4-2rc hosted-engine don't boot error:cannot allocate kernel buffer

Hi after successfully deployed fresh 4.2_rc with ovirt node, I'm facing with a blocking problem. hosted-engine won't boot. Reaching the console via vnc hook, I can see that it is at initial boot screen, but for any OS release available, I receive: [image: Immagine incorporata 1] then [image: Immagine incorporata 2] googling around, I'm not able to find suggestions. Any hints ? Thanks -- Roberto
{kind=link}
{kind=link}
Hello all during weekend, I've re-tried to deploy my 4.2_rc lab. Everything was fine, apart the fact host 2 and 3 weren't imported. I had to add them to the cluster manually, with the NEW function. After this Gluster volumes were added fine to the environment. Next engine deploy on nodes 2 and 3, ended with ok status. Tring to migrate HE from host 1 to host 2 was fine, the same from host 2 to host 3. After these two attempts, no way to migrate HE back to any host. Tried Maintenance mode set to global, reboot the HE and now I'm in the same condition reported below, not anymore able to boot the HE. Here's hosted-engine --vm-status: !! Cluster is in GLOBAL MAINTENANCE mode !! --== Host 1 status ==-- conf_on_shared_storage : True Status up-to-date : True Hostname : aps-te61-mng.example.com Host ID : 1 Engine status : {"reason": "vm not running on this host", "health": "bad", "vm": "down", "detail": "unknown"} Score : 3400 stopped : False Local maintenance : False crc32 : 7dfc420b local_conf_timestamp : 181953 Host timestamp : 181952 Extra metadata (valid at timestamp): metadata_parse_version=1 metadata_feature_version=1 timestamp=181952 (Mon Dec 11 09:21:46 2017) host-id=1 score=3400 vm_conf_refresh_time=181953 (Mon Dec 11 09:21:47 2017) conf_on_shared_storage=True maintenance=False state=GlobalMaintenance stopped=False --== Host 2 status ==-- conf_on_shared_storage : True Status up-to-date : True Hostname : aps-te64-mng.example.com Host ID : 2 Engine status : {"reason": "vm not running on this host", "health": "bad", "vm": "down", "detail": "unknown"} Score : 3400 stopped : False Local maintenance : False crc32 : 67c7dd1d local_conf_timestamp : 181946 Host timestamp : 181946 Extra metadata (valid at timestamp): metadata_parse_version=1 metadata_feature_version=1 timestamp=181946 (Mon Dec 11 09:21:49 2017) host-id=2 score=3400 vm_conf_refresh_time=181946 (Mon Dec 11 09:21:49 2017) conf_on_shared_storage=True maintenance=False state=GlobalMaintenance stopped=False --== Host 3 status ==-- conf_on_shared_storage : True Status up-to-date : True Hostname : aps-te68-mng.example.com Host ID : 3 Engine status : {"reason": "failed liveliness check", "health": "bad", "vm": "up", "detail": "Up"} Score : 3400 stopped : False Local maintenance : False crc32 : 4daea041 local_conf_timestamp : 181078 Host timestamp : 181078 Extra metadata (valid at timestamp): metadata_parse_version=1 metadata_feature_version=1 timestamp=181078 (Mon Dec 11 09:21:53 2017) host-id=3 score=3400 vm_conf_refresh_time=181078 (Mon Dec 11 