
The same exact problem occurred this morning, at approximately the same time (Monday morning, right around 8:00am Eastern Time) as before (14 days ago). I see that "ETL Service Started" in the logs. And then, after that, all hell broke loose, and I lost access to the whole environment before the engine came back online. When I logged into the oVirt admin portal / Engine web UI, most VMs were healthy (again, after they were all down for a brief period of time), but 2-3 of the VMs were in a paused state. I wound up having to power them down before they would come back online. This time, unlike 14 days ago, all 3 volumes and bricks were healthy. Gluster replication between the hosts wasn't behind or anything. I need to track down why this is happening, and try to prevent it. Right now, I only have 1Gbps connectivity on the storage network. Is it possible that the storage network is getting too congested? Are there any logs or indicators I can look for to find out if that is the case of the problem?I do have 10Gbps network cards, but have only installed that onto 1 of the hosts. I still need to install onto the other two hosts. Anything else to look for? Sent with ProtonMail Secure Email. ‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Monday, April 26, 2021 11:30 PM, Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Check '/var/log/messages' and 'journalctl' for the affected host. Try to identify if you got a Network issue. Next check gluster logs on the affected host (both bricks and fuse client).
Of course, you should also check the engine's logs.
This sounds like your gluster problem "escalated" and cause the outage for the affected VMs.
Usually, when I have issues with a host - I just put it down to maintenance with the checkmark to stop Gluster services. Once it completes , activate.
Best Regards, Strahil Nikolov
On Mon, Apr 26, 2021 at 23:51, David White via Users <users@ovirt.org> wrote: As the subject suggestions, something in oVirt HCI broke. I have no idea what, and it recovered on its own after about 20 minutes or so.
I believe that the issue was limited to a single host (although I don't know that for sure), as we had two VMs go completely unresponsive, but a 3rd VM remained operational. For a while during the outage, I was able to log into the oVirt admin web portal, and I noticed at least 1-2 of my hosts (I have 3 hosts) showed the problematic VMs as being problematic inside of oVirt.
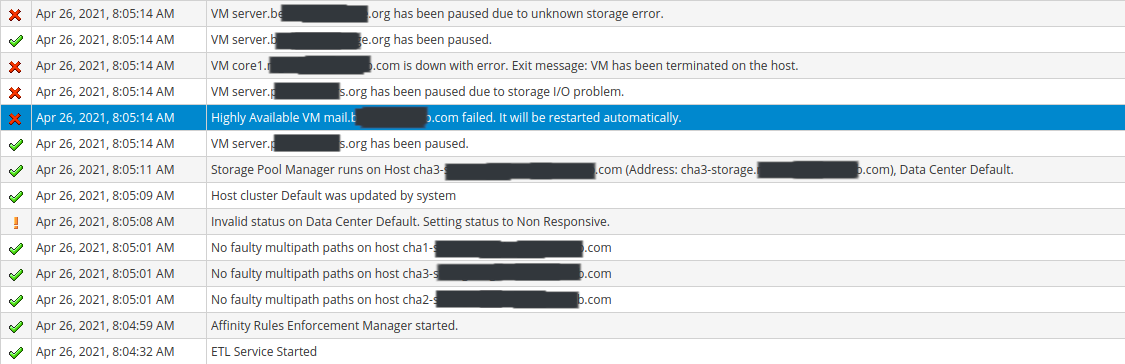
Reviewing the oVirt Events, I see that this basically started right when the ETL Service Started. There were no events before that point since yesterday, but right when the ETL Service started, it seems like all hell broke loose.
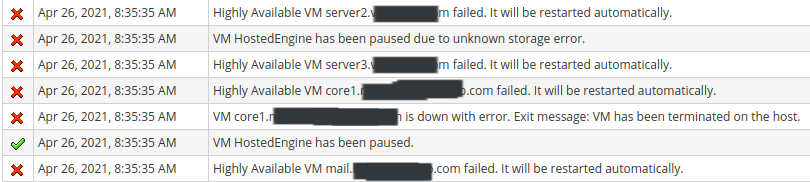
oVirt detected "No faulty multipaths" on any of the hosts, but then very quickly started indicating that hosts, vms, and storage targets were unavailable. See my screenshot below. Around 30 - 35 minutes later, it appears that the Hosted Engine terminated due to a storage issue, and auto recovered on a different host. There's a 2nd screenshot beneath the first.
Everything came back up shortly before 9am, and has been stable since. In fact, the Volume replication issues that I saw in my environment after I performed maintenance on 1 of my hosts on Friday are no longer present. It appears that the Hosted Engine sees the storage as being perfectly healthy.
How do I even begin to figure out what happened, and try to prevent it from happening again?
[Screenshot from 2021-04-26 16-36-47.png]
[Screenshot from 2021-04-26 16-44-08.png]
Sent with ProtonMail Secure Email.
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/K5UJJNQXHAGMRV...
{kind=link}
{kind=link}