Re: [ovirt-users] Re: [=EXTERNAL=] Re: help using nvme/tcp storage with cinderlib and Managed Block Storage

On Wed, Feb 23, 2022 at 6:24 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
Thanks for the detailed instructions, Nir. I'm going to scrounge up some hardware. By the way, if anyone else would like to work on NVMe/TCP support, for NVMe/TCP target you can either use Lightbits (talk to me offline for details) or use the upstream Linux NVMe/TCP target. Lightbits is a clustered storage system while upstream is a single target, but the client side should be close enough for vdsm/ovirt purposes.
I played with NVMe/TCP a little bit, using qemu to create a virtual NVMe disk, and export it using the kernel on one VM, and consume it on another VM. https://futurewei-cloud.github.io/ARM-Datacenter/qemu/nvme-of-tcp-vms/ One question about device naming - do we always get the same name of the device in all hosts? To support VM migration, every device must have unique name in the cluster. With multipath we always have unique name, since we disable "friendly names", so we always have: /dev/mapper/{wwid} With rbd we also do not use /dev/rbdN but a unique path: /dev/rbd/poolname/volume-vol-id How do we ensure cluster-unique device path? If os_brick does not handle it, we can to do in ovirt, for example: /run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42 but I think this should be handled in cinderlib, since openstack have the same problem with migration. Nir
Cheers, Muli -- Muli Ben-Yehuda Co-Founder and Chief Scientist @ http://www.lightbitslabs.com LightOS: The Special Storage Sauce For Your Cloud
On Wed, Feb 23, 2022 at 4:55 PM Nir Soffer <nsoffer@redhat.com> wrote:
On Wed, Feb 23, 2022 at 4:20 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
Thanks, Nir and Benny (nice to run into you again, Nir!). I'm a neophyte in ovirt and vdsm... What's the simplest way to set up a development environment? Is it possible to set up a "standalone" vdsm environment to hack support for nvme/tcp or do I need "full ovirt" to make it work?
It should be possible to install vdsm on a single host or vm, and use vdsm API to bring the host to the right state, and then attach devices and run vms. But I don't know anyone that can pull this out since simulating what engine is doing is hard.
So the best way is to set up at least one host and engine host using the latest 4.5 rpms, and continue from there. Once you have a host, building vdsm on the host and upgrading the rpms is pretty easy.
My preferred setup is to create vms using virt-manager for hosts, engine and storage and run all the vms on my laptop.
Note that you must have some traditional storage (NFS/iSCSI) to bring up the system even if you plan to use only managed block storage (MBS). Unfortunately when we add MBS support we did have time to fix the huge technical debt so you still need a master storage domain using one of the traditional legacy options.
To build a setup, you can use:
- engine vm: 6g ram, 2 cpus, centos stream 8 - hosts vm: 4g ram, 2 cpus, centos stream 8 you can start with one host and add more hosts later if you want to test migration. - storage vm: 2g ram, 2 cpus, any os you like, I use alpine since it takes very little memory and its NFS server is fast.
See vdsm README for instructions how to setup a host: https://github.com/oVirt/vdsm#manual-installation
For engine host you can follow: https://ovirt.org/documentation/installing_ovirt_as_a_self-hosted_engine_usi...
And after that this should work:
dnf install ovirt-engine engine-setup
Accepting all the defaults should work.
When you have engine running, you can add a new host with the ip address or dns name of you host(s) vm, and engine will do everything for you. Note that you must install the ovirt-release-master rpm on the host before you add it to engine.
Nir
Cheers, Muli -- Muli Ben-Yehuda Co-Founder and Chief Scientist @ http://www.lightbitslabs.com LightOS: The Special Storage Sauce For Your Cloud
On Wed, Feb 23, 2022 at 4:16 PM Nir Soffer <nsoffer@redhat.com> wrote:
On Wed, Feb 23, 2022 at 2:48 PM Benny Zlotnik <bzlotnik@redhat.com> wrote:
So I started looking in the logs and tried to follow along with the code, but things didn't make sense and then I saw it's ovirt 4.3 which makes things more complicated :) Unfortunately because GUID is sent in the metadata the volume is treated as a vdsm managed volume[2] for the udev rule generation and it prepends the /dev/mapper prefix to an empty string as a result. I don't have the vdsm logs, so I am not sure where exactly this fails, but if it's after [4] it may be possible to workaround it with a vdsm hook
In 4.4.6 we moved the udev rule triggering the volume mapping phase, before starting the VM. But it could still not work because we check the driver_volume_type in[1], and I saw it's "driver_volume_type": "lightos" for lightbits In theory it looks like it wouldn't take much to add support for your driver in a future release (as it's pretty late for 4.5)
Adding support for nvme/tcp in 4.3 is probably not feasible, but we will be happy to accept patches for 4.5.
To debug such issues vdsm log is the best place to check. We should see the connection info passed to vdsm, and we have pretty simple code using it with os_brick to attach the device to the system and setting up the udev rule (which may need some tweaks).
Nir
[1] https://github.com/oVirt/vdsm/blob/500c035903dd35180d71c97791e0ce4356fb77ad/...
(4.3) [2] https://github.com/oVirt/vdsm/blob/b42d4a816b538e00ea4955576a5fe762367be787/... [3] https://github.com/oVirt/vdsm/blob/b42d4a816b538e00ea4955576a5fe762367be787/... [4] https://github.com/oVirt/vdsm/blob/b42d4a816b538e00ea4955576a5fe762367be787/...
On Wed, Feb 23, 2022 at 12:44 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
Certainly, thanks for your help! I put cinderlib and engine.log here: http://www.mulix.org/misc/ovirt-logs-20220223123641.tar.gz If you grep for 'mulivm1' you will see for example:
2022-02-22 04:31:04,473-05 ERROR [org.ovirt.engine.core.vdsbroker.vdsbroker.HotPlugDiskVDSCommand] (default task-10) [36d8a122] Command 'HotPlugDiskVDSCommand(HostName = client1, HotPlugDiskVDSParameters:{hostId='fc5c2860-36b1-4213-843f-10ca7b35556c', vmId='e13f73a0-8e20-4ec3-837f-aeacc082c7aa', diskId='d1e1286b-38cc-4d56-9d4e-f331ffbe830f', addressMap='[bus=0, controller=0, unit=2, type=drive, target=0]'})' execution failed: VDSGenericException: VDSErrorException: Failed to HotPlugDiskVDS, error = Failed to bind /dev/mapper/ on to /var/run/libvirt/qemu/21-mulivm1.mapper.: Not a directory, code = 45
Please let me know what other information will be useful and I will prove.
Cheers, Muli
On Wed, Feb 23, 2022 at 11:14 AM Benny Zlotnik <bzlotnik@redhat.com> wrote: > > Hi, > > We haven't tested this, and we do not have any code to handle nvme/tcp > drivers, only iscsi and rbd. Given the path seen in the logs > '/dev/mapper', it looks like it might require code changes to support > this. > Can you share cinderlib[1] and engine logs to see what is returned by > the driver? I may be able to estimate what would be required (it's > possible that it would be enough to just change the handling of the > path in the engine) > > [1] /var/log/ovirt-engine/cinderlib/cinderlib//log > > On Wed, Feb 23, 2022 at 10:54 AM <muli@lightbitslabs.com> wrote: > > > > Hi everyone, > > > > We are trying to set up ovirt (4.3.10 at the moment, customer preference) to use Lightbits (https://www.lightbitslabs.com) storage via our openstack cinder driver with cinderlib. The cinderlib and cinder driver bits are working fine but when ovirt tries to attach the device to a VM we get the following error: > > > > libvirt: error : cannot create file '/var/run/libvirt/qemu/18-mulivm1.dev/mapper/': Is a directory > > > > We get the same error regardless of whether I try to run the VM or try to attach the device while it is running. The error appears to come from vdsm which passes /dev/mapper as the prefered device? > > > > 2022-02-22 09:50:11,848-0500 INFO (vm/3ae7dcf4) [vdsm.api] FINISH appropriateDevice return={'path': '/dev/mapper/', 'truesize': '53687091200', 'apparentsize': '53687091200'} from=internal, task_id=77f40c4e-733d-4d82-b418-aaeb6b912d39 (api:54) > > 2022-02-22 09:50:11,849-0500 INFO (vm/3ae7dcf4) [vds] prepared volume path: /dev/mapper/ (clientIF:510) > > > > Suggestions for how to debug this further? Is this a known issue? Did anyone get nvme/tcp storage working with ovirt and/or vdsm? > > > > Thanks, > > Muli > > > > _______________________________________________ > > Users mailing list -- users@ovirt.org > > To unsubscribe send an email to users-leave@ovirt.org > > Privacy Statement: https://www.ovirt.org/privacy-policy.html > > oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ > > List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/I3PAG5HMBHUOJY... >
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/DKFOCYQA6E4N3Y...
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.

On Thu, Feb 24, 2022 at 3:58 PM Nir Soffer <nsoffer@redhat.com> wrote:
On Wed, Feb 23, 2022 at 6:24 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
Thanks for the detailed instructions, Nir. I'm going to scrounge up some
By the way, if anyone else would like to work on NVMe/TCP support, for NVMe/TCP target you can either use Lightbits (talk to me offline for
hardware. details) or use the upstream Linux NVMe/TCP target. Lightbits is a clustered storage system while upstream is a single target, but the client side should be close enough for vdsm/ovirt purposes.
I played with NVMe/TCP a little bit, using qemu to create a virtual NVMe disk, and export it using the kernel on one VM, and consume it on another VM. https://futurewei-cloud.github.io/ARM-Datacenter/qemu/nvme-of-tcp-vms/
One question about device naming - do we always get the same name of the device in all hosts?
No, we do not, see below how we handle migration in os_brick. To support VM migration, every device must have unique name in the cluster.
With multipath we always have unique name, since we disable "friendly names", so we always have:
/dev/mapper/{wwid}
With rbd we also do not use /dev/rbdN but a unique path:
/dev/rbd/poolname/volume-vol-id
How do we ensure cluster-unique device path? If os_brick does not handle it, we can to do in ovirt, for example:
/run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42
but I think this should be handled in cinderlib, since openstack have the same problem with migration.
Indeed. Both the Lightbits LightOS connector and the nvmeof connector do this through the target provided namespace (LUN) UUID. After connecting to the target, the connectors wait for the local friendly-named device file that has the right UUID to show up, and then return the friendly name. So different hosts will have different friendly names, but the VMs will be attached to the right namespace since we return the friendly name on the current host that has the right UUID. Does this also work for you? Cheers, Muli -- *Lightbits Labs** *Lead the cloud-native data center transformation by delivering *scalable *and *efficient *software defined storage that is *easy *to consume. *This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.*
On Thu, Feb 24, 2022 at 6:10 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
On Thu, Feb 24, 2022 at 3:58 PM Nir Soffer <nsoffer@redhat.com> wrote:
On Wed, Feb 23, 2022 at 6:24 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
Thanks for the detailed instructions, Nir. I'm going to scrounge up some hardware. By the way, if anyone else would like to work on NVMe/TCP support, for NVMe/TCP target you can either use Lightbits (talk to me offline for details) or use the upstream Linux NVMe/TCP target. Lightbits is a clustered storage system while upstream is a single target, but the client side should be close enough for vdsm/ovirt purposes.
I played with NVMe/TCP a little bit, using qemu to create a virtual NVMe disk, and export it using the kernel on one VM, and consume it on another VM. https://futurewei-cloud.github.io/ARM-Datacenter/qemu/nvme-of-tcp-vms/
One question about device naming - do we always get the same name of the device in all hosts?
No, we do not, see below how we handle migration in os_brick.
To support VM migration, every device must have unique name in the cluster. With multipath we always have unique name, since we disable "friendly names", so we always have:
/dev/mapper/{wwid}
With rbd we also do not use /dev/rbdN but a unique path:
/dev/rbd/poolname/volume-vol-id
How do we ensure cluster-unique device path? If os_brick does not handle it, we can to do in ovirt, for example:
/run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42
but I think this should be handled in cinderlib, since openstack have the same problem with migration.
Indeed. Both the Lightbits LightOS connector and the nvmeof connector do this through the target provided namespace (LUN) UUID. After connecting to the target, the connectors wait for the local friendly-named device file that has the right UUID to show up, and then return the friendly name. So different hosts will have different friendly names, but the VMs will be attached to the right namespace since we return the friendly name on the current host that has the right UUID. Does this also work for you?
It will not work for oVirt. Migration in oVirt works like this: 1. Attach disks to destination host 2. Send VM XML from source host to destination host, and start the VM is paused mode 3. Start the migration on the source host 4. When migration is done, start the CPU on the destination host 5. Detach the disks from the source This will break in step 2, since the source xml refer to nvme device that does not exist or already used by another VM. To make this work, the VM XML must use the same path, existing on both hosts. The issue can be solved by libvirt hook updating the paths before qemu is started on the destination, but I think the right way to handle this is to have the same path. Nir
On Thu, Feb 24, 2022 at 6:28 PM Nir Soffer <nsoffer@redhat.com> wrote:
On Thu, Feb 24, 2022 at 6:10 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
On Thu, Feb 24, 2022 at 3:58 PM Nir Soffer <nsoffer@redhat.com> wrote:
On Wed, Feb 23, 2022 at 6:24 PM Muli Ben-Yehuda <muli@lightbitslabs.com>
Thanks for the detailed instructions, Nir. I'm going to scrounge up
some hardware.
By the way, if anyone else would like to work on NVMe/TCP support, for NVMe/TCP target you can either use Lightbits (talk to me offline for
I played with NVMe/TCP a little bit, using qemu to create a virtual NVMe disk, and export it using the kernel on one VM, and consume it on another VM. https://futurewei-cloud.github.io/ARM-Datacenter/qemu/nvme-of-tcp-vms/
One question about device naming - do we always get the same name of the device in all hosts?
No, we do not, see below how we handle migration in os_brick.
To support VM migration, every device must have unique name in the cluster. With multipath we always have unique name, since we disable "friendly names", so we always have:
/dev/mapper/{wwid}
With rbd we also do not use /dev/rbdN but a unique path:
/dev/rbd/poolname/volume-vol-id
How do we ensure cluster-unique device path? If os_brick does not handle it, we can to do in ovirt, for example:
/run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42
but I think this should be handled in cinderlib, since openstack have the same problem with migration.
Indeed. Both the Lightbits LightOS connector and the nvmeof connector do
wrote: details) or use the upstream Linux NVMe/TCP target. Lightbits is a clustered storage system while upstream is a single target, but the client side should be close enough for vdsm/ovirt purposes. this through the target provided namespace (LUN) UUID. After connecting to the target, the connectors wait for the local friendly-named device file that has the right UUID to show up, and then return the friendly name. So different hosts will have different friendly names, but the VMs will be attached to the right namespace since we return the friendly name on the current host that has the right UUID. Does this also work for you?
It will not work for oVirt.
Migration in oVirt works like this:
1. Attach disks to destination host 2. Send VM XML from source host to destination host, and start the VM is paused mode 3. Start the migration on the source host 4. When migration is done, start the CPU on the destination host 5. Detach the disks from the source
This will break in step 2, since the source xml refer to nvme device that does not exist or already used by another VM.
Indeed. To make this work, the VM XML must use the same path, existing on
both hosts.
The issue can be solved by libvirt hook updating the paths before qemu is started on the destination, but I think the right way to handle this is to have the same path.
You mentioned above that it can be handled in ovirt (c.f., /run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42), which seems like a reasonable approach given the constraint imposed by the oVirt migration flow you outlined above. What information does vdsm need to create and use the /var/run/vdsm/managedvolumes/{uuid} link? Today the connector does (trimmed for brevity): def connect_volume(self, connection_properties): device_info = {'type': 'block'} uuid = connection_properties['uuid'] device_path = self._get_device_by_uuid(uuid) device_info['path'] = device_path return device_info Cheers, Muli -- *Lightbits Labs** *Lead the cloud-native data center transformation by delivering *scalable *and *efficient *software defined storage that is *easy *to consume. *This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.*
On Thu, Feb 24, 2022 at 6:35 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
On Thu, Feb 24, 2022 at 6:28 PM Nir Soffer <nsoffer@redhat.com> wrote:
On Thu, Feb 24, 2022 at 6:10 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
On Thu, Feb 24, 2022 at 3:58 PM Nir Soffer <nsoffer@redhat.com> wrote:
On Wed, Feb 23, 2022 at 6:24 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
Thanks for the detailed instructions, Nir. I'm going to scrounge up some hardware. By the way, if anyone else would like to work on NVMe/TCP support, for NVMe/TCP target you can either use Lightbits (talk to me offline for details) or use the upstream Linux NVMe/TCP target. Lightbits is a clustered storage system while upstream is a single target, but the client side should be close enough for vdsm/ovirt purposes.
I played with NVMe/TCP a little bit, using qemu to create a virtual NVMe disk, and export it using the kernel on one VM, and consume it on another VM. https://futurewei-cloud.github.io/ARM-Datacenter/qemu/nvme-of-tcp-vms/
One question about device naming - do we always get the same name of the device in all hosts?
No, we do not, see below how we handle migration in os_brick.
To support VM migration, every device must have unique name in the cluster. With multipath we always have unique name, since we disable "friendly names", so we always have:
/dev/mapper/{wwid}
With rbd we also do not use /dev/rbdN but a unique path:
/dev/rbd/poolname/volume-vol-id
How do we ensure cluster-unique device path? If os_brick does not handle it, we can to do in ovirt, for example:
/run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42
but I think this should be handled in cinderlib, since openstack have the same problem with migration.
Indeed. Both the Lightbits LightOS connector and the nvmeof connector do this through the target provided namespace (LUN) UUID. After connecting to the target, the connectors wait for the local friendly-named device file that has the right UUID to show up, and then return the friendly name. So different hosts will have different friendly names, but the VMs will be attached to the right namespace since we return the friendly name on the current host that has the right UUID. Does this also work for you?
It will not work for oVirt.
Migration in oVirt works like this:
1. Attach disks to destination host 2. Send VM XML from source host to destination host, and start the VM is paused mode 3. Start the migration on the source host 4. When migration is done, start the CPU on the destination host 5. Detach the disks from the source
This will break in step 2, since the source xml refer to nvme device that does not exist or already used by another VM.
Indeed.
To make this work, the VM XML must use the same path, existing on both hosts.
The issue can be solved by libvirt hook updating the paths before qemu is started on the destination, but I think the right way to handle this is to have the same path.
You mentioned above that it can be handled in ovirt (c.f., /run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42), which seems like a reasonable approach given the constraint imposed by the oVirt migration flow you outlined above. What information does vdsm need to create and use the /var/run/vdsm/managedvolumes/{uuid} link? Today the connector does (trimmed for brevity):
def connect_volume(self, connection_properties): device_info = {'type': 'block'} uuid = connection_properties['uuid'] device_path = self._get_device_by_uuid(uuid) device_info['path'] = device_path return device_info
I think we have 2 options: 1. unique path created by os_brick using the underlying uuid In this case the connector will return the uuid, and ovirt will use it to resolve the unique path that will be stored and used on engine side to create the vm xml. I'm not sure how the connector should return this uuid. Looking in current vdsm code: if vol_type in ("iscsi", "fibre_channel"): if "multipath_id" not in attachment: raise se.ManagedVolumeUnsupportedDevice(vol_id, attachment) # /dev/mapper/xxxyyy return os.path.join(DEV_MAPPER, attachment["multipath_id"]) elif vol_type == "rbd": # /dev/rbd/poolname/volume-vol-id return os.path.join(DEV_RBD, connection_info['data']['name']) os_brick does not have a uniform way to address different devices. Maybe Gorka can help with this. 2. unique path created by oVirt In this case oVirt will use the disk uuid already used in ManagedVolume.{attach,detach}_volume APIs: https://github.com/oVirt/vdsm/blob/500c035903dd35180d71c97791e0ce4356fb77ad/... https://github.com/oVirt/vdsm/blob/500c035903dd35180d71c97791e0ce4356fb77ad/... From oVirt point of view, using the disk uuid seems better. It makes it easy to debug when you can follow the uuid in all logs on different systems and locate the actual disk using the same uuid. Nir

On 24/02, Nir Soffer wrote:
On Thu, Feb 24, 2022 at 6:35 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
On Thu, Feb 24, 2022 at 6:28 PM Nir Soffer <nsoffer@redhat.com> wrote:
On Thu, Feb 24, 2022 at 6:10 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
On Thu, Feb 24, 2022 at 3:58 PM Nir Soffer <nsoffer@redhat.com> wrote:
On Wed, Feb 23, 2022 at 6:24 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
Thanks for the detailed instructions, Nir. I'm going to scrounge up some hardware. By the way, if anyone else would like to work on NVMe/TCP support, for NVMe/TCP target you can either use Lightbits (talk to me offline for details) or use the upstream Linux NVMe/TCP target. Lightbits is a clustered storage system while upstream is a single target, but the client side should be close enough for vdsm/ovirt purposes.
I played with NVMe/TCP a little bit, using qemu to create a virtual NVMe disk, and export it using the kernel on one VM, and consume it on another VM. https://futurewei-cloud.github.io/ARM-Datacenter/qemu/nvme-of-tcp-vms/
One question about device naming - do we always get the same name of the device in all hosts?
No, we do not, see below how we handle migration in os_brick.
To support VM migration, every device must have unique name in the cluster. With multipath we always have unique name, since we disable "friendly names", so we always have:
/dev/mapper/{wwid}
With rbd we also do not use /dev/rbdN but a unique path:
/dev/rbd/poolname/volume-vol-id
How do we ensure cluster-unique device path? If os_brick does not handle it, we can to do in ovirt, for example:
/run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42
but I think this should be handled in cinderlib, since openstack have the same problem with migration.
Indeed. Both the Lightbits LightOS connector and the nvmeof connector do this through the target provided namespace (LUN) UUID. After connecting to the target, the connectors wait for the local friendly-named device file that has the right UUID to show up, and then return the friendly name. So different hosts will have different friendly names, but the VMs will be attached to the right namespace since we return the friendly name on the current host that has the right UUID. Does this also work for you?
It will not work for oVirt.
Migration in oVirt works like this:
1. Attach disks to destination host 2. Send VM XML from source host to destination host, and start the VM is paused mode 3. Start the migration on the source host 4. When migration is done, start the CPU on the destination host 5. Detach the disks from the source
This will break in step 2, since the source xml refer to nvme device that does not exist or already used by another VM.
Indeed.
To make this work, the VM XML must use the same path, existing on both hosts.
The issue can be solved by libvirt hook updating the paths before qemu is started on the destination, but I think the right way to handle this is to have the same path.
