
I just finished deploying oVirt 4.4.5 onto a 3-node hyperconverged cluster running on Red Hat 8.3 OS. Over the course of the setup, I noticed that I had to setup the storage for the engine separately from the gluster bricks. It looks like the engine was installed onto /rhev/data-center/ on the first host, whereas the gluster bricks for all 3 hosts are on /gluster_bricks/. I fear that I may already know the answer to this, but: Is it possible to make the engine highly available? Also, thinking hypothetically here, what would happen to my VMs that are physically on the first server, if the first server crashed? The engine is what handles the high availability, correct? So what if a VM was running on the first host? There would be nothing to automatically "move" it to one of the remaining healthy hosts. Or am I misunderstanding something here? Sent with ProtonMail Secure Email.

If you deployed with wizard the hosted engine should already be HA and can run on any host. I’d you look at GUI you will see a crown beside each host that is capable of running the hostess engine. On Sat, Mar 20, 2021 at 5:14 PM David White via Users <users@ovirt.org> wrote:
I just finished deploying oVirt 4.4.5 onto a 3-node hyperconverged cluster running on Red Hat 8.3 OS.
Over the course of the setup, I noticed that I had to setup the storage for the engine separately from the gluster bricks.
It looks like the engine was installed onto /rhev/data-center/ on the first host, whereas the gluster bricks for all 3 hosts are on /gluster_bricks/.
I fear that I may already know the answer to this, but: Is it possible to make the engine highly available?
Also, thinking hypothetically here, what would happen to my VMs that are physically on the first server, if the first server crashed? The engine is what handles the high availability, correct? So what if a VM was running on the first host? There would be nothing to automatically "move" it to one of the remaining healthy hosts.
Or am I misunderstanding something here?
Sent with ProtonMail <https://protonmail.com> Secure Email.
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/L6MMZSMSGIK7BT...
There may be a bug in the latest installer. Or I might have missed a step somewhere. I did use the 4.4.5 installer for hyperconverged wizard, yes. I'm currently in the Engine console right now, and I only see 1 host. I've navigated to Compute -> Hosts. That said, when I navigate to Compute -> Clusters -> Default, I see this message: Some new hosts are detected in the cluster. You can Import them to engine or Detach them from the cluster. I clicked on Import to try to import them into the engine. On the next screen, I see the other two physical hosts. I verified the Gluster peer address, as well as the front-end Host address, typed in the root password, and clicked OK. The system acted like it was doing stuff, but then eventually I landed back on the same "Add Hosts" screen as before: [Screenshot from 2021-03-20 16-28-56.png] Am I missing something? Sent with ProtonMail Secure Email. ‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Saturday, March 20, 2021 4:17 PM, Jayme <jaymef@gmail.com> wrote:
If you deployed with wizard the hosted engine should already be HA and can run on any host. I’d you look at GUI you will see a crown beside each host that is capable of running the hostess engine.
On Sat, Mar 20, 2021 at 5:14 PM David White via Users <users@ovirt.org> wrote:
I just finished deploying oVirt 4.4.5 onto a 3-node hyperconverged cluster running on Red Hat 8.3 OS.
Over the course of the setup, I noticed that I had to setup the storage for the engine separately from the gluster bricks.
It looks like the engine was installed onto /rhev/data-center/ on the first host, whereas the gluster bricks for all 3 hosts are on /gluster_bricks/.
I fear that I may already know the answer to this, but: Is it possible to make the engine highly available?
Also, thinking hypothetically here, what would happen to my VMs that are physically on the first server, if the first server crashed? The engine is what handles the high availability, correct? So what if a VM was running on the first host? There would be nothing to automatically "move" it to one of the remaining healthy hosts.
Or am I misunderstanding something here?
Sent with ProtonMail Secure Email.
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/L6MMZSMSGIK7BT...
