Need help recovering ovirt engine (was: New Management VLAN for hyperconverged cluster)

I was able to fix the connectivity issues between all 3 hosts. It turned out that I hadn't completely deleted the old vlan settings from the host. I re-ran "nmcli connection delete" on the old vlan. After that, I had to edit a network-scripts file and change/fix the bridge to use ifcfg-ovirtmgmt. After I did all that, the problematic host was accessible again. All 3 Gluster peers are now able to see each other and communicate over the management network. From the command line, I was then able to successfully run "hosted-engine --connect-storage" without errors. I was also able to then run "hosted-engine --vm-start". Unfortunately, the engine itself is still unstable, and when I access the web UI / oVirt Manager, it shows that all 3 hosts are inaccessible and down. I don't understand how the web UI is operational at all if the engine thinks that all 3 hosts are inaccessible. What's going on there? Although the initial problem was my own doing (I changed the management vlan), I'm deeply concerned with how unstable everything became - and has continued to be- ever since I lost connectivity to the 1 host. I thought the point of all of this was that things would (should) continue to work if 1 of the hosts went away. Anyway, at that point, all 3 hosts are able to communicate with each other over the management network, but the engine still thinks that all 3 hosts are down, and is unable to manage anything. Any suggestions on how to proceed would be much appreciated. Sent with ProtonMail Secure Email. ‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Wednesday, April 7, 2021 8:28 PM, David White <dmwhite823@protonmail.com> wrote:
I still haven't been able to resurrect the 1st host, so I've spent some time trying to get the hosted engine stable. I would welcome input on how to fix the problematic host so that it can be accessible again.
As per my original email, this all started when I tried to change the management vlan. I honestly cannot remember what I did (if anything) to the actual hosts when this all started, but my troubleshooting steps today have been to try to fiddle with the vlan settings and /etc/sysconfig/network-scripts/ files on the problematic host to switch from the original vlan (1) to the new vlan (10).
Until then, I'm troubleshooting why the hosted engine isn't really working, since the other two hosts are operational.
The hosted engine is "running" -- I can access and navigate around the oVirt Manager. However, it appears that all of the storage domains are down, and all of the hosts are "NonOperational". I was, however, able to put two of the hosts into Maintenance Mode, including the problematic 1st host.
This is what I see on the 2nd host:
[root@cha2-storage network-scripts]# gluster peer status Number of Peers: 2
Hostname: cha1-storage.mgt.example.com Uuid: 348de1f3-5efe-4e0c-b58e-9cf48071e8e1 State: Peer in Cluster (Disconnected)
Hostname: cha3-storage.mgt.example.com Uuid: 0563c3e8-237d-4409-a09a-ec51719b0da6 State: Peer in Cluster (Connected)
[root@cha2-storage network-scripts]# hosted-engine --vm-status The hosted engine configuration has not been retrieved from shared storage. Please ensure that ovirt-ha-agent is running and the storage server is reachable.
[root@cha2-storage network-scripts]# hosted-engine --connect-storage Traceback (most recent call last): File "/usr/lib64/python3.6/runpy.py", line 193, in _run_module_as_main "__main__", mod_spec) File "/usr/lib64/python3.6/runpy.py", line 85, in _run_code exec(code, run_globals) File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_setup/connect_storage_server.py", line 30, in <module> timeout=ohostedcons.Const.STORAGE_SERVER_TIMEOUT, File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/client/client.py", line 312, in connect_storage_server sserver.connect_storage_server(timeout=timeout) File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/lib/storage_server.py", line 394, in connect_storage_server 'Connection to storage server failed' RuntimeError: Connection to storage server failed
The ovirt-engine-ha service seems to be continuously trying to load / activate, but failing: [root@cha2-storage network-scripts]# systemctl status -l ovirt-ha-agent ● ovirt-ha-agent.service - oVirt Hosted Engine High Availability Monitoring Agent Loaded: loaded (/usr/lib/systemd/system/ovirt-ha-agent.service; enabled; vendor preset: disabled) Active: activating (auto-restart) (Result: exit-code) since Wed 2021-04-07 20:24:46 EDT; 60ms ago Process: 124306 ExecStart=/usr/share/ovirt-hosted-engine-ha/ovirt-ha-agent (code=exited, status=157) Main PID: 124306 (code=exited, status=157)
Some recent entries in /var/log/ovirt-hosted-engine-ha/agent.log MainThread::ERROR::2021-04-07 20:22:59,115::agent::144::ovirt_hosted_engine_ha.agent.agent.Agent::(_run_agent) Trying to restart agent MainThread::INFO::2021-04-07 20:22:59,115::agent::89::ovirt_hosted_engine_ha.agent.agent.Agent::(run) Agent shutting down MainThread::INFO::2021-04-07 20:23:09,717::agent::67::ovirt_hosted_engine_ha.agent.agent.Agent::(run) ovirt-hosted-engine-ha agent 2.4.6 started MainThread::INFO::2021-04-07 20:23:09,742::hosted_engine::242::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_hostname) Certificate common name not found, using hostname to identify host MainThread::INFO::2021-04-07 20:23:09,837::hosted_engine::548::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_initialize_broker) Initializing ha-broker connection MainThread::INFO::2021-04-07 20:23:09,838::brokerlink::82::ovirt_hosted_engine_ha.lib.brokerlink.BrokerLink::(start_monitor) Starting monitor network, options {'addr': '10.1.0.1', 'network_test': 'dns', 'tcp_t_address': '', 'tcp_t_port': ''} MainThread::ERROR::2021-04-07 20:23:09,839::hosted_engine::564::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_initialize_broker) Failed to start necessary monitors MainThread::ERROR::2021-04-07 20:23:09,842::agent::143::ovirt_hosted_engine_ha.agent.agent.Agent::(_run_agent) Traceback (most recent call last): File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/lib/brokerlink.py", line 85, in start_monitor response = self._proxy.start_monitor(type, options) File "/usr/lib64/python3.6/xmlrpc/client.py", line 1112, in __call__ return self.__send(self.__name, args) File "/usr/lib64/python3.6/xmlrpc/client.py", line 1452, in __request verbose=self.__verbose File "/usr/lib64/python3.6/xmlrpc/client.py", line 1154, in request return self.single_request(host, handler, request_body, verbose) File "/usr/lib64/python3.6/xmlrpc/client.py", line 1166, in single_request http_conn = self.send_request(host, handler, request_body, verbose) File "/usr/lib64/python3.6/xmlrpc/client.py", line 1279, in send_request self.send_content(connection, request_body) File "/usr/lib64/python3.6/xmlrpc/client.py", line 1309, in send_content connection.endheaders(request_body) File "/usr/lib64/python3.6/http/client.py", line 1249, in endheaders self._send_output(message_body, encode_chunked=encode_chunked) File "/usr/lib64/python3.6/http/client.py", line 1036, in _send_output self.send(msg) File "/usr/lib64/python3.6/http/client.py", line 974, in send self.connect() File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/lib/unixrpc.py", line 74, in connect self.sock.connect(base64.b16decode(self.host)) FileNotFoundError: [Errno 2] No such file or directory
During handling of the above exception, another exception occurred:
Traceback (most recent call last): File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/agent/agent.py", line 131, in _run_agent return action(he) File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/agent/agent.py", line 55, in action_proper return he.start_monitoring() File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 437, in start_monitoring self._initialize_broker() File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 561, in _initialize_broker m.get('options', {})) File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/lib/brokerlink.py", line 91, in start_monitor ).format(t=type, o=options, e=e) ovirt_hosted_engine_ha.lib.exceptions.RequestError: brokerlink - failed to start monitor via ovirt-ha-broker: [Errno 2] No such file or directory, [monitor: 'network', options: {'addr': '10.1.0.1', 'network_test': 'dns', 'tcp_t_address': '', 'tcp_t_port': ''}]
MainThread::ERROR::2021-04-07 20:23:09,842::agent::144::ovirt_hosted_engine_ha.agent.agent.Agent::(_run_agent) Trying to restart agent MainThread::INFO::2021-04-07 20:23:09,842::agent::89::ovirt_hosted_engine_ha.agent.agent.Agent::(run) Agent shutting down
Sent with ProtonMail Secure Email.
‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Wednesday, April 7, 2021 5:36 PM, David White via Users <users@ovirt.org> wrote:
I'm working on setting up my environment prior to production, and have run into an issue.
I got most things configured, but due to a limitation on one of my switches, I decided to change the management vlan that the hosts communicate on. Over the course of changing that vlan, I wound up resetting my router to default settings.
I have the router operational again, and I also have 1 of my switches operational. Now, I'm trying to bring the oVirt cluster back online. This is oVirt 4.5 running on RHEL 8.3.
The old vlan is 1, and the new vlan is 10.
Currently, hosts 2 & 3 are accessible over the new vlan, and can ping each other. I'm able to ssh to both hosts, and when I run "gluster peer status", I see that they are connected to each other.
However, host 1 is not accessible from anything. I can't ping it, and it cannot get out.
As part of my troubleshooting, I've done the following: From the host console, I ran `nmcli connection delete` to delete the old vlan (VLAN 1). I moved the /etc/sysconfig/network-scripts/interface.1 file to interface.10, and edited the file accordingly to make sure the vlan and device settings are set to 10 instead of 1, and I rebooted the host.
The engine seems to be running, but I don't understand why. From each of the hosts that are working (host 2 and host 3), I ran "hosted-engine --check-liveliness" and both hosts indicate that the engine is NOT running.