You mentioned above that it can be handled in ovirt (c.f., /run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42), which seems like a reasonable approach given the constraint imposed by the oVirt migration flow you outlined above. What information does vdsm need to create and use the /var/run/vdsm/managedvolumes/{uuid} link? Today the connector does (trimmed for brevity):
def connect_volume(self, connection_properties): device_info = {'type': 'block'} uuid = connection_properties['uuid'] device_path = self._get_device_by_uuid(uuid) device_info['path'] = device_path return device_info
I think we have 2 options:
1. unique path created by os_brick using the underlying uuid
In this case the connector will return the uuid, and ovirt will use it to resolve the unique path that will be stored and used on engine side to create the vm xml.
I'm not sure how the connector should return this uuid. Looking in current vdsm code:
if vol_type in ("iscsi", "fibre_channel"): if "multipath_id" not in attachment: raise se.ManagedVolumeUnsupportedDevice(vol_id, attachment) # /dev/mapper/xxxyyy return os.path.join(DEV_MAPPER, attachment["multipath_id"]) elif vol_type == "rbd": # /dev/rbd/poolname/volume-vol-id return os.path.join(DEV_RBD, connection_info['data']['name'])
os_brick does not have a uniform way to address different devices.
Maybe Gorka can help with this.
Hi, That is true, because in OpenStack we haven't had the need to have the same path on every host or even on the same host during different connections. For nvme a new `elif` clause could be added there, though it will be a bit trickier, because the nvme connection properties format are a bit of a mess... We have 2 different formats for the nvme properties, and the wwid that appears in symlink /dev/disk/by-id/nvme-<wwid> may or may not be the volume id, may be the uuid in the connection info if present or the nguid if the nvme device doesn't have uuid. For these reasons I would recommend not relying on the connection information and relying on the path from the attachment instead. Something like this should be probably fine: elif vol_type == 'nvme': device_name = os.path.basename(attachment['path']) controller = device_name.rsplit('n', 1)[0] wwid_filename = f'/sys/class/nvme/{controller}/{device_name}/wwid' with open(wwid_filename, 'r') as f: uuid = f.read().strip() return os.path.join('/dev/disk/by-id/nvme-', uuid) Cheers, Gorka.
2. unique path created by oVirt
In this case oVirt will use the disk uuid already used in ManagedVolume.{attach,detach}_volume APIs: https://github.com/oVirt/vdsm/blob/500c035903dd35180d71c97791e0ce4356fb77ad/... https://github.com/oVirt/vdsm/blob/500c035903dd35180d71c97791e0ce4356fb77ad/...
From oVirt point of view, using the disk uuid seems better. It makes it easy to debug when you can follow the uuid in all logs on different systems and locate the actual disk using the same uuid.
Nir
On Thu, Feb 24, 2022 at 8:46 PM Gorka Eguileor <geguileo@redhat.com> wrote:
On 24/02, Nir Soffer wrote:
On Thu, Feb 24, 2022 at 6:35 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
On Thu, Feb 24, 2022 at 6:28 PM Nir Soffer <nsoffer@redhat.com> wrote:
On Thu, Feb 24, 2022 at 6:10 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
On Thu, Feb 24, 2022 at 3:58 PM Nir Soffer <nsoffer@redhat.com> wrote:
On Wed, Feb 23, 2022 at 6:24 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote: > > Thanks for the detailed instructions, Nir. I'm going to scrounge up some hardware. > By the way, if anyone else would like to work on NVMe/TCP support, for NVMe/TCP target you can either use Lightbits (talk to me offline for details) or use the upstream Linux NVMe/TCP target. Lightbits is a clustered storage system while upstream is a single target, but the client side should be close enough for vdsm/ovirt purposes.
I played with NVMe/TCP a little bit, using qemu to create a virtual NVMe disk, and export it using the kernel on one VM, and consume it on another VM. https://futurewei-cloud.github.io/ARM-Datacenter/qemu/nvme-of-tcp-vms/
One question about device naming - do we always get the same name of the device in all hosts?
No, we do not, see below how we handle migration in os_brick.
To support VM migration, every device must have unique name in the cluster. With multipath we always have unique name, since we disable "friendly names", so we always have:
/dev/mapper/{wwid}
With rbd we also do not use /dev/rbdN but a unique path:
/dev/rbd/poolname/volume-vol-id
How do we ensure cluster-unique device path? If os_brick does not handle it, we can to do in ovirt, for example:
/run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42
but I think this should be handled in cinderlib, since openstack have the same problem with migration.
Indeed. Both the Lightbits LightOS connector and the nvmeof connector do this through the target provided namespace (LUN) UUID. After connecting to the target, the connectors wait for the local friendly-named device file that has the right UUID to show up, and then return the friendly name. So different hosts will have different friendly names, but the VMs will be attached to the right namespace since we return the friendly name on the current host that has the right UUID. Does this also work for you?
It will not work for oVirt.
Migration in oVirt works like this:
1. Attach disks to destination host 2. Send VM XML from source host to destination host, and start the VM is paused mode 3. Start the migration on the source host 4. When migration is done, start the CPU on the destination host 5. Detach the disks from the source
This will break in step 2, since the source xml refer to nvme device that does not exist or already used by another VM.
Indeed.
To make this work, the VM XML must use the same path, existing on both hosts.
The issue can be solved by libvirt hook updating the paths before qemu is started on the destination, but I think the right way to handle this is to have the same path.
You mentioned above that it can be handled in ovirt (c.f., /run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42), which seems like a reasonable approach given the constraint imposed by the oVirt migration flow you outlined above. What information does vdsm need to create and use the /var/run/vdsm/managedvolumes/{uuid} link? Today the connector does (trimmed for brevity):
def connect_volume(self, connection_properties): device_info = {'type': 'block'} uuid = connection_properties['uuid'] device_path = self._get_device_by_uuid(uuid) device_info['path'] = device_path return device_info
I think we have 2 options:
1. unique path created by os_brick using the underlying uuid
In this case the connector will return the uuid, and ovirt will use it to resolve the unique path that will be stored and used on engine side to create the vm xml.
I'm not sure how the connector should return this uuid. Looking in current vdsm code:
if vol_type in ("iscsi", "fibre_channel"): if "multipath_id" not in attachment: raise se.ManagedVolumeUnsupportedDevice(vol_id, attachment) # /dev/mapper/xxxyyy return os.path.join(DEV_MAPPER, attachment["multipath_id"]) elif vol_type == "rbd": # /dev/rbd/poolname/volume-vol-id return os.path.join(DEV_RBD, connection_info['data']['name'])
os_brick does not have a uniform way to address different devices.
Maybe Gorka can help with this.
Hi,
That is true, because in OpenStack we haven't had the need to have the same path on every host or even on the same host during different connections.
For nvme a new `elif` clause could be added there, though it will be a bit trickier, because the nvme connection properties format are a bit of a mess...
We have 2 different formats for the nvme properties, and the wwid that appears in symlink /dev/disk/by-id/nvme-<wwid> may or may not be the volume id, may be the uuid in the connection info if present or the nguid if the nvme device doesn't have uuid.
For these reasons I would recommend not relying on the connection information and relying on the path from the attachment instead.
Something like this should be probably fine:
elif vol_type == 'nvme': device_name = os.path.basename(attachment['path']) controller = device_name.rsplit('n', 1)[0] wwid_filename = f'/sys/class/nvme/{controller}/{device_name}/wwid' with open(wwid_filename, 'r') as f: uuid = f.read().strip() return os.path.join('/dev/disk/by-id/nvme-', uuid)
Thanks Gorka! but isn't this duplicating logic already in os brick? https://github.com/openstack/os-brick/blob/56bf0272b55dcbbc7f5b03150973a80af... Another interesting detail is this wait: https://github.com/openstack/os-brick/blob/56bf0272b55dcbbc7f5b03150973a80af... def _get_device_by_uuid(self, uuid): endtime = time.time() + self.WAIT_DEVICE_TIMEOUT while time.time() < endtime: try: device = self._check_device_exists_using_dev_lnk(uuid) if device: return device except Exception as e: LOG.debug(f'LIGHTOS: {e}') device = self._check_device_exists_reading_block_class(uuid) if device: return device time.sleep(1) return None The code does not explain why it tries to use the /dev/disk/by-id link and fallback to sysfs on errors. Based on our experience with udev, I guess that the author does not trust udev. I wonder if we can trust it as the stable device path. If we can trust this path, maybe os_brick can return the stable path in a uniform way for all kind of devices?
Cheers, Gorka.
2. unique path created by oVirt
In this case oVirt will use the disk uuid already used in ManagedVolume.{attach,detach}_volume APIs: https://github.com/oVirt/vdsm/blob/500c035903dd35180d71c97791e0ce4356fb77ad/... https://github.com/oVirt/vdsm/blob/500c035903dd35180d71c97791e0ce4356fb77ad/...
From oVirt point of view, using the disk uuid seems better. It makes it easy to debug when you can follow the uuid in all logs on different systems and locate the actual disk using the same uuid.
Nir
On 24/02, Nir Soffer wrote:
On Thu, Feb 24, 2022 at 8:46 PM Gorka Eguileor <geguileo@redhat.com> wrote:
On 24/02, Nir Soffer wrote:
On Thu, Feb 24, 2022 at 6:35 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
On Thu, Feb 24, 2022 at 6:28 PM Nir Soffer <nsoffer@redhat.com> wrote:
On Thu, Feb 24, 2022 at 6:10 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
On Thu, Feb 24, 2022 at 3:58 PM Nir Soffer <nsoffer@redhat.com> wrote: > > On Wed, Feb 23, 2022 at 6:24 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote: > > > > Thanks for the detailed instructions, Nir. I'm going to scrounge up some hardware. > > By the way, if anyone else would like to work on NVMe/TCP support, for NVMe/TCP target you can either use Lightbits (talk to me offline for details) or use the upstream Linux NVMe/TCP target. Lightbits is a clustered storage system while upstream is a single target, but the client side should be close enough for vdsm/ovirt purposes. > > I played with NVMe/TCP a little bit, using qemu to create a virtual > NVMe disk, and export > it using the kernel on one VM, and consume it on another VM. > https://futurewei-cloud.github.io/ARM-Datacenter/qemu/nvme-of-tcp-vms/ > > One question about device naming - do we always get the same name of the > device in all hosts?
No, we do not, see below how we handle migration in os_brick.
> To support VM migration, every device must have unique name in the cluster. > With multipath we always have unique name, since we disable "friendly names", > so we always have: > > /dev/mapper/{wwid} > > With rbd we also do not use /dev/rbdN but a unique path: > > /dev/rbd/poolname/volume-vol-id > > How do we ensure cluster-unique device path? If os_brick does not handle it, we > can to do in ovirt, for example: > > /run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42 > > but I think this should be handled in cinderlib, since openstack have > the same problem with migration.
Indeed. Both the Lightbits LightOS connector and the nvmeof connector do this through the target provided namespace (LUN) UUID. After connecting to the target, the connectors wait for the local friendly-named device file that has the right UUID to show up, and then return the friendly name. So different hosts will have different friendly names, but the VMs will be attached to the right namespace since we return the friendly name on the current host that has the right UUID. Does this also work for you?
It will not work for oVirt.
Migration in oVirt works like this:
1. Attach disks to destination host 2. Send VM XML from source host to destination host, and start the VM is paused mode 3. Start the migration on the source host 4. When migration is done, start the CPU on the destination host 5. Detach the disks from the source
This will break in step 2, since the source xml refer to nvme device that does not exist or already used by another VM.
Indeed.
To make this work, the VM XML must use the same path, existing on both hosts.
The issue can be solved by libvirt hook updating the paths before qemu is started on the destination, but I think the right way to handle this is to have the same path.
You mentioned above that it can be handled in ovirt (c.f., /run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42), which seems like a reasonable approach given the constraint imposed by the oVirt migration flow you outlined above. What information does vdsm need to create and use the /var/run/vdsm/managedvolumes/{uuid} link? Today the connector does (trimmed for brevity):
def connect_volume(self, connection_properties): device_info = {'type': 'block'} uuid = connection_properties['uuid'] device_path = self._get_device_by_uuid(uuid) device_info['path'] = device_path return device_info
I think we have 2 options:
1. unique path created by os_brick using the underlying uuid
In this case the connector will return the uuid, and ovirt will use it to resolve the unique path that will be stored and used on engine side to create the vm xml.
I'm not sure how the connector should return this uuid. Looking in current vdsm code:
if vol_type in ("iscsi", "fibre_channel"): if "multipath_id" not in attachment: raise se.ManagedVolumeUnsupportedDevice(vol_id, attachment) # /dev/mapper/xxxyyy return os.path.join(DEV_MAPPER, attachment["multipath_id"]) elif vol_type == "rbd": # /dev/rbd/poolname/volume-vol-id return os.path.join(DEV_RBD, connection_info['data']['name'])
os_brick does not have a uniform way to address different devices.
Maybe Gorka can help with this.
Hi,
That is true, because in OpenStack we haven't had the need to have the same path on every host or even on the same host during different connections.
For nvme a new `elif` clause could be added there, though it will be a bit trickier, because the nvme connection properties format are a bit of a mess...
We have 2 different formats for the nvme properties, and the wwid that appears in symlink /dev/disk/by-id/nvme-<wwid> may or may not be the volume id, may be the uuid in the connection info if present or the nguid if the nvme device doesn't have uuid.
For these reasons I would recommend not relying on the connection information and relying on the path from the attachment instead.
Something like this should be probably fine:
elif vol_type == 'nvme': device_name = os.path.basename(attachment['path']) controller = device_name.rsplit('n', 1)[0] wwid_filename = f'/sys/class/nvme/{controller}/{device_name}/wwid' with open(wwid_filename, 'r') as f: uuid = f.read().strip() return os.path.join('/dev/disk/by-id/nvme-', uuid)
Thanks Gorka!
but isn't this duplicating logic already in os brick? https://github.com/openstack/os-brick/blob/56bf0272b55dcbbc7f5b03150973a80af...
Hi Nir, Oh! I thought we were talking about the generic NVMe-oF connector, didn't know this was specific about the LightOS one. The link is used as an easy way to locate the volume, it doesn't mean that it is returned to the caller of the `connect_volume` method. In fact, we can see how that method actually returns the real path and not the link's path: def _check_device_exists_using_dev_lnk(self, uuid): lnk_path = f"/dev/disk/by-id/nvme-uuid.{uuid}" --> if os.path.exists(lnk_path): ^^^ Check link exists --> devname = os.path.realpath(lnk_path) ^^^ Get the real path for the symlink --> if devname.startswith("/dev/nvme"): ^^^ Make extra sure it's not pointing to something crazy LOG.info("LIGHTOS: devpath %s detected for uuid %s", devname, uuid) --> return devname ^^^ Return it return None
Another interesting detail is this wait: https://github.com/openstack/os-brick/blob/56bf0272b55dcbbc7f5b03150973a80af...
def _get_device_by_uuid(self, uuid): endtime = time.time() + self.WAIT_DEVICE_TIMEOUT while time.time() < endtime: try: device = self._check_device_exists_using_dev_lnk(uuid) if device: return device except Exception as e: LOG.debug(f'LIGHTOS: {e}') device = self._check_device_exists_reading_block_class(uuid) if device: return device
time.sleep(1) return None
The code does not explain why it tries to use the /dev/disk/by-id link and fallback to sysfs on errors. Based on our experience with udev, I guess that the author does not trust udev. I wonder if we can trust it as the stable device path.
In my experience udev rules (which is different from udev itself) are less that reliable as a way of finding devices when working "in the wild". They are only reliable if you have full control over the host system and are sure nobody (admin or distro) can break things. For reference, at Red Hat we have an RFE to improve os-brick [1] and stop using symlinks at all. While they are not 100% reliable in the wild, they are quite reliable once they are working on a specific system, which means that if we confirm they are working on a system we can rely on them if no changes are made on the system (and if CPU is not 100% during attachment). [1]: https://bugzilla.redhat.com/show_bug.cgi?id=1697319
If we can trust this path, maybe os_brick can return the stable path in a uniform way for all kind of devices?
I don't think this is likely to happen, because it has no real value for OpenStack so it's unlikely to get prioritized (for coding and reviews). Cheers, Gorka.
Cheers, Gorka.
2. unique path created by oVirt
In this case oVirt will use the disk uuid already used in ManagedVolume.{attach,detach}_volume APIs: https://github.com/oVirt/vdsm/blob/500c035903dd35180d71c97791e0ce4356fb77ad/... https://github.com/oVirt/vdsm/blob/500c035903dd35180d71c97791e0ce4356fb77ad/...
From oVirt point of view, using the disk uuid seems better. It makes it easy to debug when you can follow the uuid in all logs on different systems and locate the actual disk using the same uuid.
Nir
On Fri, Feb 25, 2022 at 12:04 PM Gorka Eguileor <geguileo@redhat.com> wrote:
On 24/02, Nir Soffer wrote:
On Thu, Feb 24, 2022 at 8:46 PM Gorka Eguileor <geguileo@redhat.com> wrote:
On 24/02, Nir Soffer wrote:
On Thu, Feb 24, 2022 at 6:35 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
On Thu, Feb 24, 2022 at 6:28 PM Nir Soffer <nsoffer@redhat.com> wrote:
On Thu, Feb 24, 2022 at 6:10 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote: > > On Thu, Feb 24, 2022 at 3:58 PM Nir Soffer <nsoffer@redhat.com> wrote: >> >> On Wed, Feb 23, 2022 at 6:24 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote: >> > >> > Thanks for the detailed instructions, Nir. I'm going to scrounge up some hardware. >> > By the way, if anyone else would like to work on NVMe/TCP support, for NVMe/TCP target you can either use Lightbits (talk to me offline for details) or use the upstream Linux NVMe/TCP target. Lightbits is a clustered storage system while upstream is a single target, but the client side should be close enough for vdsm/ovirt purposes. >> >> I played with NVMe/TCP a little bit, using qemu to create a virtual >> NVMe disk, and export >> it using the kernel on one VM, and consume it on another VM. >> https://futurewei-cloud.github.io/ARM-Datacenter/qemu/nvme-of-tcp-vms/ >> >> One question about device naming - do we always get the same name of the >> device in all hosts? > > > No, we do not, see below how we handle migration in os_brick. > >> To support VM migration, every device must have unique name in the cluster. >> With multipath we always have unique name, since we disable "friendly names", >> so we always have: >> >> /dev/mapper/{wwid} >> >> With rbd we also do not use /dev/rbdN but a unique path: >> >> /dev/rbd/poolname/volume-vol-id >> >> How do we ensure cluster-unique device path? If os_brick does not handle it, we >> can to do in ovirt, for example: >> >> /run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42 >> >> but I think this should be handled in cinderlib, since openstack have >> the same problem with migration. > > > Indeed. Both the Lightbits LightOS connector and the nvmeof connector do this through the target provided namespace (LUN) UUID. After connecting to the target, the connectors wait for the local friendly-named device file that has the right UUID to show up, and then return the friendly name. So different hosts will have different friendly names, but the VMs will be attached to the right namespace since we return the friendly name on the current host that has the right UUID. Does this also work for you?
It will not work for oVirt.
Migration in oVirt works like this:
1. Attach disks to destination host 2. Send VM XML from source host to destination host, and start the VM is paused mode 3. Start the migration on the source host 4. When migration is done, start the CPU on the destination host 5. Detach the disks from the source
This will break in step 2, since the source xml refer to nvme device that does not exist or already used by another VM.
Indeed.
To make this work, the VM XML must use the same path, existing on both hosts.
The issue can be solved by libvirt hook updating the paths before qemu is started on the destination, but I think the right way to handle this is to have the same path.
You mentioned above that it can be handled in ovirt (c.f., /run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42), which seems like a reasonable approach given the constraint imposed by the oVirt migration flow you outlined above. What information does vdsm need to create and use the /var/run/vdsm/managedvolumes/{uuid} link? Today the connector does (trimmed for brevity):
def connect_volume(self, connection_properties): device_info = {'type': 'block'} uuid = connection_properties['uuid'] device_path = self._get_device_by_uuid(uuid) device_info['path'] = device_path return device_info
I think we have 2 options:
1. unique path created by os_brick using the underlying uuid
In this case the connector will return the uuid, and ovirt will use it to resolve the unique path that will be stored and used on engine side to create the vm xml.
I'm not sure how the connector should return this uuid. Looking in current vdsm code:
if vol_type in ("iscsi", "fibre_channel"): if "multipath_id" not in attachment: raise se.ManagedVolumeUnsupportedDevice(vol_id, attachment) # /dev/mapper/xxxyyy return os.path.join(DEV_MAPPER, attachment["multipath_id"]) elif vol_type == "rbd": # /dev/rbd/poolname/volume-vol-id return os.path.join(DEV_RBD, connection_info['data']['name'])
os_brick does not have a uniform way to address different devices.
Maybe Gorka can help with this.
Hi,
That is true, because in OpenStack we haven't had the need to have the same path on every host or even on the same host during different connections.
For nvme a new `elif` clause could be added there, though it will be a bit trickier, because the nvme connection properties format are a bit of a mess...
We have 2 different formats for the nvme properties, and the wwid that appears in symlink /dev/disk/by-id/nvme-<wwid> may or may not be the volume id, may be the uuid in the connection info if present or the nguid if the nvme device doesn't have uuid.
For these reasons I would recommend not relying on the connection information and relying on the path from the attachment instead.
Something like this should be probably fine:
elif vol_type == 'nvme': device_name = os.path.basename(attachment['path']) controller = device_name.rsplit('n', 1)[0] wwid_filename = f'/sys/class/nvme/{controller}/{device_name}/wwid' with open(wwid_filename, 'r') as f: uuid = f.read().strip() return os.path.join('/dev/disk/by-id/nvme-', uuid)
Thanks Gorka!
but isn't this duplicating logic already in os brick? https://github.com/openstack/os-brick/blob/56bf0272b55dcbbc7f5b03150973a80af...
Hi Nir,
Oh! I thought we were talking about the generic NVMe-oF connector, didn't know this was specific about the LightOS one.
The link is used as an easy way to locate the volume, it doesn't mean that it is returned to the caller of the `connect_volume` method. In fact, we can see how that method actually returns the real path and not the link's path:
def _check_device_exists_using_dev_lnk(self, uuid): lnk_path = f"/dev/disk/by-id/nvme-uuid.{uuid}" --> if os.path.exists(lnk_path): ^^^ Check link exists
--> devname = os.path.realpath(lnk_path) ^^^ Get the real path for the symlink
--> if devname.startswith("/dev/nvme"): ^^^ Make extra sure it's not pointing to something crazy
LOG.info("LIGHTOS: devpath %s detected for uuid %s", devname, uuid)
--> return devname ^^^ Return it
return None
Another interesting detail is this wait: https://github.com/openstack/os-brick/blob/56bf0272b55dcbbc7f5b03150973a80af...
def _get_device_by_uuid(self, uuid): endtime = time.time() + self.WAIT_DEVICE_TIMEOUT while time.time() < endtime: try: device = self._check_device_exists_using_dev_lnk(uuid) if device: return device except Exception as e: LOG.debug(f'LIGHTOS: {e}') device = self._check_device_exists_reading_block_class(uuid) if device: return device
time.sleep(1) return None
The code does not explain why it tries to use the /dev/disk/by-id link and fallback to sysfs on errors. Based on our experience with udev, I guess that the author does not trust udev. I wonder if we can trust it as the stable device path.
