Weird problem starting VMs in oVirt-4.4

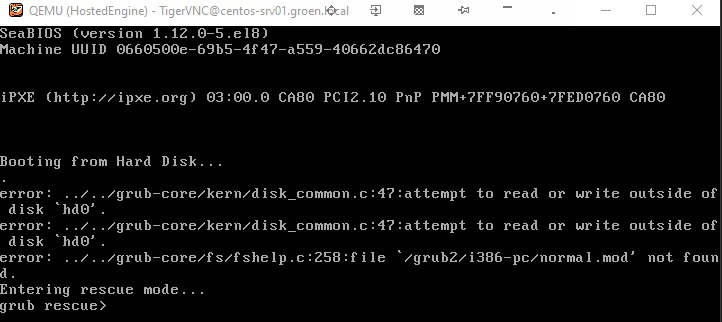
Hi All, Just had a rather new experience in that starting a VM worked but the kernel entered grub2 rescue console due to the fact that something was wrong with its virtio-scsi disk. The message is Booting from Hard Disk .... error: ../../grub-core/kern/dl.c:266:invalid arch-independent ELF maginc. entering rescue mode... Doing a CTRL-ALT-Del through the spice console let the VM boot correctly. Shutting it down and repeating the procedure I get a disk problem everytime. Weird thing is if I activate the BootMenu and then straight away start the VM all is OK. I don't see any ERROR messages in either vdsm.log, engine.log If I would have to guess it looks like the disk image isn't connected yet when the VM boots but thats weird isn't it? Regards, Joop
On 3-6-2020 14:58, Joop wrote:
Hi All,
Just had a rather new experience in that starting a VM worked but the kernel entered grub2 rescue console due to the fact that something was wrong with its virtio-scsi disk. The message is Booting from Hard Disk .... error: ../../grub-core/kern/dl.c:266:invalid arch-independent ELF maginc. entering rescue mode...
Doing a CTRL-ALT-Del through the spice console let the VM boot correctly. Shutting it down and repeating the procedure I get a disk problem everytime. Weird thing is if I activate the BootMenu and then straight away start the VM all is OK. I don't see any ERROR messages in either vdsm.log, engine.log
If I would have to guess it looks like the disk image isn't connected yet when the VM boots but thats weird isn't it?
Additional after testing snapshot functionality, I noted that not once I had this problem but as soon as I removed all snapshots it returned. Joop

Hi Joop I am having the same problem -- thought initially was due to the VM import but it is now happening even on newly created VMs. Rebooting (e.g. ctrl-alt-del) the machine a couple of times solves the issue, but a power off / power on might cause it again... Not sure how best to capture this behaviour in the logs yet... Regards, Marco On Wed, 3 Jun 2020 at 14:00, Joop <jvdwege@xs4all.nl> wrote:
Hi All,
Just had a rather new experience in that starting a VM worked but the kernel entered grub2 rescue console due to the fact that something was wrong with its virtio-scsi disk. The message is Booting from Hard Disk .... error: ../../grub-core/kern/dl.c:266:invalid arch-independent ELF maginc. entering rescue mode...
Doing a CTRL-ALT-Del through the spice console let the VM boot correctly. Shutting it down and repeating the procedure I get a disk problem everytime. Weird thing is if I activate the BootMenu and then straight away start the VM all is OK. I don't see any ERROR messages in either vdsm.log, engine.log
If I would have to guess it looks like the disk image isn't connected yet when the VM boots but thats weird isn't it?
Regards,
Joop
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/TA6BJ2A4XUGKU7...

Is it UEFI based or the lagacy bios ? Best Regards, Strahil Nikolov На 3 юни 2020 г. 19:00:48 GMT+03:00, Marco Fais <evilmf@gmail.com> написа:
Hi Joop
I am having the same problem -- thought initially was due to the VM import but it is now happening even on newly created VMs. Rebooting (e.g. ctrl-alt-del) the machine a couple of times solves the issue, but a power off / power on might cause it again...
Not sure how best to capture this behaviour in the logs yet...
Regards, Marco
On Wed, 3 Jun 2020 at 14:00, Joop <jvdwege@xs4all.nl> wrote:
Hi All,
Just had a rather new experience in that starting a VM worked but the kernel entered grub2 rescue console due to the fact that something was wrong with its virtio-scsi disk. The message is Booting from Hard Disk .... error: ../../grub-core/kern/dl.c:266:invalid arch-independent ELF maginc. entering rescue mode...
Doing a CTRL-ALT-Del through the spice console let the VM boot correctly. Shutting it down and repeating the procedure I get a disk problem everytime. Weird thing is if I activate the BootMenu and then straight away start the VM all is OK. I don't see any ERROR messages in either vdsm.log, engine.log
If I would have to guess it looks like the disk image isn't connected yet when the VM boots but thats weird isn't it?
Regards,
Joop
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives:
https://lists.ovirt.org/archives/list/users@ovirt.org/message/TA6BJ2A4XUGKU7...
On 3-6-2020 22:13, Strahil Nikolov wrote:
Is it UEFI based or the lagacy bios ? Legacy BIOS.
Joop
Best Regards, Strahil Nikolov
На 3 юни 2020 г. 19:00:48 GMT+03:00, Marco Fais <evilmf@gmail.com> написа:
Hi Joop
I am having the same problem -- thought initially was due to the VM import but it is now happening even on newly created VMs. Rebooting (e.g. ctrl-alt-del) the machine a couple of times solves the issue, but a power off / power on might cause it again...
Not sure how best to capture this behaviour in the logs yet...
Regards, Marco
On Wed, 3 Jun 2020 at 14:00, Joop <jvdwege@xs4all.nl> wrote:
Hi All,
Just had a rather new experience in that starting a VM worked but the kernel entered grub2 rescue console due to the fact that something was wrong with its virtio-scsi disk. The message is Booting from Hard Disk .... error: ../../grub-core/kern/dl.c:266:invalid arch-independent ELF maginc. entering rescue mode...
Doing a CTRL-ALT-Del through the spice console let the VM boot correctly. Shutting it down and repeating the procedure I get a disk problem everytime. Weird thing is if I activate the BootMenu and then straight away start the VM all is OK. I don't see any ERROR messages in either vdsm.log, engine.log
If I would have to guess it looks like the disk image isn't connected yet when the VM boots but thats weird isn't it?
Regards,
Joop
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives:
https://lists.ovirt.org/archives/list/users@ovirt.org/message/TA6BJ2A4XUGKU7...

On 4 Jun 2020, at 13:08, Joop <jvdwege@xs4all.nl> wrote:
On 3-6-2020 22:13, Strahil Nikolov wrote:
Is it UEFI based or the lagacy bios ? Legacy BIOS.
Hi,
it is indeed weird and I’m afraid there’s no clear indication where to start. maybe try with different guests? create a different VM and attach the same disk? things like that to narrow it down…
Joop
Best Regards, Strahil Nikolov
На 3 юни 2020 г. 19:00:48 GMT+03:00, Marco Fais <evilmf@gmail.com> написа:
Hi Joop
I am having the same problem -- thought initially was due to the VM import but it is now happening even on newly created VMs. Rebooting (e.g. ctrl-alt-del) the machine a couple of times solves the issue, but a power off / power on might cause it again...
Not sure how best to capture this behaviour in the logs yet...
Regards, Marco
On Wed, 3 Jun 2020 at 14:00, Joop <jvdwege@xs4all.nl> wrote:
Hi All,
Just had a rather new experience in that starting a VM worked but the kernel entered grub2 rescue console due to the fact that something was wrong with its virtio-scsi disk. The message is Booting from Hard Disk .... error: ../../grub-core/kern/dl.c:266:invalid arch-independent ELF maginc. entering rescue mode...
