Something broke & took down multiple VMs for ~20 minutes

As the subject suggestions, something in oVirt HCI broke. I have no idea what, and it recovered on its own after about 20 minutes or so. I believe that the issue was limited to a single host (although I don't know that for sure), as we had two VMs go completely unresponsive, but a 3rd VM remained operational. For a while during the outage, I was able to log into the oVirt admin web portal, and I noticed at least 1-2 of my hosts (I have 3 hosts) showed the problematic VMs as being problematic inside of oVirt. Reviewing the oVirt Events, I see that this basically started right when the ETL Service Started. There were no events before that point since yesterday, but right when the ETL Service started, it seems like all hell broke loose. oVirt detected "No faulty multipaths" on any of the hosts, but then very quickly started indicating that hosts, vms, and storage targets were unavailable. See my screenshot below. Around 30 - 35 minutes later, it appears that the Hosted Engine terminated due to a storage issue, and auto recovered on a different host. There's a 2nd screenshot beneath the first. Everything came back up shortly before 9am, and has been stable since. In fact, the Volume replication issues that I saw in my environment after I performed maintenance on 1 of my hosts on Friday are no longer present. It appears that the Hosted Engine sees the storage as being perfectly healthy. How do I even begin to figure out what happened, and try to prevent it from happening again? [Screenshot from 2021-04-26 16-36-47.png] [Screenshot from 2021-04-26 16-44-08.png] Sent with ProtonMail Secure Email.
{kind=link}
{kind=link}

Check '/var/log/messages' and 'journalctl' for the affected host. Try to identify if you got a Network issue.Next check gluster logs on the affected host (both bricks and fuse client). Of course, you should also check the engine's logs. This sounds like your gluster problem "escalated" and cause the outage for the affected VMs. Usually, when I have issues with a host - I just put it down to maintenance with the checkmark to stop Gluster services. Once it completes , activate. Best Regards,Strahil Nikolov On Mon, Apr 26, 2021 at 23:51, David White via Users<users@ovirt.org> wrote: As the subject suggestions, something in oVirt HCI broke. I have no idea what, and it recovered on its own after about 20 minutes or so. I believe that the issue was limited to a single host (although I don't know that for sure), as we had two VMs go completely unresponsive, but a 3rd VM remained operational. For a while during the outage, I was able to log into the oVirt admin web portal, and I noticed at least 1-2 of my hosts (I have 3 hosts) showed the problematic VMs as being problematic inside of oVirt. Reviewing the oVirt Events, I see that this basically started right when the ETL Service Started. There were no events before that point since yesterday, but right when the ETL Service started, it seems like all hell broke loose. oVirt detected "No faulty multipaths" on any of the hosts, but then very quickly started indicating that hosts, vms, and storage targets were unavailable. See my screenshot below. Around 30 - 35 minutes later, it appears that the Hosted Engine terminated due to a storage issue, and auto recovered on a different host. There's a 2nd screenshot beneath the first. Everything came back up shortly before 9am, and has been stable since. In fact, the Volume replication issues that I saw in my environment after I performed maintenance on 1 of my hosts on Friday are no longer present. It appears that the Hosted Engine sees the storage as being perfectly healthy. How do I even begin to figure out what happened, and try to prevent it from happening again? Sent with ProtonMail Secure Email. _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/K5UJJNQXHAGMRV...
{kind=link}
{kind=link}
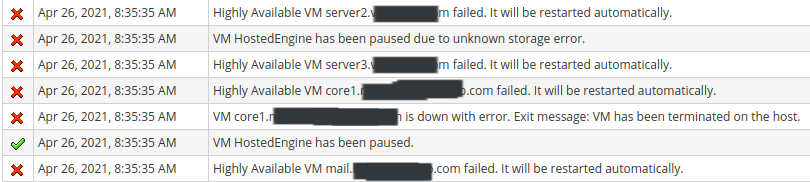
The same exact problem occurred this morning, at approximately the same time (Monday morning, right around 8:00am Eastern Time) as before (14 days ago). I see that "ETL Service Started" in the logs. And then, after that, all hell broke loose, and I lost access to the whole environment before the engine came back online. When I logged into the oVirt admin portal / Engine web UI, most VMs were healthy (again, after they were all down for a brief period of time), but 2-3 of the VMs were in a paused state. I wound up having to power them down before they would come back online. This time, unlike 14 days ago, all 3 volumes and bricks were healthy. Gluster replication between the hosts wasn't behind or anything. I need to track down why this is happening, and try to prevent it. Right now, I only have 1Gbps connectivity on the storage network. Is it possible that the storage network is getting too congested? Are there any logs or indicators I can look for to find out if that is the case of the problem?I do have 10Gbps network cards, but have only installed that onto 1 of the hosts. I still need to install onto the other two hosts. Anything else to look for? Sent with ProtonMail Secure Email. ‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Monday, April 26, 2021 11:30 PM, Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Check '/var/log/messages' and 'journalctl' for the affected host. Try to identify if you got a Network issue. Next check gluster logs on the affected host (both bricks and fuse client).