In my experience udev rules (which is different from udev itself) are less that reliable as a way of finding devices when working "in the wild". They are only reliable if you have full control over the host system and are sure nobody (admin or distro) can break things.
For reference, at Red Hat we have an RFE to improve os-brick [1] and stop using symlinks at all.
While they are not 100% reliable in the wild, they are quite reliable once they are working on a specific system, which means that if we confirm they are working on a system we can rely on them if no changes are made on the system (and if CPU is not 100% during attachment).
[1]: https://bugzilla.redhat.com/show_bug.cgi?id=1697319
If we can trust this path, maybe os_brick can return the stable path in a uniform way for all kind of devices?
I don't think this is likely to happen, because it has no real value for OpenStack so it's unlikely to get prioritized (for coding and reviews).
Since we cannot get a stable path from os-brick, and stable path is a oVirt specific requirement, we need to handle this in oVirt, similar to the way we handle multipath and rbd and traditional storage. Nir
Will this support require changes in ovirt-engine or just in vdsm? I have started to look into vdsm's managedvolume.py and its tests and it seems like adding support for LightOS there should be pretty simple (famous last words...). Should this be enough or do you think it will require changes in other parts of ovirt as well? Cheers, Muli On Mon, Feb 28, 2022 at 9:09 AM Nir Soffer <nsoffer@redhat.com> wrote:
On Fri, Feb 25, 2022 at 12:04 PM Gorka Eguileor <geguileo@redhat.com> wrote:
On 24/02, Nir Soffer wrote:
On Thu, Feb 24, 2022 at 8:46 PM Gorka Eguileor <geguileo@redhat.com>
On 24/02, Nir Soffer wrote:
On Thu, Feb 24, 2022 at 6:35 PM Muli Ben-Yehuda <
muli@lightbitslabs.com> wrote:
On Thu, Feb 24, 2022 at 6:28 PM Nir Soffer <nsoffer@redhat.com>
wrote:
> > On Thu, Feb 24, 2022 at 6:10 PM Muli Ben-Yehuda < muli@lightbitslabs.com> wrote: > > > > On Thu, Feb 24, 2022 at 3:58 PM Nir Soffer < nsoffer@redhat.com> wrote: > >> > >> On Wed, Feb 23, 2022 at 6:24 PM Muli Ben-Yehuda < muli@lightbitslabs.com> wrote: > >> > > >> > Thanks for the detailed instructions, Nir. I'm going to scrounge up some hardware. > >> > By the way, if anyone else would like to work on NVMe/TCP support, for NVMe/TCP target you can either use Lightbits (talk to me offline for details) or use the upstream Linux NVMe/TCP target. Lightbits is a clustered storage system while upstream is a single target, but the client side should be close enough for vdsm/ovirt purposes. > >> > >> I played with NVMe/TCP a little bit, using qemu to create a virtual > >> NVMe disk, and export > >> it using the kernel on one VM, and consume it on another VM. > >> https://futurewei-cloud.github.io/ARM-Datacenter/qemu/nvme-of-tcp-vms/ > >> > >> One question about device naming - do we always get the same name of the > >> device in all hosts? > > > > > > No, we do not, see below how we handle migration in os_brick. > > > >> To support VM migration, every device must have unique name in the cluster. > >> With multipath we always have unique name, since we disable "friendly names", > >> so we always have: > >> > >> /dev/mapper/{wwid} > >> > >> With rbd we also do not use /dev/rbdN but a unique path: > >> > >> /dev/rbd/poolname/volume-vol-id > >> > >> How do we ensure cluster-unique device path? If os_brick does not handle it, we > >> can to do in ovirt, for example: > >> > >> /run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42 > >> > >> but I think this should be handled in cinderlib, since openstack have > >> the same problem with migration. > > > > > > Indeed. Both the Lightbits LightOS connector and the nvmeof connector do this through the target provided namespace (LUN) UUID. After connecting to the target, the connectors wait for the local friendly-named device file that has the right UUID to show up, and then return the friendly name. So different hosts will have different friendly names, but
> > It will not work for oVirt. > > Migration in oVirt works like this: > > 1. Attach disks to destination host > 2. Send VM XML from source host to destination host, and start
> VM is paused mode > 3. Start the migration on the source host > 4. When migration is done, start the CPU on the destination host > 5. Detach the disks from the source > > This will break in step 2, since the source xml refer to nvme device > that does not exist or already used by another VM.
Indeed.
> To make this work, the VM XML must use the same path, existing on > both hosts. > > The issue can be solved by libvirt hook updating the paths before qemu > is started on the destination, but I think the right way to handle this is to > have the same path.
You mentioned above that it can be handled in ovirt (c.f., /run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42), which seems like a reasonable approach given the constraint imposed by the oVirt migration flow you outlined above. What information does vdsm need to create and use
def connect_volume(self, connection_properties): device_info = {'type': 'block'} uuid = connection_properties['uuid'] device_path = self._get_device_by_uuid(uuid) device_info['path'] = device_path return device_info
I think we have 2 options:
1. unique path created by os_brick using the underlying uuid
In this case the connector will return the uuid, and ovirt will use it to resolve the unique path that will be stored and used on engine side to create the vm xml.
I'm not sure how the connector should return this uuid. Looking in current vdsm code:
if vol_type in ("iscsi", "fibre_channel"): if "multipath_id" not in attachment: raise se.ManagedVolumeUnsupportedDevice(vol_id, attachment) # /dev/mapper/xxxyyy return os.path.join(DEV_MAPPER, attachment["multipath_id"]) elif vol_type == "rbd": # /dev/rbd/poolname/volume-vol-id return os.path.join(DEV_RBD, connection_info['data']['name'])
os_brick does not have a uniform way to address different devices.
Maybe Gorka can help with this.
Hi,
That is true, because in OpenStack we haven't had the need to have
same path on every host or even on the same host during different connections.
For nvme a new `elif` clause could be added there, though it will be a bit trickier, because the nvme connection properties format are a bit of a mess...
We have 2 different formats for the nvme properties, and the wwid
wrote: the VMs will be attached to the right namespace since we return the friendly name on the current host that has the right UUID. Does this also work for you? the the /var/run/vdsm/managedvolumes/{uuid} link? Today the connector does (trimmed for brevity): the that
appears in symlink /dev/disk/by-id/nvme-<wwid> may or may not be the volume id, may be the uuid in the connection info if present or the nguid if the nvme device doesn't have uuid.
For these reasons I would recommend not relying on the connection information and relying on the path from the attachment instead.
Something like this should be probably fine:
elif vol_type == 'nvme': device_name = os.path.basename(attachment['path']) controller = device_name.rsplit('n', 1)[0] wwid_filename = f'/sys/class/nvme/{controller}/{device_name}/wwid' with open(wwid_filename, 'r') as f: uuid = f.read().strip() return os.path.join('/dev/disk/by-id/nvme-', uuid)
Thanks Gorka!
but isn't this duplicating logic already in os brick?
https://github.com/openstack/os-brick/blob/56bf0272b55dcbbc7f5b03150973a80af...
Hi Nir,
Oh! I thought we were talking about the generic NVMe-oF connector, didn't know this was specific about the LightOS one.
The link is used as an easy way to locate the volume, it doesn't mean that it is returned to the caller of the `connect_volume` method. In fact, we can see how that method actually returns the real path and not the link's path:
def _check_device_exists_using_dev_lnk(self, uuid): lnk_path = f"/dev/disk/by-id/nvme-uuid.{uuid}" --> if os.path.exists(lnk_path): ^^^ Check link exists
--> devname = os.path.realpath(lnk_path) ^^^ Get the real path for the symlink
--> if devname.startswith("/dev/nvme"): ^^^ Make extra sure it's not pointing to something crazy
LOG.info("LIGHTOS: devpath %s detected for uuid %s", devname, uuid)
--> return devname ^^^ Return it
return None
Another interesting detail is this wait:
https://github.com/openstack/os-brick/blob/56bf0272b55dcbbc7f5b03150973a80af...
def _get_device_by_uuid(self, uuid): endtime = time.time() + self.WAIT_DEVICE_TIMEOUT while time.time() < endtime: try: device = self._check_device_exists_using_dev_lnk(uuid) if device: return device except Exception as e: LOG.debug(f'LIGHTOS: {e}') device =
self._check_device_exists_reading_block_class(uuid)
if device: return device
time.sleep(1) return None
The code does not explain why it tries to use the /dev/disk/by-id link and fallback to sysfs on errors. Based on our experience with udev, I guess that the author does not trust udev. I wonder if we can trust it as the stable device path.
In my experience udev rules (which is different from udev itself) are less that reliable as a way of finding devices when working "in the wild". They are only reliable if you have full control over the host system and are sure nobody (admin or distro) can break things.
For reference, at Red Hat we have an RFE to improve os-brick [1] and stop using symlinks at all.
While they are not 100% reliable in the wild, they are quite reliable once they are working on a specific system, which means that if we confirm they are working on a system we can rely on them if no changes are made on the system (and if CPU is not 100% during attachment).
[1]: https://bugzilla.redhat.com/show_bug.cgi?id=1697319
If we can trust this path, maybe os_brick can return the stable path in a uniform way for all kind of devices?
I don't think this is likely to happen, because it has no real value for OpenStack so it's unlikely to get prioritized (for coding and reviews).
Since we cannot get a stable path from os-brick, and stable path is a oVirt specific requirement, we need to handle this in oVirt, similar to the way we handle multipath and rbd and traditional storage.
Nir
-- *Lightbits Labs** *Lead the cloud-native data center transformation by delivering *scalable *and *efficient *software defined storage that is *easy *to consume. *This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.*

Hi, Just by browsing the code, I can think of one issue in[1], as a result of[2] where we only considered iscsi and rbd drivers, I suspect your driver will go into this branch, based on the issue in the 4.3 logs I went over: backend/manager/modules/vdsbroker/src/main/java/org/ovirt/engine/core/vdsbroker/builder/vminfo/LibvirtVmXmlBuilder.java } else if (managedBlockStorageDisk.getCinderVolumeDriver() == CinderVolumeDriver.BLOCK) { Map<String, Object> attachment = (Map<String, Object>) managedBlockStorageDisk.getDevice().get(DeviceInfoReturn.ATTACHMENT); metadata = Map.of( "GUID", (String)attachment.get(DeviceInfoReturn.SCSI_WWN), "managed", "true" Which will make it go into the wrong branch in clientIF.py, appending the empty GUID to /dev/mapper. Perhaps it is possible workaround it in clientIF if you just want to try and get the VM started for now, by checking if GUID is empty and deferring to: volPath = drive['path'] But as discussed in this thread, our attempt at constructing the stable paths ourselves doesn't really scale. After further discussion with Nir I started working on creating a link in vdsm in managevolume.py#attach_volume to the path returned by the driver, and engine will use our link to run the VMs. This should simplify the code and resolve the live VM migration issue. I had some preliminary success with this so I'll try to post the patches soon [1] https://github.com/oVirt/vdsm/blob/d957a06a4d988489c83da171fcd9cfd254b12ca4/... [2] https://github.com/oVirt/ovirt-engine/blob/24530d17874e20581deee4b0e319146cd... On Tue, Mar 1, 2022 at 6:12 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
Will this support require changes in ovirt-engine or just in vdsm? I have started to look into vdsm's managedvolume.py and its tests and it seems like adding support for LightOS there should be pretty simple (famous last words...). Should this be enough or do you think it will require changes in other parts of ovirt as well?
Cheers, Muli
On Mon, Feb 28, 2022 at 9:09 AM Nir Soffer <nsoffer@redhat.com> wrote:
On Fri, Feb 25, 2022 at 12:04 PM Gorka Eguileor <geguileo@redhat.com> wrote:
On 24/02, Nir Soffer wrote:
On Thu, Feb 24, 2022 at 8:46 PM Gorka Eguileor <geguileo@redhat.com> wrote:
On 24/02, Nir Soffer wrote:
On Thu, Feb 24, 2022 at 6:35 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote: > > On Thu, Feb 24, 2022 at 6:28 PM Nir Soffer <nsoffer@redhat.com> wrote: >> >> On Thu, Feb 24, 2022 at 6:10 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote: >> > >> > On Thu, Feb 24, 2022 at 3:58 PM Nir Soffer <nsoffer@redhat.com> wrote: >> >> >> >> On Wed, Feb 23, 2022 at 6:24 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote: >> >> > >> >> > Thanks for the detailed instructions, Nir. I'm going to scrounge up some hardware. >> >> > By the way, if anyone else would like to work on NVMe/TCP support, for NVMe/TCP target you can either use Lightbits (talk to me offline for details) or use the upstream Linux NVMe/TCP target. Lightbits is a clustered storage system while upstream is a single target, but the client side should be close enough for vdsm/ovirt purposes. >> >> >> >> I played with NVMe/TCP a little bit, using qemu to create a virtual >> >> NVMe disk, and export >> >> it using the kernel on one VM, and consume it on another VM. >> >> https://futurewei-cloud.github.io/ARM-Datacenter/qemu/nvme-of-tcp-vms/ >> >> >> >> One question about device naming - do we always get the same name of the >> >> device in all hosts? >> > >> > >> > No, we do not, see below how we handle migration in os_brick. >> > >> >> To support VM migration, every device must have unique name in the cluster. >> >> With multipath we always have unique name, since we disable "friendly names", >> >> so we always have: >> >> >> >> /dev/mapper/{wwid} >> >> >> >> With rbd we also do not use /dev/rbdN but a unique path: >> >> >> >> /dev/rbd/poolname/volume-vol-id >> >> >> >> How do we ensure cluster-unique device path? If os_brick does not handle it, we >> >> can to do in ovirt, for example: >> >> >> >> /run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42 >> >> >> >> but I think this should be handled in cinderlib, since openstack have >> >> the same problem with migration. >> > >> > >> > Indeed. Both the Lightbits LightOS connector and the nvmeof connector do this through the target provided namespace (LUN) UUID. After connecting to the target, the connectors wait for the local friendly-named device file that has the right UUID to show up, and then return the friendly name. So different hosts will have different friendly names, but the VMs will be attached to the right namespace since we return the friendly name on the current host that has the right UUID. Does this also work for you? >> >> It will not work for oVirt. >> >> Migration in oVirt works like this: >> >> 1. Attach disks to destination host >> 2. Send VM XML from source host to destination host, and start the >> VM is paused mode >> 3. Start the migration on the source host >> 4. When migration is done, start the CPU on the destination host >> 5. Detach the disks from the source >> >> This will break in step 2, since the source xml refer to nvme device >> that does not exist or already used by another VM. > > > Indeed. > >> To make this work, the VM XML must use the same path, existing on >> both hosts. >> >> The issue can be solved by libvirt hook updating the paths before qemu >> is started on the destination, but I think the right way to handle this is to >> have the same path. > > > You mentioned above that it can be handled in ovirt (c.f., /run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42), which seems like a reasonable approach given the constraint imposed by the oVirt migration flow you outlined above. What information does vdsm need to create and use the /var/run/vdsm/managedvolumes/{uuid} link? Today the connector does (trimmed for brevity): > > def connect_volume(self, connection_properties): > device_info = {'type': 'block'} > uuid = connection_properties['uuid'] > device_path = self._get_device_by_uuid(uuid) > device_info['path'] = device_path > return device_info
I think we have 2 options:
1. unique path created by os_brick using the underlying uuid
In this case the connector will return the uuid, and ovirt will use it to resolve the unique path that will be stored and used on engine side to create the vm xml.
I'm not sure how the connector should return this uuid. Looking in current vdsm code:
if vol_type in ("iscsi", "fibre_channel"): if "multipath_id" not in attachment: raise se.ManagedVolumeUnsupportedDevice(vol_id, attachment) # /dev/mapper/xxxyyy return os.path.join(DEV_MAPPER, attachment["multipath_id"]) elif vol_type == "rbd": # /dev/rbd/poolname/volume-vol-id return os.path.join(DEV_RBD, connection_info['data']['name'])
os_brick does not have a uniform way to address different devices.
Maybe Gorka can help with this.
Hi,
That is true, because in OpenStack we haven't had the need to have the same path on every host or even on the same host during different connections.
For nvme a new `elif` clause could be added there, though it will be a bit trickier, because the nvme connection properties format are a bit of a mess...
We have 2 different formats for the nvme properties, and the wwid that appears in symlink /dev/disk/by-id/nvme-<wwid> may or may not be the volume id, may be the uuid in the connection info if present or the nguid if the nvme device doesn't have uuid.
For these reasons I would recommend not relying on the connection information and relying on the path from the attachment instead.
Something like this should be probably fine:
elif vol_type == 'nvme': device_name = os.path.basename(attachment['path']) controller = device_name.rsplit('n', 1)[0] wwid_filename = f'/sys/class/nvme/{controller}/{device_name}/wwid' with open(wwid_filename, 'r') as f: uuid = f.read().strip() return os.path.join('/dev/disk/by-id/nvme-', uuid)
Thanks Gorka!
but isn't this duplicating logic already in os brick? https://github.com/openstack/os-brick/blob/56bf0272b55dcbbc7f5b03150973a80af...
Hi Nir,
Oh! I thought we were talking about the generic NVMe-oF connector, didn't know this was specific about the LightOS one.
The link is used as an easy way to locate the volume, it doesn't mean that it is returned to the caller of the `connect_volume` method. In fact, we can see how that method actually returns the real path and not the link's path:
def _check_device_exists_using_dev_lnk(self, uuid): lnk_path = f"/dev/disk/by-id/nvme-uuid.{uuid}" --> if os.path.exists(lnk_path): ^^^ Check link exists
--> devname = os.path.realpath(lnk_path) ^^^ Get the real path for the symlink
--> if devname.startswith("/dev/nvme"): ^^^ Make extra sure it's not pointing to something crazy
LOG.info("LIGHTOS: devpath %s detected for uuid %s", devname, uuid)
--> return devname ^^^ Return it
return None
Another interesting detail is this wait: https://github.com/openstack/os-brick/blob/56bf0272b55dcbbc7f5b03150973a80af...
def _get_device_by_uuid(self, uuid): endtime = time.time() + self.WAIT_DEVICE_TIMEOUT while time.time() < endtime: try: device = self._check_device_exists_using_dev_lnk(uuid) if device: return device except Exception as e: LOG.debug(f'LIGHTOS: {e}') device = self._check_device_exists_reading_block_class(uuid) if device: return device
time.sleep(1) return None
The code does not explain why it tries to use the /dev/disk/by-id link and fallback to sysfs on errors. Based on our experience with udev, I guess that the author does not trust udev. I wonder if we can trust it as the stable device path.
In my experience udev rules (which is different from udev itself) are less that reliable as a way of finding devices when working "in the wild". They are only reliable if you have full control over the host system and are sure nobody (admin or distro) can break things.
For reference, at Red Hat we have an RFE to improve os-brick [1] and stop using symlinks at all.
While they are not 100% reliable in the wild, they are quite reliable once they are working on a specific system, which means that if we confirm they are working on a system we can rely on them if no changes are made on the system (and if CPU is not 100% during attachment).
[1]: https://bugzilla.redhat.com/show_bug.cgi?id=1697319
If we can trust this path, maybe os_brick can return the stable path in a uniform way for all kind of devices?
I don't think this is likely to happen, because it has no real value for OpenStack so it's unlikely to get prioritized (for coding and reviews).
Since we cannot get a stable path from os-brick, and stable path is a oVirt specific requirement, we need to handle this in oVirt, similar to the way we handle multipath and rbd and traditional storage.
Nir
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.
Thanks for the update, Benny. How can I help? For example, would logs from running the connector with the exact data it returns be useful? Cheers, Muli On Tue, Mar 1, 2022 at 8:39 PM Benny Zlotnik <bzlotnik@redhat.com> wrote:
Hi,
Just by browsing the code, I can think of one issue in[1], as a result of[2] where we only considered iscsi and rbd drivers, I suspect your driver will go into this branch, based on the issue in the 4.3 logs I went over:
backend/manager/modules/vdsbroker/src/main/java/org/ovirt/engine/core/vdsbroker/builder/vminfo/LibvirtVmXmlBuilder.java
} else if (managedBlockStorageDisk.getCinderVolumeDriver() == CinderVolumeDriver.BLOCK) { Map<String, Object> attachment = (Map<String, Object>) managedBlockStorageDisk.getDevice().get(DeviceInfoReturn.ATTACHMENT); metadata = Map.of( "GUID", (String)attachment.get(DeviceInfoReturn.SCSI_WWN), "managed", "true"
Which will make it go into the wrong branch in clientIF.py, appending the empty GUID to /dev/mapper. Perhaps it is possible workaround it in clientIF if you just want to try and get the VM started for now, by checking if GUID is empty and deferring to: volPath = drive['path']
But as discussed in this thread, our attempt at constructing the stable paths ourselves doesn't really scale. After further discussion with Nir I started working on creating a link in vdsm in managevolume.py#attach_volume to the path returned by the driver, and engine will use our link to run the VMs. This should simplify the code and resolve the live VM migration issue. I had some preliminary success with this so I'll try to post the patches soon
[1] https://github.com/oVirt/vdsm/blob/d957a06a4d988489c83da171fcd9cfd254b12ca4/... [2] https://github.com/oVirt/ovirt-engine/blob/24530d17874e20581deee4b0e319146cd...
On Tue, Mar 1, 2022 at 6:12 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
Will this support require changes in ovirt-engine or just in vdsm? I
have started to look into vdsm's managedvolume.py and its tests and it seems like adding support for LightOS there should be pretty simple (famous last words...). Should this be enough or do you think it will require changes in other parts of ovirt as well?
