Stuck completing last step of 4.3 upgrade

Environment setup: 3 Host HCI GlusterFS setup. Identical hosts, Dell R720s w/ Intel E5-2690 CPUs 1 default data center (4.2 compat) 1 default cluster (4.2 compat) Situation: I recently upgraded my three node HCI cluster from Ovirt 4.2 to 4.3. I did so by first updating the engine to 4.3 then upgrading each ovirt-node host to 4.3 and rebooting. Currently engine and all hosts are running 4.3 and all is working fine. To complete the upgrade I need to update cluster compatibility to 4.3 and then data centre to 4.3. This is where I am stuck. The CPU type on cluster is "Intel SandyBridge IBRS Family". This option is no longer available if I select 4.3 compatibility. Any other option chosen such as SandyBridge IBRS SSBD will not allow me to switch to 4.3 as all hosts must be in maintenance mode (which is not possible w/ self hosted engine). I saw another post about this where someone else followed steps to create a second cluster on 4.3 with new CPU type then move one host to it, start engine on it then perform other steps to eventually get to 4.3 compatibility. I tried to add a 4.3 cluster with gluster service and put one of my hosts in to maintenance mode but could not move it to the new cluster, it gave me an error about the host having gluster service. If I try to import gluster config in cluster add UI it fails in engine log with "SERVER_ALREADY_EXISTS_IN_ANOTHER_CLUSTER" My question is, what is the proper procedure for me to complete upgrading my three node HCI environment to 4.3 cluster compatibility along with changing CPU type? Do I really need to create a second cluster and move host(s) to it? If so how can I move an existing host with running gluster service to a new cluster? Thanks in advance!

Environment setup:
3 Host HCI GlusterFS setup. Identical hosts, Dell R720s w/ Intel E5-2690 CPUs
1 default data center (4.2 compat) 1 default cluster (4.2 compat)
Situation: I recently upgraded my three node HCI cluster from Ovirt 4.2 to 4.3. I did so by first updating the engine to 4.3 then upgrading each ovirt-node host to 4.3 and rebooting.
Currently engine and all hosts are running 4.3 and all is working fine.
To complete the upgrade I need to update cluster compatibility to 4.3 and then data centre to 4.3. This is where I am stuck.
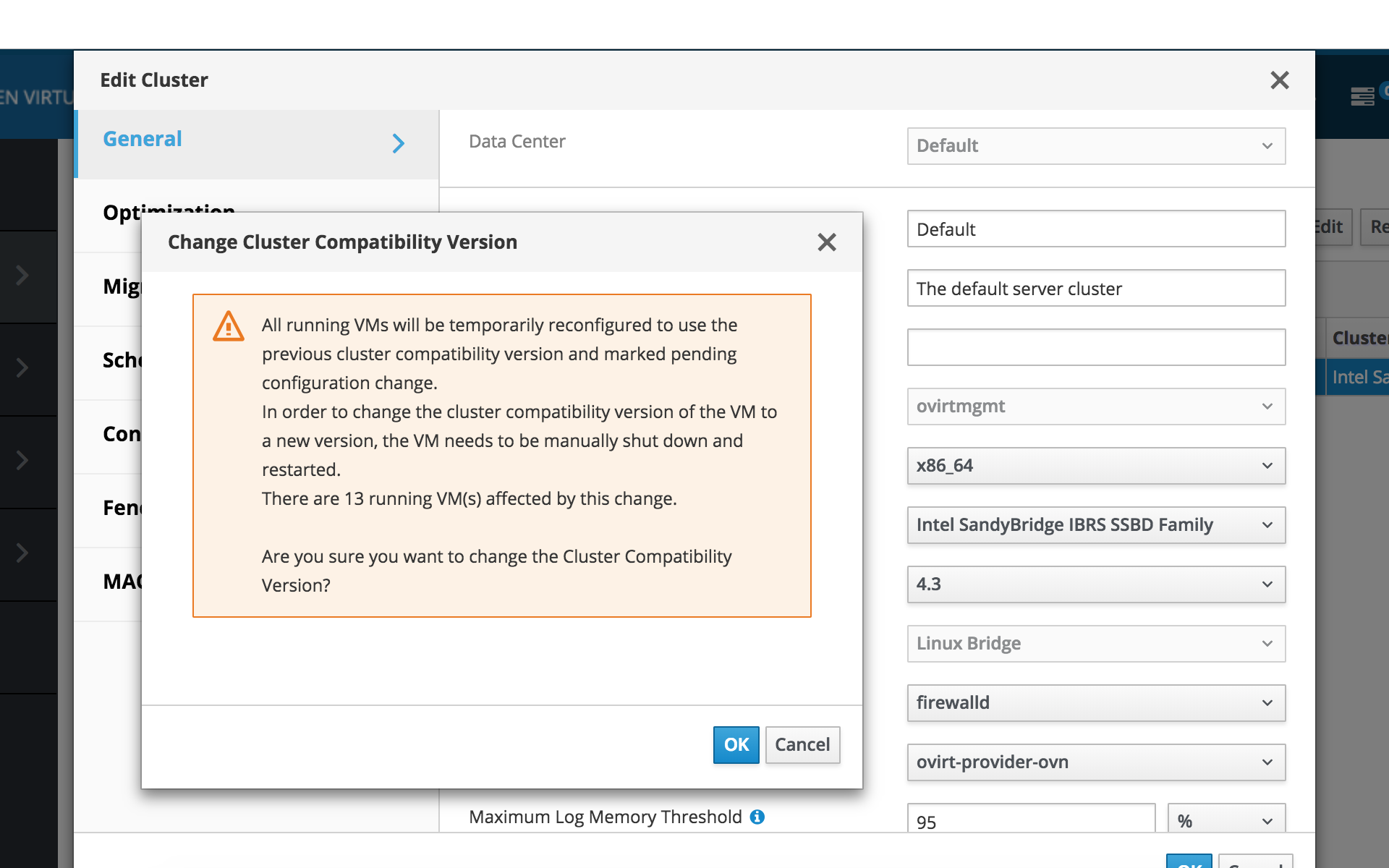
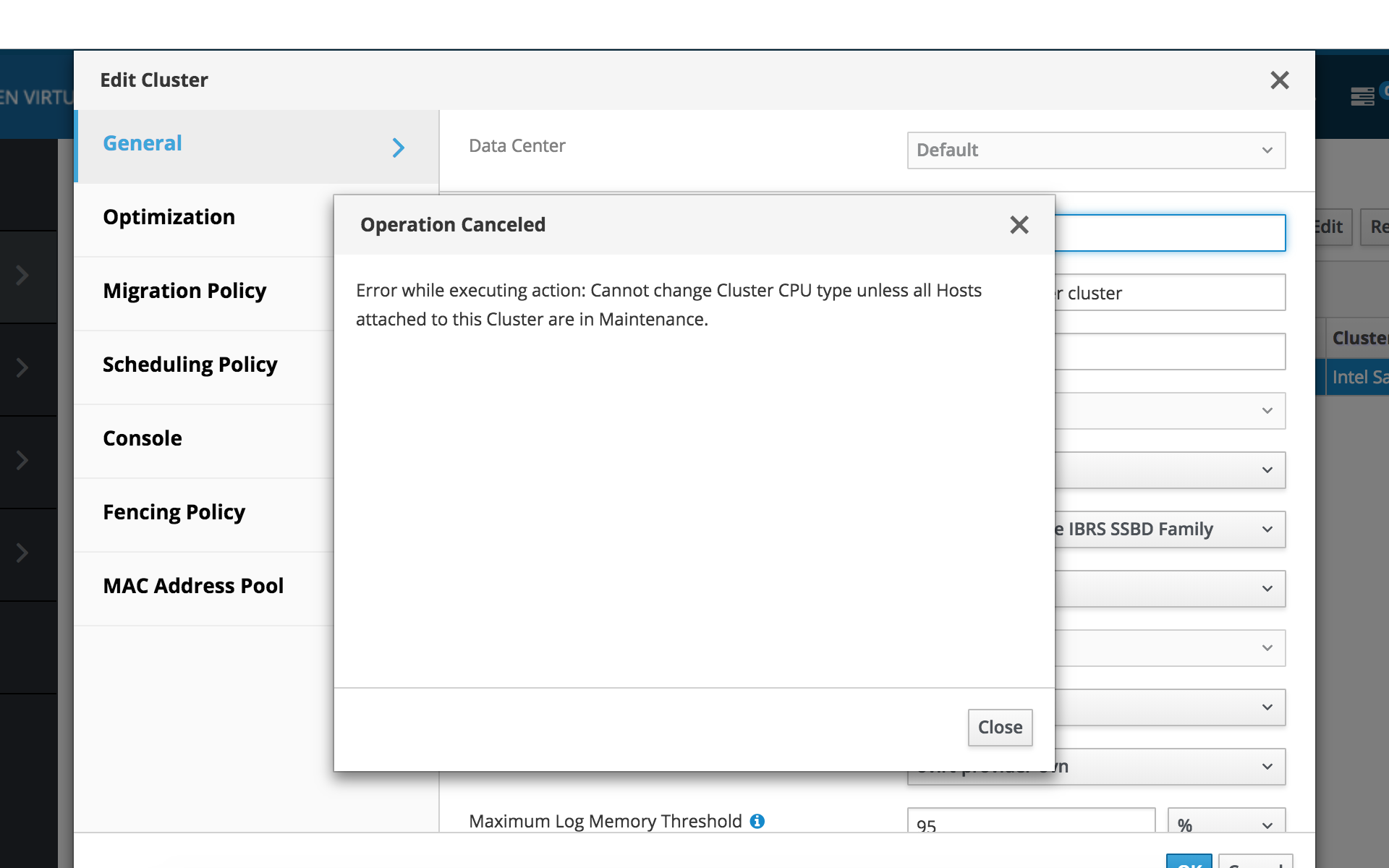
The CPU type on cluster is "Intel SandyBridge IBRS Family". This option is no longer available if I select 4.3 compatibility. Any other option chosen such as SandyBridge IBRS SSBD will not allow me to switch to 4.3 as all hosts must be in maintenance mode (which is not possible w/ self hosted engine).
I saw another post about this where someone else followed steps to create a second cluster on 4.3 with new CPU type then move one host to it, start engine on it then perform other steps to eventually get to 4.3 compatibility.
I have the exact same hardware configuration and was able to change to "SandyBridge IBRS SSBD" without creating a new cluster. How I made that happen, I'm not so sure, but the cluster may have been in "Global Maintenance" mode when I changed it.
Hmm interesting, I wonder how you were able to switch from SandyBridge IBRS to SandyBridge IBRS SSBD. I just attempted the same in both regular mode and in global maintenance mode and it won't allow me to, it says that all hosts have to be in maintenance mode (screenshots attached). Are you also running HCI/Gluster setup? On Wed, Feb 13, 2019 at 12:44 PM Ron Jerome <ronjero@gmail.com> wrote:
Environment setup:
3 Host HCI GlusterFS setup. Identical hosts, Dell R720s w/ Intel E5-2690 CPUs
1 default data center (4.2 compat) 1 default cluster (4.2 compat)
Situation: I recently upgraded my three node HCI cluster from Ovirt 4.2 to 4.3. I did so by first updating the engine to 4.3 then upgrading each ovirt-node host to 4.3 and rebooting.
Currently engine and all hosts are running 4.3 and all is working fine.
To complete the upgrade I need to update cluster compatibility to 4.3 and then data centre to 4.3. This is where I am stuck.
The CPU type on cluster is "Intel SandyBridge IBRS Family". This option is no longer available if I select 4.3 compatibility. Any other option chosen such as SandyBridge IBRS SSBD will not allow me to switch to 4.3 as all hosts must be in maintenance mode (which is not possible w/ self hosted engine).
I saw another post about this where someone else followed steps to create a second cluster on 4.3 with new CPU type then move one host to it, start engine on it then perform other steps to eventually get to 4.3 compatibility.
I have the exact same hardware configuration and was able to change to "SandyBridge IBRS SSBD" without creating a new cluster. How I made that happen, I'm not so sure, but the cluster may have been in "Global Maintenance" mode when I changed it.
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/site/privacy-policy/ oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/5B3TAXKO7IBTWR...
{kind=link}
{kind=link}
I think I just figured out what I was doing wrong. On edit cluster screen I was changing both the CPU type and cluster level 4.3. I tried it again by switching to the new CPU type first (leaving cluster on 4.2) then saving, then going back in and switching compat level to 4.3. It appears that you need to do this in two steps for it to work. On Wed, Feb 13, 2019 at 12:57 PM Jayme <jaymef@gmail.com> wrote:
Hmm interesting, I wonder how you were able to switch from SandyBridge IBRS to SandyBridge IBRS SSBD. I just attempted the same in both regular mode and in global maintenance mode and it won't allow me to, it says that all hosts have to be in maintenance mode (screenshots attached). Are you also running HCI/Gluster setup?
On Wed, Feb 13, 2019 at 12:44 PM Ron Jerome <ronjero@gmail.com> wrote:
Environment setup:
3 Host HCI GlusterFS setup. Identical hosts, Dell R720s w/ Intel E5-2690 CPUs
1 default data center (4.2 compat) 1 default cluster (4.2 compat)
Situation: I recently upgraded my three node HCI cluster from Ovirt 4.2 to 4.3. I did so by first updating the engine to 4.3 then upgrading each ovirt-node host to 4.3 and rebooting.