Of course, you should also check the engine's logs.
This sounds like your gluster problem "escalated" and cause the outage for the affected VMs.
Usually, when I have issues with a host - I just put it down to maintenance with the checkmark to stop Gluster services. Once it completes , activate.
Best Regards, Strahil Nikolov
On Mon, Apr 26, 2021 at 23:51, David White via Users <users@ovirt.org> wrote: As the subject suggestions, something in oVirt HCI broke. I have no idea what, and it recovered on its own after about 20 minutes or so.
I believe that the issue was limited to a single host (although I don't know that for sure), as we had two VMs go completely unresponsive, but a 3rd VM remained operational. For a while during the outage, I was able to log into the oVirt admin web portal, and I noticed at least 1-2 of my hosts (I have 3 hosts) showed the problematic VMs as being problematic inside of oVirt.
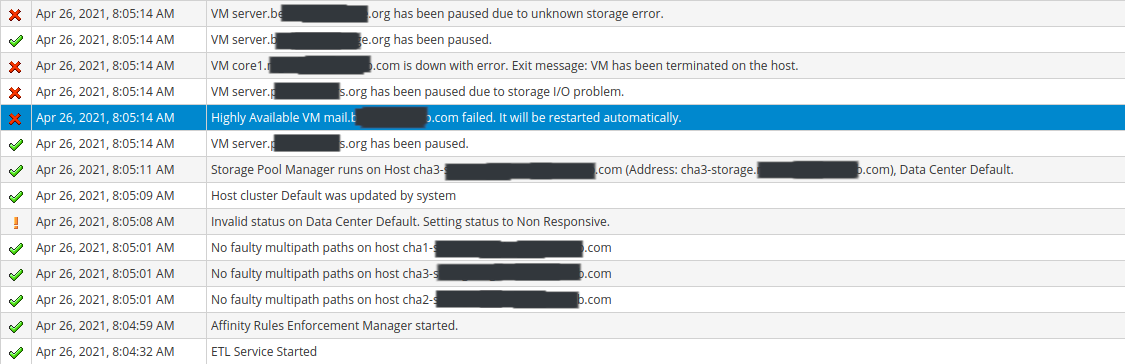
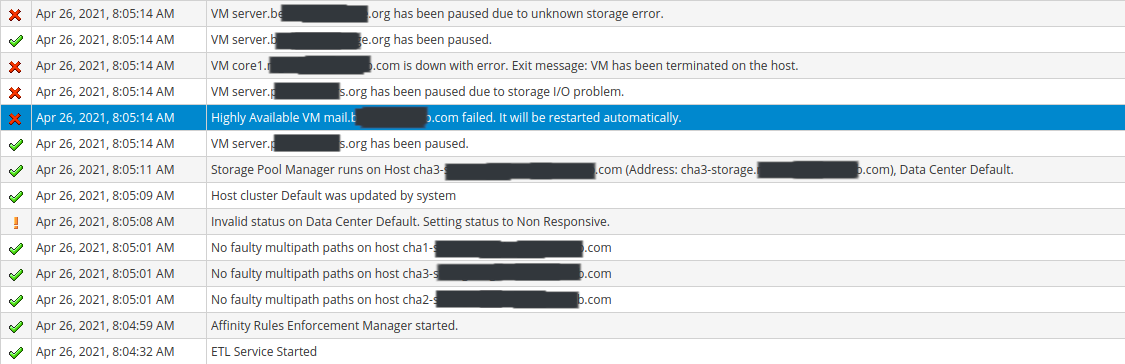
Reviewing the oVirt Events, I see that this basically started right when the ETL Service Started. There were no events before that point since yesterday, but right when the ETL Service started, it seems like all hell broke loose.