Cheers, Muli
On Mon, Feb 28, 2022 at 9:09 AM Nir Soffer <nsoffer@redhat.com> wrote:
On Fri, Feb 25, 2022 at 12:04 PM Gorka Eguileor <geguileo@redhat.com>
On 24/02, Nir Soffer wrote:
On Thu, Feb 24, 2022 at 8:46 PM Gorka Eguileor <geguileo@redhat.com>
wrote:
On 24/02, Nir Soffer wrote: > On Thu, Feb 24, 2022 at 6:35 PM Muli Ben-Yehuda <
muli@lightbitslabs.com> wrote:
> > > > On Thu, Feb 24, 2022 at 6:28 PM Nir Soffer < nsoffer@redhat.com> wrote: > >> > >> On Thu, Feb 24, 2022 at 6:10 PM Muli Ben-Yehuda < muli@lightbitslabs.com> wrote: > >> > > >> > On Thu, Feb 24, 2022 at 3:58 PM Nir Soffer < nsoffer@redhat.com> wrote: > >> >> > >> >> On Wed, Feb 23, 2022 at 6:24 PM Muli Ben-Yehuda < muli@lightbitslabs.com> wrote: > >> >> > > >> >> > Thanks for the detailed instructions, Nir. I'm going to scrounge up some hardware. > >> >> > By the way, if anyone else would like to work on NVMe/TCP support, for NVMe/TCP target you can either use Lightbits (talk to me offline for details) or use the upstream Linux NVMe/TCP target. Lightbits is a clustered storage system while upstream is a single target, but the client side should be close enough for vdsm/ovirt purposes. > >> >> > >> >> I played with NVMe/TCP a little bit, using qemu to create a virtual > >> >> NVMe disk, and export > >> >> it using the kernel on one VM, and consume it on another VM. > >> >> https://futurewei-cloud.github.io/ARM-Datacenter/qemu/nvme-of-tcp-vms/ > >> >> > >> >> One question about device naming - do we always get the same name of the > >> >> device in all hosts? > >> > > >> > > >> > No, we do not, see below how we handle migration in os_brick. > >> > > >> >> To support VM migration, every device must have unique name in the cluster. > >> >> With multipath we always have unique name, since we disable "friendly names", > >> >> so we always have: > >> >> > >> >> /dev/mapper/{wwid} > >> >> > >> >> With rbd we also do not use /dev/rbdN but a unique path: > >> >> > >> >> /dev/rbd/poolname/volume-vol-id > >> >> > >> >> How do we ensure cluster-unique device path? If os_brick does not handle it, we > >> >> can to do in ovirt, for example: > >> >> > >> >> /run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42 > >> >> > >> >> but I think this should be handled in cinderlib, since openstack have > >> >> the same problem with migration. > >> > > >> > > >> > Indeed. Both the Lightbits LightOS connector and the nvmeof connector do this through the target provided namespace (LUN) UUID. After connecting to the target, the connectors wait for the local friendly-named device file that has the right UUID to show up, and then return the friendly name. So different hosts will have different friendly names, but the VMs will be attached to the right namespace since we return
> >> > >> It will not work for oVirt. > >> > >> Migration in oVirt works like this: > >> > >> 1. Attach disks to destination host > >> 2. Send VM XML from source host to destination host, and start the > >> VM is paused mode > >> 3. Start the migration on the source host > >> 4. When migration is done, start the CPU on the destination host > >> 5. Detach the disks from the source > >> > >> This will break in step 2, since the source xml refer to nvme device > >> that does not exist or already used by another VM. > > > > > > Indeed. > > > >> To make this work, the VM XML must use the same path, existing on > >> both hosts. > >> > >> The issue can be solved by libvirt hook updating the paths before qemu > >> is started on the destination, but I think the right way to handle this is to > >> have the same path. > > > > > > You mentioned above that it can be handled in ovirt (c.f., /run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42), which seems like a reasonable approach given the constraint imposed by the oVirt migration flow you outlined above. What information does vdsm need to create and use
> > > > def connect_volume(self, connection_properties): > > device_info = {'type': 'block'} > > uuid = connection_properties['uuid'] > > device_path = self._get_device_by_uuid(uuid) > > device_info['path'] = device_path > > return device_info > > I think we have 2 options: > > 1. unique path created by os_brick using the underlying uuid > > In this case the connector will return the uuid, and ovirt will use > it to resolve the unique path that will be stored and used on engine > side to create the vm xml. > > I'm not sure how the connector should return this uuid. Looking in current > vdsm code: > > if vol_type in ("iscsi", "fibre_channel"): > if "multipath_id" not in attachment: > raise se.ManagedVolumeUnsupportedDevice(vol_id, attachment) > # /dev/mapper/xxxyyy > return os.path.join(DEV_MAPPER, attachment["multipath_id"]) > elif vol_type == "rbd": > # /dev/rbd/poolname/volume-vol-id > return os.path.join(DEV_RBD, connection_info['data']['name']) > > os_brick does not have a uniform way to address different devices. > > Maybe Gorka can help with this.
Hi,
That is true, because in OpenStack we haven't had the need to have the same path on every host or even on the same host during different connections.
For nvme a new `elif` clause could be added there, though it will be a bit trickier, because the nvme connection properties format are a bit of a mess...
We have 2 different formats for the nvme properties, and the wwid
appears in symlink /dev/disk/by-id/nvme-<wwid> may or may not be
volume id, may be the uuid in the connection info if present or
nguid if the nvme device doesn't have uuid.
For these reasons I would recommend not relying on the connection information and relying on the path from the attachment instead.
Something like this should be probably fine:
elif vol_type == 'nvme': device_name = os.path.basename(attachment['path']) controller = device_name.rsplit('n', 1)[0] wwid_filename = f'/sys/class/nvme/{controller}/{device_name}/wwid' with open(wwid_filename, 'r') as f: uuid = f.read().strip() return os.path.join('/dev/disk/by-id/nvme-', uuid)
Thanks Gorka!
but isn't this duplicating logic already in os brick?
https://github.com/openstack/os-brick/blob/56bf0272b55dcbbc7f5b03150973a80af...
Hi Nir,
Oh! I thought we were talking about the generic NVMe-oF connector, didn't know this was specific about the LightOS one.
The link is used as an easy way to locate the volume, it doesn't mean that it is returned to the caller of the `connect_volume` method. In fact, we can see how that method actually returns the real path and not the link's path:
def _check_device_exists_using_dev_lnk(self, uuid): lnk_path = f"/dev/disk/by-id/nvme-uuid.{uuid}" --> if os.path.exists(lnk_path): ^^^ Check link exists
--> devname = os.path.realpath(lnk_path) ^^^ Get the real path for the symlink
--> if devname.startswith("/dev/nvme"): ^^^ Make extra sure it's not pointing to something crazy
LOG.info("LIGHTOS: devpath %s detected for uuid %s", devname, uuid)
--> return devname ^^^ Return it
return None
Another interesting detail is this wait:
https://github.com/openstack/os-brick/blob/56bf0272b55dcbbc7f5b03150973a80af...
def _get_device_by_uuid(self, uuid): endtime = time.time() + self.WAIT_DEVICE_TIMEOUT while time.time() < endtime: try: device =
self._check_device_exists_using_dev_lnk(uuid)
if device: return device except Exception as e: LOG.debug(f'LIGHTOS: {e}') device =
self._check_device_exists_reading_block_class(uuid)
if device: return device
time.sleep(1) return None
The code does not explain why it tries to use the /dev/disk/by-id
and fallback to sysfs on errors. Based on our experience with udev, I guess that the author does not trust udev. I wonder if we can
wrote: the friendly name on the current host that has the right UUID. Does this also work for you? the /var/run/vdsm/managedvolumes/{uuid} link? Today the connector does (trimmed for brevity): that the the link trust
it as the stable device path.
In my experience udev rules (which is different from udev itself) are less that reliable as a way of finding devices when working "in the wild". They are only reliable if you have full control over the host system and are sure nobody (admin or distro) can break things.
For reference, at Red Hat we have an RFE to improve os-brick [1] and stop using symlinks at all.
While they are not 100% reliable in the wild, they are quite reliable once they are working on a specific system, which means that if we confirm they are working on a system we can rely on them if no changes are made on the system (and if CPU is not 100% during attachment).
[1]: https://bugzilla.redhat.com/show_bug.cgi?id=1697319
If we can trust this path, maybe os_brick can return the stable path in a uniform way for all kind of devices?
I don't think this is likely to happen, because it has no real value for OpenStack so it's unlikely to get prioritized (for coding and reviews).
Since we cannot get a stable path from os-brick, and stable path is a oVirt specific requirement, we need to handle this in oVirt, similar to the way we handle multipath and rbd and traditional storage.
Nir
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.
-- *Lightbits Labs** *Lead the cloud-native data center transformation by delivering *scalable *and *efficient *software defined storage that is *easy *to consume. *This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.*
Hi, I posted draft PRs for engine[1] and vdsm[2], they are still raw and I only tested running starting VMs with ceph. If you can apply the changes for lightos (only vdsm should be needed) and try it out it would be great :) Also, if you have any suggestions/comments/etc feel free to comment on the PRs directly If you don't want to build ovirt-engine from source, CI generated RPMs should be available in[3] (the job is still running while I'm writing this email) [1] https://github.com/oVirt/ovirt-engine/pull/104 [2] https://github.com/oVirt/vdsm/pull/89 [3] https://github.com/oVirt/ovirt-engine/actions/runs/1929008680 On Wed, Mar 2, 2022 at 4:55 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
Thanks for the update, Benny. How can I help? For example, would logs from running the connector with the exact data it returns be useful?
Cheers, Muli
On Tue, Mar 1, 2022 at 8:39 PM Benny Zlotnik <bzlotnik@redhat.com> wrote:
Hi,
Just by browsing the code, I can think of one issue in[1], as a result of[2] where we only considered iscsi and rbd drivers, I suspect your driver will go into this branch, based on the issue in the 4.3 logs I went over: backend/manager/modules/vdsbroker/src/main/java/org/ovirt/engine/core/vdsbroker/builder/vminfo/LibvirtVmXmlBuilder.java
} else if (managedBlockStorageDisk.getCinderVolumeDriver() == CinderVolumeDriver.BLOCK) { Map<String, Object> attachment = (Map<String, Object>) managedBlockStorageDisk.getDevice().get(DeviceInfoReturn.ATTACHMENT); metadata = Map.of( "GUID", (String)attachment.get(DeviceInfoReturn.SCSI_WWN), "managed", "true"
Which will make it go into the wrong branch in clientIF.py, appending the empty GUID to /dev/mapper. Perhaps it is possible workaround it in clientIF if you just want to try and get the VM started for now, by checking if GUID is empty and deferring to: volPath = drive['path']
But as discussed in this thread, our attempt at constructing the stable paths ourselves doesn't really scale. After further discussion with Nir I started working on creating a link in vdsm in managevolume.py#attach_volume to the path returned by the driver, and engine will use our link to run the VMs. This should simplify the code and resolve the live VM migration issue. I had some preliminary success with this so I'll try to post the patches soon
[1] https://github.com/oVirt/vdsm/blob/d957a06a4d988489c83da171fcd9cfd254b12ca4/... [2] https://github.com/oVirt/ovirt-engine/blob/24530d17874e20581deee4b0e319146cd...
On Tue, Mar 1, 2022 at 6:12 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
Will this support require changes in ovirt-engine or just in vdsm? I have started to look into vdsm's managedvolume.py and its tests and it seems like adding support for LightOS there should be pretty simple (famous last words...). Should this be enough or do you think it will require changes in other parts of ovirt as well?
Cheers, Muli
On Mon, Feb 28, 2022 at 9:09 AM Nir Soffer <nsoffer@redhat.com> wrote:
On Fri, Feb 25, 2022 at 12:04 PM Gorka Eguileor <geguileo@redhat.com> wrote:
On 24/02, Nir Soffer wrote:
On Thu, Feb 24, 2022 at 8:46 PM Gorka Eguileor <geguileo@redhat.com> wrote: > > On 24/02, Nir Soffer wrote: > > On Thu, Feb 24, 2022 at 6:35 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote: > > > > > > On Thu, Feb 24, 2022 at 6:28 PM Nir Soffer <nsoffer@redhat.com> wrote: > > >> > > >> On Thu, Feb 24, 2022 at 6:10 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote: > > >> > > > >> > On Thu, Feb 24, 2022 at 3:58 PM Nir Soffer <nsoffer@redhat.com> wrote: > > >> >> > > >> >> On Wed, Feb 23, 2022 at 6:24 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote: > > >> >> > > > >> >> > Thanks for the detailed instructions, Nir. I'm going to scrounge up some hardware. > > >> >> > By the way, if anyone else would like to work on NVMe/TCP support, for NVMe/TCP target you can either use Lightbits (talk to me offline for details) or use the upstream Linux NVMe/TCP target. Lightbits is a clustered storage system while upstream is a single target, but the client side should be close enough for vdsm/ovirt purposes. > > >> >> > > >> >> I played with NVMe/TCP a little bit, using qemu to create a virtual > > >> >> NVMe disk, and export > > >> >> it using the kernel on one VM, and consume it on another VM. > > >> >> https://futurewei-cloud.github.io/ARM-Datacenter/qemu/nvme-of-tcp-vms/ > > >> >> > > >> >> One question about device naming - do we always get the same name of the > > >> >> device in all hosts? > > >> > > > >> > > > >> > No, we do not, see below how we handle migration in os_brick. > > >> > > > >> >> To support VM migration, every device must have unique name in the cluster. > > >> >> With multipath we always have unique name, since we disable "friendly names", > > >> >> so we always have: > > >> >> > > >> >> /dev/mapper/{wwid} > > >> >> > > >> >> With rbd we also do not use /dev/rbdN but a unique path: > > >> >> > > >> >> /dev/rbd/poolname/volume-vol-id > > >> >> > > >> >> How do we ensure cluster-unique device path? If os_brick does not handle it, we > > >> >> can to do in ovirt, for example: > > >> >> > > >> >> /run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42 > > >> >> > > >> >> but I think this should be handled in cinderlib, since openstack have > > >> >> the same problem with migration. > > >> > > > >> > > > >> > Indeed. Both the Lightbits LightOS connector and the nvmeof connector do this through the target provided namespace (LUN) UUID. After connecting to the target, the connectors wait for the local friendly-named device file that has the right UUID to show up, and then return the friendly name. So different hosts will have different friendly names, but the VMs will be attached to the right namespace since we return the friendly name on the current host that has the right UUID. Does this also work for you? > > >> > > >> It will not work for oVirt. > > >> > > >> Migration in oVirt works like this: > > >> > > >> 1. Attach disks to destination host > > >> 2. Send VM XML from source host to destination host, and start the > > >> VM is paused mode > > >> 3. Start the migration on the source host > > >> 4. When migration is done, start the CPU on the destination host > > >> 5. Detach the disks from the source > > >> > > >> This will break in step 2, since the source xml refer to nvme device > > >> that does not exist or already used by another VM. > > > > > > > > > Indeed. > > > > > >> To make this work, the VM XML must use the same path, existing on > > >> both hosts. > > >> > > >> The issue can be solved by libvirt hook updating the paths before qemu > > >> is started on the destination, but I think the right way to handle this is to > > >> have the same path. > > > > > > > > > You mentioned above that it can be handled in ovirt (c.f., /run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42), which seems like a reasonable approach given the constraint imposed by the oVirt migration flow you outlined above. What information does vdsm need to create and use the /var/run/vdsm/managedvolumes/{uuid} link? Today the connector does (trimmed for brevity): > > > > > > def connect_volume(self, connection_properties): > > > device_info = {'type': 'block'} > > > uuid = connection_properties['uuid'] > > > device_path = self._get_device_by_uuid(uuid) > > > device_info['path'] = device_path > > > return device_info > > > > I think we have 2 options: > > > > 1. unique path created by os_brick using the underlying uuid > > > > In this case the connector will return the uuid, and ovirt will use > > it to resolve the unique path that will be stored and used on engine > > side to create the vm xml. > > > > I'm not sure how the connector should return this uuid. Looking in current > > vdsm code: > > > > if vol_type in ("iscsi", "fibre_channel"): > > if "multipath_id" not in attachment: > > raise se.ManagedVolumeUnsupportedDevice(vol_id, attachment) > > # /dev/mapper/xxxyyy > > return os.path.join(DEV_MAPPER, attachment["multipath_id"]) > > elif vol_type == "rbd": > > # /dev/rbd/poolname/volume-vol-id > > return os.path.join(DEV_RBD, connection_info['data']['name']) > > > > os_brick does not have a uniform way to address different devices. > > > > Maybe Gorka can help with this. > > Hi, > > That is true, because in OpenStack we haven't had the need to have the > same path on every host or even on the same host during different > connections. > > For nvme a new `elif` clause could be added there, though it will be a > bit trickier, because the nvme connection properties format are a bit of > a mess... > > We have 2 different formats for the nvme properties, and the wwid that > appears in symlink /dev/disk/by-id/nvme-<wwid> may or may not be the > volume id, may be the uuid in the connection info if present or the > nguid if the nvme device doesn't have uuid. > > For these reasons I would recommend not relying on the connection > information and relying on the path from the attachment instead. > > Something like this should be probably fine: > > elif vol_type == 'nvme': > device_name = os.path.basename(attachment['path']) > controller = device_name.rsplit('n', 1)[0] > wwid_filename = f'/sys/class/nvme/{controller}/{device_name}/wwid' > with open(wwid_filename, 'r') as f: > uuid = f.read().strip() > return os.path.join('/dev/disk/by-id/nvme-', uuid)
Thanks Gorka!
but isn't this duplicating logic already in os brick? https://github.com/openstack/os-brick/blob/56bf0272b55dcbbc7f5b03150973a80af...
Hi Nir,
Oh! I thought we were talking about the generic NVMe-oF connector, didn't know this was specific about the LightOS one.
The link is used as an easy way to locate the volume, it doesn't mean that it is returned to the caller of the `connect_volume` method. In fact, we can see how that method actually returns the real path and not the link's path:
def _check_device_exists_using_dev_lnk(self, uuid): lnk_path = f"/dev/disk/by-id/nvme-uuid.{uuid}" --> if os.path.exists(lnk_path): ^^^ Check link exists
--> devname = os.path.realpath(lnk_path) ^^^ Get the real path for the symlink
--> if devname.startswith("/dev/nvme"): ^^^ Make extra sure it's not pointing to something crazy
LOG.info("LIGHTOS: devpath %s detected for uuid %s", devname, uuid)
--> return devname ^^^ Return it
return None
Another interesting detail is this wait: https://github.com/openstack/os-brick/blob/56bf0272b55dcbbc7f5b03150973a80af...
def _get_device_by_uuid(self, uuid): endtime = time.time() + self.WAIT_DEVICE_TIMEOUT while time.time() < endtime: try: device = self._check_device_exists_using_dev_lnk(uuid) if device: return device except Exception as e: LOG.debug(f'LIGHTOS: {e}') device = self._check_device_exists_reading_block_class(uuid) if device: return device
time.sleep(1) return None
The code does not explain why it tries to use the /dev/disk/by-id link and fallback to sysfs on errors. Based on our experience with udev, I guess that the author does not trust udev. I wonder if we can trust it as the stable device path.
In my experience udev rules (which is different from udev itself) are less that reliable as a way of finding devices when working "in the wild". They are only reliable if you have full control over the host system and are sure nobody (admin or distro) can break things.
For reference, at Red Hat we have an RFE to improve os-brick [1] and stop using symlinks at all.
While they are not 100% reliable in the wild, they are quite reliable once they are working on a specific system, which means that if we confirm they are working on a system we can rely on them if no changes are made on the system (and if CPU is not 100% during attachment).
[1]: https://bugzilla.redhat.com/show_bug.cgi?id=1697319
If we can trust this path, maybe os_brick can return the stable path in a uniform way for all kind of devices?
I don't think this is likely to happen, because it has no real value for OpenStack so it's unlikely to get prioritized (for coding and reviews).
Since we cannot get a stable path from os-brick, and stable path is a oVirt specific requirement, we need to handle this in oVirt, similar to the way we handle multipath and rbd and traditional storage.
Nir
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.
Hi Benny, Any update on this one? Also, is there a way I can test this with vdsm-client without resorting to full ovirt? We have run into some issues with getting ovirt working with the nightlies, but vdsm and vdsm-client appear to work fine with the patches applied, or at least, they run. Cheers, Muli On Thu, Mar 3, 2022 at 6:09 PM Benny Zlotnik <bzlotnik@redhat.com> wrote:
Hi,
I posted draft PRs for engine[1] and vdsm[2], they are still raw and I only tested running starting VMs with ceph. If you can apply the changes for lightos (only vdsm should be needed) and try it out it would be great :) Also, if you have any suggestions/comments/etc feel free to comment on the PRs directly
If you don't want to build ovirt-engine from source, CI generated RPMs should be available in[3] (the job is still running while I'm writing this email)
[1] https://github.com/oVirt/ovirt-engine/pull/104 [2] https://github.com/oVirt/vdsm/pull/89 [3] https://github.com/oVirt/ovirt-engine/actions/runs/1929008680
On Wed, Mar 2, 2022 at 4:55 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
Thanks for the update, Benny. How can I help? For example, would logs
from running the connector with the exact data it returns be useful?
Cheers, Muli
On Tue, Mar 1, 2022 at 8:39 PM Benny Zlotnik <bzlotnik@redhat.com>
Hi,
Just by browsing the code, I can think of one issue in[1], as a result of[2] where we only considered iscsi and rbd drivers, I suspect your driver will go into this branch, based on the issue in the 4.3 logs I went over:
backend/manager/modules/vdsbroker/src/main/java/org/ovirt/engine/core/vdsbroker/builder/vminfo/LibvirtVmXmlBuilder.java
} else if (managedBlockStorageDisk.getCinderVolumeDriver() == CinderVolumeDriver.BLOCK) { Map<String, Object> attachment = (Map<String, Object>) managedBlockStorageDisk.getDevice().get(DeviceInfoReturn.ATTACHMENT); metadata = Map.of( "GUID", (String)attachment.get(DeviceInfoReturn.SCSI_WWN), "managed", "true"
Which will make it go into the wrong branch in clientIF.py, appending the empty GUID to /dev/mapper. Perhaps it is possible workaround it in clientIF if you just want to try and get the VM started for now, by checking if GUID is empty and deferring to: volPath = drive['path']
But as discussed in this thread, our attempt at constructing the stable paths ourselves doesn't really scale. After further discussion with Nir I started working on creating a link in vdsm in managevolume.py#attach_volume to the path returned by the driver, and engine will use our link to run the VMs. This should simplify the code and resolve the live VM migration issue. I had some preliminary success with this so I'll try to post the patches soon
[1]
https://github.com/oVirt/vdsm/blob/d957a06a4d988489c83da171fcd9cfd254b12ca4/...
[2] https://github.com/oVirt/ovirt-engine/blob/24530d17874e20581deee4b0e319146cd...
On Tue, Mar 1, 2022 at 6:12 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
Will this support require changes in ovirt-engine or just in vdsm? I
have started to look into vdsm's managedvolume.py and its tests and it seems like adding support for LightOS there should be pretty simple (famous last words...). Should this be enough or do you think it will require changes in other parts of ovirt as well?
