
Hi folks, I am facing frequently the following issue: On some large VMs (Windows 2016 with two disk drives, 60GB and 500GB) when attempting to create a snapshot of the VM, the VM becomes unresponsive. The errors that I managed to collect were: vdsm error at host hosting the VM: 2018-03-25 14:40:13,442+0000 WARN (vdsm.Scheduler) [Executor] Worker blocked: <Worker name=jsonrpc/7 running <Task <JsonRpcTask {'params': {u'frozen': False, u'vmID': u'a5c761a2-41cd-40c2-b65f-f3819293e8a4', u'snapDrives': [{u'baseVolumeID': u'2a33e585-ece8-4f4d-b45d-5ecc9239200e', u'domainID': u'888e3aae-f49f-42f7-a7fa-76700befabea', u'volumeID': u'e9a01ebd-83dd-40c3-8c83-5302b0d15e04', u'imageID': u'c75b8e93-3067-4472-bf24-dafada224e4d'}, {u'baseVolumeID': u'3fb2278c-1b0d-4677-a529-99084e4b08af', u'domainID': u'888e3aae-f49f-42f7-a7fa-76700befabea', u'volumeID': u'78e6b6b1-2406-4393-8d92-831a6d4f1337', u'imageID': u'd4223744-bf5d-427b-bec2-f14b9bc2ef81'}]}, 'jsonrpc': '2.0', 'method': u'VM.snapshot', 'id': u'89555c87-9701-4260-9952-789965261e65'} at 0x7fca4004cc90> timeout=60, duration=60 at 0x39d8210> task#=155842 at 0x2240e10> (executor:351) 2018-03-25 14:40:15,261+0000 INFO (jsonrpc/3) [jsonrpc.JsonRpcServer] RPC call VM.getStats failed (error 1) in 0.01 seconds (__init__:539) 2018-03-25 14:40:17,471+0000 WARN (jsonrpc/5) [virt.vm] (vmId='a5c761a2-41cd-40c2-b65f-f3819293e8a4') monitor became unresponsive (command timeout, age=67.9100000001) (vm:5132) engine.log: 2018-03-25 14:40:19,875Z WARN [org.ovirt.engine.core.dal.dbbroker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler2) [1d737df7] EVENT_ID: VM_NOT_RESPONDING(126), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: VM Data-Server is not responding. 2018-03-25 14:42:13,708Z ERROR [org.ovirt.engine.core.dal.dbbroker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: VDS_BROKER_COMMAND_FAILURE(10,802), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: VDSM v1.cluster command SnapshotVDS failed: Message timeout which can be caused by communication issues 2018-03-25 14:42:13,708Z ERROR [org.ovirt.engine.core.vdsbroker.vdsbroker.SnapshotVDSCommand] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] Command 'SnapshotVDSCommand(HostName = v1.cluster, SnapshotVDSCommandParameters:{runAsync='true', hostId='a713d988-ee03-4ff0-a0cd-dc4cde1507f4', vmId='a5c761a2-41cd-40c2-b65f-f3819293e8a4'})' execution failed: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues 2018-03-25 14:42:13,708Z WARN [org.ovirt.engine.core.bll.snapshots.CreateAllSnapshotsFromVmCommand] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] Could not perform live snapshot due to error, VM will still be configured to the new created snapshot: EngineException: org.ovirt.engine.core.vdsbroker.vdsbroker.VDSNetworkException: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues (Failed with error VDS_NETWORK_ERROR and code 5022) 2018-03-25 14:42:13,708Z WARN [org.ovirt.engine.core.vdsbroker.VdsManager] (org.ovirt.thread.pool-6-thread-15) [17789048-009a-454b-b8ad-2c72c7cd37aa] Host 'v1.cluster' is not responding. It will stay in Connecting state for a grace period of 61 seconds and after that an attempt to fence the host will be issued. 2018-03-25 14:42:13,725Z WARN [org.ovirt.engine.core.dal.dbbroker.auditloghandling.AuditLogDirector] (org.ovirt.thread.pool-6-thread-15) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: VDS_HOST_NOT_RESPONDING_CONNECTING(9,008), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: Host v1.cluster is not responding. It will stay in Connecting state for a grace period of 61 seconds and after that an attempt to fence the host will be issued. 