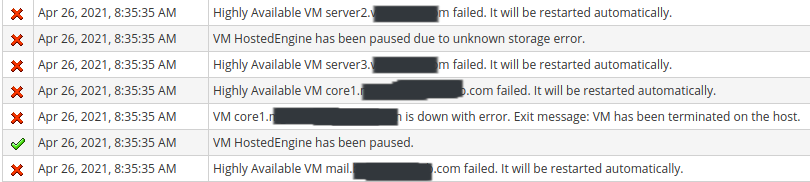
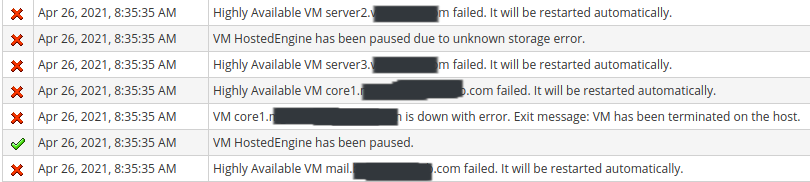
oVirt detected "No faulty multipaths" on any of the hosts, but then very quickly started indicating that hosts, vms, and storage targets were unavailable. See my screenshot below. Around 30 - 35 minutes later, it appears that the Hosted Engine terminated due to a storage issue, and auto recovered on a different host. There's a 2nd screenshot beneath the first.
Everything came back up shortly before 9am, and has been stable since. In fact, the Volume replication issues that I saw in my environment after I performed maintenance on 1 of my hosts on Friday are no longer present. It appears that the Hosted Engine sees the storage as being perfectly healthy.
How do I even begin to figure out what happened, and try to prevent it from happening again?
[Screenshot from 2021-04-26 16-36-47.png]
[Screenshot from 2021-04-26 16-44-08.png]
Sent with ProtonMail Secure Email.
_______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/K5UJJNQXHAGMRV...
{kind=link}
{kind=link}
The symptoms are similar to a loss of quorum (like in a network outage/disruption). Check the gluster logs for any indication of the root cause.As you have only one gigabit network, consider enabling cluster choose-local option which will make FUSE client to try to read from local brick instead of a remote one. Theoretically congestion on storage network could be the root cause, but this is usually a symptom and not the real problem. Maybe you got too many backups running in parallel ? Best Regards,Strahil Nikolov On Mon, May 10, 2021 at 19:13, David White via Users<users@ovirt.org> wrote: _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/DOI6BEFMTS3PEE...
I'm not sure what to make of this, but looking at /var/log/messages on all 3 of the hosts,it appears that the kernel disabled my oVirt networks at the same exact time on all 3 hosts. This occurred twice this morning, once around 8am and again around 8:30am: ovirtmgmt is the storage network. Private is the frond-end network. I actually don't have *any* backup storage domains currently, and no backups to speak of, so that wouldn't have been a cause from this morning. My goal for this week is to install a 4th physical server with some spinning disks, and expose those as an NFS mount point so that I can build a backup domain. I also hope to get the 10Gbps network cards installed on the remaining two hosts, to get 10Gbps connectivity up and running between all 3 of the HCI hosts. Host 1May 10 08:00:23 cha1-storage kernel: tg3 0000:04:00.0 enp4s0f0: Link is downMay 10 08:00:23 cha1-storage kernel: ovirtmgmt: port 1(enp4s0f0) entered disabled stateMay 10 08:00:23 cha1-storage kernel: tg3 0000:01:00.0 eno1: Link is downMay 10 08:00:24 cha1-storage kernel: Private: port 1(eno1) entered disabled state{snip}May 10 08:01:10 cha1-storage kernel: tg3 0000:01:00.0 eno1: Link is up at 1000 Mbps, full duplexMay 10 08:01:10 cha1-storage kernel: tg3 0000:01:00.0 eno1: Flow control is off for TX and off for RXMay 10 08:01:10 cha1-storage kernel: tg3 0000:01:00.0 eno1: EEE is disabledMay 10 08:01:10 cha1-storage kernel: Private: port 1(eno1) entered blocking stateMay 10 08:01:10 cha1-storage kernel: Private: port 1(eno1) entered forwarding stateMay 10 08:01:10 cha1-storage NetworkManager[1805]: <info> [1620648070.6021] device (eno1): carrier: link connectedMay 10 08:30:01 cha1-storage kernel: tg3 0000:04:00.0 enp4s0f0: Link is downMay 10 08:30:01 cha1-storage