[Call for feedback] did you install/update to 4.1.0?

Hi, did you install/update to 4.1.0? Let us know your experience! We end up knowing only when things doesn't work well, let us know it works fine for you :-) If you're not planning an update to 4.1.0 in the near future, let us know why. Maybe we can help. Thanks! -- Sandro Bonazzola Better technology. Faster innovation. Powered by community collaboration. See how it works at redhat.com


This is a multi-part message in MIME format. --------------C38D138BEB37CEA880DBBAE4 Content-Type: text/plain; charset=UTF-8; format=flowed Content-Transfer-Encoding: 8bit Hello Thanks for sharing your procedures. Why did you have to restart VMs for the migration to work ? Is it mandatory for an upgrade ? Fernando On 02/02/2017 12:23, Краснобаев Михаил wrote:
Hi, upgraded my cluster (3 hosts, engine, nfs-share) to the latest 4.1 release and Centos 7.3 (from 4.06). Did the following: 1. Upgraded engine machine to Centos 7.3 2. Upgraded engine packages and ran "engine-setup" 3. Upgraded one by one hosts to 7.3 + packages from the new 4.1. repo and refreshed hosts capabilities. 4. Raised cluster and datacenter compatibility level to 4.1. 5. Restarted virtual machines and tested migration. 6. Profit! Everything went really smoothly. No errors. Now trying to figure out how the sparsify function works. I need to run trimming from inside the VM first? Best regards, Mikhail. 02.02.2017, 15:19, "Sandro Bonazzola" <sbonazzo@redhat.com>:
Hi, did you install/update to 4.1.0? Let us know your experience! We end up knowing only when things doesn't work well, let us know it works fine for you :-) If you're not planning an update to 4.1.0 in the near future, let us know why. Maybe we can help. Thanks! -- Sandro Bonazzola Better technology. Faster innovation. Powered by community collaboration. See how it works at redhat.com <http://redhat.com/> ,
_______________________________________________ Users mailing list Users@ovirt.org <mailto:Users@ovirt.org> http://lists.ovirt.org/mailman/listinfo/users
-- С уважением, Краснобаев Михаил.
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
--------------C38D138BEB37CEA880DBBAE4 Content-Type: text/html; charset=UTF-8 Content-Transfer-Encoding: 8bit <html> <head> <meta content="text/html; charset=UTF-8" http-equiv="Content-Type"> </head> <body bgcolor="#FFFFFF" text="#000000"> <p>Hello</p> <p>Thanks for sharing your procedures.</p> <p>Why did you have to restart VMs for the migration to work ? Is it mandatory for an upgrade ?</p> <p>Fernando<br> </p> <br> <div class="moz-cite-prefix">On 02/02/2017 12:23, Краснобаев Михаил wrote:<br> </div> <blockquote cite="mid:264121486045383@web14m.yandex.ru" type="cite"> <div>Hi,</div> <div> </div> <div>upgraded my cluster (3 hosts, engine, nfs-share) to the latest 4.1 release and Centos 7.3 (from 4.06).</div> <div> </div> <div>Did the following:</div> <div> </div> <div>1. Upgraded engine machine to Centos 7.3</div> <div>2. Upgraded engine packages and ran "engine-setup"</div> <div>3. Upgraded one by one hosts to 7.3 + packages from the new 4.1. repo and refreshed hosts capabilities.</div> <div>4. Raised cluster and datacenter compatibility level to 4.1.</div> <div>5. Restarted virtual machines and tested migration.</div> <div>6. Profit! Everything went really smoothly. No errors.</div> <div> </div> <div>Now trying to figure out how the sparsify function works. I need to run trimming from inside the VM first?</div> <div> </div> <div>Best regards, Mikhail.</div> <div> </div> <div> </div> <div> </div> <div>02.02.2017, 15:19, "Sandro Bonazzola" <a class="moz-txt-link-rfc2396E" href="mailto:sbonazzo@redhat.com"><sbonazzo@redhat.com></a>:</div> <blockquote type="cite"> <div>Hi, <div>did you install/update to 4.1.0? Let us know your experience!</div> <div>We end up knowing only when things doesn't work well, let us know it works fine for you :-)</div> <div> </div> <div>If you're not planning an update to 4.1.0 in the near future, let us know why.</div> <div>Maybe we can help. <div> </div> <div>Thanks!</div> -- <div> <div> <div> <div> <div> <div> <div> <div>Sandro Bonazzola<br> Better technology. Faster innovation. Powered by community collaboration.<br> See how it works at <a moz-do-not-send="true" target="_blank" href="http://redhat.com/">redhat.com</a></div> </div> </div> </div> </div> </div> </div> </div> </div> </div> , <p>_______________________________________________<br> Users mailing list<br> <a moz-do-not-send="true" href="mailto:Users@ovirt.org">Users@ovirt.org</a><br> <a moz-do-not-send="true" href="http://lists.ovirt.org/mailman/listinfo/users">http://lists.ovirt.org/mailman/listinfo/users</a></p> </blockquote> <div> </div> <div> </div> <div>-- </div> <div>С уважением, Краснобаев Михаил.</div> <div> </div> <div> </div> <br> <fieldset class="mimeAttachmentHeader"></fieldset> <br> <pre wrap="">_______________________________________________ Users mailing list <a class="moz-txt-link-abbreviated" href="mailto:Users@ovirt.org">Users@ovirt.org</a> <a class="moz-txt-link-freetext" href="http://lists.ovirt.org/mailman/listinfo/users">http://lists.ovirt.org/mailman/listinfo/users</a> </pre> </blockquote> <br> </body> </html> --------------C38D138BEB37CEA880DBBAE4--

On Thu, Feb 2, 2017 at 4:23 PM, Краснобаев Михаил <milo1@ya.ru> wrote:
Hi,
upgraded my cluster (3 hosts, engine, nfs-share) to the latest 4.1 release and Centos 7.3 (from 4.06).
Did the following:
1. Upgraded engine machine to Centos 7.3 2. Upgraded engine packages and ran "engine-setup" 3. Upgraded one by one hosts to 7.3 + packages from the new 4.1. repo and refreshed hosts capabilities. 4. Raised cluster and datacenter compatibility level to 4.1. 5. Restarted virtual machines and tested migration. 6. Profit! Everything went really smoothly. No errors.
Now trying to figure out how the sparsify function works. I need to run trimming from inside the VM first?
If you've configured it to use virtio-SCSI, and DISCARD is enabled, you can. But I believe virt-sparsify does a bit. BTW, depending on the OS, if DISCARD is enabled, I would not do anything - for example, in Fedora, there's a systemd timer that once a week runs fstrim for you. If not, then it has to be turned off and then you can run virt-sparsify. Y.
Best regards, Mikhail.
02.02.2017, 15:19, "Sandro Bonazzola" <sbonazzo@redhat.com>:
Hi, did you install/update to 4.1.0? Let us know your experience! We end up knowing only when things doesn't work well, let us know it works fine for you :-)
If you're not planning an update to 4.1.0 in the near future, let us know why. Maybe we can help.
Thanks! -- Sandro Bonazzola Better technology. Faster innovation. Powered by community collaboration. See how it works at redhat.com ,
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
-- С уважением, Краснобаев Михаил.
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users

On Thu, Feb 2, 2017 at 9:59 PM, <serg_k@msm.ru> wrote:
Updated from 4.0.6 Docs are quite incomplete, it's not mentioned about installing ovirt-release41 on centos HV and ovirt-nodes manually, you need to guess. Also links in release notes are broken ( https://www.ovirt.org/release/ 4.1.0/ ) They are going to https://www.ovirt.org/release/4.1.0/Hosted_Engine_Howto <https://www.ovirt.org/release/4.1.0/Hosted_Engine_Howto#Upgrade_Hosted_Engine> , but docs for 4.1.0 are absent.
Thanks, opened https://github.com/oVirt/ovirt-site/issues/765 I'd like to ask you if you can push your suggestion on documentation fixes / improvements editing the website following "Edit this page on GitHub" link at the bottom of the page. Any help getting documentation updated and more useful to users is really appreciated.
Upgrade went well, everything migrated without problems(I need to restart VMs only to change cluster level to 4.1). Good news, SPICE HTML 5 client now working for me on Win client with firefox, before on 4.x it was sending connect requests forever.
There is some bugs I've found playing with new version: 1) some storage tabs displaying "No items to display " for example: if I'm expanding System\Data centers\[dc name]\ and selecting Storage it displays nothing in main tab, but displays all domains in tree, if I'm selecting [dc name] and Storage tab, also nothing, but in System \ Strorage tab all domains present, also in Clusters\[cluster name]\ Storage tab they present.
Thanks, opened https://bugzilla.redhat.com/show_bug.cgi?id=1418924
2) links to embedded files and clients aren't working, engine says 404, examples: https://[your manager's address]/ovirt-engine/services/files/spice/usbdk- x64.msi https://[your manager's address]/ovirt-engine/services/files/spice/virt- viewer-x64.msi and other, but they are in docs(in ovirt and also in rhel)
Thanks, opened https://bugzilla.redhat.com/show_bug.cgi?id=1418923
3) there is also link in "Console options" menu (right click on VM) called "Console Client Resources", it's going to dead location: http://www.ovirt.org/documentation/admin-guide/ virt/console-client-resources If you are going to fix issue №2 maybe also adding links directly to installation files embedded will be more helpful for users)
Thanks, opened https://bugzilla.redhat.com/show_bug.cgi?id=1418921
4) little disappointed about "pass discards" on NFS storage, as I've found NFS implementation(even 4.1) in Centos 7 doesn't support fallocate(FALLOC_FL_PUNCH_HOLE), that quemu uses for file storage, it was added only in kernel 3.18, sparsify also not working, but I'll mail separate thread with this question.
*-- Thursday, February 2, 2017, 15:19:29: *
Hi, did you install/update to 4.1.0? Let us know your experience! We end up knowing only when things doesn't work well, let us know it works fine for you :-)
If you're not planning an update to 4.1.0 in the near future, let us know why. Maybe we can help.
Thanks! -- Sandro Bonazzola Better technology. Faster innovation. Powered by community collaboration. See how it works at redhat.com
-- Sandro Bonazzola Better technology. Faster innovation. Powered by community collaboration. See how it works at redhat.com

On Thu, Feb 02, 2017 at 01:19:29PM +0100, Sandro Bonazzola wrote:
did you install/update to 4.1.0? Let us know your experience! We end up knowing only when things doesn't work well, let us know it works fine for you :-)
Will do that in a week or so. What's the preferred way to upgrade to 4.1.0 starting from a 4.0.x setup with a hosted engine? Is it recommended to use engine-setup/yum (i.e. chapter 2 of the Upgrade Guide) or would you prefer an appliance upgrade using hosted-engine(8) as described in the HE guide?
On Fri, Feb 3, 2017 at 7:02 AM, Lars Seipel <lars.seipel@gmail.com> wrote:
On Thu, Feb 02, 2017 at 01:19:29PM +0100, Sandro Bonazzola wrote:
did you install/update to 4.1.0? Let us know your experience! We end up knowing only when things doesn't work well, let us know it works fine for you :-)
Will do that in a week or so. What's the preferred way to upgrade to 4.1.0 starting from a 4.0.x setup with a hosted engine?
Is it recommended to use engine-setup/yum (i.e. chapter 2 of the Upgrade Guide) or would you prefer an appliance upgrade using hosted-engine(8) as described in the HE guide?
Appliance upgrade was designed to help transitioning from 3.6 el6 to 4.0 el7 appliances. I would recommend to use engine-setup/yum within the appliance to upgrade the engine. -- Sandro Bonazzola Better technology. Faster innovation. Powered by community collaboration. See how it works at redhat.com

This is a multi-part message in MIME format. --------------30F8A2A0E6135E272C8BA558 Content-Type: text/plain; charset=UTF-8; format=flowed Content-Transfer-Encoding: 8bit I've done an upgrade of ovirt-engine tomorrow. There were two problems. The first - packages from epel repo, solved by disable repo and downgrade package to an existing version in ovirt-release40 repo (yes, there is info in documentation about epel repo). The second (and it is not only for current version) - run the engine-setup always not complete successfully because cat not start ovirt-engine-notifier.service after upgrade, and the error in notifier is that there is no MAIL_SERVER. Every time I am upgrading engine I have the same error. Than I add MAIL_SERVER=127.0.0.1 to /usr/share/ovirt-engine/services/ovirt-engine-notifier/ovirt-engine-notifier.conf and start notifier without problem. Is it my mistake? And one more question. In Events tab I can see "User vasya@internal logged out.", but there are no message that 'vasya' logged in. Could someone tell me how to debug this issue? 02.02.2017 14:19, Sandro Bonazzola пишет:
Hi, did you install/update to 4.1.0? Let us know your experience! We end up knowing only when things doesn't work well, let us know it works fine for you :-)
If you're not planning an update to 4.1.0 in the near future, let us know why. Maybe we can help.
Thanks! -- Sandro Bonazzola Better technology. Faster innovation. Powered by community collaboration. See how it works at redhat.com <http://redhat.com>
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
--------------30F8A2A0E6135E272C8BA558 Content-Type: text/html; charset=UTF-8 Content-Transfer-Encoding: 8bit <html> <head> <meta content="text/html; charset=UTF-8" http-equiv="Content-Type"> </head> <body bgcolor="#FFFFFF" text="#000000"> <p>I've done an upgrade of ovirt-engine tomorrow. There were two problems. <br> </p> <p>The first - packages from epel repo, solved by disable repo and downgrade package to an existing version in ovirt-release40 repo (yes, there is info in documentation about epel repo).</p> <p>The second (and it is not only for current version) - run the engine-setup always not complete successfully because cat not start ovirt-engine-notifier.service after upgrade, and the error in notifier is that there is no MAIL_SERVER. Every time I am upgrading engine I have the same error. Than I add MAIL_SERVER=127.0.0.1 to /usr/share/ovirt-engine/services/ovirt-engine-notifier/ovirt-engine-notifier.conf and start notifier without problem. Is it my mistake?</p> <p>And one more question. In Events tab I can see "User vasya@internal logged out.", but there are no message that 'vasya' logged in. Could someone tell me how to debug this issue?<br> </p> <br> <div class="moz-cite-prefix">02.02.2017 14:19, Sandro Bonazzola пишет:<br> </div> <blockquote cite="mid:CAPQRNT=zqmmbyXW-xgsa7CnRb4KOyyOy0Hr4+upcDL1n4xT+YQ@mail.gmail.com" type="cite"> <div dir="ltr">Hi, <div>did you install/update to 4.1.0? Let us know your experience!</div> <div>We end up knowing only when things doesn't work well, let us know it works fine for you :-)</div> <div><br> </div> <div>If you're not planning an update to 4.1.0 in the near future, let us know why.</div> <div>Maybe we can help.<br clear="all"> <div><br> </div> <div>Thanks!</div> -- <br> <div class="gmail_signature"> <div dir="ltr"> <div> <div dir="ltr"> <div> <div dir="ltr"> <div> <div dir="ltr">Sandro Bonazzola<br> Better technology. Faster innovation. Powered by community collaboration.<br> See how it works at <a moz-do-not-send="true" href="http://redhat.com" target="_blank">redhat.com</a></div> </div> </div> </div> </div> </div> </div> </div> </div> </div> <br> <fieldset class="mimeAttachmentHeader"></fieldset> <br> <pre wrap="">_______________________________________________ Users mailing list <a class="moz-txt-link-abbreviated" href="mailto:Users@ovirt.org">Users@ovirt.org</a> <a class="moz-txt-link-freetext" href="http://lists.ovirt.org/mailman/listinfo/users">http://lists.ovirt.org/mailman/listinfo/users</a> </pre> </blockquote> <br> </body> </html> --------------30F8A2A0E6135E272C8BA558--
On Fri, Feb 3, 2017 at 9:14 AM, Yura Poltoratskiy <yurapoltora@gmail.com> wrote:
I've done an upgrade of ovirt-engine tomorrow. There were two problems.
The first - packages from epel repo, solved by disable repo and downgrade package to an existing version in ovirt-release40 repo (yes, there is info in documentation about epel repo).
The second (and it is not only for current version) - run the engine-setup always not complete successfully because cat not start ovirt-engine-notifier.service after upgrade, and the error in notifier is that there is no MAIL_SERVER. Every time I am upgrading engine I have the same error. Than I add MAIL_SERVER=127.0.0.1 to /usr/share/ovirt-engine/ services/ovirt-engine-notifier/ovirt-engine-notifier.conf and start notifier without problem. Is it my mistake?
Adding Martin Perina, he may be able to assist you on this.
And one more question. In Events tab I can see "User vasya@internal logged out.", but there are no message that 'vasya' logged in. Could someone tell me how to debug this issue?
Martin can probably help as well here, adding also Greg and Alexander.
02.02.2017 14:19, Sandro Bonazzola пишет:
Hi, did you install/update to 4.1.0? Let us know your experience! We end up knowing only when things doesn't work well, let us know it works fine for you :-)
If you're not planning an update to 4.1.0 in the near future, let us know why. Maybe we can help.
Thanks! -- Sandro Bonazzola Better technology. Faster innovation. Powered by community collaboration. See how it works at redhat.com
_______________________________________________ Users mailing listUsers@ovirt.orghttp://lists.ovirt.org/mailman/listinfo/users
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
-- Sandro Bonazzola Better technology. Faster innovation. Powered by community collaboration. See how it works at redhat.com

On Fri, Feb 3, 2017 at 9:24 AM, Sandro Bonazzola <sbonazzo@redhat.com> wrote:
On Fri, Feb 3, 2017 at 9:14 AM, Yura Poltoratskiy <yurapoltora@gmail.com> wrote:
I've done an upgrade of ovirt-engine tomorrow. There were two problems.
The first - packages from epel repo, solved by disable repo and downgrade package to an existing version in ovirt-release40 repo (yes, there is info in documentation about epel repo).
The second (and it is not only for current version) - run the engine-setup always not complete successfully because cat not start ovirt-engine-notifier.service after upgrade, and the error in notifier is that there is no MAIL_SERVER. Every time I am upgrading engine I have the same error. Than I add MAIL_SERVER=127.0.0.1 to /usr/share/ovirt-engine/services/ovirt-engine-notifier/ovirt-engine-notifier.conf and start notifier without problem. Is it my mistake?
Please never change anything in /usr/share/ovirt-engine, those files are always overwritten during upgrade. If you need change any option in ovirt-engine-notifier, please create new configuration file in /etc/ovirt-engine/notifier/notifier.conf.d directory. For example if you need to set MAIL_SERVER please create /etc/ovirt-engine/notifier/notifier.conf.d/99-custom.conf with following content: MAIL_SERVER=127.0.0.1 After saving the file please restart ovirt-engine-notifier service: systemctl restart ovirt-engine-notifier
Adding Martin Perina, he may be able to assist you on this.
And one more question. In Events tab I can see "User vasya@internal logged out.", but there are no message that 'vasya' logged in. Could someone tell me how to debug this issue?
Please share complete log to analyze this, but this user may be logged in before upgrade and we just clean its session after upgrade.
Martin can probably help as well here, adding also Greg and Alexander.
02.02.2017 14:19, Sandro Bonazzola пишет:
Hi, did you install/update to 4.1.0? Let us know your experience! We end up knowing only when things doesn't work well, let us know it works fine for you :-)
If you're not planning an update to 4.1.0 in the near future, let us know why. Maybe we can help.
Thanks! -- Sandro Bonazzola Better technology. Faster innovation. Powered by community collaboration. See how it works at redhat.com
_______________________________________________ Users mailing listUsers@ovirt.orghttp://lists.ovirt.org/mailman/listinfo/users
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
-- Sandro Bonazzola Better technology. Faster innovation. Powered by community collaboration. See how it works at redhat.com

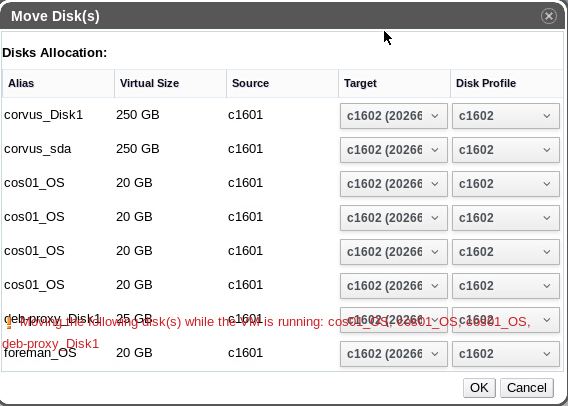
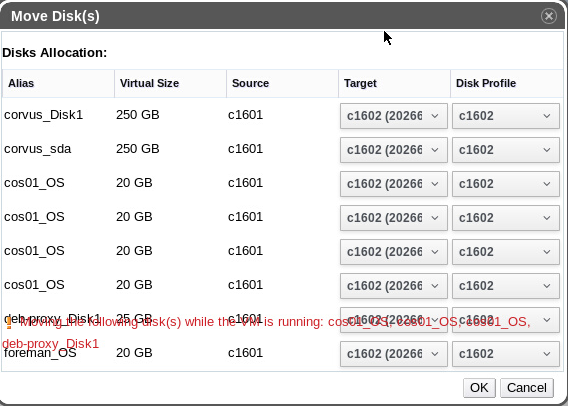
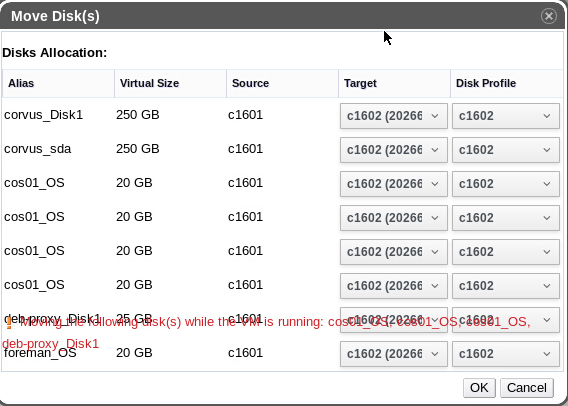
All upgrades are went smoothly! Thanks for the release. There is an minor problem I saw: After upgrading from 4.0.6 to 4.1 the GUI dialog for moving the disks from one Storage to another is not rendered correctly when multiple disks(>8) are selected for move. please see the attachment: *********************************************************** Dr. Arman Khalatyan eScience -SuperComputing Leibniz-Institut für Astrophysik Potsdam (AIP) An der Sternwarte 16, 14482 Potsdam, Germany *********************************************************** On Sat, Feb 4, 2017 at 5:08 PM, Martin Perina <mperina@redhat.com> wrote:
On Fri, Feb 3, 2017 at 9:24 AM, Sandro Bonazzola <sbonazzo@redhat.com> wrote:
On Fri, Feb 3, 2017 at 9:14 AM, Yura Poltoratskiy <yurapoltora@gmail.com> wrote:
I've done an upgrade of ovirt-engine tomorrow. There were two problems.
The first - packages from epel repo, solved by disable repo and downgrade package to an existing version in ovirt-release40 repo (yes, there is info in documentation about epel repo).
The second (and it is not only for current version) - run the engine-setup always not complete successfully because cat not start ovirt-engine-notifier.service after upgrade, and the error in notifier is that there is no MAIL_SERVER. Every time I am upgrading engine I have the same error. Than I add MAIL_SERVER=127.0.0.1 to /usr/share/ovirt-engine/services/ovirt-engine-notifier/ovirt-engine-notifier.conf and start notifier without problem. Is it my mistake?
Please never change anything in /usr/share/ovirt-engine, those files are always overwritten during upgrade. If you need change any option in ovirt-engine-notifier, please create new configuration file in /etc/ovirt-engine/notifier/notifier.conf.d directory. For example if you need to set MAIL_SERVER please create /etc/ovirt-engine/notifier/notifier.conf.d/99-custom.conf with following content:
MAIL_SERVER=127.0.0.1
After saving the file please restart ovirt-engine-notifier service:
systemctl restart ovirt-engine-notifier
Adding Martin Perina, he may be able to assist you on this.
And one more question. In Events tab I can see "User vasya@internal logged out.", but there are no message that 'vasya' logged in. Could someone tell me how to debug this issue?
Please share complete log to analyze this, but this user may be logged in before upgrade and we just clean its session after upgrade.
Martin can probably help as well here, adding also Greg and Alexander.
02.02.2017 14:19, Sandro Bonazzola пишет:
Hi, did you install/update to 4.1.0? Let us know your experience! We end up knowing only when things doesn't work well, let us know it works fine for you :-)
If you're not planning an update to 4.1.0 in the near future, let us know why. Maybe we can help.
Thanks! -- Sandro Bonazzola Better technology. Faster innovation. Powered by community collaboration. See how it works at redhat.com
_______________________________________________ Users mailing listUsers@ovirt.orghttp://lists.ovirt.org/mailman/listinfo/users
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
-- Sandro Bonazzola Better technology. Faster innovation. Powered by community collaboration. See how it works at redhat.com
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
{kind=link}