Doing a CTRL-ALT-Del through the spice console let the VM boot correctly. Shutting it down and repeating the procedure I get a disk problem everytime. Weird thing is if I activate the BootMenu and then straight away start the VM all is OK. I don't see any ERROR messages in either vdsm.log, engine.log
If I would have to guess it looks like the disk image isn't connected yet when the VM boots but thats weird isn't it?
Regards,
Joop
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives:
https://lists.ovirt.org/archives/list/users@ovirt.org/message/TA6BJ2A4XUGKU7...
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/EKU7MBUWBTXMUX...
On 3-6-2020 14:58, Joop wrote:
Hi All,
Just had a rather new experience in that starting a VM worked but the kernel entered grub2 rescue console due to the fact that something was wrong with its virtio-scsi disk. The message is Booting from Hard Disk .... error: ../../grub-core/kern/dl.c:266:invalid arch-independent ELF maginc. entering rescue mode...
Doing a CTRL-ALT-Del through the spice console let the VM boot correctly. Shutting it down and repeating the procedure I get a disk problem everytime. Weird thing is if I activate the BootMenu and then straight away start the VM all is OK. I don't see any ERROR messages in either vdsm.log, engine.log
If I would have to guess it looks like the disk image isn't connected yet when the VM boots but thats weird isn't it?
As an update to this: Just had the same problem with a Windows VM but more importantly also with HostedEngine itself. On the host did: hosted-engine --set-maintenance --mode=global hosted-engine --vm-shutdown Stopped all oVirt related services, cleared all oVirt related logs from /var/log/..., restarted the host, ran hosted-engine --set-maintenance --mode=none Watched /var/spool/mail/root to see the engine coming up. It went to starting but never came into the Up status. Set a password and used vncviewer to see the console, see attached screenschot. hosted-engine --vm-poweroff, and tried again, same result hosted-engine --vm-start, works Let it startup and then shut it down after enabling maintenance mode. Copied, hopefully, all relevant logs and attached them. A sosreport is also available, size 12Mb. I can provide a download link if needed. Hopefully someone is able to spot what is going wrong. Regards, Joop
{kind=link}
Are you using ECC ram ? Best Regards, Strahil Nikolov На 8 юни 2020 г. 15:06:22 GMT+03:00, Joop <jvdwege@xs4all.nl> написа:
On 3-6-2020 14:58, Joop wrote:
Hi All,
Just had a rather new experience in that starting a VM worked but the kernel entered grub2 rescue console due to the fact that something was wrong with its virtio-scsi disk. The message is Booting from Hard Disk .... error: ../../grub-core/kern/dl.c:266:invalid arch-independent ELF maginc. entering rescue mode...
Doing a CTRL-ALT-Del through the spice console let the VM boot correctly. Shutting it down and repeating the procedure I get a disk problem everytime. Weird thing is if I activate the BootMenu and then straight away start the VM all is OK. I don't see any ERROR messages in either vdsm.log, engine.log
If I would have to guess it looks like the disk image isn't connected yet when the VM boots but thats weird isn't it?
As an update to this: Just had the same problem with a Windows VM but more importantly also with HostedEngine itself. On the host did: hosted-engine --set-maintenance --mode=global hosted-engine --vm-shutdown
Stopped all oVirt related services, cleared all oVirt related logs from /var/log/..., restarted the host, ran hosted-engine --set-maintenance --mode=none Watched /var/spool/mail/root to see the engine coming up. It went to starting but never came into the Up status. Set a password and used vncviewer to see the console, see attached screenschot. hosted-engine --vm-poweroff, and tried again, same result hosted-engine --vm-start, works Let it startup and then shut it down after enabling maintenance mode. Copied, hopefully, all relevant logs and attached them.
A sosreport is also available, size 12Mb. I can provide a download link if needed.
Hopefully someone is able to spot what is going wrong.
Regards,
Joop
On 8-6-2020 17:52, Strahil Nikolov wrote:
Are you using ECC ram ? No, but what are the chances that starting a VM by using Run directly vs using the Boot wait menu and it hitting that bad bit each and every time? BTW: this setup worked perfectly for over 9 months using 4.3.X.
Joop
Best Regards, Strahil Nikolov
На 8 юни 2020 г. 15:06:22 GMT+03:00, Joop <jvdwege@xs4all.nl> написа:
On 3-6-2020 14:58, Joop wrote:
Hi All,
Just had a rather new experience in that starting a VM worked but the kernel entered grub2 rescue console due to the fact that something was wrong with its virtio-scsi disk. The message is Booting from Hard Disk .... error: ../../grub-core/kern/dl.c:266:invalid arch-independent ELF maginc. entering rescue mode...
Doing a CTRL-ALT-Del through the spice console let the VM boot correctly. Shutting it down and repeating the procedure I get a disk problem everytime. Weird thing is if I activate the BootMenu and then straight away start the VM all is OK. I don't see any ERROR messages in either vdsm.log, engine.log
If I would have to guess it looks like the disk image isn't connected yet when the VM boots but thats weird isn't it?
As an update to this: Just had the same problem with a Windows VM but more importantly also with HostedEngine itself. On the host did: hosted-engine --set-maintenance --mode=global hosted-engine --vm-shutdown
Stopped all oVirt related services, cleared all oVirt related logs from /var/log/..., restarted the host, ran hosted-engine --set-maintenance --mode=none Watched /var/spool/mail/root to see the engine coming up. It went to starting but never came into the Up status. Set a password and used vncviewer to see the console, see attached screenschot. hosted-engine --vm-poweroff, and tried again, same result hosted-engine --vm-start, works Let it startup and then shut it down after enabling maintenance mode. Copied, hopefully, all relevant logs and attached them.
A sosreport is also available, size 12Mb. I can provide a download link if needed.
Hopefully someone is able to spot what is going wrong.
Regards,
Joop
On 8-6-2020 19:55, Joop wrote:
On 8-6-2020 17:52, Strahil Nikolov wrote:
Are you using ECC ram ? No, but what are the chances that starting a VM by using Run directly vs using the Boot wait menu and it hitting that bad bit each and every time? BTW: this setup worked perfectly for over 9 months using 4.3.X.