kernel: ovirtmgmt: port 1(enp4s0f0) entered disabled stateMay 10 08:30:01 cha1-storage systemd[1]: Starting system activity accounting tool...May 10 08:30:01 cha1-storage systemd[1]: sysstat-collect.service: Succeeded.May 10 08:30:01 cha1-storage systemd[1]: Started system activity accounting tool.May 10 08:30:01 cha1-storage kernel: tg3 0000:01:00.0 eno1: Link is downMay 10 08:30:02 cha1-storage kernel: Private: port 1(eno1) entered disabled state{snip}May 10 08:30:47 cha1-storage kernel: tg3 0000:01:00.0 eno1: Link is up at 1000 Mbps, full duplexMay 10 08:30:47 cha1-storage kernel: tg3 0000:01:00.0 eno1: Flow control is off for TX and off for RXMay 10 08:30:47 cha1-storage kernel: tg3 0000:01:00.0 eno1: EEE is disabledMay 10 08:30:47 cha1-storage kernel: Private: port 1(eno1) entered blocking stateMay 10 08:30:47 cha1-storage kernel: Private: port 1(eno1) entered forwarding stateMay 10 08:30:47 cha1-storage NetworkManager[1805]: <info> [1620649847.8592] device (eno1): carrier: link connectedMay 10 08:30:47 cha1-storage NetworkManager[1805]: <info> [1620649847.8602] device (Private): carrier: link connectedHost 2May 10 08:00:23 cha2-storage kernel: ixgbe 0000:01:00.1 eno2: NIC Link is DownMay 10 08:00:23 cha2-storage kernel: ovirtmgmt: port 1(eno2) entered disabled stateMay 10 08:00:23 cha2-storage kernel: ixgbe 0000:01:00.0 eno1: NIC Link is DownMay 10 08:00:24 cha2-storage kernel: Private: port 1(eno1) entered disabled state{snip}May 10 08:01:10 cha2-storage kernel: ixgbe 0000:01:00.0 eno1: NIC Link is Up 1 Gbps, Flow Control: NoneMay 10 08:01:10 cha2-storage kernel: Private: port 1(eno1) entered blocking stateMay 10 08:01:10 cha2-storage kernel: Private: port 1(eno1) entered forwarding stateMay 10 08:01:10 cha2-storage NetworkManager[16957]: <info> [1620648070.1303] device (eno1): carrier: link connected{snip}May 10 08:30:01 cha2-storage kernel: ixgbe 0000:01:00.1 eno2: NIC Link is DownMay 10 08:30:01 cha2-storage kernel: ovirtmgmt: port 1(eno2) entered disabled stateMay 10 08:30:01 cha2-storage systemd[1]: Starting system activity accounting tool...May 10 08:30:01 cha2-storage systemd[1]: sysstat-collect.service: Succeeded.May 10 08:30:01 cha2-storage systemd[1]: Started system activity accounting tool.May 10 08:30:01 cha2-storage kernel: ixgbe 0000:01:00.0 eno1: NIC Link is DownMay 10 08:30:02 cha2-storage kernel: Private: port 1(eno1) entered disabled state{snip}May 10 08:30:47 cha2-storage kernel: ixgbe 0000:01:00.0 eno1: NIC Link is Up 1 Gbps, Flow Control: NoneMay 10 08:30:47 cha2-storage kernel: Private: port 1(eno1) entered blocking stateMay 10 08:30:47 cha2-storage kernel: Private: port 1(eno1) entered forwarding stateMay 10 08:30:47 cha2-storage NetworkManager[16957]: <info> [1620649847.5041] device (eno1): carrier: link connectedHost 3May 10 08:00:23 cha3-storage kernel: tg3 0000:01:00.0 eno1: Link is downMay 10 08:00:24 cha3-storage journal[2196]: Guest agent is not responding: Guest agent not available for nowMay 10 08:00:24 cha3-storage kernel: Private: port 1(eno1) entered disabled stateMay 10 08:00:30 cha3-storage journal[2196]: Guest agent is not responding: Guest agent not available for now{snip}May 10 08:01:10 cha3-storage sanlock[1477]: 2021-05-10 08:01:10 490364 [17727]: s4 renewal error -107 delta_length 0 last_success 490310May 10 08:01:10 cha3-storage kernel: tg3 0000:01:00.0 eno1: Link is up at 1000 Mbps, full duplexMay 10 08:01:10 cha3-storage kernel: tg3 0000:01:00.0 eno1: Flow control is off for TX