On Sun, Feb 5, 2017 at 9:39 PM, Arman Khalatyan <arm2arm@gmail.com> wrote:
All upgrades are went smoothly! Thanks for the release. There is an minor problem I saw: After upgrading from 4.0.6 to 4.1 the GUI dialog for moving the disks from one Storage to another is not rendered correctly when multiple disks(>8) are selected for move. please see the attachment:
Thanks for reporting this, would you file a bug? https://bugzilla.redhat.com/enter_bug.cgi?product=ovirt-engine
***********************************************************
Dr. Arman Khalatyan eScience -SuperComputing Leibniz-Institut für Astrophysik Potsdam (AIP) An der Sternwarte 16, 14482 Potsdam, Germany
***********************************************************
On Sat, Feb 4, 2017 at 5:08 PM, Martin Perina <mperina@redhat.com> wrote:
On Fri, Feb 3, 2017 at 9:24 AM, Sandro Bonazzola <sbonazzo@redhat.com> wrote:
On Fri, Feb 3, 2017 at 9:14 AM, Yura Poltoratskiy <yurapoltora@gmail.com
wrote:
I've done an upgrade of ovirt-engine tomorrow. There were two problems.
The first - packages from epel repo, solved by disable repo and downgrade package to an existing version in ovirt-release40 repo (yes, there is info in documentation about epel repo).
The second (and it is not only for current version) - run the engine-setup always not complete successfully because cat not start ovirt-engine-notifier.service after upgrade, and the error in notifier is that there is no MAIL_SERVER. Every time I am upgrading engine I have the same error. Than I add MAIL_SERVER=127.0.0.1 to /usr/share/ovirt-engine/services/ovirt-engine-notifier/ovirt-engine-notifier.conf and start notifier without problem. Is it my mistake?
Please never change anything in /usr/share/ovirt-engine, those files are always overwritten during upgrade. If you need change any option in ovirt-engine-notifier, please create new configuration file in /etc/ovirt-engine/notifier/notifier.conf.d directory. For example if you need to set MAIL_SERVER please create /etc/ovirt-engine/notifier/notifier.conf.d/99-custom.conf with following content:
MAIL_SERVER=127.0.0.1
After saving the file please restart ovirt-engine-notifier service:
systemctl restart ovirt-engine-notifier
Adding Martin Perina, he may be able to assist you on this.
And one more question. In Events tab I can see "User vasya@internal logged out.", but there are no message that 'vasya' logged in. Could someone tell me how to debug this issue?
Please share complete log to analyze this, but this user may be logged in before upgrade and we just clean its session after upgrade.
Martin can probably help as well here, adding also Greg and Alexander.
02.02.2017 14:19, Sandro Bonazzola пишет:
Hi, did you install/update to 4.1.0? Let us know your experience! We end up knowing only when things doesn't work well, let us know it works fine for you :-)
If you're not planning an update to 4.1.0 in the near future, let us know why. Maybe we can help.
Thanks! -- Sandro Bonazzola Better technology. Faster innovation. Powered by community collaboration. See how it works at redhat.com
_______________________________________________ Users mailing listUsers@ovirt.orghttp://lists.ovirt.org/mailman/listinfo/users
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
-- Sandro Bonazzola Better technology. Faster innovation. Powered by community collaboration. See how it works at redhat.com
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
{kind=link}
https://bugzilla.redhat.com/show_bug.cgi?id=1419352 Done. *********************************************************** Dr. Arman Khalatyan eScience -SuperComputing Leibniz-Institut für Astrophysik Potsdam (AIP) An der Sternwarte 16, 14482 Potsdam, Germany *********************************************************** On Sun, Feb 5, 2017 at 8:55 PM, Nir Soffer <nsoffer@redhat.com> wrote:
On Sun, Feb 5, 2017 at 9:39 PM, Arman Khalatyan <arm2arm@gmail.com> wrote:
All upgrades are went smoothly! Thanks for the release. There is an minor problem I saw: After upgrading from 4.0.6 to 4.1 the GUI dialog for moving the disks from one Storage to another is not rendered correctly when multiple disks(>8) are selected for move. please see the attachment:
Thanks for reporting this, would you file a bug? https://bugzilla.redhat.com/enter_bug.cgi?product=ovirt-engine
***********************************************************
Dr. Arman Khalatyan eScience -SuperComputing Leibniz-Institut für Astrophysik Potsdam (AIP) An der Sternwarte 16, 14482 Potsdam, Germany
***********************************************************
On Sat, Feb 4, 2017 at 5:08 PM, Martin Perina <mperina@redhat.com> wrote:
On Fri, Feb 3, 2017 at 9:24 AM, Sandro Bonazzola <sbonazzo@redhat.com> wrote:
On Fri, Feb 3, 2017 at 9:14 AM, Yura Poltoratskiy < yurapoltora@gmail.com> wrote:
I've done an upgrade of ovirt-engine tomorrow. There were two problems.
The first - packages from epel repo, solved by disable repo and downgrade package to an existing version in ovirt-release40 repo (yes, there is info in documentation about epel repo).
The second (and it is not only for current version) - run the engine-setup always not complete successfully because cat not start ovirt-engine-notifier.service after upgrade, and the error in notifier is that there is no MAIL_SERVER. Every time I am upgrading engine I have the same error. Than I add MAIL_SERVER=127.0.0.1 to /usr/share/ovirt-engine/services/ovirt-engine-notifier/ovirt-engine-notifier.conf and start notifier without problem. Is it my mistake?
Please never change anything in /usr/share/ovirt-engine, those files are always overwritten during upgrade. If you need change any option in ovirt-engine-notifier, please create new configuration file in /etc/ovirt-engine/notifier/notifier.conf.d directory. For example if you need to set MAIL_SERVER please create /etc/ovirt-engine/notifier/notifier.conf.d/99-custom.conf with following content:
MAIL_SERVER=127.0.0.1
After saving the file please restart ovirt-engine-notifier service:
systemctl restart ovirt-engine-notifier
Adding Martin Perina, he may be able to assist you on this.
And one more question. In Events tab I can see "User vasya@internal logged out.", but there are no message that 'vasya' logged in. Could someone tell me how to debug this issue?
Please share complete log to analyze this, but this user may be logged in before upgrade and we just clean its session after upgrade.
Martin can probably help as well here, adding also Greg and Alexander.
02.02.2017 14:19, Sandro Bonazzola пишет:
Hi, did you install/update to 4.1.0? Let us know your experience! We end up knowing only when things doesn't work well, let us know it works fine for you :-)
If you're not planning an update to 4.1.0 in the near future, let us know why. Maybe we can help.
Thanks! -- Sandro Bonazzola Better technology. Faster innovation. Powered by community collaboration. See how it works at redhat.com
_______________________________________________ Users mailing listUsers@ovirt.orghttp://lists.ovirt.org/mailman/listinfo/users
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
-- Sandro Bonazzola Better technology. Faster innovation. Powered by community collaboration. See how it works at redhat.com
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
{kind=link}

This is a multi-part message in MIME format. --------------6531EB0B252802DEF6E22DB2 Content-Type: text/plain; charset=windows-1252 Content-Transfer-Encoding: 8bit Hello, I upgraded my cluster of 8 hosts with gluster storage and hosted-engine-ha. They were already Centos 7.3 and using Ovirt 4.0.6 and gluster 3.7.x packages from storage-sig testing. I'm missing the storage listed under storage tab but this is already filed by a bug. Increasing Cluster and Storage Compability level and also "reset emulated machine" after having upgraded one host after another without the need to shutdown vm's works well. (VM's get sign that there will be changes after reboot). Important: you also have to issue a yum update on the host for upgrading additional components like i.e. gluster to 3.8.x. I was frightened of this step but It worked well except a configuration issue I was responsible for in gluster.vol (I had "transport socket, rdma") Bugs/Quirks so far: 1. After restarting a single VM that used RNG-Device I got an error (it was german) but like "RNG Device not supported by cluster". I hat to disable RNG Device save the settings. Again settings and enable RNG Device. Then machine boots up. I think there is a migration step missing from /dev/random to /dev/urandom for exisiting VM's. 2. I'm missing any gluster specific management features as my gluster is not managable in any way from the GUI. I expected to see my gluster now in dashboard and be able to add volumes etc. What do I need to do to "import" my existing gluster (Only one volume so far) to be managable ? 3. Three of my hosts have the hosted engine deployed for ha. First all three where marked by a crown (running was gold and others where silver). After upgrading the 3 Host deployed hosted engine ha is not active anymore. I can't get this host back with working ovirt-ha-agent/broker. I already rebooted, manually restarted the services but It isn't able to get cluster state according to "hosted-engine --vm-status". The other hosts state the host status as "unknown stale-data" I already shut down all agents on all hosts and issued a "hosted-engine --reinitialize-lockspace" but that didn't help. Agents stops working after a timeout-error according to log: MainThread::INFO::2017-02-02 19:24:52,040::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:24:59,185::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:06,333::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:13,554::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:20,710::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:27,865::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::815::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_initialize_domain_monitor) Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine::469::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Error while monitoring engine: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine::472::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Unexpected error Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 443, in start_monitoring self._initialize_domain_monitor() File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 816, in _initialize_domain_monitor raise Exception(msg) Exception: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::485::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Shutting down the agent because of 3 failures in a row! MainThread::INFO::2017-02-02 19:25:32,087::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:34,250::hosted_engine::769::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_stop_domain_monitor) Failed to stop monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96): Storage domain is member of pool: u'domain=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96' MainThread::INFO::2017-02-02 19:25:34,254::agent::143::ovirt_hosted_engine_ha.agent.agent.Agent::(run) Agent shutting down The gluster volume of the engine is mounted corrctly in the host and accessible. Files are also readable etc. No clue what to do. 4. Last but not least: Ovirt is still using fuse to access VM-Disks on Gluster. I know - scheduled for 4.1.1 - but it was already there in 3.5.x and was scheduled for every release since then. I had this feature with opennebula already two years ago and performance is sooo much better.... So please GET IT IN ! Bye Am 02.02.2017 um 13:19 schrieb Sandro Bonazzola:
Hi, did you install/update to 4.1.0? Let us know your experience! We end up knowing only when things doesn't work well, let us know it works fine for you :-)
-- *Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 fax +49 (0) 24 05 / 40 83 759 mail *rs@databay.de* <mailto:rs@databay.de> *Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de> Sitz/Amtsgericht Aachen HRB:8437 USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen ------------------------------------------------------------------------ --------------6531EB0B252802DEF6E22DB2 Content-Type: multipart/related; boundary="------------9D3918195F67A45D867502C6" --------------9D3918195F67A45D867502C6 Content-Type: text/html; charset=windows-1252 Content-Transfer-Encoding: 8bit <html> <head> <meta content="text/html; charset=windows-1252" http-equiv="Content-Type"> </head> <body bgcolor="#FFFFFF" text="#000000"> <p>Hello,</p> <p>I upgraded my cluster of 8 hosts with gluster storage and hosted-engine-ha. They were already Centos 7.3 and using Ovirt 4.0.6 and gluster 3.7.x packages from storage-sig testing.<br> </p> <p>I'm missing the storage listed under storage tab but this is already filed by a bug. Increasing Cluster and Storage Compability level and also "reset emulated machine" after having upgraded one host after another without the need to shutdown vm's works well. (VM's get sign that there will be changes after reboot).</p> <p>Important: you also have to issue a yum update on the host for upgrading additional components like i.e. gluster to 3.8.x. I was frightened of this step but It worked well except a configuration issue I was responsible for in gluster.vol (I had "transport socket, rdma") <br> </p> <p>Bugs/Quirks so far:<br> </p> <p>1. After restarting a single VM that used RNG-Device I got an error (it was german) but like "RNG Device not supported by cluster". I hat to disable RNG Device save the settings. Again settings and enable RNG Device. Then machine boots up. <br> I think there is a migration step missing from /dev/random to /dev/urandom for exisiting VM's.</p> <p>2. I'm missing any gluster specific management features as my gluster is not managable in any way from the GUI. I expected to see my gluster now in dashboard and be able to add volumes etc. What do I need to do to "import" my existing gluster (Only one volume so far) to be managable ? <br> </p> <p>3. Three of my hosts have the hosted engine deployed for ha. First all three where marked by a crown (running was gold and others where silver). After upgrading the 3 Host deployed hosted engine ha is not active anymore.</p> <p>I can't get this host back with working ovirt-ha-agent/broker. I already rebooted, manually restarted the services but It isn't able to get cluster state according to <br> "hosted-engine --vm-status". The other hosts state the host status as "unknown stale-data"</p> <p>I already shut down all agents on all hosts and issued a "hosted-engine --reinitialize-lockspace" but that didn't help.<br> </p> <p>Agents stops working after a timeout-error according to log:</p> <p><tt>MainThread::INFO::2017-02-02 19:24:52,040::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING</tt><tt><br> </tt><tt>MainThread::INFO::2017-02-02 19:24:59,185::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING</tt><tt><br> </tt><tt>MainThread::INFO::2017-02-02 19:25:06,333::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING</tt><tt><br> </tt><tt>MainThread::INFO::2017-02-02 19:25:13,554::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING</tt><tt><br> </tt><tt>MainThread::INFO::2017-02-02 19:25:20,710::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING</tt><tt><br> </tt><tt>MainThread::INFO::2017-02-02 19:25:27,865::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING</tt><tt><br> </tt><tt>MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::815::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_initialize_domain_monitor) Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition</tt><tt><br> </tt><tt>MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine::469::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Error while monitoring engine: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition</tt><tt><br> </tt><tt>MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine::472::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Unexpected error</tt><tt><br> </tt><tt>Traceback (most recent call last):</tt><tt><br> </tt><tt> File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 443, in start_monitoring</tt><tt><br> </tt><tt> self._initialize_domain_monitor()</tt><tt><br> </tt><tt> File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 816, in _initialize_domain_monitor</tt><tt><br> </tt><tt> raise Exception(msg)</tt><tt><br> </tt><tt>Exception: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition</tt><tt><br> </tt><tt>MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::485::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Shutting down the agent because of 3 failures in a row!</tt><tt><br> </tt><tt>MainThread::INFO::2017-02-02 19:25:32,087::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING</tt><tt><br> </tt><tt>MainThread::INFO::2017-02-02 19:25:34,250::hosted_engine::769::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_stop_domain_monitor) Failed to stop monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96): Storage domain is member of pool: u'domain=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96'</tt><tt><br> </tt><tt>MainThread::INFO::2017-02-02 19:25:34,254::agent::143::ovirt_hosted_engine_ha.agent.agent.Agent::(run) Agent shutting down</tt><tt><br> </tt><br> </p> <p>The gluster volume of the engine is mounted corrctly in the host and accessible. Files are also readable etc. No clue what to do.<br> </p> <p>4. Last but not least: Ovirt is still using fuse to access VM-Disks on Gluster. I know - scheduled for 4.1.1 - but it was already there in 3.5.x and was scheduled for every release since then. I had this feature with opennebula already two years ago and performance is sooo much better.... So please GET IT IN !<br> </p> <p>Bye<br> </p> <p><br> </p> <br> <div class="moz-cite-prefix">Am 02.02.2017 um 13:19 schrieb Sandro Bonazzola:<br> </div> <blockquote cite="mid:CAPQRNT=zqmmbyXW-xgsa7CnRb4KOyyOy0Hr4+upcDL1n4xT+YQ@mail.gmail.com" type="cite">Hi, <div>did you install/update to 4.1.0? Let us know your experience!</div> <div>We end up knowing only when things doesn't work well, let us know it works fine for you :-)</div> </blockquote> <br> <div class="moz-signature">-- <br> <p> </p> <table border="0" cellpadding="0" cellspacing="0"> <tbody> <tr> <td colspan="3"><img src="cid:part1.46D494BA.8C43FBE5@databay.de" height="30" border="0" width="151"></td> </tr> <tr> <td valign="top"> <font face="Verdana, Arial, sans-serif" size="-1"><br> <b>Ralf Schenk</b><br> fon +49 (0) 24 05 / 40 83 70<br> fax +49 (0) 24 05 / 40 83 759<br> mail <a href="mailto:rs@databay.de"><font color="#FF0000"><b>rs@databay.de</b></font></a><br> </font> </td> <td width="30"> </td> <td valign="top"> <font face="Verdana, Arial, sans-serif" size="-1"><br> <b>Databay AG</b><br> Jens-Otto-Krag-Straße 11<br> D-52146 Würselen<br> <a href="http://www.databay.de"><font color="#FF0000"><b>www.databay.de</b></font></a> </font> </td> </tr> <tr> <td colspan="3" valign="top"> <font face="Verdana, Arial, sans-serif" size="1"><br> Sitz/Amtsgericht Aachen HRB:8437 USt-IdNr.: DE 210844202<br> Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns<br> Aufsichtsratsvorsitzender: Wilhelm Dohmen </font> </td> </tr> </tbody> </table> <hr color="#000000" noshade="noshade" size="1" width="100%"> </div> </body> </html> --------------9D3918195F67A45D867502C6 Content-Type: image/gif; name="logo_databay_email.gif" Content-Transfer-Encoding: base64 Content-ID: <part1.46D494BA.8C43FBE5@databay.de> Content-Disposition: inline; filename="logo_databay_email.gif" R0lGODlhlwAeAMQAAObm5v9QVf/R0oKBgfDw8NfX105MTLi3t/r6+sfHx/+rrf98gC0sLP8L EhIQEKalpf/g4ZmYmHd2dmppaf8uNP/y8v8cIv+Ym//AwkE/P46NjRwbG11cXP8ABwUDA/// /yH5BAAAAAAALAAAAACXAB4AAAX/4CeOYnUJZKqubOu+cCzPNA0tVnfVfO//wGAKk+t0Ap+K QMFUYCDCqHRKJVUWDaPRUsFktZ1G4AKtms9o1gKsFVS+7I5ll67bpd647hPQawNld4KDMQJF bA07F35aFBiEkJEpfXEBjx8KjI0Vkp2DEIdaCySgFBShbEgrCQOtrq+uEQcALQewrQUjEbe8 rgkkD7y5KhMZB3drqSoVFQhdlHGXKQYe1dbX2BvHKwzY1RMiAN7j1xEjBeTmKeIeD3cYCxRf FigvChRxFJwkBBvk5A7cpZhAjgGCDwn+kfslgto4CSoSehh2BwEEBQvowDAUR0EKdArHZTg4 4oDCXBFC/3qj9SEluZEpHnjYQFIGgpo1KgSasYjNKBImrzF4NaFbNgIjCGRQeIyVKwneOLzS cLCAg38OWI4Y4GECgQcSOEwYcADnh6/FNjAwoGFYAQ0atI4AAFeEFwsLFLiJUQEfGH0kNGAD x8+oNQdIRQg+7NCaOhIgD8sVgYADNsPVGI5YWjRqzQTdHDDIYHRDLokaUhCglkFEJi0NKJhl 0RP2TsvXUg88KiLBVWsZrF6DmMKlNYMqglqTik1guN8OBgAgkGCpB+L9ugK4iSCBvwEfECw1 kILrBpa1jVCQIQBRvbP+rlEcQVAoSevWyv6uhpwE12uEkQAAZucpVw1xIsjkgf8B863mQVYt eQATCZYJZJ5WBfij2wfpHcEeHGG8Z+BMszVWDXkfKLhceJhBSAJ+1ThH32AfRFZNayNAtUFi wFSTSwEHJIYAAQU84IADwyjIEALU9MchG+vFgIF7W2GDI2T7HfjBgNcgKQKMHmwjgnCSpeCb ULRkdxhF1CDY40RjgmUAA/v1J5FAKW2gGSZscBFDMraNgJs1AYpAAGYP5jJoNQ4Y4Gh8jpFg HH9mgbmWo1l6oA4C3Ygp6UwEIFBfNRtkMIBlKMLnAXgAXLWhXXH85EIFqMhGGZgDEKArABGA ed0HI4bk5qgnprCYSt88B6dqS0FEEAMPJDCdCJYViur/B1BlwGMJqDTwnhqxJgUpo0ceOQ4D 0yEakpMm/jqCRMgWm2I1j824Y6vLvuuPjHnqOJkIgP6xzwp5sCFNsCFp88Gxh11lrjfDcNrc CEx64/CD3iAHlQcMUEQXvcA+qBkBB4Q2X1CusjBlJdKMYAKI6g28MbKN5hJsBAXknHOwutn4 oFYqkpqAzjnPbE0u1PxmwAQGXLWBbvhuIIEGEnRjlAHO4SvhbCNAkwoGzEBwgV9U0lfu2WiX OkDEGaCdKgl0nk2YkWdPOCDabvaGdkAftL1LlgwCM+7Tq11V71IO7LkM2XE0YAHMYMhqqK6U V165CpaHukLmiXFO8XSVzzakX+UH6TrmAajPNxfqByTQec41AeBPvSwIALkmAnuiexCsca3C BajgfsROuxcPA8kHQJX4DAIwjnsAvhsvfXHWKEwDAljg7sj03L9wwAQTxOWD2AE0YP75eCkw cPfs+xACADs= --------------9D3918195F67A45D867502C6-- --------------6531EB0B252802DEF6E22DB2--
On Fri, Feb 3, 2017 at 10:54 AM, Ralf Schenk <rs@databay.de> wrote:
Hello,
I upgraded my cluster of 8 hosts with gluster storage and hosted-engine-ha. They were already Centos 7.3 and using Ovirt 4.0.6 and gluster 3.7.x packages from storage-sig testing.
I'm missing the storage listed under storage tab but this is already filed by a bug. Increasing Cluster and Storage Compability level and also "reset emulated machine" after having upgraded one host after another without the need to shutdown vm's works well. (VM's get sign that there will be changes after reboot).
Important: you also have to issue a yum update on the host for upgrading additional components like i.e. gluster to 3.8.x. I was frightened of this step but It worked well except a configuration issue I was responsible for in gluster.vol (I had "transport socket, rdma")
Bugs/Quirks so far:
1. After restarting a single VM that used RNG-Device I got an error (it was german) but like "RNG Device not supported by cluster". I hat to disable RNG Device save the settings. Again settings and enable RNG Device. Then machine boots up. I think there is a migration step missing from /dev/random to /dev/urandom for exisiting VM's.
Tomas, Francesco, Michal, can you please follow up on this?
2. I'm missing any gluster specific management features as my gluster is not managable in any way from the GUI. I expected to see my gluster now in dashboard and be able to add volumes etc. What do I need to do to "import" my existing gluster (Only one volume so far) to be managable ?
Sahina, can you please follow up on this?
3. Three of my hosts have the hosted engine deployed for ha. First all three where marked by a crown (running was gold and others where silver). After upgrading the 3 Host deployed hosted engine ha is not active anymore.
I can't get this host back with working ovirt-ha-agent/broker. I already rebooted, manually restarted the services but It isn't able to get cluster state according to "hosted-engine --vm-status". The other hosts state the host status as "unknown stale-data"
I already shut down all agents on all hosts and issued a "hosted-engine --reinitialize-lockspace" but that didn't help.
Agents stops working after a timeout-error according to log:
MainThread::INFO::2017-02-02 19:24:52,040::hosted_engine:: 841::ovirt_hosted_engine_ha.agent.hosted_engine. HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:24:59,185::hosted_engine:: 841::ovirt_hosted_engine_ha.agent.hosted_engine. HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:06,333::hosted_engine:: 841::ovirt_hosted_engine_ha.agent.hosted_engine. HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:13,554::hosted_engine:: 841::ovirt_hosted_engine_ha.agent.hosted_engine. HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:20,710::hosted_engine:: 841::ovirt_hosted_engine_ha.agent.hosted_engine. HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:27,865::hosted_engine:: 841::ovirt_hosted_engine_ha.agent.hosted_engine. HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine:: 815::ovirt_hosted_engine_ha.agent.hosted_engine. HostedEngine::(_initialize_domain_monitor) Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine:: 469::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Error while monitoring engine: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine:: 472::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Unexpected error Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 443, in start_monitoring self._initialize_domain_monitor() File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 816, in _initialize_domain_monitor raise Exception(msg) Exception: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine:: 485::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Shutting down the agent because of 3 failures in a row! MainThread::INFO::2017-02-02 19:25:32,087::hosted_engine:: 841::ovirt_hosted_engine_ha.agent.hosted_engine. HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:34,250::hosted_engine:: 769::ovirt_hosted_engine_ha.agent.hosted_engine. HostedEngine::(_stop_domain_monitor) Failed to stop monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96): Storage domain is member of pool: u'domain=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96' MainThread::INFO::2017-02-02 19:25:34,254::agent::143:: ovirt_hosted_engine_ha.agent.agent.Agent::(run) Agent shutting down
Simone, Martin, can you please follow up on this?
The gluster volume of the engine is mounted corrctly in the host and accessible. Files are also readable etc. No clue what to do.
4. Last but not least: Ovirt is still using fuse to access VM-Disks on Gluster. I know - scheduled for 4.1.1 - but it was already there in 3.5.x and was scheduled for every release since then. I had this feature with opennebula already two years ago and performance is sooo much better.... So please GET IT IN !
We're aware of the performance increase, storage and gluster teams are working on it. Maybe Sahina or Allon may follow up with current status of the feature.
Bye
Am 02.02.2017 um 13:19 schrieb Sandro Bonazzola:
Hi, did you install/update to 4.1.0? Let us know your experience! We end up knowing only when things doesn't work well, let us know it works fine for you :-)
--
*Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 <+49%202405%20408370> fax +49 (0) 24 05 / 40 83 759 <+49%202405%204083759> mail *rs@databay.de* <rs@databay.de>
*Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de>
Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen ------------------------------
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
-- Sandro Bonazzola Better technology. Faster innovation. Powered by community collaboration. See how it works at redhat.com
{kind=link}