2018-03-25 14:42:13,751Z WARN [org.ovirt.engine.core.dal.dbbroker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: USER_CREATE_LIVE_SNAPSHOT_FINISHED_FAILURE(170), Correlation ID: 17789048-009a-454b-b8ad-2c72c7cd37aa, Job ID: 16e48c28-a8c7-4841-bd81-1f2d370f345d, Call Stack: org.ovirt.engine.core.common.errors.EngineException: EngineException: org.ovirt.engine.core.vdsbroker.vdsbroker.VDSNetworkException: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues (Failed with error VDS_NETWORK_ERROR and code 5022) 2018-03-25 14:42:14,372Z ERROR [org.ovirt.engine.core.dal.dbbroker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [] EVENT_ID: USER_CREATE_SNAPSHOT_FINISHED_FAILURE(69), Correlation ID: 17789048-009a-454b-b8ad-2c72c7cd37aa, Job ID: 16e48c28-a8c7-4841-bd81-1f2d370f345d, Call Stack: org.ovirt.engine.core.common.errors.EngineException: EngineException: org.ovirt.engine.core.vdsbroker.vdsbroker.VDSNetworkException: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues (Failed with error VDS_NETWORK_ERROR and code 5022) 2018-03-25 14:42:14,372Z WARN [org.ovirt.engine.core.bll.ConcurrentChildCommandsExecutionCallback] (DefaultQuartzScheduler5) [] Command 'CreateAllSnapshotsFromVm' id: 'bad4f5be-5306-413f-a86a-513b3cfd3c66' end method execution failed, as the command isn't marked for endAction() retries silently ignoring 2018-03-25 14:42:15,951Z WARN [org.ovirt.engine.core.dal.dbbroker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [5017c163] EVENT_ID: VDS_NO_SELINUX_ENFORCEMENT(25), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: Host v1.cluster does not enforce SELinux. Current status: DISABLED 2018-03-25 14:42:15,951Z WARN [org.ovirt.engine.core.vdsbroker.VdsManager] (DefaultQuartzScheduler5) [5017c163] Host 'v1.cluster' is running with SELinux in 'DISABLED' mode As soon as the VM is unresponsive, the VM console that was already open freezes. I can resume the VM only by powering off and on. I am using ovirt 4.1.9 with 3 nodes and self-hosted engine. I am running mostly Windows 10 and Windows 2016 server VMs. I have installed latest guest agents from: http://resources.ovirt.org/pub/ovirt-4.2/iso/oVirt-toolsSetup/4.2-1.el7.cent... At the screen where one takes a snapshot I get a warning saying "Could not detect guest agent on the VM. Note that without guest agent the data on the created snapshot may be inconsistent". See attached. I have verified that ovirt guest tools are installed and shown at installed apps at engine GUI. Also Ovirt Guest Agent (32 bit) and qemu-ga are listed as running at the windows tasks manager. Shouldn't ovirt guest agent be 64 bit on Windows 64 bit? Any advice will be much appreciated. Alex
{kind=link}
Hi All, Any idea on the below? I am using oVirt Guest Tools 4.2-1.el7.centos for the VM. The Window 2016 server VM (which it the one with the relatively big disks: 500 GB) it is consistently rendered unresponsive when trying to get a snapshot. I amy provide any other additional logs if needed. Alex On Sun, Mar 25, 2018 at 7:30 PM, Alex K <rightkicktech@gmail.com> wrote:
Hi folks,
I am facing frequently the following issue:
On some large VMs (Windows 2016 with two disk drives, 60GB and 500GB) when attempting to create a snapshot of the VM, the VM becomes unresponsive.
The errors that I managed to collect were:
vdsm error at host hosting the VM: 2018-03-25 14:40:13,442+0000 WARN (vdsm.Scheduler) [Executor] Worker blocked: <Worker name=jsonrpc/7 running <Task <JsonRpcTask {'params': {u'frozen': False, u'vmID': u'a5c761a2-41cd-40c2-b65f-f3819293e8a4', u'snapDrives': [{u'baseVolumeID': u'2a33e585-ece8-4f4d-b45d-5ecc9239200e', u'domainID': u'888e3aae-f49f-42f7-a7fa-76700befabea', u'volumeID': u'e9a01ebd-83dd-40c3-8c83-5302b0d15e04', u'imageID': u'c75b8e93-3067-4472-bf24-dafada224e4d'}, {u'baseVolumeID': u'3fb2278c-1b0d-4677-a529-99084e4b08af', u'domainID': u'888e3aae-f49f-42f7-a7fa-76700befabea', u'volumeID': u'78e6b6b1-2406-4393-8d92-831a6d4f1337', u'imageID': u'd4223744-bf5d-427b-bec2-f14b9bc2ef81'}]}, 'jsonrpc': '2.0', 'method': u'VM.snapshot', 'id': u'89555c87-9701-4260-9952-789965261e65'} at 0x7fca4004cc90> timeout=60, duration=60 at 0x39d8210> task#=155842 at 0x2240e10> (executor:351) 2018-03-25 14:40:15,261+0000 INFO (jsonrpc/3) [jsonrpc.JsonRpcServer] RPC call VM.getStats failed (error 1) in 0.01 seconds (__init__:539) 2018-03-25 14:40:17,471+0000 WARN (jsonrpc/5) [virt.vm] (vmId='a5c761a2-41cd-40c2-b65f-f3819293e8a4') monitor became unresponsive (command timeout, age=67.9100000001) (vm:5132)
engine.log: 2018-03-25 14:40:19,875Z WARN [org.ovirt.engine.core.dal. dbbroker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler2) [1d737df7] EVENT_ID: VM_NOT_RESPONDING(126), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: VM Data-Server is not responding.