Currently engine and all hosts are running 4.3 and all is working fine.
To complete the upgrade I need to update cluster compatibility to 4.3 and then data centre to 4.3. This is where I am stuck.
The CPU type on cluster is "Intel SandyBridge IBRS Family". This option is no longer available if I select 4.3 compatibility. Any other option chosen such as SandyBridge IBRS SSBD will not allow me to switch to 4.3 as all hosts must be in maintenance mode (which is not possible w/ self hosted engine).
I saw another post about this where someone else followed steps to create a second cluster on 4.3 with new CPU type then move one host to it, start engine on it then perform other steps to eventually get to 4.3 compatibility.
I have the exact same hardware configuration and was able to change to "SandyBridge IBRS SSBD" without creating a new cluster. How I made that happen, I'm not so sure, but the cluster may have been in "Global Maintenance" mode when I changed it.
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/site/privacy-policy/ oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/5B3TAXKO7IBTWR...
I may have made matters worse. So I changed to 4.3 compatible cluster then 4.3 compatible data center. All VMs were marked as requiring a reboot. I restarted a couple of them and none of them will start up, they are saying "bad volume specification". The ones running that I did not yet restart are still running ok. I need to figure out why the VMs aren't restarting. Here is an example from vdsm.log olumeError: Bad volume specification {'address': {'function': '0x0', 'bus': '0x00', 'domain': '0x0000', 'type': 'pci', 'slot': '0x06'}, 'serial': 'd81a6826-dc46-44db-8de7-405d30e44d57', 'index': 0, 'iface': 'virtio', 'apparentsize': '64293699584', 'specParams': {}, 'cache': 'none', 'imageID': 'd81a6826-dc46-44db-8de7-405d30e44d57', 'truesize': '64293814272', 'type': 'disk', 'domainID': '1f2e9989-9ab3-43d5-971d-568b8feca918', 'reqsize': '0', 'format': 'cow', 'poolID': 'a45e442e-9989-11e8-b0e4-00163e4bf18a', 'device': 'disk', 'path': '/rhev/data-center/a45e442e-9989-11e8-b0e4-00163e4bf18a/1f2e9989-9ab3-43d5-971d-568b8feca918/images/d81a6826-dc46-44db-8de7-405d30e44d57/2d6d5f87-ccb0-48ce-b3ac-84495bd12d32', 'propagateErrors': 'off', 'name': 'vda', 'bootOrder': '1', 'volumeID': '2d6d5f87-ccb0-48ce-b3ac-84495bd12d32', 'diskType': 'file', 'alias': 'ua-d81a6826-dc46-44db-8de7-405d30e44d57', 'discard': False} On Wed, Feb 13, 2019 at 1:01 PM Jayme <jaymef@gmail.com> wrote:
I think I just figured out what I was doing wrong. On edit cluster screen I was changing both the CPU type and cluster level 4.3. I tried it again by switching to the new CPU type first (leaving cluster on 4.2) then saving, then going back in and switching compat level to 4.3. It appears that you need to do this in two steps for it to work.
On Wed, Feb 13, 2019 at 12:57 PM Jayme <jaymef@gmail.com> wrote:
Hmm interesting, I wonder how you were able to switch from SandyBridge IBRS to SandyBridge IBRS SSBD. I just attempted the same in both regular mode and in global maintenance mode and it won't allow me to, it says that all hosts have to be in maintenance mode (screenshots attached). Are you also running HCI/Gluster setup?
On Wed, Feb 13, 2019 at 12:44 PM Ron Jerome <ronjero@gmail.com> wrote:
Environment setup:
3 Host HCI GlusterFS setup. Identical hosts, Dell R720s w/ Intel E5-2690 CPUs
1 default data center (4.2 compat) 1 default cluster (4.2 compat)
Situation: I recently upgraded my three node HCI cluster from Ovirt 4.2 to 4.3. I did so by first updating the engine to 4.3 then upgrading each ovirt-node host to 4.3 and rebooting.
Currently engine and all hosts are running 4.3 and all is working fine.
To complete the upgrade I need to update cluster compatibility to 4.3 and then data centre to 4.3. This is where I am stuck.
The CPU type on cluster is "Intel SandyBridge IBRS Family". This option is no longer available if I select 4.3 compatibility. Any other option chosen such as SandyBridge IBRS SSBD will not allow me to switch to 4.3 as all hosts must be in maintenance mode (which is not possible w/ self hosted engine).
I saw another post about this where someone else followed steps to create a second cluster on 4.3 with new CPU type then move one host to it, start engine on it then perform other steps to eventually get to 4.3 compatibility.
I have the exact same hardware configuration and was able to change to "SandyBridge IBRS SSBD" without creating a new cluster. How I made that happen, I'm not so sure, but the cluster may have been in "Global Maintenance" mode when I changed it.
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/site/privacy-policy/ oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/5B3TAXKO7IBTWR...
This may be happening because I changed cluster compatibility to 4.3 then immediately after changed data center compatibility to 4.3 (before restarting VMs after cluster compatibility change). If this is the case I can't fix by downgrading the data center compatibility to 4.2 as it won't allow me to do so. What can I do to fix this, any VM I restart will break (I am leaving the others running for now, but there are some down that I can't start). Full error from VDSM: 2019-02-13 13:30:55,465-0400 ERROR (vm/d070ce80) [storage.TaskManager.Task] (Task='d5c8e50a-0a6f-4fe7-be79-fd322b273a1e') Unexpected error (task:875) Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/vdsm/storage/task.py", line 882, in _run return fn(*args, **kargs) File "<string>", line 2, in prepareImage File "/usr/lib/python2.7/site-packages/vdsm/common/api.py", line 50, in method ret = func(*args, **kwargs) File "/usr/lib/python2.7/site-packages/vdsm/storage/hsm.py", line 3198, in prepareImage legality = dom.produceVolume(imgUUID, volUUID).getLegality() File "/usr/lib/python2.7/site-packages/vdsm/storage/sd.py", line 818, in produceVolume volUUID) File "/usr/lib/python2.7/site-packages/vdsm/storage/glusterVolume.py", line 45, in __init__ volUUID) File "/usr/lib/python2.7/site-packages/vdsm/storage/volume.py", line 800, in __init__ self._manifest = self.manifestClass(repoPath, sdUUID, imgUUID, volUUID) File "/usr/lib/python2.7/site-packages/vdsm/storage/fileVolume.py", line 71, in __init__ volUUID) File "/usr/lib/python2.7/site-packages/vdsm/storage/volume.py", line 86, in __init__ self.validate() File "/usr/lib/python2.7/site-packages/vdsm/storage/volume.py", line 112, in validate self.validateVolumePath() File "/usr/lib/python2.7/site-packages/vdsm/storage/fileVolume.py", line 131, in validateVolumePath raise se.VolumeDoesNotExist(self.volUUID) VolumeDoesNotExist: Volume does not exist: (u'2d6d5f87-ccb0-48ce-b3ac-84495bd12d32',) 2019-02-13 13:30:55,468-0400 ERROR (vm/d070ce80) [storage.Dispatcher] FINISH prepareImage error=Volume does not exist: (u'2d6d5f87-ccb0-48ce-b3ac-84495bd12d32',) (dispatcher:81) 2019-02-13 13:30:55,469-0400 ERROR (vm/d070ce80) [virt.vm] (vmId='d070ce80-e0bc-489d-8ee0-47d5926d5ae2') The vm start process failed (vm:937) Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/vdsm/virt/vm.py", line 866, in _startUnderlyingVm self._run() File "/usr/lib/python2.7/site-packages/vdsm/virt/vm.py", line 2749, in _run self._devices = self._make_devices() File "/usr/lib/python2.7/site-packages/vdsm/virt/vm.py", line 2589, in _make_devices disk_objs = self._perform_host_local_adjustment() File "/usr/lib/python2.7/site-packages/vdsm/virt/vm.py", line 2662, in _perform_host_local_adjustment self._preparePathsForDrives(disk_params) File "/usr/lib/python2.7/site-packages/vdsm/virt/vm.py", line 1011, in _preparePathsForDrives drive['path'] = self.cif.prepareVolumePath(drive, self.id) File "/usr/lib/python2.7/site-packages/vdsm/clientIF.py", line 415, in prepareVolumePath raise vm.VolumeError(drive) VolumeError: Bad volume specification {'address': {'function': '0x0', 'bus': '0x00', 'domain': '0x0000', 'type': 'pci', 'slot': '0x06'}, 'serial': 'd81a6826-dc46-44db-8de7-405d30e44d57', 'index': 0, 'iface': 'virtio', 'apparentsize': '64293699584', 'specParams': {}, 'cache': 'none', 'imageID': 'd81a6826-dc46-44db-8de7-405d30e44d57', 'truesize': '64293814272', 'type': 'disk', 'domainID': '1f2e9989-9ab3-43d5-971d-568b8feca918', 'reqsize': '0', 'format': 'cow', 'poolID': 'a45e442e-9989-11e8-b0e4-00163e4bf18a', 'device': 'disk', 'path': '/rhev/data-center/a45e442e-9989-11e8-b0e4-00163e4bf18a/1f2e9989-9ab3-43d5-971d-568b8feca918/images/d81a6826-dc46-44db-8de7-405d30e44d57/2d6d5f87-ccb0-48ce-b3ac-84495bd12d32', 'propagateErrors': 'off', 'name': 'vda', 'bootOrder': '1', 'volumeID': '2d6d5f87-ccb0-48ce-b3ac-84495bd12d32', 'diskType': 'file', 'alias': 'ua-d81a6826-dc46-44db-8de7-405d30e44d57', 'discard': False} On Wed, Feb 13, 2019 at 1:19 PM Jayme <jaymef@gmail.com> wrote:
I may have made matters worse. So I changed to 4.3 compatible cluster then 4.3 compatible data center. All VMs were marked as requiring a reboot. I restarted a couple of them and none of them will start up, they are saying "bad volume specification". The ones running that I did not yet restart are still running ok. I need to figure out why the VMs aren't restarting.
Here is an example from vdsm.log
olumeError: Bad volume specification {'address': {'function': '0x0', 'bus': '0x00', 'domain': '0x0000', 'type': 'pci', 'slot': '0x06'}, 'serial': 'd81a6826-dc46-44db-8de7-405d30e44d57', 'index': 0, 'iface': 'virtio', 'apparentsize': '64293699584', 'specParams': {}, 'cache': 'none', 'imageID': 'd81a6826-dc46-44db-8de7-405d30e44d57', 'truesize': '64293814272', 'type': 'disk', 'domainID': '1f2e9989-9ab3-43d5-971d-568b8feca918', 'reqsize': '0', 'format': 'cow', 'poolID': 'a45e442e-9989-11e8-b0e4-00163e4bf18a', 'device': 'disk', 'path': '/rhev/data-center/a45e442e-9989-11e8-b0e4-00163e4bf18a/1f2e9989-9ab3-43d5-971d-568b8feca918/images/d81a6826-dc46-44db-8de7-405d30e44d57/2d6d5f87-ccb0-48ce-b3ac-84495bd12d32', 'propagateErrors': 'off', 'name': 'vda', 'bootOrder': '1', 'volumeID': '2d6d5f87-ccb0-48ce-b3ac-84495bd12d32', 'diskType': 'file', 'alias': 'ua-d81a6826-dc46-44db-8de7-405d30e44d57', 'discard': False}
On Wed, Feb 13, 2019 at 1:01 PM Jayme <jaymef@gmail.com> wrote:
I think I just figured out what I was doing wrong. On edit cluster screen I was changing both the CPU type and cluster level 4.3. I tried it again by switching to the new CPU type first (leaving cluster on 4.2) then saving, then going back in and switching compat level to 4.3. It appears that you need to do this in two steps for it to work.
On Wed, Feb 13, 2019 at 12:57 PM Jayme <jaymef@gmail.com> wrote:
Hmm interesting, I wonder how you were able to switch from SandyBridge IBRS to SandyBridge IBRS SSBD. I just attempted the same in both regular mode and in global maintenance mode and it won't allow me to, it says that all hosts have to be in maintenance mode (screenshots attached). Are you also running HCI/Gluster setup?
On Wed, Feb 13, 2019 at 12:44 PM Ron Jerome <ronjero@gmail.com> wrote:
Environment setup:
3 Host HCI GlusterFS setup. Identical hosts, Dell R720s w/ Intel E5-2690 CPUs
1 default data center (4.2 compat) 1 default cluster (4.2 compat)
Situation: I recently upgraded my three node HCI cluster from Ovirt 4.2 to 4.3. I did so by first updating the engine to 4.3 then upgrading each ovirt-node host to 4.3 and rebooting.
Currently engine and all hosts are running 4.3 and all is working fine.
To complete the upgrade I need to update cluster compatibility to 4.3 and then data centre to 4.3. This is where I am stuck.
The CPU type on cluster is "Intel SandyBridge IBRS Family". This option is no longer available if I select 4.3 compatibility. Any other option chosen such as SandyBridge IBRS SSBD will not allow me to switch to 4.3 as all hosts must be in maintenance mode (which is not possible w/ self hosted engine).