Joop
Correction, we are using ecc and ran memtest and didn't find anything wrong. Reinstalled the server and I have the same problem again. Started reading up on vdsm-hooks because I could get my VM up consistently when using bootmenu=enabled. So wrote this small piece of code, most of it is copy pasted: #!/usr/bin/python3 # # from __future__ import absolute_import import os import sys import subprocess import hooking if hooking.tobool(os.environ.get('boot_timeout', True)): domxml = hooking.read_domxml() os = domxml.getElementsByTagName('os')[0] bootelem = domxml.createElement('bootmenu') bootelem.setAttribute('timeout', '1000') bootelem.setAttribute('enable', 'yes') os.appendChild(bootelem) hooking.write_domxml(domxml) # pretty_xml_as_string = os.toprettyxml() # sys.stderr.write('%s\n' % pretty_xml_as_string) Saved it in /usr/libexec/vdsm/hooks/before_vm_start as 90_wait Played around with the timeout but lower than 1000 (1sec) and the problem reappears. For the time being I'm going forward with this workaround. For good measure I'll include my versions of ovirt/vdsm/gluster/engine cockpit-ovirt-dashboard-0.14.6-1.el8.noarch ovirt-ansible-engine-setup-1.2.4-1.el8.noarch ovirt-ansible-hosted-engine-setup-1.1.4-1.el8.noarch ovirt-host-4.4.1-1.el8.x86_64 ovirt-host-dependencies-4.4.1-1.el8.x86_64 ovirt-hosted-engine-ha-2.4.3-1.el8.noarch ovirt-hosted-engine-setup-2.4.4-1.el8.noarch ovirt-imageio-client-2.0.6-0.el8.x86_64 ovirt-imageio-common-2.0.6-0.el8.x86_64 ovirt-imageio-daemon-2.0.6-0.el8.x86_64 ovirt-provider-ovn-driver-1.2.30-1.el8.noarch ovirt-release44-4.4.0-2.el8.noarch ovirt-vmconsole-1.0.8-1.el8.noarch ovirt-vmconsole-host-1.0.8-1.el8.noarch python3-ovirt-engine-sdk4-4.4.3-1.el8.x86_64 python3-ovirt-setup-lib-1.3.0-1.el8.noarch vdsm-4.40.16-1.el8.x86_64 vdsm-api-4.40.16-1.el8.noarch vdsm-client-4.40.16-1.el8.noarch vdsm-common-4.40.16-1.el8.noarch vdsm-gluster-4.40.16-1.el8.x86_64 vdsm-hook-ethtool-options-4.40.16-1.el8.noarch vdsm-hook-fcoe-4.40.16-1.el8.noarch vdsm-hook-openstacknet-4.40.16-1.el8.noarch vdsm-hook-vhostmd-4.40.16-1.el8.noarch vdsm-hook-vmfex-dev-4.40.16-1.el8.noarch vdsm-http-4.40.16-1.el8.noarch vdsm-jsonrpc-4.40.16-1.el8.noarch vdsm-network-4.40.16-1.el8.x86_64 vdsm-python-4.40.16-1.el8.noarch vdsm-yajsonrpc-4.40.16-1.el8.noarch gluster-ansible-cluster-1.0.0-1.el8.noarch gluster-ansible-features-1.0.5-6.el8.noarch gluster-ansible-infra-1.0.4-10.el8.noarch gluster-ansible-maintenance-1.0.1-3.el8.noarch gluster-ansible-repositories-1.0.1-2.el8.noarch gluster-ansible-roles-1.0.5-12.el8.noarch glusterfs-7.5-1.el8.x86_64 glusterfs-api-7.5-1.el8.x86_64 glusterfs-cli-7.5-1.el8.x86_64 glusterfs-client-xlators-7.5-1.el8.x86_64 glusterfs-events-7.5-1.el8.x86_64 glusterfs-fuse-7.5-1.el8.x86_64 glusterfs-geo-replication-7.5-1.el8.x86_64 glusterfs-libs-7.5-1.el8.x86_64 glusterfs-rdma-7.5-1.el8.x86_64 glusterfs-server-7.5-1.el8.x86_64 libvirt-daemon-driver-storage-gluster-5.6.0-10.el8.x86_64 python3-gluster-7.5-1.el8.x86_64 qemu-kvm-block-gluster-4.1.0-23.el8.1.x86_64 vdsm-gluster-4.40.16-1.el8.x86_64 ipxe-roms-qemu-20181214-3.git133f4c47.el8.noarch libvirt-daemon-driver-qemu-5.6.0-10.el8.x86_64 qemu-img-4.1.0-23.el8.1.x86_64 qemu-kvm-4.1.0-23.el8.1.x86_64 qemu-kvm-block-curl-4.1.0-23.el8.1.x86_64 qemu-kvm-block-gluster-4.1.0-23.el8.1.x86_64 qemu-kvm-block-iscsi-4.1.0-23.el8.1.x86_64 qemu-kvm-block-rbd-4.1.0-23.el8.1.x86_64 qemu-kvm-block-ssh-4.1.0-23.el8.1.x86_64 qemu-kvm-common-4.1.0-23.el8.1.x86_64 qemu-kvm-core-4.1.0-23.el8.1.x86_64 libvirt-admin-5.6.0-10.el8.x86_64 libvirt-bash-completion-5.6.0-10.el8.x86_64 libvirt-client-5.6.0-10.el8.x86_64 libvirt-daemon-5.6.0-10.el8.x86_64 libvirt-daemon-config-network-5.6.0-10.el8.x86_64 libvirt-daemon-config-nwfilter-5.6.0-10.el8.x86_64 libvirt-daemon-driver-interface-5.6.0-10.el8.x86_64 libvirt-daemon-driver-network-5.6.0-10.el8.x86_64 libvirt-daemon-driver-nodedev-5.6.0-10.el8.x86_64 libvirt-daemon-driver-nwfilter-5.6.0-10.el8.x86_64 libvirt-daemon-driver-qemu-5.6.0-10.el8.x86_64 libvirt-daemon-driver-secret-5.6.0-10.el8.x86_64 libvirt-daemon-driver-storage-5.6.0-10.el8.x86_64 libvirt-daemon-driver-storage-core-5.6.0-10.el8.x86_64 libvirt-daemon-driver-storage-disk-5.6.0-10.el8.x86_64 libvirt-daemon-driver-storage-gluster-5.6.0-10.el8.x86_64 libvirt-daemon-driver-storage-iscsi-5.6.0-10.el8.x86_64 libvirt-daemon-driver-storage-iscsi-direct-5.6.0-10.el8.x86_64 libvirt-daemon-driver-storage-logical-5.6.0-10.el8.x86_64 libvirt-daemon-driver-storage-mpath-5.6.0-10.el8.x86_64 libvirt-daemon-driver-storage-rbd-5.6.0-10.el8.x86_64 libvirt-daemon-driver-storage-scsi-5.6.0-10.el8.x86_64 libvirt-daemon-kvm-5.6.0-10.el8.x86_64 libvirt-libs-5.6.0-10.el8.x86_64 libvirt-lock-sanlock-5.6.0-10.el8.x86_64 python3-libvirt-5.6.0-3.el8.x86_64 ovirt-ansible-cluster-upgrade-1.2.2-1.el8.noarch ovirt-ansible-disaster-recovery-1.3.0-1.el8.noarch ovirt-ansible-engine-setup-1.2.4-1.el8.noarch ovirt-ansible-hosted-engine-setup-1.1.4-1.el8.noarch ovirt-ansible-image-template-1.2.2-1.el8.noarch ovirt-ansible-infra-1.2.1-1.el8.noarch ovirt-ansible-manageiq-1.2.1-1.el8.noarch ovirt-ansible-repositories-1.2.3-1.el8.noarch ovirt-ansible-roles-1.2.3-1.el8.noarch ovirt-ansible-shutdown-env-1.0.4-1.el8.noarch ovirt-ansible-vm-infra-1.2.3-1.el8.noarch ovirt-cockpit-sso-0.1.4-1.el8.noarch ovirt-engine-4.4.0.3-1.el8.noarch ovirt-engine-api-explorer-0.0.6-1.el8.noarch ovirt-engine-backend-4.4.0.3-1.el8.noarch ovirt-engine-dbscripts-4.4.0.3-1.el8.noarch ovirt-engine-dwh-4.4.0.2-1.el8.noarch ovirt-engine-dwh-setup-4.4.0.2-1.el8.noarch ovirt-engine-extension-aaa-jdbc-1.2.0-1.el8.noarch ovirt-engine-extension-aaa-ldap-1.4.0-1.el8.noarch ovirt-engine-extension-aaa-ldap-setup-1.4.0-1.el8.noarch ovirt-engine-extensions-api-1.0.1-1.el8.noarch ovirt-engine-metrics-1.4.0.2-1.el8.noarch ovirt-engine-restapi-4.4.0.3-1.el8.noarch ovirt-engine-setup-4.4.0.3-1.el8.noarch ovirt-engine-setup-base-4.4.0.3-1.el8.noarch ovirt-engine-setup-plugin-cinderlib-4.4.0.3-1.el8.noarch ovirt-engine-setup-plugin-imageio-4.4.0.3-1.el8.noarch ovirt-engine-setup-plugin-ovirt-engine-4.4.0.3-1.el8.noarch ovirt-engine-setup-plugin-ovirt-engine-common-4.4.0.3-1.el8.noarch ovirt-engine-setup-plugin-vmconsole-proxy-helper-4.4.0.3-1.el8.noarch ovirt-engine-setup-plugin-websocket-proxy-4.4.0.3-1.el8.noarch ovirt-engine-tools-4.4.0.3-1.el8.noarch ovirt-engine-tools-backup-4.4.0.3-1.el8.noarch ovirt-engine-ui-extensions-1.2.0-1.el8.noarch ovirt-engine-vmconsole-proxy-helper-4.4.0.3-1.el8.noarch ovirt-engine-webadmin-portal-4.4.0.3-1.el8.noarch ovirt-engine-websocket-proxy-4.4.0.3-1.el8.noarch ovirt-engine-wildfly-18.0.1-1.el8.x86_64 ovirt-engine-wildfly-overlay-18.0.1-1.el8.noarch ovirt-imageio-common-2.0.6-0.el8.x86_64 ovirt-imageio-daemon-2.0.6-0.el8.x86_64 ovirt-provider-ovn-1.2.30-1.el8.noarch ovirt-release44-4.4.0-2.el8.noarch ovirt-vmconsole-1.0.8-1.el8.noarch ovirt-vmconsole-proxy-1.0.8-1.el8.noarch ovirt-web-ui-1.6.2-1.el8.noarch python3-ovirt-engine-lib-4.4.0.3-1.el8.noarch python3-ovirt-engine-sdk4-4.4.3-1.el8.x86_64 python3-ovirt-setup-lib-1.3.0-1.el8.noarch Regards, Joop

On Wed, Jun 10, 2020 at 6:32 PM Joop <jvdwege@xs4all.nl> wrote:
On 8-6-2020 19:55, Joop wrote:
On 8-6-2020 17:52, Strahil Nikolov wrote:
Are you using ECC ram ? No, but what are the chances that starting a VM by using Run directly vs using the Boot wait menu and it hitting that bad bit each and every time? BTW: this setup worked perfectly for over 9 months using 4.3.X.