2018-03-25 14:42:13,708Z ERROR [org.ovirt.engine.core.dal. dbbroker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: VDS_BROKER_COMMAND_FAILURE(10,802), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: VDSM v1.cluster command SnapshotVDS failed: Message timeout which can be caused by communication issues 2018-03-25 14:42:13,708Z ERROR [org.ovirt.engine.core.vdsbroker.vdsbroker.SnapshotVDSCommand] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] Command 'SnapshotVDSCommand(HostName = v1.cluster, SnapshotVDSCommandParameters:{runAsync='true', hostId='a713d988-ee03-4ff0-a0cd-dc4cde1507f4', vmId='a5c761a2-41cd-40c2-b65f-f3819293e8a4'})' execution failed: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues 2018-03-25 14:42:13,708Z WARN [org.ovirt.engine.core.bll.snapshots. CreateAllSnapshotsFromVmCommand] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] Could not perform live snapshot due to error, VM will still be configured to the new created snapshot: EngineException: org.ovirt.engine.core.vdsbroker.vdsbroker.VDSNetworkException: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues (Failed with error VDS_NETWORK_ERROR and code 5022) 2018-03-25 14:42:13,708Z WARN [org.ovirt.engine.core.vdsbroker.VdsManager] (org.ovirt.thread.pool-6-thread-15) [17789048-009a-454b-b8ad-2c72c7cd37aa] Host 'v1.cluster' is not responding. It will stay in Connecting state for a grace period of 61 seconds and after that an attempt to fence the host will be issued. 2018-03-25 14:42:13,725Z WARN [org.ovirt.engine.core.dal. dbbroker.auditloghandling.AuditLogDirector] (org.ovirt.thread.pool-6-thread-15) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: VDS_HOST_NOT_RESPONDING_CONNECTING(9,008), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: Host v1.cluster is not responding. It will stay in Connecting state for a grace period of 61 seconds and after that an attempt to fence the host will be issued. 2018-03-25 14:42:13,751Z WARN [org.ovirt.engine.core.dal. dbbroker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: USER_CREATE_LIVE_SNAPSHOT_FINISHED_FAILURE(170), Correlation ID: 17789048-009a-454b-b8ad-2c72c7cd37aa, Job ID: 16e48c28-a8c7-4841-bd81-1f2d370f345d, Call Stack: org.ovirt.engine.core.common.errors.EngineException: EngineException: org.ovirt.engine.core.vdsbroker.vdsbroker.VDSNetworkException: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues (Failed with error VDS_NETWORK_ERROR and code 5022) 2018-03-25 14:42:14,372Z ERROR [org.ovirt.engine.core.dal. dbbroker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [] EVENT_ID: USER_CREATE_SNAPSHOT_FINISHED_FAILURE(69), Correlation ID: 17789048-009a-454b-b8ad-2c72c7cd37aa, Job ID: 16e48c28-a8c7-4841-bd81-1f2d370f345d, Call Stack: org.ovirt.engine.core.common.errors.EngineException: EngineException: org.ovirt.engine.core.vdsbroker.vdsbroker.VDSNetworkException: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues (Failed with error VDS_NETWORK_ERROR and code 5022) 2018-03-25 14:42:14,372Z WARN [org.ovirt.engine.core.bll. ConcurrentChildCommandsExecutionCallback] (DefaultQuartzScheduler5) [] Command 'CreateAllSnapshotsFromVm' id: 'bad4f5be-5306-413f-a86a-513b3cfd3c66' end method execution failed, as the command isn't marked for endAction() retries silently ignoring 2018-03-25 14:42:15,951Z WARN [org.ovirt.engine.core.dal. dbbroker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [5017c163] EVENT_ID: VDS_NO_SELINUX_ENFORCEMENT(25), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: Host v1.cluster does not enforce SELinux. Current status: DISABLED 2018-03-25 14:42:15,951Z WARN [org.ovirt.engine.core.vdsbroker.VdsManager] (DefaultQuartzScheduler5) [5017c163] Host 'v1.cluster' is running with SELinux in 'DISABLED' mode
As soon as the VM is unresponsive, the VM console that was already open freezes. I can resume the VM only by powering off and on.