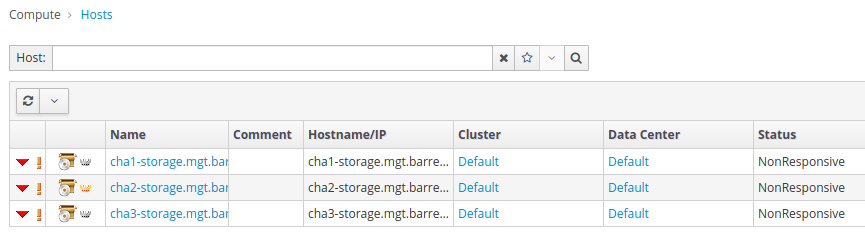
Yet the engine loads in a web browser, and I'm able to log into /ovirt-engine/webadmin/. The engine thinks that all 3 hosts is nonresponsive. See screenshot below:
[Screenshot from 2021-04-07 17-33-48.png]
What I'm really looking for help with is to get the first host back online. Once it is healthy and gluster is healthy, I feel confident I can get the engine operational again.
What else should I look for on this host?
Sent with ProtonMail Secure Email.
{kind=link}
This is resolved, and my environment is 100% stable now. Or was, until I then used the engine to "upgrade" one of the hosts, at which point I started having problems again after the reboot, because the old vlan came back. I'll finish getting things stabilized today, and hopefully won't run into this again. I've been turning things on and off quite a bit, because they aren't in a proper data center (yet) and are just sitting here in my home office. So I'm sure shutting them down and turning them back on fairly often hasn't helped the situation. I initially had a few issues going on: 1. I of course first broke things when I tried to change the management vlan 2. Aside from my notes below and the troubleshooting steps I went through, yesterday, I had forgotten that connectivity to the DNS server hadn't been restored. Once I got DNS operational, the engine was able to see two of the hosts, and finally started showing some green. 3. I then went in and ran `hosted-engine --vm-stop` to shutdown the engine, and then I started it again... and viola. The last remaining problematic host came online, and a few minutes later, the disks, volumes, and datacenter came online. 4. I think part of my problem has been this switch. I purchased a Netgear GS324T for my frontend traffic. But I've also needed to put my backend traffic onto some temporary ports on that switch until I can get a VM controller setup that will run my other switch, a Ubiquiti US-XG-16 for my permanent backend traffic. The Netgear hasn't been nearly as simple to configure as I had hoped. The vlan behavior has also been inconsistent - sometimes I have vlan settings in place, and things work. Sometimes they don't work. It has also been re-assigning a of the vlans occasionally after reboots, which has been frustrating. I'm close to being completely done configuring the infrastructure, but I'm also getting increasingly tempted to go find a different switch. Lessons learned: 1. Always make sure DNS is functional 1. I was really hoping that I could run DNS as a VM (or multiple VMs) inside the cluster. 2. That said, if the cluster and the engine won't even start correctly without, then I may need to run DNS externally. I'm open to feedback on this. 1. I have 1 extra U of space at the datacenter reserved, and I do have a 4th spare server that I haven't decided what to do with yet. It has way more CPU and RAM than would be necessary to run an internal DNS server... but perhaps I have no choice. Thoughts? 3. Make sure your vlan settings are correct before you start deploying the hosted engine and configure oVirt. 4. If possible, don't turn off and turn on your servers constantly. :) I realize this is a given. I just don't have much choice in the matter right now, due to lack of datacenter in my home office. Sent with ProtonMail Secure Email. ‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Friday, April 9, 2021 5:55 AM, David White via Users <users@ovirt.org> wrote:
I was able to fix the connectivity issues between all 3 hosts. It turned out that I hadn't completely deleted the old vlan settings from the host. I re-ran "nmcli connection delete" on the old vlan. After that, I had to edit a network-scripts file and change/fix the bridge to use ifcfg-ovirtmgmt. After I did all that, the problematic host was accessible again. All 3 Gluster peers are now able to see each other and communicate over the management network.
From the command line, I was then able to successfully run "hosted-engine --connect-storage" without errors. I was also able to then run "hosted-engine --vm-start". Unfortunately, the engine itself is still unstable, and when I access the web UI / oVirt Manager, it shows that all 3 hosts are inaccessible and down.
I don't understand how the web UI is operational at all if the engine thinks that all 3 hosts are inaccessible. What's going on there?
Although the initial problem was my own doing (I changed the management vlan), I'm deeply concerned with how unstable everything became - and has continued to be- ever since I lost connectivity to the 1 host. I thought the point of all of this was that things would (should) continue to work if 1 of the hosts went away.
Anyway, at that point, all 3 hosts are able to communicate with each other over the management network, but the engine still thinks that all 3 hosts are down, and is unable to manage anything. Any suggestions on how to proceed would be much appreciated.
Sent with ProtonMail Secure Email.
‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Wednesday, April 7, 2021 8:28 PM, David White <dmwhite823@protonmail.com> wrote:
I still haven't been able to resurrect the 1st host, so I've spent some time trying to get the hosted engine stable. I would welcome input on how to fix the problematic host so that it can be accessible again.
As per my original email, this all started when I tried to change the management vlan. I honestly cannot remember what I did (if anything) to the actual hosts when this all started, but my troubleshooting steps today have been to try to fiddle with the vlan settings and /etc/sysconfig/network-scripts/ files on the problematic host to switch from the original vlan (1) to the new vlan (10).
Until then, I'm troubleshooting why the hosted engine isn't really working, since the other two hosts are operational.
The hosted engine is "running" -- I can access and navigate around the oVirt Manager. However, it appears that all of the storage domains are down, and all of the hosts are "NonOperational". I was, however, able to put two of the hosts into Maintenance Mode, including the problematic 1st host.
This is what I see on the 2nd host:
[root@cha2-storage network-scripts]# gluster peer status Number of Peers: 2
Hostname: cha1-storage.mgt.example.com Uuid: 348de1f3-5efe-4e0c-b58e-9cf48071e8e1 State: Peer in Cluster (Disconnected)
Hostname: cha3-storage.mgt.example.com Uuid: 0563c3e8-237d-4409-a09a-ec51719b0da6 State: Peer in Cluster (Connected)
[root@cha2-storage network-scripts]# hosted-engine --vm-status The hosted engine configuration has not been retrieved from shared storage. Please ensure that ovirt-ha-agent is running and the storage server is reachable.
[root@cha2-storage network-scripts]# hosted-engine --connect-storage Traceback (most recent call last): File "/usr/lib64/python3.6/runpy.py", line 193, in _run_module_as_main "__main__", mod_spec) File "/usr/lib64/python3.6/runpy.py", line 85, in _run_code exec(code, run_globals) File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_setup/connect_storage_server.py", line 30, in <module> timeout=ohostedcons.Const.STORAGE_SERVER_TIMEOUT, File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/client/client.py", line 312, in connect_storage_server sserver.connect_storage_server(timeout=timeout) File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/lib/storage_server.py", line 394, in connect_storage_server 'Connection to storage server failed' RuntimeError: Connection to storage server failed
The ovirt-engine-ha service seems to be continuously trying to load / activate, but failing: [root@cha2-storage network-scripts]# systemctl status -l ovirt-ha-agent ● ovirt-ha-agent.service - oVirt Hosted Engine High Availability Monitoring Agent Loaded: loaded (/usr/lib/systemd/system/ovirt-ha-agent.service; enabled; vendor preset: disabled) Active: activating (auto-restart) (Result: exit-code) since Wed 2021-04-07 20:24:46 EDT; 60ms ago Process: 124306 ExecStart=/usr/share/ovirt-hosted-engine-ha/ovirt-ha-agent (code=exited, status=157) Main PID: 124306 (code=exited, status=157)
Some recent entries in /var/log/ovirt-hosted-engine-ha/agent.log MainThread::ERROR::2021-04-07 20:22:59,115::agent::144::ovirt_hosted_engine_ha.agent.agent.Agent::(_run_agent) Trying to restart agent MainThread::INFO::2021-04-07 20:22:59,115::agent::89::ovirt_hosted_engine_ha.agent.agent.Agent::(run) Agent shutting down MainThread::INFO::2021-04-07 20:23:09,717::agent::67::ovirt_hosted_engine_ha.agent.agent.Agent::(run) ovirt-hosted-engine-ha agent 2.4.6 started MainThread::INFO::2021-04-07 20:23:09,742::hosted_engine::242::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_hostname) Certificate common name not found, using hostname to identify host MainThread::INFO::2021-04-07 20:23:09,837::hosted_engine::548::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_initialize_broker) Initializing ha-broker connection MainThread::INFO::2021-04-07 20:23:09,838::brokerlink::82::ovirt_hosted_engine_ha.lib.brokerlink.BrokerLink::(start_monitor) Starting monitor network, options {'addr': '10.1.0.1', 'network_test': 'dns', 'tcp_t_address': '', 'tcp_t_port': ''} MainThread::ERROR::2021-04-07 20:23:09,839::hosted_engine::564::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_initialize_broker) Failed to start necessary monitors MainThread::ERROR::2021-04-07 20:23:09,842::agent::143::ovirt_hosted_engine_ha.agent.agent.Agent::(_run_agent) Traceback (most recent call last): File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/lib/brokerlink.py", line 85, in start_monitor response = self._proxy.start_monitor(type, options) File "/usr/lib64/python3.6/xmlrpc/client.py", line 1112, in __call__ return self.__send(self.__name, args) File "/usr/lib64/python3.6/xmlrpc/client.py", line 1452, in __request verbose=self.__verbose File "/usr/lib64/python3.6/xmlrpc/client.py", line 1154, in request return self.single_request(host, handler, request_body, verbose) File "/usr/lib64/python3.6/xmlrpc/client.py", line 1166, in single_request http_conn = self.send_request(host, handler, request_body, verbose) File "/usr/lib64/python3.6/xmlrpc/client.py", line 1279, in send_request self.send_content(connection, request_body) File "/usr/lib64/python3.6/xmlrpc/client.py", line 1309, in send_content connection.endheaders(request_body) File "/usr/lib64/python3.6/http/client.py", line 1249, in endheaders self._send_output(message_body, encode_chunked=encode_chunked) File "/usr/lib64/python3.6/http/client.py", line 1036, in _send_output self.send(msg) File "/usr/lib64/python3.6/http/client.py", line 974, in send self.connect() File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/lib/unixrpc.py", line 74, in connect self.sock.connect(base64.b16decode(self.host)) FileNotFoundError: [Errno 2] No such file or directory
During handling of the above exception, another exception occurred:
Traceback (most recent call last): File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/agent/agent.py", line 131, in _run_agent return action(he) File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/agent/agent.py", line 55, in action_proper return he.start_monitoring() File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 437, in start_monitoring self._initialize_broker() File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 561, in _initialize_broker m.get('options', {})) File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/lib/brokerlink.py", line 91, in start_monitor ).format(t=type, o=options, e=e) ovirt_hosted_engine_ha.lib.exceptions.RequestError: brokerlink - failed to start monitor via ovirt-ha-broker: [Errno 2] No such file or directory, [monitor: 'network', options: {'addr': '10.1.0.1', 'network_test': 'dns', 'tcp_t_address': '', 'tcp_t_port': ''}]
MainThread::ERROR::2021-04-07 20:23:09,842::agent::144::ovirt_hosted_engine_ha.agent.agent.Agent::(_run_agent) Trying to restart agent MainThread::INFO::2021-04-07 20:23:09,842::agent::89::ovirt_hosted_engine_ha.agent.agent.Agent::(run) Agent shutting down
Sent with ProtonMail Secure Email.
‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Wednesday, April 7, 2021 5:36 PM, David White via Users <users@ovirt.org> wrote:
I'm working on setting up my environment prior to production, and have run into an issue.
I got most things configured, but due to a limitation on one of my switches, I decided to change the management vlan that the hosts communicate on. Over the course of changing that vlan, I wound up resetting my router to default settings.
I have the router operational again, and I also have 1 of my switches operational. Now, I'm trying to bring the oVirt cluster back online. This is oVirt 4.5 running on RHEL 8.3.
The old vlan is 1, and the new vlan is 10.
Currently, hosts 2 & 3 are accessible over the new vlan, and can ping each other. I'm able to ssh to both hosts, and when I run "gluster peer status", I see that they are connected to each other.
However, host 1 is not accessible from anything. I can't ping it, and it cannot get out.
As part of my troubleshooting, I've done the following: From the host console, I ran `nmcli connection delete` to delete the old vlan (VLAN 1). I moved the /etc/sysconfig/network-scripts/interface.1 file to interface.10, and edited the file accordingly to make sure the vlan and device settings are set to 10 instead of 1, and I rebooted the host.
The engine seems to be running, but I don't understand why. From each of the hosts that are working (host 2 and host 3), I ran "hosted-engine --check-liveliness" and both hosts indicate that the engine is NOT running.
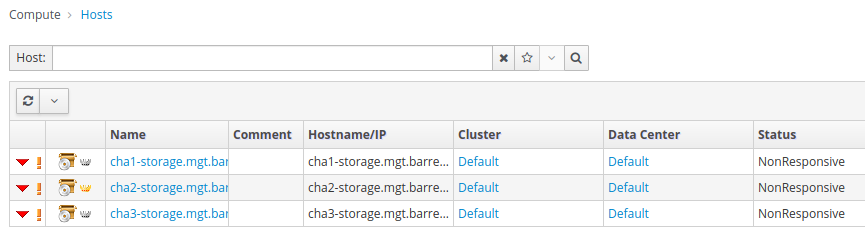
Yet the engine loads in a web browser, and I'm able to log into /ovirt-engine/webadmin/. The engine thinks that all 3 hosts is nonresponsive. See screenshot below:
[Screenshot from 2021-04-07 17-33-48.png]
What I'm really looking for help with is to get the first host back online. Once it is healthy and gluster is healthy, I feel confident I can get the engine operational again.
What else should I look for on this host?
Sent with ProtonMail Secure Email.
{kind=link}

On Sat, Apr 10, 2021 at 1:14 PM David White via Users <users@ovirt.org> wrote:
This is resolved, and my environment is 100% stable now.
Glad to hear that, thanks for the report!
Or was, until I then used the engine to "upgrade" one of the hosts, at which point I started having problems again after the reboot, because the old vlan came back. I'll finish getting things stabilized today, and hopefully won't run into this again.
I've been turning things on and off quite a bit, because they aren't in a proper data center (yet) and are just sitting here in my home office. So I'm sure shutting them down and turning them back on fairly often hasn't helped the situation.
I initially had a few issues going on:
1. I of course first broke things when I tried to change the management vlan 2. Aside from my notes below and the troubleshooting steps I went through, yesterday, I had forgotten that connectivity to the DNS server hadn't been restored. Once I got DNS operational, the engine was able to see two of the hosts, and finally started showing some green. 3. I then went in and ran `hosted-engine --vm-stop` to shutdown the engine, and then I started it again... and viola. The last remaining problematic host came online, and a few minutes later, the disks, volumes, and datacenter came online. 4. I think part of my problem has been this switch. I purchased a Netgear GS324T for my frontend traffic. But I've also needed to put my backend traffic onto some temporary ports on that switch until I can get a VM controller setup that will run my other switch, a Ubiquiti US-XG-16 for my permanent backend traffic. The Netgear hasn't been nearly as simple to configure as I had hoped. The vlan behavior has also been inconsistent - sometimes I have vlan settings in place, and things work. Sometimes they don't work. It has also been re-assigning a of the vlans occasionally after reboots, which has been frustrating. I'm close to being completely done configuring the infrastructure, but I'm also getting increasingly tempted to go find a different switch.
Lessons learned:
1. Always make sure DNS is functional 1. I was really hoping that I could run DNS as a VM (or multiple VMs) *inside* the cluster. 2. That said, if the cluster and the engine won't even start correctly without, then I may need to run DNS externally. I'm open to feedback on this. 1. I have 1 extra U of space at the datacenter reserved, and I do have a 4th spare server that I haven't decided what to do with yet. It has way more CPU and RAM than would be necessary to run an internal DNS server... but perhaps I have no choice. *Thoughts*?
You can also have the IP addresses of the engine and hosts in /etc/hosts of all machines (engine and hosts) - then things should work fine. It does mean you'll have to manually maintain these hosts files somehow.
1. 1. Make sure your vlan settings are correct *before* you start deploying the hosted engine and configure oVirt.
Definitely. As well as making sure that IP addresses (and netmasks, routes, etc.) are as intended and working, name resolution is correct (DNS or /etc/hosts), etc. .
1. 2. If possible, don't turn off and turn on your servers constantly. :) I realize this is a given. I just don't have much choice in the matter right now, due to lack of datacenter in my home office.
While definitely not recommended, in principle this should be harmless. If you find concrete reproducible bugs around this, please report them (with clear accurate details - just "I turn off and on my hosts and things stop working" is not helpful, obviously...). Thanks again and best regards,
Sent with ProtonMail <https://protonmail.com> Secure Email.
‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Friday, April 9, 2021 5:55 AM, David White via Users <users@ovirt.org> wrote:
I was able to fix the connectivity issues between all 3 hosts. It turned out that I hadn't completely deleted the old vlan settings from the host. I re-ran "nmcli connection delete" on the old vlan. After that, I had to edit a network-scripts file and change/fix the bridge to use ifcfg-ovirtmgmt. After I did all that, the problematic host was accessible again. All 3 Gluster peers are now able to see each other and communicate over the management network.
From the command line, I was then able to successfully run "hosted-engine --connect-storage" without errors. I was also able to then run "hosted-engine --vm-start". Unfortunately, the engine itself is still unstable, and when I access the web UI / oVirt Manager, it shows that all 3 hosts are inaccessible and down.
I don't understand how the web UI is operational at all if the engine thinks that all 3 hosts are inaccessible. What's going on there?
Although the initial problem was my own doing (I changed the management vlan), I'm deeply concerned with how unstable everything became - and has continued to be- ever since I lost connectivity to the 1 host. I thought the point of all of this was that things would (should) continue to work if 1 of the hosts went away.
Anyway, at that point, all 3 hosts are able to communicate with each other over the management network, but the engine still thinks that all 3 hosts are down, and is unable to manage anything. Any suggestions on how to proceed would be much appreciated.
Sent with ProtonMail <https://protonmail.com> Secure Email.
‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Wednesday, April 7, 2021 8:28 PM, David White < dmwhite823@protonmail.com> wrote:
I still haven't been able to resurrect the 1st host, so I've spent some time trying to get the hosted engine stable. I would welcome input on how to fix the problematic host so that it can be accessible again.
As per my original email, this all started when I tried to change the management vlan. I honestly cannot remember what I did (if anything) to the actual hosts when this all started, but my troubleshooting steps today have been to try to fiddle with the vlan settings and /etc/sysconfig/network-scripts/ files on the problematic host to switch from the original vlan (1) to the new vlan (10).