Joop
Correction, we are using ecc and ran memtest and didn't find anything wrong.
Reinstalled the server and I have the same problem again.
Started reading up on vdsm-hooks because I could get my VM up consistently when using bootmenu=enabled.
When you edit a VM in the UI, there is a "[ ] Enable menu to select boot device" in the "Boot Options" tab. Did you try it? Nir
So wrote this small piece of code, most of it is copy pasted:
#!/usr/bin/python3 # # from __future__ import absolute_import
import os import sys import subprocess import hooking
if hooking.tobool(os.environ.get('boot_timeout', True)): domxml = hooking.read_domxml()
os = domxml.getElementsByTagName('os')[0] bootelem = domxml.createElement('bootmenu') bootelem.setAttribute('timeout', '1000') bootelem.setAttribute('enable', 'yes') os.appendChild(bootelem)
hooking.write_domxml(domxml) # pretty_xml_as_string = os.toprettyxml() # sys.stderr.write('%s\n' % pretty_xml_as_string)
Saved it in /usr/libexec/vdsm/hooks/before_vm_start as 90_wait Played around with the timeout but lower than 1000 (1sec) and the problem reappears. For the time being I'm going forward with this workaround.
For good measure I'll include my versions of ovirt/vdsm/gluster/engine cockpit-ovirt-dashboard-0.14.6-1.el8.noarch ovirt-ansible-engine-setup-1.2.4-1.el8.noarch ovirt-ansible-hosted-engine-setup-1.1.4-1.el8.noarch ovirt-host-4.4.1-1.el8.x86_64 ovirt-host-dependencies-4.4.1-1.el8.x86_64 ovirt-hosted-engine-ha-2.4.3-1.el8.noarch ovirt-hosted-engine-setup-2.4.4-1.el8.noarch ovirt-imageio-client-2.0.6-0.el8.x86_64 ovirt-imageio-common-2.0.6-0.el8.x86_64 ovirt-imageio-daemon-2.0.6-0.el8.x86_64 ovirt-provider-ovn-driver-1.2.30-1.el8.noarch ovirt-release44-4.4.0-2.el8.noarch ovirt-vmconsole-1.0.8-1.el8.noarch ovirt-vmconsole-host-1.0.8-1.el8.noarch python3-ovirt-engine-sdk4-4.4.3-1.el8.x86_64 python3-ovirt-setup-lib-1.3.0-1.el8.noarch
vdsm-4.40.16-1.el8.x86_64 vdsm-api-4.40.16-1.el8.noarch vdsm-client-4.40.16-1.el8.noarch vdsm-common-4.40.16-1.el8.noarch vdsm-gluster-4.40.16-1.el8.x86_64 vdsm-hook-ethtool-options-4.40.16-1.el8.noarch vdsm-hook-fcoe-4.40.16-1.el8.noarch vdsm-hook-openstacknet-4.40.16-1.el8.noarch vdsm-hook-vhostmd-4.40.16-1.el8.noarch vdsm-hook-vmfex-dev-4.40.16-1.el8.noarch vdsm-http-4.40.16-1.el8.noarch vdsm-jsonrpc-4.40.16-1.el8.noarch vdsm-network-4.40.16-1.el8.x86_64 vdsm-python-4.40.16-1.el8.noarch vdsm-yajsonrpc-4.40.16-1.el8.noarch
gluster-ansible-cluster-1.0.0-1.el8.noarch gluster-ansible-features-1.0.5-6.el8.noarch gluster-ansible-infra-1.0.4-10.el8.noarch gluster-ansible-maintenance-1.0.1-3.el8.noarch gluster-ansible-repositories-1.0.1-2.el8.noarch gluster-ansible-roles-1.0.5-12.el8.noarch glusterfs-7.5-1.el8.x86_64 glusterfs-api-7.5-1.el8.x86_64 glusterfs-cli-7.5-1.el8.x86_64 glusterfs-client-xlators-7.5-1.el8.x86_64 glusterfs-events-7.5-1.el8.x86_64 glusterfs-fuse-7.5-1.el8.x86_64 glusterfs-geo-replication-7.5-1.el8.x86_64 glusterfs-libs-7.5-1.el8.x86_64 glusterfs-rdma-7.5-1.el8.x86_64 glusterfs-server-7.5-1.el8.x86_64 libvirt-daemon-driver-storage-gluster-5.6.0-10.el8.x86_64 python3-gluster-7.5-1.el8.x86_64 qemu-kvm-block-gluster-4.1.0-23.el8.1.x86_64 vdsm-gluster-4.40.16-1.el8.x86_64
ipxe-roms-qemu-20181214-3.git133f4c47.el8.noarch libvirt-daemon-driver-qemu-5.6.0-10.el8.x86_64 qemu-img-4.1.0-23.el8.1.x86_64 qemu-kvm-4.1.0-23.el8.1.x86_64 qemu-kvm-block-curl-4.1.0-23.el8.1.x86_64 qemu-kvm-block-gluster-4.1.0-23.el8.1.x86_64 qemu-kvm-block-iscsi-4.1.0-23.el8.1.x86_64 qemu-kvm-block-rbd-4.1.0-23.el8.1.x86_64 qemu-kvm-block-ssh-4.1.0-23.el8.1.x86_64 qemu-kvm-common-4.1.0-23.el8.1.x86_64 qemu-kvm-core-4.1.0-23.el8.1.x86_64
libvirt-admin-5.6.0-10.el8.x86_64 libvirt-bash-completion-5.6.0-10.el8.x86_64 libvirt-client-5.6.0-10.el8.x86_64 libvirt-daemon-5.6.0-10.el8.x86_64 libvirt-daemon-config-network-5.6.0-10.el8.x86_64 libvirt-daemon-config-nwfilter-5.6.0-10.el8.x86_64 libvirt-daemon-driver-interface-5.6.0-10.el8.x86_64 libvirt-daemon-driver-network-5.6.0-10.el8.x86_64 libvirt-daemon-driver-nodedev-5.6.0-10.el8.x86_64 libvirt-daemon-driver-nwfilter-5.6.0-10.el8.x86_64 libvirt-daemon-driver-qemu-5.6.0-10.el8.x86_64 libvirt-daemon-driver-secret-5.6.0-10.el8.x86_64 libvirt-daemon-driver-storage-5.6.0-10.el8.x86_64 libvirt-daemon-driver-storage-core-5.6.0-10.el8.x86_64 libvirt-daemon-driver-storage-disk-5.6.0-10.el8.x86_64 libvirt-daemon-driver-storage-gluster-5.6.0-10.el8.x86_64 libvirt-daemon-driver-storage-iscsi-5.6.0-10.el8.x86_64 libvirt-daemon-driver-storage-iscsi-direct-5.6.0-10.el8.x86_64 libvirt-daemon-driver-storage-logical-5.6.0-10.el8.x86_64 libvirt-daemon-driver-storage-mpath-5.6.0-10.el8.x86_64 libvirt-daemon-driver-storage-rbd-5.6.0-10.el8.x86_64 libvirt-daemon-driver-storage-scsi-5.6.0-10.el8.x86_64 libvirt-daemon-kvm-5.6.0-10.el8.x86_64 libvirt-libs-5.6.0-10.el8.x86_64 libvirt-lock-sanlock-5.6.0-10.el8.x86_64 python3-libvirt-5.6.0-3.el8.x86_64