I am using ovirt 4.1.9 with 3 nodes and self-hosted engine. I am running mostly Windows 10 and Windows 2016 server VMs. I have installed latest guest agents from:
http://resources.ovirt.org/pub/ovirt-4.2/iso/oVirt- toolsSetup/4.2-1.el7.centos/
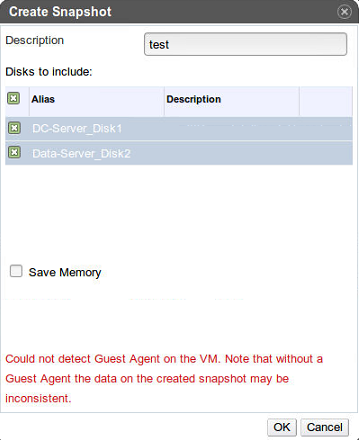
At the screen where one takes a snapshot I get a warning saying "Could not detect guest agent on the VM. Note that without guest agent the data on the created snapshot may be inconsistent". See attached. I have verified that ovirt guest tools are installed and shown at installed apps at engine GUI. Also Ovirt Guest Agent (32 bit) and qemu-ga are listed as running at the windows tasks manager. Shouldn't ovirt guest agent be 64 bit on Windows 64 bit?
Any advice will be much appreciated.
Alex

2018-03-27 14:34 GMT+02:00 Alex K <rightkicktech@gmail.com>:
Hi All,
Any idea on the below?
I am using oVirt Guest Tools 4.2-1.el7.centos for the VM. The Window 2016 server VM (which it the one with the relatively big disks: 500 GB) it is consistently rendered unresponsive when trying to get a snapshot. I amy provide any other additional logs if needed.
Adding some people to the thread
Alex
On Sun, Mar 25, 2018 at 7:30 PM, Alex K <rightkicktech@gmail.com> wrote:
Hi folks,
I am facing frequently the following issue:
On some large VMs (Windows 2016 with two disk drives, 60GB and 500GB) when attempting to create a snapshot of the VM, the VM becomes unresponsive.
The errors that I managed to collect were:
vdsm error at host hosting the VM: 2018-03-25 14:40:13,442+0000 WARN (vdsm.Scheduler) [Executor] Worker blocked: <Worker name=jsonrpc/7 running <Task <JsonRpcTask {'params': {u'frozen': False, u'vmID': u'a5c761a2-41cd-40c2-b65f-f3819293e8a4', u'snapDrives': [{u'baseVolumeID': u'2a33e585-ece8-4f4d-b45d-5ecc9239200e', u'domainID': u'888e3aae-f49f-42f7-a7fa-76700befabea', u'volumeID': u'e9a01ebd-83dd-40c3-8c83-5302b0d15e04', u'imageID': u'c75b8e93-3067-4472-bf24-dafada224e4d'}, {u'baseVolumeID': u'3fb2278c-1b0d-4677-a529-99084e4b08af', u'domainID': u'888e3aae-f49f-42f7-a7fa-76700befabea', u'volumeID': u'78e6b6b1-2406-4393-8d92-831a6d4f1337', u'imageID': u'd4223744-bf5d-427b-bec2-f14b9bc2ef81'}]}, 'jsonrpc': '2.0', 'method': u'VM.snapshot', 'id': u'89555c87-9701-4260-9952-789965261e65'} at 0x7fca4004cc90> timeout=60, duration=60 at 0x39d8210> task#=155842 at 0x2240e10> (executor:351) 2018-03-25 14:40:15,261+0000 INFO (jsonrpc/3) [jsonrpc.JsonRpcServer] RPC call VM.getStats failed (error 1) in 0.01 seconds (__init__:539) 2018-03-25 14:40:17,471+0000 WARN (jsonrpc/5) [virt.vm] (vmId='a5c761a2-41cd-40c2-b65f-f3819293e8a4') monitor became unresponsive (command timeout, age=67.9100000001) (vm:5132)
engine.log: 2018-03-25 14:40:19,875Z WARN [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler2) [1d737df7] EVENT_ID: VM_NOT_RESPONDING(126), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: VM Data-Server is not responding.