09:21:53 2017) conf_on_shared_storage=True maintenance=False state=GlobalMaintenance stopped=False !! Cluster is in GLOBAL MAINTENANCE mode !! (it is in global maintenance to avoid messages to be sent to admin mailbox). Engine image is available on all three hosts, gluster is working fine: Volume Name: engine Type: Replicate Volume ID: 95355a0b-1f45-4329-95c7-604682e812d0 Status: Started Snapshot Count: 0 Number of Bricks: 1 x 3 = 3 Transport-type: tcp Bricks: Brick1: aps-te61-mng.example.com:/gluster_bricks/engine/engine Brick2: aps-te64-mng.example.com:/gluster_bricks/engine/engine Brick3: aps-te68-mng.example.com:/gluster_bricks/engine/engine Options Reconfigured: nfs.disable: on transport.address-family: inet performance.quick-read: off performance.read-ahead: off performance.io-cache: off performance.low-prio-threads: 32 network.remote-dio: off cluster.eager-lock: enable cluster.quorum-type: auto cluster.server-quorum-type: server cluster.data-self-heal-algorithm: full cluster.locking-scheme: granular cluster.shd-max-threads: 8 cluster.shd-wait-qlength: 10000 features.shard: on user.cifs: off storage.owner-uid: 36 storage.owner-gid: 36 network.ping-timeout: 30 performance.strict-o-direct: on cluster.granular-entry-heal: enable features.shard-block-size: 64MB Engine qemu image seems to be ok: [root@aps-te68-mng 9998de26-8a5c-4495-b450-c8dfc1e016da]# l total 2660796 -rw-rw----. 1 vdsm kvm 53687091200 Dec 8 17:22 35ac0f88-e97d-4710-a385-127c751a3190 -rw-rw----. 1 vdsm kvm 1048576 Dec 11 09:04 35ac0f88-e97d-4710-a385-127c751a3190.lease -rw-r--r--. 1 vdsm kvm 285 Dec 8 11:19 35ac0f88-e97d-4710-a385-127c751a3190.meta [root@aps-te68-mng 9998de26-8a5c-4495-b450-c8dfc1e016da]# qemu-img info 35ac0f88-e97d-4710-a385-127c751a3190 image: 35ac0f88-e97d-4710-a385-127c751a3190 file format: raw virtual size: 50G (53687091200 bytes) disk size: 2.5G [root@aps-te68-mng 9998de26-8a5c-4495-b450-c8dfc1e016da]# Attached agent and broker logs from the last host where HE startup was attempted. Only last two hours. Any hint to perform further investigation ? Thanks in advance. Environment: 3 HPE Proliant BL680cG7, OS on mirrored volume 1, gluster on mirrored volume 2, 1 TB for each server. Multiple network adapters (6), configured only one. I've used last ovirt-node-ng iso image : ovirt-node-ng-installer-ovirt-4.2-pre-2017120512.iso and ovirt-hosted-engine-setup-2.2.1-0.0.master.20171206123553.git94f4c9e.el7.centos.noarch to work around HE static ip address not masked correctly. -- Roberto 2017-12-07 12:44 GMT+01:00 Roberto Nunin <robnunin@gmail.com>:
Hi
after successfully deployed fresh 4.2_rc with ovirt node, I'm facing with a blocking problem.
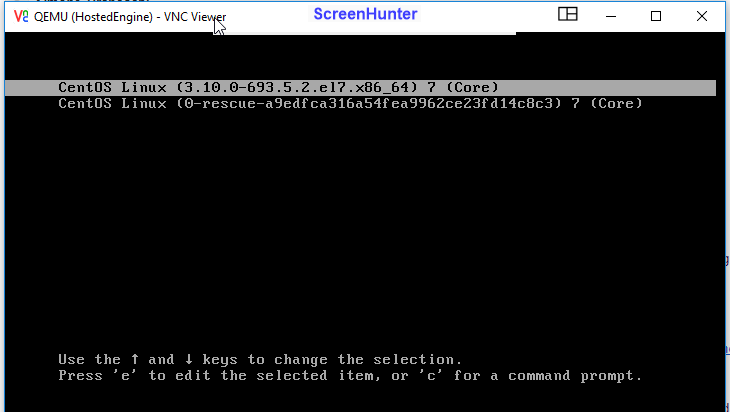
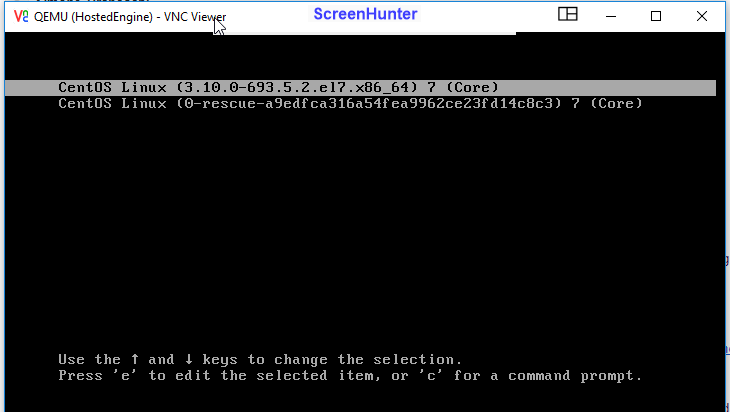
hosted-engine won't boot. Reaching the console via vnc hook, I can see that it is at initial boot screen, but for any OS release available, I receive:
[image: Immagine incorporata 1] then [image: Immagine incorporata 2]
googling around, I'm not able to find suggestions. Any hints ?