Until then, I'm troubleshooting why the hosted engine isn't really working, since the other two hosts are operational.
The hosted engine is "running" -- I can access and navigate around the oVirt Manager. However, it appears that all of the storage domains are down, and all of the hosts are "NonOperational". I was, however, able to put two of the hosts into Maintenance Mode, including the problematic 1st host.
This is what I see on the 2nd host:
*[root@cha2-storage network-scripts]# gluster peer status* Number of Peers: 2
Hostname: cha1-storage.mgt.example.com Uuid: 348de1f3-5efe-4e0c-b58e-9cf48071e8e1 State: Peer in Cluster (Disconnected)
Hostname: cha3-storage.mgt.example.com Uuid: 0563c3e8-237d-4409-a09a-ec51719b0da6 State: Peer in Cluster (Connected)
*[root@cha2-storage network-scripts]# hosted-engine --vm-status* The hosted engine configuration has not been retrieved from shared storage. Please ensure that ovirt-ha-agent is running and the storage server is reachable.
*[root@cha2-storage network-scripts]# hosted-engine --connect-storage* Traceback (most recent call last): File "/usr/lib64/python3.6/runpy.py", line 193, in _run_module_as_main "__main__", mod_spec) File "/usr/lib64/python3.6/runpy.py", line 85, in _run_code exec(code, run_globals) File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_setup/connect_storage_server.py", line 30, in <module> timeout=ohostedcons.Const.STORAGE_SERVER_TIMEOUT, File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/client/client.py", line 312, in connect_storage_server sserver.connect_storage_server(timeout=timeout) File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/lib/storage_server.py", line 394, in connect_storage_server 'Connection to storage server failed' RuntimeError: Connection to storage server failed
The ovirt-engine-ha service seems to be continuously trying to load / activate, but failing: *[root@cha2-storage network-scripts]# systemctl status -l ovirt-ha-agent* ● ovirt-ha-agent.service - oVirt Hosted Engine High Availability Monitoring Agent Loaded: loaded (/usr/lib/systemd/system/ovirt-ha-agent.service; enabled; vendor preset: disabled) Active: activating (auto-restart) (Result: exit-code) since Wed 2021-04-07 20:24:46 EDT; 60ms ago Process: 124306 ExecStart=/usr/share/ovirt-hosted-engine-ha/ovirt-ha-agent (code=exited, status=157) Main PID: 124306 (code=exited, status=157)
*Some recent entries in /var/log/ovirt-hosted-engine-ha/agent.log* MainThread::ERROR::2021-04-07 20:22:59,115::agent::144::ovirt_hosted_engine_ha.agent.agent.Agent::(_run_agent) Trying to restart agent MainThread::INFO::2021-04-07 20:22:59,115::agent::89::ovirt_hosted_engine_ha.agent.agent.Agent::(run) Agent shutting down MainThread::INFO::2021-04-07 20:23:09,717::agent::67::ovirt_hosted_engine_ha.agent.agent.Agent::(run) ovirt-hosted-engine-ha agent 2.4.6 started MainThread::INFO::2021-04-07 20:23:09,742::hosted_engine::242::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_get_hostname) Certificate common name not found, using hostname to identify host MainThread::INFO::2021-04-07 20:23:09,837::hosted_engine::548::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_initialize_broker) Initializing ha-broker connection MainThread::INFO::2021-04-07 20:23:09,838::brokerlink::82::ovirt_hosted_engine_ha.lib.brokerlink.BrokerLink::(start_monitor) Starting monitor network, options {'addr': '10.1.0.1', 'network_test': 'dns', 'tcp_t_address': '', 'tcp_t_port': ''} MainThread::ERROR::2021-04-07 20:23:09,839::hosted_engine::564::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_initialize_broker) Failed to start necessary monitors MainThread::ERROR::2021-04-07 20:23:09,842::agent::143::ovirt_hosted_engine_ha.agent.agent.Agent::(_run_agent) Traceback (most recent call last): File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/lib/brokerlink.py", line 85, in start_monitor response = self._proxy.start_monitor(type, options) File "/usr/lib64/python3.6/xmlrpc/client.py", line 1112, in __call__ return self.__send(self.__name, args) File "/usr/lib64/python3.6/xmlrpc/client.py", line 1452, in __request verbose=self.__verbose File "/usr/lib64/python3.6/xmlrpc/client.py", line 1154, in request return self.single_request(host, handler, request_body, verbose) File "/usr/lib64/python3.6/xmlrpc/client.py", line 1166, in single_request http_conn = self.send_request(host, handler, request_body, verbose) File "/usr/lib64/python3.6/xmlrpc/client.py", line 1279, in send_request self.send_content(connection, request_body) File "/usr/lib64/python3.6/xmlrpc/client.py", line 1309, in send_content connection.endheaders(request_body) File "/usr/lib64/python3.6/http/client.py", line 1249, in endheaders self._send_output(message_body, encode_chunked=encode_chunked) File "/usr/lib64/python3.6/http/client.py", line 1036, in _send_output self.send(msg) File "/usr/lib64/python3.6/http/client.py", line 974, in send self.connect() File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/lib/unixrpc.py", line 74, in connect self.sock.connect(base64.b16decode(self.host)) FileNotFoundError: [Errno 2] No such file or directory
During handling of the above exception, another exception occurred:
Traceback (most recent call last): File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/agent/agent.py", line 131, in _run_agent return action(he) File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/agent/agent.py", line 55, in action_proper return he.start_monitoring() File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 437, in start_monitoring self._initialize_broker() File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/agent/hosted_engine.py", line 561, in _initialize_broker m.get('options', {})) File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/lib/brokerlink.py", line 91, in start_monitor ).format(t=type, o=options, e=e) ovirt_hosted_engine_ha.lib.exceptions.RequestError: brokerlink - failed to start monitor via ovirt-ha-broker: [Errno 2] No such file or directory, [monitor: 'network', options: {'addr': '10.1.0.1', 'network_test': 'dns', 'tcp_t_address': '', 'tcp_t_port': ''}]
MainThread::ERROR::2021-04-07 20:23:09,842::agent::144::ovirt_hosted_engine_ha.agent.agent.Agent::(_run_agent) Trying to restart agent MainThread::INFO::2021-04-07 20:23:09,842::agent::89::ovirt_hosted_engine_ha.agent.agent.Agent::(run) Agent shutting down
Sent with ProtonMail <https://protonmail.com> Secure Email.
‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Wednesday, April 7, 2021 5:36 PM, David White via Users < users@ovirt.org> wrote:
I'm working on setting up my environment prior to production, and have run into an issue.
I got most things configured, but due to a limitation on one of my switches, I decided to change the management vlan that the hosts communicate on. Over the course of changing that vlan, I wound up resetting my router to default settings.
I have the router operational again, and I also have 1 of my switches operational. Now, I'm trying to bring the oVirt cluster back online. This is oVirt 4.5 running on RHEL 8.3.
The old vlan is 1, and the new vlan is 10.
Currently, hosts 2 & 3 are accessible over the new vlan, and can ping each other. I'm able to ssh to both hosts, and when I run "gluster peer status", I see that they are connected to each other.
However, host 1 is not accessible from anything. I can't ping it, and it cannot get out.
As part of my troubleshooting, I've done the following: From the host console, I ran `nmcli connection delete` to delete the old vlan (VLAN 1). I moved the /etc/sysconfig/network-scripts/interface.1 file to interface.10, and edited the file accordingly to make sure the vlan and device settings are set to 10 instead of 1, and I rebooted the host.
The engine seems to be running, but I don't understand why. From each of the hosts that are working (host 2 and host 3), I ran "hosted-engine --check-liveliness" and both hosts indicate that the engine is NOT running.
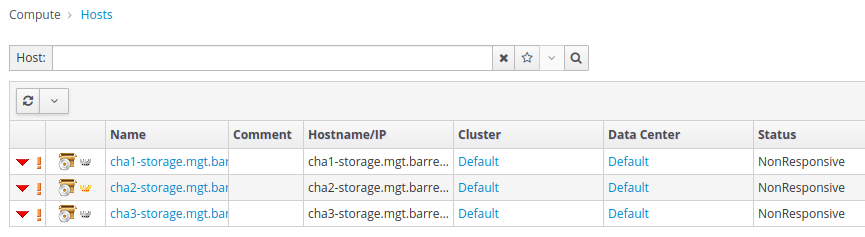
Yet the engine loads in a web browser, and I'm able to log into /ovirt-engine/webadmin/. The engine thinks that all 3 hosts is nonresponsive. See screenshot below:
[image: Screenshot from 2021-04-07 17-33-48.png]
What I'm really looking for help with is to get the first host back online. Once it is healthy and gluster is healthy, I feel confident I can get the engine operational again.
What else should I look for on this host?
Sent with ProtonMail <https://protonmail.com> Secure Email.
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/6TWZCFKAYF75GF...