Cheers, Muli
On Mon, Feb 28, 2022 at 9:09 AM Nir Soffer <nsoffer@redhat.com>
wrote:
On Fri, Feb 25, 2022 at 12:04 PM Gorka Eguileor <geguileo@redhat.com>
wrote:
On 24/02, Nir Soffer wrote: > On Thu, Feb 24, 2022 at 8:46 PM Gorka Eguileor <
geguileo@redhat.com> wrote:
> > > > On 24/02, Nir Soffer wrote: > > > On Thu, Feb 24, 2022 at 6:35 PM Muli Ben-Yehuda < muli@lightbitslabs.com> wrote: > > > > > > > > On Thu, Feb 24, 2022 at 6:28 PM Nir Soffer < nsoffer@redhat.com> wrote: > > > >> > > > >> On Thu, Feb 24, 2022 at 6:10 PM Muli Ben-Yehuda < muli@lightbitslabs.com> wrote: > > > >> > > > > >> > On Thu, Feb 24, 2022 at 3:58 PM Nir Soffer < nsoffer@redhat.com> wrote: > > > >> >> > > > >> >> On Wed, Feb 23, 2022 at 6:24 PM Muli Ben-Yehuda < muli@lightbitslabs.com> wrote: > > > >> >> > > > > >> >> > Thanks for the detailed instructions, Nir. I'm going to scrounge up some hardware. > > > >> >> > By the way, if anyone else would like to work on NVMe/TCP support, for NVMe/TCP target you can either use Lightbits (talk to me offline for details) or use the upstream Linux NVMe/TCP target. Lightbits is a clustered storage system while upstream is a single target, but the client side should be close enough for vdsm/ovirt purposes. > > > >> >> > > > >> >> I played with NVMe/TCP a little bit, using qemu to create a virtual > > > >> >> NVMe disk, and export > > > >> >> it using the kernel on one VM, and consume it on another VM. > > > >> >> https://futurewei-cloud.github.io/ARM-Datacenter/qemu/nvme-of-tcp-vms/ > > > >> >> > > > >> >> One question about device naming - do we always get
> > > >> >> device in all hosts? > > > >> > > > > >> > > > > >> > No, we do not, see below how we handle migration in os_brick. > > > >> > > > > >> >> To support VM migration, every device must have unique name in the cluster. > > > >> >> With multipath we always have unique name, since we disable "friendly names", > > > >> >> so we always have: > > > >> >> > > > >> >> /dev/mapper/{wwid} > > > >> >> > > > >> >> With rbd we also do not use /dev/rbdN but a unique
> > > >> >> > > > >> >> /dev/rbd/poolname/volume-vol-id > > > >> >> > > > >> >> How do we ensure cluster-unique device path? If os_brick does not handle it, we > > > >> >> can to do in ovirt, for example: > > > >> >> > > > >> >> /run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42 > > > >> >> > > > >> >> but I think this should be handled in cinderlib, since openstack have > > > >> >> the same problem with migration. > > > >> > > > > >> > > > > >> > Indeed. Both the Lightbits LightOS connector and the nvmeof connector do this through the target provided namespace (LUN) UUID. After connecting to the target, the connectors wait for the local friendly-named device file that has the right UUID to show up, and then return the friendly name. So different hosts will have different friendly names, but the VMs will be attached to the right namespace since we return
> > > >> > > > >> It will not work for oVirt. > > > >> > > > >> Migration in oVirt works like this: > > > >> > > > >> 1. Attach disks to destination host > > > >> 2. Send VM XML from source host to destination host, and start the > > > >> VM is paused mode > > > >> 3. Start the migration on the source host > > > >> 4. When migration is done, start the CPU on the destination host > > > >> 5. Detach the disks from the source > > > >> > > > >> This will break in step 2, since the source xml refer to nvme device > > > >> that does not exist or already used by another VM. > > > > > > > > > > > > Indeed. > > > > > > > >> To make this work, the VM XML must use the same path, existing on > > > >> both hosts. > > > >> > > > >> The issue can be solved by libvirt hook updating the
> > > >> is started on the destination, but I think the right way to handle this is to > > > >> have the same path. > > > > > > > > > > > > You mentioned above that it can be handled in ovirt (c.f., /run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42), which seems like a reasonable approach given the constraint imposed by the oVirt migration flow you outlined above. What information does vdsm need to create and use
> > > > > > > > def connect_volume(self, connection_properties): > > > > device_info = {'type': 'block'} > > > > uuid = connection_properties['uuid'] > > > > device_path = self._get_device_by_uuid(uuid) > > > > device_info['path'] = device_path > > > > return device_info > > > > > > I think we have 2 options: > > > > > > 1. unique path created by os_brick using the underlying uuid > > > > > > In this case the connector will return the uuid, and ovirt will use > > > it to resolve the unique path that will be stored and used on engine > > > side to create the vm xml. > > > > > > I'm not sure how the connector should return this uuid. Looking in current > > > vdsm code: > > > > > > if vol_type in ("iscsi", "fibre_channel"): > > > if "multipath_id" not in attachment: > > > raise se.ManagedVolumeUnsupportedDevice(vol_id, attachment) > > > # /dev/mapper/xxxyyy > > > return os.path.join(DEV_MAPPER, attachment["multipath_id"]) > > > elif vol_type == "rbd": > > > # /dev/rbd/poolname/volume-vol-id > > > return os.path.join(DEV_RBD, connection_info['data']['name']) > > > > > > os_brick does not have a uniform way to address different devices. > > > > > > Maybe Gorka can help with this. > > > > Hi, > > > > That is true, because in OpenStack we haven't had the need to have the > > same path on every host or even on the same host during different > > connections. > > > > For nvme a new `elif` clause could be added there, though it will be a > > bit trickier, because the nvme connection properties format are a bit of > > a mess... > > > > We have 2 different formats for the nvme properties, and the wwid that > > appears in symlink /dev/disk/by-id/nvme-<wwid> may or may not be the > > volume id, may be the uuid in the connection info if present or the > > nguid if the nvme device doesn't have uuid. > > > > For these reasons I would recommend not relying on the connection > > information and relying on the path from the attachment instead. > > > > Something like this should be probably fine: > > > > elif vol_type == 'nvme': > > device_name = os.path.basename(attachment['path']) > > controller = device_name.rsplit('n', 1)[0] > > wwid_filename = f'/sys/class/nvme/{controller}/{device_name}/wwid' > > with open(wwid_filename, 'r') as f: > > uuid = f.read().strip() > > return os.path.join('/dev/disk/by-id/nvme-', uuid) > > Thanks Gorka! > > but isn't this duplicating logic already in os brick? > https://github.com/openstack/os-brick/blob/56bf0272b55dcbbc7f5b03150973a80af... >
Hi Nir,
Oh! I thought we were talking about the generic NVMe-oF connector, didn't know this was specific about the LightOS one.
The link is used as an easy way to locate the volume, it doesn't mean that it is returned to the caller of the `connect_volume` method. In fact, we can see how that method actually returns the real path and not the link's path:
def _check_device_exists_using_dev_lnk(self, uuid): lnk_path = f"/dev/disk/by-id/nvme-uuid.{uuid}" --> if os.path.exists(lnk_path): ^^^ Check link exists
--> devname = os.path.realpath(lnk_path) ^^^ Get the real path for the symlink
--> if devname.startswith("/dev/nvme"): ^^^ Make extra sure it's not pointing to something crazy
LOG.info("LIGHTOS: devpath %s detected for uuid %s", devname, uuid)
--> return devname ^^^ Return it
return None
> Another interesting detail is this wait: > https://github.com/openstack/os-brick/blob/56bf0272b55dcbbc7f5b03150973a80af... > > def _get_device_by_uuid(self, uuid): > endtime = time.time() + self.WAIT_DEVICE_TIMEOUT > while time.time() < endtime: > try: > device = self._check_device_exists_using_dev_lnk(uuid) > if device: > return device > except Exception as e: > LOG.debug(f'LIGHTOS: {e}') > device = self._check_device_exists_reading_block_class(uuid) > if device: > return device > > time.sleep(1) > return None > > The code does not explain why it tries to use the /dev/disk/by-id link > and fallback to sysfs on errors. Based on our experience with udev, > I guess that the author does not trust udev. I wonder if we can
> it as the stable device path. >
In my experience udev rules (which is different from udev itself) are less that reliable as a way of finding devices when working "in the wild". They are only reliable if you have full control over the host system and are sure nobody (admin or distro) can break things.
For reference, at Red Hat we have an RFE to improve os-brick [1] and stop using symlinks at all.
While they are not 100% reliable in the wild, they are quite reliable once they are working on a specific system, which means that if we confirm they are working on a system we can rely on them if no changes are made on the system (and if CPU is not 100% during attachment).
[1]: https://bugzilla.redhat.com/show_bug.cgi?id=1697319
> If we can trust this path, maybe os_brick can return the stable
> in a uniform way for all kind of devices?
I don't think this is likely to happen, because it has no real value for OpenStack so it's unlikely to get prioritized (for coding and reviews).
Since we cannot get a stable path from os-brick, and stable path is a oVirt specific requirement, we need to handle this in oVirt, similar to
wrote: the same name of the path: the friendly name on the current host that has the right UUID. Does this also work for you? paths before qemu the /var/run/vdsm/managedvolumes/{uuid} link? Today the connector does (trimmed for brevity): trust path the way we
handle multipath and rbd and traditional storage.
Nir
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.
-- *Lightbits Labs** *Lead the cloud-native data center transformation by delivering *scalable *and *efficient *software defined storage that is *easy *to consume. *This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.*
Hi, I replied in the PR Regarding testing this with vdsm-client, in theory it's possible, but would be quite difficult as you'd have to prepare the datacenter and add traditional storage (vdsm managed iscsi/nfs), with: $ vdsm-client StoragePool create/connect then with StorageDomain namespaces, and probably a bunch of other stuff ovirt-engine does automatically, until you can get to the $ vdsm-client ManagedVolume attach_volume operations. but I am not sure how practical it is to do this, I am pretty sure it would be much easier to do this with ovirt-engine... Can you share what issues you ran into with ovirt-engine? I rebased my engine PR[1] that's required to test this, new RPMs should be available soon [1] https://github.com/oVirt/ovirt-engine/pull/104 On Sun, Mar 27, 2022 at 1:47 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
Hi Benny,
Any update on this one? Also, is there a way I can test this with vdsm-client without resorting to full ovirt? We have run into some issues with getting ovirt working with the nightlies, but vdsm and vdsm-client appear to work fine with the patches applied, or at least, they run.
Cheers, Muli
On Thu, Mar 3, 2022 at 6:09 PM Benny Zlotnik <bzlotnik@redhat.com> wrote:
Hi,
I posted draft PRs for engine[1] and vdsm[2], they are still raw and I only tested running starting VMs with ceph. If you can apply the changes for lightos (only vdsm should be needed) and try it out it would be great :) Also, if you have any suggestions/comments/etc feel free to comment on the PRs directly
If you don't want to build ovirt-engine from source, CI generated RPMs should be available in[3] (the job is still running while I'm writing this email)
[1] https://github.com/oVirt/ovirt-engine/pull/104 [2] https://github.com/oVirt/vdsm/pull/89 [3] https://github.com/oVirt/ovirt-engine/actions/runs/1929008680
On Wed, Mar 2, 2022 at 4:55 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
Thanks for the update, Benny. How can I help? For example, would logs from running the connector with the exact data it returns be useful?
Cheers, Muli
On Tue, Mar 1, 2022 at 8:39 PM Benny Zlotnik <bzlotnik@redhat.com> wrote:
Hi,
Just by browsing the code, I can think of one issue in[1], as a result of[2] where we only considered iscsi and rbd drivers, I suspect your driver will go into this branch, based on the issue in the 4.3 logs I went over: backend/manager/modules/vdsbroker/src/main/java/org/ovirt/engine/core/vdsbroker/builder/vminfo/LibvirtVmXmlBuilder.java
} else if (managedBlockStorageDisk.getCinderVolumeDriver() == CinderVolumeDriver.BLOCK) { Map<String, Object> attachment = (Map<String, Object>) managedBlockStorageDisk.getDevice().get(DeviceInfoReturn.ATTACHMENT); metadata = Map.of( "GUID", (String)attachment.get(DeviceInfoReturn.SCSI_WWN), "managed", "true"
Which will make it go into the wrong branch in clientIF.py, appending the empty GUID to /dev/mapper. Perhaps it is possible workaround it in clientIF if you just want to try and get the VM started for now, by checking if GUID is empty and deferring to: volPath = drive['path']
But as discussed in this thread, our attempt at constructing the stable paths ourselves doesn't really scale. After further discussion with Nir I started working on creating a link in vdsm in managevolume.py#attach_volume to the path returned by the driver, and engine will use our link to run the VMs. This should simplify the code and resolve the live VM migration issue. I had some preliminary success with this so I'll try to post the patches soon
[1] https://github.com/oVirt/vdsm/blob/d957a06a4d988489c83da171fcd9cfd254b12ca4/... [2] https://github.com/oVirt/ovirt-engine/blob/24530d17874e20581deee4b0e319146cd...
On Tue, Mar 1, 2022 at 6:12 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
Will this support require changes in ovirt-engine or just in vdsm? I have started to look into vdsm's managedvolume.py and its tests and it seems like adding support for LightOS there should be pretty simple (famous last words...). Should this be enough or do you think it will require changes in other parts of ovirt as well?
Cheers, Muli
On Mon, Feb 28, 2022 at 9:09 AM Nir Soffer <nsoffer@redhat.com> wrote:
On Fri, Feb 25, 2022 at 12:04 PM Gorka Eguileor <geguileo@redhat.com> wrote: > > On 24/02, Nir Soffer wrote: > > On Thu, Feb 24, 2022 at 8:46 PM Gorka Eguileor <geguileo@redhat.com> wrote: > > > > > > On 24/02, Nir Soffer wrote: > > > > On Thu, Feb 24, 2022 at 6:35 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote: > > > > > > > > > > On Thu, Feb 24, 2022 at 6:28 PM Nir Soffer <nsoffer@redhat.com> wrote: > > > > >> > > > > >> On Thu, Feb 24, 2022 at 6:10 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote: > > > > >> > > > > > >> > On Thu, Feb 24, 2022 at 3:58 PM Nir Soffer <nsoffer@redhat.com> wrote: > > > > >> >> > > > > >> >> On Wed, Feb 23, 2022 at 6:24 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote: > > > > >> >> > > > > > >> >> > Thanks for the detailed instructions, Nir. I'm going to scrounge up some hardware. > > > > >> >> > By the way, if anyone else would like to work on NVMe/TCP support, for NVMe/TCP target you can either use Lightbits (talk to me offline for details) or use the upstream Linux NVMe/TCP target. Lightbits is a clustered storage system while upstream is a single target, but the client side should be close enough for vdsm/ovirt purposes. > > > > >> >> > > > > >> >> I played with NVMe/TCP a little bit, using qemu to create a virtual > > > > >> >> NVMe disk, and export > > > > >> >> it using the kernel on one VM, and consume it on another VM. > > > > >> >> https://futurewei-cloud.github.io/ARM-Datacenter/qemu/nvme-of-tcp-vms/ > > > > >> >> > > > > >> >> One question about device naming - do we always get the same name of the > > > > >> >> device in all hosts? > > > > >> > > > > > >> > > > > > >> > No, we do not, see below how we handle migration in os_brick. > > > > >> > > > > > >> >> To support VM migration, every device must have unique name in the cluster. > > > > >> >> With multipath we always have unique name, since we disable "friendly names", > > > > >> >> so we always have: > > > > >> >> > > > > >> >> /dev/mapper/{wwid} > > > > >> >> > > > > >> >> With rbd we also do not use /dev/rbdN but a unique path: > > > > >> >> > > > > >> >> /dev/rbd/poolname/volume-vol-id > > > > >> >> > > > > >> >> How do we ensure cluster-unique device path? If os_brick does not handle it, we > > > > >> >> can to do in ovirt, for example: > > > > >> >> > > > > >> >> /run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42 > > > > >> >> > > > > >> >> but I think this should be handled in cinderlib, since openstack have > > > > >> >> the same problem with migration. > > > > >> > > > > > >> > > > > > >> > Indeed. Both the Lightbits LightOS connector and the nvmeof connector do this through the target provided namespace (LUN) UUID. After connecting to the target, the connectors wait for the local friendly-named device file that has the right UUID to show up, and then return the friendly name. So different hosts will have different friendly names, but the VMs will be attached to the right namespace since we return the friendly name on the current host that has the right UUID. Does this also work for you? > > > > >> > > > > >> It will not work for oVirt. > > > > >> > > > > >> Migration in oVirt works like this: > > > > >> > > > > >> 1. Attach disks to destination host > > > > >> 2. Send VM XML from source host to destination host, and start the > > > > >> VM is paused mode > > > > >> 3. Start the migration on the source host > > > > >> 4. When migration is done, start the CPU on the destination host > > > > >> 5. Detach the disks from the source > > > > >> > > > > >> This will break in step 2, since the source xml refer to nvme device > > > > >> that does not exist or already used by another VM. > > > > > > > > > > > > > > > Indeed. > > > > > > > > > >> To make this work, the VM XML must use the same path, existing on > > > > >> both hosts. > > > > >> > > > > >> The issue can be solved by libvirt hook updating the paths before qemu > > > > >> is started on the destination, but I think the right way to handle this is to > > > > >> have the same path. > > > > > > > > > > > > > > > You mentioned above that it can be handled in ovirt (c.f., /run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42), which seems like a reasonable approach given the constraint imposed by the oVirt migration flow you outlined above. What information does vdsm need to create and use the /var/run/vdsm/managedvolumes/{uuid} link? Today the connector does (trimmed for brevity): > > > > > > > > > > def connect_volume(self, connection_properties): > > > > > device_info = {'type': 'block'} > > > > > uuid = connection_properties['uuid'] > > > > > device_path = self._get_device_by_uuid(uuid) > > > > > device_info['path'] = device_path > > > > > return device_info > > > > > > > > I think we have 2 options: > > > > > > > > 1. unique path created by os_brick using the underlying uuid > > > > > > > > In this case the connector will return the uuid, and ovirt will use > > > > it to resolve the unique path that will be stored and used on engine > > > > side to create the vm xml. > > > > > > > > I'm not sure how the connector should return this uuid. Looking in current > > > > vdsm code: > > > > > > > > if vol_type in ("iscsi", "fibre_channel"): > > > > if "multipath_id" not in attachment: > > > > raise se.ManagedVolumeUnsupportedDevice(vol_id, attachment) > > > > # /dev/mapper/xxxyyy > > > > return os.path.join(DEV_MAPPER, attachment["multipath_id"]) > > > > elif vol_type == "rbd": > > > > # /dev/rbd/poolname/volume-vol-id > > > > return os.path.join(DEV_RBD, connection_info['data']['name']) > > > > > > > > os_brick does not have a uniform way to address different devices. > > > > > > > > Maybe Gorka can help with this. > > > > > > Hi, > > > > > > That is true, because in OpenStack we haven't had the need to have the > > > same path on every host or even on the same host during different > > > connections. > > > > > > For nvme a new `elif` clause could be added there, though it will be a > > > bit trickier, because the nvme connection properties format are a bit of > > > a mess... > > > > > > We have 2 different formats for the nvme properties, and the wwid that > > > appears in symlink /dev/disk/by-id/nvme-<wwid> may or may not be the > > > volume id, may be the uuid in the connection info if present or the > > > nguid if the nvme device doesn't have uuid. > > > > > > For these reasons I would recommend not relying on the connection > > > information and relying on the path from the attachment instead. > > > > > > Something like this should be probably fine: > > > > > > elif vol_type == 'nvme': > > > device_name = os.path.basename(attachment['path']) > > > controller = device_name.rsplit('n', 1)[0] > > > wwid_filename = f'/sys/class/nvme/{controller}/{device_name}/wwid' > > > with open(wwid_filename, 'r') as f: > > > uuid = f.read().strip() > > > return os.path.join('/dev/disk/by-id/nvme-', uuid) > > > > Thanks Gorka! > > > > but isn't this duplicating logic already in os brick? > > https://github.com/openstack/os-brick/blob/56bf0272b55dcbbc7f5b03150973a80af... > > > > Hi Nir, > > Oh! I thought we were talking about the generic NVMe-oF connector, > didn't know this was specific about the LightOS one. > > The link is used as an easy way to locate the volume, it doesn't mean > that it is returned to the caller of the `connect_volume` method. In > fact, we can see how that method actually returns the real path and not > the link's path: > > def _check_device_exists_using_dev_lnk(self, uuid): > lnk_path = f"/dev/disk/by-id/nvme-uuid.{uuid}" > --> if os.path.exists(lnk_path): > ^^^ Check link exists > > --> devname = os.path.realpath(lnk_path) > ^^^ Get the real path for the symlink > > --> if devname.startswith("/dev/nvme"): > ^^^ Make extra sure it's not pointing to something crazy > > LOG.info("LIGHTOS: devpath %s detected for uuid %s", > devname, uuid) > > --> return devname > ^^^ Return it > > return None > > > Another interesting detail is this wait: > > https://github.com/openstack/os-brick/blob/56bf0272b55dcbbc7f5b03150973a80af... > > > > def _get_device_by_uuid(self, uuid): > > endtime = time.time() + self.WAIT_DEVICE_TIMEOUT > > while time.time() < endtime: > > try: > > device = self._check_device_exists_using_dev_lnk(uuid) > > if device: > > return device > > except Exception as e: > > LOG.debug(f'LIGHTOS: {e}') > > device = self._check_device_exists_reading_block_class(uuid) > > if device: > > return device > > > > time.sleep(1) > > return None > > > > The code does not explain why it tries to use the /dev/disk/by-id link > > and fallback to sysfs on errors. Based on our experience with udev, > > I guess that the author does not trust udev. I wonder if we can trust > > it as the stable device path. > > > > In my experience udev rules (which is different from udev itself) are > less that reliable as a way of finding devices when working "in the > wild". They are only reliable if you have full control over the host > system and are sure nobody (admin or distro) can break things. > > For reference, at Red Hat we have an RFE to improve os-brick [1] and > stop using symlinks at all. > > While they are not 100% reliable in the wild, they are quite reliable > once they are working on a specific system, which means that if we > confirm they are working on a system we can rely on them if no changes > are made on the system (and if CPU is not 100% during attachment). > > > [1]: https://bugzilla.redhat.com/show_bug.cgi?id=1697319 > > > > If we can trust this path, maybe os_brick can return the stable path > > in a uniform way for all kind of devices? > > I don't think this is likely to happen, because it has no real value for > OpenStack so it's unlikely to get prioritized (for coding and reviews).