Thanks
-- Roberto
{kind=link}
{kind=link}

On Mon, Dec 11, 2017 at 9:47 AM, Roberto Nunin <robnunin@gmail.com> wrote:
Hello all
during weekend, I've re-tried to deploy my 4.2_rc lab. Everything was fine, apart the fact host 2 and 3 weren't imported. I had to add them to the cluster manually, with the NEW function. After this Gluster volumes were added fine to the environment.
Next engine deploy on nodes 2 and 3, ended with ok status.
Tring to migrate HE from host 1 to host 2 was fine, the same from host 2 to host 3.
After these two attempts, no way to migrate HE back to any host. Tried Maintenance mode set to global, reboot the HE and now I'm in the same condition reported below, not anymore able to boot the HE.
Here's hosted-engine --vm-status:
!! Cluster is in GLOBAL MAINTENANCE mode !!
--== Host 1 status ==--
conf_on_shared_storage : True Status up-to-date : True Hostname : aps-te61-mng.example.com Host ID : 1 Engine status : {"reason": "vm not running on this host", "health": "bad", "vm": "down", "detail": "unknown"} Score : 3400 stopped : False Local maintenance : False crc32 : 7dfc420b local_conf_timestamp : 181953 Host timestamp : 181952 Extra metadata (valid at timestamp): metadata_parse_version=1 metadata_feature_version=1 timestamp=181952 (Mon Dec 11 09:21:46 2017) host-id=1 score=3400 vm_conf_refresh_time=181953 (Mon Dec 11 09:21:47 2017) conf_on_shared_storage=True maintenance=False state=GlobalMaintenance stopped=False
--== Host 2 status ==--
conf_on_shared_storage : True Status up-to-date : True Hostname : aps-te64-mng.example.com Host ID : 2 Engine status : {"reason": "vm not running on this host", "health": "bad", "vm": "down", "detail": "unknown"} Score : 3400 stopped : False Local maintenance : False crc32 : 67c7dd1d local_conf_timestamp : 181946 Host timestamp : 181946 Extra metadata (valid at timestamp): metadata_parse_version=1 metadata_feature_version=1 timestamp=181946 (Mon Dec 11 09:21:49 2017) host-id=2 score=3400 vm_conf_refresh_time=181946 (Mon Dec 11 09:21:49 2017) conf_on_shared_storage=True maintenance=False state=GlobalMaintenance stopped=False
--== Host 3 status ==--
conf_on_shared_storage : True Status up-to-date : True Hostname : aps-te68-mng.example.com Host ID : 3 Engine status : {"reason": "failed liveliness check", "health": "bad", "vm": "up", "detail": "Up"} Score : 3400 stopped : False Local maintenance : False crc32 : 4daea041 local_conf_timestamp : 181078 Host timestamp : 181078 Extra metadata (valid at timestamp): metadata_parse_version=1 metadata_feature_version=1 timestamp=181078 (Mon Dec 11 09:21:53 2017) host-id=3 score=3400 vm_conf_refresh_time=181078 (Mon Dec 11 09:21:53 2017) conf_on_shared_storage=True maintenance=False state=GlobalMaintenance stopped=False
!! Cluster is in GLOBAL MAINTENANCE mode !!
(it is in global maintenance to avoid messages to be sent to admin mailbox).