I saw another post about this where someone else followed steps to create a second cluster on 4.3 with new CPU type then move one host to it, start engine on it then perform other steps to eventually get to 4.3 compatibility.
I have the exact same hardware configuration and was able to change to "SandyBridge IBRS SSBD" without creating a new cluster. How I made that happen, I'm not so sure, but the cluster may have been in "Global Maintenance" mode when I changed it.
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/site/privacy-policy/ oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/5B3TAXKO7IBTWR...
I might be hitting this bug: https://bugzilla.redhat.com/show_bug.cgi?id=1666795 On Wed, Feb 13, 2019 at 1:35 PM Jayme <jaymef@gmail.com> wrote:
This may be happening because I changed cluster compatibility to 4.3 then immediately after changed data center compatibility to 4.3 (before restarting VMs after cluster compatibility change). If this is the case I can't fix by downgrading the data center compatibility to 4.2 as it won't allow me to do so. What can I do to fix this, any VM I restart will break (I am leaving the others running for now, but there are some down that I can't start).
Full error from VDSM:
2019-02-13 13:30:55,465-0400 ERROR (vm/d070ce80) [storage.TaskManager.Task] (Task='d5c8e50a-0a6f-4fe7-be79-fd322b273a1e') Unexpected error (task:875) Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/vdsm/storage/task.py", line 882, in _run return fn(*args, **kargs) File "<string>", line 2, in prepareImage File "/usr/lib/python2.7/site-packages/vdsm/common/api.py", line 50, in method ret = func(*args, **kwargs) File "/usr/lib/python2.7/site-packages/vdsm/storage/hsm.py", line 3198, in prepareImage legality = dom.produceVolume(imgUUID, volUUID).getLegality() File "/usr/lib/python2.7/site-packages/vdsm/storage/sd.py", line 818, in produceVolume volUUID) File "/usr/lib/python2.7/site-packages/vdsm/storage/glusterVolume.py", line 45, in __init__ volUUID) File "/usr/lib/python2.7/site-packages/vdsm/storage/volume.py", line 800, in __init__ self._manifest = self.manifestClass(repoPath, sdUUID, imgUUID, volUUID) File "/usr/lib/python2.7/site-packages/vdsm/storage/fileVolume.py", line 71, in __init__ volUUID) File "/usr/lib/python2.7/site-packages/vdsm/storage/volume.py", line 86, in __init__ self.validate() File "/usr/lib/python2.7/site-packages/vdsm/storage/volume.py", line 112, in validate self.validateVolumePath() File "/usr/lib/python2.7/site-packages/vdsm/storage/fileVolume.py", line 131, in validateVolumePath raise se.VolumeDoesNotExist(self.volUUID) VolumeDoesNotExist: Volume does not exist: (u'2d6d5f87-ccb0-48ce-b3ac-84495bd12d32',) 2019-02-13 13:30:55,468-0400 ERROR (vm/d070ce80) [storage.Dispatcher] FINISH prepareImage error=Volume does not exist: (u'2d6d5f87-ccb0-48ce-b3ac-84495bd12d32',) (dispatcher:81) 2019-02-13 13:30:55,469-0400 ERROR (vm/d070ce80) [virt.vm] (vmId='d070ce80-e0bc-489d-8ee0-47d5926d5ae2') The vm start process failed (vm:937) Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/vdsm/virt/vm.py", line 866, in _startUnderlyingVm self._run() File "/usr/lib/python2.7/site-packages/vdsm/virt/vm.py", line 2749, in _run self._devices = self._make_devices() File "/usr/lib/python2.7/site-packages/vdsm/virt/vm.py", line 2589, in _make_devices disk_objs = self._perform_host_local_adjustment() File "/usr/lib/python2.7/site-packages/vdsm/virt/vm.py", line 2662, in _perform_host_local_adjustment self._preparePathsForDrives(disk_params) File "/usr/lib/python2.7/site-packages/vdsm/virt/vm.py", line 1011, in _preparePathsForDrives drive['path'] = self.cif.prepareVolumePath(drive, self.id) File "/usr/lib/python2.7/site-packages/vdsm/clientIF.py", line 415, in prepareVolumePath raise vm.VolumeError(drive) VolumeError: Bad volume specification {'address': {'function': '0x0', 'bus': '0x00', 'domain': '0x0000', 'type': 'pci', 'slot': '0x06'}, 'serial': 'd81a6826-dc46-44db-8de7-405d30e44d57', 'index': 0, 'iface': 'virtio', 'apparentsize': '64293699584', 'specParams': {}, 'cache': 'none', 'imageID': 'd81a6826-dc46-44db-8de7-405d30e44d57', 'truesize': '64293814272', 'type': 'disk', 'domainID': '1f2e9989-9ab3-43d5-971d-568b8feca918', 'reqsize': '0', 'format': 'cow', 'poolID': 'a45e442e-9989-11e8-b0e4-00163e4bf18a', 'device': 'disk', 'path': '/rhev/data-center/a45e442e-9989-11e8-b0e4-00163e4bf18a/1f2e9989-9ab3-43d5-971d-568b8feca918/images/d81a6826-dc46-44db-8de7-405d30e44d57/2d6d5f87-ccb0-48ce-b3ac-84495bd12d32', 'propagateErrors': 'off', 'name': 'vda', 'bootOrder': '1', 'volumeID': '2d6d5f87-ccb0-48ce-b3ac-84495bd12d32', 'diskType': 'file', 'alias': 'ua-d81a6826-dc46-44db-8de7-405d30e44d57', 'discard': False}
On Wed, Feb 13, 2019 at 1:19 PM Jayme <jaymef@gmail.com> wrote:
I may have made matters worse. So I changed to 4.3 compatible cluster then 4.3 compatible data center. All VMs were marked as requiring a reboot. I restarted a couple of them and none of them will start up, they are saying "bad volume specification". The ones running that I did not yet restart are still running ok. I need to figure out why the VMs aren't restarting.
Here is an example from vdsm.log
olumeError: Bad volume specification {'address': {'function': '0x0', 'bus': '0x00', 'domain': '0x0000', 'type': 'pci', 'slot': '0x06'}, 'serial': 'd81a6826-dc46-44db-8de7-405d30e44d57', 'index': 0, 'iface': 'virtio', 'apparentsize': '64293699584', 'specParams': {}, 'cache': 'none', 'imageID': 'd81a6826-dc46-44db-8de7-405d30e44d57', 'truesize': '64293814272', 'type': 'disk', 'domainID': '1f2e9989-9ab3-43d5-971d-568b8feca918', 'reqsize': '0', 'format': 'cow', 'poolID': 'a45e442e-9989-11e8-b0e4-00163e4bf18a', 'device': 'disk', 'path': '/rhev/data-center/a45e442e-9989-11e8-b0e4-00163e4bf18a/1f2e9989-9ab3-43d5-971d-568b8feca918/images/d81a6826-dc46-44db-8de7-405d30e44d57/2d6d5f87-ccb0-48ce-b3ac-84495bd12d32', 'propagateErrors': 'off', 'name': 'vda', 'bootOrder': '1', 'volumeID': '2d6d5f87-ccb0-48ce-b3ac-84495bd12d32', 'diskType': 'file', 'alias': 'ua-d81a6826-dc46-44db-8de7-405d30e44d57', 'discard': False}
On Wed, Feb 13, 2019 at 1:01 PM Jayme <jaymef@gmail.com> wrote:
I think I just figured out what I was doing wrong. On edit cluster screen I was changing both the CPU type and cluster level 4.3. I tried it again by switching to the new CPU type first (leaving cluster on 4.2) then saving, then going back in and switching compat level to 4.3. It appears that you need to do this in two steps for it to work.
On Wed, Feb 13, 2019 at 12:57 PM Jayme <jaymef@gmail.com> wrote:
Hmm interesting, I wonder how you were able to switch from SandyBridge IBRS to SandyBridge IBRS SSBD. I just attempted the same in both regular mode and in global maintenance mode and it won't allow me to, it says that all hosts have to be in maintenance mode (screenshots attached). Are you also running HCI/Gluster setup?
On Wed, Feb 13, 2019 at 12:44 PM Ron Jerome <ronjero@gmail.com> wrote:
Environment setup:
3 Host HCI GlusterFS setup. Identical hosts, Dell R720s w/ Intel E5-2690 CPUs
1 default data center (4.2 compat) 1 default cluster (4.2 compat)
Situation: I recently upgraded my three node HCI cluster from Ovirt 4.2 to 4.3. I did so by first updating the engine to 4.3 then upgrading each ovirt-node host to 4.3 and rebooting.
Currently engine and all hosts are running 4.3 and all is working fine.
To complete the upgrade I need to update cluster compatibility to 4.3 and then data centre to 4.3. This is where I am stuck.
The CPU type on cluster is "Intel SandyBridge IBRS Family". This option is no longer available if I select 4.3 compatibility. Any other option chosen such as SandyBridge IBRS SSBD will not allow me to switch to 4.3 as all hosts must be in maintenance mode (which is not possible w/ self hosted engine).
I saw another post about this where someone else followed steps to create a second cluster on 4.3 with new CPU type then move one host to it, start engine on it then perform other steps to eventually get to 4.3 compatibility.
I have the exact same hardware configuration and was able to change to "SandyBridge IBRS SSBD" without creating a new cluster. How I made that happen, I'm not so sure, but the cluster may have been in "Global Maintenance" mode when I changed it.
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/site/privacy-policy/ oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/5B3TAXKO7IBTWR...

On Wed, Feb 13, 2019 at 8:06 PM Jayme <jaymef@gmail.com> wrote:
I might be hitting this bug: https://bugzilla.redhat.com/show_bug.cgi?id=1666795
Yes, you definitively are. Fixing files ownership on file system side is a valid workaround.
On Wed, Feb 13, 2019 at 1:35 PM Jayme <jaymef@gmail.com> wrote:
This may be happening because I changed cluster compatibility to 4.3 then immediately after changed data center compatibility to 4.3 (before restarting VMs after cluster compatibility change). If this is the case I can't fix by downgrading the data center compatibility to 4.2 as it won't allow me to do so. What can I do to fix this, any VM I restart will break (I am leaving the others running for now, but there are some down that I can't start).
Full error from VDSM:
2019-02-13 13:30:55,465-0400 ERROR (vm/d070ce80) [storage.TaskManager.Task] (Task='d5c8e50a-0a6f-4fe7-be79-fd322b273a1e') Unexpected error (task:875) Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/vdsm/storage/task.py", line 882, in _run return fn(*args, **kargs) File "<string>", line 2, in prepareImage File "/usr/lib/python2.7/site-packages/vdsm/common/api.py", line 50, in method ret = func(*args, **kwargs) File "/usr/lib/python2.7/site-packages/vdsm/storage/hsm.py", line 3198, in prepareImage legality = dom.produceVolume(imgUUID, volUUID).getLegality() File "/usr/lib/python2.7/site-packages/vdsm/storage/sd.py", line 818, in produceVolume volUUID) File "/usr/lib/python2.7/site-packages/vdsm/storage/glusterVolume.py", line 45, in __init__ volUUID) File "/usr/lib/python2.7/site-packages/vdsm/storage/volume.py", line 800, in __init__ self._manifest = self.manifestClass(repoPath, sdUUID, imgUUID, volUUID) File "/usr/lib/python2.7/site-packages/vdsm/storage/fileVolume.py", line 71, in __init__ volUUID) File "/usr/lib/python2.7/site-packages/vdsm/storage/volume.py", line 86, in __init__ self.validate() File "/usr/lib/python2.7/site-packages/vdsm/storage/volume.py", line 112, in validate self.validateVolumePath() File "/usr/lib/python2.7/site-packages/vdsm/storage/fileVolume.py", line 131, in validateVolumePath raise se.VolumeDoesNotExist(self.volUUID) VolumeDoesNotExist: Volume does not exist: (u'2d6d5f87-ccb0-48ce-b3ac-84495bd12d32',) 2019-02-13 13:30:55,468-0400 ERROR (vm/d070ce80) [storage.Dispatcher] FINISH prepareImage error=Volume does not exist: (u'2d6d5f87-ccb0-48ce-b3ac-84495bd12d32',) (dispatcher:81) 2019-02-13 13:30:55,469-0400 ERROR (vm/d070ce80) [virt.vm] (vmId='d070ce80-e0bc-489d-8ee0-47d5926d5ae2') The vm start process failed (vm:937) Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/vdsm/virt/vm.py", line 866, in _startUnderlyingVm self._run() File "/usr/lib/python2.7/site-packages/vdsm/virt/vm.py", line 2749, in _run self._devices = self._make_devices() File "/usr/lib/python2.7/site-packages/vdsm/virt/vm.py", line 2589, in _make_devices disk_objs = self._perform_host_local_adjustment() File "/usr/lib/python2.7/site-packages/vdsm/virt/vm.py", line 2662, in _perform_host_local_adjustment self._preparePathsForDrives(disk_params) File "/usr/lib/python2.7/site-packages/vdsm/virt/vm.py", line 1011, in _preparePathsForDrives drive['path'] = self.cif.prepareVolumePath(drive, self.id) File "/usr/lib/python2.7/site-packages/vdsm/clientIF.py", line 415, in prepareVolumePath raise vm.VolumeError(drive) VolumeError: Bad volume specification {'address': {'function': '0x0', 'bus': '0x00', 'domain': '0x0000', 'type': 'pci', 'slot': '0x06'}, 'serial': 'd81a6826-dc46-44db-8de7-405d30e44d57', 'index': 0, 'iface': 'virtio', 'apparentsize': '64293699584', 'specParams': {}, 'cache': 'none', 'imageID': 'd81a6826-dc46-44db-8de7-405d30e44d57', 'truesize': '64293814272', 'type': 'disk', 'domainID': '1f2e9989-9ab3-43d5-971d-568b8feca918', 'reqsize': '0', 'format': 'cow', 'poolID': 'a45e442e-9989-11e8-b0e4-00163e4bf18a', 'device': 'disk', 'path': '/rhev/data-center/a45e442e-9989-11e8-b0e4-00163e4bf18a/1f2e9989-9ab3-43d5-971d-568b8feca918/images/d81a6826-dc46-44db-8de7-405d30e44d57/2d6d5f87-ccb0-48ce-b3ac-84495bd12d32', 'propagateErrors': 'off', 'name': 'vda', 'bootOrder': '1', 'volumeID': '2d6d5f87-ccb0-48ce-b3ac-84495bd12d32', 'diskType': 'file', 'alias': 'ua-d81a6826-dc46-44db-8de7-405d30e44d57', 'discard': False}
On Wed, Feb 13, 2019 at 1:19 PM Jayme <jaymef@gmail.com> wrote:
I may have made matters worse. So I changed to 4.3 compatible cluster then 4.3 compatible data center. All VMs were marked as requiring a reboot. I restarted a couple of them and none of them will start up, they are saying "bad volume specification". The ones running that I did not yet restart are still running ok. I need to figure out why the VMs aren't restarting.