2018-03-25 14:42:13,708Z ERROR [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: VDS_BROKER_COMMAND_FAILURE(10,802), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: VDSM v1.cluster command SnapshotVDS failed: Message timeout which can be caused by communication issues 2018-03-25 14:42:13,708Z ERROR [org.ovirt.engine.core.vdsbrok er.vdsbroker.SnapshotVDSCommand] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] Command 'SnapshotVDSCommand(HostName = v1.cluster, SnapshotVDSCommandParameters:{runAsync='true', hostId='a713d988-ee03-4ff0-a0cd-dc4cde1507f4', vmId='a5c761a2-41cd-40c2-b65f-f3819293e8a4'})' execution failed: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues 2018-03-25 14:42:13,708Z WARN [org.ovirt.engine.core.bll.sna pshots.CreateAllSnapshotsFromVmCommand] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] Could not perform live snapshot due to error, VM will still be configured to the new created snapshot: EngineException: org.ovirt.engine.core.vdsbroke r.vdsbroker.VDSNetworkException: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues (Failed with error VDS_NETWORK_ERROR and code 5022) 2018-03-25 14:42:13,708Z WARN [org.ovirt.engine.core.vdsbroker.VdsManager] (org.ovirt.thread.pool-6-thread-15) [17789048-009a-454b-b8ad-2c72c7cd37aa] Host 'v1.cluster' is not responding. It will stay in Connecting state for a grace period of 61 seconds and after that an attempt to fence the host will be issued. 2018-03-25 14:42:13,725Z WARN [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (org.ovirt.thread.pool-6-thread-15) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: VDS_HOST_NOT_RESPONDING_CONNECTING(9,008), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: Host v1.cluster is not responding. It will stay in Connecting state for a grace period of 61 seconds and after that an attempt to fence the host will be issued. 2018-03-25 14:42:13,751Z WARN [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: USER_CREATE_LIVE_SNAPSHOT_FINISHED_FAILURE(170), Correlation ID: 17789048-009a-454b-b8ad-2c72c7cd37aa, Job ID: 16e48c28-a8c7-4841-bd81-1f2d370f345d, Call Stack: org.ovirt.engine.core.common.errors.EngineException: EngineException: org.ovirt.engine.core.vdsbroker.vdsbroker.VDSNetworkException: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues (Failed with error VDS_NETWORK_ERROR and code 5022) 2018-03-25 14:42:14,372Z ERROR [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [] EVENT_ID: USER_CREATE_SNAPSHOT_FINISHED_FAILURE(69), Correlation ID: 17789048-009a-454b-b8ad-2c72c7cd37aa, Job ID: 16e48c28-a8c7-4841-bd81-1f2d370f345d, Call Stack: org.ovirt.engine.core.common.errors.EngineException: EngineException: org.ovirt.engine.core.vdsbroker.vdsbroker.VDSNetworkException: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues (Failed with error VDS_NETWORK_ERROR and code 5022) 2018-03-25 14:42:14,372Z WARN [org.ovirt.engine.core.bll.Con currentChildCommandsExecutionCallback] (DefaultQuartzScheduler5) [] Command 'CreateAllSnapshotsFromVm' id: 'bad4f5be-5306-413f-a86a-513b3cfd3c66' end method execution failed, as the command isn't marked for endAction() retries silently ignoring 2018-03-25 14:42:15,951Z WARN [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [5017c163] EVENT_ID: VDS_NO_SELINUX_ENFORCEMENT(25), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: Host v1.cluster does not enforce SELinux. Current status: DISABLED 2018-03-25 14:42:15,951Z WARN [org.ovirt.engine.core.vdsbroker.VdsManager] (DefaultQuartzScheduler5) [5017c163] Host 'v1.cluster' is running with SELinux in 'DISABLED' mode
As soon as the VM is unresponsive, the VM console that was already open freezes. I can resume the VM only by powering off and on.
I am using ovirt 4.1.9 with 3 nodes and self-hosted engine. I am running mostly Windows 10 and Windows 2016 server VMs. I have installed latest guest agents from:
http://resources.ovirt.org/pub/ovirt-4.2/iso/oVirt-toolsSetu p/4.2-1.el7.centos/
At the screen where one takes a snapshot I get a warning saying "Could not detect guest agent on the VM. Note that without guest agent the data on the created snapshot may be inconsistent". See attached. I have verified that ovirt guest tools are installed and shown at installed apps at engine GUI. Also Ovirt Guest Agent (32 bit) and qemu-ga are listed as running at the windows tasks manager. Shouldn't ovirt guest agent be 64 bit on Windows 64 bit?
Any advice will be much appreciated.