On Fri, Feb 3, 2017 at 11:17 AM, Sandro Bonazzola <sbonazzo@redhat.com> wrote:
On Fri, Feb 3, 2017 at 10:54 AM, Ralf Schenk <rs@databay.de> wrote:
Hello,
I upgraded my cluster of 8 hosts with gluster storage and hosted-engine-ha. They were already Centos 7.3 and using Ovirt 4.0.6 and gluster 3.7.x packages from storage-sig testing.
I'm missing the storage listed under storage tab but this is already filed by a bug. Increasing Cluster and Storage Compability level and also "reset emulated machine" after having upgraded one host after another without the need to shutdown vm's works well. (VM's get sign that there will be changes after reboot).
Important: you also have to issue a yum update on the host for upgrading additional components like i.e. gluster to 3.8.x. I was frightened of this step but It worked well except a configuration issue I was responsible for in gluster.vol (I had "transport socket, rdma")
Bugs/Quirks so far:
1. After restarting a single VM that used RNG-Device I got an error (it was german) but like "RNG Device not supported by cluster". I hat to disable RNG Device save the settings. Again settings and enable RNG Device. Then machine boots up. I think there is a migration step missing from /dev/random to /dev/urandom for exisiting VM's.
Tomas, Francesco, Michal, can you please follow up on this?
2. I'm missing any gluster specific management features as my gluster is not managable in any way from the GUI. I expected to see my gluster now in dashboard and be able to add volumes etc. What do I need to do to "import" my existing gluster (Only one volume so far) to be managable ?
Sahina, can you please follow up on this?
3. Three of my hosts have the hosted engine deployed for ha. First all three where marked by a crown (running was gold and others where silver). After upgrading the 3 Host deployed hosted engine ha is not active anymore.
I can't get this host back with working ovirt-ha-agent/broker. I already rebooted, manually restarted the services but It isn't able to get cluster state according to "hosted-engine --vm-status". The other hosts state the host status as "unknown stale-data"
I already shut down all agents on all hosts and issued a "hosted-engine --reinitialize-lockspace" but that didn't help.
Agents stops working after a timeout-error according to log:
MainThread::INFO::2017-02-02 19:24:52,040::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:24:59,185::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:06,333::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:13,554::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:20,710::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:27,865::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::8 15::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_initialize_domain_monitor) Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine::4 69::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Error while monitoring engine: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine::4 72::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Unexpected error Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 443, in start_monitoring self._initialize_domain_monitor() File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 816, in _initialize_domain_monitor raise Exception(msg) Exception: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::4 85::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Shutting down the agent because of 3 failures in a row! MainThread::INFO::2017-02-02 19:25:32,087::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:34,250::hosted_engine::7 69::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_stop_domain_monitor) Failed to stop monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96): Storage domain is member of pool: u'domain=7c8deaa8-be02-4aaf-b9 b4-ddc8da99ad96' MainThread::INFO::2017-02-02 19:25:34,254::agent::143::ovir t_hosted_engine_ha.agent.agent.Agent::(run) Agent shutting down
Simone, Martin, can you please follow up on this?
Ralph, could you please attach vdsm logs from on of your hosts for the relevant time frame?
The gluster volume of the engine is mounted corrctly in the host and accessible. Files are also readable etc. No clue what to do.
4. Last but not least: Ovirt is still using fuse to access VM-Disks on Gluster. I know - scheduled for 4.1.1 - but it was already there in 3.5.x and was scheduled for every release since then. I had this feature with opennebula already two years ago and performance is sooo much better.... So please GET IT IN !
We're aware of the performance increase, storage and gluster teams are working on it. Maybe Sahina or Allon may follow up with current status of the feature.
Bye
Am 02.02.2017 um 13:19 schrieb Sandro Bonazzola:
Hi, did you install/update to 4.1.0? Let us know your experience! We end up knowing only when things doesn't work well, let us know it works fine for you :-)
--
*Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 <+49%202405%20408370> fax +49 (0) 24 05 / 40 83 759 <+49%202405%204083759> mail *rs@databay.de* <rs@databay.de>
*Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de>
Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen ------------------------------
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
-- Sandro Bonazzola Better technology. Faster innovation. Powered by community collaboration. See how it works at redhat.com
{kind=link}
Hello, attached is my vdsm.log from the host with hosted-engine-ha around the time-frame of agent timeout that is not working anymore for engine (it works in Ovirt and is active). It simply isn't working for engine-ha anymore after Update. At 2017-02-02 19:25:34,248 you'll find an error corresponoding to agent timeout error. Bye Am 03.02.2017 um 11:28 schrieb Simone Tiraboschi:
3. Three of my hosts have the hosted engine deployed for ha. First all three where marked by a crown (running was gold and others where silver). After upgrading the 3 Host deployed hosted engine ha is not active anymore.
I can't get this host back with working ovirt-ha-agent/broker. I already rebooted, manually restarted the services but It isn't able to get cluster state according to "hosted-engine --vm-status". The other hosts state the host status as "unknown stale-data"
I already shut down all agents on all hosts and issued a "hosted-engine --reinitialize-lockspace" but that didn't help.
Agents stops working after a timeout-error according to log:
MainThread::INFO::2017-02-02 19:24:52,040::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:24:59,185::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:06,333::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:13,554::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:20,710::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:27,865::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::815::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_initialize_domain_monitor) Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine::469::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Error while monitoring engine: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine::472::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Unexpected error Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 443, in start_monitoring self._initialize_domain_monitor() File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 816, in _initialize_domain_monitor raise Exception(msg) Exception: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::485::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Shutting down the agent because of 3 failures in a row! MainThread::INFO::2017-02-02 19:25:32,087::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:34,250::hosted_engine::769::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_stop_domain_monitor) Failed to stop monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96): Storage domain is member of pool: u'domain=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96' MainThread::INFO::2017-02-02 19:25:34,254::agent::143::ovirt_hosted_engine_ha.agent.agent.Agent::(run) Agent shutting down
Simone, Martin, can you please follow up on this?
Ralph, could you please attach vdsm logs from on of your hosts for the relevant time frame?
-- *Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 fax +49 (0) 24 05 / 40 83 759 mail *rs@databay.de* <mailto:rs@databay.de> *Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de> Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen ------------------------------------------------------------------------
{kind=link}
I see there an ERROR on stopMonitoringDomain but I cannot see the correspondent startMonitoringDomain; could you please look for it? On Fri, Feb 3, 2017 at 1:16 PM, Ralf Schenk <rs@databay.de> wrote:
Hello,
attached is my vdsm.log from the host with hosted-engine-ha around the time-frame of agent timeout that is not working anymore for engine (it works in Ovirt and is active). It simply isn't working for engine-ha anymore after Update.
At 2017-02-02 19:25:34,248 you'll find an error corresponoding to agent timeout error.
Bye
Am 03.02.2017 um 11:28 schrieb Simone Tiraboschi:
3. Three of my hosts have the hosted engine deployed for ha. First all
three where marked by a crown (running was gold and others where silver). After upgrading the 3 Host deployed hosted engine ha is not active anymore.
I can't get this host back with working ovirt-ha-agent/broker. I already rebooted, manually restarted the services but It isn't able to get cluster state according to "hosted-engine --vm-status". The other hosts state the host status as "unknown stale-data"
I already shut down all agents on all hosts and issued a "hosted-engine --reinitialize-lockspace" but that didn't help.
Agents stops working after a timeout-error according to log:
MainThread::INFO::2017-02-02 19:24:52,040::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:24:59,185::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:06,333::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:13,554::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:20,710::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:27,865::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::8 15::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_initialize_domain_monitor) Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine::4 69::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Error while monitoring engine: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine::4 72::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Unexpected error Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 443, in start_monitoring self._initialize_domain_monitor() File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 816, in _initialize_domain_monitor raise Exception(msg) Exception: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::4 85::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Shutting down the agent because of 3 failures in a row! MainThread::INFO::2017-02-02 19:25:32,087::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:34,250::hosted_engine::7 69::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_stop_domain_monitor) Failed to stop monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96): Storage domain is member of pool: u'domain=7c8deaa8-be02-4aaf-b9 b4-ddc8da99ad96' MainThread::INFO::2017-02-02 19:25:34,254::agent::143::ovir t_hosted_engine_ha.agent.agent.Agent::(run) Agent shutting down
Simone, Martin, can you please follow up on this?
Ralph, could you please attach vdsm logs from on of your hosts for the relevant time frame?
--
*Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 <+49%202405%20408370> fax +49 (0) 24 05 / 40 83 759 <+49%202405%204083759> mail *rs@databay.de* <rs@databay.de>
*Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de>
Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen ------------------------------
{kind=link}
Hello, I currently restarted ovirt-ha-agent and I don't see any "startMonitoringDomain" in vdsm.log (see attachement). I attach vdsm.log and agent.log from restart of agent to timeout. (Agent sleeps and continues and exits in about 30 Minutes) In agent-log is states every 7 seconds: MainThread::INFO::2017-02-03 15:10:21,915::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-03 15:10:29,058::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-03 15:10:36,206::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-03 15:10:43,346::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING until uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-03 15:11:19,111::hosted_engine::469::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Error while monitoring engine: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-03 15:11:19,111::hosted_engine::472::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Unexpected error Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 443, in start_monitoring self._initialize_domain_monitor() File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 816, in _initialize_domain_monitor raise Exception(msg) Exception: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::INFO::2017-02-03 15:11:19,112::hosted_engine::488::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Sleeping 60 seconds Am 03.02.2017 um 13:39 schrieb Simone Tiraboschi:
I see there an ERROR on stopMonitoringDomain but I cannot see the correspondent startMonitoringDomain; could you please look for it?
On Fri, Feb 3, 2017 at 1:16 PM, Ralf Schenk <rs@databay.de <mailto:rs@databay.de>> wrote:
Hello,
attached is my vdsm.log from the host with hosted-engine-ha around the time-frame of agent timeout that is not working anymore for engine (it works in Ovirt and is active). It simply isn't working for engine-ha anymore after Update.
At 2017-02-02 19:25:34,248 you'll find an error corresponoding to agent timeout error.
Bye
Am 03.02.2017 um 11:28 schrieb Simone Tiraboschi:
3. Three of my hosts have the hosted engine deployed for ha. First all three where marked by a crown (running was gold and others where silver). After upgrading the 3 Host deployed hosted engine ha is not active anymore.
I can't get this host back with working ovirt-ha-agent/broker. I already rebooted, manually restarted the services but It isn't able to get cluster state according to "hosted-engine --vm-status". The other hosts state the host status as "unknown stale-data"
I already shut down all agents on all hosts and issued a "hosted-engine --reinitialize-lockspace" but that didn't help.
Agents stops working after a timeout-error according to log:
MainThread::INFO::2017-02-02 19:24:52,040::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:24:59,185::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:06,333::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:13,554::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:20,710::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:27,865::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::815::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_initialize_domain_monitor) Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine::469::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Error while monitoring engine: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine::472::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Unexpected error Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 443, in start_monitoring self._initialize_domain_monitor() File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 816, in _initialize_domain_monitor raise Exception(msg) Exception: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::485::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Shutting down the agent because of 3 failures in a row! MainThread::INFO::2017-02-02 19:25:32,087::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:34,250::hosted_engine::769::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_stop_domain_monitor) Failed to stop monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96): Storage domain is member of pool: u'domain=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96' MainThread::INFO::2017-02-02 19:25:34,254::agent::143::ovirt_hosted_engine_ha.agent.agent.Agent::(run) Agent shutting down
Simone, Martin, can you please follow up on this?
Ralph, could you please attach vdsm logs from on of your hosts for the relevant time frame?
--
*Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 <tel:+49%202405%20408370> fax +49 (0) 24 05 / 40 83 759 <tel:+49%202405%204083759> mail *rs@databay.de* <mailto:rs@databay.de>
*Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de>
Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen
------------------------------------------------------------------------
-- *Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 fax +49 (0) 24 05 / 40 83 759 mail *rs@databay.de* <mailto:rs@databay.de> *Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de> Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen ------------------------------------------------------------------------
{kind=link}
{kind=link}
This is a multi-part message in MIME format. --------------C9EE446E673EA16FD96BD311 Content-Type: text/plain; charset=utf-8 Content-Transfer-Encoding: 8bit Hello, I also put host in Maintenance and restarted vdsm while ovirt-ha-agent is running. I can mount the gluster Volume "engine" manually in the host. I get this repeatedly in /var/log/vdsm.log: 2017-02-03 15:29:28,891 INFO (MainThread) [vds] Exiting (vdsm:167) 2017-02-03 15:29:30,974 INFO (MainThread) [vds] (PID: 11456) I am the actual vdsm 4.19.4-1.el7.centos microcloud27 (3.10.0-514.6.1.el7.x86_64) (vdsm:145) 2017-02-03 15:29:30,974 INFO (MainThread) [vds] VDSM will run with cpu affinity: frozenset([1]) (vdsm:251) 2017-02-03 15:29:31,013 INFO (MainThread) [storage.check] Starting check service (check:91) 2017-02-03 15:29:31,017 INFO (MainThread) [storage.Dispatcher] Starting StorageDispatcher... (dispatcher:47) 2017-02-03 15:29:31,017 INFO (check/loop) [storage.asyncevent] Starting <EventLoop running=True closed=False at 0x37480464> (asyncevent:122) 2017-02-03 15:29:31,156 INFO (MainThread) [dispatcher] Run and protect: registerDomainStateChangeCallback(callbackFunc=<functools.partial object at 0x2881fc8>) (logUtils:49) 2017-02-03 15:29:31,156 INFO (MainThread) [dispatcher] Run and protect: registerDomainStateChangeCallback, Return response: None (logUtils:52) 2017-02-03 15:29:31,160 INFO (MainThread) [MOM] Preparing MOM interface (momIF:49) 2017-02-03 15:29:31,161 INFO (MainThread) [MOM] Using named unix socket /var/run/vdsm/mom-vdsm.sock (momIF:58) 2017-02-03 15:29:31,162 INFO (MainThread) [root] Unregistering all secrets (secret:91) 2017-02-03 15:29:31,164 INFO (MainThread) [vds] Setting channels' timeout to 30 seconds. (vmchannels:223) 2017-02-03 15:29:31,165 INFO (MainThread) [vds.MultiProtocolAcceptor] Listening at :::54321 (protocoldetector:185) 2017-02-03 15:29:31,354 INFO (vmrecovery) [vds] recovery: completed in 0s (clientIF:495) 2017-02-03 15:29:31,371 INFO (BindingXMLRPC) [vds] XMLRPC server running (bindingxmlrpc:63) 2017-02-03 15:29:31,471 INFO (periodic/1) [dispatcher] Run and protect: repoStats(options=None) (logUtils:49) 2017-02-03 15:29:31,472 INFO (periodic/1) [dispatcher] Run and protect: repoStats, Return response: {} (logUtils:52) 2017-02-03 15:29:31,472 WARN (periodic/1) [MOM] MOM not available. (momIF:116) 2017-02-03 15:29:31,473 WARN (periodic/1) [MOM] MOM not available, KSM stats will be missing. (momIF:79) 2017-02-03 15:29:31,474 ERROR (periodic/1) [root] failed to retrieve Hosted Engine HA info (api:252) Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/vdsm/host/api.py", line 231, in _getHaInfo stats = instance.get_all_stats() File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/client/client.py", line 103, in get_all_stats self._configure_broker_conn(broker) File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/client/client.py", line 180, in _configure_broker_conn dom_type=dom_type) File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/lib/brokerlink.py", line 177, in set_storage_domain .format(sd_type, options, e)) RequestError: Failed to set storage domain FilesystemBackend, options {'dom_type': 'glusterfs', 'sd_uuid': '7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96'}: Request failed: <class 'ovirt_hos ted_engine_ha.lib.storage_backends.BackendFailureException'> 2017-02-03 15:29:35,920 INFO (Reactor thread) [ProtocolDetector.AcceptorImpl] Accepted connection from ::1:49506 (protocoldetector:72) 2017-02-03 15:29:35,929 INFO (Reactor thread) [ProtocolDetector.Detector] Detected protocol stomp from ::1:49506 (protocoldetector:127) 2017-02-03 15:29:35,930 INFO (Reactor thread) [Broker.StompAdapter] Processing CONNECT request (stompreactor:102) 2017-02-03 15:29:35,930 INFO (JsonRpc (StompReactor)) [Broker.StompAdapter] Subscribe command received (stompreactor:129) 2017-02-03 15:29:36,067 INFO (jsonrpc/0) [jsonrpc.JsonRpcServer] RPC call Host.ping succeeded in 0.00 seconds (__init__:515) 2017-02-03 15:29:36,071 INFO (jsonrpc/1) [throttled] Current getAllVmStats: {} (throttledlog:105) 2017-02-03 15:29:36,071 INFO (jsonrpc/1) [jsonrpc.JsonRpcServer] RPC call Host.getAllVmStats succeeded in 0.00 seconds (__init__:515) 2017-02-03 15:29:46,435 INFO (periodic/0) [dispatcher] Run and protect: repoStats(options=None) (logUtils:49) 2017-02-03 15:29:46,435 INFO (periodic/0) [dispatcher] Run and protect: repoStats, Return response: {} (logUtils:52) 2017-02-03 15:29:46,439 ERROR (periodic/0) [root] failed to retrieve Hosted Engine HA info (api:252) Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/vdsm/host/api.py", line 231, in _getHaInfo stats = instance.get_all_stats() File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/client/client.py", line 103, in get_all_stats self._configure_broker_conn(broker) File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/client/client.py", line 180, in _configure_broker_conn dom_type=dom_type) File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/lib/brokerlink.py", line 177, in set_storage_domain .format(sd_type, options, e)) RequestError: Failed to set storage domain FilesystemBackend, options {'dom_type': 'glusterfs', 'sd_uuid': '7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96'}: Request failed: <class 'ovirt_hos ted_engine_ha.lib.storage_backends.BackendFailureException'> 2017-02-03 15:29:51,095 INFO (jsonrpc/2) [jsonrpc.JsonRpcServer] RPC call Host.getAllVmStats succeeded in 0.00 seconds (__init__:515) 2017-02-03 15:29:51,219 INFO (jsonrpc/3) [jsonrpc.JsonRpcServer] RPC call Host.setKsmTune succeeded in 0.00 seconds (__init__:515) 2017-02-03 15:30:01,444 INFO (periodic/1) [dispatcher] Run and protect: repoStats(options=None) (logUtils:49) 2017-02-03 15:30:01,444 INFO (periodic/1) [dispatcher] Run and protect: repoStats, Return response: {} (logUtils:52) 2017-02-03 15:30:01,448 ERROR (periodic/1) [root] failed to retrieve Hosted Engine HA info (api:252) Am 03.02.2017 um 13:39 schrieb Simone Tiraboschi:
I see there an ERROR on stopMonitoringDomain but I cannot see the correspondent startMonitoringDomain; could you please look for it?
On Fri, Feb 3, 2017 at 1:16 PM, Ralf Schenk <rs@databay.de <mailto:rs@databay.de>> wrote:
Hello,
attached is my vdsm.log from the host with hosted-engine-ha around the time-frame of agent timeout that is not working anymore for engine (it works in Ovirt and is active). It simply isn't working for engine-ha anymore after Update.
At 2017-02-02 19:25:34,248 you'll find an error corresponoding to agent timeout error.
Bye
Am 03.02.2017 um 11:28 schrieb Simone Tiraboschi:
3. Three of my hosts have the hosted engine deployed for ha. First all three where marked by a crown (running was gold and others where silver). After upgrading the 3 Host deployed hosted engine ha is not active anymore.
I can't get this host back with working ovirt-ha-agent/broker. I already rebooted, manually restarted the services but It isn't able to get cluster state according to "hosted-engine --vm-status". The other hosts state the host status as "unknown stale-data"
I already shut down all agents on all hosts and issued a "hosted-engine --reinitialize-lockspace" but that didn't help.
Agents stops working after a timeout-error according to log:
MainThread::INFO::2017-02-02 19:24:52,040::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:24:59,185::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:06,333::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:13,554::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:20,710::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:27,865::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::815::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_initialize_domain_monitor) Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine::469::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Error while monitoring engine: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine::472::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Unexpected error Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 443, in start_monitoring self._initialize_domain_monitor() File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 816, in _initialize_domain_monitor raise Exception(msg) Exception: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::485::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Shutting down the agent because of 3 failures in a row! MainThread::INFO::2017-02-02 19:25:32,087::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:34,250::hosted_engine::769::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_stop_domain_monitor) Failed to stop monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96): Storage domain is member of pool: u'domain=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96' MainThread::INFO::2017-02-02 19:25:34,254::agent::143::ovirt_hosted_engine_ha.agent.agent.Agent::(run) Agent shutting down
Simone, Martin, can you please follow up on this?
Ralph, could you please attach vdsm logs from on of your hosts for the relevant time frame?
--
*Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 <tel:+49%202405%20408370> fax +49 (0) 24 05 / 40 83 759 <tel:+49%202405%204083759> mail *rs@databay.de* <mailto:rs@databay.de>
*Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de>
Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen
------------------------------------------------------------------------
-- *Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 fax +49 (0) 24 05 / 40 83 759 mail *rs@databay.de* <mailto:rs@databay.de> *Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de> Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen ------------------------------------------------------------------------ --------------C9EE446E673EA16FD96BD311 Content-Type: multipart/related; boundary="------------27C892A9C9EF2750A20ED420" --------------27C892A9C9EF2750A20ED420 Content-Type: text/html; charset=utf-8 Content-Transfer-Encoding: 8bit <html> <head> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"> </head> <body bgcolor="#FFFFFF" text="#000000"> <p>Hello,</p> <p>I also put host in Maintenance and restarted vdsm while ovirt-ha-agent is running. I can mount the gluster Volume "engine" manually in the host.<br> </p> <p>I get this repeatedly in /var/log/vdsm.log:</p> <p><tt>2017-02-03 15:29:28,891 INFO (MainThread) [vds] Exiting (vdsm:167)</tt><tt><br> </tt><tt>2017-02-03 15:29:30,974 INFO (MainThread) [vds] (PID: 11456) I am the actual vdsm 4.19.4-1.el7.centos microcloud27 (3.10.0-514.6.1.el7.x86_64) (vdsm:145)</tt><tt><br> </tt><tt>2017-02-03 15:29:30,974 INFO (MainThread) [vds] VDSM will run with cpu affinity: frozenset([1]) (vdsm:251)</tt><tt><br> </tt><tt>2017-02-03 15:29:31,013 INFO (MainThread) [storage.check] Starting check service (check:91)</tt><tt><br> </tt><tt>2017-02-03 15:29:31,017 INFO (MainThread) [storage.Dispatcher] Starting StorageDispatcher... (dispatcher:47)</tt><tt><br> </tt><tt>2017-02-03 15:29:31,017 INFO (check/loop) [storage.asyncevent] Starting <EventLoop running=True closed=False at 0x37480464> (asyncevent:122)</tt><tt><br> </tt><tt>2017-02-03 15:29:31,156 INFO (MainThread) [dispatcher] Run and protect: registerDomainStateChangeCallback(callbackFunc=<functools.partial object at 0x2881fc8>) (logUtils:49)</tt><tt><br> </tt><tt>2017-02-03 15:29:31,156 INFO (MainThread) [dispatcher] Run and protect: registerDomainStateChangeCallback, Return response: None (logUtils:52)</tt><tt><br> </tt><tt>2017-02-03 15:29:31,160 INFO (MainThread) [MOM] Preparing MOM interface (momIF:49)</tt><tt><br> </tt><tt>2017-02-03 15:29:31,161 INFO (MainThread) [MOM] Using named unix socket /var/run/vdsm/mom-vdsm.sock (momIF:58)</tt><tt><br> </tt><tt>2017-02-03 15:29:31,162 INFO (MainThread) [root] Unregistering all secrets (secret:91)</tt><tt><br> </tt><tt>2017-02-03 15:29:31,164 INFO (MainThread) [vds] Setting channels' timeout to 30 seconds. (vmchannels:223)</tt><tt><br> </tt><tt>2017-02-03 15:29:31,165 INFO (MainThread) [vds.MultiProtocolAcceptor] Listening at :::54321 (protocoldetector:185)</tt><tt><br> </tt><tt>2017-02-03 15:29:31,354 INFO (vmrecovery) [vds] recovery: completed in 0s (clientIF:495)</tt><tt><br> </tt><tt>2017-02-03 15:29:31,371 INFO (BindingXMLRPC) [vds] XMLRPC server running (bindingxmlrpc:63)</tt><tt><br> </tt><tt>2017-02-03 15:29:31,471 INFO (periodic/1) [dispatcher] Run and protect: repoStats(options=None) (logUtils:49)</tt><tt><br> </tt><tt>2017-02-03 15:29:31,472 INFO (periodic/1) [dispatcher] Run and protect: repoStats, Return response: {} (logUtils:52)</tt><tt><br> </tt><tt>2017-02-03 15:29:31,472 WARN (periodic/1) [MOM] MOM not available. (momIF:116)</tt><tt><br> </tt><tt>2017-02-03 15:29:31,473 WARN (periodic/1) [MOM] MOM not available, KSM stats will be missing. (momIF:79)</tt><tt><br> </tt><tt>2017-02-03 15:29:31,474 ERROR (periodic/1) [root] failed to retrieve Hosted Engine HA info (api:252)</tt><tt><br> </tt><tt>Traceback (most recent call last):</tt><tt><br> </tt><tt> File "/usr/lib/python2.7/site-packages/vdsm/host/api.py", line 231, in _getHaInfo</tt><tt><br> </tt><tt> stats = instance.get_all_stats()</tt><tt><br> </tt><tt> File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/client/client.py", line 103, in get_all_stats</tt><tt><br> </tt><tt> self._configure_broker_conn(broker)</tt><tt><br> </tt><tt> File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/client/client.py", line 180, in _configure_broker_conn</tt><tt><br> </tt><tt> dom_type=dom_type)</tt><tt><br> </tt><tt> File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/lib/brokerlink.py", line 177, in set_storage_domain</tt><tt><br> </tt><tt> .format(sd_type, options, e))</tt><tt><br> </tt><tt>RequestError: Failed to set storage domain FilesystemBackend, options {'dom_type': 'glusterfs', 'sd_uuid': '7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96'}: Request failed: <class 'ovirt_hos</tt><tt><br> </tt><tt>ted_engine_ha.lib.storage_backends.BackendFailureException'></tt><tt><br> </tt><tt>2017-02-03 15:29:35,920 INFO (Reactor thread) [ProtocolDetector.AcceptorImpl] Accepted connection from ::1:49506 (protocoldetector:72)</tt><tt><br> </tt><tt>2017-02-03 15:29:35,929 INFO (Reactor thread) [ProtocolDetector.Detector] Detected protocol stomp from ::1:49506 (protocoldetector:127)</tt><tt><br> </tt><tt>2017-02-03 15:29:35,930 INFO (Reactor thread) [Broker.StompAdapter] Processing CONNECT request (stompreactor:102)</tt><tt><br> </tt><tt>2017-02-03 15:29:35,930 INFO (JsonRpc (StompReactor)) [Broker.StompAdapter] Subscribe command received (stompreactor:129)</tt><tt><br> </tt><tt>2017-02-03 15:29:36,067 INFO (jsonrpc/0) [jsonrpc.JsonRpcServer] RPC call Host.ping succeeded in 0.00 seconds (__init__:515)</tt><tt><br> </tt><tt>2017-02-03 15:29:36,071 INFO (jsonrpc/1) [throttled] Current getAllVmStats: {} (throttledlog:105)</tt><tt><br> </tt><tt>2017-02-03 15:29:36,071 INFO (jsonrpc/1) [jsonrpc.JsonRpcServer] RPC call Host.getAllVmStats succeeded in 0.00 seconds (__init__:515)</tt><tt><br> </tt><tt>2017-02-03 15:29:46,435 INFO (periodic/0) [dispatcher] Run and protect: repoStats(options=None) (logUtils:49)</tt><tt><br> </tt><tt>2017-02-03 15:29:46,435 INFO (periodic/0) [dispatcher] Run and protect: repoStats, Return response: {} (logUtils:52)</tt><tt><br> </tt><tt>2017-02-03 15:29:46,439 ERROR (periodic/0) [root] failed to retrieve Hosted Engine HA info (api:252)</tt><tt><br> </tt><tt>Traceback (most recent call last):</tt><tt><br> </tt><tt> File "/usr/lib/python2.7/site-packages/vdsm/host/api.py", line 231, in _getHaInfo</tt><tt><br> </tt><tt> stats = instance.get_all_stats()</tt><tt><br> </tt><tt> File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/client/client.py", line 103, in get_all_stats</tt><tt><br> </tt><tt> self._configure_broker_conn(broker)</tt><tt><br> </tt><tt> File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/client/client.py", line 180, in _configure_broker_conn</tt><tt><br> </tt><tt> dom_type=dom_type)</tt><tt><br> </tt><tt> File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/lib/brokerlink.py", line 177, in set_storage_domain</tt><tt><br> </tt><tt> .format(sd_type, options, e))</tt><tt><br> </tt><tt>RequestError: Failed to set storage domain FilesystemBackend, options {'dom_type': 'glusterfs', 'sd_uuid': '7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96'}: Request failed: <class 'ovirt_hos</tt><tt><br> </tt><tt>ted_engine_ha.lib.storage_backends.BackendFailureException'></tt><tt><br> </tt><tt>2017-02-03 15:29:51,095 INFO (jsonrpc/2) [jsonrpc.JsonRpcServer] RPC call Host.getAllVmStats succeeded in 0.00 seconds (__init__:515)</tt><tt><br> </tt><tt>2017-02-03 15:29:51,219 INFO (jsonrpc/3) [jsonrpc.JsonRpcServer] RPC call Host.setKsmTune succeeded in 0.00 seconds (__init__:515)</tt><tt><br> </tt><tt>2017-02-03 15:30:01,444 INFO (periodic/1) [dispatcher] Run and protect: repoStats(options=None) (logUtils:49)</tt><tt><br> </tt><tt>2017-02-03 15:30:01,444 INFO (periodic/1) [dispatcher] Run and protect: repoStats, Return response: {} (logUtils:52)</tt><tt><br> </tt><tt>2017-02-03 15:30:01,448 ERROR (periodic/1) [root] failed to retrieve Hosted Engine HA info (api:252)</tt><br> <br> </p> <p><br> </p> <br> <div class="moz-cite-prefix">Am 03.02.2017 um 13:39 schrieb Simone Tiraboschi:<br> </div> <blockquote cite="mid:CAN8-ONrThxOsyRJRkPXVK8=Tot0OVW+bbN7pY2gJD4SihDxzHw@mail.gmail.com" type="cite"> <div dir="ltr">I see there an ERROR on stopMonitoringDomain but I cannot see the correspondent startMonitoringDomain; could you please look for it?</div> <div class="gmail_extra"><br> <div class="gmail_quote">On Fri, Feb 3, 2017 at 1:16 PM, Ralf Schenk <span dir="ltr"><<a moz-do-not-send="true" href="mailto:rs@databay.de" target="_blank">rs@databay.de</a>></span> wrote:<br> <blockquote class="gmail_quote" style="margin:0 0 0 .8ex;border-left:1px #ccc solid;padding-left:1ex"> <div bgcolor="#FFFFFF" text="#000000"> <p>Hello,</p> <p>attached is my vdsm.log from the host with hosted-engine-ha around the time-frame of agent timeout that is not working anymore for engine (it works in Ovirt and is active). It simply isn't working for engine-ha anymore after Update.</p> <p>At 2017-02-02 19:25:34,248 you'll find an error corresponoding to agent timeout error.</p> <p>Bye<br> </p> <div> <div class="h5"> <p><br> </p> <br> <div class="m_-5371711976759655950moz-cite-prefix">Am 03.02.2017 um 11:28 schrieb Simone Tiraboschi:<br> </div> <blockquote type="cite"> <blockquote class="gmail_quote" style="margin:0 0 0 .8ex;border-left:1px #ccc solid;padding-left:1ex"> <div dir="ltr"> <div class="gmail_extra"> <div class="gmail_quote"><span> <blockquote class="gmail_quote" style="margin:0 0 0 .8ex;border-left:1px #ccc solid;padding-left:1ex"> <div bgcolor="#FFFFFF" text="#000000"> <p>3. Three of my hosts have the hosted engine deployed for ha. First all three where marked by a crown (running was gold and others where silver). After upgrading the 3 Host deployed hosted engine ha is not active anymore.</p> <p>I can't get this host back with working ovirt-ha-agent/broker. I already rebooted, manually restarted the services but It isn't able to get cluster state according to <br> "hosted-engine --vm-status". The other hosts state the host status as "unknown stale-data"</p> <p>I already shut down all agents on all hosts and issued a "hosted-engine --reinitialize-lockspace" but that didn't help.<br> </p> <p>Agents stops working after a timeout-error according to log:</p> <p><tt>MainThread::INFO::2017-02-02 19:24:52,040::hosted_engine::8<wbr>41::ovirt_hosted_engine_ha.age<wbr>nt.hosted_engine.HostedEngine:<wbr>:(_get_domain_monitor_status) VDSM domain monitor status: PENDING</tt><tt><br> </tt><tt>MainThread::INFO::2017-02-02 19:24:59,185::hosted_engine::8<wbr>41::ovirt_hosted_engine_ha.age<wbr>nt.hosted_engine.HostedEngine:<wbr>:(_get_domain_monitor_status) VDSM domain monitor status: PENDING</tt><tt><br> </tt><tt>MainThread::INFO::2017-02-02 19:25:06,333::hosted_engine::8<wbr>41::ovirt_hosted_engine_ha.age<wbr>nt.hosted_engine.HostedEngine:<wbr>:(_get_domain_monitor_status) VDSM domain monitor status: PENDING</tt><tt><br> </tt><tt>MainThread::INFO::2017-02-02 19:25:13,554::hosted_engine::8<wbr>41::ovirt_hosted_engine_ha.age<wbr>nt.hosted_engine.HostedEngine:<wbr>:(_get_domain_monitor_status) VDSM domain monitor status: PENDING</tt><tt><br> </tt><tt>MainThread::INFO::2017-02-02 19:25:20,710::hosted_engine::8<wbr>41::ovirt_hosted_engine_ha.age<wbr>nt.hosted_engine.HostedEngine:<wbr>:(_get_domain_monitor_status) VDSM domain monitor status: PENDING</tt><tt><br> </tt><tt>MainThread::INFO::2017-02-02 19:25:27,865::hosted_engine::8<wbr>41::ovirt_hosted_engine_ha.age<wbr>nt.hosted_engine.HostedEngine:<wbr>:(_get_domain_monitor_status) VDSM domain monitor status: PENDING</tt><tt><br> </tt><tt>MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::8<wbr>15::ovirt_hosted_engine_ha.age<wbr>nt.hosted_engine.HostedEngine:<wbr>:(_initialize_domain_monitor) Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9<wbr>b4-ddc8da99ad96, host_id=3): timeout during domain acquisition</tt><tt><br> </tt><tt>MainThread::WARNING::2017-02-0<wbr>2 19:25:27,866::hosted_engine::4<wbr>69::ovirt_hosted_engine_ha.age<wbr>nt.hosted_engine.HostedEngine:<wbr>:(start_monitoring) Error while monitoring engine: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9<wbr>b4-ddc8da99ad96, host_id=3): timeout during domain acquisition</tt><tt><br> </tt><tt>MainThread::WARNING::2017-02-0<wbr>2 19:25:27,866::hosted_engine::4<wbr>72::ovirt_hosted_engine_ha.age<wbr>nt.hosted_engine.HostedEngine:<wbr>:(start_monitoring) Unexpected error</tt><tt><br> </tt><tt>Traceback (most recent call last):</tt><tt><br> </tt><tt> File "/usr/lib/python2.7/site-packa<wbr>ges/ovirt_hosted_engine_ha/age<wbr>nt/hosted_engine.py", line 443, in start_monitoring</tt><tt><br> </tt><tt> self._initialize_domain_monito<wbr>r()</tt><tt><br> </tt><tt> File "/usr/lib/python2.7/site-packa<wbr>ges/ovirt_hosted_engine_ha/age<wbr>nt/hosted_engine.py", line 816, in _initialize_domain_monitor</tt><tt><br> </tt><tt> raise Exception(msg)</tt><tt><br> </tt><tt>Exception: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9<wbr>b4-ddc8da99ad96, host_id=3): timeout during domain acquisition</tt><tt><br> </tt><tt>MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::4<wbr>85::ovirt_hosted_engine_ha.age<wbr>nt.hosted_engine.HostedEngine:<wbr>:(start_monitoring) Shutting down the agent because of 3 failures in a row!</tt><tt><br> </tt><tt>MainThread::INFO::2017-02-02 19:25:32,087::hosted_engine::8<wbr>41::ovirt_hosted_engine_ha.age<wbr>nt.hosted_engine.HostedEngine:<wbr>:(_get_domain_monitor_status) VDSM domain monitor status: PENDING</tt><tt><br> </tt><tt>MainThread::INFO::2017-02-02 19:25:34,250::hosted_engine::7<wbr>69::ovirt_hosted_engine_ha.age<wbr>nt.hosted_engine.HostedEngine:<wbr>:(_stop_domain_monitor) Failed to stop monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9<wbr>b4-ddc8da99ad96): Storage domain is member of pool: u'domain=7c8deaa8-be02-4aaf-b9<wbr>b4-ddc8da99ad96'</tt><tt><br> </tt><tt>MainThread::INFO::2017-02-02 19:25:34,254::agent::143::ovir<wbr>t_hosted_engine_ha.agent.agent<wbr>.Agent::(run) Agent shutting down</tt></p> </div> </blockquote> </span> <div>Simone, Martin, can you please follow up on this?</div> </div> </div> </div> </blockquote> <div><br> </div> <div>Ralph, could you please attach vdsm logs from on of your hosts for the relevant time frame?</div> </blockquote> <br> </div> </div> <span class=""> <div class="m_-5371711976759655950moz-signature">-- <br> <p> </p> <table border="0" cellpadding="0" cellspacing="0"> <tbody> <tr> <td colspan="3"><img src="cid:part2.442CE625.84474DBE@databay.de" height="30" border="0" width="151"></td> </tr> <tr> <td valign="top"> <font face="Verdana, Arial, sans-serif" size="-1"><br> <b>Ralf Schenk</b><br> fon <a moz-do-not-send="true" href="tel:+49%202405%20408370" value="+492405408370" target="_blank">+49 (0) 24 05 / 40 83 70</a><br> fax <a moz-do-not-send="true" href="tel:+49%202405%204083759" value="+4924054083759" target="_blank">+49 (0) 24 05 / 40 83 759</a><br> mail <a moz-do-not-send="true" href="mailto:rs@databay.de" target="_blank"><font color="#FF0000"><b>rs@databay.de</b></font></a><br> </font> </td> <td width="30"> </td> <td valign="top"> <font face="Verdana, Arial, sans-serif" size="-1"><br> <b>Databay AG</b><br> Jens-Otto-Krag-Straße 11<br> D-52146 Würselen<br> <a moz-do-not-send="true" href="http://www.databay.de" target="_blank"><font color="#FF0000"><b>www.databay.de</b></font></a> </font> </td> </tr> <tr> <td colspan="3" valign="top"> <font face="Verdana, Arial, sans-serif" size="1"><br> Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202<br> Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns<br> Aufsichtsratsvorsitzender: Wilhelm Dohmen </font> </td> </tr> </tbody> </table> <hr color="#000000" noshade="noshade" size="1" width="100%"> </div> </span></div> </blockquote> </div> <br> </div> </blockquote> <br> <div class="moz-signature">-- <br> <p> </p> <table border="0" cellpadding="0" cellspacing="0"> <tbody> <tr> <td colspan="3"><img src="cid:part7.257995E9.651557B2@databay.de" height="30" border="0" width="151"></td> </tr> <tr> <td valign="top"> <font face="Verdana, Arial, sans-serif" size="-1"><br> <b>Ralf Schenk</b><br> fon +49 (0) 24 05 / 40 83 70<br> fax +49 (0) 24 05 / 40 83 759<br> mail <a href="mailto:rs@databay.de"><font color="#FF0000"><b>rs@databay.de</b></font></a><br> </font> </td> <td width="30"> </td> <td valign="top"> <font face="Verdana, Arial, sans-serif" size="-1"><br> <b>Databay AG</b><br> Jens-Otto-Krag-Straße 11<br> D-52146 Würselen<br> <a href="http://www.databay.de"><font color="#FF0000"><b>www.databay.de</b></font></a> </font> </td> </tr> <tr> <td colspan="3" valign="top"> <font face="Verdana, Arial, sans-serif" size="1"><br> Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202<br> Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns<br> Aufsichtsratsvorsitzender: Wilhelm Dohmen </font> </td> </tr> </tbody> </table> <hr color="#000000" noshade="noshade" size="1" width="100%"> </div> </body> </html> --------------27C892A9C9EF2750A20ED420 Content-Type: image/gif Content-Transfer-Encoding: base64 Content-ID: <part2.442CE625.84474DBE@databay.de> R0lGODlhlwAeAMQAAObm5v9QVf/R0oKBgfDw8NfX105MTLi3t/r6+sfHx/+rrf98gC0sLP8L EhIQEKalpf/g4ZmYmHd2dmppaf8uNP/y8v8cIv+Ym//AwkE/P46NjRwbG11cXP8ABwUDA/// /yH5BAAAAAAALAAAAACXAB4AAAX/4CeOYnUJZKqubOu+cCzPNA0tVnfVfO//wGAKk+t0Ap+K QMFUYCDCqHRKJVUWDaPRUsFktZ1G4AKtms9o1gKsFVS+7I5ll67bpd647hPQawNld4KDMQJF bA07F35aFBiEkJEpfXEBjx8KjI0Vkp2DEIdaCySgFBShbEgrCQOtrq+uEQcALQewrQUjEbe8 rgkkD7y5KhMZB3drqSoVFQhdlHGXKQYe1dbX2BvHKwzY1RMiAN7j1xEjBeTmKeIeD3cYCxRf FigvChRxFJwkBBvk5A7cpZhAjgGCDwn+kfslgto4CSoSehh2BwEEBQvowDAUR0EKdArHZTg4 4oDCXBFC/3qj9SEluZEpHnjYQFIGgpo1KgSasYjNKBImrzF4NaFbNgIjCGRQeIyVKwneOLzS cLCAg38OWI4Y4GECgQcSOEwYcADnh6/FNjAwoGFYAQ0atI4AAFeEFwsLFLiJUQEfGH0kNGAD x8+oNQdIRQg+7NCaOhIgD8sVgYADNsPVGI5YWjRqzQTdHDDIYHRDLokaUhCglkFEJi0NKJhl 0RP2TsvXUg88KiLBVWsZrF6DmMKlNYMqglqTik1guN8OBgAgkGCpB+L9ugK4iSCBvwEfECw1 kILrBpa1jVCQIQBRvbP+rlEcQVAoSevWyv6uhpwE12uEkQAAZucpVw1xIsjkgf8B863mQVYt eQATCZYJZJ5WBfij2wfpHcEeHGG8Z+BMszVWDXkfKLhceJhBSAJ+1ThH32AfRFZNayNAtUFi wFSTSwEHJIYAAQU84IADwyjIEALU9MchG+vFgIF7W2GDI2T7HfjBgNcgKQKMHmwjgnCSpeCb ULRkdxhF1CDY40RjgmUAA/v1J5FAKW2gGSZscBFDMraNgJs1AYpAAGYP5jJoNQ4Y4Gh8jpFg HH9mgbmWo1l6oA4C3Ygp6UwEIFBfNRtkMIBlKMLnAXgAXLWhXXH85EIFqMhGGZgDEKArABGA ed0HI4bk5qgnprCYSt88B6dqS0FEEAMPJDCdCJYViur/B1BlwGMJqDTwnhqxJgUpo0ceOQ4D 0yEakpMm/jqCRMgWm2I1j824Y6vLvuuPjHnqOJkIgP6xzwp5sCFNsCFp88Gxh11lrjfDcNrc CEx64/CD3iAHlQcMUEQXvcA+qBkBB4Q2X1CusjBlJdKMYAKI6g28MbKN5hJsBAXknHOwutn4 oFYqkpqAzjnPbE0u1PxmwAQGXLWBbvhuIIEGEnRjlAHO4SvhbCNAkwoGzEBwgV9U0lfu2WiX OkDEGaCdKgl0nk2YkWdPOCDabvaGdkAftL1LlgwCM+7Tq11V71IO7LkM2XE0YAHMYMhqqK6U V165CpaHukLmiXFO8XSVzzakX+UH6TrmAajPNxfqByTQec41AeBPvSwIALkmAnuiexCsca3C BajgfsROuxcPA8kHQJX4DAIwjnsAvhsvfXHWKEwDAljg7sj03L9wwAQTxOWD2AE0YP75eCkw cPfs+xACADs= --------------27C892A9C9EF2750A20ED420 Content-Type: image/gif; name="logo_databay_email.gif" Content-Transfer-Encoding: base64 Content-ID: <part7.257995E9.651557B2@databay.de> Content-Disposition: inline; filename="logo_databay_email.gif" R0lGODlhlwAeAMQAAObm5v9QVf/R0oKBgfDw8NfX105MTLi3t/r6+sfHx/+rrf98gC0sLP8L EhIQEKalpf/g4ZmYmHd2dmppaf8uNP/y8v8cIv+Ym//AwkE/P46NjRwbG11cXP8ABwUDA/// /yH5BAAAAAAALAAAAACXAB4AAAX/4CeOYnUJZKqubOu+cCzPNA0tVnfVfO//wGAKk+t0Ap+K QMFUYCDCqHRKJVUWDaPRUsFktZ1G4AKtms9o1gKsFVS+7I5ll67bpd647hPQawNld4KDMQJF bA07F35aFBiEkJEpfXEBjx8KjI0Vkp2DEIdaCySgFBShbEgrCQOtrq+uEQcALQewrQUjEbe8 rgkkD7y5KhMZB3drqSoVFQhdlHGXKQYe1dbX2BvHKwzY1RMiAN7j1xEjBeTmKeIeD3cYCxRf FigvChRxFJwkBBvk5A7cpZhAjgGCDwn+kfslgto4CSoSehh2BwEEBQvowDAUR0EKdArHZTg4 4oDCXBFC/3qj9SEluZEpHnjYQFIGgpo1KgSasYjNKBImrzF4NaFbNgIjCGRQeIyVKwneOLzS cLCAg38OWI4Y4GECgQcSOEwYcADnh6/FNjAwoGFYAQ0atI4AAFeEFwsLFLiJUQEfGH0kNGAD x8+oNQdIRQg+7NCaOhIgD8sVgYADNsPVGI5YWjRqzQTdHDDIYHRDLokaUhCglkFEJi0NKJhl 0RP2TsvXUg88KiLBVWsZrF6DmMKlNYMqglqTik1guN8OBgAgkGCpB+L9ugK4iSCBvwEfECw1 kILrBpa1jVCQIQBRvbP+rlEcQVAoSevWyv6uhpwE12uEkQAAZucpVw1xIsjkgf8B863mQVYt eQATCZYJZJ5WBfij2wfpHcEeHGG8Z+BMszVWDXkfKLhceJhBSAJ+1ThH32AfRFZNayNAtUFi wFSTSwEHJIYAAQU84IADwyjIEALU9MchG+vFgIF7W2GDI2T7HfjBgNcgKQKMHmwjgnCSpeCb ULRkdxhF1CDY40RjgmUAA/v1J5FAKW2gGSZscBFDMraNgJs1AYpAAGYP5jJoNQ4Y4Gh8jpFg HH9mgbmWo1l6oA4C3Ygp6UwEIFBfNRtkMIBlKMLnAXgAXLWhXXH85EIFqMhGGZgDEKArABGA ed0HI4bk5qgnprCYSt88B6dqS0FEEAMPJDCdCJYViur/B1BlwGMJqDTwnhqxJgUpo0ceOQ4D 0yEakpMm/jqCRMgWm2I1j824Y6vLvuuPjHnqOJkIgP6xzwp5sCFNsCFp88Gxh11lrjfDcNrc CEx64/CD3iAHlQcMUEQXvcA+qBkBB4Q2X1CusjBlJdKMYAKI6g28MbKN5hJsBAXknHOwutn4 oFYqkpqAzjnPbE0u1PxmwAQGXLWBbvhuIIEGEnRjlAHO4SvhbCNAkwoGzEBwgV9U0lfu2WiX OkDEGaCdKgl0nk2YkWdPOCDabvaGdkAftL1LlgwCM+7Tq11V71IO7LkM2XE0YAHMYMhqqK6U V165CpaHukLmiXFO8XSVzzakX+UH6TrmAajPNxfqByTQec41AeBPvSwIALkmAnuiexCsca3C BajgfsROuxcPA8kHQJX4DAIwjnsAvhsvfXHWKEwDAljg7sj03L9wwAQTxOWD2AE0YP75eCkw cPfs+xACADs= --------------27C892A9C9EF2750A20ED420-- --------------C9EE446E673EA16FD96BD311--
The hosted-engine storage domain is mounted for sure, but the issue is here: Exception: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition The point is that in VDSM logs I see just something like: 2017-02-02 21:05:22,283 INFO (jsonrpc/1) [dispatcher] Run and protect: repoStats(options=None) (logUtils:49) 2017-02-02 21:05:22,285 INFO (jsonrpc/1) [dispatcher] Run and protect: repoStats, Return response: {u'a7fbaaad-7043-4391-9523-3bedcdc4fb0d': {'code': 0, 'actual': True, 'version': 0, 'acquired': True, 'delay': '0.000748727', 'lastCheck': '0.1', 'valid': True}, u'2b2a44fc-f2bd-47cd-b7af-00be59e30a35': {'code': 0, 'actual': True, 'version': 0, 'acquired': True, 'delay': '0.00082529', 'lastCheck': '0.1', 'valid': True}, u'5d99af76-33b5-47d8-99da-1f32413c7bb0': {'code': 0, 'actual': True, 'version': 4, 'acquired': True, 'delay': '0.000349356', 'lastCheck': '5.3', 'valid': True}, u'7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96': {'code': 0, 'actual': True, 'version': 4, 'acquired': False, 'delay': '0.000377052', 'lastCheck': '0.6', 'valid': True}} (logUtils:52) Where the other storage domains have 'acquired': True whil it's always 'acquired': False for the hosted-engine storage domain. Could you please share your /var/log/sanlock.log from the same host and the output of sanlock client status ? On Fri, Feb 3, 2017 at 3:52 PM, Ralf Schenk <rs@databay.de> wrote:
Hello,
I also put host in Maintenance and restarted vdsm while ovirt-ha-agent is running. I can mount the gluster Volume "engine" manually in the host.
I get this repeatedly in /var/log/vdsm.log:
2017-02-03 15:29:28,891 INFO (MainThread) [vds] Exiting (vdsm:167) 2017-02-03 15:29:30,974 INFO (MainThread) [vds] (PID: 11456) I am the actual vdsm 4.19.4-1.el7.centos microcloud27 (3.10.0-514.6.1.el7.x86_64) (vdsm:145) 2017-02-03 15:29:30,974 INFO (MainThread) [vds] VDSM will run with cpu affinity: frozenset([1]) (vdsm:251) 2017-02-03 15:29:31,013 INFO (MainThread) [storage.check] Starting check service (check:91) 2017-02-03 15:29:31,017 INFO (MainThread) [storage.Dispatcher] Starting StorageDispatcher... (dispatcher:47) 2017-02-03 15:29:31,017 INFO (check/loop) [storage.asyncevent] Starting <EventLoop running=True closed=False at 0x37480464> (asyncevent:122) 2017-02-03 15:29:31,156 INFO (MainThread) [dispatcher] Run and protect: registerDomainStateChangeCallback(callbackFunc=<functools.partial object at 0x2881fc8>) (logUtils:49) 2017-02-03 15:29:31,156 INFO (MainThread) [dispatcher] Run and protect: registerDomainStateChangeCallback, Return response: None (logUtils:52) 2017-02-03 15:29:31,160 INFO (MainThread) [MOM] Preparing MOM interface (momIF:49) 2017-02-03 15:29:31,161 INFO (MainThread) [MOM] Using named unix socket /var/run/vdsm/mom-vdsm.sock (momIF:58) 2017-02-03 15:29:31,162 INFO (MainThread) [root] Unregistering all secrets (secret:91) 2017-02-03 15:29:31,164 INFO (MainThread) [vds] Setting channels' timeout to 30 seconds. (vmchannels:223) 2017-02-03 15:29:31,165 INFO (MainThread) [vds.MultiProtocolAcceptor] Listening at :::54321 (protocoldetector:185) 2017-02-03 15:29:31,354 INFO (vmrecovery) [vds] recovery: completed in 0s (clientIF:495) 2017-02-03 15:29:31,371 INFO (BindingXMLRPC) [vds] XMLRPC server running (bindingxmlrpc:63) 2017-02-03 15:29:31,471 INFO (periodic/1) [dispatcher] Run and protect: repoStats(options=None) (logUtils:49) 2017-02-03 15:29:31,472 INFO (periodic/1) [dispatcher] Run and protect: repoStats, Return response: {} (logUtils:52) 2017-02-03 15:29:31,472 WARN (periodic/1) [MOM] MOM not available. (momIF:116) 2017-02-03 15:29:31,473 WARN (periodic/1) [MOM] MOM not available, KSM stats will be missing. (momIF:79) 2017-02-03 15:29:31,474 ERROR (periodic/1) [root] failed to retrieve Hosted Engine HA info (api:252) Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/vdsm/host/api.py", line 231, in _getHaInfo stats = instance.get_all_stats() File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/client/client.py", line 103, in get_all_stats self._configure_broker_conn(broker) File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/client/client.py", line 180, in _configure_broker_conn dom_type=dom_type) File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/lib/brokerlink.py", line 177, in set_storage_domain .format(sd_type, options, e)) RequestError: Failed to set storage domain FilesystemBackend, options {'dom_type': 'glusterfs', 'sd_uuid': '7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96'}: Request failed: <class 'ovirt_hos ted_engine_ha.lib.storage_backends.BackendFailureException'> 2017-02-03 15:29:35,920 INFO (Reactor thread) [ProtocolDetector.AcceptorImpl] Accepted connection from ::1:49506 (protocoldetector:72) 2017-02-03 15:29:35,929 INFO (Reactor thread) [ProtocolDetector.Detector] Detected protocol stomp from ::1:49506 (protocoldetector:127) 2017-02-03 15:29:35,930 INFO (Reactor thread) [Broker.StompAdapter] Processing CONNECT request (stompreactor:102) 2017-02-03 15:29:35,930 INFO (JsonRpc (StompReactor)) [Broker.StompAdapter] Subscribe command received (stompreactor:129) 2017-02-03 15:29:36,067 INFO (jsonrpc/0) [jsonrpc.JsonRpcServer] RPC call Host.ping succeeded in 0.00 seconds (__init__:515) 2017-02-03 15:29:36,071 INFO (jsonrpc/1) [throttled] Current getAllVmStats: {} (throttledlog:105) 2017-02-03 15:29:36,071 INFO (jsonrpc/1) [jsonrpc.JsonRpcServer] RPC call Host.getAllVmStats succeeded in 0.00 seconds (__init__:515) 2017-02-03 15:29:46,435 INFO (periodic/0) [dispatcher] Run and protect: repoStats(options=None) (logUtils:49) 2017-02-03 15:29:46,435 INFO (periodic/0) [dispatcher] Run and protect: repoStats, Return response: {} (logUtils:52) 2017-02-03 15:29:46,439 ERROR (periodic/0) [root] failed to retrieve Hosted Engine HA info (api:252) Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/vdsm/host/api.py", line 231, in _getHaInfo stats = instance.get_all_stats() File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/client/client.py", line 103, in get_all_stats self._configure_broker_conn(broker) File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/client/client.py", line 180, in _configure_broker_conn dom_type=dom_type) File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/lib/brokerlink.py", line 177, in set_storage_domain .format(sd_type, options, e)) RequestError: Failed to set storage domain FilesystemBackend, options {'dom_type': 'glusterfs', 'sd_uuid': '7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96'}: Request failed: <class 'ovirt_hos ted_engine_ha.lib.storage_backends.BackendFailureException'> 2017-02-03 15:29:51,095 INFO (jsonrpc/2) [jsonrpc.JsonRpcServer] RPC call Host.getAllVmStats succeeded in 0.00 seconds (__init__:515) 2017-02-03 15:29:51,219 INFO (jsonrpc/3) [jsonrpc.JsonRpcServer] RPC call Host.setKsmTune succeeded in 0.00 seconds (__init__:515) 2017-02-03 15:30:01,444 INFO (periodic/1) [dispatcher] Run and protect: repoStats(options=None) (logUtils:49) 2017-02-03 15:30:01,444 INFO (periodic/1) [dispatcher] Run and protect: repoStats, Return response: {} (logUtils:52) 2017-02-03 15:30:01,448 ERROR (periodic/1) [root] failed to retrieve Hosted Engine HA info (api:252)
Am 03.02.2017 um 13:39 schrieb Simone Tiraboschi:
I see there an ERROR on stopMonitoringDomain but I cannot see the correspondent startMonitoringDomain; could you please look for it?
On Fri, Feb 3, 2017 at 1:16 PM, Ralf Schenk <rs@databay.de> wrote:
Hello,
attached is my vdsm.log from the host with hosted-engine-ha around the time-frame of agent timeout that is not working anymore for engine (it works in Ovirt and is active). It simply isn't working for engine-ha anymore after Update.
At 2017-02-02 19:25:34,248 you'll find an error corresponoding to agent timeout error.
Bye
Am 03.02.2017 um 11:28 schrieb Simone Tiraboschi:
3. Three of my hosts have the hosted engine deployed for ha. First all
three where marked by a crown (running was gold and others where silver). After upgrading the 3 Host deployed hosted engine ha is not active anymore.
I can't get this host back with working ovirt-ha-agent/broker. I already rebooted, manually restarted the services but It isn't able to get cluster state according to "hosted-engine --vm-status". The other hosts state the host status as "unknown stale-data"
I already shut down all agents on all hosts and issued a "hosted-engine --reinitialize-lockspace" but that didn't help.
Agents stops working after a timeout-error according to log:
MainThread::INFO::2017-02-02 19:24:52,040::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:24:59,185::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:06,333::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:13,554::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:20,710::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:27,865::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::8 15::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_initialize_domain_monitor) Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine::4 69::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Error while monitoring engine: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine::4 72::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Unexpected error Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 443, in start_monitoring self._initialize_domain_monitor() File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 816, in _initialize_domain_monitor raise Exception(msg) Exception: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::4 85::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Shutting down the agent because of 3 failures in a row! MainThread::INFO::2017-02-02 19:25:32,087::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:34,250::hosted_engine::7 69::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_stop_domain_monitor) Failed to stop monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96): Storage domain is member of pool: u'domain=7c8deaa8-be02-4aaf-b9 b4-ddc8da99ad96' MainThread::INFO::2017-02-02 19:25:34,254::agent::143::ovir t_hosted_engine_ha.agent.agent.Agent::(run) Agent shutting down
Simone, Martin, can you please follow up on this?
Ralph, could you please attach vdsm logs from on of your hosts for the relevant time frame?
--
*Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 <+49%202405%20408370> fax +49 (0) 24 05 / 40 83 759 <+49%202405%204083759> mail *rs@databay.de* <rs@databay.de>
*Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de>
Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen ------------------------------
--
*Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 <+49%202405%20408370> fax +49 (0) 24 05 / 40 83 759 <+49%202405%204083759> mail *rs@databay.de* <rs@databay.de>
*Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de>
Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen ------------------------------
{kind=link}
{kind=link}
Hello, of course: [root@microcloud27 mnt]# sanlock client status daemon 8a93c9ea-e242-408c-a63d-a9356bb22df5.microcloud p -1 helper p -1 listener p -1 status sanlock.log attached. (Beginning 2017-01-27 where everything was fine) Bye Am 03.02.2017 um 16:12 schrieb Simone Tiraboschi:
The hosted-engine storage domain is mounted for sure, but the issue is here: Exception: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition
The point is that in VDSM logs I see just something like: 2017-02-02 21:05:22,283 INFO (jsonrpc/1) [dispatcher] Run and protect: repoStats(options=None) (logUtils:49) 2017-02-02 21:05:22,285 INFO (jsonrpc/1) [dispatcher] Run and protect: repoStats, Return response: {u'a7fbaaad-7043-4391-9523-3bedcdc4fb0d': {'code': 0, 'actual': True, 'version': 0, 'acquired': True, 'delay': '0.000748727', 'lastCheck': '0.1', 'valid': True}, u'2b2a44fc-f2bd-47cd-b7af-00be59e30a35': {'code': 0, 'actual': True, 'version': 0, 'acquired': True, 'delay': '0.00082529', 'lastCheck': '0.1', 'valid': True}, u'5d99af76-33b5-47d8-99da-1f32413c7bb0': {'code': 0, 'actual': True, 'version': 4, 'acquired': True, 'delay': '0.000349356', 'lastCheck': '5.3', 'valid': True}, u'7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96': {'code': 0, 'actual': True, 'version': 4, 'acquired': False, 'delay': '0.000377052', 'lastCheck': '0.6', 'valid': True}} (logUtils:52)
Where the other storage domains have 'acquired': True whil it's always 'acquired': False for the hosted-engine storage domain.
Could you please share your /var/log/sanlock.log from the same host and the output of sanlock client status ?
On Fri, Feb 3, 2017 at 3:52 PM, Ralf Schenk <rs@databay.de <mailto:rs@databay.de>> wrote:
Hello,
I also put host in Maintenance and restarted vdsm while ovirt-ha-agent is running. I can mount the gluster Volume "engine" manually in the host.
I get this repeatedly in /var/log/vdsm.log:
2017-02-03 15:29:28,891 INFO (MainThread) [vds] Exiting (vdsm:167) 2017-02-03 15:29:30,974 INFO (MainThread) [vds] (PID: 11456) I am the actual vdsm 4.19.4-1.el7.centos microcloud27 (3.10.0-514.6.1.el7.x86_64) (vdsm:145) 2017-02-03 15:29:30,974 INFO (MainThread) [vds] VDSM will run with cpu affinity: frozenset([1]) (vdsm:251) 2017-02-03 15:29:31,013 INFO (MainThread) [storage.check] Starting check service (check:91) 2017-02-03 15:29:31,017 INFO (MainThread) [storage.Dispatcher] Starting StorageDispatcher... (dispatcher:47) 2017-02-03 15:29:31,017 INFO (check/loop) [storage.asyncevent] Starting <EventLoop running=True closed=False at 0x37480464> (asyncevent:122) 2017-02-03 15:29:31,156 INFO (MainThread) [dispatcher] Run and protect: registerDomainStateChangeCallback(callbackFunc=<functools.partial object at 0x2881fc8>) (logUtils:49) 2017-02-03 15:29:31,156 INFO (MainThread) [dispatcher] Run and protect: registerDomainStateChangeCallback, Return response: None (logUtils:52) 2017-02-03 15:29:31,160 INFO (MainThread) [MOM] Preparing MOM interface (momIF:49) 2017-02-03 15:29:31,161 INFO (MainThread) [MOM] Using named unix socket /var/run/vdsm/mom-vdsm.sock (momIF:58) 2017-02-03 15:29:31,162 INFO (MainThread) [root] Unregistering all secrets (secret:91) 2017-02-03 15:29:31,164 INFO (MainThread) [vds] Setting channels' timeout to 30 seconds. (vmchannels:223) 2017-02-03 15:29:31,165 INFO (MainThread) [vds.MultiProtocolAcceptor] Listening at :::54321 (protocoldetector:185) 2017-02-03 15:29:31,354 INFO (vmrecovery) [vds] recovery: completed in 0s (clientIF:495) 2017-02-03 15:29:31,371 INFO (BindingXMLRPC) [vds] XMLRPC server running (bindingxmlrpc:63) 2017-02-03 15:29:31,471 INFO (periodic/1) [dispatcher] Run and protect: repoStats(options=None) (logUtils:49) 2017-02-03 15:29:31,472 INFO (periodic/1) [dispatcher] Run and protect: repoStats, Return response: {} (logUtils:52) 2017-02-03 15:29:31,472 WARN (periodic/1) [MOM] MOM not available. (momIF:116) 2017-02-03 15:29:31,473 WARN (periodic/1) [MOM] MOM not available, KSM stats will be missing. (momIF:79) 2017-02-03 15:29:31,474 ERROR (periodic/1) [root] failed to retrieve Hosted Engine HA info (api:252) Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/vdsm/host/api.py", line 231, in _getHaInfo stats = instance.get_all_stats() File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/client/client.py", line 103, in get_all_stats self._configure_broker_conn(broker) File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/client/client.py", line 180, in _configure_broker_conn dom_type=dom_type) File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/lib/brokerlink.py", line 177, in set_storage_domain .format(sd_type, options, e)) RequestError: Failed to set storage domain FilesystemBackend, options {'dom_type': 'glusterfs', 'sd_uuid': '7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96'}: Request failed: <class 'ovirt_hos ted_engine_ha.lib.storage_backends.BackendFailureException'> 2017-02-03 15:29:35,920 INFO (Reactor thread) [ProtocolDetector.AcceptorImpl] Accepted connection from ::1:49506 (protocoldetector:72) 2017-02-03 15:29:35,929 INFO (Reactor thread) [ProtocolDetector.Detector] Detected protocol stomp from ::1:49506 (protocoldetector:127) 2017-02-03 15:29:35,930 INFO (Reactor thread) [Broker.StompAdapter] Processing CONNECT request (stompreactor:102) 2017-02-03 15:29:35,930 INFO (JsonRpc (StompReactor)) [Broker.StompAdapter] Subscribe command received (stompreactor:129) 2017-02-03 15:29:36,067 INFO (jsonrpc/0) [jsonrpc.JsonRpcServer] RPC call Host.ping succeeded in 0.00 seconds (__init__:515) 2017-02-03 15:29:36,071 INFO (jsonrpc/1) [throttled] Current getAllVmStats: {} (throttledlog:105) 2017-02-03 15:29:36,071 INFO (jsonrpc/1) [jsonrpc.JsonRpcServer] RPC call Host.getAllVmStats succeeded in 0.00 seconds (__init__:515) 2017-02-03 15:29:46,435 INFO (periodic/0) [dispatcher] Run and protect: repoStats(options=None) (logUtils:49) 2017-02-03 15:29:46,435 INFO (periodic/0) [dispatcher] Run and protect: repoStats, Return response: {} (logUtils:52) 2017-02-03 15:29:46,439 ERROR (periodic/0) [root] failed to retrieve Hosted Engine HA info (api:252) Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/vdsm/host/api.py", line 231, in _getHaInfo stats = instance.get_all_stats() File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/client/client.py", line 103, in get_all_stats self._configure_broker_conn(broker) File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/client/client.py", line 180, in _configure_broker_conn dom_type=dom_type) File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/lib/brokerlink.py", line 177, in set_storage_domain .format(sd_type, options, e)) RequestError: Failed to set storage domain FilesystemBackend, options {'dom_type': 'glusterfs', 'sd_uuid': '7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96'}: Request failed: <class 'ovirt_hos ted_engine_ha.lib.storage_backends.BackendFailureException'> 2017-02-03 15:29:51,095 INFO (jsonrpc/2) [jsonrpc.JsonRpcServer] RPC call Host.getAllVmStats succeeded in 0.00 seconds (__init__:515) 2017-02-03 15:29:51,219 INFO (jsonrpc/3) [jsonrpc.JsonRpcServer] RPC call Host.setKsmTune succeeded in 0.00 seconds (__init__:515) 2017-02-03 15:30:01,444 INFO (periodic/1) [dispatcher] Run and protect: repoStats(options=None) (logUtils:49) 2017-02-03 15:30:01,444 INFO (periodic/1) [dispatcher] Run and protect: repoStats, Return response: {} (logUtils:52) 2017-02-03 15:30:01,448 ERROR (periodic/1) [root] failed to retrieve Hosted Engine HA info (api:252)