-- Didi
{kind=link}
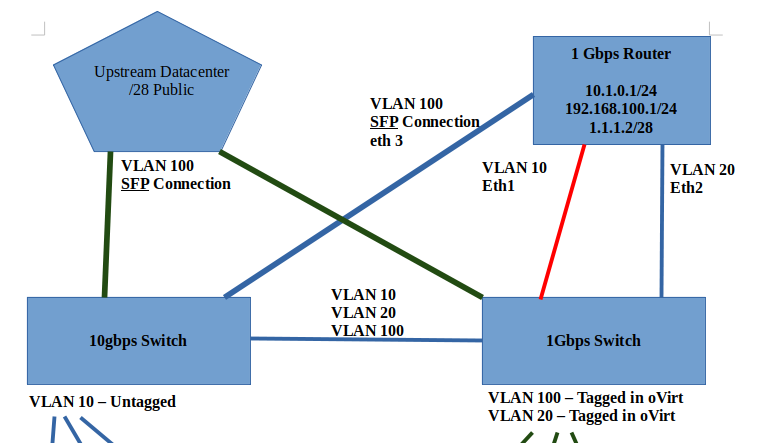
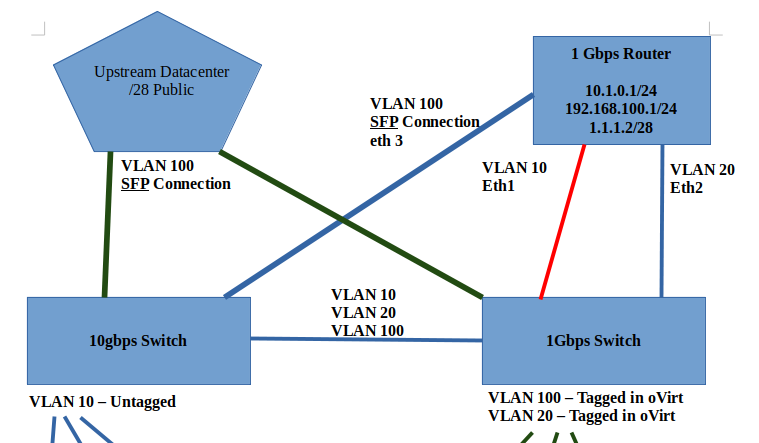
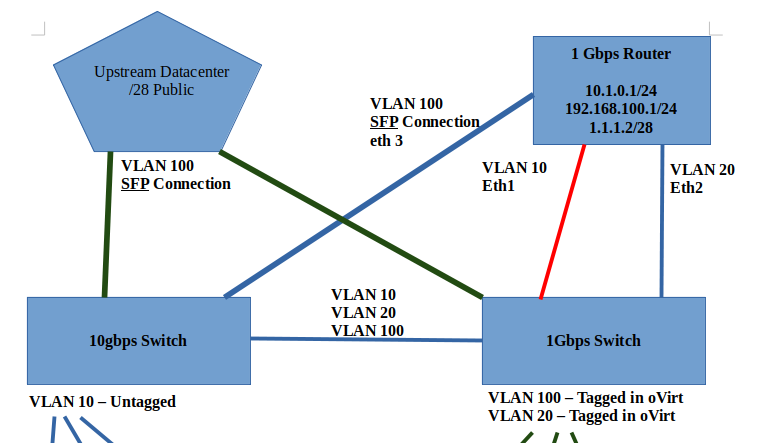
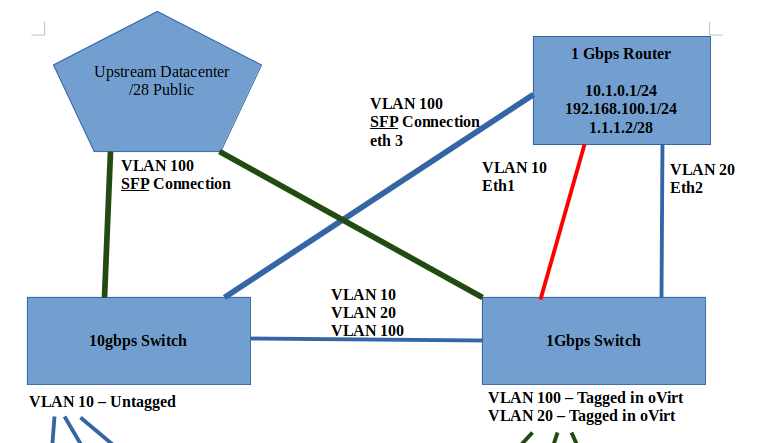
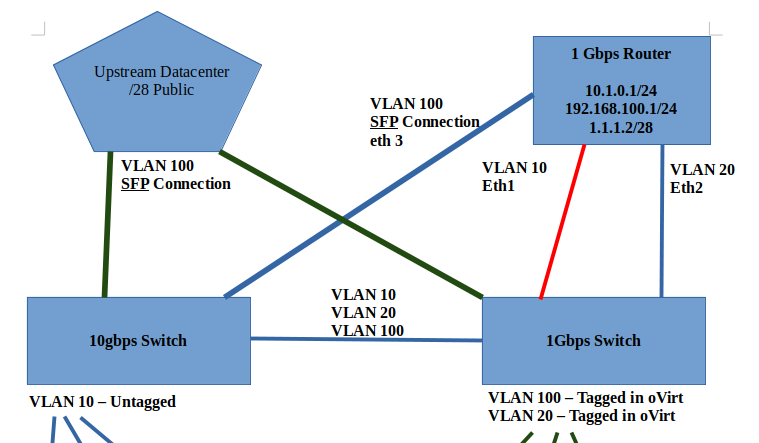
Thanks for the response here. Unfortunately, things are still not 100% stable after I performed that host upgrade.It appears to me that 1 of the hosts keeps booting back with the old management vlan (VLAN 1) instead of the new vlan (VLAN 10). I'm able to (mostly) fiddle around with it and get it back online, but it seems like every reboot, vlan 1 comes back, and breaks connectivity with the other two hosts. I also didn't realize, until late yesterday afternoon, that you could use the oVirt Manager web UI to configure each host's network settings. This whole time, I've been trying to use nmcli, nmtui, and manually editing /etc/sysconfig/network-scripts/ files by hand. When I found the network settings inside of the Engine / manager web UI, I discovered that, for example, oVirt Engine manager saw that the new vlan (VLAN 10) was "unmanaged" by the engine. Question: Would you recommend that all network settings be modified by the oVirt engine instead of the manual process on the OS? Question: Is it possible to setup a vlan inside the engine without an IP address being assigned to each of the physical hosts? I was really hoping to setup VLAN 100 with public IP addresses, and use layer 2 switching to send that traffic into the oVirt cluster. Here is a screenshot overview of what I want my environment to look like, logically. You'll note that I was going to put VLAN 20 and VLAN 100 onto the same host physical interface. This is what I - and I think the oVirt documentation - refers to as the front-end traffic. VLAN 10 is/was going to be on its own interface going to the 10Gbps switch. Question: Do you see anything "wrong" with this picture? Are there ways I can / should change it to improve? As for the /etc/hosts files, I'm actually doing that. However, as I'm typing this, I realized that I never defined the Engine IP address in the hosts, nor do I put anything inside the Engine's /etc/hosts file. Question: Perhaps this was part of my problem, when DNS connectivity was not working. Thoughts? Thanks again, David [Screenshot from 2021-04-10 17-21-39.png] Sent with ProtonMail Secure Email. ‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Sunday, April 11, 2021 3:05 AM, Yedidyah Bar David <didi@redhat.com> wrote:
On Sat, Apr 10, 2021 at 1:14 PM David White via Users <users@ovirt.org> wrote:
This is resolved, and my environment is 100% stable now.
Glad to hear that, thanks for the report!
Or was, until I then used the engine to "upgrade" one of the hosts, at which point I started having problems again after the reboot, because the old vlan came back. I'll finish getting things stabilized today, and hopefully won't run into this again.
I've been turning things on and off quite a bit, because they aren't in a proper data center (yet) and are just sitting here in my home office. So I'm sure shutting them down and turning them back on fairly often hasn't helped the situation.
I initially had a few issues going on:
1. I of course first broke things when I tried to change the management vlan 2. Aside from my notes below and the troubleshooting steps I went through, yesterday, I had forgotten that connectivity to the DNS server hadn't been restored. Once I got DNS operational, the engine was able to see two of the hosts, and finally started showing some green. 3. I then went in and ran `hosted-engine --vm-stop` to shutdown the engine, and then I started it again... and viola. The last remaining problematic host came online, and a few minutes later, the disks, volumes, and datacenter came online. 4. I think part of my problem has been this switch. I purchased a Netgear GS324T for my frontend traffic. But I've also needed to put my backend traffic onto some temporary ports on that switch until I can get a VM controller setup that will run my other switch, a Ubiquiti US-XG-16 for my permanent backend traffic. The Netgear hasn't been nearly as simple to configure as I had hoped. The vlan behavior has also been inconsistent - sometimes I have vlan settings in place, and things work. Sometimes they don't work. It has also been re-assigning a of the vlans occasionally after reboots, which has been frustrating. I'm close to being completely done configuring the infrastructure, but I'm also getting increasingly tempted to go find a different switch.
Lessons learned:
1. Always make sure DNS is functional
1. I was really hoping that I could run DNS as a VM (or multiple VMs) inside the cluster. 2. That said, if the cluster and the engine won't even start correctly without, then I may need to run DNS externally. I'm open to feedback on this.
1. I have 1 extra U of space at the datacenter reserved, and I do have a 4th spare server that I haven't decided what to do with yet. It has way more CPU and RAM than would be necessary to run an internal DNS server... but perhaps I have no choice. Thoughts?
You can also have the IP addresses of the engine and hosts in /etc/hosts of all machines (engine and hosts) - then things should work fine. It does mean you'll have to manually maintain these hosts files somehow.
1.
2. Make sure your vlan settings are correct before you start deploying the hosted engine and configure oVirt.
Definitely. As well as making sure that IP addresses (and netmasks, routes, etc.) are as intended and working, name resolution is correct (DNS or /etc/hosts), etc. .