{kind=link}
To clarify: My screenshot keeps defaulting the "Host Address" to the Storage FQDN, so I keep changing it to the correct fqdn. Sent with ProtonMail Secure Email. ‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Saturday, March 20, 2021 4:30 PM, David White <dmwhite823@protonmail.com> wrote:
There may be a bug in the latest installer. Or I might have missed a step somewhere. I did use the 4.4.5 installer for hyperconverged wizard, yes.
I'm currently in the Engine console right now, and I only see 1 host. I've navigated to Compute -> Hosts.
That said, when I navigate to Compute -> Clusters -> Default, I see this message: Some new hosts are detected in the cluster. You can Import them to engine or Detach them from the cluster.
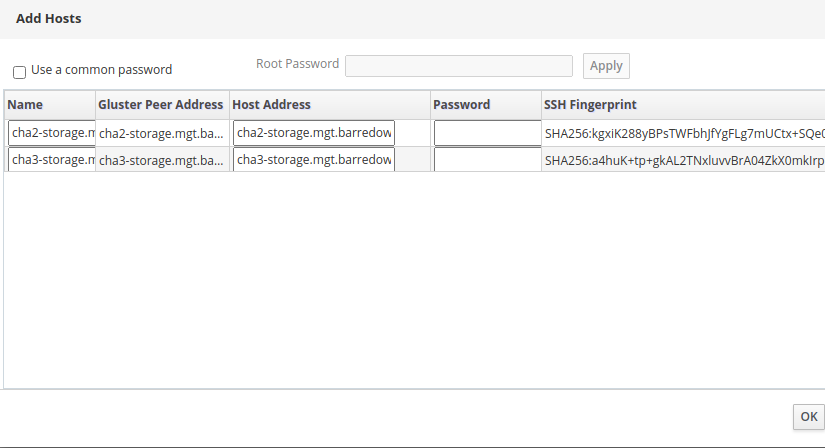
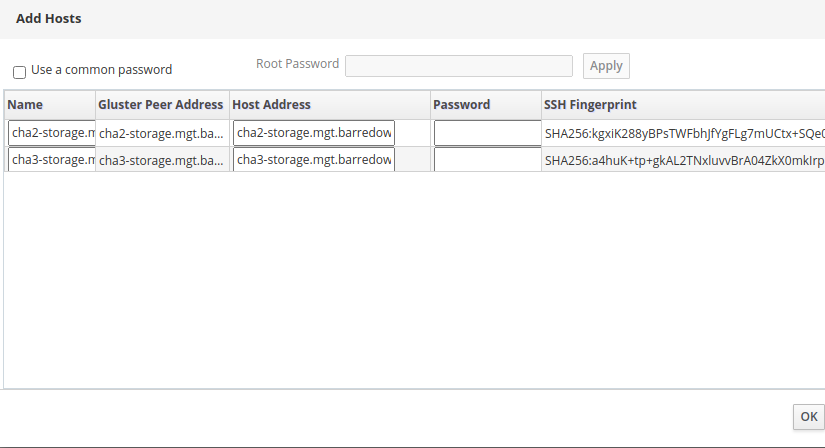
I clicked on Import to try to import them into the engine. On the next screen, I see the other two physical hosts.
I verified the Gluster peer address, as well as the front-end Host address, typed in the root password, and clicked OK. The system acted like it was doing stuff, but then eventually I landed back on the same "Add Hosts" screen as before:
[Screenshot from 2021-03-20 16-28-56.png]
Am I missing something?
Sent with ProtonMail Secure Email.
‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Saturday, March 20, 2021 4:17 PM, Jayme <jaymef@gmail.com> wrote:
If you deployed with wizard the hosted engine should already be HA and can run on any host. I’d you look at GUI you will see a crown beside each host that is capable of running the hostess engine.
On Sat, Mar 20, 2021 at 5:14 PM David White via Users <users@ovirt.org> wrote:
I just finished deploying oVirt 4.4.5 onto a 3-node hyperconverged cluster running on Red Hat 8.3 OS.
Over the course of the setup, I noticed that I had to setup the storage for the engine separately from the gluster bricks.
