strahil, >> >>> >> >> >>>> > >> >>> >> >> >>>> > I understand. Please keep me posted. >> >>> >> >> >>>> > >> >>> >> >> >>>> > Thanks For The Help ! >> >>> >> >> >>>> > >> >>> >> >> >>>> > On Sat, Jun 20, 2020 at 4:36 AM Strahil Nikolov >> >>> >> >> ><hunter86_bg@yahoo.com> >> >>> >> >> >>>> wrote: >> >>> >> >> >>>> >> Hey C Williams, >> >>> >> >> >>>> >> >> >>> >> >> >>>> >> sorry for the delay, but I couldn't get somw time >to >> >>> >check >> >>> >> >your >> >>> >> >> >>>> logs. Will try a little bit later. >> >>> >> >> >>>> >> >> >>> >> >> >>>> >> Best Regards, >> >>> >> >> >>>> >> Strahil Nikolov >> >>> >> >> >>>> >> >> >>> >> >> >>>> >> На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams < >> >>> >> >> >>>> cwilliams3320@gmail.com> написа: >> >>> >> >> >>>> >>>Hello, >> >>> >> >> >>>> >>> >> >>> >> >> >>>> >>>Was wanting to follow up on this issue. Users are >> >>> >impacted. >> >>> >> >> >>>> >>> >> >>> >> >> >>>> >>>Thank You >> >>> >> >> >>>> >>> >> >>> >> >> >>>> >>>On Fri, Jun 19, 2020 at 9:20 AM C Williams >> >>> >> >> ><cwilliams3320@gmail.com> >> >>> >> >> >>>> >>>wrote: >> >>> >> >> >>>> >>> >> >>> >> >> >>>> >>>> Hello, >> >>> >> >> >>>> >>>> >> >>> >> >> >>>> >>>> Here are the logs (some IPs are changed ) >> >>> >> >> >>>> >>>> >> >>> >> >> >>>> >>>> ov05 is the SPM >> >>> >> >> >>>> >>>> >> >>> >> >> >>>> >>>> Thank You For Your Help ! >> >>> >> >> >>>> >>>> >> >>> >> >> >>>> >>>> On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov >> >>> >> >> >>>> >>><hunter86_bg@yahoo.com> >> >>> >> >> >>>> >>>> wrote: >> >>> >> >> >>>> >>>> >> >>> >> >> >>>> >>>>> Check on the hosts tab , which is your current >SPM >> >>> >(last >> >>> >> >> >column in >> >>> >> >> >>>> >>>Admin >> >>> >> >> >>>> >>>>> UI). >> >>> >> >> >>>> >>>>> Then open the /var/log/vdsm/vdsm.log and repeat >> >the >> >>> >> >> >operation. >> >>> >> >> >>>> >>>>> Then provide the log from that host and
https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3/html... the tree the
>> >engine's >> >>> >log >> >>> >> >(on >> >>> >> >> >the >> >>> >> >> >>>> >>>>> HostedEngine VM or on your standalone engine). >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> Best Regards, >> >>> >> >> >>>> >>>>> Strahil Nikolov >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> На 18 юни 2020 г. 23:59:36 GMT+03:00, C Williams >> >>> >> >> >>>> >>><cwilliams3320@gmail.com> >> >>> >> >> >>>> >>>>> написа: >> >>> >> >> >>>> >>>>> >Resending to eliminate email issues >> >>> >> >> >>>> >>>>> > >> >>> >> >> >>>> >>>>> >---------- Forwarded message --------- >> >>> >> >> >>>> >>>>> >From: C Williams <cwilliams3320@gmail.com> >> >>> >> >> >>>> >>>>> >Date: Thu, Jun 18, 2020 at 4:01 PM >> >>> >> >> >>>> >>>>> >Subject: Re: [ovirt-users] Fwd: Issues with >> >Gluster >> >>> >> >Domain >> >>> >> >> >>>> >>>>> >To: Strahil Nikolov <hunter86_bg@yahoo.com> >> >>> >> >> >>>> >>>>> > >> >>> >> >> >>>> >>>>> > >> >>> >> >> >>>> >>>>> >Here is output from mount >> >>> >> >> >>>> >>>>> > >> >>> >> >> >>>> >>>>> >192.168.24.12:/stor/import0 on >> >>> >> >> >>>> >>>>> >>/rhev/data-center/mnt/192.168.24.12:_stor_import0 >> >>> >> >> >>>> >>>>> >type nfs4 >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >> >>> >> >> >>>> >> >>> >> >> >> >>> >> >> >> >>> >> >> >>> >> >> >>> >> >>> >> >>
>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12) >> >>> >> >> >>>> >>>>> >192.168.24.13:/stor/import1 on >> >>> >> >> >>>> >>>>> >>/rhev/data-center/mnt/192.168.24.13:_stor_import1 >> >>> >> >> >>>> >>>>> >type nfs4 >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >> >>> >> >> >>>> >> >>> >> >> >> >>> >> >> >> >>> >> >> >>> >> >> >>> >> >>> >> >>
>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >> >>> >> >> >>>> >>>>> >192.168.24.13:/stor/iso1 on >> >>> >> >> >>>> >>>>> /rhev/data-center/mnt/192.168.24.13:_stor_iso1 >> >>> >> >> >>>> >>>>> >type nfs4 >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >> >>> >> >> >>>> >> >>> >> >> >> >>> >> >> >> >>> >> >> >>> >> >> >>> >> >>> >> >>
>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >> >>> >> >> >>>> >>>>> >192.168.24.13:/stor/export0 on >> >>> >> >> >>>> >>>>> >>/rhev/data-center/mnt/192.168.24.13:_stor_export0 >> >>> >> >> >>>> >>>>> >type nfs4 >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >> >>> >> >> >>>> >> >>> >> >> >> >>> >> >> >> >>> >> >> >>> >> >> >>> >> >>> >> >>
>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >> >>> >> >> >>>> >>>>> >192.168.24.15:/images on >> >>> >> >> >>>> >>>>> >> >>/rhev/data-center/mnt/glusterSD/192.168.24.15:_images >> >>> >> >> >>>> >>>>> >type fuse.glusterfs >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >> >>> >> >> >>>> >> >>> >> >> >> >>> >> >> >> >>> >> >> >>> >> >> >>> >> >>> >> >>
>>>>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) >> >>> >> >> >>>> >>>>> >192.168.24.18:/images3 on >> >>> >> >> >>>> >>>>> >> >>/rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 >> >>> >> >> >>>> >>>>> >type fuse.glusterfs >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >> >>> >> >> >>>> >> >>> >> >> >> >>> >> >> >> >>> >> >> >>> >> >> >>> >> >>> >> >>
>>>>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) >> >>> >> >> >>>> >>>>> >tmpfs on /run/user/0 type tmpfs >> >>> >> >> >>>> >>>>> >> >>> >> (rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) >> >>> >> >> >>>> >>>>> >[root@ov06 glusterfs]# >> >>> >> >> >>>> >>>>> > >> >>> >> >> >>>> >>>>> >Also here is a screenshot of the console >> >>> >> >> >>>> >>>>> > >> >>> >> >> >>>> >>>>> >[image: image.png] >> >>> >> >> >>>> >>>>> >The other domains are up >> >>> >> >> >>>> >>>>> > >> >>> >> >> >>>> >>>>> >Import0 and Import1 are NFS . GLCL0 is gluster. >> >They >> >>> >all >> >>> >> >are >> >>> >> >> >>>> >>>running >> >>> >> >> >>>> >>>>> >VMs >> >>> >> >> >>>> >>>>> > >> >>> >> >> >>>> >>>>> >Thank You For Your Help ! >> >>> >> >> >>>> >>>>> > >> >>> >> >> >>>> >>>>> >On Thu, Jun 18, 2020 at 3:51 PM Strahil Nikolov >> >>> >> >> >>>> >>><hunter86_bg@yahoo.com> >> >>> >> >> >>>> >>>>> >wrote: >> >>> >> >> >>>> >>>>> > >> >>> >> >> >>>> >>>>> >> I don't see >> >>> >> >> '/rhev/data-center/mnt/192.168.24.13:_stor_import1' >> >>> >> >> >>>> >>>>> >mounted >> >>> >> >> >>>> >>>>> >> at all . >> >>> >> >> >>>> >>>>> >> What is the status of all storage domains ? >> >>> >> >> >>>> >>>>> >> >> >>> >> >> >>>> >>>>> >> Best Regards, >> >>> >> >> >>>> >>>>> >> Strahil Nikolov >> >>> >> >> >>>> >>>>> >> >> >>> >> >> >>>> >>>>> >> На 18 юни 2020 г. 21:43:44 GMT+03:00, C >Williams >> >>> >> >> >>>> >>>>> ><cwilliams3320@gmail.com> >> >>> >> >> >>>> >>>>> >> написа: >> >>> >> >> >>>> >>>>> >> > Resending to deal with possible email >issues >> >>> >> >> >>>> >>>>> >> > >> >>> >> >> >>>> >>>>> >> >---------- Forwarded message
>> >>> >> >> >>>> >>>>> >> >From: C Williams <cwilliams3320@gmail.com> >> >>> >> >> >>>> >>>>> >> >Date: Thu, Jun 18, 2020 at 2:07 PM >> >>> >> >> >>>> >>>>> >> >Subject: Re: [ovirt-users] Issues with >Gluster >> >>> >Domain >> >>> >> >> >>>> >>>>> >> >To: Strahil Nikolov <hunter86_bg@yahoo.com> >> >>> >> >> >>>> >>>>> >> > >> >>> >> >> >>>> >>>>> >> > >> >>> >> >> >>>> >>>>> >> >More >> >>> >> >> >>>> >>>>> >> > >> >>> >> >> >>>> >>>>> >> >[root@ov06 ~]# for i in $(gluster volume >list); >> > do >> >>> >> >echo >> >>> >> >> >>>> >>>$i;echo; >> >>> >> >> >>>> >>>>> >> >gluster >> >>> >> >> >>>> >>>>> >> >volume info $i; echo;echo;gluster volume >status >> >>> >> >> >>>> >>>>> >$i;echo;echo;echo;done >> >>> >> >> >>>> >>>>> >> >images3 >> >>> >> >> >>>> >>>>> >> > >> >>> >> >> >>>> >>>>> >> > >> >>> >> >> >>>> >>>>> >> >Volume Name: images3 >> >>> >> >> >>>> >>>>> >> >Type: Replicate >> >>> >> >> >>>> >>>>> >> >Volume ID: >0243d439-1b29-47d0-ab39-d61c2f15ae8b >> >>> >> >> >>>> >>>>> >> >Status: Started >> >>> >> >> >>>> >>>>> >> >Snapshot Count: 0 >> >>> >> >> >>>> >>>>> >> >Number of Bricks: 1 x 3 = 3 >> >>> >> >> >>>> >>>>> >> >Transport-type: tcp >> >>> >> >> >>>> >>>>> >> >Bricks: >> >>> >> >> >>>> >>>>> >> >Brick1: >192.168.24.18:/bricks/brick04/images3 >> >>> >> >> >>>> >>>>> >> >Brick2: >192.168.24.19:/bricks/brick05/images3 >> >>> >> >> >>>> >>>>> >> >Brick3: >192.168.24.20:/bricks/brick06/images3 >> >>> >> >> >>>> >>>>> >> >Options Reconfigured: >> >>> >> >> >>>> >>>>> >> >performance.client-io-threads: on >> >>> >> >> >>>> >>>>> >> >nfs.disable: on >> >>> >> >> >>>> >>>>> >> >transport.address-family: inet >> >>> >> >> >>>> >>>>> >> >user.cifs: off >> >>> >> >> >>>> >>>>> >> >auth.allow: * >> >>> >> >> >>>> >>>>> >> >performance.quick-read: off >> >>> >> >> >>>> >>>>> >> >performance.read-ahead: off >> >>> >> >> >>>> >>>>> >> >performance.io-cache: off >> >>> >> >> >>>> >>>>> >> >performance.low-prio-threads: 32 >> >>> >> >> >>>> >>>>> >> >network.remote-dio: off >> >>> >> >> >>>> >>>>> >> >cluster.eager-lock: enable >> >>> >> >> >>>> >>>>> >> >cluster.quorum-type: auto >> >>> >> >> >>>> >>>>> >> >cluster.server-quorum-type: server >> >>> >> >> >>>> >>>>> >> >cluster.data-self-heal-algorithm: full >> >>> >> >> >>>> >>>>> >> >cluster.locking-scheme: granular >> >>> >> >> >>>> >>>>> >> >cluster.shd-max-threads: 8 >> >>> >> >> >>>> >>>>> >> >cluster.shd-wait-qlength: 10000 >> >>> >> >> >>>> >>>>> >> >features.shard: on >> >>> >> >> >>>> >>>>> >> >cluster.choose-local: off >> >>> >> >> >>>> >>>>> >> >client.event-threads: 4 >> >>> >> >> >>>> >>>>> >> >server.event-threads: 4 >> >>> >> >> >>>> >>>>> >> >storage.owner-uid: 36 >> >>> >> >> >>>> >>>>> >> >storage.owner-gid: 36 >> >>> >> >> >>>> >>>>> >> >performance.strict-o-direct: on >> >>> >> >> >>>> >>>>> >> >network.ping-timeout: 30 >> >>> >> >> >>>> >>>>> >> >cluster.granular-entry-heal: enable >> >>> >> >> >>>> >>>>> >> > >> >>> >> >> >>>> >>>>> >> > >> >>> >> >> >>>> >>>>> >> >Status of volume: images3 >> >>> >> >> >>>> >>>>> >> >Gluster process >TCP >> >>> >Port >> >>> >> >> >RDMA Port >> >>> >> >> >>>> >>>>> >Online >> >>> >> >> >>>> >>>>> >> > Pid >> >>> >> >> >>>> >>>>> >> >> >>> >> >> >>>> >>>>> >> >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >> >>> >> >> >>>> >> >>> >> >> >> >>> >> >> >> >>> >> >> >>> >> >> >>> >> >>> >> >>
>>>>>>>------------------------------------------------------------------------------ >> >>> >> >> >>>> >>>>> >> >Brick 192.168.24.18:/bricks/brick04/images3 >> >49152 >> >>> >> >0 >> >>> >> >> >>>> >> >>> >> >> >>>> >>>Y >> >>> >> >> >>>> >>>>> >> >6666 >> >>> >> >> >>>> >>>>> >> >Brick 192.168.24.19:/bricks/brick05/images3 >> >49152 >> >>> >> >0 >> >>> >> >> >>>> >> >>> >> >> >>>> >>>Y >> >>> >> >> >>>> >>>>> >> >6779 >> >>> >> >> >>>> >>>>> >> >Brick 192.168.24.20:/bricks/brick06/images3 >> >49152 >> >>> >> >0 >> >>> >> >> >>>> >> >>> >> >> >>>> >>>Y >> >>> >> >> >>>> >>>>> >> >7227 >> >>> >> >> >>>> >>>>> >> >Self-heal Daemon on localhost >N/A >> >>> >> >N/A >> >>> >> >> >>>> >> >>> >> >> >>>> >>>Y >> >>> >> >> >>>> >>>>> >> >6689 >> >>> >> >> >>>> >>>>> >> >Self-heal Daemon on ov07.ntc.srcle.com >N/A >> >>> >> >N/A >> >>> >> >> >>>> >> >>> >> >> >>>> >>>Y >> >>> >> >> >>>> >>>>> >> >6802 >> >>> >> >> >>>> >>>>> >> >Self-heal Daemon on ov08.ntc.srcle.com >N/A >> >>> >> >N/A >> >>> >> >> >>>> >> >>> >> >> >>>> >>>Y >> >>> >> >> >>>> >>>>> >> >7250 >> >>> >> >> >>>> >>>>> >> > >> >>> >> >> >>>> >>>>> >> >Task Status of Volume images3 >> >>> >> >> >>>> >>>>> >> >> >>> >> >> >>>> >>>>> >> >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >> >>> >> >> >>>> >> >>> >> >> >> >>> >> >> >> >>> >> >> >>> >> >> >>> >> >>> >> >>
>>>>>>>------------------------------------------------------------------------------ >> >>> >> >> >>>> >>>>> >> >There are no active volume tasks >> >>> >> >> >>>> >>>>> >> > >> >>> >> >> >>>> >>>>> >> > >> >>> >> >> >>>> >>>>> >> > >> >>> >> >> >>>> >>>>> >> > >> >>> >> >> >>>> >>>>> >> >[root@ov06 ~]# ls -l >> >>> >/rhev/data-center/mnt/glusterSD/ >> >>> >> >> >>>> >>>>> >> >total 16 >> >>> >> >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 >> >>> >> >> >192.168.24.15:_images >> >>> >> >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 >> >>> >> >192.168.24.18: >> >>> >> >> >>>> _images3 >> >>> >> >> >>>> >>>>> >> >[root@ov06 ~]# >> >>> >> >> >>>> >>>>> >> > >> >>> >> >> >>>> >>>>> >> >On Thu, Jun 18, 2020 at 2:03 PM C Williams >> >>> >> >> >>>> >>><cwilliams3320@gmail.com> >> >>> >> >> >>>> >>>>> >> >wrote: >> >>> >> >> >>>> >>>>> >> > >> >>> >> >> >>>> >>>>> >> >> Strahil, >> >>> >> >> >>>> >>>>> >> >> >> >>> >> >> >>>> >>>>> >> >> Here you go -- Thank You For Your Help ! >> >>> >> >> >>>> >>>>> >> >> >> >>> >> >> >>>> >>>>> >> >> BTW -- I can write a test file to gluster >and >> >it >> >>> >> >> >replicates >> >>> >> >> >>>> >>>>> >properly. >> >>> >> >> >>>> >>>>> >> >> Thinking something about the oVirt Storage >> >Domain >> >>> >? >> >>> >> >> >>>> >>>>> >> >> >> >>> >> >> >>>> >>>>> >> >> [root@ov08 ~]# gluster pool list >> >>> >> >> >>>> >>>>> >> >> UUID >> >Hostname >> >>> >> >> >>>> >>>>> >State >> >>> >> >> >>>> >>>>> >> >> 5b40c659-d9ab-43c3-9af8-18b074ea0b83 >ov06 >> >>> >> >> >>>> >>>>> >> >Connected >> >>> >> >> >>>> >>>>> >> >> 36ce5a00-6f65-4926-8438-696944ebadb5 >> >>> >> >> >ov07.ntc.srcle.com >> >>> >> >> >>>> >>>>> >> >Connected >> >>> >> >> >>>> >>>>> >> >> c7e7abdb-a8f4-4842-924c-e227f0db1b29 >> >localhost >> >>> >> >> >>>> >>>>> >> >Connected >> >>> >> >> >>>> >>>>> >> >> [root@ov08 ~]# gluster volume list >> >>> >> >> >>>> >>>>> >> >> images3 >> >>> >> >> >>>> >>>>> >> >> >> >>> >> >> >>>> >>>>> >> >> On Thu, Jun 18, 2020 at 1:13 PM Strahil >> >Nikolov >> >>> >> >> >>>> >>>>> >> ><hunter86_bg@yahoo.com> >> >>> >> >> >>>> >>>>> >> >> wrote: >> >>> >> >> >>>> >>>>> >> >> >> >>> >> >> >>>> >>>>> >> >>> Log to the oVirt cluster and provide the >> >output >> >>> >of: >> >>> >> >> >>>> >>>>> >> >>> gluster pool list >> >>> >> >> >>>> >>>>> >> >>> gluster volume list >> >>> >> >> >>>> >>>>> >> >>> for i in $(gluster volume list); do >echo >> >>> >$i;echo; >> >>> >> >> >gluster >> >>> >> >> >>>> >>>>> >volume >> >>> >> >> >>>> >>>>> >> >info >> >>> >> >> >>>> >>>>> >> >>> $i; echo;echo;gluster volume status >> >>> >> >> >$i;echo;echo;echo;done >> >>> >> >> >>>> >>>>> >> >>> >> >>> >> >> >>>> >>>>> >> >>> ls -l /rhev/data-center/mnt/glusterSD/ >> >>> >> >> >>>> >>>>> >> >>> >> >>> >> >> >>>> >>>>> >> >>> Best Regards, >> >>> >> >> >>>> >>>>> >> >>> Strahil Nikolov >> >>> >> >> >>>> >>>>> >> >>> >> >>> >> >> >>>> >>>>> >> >>> >> >>> >> >> >>>> >>>>> >> >>> На 18 юни 2020 г. 19:17:46 GMT+03:00, C >> >Williams >> >>> >> >> >>>> >>>>> >> ><cwilliams3320@gmail.com> >> >>> >> >> >>>> >>>>> >> >>> написа: >> >>> >> >> >>>> >>>>> >> >>> >Hello, >> >>> >> >> >>>> >>>>> >> >>> > >> >>> >> >> >>>> >>>>> >> >>> >I recently added 6 hosts to an existing >> >oVirt >> >>> >> >> >>>> >>>compute/gluster >> >>> >> >> >>>> >>>>> >> >cluster. >> >>> >> >> >>>> >>>>> >> >>> > >> >>> >> >> >>>> >>>>> >> >>> >Prior to this attempted addition, my >> >cluster >> >>> >had 3 >> >>> >> >> >>>> >>>Hypervisor >> >>> >> >> >>>> >>>>> >hosts >> >>> >> >> >>>> >>>>> >> >and >> >>> >> >> >>>> >>>>> >> >>> >3 >> >>> >> >> >>>> >>>>> >> >>> >gluster bricks which made up a single >> >gluster >> >>> >> >volume >> >>> >> >> >>>> >>>(replica 3 >> >>> >> >> >>>> >>>>> >> >volume) >> >>> >> >> >>>> >>>>> >> >>> >. I >> >>> >> >> >>>> >>>>> >> >>> >added the additional hosts and made a >brick >> >on >> >>> >3 >> >>> >> >of >> >>> >> >> >the new >> >>> >> >> >>>> >>>>> >hosts >> >>> >> >> >>>> >>>>> >> >and >> >>> >> >> >>>> >>>>> >> >>> >attempted to make a new replica 3 >volume. I >> >had >> >>> >> >> >difficulty >> >>> >> >> >>>> >>>>> >> >creating >> >>> >> >> >>>> >>>>> >> >>> >the >> >>> >> >> >>>> >>>>> >> >>> >new volume. So, I decided that I would >make >> >a >> >>> >new >> >>> >> >> >>>> >>>>> >compute/gluster >> >>> >> >> >>>> >>>>> >> >>> >cluster >> >>> >> >> >>>> >>>>> >> >>> >for each set of 3 new hosts. >> >>> >> >> >>>> >>>>> >> >>> > >> >>> >> >> >>>> >>>>> >> >>> >I removed the 6 new hosts from the >existing >> >>> >oVirt >> >>> >> >> >>>> >>>>> >Compute/Gluster >> >>> >> >> >>>> >>>>> >> >>> >Cluster >> >>> >> >> >>>> >>>>> >> >>> >leaving the 3 original hosts in place >with >> >>> >their >> >>> >> >> >bricks. At >> >>> >> >> >>>> >>>that >> >>> >> >> >>>> >>>>> >> >point >> >>> >> >> >>>> >>>>> >> >>> >my >> >>> >> >> >>>> >>>>> >> >>> >original bricks went down and came back >up >> >. >> >>> >The >> >>> >> >> >volume >> >>> >> >> >>>> >>>showed >> >>> >> >> >>>> >>>>> >> >entries >> >>> >> >> >>>> >>>>> >> >>> >that >> >>> >> >> >>>> >>>>> >> >>> >needed healing. At that point I ran >gluster >> >>> >volume >> >>> >> >> >heal >> >>> >> >> >>>> >>>images3 >> >>> >> >> >>>> >>>>> >> >full, >> >>> >> >> >>>> >>>>> >> >>> >etc. >> >>> >> >> >>>> >>>>> >> >>> >The volume shows no unhealed entries. I >> >also >> >>> >> >> >corrected some >> >>> >> >> >>>> >>>peer >> >>> >> >> >>>> >>>>> >> >>> >errors. >> >>> >> >> >>>> >>>>> >> >>> > >> >>> >> >> >>>> >>>>> >> >>> >However, I am unable to copy disks, move >> >disks >> >>> >to >> >>> >> >> >another >> >>> >> >> >>>> >>>>> >domain, >> >>> >> >> >>>> >>>>> >> >>> >export >> >>> >> >> >>>> >>>>> >> >>> >disks, etc. It appears that the engine >> >cannot >> >>> >> >locate >> >>> >> >> >disks >> >>> >> >> >>>> >>>>> >properly >> >>> >> >> >>>> >>>>> >> >and >> >>> >> >> >>>> >>>>> >> >>> >I >> >>> >> >> >>>> >>>>> >> >>> >get storage I/O errors. >> >>> >> >> >>>> >>>>> >> >>> > >> >>> >> >> >>>> >>>>> >> >>> >I have detached and removed the oVirt >> >Storage >> >>> >> >Domain. >> >>> >> >> >I >> >>> >> >> >>>> >>>>> >reimported >> >>> >> >> >>>> >>>>> >> >the >> >>> >> >> >>>> >>>>> >> >>> >domain and imported 2 VMs, But the VM >disks >> >>> >> >exhibit >> >>> >> >> >the >> >>> >> >> >>>> same >> >>> >> >> >>>> >>>>> >> >behaviour >> >>> >> >> >>>> >>>>> >> >>> >and >> >>> >> >> >>>> >>>>> >> >>> >won't run from the hard disk. >> >>> >> >> >>>> >>>>> >> >>> > >> >>> >> >> >>>> >>>>> >> >>> > >> >>> >> >> >>>> >>>>> >> >>> >I get errors such as this >> >>> >> >> >>>> >>>>> >> >>> > >> >>> >> >> >>>> >>>>> >> >>> >VDSM ov05 command >HSMGetAllTasksStatusesVDS >> >>> >> >failed: >> >>> >> >> >low >> >>> >> >> >>>> >>>level >> >>> >> >> >>>> >>>>> >Image >> >>> >> >> >>>> >>>>> >> >>> >copy >> >>> >> >> >>>> >>>>> >> >>> >failed: ("Command ['/usr/bin/qemu-img', >> >>> >'convert', >> >>> >> >> >'-p', >> >>> >> >> >>>> >>>'-t', >> >>> >> >> >>>> >>>>> >> >'none', >> >>> >> >> >>>> >>>>> >> >>> >'-T', 'none', '-f', 'raw', >> >>> >> >> >>>> >>>>> >> >>> >> >>> >>u'/rhev/data-center/mnt/glusterSD/192.168.24.18: >> >>> >> >> >>>> >>>>> >> >>> >> >>> >> >> >>>> >>>>> >> >> >>> >> >> >>>> >>>>> >> >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >> >>> >> >> >>>> >> >>> >> >> >> >>> >> >> >> >>> >> >> >>> >> >> >>> >> >>> >> >>
>>>>>>>_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510', >> >>> >> >> >>>> >>>>> >> >>> >'-O', 'raw', >> >>> >> >> >>>> >>>>> >> >>> u'/rhev/data-center/mnt/192.168.24.13: >> >>> >> >> >>>> >>>>> >> >>> >> >>> >> >> >>>> >>>>> >> >> >>> >> >> >>>> >>>>> >> >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >> >>> >> >> >>>> >> >>> >> >> >> >>> >> >> >> >>> >> >> >>> >> >> >>> >> >>> >> >>
>>>>>>>_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5'] >> >>> >> >> >>>> >>>>> >> >>> >failed with rc=1 out='' >> >>> >err=bytearray(b'qemu-img: >> >>> >> >> >error >> >>> >> >> >>>> >>>while >> >>> >> >> >>>> >>>>> >> >reading >> >>> >> >> >>>> >>>>> >> >>> >sector 135168: Transport endpoint is not >> >>> >> >> >>>> >>>connected\\nqemu-img: >> >>> >> >> >>>> >>>>> >> >error >> >>> >> >> >>>> >>>>> >> >>> >while >> >>> >> >> >>>> >>>>> >> >>> >reading sector 131072: Transport >endpoint >> >is >> >>> >not >> >>> >> >> >>>> >>>>> >> >connected\\nqemu-img: >> >>> >> >> >>>> >>>>> >> >>> >error while reading sector 139264: >> >Transport >> >>> >> >endpoint >> >>> >> >> >is >> >>> >> >> >>>> not >> >>> >> >> >>>> >>>>> >> >>> >connected\\nqemu-img: error while >reading >> >>> >sector >> >>> >> >> >143360: >> >>> >> >> >>>> >>>>> >Transport >> >>> >> >> >>>> >>>>> >> >>> >endpoint >> >>> >> >> >>>> >>>>> >> >>> >is not connected\\nqemu-img: error while >> >>> >reading >> >>> >> >> >sector >> >>> >> >> >>>> >>>147456: >> >>> >> >> >>>> >>>>> >> >>> >Transport >> >>> >> >> >>>> >>>>> >> >>> >endpoint is not connected\\nqemu-img: >error >> >>> >while >> >>> >> >> >reading >> >>> >> >> >>>> >>>sector >> >>> >> >> >>>> >>>>> >> >>> >155648: >> >>> >> >> >>>> >>>>> >> >>> >Transport endpoint is not >> >connected\\nqemu-img: >> >>> >> >error >> >>> >> >> >while >> >>> >> >> >>>> >>>>> >reading >> >>> >> >> >>>> >>>>> >> >>> >sector >> >>> >> >> >>>> >>>>> >> >>> >151552: Transport endpoint is not >> >>> >> >> >connected\\nqemu-img: >> >>> >> >> >>>> >>>error >> >>> >> >> >>>> >>>>> >while >> >>> >> >> >>>> >>>>> >> >>> >reading >> >>> >> >> >>>> >>>>> >> >>> >sector 159744: Transport endpoint is not >> >>> >> >> >connected\\n')",) >> >>> >> >> >>>> >>>>> >> >>> > >> >>> >> >> >>>> >>>>> >> >>> >oVirt version is 4.3.82-1.el7 >> >>> >> >> >>>> >>>>> >> >>> >OS CentOS Linux release 7.7.1908 (Core) >> >>> >> >> >>>> >>>>> >> >>> > >> >>> >> >> >>>> >>>>> >> >>> >The Gluster Cluster has been working >very >> >well >> >>> >> >until >> >>> >> >> >this >> >>> >> >> >>>> >>>>> >incident. >> >>> >> >> >>>> >>>>> >> >>> > >> >>> >> >> >>>> >>>>> >> >>> >Please help. >> >>> >> >> >>>> >>>>> >> >>> > >> >>> >> >> >>>> >>>>> >> >>> >Thank You >> >>> >> >> >>>> >>>>> >> >>> > >> >>> >> >> >>>> >>>>> >> >>> >Charles Williams >> >>> >> >> >>>> >>>>> >> >>> >> >>> >> >> >>>> >>>>> >> >> >> >>> >> >> >>>> >>>>> >> >> >>> >> >> >>>> >>>>> >> >>> >> >> >>>> >>>> >> >>> >> >> >>>> >> >> >>> >> >> >>>> > >> >>> >> >> >>>>
>> >>> >> >> >>>> Users mailing list -- users@ovirt.org >> >>> >> >> >>>> To unsubscribe send an email to users-leave@ovirt.org >> >>> >> >> >>>> Privacy Statement: >> >https://www.ovirt.org/privacy-policy.html >> >>> >> >> >>>> oVirt Code of Conduct: >> >>> >> >> >>>> >> >https://www.ovirt.org/community/about/community-guidelines/ >> >>> >> >> >>>> List Archives: >> >>> >> >> >>>> >> >>> >> >> > >> >>> >> >> >> >>> >> > >> >>> >> >> >>> > >> >>> >> > >> >
https://lists.ovirt.org/archives/list/users@ovirt.org/message/YY3VUKEJLI7MRW...
>> >>> >> >> >>>> >> >>> >> >> >>> >> >>> >> >> >> >>> >> >> >>> >> >> >>
Strahil, Thank you for the suggestions on safely upgrading oVirt/Gluster ! Thank You For Your Help ! On Tue, Jun 23, 2020 at 8:12 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
As far as I know, oVirt 4.4 uses gluster v7.X , so you will eventually have to upgrade the version.
As I mentioned, I have created my new volume while I was running a higher version and copied the data to it, which prevented the acl bug hitting me again.
I can recommend you to: 1. Mount the new gluster volume via FUSE 2. Wipe the data, as you don't need it 3. Attach the new gluster volume as a fresh storage domain in ovirt 4. Live migrate the VM disks to the new volume prior to upgrading gluster
I cannot guarantee that the issue will be avoided , but it's worth trying .
Best Regards, Strahil Nikolov
На 23 юни 2020 г. 23:42:13 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа:
Strahil,
Thanks for getting back with me !
Sounds like it is best to evacuate VM disks to another storage domain -- if possible from a Gluster storage domain -- prior to an upgrade .
Per your questions ...
1. Which version of oVirt and Gluster are you using ? oVirt 4.3.8.2-1 Gluster 6.5 , 6.7, 6.9 (depends on the cluster)
2. You now have your old gluster volume attached to oVirt and the new volume unused, right ? Correct -- intending to dispose of data on the new volume since the old one is now working
3. Did you copy the contents of the old volume to the new one ? I did prior to trying to downgrade the Gluster version on the hosts for the old volume. I am planning to delete the data now that the old volume is working.
Thanks Again For Your Help !!
On Mon, Jun 22, 2020 at 11:34 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
As I told you, you could just downgrade gluster on all nodes and later plan to live migrate the VM disks. I had to copy my data to the new volume, so I can avoid the ACL bug , when I use newer versions of gluster.
Let's clarify some details: 1. Which version of oVirt and Gluster are you using ? 2. You now have your old gluster volume attached to oVirt and the new volume unused, right ? 3. Did you copy the contents of the old volume to the new one ?
Best Regards, Strahil Nikolov
Strahil,
Thank You For Help !
Downgrading Gluster to 6.5 got the original storage domain working again !