Here is an example from vdsm.log
olumeError: Bad volume specification {'address': {'function': '0x0', 'bus': '0x00', 'domain': '0x0000', 'type': 'pci', 'slot': '0x06'}, 'serial': 'd81a6826-dc46-44db-8de7-405d30e44d57', 'index': 0, 'iface': 'virtio', 'apparentsize': '64293699584', 'specParams': {}, 'cache': 'none', 'imageID': 'd81a6826-dc46-44db-8de7-405d30e44d57', 'truesize': '64293814272', 'type': 'disk', 'domainID': '1f2e9989-9ab3-43d5-971d-568b8feca918', 'reqsize': '0', 'format': 'cow', 'poolID': 'a45e442e-9989-11e8-b0e4-00163e4bf18a', 'device': 'disk', 'path': '/rhev/data-center/a45e442e-9989-11e8-b0e4-00163e4bf18a/1f2e9989-9ab3-43d5-971d-568b8feca918/images/d81a6826-dc46-44db-8de7-405d30e44d57/2d6d5f87-ccb0-48ce-b3ac-84495bd12d32', 'propagateErrors': 'off', 'name': 'vda', 'bootOrder': '1', 'volumeID': '2d6d5f87-ccb0-48ce-b3ac-84495bd12d32', 'diskType': 'file', 'alias': 'ua-d81a6826-dc46-44db-8de7-405d30e44d57', 'discard': False}
On Wed, Feb 13, 2019 at 1:01 PM Jayme <jaymef@gmail.com> wrote:
I think I just figured out what I was doing wrong. On edit cluster screen I was changing both the CPU type and cluster level 4.3. I tried it again by switching to the new CPU type first (leaving cluster on 4.2) then saving, then going back in and switching compat level to 4.3. It appears that you need to do this in two steps for it to work.
On Wed, Feb 13, 2019 at 12:57 PM Jayme <jaymef@gmail.com> wrote:
Hmm interesting, I wonder how you were able to switch from SandyBridge IBRS to SandyBridge IBRS SSBD. I just attempted the same in both regular mode and in global maintenance mode and it won't allow me to, it says that all hosts have to be in maintenance mode (screenshots attached). Are you also running HCI/Gluster setup?
On Wed, Feb 13, 2019 at 12:44 PM Ron Jerome <ronjero@gmail.com> wrote:
> Environment setup: > > 3 Host HCI GlusterFS setup. Identical hosts, Dell R720s w/ Intel E5-2690 > CPUs > > 1 default data center (4.2 compat) > 1 default cluster (4.2 compat) > > Situation: I recently upgraded my three node HCI cluster from Ovirt 4.2 to > 4.3. I did so by first updating the engine to 4.3 then upgrading each > ovirt-node host to 4.3 and rebooting. > > Currently engine and all hosts are running 4.3 and all is working fine. > > To complete the upgrade I need to update cluster compatibility to 4.3 and > then data centre to 4.3. This is where I am stuck. > > The CPU type on cluster is "Intel SandyBridge IBRS Family". This option is > no longer available if I select 4.3 compatibility. Any other option chosen > such as SandyBridge IBRS SSBD will not allow me to switch to 4.3 as all > hosts must be in maintenance mode (which is not possible w/ self hosted > engine). > > I saw another post about this where someone else followed steps to create a > second cluster on 4.3 with new CPU type then move one host to it, start > engine on it then perform other steps to eventually get to 4.3 > compatibility. >
I have the exact same hardware configuration and was able to change to "SandyBridge IBRS SSBD" without creating a new cluster. How I made that happen, I'm not so sure, but the cluster may have been in "Global Maintenance" mode when I changed it.
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/site/privacy-policy/ oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/5B3TAXKO7IBTWR...
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/site/privacy-policy/ oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/PK7IR27DGLZRZS...
I can confirm that this worked. I had to shut down every single VM then change ownership to vdsm:kvm of the image file then start VM back up. On Wed, Feb 13, 2019 at 3:08 PM Simone Tiraboschi <stirabos@redhat.com> wrote:
On Wed, Feb 13, 2019 at 8:06 PM Jayme <jaymef@gmail.com> wrote:
I might be hitting this bug: https://bugzilla.redhat.com/show_bug.cgi?id=1666795
Yes, you definitively are. Fixing files ownership on file system side is a valid workaround.
On Wed, Feb 13, 2019 at 1:35 PM Jayme <jaymef@gmail.com> wrote:
This may be happening because I changed cluster compatibility to 4.3 then immediately after changed data center compatibility to 4.3 (before restarting VMs after cluster compatibility change). If this is the case I can't fix by downgrading the data center compatibility to 4.2 as it won't allow me to do so. What can I do to fix this, any VM I restart will break (I am leaving the others running for now, but there are some down that I can't start).
Full error from VDSM:
2019-02-13 13:30:55,465-0400 ERROR (vm/d070ce80) [storage.TaskManager.Task] (Task='d5c8e50a-0a6f-4fe7-be79-fd322b273a1e') Unexpected error (task:875) Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/vdsm/storage/task.py", line 882, in _run return fn(*args, **kargs) File "<string>", line 2, in prepareImage File "/usr/lib/python2.7/site-packages/vdsm/common/api.py", line 50, in method ret = func(*args, **kwargs) File "/usr/lib/python2.7/site-packages/vdsm/storage/hsm.py", line 3198, in prepareImage legality = dom.produceVolume(imgUUID, volUUID).getLegality() File "/usr/lib/python2.7/site-packages/vdsm/storage/sd.py", line 818, in produceVolume volUUID) File "/usr/lib/python2.7/site-packages/vdsm/storage/glusterVolume.py", line 45, in __init__ volUUID) File "/usr/lib/python2.7/site-packages/vdsm/storage/volume.py", line 800, in __init__ self._manifest = self.manifestClass(repoPath, sdUUID, imgUUID, volUUID) File "/usr/lib/python2.7/site-packages/vdsm/storage/fileVolume.py", line 71, in __init__ volUUID) File "/usr/lib/python2.7/site-packages/vdsm/storage/volume.py", line 86, in __init__ self.validate() File "/usr/lib/python2.7/site-packages/vdsm/storage/volume.py", line 112, in validate self.validateVolumePath() File "/usr/lib/python2.7/site-packages/vdsm/storage/fileVolume.py", line 131, in validateVolumePath raise se.VolumeDoesNotExist(self.volUUID) VolumeDoesNotExist: Volume does not exist: (u'2d6d5f87-ccb0-48ce-b3ac-84495bd12d32',) 2019-02-13 13:30:55,468-0400 ERROR (vm/d070ce80) [storage.Dispatcher] FINISH prepareImage error=Volume does not exist: (u'2d6d5f87-ccb0-48ce-b3ac-84495bd12d32',) (dispatcher:81) 2019-02-13 13:30:55,469-0400 ERROR (vm/d070ce80) [virt.vm] (vmId='d070ce80-e0bc-489d-8ee0-47d5926d5ae2') The vm start process failed (vm:937) Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/vdsm/virt/vm.py", line 866, in _startUnderlyingVm self._run() File "/usr/lib/python2.7/site-packages/vdsm/virt/vm.py", line 2749, in _run self._devices = self._make_devices() File "/usr/lib/python2.7/site-packages/vdsm/virt/vm.py", line 2589, in _make_devices disk_objs = self._perform_host_local_adjustment() File "/usr/lib/python2.7/site-packages/vdsm/virt/vm.py", line 2662, in _perform_host_local_adjustment self._preparePathsForDrives(disk_params) File "/usr/lib/python2.7/site-packages/vdsm/virt/vm.py", line 1011, in _preparePathsForDrives drive['path'] = self.cif.prepareVolumePath(drive, self.id) File "/usr/lib/python2.7/site-packages/vdsm/clientIF.py", line 415, in prepareVolumePath raise vm.VolumeError(drive) VolumeError: Bad volume specification {'address': {'function': '0x0', 'bus': '0x00', 'domain': '0x0000', 'type': 'pci', 'slot': '0x06'}, 'serial': 'd81a6826-dc46-44db-8de7-405d30e44d57', 'index': 0, 'iface': 'virtio', 'apparentsize': '64293699584', 'specParams': {}, 'cache': 'none', 'imageID': 'd81a6826-dc46-44db-8de7-405d30e44d57', 'truesize': '64293814272', 'type': 'disk', 'domainID': '1f2e9989-9ab3-43d5-971d-568b8feca918', 'reqsize': '0', 'format': 'cow', 'poolID': 'a45e442e-9989-11e8-b0e4-00163e4bf18a', 'device': 'disk', 'path': '/rhev/data-center/a45e442e-9989-11e8-b0e4-00163e4bf18a/1f2e9989-9ab3-43d5-971d-568b8feca918/images/d81a6826-dc46-44db-8de7-405d30e44d57/2d6d5f87-ccb0-48ce-b3ac-84495bd12d32', 'propagateErrors': 'off', 'name': 'vda', 'bootOrder': '1', 'volumeID': '2d6d5f87-ccb0-48ce-b3ac-84495bd12d32', 'diskType': 'file', 'alias': 'ua-d81a6826-dc46-44db-8de7-405d30e44d57', 'discard': False}
On Wed, Feb 13, 2019 at 1:19 PM Jayme <jaymef@gmail.com> wrote:
I may have made matters worse. So I changed to 4.3 compatible cluster then 4.3 compatible data center. All VMs were marked as requiring a reboot. I restarted a couple of them and none of them will start up, they are saying "bad volume specification". The ones running that I did not yet restart are still running ok. I need to figure out why the VMs aren't restarting.
Here is an example from vdsm.log
olumeError: Bad volume specification {'address': {'function': '0x0', 'bus': '0x00', 'domain': '0x0000', 'type': 'pci', 'slot': '0x06'}, 'serial': 'd81a6826-dc46-44db-8de7-405d30e44d57', 'index': 0, 'iface': 'virtio', 'apparentsize': '64293699584', 'specParams': {}, 'cache': 'none', 'imageID': 'd81a6826-dc46-44db-8de7-405d30e44d57', 'truesize': '64293814272', 'type': 'disk', 'domainID': '1f2e9989-9ab3-43d5-971d-568b8feca918', 'reqsize': '0', 'format': 'cow', 'poolID': 'a45e442e-9989-11e8-b0e4-00163e4bf18a', 'device': 'disk', 'path': '/rhev/data-center/a45e442e-9989-11e8-b0e4-00163e4bf18a/1f2e9989-9ab3-43d5-971d-568b8feca918/images/d81a6826-dc46-44db-8de7-405d30e44d57/2d6d5f87-ccb0-48ce-b3ac-84495bd12d32', 'propagateErrors': 'off', 'name': 'vda', 'bootOrder': '1', 'volumeID': '2d6d5f87-ccb0-48ce-b3ac-84495bd12d32', 'diskType': 'file', 'alias': 'ua-d81a6826-dc46-44db-8de7-405d30e44d57', 'discard': False}
On Wed, Feb 13, 2019 at 1:01 PM Jayme <jaymef@gmail.com> wrote:
I think I just figured out what I was doing wrong. On edit cluster screen I was changing both the CPU type and cluster level 4.3. I tried it again by switching to the new CPU type first (leaving cluster on 4.2) then saving, then going back in and switching compat level to 4.3. It appears that you need to do this in two steps for it to work.