and off for RXMay 10 08:01:10 cha3-storage kernel: tg3 0000:01:00.0 eno1: EEE is disabledMay 10 08:01:10 cha3-storage kernel: Private: port 1(eno1) entered blocking stateMay 10 08:01:10 cha3-storage kernel: Private: port 1(eno1) entered forwarding stateMay 10 08:01:10 cha3-storage NetworkManager[1812]: <info> [1620648070.5575] device (eno1): carrier: link connected{snip}May 10 08:30:01 cha3-storage kernel: tg3 0000:04:00.0 enp4s0f0: Link is downMay 10 08:30:01 cha3-storage kernel: ovirtmgmt: port 1(enp4s0f0) entered disabled stateMay 10 08:30:01 cha3-storage kernel: tg3 0000:01:00.0 eno1: Link is downMay 10 08:30:02 cha3-storage kernel: Private: port 1(eno1) entered disabled state{snip}May 10 08:30:48 cha3-storage kernel: tg3 0000:01:00.0 eno1: Link is up at 1000 Mbps, full duplexMay 10 08:30:48 cha3-storage kernel: tg3 0000:01:00.0 eno1: Flow control is off for TX and off for RXMay 10 08:30:48 cha3-storage kernel: tg3 0000:01:00.0 eno1: EEE is disabledMay 10 08:30:48 cha3-storage kernel: Private: port 1(eno1) entered blocking stateMay 10 08:30:48 cha3-storage kernel: Private: port 1(eno1) entered forwarding stateMay 10 08:30:48 cha3-storage NetworkManager[1812]: <info> [1620649848.0309] device (eno1): carrier: link connected Sent with ProtonMail Secure Email. ‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Monday, May 10, 2021 3:01 PM, Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
The symptoms are similar to a loss of quorum (like in a network outage/disruption).
Check the gluster logs for any indication of the root cause. As you have only one gigabit network, consider enabling cluster choose-local option which will make FUSE client to try to read from local brick instead of a remote one.
Theoretically congestion on storage network could be the root cause, but this is usually a symptom and not the real problem. Maybe you got too many backups running in parallel ?
Best Regards, Strahil Nikolov
On Mon, May 10, 2021 at 19:13, David White via Users <users@ovirt.org> wrote: _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/DOI6BEFMTS3PEE...
Just a point of clarification, for all of these hosts, 1 of these interfaces is connected to my 1Gbps switch, and the other interface is connected to my 10Gbps switch. For Host 1 specifically, enp4s0f0 is physically connected to 1 switch. eno1 is physically connected to another. But those interfaces are also bridged - and controlled - by oVirt itself. Is it possible that oVirt took them down for some reason. I don't know what that reason might be? Sent with ProtonMail Secure Email. ‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Monday, May 10, 2021 7:14 PM, David White via Users <users@ovirt.org> wrote:
I'm not sure what to make of this, but looking at /var/log/messages on all 3 of the hosts,it appears that the kernel disabled my oVirt networks at the same exact time on all 3 hosts. This occurred twice this morning, once around 8am and again around 8:30am:
ovirtmgmt is the storage network. Private is the frond-end network.
I actually don't have *any* backup storage domains currently, and no backups to speak of, so that wouldn't have been a cause from this morning. My goal for this week is to install a 4th physical server with some spinning disks, and expose those as an NFS mount point so that I can build a backup domain. I also hope to get the 10Gbps network cards installed on the remaining two hosts, to get 10Gbps connectivity up and running between all 3 of the HCI hosts.