As soon as you exit the global maintenance mode, one of the hosts should take care of automatically restarting the engine VM within a couple of minutes. If you want to manually start the engine VM over a specific host while in maintenance mode you can use: hosted-engine --vm-start on the specific host
Engine image is available on all three hosts, gluster is working fine:
Volume Name: engine Type: Replicate Volume ID: 95355a0b-1f45-4329-95c7-604682e812d0 Status: Started Snapshot Count: 0 Number of Bricks: 1 x 3 = 3 Transport-type: tcp Bricks: Brick1: aps-te61-mng.example.com:/gluster_bricks/engine/engine Brick2: aps-te64-mng.example.com:/gluster_bricks/engine/engine Brick3: aps-te68-mng.example.com:/gluster_bricks/engine/engine Options Reconfigured: nfs.disable: on transport.address-family: inet performance.quick-read: off performance.read-ahead: off performance.io-cache: off performance.low-prio-threads: 32 network.remote-dio: off cluster.eager-lock: enable cluster.quorum-type: auto cluster.server-quorum-type: server cluster.data-self-heal-algorithm: full cluster.locking-scheme: granular cluster.shd-max-threads: 8 cluster.shd-wait-qlength: 10000 features.shard: on user.cifs: off storage.owner-uid: 36 storage.owner-gid: 36 network.ping-timeout: 30 performance.strict-o-direct: on cluster.granular-entry-heal: enable features.shard-block-size: 64MB
Engine qemu image seems to be ok:
[root@aps-te68-mng 9998de26-8a5c-4495-b450-c8dfc1e016da]# l total 2660796 -rw-rw----. 1 vdsm kvm 53687091200 Dec 8 17:22 35ac0f88-e97d-4710-a385- 127c751a3190 -rw-rw----. 1 vdsm kvm 1048576 Dec 11 09:04 35ac0f88-e97d-4710-a385- 127c751a3190.lease -rw-r--r--. 1 vdsm kvm 285 Dec 8 11:19 35ac0f88-e97d-4710-a385- 127c751a3190.meta [root@aps-te68-mng 9998de26-8a5c-4495-b450-c8dfc1e016da]# qemu-img info 35ac0f88-e97d-4710-a385-127c751a3190 image: 35ac0f88-e97d-4710-a385-127c751a3190 file format: raw virtual size: 50G (53687091200 bytes) disk size: 2.5G [root@aps-te68-mng 9998de26-8a5c-4495-b450-c8dfc1e016da]#
Attached agent and broker logs from the last host where HE startup was attempted. Only last two hours.
Any hint to perform further investigation ?
Thanks in advance.
Environment: 3 HPE Proliant BL680cG7, OS on mirrored volume 1, gluster on mirrored volume 2, 1 TB for each server. Multiple network adapters (6), configured only one. I've used last ovirt-node-ng iso image : ovirt-node-ng-installer-ovirt- 4.2-pre-2017120512 <(201)%20712-0512>.iso and ovirt-hosted-engine-setup- 2.2.1-0.0.master.20171206123553.git94f4c9e.el7.centos.noarch to work around HE static ip address not masked correctly.
-- Roberto
2017-12-07 12:44 GMT+01:00 Roberto Nunin <robnunin@gmail.com>:
Hi
after successfully deployed fresh 4.2_rc with ovirt node, I'm facing with a blocking problem.
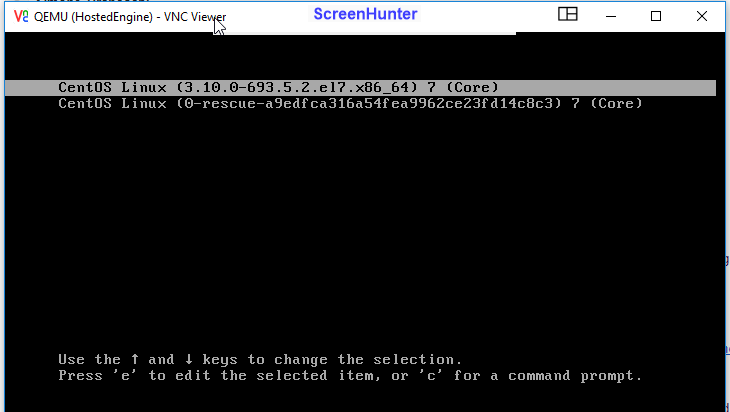
hosted-engine won't boot. Reaching the console via vnc hook, I can see that it is at initial boot screen, but for any OS release available, I receive:
[image: Immagine incorporata 1] then [image: Immagine incorporata 2]
googling around, I'm not able to find suggestions. Any hints ?