On Wed, Feb 13, 2019 at 12:57 PM Jayme <jaymef@gmail.com> wrote:
Hmm interesting, I wonder how you were able to switch from SandyBridge IBRS to SandyBridge IBRS SSBD. I just attempted the same in both regular mode and in global maintenance mode and it won't allow me to, it says that all hosts have to be in maintenance mode (screenshots attached). Are you also running HCI/Gluster setup?
On Wed, Feb 13, 2019 at 12:44 PM Ron Jerome <ronjero@gmail.com> wrote:
> > Environment setup: > > > > 3 Host HCI GlusterFS setup. Identical hosts, Dell R720s w/ Intel > E5-2690 > > CPUs > > > > 1 default data center (4.2 compat) > > 1 default cluster (4.2 compat) > > > > Situation: I recently upgraded my three node HCI cluster from > Ovirt 4.2 to > > 4.3. I did so by first updating the engine to 4.3 then upgrading > each > > ovirt-node host to 4.3 and rebooting. > > > > Currently engine and all hosts are running 4.3 and all is working > fine. > > > > To complete the upgrade I need to update cluster compatibility to > 4.3 and > > then data centre to 4.3. This is where I am stuck. > > > > The CPU type on cluster is "Intel SandyBridge IBRS Family". This > option is > > no longer available if I select 4.3 compatibility. Any other > option chosen > > such as SandyBridge IBRS SSBD will not allow me to switch to 4.3 > as all > > hosts must be in maintenance mode (which is not possible w/ self > hosted > > engine). > > > > I saw another post about this where someone else followed steps to > create a > > second cluster on 4.3 with new CPU type then move one host to it, > start > > engine on it then perform other steps to eventually get to 4.3 > > compatibility. > > > > I have the exact same hardware configuration and was able to change > to "SandyBridge IBRS SSBD" without creating a new cluster. How I made that > happen, I'm not so sure, but the cluster may have been in "Global > Maintenance" mode when I changed it. > > > _______________________________________________ > Users mailing list -- users@ovirt.org > To unsubscribe send an email to users-leave@ovirt.org > Privacy Statement: https://www.ovirt.org/site/privacy-policy/ > oVirt Code of Conduct: > https://www.ovirt.org/community/about/community-guidelines/ > List Archives: > https://lists.ovirt.org/archives/list/users@ovirt.org/message/5B3TAXKO7IBTWR... > _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/site/privacy-policy/ oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/PK7IR27DGLZRZS...
I can confirm that this worked. I had to shut down every single VM then change ownership to vdsm:kvm of the image file then start VM back up.
Not to rain on your parade, but you should keep a close eye on your gluster file system after the upgrade. The stability of my gluster file system was markedly decreased after the upgrade to gluster 5.3 :-(

On Wed, Feb 13, 2019 at 3:06 PM Ron Jerome <ronjero@gmail.com> wrote:
I can confirm that this worked. I had to shut down every single VM then change ownership to vdsm:kvm of the image file then start VM back up.
Not to rain on your parade, but you should keep a close eye on your gluster file system after the upgrade. The stability of my gluster file system was markedly decreased after the upgrade to gluster 5.3 :-(
Can you be more specific? What things did you see, and did you report bugs? Thanks! Best wishes, Greg
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/site/privacy-policy/ oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/3Q55MP7XZJJSE3...
-- GREG SHEREMETA SENIOR SOFTWARE ENGINEER - TEAM LEAD - RHV UX Red Hat NA <https://www.redhat.com/> gshereme@redhat.com IRC: gshereme <https://red.ht/sig>
Can you be more specific? What things did you see, and did you report bugs?
I've got this one: https://bugzilla.redhat.com/show_bug.cgi?id=1649054 and this one: https://bugzilla.redhat.com/show_bug.cgi?id=1651246 and I've got bricks randomly going offline and getting out of sync with the others at which point I've had to manually stop and start the volume to get things back in sync.
Ron, sorry to hear about the troubles. I haven't seen any gluster crashes yet *knock on wood*. I will monitor closely. Thanks for the heads up! On Wed, Feb 13, 2019 at 5:09 PM Ron Jerome <ronjero@gmail.com> wrote:
Can you be more specific? What things did you see, and did you report
bugs?
I've got this one: https://bugzilla.redhat.com/show_bug.cgi?id=1649054 and this one: https://bugzilla.redhat.com/show_bug.cgi?id=1651246 and I've got bricks randomly going offline and getting out of sync with the others at which point I've had to manually stop and start the volume to get things back in sync. _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/site/privacy-policy/ oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/3RVMLCRK4BWCSB...
Ron, well it looks like you're not wrong. Less than 24 hours after upgrading my cluster I have a Gluster brick down... On Wed, Feb 13, 2019 at 5:58 PM Jayme <jaymef@gmail.com> wrote:
Ron, sorry to hear about the troubles. I haven't seen any gluster crashes yet *knock on wood*. I will monitor closely. Thanks for the heads up!
On Wed, Feb 13, 2019 at 5:09 PM Ron Jerome <ronjero@gmail.com> wrote:
Can you be more specific? What things did you see, and did you report
bugs?
I've got this one: https://bugzilla.redhat.com/show_bug.cgi?id=1649054 and this one: https://bugzilla.redhat.com/show_bug.cgi?id=1651246 and I've got bricks randomly going offline and getting out of sync with the others at which point I've had to manually stop and start the volume to get things back in sync. _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/site/privacy-policy/ oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/3RVMLCRK4BWCSB...

On Thu, Feb 14, 2019 at 2:39 AM Ron Jerome <ronjero@gmail.com> wrote:
Can you be more specific? What things did you see, and did you report bugs?
I've got this one: https://bugzilla.redhat.com/show_bug.cgi?id=1649054 and this one: https://bugzilla.redhat.com/show_bug.cgi?id=1651246 and I've got bricks randomly going offline and getting out of sync with the others at which point I've had to manually stop and start the volume to get things back in sync.
Thanks for reporting these. Will follow up on the bugs to ensure they're addressed. Regarding brciks going offline - are the brick processes crashing? Can you provide logs of glusterd and bricks. Or is this to do with ovirt-engine and brick status not being in sync?
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/site/privacy-policy/ oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/3RVMLCRK4BWCSB...

I was just helping Tristam on #ovirt with a similar problem, we found that his two upgraded nodes were running multiple glusterfsd processes per brick (but not all bricks). His volume & brick files in /var/lib/gluster looked normal, but starting glusterd would often spawn extra fsd processes per brick, seemed random. Gluster bug? Maybe related to https://bugzilla.redhat.com/show_bug.cgi?id=1651246 <https://bugzilla.redhat.com/show_bug.cgi?id=1651246>, but I’m helping debug this one second hand… Possibly related to the brick crashes? We wound up stopping glusterd, killing off all the fsds, restarting glusterd, and repeating until it only spawned one fsd per brick. Did that to each updated server, then restarted glusterd on the not-yet-updated server to get it talking to the right bricks. That seemed to get to a mostly stable gluster environment, but he’s still seeing 1-2 files listed as needing healing on the upgraded bricks (but not the 3.12 brick). Mainly the DIRECT_IO_TEST and one of the dom/ids files, but he can probably update that. Did manage to get his engine going again, waiting to see if he’s stable now. Anyway, figured it was worth posting about so people could check for multiple brick processes (glusterfsd) if they hit this stability issue as well, maybe find common ground. Note: also encountered https://bugzilla.redhat.com/show_bug.cgi?id=1348434 <https://bugzilla.redhat.com/show_bug.cgi?id=1348434> trying to get his engine back up, restarting libvirtd let us get it going again. Maybe un-needed if he’d been able to complete his third node upgrades, but he got stuck before then, so... -Darrell
On Feb 14, 2019, at 1:12 AM, Sahina Bose <sabose@redhat.com> wrote:
On Thu, Feb 14, 2019 at 2:39 AM Ron Jerome <ronjero@gmail.com> wrote:
Can you be more specific? What things did you see, and did you report bugs?
I've got this one: https://bugzilla.redhat.com/show_bug.cgi?id=1649054 and this one: https://bugzilla.redhat.com/show_bug.cgi?id=1651246 and I've got bricks randomly going offline and getting out of sync with the others at which point I've had to manually stop and start the volume to get things back in sync.
Thanks for reporting these. Will follow up on the bugs to ensure they're addressed. Regarding brciks going offline - are the brick processes crashing? Can you provide logs of glusterd and bricks. Or is this to do with ovirt-engine and brick status not being in sync?
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/site/privacy-policy/ oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/3RVMLCRK4BWCSB...
Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/site/privacy-policy/ oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/4PKJSVDIH3V4H7...

On 2/20/19 5:33 PM, Darrell Budic wrote:
I was just helping Tristam on #ovirt with a similar problem, we found that his two upgraded nodes were running multiple glusterfsd processes per brick (but not all bricks). His volume & brick files in /var/lib/gluster looked normal, but starting glusterd would often spawn extra fsd processes per brick, seemed random. Gluster bug? Maybe related to https://bugzilla.redhat.com/show_bug.cgi?id=1651246 <https://secure-web.cisco.com/11uS9v5-7B1hISSgr4n1jaC1x9yTQKn-73yRRcNpYlFWQuyAq0qlnLc5Vp-8-byYj9kreIYU4ghMQQNKCEaI_BIX0GplZhmYPkXpi0CoytAGS_00jcrCUb9H-8ZSLD6-FYCBtS5-28Mw4CLWzWB0MQkDiB8ETqmUBHAzqIjG0T4ZfgHocfHTHL8xH3rquO2fcZR5JUoz4vmdE0O9ENH1yTCUgjGvcVpNH5RuVtEqnECsa3by2QNcEShDk1r-ykY2jIpAhFbxqO9PdlDMEOHaPdqH1PYT1lS3m7zrqwMPyV_g3yBzcntqxG4iBi0tO_suG6xv5z6ENE0l-VjQlRTSb7GBdP9QwEz_tbU8Fak-wBWVPJoU_m2u17D_x3nfaQoSBrVkcsUni07c3L9UqQEMxbnf49B1wWf9ltawz9K0h41WxcPTiig5tgk2_Xvn-oEOq/https%3A%2F%2Fbugzilla.redhat.com%2Fshow_bug.cgi%3Fid%3D1651246>, but I’m helping debug this one second hand… Possibly related to the brick crashes? We wound up stopping glusterd, killing off all the fsds, restarting glusterd, and repeating until it only spawned one fsd per brick. Did that to each updated server, then restarted glusterd on the not-yet-updated server to get it talking to the right bricks. That seemed to get to a mostly stable gluster environment, but he’s still seeing 1-2 files listed as needing healing on the upgraded bricks (but not the 3.12 brick). Mainly the DIRECT_IO_TEST and one of the dom/ids files, but he can probably update that. Did manage to get his engine going again, waiting to see if he’s stable now.
Anyway, figured it was worth posting about so people could check for multiple brick processes (glusterfsd) if they hit this stability issue as well, maybe find common ground.
Note: also encountered https://bugzilla.redhat.com/show_bug.cgi?id=1348434 <https://secure-web.cisco.com/1CJbhPkGP3eo9xS3wOwhXfdnHZ0eGLtZYnuANAHXoIbmaNKsfRvhlux2NkAnSFtNdejSoaNsQadYcEOJ-ryAFMCZu0yth5hXlt4yNvrODtCDyr4E2UzZDLZnF2O7BRViiOoIc5ZxAYofY-YdGtOpjzGECO-df752kLvccOPRLiUmoMZz-LwfzLildypeMCjaAnFu1fvIikKKHD9v6_Scwjb9lk9yLtoEC2_WKkAGchpgrqX3VOLn0LBT78YoRWjRg6bBHSY4UTzGW5aDqRs6gthY2aeXrgbocpGxnI-NJKTghTAF_AiazNzS9O8Ma2PpntJXZkRVS_LvmB6jZhSS5SkbDOkpTnPrfxDyyA70d0OxXFHd6ZMiKtsUDJ00mDPObjj4tGATBxW8Ohby9iP7kPwZ8o5nIHPW-qr_u3kSviU6RNBPvc3eMmOe8zmBsgWZK/https%3A%2F%2Fbugzilla.redhat.com%2Fshow_bug.cgi%3Fid%3D1348434> trying to get his engine back up, restarting libvirtd let us get it going again. Maybe un-needed if he’d been able to complete his third node upgrades, but he got stuck before then, so...
-Darrell
Stable is a relative term. My unsynced entries total for each of my 4 volumes changes drastically (with the exception of the engine volume, it pretty much bounces between 1 and 4). The cluster has been "healing" for 18 hours or so and only the unupgraded HC node has healed bricks. I did have the problem that some files/directories were owned by root:root. These VMs did not boot until I changed ownership to 36:36. Even after 18 hours, there's anywhere from 20-386 entries in vol heal info for my 3 non engine bricks. Overnight I had one brick on one volume go down on one HC node. When I bounced glusterd, it brought up a new fsd process for that brick. I killed the old one and now vol status reports the right pid on each of the nodes. This is quite the debacle. If I can provide any info that might help get this debacle moving in the right direction, let me know. Jason aka Tristam
On Feb 14, 2019, at 1:12 AM, Sahina Bose <sabose@redhat.com <mailto:sabose@redhat.com>> wrote:
On Thu, Feb 14, 2019 at 2:39 AM Ron Jerome <ronjero@gmail.com <mailto:ronjero@gmail.com>> wrote:
Can you be more specific? What things did you see, and did you report bugs?