Alex
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
-- SANDRO BONAZZOLA ASSOCIATE MANAGER, SOFTWARE ENGINEERING, EMEA ENG VIRTUALIZATION R&D Red Hat EMEA <https://www.redhat.com/> sbonazzo@redhat.com <https://red.ht/sig> <https://redhat.com/summit>

On Tue, Mar 27, 2018 at 3:38 PM, Sandro Bonazzola <sbonazzo@redhat.com> wrote:
2018-03-27 14:34 GMT+02:00 Alex K <rightkicktech@gmail.com>:
Hi All,
Any idea on the below?
I am using oVirt Guest Tools 4.2-1.el7.centos for the VM. The Window 2016 server VM (which it the one with the relatively big disks: 500 GB) it is consistently rendered unresponsive when trying to get a snapshot. I amy provide any other additional logs if needed.
Adding some people to the thread
Adding more people for this part.
Alex
On Sun, Mar 25, 2018 at 7:30 PM, Alex K <rightkicktech@gmail.com> wrote:
Hi folks,
I am facing frequently the following issue:
On some large VMs (Windows 2016 with two disk drives, 60GB and 500GB) when attempting to create a snapshot of the VM, the VM becomes unresponsive.
The errors that I managed to collect were:
vdsm error at host hosting the VM: 2018-03-25 14:40:13,442+0000 WARN (vdsm.Scheduler) [Executor] Worker blocked: <Worker name=jsonrpc/7 running <Task <JsonRpcTask {'params': {u'frozen': False, u'vmID': u'a5c761a2-41cd-40c2-b65f-f3819293e8a4', u'snapDrives': [{u'baseVolumeID': u'2a33e585-ece8-4f4d-b45d-5ecc9239200e', u'domainID': u'888e3aae-f49f-42f7-a7fa-76700befabea', u'volumeID': u'e9a01ebd-83dd-40c3-8c83-5302b0d15e04', u'imageID': u'c75b8e93-3067-4472-bf24-dafada224e4d'}, {u'baseVolumeID': u'3fb2278c-1b0d-4677-a529-99084e4b08af', u'domainID': u'888e3aae-f49f-42f7-a7fa-76700befabea', u'volumeID': u'78e6b6b1-2406-4393-8d92-831a6d4f1337', u'imageID': u'd4223744-bf5d-427b-bec2-f14b9bc2ef81'}]}, 'jsonrpc': '2.0', 'method': u'VM.snapshot', 'id': u'89555c87-9701-4260-9952-789965261e65'} at 0x7fca4004cc90> timeout=60, duration=60 at 0x39d8210> task#=155842 at 0x2240e10> (executor:351) 2018-03-25 14:40:15,261+0000 INFO (jsonrpc/3) [jsonrpc.JsonRpcServer] RPC call VM.getStats failed (error 1) in 0.01 seconds (__init__:539) 2018-03-25 14:40:17,471+0000 WARN (jsonrpc/5) [virt.vm] (vmId='a5c761a2-41cd-40c2-b65f-f3819293e8a4') monitor became unresponsive (command timeout, age=67.9100000001) (vm:5132)
engine.log: 2018-03-25 14:40:19,875Z WARN [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler2) [1d737df7] EVENT_ID: VM_NOT_RESPONDING(126), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: VM Data-Server is not responding.
2018-03-25 14:42:13,708Z ERROR [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: VDS_BROKER_COMMAND_FAILURE(10,802), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: VDSM v1.cluster command SnapshotVDS failed: Message timeout which can be caused by communication issues 2018-03-25 14:42:13,708Z ERROR [org.ovirt.engine.core.vdsbrok er.vdsbroker.SnapshotVDSCommand] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] Command 'SnapshotVDSCommand(HostName = v1.cluster, SnapshotVDSCommandParameters:{runAsync='true', hostId='a713d988-ee03-4ff0-a0cd-dc4cde1507f4', vmId='a5c761a2-41cd-40c2-b65f-f3819293e8a4'})' execution failed: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues 2018-03-25 14:42:13,708Z WARN [org.ovirt.engine.core.bll.sna pshots.CreateAllSnapshotsFromVmCommand] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] Could not perform live snapshot due to error, VM will still be configured to the new created snapshot: EngineException: org.ovirt.engine.core.vdsbroke r.vdsbroker.VDSNetworkException: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues (Failed with error VDS_NETWORK_ERROR and code 5022) 2018-03-25 14:42:13,708Z WARN [org.ovirt.engine.core.vdsbroker.VdsManager] (org.ovirt.thread.pool-6-thread-15) [17789048-009a-454b-b8ad-2c72c7cd37aa] Host 'v1.cluster' is not responding. It will stay in Connecting state for a grace period of 61 seconds and after that an attempt to fence the host will be issued. 