Thanks
-- Roberto
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
{kind=link}
{kind=link}

Hi Roberto can you check how much RAM is allocated to the HE VM ? virsh -c qemu:///system?authfile=/etc/ovirt-hosted-engine/virsh_auth.conf virsh # dominfo HostedEngine The last update I did seems to have changed the HE RAM from 4GB to 4MB! On 11 December 2017 at 09:08, Simone Tiraboschi <stirabos@redhat.com> wrote:
On Mon, Dec 11, 2017 at 9:47 AM, Roberto Nunin <robnunin@gmail.com> wrote:
Hello all
during weekend, I've re-tried to deploy my 4.2_rc lab. Everything was fine, apart the fact host 2 and 3 weren't imported. I had to add them to the cluster manually, with the NEW function. After this Gluster volumes were added fine to the environment.
Next engine deploy on nodes 2 and 3, ended with ok status.
Tring to migrate HE from host 1 to host 2 was fine, the same from host 2 to host 3.
After these two attempts, no way to migrate HE back to any host. Tried Maintenance mode set to global, reboot the HE and now I'm in the same condition reported below, not anymore able to boot the HE.
Here's hosted-engine --vm-status:
!! Cluster is in GLOBAL MAINTENANCE mode !!
--== Host 1 status ==--
conf_on_shared_storage : True Status up-to-date : True Hostname : aps-te61-mng.example.com Host ID : 1 Engine status : {"reason": "vm not running on this host", "health": "bad", "vm": "down", "detail": "unknown"} Score : 3400 stopped : False Local maintenance : False crc32 : 7dfc420b local_conf_timestamp : 181953 Host timestamp : 181952 Extra metadata (valid at timestamp): metadata_parse_version=1 metadata_feature_version=1 timestamp=181952 (Mon Dec 11 09:21:46 2017) host-id=1 score=3400 vm_conf_refresh_time=181953 (Mon Dec 11 09:21:47 2017) conf_on_shared_storage=True maintenance=False state=GlobalMaintenance stopped=False
--== Host 2 status ==--
conf_on_shared_storage : True Status up-to-date : True Hostname : aps-te64-mng.example.com Host ID : 2 Engine status : {"reason": "vm not running on this host", "health": "bad", "vm": "down", "detail": "unknown"} Score : 3400 stopped : False Local maintenance : False crc32 : 67c7dd1d local_conf_timestamp : 181946 Host timestamp : 181946 Extra metadata (valid at timestamp): metadata_parse_version=1 metadata_feature_version=1 timestamp=181946 (Mon Dec 11 09:21:49 2017) host-id=2 score=3400 vm_conf_refresh_time=181946 (Mon Dec 11 09:21:49 2017) conf_on_shared_storage=True maintenance=False state=GlobalMaintenance stopped=False
--== Host 3 status ==--
conf_on_shared_storage : True Status up-to-date : True Hostname : aps-te68-mng.example.com Host ID : 3 Engine status : {"reason": "failed liveliness check", "health": "bad", "vm": "up", "detail": "Up"} Score : 3400 stopped : False Local maintenance : False crc32 : 4daea041 local_conf_timestamp : 181078 Host timestamp : 181078 Extra metadata (valid at timestamp): metadata_parse_version=1 metadata_feature_version=1 timestamp=181078 (Mon Dec 11 09:21:53 2017) host-id=3 score=3400 vm_conf_refresh_time=181078 (Mon Dec 11 09:21:53 2017) conf_on_shared_storage=True maintenance=False state=GlobalMaintenance stopped=False
!! Cluster is in GLOBAL MAINTENANCE mode !!
(it is in global maintenance to avoid messages to be sent to admin mailbox).
As soon as you exit the global maintenance mode, one of the hosts should take care of automatically restarting the engine VM within a couple of minutes.
