
Can you please attach agent.log from one of your hosts? On Mon, Jul 1, 2019 at 9:12 AM Crazy Ayansh <shashank123rastogi@gmail.com> wrote:
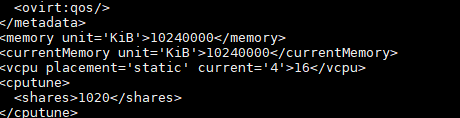
Hi Simon, It seems to be a memory issue but why it's not showing correct memory there i mean in hosted engine i have given below memory : [image: image.png]
whereas it is showing on virsh -r *** command is bit lesser why ? [image: image.png]
why both are different ?
On Mon, Jul 1, 2019 at 12:31 PM Crazy Ayansh <shashank123rastogi@gmail.com> wrote:
Hi Simon, It seems to be a memory issue but why it's not showing correct memory there i mean in hosted engine i have given below memory : [image: image.png]
whereas it is showing on virsh -r *** command is bit lesser why ? [image: image.png]
why both are different ?
Thanks
On Fri, Jun 28, 2019 at 7:11 PM Simone Tiraboschi <stirabos@redhat.com> wrote:
Can you please check how much memory it got in the output of virsh -r dumpxml HostedEngine ?
On Fri, Jun 28, 2019 at 3:27 PM Crazy Ayansh < shashank123rastogi@gmail.com> wrote:
Hi Team,
Today i rebooted my hosted engine and found it was not getting up. After connecting through remote viewer i found the error "error:cannot allocate kernel buffer" and i am not able to start hosted engine.any suggestions ? _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/site/privacy-policy/ oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/MTDRNK2DZVW4UN...
--
Simone Tiraboschi
He / Him / His
Principal Software Engineer
Red Hat <https://www.redhat.com/>
stirabos@redhat.com @redhatjobs <https://twitter.com/redhatjobs> redhatjobs <https://www.facebook.com/redhatjobs> @redhatjobs <https://instagram.com/redhatjobs> <https://red.ht/sig> <https://redhat.com/summit>
-- Simone Tiraboschi He / Him / His Principal Software Engineer Red Hat <https://www.redhat.com/> stirabos@redhat.com @redhatjobs <https://twitter.com/redhatjobs> redhatjobs <https://www.facebook.com/redhatjobs> @redhatjobs <https://instagram.com/redhatjobs> <https://red.ht/sig> <https://redhat.com/summit>
{kind=link}
{kind=link}