After, I finished my copy of the contents of the problematic volume to a new volume, I did the following
Unmounted the mount points Stopped the original problematic Gluster volume On each problematic peer, I downgraded Gluster to 6.5 (yum downgrade glusterfs-6.5-1.el7.x86_64 vdsm-gluster-4.30.46-1.el7.x86_64 python2-gluster-6.5-1.el7.x86_64 glusterfs-libs-6.5-1.el7.x86_64 glusterfs-cli-6.5-1.el7.x86_64 glusterfs-fuse-6.5-1.el7.x86_64 glusterfs-rdma-6.5-1.el7.x86_64 glusterfs-api-6.5-1.el7.x86_64 glusterfs-server-6.5-1.el7.x86_64 glusterfs-events-6.5-1.el7.x86_64 glusterfs-client-xlators-6.5-1.el7.x86_64 glusterfs-geo-replication-6.5-1.el7.x86_64) Restarted glusterd (systemctl restart glusterd) Restarted the problematic Gluster volume Reattached the problematic storage domain Started the problematic storage domain
Things work now. I can now run VMs and write data, copy virtual disks, move virtual disks to other storage domains, etc.
I am very thankful that the storage domain is working again !
How can I safely perform upgrades on Gluster ! When will it be safe to do so ?
Thank You Again For Your Help !
On Mon, Jun 22, 2020 at 10:58 AM C Williams <cwilliams3320@gmail.com> wrote:
Strahil,
I have downgraded the target. The copy from the problematic volume to the target is going on now. Once I have the data copied, I might downgrade the problematic volume's Gluster to 6.5. At that point I might reattach the original ovirt domain and see if it will work again. But the copy is going on right now.
Thank You For Your Help !
On Mon, Jun 22, 2020 at 10:52 AM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
You should ensure that in the storage domain tab, the old storage is not visible.
I still wander why yoiu didn't try to downgrade first.
Best Regards, Strahil Nikolov
На 22 юни 2020 г. 13:58:33 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: >Strahil, > >The GLCL3 storage domain was detached prior to attempting to add the >new >storage domain. > >Should I also "Remove" it ? > >Thank You For Your Help ! > >---------- Forwarded message --------- >From: Strahil Nikolov <hunter86_bg@yahoo.com> >Date: Mon, Jun 22, 2020 at 12:50 AM >Subject: Re: [ovirt-users] Re: Fwd: Fwd: Issues with Gluster Domain >To: C Williams <cwilliams3320@gmail.com> >Cc: users <Users@ovirt.org> > > >You can't add the new volume as it contains the same data (UUID) as the >old >one , thus you need to detach the old one before adding the new one
>of >course this means downtime for all VMs on that storage. > >As you see , downgrading is more simpler. For me v6.5 was working, >while >anything above (6.6+) was causing complete lockdown. Also v7.0 was >working, but it's supported in oVirt 4.4. > >Best Regards, >Strahil Nikolov > >На 22 юни 2020 г. 7:21:15 GMT+03:00, C Williams ><cwilliams3320@gmail.com> >написа: >>Another question >> >>What version could I downgrade to safely ? I am at 6.9 . >> >>Thank You For Your Help !! >> >>On Sun, Jun 21, 2020 at 11:38 PM Strahil Nikolov >><hunter86_bg@yahoo.com> >>wrote: >> >>> You are definitely reading it wrong. >>> 1. I didn't create a new storage domain ontop this new volume. >>> 2. I used cli >>> >>> Something like this (in your case it should be 'replica 3'): >>> gluster volume create newvol replica 3 arbiter 1 >>ovirt1:/new/brick/path >>> ovirt2:/new/brick/path ovirt3:/new/arbiter/brick/path >>> gluster volume start newvol >>> >>> #Detach oldvol from ovirt >>> >>> mount -t glusterfs ovirt1:/oldvol /mnt/oldvol >>> mount -t glusterfs ovirt1:/newvol /mnt/newvol >>> cp -a /mnt/oldvol/* /mnt/newvol >>> >>> #Add only newvol as a storage domain in oVirt >>> #Import VMs >>> >>> I still think that you should downgrade your gluster
>>> >>> Best Regards, >>> Strahil Nikolov >>> >>> На 22 юни 2020 г. 0:43:46 GMT+03:00, C Williams >><cwilliams3320@gmail.com> >>> написа: >>> >Strahil, >>> > >>> >It sounds like you used a "System Managed Volume" for the new >>storage >>> >domain,is that correct? >>> > >>> >Thank You For Your Help ! >>> > >>> >On Sun, Jun 21, 2020 at 5:40 PM C Williams ><cwilliams3320@gmail.com> >>> >wrote: >>> > >>> >> Strahil, >>> >> >>> >> So you made another oVirt Storage Domain -- then copied
data
>>with >>> >cp >>> >> -a from the failed volume to the new volume. >>> >> >>> >> At the root of the volume there will be the old domain folder id >>ex >>> >> 5fe3ad3f-2d21-404c-832e-4dc7318ca10d >>> >> in my case. Did that cause issues with making the new domain >>since >>> >it is >>> >> the same folder id as the old one ? >>> >> >>> >> Thank You For Your Help ! >>> >> >>> >> On Sun, Jun 21, 2020 at 5:18 PM Strahil Nikolov >>> ><hunter86_bg@yahoo.com> >>> >> wrote: >>> >> >>> >>> In my situation I had only the ovirt nodes. >>> >>> >>> >>> На 21 юни 2020 г. 22:43:04 GMT+03:00, C Williams >>> ><cwilliams3320@gmail.com> >>> >>> написа: >>> >>> >Strahil, >>> >>> > >>> >>> >So should I make the target volume on 3 bricks which do not >have >>> >ovirt >>> >>> >-- >>> >>> >just gluster ? In other words (3) Centos 7 hosts ? >>> >>> > >>> >>> >Thank You For Your Help ! >>> >>> > >>> >>> >On Sun, Jun 21, 2020 at 3:08 PM Strahil Nikolov >>> ><hunter86_bg@yahoo.com> >>> >>> >wrote: >>> >>> > >>> >>> >> I created a fresh volume (which is not an ovirt sgorage >>> >domain), >>> >>> >set >>> >>> >> the original storage domain in maintenance and detached >>it. >>> >>> >> Then I 'cp -a ' the data from the old to the new volume. >>Next, >>> >I >>> >>> >just >>> >>> >> added the new storage domain (the old one was a kind >>of a >>> >>> >> 'backup') - pointing to the new volume name. >>> >>> >> >>> >>> >> If you observe issues , I would recommend you to >>downgrade >>> >>> >> gluster packages one node at a time . Then you might be >>able >>> >to >>> >>> >> restore your oVirt operations. >>> >>> >> >>> >>> >> Best Regards, >>> >>> >> Strahil Nikolov >>> >>> >> >>> >>> >> На 21 юни 2020 г. 18:01:31 GMT+03:00, C Williams >>> >>> ><cwilliams3320@gmail.com> >>> >>> >> написа: >>> >>> >> >Strahil, >>> >>> >> > >>> >>> >> >Thanks for the follow up ! >>> >>> >> > >>> >>> >> >How did you copy the data to another volume ? >>> >>> >> > >>> >>> >> >I have set up another storage domain GLCLNEW1 with a new >>volume >>> >>> >imgnew1 >>> >>> >> >. >>> >>> >> >How would you copy all of the data from the
На 23 юни 2020 г. 4:34:19 GMT+03:00, C Williams <cwilliams3320@gmail.com> написа: packages!!! the problematic
>>domain >>> >GLCL3 >>> >>> >> >with >>> >>> >> >volume images3 to GLCLNEW1 and volume imgnew1 and preserve >>all >>> >the >>> >>> >VMs, >>> >>> >> >VM >>> >>> >> >disks, settings, etc. ? >>> >>> >> > >>> >>> >> >Remember all of the regular ovirt disk copy, disk move, VM >>> >export >>> >>> >> >tools >>> >>> >> >are failing and my VMs and disks are trapped on domain GLCL3 >>and >>> >>> >volume >>> >>> >> >images3 right now. >>> >>> >> > >>> >>> >> >Please let me know >>> >>> >> > >>> >>> >> >Thank You For Your Help ! >>> >>> >> > >>> >>> >> > >>> >>> >> > >>> >>> >> > >>> >>> >> > >>> >>> >> >On Sun, Jun 21, 2020 at 8:27 AM Strahil Nikolov >>> >>> ><hunter86_bg@yahoo.com> >>> >>> >> >wrote: >>> >>> >> > >>> >>> >> >> Sorry to hear that. >>> >>> >> >> I can say that for me 6.5 was working, while 6.6 >didn't >>> >and I >>> >>> >> >upgraded >>> >>> >> >> to 7.0 . >>> >>> >> >> In the ended , I have ended with creating a new fresh >>> >volume >>> >>> >and >>> >>> >> >> physically copying the data there, then I detached the >>> >storage >>> >>> >> >domains and >>> >>> >> >> attached to the new ones (which holded the old data), >>but >>> >I >>> >>> >> >could >>> >>> >> >> afford the downtime. >>> >>> >> >> Also, I can say that v7.0 ( but not 7.1 or anything >>later) >>> >>> >also >>> >>> >> >> worked without the ACL issue, but it causes some >trouble >>> >in >>> >>> >oVirt >>> >>> >> >- so >>> >>> >> >> avoid that unless you have no other options. >>> >>> >> >> >>> >>> >> >> Best Regards, >>> >>> >> >> Strahil Nikolov >>> >>> >> >> >>> >>> >> >> >>> >>> >> >> >>> >>> >> >> >>> >>> >> >> На 21 юни 2020 г. 4:39:46 GMT+03:00, C Williams >>> >>> >> ><cwilliams3320@gmail.com> >>> >>> >> >> написа: >>> >>> >> >> >Hello, >>> >>> >> >> > >>> >>> >> >> >Upgrading diidn't help >>> >>> >> >> > >>> >>> >> >> >Still acl errors trying to use a Virtual Disk from a VM >>> >>> >> >> > >>> >>> >> >> >[root@ov06 bricks]# tail bricks-brick04-images3.log | >grep >>> >acl >>> >>> >> >> >[2020-06-21 01:33:45.665888] I [MSGID: 139001] >>> >>> >> >> >[posix-acl.c:263:posix_acl_log_permit_denied] >>> >>> >> >0-images3-access-control: >>> >>> >> >> >client: >>> >>> >> >> >>> >>> >> >> >>> >>> >> >>> >>> >> >>> >>> >>> >>> >>> >>>