Since we cannot get a stable path from os-brick, and stable path is a oVirt specific requirement, we need to handle this in oVirt, similar to the way we handle multipath and rbd and traditional storage.
Nir
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.

Hi Benny et all, Quick recap on the last testing environment I put together for Muli on this topic. - 2-3 weeks ago I deployed oVirt 4.4 back then and that’s when I captured my original traces. - Muli asked me to deploy 4.5 from the master branch to bring the cluster with the latest code so it would be closer to what you are working on With 4.4 I was able to bring up the cluster with 1 host attached to the cluster. Everything running on a single machine called client2 With 4.5 I can not bring the host up Here is my cluster spec In the UI I see the following when trying to add host client2 However when I check the nodes capabilities using Vdsm client I get this for each flag mentioned [root@client2 ~]# vdsm-client Host getCapabilities | grep kvm "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", "kvmEnabled": "true", "qemu-kvm": { "kvm" [root@client2 ~]# vdsm-client Host getCapabilities | grep nx "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", [root@client2 ~]# vdsm-client Host getCapabilities | grep vmx "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", [root@client2 ~]# vdsm-client Host getCapabilities | grep Broadwell "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", So all the flags the UI claims as missing are actually present. Here is my repository configuration for this environment: # yum repolist Repository copr:copr.fedorainfracloud.org:ovirt:ovirt-master-snapshot is listed more than once in the configuration repo id repo name appstream CentOS Stream 8 - AppStream baseos CentOS Stream 8 - BaseOS copr:copr.fedorainfracloud.org:ovirt:ovirt-master-snapshot Copr repo for ovirt-master-snapshot owned by ovirt elrepo ELRepo.org Community Enterprise Linux Repository - el8 extras CentOS Stream 8 - Extras lightbits-lightos-openstack lightbits-lightos-openstack lightbits-lightos-openstack-noarch lightbits-lightos-openstack-noarch lightbits-lightos-openstack-source lightbits-lightos-openstack-source ovirt-appliance-master-snapshot oVirt appliance with ovirt-master-snapshot content ovirt-master-centos-opstools-testing CentOS Stream 8 - OpsTools - collectd ovirt-master-centos-stream-ceph-pacific CentOS Stream 8 - Ceph packages for x86_64 ovirt-master-centos-stream-gluster10-testing CentOS Stream 8 - Glusterfs 10 - testing ovirt-master-centos-stream-nfv-openvswitch2-testing CentOS Stream 8 - NFV OpenVSwitch 2 - testing ovirt-master-centos-stream-openstack-yoga-testing CentOS Stream 8 - OpenStack Yoga Repository - testing ovirt-master-centos-stream-ovirt45-testing CentOS Stream 8 - oVirt 4.5 - testing ovirt-master-copr:copr.fedorainfracloud.org:sac:gluster-ansible Copr repo for gluster-ansible owned by sac ovirt-master-epel Extra Packages for Enterprise Linux 8 - x86_64 ovirt-master-virtio-win-latest virtio-win builds roughly matching what will be shipped in upcoming RHEL ovirt-node-master-snapshot oVirt Node with ovirt-master-snapshot content powertools CentOS Stream 8 - PowerTools rdo-delorean-component-cinder RDO Delorean OpenStack Cinder - current rdo-delorean-component-clients RDO Delorean Clients - current rdo-delorean-component-common RDO Delorean Common - current rdo-delorean-component-network RDO Delorean Network - current Not sure if you could provide some guidance for me to be able to fix this. Any additional info you need let me know and I’ll provide. Best regards JC
On Mar 27, 2022, at 06:24, Benny Zlotnik <bzlotnik@redhat.com> wrote:
Hi, I replied in the PR
Regarding testing this with vdsm-client, in theory it's possible, but would be quite difficult as you'd have to prepare the datacenter and add traditional storage (vdsm managed iscsi/nfs), with: $ vdsm-client StoragePool create/connect then with StorageDomain namespaces, and probably a bunch of other stuff ovirt-engine does automatically, until you can get to the $ vdsm-client ManagedVolume attach_volume operations. but I am not sure how practical it is to do this, I am pretty sure it would be much easier to do this with ovirt-engine...
Can you share what issues you ran into with ovirt-engine? I rebased my engine PR[1] that's required to test this, new RPMs should be available soon
[1] https://github.com/oVirt/ovirt-engine/pull/104
On Sun, Mar 27, 2022 at 1:47 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
Hi Benny,
Any update on this one? Also, is there a way I can test this with vdsm-client without resorting to full ovirt? We have run into some issues with getting ovirt working with the nightlies, but vdsm and vdsm-client appear to work fine with the patches applied, or at least, they run.
Cheers, Muli
On Thu, Mar 3, 2022 at 6:09 PM Benny Zlotnik <bzlotnik@redhat.com> wrote:
Hi,
I posted draft PRs for engine[1] and vdsm[2], they are still raw and I only tested running starting VMs with ceph. If you can apply the changes for lightos (only vdsm should be needed) and try it out it would be great :) Also, if you have any suggestions/comments/etc feel free to comment on the PRs directly
If you don't want to build ovirt-engine from source, CI generated RPMs should be available in[3] (the job is still running while I'm writing this email)
[1] https://github.com/oVirt/ovirt-engine/pull/104 [2] https://github.com/oVirt/vdsm/pull/89 [3] https://github.com/oVirt/ovirt-engine/actions/runs/1929008680
On Wed, Mar 2, 2022 at 4:55 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
Thanks for the update, Benny. How can I help? For example, would logs from running the connector with the exact data it returns be useful?
Cheers, Muli
On Tue, Mar 1, 2022 at 8:39 PM Benny Zlotnik <bzlotnik@redhat.com> wrote:
Hi,
Just by browsing the code, I can think of one issue in[1], as a result of[2] where we only considered iscsi and rbd drivers, I suspect your driver will go into this branch, based on the issue in the 4.3 logs I went over: backend/manager/modules/vdsbroker/src/main/java/org/ovirt/engine/core/vdsbroker/builder/vminfo/LibvirtVmXmlBuilder.java
} else if (managedBlockStorageDisk.getCinderVolumeDriver() == CinderVolumeDriver.BLOCK) { Map<String, Object> attachment = (Map<String, Object>) managedBlockStorageDisk.getDevice().get(DeviceInfoReturn.ATTACHMENT); metadata = Map.of( "GUID", (String)attachment.get(DeviceInfoReturn.SCSI_WWN), "managed", "true"
Which will make it go into the wrong branch in clientIF.py, appending the empty GUID to /dev/mapper. Perhaps it is possible workaround it in clientIF if you just want to try and get the VM started for now, by checking if GUID is empty and deferring to: volPath = drive['path']
But as discussed in this thread, our attempt at constructing the stable paths ourselves doesn't really scale. After further discussion with Nir I started working on creating a link in vdsm in managevolume.py#attach_volume to the path returned by the driver, and engine will use our link to run the VMs. This should simplify the code and resolve the live VM migration issue. I had some preliminary success with this so I'll try to post the patches soon
[1] https://github.com/oVirt/vdsm/blob/d957a06a4d988489c83da171fcd9cfd254b12ca4/... [2] https://github.com/oVirt/ovirt-engine/blob/24530d17874e20581deee4b0e319146cd...
On Tue, Mar 1, 2022 at 6:12 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
Will this support require changes in ovirt-engine or just in vdsm? I have started to look into vdsm's managedvolume.py and its tests and it seems like adding support for LightOS there should be pretty simple (famous last words...). Should this be enough or do you think it will require changes in other parts of ovirt as well?
Cheers, Muli
On Mon, Feb 28, 2022 at 9:09 AM Nir Soffer <nsoffer@redhat.com> wrote: > > On Fri, Feb 25, 2022 at 12:04 PM Gorka Eguileor <geguileo@redhat.com> wrote: >> >> On 24/02, Nir Soffer wrote: >>> On Thu, Feb 24, 2022 at 8:46 PM Gorka Eguileor <geguileo@redhat.com> wrote: >>>> >>>> On 24/02, Nir Soffer wrote: >>>>> On Thu, Feb 24, 2022 at 6:35 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote: >>>>>> >>>>>> On Thu, Feb 24, 2022 at 6:28 PM Nir Soffer <nsoffer@redhat.com> wrote: >>>>>>> >>>>>>> On Thu, Feb 24, 2022 at 6:10 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote: >>>>>>>> >>>>>>>> On Thu, Feb 24, 2022 at 3:58 PM Nir Soffer <nsoffer@redhat.com> wrote: >>>>>>>>> >>>>>>>>> On Wed, Feb 23, 2022 at 6:24 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote: >>>>>>>>>> >>>>>>>>>> Thanks for the detailed instructions, Nir. I'm going to scrounge up some hardware. >>>>>>>>>> By the way, if anyone else would like to work on NVMe/TCP support, for NVMe/TCP target you can either use Lightbits (talk to me offline for details) or use the upstream Linux NVMe/TCP target. Lightbits is a clustered storage system while upstream is a single target, but the client side should be close enough for vdsm/ovirt purposes. >>>>>>>>> >>>>>>>>> I played with NVMe/TCP a little bit, using qemu to create a virtual >>>>>>>>> NVMe disk, and export >>>>>>>>> it using the kernel on one VM, and consume it on another VM. >>>>>>>>> https://futurewei-cloud.github.io/ARM-Datacenter/qemu/nvme-of-tcp-vms/ >>>>>>>>> >>>>>>>>> One question about device naming - do we always get the same name of the >>>>>>>>> device in all hosts? >>>>>>>> >>>>>>>> >>>>>>>> No, we do not, see below how we handle migration in os_brick. >>>>>>>> >>>>>>>>> To support VM migration, every device must have unique name in the cluster. >>>>>>>>> With multipath we always have unique name, since we disable "friendly names", >>>>>>>>> so we always have: >>>>>>>>> >>>>>>>>> /dev/mapper/{wwid} >>>>>>>>> >>>>>>>>> With rbd we also do not use /dev/rbdN but a unique path: >>>>>>>>> >>>>>>>>> /dev/rbd/poolname/volume-vol-id >>>>>>>>> >>>>>>>>> How do we ensure cluster-unique device path? If os_brick does not handle it, we >>>>>>>>> can to do in ovirt, for example: >>>>>>>>> >>>>>>>>> /run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42 >>>>>>>>> >>>>>>>>> but I think this should be handled in cinderlib, since openstack have >>>>>>>>> the same problem with migration. >>>>>>>> >>>>>>>> >>>>>>>> Indeed. Both the Lightbits LightOS connector and the nvmeof connector do this through the target provided namespace (LUN) UUID. After connecting to the target, the connectors wait for the local friendly-named device file that has the right UUID to show up, and then return the friendly name. So different hosts will have different friendly names, but the VMs will be attached to the right namespace since we return the friendly name on the current host that has the right UUID. Does this also work for you? >>>>>>> >>>>>>> It will not work for oVirt. >>>>>>> >>>>>>> Migration in oVirt works like this: >>>>>>> >>>>>>> 1. Attach disks to destination host >>>>>>> 2. Send VM XML from source host to destination host, and start the >>>>>>> VM is paused mode >>>>>>> 3. Start the migration on the source host >>>>>>> 4. When migration is done, start the CPU on the destination host >>>>>>> 5. Detach the disks from the source >>>>>>> >>>>>>> This will break in step 2, since the source xml refer to nvme device >>>>>>> that does not exist or already used by another VM. >>>>>> >>>>>> >>>>>> Indeed. >>>>>> >>>>>>> To make this work, the VM XML must use the same path, existing on >>>>>>> both hosts. >>>>>>> >>>>>>> The issue can be solved by libvirt hook updating the paths before qemu >>>>>>> is started on the destination, but I think the right way to handle this is to >>>>>>> have the same path. >>>>>> >>>>>> >>>>>> You mentioned above that it can be handled in ovirt (c.f., /run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42), which seems like a reasonable approach given the constraint imposed by the oVirt migration flow you outlined above. What information does vdsm need to create and use the /var/run/vdsm/managedvolumes/{uuid} link? Today the connector does (trimmed for brevity): >>>>>> >>>>>> def connect_volume(self, connection_properties): >>>>>> device_info = {'type': 'block'} >>>>>> uuid = connection_properties['uuid'] >>>>>> device_path = self._get_device_by_uuid(uuid) >>>>>> device_info['path'] = device_path >>>>>> return device_info >>>>> >>>>> I think we have 2 options: >>>>> >>>>> 1. unique path created by os_brick using the underlying uuid >>>>> >>>>> In this case the connector will return the uuid, and ovirt will use >>>>> it to resolve the unique path that will be stored and used on engine >>>>> side to create the vm xml. >>>>> >>>>> I'm not sure how the connector should return this uuid. Looking in current >>>>> vdsm code: >>>>> >>>>> if vol_type in ("iscsi", "fibre_channel"): >>>>> if "multipath_id" not in attachment: >>>>> raise se.ManagedVolumeUnsupportedDevice(vol_id, attachment) >>>>> # /dev/mapper/xxxyyy >>>>> return os.path.join(DEV_MAPPER, attachment["multipath_id"]) >>>>> elif vol_type == "rbd": >>>>> # /dev/rbd/poolname/volume-vol-id >>>>> return os.path.join(DEV_RBD, connection_info['data']['name']) >>>>> >>>>> os_brick does not have a uniform way to address different devices. >>>>> >>>>> Maybe Gorka can help with this. >>>> >>>> Hi, >>>> >>>> That is true, because in OpenStack we haven't had the need to have the >>>> same path on every host or even on the same host during different >>>> connections. >>>> >>>> For nvme a new `elif` clause could be added there, though it will be a >>>> bit trickier, because the nvme connection properties format are a bit of >>>> a mess... >>>> >>>> We have 2 different formats for the nvme properties, and the wwid that >>>> appears in symlink /dev/disk/by-id/nvme-<wwid> may or may not be the >>>> volume id, may be the uuid in the connection info if present or the >>>> nguid if the nvme device doesn't have uuid. >>>> >>>> For these reasons I would recommend not relying on the connection >>>> information and relying on the path from the attachment instead. >>>> >>>> Something like this should be probably fine: >>>> >>>> elif vol_type == 'nvme': >>>> device_name = os.path.basename(attachment['path']) >>>> controller = device_name.rsplit('n', 1)[0] >>>> wwid_filename = f'/sys/class/nvme/{controller}/{device_name}/wwid' >>>> with open(wwid_filename, 'r') as f: >>>> uuid = f.read().strip() >>>> return os.path.join('/dev/disk/by-id/nvme-', uuid) >>> >>> Thanks Gorka! >>> >>> but isn't this duplicating logic already in os brick? >>> https://github.com/openstack/os-brick/blob/56bf0272b55dcbbc7f5b03150973a80af... >>> >> >> Hi Nir, >> >> Oh! I thought we were talking about the generic NVMe-oF connector, >> didn't know this was specific about the LightOS one. >> >> The link is used as an easy way to locate the volume, it doesn't mean >> that it is returned to the caller of the `connect_volume` method. In >> fact, we can see how that method actually returns the real path and not >> the link's path: >> >> def _check_device_exists_using_dev_lnk(self, uuid): >> lnk_path = f"/dev/disk/by-id/nvme-uuid.{uuid}" >> --> if os.path.exists(lnk_path): >> ^^^ Check link exists >> >> --> devname = os.path.realpath(lnk_path) >> ^^^ Get the real path for the symlink >> >> --> if devname.startswith("/dev/nvme"): >> ^^^ Make extra sure it's not pointing to something crazy >> >> LOG.info("LIGHTOS: devpath %s detected for uuid %s", >> devname, uuid) >> >> --> return devname >> ^^^ Return it >> >> return None >> >>> Another interesting detail is this wait: >>> https://github.com/openstack/os-brick/blob/56bf0272b55dcbbc7f5b03150973a80af... >>> >>> def _get_device_by_uuid(self, uuid): >>> endtime = time.time() + self.WAIT_DEVICE_TIMEOUT >>> while time.time() < endtime: >>> try: >>> device = self._check_device_exists_using_dev_lnk(uuid) >>> if device: >>> return device >>> except Exception as e: >>> LOG.debug(f'LIGHTOS: {e}') >>> device = self._check_device_exists_reading_block_class(uuid) >>> if device: >>> return device >>> >>> time.sleep(1) >>> return None >>> >>> The code does not explain why it tries to use the /dev/disk/by-id link >>> and fallback to sysfs on errors. Based on our experience with udev, >>> I guess that the author does not trust udev. I wonder if we can trust >>> it as the stable device path. >>> >> >> In my experience udev rules (which is different from udev itself) are >> less that reliable as a way of finding devices when working "in the >> wild". They are only reliable if you have full control over the host >> system and are sure nobody (admin or distro) can break things. >> >> For reference, at Red Hat we have an RFE to improve os-brick [1] and >> stop using symlinks at all. >> >> While they are not 100% reliable in the wild, they are quite reliable >> once they are working on a specific system, which means that if we >> confirm they are working on a system we can rely on them if no changes >> are made on the system (and if CPU is not 100% during attachment). >> >> >> [1]: https://bugzilla.redhat.com/show_bug.cgi?id=1697319 >> >> >>> If we can trust this path, maybe os_brick can return the stable path >>> in a uniform way for all kind of devices? >> >> I don't think this is likely to happen, because it has no real value for >> OpenStack so it's unlikely to get prioritized (for coding and reviews). > > Since we cannot get a stable path from os-brick, and stable path is a oVirt > specific requirement, we need to handle this in oVirt, similar to the way we > handle multipath and rbd and traditional storage. > > Nir >
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.
-- *Lightbits Labs** *Lead the cloud-native data center transformation by delivering *scalable *and *efficient *software defined storage that is *easy *to consume. *This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.*
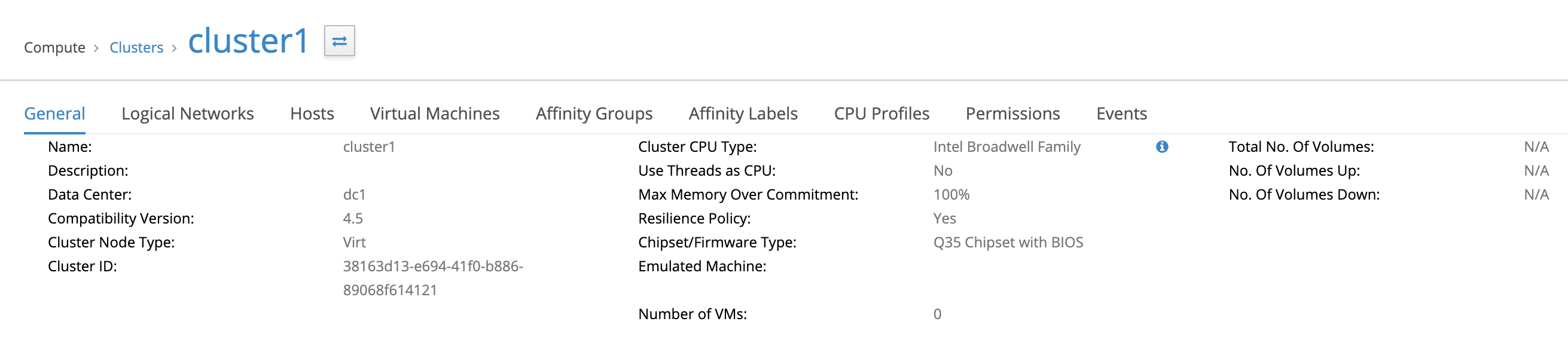{kind=link}
{kind=link}
On Mon, Mar 28, 2022 at 10:48 PM JC Lopez <jc@lightbitslabs.com> wrote:
Hi Benny et all,
...
With 4.5 I can not bring the host up
Here is my cluster spec In the UI I see the following when trying to add host client2
In the screenshot we see 2 issues: - host does not default route - host cpu missing some features To resolve the default route issue, click on the host name in the "Hosts" page, then click on the "Network interfaces", and then "Setup networks" button, and make sure the ovirtmgmt network is assigned to the right network interface, and edit it as needed. To quickly avoid this issue, select an older cpu from the list. This should be good enough for development. Maybe Arik can help with using the actual CPU you have.
However when I check the nodes capabilities using Vdsm client I get this for each flag mentioned [root@client2 ~]# vdsm-client Host getCapabilities | grep kvm "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", "kvmEnabled": "true", "qemu-kvm": { "kvm" [root@client2 ~]# vdsm-client Host getCapabilities | grep nx "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", [root@client2 ~]# vdsm-client Host getCapabilities | grep vmx "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", [root@client2 ~]# vdsm-client Host getCapabilities | grep Broadwell "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2",
So all the flags the UI claims as missing are actually present.
Nir
On Mon, Mar 28, 2022 at 11:31 PM Nir Soffer <nsoffer@redhat.com> wrote:
On Mon, Mar 28, 2022 at 10:48 PM JC Lopez <jc@lightbitslabs.com> wrote:
Hi Benny et all,
...
With 4.5 I can not bring the host up
Here is my cluster spec In the UI I see the following when trying to add host client2
In the screenshot we see 2 issues: - host does not default route - host cpu missing some features
To resolve the default route issue, click on the host name in the "Hosts" page, then click on the "Network interfaces", and then "Setup networks" button, and make sure the ovirtmgmt network is assigned to the right network interface, and edit it as needed.
Adding screenshot in case it was not clear enough.
To quickly avoid this issue, select an older cpu from the list. This should be good enough for development. Maybe Arik can help with using the actual CPU you have.
However when I check the nodes capabilities using Vdsm client I get this for each flag mentioned [root@client2 ~]# vdsm-client Host getCapabilities | grep kvm "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", "kvmEnabled": "true", "qemu-kvm": { "kvm" [root@client2 ~]# vdsm-client Host getCapabilities | grep nx "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", [root@client2 ~]# vdsm-client Host getCapabilities | grep vmx "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", [root@client2 ~]# vdsm-client Host getCapabilities | grep Broadwell "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2",
So all the flags the UI claims as missing are actually present.
Nir
{kind=link}
Hi Nir, Tried to do this but somehow the UI does not let me drag the network anywhere in the window. Just in case I tried with both the host in maintenance mode and not in maintenance mode. Tried drag and drop on any area of the dialog box I could think off without success Tried with 3 different browsers to rule out browser incompatibility - Safari - Chrome - Firefox So NO idea why no network interfaces are detected on this node. FYI my CPU model is a Broadwell one. Best regards JC Initial window sees no network interface Clicking on setup network does not have any interface to which I can assign the ovirtmgmt network
On Mar 28, 2022, at 13:38, Nir Soffer <nsoffer@redhat.com> wrote:
On Mon, Mar 28, 2022 at 11:31 PM Nir Soffer <nsoffer@redhat.com <mailto:nsoffer@redhat.com>> wrote:
On Mon, Mar 28, 2022 at 10:48 PM JC Lopez <jc@lightbitslabs.com> wrote:
Hi Benny et all,
...