I've got this one: https://bugzilla.redhat.com/show_bug.cgi?id=1649054 <https://secure-web.cisco.com/1fdvHVkDZwPN_s0gUWUKOUmyHFx9oetGXKTmYB2gI-cqpT2dRWUd6Hhl4aNUKj1UFStmJ_ETSiVaDe858FH1sZMF7L033k-_bzU9OwljTte4lStS2YgGKNvBBzGDaJNIAE7rj1QtDimcP0iAnVz6kC_Z8ruqQrCGaiqUS7CzUj9IiqysqiTVk2rB0FdxamqBVOZM8E__MoWWH1-wLg5MOj1etVvC8awxKD-a5TG9yLALi4e2CLU-GKdAh3bliFFfIZdNct6AjSA5mAGLXiauAXqqhMfKj6tv42JsoHcmoLacD3Fr7wC61_BXVztc1XpJYCVjvdmmpCdveZrBfs80yxRt0zZoh6W4OBRcj1KThQciOBejCQ4_IqjFeJqBbQCYUXlAAk9nRuhMOP_t7UjnNI-khPI9_RtcUGUXnj_4ljx9FiA8yXJoNNMfsH76nYtvw/https%3A%2F%2Fbugzilla.redhat.com%2Fshow_bug.cgi%3Fid%3D1649054> and this one: https://bugzilla.redhat.com/show_bug.cgi?id=1651246 <https://secure-web.cisco.com/11uS9v5-7B1hISSgr4n1jaC1x9yTQKn-73yRRcNpYlFWQuyAq0qlnLc5Vp-8-byYj9kreIYU4ghMQQNKCEaI_BIX0GplZhmYPkXpi0CoytAGS_00jcrCUb9H-8ZSLD6-FYCBtS5-28Mw4CLWzWB0MQkDiB8ETqmUBHAzqIjG0T4ZfgHocfHTHL8xH3rquO2fcZR5JUoz4vmdE0O9ENH1yTCUgjGvcVpNH5RuVtEqnECsa3by2QNcEShDk1r-ykY2jIpAhFbxqO9PdlDMEOHaPdqH1PYT1lS3m7zrqwMPyV_g3yBzcntqxG4iBi0tO_suG6xv5z6ENE0l-VjQlRTSb7GBdP9QwEz_tbU8Fak-wBWVPJoU_m2u17D_x3nfaQoSBrVkcsUni07c3L9UqQEMxbnf49B1wWf9ltawz9K0h41WxcPTiig5tgk2_Xvn-oEOq/https%3A%2F%2Fbugzilla.redhat.com%2Fshow_bug.cgi%3Fid%3D1651246> and I've got bricks randomly going offline and getting out of sync with the others at which point I've had to manually stop and start the volume to get things back in sync.
Thanks for reporting these. Will follow up on the bugs to ensure they're addressed. Regarding brciks going offline - are the brick processes crashing? Can you provide logs of glusterd and bricks. Or is this to do with ovirt-engine and brick status not being in sync?
_______________________________________________ Users mailing list -- users@ovirt.org <mailto:users@ovirt.org> To unsubscribe send an email to users-leave@ovirt.org <mailto:users-leave@ovirt.org> Privacy Statement: https://www.ovirt.org/site/privacy-policy/ <https://secure-web.cisco.com/1ubMaXUij250PN8zKVQvmo6NUYWPOdVDirkU4lwkRkpCkQix6ZJlGJiEF1lWy8_04u2Ems0FwTKbgPFhm06jfILR59nJDNUIiCeN5YkYj0RU-r9UbaWrCmz_uLZJISuevoC0ELHCC121je2k5qatuVVcZL3XrG4eOeOFlhAd7riOB_HVcTdkWXGXF5hw6IiQj4E33rY5vEP9waE6nkhZO6bk08CLKlYrPyVF0o8d1-X8ntzhjWIE311h2ZNlu9KFarFqe5cckSGvVh1UiHQ3AKuBPZAvPKIH7KXsL6iFBNG-pJm-uVP27ZUnoeEQaG8kAVc6jW43e7fxfBUvrzmiFlQyD2o3HBrNNlbtHGjYU5Wy3Ao2H09QtCReoIaypCYbwS6Di3wqgY0lNuxB7swSo1vziW4Uez_j5sRmSl43UgIXzzjoeu4gWwRyfeteXo88x/https%3A%2F%2Fwww.ovirt.org%2Fsite%2Fprivacy-policy%2F> oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ <https://secure-web.cisco.com/1HjeIIkwx_NRkoCsnonfHu87z-MFaPfE3HOMBJ02Mzwyj-9AxzEENIuSMb_cTt98gAuZrWnSWq26-hUbz4lqcziFPWDUWOpWeYyBfQFYYld79cH960SfEhrOi44Gl9GDPCs27iXPJ1Kpxbp0t3iyi0HmC9QqLoXswWm8sIRPgvg4g1q9sSRKmrTyqylP8-MEETXdMXW-SwYeQT0I-_w1GH9VHOuy6cYf8bqaAwYFtAQ_TDrJX0atMmNh1bqDF3BLKxeXePEZCwqondC9a5ovB9-FzZcpUHrT4YK6gOIng55mdlAj6j-6lyw9N5gNXtfz9oq5DH78nE15q6iFyyEVG58pbrUje45FJdy9WsRRvNttcFbzgtb5E5-RtoFgdIYf5fJfchr0o1NVNHWpb1beyhLeM8_fS1Pzy-Fo8m0r_ZcYtOQ1WOdfE5fs5QRz2UVVZ/https%3A%2F%2Fwww.ovirt.org%2Fcommunity%2Fabout%2Fcommunity-guidelines%2F> List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/3RVMLCRK4BWCSB... <https://secure-web.cisco.com/1UWvyzTQ1hvgxQjlr5U2FtRchlkKEt3X3o8pIWpYnEnmcmJCwp9aSYXqRPagkIt4KGvzWQZxd0fuPK8nUqz8V7Xr16a3UOqQS5DSQfKb6DPGLb3r_729tIqayOG5pjIAHc4kJBaia7GifoZJVVIe3Ycuq8qMUSDu1aefJtSstLXG3XInCr3FgZC0FEc6-J7Y4KkHUFcln2v2Mm9Q9rzEwvFPsulMZHx9XhP8rgSyRzrc_mzAYR-aggc6vafvjnhGHt5S-yBmCA3bsV9UnIUhr8qaxSv3LyII3qYOnWuchFyMewkjV-5x71gefQIAEggPAfjrFP_RCwtdza6VMR0tR22tZGSyY7FATZLF1VADlg5wyBLITcp1LH6NQvMV3mY8nRJrEZ1kUCjEIZ2XcCDuPeIgrkYCERDrUTnAxEd7RBSAuV3-7MrVBJDLKgm622UEi/https%3A%2F%2Flists.ovirt.org%2Farchives%2Flist%2Fusers%40ovirt.org%2Fmessage%2F3RVMLCRK4BWCSBTWVXU2JTIDBWU7WEOP%2F>
Users mailing list -- users@ovirt.org <mailto:users@ovirt.org> To unsubscribe send an email to users-leave@ovirt.org <mailto:users-leave@ovirt.org> Privacy Statement: https://www.ovirt.org/site/privacy-policy/ <https://secure-web.cisco.com/1ubMaXUij250PN8zKVQvmo6NUYWPOdVDirkU4lwkRkpCkQix6ZJlGJiEF1lWy8_04u2Ems0FwTKbgPFhm06jfILR59nJDNUIiCeN5YkYj0RU-r9UbaWrCmz_uLZJISuevoC0ELHCC121je2k5qatuVVcZL3XrG4eOeOFlhAd7riOB_HVcTdkWXGXF5hw6IiQj4E33rY5vEP9waE6nkhZO6bk08CLKlYrPyVF0o8d1-X8ntzhjWIE311h2ZNlu9KFarFqe5cckSGvVh1UiHQ3AKuBPZAvPKIH7KXsL6iFBNG-pJm-uVP27ZUnoeEQaG8kAVc6jW43e7fxfBUvrzmiFlQyD2o3HBrNNlbtHGjYU5Wy3Ao2H09QtCReoIaypCYbwS6Di3wqgY0lNuxB7swSo1vziW4Uez_j5sRmSl43UgIXzzjoeu4gWwRyfeteXo88x/https%3A%2F%2Fwww.ovirt.org%2Fsite%2Fprivacy-policy%2F> oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ <https://secure-web.cisco.com/1HjeIIkwx_NRkoCsnonfHu87z-MFaPfE3HOMBJ02Mzwyj-9AxzEENIuSMb_cTt98gAuZrWnSWq26-hUbz4lqcziFPWDUWOpWeYyBfQFYYld79cH960SfEhrOi44Gl9GDPCs27iXPJ1Kpxbp0t3iyi0HmC9QqLoXswWm8sIRPgvg4g1q9sSRKmrTyqylP8-MEETXdMXW-SwYeQT0I-_w1GH9VHOuy6cYf8bqaAwYFtAQ_TDrJX0atMmNh1bqDF3BLKxeXePEZCwqondC9a5ovB9-FzZcpUHrT4YK6gOIng55mdlAj6j-6lyw9N5gNXtfz9oq5DH78nE15q6iFyyEVG58pbrUje45FJdy9WsRRvNttcFbzgtb5E5-RtoFgdIYf5fJfchr0o1NVNHWpb1beyhLeM8_fS1Pzy-Fo8m0r_ZcYtOQ1WOdfE5fs5QRz2UVVZ/https%3A%2F%2Fwww.ovirt.org%2Fcommunity%2Fabout%2Fcommunity-guidelines%2F> List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/4PKJSVDIH3V4H7... <https://secure-web.cisco.com/1kVJCekzD6OmVhEVJvL2ektzS5SnUq6q8sPriKIqMftlg0hG5PaqWRgPkpDqZAHTMmqyvoB7mfNSpfV8zxuM1mzW6ynMGx9WQVt5Xd_xCFgC2dbQ4PdR23vNl0msJXB--661UIZCEI1LSjddYeq1s5SlxRTydw_nXcxRNyZMRoY46Cx2EFcFKPfG7VSCp05HJOWrbzBs6VYxfhErvIGWF-CgsuFx2KmT0Jb_onCU8T-vFou3CCEULx6OetZEknFpNOqLlqawbeKAZUBUo7SDTIwhQrr65gGEMhEbjjqGBOD4VzBnBtW_6XGlUqjjwLhlKOMud9G6YgYJ94ZmCnchhJADgYHoOW7Wy5ICHvabShSuYp4dwQzQ58if9ffVhKTGOryRNgTscs_aM49L0b6ncLjJK_E1c2ry1DnnZ7VHufzjLpFT8iXfWWw-PW6UIEYAE/https%3A%2F%2Flists.ovirt.org%2Farchives%2Flist%2Fusers%40ovirt.org%2Fmessage%2F4PKJSVDIH3V4H7Q2RKS2C4ZUMWDODQY6%2F>
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://secure-web.cisco.com/1ubMaXUij250PN8zKVQvmo6NUYWPOdVDirkU4lwkRkpCkQi... oVirt Code of Conduct: https://secure-web.cisco.com/1HjeIIkwx_NRkoCsnonfHu87z-MFaPfE3HOMBJ02Mzwyj-9... List Archives: https://secure-web.cisco.com/1XcKrt1wH3y9o2mcDXqQa9v-MXc1VugRHkrHz1HJwNk-1Mv...
On Thu, Feb 21, 2019 at 12:42 PM Jason P. Thomas <jthomasp@gmualumni.org> wrote:
On 2/20/19 5:33 PM, Darrell Budic wrote:
I was just helping Tristam on #ovirt with a similar problem, we found that his two upgraded nodes were running multiple glusterfsd processes per brick (but not all bricks). His volume & brick files in /var/lib/gluster looked normal, but starting glusterd would often spawn extra fsd processes per brick, seemed random. Gluster bug? Maybe related to https://bugzilla.redhat.com/show_bug.cgi?id=1651246 <https://secure-web.cisco.com/11uS9v5-7B1hISSgr4n1jaC1x9yTQKn-73yRRcNpYlFWQuyAq0qlnLc5Vp-8-byYj9kreIYU4ghMQQNKCEaI_BIX0GplZhmYPkXpi0CoytAGS_00jcrCUb9H-8ZSLD6-FYCBtS5-28Mw4CLWzWB0MQkDiB8ETqmUBHAzqIjG0T4ZfgHocfHTHL8xH3rquO2fcZR5JUoz4vmdE0O9ENH1yTCUgjGvcVpNH5RuVtEqnECsa3by2QNcEShDk1r-ykY2jIpAhFbxqO9PdlDMEOHaPdqH1PYT1lS3m7zrqwMPyV_g3yBzcntqxG4iBi0tO_suG6xv5z6ENE0l-VjQlRTSb7GBdP9QwEz_tbU8Fak-wBWVPJoU_m2u17D_x3nfaQoSBrVkcsUni07c3L9UqQEMxbnf49B1wWf9ltawz9K0h41WxcPTiig5tgk2_Xvn-oEOq/https%3A%2F%2Fbugzilla.redhat.com%2Fshow_bug.cgi%3Fid%3D1651246>, but I’m helping debug this one second hand… Possibly related to the brick crashes? We wound up stopping glusterd, killing off all the fsds, restarting glusterd, and repeating until it only spawned one fsd per brick. Did that to each updated server, then restarted glusterd on the not-yet-updated server to get it talking to the right bricks. That seemed to get to a mostly stable gluster environment, but he’s still seeing 1-2 files listed as needing healing on the upgraded bricks (but not the 3.12 brick). Mainly the DIRECT_IO_TEST and one of the dom/ids files, but he can probably update that. Did manage to get his engine going again, waiting to see if he’s stable now.