>>>CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0, >>> >>> >> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >>> >>> >> >> >req(uid:107,gid:107,perm:1,ngrps:3), >>> >>> >> >> ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, >>> >acl:-) >>> >>> >> >> >[Permission denied] >>> >>> >> >> >The message "I [MSGID: 139001] >>> >>> >> >> >[posix-acl.c:263:posix_acl_log_permit_denied] >>> >>> >> >0-images3-access-control: >>> >>> >> >> >client: >>> >>> >> >> >>> >>> >> >> >>> >>> >> >>> >>> >> >>> >>> >>> >>> >>> >>>
>>>CTX_ID:3697a7f1-44fb-4258-96b0-98cb4137d195-GRAPH_ID:0-PID:6706-HOST:ov06.ntc.srcle.com-PC_NAME:images3-client-0-RECON_NO:-0, >>> >>> >> >> >gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >>> >>> >> >> >req(uid:107,gid:107,perm:1,ngrps:3), >>> >>> >> >> ctx(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, >>> >acl:-) >>> >>> >> >> >[Permission denied]" repeated 2 times between [2020-06-21 >>> >>> >> >> >01:33:45.665888] >>> >>> >> >> >and [2020-06-21 01:33:45.806779] >>> >>> >> >> > >>> >>> >> >> >Thank You For Your Help ! >>> >>> >> >> > >>> >>> >> >> >On Sat, Jun 20, 2020 at 8:59 PM C Williams >>> >>> ><cwilliams3320@gmail.com> >>> >>> >> >> >wrote: >>> >>> >> >> > >>> >>> >> >> >> Hello, >>> >>> >> >> >> >>> >>> >> >> >> Based on the situation, I am planning to upgrade the 3 >>> >affected >>> >>> >> >> >hosts. >>> >>> >> >> >> >>> >>> >> >> >> My reasoning is that the hosts/bricks were attached to >>6.9 >>> >at >>> >>> >one >>> >>> >> >> >time. >>> >>> >> >> >> >>> >>> >> >> >> Thanks For Your Help ! >>> >>> >> >> >> >>> >>> >> >> >> On Sat, Jun 20, 2020 at 8:38 PM C Williams >>> >>> >> ><cwilliams3320@gmail.com> >>> >>> >> >> >> wrote: >>> >>> >> >> >> >>> >>> >> >> >>> Strahil, >>> >>> >> >> >>> >>> >>> >> >> >>> The gluster version on the current 3 gluster hosts is >>6.7 >>> >>> >(last >>> >>> >> >> >update >>> >>> >> >> >>> 2/26). These 3 hosts provide 1 brick each for the >>replica >>> >3 >>> >>> >> >volume. >>> >>> >> >> >>> >>> >>> >> >> >>> Earlier I had tried to add 6 additional hosts to the >>> >cluster. >>> >>> >> >Those >>> >>> >> >> >new >>> >>> >> >> >>> hosts were 6.9 gluster. >>> >>> >> >> >>> >>> >>> >> >> >>> I attempted to make a new separate volume with 3 >bricks >>> >>> >provided >>> >>> >> >by >>> >>> >> >> >the 3 >>> >>> >> >> >>> new gluster 6.9 hosts. After having many errors from >>the >>> >>> >oVirt >>> >>> >> >> >interface, >>> >>> >> >> >>> I gave up and removed the 6 new hosts from the >cluster. >>> >That >>> >>> >is >>> >>> >> >> >where the >>> >>> >> >> >>> problems started. The intent was to expand the gluster >>> >cluster >>> >>> >> >while >>> >>> >> >> >making >>> >>> >> >> >>> 2 new volumes for that cluster. The ovirt compute >>cluster >>> >>> >would >>> >>> >> >> >allow for >>> >>> >> >> >>> efficient VM migration between 9 hosts -- while having >>> >>> >separate >>> >>> >> >> >gluster >>> >>> >> >> >>> volumes for safety purposes. >>> >>> >> >> >>> >>> >>> >> >> >>> Looking at the brick logs, I see where there are acl >>> >errors >>> >>> >> >starting >>> >>> >> >> >from >>> >>> >> >> >>> the time of the removal of the 6 new hosts. >>> >>> >> >> >>> >>> >>> >> >> >>> Please check out the attached brick log from 6/14-18. >>The >>> >>> >events >>> >>> >> >> >started >>> >>> >> >> >>> on 6/17. >>> >>> >> >> >>> >>> >>> >> >> >>> I wish I had a downgrade path. >>> >>> >> >> >>> >>> >>> >> >> >>> Thank You For The Help !! >>> >>> >> >> >>> >>> >>> >> >> >>> On Sat, Jun 20, 2020 at 7:47 PM Strahil Nikolov >>> >>> >> >> ><hunter86_bg@yahoo.com> >>> >>> >> >> >>> wrote: >>> >>> >> >> >>> >>> >>> >> >> >>>> Hi , >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>> >>> >> >> >>>> This one really looks like the ACL bug I was hit with >>> >when I >>> >>> >> >> >updated >>> >>> >> >> >>>> from Gluster v6.5 to 6.6 and later from 7.0 to 7.2. >>> >>> >> >> >>>> >>> >>> >> >> >>>> Did you update your setup recently ? Did you upgrade >>> >gluster >>> >>> >> >also ? >>> >>> >> >> >>>> >>> >>> >> >> >>>> You have to check the gluster logs in order to verify >>> >that, >>> >>> >so >>> >>> >> >you >>> >>> >> >> >can >>> >>> >> >> >>>> try: >>> >>> >> >> >>>> >>> >>> >> >> >>>> 1. Set Gluster logs to trace level (for details >check: >>> >>> >> >> >>>> >>> >>> >> >> > >>> >>> >> >> >>> >>> >> > >>> >>> >> >>> >>> > >>> >>> >>> > >>> >> >
https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3/html...
>>> >>> >> >> >>>> ) >>> >>> >> >> >>>> 2. Power up a VM that was already off , or retry the >>> >>> >procedure >>> >>> >> >from >>> >>> >> >> >the >>> >>> >> >> >>>> logs you sent. >>> >>> >> >> >>>> 3. Stop the trace level of the logs >>> >>> >> >> >>>> 4. Check libvirt logs on the host that was supposed >to >>> >power >>> >>> >up >>> >>> >> >the >>> >>> >> >> >VM >>> >>> >> >> >>>> (in case a VM was powered on) >>> >>> >> >> >>>> 5. Check the gluster brick logs on all nodes for ACL >>> >errors. >>> >>> >> >> >>>> Here is a sample from my old logs: >>> >>> >> >> >>>> >>> >>> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 >>> >>> >> >> >13:19:41.489047] I >>> >>> >> >> >>>> [MSGID: 139001] >>> >[posix-acl.c:262:posix_acl_log_permit_denied] >>> >>> >> >> >>>> 0-data_fast4-access-control: client: >>> >CTX_ID:4a654305-d2e4- >>> >>> >> >> >>>> >>> >>> >> >> >>> >>> >> >> >>> >>> >> >>> >>> >> >>> >>> >>> >>> >>> >>>
>>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, >>> >>> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >>> >>> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx >>> >>> >> >> >>>> >(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, >>> >acl:-) >>> >>> >> >> >>>> [Permission denied] >>> >>> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 >>> >>> >> >> >13:22:51.818796] I >>> >>> >> >> >>>> [MSGID: 139001] >>> >[posix-acl.c:262:posix_acl_log_permit_denied] >>> >>> >> >> >>>> 0-data_fast4-access-control: client: >>> >CTX_ID:4a654305-d2e4- >>> >>> >> >> >>>> >>> >>> >> >> >>> >>> >> >> >>> >>> >> >>> >>> >> >>> >>> >>> >>> >>> >>>
>>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, >>> >>> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >>> >>> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx >>> >>> >> >> >>>> >(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, >>> >acl:-) >>> >>> >> >> >>>> [Permission denied] >>> >>> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 >>> >>> >> >> >13:24:43.732856] I >>> >>> >> >> >>>> [MSGID: 139001] >>> >[posix-acl.c:262:posix_acl_log_permit_denied] >>> >>> >> >> >>>> 0-data_fast4-access-control: client: >>> >CTX_ID:4a654305-d2e4- >>> >>> >> >> >>>> >>> >>> >> >> >>> >>> >> >> >>> >>> >> >>> >>> >> >>> >>> >>> >>> >>> >>>
>>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, >>> >>> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >>> >>> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx >>> >>> >> >> >>>> >(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, >>> >acl:-) >>> >>> >> >> >>>> [Permission denied] >>> >>> >> >> >>>> gluster_bricks-data_fast4-data_fast4.log:[2020-03-18 >>> >>> >> >> >13:26:50.758178] I >>> >>> >> >> >>>> [MSGID: 139001] >>> >[posix-acl.c:262:posix_acl_log_permit_denied] >>> >>> >> >> >>>> 0-data_fast4-access-control: client: >>> >CTX_ID:4a654305-d2e4- >>> >>> >> >> >>>> >>> >>> >> >> >>> >>> >> >> >>> >>> >> >>> >>> >> >>> >>> >>> >>> >>> >>>