ovirt-ansible-cluster-upgrade-1.2.2-1.el8.noarch ovirt-ansible-disaster-recovery-1.3.0-1.el8.noarch ovirt-ansible-engine-setup-1.2.4-1.el8.noarch ovirt-ansible-hosted-engine-setup-1.1.4-1.el8.noarch ovirt-ansible-image-template-1.2.2-1.el8.noarch ovirt-ansible-infra-1.2.1-1.el8.noarch ovirt-ansible-manageiq-1.2.1-1.el8.noarch ovirt-ansible-repositories-1.2.3-1.el8.noarch ovirt-ansible-roles-1.2.3-1.el8.noarch ovirt-ansible-shutdown-env-1.0.4-1.el8.noarch ovirt-ansible-vm-infra-1.2.3-1.el8.noarch ovirt-cockpit-sso-0.1.4-1.el8.noarch ovirt-engine-4.4.0.3-1.el8.noarch ovirt-engine-api-explorer-0.0.6-1.el8.noarch ovirt-engine-backend-4.4.0.3-1.el8.noarch ovirt-engine-dbscripts-4.4.0.3-1.el8.noarch ovirt-engine-dwh-4.4.0.2-1.el8.noarch ovirt-engine-dwh-setup-4.4.0.2-1.el8.noarch ovirt-engine-extension-aaa-jdbc-1.2.0-1.el8.noarch ovirt-engine-extension-aaa-ldap-1.4.0-1.el8.noarch ovirt-engine-extension-aaa-ldap-setup-1.4.0-1.el8.noarch ovirt-engine-extensions-api-1.0.1-1.el8.noarch ovirt-engine-metrics-1.4.0.2-1.el8.noarch ovirt-engine-restapi-4.4.0.3-1.el8.noarch ovirt-engine-setup-4.4.0.3-1.el8.noarch ovirt-engine-setup-base-4.4.0.3-1.el8.noarch ovirt-engine-setup-plugin-cinderlib-4.4.0.3-1.el8.noarch ovirt-engine-setup-plugin-imageio-4.4.0.3-1.el8.noarch ovirt-engine-setup-plugin-ovirt-engine-4.4.0.3-1.el8.noarch ovirt-engine-setup-plugin-ovirt-engine-common-4.4.0.3-1.el8.noarch ovirt-engine-setup-plugin-vmconsole-proxy-helper-4.4.0.3-1.el8.noarch ovirt-engine-setup-plugin-websocket-proxy-4.4.0.3-1.el8.noarch ovirt-engine-tools-4.4.0.3-1.el8.noarch ovirt-engine-tools-backup-4.4.0.3-1.el8.noarch ovirt-engine-ui-extensions-1.2.0-1.el8.noarch ovirt-engine-vmconsole-proxy-helper-4.4.0.3-1.el8.noarch ovirt-engine-webadmin-portal-4.4.0.3-1.el8.noarch ovirt-engine-websocket-proxy-4.4.0.3-1.el8.noarch ovirt-engine-wildfly-18.0.1-1.el8.x86_64 ovirt-engine-wildfly-overlay-18.0.1-1.el8.noarch ovirt-imageio-common-2.0.6-0.el8.x86_64 ovirt-imageio-daemon-2.0.6-0.el8.x86_64 ovirt-provider-ovn-1.2.30-1.el8.noarch ovirt-release44-4.4.0-2.el8.noarch ovirt-vmconsole-1.0.8-1.el8.noarch ovirt-vmconsole-proxy-1.0.8-1.el8.noarch ovirt-web-ui-1.6.2-1.el8.noarch python3-ovirt-engine-lib-4.4.0.3-1.el8.noarch python3-ovirt-engine-sdk4-4.4.3-1.el8.x86_64 python3-ovirt-setup-lib-1.3.0-1.el8.noarch
Regards,
Joop
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/7FWSHBGGN7KED2...

I ended up making a BZ about this same issue a few weeks ago, but misdiagnosed the root cause. Maybe we could add to that? https://bugzilla.redhat.com/show_bug.cgi?id=1839598 On Mon, Jun 8, 2020, 11:54 AM Strahil Nikolov via Users <users@ovirt.org> wrote:
Are you using ECC ram ?
Best Regards, Strahil Nikolov
На 8 юни 2020 г. 15:06:22 GMT+03:00, Joop <jvdwege@xs4all.nl> написа:
On 3-6-2020 14:58, Joop wrote:
Hi All,
Just had a rather new experience in that starting a VM worked but the kernel entered grub2 rescue console due to the fact that something was wrong with its virtio-scsi disk. The message is Booting from Hard Disk .... error: ../../grub-core/kern/dl.c:266:invalid arch-independent ELF maginc. entering rescue mode...
Doing a CTRL-ALT-Del through the spice console let the VM boot correctly. Shutting it down and repeating the procedure I get a disk problem everytime. Weird thing is if I activate the BootMenu and then straight away start the VM all is OK. I don't see any ERROR messages in either vdsm.log, engine.log
If I would have to guess it looks like the disk image isn't connected yet when the VM boots but thats weird isn't it?
As an update to this: Just had the same problem with a Windows VM but more importantly also with HostedEngine itself. On the host did: hosted-engine --set-maintenance --mode=global hosted-engine --vm-shutdown
Stopped all oVirt related services, cleared all oVirt related logs from /var/log/..., restarted the host, ran hosted-engine --set-maintenance --mode=none Watched /var/spool/mail/root to see the engine coming up. It went to starting but never came into the Up status. Set a password and used vncviewer to see the console, see attached screenschot. hosted-engine --vm-poweroff, and tried again, same result hosted-engine --vm-start, works Let it startup and then shut it down after enabling maintenance mode. Copied, hopefully, all relevant logs and attached them.
A sosreport is also available, size 12Mb. I can provide a download link if needed.
Hopefully someone is able to spot what is going wrong.
Regards,
Joop
Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/XASNIEZTZIMWAU...
On 8-6-2020 19:56, Stephen Panicho wrote:
I ended up making a BZ about this same issue a few weeks ago, but misdiagnosed the root cause. Maybe we could add to that?
https://bugzilla.redhat.com/show_bug.cgi?id=1839598 And maybe change the title to something else. I'm ok with my logs/mail being added to it. I can do it sometime today or tomorrow but feel free to do it if that suits you.
Regards, Joop
On Mon, Jun 8, 2020, 11:54 AM Strahil Nikolov via Users <users@ovirt.org <mailto:users@ovirt.org>> wrote:
Are you using ECC ram ?