Am 03.02.2017 um 13:39 schrieb Simone Tiraboschi:
I see there an ERROR on stopMonitoringDomain but I cannot see the correspondent startMonitoringDomain; could you please look for it?
On Fri, Feb 3, 2017 at 1:16 PM, Ralf Schenk <rs@databay.de <mailto:rs@databay.de>> wrote:
Hello,
attached is my vdsm.log from the host with hosted-engine-ha around the time-frame of agent timeout that is not working anymore for engine (it works in Ovirt and is active). It simply isn't working for engine-ha anymore after Update.
At 2017-02-02 19:25:34,248 you'll find an error corresponoding to agent timeout error.
Bye
Am 03.02.2017 um 11:28 schrieb Simone Tiraboschi:
3. Three of my hosts have the hosted engine deployed for ha. First all three where marked by a crown (running was gold and others where silver). After upgrading the 3 Host deployed hosted engine ha is not active anymore.
I can't get this host back with working ovirt-ha-agent/broker. I already rebooted, manually restarted the services but It isn't able to get cluster state according to "hosted-engine --vm-status". The other hosts state the host status as "unknown stale-data"
I already shut down all agents on all hosts and issued a "hosted-engine --reinitialize-lockspace" but that didn't help.
Agents stops working after a timeout-error according to log:
MainThread::INFO::2017-02-02 19:24:52,040::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:24:59,185::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:06,333::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:13,554::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:20,710::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:27,865::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::815::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_initialize_domain_monitor) Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine::469::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Error while monitoring engine: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine::472::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Unexpected error Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 443, in start_monitoring self._initialize_domain_monitor() File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 816, in _initialize_domain_monitor raise Exception(msg) Exception: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::485::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Shutting down the agent because of 3 failures in a row! MainThread::INFO::2017-02-02 19:25:32,087::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:34,250::hosted_engine::769::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_stop_domain_monitor) Failed to stop monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96): Storage domain is member of pool: u'domain=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96' MainThread::INFO::2017-02-02 19:25:34,254::agent::143::ovirt_hosted_engine_ha.agent.agent.Agent::(run) Agent shutting down
Simone, Martin, can you please follow up on this?
Ralph, could you please attach vdsm logs from on of your hosts for the relevant time frame?
--
*Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 <tel:+49%202405%20408370> fax +49 (0) 24 05 / 40 83 759 <tel:+49%202405%204083759> mail *rs@databay.de* <mailto:rs@databay.de>
*Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de>
Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen
------------------------------------------------------------------------
--
*Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 <tel:+49%202405%20408370> fax +49 (0) 24 05 / 40 83 759 <tel:+49%202405%204083759> mail *rs@databay.de* <mailto:rs@databay.de>
*Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de>
Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen
------------------------------------------------------------------------
-- *Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 fax +49 (0) 24 05 / 40 83 759 mail *rs@databay.de* <mailto:rs@databay.de> *Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de> Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen ------------------------------------------------------------------------
{kind=link}
{kind=link}
{kind=link}
On Fri, Feb 3, 2017 at 5:22 PM, Ralf Schenk <rs@databay.de> wrote:
Hello,
of course:
[root@microcloud27 mnt]# sanlock client status daemon 8a93c9ea-e242-408c-a63d-a9356bb22df5.microcloud p -1 helper p -1 listener p -1 status
sanlock.log attached. (Beginning 2017-01-27 where everything was fine)
Thanks, the issue is here: 2017-02-02 19:01:22+0100 4848 [1048]: s36 lockspace 7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96:3:/rhev/data-center/mnt/glusterSD/glusterfs.rxmgmt.databay.de:_engine/7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96/dom_md/ids:0 2017-02-02 19:03:42+0100 4988 [12983]: s36 delta_acquire host_id 3 busy1 3 15 13129 7ad427b1-fbb6-4cee-b9ee-01f596fddfbb.microcloud 2017-02-02 19:03:43+0100 4989 [1048]: s36 add_lockspace fail result -262 Could you please check if you have other hosts contending for the same ID (id=3 in this case).
Bye
Am 03.02.2017 um 16:12 schrieb Simone Tiraboschi:
The hosted-engine storage domain is mounted for sure, but the issue is here: Exception: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition
The point is that in VDSM logs I see just something like: 2017-02-02 21:05:22,283 INFO (jsonrpc/1) [dispatcher] Run and protect: repoStats(options=None) (logUtils:49) 2017-02-02 21:05:22,285 INFO (jsonrpc/1) [dispatcher] Run and protect: repoStats, Return response: {u'a7fbaaad-7043-4391-9523-3bedcdc4fb0d': {'code': 0, 'actual': True, 'version': 0, 'acquired': True, 'delay': '0.000748727', 'lastCheck': '0.1', 'valid': True}, u'2b2a44fc-f2bd-47cd-b7af-00be59e30a35': {'code': 0, 'actual': True, 'version': 0, 'acquired': True, 'delay': '0.00082529', 'lastCheck': '0.1', 'valid': True}, u'5d99af76-33b5-47d8-99da-1f32413c7bb0': {'code': 0, 'actual': True, 'version': 4, 'acquired': True, 'delay': '0.000349356', 'lastCheck': '5.3', 'valid': True}, u'7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96': {'code': 0, 'actual': True, 'version': 4, 'acquired': False, 'delay': '0.000377052', 'lastCheck': '0.6', 'valid': True}} (logUtils:52)
Where the other storage domains have 'acquired': True whil it's always 'acquired': False for the hosted-engine storage domain.
Could you please share your /var/log/sanlock.log from the same host and the output of sanlock client status ?
On Fri, Feb 3, 2017 at 3:52 PM, Ralf Schenk <rs@databay.de> wrote:
Hello,
I also put host in Maintenance and restarted vdsm while ovirt-ha-agent is running. I can mount the gluster Volume "engine" manually in the host.
I get this repeatedly in /var/log/vdsm.log:
2017-02-03 15:29:28,891 INFO (MainThread) [vds] Exiting (vdsm:167) 2017-02-03 15:29:30,974 INFO (MainThread) [vds] (PID: 11456) I am the actual vdsm 4.19.4-1.el7.centos microcloud27 (3.10.0-514.6.1.el7.x86_64) (vdsm:145) 2017-02-03 15:29:30,974 INFO (MainThread) [vds] VDSM will run with cpu affinity: frozenset([1]) (vdsm:251) 2017-02-03 15:29:31,013 INFO (MainThread) [storage.check] Starting check service (check:91) 2017-02-03 15:29:31,017 INFO (MainThread) [storage.Dispatcher] Starting StorageDispatcher... (dispatcher:47) 2017-02-03 15:29:31,017 INFO (check/loop) [storage.asyncevent] Starting <EventLoop running=True closed=False at 0x37480464> (asyncevent:122) 2017-02-03 15:29:31,156 INFO (MainThread) [dispatcher] Run and protect: registerDomainStateChangeCallback(callbackFunc=<functools.partial object at 0x2881fc8>) (logUtils:49) 2017-02-03 15:29:31,156 INFO (MainThread) [dispatcher] Run and protect: registerDomainStateChangeCallback, Return response: None (logUtils:52) 2017-02-03 15:29:31,160 INFO (MainThread) [MOM] Preparing MOM interface (momIF:49) 2017-02-03 15:29:31,161 INFO (MainThread) [MOM] Using named unix socket /var/run/vdsm/mom-vdsm.sock (momIF:58) 2017-02-03 15:29:31,162 INFO (MainThread) [root] Unregistering all secrets (secret:91) 2017-02-03 15:29:31,164 INFO (MainThread) [vds] Setting channels' timeout to 30 seconds. (vmchannels:223) 2017-02-03 15:29:31,165 INFO (MainThread) [vds.MultiProtocolAcceptor] Listening at :::54321 (protocoldetector:185) 2017-02-03 15:29:31,354 INFO (vmrecovery) [vds] recovery: completed in 0s (clientIF:495) 2017-02-03 15:29:31,371 INFO (BindingXMLRPC) [vds] XMLRPC server running (bindingxmlrpc:63) 2017-02-03 15:29:31,471 INFO (periodic/1) [dispatcher] Run and protect: repoStats(options=None) (logUtils:49) 2017-02-03 15:29:31,472 INFO (periodic/1) [dispatcher] Run and protect: repoStats, Return response: {} (logUtils:52) 2017-02-03 15:29:31,472 WARN (periodic/1) [MOM] MOM not available. (momIF:116) 2017-02-03 15:29:31,473 WARN (periodic/1) [MOM] MOM not available, KSM stats will be missing. (momIF:79) 2017-02-03 15:29:31,474 ERROR (periodic/1) [root] failed to retrieve Hosted Engine HA info (api:252) Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/vdsm/host/api.py", line 231, in _getHaInfo stats = instance.get_all_stats() File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/client/client.py", line 103, in get_all_stats self._configure_broker_conn(broker) File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/client/client.py", line 180, in _configure_broker_conn dom_type=dom_type) File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/lib/brokerlink.py", line 177, in set_storage_domain .format(sd_type, options, e)) RequestError: Failed to set storage domain FilesystemBackend, options {'dom_type': 'glusterfs', 'sd_uuid': '7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96'}: Request failed: <class 'ovirt_hos ted_engine_ha.lib.storage_backends.BackendFailureException'> 2017-02-03 15:29:35,920 INFO (Reactor thread) [ProtocolDetector.AcceptorImpl] Accepted connection from ::1:49506 (protocoldetector:72) 2017-02-03 15:29:35,929 INFO (Reactor thread) [ProtocolDetector.Detector] Detected protocol stomp from ::1:49506 (protocoldetector:127) 2017-02-03 15:29:35,930 INFO (Reactor thread) [Broker.StompAdapter] Processing CONNECT request (stompreactor:102) 2017-02-03 15:29:35,930 INFO (JsonRpc (StompReactor)) [Broker.StompAdapter] Subscribe command received (stompreactor:129) 2017-02-03 15:29:36,067 INFO (jsonrpc/0) [jsonrpc.JsonRpcServer] RPC call Host.ping succeeded in 0.00 seconds (__init__:515) 2017-02-03 15:29:36,071 INFO (jsonrpc/1) [throttled] Current getAllVmStats: {} (throttledlog:105) 2017-02-03 15:29:36,071 INFO (jsonrpc/1) [jsonrpc.JsonRpcServer] RPC call Host.getAllVmStats succeeded in 0.00 seconds (__init__:515) 2017-02-03 15:29:46,435 INFO (periodic/0) [dispatcher] Run and protect: repoStats(options=None) (logUtils:49) 2017-02-03 15:29:46,435 INFO (periodic/0) [dispatcher] Run and protect: repoStats, Return response: {} (logUtils:52) 2017-02-03 15:29:46,439 ERROR (periodic/0) [root] failed to retrieve Hosted Engine HA info (api:252) Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/vdsm/host/api.py", line 231, in _getHaInfo stats = instance.get_all_stats() File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/client/client.py", line 103, in get_all_stats self._configure_broker_conn(broker) File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/client/client.py", line 180, in _configure_broker_conn dom_type=dom_type) File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/lib/brokerlink.py", line 177, in set_storage_domain .format(sd_type, options, e)) RequestError: Failed to set storage domain FilesystemBackend, options {'dom_type': 'glusterfs', 'sd_uuid': '7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96'}: Request failed: <class 'ovirt_hos ted_engine_ha.lib.storage_backends.BackendFailureException'> 2017-02-03 15:29:51,095 INFO (jsonrpc/2) [jsonrpc.JsonRpcServer] RPC call Host.getAllVmStats succeeded in 0.00 seconds (__init__:515) 2017-02-03 15:29:51,219 INFO (jsonrpc/3) [jsonrpc.JsonRpcServer] RPC call Host.setKsmTune succeeded in 0.00 seconds (__init__:515) 2017-02-03 15:30:01,444 INFO (periodic/1) [dispatcher] Run and protect: repoStats(options=None) (logUtils:49) 2017-02-03 15:30:01,444 INFO (periodic/1) [dispatcher] Run and protect: repoStats, Return response: {} (logUtils:52) 2017-02-03 15:30:01,448 ERROR (periodic/1) [root] failed to retrieve Hosted Engine HA info (api:252)
Am 03.02.2017 um 13:39 schrieb Simone Tiraboschi:
I see there an ERROR on stopMonitoringDomain but I cannot see the correspondent startMonitoringDomain; could you please look for it?
On Fri, Feb 3, 2017 at 1:16 PM, Ralf Schenk <rs@databay.de> wrote:
Hello,
attached is my vdsm.log from the host with hosted-engine-ha around the time-frame of agent timeout that is not working anymore for engine (it works in Ovirt and is active). It simply isn't working for engine-ha anymore after Update.
At 2017-02-02 19:25:34,248 you'll find an error corresponoding to agent timeout error.
Bye
Am 03.02.2017 um 11:28 schrieb Simone Tiraboschi:
3. Three of my hosts have the hosted engine deployed for ha. First all
three where marked by a crown (running was gold and others where silver). After upgrading the 3 Host deployed hosted engine ha is not active anymore.
I can't get this host back with working ovirt-ha-agent/broker. I already rebooted, manually restarted the services but It isn't able to get cluster state according to "hosted-engine --vm-status". The other hosts state the host status as "unknown stale-data"
I already shut down all agents on all hosts and issued a "hosted-engine --reinitialize-lockspace" but that didn't help.
Agents stops working after a timeout-error according to log:
MainThread::INFO::2017-02-02 19:24:52,040::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:24:59,185::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:06,333::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:13,554::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:20,710::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:27,865::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::8 15::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_initialize_domain_monitor) Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine::4 69::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Error while monitoring engine: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine::4 72::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Unexpected error Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 443, in start_monitoring self._initialize_domain_monitor() File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 816, in _initialize_domain_monitor raise Exception(msg) Exception: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::4 85::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Shutting down the agent because of 3 failures in a row! MainThread::INFO::2017-02-02 19:25:32,087::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:34,250::hosted_engine::7 69::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_stop_domain_monitor) Failed to stop monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96): Storage domain is member of pool: u'domain=7c8deaa8-be02-4aaf-b9 b4-ddc8da99ad96' MainThread::INFO::2017-02-02 19:25:34,254::agent::143::ovir t_hosted_engine_ha.agent.agent.Agent::(run) Agent shutting down
Simone, Martin, can you please follow up on this?
Ralph, could you please attach vdsm logs from on of your hosts for the relevant time frame?
--
*Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 <+49%202405%20408370> fax +49 (0) 24 05 / 40 83 759 <+49%202405%204083759> mail *rs@databay.de* <rs@databay.de>
*Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de>
Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen ------------------------------
--
*Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 <+49%202405%20408370> fax +49 (0) 24 05 / 40 83 759 <+49%202405%204083759> mail *rs@databay.de* <rs@databay.de>
*Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de>
Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen ------------------------------
--
*Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 <+49%202405%20408370> fax +49 (0) 24 05 / 40 83 759 <+49%202405%204083759> mail *rs@databay.de* <rs@databay.de>
*Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de>
Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen ------------------------------
{kind=link}
{kind=link}
{kind=link}
On Fri, Feb 3, 2017 at 7:20 PM, Simone Tiraboschi <stirabos@redhat.com> wrote:
On Fri, Feb 3, 2017 at 5:22 PM, Ralf Schenk <rs@databay.de> wrote:
Hello,
of course:
[root@microcloud27 mnt]# sanlock client status daemon 8a93c9ea-e242-408c-a63d-a9356bb22df5.microcloud p -1 helper p -1 listener p -1 status
sanlock.log attached. (Beginning 2017-01-27 where everything was fine)
Thanks, the issue is here:
2017-02-02 19:01:22+0100 4848 [1048]: s36 lockspace 7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96:3:/rhev/data-center/mnt/glusterSD/glusterfs.rxmgmt.databay.de:_engine/7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96/dom_md/ids:0 2017-02-02 19:03:42+0100 4988 [12983]: s36 delta_acquire host_id 3 busy1 3 15 13129 7ad427b1-fbb6-4cee-b9ee-01f596fddfbb.microcloud 2017-02-02 19:03:43+0100 4989 [1048]: s36 add_lockspace fail result -262
Could you please check if you have other hosts contending for the same ID (id=3 in this case).
Another option is to manually force a sanlock renewal on that host and check what happens, something like: sanlock client renewal -s 7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96:3:/rhev/data- center/mnt/glusterSD/glusterfs.rxmgmt.databay.de:_engine/7c8deaa8-be02-4aaf- b9b4-ddc8da99ad96/dom_md/ids:0
Bye
Am 03.02.2017 um 16:12 schrieb Simone Tiraboschi:
The hosted-engine storage domain is mounted for sure, but the issue is here: Exception: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition
The point is that in VDSM logs I see just something like: 2017-02-02 21:05:22,283 INFO (jsonrpc/1) [dispatcher] Run and protect: repoStats(options=None) (logUtils:49) 2017-02-02 21:05:22,285 INFO (jsonrpc/1) [dispatcher] Run and protect: repoStats, Return response: {u'a7fbaaad-7043-4391-9523-3bedcdc4fb0d': {'code': 0, 'actual': True, 'version': 0, 'acquired': True, 'delay': '0.000748727', 'lastCheck': '0.1', 'valid': True}, u'2b2a44fc-f2bd-47cd-b7af-00be59e30a35': {'code': 0, 'actual': True, 'version': 0, 'acquired': True, 'delay': '0.00082529', 'lastCheck': '0.1', 'valid': True}, u'5d99af76-33b5-47d8-99da-1f32413c7bb0': {'code': 0, 'actual': True, 'version': 4, 'acquired': True, 'delay': '0.000349356', 'lastCheck': '5.3', 'valid': True}, u'7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96': {'code': 0, 'actual': True, 'version': 4, 'acquired': False, 'delay': '0.000377052', 'lastCheck': '0.6', 'valid': True}} (logUtils:52)
Where the other storage domains have 'acquired': True whil it's always 'acquired': False for the hosted-engine storage domain.
Could you please share your /var/log/sanlock.log from the same host and the output of sanlock client status ?
On Fri, Feb 3, 2017 at 3:52 PM, Ralf Schenk <rs@databay.de> wrote:
Hello,
I also put host in Maintenance and restarted vdsm while ovirt-ha-agent is running. I can mount the gluster Volume "engine" manually in the host.
I get this repeatedly in /var/log/vdsm.log:
2017-02-03 15:29:28,891 INFO (MainThread) [vds] Exiting (vdsm:167) 2017-02-03 15:29:30,974 INFO (MainThread) [vds] (PID: 11456) I am the actual vdsm 4.19.4-1.el7.centos microcloud27 (3.10.0-514.6.1.el7.x86_64) (vdsm:145) 2017-02-03 15:29:30,974 INFO (MainThread) [vds] VDSM will run with cpu affinity: frozenset([1]) (vdsm:251) 2017-02-03 15:29:31,013 INFO (MainThread) [storage.check] Starting check service (check:91) 2017-02-03 15:29:31,017 INFO (MainThread) [storage.Dispatcher] Starting StorageDispatcher... (dispatcher:47) 2017-02-03 15:29:31,017 INFO (check/loop) [storage.asyncevent] Starting <EventLoop running=True closed=False at 0x37480464> (asyncevent:122) 2017-02-03 15:29:31,156 INFO (MainThread) [dispatcher] Run and protect: registerDomainStateChangeCallback(callbackFunc=<functools.partial object at 0x2881fc8>) (logUtils:49) 2017-02-03 15:29:31,156 INFO (MainThread) [dispatcher] Run and protect: registerDomainStateChangeCallback, Return response: None (logUtils:52) 2017-02-03 15:29:31,160 INFO (MainThread) [MOM] Preparing MOM interface (momIF:49) 2017-02-03 15:29:31,161 INFO (MainThread) [MOM] Using named unix socket /var/run/vdsm/mom-vdsm.sock (momIF:58) 2017-02-03 15:29:31,162 INFO (MainThread) [root] Unregistering all secrets (secret:91) 2017-02-03 15:29:31,164 INFO (MainThread) [vds] Setting channels' timeout to 30 seconds. (vmchannels:223) 2017-02-03 15:29:31,165 INFO (MainThread) [vds.MultiProtocolAcceptor] Listening at :::54321 (protocoldetector:185) 2017-02-03 15:29:31,354 INFO (vmrecovery) [vds] recovery: completed in 0s (clientIF:495) 2017-02-03 15:29:31,371 INFO (BindingXMLRPC) [vds] XMLRPC server running (bindingxmlrpc:63) 2017-02-03 15:29:31,471 INFO (periodic/1) [dispatcher] Run and protect: repoStats(options=None) (logUtils:49) 2017-02-03 15:29:31,472 INFO (periodic/1) [dispatcher] Run and protect: repoStats, Return response: {} (logUtils:52) 2017-02-03 15:29:31,472 WARN (periodic/1) [MOM] MOM not available. (momIF:116) 2017-02-03 15:29:31,473 WARN (periodic/1) [MOM] MOM not available, KSM stats will be missing. (momIF:79) 2017-02-03 15:29:31,474 ERROR (periodic/1) [root] failed to retrieve Hosted Engine HA info (api:252) Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/vdsm/host/api.py", line 231, in _getHaInfo stats = instance.get_all_stats() File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/client/client.py", line 103, in get_all_stats self._configure_broker_conn(broker) File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/client/client.py", line 180, in _configure_broker_conn dom_type=dom_type) File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/lib/brokerlink.py", line 177, in set_storage_domain .format(sd_type, options, e)) RequestError: Failed to set storage domain FilesystemBackend, options {'dom_type': 'glusterfs', 'sd_uuid': '7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96'}: Request failed: <class 'ovirt_hos ted_engine_ha.lib.storage_backends.BackendFailureException'> 2017-02-03 15:29:35,920 INFO (Reactor thread) [ProtocolDetector.AcceptorImpl] Accepted connection from ::1:49506 (protocoldetector:72) 2017-02-03 15:29:35,929 INFO (Reactor thread) [ProtocolDetector.Detector] Detected protocol stomp from ::1:49506 (protocoldetector:127) 2017-02-03 15:29:35,930 INFO (Reactor thread) [Broker.StompAdapter] Processing CONNECT request (stompreactor:102) 2017-02-03 15:29:35,930 INFO (JsonRpc (StompReactor)) [Broker.StompAdapter] Subscribe command received (stompreactor:129) 2017-02-03 15:29:36,067 INFO (jsonrpc/0) [jsonrpc.JsonRpcServer] RPC call Host.ping succeeded in 0.00 seconds (__init__:515) 2017-02-03 15:29:36,071 INFO (jsonrpc/1) [throttled] Current getAllVmStats: {} (throttledlog:105) 2017-02-03 15:29:36,071 INFO (jsonrpc/1) [jsonrpc.JsonRpcServer] RPC call Host.getAllVmStats succeeded in 0.00 seconds (__init__:515) 2017-02-03 15:29:46,435 INFO (periodic/0) [dispatcher] Run and protect: repoStats(options=None) (logUtils:49) 2017-02-03 15:29:46,435 INFO (periodic/0) [dispatcher] Run and protect: repoStats, Return response: {} (logUtils:52) 2017-02-03 15:29:46,439 ERROR (periodic/0) [root] failed to retrieve Hosted Engine HA info (api:252) Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/vdsm/host/api.py", line 231, in _getHaInfo stats = instance.get_all_stats() File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/client/client.py", line 103, in get_all_stats self._configure_broker_conn(broker) File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/client/client.py", line 180, in _configure_broker_conn dom_type=dom_type) File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/lib/brokerlink.py", line 177, in set_storage_domain .format(sd_type, options, e)) RequestError: Failed to set storage domain FilesystemBackend, options {'dom_type': 'glusterfs', 'sd_uuid': '7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96'}: Request failed: <class 'ovirt_hos ted_engine_ha.lib.storage_backends.BackendFailureException'> 2017-02-03 15:29:51,095 INFO (jsonrpc/2) [jsonrpc.JsonRpcServer] RPC call Host.getAllVmStats succeeded in 0.00 seconds (__init__:515) 2017-02-03 15:29:51,219 INFO (jsonrpc/3) [jsonrpc.JsonRpcServer] RPC call Host.setKsmTune succeeded in 0.00 seconds (__init__:515) 2017-02-03 15:30:01,444 INFO (periodic/1) [dispatcher] Run and protect: repoStats(options=None) (logUtils:49) 2017-02-03 15:30:01,444 INFO (periodic/1) [dispatcher] Run and protect: repoStats, Return response: {} (logUtils:52) 2017-02-03 15:30:01,448 ERROR (periodic/1) [root] failed to retrieve Hosted Engine HA info (api:252)
Am 03.02.2017 um 13:39 schrieb Simone Tiraboschi:
I see there an ERROR on stopMonitoringDomain but I cannot see the correspondent startMonitoringDomain; could you please look for it?
On Fri, Feb 3, 2017 at 1:16 PM, Ralf Schenk <rs@databay.de> wrote:
Hello,
attached is my vdsm.log from the host with hosted-engine-ha around the time-frame of agent timeout that is not working anymore for engine (it works in Ovirt and is active). It simply isn't working for engine-ha anymore after Update.
At 2017-02-02 19:25:34,248 you'll find an error corresponoding to agent timeout error.
Bye
Am 03.02.2017 um 11:28 schrieb Simone Tiraboschi:
3. Three of my hosts have the hosted engine deployed for ha. First all
three where marked by a crown (running was gold and others where silver). After upgrading the 3 Host deployed hosted engine ha is not active anymore.
I can't get this host back with working ovirt-ha-agent/broker. I already rebooted, manually restarted the services but It isn't able to get cluster state according to "hosted-engine --vm-status". The other hosts state the host status as "unknown stale-data"
I already shut down all agents on all hosts and issued a "hosted-engine --reinitialize-lockspace" but that didn't help.
Agents stops working after a timeout-error according to log:
MainThread::INFO::2017-02-02 19:24:52,040::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:24:59,185::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:06,333::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:13,554::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:20,710::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:27,865::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::8 15::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_initialize_domain_monitor) Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine::4 69::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Error while monitoring engine: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine::4 72::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Unexpected error Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 443, in start_monitoring self._initialize_domain_monitor() File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 816, in _initialize_domain_monitor raise Exception(msg) Exception: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::4 85::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Shutting down the agent because of 3 failures in a row! MainThread::INFO::2017-02-02 19:25:32,087::hosted_engine::8 41::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:34,250::hosted_engine::7 69::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_stop_domain_monitor) Failed to stop monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96): Storage domain is member of pool: u'domain=7c8deaa8-be02-4aaf-b9 b4-ddc8da99ad96' MainThread::INFO::2017-02-02 19:25:34,254::agent::143::ovir t_hosted_engine_ha.agent.agent.Agent::(run) Agent shutting down
Simone, Martin, can you please follow up on this?
Ralph, could you please attach vdsm logs from on of your hosts for the relevant time frame?
--
*Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 <+49%202405%20408370> fax +49 (0) 24 05 / 40 83 759 <+49%202405%204083759> mail *rs@databay.de* <rs@databay.de>
*Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de>
Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen ------------------------------
--
*Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 <+49%202405%20408370> fax +49 (0) 24 05 / 40 83 759 <+49%202405%204083759> mail *rs@databay.de* <rs@databay.de>
*Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de>
Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen ------------------------------
--
*Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 <+49%202405%20408370> fax +49 (0) 24 05 / 40 83 759 <+49%202405%204083759> mail *rs@databay.de* <rs@databay.de>
*Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de>
Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen ------------------------------
{kind=link}
{kind=link}
{kind=link}
This is a multi-part message in MIME format. --------------90504E1C27EE95060580B78B Content-Type: text/plain; charset=utf-8 Content-Transfer-Encoding: quoted-printable Hello, I have set up 3 hosts for engine, 2 of them are working correct. There is no other host even having broker/agent installed. Is it possible that the error occurs because the hosts are multihomed (Management IP, IP for storage) and can communicate with different IP's ? hosted-engine --vm-status on both working hosts seems correct: (3 is out of order...) [root@microcloud21 ~]# hosted-engine --vm-status --=3D=3D Host 1 status =3D=3D-- conf_on_shared_storage : True Status up-to-date : True Hostname : microcloud21.sub.mydomain.de Host ID : 1 Engine status : {"health": "good", "vm": "up", "detail": "up"} Score : 3400 stopped : False Local maintenance : False crc32 : 5941227d local_conf_timestamp : 152316 Host timestamp : 152302 Extra metadata (valid at timestamp): metadata_parse_version=3D1 metadata_feature_version=3D1 timestamp=3D152302 (Sat Feb 4 11:49:29 2017) host-id=3D1 score=3D3400 vm_conf_refresh_time=3D152316 (Sat Feb 4 11:49:43 2017) conf_on_shared_storage=3DTrue maintenance=3DFalse state=3DEngineUp stopped=3DFalse --=3D=3D Host 2 status =3D=3D-- conf_on_shared_storage : True Status up-to-date : True Hostname : microcloud24.sub.mydomain.de Host ID : 2 Engine status : {"reason": "vm not running on this host", "health": "bad", " vm": "down", "detail": "unknown"} Score : 3400 stopped : False Local maintenance : False crc32 : 77e25433 local_conf_timestamp : 157637 Host timestamp : 157623 Extra metadata (valid at timestamp): metadata_parse_version=3D1 metadata_feature_version=3D1 timestamp=3D157623 (Sat Feb 4 11:49:34 2017) host-id=3D2 score=3D3400 vm_conf_refresh_time=3D157637 (Sat Feb 4 11:49:48 2017) conf_on_shared_storage=3DTrue maintenance=3DFalse state=3DEngineDown stopped=3DFalse --=3D=3D Host 3 status =3D=3D-- conf_on_shared_storage : True Status up-to-date : False Hostname : microcloud27.sub.mydomain.de Host ID : 3 Engine status : unknown stale-data Score : 0 stopped : True Local maintenance : False crc32 : 74798986 local_conf_timestamp : 77946 Host timestamp : 77932 Extra metadata (valid at timestamp): metadata_parse_version=3D1 metadata_feature_version=3D1 timestamp=3D77932 (Fri Feb 3 15:19:25 2017) host-id=3D3 score=3D0 vm_conf_refresh_time=3D77946 (Fri Feb 3 15:19:39 2017) conf_on_shared_storage=3DTrue maintenance=3DFalse state=3DAgentStopped stopped=3DTrue Am 03.02.2017 um 19:20 schrieb Simone Tiraboschi:
On Fri, Feb 3, 2017 at 5:22 PM, Ralf Schenk <rs@databay.de <mailto:rs@databay.de>> wrote:
Hello,
of course:
[root@microcloud27 mnt]# sanlock client status daemon 8a93c9ea-e242-408c-a63d-a9356bb22df5.microcloud p -1 helper p -1 listener p -1 status
sanlock.log attached. (Beginning 2017-01-27 where everything was fi=
ne)
Thanks, the issue is here: 2017-02-02 19:01:22+0100 4848 [1048]: s36 lockspace 7c8deaa8-be02-4aaf-=
b9b4-ddc8da99ad96:3:/rhev/data-center/mnt/glusterSD/glusterfs.sub.mydomai= n.de:_engine/7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96/dom_md/ids:0
2017-02-02 19:03:42+0100 4988 [12983]: s36 delta_acquire host_id 3 busy= 1 3 15 13129 7ad427b1-fbb6-4cee-b9ee-01f596fddfbb.microcloud 2017-02-02 19:03:43+0100 4989 [1048]: s36 add_lockspace fail result -26= 2 Could you please check if you have other hosts contending for the same ID (id=3D3 in this case). =20
--=20 *Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 fax +49 (0) 24 05 / 40 83 759 mail *rs@databay.de* <mailto:rs@databay.de> =09 *Databay AG* Jens-Otto-Krag-Stra=C3=9Fe 11 D-52146 W=C3=BCrselen *www.databay.de* <http://www.databay.de> Sitz/Amtsgericht Aachen =E2=80=A2 HRB:8437 =E2=80=A2 USt-IdNr.: DE 210844= 202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Klaus Scholzen (RA) ------------------------------------------------------------------------ --------------90504E1C27EE95060580B78B Content-Type: multipart/related; boundary="------------AADA2BBC8C36F1CE2A14BB50" --------------AADA2BBC8C36F1CE2A14BB50 Content-Type: text/html; charset=utf-8 Content-Transfer-Encoding: 8bit <html> <head> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"> </head> <body bgcolor="#FFFFFF" text="#000000"> <p>Hello,</p> <p>I have set up 3 hosts for engine, 2 of them are working correct. There is no other host even having broker/agent installed. Is it possible that the error occurs because the hosts are multihomed (Management IP, IP for storage) and can communicate with different IP's ?</p> <p>hosted-engine --vm-status on both working hosts seems correct: (3 is out of order...)<br> </p> <p><tt>[root@microcloud21 ~]# hosted-engine --vm-status</tt><tt><br> </tt><tt><br> </tt><tt><br> </tt><tt>--== Host 1 status ==--</tt><tt><br> </tt><tt><br> </tt><tt>conf_on_shared_storage : True</tt><tt><br> </tt><tt>Status up-to-date : True</tt><tt><br> </tt><tt>Hostname : microcloud21.sub.mydomain.de</tt><tt><br> </tt><tt>Host ID : 1</tt><tt><br> </tt><tt>Engine status : {"health": "good", "vm": "up", "detail": "up"}</tt><tt><br> </tt><tt>Score : 3400</tt><tt><br> </tt><tt>stopped : False</tt><tt><br> </tt><tt>Local maintenance : False</tt><tt><br> </tt><tt>crc32 : 5941227d</tt><tt><br> </tt><tt>local_conf_timestamp : 152316</tt><tt><br> </tt><tt>Host timestamp : 152302</tt><tt><br> </tt><tt>Extra metadata (valid at timestamp):</tt><tt><br> </tt><tt> metadata_parse_version=1</tt><tt><br> </tt><tt> metadata_feature_version=1</tt><tt><br> </tt><tt> timestamp=152302 (Sat Feb 4 11:49:29 2017)</tt><tt><br> </tt><tt> host-id=1</tt><tt><br> </tt><tt> score=3400</tt><tt><br> </tt><tt> vm_conf_refresh_time=152316 (Sat Feb 4 11:49:43 2017)</tt><tt><br> </tt><tt> conf_on_shared_storage=True</tt><tt><br> </tt><tt> maintenance=False</tt><tt><br> </tt><tt> state=EngineUp</tt><tt><br> </tt><tt> stopped=False</tt><tt><br> </tt><tt><br> </tt><tt><br> </tt><tt>--== Host 2 status ==--</tt><tt><br> </tt><tt><br> </tt><tt>conf_on_shared_storage : True</tt><tt><br> </tt><tt>Status up-to-date : True</tt><tt><br> </tt><tt>Hostname : microcloud24.sub.mydomain.de</tt><tt><br> </tt><tt>Host ID : 2</tt><tt><br> </tt><tt>Engine status : {"reason": "vm not running on this host", "health": "bad", " vm": "down", "detail": "unknown"}</tt><tt><br> </tt><tt>Score : 3400</tt><tt><br> </tt><tt>stopped : False</tt><tt><br> </tt><tt>Local maintenance : False</tt><tt><br> </tt><tt>crc32 : 77e25433</tt><tt><br> </tt><tt>local_conf_timestamp : 157637</tt><tt><br> </tt><tt>Host timestamp : 157623</tt><tt><br> </tt><tt>Extra metadata (valid at timestamp):</tt><tt><br> </tt><tt> metadata_parse_version=1</tt><tt><br> </tt><tt> metadata_feature_version=1</tt><tt><br> </tt><tt> timestamp=157623 (Sat Feb 4 11:49:34 2017)</tt><tt><br> </tt><tt> host-id=2</tt><tt><br> </tt><tt> score=3400</tt><tt><br> </tt><tt> vm_conf_refresh_time=157637 (Sat Feb 4 11:49:48 2017)</tt><tt><br> </tt><tt> conf_on_shared_storage=True</tt><tt><br> </tt><tt> maintenance=False</tt><tt><br> </tt><tt> state=EngineDown</tt><tt><br> </tt><tt> stopped=False</tt><tt><br> </tt><tt><br> </tt><tt><br> </tt><tt>--== Host 3 status ==--</tt><tt><br> </tt><tt><br> </tt><tt>conf_on_shared_storage : True</tt><tt><br> </tt><tt>Status up-to-date : False</tt><tt><br> </tt><tt>Hostname : microcloud27.sub.mydomain.de</tt><tt><br> </tt><tt>Host ID : 3</tt><tt><br> </tt><tt>Engine status : unknown stale-data</tt><tt><br> </tt><tt>Score : 0</tt><tt><br> </tt><tt>stopped : True</tt><tt><br> </tt><tt>Local maintenance : False</tt><tt><br> </tt><tt>crc32 : 74798986</tt><tt><br> </tt><tt>local_conf_timestamp : 77946</tt><tt><br> </tt><tt>Host timestamp : 77932</tt><tt><br> </tt><tt>Extra metadata (valid at timestamp):</tt><tt><br> </tt><tt> metadata_parse_version=1</tt><tt><br> </tt><tt> metadata_feature_version=1</tt><tt><br> </tt><tt> timestamp=77932 (Fri Feb 3 15:19:25 2017)</tt><tt><br> </tt><tt> host-id=3</tt><tt><br> </tt><tt> score=0</tt><tt><br> </tt><tt> vm_conf_refresh_time=77946 (Fri Feb 3 15:19:39 2017)</tt><tt><br> </tt><tt> conf_on_shared_storage=True</tt><tt><br> </tt><tt> maintenance=False</tt><tt><br> </tt><tt> state=AgentStopped</tt><tt><br> </tt><tt> stopped=True</tt><tt><br> </tt><br> </p> <p>Am 03.02.2017 um 19:20 schrieb Simone Tiraboschi:<br> </p> <blockquote cite="mid:CAN8-ONo3+L+R3iPr1DoS0s8Fn3kZNkekKrP4ipyKPs_e_2jhiQ@mail.gmail.com" type="cite"><br> <div class="gmail_extra"><br> <div class="gmail_quote">On Fri, Feb 3, 2017 at 5:22 PM, Ralf Schenk <span dir="ltr"><<a moz-do-not-send="true" href="mailto:rs@databay.de" target="_blank">rs@databay.de</a>></span> wrote:<br> <blockquote class="gmail_quote" style="margin:0px 0px 0px 0.8ex;border-left:1px solid rgb(204,204,204);padding-left:1ex"> <div bgcolor="#FFFFFF"> <p>Hello,</p> <p>of course:</p> <p>[root@microcloud27 mnt]# sanlock client status<br> daemon 8a93c9ea-e242-408c-a63d-<wbr>a9356bb22df5.microcloud<br> p -1 helper<br> p -1 listener<br> p -1 status<br> </p> <p>sanlock.log attached. (Beginning 2017-01-27 where everything was fine)</p> </div> </blockquote> Thanks, the issue is here: <div> <pre class="gmail-aLF-aPX-K0-aPE gmail-aLF-aPX-aLK-ayr-auR">2017-02-02 19:01:22+0100 4848 [1048]: s36 lockspace 7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96:3:/rhev/data-center/mnt/glusterSD/glusterfs.sub.mydomain.de:_engine/7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96/dom_md/ids:0 2017-02-02 19:03:42+0100 4988 [12983]: s36 delta_acquire host_id 3 busy1 3 15 13129 7ad427b1-fbb6-4cee-b9ee-01f596fddfbb.microcloud 2017-02-02 19:03:43+0100 4989 [1048]: s36 add_lockspace fail result -262</pre> </div> <div>Could you please check if you have other hosts contending for the same ID (id=3 in this case).</div> <div> </div> </div> </div> </blockquote> <br> <div class="moz-signature">-- <br> <p> </p> <table border="0" cellpadding="0" cellspacing="0"> <tbody> <tr> <td colspan="3"> <img title="" alt="" src="cid:part2.0624039A.C0EFA82C@databay.de" height="30" border="0" width="151"> </td> </tr> <tr> <td valign="top"> <font face="Verdana, Arial, sans-serif" size="-1"><br> <b>Ralf Schenk</b><br> fon +49 (0) 24 05 / 40 83 70<br> fax +49 (0) 24 05 / 40 83 759<br> mail <a href="mailto:rs@databay.de"><font color="#FF0000"><b>rs@databay.de</b></font></a><br> </font> </td> <td width="30"> </td> <td valign="top"> <font face="Verdana, Arial, sans-serif" size="-1"><br> <b>Databay AG</b><br> Jens-Otto-Krag-Straße 11<br> D-52146 Würselen<br> <a href="http://www.databay.de"><font color="#FF0000"><b>www.databay.de</b></font></a> </font> </td> </tr> <tr> <td colspan="3" valign="top"> <font face="Verdana, Arial, sans-serif" size="1"><br> Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202<br> Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns<br> Aufsichtsratsvorsitzender: Klaus Scholzen (RA) </font> </td> </tr> </tbody> </table> <hr color="#000000" noshade="noshade" size="1" width="100%"> </div> </body> </html> --------------AADA2BBC8C36F1CE2A14BB50 Content-Type: image/gif; name="mgphgcckibnbbilh.gif" Content-Transfer-Encoding: base64 Content-ID: <part2.0624039A.C0EFA82C@databay.de> Content-Disposition: inline; filename="mgphgcckibnbbilh.gif" R0lGODlhlwAeAMQAAObm5v9QVf/R0oKBgfDw8NfX105MTLi3t/r6+sfHx/+rrf98gC0sLP8L EhIQEKalpf/g4ZmYmHd2dmppaf8uNP/y8v8cIv+Ym//AwkE/P46NjRwbG11cXP8ABwUDA/// /yH5BAAAAAAALAAAAACXAB4AAAX/4CeOYnUJZKqubOu+cCzPNA0tVnfVfO//wGAKk+t0Ap+K QMFUYCDCqHRKJVUWDaPRUsFktZ1G4AKtms9o1gKsFVS+7I5ll67bpd647hPQawNld4KDMQJF bA07F35aFBiEkJEpfXEBjx8KjI0Vkp2DEIdaCySgFBShbEgrCQOtrq+uEQcALQewrQUjEbe8 rgkkD7y5KhMZB3drqSoVFQhdlHGXKQYe1dbX2BvHKwzY1RMiAN7j1xEjBeTmKeIeD3cYCxRf FigvChRxFJwkBBvk5A7cpZhAjgGCDwn+kfslgto4CSoSehh2BwEEBQvowDAUR0EKdArHZTg4 4oDCXBFC/3qj9SEluZEpHnjYQFIGgpo1KgSasYjNKBImrzF4NaFbNgIjCGRQeIyVKwneOLzS cLCAg38OWI4Y4GECgQcSOEwYcADnh6/FNjAwoGFYAQ0atI4AAFeEFwsLFLiJUQEfGH0kNGAD x8+oNQdIRQg+7NCaOhIgD8sVgYADNsPVGI5YWjRqzQTdHDDIYHRDLokaUhCglkFEJi0NKJhl 0RP2TsvXUg88KiLBVWsZrF6DmMKlNYMqglqTik1guN8OBgAgkGCpB+L9ugK4iSCBvwEfECw1 kILrBpa1jVCQIQBRvbP+rlEcQVAoSevWyv6uhpwE12uEkQAAZucpVw1xIsjkgf8B863mQVYt eQATCZYJZJ5WBfij2wfpHcEeHGG8Z+BMszVWDXkfKLhceJhBSAJ+1ThH32AfRFZNayNAtUFi wFSTSwEHJIYAAQU84IADwyjIEALU9MchG+vFgIF7W2GDI2T7HfjBgNcgKQKMHmwjgnCSpeCb ULRkdxhF1CDY40RjgmUAA/v1J5FAKW2gGSZscBFDMraNgJs1AYpAAGYP5jJoNQ4Y4Gh8jpFg HH9mgbmWo1l6oA4C3Ygp6UwEIFBfNRtkMIBlKMLnAXgAXLWhXXH85EIFqMhGGZgDEKArABGA ed0HI4bk5qgnprCYSt88B6dqS0FEEAMPJDCdCJYViur/B1BlwGMJqDTwnhqxJgUpo0ceOQ4D 0yEakpMm/jqCRMgWm2I1j824Y6vLvuuPjHnqOJkIgP6xzwp5sCFNsCFp88Gxh11lrjfDcNrc CEx64/CD3iAHlQcMUEQXvcA+qBkBB4Q2X1CusjBlJdKMYAKI6g28MbKN5hJsBAXknHOwutn4 oFYqkpqAzjnPbE0u1PxmwAQGXLWBbvhuIIEGEnRjlAHO4SvhbCNAkwoGzEBwgV9U0lfu2WiX OkDEGaCdKgl0nk2YkWdPOCDabvaGdkAftL1LlgwCM+7Tq11V71IO7LkM2XE0YAHMYMhqqK6U V165CpaHukLmiXFO8XSVzzakX+UH6TrmAajPNxfqByTQec41AeBPvSwIALkmAnuiexCsca3C BajgfsROuxcPA8kHQJX4DAIwjnsAvhsvfXHWKEwDAljg7sj03L9wwAQTxOWD2AE0YP75eCkw cPfs+xACADs= --------------AADA2BBC8C36F1CE2A14BB50-- --------------90504E1C27EE95060580B78B--
On Sat, Feb 4, 2017 at 11:52 AM, Ralf Schenk <rs@databay.de> wrote:
Hello,
I have set up 3 hosts for engine, 2 of them are working correct. There is no other host even having broker/agent installed. Is it possible that the error occurs because the hosts are multihomed (Management IP, IP for storage) and can communicate with different IP's ?
Having multiple logical networks for storage, management and so on is a good practice and it's advised so I tend to exclude any issue there. The point is why your microcloud27.sub.mydomain.de fails acquiring a lock as host 3. Probably the simplest fix is just setting it in maintenance mode from the engine, removing it and deploying it from the engine as an hosted engine host again.
hosted-engine --vm-status on both working hosts seems correct: (3 is out of order...)
[root@microcloud21 ~]# hosted-engine --vm-status
--== Host 1 status ==--
conf_on_shared_storage : True Status up-to-date : True Hostname : microcloud21.sub.mydomain.de Host ID : 1 Engine status : {"health": "good", "vm": "up", "detail": "up"} Score : 3400 stopped : False Local maintenance : False crc32 : 5941227d local_conf_timestamp : 152316 Host timestamp : 152302 Extra metadata (valid at timestamp): metadata_parse_version=1 metadata_feature_version=1 timestamp=152302 (Sat Feb 4 11:49:29 2017) host-id=1 score=3400 vm_conf_refresh_time=152316 (Sat Feb 4 11:49:43 2017) conf_on_shared_storage=True maintenance=False state=EngineUp stopped=False
--== Host 2 status ==--
conf_on_shared_storage : True Status up-to-date : True Hostname : microcloud24.sub.mydomain.de Host ID : 2 Engine status : {"reason": "vm not running on this host", "health": "bad", " vm": "down", "detail": "unknown"} Score : 3400 stopped : False Local maintenance : False crc32 : 77e25433 local_conf_timestamp : 157637 Host timestamp : 157623 Extra metadata (valid at timestamp): metadata_parse_version=1 metadata_feature_version=1 timestamp=157623 (Sat Feb 4 11:49:34 2017) host-id=2 score=3400 vm_conf_refresh_time=157637 (Sat Feb 4 11:49:48 2017) conf_on_shared_storage=True maintenance=False state=EngineDown stopped=False
--== Host 3 status ==--
conf_on_shared_storage : True Status up-to-date : False Hostname : microcloud27.sub.mydomain.de Host ID : 3 Engine status : unknown stale-data Score : 0 stopped : True Local maintenance : False crc32 : 74798986 local_conf_timestamp : 77946 Host timestamp : 77932 Extra metadata (valid at timestamp): metadata_parse_version=1 metadata_feature_version=1 timestamp=77932 (Fri Feb 3 15:19:25 2017) host-id=3 score=0 vm_conf_refresh_time=77946 (Fri Feb 3 15:19:39 2017) conf_on_shared_storage=True maintenance=False state=AgentStopped stopped=True
Am 03.02.2017 um 19:20 schrieb Simone Tiraboschi:
On Fri, Feb 3, 2017 at 5:22 PM, Ralf Schenk <rs@databay.de> wrote:
Hello,
of course:
[root@microcloud27 mnt]# sanlock client status daemon 8a93c9ea-e242-408c-a63d-a9356bb22df5.microcloud p -1 helper p -1 listener p -1 status
sanlock.log attached. (Beginning 2017-01-27 where everything was fine)
Thanks, the issue is here:
2017-02-02 19:01:22+0100 4848 [1048]: s36 lockspace 7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96:3:/rhev/data-center/mnt/glusterSD/glusterfs.sub.mydomain.de:_engine/7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96/dom_md/ids:0 2017-02-02 19:03:42+0100 4988 [12983]: s36 delta_acquire host_id 3 busy1 3 15 13129 7ad427b1-fbb6-4cee-b9ee-01f596fddfbb.microcloud 2017-02-02 19:03:43+0100 4989 [1048]: s36 add_lockspace fail result -262
Could you please check if you have other hosts contending for the same ID (id=3 in this case).
--
*Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 <+49%202405%20408370> fax +49 (0) 24 05 / 40 83 759 <+49%202405%204083759> mail *rs@databay.de* <rs@databay.de>
*Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de>
Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Klaus Scholzen (RA) ------------------------------
{kind=link}
This is a multi-part message in MIME format. --------------7E35F36C91621B0CB49DBF4C Content-Type: text/plain; charset=utf-8 Content-Transfer-Encoding: 8bit Hello, I set the host to maintenance mode and tried to undeploy engine via GUI. The action in GUI doesn't show an error but afterwards it still shows only "Undeploy" on hosted-engine tab od the host. Even removing the host from the cluster doesn't work because the GUI says "The hosts maekred with * still have hosted engine deployed on them. Hosted engine should be undeployed before they are removed" Bye Am 06.02.2017 um 11:44 schrieb Simone Tiraboschi:
On Sat, Feb 4, 2017 at 11:52 AM, Ralf Schenk <rs@databay.de <mailto:rs@databay.de>> wrote:
Hello,
I have set up 3 hosts for engine, 2 of them are working correct. There is no other host even having broker/agent installed. Is it possible that the error occurs because the hosts are multihomed (Management IP, IP for storage) and can communicate with different IP's ?
Having multiple logical networks for storage, management and so on is a good practice and it's advised so I tend to exclude any issue there. The point is why your microcloud27.sub.mydomain.de <http://microcloud27.sub.mydomain.de> fails acquiring a lock as host 3. Probably the simplest fix is just setting it in maintenance mode from the engine, removing it and deploying it from the engine as an hosted engine host again.
-- *Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 fax +49 (0) 24 05 / 40 83 759 mail *rs@databay.de* <mailto:rs@databay.de> *Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de> Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen ------------------------------------------------------------------------ --------------7E35F36C91621B0CB49DBF4C Content-Type: multipart/related; boundary="------------0017E5EF4F580628EEC018F2" --------------0017E5EF4F580628EEC018F2 Content-Type: text/html; charset=utf-8 Content-Transfer-Encoding: 8bit <html> <head> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"> </head> <body bgcolor="#FFFFFF" text="#000000"> <p>Hello,</p> <p>I set the host to maintenance mode and tried to undeploy engine via GUI. The action in GUI doesn't show an error but afterwards it still shows only "Undeploy" on hosted-engine tab od the host.<br> </p> <p>Even removing the host from the cluster doesn't work because the GUI says "The hosts maekred with * still have hosted engine deployed on them. Hosted engine should be undeployed before they are removed"<br> </p> Bye<br> <div class="moz-cite-prefix">Am 06.02.2017 um 11:44 schrieb Simone Tiraboschi:<br> </div> <blockquote cite="mid:CAN8-ONop9GtYVqKv-5Npz=_q4uEpcGT9pQSWJxK1kYym8SXJ8Q@mail.gmail.com" type="cite"><br> <div class="gmail_extra"><br> <div class="gmail_quote">On Sat, Feb 4, 2017 at 11:52 AM, Ralf Schenk <span dir="ltr"><<a moz-do-not-send="true" href="mailto:rs@databay.de" target="_blank">rs@databay.de</a>></span> wrote:<br> <blockquote class="gmail_quote" style="margin:0px 0px 0px 0.8ex;border-left:1px solid rgb(204,204,204);padding-left:1ex"> <div bgcolor="#FFFFFF"> <p>Hello,</p> <p>I have set up 3 hosts for engine, 2 of them are working correct. There is no other host even having broker/agent installed. Is it possible that the error occurs because the hosts are multihomed (Management IP, IP for storage) and can communicate with different IP's ?</p> </div> </blockquote> <div>Having multiple logical networks for storage, management and so on is a good practice and it's advised so I tend to exclude any issue there.</div> <div>The point is why your <a moz-do-not-send="true" href="http://microcloud27.sub.mydomain.de">microcloud27.sub.mydomain.de</a> fails acquiring a lock as host 3.</div> <div>Probably the simplest fix is just setting it in maintenance mode from the engine, removing it and deploying it from the engine as an hosted engine host again. </div> <div><br> </div> <div> </div> </div> </div> </blockquote> <br> <div class="moz-signature">-- <br> <p> </p> <table border="0" cellpadding="0" cellspacing="0"> <tbody> <tr> <td colspan="3"><img src="cid:part3.4D06A38B.94E38946@databay.de" height="30" border="0" width="151"></td> </tr> <tr> <td valign="top"> <font face="Verdana, Arial, sans-serif" size="-1"><br> <b>Ralf Schenk</b><br> fon +49 (0) 24 05 / 40 83 70<br> fax +49 (0) 24 05 / 40 83 759<br> mail <a href="mailto:rs@databay.de"><font color="#FF0000"><b>rs@databay.de</b></font></a><br> </font> </td> <td width="30"> </td> <td valign="top"> <font face="Verdana, Arial, sans-serif" size="-1"><br> <b>Databay AG</b><br> Jens-Otto-Krag-Straße 11<br> D-52146 Würselen<br> <a href="http://www.databay.de"><font color="#FF0000"><b>www.databay.de</b></font></a> </font> </td> </tr> <tr> <td colspan="3" valign="top"> <font face="Verdana, Arial, sans-serif" size="1"><br> Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202<br> Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns<br> Aufsichtsratsvorsitzender: Wilhelm Dohmen </font> </td> </tr> </tbody> </table> <hr color="#000000" noshade="noshade" size="1" width="100%"> </div> </body> </html> --------------0017E5EF4F580628EEC018F2 Content-Type: image/gif; name="logo_databay_email.gif" Content-Transfer-Encoding: base64 Content-ID: <part3.4D06A38B.94E38946@databay.de> Content-Disposition: inline; filename="logo_databay_email.gif" R0lGODlhlwAeAMQAAObm5v9QVf/R0oKBgfDw8NfX105MTLi3t/r6+sfHx/+rrf98gC0sLP8L EhIQEKalpf/g4ZmYmHd2dmppaf8uNP/y8v8cIv+Ym//AwkE/P46NjRwbG11cXP8ABwUDA/// /yH5BAAAAAAALAAAAACXAB4AAAX/4CeOYnUJZKqubOu+cCzPNA0tVnfVfO//wGAKk+t0Ap+K QMFUYCDCqHRKJVUWDaPRUsFktZ1G4AKtms9o1gKsFVS+7I5ll67bpd647hPQawNld4KDMQJF bA07F35aFBiEkJEpfXEBjx8KjI0Vkp2DEIdaCySgFBShbEgrCQOtrq+uEQcALQewrQUjEbe8 rgkkD7y5KhMZB3drqSoVFQhdlHGXKQYe1dbX2BvHKwzY1RMiAN7j1xEjBeTmKeIeD3cYCxRf FigvChRxFJwkBBvk5A7cpZhAjgGCDwn+kfslgto4CSoSehh2BwEEBQvowDAUR0EKdArHZTg4 4oDCXBFC/3qj9SEluZEpHnjYQFIGgpo1KgSasYjNKBImrzF4NaFbNgIjCGRQeIyVKwneOLzS cLCAg38OWI4Y4GECgQcSOEwYcADnh6/FNjAwoGFYAQ0atI4AAFeEFwsLFLiJUQEfGH0kNGAD x8+oNQdIRQg+7NCaOhIgD8sVgYADNsPVGI5YWjRqzQTdHDDIYHRDLokaUhCglkFEJi0NKJhl 0RP2TsvXUg88KiLBVWsZrF6DmMKlNYMqglqTik1guN8OBgAgkGCpB+L9ugK4iSCBvwEfECw1 kILrBpa1jVCQIQBRvbP+rlEcQVAoSevWyv6uhpwE12uEkQAAZucpVw1xIsjkgf8B863mQVYt eQATCZYJZJ5WBfij2wfpHcEeHGG8Z+BMszVWDXkfKLhceJhBSAJ+1ThH32AfRFZNayNAtUFi wFSTSwEHJIYAAQU84IADwyjIEALU9MchG+vFgIF7W2GDI2T7HfjBgNcgKQKMHmwjgnCSpeCb ULRkdxhF1CDY40RjgmUAA/v1J5FAKW2gGSZscBFDMraNgJs1AYpAAGYP5jJoNQ4Y4Gh8jpFg HH9mgbmWo1l6oA4C3Ygp6UwEIFBfNRtkMIBlKMLnAXgAXLWhXXH85EIFqMhGGZgDEKArABGA ed0HI4bk5qgnprCYSt88B6dqS0FEEAMPJDCdCJYViur/B1BlwGMJqDTwnhqxJgUpo0ceOQ4D 0yEakpMm/jqCRMgWm2I1j824Y6vLvuuPjHnqOJkIgP6xzwp5sCFNsCFp88Gxh11lrjfDcNrc CEx64/CD3iAHlQcMUEQXvcA+qBkBB4Q2X1CusjBlJdKMYAKI6g28MbKN5hJsBAXknHOwutn4 oFYqkpqAzjnPbE0u1PxmwAQGXLWBbvhuIIEGEnRjlAHO4SvhbCNAkwoGzEBwgV9U0lfu2WiX OkDEGaCdKgl0nk2YkWdPOCDabvaGdkAftL1LlgwCM+7Tq11V71IO7LkM2XE0YAHMYMhqqK6U V165CpaHukLmiXFO8XSVzzakX+UH6TrmAajPNxfqByTQec41AeBPvSwIALkmAnuiexCsca3C BajgfsROuxcPA8kHQJX4DAIwjnsAvhsvfXHWKEwDAljg7sj03L9wwAQTxOWD2AE0YP75eCkw cPfs+xACADs= --------------0017E5EF4F580628EEC018F2-- --------------7E35F36C91621B0CB49DBF4C--
On Mon, Feb 6, 2017 at 12:42 PM, Ralf Schenk <rs@databay.de> wrote:
Hello,
I set the host to maintenance mode and tried to undeploy engine via GUI. The action in GUI doesn't show an error but afterwards it still shows only "Undeploy" on hosted-engine tab od the host.
Even removing the host from the cluster doesn't work because the GUI says "The hosts maekred with * still have hosted engine deployed on them. Hosted engine should be undeployed before they are removed"
Yes, sorry: it's now a two step process, you have first to undeploy hosted-engine from the host and only then you could remove the host.
Bye Am 06.02.2017 um 11:44 schrieb Simone Tiraboschi:
On Sat, Feb 4, 2017 at 11:52 AM, Ralf Schenk <rs@databay.de> wrote:
Hello,
I have set up 3 hosts for engine, 2 of them are working correct. There is no other host even having broker/agent installed. Is it possible that the error occurs because the hosts are multihomed (Management IP, IP for storage) and can communicate with different IP's ?
Having multiple logical networks for storage, management and so on is a good practice and it's advised so I tend to exclude any issue there. The point is why your microcloud27.sub.mydomain.de fails acquiring a lock as host 3. Probably the simplest fix is just setting it in maintenance mode from the engine, removing it and deploying it from the engine as an hosted engine host again.
--
*Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 <+49%202405%20408370> fax +49 (0) 24 05 / 40 83 759 <+49%202405%204083759> mail *rs@databay.de* <rs@databay.de>
*Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de>
Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen ------------------------------
{kind=link}
This is a multi-part message in MIME format. --------------96FA69B8CD47AF632DE93ACC Content-Type: text/plain; charset=utf-8 Content-Transfer-Encoding: 8bit Yes, but neither is working... Am 06.02.2017 um 13:33 schrieb Simone Tiraboschi:
On Mon, Feb 6, 2017 at 12:42 PM, Ralf Schenk <rs@databay.de <mailto:rs@databay.de>> wrote:
Hello,
I set the host to maintenance mode and tried to undeploy engine via GUI. The action in GUI doesn't show an error but afterwards it still shows only "Undeploy" on hosted-engine tab od the host.
Even removing the host from the cluster doesn't work because the GUI says "The hosts maekred with * still have hosted engine deployed on them. Hosted engine should be undeployed before they are removed"
Yes, sorry: it's now a two step process, you have first to undeploy hosted-engine from the host and only then you could remove the host.
-- *Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 fax +49 (0) 24 05 / 40 83 759 mail *rs@databay.de* <mailto:rs@databay.de> *Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de> Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen ------------------------------------------------------------------------ --------------96FA69B8CD47AF632DE93ACC Content-Type: multipart/related; boundary="------------686754961B51EFCBA94B03FA" --------------686754961B51EFCBA94B03FA Content-Type: text/html; charset=utf-8 Content-Transfer-Encoding: 8bit <html> <head> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"> </head> <body bgcolor="#FFFFFF" text="#000000"> <p>Yes, but neither is working...</p> <br> <div class="moz-cite-prefix">Am 06.02.2017 um 13:33 schrieb Simone Tiraboschi:<br> </div> <blockquote cite="mid:CAN8-ONpBXVQH7-ujtm4Fm_Vs0DLcMPHecSQGoHjtX2C2TuANGA@mail.gmail.com" type="cite">On Mon, Feb 6, 2017 at 12:42 PM, Ralf Schenk <span dir="ltr"><<a moz-do-not-send="true" href="mailto:rs@databay.de" target="_blank">rs@databay.de</a>></span> wrote:<br> <blockquote class="gmail_quote" style="margin:0 0 0 .8ex;border-left:1px #ccc solid;padding-left:1ex"> <div bgcolor="#FFFFFF" text="#000000"> <p>Hello,</p> <p>I set the host to maintenance mode and tried to undeploy engine via GUI. The action in GUI doesn't show an error but afterwards it still shows only "Undeploy" on hosted-engine tab od the host.<br> </p> <p>Even removing the host from the cluster doesn't work because the GUI says "The hosts maekred with * still have hosted engine deployed on them. Hosted engine should be undeployed before they are removed"<br> </p> </div> </blockquote> <div>Yes, sorry: it's now a two step process, you have first to undeploy hosted-engine from the host and only then you could remove the host.</div> <div><br> </div> </blockquote> <br> <div class="moz-signature">-- <br> <p> </p> <table border="0" cellpadding="0" cellspacing="0"> <tbody> <tr> <td colspan="3"><img src="cid:part2.27170889.1D2C3CA8@databay.de" height="30" border="0" width="151"></td> </tr> <tr> <td valign="top"> <font face="Verdana, Arial, sans-serif" size="-1"><br> <b>Ralf Schenk</b><br> fon +49 (0) 24 05 / 40 83 70<br> fax +49 (0) 24 05 / 40 83 759<br> mail <a href="mailto:rs@databay.de"><font color="#FF0000"><b>rs@databay.de</b></font></a><br> </font> </td> <td width="30"> </td> <td valign="top"> <font face="Verdana, Arial, sans-serif" size="-1"><br> <b>Databay AG</b><br> Jens-Otto-Krag-Straße 11<br> D-52146 Würselen<br> <a href="http://www.databay.de"><font color="#FF0000"><b>www.databay.de</b></font></a> </font> </td> </tr> <tr> <td colspan="3" valign="top"> <font face="Verdana, Arial, sans-serif" size="1"><br> Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202<br> Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns<br> Aufsichtsratsvorsitzender: Wilhelm Dohmen </font> </td> </tr> </tbody> </table> <hr color="#000000" noshade="noshade" size="1" width="100%"> </div> </body> </html> --------------686754961B51EFCBA94B03FA Content-Type: image/gif; name="logo_databay_email.gif" Content-Transfer-Encoding: base64 Content-ID: <part2.27170889.1D2C3CA8@databay.de> Content-Disposition: inline; filename="logo_databay_email.gif" R0lGODlhlwAeAMQAAObm5v9QVf/R0oKBgfDw8NfX105MTLi3t/r6+sfHx/+rrf98gC0sLP8L EhIQEKalpf/g4ZmYmHd2dmppaf8uNP/y8v8cIv+Ym//AwkE/P46NjRwbG11cXP8ABwUDA/// /yH5BAAAAAAALAAAAACXAB4AAAX/4CeOYnUJZKqubOu+cCzPNA0tVnfVfO//wGAKk+t0Ap+K QMFUYCDCqHRKJVUWDaPRUsFktZ1G4AKtms9o1gKsFVS+7I5ll67bpd647hPQawNld4KDMQJF bA07F35aFBiEkJEpfXEBjx8KjI0Vkp2DEIdaCySgFBShbEgrCQOtrq+uEQcALQewrQUjEbe8 rgkkD7y5KhMZB3drqSoVFQhdlHGXKQYe1dbX2BvHKwzY1RMiAN7j1xEjBeTmKeIeD3cYCxRf FigvChRxFJwkBBvk5A7cpZhAjgGCDwn+kfslgto4CSoSehh2BwEEBQvowDAUR0EKdArHZTg4 4oDCXBFC/3qj9SEluZEpHnjYQFIGgpo1KgSasYjNKBImrzF4NaFbNgIjCGRQeIyVKwneOLzS cLCAg38OWI4Y4GECgQcSOEwYcADnh6/FNjAwoGFYAQ0atI4AAFeEFwsLFLiJUQEfGH0kNGAD x8+oNQdIRQg+7NCaOhIgD8sVgYADNsPVGI5YWjRqzQTdHDDIYHRDLokaUhCglkFEJi0NKJhl 0RP2TsvXUg88KiLBVWsZrF6DmMKlNYMqglqTik1guN8OBgAgkGCpB+L9ugK4iSCBvwEfECw1 kILrBpa1jVCQIQBRvbP+rlEcQVAoSevWyv6uhpwE12uEkQAAZucpVw1xIsjkgf8B863mQVYt eQATCZYJZJ5WBfij2wfpHcEeHGG8Z+BMszVWDXkfKLhceJhBSAJ+1ThH32AfRFZNayNAtUFi wFSTSwEHJIYAAQU84IADwyjIEALU9MchG+vFgIF7W2GDI2T7HfjBgNcgKQKMHmwjgnCSpeCb ULRkdxhF1CDY40RjgmUAA/v1J5FAKW2gGSZscBFDMraNgJs1AYpAAGYP5jJoNQ4Y4Gh8jpFg HH9mgbmWo1l6oA4C3Ygp6UwEIFBfNRtkMIBlKMLnAXgAXLWhXXH85EIFqMhGGZgDEKArABGA ed0HI4bk5qgnprCYSt88B6dqS0FEEAMPJDCdCJYViur/B1BlwGMJqDTwnhqxJgUpo0ceOQ4D 0yEakpMm/jqCRMgWm2I1j824Y6vLvuuPjHnqOJkIgP6xzwp5sCFNsCFp88Gxh11lrjfDcNrc CEx64/CD3iAHlQcMUEQXvcA+qBkBB4Q2X1CusjBlJdKMYAKI6g28MbKN5hJsBAXknHOwutn4 oFYqkpqAzjnPbE0u1PxmwAQGXLWBbvhuIIEGEnRjlAHO4SvhbCNAkwoGzEBwgV9U0lfu2WiX OkDEGaCdKgl0nk2YkWdPOCDabvaGdkAftL1LlgwCM+7Tq11V71IO7LkM2XE0YAHMYMhqqK6U V165CpaHukLmiXFO8XSVzzakX+UH6TrmAajPNxfqByTQec41AeBPvSwIALkmAnuiexCsca3C BajgfsROuxcPA8kHQJX4DAIwjnsAvhsvfXHWKEwDAljg7sj03L9wwAQTxOWD2AE0YP75eCkw cPfs+xACADs= --------------686754961B51EFCBA94B03FA-- --------------96FA69B8CD47AF632DE93ACC--