Host 1 May 10 08:00:23 cha1-storage kernel: tg3 0000:04:00.0 enp4s0f0: Link is down May 10 08:00:23 cha1-storage kernel: ovirtmgmt: port 1(enp4s0f0) entered disabled state May 10 08:00:23 cha1-storage kernel: tg3 0000:01:00.0 eno1: Link is down May 10 08:00:24 cha1-storage kernel: Private: port 1(eno1) entered disabled state {snip} May 10 08:01:10 cha1-storage kernel: tg3 0000:01:00.0 eno1: Link is up at 1000 Mbps, full duplex May 10 08:01:10 cha1-storage kernel: tg3 0000:01:00.0 eno1: Flow control is off for TX and off for RX May 10 08:01:10 cha1-storage kernel: tg3 0000:01:00.0 eno1: EEE is disabled May 10 08:01:10 cha1-storage kernel: Private: port 1(eno1) entered blocking state May 10 08:01:10 cha1-storage kernel: Private: port 1(eno1) entered forwarding state May 10 08:01:10 cha1-storage NetworkManager[1805]: <info> [1620648070.6021] device (eno1): carrier: link connected May 10 08:30:01 cha1-storage kernel: tg3 0000:04:00.0 enp4s0f0: Link is down May 10 08:30:01 cha1-storage kernel: ovirtmgmt: port 1(enp4s0f0) entered disabled state May 10 08:30:01 cha1-storage systemd[1]: Starting system activity accounting tool... May 10 08:30:01 cha1-storage systemd[1]: sysstat-collect.service: Succeeded. May 10 08:30:01 cha1-storage systemd[1]: Started system activity accounting tool. May 10 08:30:01 cha1-storage kernel: tg3 0000:01:00.0 eno1: Link is down May 10 08:30:02 cha1-storage kernel: Private: port 1(eno1) entered disabled state {snip} May 10 08:30:47 cha1-storage kernel: tg3 0000:01:00.0 eno1: Link is up at 1000 Mbps, full duplex May 10 08:30:47 cha1-storage kernel: tg3 0000:01:00.0 eno1: Flow control is off for TX and off for RX May 10 08:30:47 cha1-storage kernel: tg3 0000:01:00.0 eno1: EEE is disabled May 10 08:30:47 cha1-storage kernel: Private: port 1(eno1) entered blocking state May 10 08:30:47 cha1-storage kernel: Private: port 1(eno1) entered forwarding state May 10 08:30:47 cha1-storage NetworkManager[1805]: <info> [1620649847.8592] device (eno1): carrier: link connected May 10 08:30:47 cha1-storage NetworkManager[1805]: <info> [1620649847.8602] device (Private): carrier: link connected
Host 2 May 10 08:00:23 cha2-storage kernel: ixgbe 0000:01:00.1 eno2: NIC Link is Down May 10 08:00:23 cha2-storage kernel: ovirtmgmt: port 1(eno2) entered disabled state May 10 08:00:23 cha2-storage kernel: ixgbe 0000:01:00.0 eno1: NIC Link is Down May 10 08:00:24 cha2-storage kernel: Private: port 1(eno1) entered disabled state {snip} May 10 08:01:10 cha2-storage kernel: ixgbe 0000:01:00.0 eno1: NIC Link is Up 1 Gbps, Flow Control: None May 10 08:01:10 cha2-storage kernel: Private: port 1(eno1) entered blocking state May 10 08:01:10 cha2-storage kernel: Private: port 1(eno1) entered forwarding state May 10 08:01:10 cha2-storage NetworkManager[16957]: <info> [1620648070.1303] device (eno1): carrier: link connected {snip} May 10 08:30:01 cha2-storage kernel: ixgbe 0000:01:00.1 eno2: NIC Link is Down May 10 08:30:01 cha2-storage kernel: ovirtmgmt: port 1(eno2) entered disabled state May 10 08:30:01 cha2-storage systemd[1]: Starting system activity accounting tool... May 10 08:30:01 cha2-storage systemd[1]: sysstat-collect.service: Succeeded. May 10 08:30:01 cha2-storage systemd[1]: Started system activity accounting tool. May 10 08:30:01 cha2-storage kernel: ixgbe 0000:01:00.0 eno1: NIC Link is Down May 10 08:30:02 cha2-storage kernel: Private: port 1(eno1) entered disabled state {snip} May 10 08:30:47 cha2-storage kernel: ixgbe 0000:01:00.0 eno1: NIC Link is Up 1 Gbps, Flow Control: None May 10 08:30:47 cha2-storage kernel: Private: port 1(eno1) entered blocking state May 10 08:30:47 cha2-storage kernel: Private: port 1(eno1) entered forwarding state May 10 08:30:47 cha2-storage NetworkManager[16957]: <info> [1620649847.5041] device (eno1): carrier: link connected