If you want to manually start the engine VM over a specific host while in maintenance mode you can use: hosted-engine --vm-start on the specific host
Engine image is available on all three hosts, gluster is working fine:
Volume Name: engine Type: Replicate Volume ID: 95355a0b-1f45-4329-95c7-604682e812d0 Status: Started Snapshot Count: 0 Number of Bricks: 1 x 3 = 3 Transport-type: tcp Bricks: Brick1: aps-te61-mng.example.com:/gluster_bricks/engine/engine Brick2: aps-te64-mng.example.com:/gluster_bricks/engine/engine Brick3: aps-te68-mng.example.com:/gluster_bricks/engine/engine Options Reconfigured: nfs.disable: on transport.address-family: inet performance.quick-read: off performance.read-ahead: off performance.io-cache: off performance.low-prio-threads: 32 network.remote-dio: off cluster.eager-lock: enable cluster.quorum-type: auto cluster.server-quorum-type: server cluster.data-self-heal-algorithm: full cluster.locking-scheme: granular cluster.shd-max-threads: 8 cluster.shd-wait-qlength: 10000 features.shard: on user.cifs: off storage.owner-uid: 36 storage.owner-gid: 36 network.ping-timeout: 30 performance.strict-o-direct: on cluster.granular-entry-heal: enable features.shard-block-size: 64MB
Engine qemu image seems to be ok:
[root@aps-te68-mng 9998de26-8a5c-4495-b450-c8dfc1e016da]# l total 2660796 -rw-rw----. 1 vdsm kvm 53687091200 Dec 8 17:22 35ac0f88-e97d-4710-a385-127c751a3190 -rw-rw----. 1 vdsm kvm 1048576 Dec 11 09:04 35ac0f88-e97d-4710-a385-127c751a3190.lease -rw-r--r--. 1 vdsm kvm 285 Dec 8 11:19 35ac0f88-e97d-4710-a385-127c751a3190.meta [root@aps-te68-mng 9998de26-8a5c-4495-b450-c8dfc1e016da]# qemu-img info 35ac0f88-e97d-4710-a385-127c751a3190 image: 35ac0f88-e97d-4710-a385-127c751a3190 file format: raw virtual size: 50G (53687091200 bytes) disk size: 2.5G [root@aps-te68-mng 9998de26-8a5c-4495-b450-c8dfc1e016da]#
Attached agent and broker logs from the last host where HE startup was attempted. Only last two hours.
Any hint to perform further investigation ?
Thanks in advance.
Environment: 3 HPE Proliant BL680cG7, OS on mirrored volume 1, gluster on mirrored volume 2, 1 TB for each server. Multiple network adapters (6), configured only one. I've used last ovirt-node-ng iso image : ovirt-node-ng-installer-ovirt- 4.2-pre-2017120512 <(201)%20712-0512>.iso and ovirt-hosted-engine-setup- 2.2.1-0.0.master.20171206123553.git94f4c9e.el7.centos.noarch to work around HE static ip address not masked correctly.
-- Roberto
2017-12-07 12:44 GMT+01:00 Roberto Nunin <robnunin@gmail.com>:
Hi
after successfully deployed fresh 4.2_rc with ovirt node, I'm facing with a blocking problem.
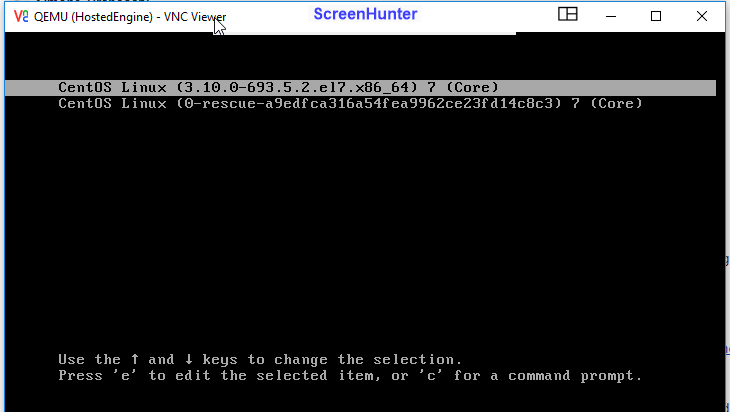
hosted-engine won't boot. Reaching the console via vnc hook, I can see that it is at initial boot screen, but for any OS release available, I receive:
[image: Immagine incorporata 1] then [image: Immagine incorporata 2]
googling around, I'm not able to find suggestions. Any hints ?
Thanks
-- Roberto
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
{kind=link}
{kind=link}

I opened the bug because I had the same issue https://bugzilla.redhat.com/show_bug.cgi?id=1524331. Best Regards On Mon, Dec 11, 2017 at 11:32 AM, Maton, Brett <matonb@ltresources.co.uk> wrote:
Hi Roberto can you check how much RAM is allocated to the HE VM ?
virsh -c qemu:///system?authfile=/etc/ovirt-hosted-engine/virsh_auth.conf
virsh # dominfo HostedEngine
The last update I did seems to have changed the HE RAM from 4GB to 4MB!