----- Original Message -----
From: "Ralf Schenk" <rs@databay.de> To: users@ovirt.org Sent: Friday, February 3, 2017 3:24:55 PM Subject: Re: [ovirt-users] [Call for feedback] did you install/update to 4.1.0?
Hello,
I upgraded my cluster of 8 hosts with gluster storage and hosted-engine-ha. They were already Centos 7.3 and using Ovirt 4.0.6 and gluster 3.7.x packages from storage-sig testing.
I'm missing the storage listed under storage tab but this is already filed by a bug. Increasing Cluster and Storage Compability level and also "reset emulated machine" after having upgraded one host after another without the need to shutdown vm's works well. (VM's get sign that there will be changes after reboot).
Important: you also have to issue a yum update on the host for upgrading additional components like i.e. gluster to 3.8.x. I was frightened of this step but It worked well except a configuration issue I was responsible for in gluster.vol (I had "transport socket, rdma")
Bugs/Quirks so far:
1. After restarting a single VM that used RNG-Device I got an error (it was german) but like "RNG Device not supported by cluster". I hat to disable RNG Device save the settings. Again settings and enable RNG Device. Then machine boots up. I think there is a migration step missing from /dev/random to /dev/urandom for exisiting VM's.
2. I'm missing any gluster specific management features as my gluster is not managable in any way from the GUI. I expected to see my gluster now in dashboard and be able to add volumes etc. What do I need to do to "import" my existing gluster (Only one volume so far) to be managable ?
If it is a hyperconverged cluster, then all your hosts are already managed by ovirt. So you just need to enable 'Gluster Service' in the Cluster, gluster volume will be imported automatically when you enable gluster service. If it is not a hyperconverged cluster, then you have to create a new cluster and enable only 'Gluster Service'. Then you can import or add the gluster hosts to this Gluster cluster. You may also need to define a gluster network if you are using a separate network for gluster data traffic. More at http://www.ovirt.org/develop/release-management/features/network/select-netw...
3. Three of my hosts have the hosted engine deployed for ha. First all three where marked by a crown (running was gold and others where silver). After upgrading the 3 Host deployed hosted engine ha is not active anymore.
I can't get this host back with working ovirt-ha-agent/broker. I already rebooted, manually restarted the services but It isn't able to get cluster state according to "hosted-engine --vm-status". The other hosts state the host status as "unknown stale-data"
I already shut down all agents on all hosts and issued a "hosted-engine --reinitialize-lockspace" but that didn't help.
Agents stops working after a timeout-error according to log:
MainThread::INFO::2017-02-02 19:24:52,040::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:24:59,185::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:06,333::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:13,554::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:20,710::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:27,865::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::815::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_initialize_domain_monitor) Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine::469::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Error while monitoring engine: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::WARNING::2017-02-02 19:25:27,866::hosted_engine::472::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Unexpected error Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 443, in start_monitoring self._initialize_domain_monitor() File "/usr/lib/python2.7/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 816, in _initialize_domain_monitor raise Exception(msg) Exception: Failed to start monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96, host_id=3): timeout during domain acquisition MainThread::ERROR::2017-02-02 19:25:27,866::hosted_engine::485::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(start_monitoring) Shutting down the agent because of 3 failures in a row! MainThread::INFO::2017-02-02 19:25:32,087::hosted_engine::841::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_domain_monitor_status) VDSM domain monitor status: PENDING MainThread::INFO::2017-02-02 19:25:34,250::hosted_engine::769::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_stop_domain_monitor) Failed to stop monitoring domain (sd_uuid=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96): Storage domain is member of pool: u'domain=7c8deaa8-be02-4aaf-b9b4-ddc8da99ad96' MainThread::INFO::2017-02-02 19:25:34,254::agent::143::ovirt_hosted_engine_ha.agent.agent.Agent::(run) Agent shutting down
The gluster volume of the engine is mounted corrctly in the host and accessible. Files are also readable etc. No clue what to do.
4. Last but not least: Ovirt is still using fuse to access VM-Disks on Gluster. I know - scheduled for 4.1.1 - but it was already there in 3.5.x and was scheduled for every release since then. I had this feature with opennebula already two years ago and performance is sooo much better.... So please GET IT IN !
This is blocked because of various changes required in libvirt/QEMU layers. But I hope this will fixed now :-) Regards, Ramesh
Bye
Am 02.02.2017 um 13:19 schrieb Sandro Bonazzola:
Hi, did you install/update to 4.1.0? Let us know your experience! We end up knowing only when things doesn't work well, let us know it works fine for you :-)
--
Ralf Schenk fon +49 (0) 24 05 / 40 83 70 fax +49 (0) 24 05 / 40 83 759 mail rs@databay.de
Databay AG Jens-Otto-Krag-Straße 11 D-52146 Würselen www.databay.de
Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
This is a multi-part message in MIME format. --------------C1360A45877BE812889B2F3F Content-Type: text/plain; charset=utf-8 Content-Transfer-Encoding: 8bit Hello, in reality my cluster is a hyper-converged cluster. But how do I tell this Ovirt Engine ? Of course I activated the checkbox "Gluster" (already some versions ago around 4.0.x) but that didn't change anything. Bye Am 03.02.2017 um 11:18 schrieb Ramesh Nachimuthu:
2. I'm missing any gluster specific management features as my gluster is not managable in any way from the GUI. I expected to see my gluster now in dashboard and be able to add volumes etc. What do I need to do to "import" my existing gluster (Only one volume so far) to be managable ?
If it is a hyperconverged cluster, then all your hosts are already managed by ovirt. So you just need to enable 'Gluster Service' in the Cluster, gluster volume will be imported automatically when you enable gluster service.
If it is not a hyperconverged cluster, then you have to create a new cluster and enable only 'Gluster Service'. Then you can import or add the gluster hosts to this Gluster cluster.
You may also need to define a gluster network if you are using a separate network for gluster data traffic. More at http://www.ovirt.org/develop/release-management/features/network/select-netw...
-- *Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 fax +49 (0) 24 05 / 40 83 759 mail *rs@databay.de* <mailto:rs@databay.de> *Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de> Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen ------------------------------------------------------------------------ --------------C1360A45877BE812889B2F3F Content-Type: multipart/related; boundary="------------E77F605A530462C56D12A693" --------------E77F605A530462C56D12A693 Content-Type: text/html; charset=utf-8 Content-Transfer-Encoding: 8bit <html> <head> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"> </head> <body bgcolor="#FFFFFF" text="#000000"> <p>Hello,</p> <p>in reality my cluster is a hyper-converged cluster. But how do I tell this Ovirt Engine ? Of course I activated the checkbox "Gluster" (already some versions ago around 4.0.x) but that didn't change anything.<br> </p> Bye<br> <div class="moz-cite-prefix">Am 03.02.2017 um 11:18 schrieb Ramesh Nachimuthu:<br> </div> <blockquote cite="mid:202232572.18715214.1486117108317.JavaMail.zimbra@redhat.com" type="cite"> <blockquote type="cite" style="color: #000000;"> <pre wrap="">2. I'm missing any gluster specific management features as my gluster is not managable in any way from the GUI. I expected to see my gluster now in dashboard and be able to add volumes etc. What do I need to do to "import" my existing gluster (Only one volume so far) to be managable ? </pre> </blockquote> <pre wrap="">If it is a hyperconverged cluster, then all your hosts are already managed by ovirt. So you just need to enable 'Gluster Service' in the Cluster, gluster volume will be imported automatically when you enable gluster service. If it is not a hyperconverged cluster, then you have to create a new cluster and enable only 'Gluster Service'. Then you can import or add the gluster hosts to this Gluster cluster. You may also need to define a gluster network if you are using a separate network for gluster data traffic. More at <a moz-do-not-send="true" class="moz-txt-link-freetext" href="http://www.ovirt.org/develop/release-management/features/network/select-network-for-gluster/">http://www.ovirt.org/develop/release-management/features/network/select-network-for-gluster/</a> </pre> </blockquote> <br> <div class="moz-signature">-- <br> <p> </p> <table border="0" cellpadding="0" cellspacing="0"> <tbody> <tr> <td colspan="3"><img src="cid:part2.5A50C68C.B23CD584@databay.de" height="30" border="0" width="151"></td> </tr> <tr> <td valign="top"> <font face="Verdana, Arial, sans-serif" size="-1"><br> <b>Ralf Schenk</b><br> fon +49 (0) 24 05 / 40 83 70<br> fax +49 (0) 24 05 / 40 83 759<br> mail <a href="mailto:rs@databay.de"><font color="#FF0000"><b>rs@databay.de</b></font></a><br> </font> </td> <td width="30"> </td> <td valign="top"> <font face="Verdana, Arial, sans-serif" size="-1"><br> <b>Databay AG</b><br> Jens-Otto-Krag-Straße 11<br> D-52146 Würselen<br> <a href="http://www.databay.de"><font color="#FF0000"><b>www.databay.de</b></font></a> </font> </td> </tr> <tr> <td colspan="3" valign="top"> <font face="Verdana, Arial, sans-serif" size="1"><br> Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202<br> Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns<br> Aufsichtsratsvorsitzender: Wilhelm Dohmen </font> </td> </tr> </tbody> </table> <hr color="#000000" noshade="noshade" size="1" width="100%"> </div> </body> </html> --------------E77F605A530462C56D12A693 Content-Type: image/gif; name="logo_databay_email.gif" Content-Transfer-Encoding: base64 Content-ID: <part2.5A50C68C.B23CD584@databay.de> Content-Disposition: inline; filename="logo_databay_email.gif" R0lGODlhlwAeAMQAAObm5v9QVf/R0oKBgfDw8NfX105MTLi3t/r6+sfHx/+rrf98gC0sLP8L EhIQEKalpf/g4ZmYmHd2dmppaf8uNP/y8v8cIv+Ym//AwkE/P46NjRwbG11cXP8ABwUDA/// /yH5BAAAAAAALAAAAACXAB4AAAX/4CeOYnUJZKqubOu+cCzPNA0tVnfVfO//wGAKk+t0Ap+K QMFUYCDCqHRKJVUWDaPRUsFktZ1G4AKtms9o1gKsFVS+7I5ll67bpd647hPQawNld4KDMQJF bA07F35aFBiEkJEpfXEBjx8KjI0Vkp2DEIdaCySgFBShbEgrCQOtrq+uEQcALQewrQUjEbe8 rgkkD7y5KhMZB3drqSoVFQhdlHGXKQYe1dbX2BvHKwzY1RMiAN7j1xEjBeTmKeIeD3cYCxRf FigvChRxFJwkBBvk5A7cpZhAjgGCDwn+kfslgto4CSoSehh2BwEEBQvowDAUR0EKdArHZTg4 4oDCXBFC/3qj9SEluZEpHnjYQFIGgpo1KgSasYjNKBImrzF4NaFbNgIjCGRQeIyVKwneOLzS cLCAg38OWI4Y4GECgQcSOEwYcADnh6/FNjAwoGFYAQ0atI4AAFeEFwsLFLiJUQEfGH0kNGAD x8+oNQdIRQg+7NCaOhIgD8sVgYADNsPVGI5YWjRqzQTdHDDIYHRDLokaUhCglkFEJi0NKJhl 0RP2TsvXUg88KiLBVWsZrF6DmMKlNYMqglqTik1guN8OBgAgkGCpB+L9ugK4iSCBvwEfECw1 kILrBpa1jVCQIQBRvbP+rlEcQVAoSevWyv6uhpwE12uEkQAAZucpVw1xIsjkgf8B863mQVYt eQATCZYJZJ5WBfij2wfpHcEeHGG8Z+BMszVWDXkfKLhceJhBSAJ+1ThH32AfRFZNayNAtUFi wFSTSwEHJIYAAQU84IADwyjIEALU9MchG+vFgIF7W2GDI2T7HfjBgNcgKQKMHmwjgnCSpeCb ULRkdxhF1CDY40RjgmUAA/v1J5FAKW2gGSZscBFDMraNgJs1AYpAAGYP5jJoNQ4Y4Gh8jpFg HH9mgbmWo1l6oA4C3Ygp6UwEIFBfNRtkMIBlKMLnAXgAXLWhXXH85EIFqMhGGZgDEKArABGA ed0HI4bk5qgnprCYSt88B6dqS0FEEAMPJDCdCJYViur/B1BlwGMJqDTwnhqxJgUpo0ceOQ4D 0yEakpMm/jqCRMgWm2I1j824Y6vLvuuPjHnqOJkIgP6xzwp5sCFNsCFp88Gxh11lrjfDcNrc CEx64/CD3iAHlQcMUEQXvcA+qBkBB4Q2X1CusjBlJdKMYAKI6g28MbKN5hJsBAXknHOwutn4 oFYqkpqAzjnPbE0u1PxmwAQGXLWBbvhuIIEGEnRjlAHO4SvhbCNAkwoGzEBwgV9U0lfu2WiX OkDEGaCdKgl0nk2YkWdPOCDabvaGdkAftL1LlgwCM+7Tq11V71IO7LkM2XE0YAHMYMhqqK6U V165CpaHukLmiXFO8XSVzzakX+UH6TrmAajPNxfqByTQec41AeBPvSwIALkmAnuiexCsca3C BajgfsROuxcPA8kHQJX4DAIwjnsAvhsvfXHWKEwDAljg7sj03L9wwAQTxOWD2AE0YP75eCkw cPfs+xACADs= --------------E77F605A530462C56D12A693-- --------------C1360A45877BE812889B2F3F--
----- Original Message -----
From: "Ralf Schenk" <rs@databay.de> To: "Ramesh Nachimuthu" <rnachimu@redhat.com> Cc: users@ovirt.org Sent: Friday, February 3, 2017 4:19:02 PM Subject: Re: [ovirt-users] [Call for feedback] did you install/update to 4.1.0?
Hello,
in reality my cluster is a hyper-converged cluster. But how do I tell this Ovirt Engine ? Of course I activated the checkbox "Gluster" (already some versions ago around 4.0.x) but that didn't change anything.
Do you see any error/warning in the engine.log? Regards, Ramesh
Bye Am 03.02.2017 um 11:18 schrieb Ramesh Nachimuthu:
2. I'm missing any gluster specific management features as my gluster is not managable in any way from the GUI. I expected to see my gluster now in dashboard and be able to add volumes etc. What do I need to do to "import" my existing gluster (Only one volume so far) to be managable ?
If it is a hyperconverged cluster, then all your hosts are already managed by ovirt. So you just need to enable 'Gluster Service' in the Cluster, gluster volume will be imported automatically when you enable gluster service.
If it is not a hyperconverged cluster, then you have to create a new cluster and enable only 'Gluster Service'. Then you can import or add the gluster hosts to this Gluster cluster.
You may also need to define a gluster network if you are using a separate network for gluster data traffic. More at http://www.ovirt.org/develop/release-management/features/network/select-netw...
--
*Ralf Schenk* fon +49 (0) 24 05 / 40 83 70 fax +49 (0) 24 05 / 40 83 759 mail *rs@databay.de* <mailto:rs@databay.de>
*Databay AG* Jens-Otto-Krag-Straße 11 D-52146 Würselen *www.databay.de* <http://www.databay.de>
Sitz/Amtsgericht Aachen • HRB:8437 • USt-IdNr.: DE 210844202 Vorstand: Ralf Schenk, Dipl.-Ing. Jens Conze, Aresch Yavari, Dipl.-Kfm. Philipp Hermanns Aufsichtsratsvorsitzender: Wilhelm Dohmen
------------------------------------------------------------------------