1.
2. If possible, don't turn off and turn on your servers constantly. :) I realize this is a given. I just don't have much choice in the matter right now, due to lack of datacenter in my home office.
While definitely not recommended, in principle this should be harmless. If you find concrete reproducible bugs around this, please report them (with clear accurate details - just "I turn off and on my hosts and things stop working" is not helpful, obviously...).
Thanks again and best regards,
Users mailing list -- users@ovirt.org
To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/6TWZCFKAYF75GF...
-- Didi
{kind=link}
On Sun, Apr 11, 2021 at 2:45 PM David White via Users <users@ovirt.org> wrote:
Thanks for the response here. Unfortunately, things are still not 100% stable after I performed that host upgrade. It appears to me that 1 of the hosts keeps booting back with the old management vlan (VLAN 1) instead of the new vlan (VLAN 10).
I'm able to (mostly) fiddle around with it and get it back online, but it seems like every reboot, vlan 1 comes back, and breaks connectivity with the other two hosts. I also didn't realize, until late yesterday afternoon, that you could use the oVirt Manager web UI to configure each host's network settings.
This whole time, I've been trying to use nmcli, nmtui, and manually editing /etc/sysconfig/network-scripts/ files by hand. When I found the network settings inside of the Engine / manager web UI, I discovered that, for example, oVirt Engine manager saw that the new vlan (VLAN 10) was "unmanaged" by the engine. *Question: *Would you recommend that all network settings be modified by the oVirt engine instead of the manual process on the OS?
I think so, but that's not my expertise. Adding Eitan.
*Question: *Is it possible to setup a vlan inside the engine *without* an IP address being assigned to each of the physical hosts? I was really hoping to setup VLAN 100 with public IP addresses, and use layer 2 switching to send that traffic into the oVirt cluster.
Eitan?
Here is a screenshot overview of what I want my environment to look like, logically. You'll note that I was going to put VLAN 20 and VLAN 100 onto the same host physical interface. This is what I - and I think the oVirt documentation - refers to as the front-end traffic. VLAN 10 is/was going to be on its own interface going to the 10Gbps switch.
*Question: *Do you see anything "wrong" with this picture? Are there ways I can / should change it to improve?
Eitan? You might also want to have a look at this somewhat-outdated-but-still-mostly-relevant document, for RHV, probably applies 99% to oVirt as well: https://www.redhat.com/en/resources/best-practice-rhv-technology-detail
As for the /etc/hosts files, I'm actually doing that. However, as I'm typing this, I realized that I never defined the Engine IP address in the hosts, nor do I put anything inside the Engine's /etc/hosts file. *Question: *Perhaps this was part of my problem, when DNS connectivity was not working. Thoughts?
Not sure about "general" hosts, but hosted-engine hosts definitely need to be able to connect to the engine (at least, for making sure it's alive), so need it to be locally-resolvable. If you plan to run DNS inside a VM, you definitely want the engine machine's IP in /etc/hosts on all hosted-engine hosts. And probably have some kind of automation for making sure this is up-to-date... Good luck,
Thanks again, David
[image: Screenshot from 2021-04-10 17-21-39.png]
Sent with ProtonMail <https://protonmail.com> Secure Email.
‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Sunday, April 11, 2021 3:05 AM, Yedidyah Bar David <didi@redhat.com> wrote:
On Sat, Apr 10, 2021 at 1:14 PM David White via Users <users@ovirt.org> wrote:
This is resolved, and my environment is 100% stable now.
Glad to hear that, thanks for the report!
Or was, until I then used the engine to "upgrade" one of the hosts, at which point I started having problems again after the reboot, because the old vlan came back. I'll finish getting things stabilized today, and hopefully won't run into this again.
I've been turning things on and off quite a bit, because they aren't in a proper data center (yet) and are just sitting here in my home office. So I'm sure shutting them down and turning them back on fairly often hasn't helped the situation.
I initially had a few issues going on:
1. I of course first broke things when I tried to change the management vlan 2. Aside from my notes below and the troubleshooting steps I went through, yesterday, I had forgotten that connectivity to the DNS server hadn't been restored. Once I got DNS operational, the engine was able to see two of the hosts, and finally started showing some green. 3. I then went in and ran `hosted-engine --vm-stop` to shutdown the engine, and then I started it again... and viola. The last remaining problematic host came online, and a few minutes later, the disks, volumes, and datacenter came online. 4. I think part of my problem has been this switch. I purchased a Netgear GS324T for my frontend traffic. But I've also needed to put my backend traffic onto some temporary ports on that switch until I can get a VM controller setup that will run my other switch, a Ubiquiti US-XG-16 for my permanent backend traffic. The Netgear hasn't been nearly as simple to configure as I had hoped. The vlan behavior has also been inconsistent - sometimes I have vlan settings in place, and things work. Sometimes they don't work. It has also been re-assigning a of the vlans occasionally after reboots, which has been frustrating. I'm close to being completely done configuring the infrastructure, but I'm also getting increasingly tempted to go find a different switch.
Lessons learned:
1. Always make sure DNS is functional 1. I was really hoping that I could run DNS as a VM (or multiple VMs) *inside* the cluster. 2. That said, if the cluster and the engine won't even start correctly without, then I may need to run DNS externally. I'm open to feedback on this. 1. I have 1 extra U of space at the datacenter reserved, and I do have a 4th spare server that I haven't decided what to do with yet. It has way more CPU and RAM than would be necessary to run an internal DNS server... but perhaps I have no choice. *Thoughts*?
You can also have the IP addresses of the engine and hosts in /etc/hosts of all machines (engine and hosts) - then things should work fine. It does mean you'll have to manually maintain these hosts files somehow.
1. 1. Make sure your vlan settings are correct *before* you start deploying the hosted engine and configure oVirt.
Definitely. As well as making sure that IP addresses (and netmasks, routes, etc.) are as intended and working, name resolution is correct (DNS or /etc/hosts), etc. .
1. 2. If possible, don't turn off and turn on your servers constantly. :) I realize this is a given. I just don't have much choice in the matter right now, due to lack of datacenter in my home office.
While definitely not recommended, in principle this should be harmless. If you find concrete reproducible bugs around this, please report them (with clear accurate details - just "I turn off and on my hosts and things stop working" is not helpful, obviously...).
Thanks again and best regards,
Users mailing list -- users@ovirt.org
To unsubscribe send an email to users-leave@ovirt.org
Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/6TWZCFKAYF75GF...
-- Didi
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/NQQPZMLIDCVYH3...
-- Didi
{kind=link}

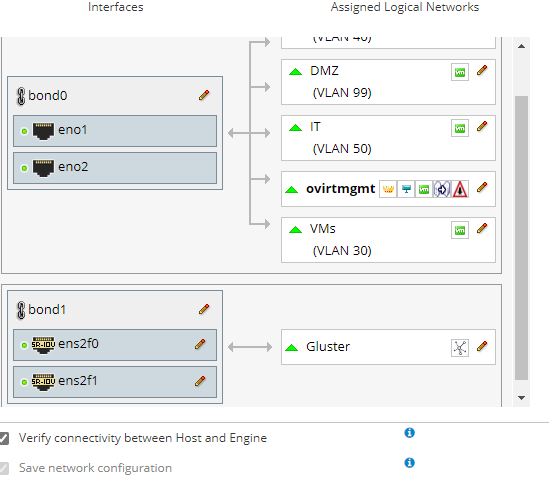
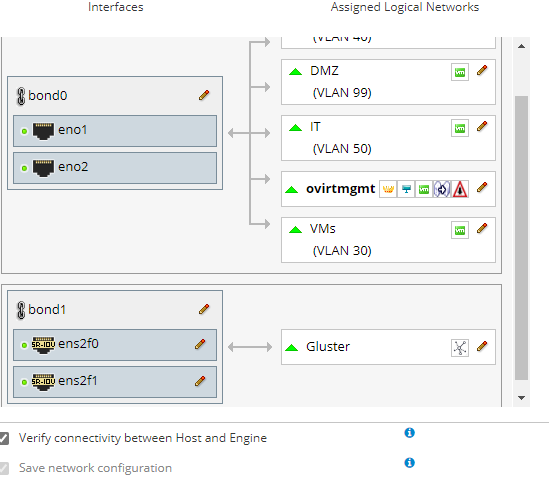
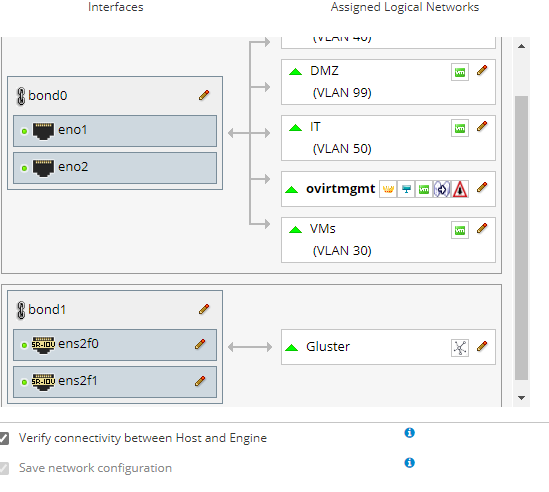
In the beginning, I made this same mistake. I setup all my networks, bonds, vlans, and tried to deploy the engine from cockpit. This never worked properly. Eventually I decided to leave the networks as simple as possible - just a static IP on a single interface for management, and same for Gluster. Then I setup the networks the way I wanted inside the 'setup host networks' window, and then 'sync all networks'. This worked much better, and now it's pretty easy to add VLANs as required. [image: image.png] On Sun, Apr 11, 2021 at 4:47 AM David White via Users <users@ovirt.org> wrote:
Thanks for the response here. Unfortunately, things are still not 100% stable after I performed that host upgrade. It appears to me that 1 of the hosts keeps booting back with the old management vlan (VLAN 1) instead of the new vlan (VLAN 10).