>>>4a10-bad9-58d670d99a97-GRAPH_ID:0-PID:32412-HOST:ovirt1.localdomain-PC_NAME:data_fast4-client-0-RECON_NO:-19, >>> >>> >> >> >>>> gfid: be318638-e8a0-4c6d-977d-7a937aa84806, >>> >>> >> >> >>>> req(uid:36,gid:36,perm:1,ngrps:3), ctx >>> >>> >> >> >>>> >(uid:0,gid:0,in-groups:0,perm:000,updated-fop:INVALID, >>> >acl:-) >>> >>> >> >> >>>> [Permission denied] >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>> >>> >> >> >>>> In my case , the workaround was to downgrade the >>gluster >>> >>> >> >packages >>> >>> >> >> >on all >>> >>> >> >> >>>> nodes (and reboot each node 1 by 1 ) if the major >>version >>> >is >>> >>> >the >>> >>> >> >> >same, but >>> >>> >> >> >>>> if you upgraded to v7.X - then you can try the v7.0 . >>> >>> >> >> >>>> >>> >>> >> >> >>>> Best Regards, >>> >>> >> >> >>>> Strahil Nikolov >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>> >>> >> >> >>>> В събота, 20 юни 2020 г., 18:48:42 ч. Гринуич+3, C >>> >Williams < >>> >>> >> >> >>>> cwilliams3320@gmail.com> написа: >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>> >>> >> >> >>>> Hello, >>> >>> >> >> >>>> >>> >>> >> >> >>>> Here are additional log tiles as well as a tree of >the >>> >>> >> >problematic >>> >>> >> >> >>>> Gluster storage domain. During this time I attempted >>to >>> >copy >>> >>> >a >>> >>> >> >> >virtual disk >>> >>> >> >> >>>> to another domain, move a virtual disk to another >>domain >>> >and >>> >>> >run >>> >>> >> >a >>> >>> >> >> >VM where >>> >>> >> >> >>>> the virtual hard disk would be used. >>> >>> >> >> >>>> >>> >>> >> >> >>>> The copies/moves failed and the VM went into pause >>mode >>> >when >>> >>> >the >>> >>> >> >> >virtual >>> >>> >> >> >>>> HDD was involved. >>> >>> >> >> >>>> >>> >>> >> >> >>>> Please check these out. >>> >>> >> >> >>>> >>> >>> >> >> >>>> Thank You For Your Help ! >>> >>> >> >> >>>> >>> >>> >> >> >>>> On Sat, Jun 20, 2020 at 9:54 AM C Williams >>> >>> >> >> ><cwilliams3320@gmail.com> >>> >>> >> >> >>>> wrote: >>> >>> >> >> >>>> > Strahil, >>> >>> >> >> >>>> > >>> >>> >> >> >>>> > I understand. Please keep me posted. >>> >>> >> >> >>>> > >>> >>> >> >> >>>> > Thanks For The Help ! >>> >>> >> >> >>>> > >>> >>> >> >> >>>> > On Sat, Jun 20, 2020 at 4:36 AM Strahil Nikolov >>> >>> >> >> ><hunter86_bg@yahoo.com> >>> >>> >> >> >>>> wrote: >>> >>> >> >> >>>> >> Hey C Williams, >>> >>> >> >> >>>> >> >>> >>> >> >> >>>> >> sorry for the delay, but I couldn't get somw time >>to >>> >>> >check >>> >>> >> >your >>> >>> >> >> >>>> logs. Will try a little bit later. >>> >>> >> >> >>>> >> >>> >>> >> >> >>>> >> Best Regards, >>> >>> >> >> >>>> >> Strahil Nikolov >>> >>> >> >> >>>> >> >>> >>> >> >> >>>> >> На 20 юни 2020 г. 2:37:22 GMT+03:00, C Williams < >>> >>> >> >> >>>> cwilliams3320@gmail.com> написа: >>> >>> >> >> >>>> >>>Hello, >>> >>> >> >> >>>> >>> >>> >>> >> >> >>>> >>>Was wanting to follow up on this issue. Users are >>> >>> >impacted. >>> >>> >> >> >>>> >>> >>> >>> >> >> >>>> >>>Thank You >>> >>> >> >> >>>> >>> >>> >>> >> >> >>>> >>>On Fri, Jun 19, 2020 at 9:20 AM C Williams >>> >>> >> >> ><cwilliams3320@gmail.com> >>> >>> >> >> >>>> >>>wrote: >>> >>> >> >> >>>> >>> >>> >>> >> >> >>>> >>>> Hello, >>> >>> >> >> >>>> >>>> >>> >>> >> >> >>>> >>>> Here are the logs (some IPs are changed ) >>> >>> >> >> >>>> >>>> >>> >>> >> >> >>>> >>>> ov05 is the SPM >>> >>> >> >> >>>> >>>> >>> >>> >> >> >>>> >>>> Thank You For Your Help ! >>> >>> >> >> >>>> >>>> >>> >>> >> >> >>>> >>>> On Thu, Jun 18, 2020 at 11:31 PM Strahil Nikolov >>> >>> >> >> >>>> >>><hunter86_bg@yahoo.com> >>> >>> >> >> >>>> >>>> wrote: >>> >>> >> >> >>>> >>>> >>> >>> >> >> >>>> >>>>> Check on the hosts tab , which is your current >>SPM >>> >>> >(last >>> >>> >> >> >column in >>> >>> >> >> >>>> >>>Admin >>> >>> >> >> >>>> >>>>> UI). >>> >>> >> >> >>>> >>>>> Then open the /var/log/vdsm/vdsm.log and >repeat >>> >the >>> >>> >> >> >operation. >>> >>> >> >> >>>> >>>>> Then provide the log from that host and the >>> >engine's >>> >>> >log >>> >>> >> >(on >>> >>> >> >> >the >>> >>> >> >> >>>> >>>>> HostedEngine VM or on your standalone engine). >>> >>> >> >> >>>> >>>>> >>> >>> >> >> >>>> >>>>> Best Regards, >>> >>> >> >> >>>> >>>>> Strahil Nikolov >>> >>> >> >> >>>> >>>>> >>> >>> >> >> >>>> >>>>> На 18 юни 2020 г. 23:59:36 GMT+03:00, C >Williams >>> >>> >> >> >>>> >>><cwilliams3320@gmail.com> >>> >>> >> >> >>>> >>>>> написа: >>> >>> >> >> >>>> >>>>> >Resending to eliminate email issues >>> >>> >> >> >>>> >>>>> > >>> >>> >> >> >>>> >>>>> >---------- Forwarded message --------- >>> >>> >> >> >>>> >>>>> >From: C Williams <cwilliams3320@gmail.com> >>> >>> >> >> >>>> >>>>> >Date: Thu, Jun 18, 2020 at 4:01 PM >>> >>> >> >> >>>> >>>>> >Subject: Re: [ovirt-users] Fwd: Issues with >>> >Gluster >>> >>> >> >Domain >>> >>> >> >> >>>> >>>>> >To: Strahil Nikolov <hunter86_bg@yahoo.com> >>> >>> >> >> >>>> >>>>> > >>> >>> >> >> >>>> >>>>> > >>> >>> >> >> >>>> >>>>> >Here is output from mount >>> >>> >> >> >>>> >>>>> > >>> >>> >> >> >>>> >>>>> >192.168.24.12:/stor/import0 on >>> >>> >> >> >>>> >>>>> >>>/rhev/data-center/mnt/192.168.24.12:_stor_import0 >>> >>> >> >> >>>> >>>>> >type nfs4 >>> >>> >> >> >>>> >>>>> >>> >>> >> >> >>>> >>>>> >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>> >>> >> >> >>> >>> >> >> >>> >>> >> >>> >>> >> >>> >>> >>> >>> >>> >>>
>>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.12) >>> >>> >> >> >>>> >>>>> >192.168.24.13:/stor/import1 on >>> >>> >> >> >>>> >>>>> >>>/rhev/data-center/mnt/192.168.24.13:_stor_import1 >>> >>> >> >> >>>> >>>>> >type nfs4 >>> >>> >> >> >>>> >>>>> >>> >>> >> >> >>>> >>>>> >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>> >>> >> >> >>> >>> >> >> >>> >>> >> >>> >>> >> >>> >>> >>> >>> >>> >>>
>>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >>> >>> >> >> >>>> >>>>> >192.168.24.13:/stor/iso1 on >>> >>> >> >> >>>> >>>>> /rhev/data-center/mnt/192.168.24.13:_stor_iso1 >>> >>> >> >> >>>> >>>>> >type nfs4 >>> >>> >> >> >>>> >>>>> >>> >>> >> >> >>>> >>>>> >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>> >>> >> >> >>> >>> >> >> >>> >>> >> >>> >>> >> >>> >>> >>> >>> >>> >>>
>>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >>> >>> >> >> >>>> >>>>> >192.168.24.13:/stor/export0 on >>> >>> >> >> >>>> >>>>> >>>/rhev/data-center/mnt/192.168.24.13:_stor_export0 >>> >>> >> >> >>>> >>>>> >type nfs4 >>> >>> >> >> >>>> >>>>> >>> >>> >> >> >>>> >>>>> >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>> >>> >> >> >>> >>> >> >> >>> >>> >> >>> >>> >> >>> >>> >>> >>> >>> >>>
>>>>>>>(rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,soft,nosharecache,proto=tcp,timeo=600,retrans=6,sec=sys,clientaddr=192.168.24.18,local_lock=none,addr=192.168.24.13) >>> >>> >> >> >>>> >>>>> >192.168.24.15:/images on >>> >>> >> >> >>>> >>>>> >>> >>/rhev/data-center/mnt/glusterSD/192.168.24.15:_images >>> >>> >> >> >>>> >>>>> >type fuse.glusterfs >>> >>> >> >> >>>> >>>>> >>> >>> >> >> >>>> >>>>> >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>> >>> >> >> >>> >>> >> >> >>> >>> >> >>> >>> >> >>> >>> >>> >>> >>> >>>
>>>>>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) >>> >>> >> >> >>>> >>>>> >192.168.24.18:/images3 on >>> >>> >> >> >>>> >>>>> >>> >>/rhev/data-center/mnt/glusterSD/192.168.24.18:_images3 >>> >>> >> >> >>>> >>>>> >type fuse.glusterfs >>> >>> >> >> >>>> >>>>> >>> >>> >> >> >>>> >>>>> >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>> >>> >> >> >>> >>> >> >> >>> >>> >> >>> >>> >> >>> >>> >>> >>> >>> >>>
>>>>>>>(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) >>> >>> >> >> >>>> >>>>> >tmpfs on /run/user/0 type tmpfs >>> >>> >> >> >>>> >>>>> >>> >>> >> (rw,nosuid,nodev,relatime,seclabel,size=13198392k,mode=700) >>> >>> >> >> >>>> >>>>> >[root@ov06 glusterfs]# >>> >>> >> >> >>>> >>>>> > >>> >>> >> >> >>>> >>>>> >Also here is a screenshot of the console >>> >>> >> >> >>>> >>>>> > >>> >>> >> >> >>>> >>>>> >[image: image.png] >>> >>> >> >> >>>> >>>>> >The other domains are up >>> >>> >> >> >>>> >>>>> > >>> >>> >> >> >>>> >>>>> >Import0 and Import1 are NFS . GLCL0 is >gluster. >>> >They >>> >>> >all >>> >>> >> >are >>> >>> >> >> >>>> >>>running >>> >>> >> >> >>>> >>>>> >VMs >>> >>> >> >> >>>> >>>>> > >>> >>> >> >> >>>> >>>>> >Thank You For Your Help ! >>> >>> >> >> >>>> >>>>> > >>> >>> >> >> >>>> >>>>> >On Thu, Jun 18, 2020 at 3:51 PM Strahil >Nikolov >>> >>> >> >> >>>> >>><hunter86_bg@yahoo.com> >>> >>> >> >> >>>> >>>>> >wrote: >>> >>> >> >> >>>> >>>>> > >>> >>> >> >> >>>> >>>>> >> I don't see >>> >>> >> >> '/rhev/data-center/mnt/192.168.24.13:_stor_import1' >>> >>> >> >> >>>> >>>>> >mounted >>> >>> >> >> >>>> >>>>> >> at all . >>> >>> >> >> >>>> >>>>> >> What is the status of all storage domains ? >>> >>> >> >> >>>> >>>>> >> >>> >>> >> >> >>>> >>>>> >> Best Regards, >>> >>> >> >> >>>> >>>>> >> Strahil Nikolov >>> >>> >> >> >>>> >>>>> >> >>> >>> >> >> >>>> >>>>> >> На 18 юни 2020 г. 21:43:44 GMT+03:00, C >>Williams >>> >>> >> >> >>>> >>>>> ><cwilliams3320@gmail.com> >>> >>> >> >> >>>> >>>>> >> написа: >>> >>> >> >> >>>> >>>>> >> > Resending to deal with possible email >>issues >>> >>> >> >> >>>> >>>>> >> > >>> >>> >> >> >>>> >>>>> >> >---------- Forwarded message