It looks like the engine was installed onto /rhev/data-center/ on the first host, whereas the gluster bricks for all 3 hosts are on /gluster_bricks/.
I fear that I may already know the answer to this, but: Is it possible to make the engine highly available?
Also, thinking hypothetically here, what would happen to my VMs that are physically on the first server, if the first server crashed? The engine is what handles the high availability, correct? So what if a VM was running on the first host? There would be nothing to automatically "move" it to one of the remaining healthy hosts.
Or am I misunderstanding something here?
Sent with ProtonMail Secure Email.
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/L6MMZSMSGIK7BT...
{kind=link}
Ah, I see. The "host" in this context does need to be the backend mgt / gluster network. I was able to add the 2nd host, and I'm working on adding the 3rd now. Sent with ProtonMail Secure Email. ‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Saturday, March 20, 2021 4:32 PM, David White via Users <users@ovirt.org> wrote:
To clarify: My screenshot keeps defaulting the "Host Address" to the Storage FQDN, so I keep changing it to the correct fqdn.
Sent with ProtonMail Secure Email.
‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Saturday, March 20, 2021 4:30 PM, David White <dmwhite823@protonmail.com> wrote:
There may be a bug in the latest installer. Or I might have missed a step somewhere. I did use the 4.4.5 installer for hyperconverged wizard, yes.
I'm currently in the Engine console right now, and I only see 1 host. I've navigated to Compute -> Hosts.
That said, when I navigate to Compute -> Clusters -> Default, I see this message: Some new hosts are detected in the cluster. You can Import them to engine or Detach them from the cluster.
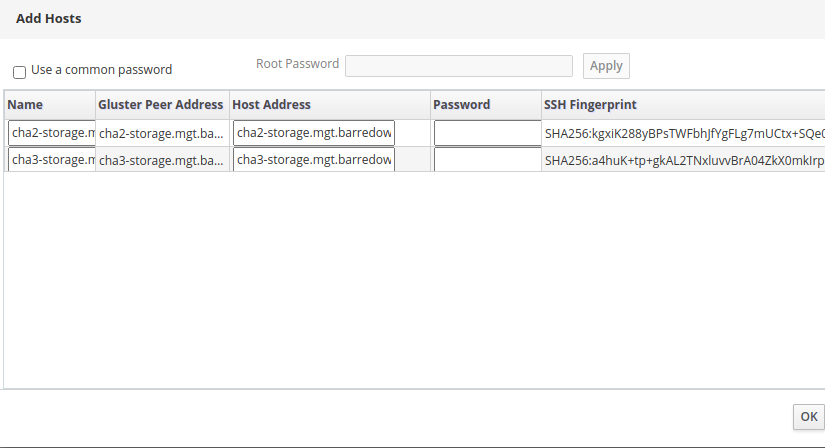
I clicked on Import to try to import them into the engine. On the next screen, I see the other two physical hosts.
I verified the Gluster peer address, as well as the front-end Host address, typed in the root password, and clicked OK. The system acted like it was doing stuff, but then eventually I landed back on the same "Add Hosts" screen as before:
[Screenshot from 2021-03-20 16-28-56.png]
Am I missing something?
Sent with ProtonMail Secure Email.
‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Saturday, March 20, 2021 4:17 PM, Jayme <jaymef@gmail.com> wrote:
If you deployed with wizard the hosted engine should already be HA and can run on any host. I’d you look at GUI you will see a crown beside each host that is capable of running the hostess engine.
On Sat, Mar 20, 2021 at 5:14 PM David White via Users <users@ovirt.org> wrote:
I just finished deploying oVirt 4.4.5 onto a 3-node hyperconverged cluster running on Red Hat 8.3 OS.
Over the course of the setup, I noticed that I had to setup the storage for the engine separately from the gluster bricks.
It looks like the engine was installed onto /rhev/data-center/ on the first host, whereas the gluster bricks for all 3 hosts are on /gluster_bricks/.
I fear that I may already know the answer to this, but: Is it possible to make the engine highly available?