Best Regards, Strahil Nikolov
На 8 юни 2020 г. 15:06:22 GMT+03:00, Joop <jvdwege@xs4all.nl <mailto:jvdwege@xs4all.nl>> написа: >On 3-6-2020 14:58, Joop wrote: >> Hi All, >> >> Just had a rather new experience in that starting a VM worked but the >> kernel entered grub2 rescue console due to the fact that something >was >> wrong with its virtio-scsi disk. >> The message is Booting from Hard Disk .... >> error: ../../grub-core/kern/dl.c:266:invalid arch-independent ELF >maginc. >> entering rescue mode... >> >> Doing a CTRL-ALT-Del through the spice console let the VM boot >> correctly. Shutting it down and repeating the procedure I get a disk >> problem everytime. Weird thing is if I activate the BootMenu and then >> straight away start the VM all is OK. >> I don't see any ERROR messages in either vdsm.log, engine.log >> >> If I would have to guess it looks like the disk image isn't connected >> yet when the VM boots but thats weird isn't it? >> >> >As an update to this: >Just had the same problem with a Windows VM but more importantly also >with HostedEngine itself. >On the host did: >hosted-engine --set-maintenance --mode=global >hosted-engine --vm-shutdown > >Stopped all oVirt related services, cleared all oVirt related logs from >/var/log/..., restarted the host, ran hosted-engine --set-maintenance >--mode=none >Watched /var/spool/mail/root to see the engine coming up. It went to >starting but never came into the Up status. >Set a password and used vncviewer to see the console, see attached >screenschot. >hosted-engine --vm-poweroff, and tried again, same result >hosted-engine --vm-start, works >Let it startup and then shut it down after enabling maintenance mode. >Copied, hopefully, all relevant logs and attached them. > >A sosreport is also available, size 12Mb. I can provide a download link >if needed. > >Hopefully someone is able to spot what is going wrong. > >Regards, > >Joop _______________________________________________ Users mailing list -- users@ovirt.org <mailto:users@ovirt.org> To unsubscribe send an email to users-leave@ovirt.org <mailto:users-leave@ovirt.org> Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/XASNIEZTZIMWAU...
On Mon, Jun 8, 2020 at 3:10 PM Joop <jvdwege@xs4all.nl> wrote:
On 3-6-2020 14:58, Joop wrote:
Hi All,
Just had a rather new experience in that starting a VM worked but the kernel entered grub2 rescue console due to the fact that something was wrong with its virtio-scsi disk. The message is Booting from Hard Disk .... error: ../../grub-core/kern/dl.c:266:invalid arch-independent ELF maginc. entering rescue mode...
Doing a CTRL-ALT-Del through the spice console let the VM boot correctly. Shutting it down and repeating the procedure I get a disk problem everytime. Weird thing is if I activate the BootMenu and then straight away start the VM all is OK. I don't see any ERROR messages in either vdsm.log, engine.log
If I would have to guess it looks like the disk image isn't connected yet when the VM boots but thats weird isn't it?
As an update to this: Just had the same problem with a Windows VM but more importantly also with HostedEngine itself. On the host did: hosted-engine --set-maintenance --mode=global hosted-engine --vm-shutdown
Stopped all oVirt related services, cleared all oVirt related logs from /var/log/..., restarted the host, ran hosted-engine --set-maintenance --mode=none Watched /var/spool/mail/root to see the engine coming up. It went to starting but never came into the Up status. Set a password and used vncviewer to see the console, see attached screenschot.
The screenshot "engine.png" show gluster bug we discovered a few weeks ago: https://bugzilla.redhat.com/1823423 Until you get a fixed version, this may fix the issues: # gluster volume set engine performance.stat-prefetch off See https://bugzilla.redhat.com/show_bug.cgi?id=1823423#c55. Krutica, can this bug affect upstream gluster? Joop, please share the gluster version in your setup.
hosted-engine --vm-poweroff, and tried again, same result hosted-engine --vm-start, works Let it startup and then shut it down after enabling maintenance mode. Copied, hopefully, all relevant logs and attached them.
A sosreport is also available, size 12Mb. I can provide a download link if needed.
Hopefully someone is able to spot what is going wrong.
Regards,
Joop
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/VJ7ZOXHCOKBNNU...

Yes, so the bug has been fixed upstream and the backports to release-7 and release-8 of gluster pending merge. The fix should be available in the next .x release of gluster-7 and 8. Until then like Nir suggested, please turn off performance.stat-prefetch on your volumes. -Krutika On Wed, Jun 17, 2020 at 5:59 AM Nir Soffer <nsoffer@redhat.com> wrote:
On Mon, Jun 8, 2020 at 3:10 PM Joop <jvdwege@xs4all.nl> wrote:
On 3-6-2020 14:58, Joop wrote:
Hi All,
Just had a rather new experience in that starting a VM worked but the kernel entered grub2 rescue console due to the fact that something was wrong with its virtio-scsi disk. The message is Booting from Hard Disk .... error: ../../grub-core/kern/dl.c:266:invalid arch-independent ELF
maginc.
entering rescue mode...
Doing a CTRL-ALT-Del through the spice console let the VM boot correctly. Shutting it down and repeating the procedure I get a disk problem everytime. Weird thing is if I activate the BootMenu and then straight away start the VM all is OK. I don't see any ERROR messages in either vdsm.log, engine.log
If I would have to guess it looks like the disk image isn't connected yet when the VM boots but thats weird isn't it?
As an update to this: Just had the same problem with a Windows VM but more importantly also with HostedEngine itself. On the host did: hosted-engine --set-maintenance --mode=global hosted-engine --vm-shutdown
Stopped all oVirt related services, cleared all oVirt related logs from /var/log/..., restarted the host, ran hosted-engine --set-maintenance --mode=none Watched /var/spool/mail/root to see the engine coming up. It went to starting but never came into the Up status. Set a password and used vncviewer to see the console, see attached screenschot.
The screenshot "engine.png" show gluster bug we discovered a few weeks ago: https://bugzilla.redhat.com/1823423
Until you get a fixed version, this may fix the issues:
# gluster volume set engine performance.stat-prefetch off
See https://bugzilla.redhat.com/show_bug.cgi?id=1823423#c55.
Krutica, can this bug affect upstream gluster?
Joop, please share the gluster version in your setup.
hosted-engine --vm-poweroff, and tried again, same result hosted-engine --vm-start, works Let it startup and then shut it down after enabling maintenance mode. Copied, hopefully, all relevant logs and attached them.
A sosreport is also available, size 12Mb. I can provide a download link if needed.
Hopefully someone is able to spot what is going wrong.
Regards,
Joop
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/VJ7ZOXHCOKBNNU...

Krutika Dhananjay wrote:
Yes, so the bug has been fixed upstream and the backports to release-7 and release-8 of gluster pending merge. The fix should be available in the next .x release of gluster-7 and 8. Until then like Nir suggested, please turn off performance.stat-prefetch on your volumes.
It looks like I ran exactly into this bug when I wrote this: https://lists.ovirt.org/archives/list/users@ovirt.org/message/3BQMCIGCEOLIOV... During my tests, the deployment went through when trying for the third time - only to discover of course that the problem persists and it, sure enough came back to haunt me when I rebooted the hosted engine. I'm not entirely sure I fully understand the problem. What I did, of course, was this: # gluster volume set engine performance.stat-prefetch off It doesn't help with my currently deployed HE - it gets stuck at the graphical BIOS screen which I can interact with using "hosted-engine --console" but the best outcome there is to "Reset" which turns the whole VM off. Assuming something got lost with the stat-prefetch setting turned on before: Is there any way to fix this? Will a redeployment surely fix it? Bonus question: I'm using oVirt Node for the VM and Gluster hosts. Will a fix be coming by way of package updates for this in the foreseeable future? Thank you Oliver
June 17, 2020 8:11 AM, "Krutika Dhananjay" <kdhananj@redhat.com> wrote:
Yes, so the bug has been fixed upstream and the backports to release-7 and release-8 of gluster pending merge. The fix should be available in the next .x release of gluster-7 and 8. Until then like Nir suggested, please turn off performance.stat-prefetch on your volumes.