Anyway, figured it was worth posting about so people could check for multiple brick processes (glusterfsd) if they hit this stability issue as well, maybe find common ground.
Note: also encountered https://bugzilla.redhat.com/show_bug.cgi?id=1348434 <https://secure-web.cisco.com/1CJbhPkGP3eo9xS3wOwhXfdnHZ0eGLtZYnuANAHXoIbmaNKsfRvhlux2NkAnSFtNdejSoaNsQadYcEOJ-ryAFMCZu0yth5hXlt4yNvrODtCDyr4E2UzZDLZnF2O7BRViiOoIc5ZxAYofY-YdGtOpjzGECO-df752kLvccOPRLiUmoMZz-LwfzLildypeMCjaAnFu1fvIikKKHD9v6_Scwjb9lk9yLtoEC2_WKkAGchpgrqX3VOLn0LBT78YoRWjRg6bBHSY4UTzGW5aDqRs6gthY2aeXrgbocpGxnI-NJKTghTAF_AiazNzS9O8Ma2PpntJXZkRVS_LvmB6jZhSS5SkbDOkpTnPrfxDyyA70d0OxXFHd6ZMiKtsUDJ00mDPObjj4tGATBxW8Ohby9iP7kPwZ8o5nIHPW-qr_u3kSviU6RNBPvc3eMmOe8zmBsgWZK/https%3A%2F%2Fbugzilla.redhat.com%2Fshow_bug.cgi%3Fid%3D1348434> trying to get his engine back up, restarting libvirtd let us get it going again. Maybe un-needed if he’d been able to complete his third node upgrades, but he got stuck before then, so...
-Darrell
Stable is a relative term. My unsynced entries total for each of my 4 volumes changes drastically (with the exception of the engine volume, it pretty much bounces between 1 and 4). The cluster has been "healing" for 18 hours or so and only the unupgraded HC node has healed bricks. I did have the problem that some files/directories were owned by root:root. These VMs did not boot until I changed ownership to 36:36. Even after 18 hours, there's anywhere from 20-386 entries in vol heal info for my 3 non engine bricks. Overnight I had one brick on one volume go down on one HC node. When I bounced glusterd, it brought up a new fsd process for that brick. I killed the old one and now vol status reports the right pid on each of the nodes. This is quite the debacle. If I can provide any info that might help get this debacle moving in the right direction, let me know.
+Sahina Bose <sabose@redhat.com>
Jason aka Tristam
On Feb 14, 2019, at 1:12 AM, Sahina Bose <sabose@redhat.com> wrote:
On Thu, Feb 14, 2019 at 2:39 AM Ron Jerome <ronjero@gmail.com> wrote:
Can you be more specific? What things did you see, and did you report bugs?
I've got this one: https://bugzilla.redhat.com/show_bug.cgi?id=1649054 <https://secure-web.cisco.com/1fdvHVkDZwPN_s0gUWUKOUmyHFx9oetGXKTmYB2gI-cqpT2dRWUd6Hhl4aNUKj1UFStmJ_ETSiVaDe858FH1sZMF7L033k-_bzU9OwljTte4lStS2YgGKNvBBzGDaJNIAE7rj1QtDimcP0iAnVz6kC_Z8ruqQrCGaiqUS7CzUj9IiqysqiTVk2rB0FdxamqBVOZM8E__MoWWH1-wLg5MOj1etVvC8awxKD-a5TG9yLALi4e2CLU-GKdAh3bliFFfIZdNct6AjSA5mAGLXiauAXqqhMfKj6tv42JsoHcmoLacD3Fr7wC61_BXVztc1XpJYCVjvdmmpCdveZrBfs80yxRt0zZoh6W4OBRcj1KThQciOBejCQ4_IqjFeJqBbQCYUXlAAk9nRuhMOP_t7UjnNI-khPI9_RtcUGUXnj_4ljx9FiA8yXJoNNMfsH76nYtvw/https%3A%2F%2Fbugzilla.redhat.com%2Fshow_bug.cgi%3Fid%3D1649054> and this one: https://bugzilla.redhat.com/show_bug.cgi?id=1651246 <https://secure-web.cisco.com/11uS9v5-7B1hISSgr4n1jaC1x9yTQKn-73yRRcNpYlFWQuyAq0qlnLc5Vp-8-byYj9kreIYU4ghMQQNKCEaI_BIX0GplZhmYPkXpi0CoytAGS_00jcrCUb9H-8ZSLD6-FYCBtS5-28Mw4CLWzWB0MQkDiB8ETqmUBHAzqIjG0T4ZfgHocfHTHL8xH3rquO2fcZR5JUoz4vmdE0O9ENH1yTCUgjGvcVpNH5RuVtEqnECsa3by2QNcEShDk1r-ykY2jIpAhFbxqO9PdlDMEOHaPdqH1PYT1lS3m7zrqwMPyV_g3yBzcntqxG4iBi0tO_suG6xv5z6ENE0l-VjQlRTSb7GBdP9QwEz_tbU8Fak-wBWVPJoU_m2u17D_x3nfaQoSBrVkcsUni07c3L9UqQEMxbnf49B1wWf9ltawz9K0h41WxcPTiig5tgk2_Xvn-oEOq/https%3A%2F%2Fbugzilla.redhat.com%2Fshow_bug.cgi%3Fid%3D1651246> and I've got bricks randomly going offline and getting out of sync with the others at which point I've had to manually stop and start the volume to get things back in sync.
Thanks for reporting these. Will follow up on the bugs to ensure they're addressed. Regarding brciks going offline - are the brick processes crashing? Can you provide logs of glusterd and bricks. Or is this to do with ovirt-engine and brick status not being in sync?
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/site/privacy-policy/ <https://secure-web.cisco.com/1ubMaXUij250PN8zKVQvmo6NUYWPOdVDirkU4lwkRkpCkQix6ZJlGJiEF1lWy8_04u2Ems0FwTKbgPFhm06jfILR59nJDNUIiCeN5YkYj0RU-r9UbaWrCmz_uLZJISuevoC0ELHCC121je2k5qatuVVcZL3XrG4eOeOFlhAd7riOB_HVcTdkWXGXF5hw6IiQj4E33rY5vEP9waE6nkhZO6bk08CLKlYrPyVF0o8d1-X8ntzhjWIE311h2ZNlu9KFarFqe5cckSGvVh1UiHQ3AKuBPZAvPKIH7KXsL6iFBNG-pJm-uVP27ZUnoeEQaG8kAVc6jW43e7fxfBUvrzmiFlQyD2o3HBrNNlbtHGjYU5Wy3Ao2H09QtCReoIaypCYbwS6Di3wqgY0lNuxB7swSo1vziW4Uez_j5sRmSl43UgIXzzjoeu4gWwRyfeteXo88x/https%3A%2F%2Fwww.ovirt.org%2Fsite%2Fprivacy-policy%2F> oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ <https://secure-web.cisco.com/1HjeIIkwx_NRkoCsnonfHu87z-MFaPfE3HOMBJ02Mzwyj-9AxzEENIuSMb_cTt98gAuZrWnSWq26-hUbz4lqcziFPWDUWOpWeYyBfQFYYld79cH960SfEhrOi44Gl9GDPCs27iXPJ1Kpxbp0t3iyi0HmC9QqLoXswWm8sIRPgvg4g1q9sSRKmrTyqylP8-MEETXdMXW-SwYeQT0I-_w1GH9VHOuy6cYf8bqaAwYFtAQ_TDrJX0atMmNh1bqDF3BLKxeXePEZCwqondC9a5ovB9-FzZcpUHrT4YK6gOIng55mdlAj6j-6lyw9N5gNXtfz9oq5DH78nE15q6iFyyEVG58pbrUje45FJdy9WsRRvNttcFbzgtb5E5-RtoFgdIYf5fJfchr0o1NVNHWpb1beyhLeM8_fS1Pzy-Fo8m0r_ZcYtOQ1WOdfE5fs5QRz2UVVZ/https%3A%2F%2Fwww.ovirt.org%2Fcommunity%2Fabout%2Fcommunity-guidelines%2F> List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/3RVMLCRK4BWCSB... <https://secure-web.cisco.com/1UWvyzTQ1hvgxQjlr5U2FtRchlkKEt3X3o8pIWpYnEnmcmJCwp9aSYXqRPagkIt4KGvzWQZxd0fuPK8nUqz8V7Xr16a3UOqQS5DSQfKb6DPGLb3r_729tIqayOG5pjIAHc4kJBaia7GifoZJVVIe3Ycuq8qMUSDu1aefJtSstLXG3XInCr3FgZC0FEc6-J7Y4KkHUFcln2v2Mm9Q9rzEwvFPsulMZHx9XhP8rgSyRzrc_mzAYR-aggc6vafvjnhGHt5S-yBmCA3bsV9UnIUhr8qaxSv3LyII3qYOnWuchFyMewkjV-5x71gefQIAEggPAfjrFP_RCwtdza6VMR0tR22tZGSyY7FATZLF1VADlg5wyBLITcp1LH6NQvMV3mY8nRJrEZ1kUCjEIZ2XcCDuPeIgrkYCERDrUTnAxEd7RBSAuV3-7MrVBJDLKgm622UEi/https%3A%2F%2Flists.ovirt.org%2Farchives%2Flist%2Fusers%40ovirt.org%2Fmessage%2F3RVMLCRK4BWCSBTWVXU2JTIDBWU7WEOP%2F>
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/site/privacy-policy/ <https://secure-web.cisco.com/1ubMaXUij250PN8zKVQvmo6NUYWPOdVDirkU4lwkRkpCkQix6ZJlGJiEF1lWy8_04u2Ems0FwTKbgPFhm06jfILR59nJDNUIiCeN5YkYj0RU-r9UbaWrCmz_uLZJISuevoC0ELHCC121je2k5qatuVVcZL3XrG4eOeOFlhAd7riOB_HVcTdkWXGXF5hw6IiQj4E33rY5vEP9waE6nkhZO6bk08CLKlYrPyVF0o8d1-X8ntzhjWIE311h2ZNlu9KFarFqe5cckSGvVh1UiHQ3AKuBPZAvPKIH7KXsL6iFBNG-pJm-uVP27ZUnoeEQaG8kAVc6jW43e7fxfBUvrzmiFlQyD2o3HBrNNlbtHGjYU5Wy3Ao2H09QtCReoIaypCYbwS6Di3wqgY0lNuxB7swSo1vziW4Uez_j5sRmSl43UgIXzzjoeu4gWwRyfeteXo88x/https%3A%2F%2Fwww.ovirt.org%2Fsite%2Fprivacy-policy%2F> oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ <https://secure-web.cisco.com/1HjeIIkwx_NRkoCsnonfHu87z-MFaPfE3HOMBJ02Mzwyj-9AxzEENIuSMb_cTt98gAuZrWnSWq26-hUbz4lqcziFPWDUWOpWeYyBfQFYYld79cH960SfEhrOi44Gl9GDPCs27iXPJ1Kpxbp0t3iyi0HmC9QqLoXswWm8sIRPgvg4g1q9sSRKmrTyqylP8-MEETXdMXW-SwYeQT0I-_w1GH9VHOuy6cYf8bqaAwYFtAQ_TDrJX0atMmNh1bqDF3BLKxeXePEZCwqondC9a5ovB9-FzZcpUHrT4YK6gOIng55mdlAj6j-6lyw9N5gNXtfz9oq5DH78nE15q6iFyyEVG58pbrUje45FJdy9WsRRvNttcFbzgtb5E5-RtoFgdIYf5fJfchr0o1NVNHWpb1beyhLeM8_fS1Pzy-Fo8m0r_ZcYtOQ1WOdfE5fs5QRz2UVVZ/https%3A%2F%2Fwww.ovirt.org%2Fcommunity%2Fabout%2Fcommunity-guidelines%2F> List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/4PKJSVDIH3V4H7... <https://secure-web.cisco.com/1kVJCekzD6OmVhEVJvL2ektzS5SnUq6q8sPriKIqMftlg0hG5PaqWRgPkpDqZAHTMmqyvoB7mfNSpfV8zxuM1mzW6ynMGx9WQVt5Xd_xCFgC2dbQ4PdR23vNl0msJXB--661UIZCEI1LSjddYeq1s5SlxRTydw_nXcxRNyZMRoY46Cx2EFcFKPfG7VSCp05HJOWrbzBs6VYxfhErvIGWF-CgsuFx2KmT0Jb_onCU8T-vFou3CCEULx6OetZEknFpNOqLlqawbeKAZUBUo7SDTIwhQrr65gGEMhEbjjqGBOD4VzBnBtW_6XGlUqjjwLhlKOMud9G6YgYJ94ZmCnchhJADgYHoOW7Wy5ICHvabShSuYp4dwQzQ58if9ffVhKTGOryRNgTscs_aM49L0b6ncLjJK_E1c2ry1DnnZ7VHufzjLpFT8iXfWWw-PW6UIEYAE/https%3A%2F%2Flists.ovirt.org%2Farchives%2Flist%2Fusers%40ovirt.org%2Fmessage%2F4PKJSVDIH3V4H7Q2RKS2C4ZUMWDODQY6%2F>
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://secure-web.cisco.com/1ubMaXUij250PN8zKVQvmo6NUYWPOdVDirkU4lwkRkpCkQi... oVirt Code of Conduct: https://secure-web.cisco.com/1HjeIIkwx_NRkoCsnonfHu87z-MFaPfE3HOMBJ02Mzwyj-9... List Archives: https://secure-web.cisco.com/1XcKrt1wH3y9o2mcDXqQa9v-MXc1VugRHkrHz1HJwNk-1Mv...