Also, thinking hypothetically here, what would happen to my VMs that are physically on the first server, if the first server crashed? The engine is what handles the high availability, correct? So what if a VM was running on the first host? There would be nothing to automatically "move" it to one of the remaining healthy hosts.
Or am I misunderstanding something here?
Sent with ProtonMail Secure Email.
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/L6MMZSMSGIK7BT...
{kind=link}

On Sat, Mar 20, 2021, 22:15 David White via Users <users@ovirt.org> wrote:
I just finished deploying oVirt 4.4.5 onto a 3-node hyperconverged cluster running on Red Hat 8.3 OS.
Over the course of the setup, I noticed that I had to setup the storage for the engine separately from the gluster bricks.
It looks like the engine was installed onto /rhev/data-center/ on the first host, whereas the gluster bricks for all 3 hosts are on /gluster_bricks/.
/rhev/data-center is a mountpoint of the gluster volume which may have its bricks in /gluster_bricks/. You can provide more info on the gluster setup to clarify this. gluster volume info <volume name>
I fear that I may already know the answer to this, but: Is it possible to make the engine highly available?
Yes, one uses 3 servers to achieve HA for the guest VMs and the engine, as long as the hosts meet the requirements of storage, network and compute.
Also, thinking hypothetically here, what would happen to my VMs that are physically on the first server, if the first server crashed? The engine is what handles the high availability, correct? So what if a VM was running on the first host? There would be nothing to automatically "move" it to one of the remaining healthy hosts.
Or am I misunderstanding something here?
Sent with ProtonMail <https://protonmail.com> Secure Email.
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/L6MMZSMSGIK7BT...

It's important to understand the oVirt design philosophy. That may be somewhat understated in the documentation, because I am afraid they copied that from VMware's vSphere who might have copied it from Nutanix, who might have copied it from who-know-else... which might explain why they are a little shy about it. The basic truth is: HA is a chicken and egg issue. Having several management engines won't get you HA, because in a case of conflict, these HA engines can't easily decide who is boss. Which is why oVirt (and vSphere/Nutanix most likely) will concede defeat (or death) on every startup. What that mostly means is that you don't really need to ensure that a smart and higly complex management machine, which can juggle dozens of infrastructure pieces against an optimal plan of operations, is in fact at all times highly available. It's quite enough to have the infrastructure pieces ensure that the last plan this ME produced is faithfully executed. So oVirt has a super intelligent management engine build a plan. That plan is written to super primitive but reliant storage. All hosts will faithfully (and without personal ambitions to improve) execute that last plan, which includes launching the management engine... And that single newly started management engine, can read the basic infrastructure data, as well as the latest plant, to hopefully create a better new plan, before it dies... And that's why, unless your ME always dies before a new plan can be created, you don't need HA for the ME: It's sufficient to have a good-enough plan for all hosts. Like far too many clusters, oVirt relegates HA to a passive storage device, that is always highly available. With SANs and NFS filers, that's hopefully solved in hardware. With HCI Glusters it's done with majority voting, hopefully. All that said... I've rarely had all 3 nodes register just perfectly in a 3 node oVirt HCI cluster. I don't have any idea why that is the case in both 4.3 and 4.4. I have almost always had to add the two additional node via 'add host' to make them available both as compute nodes and as Gluster peers. On the other hand, it just works and doing it twice or a hundred times, wont break a thing. And that is true for almost every component of oVirt: practically all services can fail, or be restarted at any time, without causing a major disruption or outrigth failure. That's where I can't but admire this fail-safe approach (which somewhat unfortunately might not have been invented at Redhat, even if Moshe Bar most likely had a hand in it). It never hurts do make sure that you add those extra nodes with the ability to run the management engine, either, but it's also something you can always add later to any host (just takes Ansible patience to do so). Today I just consider that one of dozens if not hundreds of quirks of oVirt, that I find 'amazing' in a product also sold commercially.
participants (4)
-
 Alex K
Alex K -
 David White
David White -
 Jayme
Jayme -
 Thomas Hoberg
Thomas Hoberg