On 02/03/2017 10:54 AM, Ralf Schenk wrote:
Hello,
I upgraded my cluster of 8 hosts with gluster storage and hosted-engine-ha. They were already Centos 7.3 and using Ovirt 4.0.6 and gluster 3.7.x packages from storage-sig testing.
I'm missing the storage listed under storage tab but this is already filed by a bug. Increasing Cluster and Storage Compability level and also "reset emulated machine" after having upgraded one host after another without the need to shutdown vm's works well. (VM's get sign that there will be changes after reboot).
Important: you also have to issue a yum update on the host for upgrading additional components like i.e. gluster to 3.8.x. I was frightened of this step but It worked well except a configuration issue I was responsible for in gluster.vol (I had "transport socket, rdma")
Bugs/Quirks so far:
1. After restarting a single VM that used RNG-Device I got an error (it was german) but like "RNG Device not supported by cluster". I hat to disable RNG Device save the settings. Again settings and enable RNG Device. Then machine boots up. I think there is a migration step missing from /dev/random to /dev/urandom for exisiting VM's.
Hi! Sorry about this trouble. Please file a bug about this, we will likely need some Vdsm + Engine fixes. Bests, -- Francesco Romani Red Hat Engineering Virtualization R & D IRC: fromani

--_000_CY4PR14MB1687CD655B91740165896592E94F0CY4PR14MB1687namp_ Content-Type: text/plain; charset="utf-8" Content-Transfer-Encoding: base64 UnVubmluZyBvdmlydCB2NC4wLjUuNS4xIGFuZCBub3QgcGxhbm5pbmcgdG8gdXBncmFkZSB0byA0 LjEgeWV0Lg0KV2UgYXJlIGhhcHB5IHdpdGggc3RhYmlsaXR5IG9mIG91ciBwcm9kdWN0aW9uIHNl cnZlcnMgYW5kIHdhaXQgZm9yIDQuMS4xIHRvIGNvbWUgb3V0Lg0KVGhlIG9ubHkgcmVhbCBuZWVk IHRvIHVwZ3JhZGUgZm9yIHVzIHdvdWxkIGJlIHRoZSBhZGRlZCBjb21wYXRpYmlsaXR5IHdpdGgg V2luZG93cyBzZXJ2ZXIgMjAxNiBndWVzdCB0b29scy4NCuKApiBhbmQgdGhlIHRyaW0sIG9mIGNv dXJzZSwgYnV0IHdlIGNhbiB3YWl0IGEgbGl0dGxlIGJpdCBsb25nZXIgZm9yIGl04oCmDQoNCkNo ZWVycw0KQUcNCg0KRnJvbTogdXNlcnMtYm91bmNlc0BvdmlydC5vcmcgW21haWx0bzp1c2Vycy1i b3VuY2VzQG92aXJ0Lm9yZ10gT24gQmVoYWxmIE9mIFNhbmRybyBCb25henpvbGENClNlbnQ6IFRo dXJzZGF5LCBGZWJydWFyeSAyLCAyMDE3IDE6MTkgUE0NClRvOiB1c2VycyA8dXNlcnNAb3ZpcnQu b3JnPg0KU3ViamVjdDogW292aXJ0LXVzZXJzXSBbQ2FsbCBmb3IgZmVlZGJhY2tdIGRpZCB5b3Ug aW5zdGFsbC91cGRhdGUgdG8gNC4xLjA/DQoNCkhpLA0KZGlkIHlvdSBpbnN0YWxsL3VwZGF0ZSB0 byA0LjEuMD8gTGV0IHVzIGtub3cgeW91ciBleHBlcmllbmNlIQ0KV2UgZW5kIHVwIGtub3dpbmcg b25seSB3aGVuIHRoaW5ncyBkb2Vzbid0IHdvcmsgd2VsbCwgbGV0IHVzIGtub3cgaXQgd29ya3Mg ZmluZSBmb3IgeW91IDotKQ0KDQpJZiB5b3UncmUgbm90IHBsYW5uaW5nIGFuIHVwZGF0ZSB0byA0 LjEuMCBpbiB0aGUgbmVhciBmdXR1cmUsIGxldCB1cyBrbm93IHdoeS4NCk1heWJlIHdlIGNhbiBo ZWxwLg0KDQpUaGFua3MhDQotLQ0KU2FuZHJvIEJvbmF6em9sYQ0KQmV0dGVyIHRlY2hub2xvZ3ku IEZhc3RlciBpbm5vdmF0aW9uLiBQb3dlcmVkIGJ5IGNvbW11bml0eSBjb2xsYWJvcmF0aW9uLg0K U2VlIGhvdyBpdCB3b3JrcyBhdCByZWRoYXQuY29tPGh0dHA6Ly9yZWRoYXQuY29tPg0K --_000_CY4PR14MB1687CD655B91740165896592E94F0CY4PR14MB1687namp_ Content-Type: text/html; charset="utf-8" Content-Transfer-Encoding: base64 PGh0bWwgeG1sbnM6dj0idXJuOnNjaGVtYXMtbWljcm9zb2Z0LWNvbTp2bWwiIHhtbG5zOm89InVy bjpzY2hlbWFzLW1pY3Jvc29mdC1jb206b2ZmaWNlOm9mZmljZSIgeG1sbnM6dz0idXJuOnNjaGVt YXMtbWljcm9zb2Z0LWNvbTpvZmZpY2U6d29yZCIgeG1sbnM6bT0iaHR0cDovL3NjaGVtYXMubWlj cm9zb2Z0LmNvbS9vZmZpY2UvMjAwNC8xMi9vbW1sIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcv VFIvUkVDLWh0bWw0MCI+DQo8aGVhZD4NCjxtZXRhIGh0dHAtZXF1aXY9IkNvbnRlbnQtVHlwZSIg Y29udGVudD0idGV4dC9odG1sOyBjaGFyc2V0PXV0Zi04Ij4NCjxtZXRhIG5hbWU9IkdlbmVyYXRv ciIgY29udGVudD0iTWljcm9zb2Z0IFdvcmQgMTUgKGZpbHRlcmVkIG1lZGl1bSkiPg0KPHN0eWxl PjwhLS0NCi8qIEZvbnQgRGVmaW5pdGlvbnMgKi8NCkBmb250LWZhY2UNCgl7Zm9udC1mYW1pbHk6 IkNhbWJyaWEgTWF0aCI7DQoJcGFub3NlLTE6MiA0IDUgMyA1IDQgNiAzIDIgNDt9DQpAZm9udC1m YWNlDQoJe2ZvbnQtZmFtaWx5OkNhbGlicmk7DQoJcGFub3NlLTE6MiAxNSA1IDIgMiAyIDQgMyAy IDQ7fQ0KLyogU3R5bGUgRGVmaW5pdGlvbnMgKi8NCnAuTXNvTm9ybWFsLCBsaS5Nc29Ob3JtYWws IGRpdi5Nc29Ob3JtYWwNCgl7bWFyZ2luOjBpbjsNCgltYXJnaW4tYm90dG9tOi4wMDAxcHQ7DQoJ Zm9udC1zaXplOjEyLjBwdDsNCglmb250LWZhbWlseToiVGltZXMgTmV3IFJvbWFuIixzZXJpZjt9 DQphOmxpbmssIHNwYW4uTXNvSHlwZXJsaW5rDQoJe21zby1zdHlsZS1wcmlvcml0eTo5OTsNCglj b2xvcjpibHVlOw0KCXRleHQtZGVjb3JhdGlvbjp1bmRlcmxpbmU7fQ0KYTp2aXNpdGVkLCBzcGFu Lk1zb0h5cGVybGlua0ZvbGxvd2VkDQoJe21zby1zdHlsZS1wcmlvcml0eTo5OTsNCgljb2xvcjpw dXJwbGU7DQoJdGV4dC1kZWNvcmF0aW9uOnVuZGVybGluZTt9DQpwLm1zb25vcm1hbDAsIGxpLm1z b25vcm1hbDAsIGRpdi5tc29ub3JtYWwwDQoJe21zby1zdHlsZS1uYW1lOm1zb25vcm1hbDsNCglt c28tbWFyZ2luLXRvcC1hbHQ6YXV0bzsNCgltYXJnaW4tcmlnaHQ6MGluOw0KCW1zby1tYXJnaW4t Ym90dG9tLWFsdDphdXRvOw0KCW1hcmdpbi1sZWZ0OjBpbjsNCglmb250LXNpemU6MTIuMHB0Ow0K CWZvbnQtZmFtaWx5OiJUaW1lcyBOZXcgUm9tYW4iLHNlcmlmO30NCnNwYW4uRW1haWxTdHlsZTE4 DQoJe21zby1zdHlsZS10eXBlOnBlcnNvbmFsLXJlcGx5Ow0KCWZvbnQtZmFtaWx5OiJDYWxpYnJp IixzYW5zLXNlcmlmOw0KCWNvbG9yOndpbmRvd3RleHQ7fQ0KLk1zb0NocERlZmF1bHQNCgl7bXNv LXN0eWxlLXR5cGU6ZXhwb3J0LW9ubHk7DQoJZm9udC1zaXplOjEwLjBwdDt9DQpAcGFnZSBXb3Jk U2VjdGlvbjENCgl7c2l6ZTo4LjVpbiAxMS4waW47DQoJbWFyZ2luOjEuMGluIDEuMGluIDEuMGlu IDEuMGluO30NCmRpdi5Xb3JkU2VjdGlvbjENCgl7cGFnZTpXb3JkU2VjdGlvbjE7fQ0KLS0+PC9z dHlsZT48IS0tW2lmIGd0ZSBtc28gOV0+PHhtbD4NCjxvOnNoYXBlZGVmYXVsdHMgdjpleHQ9ImVk aXQiIHNwaWRtYXg9IjEwMjYiIC8+DQo8L3htbD48IVtlbmRpZl0tLT48IS0tW2lmIGd0ZSBtc28g OV0+PHhtbD4NCjxvOnNoYXBlbGF5b3V0IHY6ZXh0PSJlZGl0Ij4NCjxvOmlkbWFwIHY6ZXh0PSJl ZGl0IiBkYXRhPSIxIiAvPg0KPC9vOnNoYXBlbGF5b3V0PjwveG1sPjwhW2VuZGlmXS0tPg0KPC9o ZWFkPg0KPGJvZHkgbGFuZz0iRU4tVVMiIGxpbms9ImJsdWUiIHZsaW5rPSJwdXJwbGUiPg0KPGRp diBjbGFzcz0iV29yZFNlY3Rpb24xIj4NCjxwIGNsYXNzPSJNc29Ob3JtYWwiPjxzcGFuIHN0eWxl PSJmb250LXNpemU6MTEuMHB0O2ZvbnQtZmFtaWx5OiZxdW90O0NhbGlicmkmcXVvdDssc2Fucy1z ZXJpZiI+UnVubmluZyBvdmlydCB2NC4wLjUuNS4xIGFuZCBub3QgcGxhbm5pbmcgdG8gdXBncmFk ZSB0byA0LjEgeWV0LjxvOnA+PC9vOnA+PC9zcGFuPjwvcD4NCjxwIGNsYXNzPSJNc29Ob3JtYWwi PjxzcGFuIHN0eWxlPSJmb250LXNpemU6MTEuMHB0O2ZvbnQtZmFtaWx5OiZxdW90O0NhbGlicmkm cXVvdDssc2Fucy1zZXJpZiI+V2UgYXJlIGhhcHB5IHdpdGggc3RhYmlsaXR5IG9mIG91ciBwcm9k dWN0aW9uIHNlcnZlcnMgYW5kIHdhaXQgZm9yIDQuMS4xIHRvIGNvbWUgb3V0LjxvOnA+PC9vOnA+ PC9zcGFuPjwvcD4NCjxwIGNsYXNzPSJNc29Ob3JtYWwiPjxzcGFuIHN0eWxlPSJmb250LXNpemU6 MTEuMHB0O2ZvbnQtZmFtaWx5OiZxdW90O0NhbGlicmkmcXVvdDssc2Fucy1zZXJpZiI+VGhlIG9u bHkgcmVhbCBuZWVkIHRvIHVwZ3JhZGUgZm9yIHVzIHdvdWxkIGJlIHRoZSBhZGRlZCBjb21wYXRp YmlsaXR5IHdpdGggV2luZG93cyBzZXJ2ZXIgMjAxNiBndWVzdCB0b29scy48bzpwPjwvbzpwPjwv c3Bhbj48L3A+DQo8cCBjbGFzcz0iTXNvTm9ybWFsIj48c3BhbiBzdHlsZT0iZm9udC1zaXplOjEx LjBwdDtmb250LWZhbWlseTomcXVvdDtDYWxpYnJpJnF1b3Q7LHNhbnMtc2VyaWYiPuKApiBhbmQg dGhlIHRyaW0sIG9mIGNvdXJzZSwgYnV0IHdlIGNhbiB3YWl0IGEgbGl0dGxlIGJpdCBsb25nZXIg Zm9yIGl04oCmPG86cD48L286cD48L3NwYW4+PC9wPg0KPHAgY2xhc3M9Ik1zb05vcm1hbCI+PHNw YW4gc3R5bGU9ImZvbnQtc2l6ZToxMS4wcHQ7Zm9udC1mYW1pbHk6JnF1b3Q7Q2FsaWJyaSZxdW90 OyxzYW5zLXNlcmlmIj48bzpwPiZuYnNwOzwvbzpwPjwvc3Bhbj48L3A+DQo8cCBjbGFzcz0iTXNv Tm9ybWFsIj48c3BhbiBzdHlsZT0iZm9udC1zaXplOjExLjBwdDtmb250LWZhbWlseTomcXVvdDtD YWxpYnJpJnF1b3Q7LHNhbnMtc2VyaWYiPkNoZWVyczxvOnA+PC9vOnA+PC9zcGFuPjwvcD4NCjxw IGNsYXNzPSJNc29Ob3JtYWwiPjxzcGFuIHN0eWxlPSJmb250LXNpemU6MTEuMHB0O2ZvbnQtZmFt aWx5OiZxdW90O0NhbGlicmkmcXVvdDssc2Fucy1zZXJpZiI+QUc8bzpwPjwvbzpwPjwvc3Bhbj48 L3A+DQo8cCBjbGFzcz0iTXNvTm9ybWFsIj48c3BhbiBzdHlsZT0iZm9udC1zaXplOjExLjBwdDtm b250LWZhbWlseTomcXVvdDtDYWxpYnJpJnF1b3Q7LHNhbnMtc2VyaWYiPjxvOnA+Jm5ic3A7PC9v OnA+PC9zcGFuPjwvcD4NCjxwIGNsYXNzPSJNc29Ob3JtYWwiPjxiPjxzcGFuIHN0eWxlPSJmb250 LXNpemU6MTEuMHB0O2ZvbnQtZmFtaWx5OiZxdW90O0NhbGlicmkmcXVvdDssc2Fucy1zZXJpZiI+ RnJvbTo8L3NwYW4+PC9iPjxzcGFuIHN0eWxlPSJmb250LXNpemU6MTEuMHB0O2ZvbnQtZmFtaWx5 OiZxdW90O0NhbGlicmkmcXVvdDssc2Fucy1zZXJpZiI+IHVzZXJzLWJvdW5jZXNAb3ZpcnQub3Jn IFttYWlsdG86dXNlcnMtYm91bmNlc0BvdmlydC5vcmddDQo8Yj5PbiBCZWhhbGYgT2YgPC9iPlNh bmRybyBCb25henpvbGE8YnI+DQo8Yj5TZW50OjwvYj4gVGh1cnNkYXksIEZlYnJ1YXJ5IDIsIDIw MTcgMToxOSBQTTxicj4NCjxiPlRvOjwvYj4gdXNlcnMgJmx0O3VzZXJzQG92aXJ0Lm9yZyZndDs8 YnI+DQo8Yj5TdWJqZWN0OjwvYj4gW292aXJ0LXVzZXJzXSBbQ2FsbCBmb3IgZmVlZGJhY2tdIGRp ZCB5b3UgaW5zdGFsbC91cGRhdGUgdG8gNC4xLjA/PG86cD48L286cD48L3NwYW4+PC9wPg0KPHAg Y2xhc3M9Ik1zb05vcm1hbCI+PG86cD4mbmJzcDs8L286cD48L3A+DQo8ZGl2Pg0KPHAgY2xhc3M9 Ik1zb05vcm1hbCI+SGksPG86cD48L286cD48L3A+DQo8ZGl2Pg0KPHAgY2xhc3M9Ik1zb05vcm1h bCI+ZGlkIHlvdSBpbnN0YWxsL3VwZGF0ZSB0byA0LjEuMD8gTGV0IHVzIGtub3cgeW91ciBleHBl cmllbmNlITxvOnA+PC9vOnA+PC9wPg0KPC9kaXY+DQo8ZGl2Pg0KPHAgY2xhc3M9Ik1zb05vcm1h bCI+V2UgZW5kIHVwIGtub3dpbmcgb25seSB3aGVuIHRoaW5ncyBkb2Vzbid0IHdvcmsgd2VsbCwg bGV0IHVzIGtub3cgaXQgd29ya3MgZmluZSBmb3IgeW91IDotKTxvOnA+PC9vOnA+PC9wPg0KPC9k aXY+DQo8ZGl2Pg0KPHAgY2xhc3M9Ik1zb05vcm1hbCI+PG86cD4mbmJzcDs8L286cD48L3A+DQo8 L2Rpdj4NCjxkaXY+DQo8cCBjbGFzcz0iTXNvTm9ybWFsIj5JZiB5b3UncmUgbm90IHBsYW5uaW5n IGFuIHVwZGF0ZSB0byA0LjEuMCBpbiB0aGUgbmVhciBmdXR1cmUsIGxldCB1cyBrbm93IHdoeS48 bzpwPjwvbzpwPjwvcD4NCjwvZGl2Pg0KPGRpdj4NCjxwIGNsYXNzPSJNc29Ob3JtYWwiPk1heWJl IHdlIGNhbiBoZWxwLjxiciBjbGVhcj0iYWxsIj4NCjxvOnA+PC9vOnA+PC9wPg0KPGRpdj4NCjxw IGNsYXNzPSJNc29Ob3JtYWwiPjxvOnA+Jm5ic3A7PC9vOnA+PC9wPg0KPC9kaXY+DQo8ZGl2Pg0K PHAgY2xhc3M9Ik1zb05vcm1hbCI+VGhhbmtzITxvOnA+PC9vOnA+PC9wPg0KPC9kaXY+DQo8cCBj bGFzcz0iTXNvTm9ybWFsIj4tLSA8bzpwPjwvbzpwPjwvcD4NCjxkaXY+DQo8ZGl2Pg0KPGRpdj4N CjxkaXY+DQo8ZGl2Pg0KPGRpdj4NCjxkaXY+DQo8ZGl2Pg0KPHAgY2xhc3M9Ik1zb05vcm1hbCI+ U2FuZHJvIEJvbmF6em9sYTxicj4NCkJldHRlciB0ZWNobm9sb2d5LiBGYXN0ZXIgaW5ub3ZhdGlv bi4gUG93ZXJlZCBieSBjb21tdW5pdHkgY29sbGFib3JhdGlvbi48YnI+DQpTZWUgaG93IGl0IHdv cmtzIGF0IDxhIGhyZWY9Imh0dHA6Ly9yZWRoYXQuY29tIiB0YXJnZXQ9Il9ibGFuayI+cmVkaGF0 LmNvbTwvYT48bzpwPjwvbzpwPjwvcD4NCjwvZGl2Pg0KPC9kaXY+DQo8L2Rpdj4NCjwvZGl2Pg0K PC9kaXY+DQo8L2Rpdj4NCjwvZGl2Pg0KPC9kaXY+DQo8L2Rpdj4NCjwvZGl2Pg0KPC9kaXY+DQo8 L2JvZHk+DQo8L2h0bWw+DQo= --_000_CY4PR14MB1687CD655B91740165896592E94F0CY4PR14MB1687namp_--