2018-03-25 14:42:13,725Z WARN [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (org.ovirt.thread.pool-6-thread-15) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: VDS_HOST_NOT_RESPONDING_CONNECTING(9,008), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: Host v1.cluster is not responding. It will stay in Connecting state for a grace period of 61 seconds and after that an attempt to fence the host will be issued. 2018-03-25 14:42:13,751Z WARN [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: USER_CREATE_LIVE_SNAPSHOT_FINISHED_FAILURE(170), Correlation ID: 17789048-009a-454b-b8ad-2c72c7cd37aa, Job ID: 16e48c28-a8c7-4841-bd81-1f2d370f345d, Call Stack: org.ovirt.engine.core.common.errors.EngineException: EngineException: org.ovirt.engine.core.vdsbroker.vdsbroker.VDSNetworkException: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues (Failed with error VDS_NETWORK_ERROR and code 5022) 2018-03-25 14:42:14,372Z ERROR [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [] EVENT_ID: USER_CREATE_SNAPSHOT_FINISHED_FAILURE(69), Correlation ID: 17789048-009a-454b-b8ad-2c72c7cd37aa, Job ID: 16e48c28-a8c7-4841-bd81-1f2d370f345d, Call Stack: org.ovirt.engine.core.common.errors.EngineException: EngineException: org.ovirt.engine.core.vdsbroker.vdsbroker.VDSNetworkException: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues (Failed with error VDS_NETWORK_ERROR and code 5022) 2018-03-25 14:42:14,372Z WARN [org.ovirt.engine.core.bll.Con currentChildCommandsExecutionCallback] (DefaultQuartzScheduler5) [] Command 'CreateAllSnapshotsFromVm' id: 'bad4f5be-5306-413f-a86a-513b3cfd3c66' end method execution failed, as the command isn't marked for endAction() retries silently ignoring 2018-03-25 14:42:15,951Z WARN [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [5017c163] EVENT_ID: VDS_NO_SELINUX_ENFORCEMENT(25), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: Host v1.cluster does not enforce SELinux. Current status: DISABLED 2018-03-25 14:42:15,951Z WARN [org.ovirt.engine.core.vdsbroker.VdsManager] (DefaultQuartzScheduler5) [5017c163] Host 'v1.cluster' is running with SELinux in 'DISABLED' mode
As soon as the VM is unresponsive, the VM console that was already open freezes. I can resume the VM only by powering off and on.
I am using ovirt 4.1.9 with 3 nodes and self-hosted engine. I am running mostly Windows 10 and Windows 2016 server VMs. I have installed latest guest agents from:
http://resources.ovirt.org/pub/ovirt-4.2/iso/oVirt-toolsSetu p/4.2-1.el7.centos/
At the screen where one takes a snapshot I get a warning saying "Could not detect guest agent on the VM. Note that without guest agent the data on the created snapshot may be inconsistent". See attached. I have verified that ovirt guest tools are installed and shown at installed apps at engine GUI. Also Ovirt Guest Agent (32 bit) and qemu-ga are listed as running at the windows tasks manager. Shouldn't ovirt guest agent be 64 bit on Windows 64 bit?
No idea, but I do not think it's related to your problem of freezing while taking a snapshot. This error was already discussed in the past, see e.g.: http://lists.ovirt.org/pipermail/users/2017-June/082577.html Best regards, -- Didi
Any idea with this issue? I am still trying to understand what may be causing this issue. Many thanx for any assistance. Alex On Wed, Mar 28, 2018 at 10:06 AM, Yedidyah Bar David <didi@redhat.com> wrote:
On Tue, Mar 27, 2018 at 3:38 PM, Sandro Bonazzola <sbonazzo@redhat.com> wrote:
2018-03-27 14:34 GMT+02:00 Alex K <rightkicktech@gmail.com>:
Hi All,
Any idea on the below?
I am using oVirt Guest Tools 4.2-1.el7.centos for the VM. The Window 2016 server VM (which it the one with the relatively big disks: 500 GB) it is consistently rendered unresponsive when trying to get a snapshot. I amy provide any other additional logs if needed.
Adding some people to the thread
Adding more people for this part.
Alex
On Sun, Mar 25, 2018 at 7:30 PM, Alex K <rightkicktech@gmail.com> wrote:
Hi folks,
I am facing frequently the following issue:
On some large VMs (Windows 2016 with two disk drives, 60GB and 500GB) when attempting to create a snapshot of the VM, the VM becomes unresponsive.