I'm able to (mostly) fiddle around with it and get it back online, but it seems like every reboot, vlan 1 comes back, and breaks connectivity with the other two hosts. I also didn't realize, until late yesterday afternoon, that you could use the oVirt Manager web UI to configure each host's network settings.
This whole time, I've been trying to use nmcli, nmtui, and manually editing /etc/sysconfig/network-scripts/ files by hand. When I found the network settings inside of the Engine / manager web UI, I discovered that, for example, oVirt Engine manager saw that the new vlan (VLAN 10) was "unmanaged" by the engine. *Question: *Would you recommend that all network settings be modified by the oVirt engine instead of the manual process on the OS?
*Question: *Is it possible to setup a vlan inside the engine *without* an IP address being assigned to each of the physical hosts? I was really hoping to setup VLAN 100 with public IP addresses, and use layer 2 switching to send that traffic into the oVirt cluster.
Here is a screenshot overview of what I want my environment to look like, logically. You'll note that I was going to put VLAN 20 and VLAN 100 onto the same host physical interface. This is what I - and I think the oVirt documentation - refers to as the front-end traffic. VLAN 10 is/was going to be on its own interface going to the 10Gbps switch.
*Question: *Do you see anything "wrong" with this picture? Are there ways I can / should change it to improve?
As for the /etc/hosts files, I'm actually doing that. However, as I'm typing this, I realized that I never defined the Engine IP address in the hosts, nor do I put anything inside the Engine's /etc/hosts file. *Question: *Perhaps this was part of my problem, when DNS connectivity was not working. Thoughts?
Thanks again, David
[image: Screenshot from 2021-04-10 17-21-39.png]
Sent with ProtonMail <https://protonmail.com> Secure Email.
‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Sunday, April 11, 2021 3:05 AM, Yedidyah Bar David <didi@redhat.com> wrote:
On Sat, Apr 10, 2021 at 1:14 PM David White via Users <users@ovirt.org> wrote:
This is resolved, and my environment is 100% stable now.
Glad to hear that, thanks for the report!
Or was, until I then used the engine to "upgrade" one of the hosts, at which point I started having problems again after the reboot, because the old vlan came back. I'll finish getting things stabilized today, and hopefully won't run into this again.
I've been turning things on and off quite a bit, because they aren't in a proper data center (yet) and are just sitting here in my home office. So I'm sure shutting them down and turning them back on fairly often hasn't helped the situation.
I initially had a few issues going on:
1. I of course first broke things when I tried to change the management vlan 2. Aside from my notes below and the troubleshooting steps I went through, yesterday, I had forgotten that connectivity to the DNS server hadn't been restored. Once I got DNS operational, the engine was able to see two of the hosts, and finally started showing some green. 3. I then went in and ran `hosted-engine --vm-stop` to shutdown the engine, and then I started it again... and viola. The last remaining problematic host came online, and a few minutes later, the disks, volumes, and datacenter came online. 4. I think part of my problem has been this switch. I purchased a Netgear GS324T for my frontend traffic. But I've also needed to put my backend traffic onto some temporary ports on that switch until I can get a VM controller setup that will run my other switch, a Ubiquiti US-XG-16 for my permanent backend traffic. The Netgear hasn't been nearly as simple to configure as I had hoped. The vlan behavior has also been inconsistent - sometimes I have vlan settings in place, and things work. Sometimes they don't work. It has also been re-assigning a of the vlans occasionally after reboots, which has been frustrating. I'm close to being completely done configuring the infrastructure, but I'm also getting increasingly tempted to go find a different switch.
Lessons learned:
1. Always make sure DNS is functional 1. I was really hoping that I could run DNS as a VM (or multiple VMs) *inside* the cluster. 2. That said, if the cluster and the engine won't even start correctly without, then I may need to run DNS externally. I'm open to feedback on this. 1. I have 1 extra U of space at the datacenter reserved, and I do have a 4th spare server that I haven't decided what to do with yet. It has way more CPU and RAM than would be necessary to run an internal DNS server... but perhaps I have no choice. *Thoughts*?
You can also have the IP addresses of the engine and hosts in /etc/hosts of all machines (engine and hosts) - then things should work fine. It does mean you'll have to manually maintain these hosts files somehow.
1. 1. Make sure your vlan settings are correct *before* you start deploying the hosted engine and configure oVirt.
Definitely. As well as making sure that IP addresses (and netmasks, routes, etc.) are as intended and working, name resolution is correct (DNS or /etc/hosts), etc. .
1. 2. If possible, don't turn off and turn on your servers constantly. :) I realize this is a given. I just don't have much choice in the matter right now, due to lack of datacenter in my home office.
While definitely not recommended, in principle this should be harmless. If you find concrete reproducible bugs around this, please report them (with clear accurate details - just "I turn off and on my hosts and things stop working" is not helpful, obviously...).
Thanks again and best regards,
Users mailing list -- users@ovirt.org
To unsubscribe send an email to users-leave@ovirt.org
Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/6TWZCFKAYF75GF...
-- Didi
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/NQQPZMLIDCVYH3...
{kind=link}
{kind=link}
Thanks to you and Did, both. Very helpful. I've whittled everything down to their most basic settings on the hosts, and did what you suggested, to try to stabilize everything on the most basic network settings. That did the trick, and everything is now able to get to everything now. I've also decided to simplify my datacenter installation, and go with a traditional NAT-based architecture. I have two routers, so I'll stick half the IPs on 1, and half the IPs on the other, with VPN capability on each, so that I and my team can quickly fail customers over from 1 router to the other, in case of an uplink or a router issue. Simplicity is king, and I think I was trying to make this way too complicated. Everything is 100% now, and I'll work on the NAT-based architecture over the next few days. Thanks again, David Sent with ProtonMail Secure Email. ‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Monday, April 12, 2021 1:49 PM, Vincent Royer <vincent@epicenergy.ca> wrote:
In the beginning, I made this same mistake. I setup all my networks, bonds, vlans, and tried to deploy the engine from cockpit. This never worked properly. Eventually I decided to leave the networks as simple as possible - just a static IP on a single interface for management, and same for Gluster. Then I setup the networks the way I wanted inside the 'setup host networks' window, and then 'sync all networks'. This worked much better, and now it's pretty easy to add VLANs as required.
[image.png]
On Sun, Apr 11, 2021 at 4:47 AM David White via Users <users@ovirt.org> wrote:
Thanks for the response here. Unfortunately, things are still not 100% stable after I performed that host upgrade. It appears to me that 1 of the hosts keeps booting back with the old management vlan (VLAN 1) instead of the new vlan (VLAN 10).
I'm able to (mostly) fiddle around with it and get it back online, but it seems like every reboot, vlan 1 comes back, and breaks connectivity with the other two hosts. I also didn't realize, until late yesterday afternoon, that you could use the oVirt Manager web UI to configure each host's network settings.
This whole time, I've been trying to use nmcli, nmtui, and manually editing /etc/sysconfig/network-scripts/ files by hand. When I found the network settings inside of the Engine / manager web UI, I discovered that, for example, oVirt Engine manager saw that the new vlan (VLAN 10) was "unmanaged" by the engine. Question: Would you recommend that all network settings be modified by the oVirt engine instead of the manual process on the OS?
Question: Is it possible to setup a vlan inside the engine without an IP address being assigned to each of the physical hosts? I was really hoping to setup VLAN 100 with public IP addresses, and use layer 2 switching to send that traffic into the oVirt cluster.
Here is a screenshot overview of what I want my environment to look like, logically. You'll note that I was going to put VLAN 20 and VLAN 100 onto the same host physical interface. This is what I - and I think the oVirt documentation - refers to as the front-end traffic. VLAN 10 is/was going to be on its own interface going to the 10Gbps switch.
Question: Do you see anything "wrong" with this picture? Are there ways I can / should change it to improve?
As for the /etc/hosts files, I'm actually doing that. However, as I'm typing this, I realized that I never defined the Engine IP address in the hosts, nor do I put anything inside the Engine's /etc/hosts file. Question: Perhaps this was part of my problem, when DNS connectivity was not working. Thoughts?
Thanks again, David
[Screenshot from 2021-04-10 17-21-39.png]
Sent with ProtonMail Secure Email.
‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Sunday, April 11, 2021 3:05 AM, Yedidyah Bar David <didi@redhat.com> wrote:
On Sat, Apr 10, 2021 at 1:14 PM David White via Users <users@ovirt.org> wrote:
This is resolved, and my environment is 100% stable now.
Glad to hear that, thanks for the report!
Or was, until I then used the engine to "upgrade" one of the hosts, at which point I started having problems again after the reboot, because the old vlan came back. I'll finish getting things stabilized today, and hopefully won't run into this again.
I've been turning things on and off quite a bit, because they aren't in a proper data center (yet) and are just sitting here in my home office. So I'm sure shutting them down and turning them back on fairly often hasn't helped the situation.