-Krutika On Wed, Jun 17, 2020 at 5:59 AM Nir Soffer <nsoffer@redhat.com> wrote:
On Mon, Jun 8, 2020 at 3:10 PM Joop <jvdwege@xs4all.nl> wrote:
On 3-6-2020 14:58, Joop wrote:
Hi All,
Just had a rather new experience in that starting a VM worked but the kernel entered grub2 rescue console due to the fact that something was wrong with its virtio-scsi disk. The message is Booting from Hard Disk .... error: ../../grub-core/kern/dl.c:266:invalid arch-independent ELF maginc. entering rescue mode...
Doing a CTRL-ALT-Del through the spice console let the VM boot correctly. Shutting it down and repeating the procedure I get a disk problem everytime. Weird thing is if I activate the BootMenu and then straight away start the VM all is OK. I don't see any ERROR messages in either vdsm.log, engine.log
If I would have to guess it looks like the disk image isn't connected yet when the VM boots but thats weird isn't it?
As an update to this: Just had the same problem with a Windows VM but more importantly also with HostedEngine itself. On the host did: hosted-engine --set-maintenance --mode=global hosted-engine --vm-shutdown
Stopped all oVirt related services, cleared all oVirt related logs from /var/log/..., restarted the host, ran hosted-engine --set-maintenance --mode=none Watched /var/spool/mail/root to see the engine coming up. It went to starting but never came into the Up status. Set a password and used vncviewer to see the console, see attached screenschot.
The screenshot "engine.png" show gluster bug we discovered a few weeks ago: https://bugzilla.redhat.com/1823423
Until you get a fixed version, this may fix the issues:
# gluster volume set engine performance.stat-prefetch off
See https://bugzilla.redhat.com/show_bug.cgi?id=1823423#c55.
Krutica, can this bug affect upstream gluster?
Joop, please share the gluster version in your setup.
gluster-ansible-cluster-1.0.0-1.el8.noarch gluster-ansible-features-1.0.5-6.el8.noarch gluster-ansible-infra-1.0.4-10.el8.noarch gluster-ansible-maintenance-1.0.1-3.el8.noarch gluster-ansible-repositories-1.0.1-2.el8.noarch gluster-ansible-roles-1.0.5-12.el8.noarch glusterfs-7.5-1.el8.x86_64 glusterfs-api-7.5-1.el8.x86_64 glusterfs-cli-7.5-1.el8.x86_64 glusterfs-client-xlators-7.5-1.el8.x86_64 glusterfs-events-7.5-1.el8.x86_64 glusterfs-fuse-7.5-1.el8.x86_64 glusterfs-geo-replication-7.5-1.el8.x86_64 glusterfs-libs-7.5-1.el8.x86_64 glusterfs-rdma-7.5-1.el8.x86_64 glusterfs-server-7.5-1.el8.x86_64 libvirt-daemon-driver-storage-gluster-6.0.0-17.el8.x86_64 python3-gluster-7.5-1.el8.x86_64 qemu-kvm-block-gluster-4.2.0-19.el8.x86_64 vdsm-gluster-4.40.16-1.el8.x86_64 I tried friday to import my VMs but had not much success with the stat-prefetch off setting. Some VMs imported correctly some didn't and no correlation between size or whatever. Sunday I decided to use features.shard off and I was able to import 1Tb worth of VM images without a hitch. I'm on HCI so I'm assuming that turning sharding off won't be a performance problem? If its fixed I can still move all VM disk to a other storage domain and back after turning sharding back on. Regards, Joop
On 3-6-2020 14:58, Joop wrote:
Hi All,
Just had a rather new experience in that starting a VM worked but the kernel entered grub2 rescue console due to the fact that something was wrong with its virtio-scsi disk. The message is Booting from Hard Disk .... error: ../../grub-core/kern/dl.c:266:invalid arch-independent ELF maginc. entering rescue mode...
Doing a CTRL-ALT-Del through the spice console let the VM boot correctly. Shutting it down and repeating the procedure I get a disk problem everytime. Weird thing is if I activate the BootMenu and then straight away start the VM all is OK. I don't see any ERROR messages in either vdsm.log, engine.log
If I would have to guess it looks like the disk image isn't connected yet when the VM boots but thats weird isn't it?
As a follow up I tried a couple of other things: - installed CentOS-7 and oVirt 4.3.10 using HCI and same problem (the previous install of 4.3 was a upgraded version. Don't know the start versie) - did some testing with copying large files into the engine gluster volume through /rhev/datacenter using 'cp' and no problems - used qemu-img convert with the engine gluster volume as destination --> problems - had a good look through lots of logfiles and stumbled across an error about missing shard which aligned with qemu-img errors - turned features.shard off on the volume and restarted the volume - reran the tests with qemu-img --> no problems any more. - reinstalled Centos8.2 + oVirt-4.0, turned off sharding before starting the engine install --> no problems installing, no problems importing, no problems starting vms, sofar I need to install another server tomorrow, so I'll do that with sharding enabled and see if it crashes too and then get the logs some place safe. Regards, Joop
Hey Joop, are you using fully allocated qcow2 images ? Best Regards, Strahil Nikolov На 16 юни 2020 г. 20:23:17 GMT+03:00, Joop <jvdwege@xs4all.nl> написа:
On 3-6-2020 14:58, Joop wrote:
Hi All,
Just had a rather new experience in that starting a VM worked but the kernel entered grub2 rescue console due to the fact that something was wrong with its virtio-scsi disk. The message is Booting from Hard Disk .... error: ../../grub-core/kern/dl.c:266:invalid arch-independent ELF maginc. entering rescue mode...
Doing a CTRL-ALT-Del through the spice console let the VM boot correctly. Shutting it down and repeating the procedure I get a disk problem everytime. Weird thing is if I activate the BootMenu and then straight away start the VM all is OK. I don't see any ERROR messages in either vdsm.log, engine.log
If I would have to guess it looks like the disk image isn't connected yet when the VM boots but thats weird isn't it?
As a follow up I tried a couple of other things: - installed CentOS-7 and oVirt 4.3.10 using HCI and same problem (the previous install of 4.3 was a upgraded version. Don't know the start versie) - did some testing with copying large files into the engine gluster volume through /rhev/datacenter using 'cp' and no problems - used qemu-img convert with the engine gluster volume as destination --> problems - had a good look through lots of logfiles and stumbled across an error about missing shard which aligned with qemu-img errors - turned features.shard off on the volume and restarted the volume - reran the tests with qemu-img --> no problems any more. - reinstalled Centos8.2 + oVirt-4.0, turned off sharding before starting the engine install --> no problems installing, no problems importing, no problems starting vms, sofar
I need to install another server tomorrow, so I'll do that with sharding enabled and see if it crashes too and then get the logs some place safe.
Regards,
Joop
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/6TNJYNVBJWCB2N...
On 16-6-2020 19:44, Strahil Nikolov wrote:
Hey Joop,
are you using fully allocated qcow2 images ?
Best Regards, Strahil Nikolov
I noticed that when I use import VM from an Export domain I see that it sometimes uses preallocated and sometimes thin-provisioned for the disk(s). Don't know why and I don't think there is a pattern. Old VMs from 3.3 or new ones from 4.2/3, its mixed. I almost always use thin-provisioned but one or two could have been preallocated by accident. How do I check? Joop
На 16 юни 2020 г. 20:23:17 GMT+03:00, Joop <jvdwege@xs4all.nl> написа:
On 3-6-2020 14:58, Joop wrote:
Hi All,
Just had a rather new experience in that starting a VM worked but the kernel entered grub2 rescue console due to the fact that something was wrong with its virtio-scsi disk. The message is Booting from Hard Disk .... error: ../../grub-core/kern/dl.c:266:invalid arch-independent ELF maginc. entering rescue mode...
