
On Mon, Jul 1, 2019 at 2:33 PM Crazy Ayansh <shashank123rastogi@gmail.com> wrote:
PFA.
I see that we have a lot of errors trying to update protected devices on the hosted-engine VM 2019-07-01 13:43:45,611+05 INFO [org.ovirt.engine.core.bll.UpdateVmCommand] (default task-5) [fe33db64-7c7a-4e5d-bdee-3e0e020df6e5] Lock Acquired to object 'EngineLock:{exclusiveLocks='[HostedEngine=VM_NAME]', sharedLocks='[edfd300f-1ab5-44a0-ab61-22e18a528fc4=VM]'}' 2019-07-01 13:43:45,618+05 WARN [org.ovirt.engine.core.bll.UpdateVmCommand] (default task-5) [fe33db64-7c7a-4e5d-bdee-3e0e020df6e5] Validation of action 'UpdateVm' failed for user admin@internal-authz. Reasons: VAR__ACTION__UPDATE,VAR__TYPE__VM,VM_CANNOT_UPDATE_HOSTED_ENGINE_FIELD 2019-07-01 13:43:45,618+05 INFO [org.ovirt.engine.core.bll.UpdateVmCommand] (default task-5) [fe33db64-7c7a-4e5d-bdee-3e0e020df6e5] Lock freed to object 'EngineLock:{exclusiveLocks='[HostedEngine=VM_NAME]', sharedLocks='[edfd300f-1ab5-44a0-ab61-22e18a528fc4=VM]'}' 2019-07-01 13:44:34,079+05 INFO [org.ovirt.engine.core.bll.SetVmTicketCommand] (default task-5) [1addd960] Running command: SetVmTicketCommand internal: false. Entities affected : ID: edfd300f-1ab5-44a0-ab61-22e18a528fc4 Type: VMAction group CONNECT_TO_VM with role type USER 2019-07-01 13:44:34,092+05 INFO [org.ovirt.engine.core.vdsbroker.vdsbroker.SetVmTicketVDSCommand] (default task-5) [1addd960] START, SetVmTicketVDSCommand(HostName = iondelsvr49.iontrading.com, SetVmTicketVDSCommandParameters:{hostId='4b56f069-d9d8-42d9-a0d8-2da529c9e0b7', vmId='edfd300f-1ab5-44a0-ab61-22e18a528fc4', protocol='VNC', ticket='8CSP39ykMO4D', validTime='120', userName='admin', userId='5ab52ac1-01ba-020f-00da-000000000331', disconnectAction='LOCK_SCREEN'}), log id: 3a7bb24d but I don't see any specific error trying to generate the OVF_STORE volume.
On Mon, Jul 1, 2019 at 5:24 PM Simone Tiraboschi <stirabos@redhat.com> wrote:
The hosted-engine VM configuration is wrote by the engine on a special volume called OVF_STORE. According to the logs ovirt-ha-agent correctly extracted it:
MainThread::INFO::2019-07-01 07:39:06,480::config::416::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine.config::(_get_vm_conf_content_from_ovf_store) Trying to get a fresher copy of vm configuration from the OVF_STORE MainThread::INFO::2019-07-01 07:39:06,481::ovf_store::132::ovirt_hosted_engine_ha.lib.ovf.ovf_store.OVFStore::(getEngineVMOVF) Extracting Engine VM OVF from the OVF_STORE MainThread::INFO::2019-07-01 07:39:06,489::ovf_store::134::ovirt_hosted_engine_ha.lib.ovf.ovf_store.OVFStore::(getEngineVMOVF) OVF_STORE volume path: /var/run/vdsm/storage/d1153bec-a29f-4196-bef2-f7c8d88d4e31/4f5084e0-10f4-4532-a747-18d568ef8d40/f02ef729-5d33-4c50-9f3c-29b6cd5a4f81
MainThread::INFO::2019-07-01 07:39:06,506::config::435::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine.config::(_get_vm_conf_content_from_ovf_store) Found an OVF for HE VM, trying to convert MainThread::INFO::2019-07-01 07:39:06,509::config::440::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine.config::(_get_vm_conf_content_from_ovf_store) Got vm.conf from OVF_STORE
Can you please check engine.log on your engine VM for errors there generating the OVF_STORE?