On 11 December 2017 at 09:08, Simone Tiraboschi <stirabos@redhat.com> wrote:
On Mon, Dec 11, 2017 at 9:47 AM, Roberto Nunin <robnunin@gmail.com> wrote:
Hello all
during weekend, I've re-tried to deploy my 4.2_rc lab. Everything was fine, apart the fact host 2 and 3 weren't imported. I had to add them to the cluster manually, with the NEW function. After this Gluster volumes were added fine to the environment.
Next engine deploy on nodes 2 and 3, ended with ok status.
Tring to migrate HE from host 1 to host 2 was fine, the same from host 2 to host 3.
After these two attempts, no way to migrate HE back to any host. Tried Maintenance mode set to global, reboot the HE and now I'm in the same condition reported below, not anymore able to boot the HE.
Here's hosted-engine --vm-status:
!! Cluster is in GLOBAL MAINTENANCE mode !!
--== Host 1 status ==--
conf_on_shared_storage : True Status up-to-date : True Hostname : aps-te61-mng.example.com Host ID : 1 Engine status : {"reason": "vm not running on this host", "health": "bad", "vm": "down", "detail": "unknown"} Score : 3400 stopped : False Local maintenance : False crc32 : 7dfc420b local_conf_timestamp : 181953 Host timestamp : 181952 Extra metadata (valid at timestamp): metadata_parse_version=1 metadata_feature_version=1 timestamp=181952 (Mon Dec 11 09:21:46 2017) host-id=1 score=3400 vm_conf_refresh_time=181953 (Mon Dec 11 09:21:47 2017) conf_on_shared_storage=True maintenance=False state=GlobalMaintenance stopped=False
--== Host 2 status ==--
conf_on_shared_storage : True Status up-to-date : True Hostname : aps-te64-mng.example.com Host ID : 2 Engine status : {"reason": "vm not running on this host", "health": "bad", "vm": "down", "detail": "unknown"} Score : 3400 stopped : False Local maintenance : False crc32 : 67c7dd1d local_conf_timestamp : 181946 Host timestamp : 181946 Extra metadata (valid at timestamp): metadata_parse_version=1 metadata_feature_version=1 timestamp=181946 (Mon Dec 11 09:21:49 2017) host-id=2 score=3400 vm_conf_refresh_time=181946 (Mon Dec 11 09:21:49 2017) conf_on_shared_storage=True maintenance=False state=GlobalMaintenance stopped=False
--== Host 3 status ==--
conf_on_shared_storage : True Status up-to-date : True Hostname : aps-te68-mng.example.com Host ID : 3 Engine status : {"reason": "failed liveliness check", "health": "bad", "vm": "up", "detail": "Up"} Score : 3400 stopped : False Local maintenance : False crc32 : 4daea041 local_conf_timestamp : 181078 Host timestamp : 181078 Extra metadata (valid at timestamp): metadata_parse_version=1 metadata_feature_version=1 timestamp=181078 (Mon Dec 11 09:21:53 2017) host-id=3 score=3400 vm_conf_refresh_time=181078 (Mon Dec 11 09:21:53 2017) conf_on_shared_storage=True maintenance=False state=GlobalMaintenance stopped=False
!! Cluster is in GLOBAL MAINTENANCE mode !!
(it is in global maintenance to avoid messages to be sent to admin mailbox).
As soon as you exit the global maintenance mode, one of the hosts should take care of automatically restarting the engine VM within a couple of minutes.