Host 3 May 10 08:00:23 cha3-storage kernel: tg3 0000:01:00.0 eno1: Link is down May 10 08:00:24 cha3-storage journal[2196]: Guest agent is not responding: Guest agent not available for now May 10 08:00:24 cha3-storage kernel: Private: port 1(eno1) entered disabled state May 10 08:00:30 cha3-storage journal[2196]: Guest agent is not responding: Guest agent not available for now {snip} May 10 08:01:10 cha3-storage sanlock[1477]: 2021-05-10 08:01:10 490364 [17727]: s4 renewal error -107 delta_length 0 last_success 490310 May 10 08:01:10 cha3-storage kernel: tg3 0000:01:00.0 eno1: Link is up at 1000 Mbps, full duplex May 10 08:01:10 cha3-storage kernel: tg3 0000:01:00.0 eno1: Flow control is off for TX and off for RX May 10 08:01:10 cha3-storage kernel: tg3 0000:01:00.0 eno1: EEE is disabled May 10 08:01:10 cha3-storage kernel: Private: port 1(eno1) entered blocking state May 10 08:01:10 cha3-storage kernel: Private: port 1(eno1) entered forwarding state May 10 08:01:10 cha3-storage NetworkManager[1812]: <info> [1620648070.5575] device (eno1): carrier: link connected {snip} May 10 08:30:01 cha3-storage kernel: tg3 0000:04:00.0 enp4s0f0: Link is down May 10 08:30:01 cha3-storage kernel: ovirtmgmt: port 1(enp4s0f0) entered disabled state May 10 08:30:01 cha3-storage kernel: tg3 0000:01:00.0 eno1: Link is down May 10 08:30:02 cha3-storage kernel: Private: port 1(eno1) entered disabled state {snip} May 10 08:30:48 cha3-storage kernel: tg3 0000:01:00.0 eno1: Link is up at 1000 Mbps, full duplex May 10 08:30:48 cha3-storage kernel: tg3 0000:01:00.0 eno1: Flow control is off for TX and off for RX May 10 08:30:48 cha3-storage kernel: tg3 0000:01:00.0 eno1: EEE is disabled May 10 08:30:48 cha3-storage kernel: Private: port 1(eno1) entered blocking state May 10 08:30:48 cha3-storage kernel: Private: port 1(eno1) entered forwarding state May 10 08:30:48 cha3-storage NetworkManager[1812]: <info> [1620649848.0309] device (eno1): carrier: link connected
Sent with ProtonMail Secure Email.
‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Monday, May 10, 2021 3:01 PM, Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
The symptoms are similar to a loss of quorum (like in a network outage/disruption).
Check the gluster logs for any indication of the root cause. As you have only one gigabit network, consider enabling cluster choose-local option which will make FUSE client to try to read from local brick instead of a remote one.
Theoretically congestion on storage network could be the root cause, but this is usually a symptom and not the real problem. Maybe you got too many backups running in parallel ?
Best Regards, Strahil Nikolov
On Mon, May 10, 2021 at 19:13, David White via Users <users@ovirt.org> wrote: _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/DOI6BEFMTS3PEE...
ovirtmgmt is using a linux bridge and maybe STP kicked in ?Do you know of any changes done in the network at that time ? Best Regards,Strahil Nikolov On Tue, May 11, 2021 at 2:27, David White via Users<users@ovirt.org> wrote: _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/SM72GL5TUF5O3H...
It appears there was a power issue at the datacenter. One of my routers (I have two of them) and both of my switches, have an uptime that corresponds with the 2nd outage I experience yesterday. Both of my switches & both routers have single PSUs. All of my servers have dual PSUs.None of my servers, and my other router were unaffected. I just contacted the datacenter to inquire about the outage. But the mystery has been solved! Sent with ProtonMail Secure Email. ‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Tuesday, May 11, 2021 12:17 AM, Strahil Nikolov via Users <users@ovirt.org> wrote:
ovirtmgmt is using a linux bridge and maybe STP kicked in ? Do you know of any changes done in the network at that time ?
Best Regards, Strahil Nikolov
On Tue, May 11, 2021 at 2:27, David White via Users <users@ovirt.org> wrote: _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/SM72GL5TUF5O3H...
participants (2)
-
 David White
David White -
 Strahil Nikolov
Strahil Nikolov