>>> >>> >> >> >>>> >>>>> >> >From: C Williams <cwilliams3320@gmail.com> >>> >>> >> >> >>>> >>>>> >> >Date: Thu, Jun 18, 2020 at 2:07 PM >>> >>> >> >> >>>> >>>>> >> >Subject: Re: [ovirt-users] Issues with >>Gluster >>> >>> >Domain >>> >>> >> >> >>>> >>>>> >> >To: Strahil Nikolov <hunter86_bg@yahoo.com> >>> >>> >> >> >>>> >>>>> >> > >>> >>> >> >> >>>> >>>>> >> > >>> >>> >> >> >>>> >>>>> >> >More >>> >>> >> >> >>>> >>>>> >> > >>> >>> >> >> >>>> >>>>> >> >[root@ov06 ~]# for i in $(gluster volume >>list); >>> > do >>> >>> >> >echo >>> >>> >> >> >>>> >>>$i;echo; >>> >>> >> >> >>>> >>>>> >> >gluster >>> >>> >> >> >>>> >>>>> >> >volume info $i; echo;echo;gluster volume >>status >>> >>> >> >> >>>> >>>>> >$i;echo;echo;echo;done >>> >>> >> >> >>>> >>>>> >> >images3 >>> >>> >> >> >>>> >>>>> >> > >>> >>> >> >> >>>> >>>>> >> > >>> >>> >> >> >>>> >>>>> >> >Volume Name: images3 >>> >>> >> >> >>>> >>>>> >> >Type: Replicate >>> >>> >> >> >>>> >>>>> >> >Volume ID: >>0243d439-1b29-47d0-ab39-d61c2f15ae8b >>> >>> >> >> >>>> >>>>> >> >Status: Started >>> >>> >> >> >>>> >>>>> >> >Snapshot Count: 0 >>> >>> >> >> >>>> >>>>> >> >Number of Bricks: 1 x 3 = 3 >>> >>> >> >> >>>> >>>>> >> >Transport-type: tcp >>> >>> >> >> >>>> >>>>> >> >Bricks: >>> >>> >> >> >>>> >>>>> >> >Brick1: >>192.168.24.18:/bricks/brick04/images3 >>> >>> >> >> >>>> >>>>> >> >Brick2: >>192.168.24.19:/bricks/brick05/images3 >>> >>> >> >> >>>> >>>>> >> >Brick3: >>192.168.24.20:/bricks/brick06/images3 >>> >>> >> >> >>>> >>>>> >> >Options Reconfigured: >>> >>> >> >> >>>> >>>>> >> >performance.client-io-threads: on >>> >>> >> >> >>>> >>>>> >> >nfs.disable: on >>> >>> >> >> >>>> >>>>> >> >transport.address-family: inet >>> >>> >> >> >>>> >>>>> >> >user.cifs: off >>> >>> >> >> >>>> >>>>> >> >auth.allow: * >>> >>> >> >> >>>> >>>>> >> >performance.quick-read: off >>> >>> >> >> >>>> >>>>> >> >performance.read-ahead: off >>> >>> >> >> >>>> >>>>> >> >performance.io-cache: off >>> >>> >> >> >>>> >>>>> >> >performance.low-prio-threads: 32 >>> >>> >> >> >>>> >>>>> >> >network.remote-dio: off >>> >>> >> >> >>>> >>>>> >> >cluster.eager-lock: enable >>> >>> >> >> >>>> >>>>> >> >cluster.quorum-type: auto >>> >>> >> >> >>>> >>>>> >> >cluster.server-quorum-type: server >>> >>> >> >> >>>> >>>>> >> >cluster.data-self-heal-algorithm: full >>> >>> >> >> >>>> >>>>> >> >cluster.locking-scheme: granular >>> >>> >> >> >>>> >>>>> >> >cluster.shd-max-threads: 8 >>> >>> >> >> >>>> >>>>> >> >cluster.shd-wait-qlength: 10000 >>> >>> >> >> >>>> >>>>> >> >features.shard: on >>> >>> >> >> >>>> >>>>> >> >cluster.choose-local: off >>> >>> >> >> >>>> >>>>> >> >client.event-threads: 4 >>> >>> >> >> >>>> >>>>> >> >server.event-threads: 4 >>> >>> >> >> >>>> >>>>> >> >storage.owner-uid: 36 >>> >>> >> >> >>>> >>>>> >> >storage.owner-gid: 36 >>> >>> >> >> >>>> >>>>> >> >performance.strict-o-direct: on >>> >>> >> >> >>>> >>>>> >> >network.ping-timeout: 30 >>> >>> >> >> >>>> >>>>> >> >cluster.granular-entry-heal: enable >>> >>> >> >> >>>> >>>>> >> > >>> >>> >> >> >>>> >>>>> >> > >>> >>> >> >> >>>> >>>>> >> >Status of volume: images3 >>> >>> >> >> >>>> >>>>> >> >Gluster process >>TCP >>> >>> >Port >>> >>> >> >> >RDMA Port >>> >>> >> >> >>>> >>>>> >Online >>> >>> >> >> >>>> >>>>> >> > Pid >>> >>> >> >> >>>> >>>>> >> >>> >>> >> >> >>>> >>>>> >> >>> >>> >> >> >>>> >>>>> >>> >>> >> >> >>>> >>>>> >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>> >>> >> >> >>> >>> >> >> >>> >>> >> >>> >>> >> >>> >>> >>> >>> >>> >>>
>>>>>>>>------------------------------------------------------------------------------ >>> >>> >> >> >>>> >>>>> >> >Brick 192.168.24.18:/bricks/brick04/images3 >>> >49152 >>> >>> >> >0 >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>>Y >>> >>> >> >> >>>> >>>>> >> >6666 >>> >>> >> >> >>>> >>>>> >> >Brick 192.168.24.19:/bricks/brick05/images3 >>> >49152 >>> >>> >> >0 >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>>Y >>> >>> >> >> >>>> >>>>> >> >6779 >>> >>> >> >> >>>> >>>>> >> >Brick 192.168.24.20:/bricks/brick06/images3 >>> >49152 >>> >>> >> >0 >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>>Y >>> >>> >> >> >>>> >>>>> >> >7227 >>> >>> >> >> >>>> >>>>> >> >Self-heal Daemon on localhost >>N/A >>> >>> >> >N/A >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>>Y >>> >>> >> >> >>>> >>>>> >> >6689 >>> >>> >> >> >>>> >>>>> >> >Self-heal Daemon on ov07.ntc.srcle.com >>N/A >>> >>> >> >N/A >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>>Y >>> >>> >> >> >>>> >>>>> >> >6802 >>> >>> >> >> >>>> >>>>> >> >Self-heal Daemon on ov08.ntc.srcle.com >>N/A >>> >>> >> >N/A >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>>Y >>> >>> >> >> >>>> >>>>> >> >7250 >>> >>> >> >> >>>> >>>>> >> > >>> >>> >> >> >>>> >>>>> >> >Task Status of Volume images3 >>> >>> >> >> >>>> >>>>> >> >>> >>> >> >> >>>> >>>>> >> >>> >>> >> >> >>>> >>>>> >>> >>> >> >> >>>> >>>>> >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>> >>> >> >> >>> >>> >> >> >>> >>> >> >>> >>> >> >>> >>> >>> >>> >>> >>>
>>>>>>>>------------------------------------------------------------------------------ >>> >>> >> >> >>>> >>>>> >> >There are no active volume tasks >>> >>> >> >> >>>> >>>>> >> > >>> >>> >> >> >>>> >>>>> >> > >>> >>> >> >> >>>> >>>>> >> > >>> >>> >> >> >>>> >>>>> >> > >>> >>> >> >> >>>> >>>>> >> >[root@ov06 ~]# ls -l >>> >>> >/rhev/data-center/mnt/glusterSD/ >>> >>> >> >> >>>> >>>>> >> >total 16 >>> >>> >> >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:04 >>> >>> >> >> >192.168.24.15:_images >>> >>> >> >> >>>> >>>>> >> >drwxr-xr-x. 5 vdsm kvm 8192 Jun 18 14:05 >>> >>> >> >192.168.24.18: >>> >>> >> >> >>>> _images3 >>> >>> >> >> >>>> >>>>> >> >[root@ov06 ~]# >>> >>> >> >> >>>> >>>>> >> > >>> >>> >> >> >>>> >>>>> >> >On Thu, Jun 18, 2020 at 2:03 PM C Williams >>> >>> >> >> >>>> >>><cwilliams3320@gmail.com> >>> >>> >> >> >>>> >>>>> >> >wrote: >>> >>> >> >> >>>> >>>>> >> > >>> >>> >> >> >>>> >>>>> >> >> Strahil, >>> >>> >> >> >>>> >>>>> >> >> >>> >>> >> >> >>>> >>>>> >> >> Here you go -- Thank You For Your Help ! >>> >>> >> >> >>>> >>>>> >> >> >>> >>> >> >> >>>> >>>>> >> >> BTW -- I can write a test file to gluster >>and >>> >it >>> >>> >> >> >replicates >>> >>> >> >> >>>> >>>>> >properly. >>> >>> >> >> >>>> >>>>> >> >> Thinking something about the oVirt >Storage >>> >Domain >>> >>> >? >>> >>> >> >> >>>> >>>>> >> >> >>> >>> >> >> >>>> >>>>> >> >> [root@ov08 ~]# gluster pool list >>> >>> >> >> >>>> >>>>> >> >> UUID >>> >Hostname >>> >>> >> >> >>>> >>>>> >State >>> >>> >> >> >>>> >>>>> >> >> 5b40c659-d9ab-43c3-9af8-18b074ea0b83 >>ov06 >>> >>> >> >> >>>> >>>>> >> >Connected >>> >>> >> >> >>>> >>>>> >> >> 36ce5a00-6f65-4926-8438-696944ebadb5 >>> >>> >> >> >ov07.ntc.srcle.com >>> >>> >> >> >>>> >>>>> >> >Connected >>> >>> >> >> >>>> >>>>> >> >> c7e7abdb-a8f4-4842-924c-e227f0db1b29 >>> >localhost >>> >>> >> >> >>>> >>>>> >> >Connected >>> >>> >> >> >>>> >>>>> >> >> [root@ov08 ~]# gluster volume list >>> >>> >> >> >>>> >>>>> >> >> images3 >>> >>> >> >> >>>> >>>>> >> >> >>> >>> >> >> >>>> >>>>> >> >> On Thu, Jun 18, 2020 at 1:13 PM Strahil >>> >Nikolov >>> >>> >> >> >>>> >>>>> >> ><hunter86_bg@yahoo.com> >>> >>> >> >> >>>> >>>>> >> >> wrote: >>> >>> >> >> >>>> >>>>> >> >> >>> >>> >> >> >>>> >>>>> >> >>> Log to the oVirt cluster and provide the >>> >output >>> >>> >of: >>> >>> >> >> >>>> >>>>> >> >>> gluster pool list >>> >>> >> >> >>>> >>>>> >> >>> gluster volume list >>> >>> >> >> >>>> >>>>> >> >>> for i in $(gluster volume list); do >>echo >>> >>> >$i;echo; >>> >>> >> >> >gluster >>> >>> >> >> >>>> >>>>> >volume >>> >>> >> >> >>>> >>>>> >> >info >>> >>> >> >> >>>> >>>>> >> >>> $i; echo;echo;gluster volume status >>> >>> >> >> >$i;echo;echo;echo;done >>> >>> >> >> >>>> >>>>> >> >>> >>> >>> >> >> >>>> >>>>> >> >>> ls -l /rhev/data-center/mnt/glusterSD/ >>> >>> >> >> >>>> >>>>> >> >>> >>> >>> >> >> >>>> >>>>> >> >>> Best Regards, >>> >>> >> >> >>>> >>>>> >> >>> Strahil Nikolov >>> >>> >> >> >>>> >>>>> >> >>> >>> >>> >> >> >>>> >>>>> >> >>> >>> >>> >> >> >>>> >>>>> >> >>> На 18 юни 2020 г. 19:17:46 GMT+03:00, C >>> >Williams >>> >>> >> >> >>>> >>>>> >> ><cwilliams3320@gmail.com> >>> >>> >> >> >>>> >>>>> >> >>> написа: >>> >>> >> >> >>>> >>>>> >> >>> >Hello, >>> >>> >> >> >>>> >>>>> >> >>> > >>> >>> >> >> >>>> >>>>> >> >>> >I recently added 6 hosts to an existing >>> >oVirt >>> >>> >> >> >>>> >>>compute/gluster >>> >>> >> >> >>>> >>>>> >> >cluster. >>> >>> >> >> >>>> >>>>> >> >>> > >>> >>> >> >> >>>> >>>>> >> >>> >Prior to this attempted addition, my >>> >cluster >>> >>> >had 3 >>> >>> >> >> >>>> >>>Hypervisor >>> >>> >> >> >>>> >>>>> >hosts >>> >>> >> >> >>>> >>>>> >> >and >>> >>> >> >> >>>> >>>>> >> >>> >3 >>> >>> >> >> >>>> >>>>> >> >>> >gluster bricks which made up a single >>> >gluster >>> >>> >> >volume >>> >>> >> >> >>>> >>>(replica 3 >>> >>> >> >> >>>> >>>>> >> >volume) >>> >>> >> >> >>>> >>>>> >> >>> >. I >>> >>> >> >> >>>> >>>>> >> >>> >added the additional hosts and made a >>brick >>> >on >>> >>> >3 >>> >>> >> >of >>> >>> >> >> >the new >>> >>> >> >> >>>> >>>>> >hosts >>> >>> >> >> >>>> >>>>> >> >and >>> >>> >> >> >>>> >>>>> >> >>> >attempted to make a new replica 3 >>volume. I >>> >had >>> >>> >> >> >difficulty >>> >>> >> >> >>>> >>>>> >> >creating >>> >>> >> >> >>>> >>>>> >> >>> >the >>> >>> >> >> >>>> >>>>> >> >>> >new volume. So, I decided that I would >>make >>> >a >>> >>> >new >>> >>> >> >> >>>> >>>>> >compute/gluster >>> >>> >> >> >>>> >>>>> >> >>> >cluster >>> >>> >> >> >>>> >>>>> >> >>> >for each set of 3 new hosts. >>> >>> >> >> >>>> >>>>> >> >>> > >>> >>> >> >> >>>> >>>>> >> >>> >I removed the 6 new hosts from the >>existing >>> >>> >oVirt >>> >>> >> >> >>>> >>>>> >Compute/Gluster >>> >>> >> >> >>>> >>>>> >> >>> >Cluster >>> >>> >> >> >>>> >>>>> >> >>> >leaving the 3 original hosts in place >>with >>> >>> >their >>> >>> >> >> >bricks. At >>> >>> >> >> >>>> >>>that >>> >>> >> >> >>>> >>>>> >> >point >>> >>> >> >> >>>> >>>>> >> >>> >my >>> >>> >> >> >>>> >>>>> >> >>> >original bricks went down and came back >>up >>> >. >>> >>> >The >>> >>> >> >> >volume >>> >>> >> >> >>>> >>>showed >>> >>> >> >> >>>> >>>>> >> >entries >>> >>> >> >> >>>> >>>>> >> >>> >that >>> >>> >> >> >>>> >>>>> >> >>> >needed healing. At that point I ran >>gluster >>> >>> >volume >>> >>> >> >> >heal >>> >>> >> >> >>>> >>>images3 >>> >>> >> >> >>>> >>>>> >> >full, >>> >>> >> >> >>>> >>>>> >> >>> >etc. >>> >>> >> >> >>>> >>>>> >> >>> >The volume shows no unhealed entries. I >>> >also >>> >>> >> >> >corrected some >>> >>> >> >> >>>> >>>peer >>> >>> >> >> >>>> >>>>> >> >>> >errors. >>> >>> >> >> >>>> >>>>> >> >>> > >>> >>> >> >> >>>> >>>>> >> >>> >However, I am unable to copy disks, >move >>> >disks >>> >>> >to >>> >>> >> >> >another >>> >>> >> >> >>>> >>>>> >domain, >>> >>> >> >> >>>> >>>>> >> >>> >export >>> >>> >> >> >>>> >>>>> >> >>> >disks, etc. It appears that the engine >>> >cannot >>> >>> >> >locate >>> >>> >> >> >disks >>> >>> >> >> >>>> >>>>> >properly >>> >>> >> >> >>>> >>>>> >> >and >>> >>> >> >> >>>> >>>>> >> >>> >I >>> >>> >> >> >>>> >>>>> >> >>> >get storage I/O errors. >>> >>> >> >> >>>> >>>>> >> >>> > >>> >>> >> >> >>>> >>>>> >> >>> >I have detached and removed the oVirt >>> >Storage >>> >>> >> >Domain. >>> >>> >> >> >I >>> >>> >> >> >>>> >>>>> >reimported >>> >>> >> >> >>>> >>>>> >> >the >>> >>> >> >> >>>> >>>>> >> >>> >domain and imported 2 VMs, But the VM >>disks >>> >>> >> >exhibit >>> >>> >> >> >the >>> >>> >> >> >>>> same >>> >>> >> >> >>>> >>>>> >> >behaviour >>> >>> >> >> >>>> >>>>> >> >>> >and >>> >>> >> >> >>>> >>>>> >> >>> >won't run from the hard disk. >>> >>> >> >> >>>> >>>>> >> >>> > >>> >>> >> >> >>>> >>>>> >> >>> > >>> >>> >> >> >>>> >>>>> >> >>> >I get errors such as this >>> >>> >> >> >>>> >>>>> >> >>> > >>> >>> >> >> >>>> >>>>> >> >>> >VDSM ov05 command >>HSMGetAllTasksStatusesVDS >>> >>> >> >failed: >>> >>> >> >> >low >>> >>> >> >> >>>> >>>level >>> >>> >> >> >>>> >>>>> >Image >>> >>> >> >> >>>> >>>>> >> >>> >copy >>> >>> >> >> >>>> >>>>> >> >>> >failed: ("Command ['/usr/bin/qemu-img', >>> >>> >'convert', >>> >>> >> >> >'-p', >>> >>> >> >> >>>> >>>'-t', >>> >>> >> >> >>>> >>>>> >> >'none', >>> >>> >> >> >>>> >>>>> >> >>> >'-T', 'none', '-f', 'raw', >>> >>> >> >> >>>> >>>>> >> >>> >>> >>> >>u'/rhev/data-center/mnt/glusterSD/192.168.24.18: >>> >>> >> >> >>>> >>>>> >> >>> >>> >>> >> >> >>>> >>>>> >> >>> >>> >> >> >>>> >>>>> >> >>> >>> >> >> >>>> >>>>> >>> >>> >> >> >>>> >>>>> >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>> >>> >> >> >>> >>> >> >> >>> >>> >> >>> >>> >> >>> >>> >>> >>> >>> >>>
>>>>>>>>_images3/5fe3ad3f-2d21-404c-832e-4dc7318ca10d/images/3ea5afbd-0fe0-4c09-8d39-e556c66a8b3d/fe6eab63-3b22-4815-bfe6-4a0ade292510', >>> >>> >> >> >>>> >>>>> >> >>> >'-O', 'raw', >>> >>> >> >> >>>> >>>>> >> >>> u'/rhev/data-center/mnt/192.168.24.13: >>> >>> >> >> >>>> >>>>> >> >>> >>> >>> >> >> >>>> >>>>> >> >>> >>> >> >> >>>> >>>>> >> >>> >>> >> >> >>>> >>>>> >>> >>> >> >> >>>> >>>>> >>> >>> >> >> >>>> >>> >>> >> >> >>>> >>> >>> >> >> >>> >>> >> >> >>> >>> >> >>> >>> >> >>> >>> >>> >>> >>> >>>
>>>>>>>>_stor_import1/1ab89386-a2ba-448b-90ab-bc816f55a328/images/f707a218-9db7-4e23-8bbd-9b12972012b6/d6591ec5-3ede-443d-bd40-93119ca7c7d5'] >>> >>> >> >> >>>> >>>>> >> >>> >failed with rc=1 out='' >>> >>> >err=bytearray(b'qemu-img: >>> >>> >> >> >error >>> >>> >> >> >>>> >>>while >>> >>> >> >> >>>> >>>>> >> >reading >>> >>> >> >> >>>> >>>>> >> >>> >sector 135168: Transport endpoint is >not >>> >>> >> >> >>>> >>>connected\\nqemu-img: >>> >>> >> >> >>>> >>>>> >> >error >>> >>> >> >> >>>> >>>>> >> >>> >while >>> >>> >> >> >>>> >>>>> >> >>> >reading sector 131072: Transport >>endpoint >>> >is >>> >>> >not >>> >>> >> >> >>>> >>>>> >> >connected\\nqemu-img: >>> >>> >> >> >>>> >>>>> >> >>> >error while reading sector 139264: >>> >Transport >>> >>> >> >endpoint >>> >>> >> >> >is >>> >>> >> >> >>>> not >>> >>> >> >> >>>> >>>>> >> >>> >connected\\nqemu-img: error while >>reading >>> >>> >sector >>> >>> >> >> >143360: >>> >>> >> >> >>>> >>>>> >Transport >>> >>> >> >> >>>> >>>>> >> >>> >endpoint >>> >>> >> >> >>>> >>>>> >> >>> >is not connected\\nqemu-img: error >while >>> >>> >reading >>> >>> >> >> >sector >>> >>> >> >> >>>> >>>147456: >>> >>> >> >> >>>> >>>>> >> >>> >Transport >>> >>> >> >> >>>> >>>>> >> >>> >endpoint is not connected\\nqemu-img: >>error >>> >>> >while >>> >>> >> >> >reading >>> >>> >> >> >>>> >>>sector >>> >>> >> >> >>>> >>>>> >> >>> >155648: >>> >>> >> >> >>>> >>>>> >> >>> >Transport endpoint is not >>> >connected\\nqemu-img: >>> >>> >> >error >>> >>> >> >> >while >>> >>> >> >> >>>> >>>>> >reading >>> >>> >> >> >>>> >>>>> >> >>> >sector >>> >>> >> >> >>>> >>>>> >> >>> >151552: Transport endpoint is not >>> >>> >> >> >connected\\nqemu-img: >>> >>> >> >> >>>> >>>error >>> >>> >> >> >>>> >>>>> >while >>> >>> >> >> >>>> >>>>> >> >>> >reading >>> >>> >> >> >>>> >>>>> >> >>> >sector 159744: Transport endpoint is >not >>> >>> >> >> >connected\\n')",) >>> >>> >> >> >>>> >>>>> >> >>> > >>> >>> >> >> >>>> >>>>> >> >>> >oVirt version is 4.3.82-1.el7 >>> >>> >> >> >>>> >>>>> >> >>> >OS CentOS Linux release 7.7.1908 (Core) >>> >>> >> >> >>>> >>>>> >> >>> > >>> >>> >> >> >>>> >>>>> >> >>> >The Gluster Cluster has been working >>very >>> >well >>> >>> >> >until >>> >>> >> >> >this >>> >>> >> >> >>>> >>>>> >incident. >>> >>> >> >> >>>> >>>>> >> >>> > >>> >>> >> >> >>>> >>>>> >> >>> >Please help. >>> >>> >> >> >>>> >>>>> >> >>> > >>> >>> >> >> >>>> >>>>> >> >>> >Thank You >>> >>> >> >> >>>> >>>>> >> >>> > >>> >>> >> >> >>>> >>>>> >> >>> >Charles Williams >>> >>> >> >> >>>> >>>>> >> >>> >>> >>> >> >> >>>> >>>>> >> >> >>> >>> >> >> >>>> >>>>> >> >>> >>> >> >> >>>> >>>>> >>> >>> >> >> >>>> >>>> >>> >>> >> >> >>>> >> >>> >>> >> >> >>>> > >>> >>> >> >> >>>>
>>> >>> >> >> >>>> Users mailing list -- users@ovirt.org >>> >>> >> >> >>>> To unsubscribe send an email to users-leave@ovirt.org >>> >>> >> >> >>>> Privacy Statement: >>> >https://www.ovirt.org/privacy-policy.html >>> >>> >> >> >>>> oVirt Code of Conduct: >>> >>> >> >> >>>> >>> >https://www.ovirt.org/community/about/community-guidelines/ >>> >>> >> >> >>>> List Archives: >>> >>> >> >> >>>> >>> >>> >> >> > >>> >>> >> >> >>> >>> >> > >>> >>> >> >>> >>> > >>> >>> >>> > >>> >> >
https://lists.ovirt.org/archives/list/users@ovirt.org/message/YY3VUKEJLI7MRW...
>>> >>> >> >> >>>> >>> >>> >> >> >>> >>> >>> >> >> >>> >>> >> >>> >>> >>> >> >>>
participants (2)
-
 C Williams
C Williams -
 Strahil Nikolov
Strahil Nikolov