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/site/privacy-policy/ oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/O2WI5F77DVZ3HZ...
-- GREG SHEREMETA SENIOR SOFTWARE ENGINEER - TEAM LEAD - RHV UX Red Hat NA <https://www.redhat.com/> gshereme@redhat.com IRC: gshereme <https://red.ht/sig>
On Thu, Feb 21, 2019 at 11:11 PM Jason P. Thomas <jthomasp@gmualumni.org> wrote:
On 2/20/19 5:33 PM, Darrell Budic wrote:
I was just helping Tristam on #ovirt with a similar problem, we found that his two upgraded nodes were running multiple glusterfsd processes per brick (but not all bricks). His volume & brick files in /var/lib/gluster looked normal, but starting glusterd would often spawn extra fsd processes per brick, seemed random. Gluster bug? Maybe related to https://bugzilla.redhat.com/show_bug.cgi?id=1651246, but I’m helping debug this one second hand… Possibly related to the brick crashes? We wound up stopping glusterd, killing off all the fsds, restarting glusterd, and repeating until it only spawned one fsd per brick. Did that to each updated server, then restarted glusterd on the not-yet-updated server to get it talking to the right bricks. That seemed to get to a mostly stable gluster environment, but he’s still seeing 1-2 files listed as needing healing on the upgraded bricks (but not the 3.12 brick). Mainly the DIRECT_IO_TEST and one of the dom/ids files, but he can probably update that. Did manage to get his engine going again, waiting to see if he’s stable now.
Anyway, figured it was worth posting about so people could check for multiple brick processes (glusterfsd) if they hit this stability issue as well, maybe find common ground.
Note: also encountered https://bugzilla.redhat.com/show_bug.cgi?id=1348434 trying to get his engine back up, restarting libvirtd let us get it going again. Maybe un-needed if he’d been able to complete his third node upgrades, but he got stuck before then, so...
-Darrell
Stable is a relative term. My unsynced entries total for each of my 4 volumes changes drastically (with the exception of the engine volume, it pretty much bounces between 1 and 4). The cluster has been "healing" for 18 hours or so and only the unupgraded HC node has healed bricks. I did have the problem that some files/directories were owned by root:root. These VMs did not boot until I changed ownership to 36:36. Even after 18 hours, there's anywhere from 20-386 entries in vol heal info for my 3 non engine bricks. Overnight I had one brick on one volume go down on one HC node. When I bounced glusterd, it brought up a new fsd process for that brick. I killed the old one and now vol status reports the right pid on each of the nodes. This is quite the debacle. If I can provide any info that might help get this debacle moving in the right direction, let me know.
Can you provide the gluster brick logs and glusterd logs from the servers (from /var/log/glusterfs/). Since you mention that heal seems to be stuck, could you also provide the heal logs from /var/log/glusterfs/glustershd.log If you can log a bug with these logs, that would be great - please use https://bugzilla.redhat.com/enter_bug.cgi?product=GlusterFS to log the bug.
Jason aka Tristam
On Feb 14, 2019, at 1:12 AM, Sahina Bose <sabose@redhat.com> wrote:
On Thu, Feb 14, 2019 at 2:39 AM Ron Jerome <ronjero@gmail.com> wrote:
Can you be more specific? What things did you see, and did you report bugs?
I've got this one: https://bugzilla.redhat.com/show_bug.cgi?id=1649054 and this one: https://bugzilla.redhat.com/show_bug.cgi?id=1651246 and I've got bricks randomly going offline and getting out of sync with the others at which point I've had to manually stop and start the volume to get things back in sync.
Thanks for reporting these. Will follow up on the bugs to ensure they're addressed. Regarding brciks going offline - are the brick processes crashing? Can you provide logs of glusterd and bricks. Or is this to do with ovirt-engine and brick status not being in sync?
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/site/privacy-policy/ oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/3RVMLCRK4BWCSB...
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/site/privacy-policy/ oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/4PKJSVDIH3V4H7...
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://secure-web.cisco.com/1ubMaXUij250PN8zKVQvmo6NUYWPOdVDirkU4lwkRkpCkQi... oVirt Code of Conduct: https://secure-web.cisco.com/1HjeIIkwx_NRkoCsnonfHu87z-MFaPfE3HOMBJ02Mzwyj-9... List Archives: https://secure-web.cisco.com/1XcKrt1wH3y9o2mcDXqQa9v-MXc1VugRHkrHz1HJwNk-1Mv...
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/site/privacy-policy/ oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/O2WI5F77DVZ3HZ...
On 2/25/19 3:49 AM, Sahina Bose wrote:
On Thu, Feb 21, 2019 at 11:11 PM Jason P. Thomas <jthomasp@gmualumni.org> wrote:
On 2/20/19 5:33 PM, Darrell Budic wrote:
I was just helping Tristam on #ovirt with a similar problem, we found that his two upgraded nodes were running multiple glusterfsd processes per brick (but not all bricks). His volume & brick files in /var/lib/gluster looked normal, but starting glusterd would often spawn extra fsd processes per brick, seemed random. Gluster bug? Maybe related to https://secure-web.cisco.com/1zutsPlj0TjKvDiGvxmw5PZZPUoEtpkcJqhpWGvx2-fJoEM..., but I’m helping debug this one second hand… Possibly related to the brick crashes? We wound up stopping glusterd, killing off all the fsds, restarting glusterd, and repeating until it only spawned one fsd per brick. Did that to each updated server, then restarted glusterd on the not-yet-updated server to get it talking to the right bricks. That seemed to get to a mostly stable gluster environment, but he’s still seeing 1-2 files listed as needing healing on the upgraded bricks (but not the 3.12 brick). Mainly the DIRECT_IO_TEST and one of the dom/ids files, but he can probably update that. Did manage to get his engine going again, waiting to see if he’s stable now.
Anyway, figured it was worth posting about so people could check for multiple brick processes (glusterfsd) if they hit this stability issue as well, maybe find common ground.
Note: also encountered https://secure-web.cisco.com/1eMDo5MMs_aJ6TOHBckwoG7rBeXsvPoHI01UBZ8YJ2GnI4d... trying to get his engine back up, restarting libvirtd let us get it going again. Maybe un-needed if he’d been able to complete his third node upgrades, but he got stuck before then, so...
-Darrell
Stable is a relative term. My unsynced entries total for each of my 4 volumes changes drastically (with the exception of the engine volume, it pretty much bounces between 1 and 4). The cluster has been "healing" for 18 hours or so and only the unupgraded HC node has healed bricks. I did have the problem that some files/directories were owned by root:root. These VMs did not boot until I changed ownership to 36:36. Even after 18 hours, there's anywhere from 20-386 entries in vol heal info for my 3 non engine bricks. Overnight I had one brick on one volume go down on one HC node. When I bounced glusterd, it brought up a new fsd process for that brick. I killed the old one and now vol status reports the right pid on each of the nodes. This is quite the debacle. If I can provide any info that might help get this debacle moving in the right direction, let me know. Can you provide the gluster brick logs and glusterd logs from the servers (from /var/log/glusterfs/). Since you mention that heal seems to be stuck, could you also provide the heal logs from /var/log/glusterfs/glustershd.log If you can log a bug with these logs, that would be great - please use https://secure-web.cisco.com/1u1JXUFgLqfmecw2r1a0ZiPWiR0AlgZ1-8A3Ax1bpyCysNv... to log the bug. I've filed Bug 1682925 <https://bugzilla.redhat.com/show_bug.cgi?id=1682925> with the requested logs during the time frame I experienced issues. Sorry for the delay, I was out of the office Friday and this morning.
Jason
Jason aka Tristam
On Feb 14, 2019, at 1:12 AM, Sahina Bose <sabose@redhat.com> wrote:
On Thu, Feb 14, 2019 at 2:39 AM Ron Jerome <ronjero@gmail.com> wrote:
Can you be more specific? What things did you see, and did you report bugs?
I've got this one: https://secure-web.cisco.com/13CTqpVLySHJsr0ExmooX7-Akp0iAcz1X7qikVLAWiuwjZE... and this one: https://secure-web.cisco.com/1zutsPlj0TjKvDiGvxmw5PZZPUoEtpkcJqhpWGvx2-fJoEM... and I've got bricks randomly going offline and getting out of sync with the others at which point I've had to manually stop and start the volume to get things back in sync.
Thanks for reporting these. Will follow up on the bugs to ensure they're addressed. Regarding brciks going offline - are the brick processes crashing? Can you provide logs of glusterd and bricks. Or is this to do with ovirt-engine and brick status not being in sync?
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://secure-web.cisco.com/1nEZk1HmmOVHI5jAXqISs80YRB-SbMsrunxvZ9XJpVCVvb-... oVirt Code of Conduct: https://secure-web.cisco.com/12Y4LEt9YRdw8K3OrOj6uPi27aZWSQ67hHP7OnuT4WeYOww... List Archives: https://secure-web.cisco.com/1ZrjEv46RcxAUmSm9tzKCuYdZL9varvvxSuqJiTCcGl2sv0...
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://secure-web.cisco.com/1nEZk1HmmOVHI5jAXqISs80YRB-SbMsrunxvZ9XJpVCVvb-... oVirt Code of Conduct: https://secure-web.cisco.com/12Y4LEt9YRdw8K3OrOj6uPi27aZWSQ67hHP7OnuT4WeYOww... List Archives: https://secure-web.cisco.com/1KzN5tLsiJy3-g9yYcOx5d8B1oOe9PrxbORUgNL0FrN3Wvl...
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://secure-web.cisco.com/1ubMaXUij250PN8zKVQvmo6NUYWPOdVDirkU4lwkRkpCkQi... oVirt Code of Conduct: https://secure-web.cisco.com/1HjeIIkwx_NRkoCsnonfHu87z-MFaPfE3HOMBJ02Mzwyj-9... List Archives: https://secure-web.cisco.com/1XcKrt1wH3y9o2mcDXqQa9v-MXc1VugRHkrHz1HJwNk-1Mv...
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://secure-web.cisco.com/1nEZk1HmmOVHI5jAXqISs80YRB-SbMsrunxvZ9XJpVCVvb-... oVirt Code of Conduct: https://secure-web.cisco.com/12Y4LEt9YRdw8K3OrOj6uPi27aZWSQ67hHP7OnuT4WeYOww... List Archives: https://secure-web.cisco.com/1VHG2GaLSYhMlJRaVcbioIc6zcifQKoE2LPKzsOAGjti4Ap...
Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://secure-web.cisco.com/1nEZk1HmmOVHI5jAXqISs80YRB-SbMsrunxvZ9XJpVCVvb-... oVirt Code of Conduct: https://secure-web.cisco.com/12Y4LEt9YRdw8K3OrOj6uPi27aZWSQ67hHP7OnuT4WeYOww... List Archives: https://secure-web.cisco.com/1Ww442-q18Ni2CsDxBntfOz7M8DrE6wAzkG6fJ0CeCJ_Jji...
This may be happening because I changed cluster compatibility to 4.3 then immediately after changed data center compatibility to 4.3 (before restarting VMs after cluster compatibility change). If this is the case I can't fix by downgrading the data center compatibility to 4.2 as it won't allow me to do so. What can I do to fix this, any VM I restart will break (I am leaving the others running for now, but there are some down that I can't start).
It would seem you ran into the "next" issue that I also ran into. During the upgrade process, the ownership of the disk image of the running VM's gets changed from vdsm.kvm to root.root. (see https://lists.ovirt.org/archives/list/users@ovirt.org/thread/6JFTGJ37KDZQ5KM...) You need to find those disk images and change the ownership back to vdsm.kvm then they will boot again.
participants (7)
-
 Darrell Budic
Darrell Budic -
 Greg Sheremeta
Greg Sheremeta -
 Jason P. Thomas
Jason P. Thomas -
 Jayme
Jayme -
 Ron Jerome
Ron Jerome -
 Sahina Bose
Sahina Bose -
 Simone Tiraboschi
Simone Tiraboschi