If you want to manually start the engine VM over a specific host while in maintenance mode you can use: hosted-engine --vm-start on the specific host
Engine image is available on all three hosts, gluster is working fine:
Volume Name: engine Type: Replicate Volume ID: 95355a0b-1f45-4329-95c7-604682e812d0 Status: Started Snapshot Count: 0 Number of Bricks: 1 x 3 = 3 Transport-type: tcp Bricks: Brick1: aps-te61-mng.example.com:/gluster_bricks/engine/engine Brick2: aps-te64-mng.example.com:/gluster_bricks/engine/engine Brick3: aps-te68-mng.example.com:/gluster_bricks/engine/engine Options Reconfigured: nfs.disable: on transport.address-family: inet performance.quick-read: off performance.read-ahead: off performance.io-cache: off performance.low-prio-threads: 32 network.remote-dio: off cluster.eager-lock: enable cluster.quorum-type: auto cluster.server-quorum-type: server cluster.data-self-heal-algorithm: full cluster.locking-scheme: granular cluster.shd-max-threads: 8 cluster.shd-wait-qlength: 10000 features.shard: on user.cifs: off storage.owner-uid: 36 storage.owner-gid: 36 network.ping-timeout: 30 performance.strict-o-direct: on cluster.granular-entry-heal: enable features.shard-block-size: 64MB
Engine qemu image seems to be ok:
[root@aps-te68-mng 9998de26-8a5c-4495-b450-c8dfc1e016da]# l total 2660796 -rw-rw----. 1 vdsm kvm 53687091200 Dec 8 17:22 35ac0f88-e97d-4710-a385-127c751a3190 -rw-rw----. 1 vdsm kvm 1048576 Dec 11 09:04 35ac0f88-e97d-4710-a385-127c751a3190.lease -rw-r--r--. 1 vdsm kvm 285 Dec 8 11:19 35ac0f88-e97d-4710-a385-127c751a3190.meta [root@aps-te68-mng 9998de26-8a5c-4495-b450-c8dfc1e016da]# qemu-img info 35ac0f88-e97d-4710-a385-127c751a3190 image: 35ac0f88-e97d-4710-a385-127c751a3190 file format: raw virtual size: 50G (53687091200 bytes) disk size: 2.5G [root@aps-te68-mng 9998de26-8a5c-4495-b450-c8dfc1e016da]#
Attached agent and broker logs from the last host where HE startup was attempted. Only last two hours.
Any hint to perform further investigation ?
Thanks in advance.
Environment: 3 HPE Proliant BL680cG7, OS on mirrored volume 1, gluster on mirrored volume 2, 1 TB for each server. Multiple network adapters (6), configured only one. I've used last ovirt-node-ng iso image : ovirt-node-ng-installer-ovirt- 4.2-pre-2017120512 <(201)%20712-0512>.iso and ovirt-hosted-engine-setup- 2.2.1-0.0.master.20171206123553.git94f4c9e.el7.centos.noarch to work around HE static ip address not masked correctly.
-- Roberto
2017-12-07 12:44 GMT+01:00 Roberto Nunin <robnunin@gmail.com>:
Hi
after successfully deployed fresh 4.2_rc with ovirt node, I'm facing with a blocking problem.
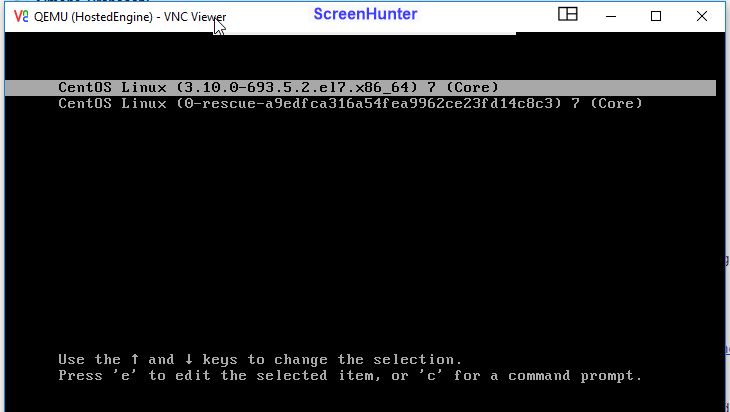
hosted-engine won't boot. Reaching the console via vnc hook, I can see that it is at initial boot screen, but for any OS release available, I receive:
[image: Immagine incorporata 1] then [image: Immagine incorporata 2]
googling around, I'm not able to find suggestions. Any hints ?
Thanks
-- Roberto
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
{kind=link}
{kind=link}
participants (4)
-
 Artyom Lukianov
Artyom Lukianov -
 Maton, Brett
Maton, Brett -
 Roberto Nunin
Roberto Nunin -
 Simone Tiraboschi
Simone Tiraboschi