With 4.5 I can not bring the host up
Here is my cluster spec In the UI I see the following when trying to add host client2
In the screenshot we see 2 issues: - host does not default route - host cpu missing some features
To resolve the default route issue, click on the host name in the "Hosts" page, then click on the "Network interfaces", and then "Setup networks" button, and make sure the ovirtmgmt network is assigned to the right network interface, and edit it as needed.
Adding screenshot in case it was not clear enough.
To quickly avoid this issue, select an older cpu from the list. This should be good enough for development. Maybe Arik can help with using the actual CPU you have.
However when I check the nodes capabilities using Vdsm client I get this for each flag mentioned [root@client2 ~]# vdsm-client Host getCapabilities | grep kvm "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", "kvmEnabled": "true", "qemu-kvm": { "kvm" [root@client2 ~]# vdsm-client Host getCapabilities | grep nx "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", [root@client2 ~]# vdsm-client Host getCapabilities | grep vmx "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", [root@client2 ~]# vdsm-client Host getCapabilities | grep Broadwell "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2",
So all the flags the UI claims as missing are actually present.
Nir
<Screenshot from 2022-03-28 23-23-38.png>
-- *Lightbits Labs** *Lead the cloud-native data center transformation by delivering *scalable *and *efficient *software defined storage that is *easy *to consume. *This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.*
{kind=link}
{kind=link}
On Tue, Mar 29, 2022 at 3:26 AM JC Lopez <jc@lightbitslabs.com> wrote:
Hi Nir,
Tried to do this but somehow the UI does not let me drag the network anywhere in the window.
Just in case I tried with both the host in maintenance mode and not in maintenance mode. Tried drag and drop on any area of the dialog box I could think off without success
Tried with 3 different browsers to rule out browser incompatibility - Safari - Chrome - Firefox
So NO idea why no network interfaces are detected on this node. FYI my CPU model is a Broadwell one.
If engine does not detect any network interface "setup networks" is not going to be very useful. I'm not sure how you got into this situation, maybe this is an upgrade issue. I suggest to start clean: 1. Remove current vdsm install on the host dnf remove vdsm\* 2. Upgrade you host to latest CentOS Stream 8 3. Add the ovirt repos: https://copr.fedorainfracloud.org/coprs/ovirt/ovirt-master-snapshot/ dnf copr enable -y ovirt/ovirt-master-snapshot centos-stream-8 dnf install -y ovirt-release-master 4. Make sure your host network configuration is right You should be able to connect from your engine machine to the host. 5. Add the host to your engine Engine will install the host and reboot it. The host should be up when this is done. 6. Add some storage so you have a master storage domain. The easier way is to add NFS storage domain but you can use also iSCSI or FC if you like. At this point you should have working setup. The next step is to update engine and vdsm with the Benny patches, but don't try this before you have a working system. If you need more help we can chat in #ovirt on oftc.net. Nir
Best regards JC Initial window sees no network interface Clicking on setup network does not have any interface to which I can assign the ovirtmgmt network
On Mar 28, 2022, at 13:38, Nir Soffer <nsoffer@redhat.com> wrote:
On Mon, Mar 28, 2022 at 11:31 PM Nir Soffer <nsoffer@redhat.com> wrote:
On Mon, Mar 28, 2022 at 10:48 PM JC Lopez <jc@lightbitslabs.com> wrote:
Hi Benny et all,
...
With 4.5 I can not bring the host up
Here is my cluster spec In the UI I see the following when trying to add host client2
In the screenshot we see 2 issues: - host does not default route - host cpu missing some features
To resolve the default route issue, click on the host name in the "Hosts" page, then click on the "Network interfaces", and then "Setup networks" button, and make sure the ovirtmgmt network is assigned to the right network interface, and edit it as needed.
Adding screenshot in case it was not clear enough.
To quickly avoid this issue, select an older cpu from the list. This should be good enough for development. Maybe Arik can help with using the actual CPU you have.
However when I check the nodes capabilities using Vdsm client I get this for each flag mentioned [root@client2 ~]# vdsm-client Host getCapabilities | grep kvm "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", "kvmEnabled": "true", "qemu-kvm": { "kvm" [root@client2 ~]# vdsm-client Host getCapabilities | grep nx "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", [root@client2 ~]# vdsm-client Host getCapabilities | grep vmx "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", [root@client2 ~]# vdsm-client Host getCapabilities | grep Broadwell "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2",
So all the flags the UI claims as missing are actually present.
Nir
<Screenshot from 2022-03-28 23-23-38.png>
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.
Hi Nir, Wiped out the node as the procedure provided did not fix the problem. Fresh CentOS Stream 8 Looks like the vddm I deployed requires Ansible 2.12 Depsolve Error occured: \n Problem: cannot install the best candidate for the job\n - nothing provides virt-install needed by ovirt-hosted-engine-setup-2.6.4-0.0.master.20220329124709.git59931a1.el8.noarch\n - nothing provides ansible-core >= 2.12 needed by ovirt-hosted-engine-setup-2.6.4-0.0.master.20220329124709.git59931a1.el8.noarch”, But the ovirt-engine requires Ansible 2.9.27-2 package ovirt-engine-4.5.0.1-0.2.master.20220330145541.gitaff1492753.el8.noarch conflicts with ansible-core >= 2.10.0 provided by ansible-core-2.12.2-2.el8.x86_64 So if I enable all my repos the deployment wants to deploy packages that require 2.12 but because of the oVirt-manager requirements it says it can not pass Ansible 2.10. So I end up in a deadlock situation Not sure what to do. Will get onto irc tomorrow to check on this with you Question: When is oVirt 4.5 being officially released. May be it will be easier for me to start from that point. Best regards JC
On Mar 29, 2022, at 11:08, Nir Soffer <nsoffer@redhat.com> wrote:
On Tue, Mar 29, 2022 at 3:26 AM JC Lopez <jc@lightbitslabs.com <mailto:jc@lightbitslabs.com>> wrote:
Hi Nir,
Tried to do this but somehow the UI does not let me drag the network anywhere in the window.
Just in case I tried with both the host in maintenance mode and not in maintenance mode. Tried drag and drop on any area of the dialog box I could think off without success
Tried with 3 different browsers to rule out browser incompatibility - Safari - Chrome - Firefox
So NO idea why no network interfaces are detected on this node. FYI my CPU model is a Broadwell one.
If engine does not detect any network interface "setup networks" is not going to be very useful.
I'm not sure how you got into this situation, maybe this is an upgrade issue.
I suggest to start clean:
1. Remove current vdsm install on the host
dnf remove vdsm\*
2. Upgrade you host to latest CentOS Stream 8
3. Add the ovirt repos: https://copr.fedorainfracloud.org/coprs/ovirt/ovirt-master-snapshot/ <https://copr.fedorainfracloud.org/coprs/ovirt/ovirt-master-snapshot/>
dnf copr enable -y ovirt/ovirt-master-snapshot centos-stream-8 dnf install -y ovirt-release-master
4. Make sure your host network configuration is right
You should be able to connect from your engine machine to the host.
5. Add the host to your engine
Engine will install the host and reboot it. The host should be up when this is done.
6. Add some storage so you have a master storage domain.
The easier way is to add NFS storage domain but you can use also iSCSI or FC if you like.
At this point you should have working setup.
The next step is to update engine and vdsm with the Benny patches, but don't try this before you have a working system.
If you need more help we can chat in #ovirt on oftc.net <http://oftc.net/>.
Nir
Best regards JC Initial window sees no network interface Clicking on setup network does not have any interface to which I can assign the ovirtmgmt network
On Mar 28, 2022, at 13:38, Nir Soffer <nsoffer@redhat.com> wrote:
On Mon, Mar 28, 2022 at 11:31 PM Nir Soffer <nsoffer@redhat.com> wrote:
On Mon, Mar 28, 2022 at 10:48 PM JC Lopez <jc@lightbitslabs.com> wrote:
Hi Benny et all,
...
With 4.5 I can not bring the host up
Here is my cluster spec In the UI I see the following when trying to add host client2
In the screenshot we see 2 issues: - host does not default route - host cpu missing some features
To resolve the default route issue, click on the host name in the "Hosts" page, then click on the "Network interfaces", and then "Setup networks" button, and make sure the ovirtmgmt network is assigned to the right network interface, and edit it as needed.
Adding screenshot in case it was not clear enough.
To quickly avoid this issue, select an older cpu from the list. This should be good enough for development. Maybe Arik can help with using the actual CPU you have.
However when I check the nodes capabilities using Vdsm client I get this for each flag mentioned [root@client2 ~]# vdsm-client Host getCapabilities | grep kvm "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", "kvmEnabled": "true", "qemu-kvm": { "kvm" [root@client2 ~]# vdsm-client Host getCapabilities | grep nx "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", [root@client2 ~]# vdsm-client Host getCapabilities | grep vmx "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", [root@client2 ~]# vdsm-client Host getCapabilities | grep Broadwell "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2",
So all the flags the UI claims as missing are actually present.
Nir
<Screenshot from 2022-03-28 23-23-38.png>
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.
-- *Lightbits Labs** *Lead the cloud-native data center transformation by delivering *scalable *and *efficient *software defined storage that is *easy *to consume. *This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.*
On Wed, Mar 30, 2022 at 11:26 PM JC Lopez <jc@lightbitslabs.com> wrote:
Hi Nir,
Wiped out the node as the procedure provided did not fix the problem.
Fresh CentOS Stream 8
Looks like the vddm I deployed requires Ansible 2.12 Depsolve Error occured: \n Problem: cannot install the best candidate for the job\n - nothing provides virt-install needed by ovirt-hosted-engine-setup-2.6.4-0.0.master.20220329124709.git59931a1.el8.noarch\n - nothing provides ansible-core >= 2.12 needed by ovirt-hosted-engine-setup-2.6.4-0.0.master.20220329124709.git59931a1.el8.noarch”,
Didi, do we have a solution to the ansible requirement? Maybe some repo is missing?
But the ovirt-engine requires Ansible 2.9.27-2 package ovirt-engine-4.5.0.1-0.2.master.20220330145541.gitaff1492753.el8.noarch conflicts with ansible-core >= 2.10.0 provided by ansible-core-2.12.2-2.el8.x86_64
So if I enable all my repos the deployment wants to deploy packages that require 2.12 but because of the oVirt-manager requirements it says it can not pass Ansible 2.10. So I end up in a deadlock situation
Not sure what to do. Will get onto irc tomorrow to check on this with you
Question: When is oVirt 4.5 being officially released. May be it will be easier for me to start from that point.
We should have 4.5 beta next week.
Best regards JC
On Mar 29, 2022, at 11:08, Nir Soffer <nsoffer@redhat.com> wrote:
On Tue, Mar 29, 2022 at 3:26 AM JC Lopez <jc@lightbitslabs.com> wrote:
Hi Nir,
Tried to do this but somehow the UI does not let me drag the network anywhere in the window.
Just in case I tried with both the host in maintenance mode and not in maintenance mode. Tried drag and drop on any area of the dialog box I could think off without success
Tried with 3 different browsers to rule out browser incompatibility - Safari - Chrome - Firefox
So NO idea why no network interfaces are detected on this node. FYI my CPU model is a Broadwell one.
If engine does not detect any network interface "setup networks" is not going to be very useful.
I'm not sure how you got into this situation, maybe this is an upgrade issue.
I suggest to start clean:
1. Remove current vdsm install on the host
dnf remove vdsm\*
2. Upgrade you host to latest CentOS Stream 8
3. Add the ovirt repos: https://copr.fedorainfracloud.org/coprs/ovirt/ovirt-master-snapshot/
dnf copr enable -y ovirt/ovirt-master-snapshot centos-stream-8 dnf install -y ovirt-release-master
4. Make sure your host network configuration is right
You should be able to connect from your engine machine to the host.
5. Add the host to your engine
Engine will install the host and reboot it. The host should be up when this is done.
6. Add some storage so you have a master storage domain.
The easier way is to add NFS storage domain but you can use also iSCSI or FC if you like.
At this point you should have working setup.
The next step is to update engine and vdsm with the Benny patches, but don't try this before you have a working system.
If you need more help we can chat in #ovirt on oftc.net.
Nir
Best regards JC Initial window sees no network interface Clicking on setup network does not have any interface to which I can assign the ovirtmgmt network
On Mar 28, 2022, at 13:38, Nir Soffer <nsoffer@redhat.com> wrote:
On Mon, Mar 28, 2022 at 11:31 PM Nir Soffer <nsoffer@redhat.com> wrote:
On Mon, Mar 28, 2022 at 10:48 PM JC Lopez <jc@lightbitslabs.com> wrote:
Hi Benny et all,
...
With 4.5 I can not bring the host up
Here is my cluster spec In the UI I see the following when trying to add host client2
In the screenshot we see 2 issues: - host does not default route - host cpu missing some features
To resolve the default route issue, click on the host name in the "Hosts" page, then click on the "Network interfaces", and then "Setup networks" button, and make sure the ovirtmgmt network is assigned to the right network interface, and edit it as needed.
Adding screenshot in case it was not clear enough.
To quickly avoid this issue, select an older cpu from the list. This should be good enough for development. Maybe Arik can help with using the actual CPU you have.
However when I check the nodes capabilities using Vdsm client I get this for each flag mentioned [root@client2 ~]# vdsm-client Host getCapabilities | grep kvm "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", "kvmEnabled": "true", "qemu-kvm": { "kvm" [root@client2 ~]# vdsm-client Host getCapabilities | grep nx "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", [root@client2 ~]# vdsm-client Host getCapabilities | grep vmx "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", [root@client2 ~]# vdsm-client Host getCapabilities | grep Broadwell "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2",
So all the flags the UI claims as missing are actually present.
Nir
<Screenshot from 2022-03-28 23-23-38.png>
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.
On Mar 30, 2022, at 13:41, Nir Soffer <nsoffer@redhat.com> wrote:
On Wed, Mar 30, 2022 at 11:26 PM JC Lopez <jc@lightbitslabs.com <mailto:jc@lightbitslabs.com>> wrote:
Hi Nir,
Wiped out the node as the procedure provided did not fix the problem.
Fresh CentOS Stream 8
Looks like the vddm I deployed requires Ansible 2.12 Depsolve Error occured: \n Problem: cannot install the best candidate for the job\n - nothing provides virt-install needed by ovirt-hosted-engine-setup-2.6.4-0.0.master.20220329124709.git59931a1.el8.noarch\n - nothing provides ansible-core >= 2.12 needed by ovirt-hosted-engine-setup-2.6.4-0.0.master.20220329124709.git59931a1.el8.noarch”,
Didi, do we have a solution to the ansible requirement? Maybe some repo is missing? Here is what I have configured on my single node if it can help [root@client2 ~]# dnf repolist Repository copr:copr.fedorainfracloud.org:ovirt:ovirt-master-snapshot is listed more than once in the configuration repo id repo name appstream CentOS Stream 8 - AppStream
See inline baseos CentOS Stream 8 - BaseOS copr:copr.fedorainfracloud.org:ovirt:ovirt-master-snapshot Copr repo for ovirt-master-snapshot owned by ovirt elrepo ELRepo.org Community Enterprise Linux Repository - el8 epel Extra Packages for Enterprise Linux 8 - x86_64 epel-modular Extra Packages for Enterprise Linux Modular 8 - x86_64 extras CentOS Stream 8 - Extras extras-common CentOS Stream 8 - Extras common packages ovirt-appliance-master-snapshot oVirt appliance with ovirt-master-snapshot content ovirt-master-centos-opstools-testing CentOS Stream 8 - OpsTools - collectd ovirt-master-centos-stream-ceph-pacific CentOS Stream 8 - Ceph packages for x86_64 ovirt-master-centos-stream-gluster10-testing CentOS Stream 8 - Glusterfs 10 - testing ovirt-master-centos-stream-nfv-openvswitch2-testing CentOS Stream 8 - NFV OpenVSwitch 2 - testing ovirt-master-centos-stream-openstack-yoga-testing CentOS Stream 8 - OpenStack Yoga Repository - testing ovirt-master-centos-stream-ovirt45-testing CentOS Stream 8 - oVirt 4.5 - testing ovirt-master-copr:copr.fedorainfracloud.org:sac:gluster-ansible Copr repo for gluster-ansible owned by sac ovirt-master-epel Extra Packages for Enterprise Linux 8 - x86_64 ovirt-master-virtio-win-latest virtio-win builds roughly matching what will be shipped in upcoming RHEL ovirt-node-master-snapshot oVirt Node with ovirt-master-snapshot content powertools CentOS Stream 8 - PowerTools rdo-delorean-component-cinder RDO Delorean OpenStack Cinder - current rdo-delorean-component-clients RDO Delorean Clients - current rdo-delorean-component-common RDO Delorean Common - current rdo-delorean-component-network RDO Delorean Network - current
But the ovirt-engine requires Ansible 2.9.27-2 package ovirt-engine-4.5.0.1-0.2.master.20220330145541.gitaff1492753.el8.noarch conflicts with ansible-core >= 2.10.0 provided by ansible-core-2.12.2-2.el8.x86_64
So if I enable all my repos the deployment wants to deploy packages that require 2.12 but because of the oVirt-manager requirements it says it can not pass Ansible 2.10. So I end up in a deadlock situation
Not sure what to do. Will get onto irc tomorrow to check on this with you
Question: When is oVirt 4.5 being officially released. May be it will be easier for me to start from that point.
We should have 4.5 beta next week.
Best regards JC
On Mar 29, 2022, at 11:08, Nir Soffer <nsoffer@redhat.com> wrote:
On Tue, Mar 29, 2022 at 3:26 AM JC Lopez <jc@lightbitslabs.com> wrote:
Hi Nir,
Tried to do this but somehow the UI does not let me drag the network anywhere in the window.
Just in case I tried with both the host in maintenance mode and not in maintenance mode. Tried drag and drop on any area of the dialog box I could think off without success
Tried with 3 different browsers to rule out browser incompatibility - Safari - Chrome - Firefox
So NO idea why no network interfaces are detected on this node. FYI my CPU model is a Broadwell one.
If engine does not detect any network interface "setup networks" is not going to be very useful.
I'm not sure how you got into this situation, maybe this is an upgrade issue.
I suggest to start clean:
1. Remove current vdsm install on the host
dnf remove vdsm\*
2. Upgrade you host to latest CentOS Stream 8
3. Add the ovirt repos: https://copr.fedorainfracloud.org/coprs/ovirt/ovirt-master-snapshot/
dnf copr enable -y ovirt/ovirt-master-snapshot centos-stream-8 dnf install -y ovirt-release-master
4. Make sure your host network configuration is right
You should be able to connect from your engine machine to the host.
5. Add the host to your engine
Engine will install the host and reboot it. The host should be up when this is done.
6. Add some storage so you have a master storage domain.
The easier way is to add NFS storage domain but you can use also iSCSI or FC if you like.
At this point you should have working setup.
The next step is to update engine and vdsm with the Benny patches, but don't try this before you have a working system.
If you need more help we can chat in #ovirt on oftc.net.
Nir
Best regards JC Initial window sees no network interface Clicking on setup network does not have any interface to which I can assign the ovirtmgmt network
On Mar 28, 2022, at 13:38, Nir Soffer <nsoffer@redhat.com> wrote:
On Mon, Mar 28, 2022 at 11:31 PM Nir Soffer <nsoffer@redhat.com> wrote:
On Mon, Mar 28, 2022 at 10:48 PM JC Lopez <jc@lightbitslabs.com> wrote:
Hi Benny et all,
...
With 4.5 I can not bring the host up
Here is my cluster spec In the UI I see the following when trying to add host client2
In the screenshot we see 2 issues: - host does not default route - host cpu missing some features
To resolve the default route issue, click on the host name in the "Hosts" page, then click on the "Network interfaces", and then "Setup networks" button, and make sure the ovirtmgmt network is assigned to the right network interface, and edit it as needed.
Adding screenshot in case it was not clear enough.
To quickly avoid this issue, select an older cpu from the list. This should be good enough for development. Maybe Arik can help with using the actual CPU you have.
However when I check the nodes capabilities using Vdsm client I get this for each flag mentioned [root@client2 ~]# vdsm-client Host getCapabilities | grep kvm "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", "kvmEnabled": "true", "qemu-kvm": { "kvm" [root@client2 ~]# vdsm-client Host getCapabilities | grep nx "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", [root@client2 ~]# vdsm-client Host getCapabilities | grep vmx "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", [root@client2 ~]# vdsm-client Host getCapabilities | grep Broadwell "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2",
So all the flags the UI claims as missing are actually present.
Nir
<Screenshot from 2022-03-28 23-23-38.png>
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.
-- *Lightbits Labs** *Lead the cloud-native data center transformation by delivering *scalable *and *efficient *software defined storage that is *easy *to consume. *This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.*

On Thu, Mar 31, 2022 at 12:10 AM JC Lopez <jc@lightbitslabs.com> wrote:
See inline
On Mar 30, 2022, at 13:41, Nir Soffer <nsoffer@redhat.com> wrote:
On Wed, Mar 30, 2022 at 11:26 PM JC Lopez <jc@lightbitslabs.com> wrote:
Hi Nir,
Wiped out the node as the procedure provided did not fix the problem.
Fresh CentOS Stream 8
Looks like the vddm I deployed requires Ansible 2.12 Depsolve Error occured: \n Problem: cannot install the best candidate for the job\n - nothing provides virt-install needed by ovirt-hosted-engine-setup-2.6.4-0.0.master.20220329124709.git59931a1.el8.noarch\n - nothing provides ansible-core >= 2.12 needed by ovirt-hosted-engine-setup-2.6.4-0.0.master.20220329124709.git59931a1.el8.noarch”,
Didi, do we have a solution to the ansible requirement? Maybe some repo is missing?