Hi, I updated our oVirt cluster day after 4.1.0 went public. Upgrade was simple but while migrating and upgrading hosts some vms was stucked with 100% cpu usage and totally non responsible. I had to power of them and start again. But it could be some problem with CentOS7.2->7.3 transition or kvm-ev upgrade. Unfortunately I had no time to examine logs yet :-( Also I experienced one or two "UI Exception" but not a big deal. UI is more and more polished. I really like how it shifts to patternfly look and feel. btw. We have standalone gluster cluster not for vms, just for general storage purposes. Is wise to use oVirt manager as web ui for its management? Is safe to import this gluster into oVirt? I saw this option there but I don't want broke things that works :-) At the end - thanks for your great work. I still see lot of features I still missing in oVirt but it is highly usable and great piece of software. And also oVirt community is nice and helpful. Cheers, Jiri On 02/02/2017 01:19 PM, Sandro Bonazzola wrote:
Hi, did you install/update to 4.1.0? Let us know your experience! We end up knowing only when things doesn't work well, let us know it works fine for you :-)
If you're not planning an update to 4.1.0 in the near future, let us know why. Maybe we can help.
Thanks! -- Sandro Bonazzola Better technology. Faster innovation. Powered by community collaboration. See how it works at redhat.com <http://redhat.com>
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users