Doing a CTRL-ALT-Del through the spice console let the VM boot correctly. Shutting it down and repeating the procedure I get a disk problem everytime. Weird thing is if I activate the BootMenu and then straight away start the VM all is OK. I don't see any ERROR messages in either vdsm.log, engine.log
If I would have to guess it looks like the disk image isn't connected yet when the VM boots but thats weird isn't it?
As a follow up I tried a couple of other things: - installed CentOS-7 and oVirt 4.3.10 using HCI and same problem (the previous install of 4.3 was a upgraded version. Don't know the start versie) - did some testing with copying large files into the engine gluster volume through /rhev/datacenter using 'cp' and no problems - used qemu-img convert with the engine gluster volume as destination --> problems - had a good look through lots of logfiles and stumbled across an error about missing shard which aligned with qemu-img errors - turned features.shard off on the volume and restarted the volume - reran the tests with qemu-img --> no problems any more. - reinstalled Centos8.2 + oVirt-4.0, turned off sharding before starting the engine install --> no problems installing, no problems importing, no problems starting vms, sofar
I need to install another server tomorrow, so I'll do that with sharding enabled and see if it crashes too and then get the logs some place safe.
Regards,
Joop
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/6TNJYNVBJWCB2N...
On Tue, Jun 16, 2020 at 11:01 PM Joop <jvdwege@xs4all.nl> wrote:
On 16-6-2020 19:44, Strahil Nikolov wrote:
Hey Joop,
are you using fully allocated qcow2 images ?
Best Regards, Strahil Nikolov
I noticed that when I use import VM from an Export domain I see that it sometimes uses preallocated and sometimes thin-provisioned for the disk(s). Don't know why and I don't think there is a pattern.
Maybe the system selects a different storage domain? On block storage the default is preallocated, but on file based storage the default is thin.
Old VMs from 3.3 or new ones from 4.2/3, its mixed. I almost always use thin-provisioned but one or two could have been preallocated by accident.
How do I check?
If the question was about creating images with: qemu-img create -f qcow2 -o preallocation=metadata ... Then it is easy, ovirt does not create such images.
Joop
На 16 юни 2020 г. 20:23:17 GMT+03:00, Joop <jvdwege@xs4all.nl> написа:
On 3-6-2020 14:58, Joop wrote:
Hi All,
Just had a rather new experience in that starting a VM worked but the kernel entered grub2 rescue console due to the fact that something was wrong with its virtio-scsi disk. The message is Booting from Hard Disk .... error: ../../grub-core/kern/dl.c:266:invalid arch-independent ELF maginc. entering rescue mode...
Doing a CTRL-ALT-Del through the spice console let the VM boot correctly. Shutting it down and repeating the procedure I get a disk problem everytime. Weird thing is if I activate the BootMenu and then straight away start the VM all is OK. I don't see any ERROR messages in either vdsm.log, engine.log
If I would have to guess it looks like the disk image isn't connected yet when the VM boots but thats weird isn't it?
As a follow up I tried a couple of other things: - installed CentOS-7 and oVirt 4.3.10 using HCI and same problem (the previous install of 4.3 was a upgraded version. Don't know the start versie) - did some testing with copying large files into the engine gluster volume through /rhev/datacenter using 'cp' and no problems - used qemu-img convert with the engine gluster volume as destination --> problems - had a good look through lots of logfiles and stumbled across an error about missing shard which aligned with qemu-img errors - turned features.shard off on the volume and restarted the volume - reran the tests with qemu-img --> no problems any more. - reinstalled Centos8.2 + oVirt-4.0, turned off sharding before starting the engine install --> no problems installing, no problems importing, no problems starting vms, sofar
I need to install another server tomorrow, so I'll do that with sharding enabled and see if it crashes too and then get the logs some place safe.
Regards,
Joop
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/6TNJYNVBJWCB2N...
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/7BPONTX2FDDNBM...
Hey Nir, in ovirt 4.3.something the default behaviour for Gluster changed from thin to fully allocated. My guess is that the shard xlator cannot catch up with the I/O. Do you think that I should file a RFE to change the shard size ? As far as I know RedHat support only 512MB shard size, while gluster's default is only 64MB. Best Rregards, Strahil Nikolov На 16 юни 2020 г. 23:22:53 GMT+03:00, Nir Soffer <nsoffer@redhat.com> написа:
On Tue, Jun 16, 2020 at 11:01 PM Joop <jvdwege@xs4all.nl> wrote:
On 16-6-2020 19:44, Strahil Nikolov wrote:
Hey Joop,
are you using fully allocated qcow2 images ?
Best Regards, Strahil Nikolov
I noticed that when I use import VM from an Export domain I see that
it
sometimes uses preallocated and sometimes thin-provisioned for the disk(s). Don't know why and I don't think there is a pattern.
Maybe the system selects a different storage domain? On block storage the default is preallocated, but on file based storage the default is thin.
Old VMs from 3.3 or new ones from 4.2/3, its mixed. I almost always use thin-provisioned but one or two could have been preallocated by accident.
How do I check?
If the question was about creating images with:
qemu-img create -f qcow2 -o preallocation=metadata ...
Then it is easy, ovirt does not create such images.
Joop
На 16 юни 2020 г. 20:23:17 GMT+03:00, Joop <jvdwege@xs4all.nl>
On 3-6-2020 14:58, Joop wrote:
Hi All,
Just had a rather new experience in that starting a VM worked but
kernel entered grub2 rescue console due to the fact that something was wrong with its virtio-scsi disk. The message is Booting from Hard Disk .... error: ../../grub-core/kern/dl.c:266:invalid arch-independent ELF maginc. entering rescue mode...
Doing a CTRL-ALT-Del through the spice console let the VM boot correctly. Shutting it down and repeating the procedure I get a disk problem everytime. Weird thing is if I activate the BootMenu and
straight away start the VM all is OK. I don't see any ERROR messages in either vdsm.log, engine.log
If I would have to guess it looks like the disk image isn't connected yet when the VM boots but thats weird isn't it?
As a follow up I tried a couple of other things: - installed CentOS-7 and oVirt 4.3.10 using HCI and same problem (the previous install of 4.3 was a upgraded version. Don't know
написа: the then the
start versie) - did some testing with copying large files into the engine gluster volume through /rhev/datacenter using 'cp' and no problems - used qemu-img convert with the engine gluster volume as destination --> problems - had a good look through lots of logfiles and stumbled across an error about missing shard which aligned with qemu-img errors - turned features.shard off on the volume and restarted the volume - reran the tests with qemu-img --> no problems any more. - reinstalled Centos8.2 + oVirt-4.0, turned off sharding before starting the engine install --> no problems installing, no problems importing, no problems starting vms, sofar
I need to install another server tomorrow, so I'll do that with sharding enabled and see if it crashes too and then get the logs some place safe.
Regards,
Joop
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives:
https://lists.ovirt.org/archives/list/users@ovirt.org/message/6TNJYNVBJWCB2N...
Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/7BPONTX2FDDNBM...
Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/NARCCR7LYDFKLT...

I had the same problem when booting vm's in ovirt 4.4.0 . The legacy bios could not detect the disk to boot up and yes as suspected was a storage problem with gluster. After upgrade to ovirt 4.4.1 and run again "Optimize for virt store " i dont see this boot problem anymore, but maybe is something else ? dont know exactly what was fixed Thanks, Emy
participants (10)
-
 Joop
Joop -
jvdwege@xs4all.nl
-
 Krutika Dhananjay
Krutika Dhananjay -
 Marco Fais
Marco Fais -
 Michal Skrivanek
Michal Skrivanek -
 Nir Soffer
Nir Soffer -
 Oliver Leinfelder
Oliver Leinfelder -
 shadow emy
shadow emy -
 Stephen Panicho
Stephen Panicho -
 Strahil Nikolov
Strahil Nikolov