I initially had a few issues going on:
1. I of course first broke things when I tried to change the management vlan 2. Aside from my notes below and the troubleshooting steps I went through, yesterday, I had forgotten that connectivity to the DNS server hadn't been restored. Once I got DNS operational, the engine was able to see two of the hosts, and finally started showing some green. 3. I then went in and ran `hosted-engine --vm-stop` to shutdown the engine, and then I started it again... and viola. The last remaining problematic host came online, and a few minutes later, the disks, volumes, and datacenter came online. 4. I think part of my problem has been this switch. I purchased a Netgear GS324T for my frontend traffic. But I've also needed to put my backend traffic onto some temporary ports on that switch until I can get a VM controller setup that will run my other switch, a Ubiquiti US-XG-16 for my permanent backend traffic. The Netgear hasn't been nearly as simple to configure as I had hoped. The vlan behavior has also been inconsistent - sometimes I have vlan settings in place, and things work. Sometimes they don't work. It has also been re-assigning a of the vlans occasionally after reboots, which has been frustrating. I'm close to being completely done configuring the infrastructure, but I'm also getting increasingly tempted to go find a different switch.
Lessons learned:
1. Always make sure DNS is functional
1. I was really hoping that I could run DNS as a VM (or multiple VMs) inside the cluster. 2. That said, if the cluster and the engine won't even start correctly without, then I may need to run DNS externally. I'm open to feedback on this.
1. I have 1 extra U of space at the datacenter reserved, and I do have a 4th spare server that I haven't decided what to do with yet. It has way more CPU and RAM than would be necessary to run an internal DNS server... but perhaps I have no choice. Thoughts?
You can also have the IP addresses of the engine and hosts in /etc/hosts of all machines (engine and hosts) - then things should work fine. It does mean you'll have to manually maintain these hosts files somehow.
1.
2. Make sure your vlan settings are correct before you start deploying the hosted engine and configure oVirt.
Definitely. As well as making sure that IP addresses (and netmasks, routes, etc.) are as intended and working, name resolution is correct (DNS or /etc/hosts), etc. .
1.
2. If possible, don't turn off and turn on your servers constantly. :) I realize this is a given. I just don't have much choice in the matter right now, due to lack of datacenter in my home office.
While definitely not recommended, in principle this should be harmless. If you find concrete reproducible bugs around this, please report them (with clear accurate details - just "I turn off and on my hosts and things stop working" is not helpful, obviously...).
Thanks again and best regards,
Users mailing list -- users@ovirt.org
To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/6TWZCFKAYF75GF...
-- Didi
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/NQQPZMLIDCVYH3...
{kind=link}
{kind=link}
Bad news. Bringing everything back online again after cold booting, it appears that the old & complicated vlan settings came back, yet again, on two of the hosts. Every time I boot the infrastructure, these old settings come back. I think at this point, I'm going to just fresh install everything, because I can't keep running into this issue, and I'm starting to run really low on available time. My plan is to have the hardware deployed into the datacenter on Friday. I don't have a whole lot of work put into the VMs themselves (thankfully). Sent with ProtonMail Secure Email. ‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Monday, April 12, 2021 5:25 PM, David White via Users <users@ovirt.org> wrote:
Thanks to you and Did, both. Very helpful.
I've whittled everything down to their most basic settings on the hosts, and did what you suggested, to try to stabilize everything on the most basic network settings. That did the trick, and everything is now able to get to everything now.
I've also decided to simplify my datacenter installation, and go with a traditional NAT-based architecture.
I have two routers, so I'll stick half the IPs on 1, and half the IPs on the other, with VPN capability on each, so that I and my team can quickly fail customers over from 1 router to the other, in case of an uplink or a router issue.
Simplicity is king, and I think I was trying to make this way too complicated.
Everything is 100% now, and I'll work on the NAT-based architecture over the next few days.
Thanks again, David
Sent with ProtonMail Secure Email.
‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Monday, April 12, 2021 1:49 PM, Vincent Royer <vincent@epicenergy.ca> wrote:
In the beginning, I made this same mistake. I setup all my networks, bonds, vlans, and tried to deploy the engine from cockpit. This never worked properly. Eventually I decided to leave the networks as simple as possible - just a static IP on a single interface for management, and same for Gluster. Then I setup the networks the way I wanted inside the 'setup host networks' window, and then 'sync all networks'. This worked much better, and now it's pretty easy to add VLANs as required.
[image.png]
On Sun, Apr 11, 2021 at 4:47 AM David White via Users <users@ovirt.org> wrote:
Thanks for the response here. Unfortunately, things are still not 100% stable after I performed that host upgrade. It appears to me that 1 of the hosts keeps booting back with the old management vlan (VLAN 1) instead of the new vlan (VLAN 10).
I'm able to (mostly) fiddle around with it and get it back online, but it seems like every reboot, vlan 1 comes back, and breaks connectivity with the other two hosts. I also didn't realize, until late yesterday afternoon, that you could use the oVirt Manager web UI to configure each host's network settings.
This whole time, I've been trying to use nmcli, nmtui, and manually editing /etc/sysconfig/network-scripts/ files by hand. When I found the network settings inside of the Engine / manager web UI, I discovered that, for example, oVirt Engine manager saw that the new vlan (VLAN 10) was "unmanaged" by the engine. Question: Would you recommend that all network settings be modified by the oVirt engine instead of the manual process on the OS?
Question: Is it possible to setup a vlan inside the engine without an IP address being assigned to each of the physical hosts? I was really hoping to setup VLAN 100 with public IP addresses, and use layer 2 switching to send that traffic into the oVirt cluster.
Here is a screenshot overview of what I want my environment to look like, logically. You'll note that I was going to put VLAN 20 and VLAN 100 onto the same host physical interface. This is what I - and I think the oVirt documentation - refers to as the front-end traffic. VLAN 10 is/was going to be on its own interface going to the 10Gbps switch.
Question: Do you see anything "wrong" with this picture? Are there ways I can / should change it to improve?
As for the /etc/hosts files, I'm actually doing that. However, as I'm typing this, I realized that I never defined the Engine IP address in the hosts, nor do I put anything inside the Engine's /etc/hosts file. Question: Perhaps this was part of my problem, when DNS connectivity was not working. Thoughts?
Thanks again, David
[Screenshot from 2021-04-10 17-21-39.png]
Sent with ProtonMail Secure Email.
‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Sunday, April 11, 2021 3:05 AM, Yedidyah Bar David <didi@redhat.com> wrote:
On Sat, Apr 10, 2021 at 1:14 PM David White via Users <users@ovirt.org> wrote:
This is resolved, and my environment is 100% stable now.
Glad to hear that, thanks for the report!
Or was, until I then used the engine to "upgrade" one of the hosts, at which point I started having problems again after the reboot, because the old vlan came back. I'll finish getting things stabilized today, and hopefully won't run into this again.
I've been turning things on and off quite a bit, because they aren't in a proper data center (yet) and are just sitting here in my home office. So I'm sure shutting them down and turning them back on fairly often hasn't helped the situation.
I initially had a few issues going on:
1. I of course first broke things when I tried to change the management vlan 2. Aside from my notes below and the troubleshooting steps I went through, yesterday, I had forgotten that connectivity to the DNS server hadn't been restored. Once I got DNS operational, the engine was able to see two of the hosts, and finally started showing some green. 3. I then went in and ran `hosted-engine --vm-stop` to shutdown the engine, and then I started it again... and viola. The last remaining problematic host came online, and a few minutes later, the disks, volumes, and datacenter came online. 4. I think part of my problem has been this switch. I purchased a Netgear GS324T for my frontend traffic. But I've also needed to put my backend traffic onto some temporary ports on that switch until I can get a VM controller setup that will run my other switch, a Ubiquiti US-XG-16 for my permanent backend traffic. The Netgear hasn't been nearly as simple to configure as I had hoped. The vlan behavior has also been inconsistent - sometimes I have vlan settings in place, and things work. Sometimes they don't work. It has also been re-assigning a of the vlans occasionally after reboots, which has been frustrating. I'm close to being completely done configuring the infrastructure, but I'm also getting increasingly tempted to go find a different switch.
Lessons learned:
1. Always make sure DNS is functional
1. I was really hoping that I could run DNS as a VM (or multiple VMs) inside the cluster. 2. That said, if the cluster and the engine won't even start correctly without, then I may need to run DNS externally. I'm open to feedback on this.
1. I have 1 extra U of space at the datacenter reserved, and I do have a 4th spare server that I haven't decided what to do with yet. It has way more CPU and RAM than would be necessary to run an internal DNS server... but perhaps I have no choice. Thoughts?
You can also have the IP addresses of the engine and hosts in /etc/hosts of all machines (engine and hosts) - then things should work fine. It does mean you'll have to manually maintain these hosts files somehow.
1.
2. Make sure your vlan settings are correct before you start deploying the hosted engine and configure oVirt.
Definitely. As well as making sure that IP addresses (and netmasks, routes, etc.) are as intended and working, name resolution is correct (DNS or /etc/hosts), etc. .
1.
2. If possible, don't turn off and turn on your servers constantly. :) I realize this is a given. I just don't have much choice in the matter right now, due to lack of datacenter in my home office.
While definitely not recommended, in principle this should be harmless. If you find concrete reproducible bugs around this, please report them (with clear accurate details - just "I turn off and on my hosts and things stop working" is not helpful, obviously...).
Thanks again and best regards,
Users mailing list -- users@ovirt.org
To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/6TWZCFKAYF75GF...
-- Didi
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/NQQPZMLIDCVYH3...
{kind=link}
{kind=link}
participants (3)
-
 David White
David White -
 Vincent Royer
Vincent Royer -
 Yedidyah Bar David
Yedidyah Bar David