On Mon, Jul 1, 2019 at 1:46 PM Crazy Ayansh <shashank123rastogi@gmail.com> wrote:
Hi Simone,
Few minutes ago i have done below changes.
I edited /var/run/ovirt-hosted-engine-ha/vm.conf where memory was very low so i increased it upto 16 gb and hence hosted engine is up but i am not sure why it was in that state. I have attached agen.log of the host server (hosted engine is also running on this server)
Thanks Shashank
On Mon, Jul 1, 2019 at 4:49 PM Simone Tiraboschi <stirabos@redhat.com> wrote:
Can you please attach agent.log from one of your hosts?
On Mon, Jul 1, 2019 at 9:12 AM Crazy Ayansh < shashank123rastogi@gmail.com> wrote:
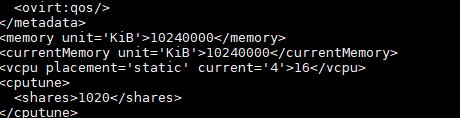
Hi Simon, It seems to be a memory issue but why it's not showing correct memory there i mean in hosted engine i have given below memory : [image: image.png]
whereas it is showing on virsh -r *** command is bit lesser why ? [image: image.png]
why both are different ?
On Mon, Jul 1, 2019 at 12:31 PM Crazy Ayansh < shashank123rastogi@gmail.com> wrote:
Hi Simon, It seems to be a memory issue but why it's not showing correct memory there i mean in hosted engine i have given below memory : [image: image.png]
whereas it is showing on virsh -r *** command is bit lesser why ? [image: image.png]
why both are different ?
Thanks
On Fri, Jun 28, 2019 at 7:11 PM Simone Tiraboschi < stirabos@redhat.com> wrote:
> Can you please check how much memory it got in the output of virsh > -r dumpxml HostedEngine ? > > > On Fri, Jun 28, 2019 at 3:27 PM Crazy Ayansh < > shashank123rastogi@gmail.com> wrote: > >> Hi Team, >> >> Today i rebooted my hosted engine and found it was not getting up. >> After connecting through remote viewer i found the error "error:cannot >> allocate kernel buffer" and i am not able to start hosted engine.any >> suggestions ? >> _______________________________________________ >> Users mailing list -- users@ovirt.org >> To unsubscribe send an email to users-leave@ovirt.org >> Privacy Statement: https://www.ovirt.org/site/privacy-policy/ >> oVirt Code of Conduct: >> https://www.ovirt.org/community/about/community-guidelines/ >> List Archives: >> https://lists.ovirt.org/archives/list/users@ovirt.org/message/MTDRNK2DZVW4UN... >> > > > -- > > Simone Tiraboschi > > He / Him / His > > Principal Software Engineer > > Red Hat <https://www.redhat.com/> > > stirabos@redhat.com > @redhatjobs <https://twitter.com/redhatjobs> redhatjobs > <https://www.facebook.com/redhatjobs> @redhatjobs > <https://instagram.com/redhatjobs> > <https://red.ht/sig> > <https://redhat.com/summit> >
--
Simone Tiraboschi
He / Him / His
Principal Software Engineer
Red Hat <https://www.redhat.com/>
stirabos@redhat.com @redhatjobs <https://twitter.com/redhatjobs> redhatjobs <https://www.facebook.com/redhatjobs> @redhatjobs <https://instagram.com/redhatjobs> <https://red.ht/sig> <https://redhat.com/summit>
--
Simone Tiraboschi
He / Him / His
Principal Software Engineer
Red Hat <https://www.redhat.com/>
stirabos@redhat.com @redhatjobs <https://twitter.com/redhatjobs> redhatjobs <https://www.facebook.com/redhatjobs> @redhatjobs <https://instagram.com/redhatjobs> <https://red.ht/sig> <https://redhat.com/summit>
-- Simone Tiraboschi He / Him / His Principal Software Engineer Red Hat <https://www.redhat.com/> stirabos@redhat.com @redhatjobs <https://twitter.com/redhatjobs> redhatjobs <https://www.facebook.com/redhatjobs> @redhatjobs <https://instagram.com/redhatjobs> <https://red.ht/sig> <https://redhat.com/summit>
{kind=link}
{kind=link}