Hi all, Am 02.02.2017 um 13:19 schrieb Sandro Bonazzola:
did you install/update to 4.1.0? Let us know your experience! We end up knowing only when things doesn't work well, let us know it works fine for you :-)
I just updated my test environment (3 hosts, hosted engine, iSCSI) to 4.1 and it worked very well. I initially had a problem to migrate my engine vm to another host but this could have been a local problem. The only thing that could be improved is the online documentation (404 errors, already adressed in another thread). ;) Otherwise erverything runs very well so far, thank you for your work! cu, Uwe

Hi Sandro, I upgraded my 2 host setup + engine (engine is currently on separate hardware, but I plan to make it self-hosted), and it went like clockwork. My engine + hosts were running 4.0.5 and 7.2, so after installing 4.1 release, I did an OS update to 7.3 first, starting with the engine, then ran engine-setup. I opted to do a 'yum upgrade' on the the first host, which actually updated all the ovirt packages as well and rebooted (I'm not sure this is an approved method, but it worked fine). After the first host was back, I upgraded the second host from the GUI, but then I ran a yum upgrade to update all the OS stuff, such as the kernel, libc etc, and rebooted. Many thanks for making the upgrade process so smooth! Cheers, Cam On Thu, Feb 2, 2017 at 12:19 PM, Sandro Bonazzola <sbonazzo@redhat.com> wrote:
Hi, did you install/update to 4.1.0? Let us know your experience! We end up knowing only when things doesn't work well, let us know it works fine for you :-)
If you're not planning an update to 4.1.0 in the near future, let us know why. Maybe we can help.
Thanks! -- Sandro Bonazzola Better technology. Faster innovation. Powered by community collaboration. See how it works at redhat.com
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
participants (19)
-
 Andrea Ghelardi
Andrea Ghelardi -
 Arman Khalatyan
Arman Khalatyan -
 cmc
cmc -
 Fernando Frediani
Fernando Frediani -
 Francesco Romani
Francesco Romani -
 Jiri Slezka
Jiri Slezka -
 Lars Seipel
Lars Seipel -
 Martin Perina
Martin Perina -
 Nir Soffer
Nir Soffer -
 Ralf Schenk
Ralf Schenk -
 Ramesh Nachimuthu
Ramesh Nachimuthu -
 Sandro Bonazzola
Sandro Bonazzola -
 serg_k@msm.ru
serg_k@msm.ru -
Sergey Kulikov
-
 Simone Tiraboschi
Simone Tiraboschi -
 Uwe Laverenz
Uwe Laverenz -
 Yaniv Kaul
Yaniv Kaul -
 Yura Poltoratskiy
Yura Poltoratskiy -
 Краснобаев Михаил
Краснобаев Михаил