Sorry, I do not have the full picture. Anyway: 1. Right now, the engine still requires ansible-2.9 [1]. 2. The hosts - el8stream (or ovirt-node) - require (or include) ansible-core-2.12. So if you run into conflicts/requirements issues, please clarify exactly what you do and on which machine (engine or host). This is all changing quickly and has changed in the last few days. I hope [1] will be merged by the time of beta, not sure. If you want to test the very current state, I recommend to run a full 'dnf update' or 'dnf update --nobest' (and note what wasn't upgraded), perhaps after doing 'dnf update \*release\*'. On my own machines, I have both virt-install and ansible-core from repo "appstream" (meaning CentOS, not oVirt). [1] https://github.com/oVirt/ovirt-engine/pull/199
Here is what I have configured on my single node if it can help [root@client2 ~]# dnf repolist
I quickly skimmed through the list below and did not notice anything obviously wrong. Good luck and best regards,
Repository copr:copr.fedorainfracloud.org:ovirt:ovirt-master-snapshot is listed more than once in the configuration repo id repo name appstream CentOS Stream 8 - AppStream baseos CentOS Stream 8 - BaseOS copr:copr.fedorainfracloud.org:ovirt:ovirt-master-snapshot Copr repo for ovirt-master-snapshot owned by ovirt elrepo
ELRepo.org Community Enterprise Linux Repository - el8 epel Extra Packages for Enterprise Linux 8 - x86_64 epel-modular Extra Packages for Enterprise Linux Modular 8 - x86_64 extras CentOS Stream 8 - Extras extras-common CentOS Stream 8 - Extras common packages ovirt-appliance-master-snapshot oVirt appliance with ovirt-master-snapshot content ovirt-master-centos-opstools-testing CentOS Stream 8 - OpsTools - collectd ovirt-master-centos-stream-ceph-pacific CentOS Stream 8 - Ceph packages for x86_64 ovirt-master-centos-stream-gluster10-testing CentOS Stream 8 - Glusterfs 10 - testing ovirt-master-centos-stream-nfv-openvswitch2-testing CentOS Stream 8 - NFV OpenVSwitch 2 - testing ovirt-master-centos-stream-openstack-yoga-testing CentOS Stream 8 - OpenStack Yoga Repository - testing ovirt-master-centos-stream-ovirt45-testing CentOS Stream 8 - oVirt 4.5 - testing ovirt-master-copr:copr.fedorainfracloud.org:sac:gluster-ansible Copr repo for gluster-ansible owned by sac ovirt-master-epel Extra Packages for Enterprise Linux 8 - x86_64 ovirt-master-virtio-win-latest
virtio-win builds roughly matching what will be shipped in upcoming RHEL ovirt-node-master-snapshot oVirt Node with ovirt-master-snapshot content powertools CentOS Stream 8 - PowerTools rdo-delorean-component-cinder RDO Delorean OpenStack Cinder - current rdo-delorean-component-clients RDO Delorean Clients - current rdo-delorean-component-common RDO Delorean Common - current rdo-delorean-component-network RDO Delorean Network - current
But the ovirt-engine requires Ansible 2.9.27-2 package ovirt-engine-4.5.0.1-0.2.master.20220330145541.gitaff1492753.el8.noarch conflicts with ansible-core >= 2.10.0 provided by ansible-core-2.12.2-2.el8.x86_64
So if I enable all my repos the deployment wants to deploy packages that require 2.12 but because of the oVirt-manager requirements it says it can not pass Ansible 2.10. So I end up in a deadlock situation
Not sure what to do. Will get onto irc tomorrow to check on this with you
Question: When is oVirt 4.5 being officially released. May be it will be easier for me to start from that point.
We should have 4.5 beta next week.
Best regards JC
On Mar 29, 2022, at 11:08, Nir Soffer <nsoffer@redhat.com> wrote:
On Tue, Mar 29, 2022 at 3:26 AM JC Lopez <jc@lightbitslabs.com> wrote:
Hi Nir,
Tried to do this but somehow the UI does not let me drag the network anywhere in the window.
Just in case I tried with both the host in maintenance mode and not in maintenance mode. Tried drag and drop on any area of the dialog box I could think off without success
Tried with 3 different browsers to rule out browser incompatibility - Safari - Chrome - Firefox
So NO idea why no network interfaces are detected on this node. FYI my CPU model is a Broadwell one.
If engine does not detect any network interface "setup networks" is not going to be very useful.
I'm not sure how you got into this situation, maybe this is an upgrade issue.
I suggest to start clean:
1. Remove current vdsm install on the host
dnf remove vdsm\*
2. Upgrade you host to latest CentOS Stream 8
3. Add the ovirt repos: https://copr.fedorainfracloud.org/coprs/ovirt/ovirt-master-snapshot/
dnf copr enable -y ovirt/ovirt-master-snapshot centos-stream-8 dnf install -y ovirt-release-master
4. Make sure your host network configuration is right
You should be able to connect from your engine machine to the host.
5. Add the host to your engine
Engine will install the host and reboot it. The host should be up when this is done.
6. Add some storage so you have a master storage domain.
The easier way is to add NFS storage domain but you can use also iSCSI or FC if you like.
At this point you should have working setup.
The next step is to update engine and vdsm with the Benny patches, but don't try this before you have a working system.
If you need more help we can chat in #ovirt on oftc.net.
Nir
Best regards JC Initial window sees no network interface Clicking on setup network does not have any interface to which I can assign the ovirtmgmt network
On Mar 28, 2022, at 13:38, Nir Soffer <nsoffer@redhat.com> wrote:
On Mon, Mar 28, 2022 at 11:31 PM Nir Soffer <nsoffer@redhat.com> wrote:
On Mon, Mar 28, 2022 at 10:48 PM JC Lopez <jc@lightbitslabs.com> wrote:
Hi Benny et all,
...
With 4.5 I can not bring the host up
Here is my cluster spec In the UI I see the following when trying to add host client2
In the screenshot we see 2 issues: - host does not default route - host cpu missing some features
To resolve the default route issue, click on the host name in the "Hosts" page, then click on the "Network interfaces", and then "Setup networks" button, and make sure the ovirtmgmt network is assigned to the right network interface, and edit it as needed.
Adding screenshot in case it was not clear enough.
To quickly avoid this issue, select an older cpu from the list. This should be good enough for development. Maybe Arik can help with using the actual CPU you have.
However when I check the nodes capabilities using Vdsm client I get this for each flag mentioned [root@client2 ~]# vdsm-client Host getCapabilities | grep kvm "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", "kvmEnabled": "true", "qemu-kvm": { "kvm" [root@client2 ~]# vdsm-client Host getCapabilities | grep nx "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", [root@client2 ~]# vdsm-client Host getCapabilities | grep vmx "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2", [root@client2 ~]# vdsm-client Host getCapabilities | grep Broadwell "cpuFlags": "clflush,cqm_llc,sdbg,abm,movbe,bmi1,intel_ppin,apic,sse2,mce,arat,amd-ssbd,monitor,xsaveopt,ida,bmi2,pclmulqdq,ssse3,pni,ss,rdrand,xsave,avx2,intel_pt,sse4_2,ept_ad,stibp,rdseed,pse,dts,dtes64,3dnowprefetch,cpuid_fault,acpi,fsgsbase,cdp_l3,x2apic,fpu,invpcid_single,sse4_1,pti,amd-stibp,ht,pae,pat,tsc,mmx,nonstop_tsc,pdcm,ssbd,invpcid,cqm,de,lahf_lm,vpid,smep,tm,vmx,bts,rdtscp,flexpriority,rtm,pse36,smap,cqm_mbm_total,cmov,smx,skip-l1dfl-vmentry,est,tm2,hypervisor,pge,tsc_deadline_timer,invtsc,nx,pbe,f16c,vnmi,nopl,epb,cx8,msr,umip,pcid,aperfmperf,xtpr,avx,cqm_occup_llc,pdpe1gb,constant_tsc,tsc_adjust,sse,arch_perfmon,ept,ibrs,adx,dtherm,pschange-mc-no,cat_l3,rep_good,ibpb,pln,fma,sep,aes,pts,syscall,xtopology,rdt_a,erms,cpuid,flush_l1d,vme,cx16,popcnt,mca,cqm_mbm_local,mtrr,arch-capabilities,dca,tpr_shadow,lm,ds_cpl,fxsr,hle,pebs,spec_ctrl,model_Opteron_G1,model_486,model_Broadwell-noTSX-IBRS,model_Westmere-IBRS,model_IvyBridge-IBRS,model_Conroe,model_Opteron_G2,model_Broadwell-noTSX,model_qemu32,model_Haswell,model_Westmere,model_Haswell-IBRS,model_core2duo,model_Broadwell-IBRS,model_Broadwell,model_n270,model_Haswell-noTSX-IBRS,model_IvyBridge,model_pentium3,model_Penryn,model_Nehalem,model_kvm64,model_qemu64,model_SandyBridge-IBRS,model_coreduo,model_Haswell-noTSX,model_Nehalem-IBRS,model_kvm32,model_pentium,model_SandyBridge,model_pentium2",
So all the flags the UI claims as missing are actually present.
Nir
<Screenshot from 2022-03-28 23-23-38.png>
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.
*Lightbits Labs* Lead the cloud-native data center transformation by delivering *scalable * and *efficient *software defined storage that is *easy *to consume.
*This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.*
-- Didi
On Tue, Mar 29, 2022 at 3:26 AM JC Lopez <jc@lightbitslabs.com> wrote:
Hi Nir,
Tried to do this but somehow the UI does not let me drag the network anywhere in the window.
Just in case I tried with both the host in maintenance mode and not in maintenance mode. Tried drag and drop on any area of the dialog box I could think off without success
Tried with 3 different browsers to rule out browser incompatibility - Safari - Chrome - Firefox
So NO idea why no network interfaces are detected on this node. FYI my CPU model is a Broadwell one.
Best regards JC Initial window sees no network interface Clicking on setup network does not have any interface to which I can assign the ovirtmgmt network
I did a clean engine and host installation, and reproduced the same issue you had. 1. Host is stuck in "Connecting state" 2. Host warning about: - no default route - incompatible cpu - missing cpu flags 3. No network interfaces See attached screenshots. In my setup, the issue was broken /etc/hosts file in engine host. Before I started, I had a working engine (built few weeks ago) with /etc/hosts file with all the oVirt hosts in my environment. After running engine-cleanup and engine-setup, and removing fighting with snsible versions (updating ansible removed ovirt-engine, updating ovirt-engine requires using --nobest), my /etc/hosts was replaced with default file with the defaults localhost entries. After adding back my hosts to /etc/hosts, adding a new fresh Centos Stream 8 hosts was successful. Please check if you access the host from engine host using the DNS name used in engine UI, or the IP address. I think we need an engine bug for this - when the host is not reachable from engine adding a host should fail fast with a clear message about an unreachable host, instead of the bogus errors about default route and incompatible CPU. Nir
{kind=link}
{kind=link}
On 24/02, Nir Soffer wrote:
On Wed, Feb 23, 2022 at 6:24 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
Thanks for the detailed instructions, Nir. I'm going to scrounge up some hardware. By the way, if anyone else would like to work on NVMe/TCP support, for NVMe/TCP target you can either use Lightbits (talk to me offline for details) or use the upstream Linux NVMe/TCP target. Lightbits is a clustered storage system while upstream is a single target, but the client side should be close enough for vdsm/ovirt purposes.
I played with NVMe/TCP a little bit, using qemu to create a virtual NVMe disk, and export it using the kernel on one VM, and consume it on another VM. https://futurewei-cloud.github.io/ARM-Datacenter/qemu/nvme-of-tcp-vms/
Hi, You can also use nvmetcli to create nvme-of devices using the kernel's nvmet. I haven't tested any cinder NVMe driver with cinderlib yet, but I'll test it with the LVM driver and nvmet target, since I'm currently working on improvements/fixes on both the nvmet target and the os-brick connector. I have played with both iSCSI and RDMA (using Soft-RoCE) as transport protocols for NVMe-oF and they worked fine in OpenStack. Something important to consider when thinking about making it enterprise ready is that the NVMe-oF connector in os-brick doesn't currently support any kind of multipathing: native (ANA) or using device mapper. But it's something we'll be working on. I'll let you know how the cinderlib testing goes, though I already know that the LVM with nvmet has problems in the disconnection [1]. [1]: https://bugs.launchpad.net/os-brick/+bug/1961102
One question about device naming - do we always get the same name of the device in all hosts?
Definitely not, depending on the transport protocol used and the features enabled (such as multipathing), os-brick will return a different path to the device. In the case of nvme-of it will return devices like /dev/nvme0n1 ==> This means controller 0 and namespace 1 in the nvme host system. And the namespace 1 in the system can actually have a different namespace id (for example 10). Example from a test system using LVM and a nvmet target variant I'm working on: $ sudo nvme list Node SN Model Namespace Usage Format FW Rev -------------- ------------------ ------- --------- ------------------------- ---------------- -------- /dev/nvme0n1 9a9bd17b53e6725f Linux 11 1.07 GB / 1.07 GB 512 B + 0 B 4.18.0-2 /dev/nvme0n2 9a9bd17b53e6725f Linux 10 1.07 GB / 1.07 GB 512 B + 0 B 4.18.0-2
To support VM migration, every device must have unique name in the cluster. With multipath we always have unique name, since we disable "friendly names", so we always have:
/dev/mapper/{wwid}
With rbd we also do not use /dev/rbdN but a unique path:
/dev/rbd/poolname/volume-vol-id
How do we ensure cluster-unique device path? If os_brick does not handle it, we can to do in ovirt, for example:
/run/vdsm/mangedvolumes/{uuid} -> /dev/nvme7n42
os-brick will not handle this, but assuming udev rules are working consistently in both migration systems (source and target) there will be a symlink in /dev/disk/by-id that is formed using the NVMe UUID of the volume. In the example above we have: $ ls -l /dev/disk/by-id/nvme* lrwxrwxrwx. 1 root root 13 Feb 24 16:30 /dev/disk/by-id/nvme-Linux_9a9bd17b53e6725f -> ../../nvme0n2 lrwxrwxrwx. 1 root root 13 Feb 24 16:30 /dev/disk/by-id/nvme-uuid.5310ef24-8301-4e38-a8b8-b61cd61d8b36 -> ../../nvme0n2 lrwxrwxrwx. 1 root root 13 Feb 24 16:30 /dev/disk/by-id/nvme-uuid.e31b8c9c-b943-430e-afa4-55a110341dcb -> ../../nvme0n1 The uuid may not be the volume uuid, it will depend on the cinder driver, but we can find the uuid for the specific nvme device easily enough: $ cat /sys/class/nvme/nvme0/nvme0n2/wwid uuid.5310ef24-8301-4e38-a8b8-b61cd61d8b36
but I think this should be handled in cinderlib, since openstack have the same problem with migration.
OpenStack doesn't have that problem with migrations. In OpenStack we don't care where the device appears, because nova knows the volume id of the volume before calling os-brick to connect to it, and then when os-brick returns the path it knows it belongs to that specific volume. Cheers, Gorka.
Nir
Cheers, Muli -- Muli Ben-Yehuda Co-Founder and Chief Scientist @ http://www.lightbitslabs.com LightOS: The Special Storage Sauce For Your Cloud
On Wed, Feb 23, 2022 at 4:55 PM Nir Soffer <nsoffer@redhat.com> wrote:
On Wed, Feb 23, 2022 at 4:20 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote:
Thanks, Nir and Benny (nice to run into you again, Nir!). I'm a neophyte in ovirt and vdsm... What's the simplest way to set up a development environment? Is it possible to set up a "standalone" vdsm environment to hack support for nvme/tcp or do I need "full ovirt" to make it work?
It should be possible to install vdsm on a single host or vm, and use vdsm API to bring the host to the right state, and then attach devices and run vms. But I don't know anyone that can pull this out since simulating what engine is doing is hard.
So the best way is to set up at least one host and engine host using the latest 4.5 rpms, and continue from there. Once you have a host, building vdsm on the host and upgrading the rpms is pretty easy.
My preferred setup is to create vms using virt-manager for hosts, engine and storage and run all the vms on my laptop.
Note that you must have some traditional storage (NFS/iSCSI) to bring up the system even if you plan to use only managed block storage (MBS). Unfortunately when we add MBS support we did have time to fix the huge technical debt so you still need a master storage domain using one of the traditional legacy options.
To build a setup, you can use:
- engine vm: 6g ram, 2 cpus, centos stream 8 - hosts vm: 4g ram, 2 cpus, centos stream 8 you can start with one host and add more hosts later if you want to test migration. - storage vm: 2g ram, 2 cpus, any os you like, I use alpine since it takes very little memory and its NFS server is fast.
See vdsm README for instructions how to setup a host: https://github.com/oVirt/vdsm#manual-installation
For engine host you can follow: https://ovirt.org/documentation/installing_ovirt_as_a_self-hosted_engine_usi...
And after that this should work:
dnf install ovirt-engine engine-setup
Accepting all the defaults should work.
When you have engine running, you can add a new host with the ip address or dns name of you host(s) vm, and engine will do everything for you. Note that you must install the ovirt-release-master rpm on the host before you add it to engine.
Nir
Cheers, Muli -- Muli Ben-Yehuda Co-Founder and Chief Scientist @ http://www.lightbitslabs.com LightOS: The Special Storage Sauce For Your Cloud
On Wed, Feb 23, 2022 at 4:16 PM Nir Soffer <nsoffer@redhat.com> wrote:
On Wed, Feb 23, 2022 at 2:48 PM Benny Zlotnik <bzlotnik@redhat.com> wrote:
So I started looking in the logs and tried to follow along with the code, but things didn't make sense and then I saw it's ovirt 4.3 which makes things more complicated :) Unfortunately because GUID is sent in the metadata the volume is treated as a vdsm managed volume[2] for the udev rule generation and it prepends the /dev/mapper prefix to an empty string as a result. I don't have the vdsm logs, so I am not sure where exactly this fails, but if it's after [4] it may be possible to workaround it with a vdsm hook
In 4.4.6 we moved the udev rule triggering the volume mapping phase, before starting the VM. But it could still not work because we check the driver_volume_type in[1], and I saw it's "driver_volume_type": "lightos" for lightbits In theory it looks like it wouldn't take much to add support for your driver in a future release (as it's pretty late for 4.5)
Adding support for nvme/tcp in 4.3 is probably not feasible, but we will be happy to accept patches for 4.5.
To debug such issues vdsm log is the best place to check. We should see the connection info passed to vdsm, and we have pretty simple code using it with os_brick to attach the device to the system and setting up the udev rule (which may need some tweaks).
Nir
[1] https://github.com/oVirt/vdsm/blob/500c035903dd35180d71c97791e0ce4356fb77ad/...
(4.3) [2] https://github.com/oVirt/vdsm/blob/b42d4a816b538e00ea4955576a5fe762367be787/... [3] https://github.com/oVirt/vdsm/blob/b42d4a816b538e00ea4955576a5fe762367be787/... [4] https://github.com/oVirt/vdsm/blob/b42d4a816b538e00ea4955576a5fe762367be787/...
On Wed, Feb 23, 2022 at 12:44 PM Muli Ben-Yehuda <muli@lightbitslabs.com> wrote: > > Certainly, thanks for your help! > I put cinderlib and engine.log here: http://www.mulix.org/misc/ovirt-logs-20220223123641.tar.gz > If you grep for 'mulivm1' you will see for example: > > 2022-02-22 04:31:04,473-05 ERROR [org.ovirt.engine.core.vdsbroker.vdsbroker.HotPlugDiskVDSCommand] (default task-10) [36d8a122] Command 'HotPlugDiskVDSCommand(HostName = client1, HotPlugDiskVDSParameters:{hostId='fc5c2860-36b1-4213-843f-10ca7b35556c', vmId='e13f73a0-8e20-4ec3-837f-aeacc082c7aa', diskId='d1e1286b-38cc-4d56-9d4e-f331ffbe830f', addressMap='[bus=0, controller=0, unit=2, type=drive, target=0]'})' execution failed: VDSGenericException: VDSErrorException: Failed to HotPlugDiskVDS, error = Failed to bind /dev/mapper/ on to /var/run/libvirt/qemu/21-mulivm1.mapper.: Not a directory, code = 45 > > Please let me know what other information will be useful and I will prove. > > Cheers, > Muli > > On Wed, Feb 23, 2022 at 11:14 AM Benny Zlotnik <bzlotnik@redhat.com> wrote: >> >> Hi, >> >> We haven't tested this, and we do not have any code to handle nvme/tcp >> drivers, only iscsi and rbd. Given the path seen in the logs >> '/dev/mapper', it looks like it might require code changes to support >> this. >> Can you share cinderlib[1] and engine logs to see what is returned by >> the driver? I may be able to estimate what would be required (it's >> possible that it would be enough to just change the handling of the >> path in the engine) >> >> [1] /var/log/ovirt-engine/cinderlib/cinderlib//log >> >> On Wed, Feb 23, 2022 at 10:54 AM <muli@lightbitslabs.com> wrote: >> > >> > Hi everyone, >> > >> > We are trying to set up ovirt (4.3.10 at the moment, customer preference) to use Lightbits (https://www.lightbitslabs.com) storage via our openstack cinder driver with cinderlib. The cinderlib and cinder driver bits are working fine but when ovirt tries to attach the device to a VM we get the following error: >> > >> > libvirt: error : cannot create file '/var/run/libvirt/qemu/18-mulivm1.dev/mapper/': Is a directory >> > >> > We get the same error regardless of whether I try to run the VM or try to attach the device while it is running. The error appears to come from vdsm which passes /dev/mapper as the prefered device? >> > >> > 2022-02-22 09:50:11,848-0500 INFO (vm/3ae7dcf4) [vdsm.api] FINISH appropriateDevice return={'path': '/dev/mapper/', 'truesize': '53687091200', 'apparentsize': '53687091200'} from=internal, task_id=77f40c4e-733d-4d82-b418-aaeb6b912d39 (api:54) >> > 2022-02-22 09:50:11,849-0500 INFO (vm/3ae7dcf4) [vds] prepared volume path: /dev/mapper/ (clientIF:510) >> > >> > Suggestions for how to debug this further? Is this a known issue? Did anyone get nvme/tcp storage working with ovirt and/or vdsm? >> > >> > Thanks, >> > Muli >> > >> > _______________________________________________ >> > Users mailing list -- users@ovirt.org >> > To unsubscribe send an email to users-leave@ovirt.org >> > Privacy Statement: https://www.ovirt.org/privacy-policy.html >> > oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ >> > List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/I3PAG5HMBHUOJY... >> > > Lightbits Labs > Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume. > > This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems. > > _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/DKFOCYQA6E4N3Y...
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.
Lightbits Labs Lead the cloud-native data center transformation by delivering scalable and efficient software defined storage that is easy to consume.
This message is sent in confidence for the addressee only. It may contain legally privileged information. The contents are not to be disclosed to anyone other than the addressee. Unauthorized recipients are requested to preserve this confidentiality, advise the sender immediately of any error in transmission and delete the email from their systems.
participants (6)
-
 Benny Zlotnik
Benny Zlotnik -
 Gorka Eguileor
Gorka Eguileor -
 JC Lopez
JC Lopez -
 Muli Ben-Yehuda
Muli Ben-Yehuda -
 Nir Soffer
Nir Soffer -
 Yedidyah Bar David
Yedidyah Bar David