The errors that I managed to collect were:
vdsm error at host hosting the VM: 2018-03-25 14:40:13,442+0000 WARN (vdsm.Scheduler) [Executor] Worker blocked: <Worker name=jsonrpc/7 running <Task <JsonRpcTask {'params': {u'frozen': False, u'vmID': u'a5c761a2-41cd-40c2-b65f-f3819293e8a4', u'snapDrives': [{u'baseVolumeID': u'2a33e585-ece8-4f4d-b45d-5ecc9239200e', u'domainID': u'888e3aae-f49f-42f7-a7fa-76700befabea', u'volumeID': u'e9a01ebd-83dd-40c3-8c83-5302b0d15e04', u'imageID': u'c75b8e93-3067-4472-bf24-dafada224e4d'}, {u'baseVolumeID': u'3fb2278c-1b0d-4677-a529-99084e4b08af', u'domainID': u'888e3aae-f49f-42f7-a7fa-76700befabea', u'volumeID': u'78e6b6b1-2406-4393-8d92-831a6d4f1337', u'imageID': u'd4223744-bf5d-427b-bec2-f14b9bc2ef81'}]}, 'jsonrpc': '2.0', 'method': u'VM.snapshot', 'id': u'89555c87-9701-4260-9952-789965261e65'} at 0x7fca4004cc90> timeout=60, duration=60 at 0x39d8210> task#=155842 at 0x2240e10> (executor:351) 2018-03-25 14:40:15,261+0000 INFO (jsonrpc/3) [jsonrpc.JsonRpcServer] RPC call VM.getStats failed (error 1) in 0.01 seconds (__init__:539) 2018-03-25 14:40:17,471+0000 WARN (jsonrpc/5) [virt.vm] (vmId='a5c761a2-41cd-40c2-b65f-f3819293e8a4') monitor became unresponsive (command timeout, age=67.9100000001) (vm:5132)
engine.log: 2018-03-25 14:40:19,875Z WARN [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler2) [1d737df7] EVENT_ID: VM_NOT_RESPONDING(126), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: VM Data-Server is not responding.
2018-03-25 14:42:13,708Z ERROR [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: VDS_BROKER_COMMAND_FAILURE(10,802), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: VDSM v1.cluster command SnapshotVDS failed: Message timeout which can be caused by communication issues 2018-03-25 14:42:13,708Z ERROR [org.ovirt.engine.core.vdsbrok er.vdsbroker.SnapshotVDSCommand] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] Command 'SnapshotVDSCommand(HostName = v1.cluster, SnapshotVDSCommandParameters:{runAsync='true', hostId='a713d988-ee03-4ff0-a0cd-dc4cde1507f4', vmId='a5c761a2-41cd-40c2-b65f-f3819293e8a4'})' execution failed: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues 2018-03-25 14:42:13,708Z WARN [org.ovirt.engine.core.bll.sna pshots.CreateAllSnapshotsFromVmCommand] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] Could not perform live snapshot due to error, VM will still be configured to the new created snapshot: EngineException: org.ovirt.engine.core.vdsbroke r.vdsbroker.VDSNetworkException: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues (Failed with error VDS_NETWORK_ERROR and code 5022) 2018-03-25 14:42:13,708Z WARN [org.ovirt.engine.core.vdsbroker.VdsManager] (org.ovirt.thread.pool-6-thread-15) [17789048-009a-454b-b8ad-2c72c7cd37aa] Host 'v1.cluster' is not responding. It will stay in Connecting state for a grace period of 61 seconds and after that an attempt to fence the host will be issued. 2018-03-25 14:42:13,725Z WARN [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (org.ovirt.thread.pool-6-thread-15) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: VDS_HOST_NOT_RESPONDING_CONNECTING(9,008), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: Host v1.cluster is not responding. It will stay in Connecting state for a grace period of 61 seconds and after that an attempt to fence the host will be issued. 2018-03-25 14:42:13,751Z WARN [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: USER_CREATE_LIVE_SNAPSHOT_FINISHED_FAILURE(170), Correlation ID: 17789048-009a-454b-b8ad-2c72c7cd37aa, Job ID: 16e48c28-a8c7-4841-bd81-1f2d370f345d, Call Stack: org.ovirt.engine.core.common.errors.EngineException: EngineException: org.ovirt.engine.core.vdsbroker.vdsbroker.VDSNetworkException: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues (Failed with error VDS_NETWORK_ERROR and code 5022) 2018-03-25 14:42:14,372Z ERROR [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [] EVENT_ID: USER_CREATE_SNAPSHOT_FINISHED_FAILURE(69), Correlation ID: 17789048-009a-454b-b8ad-2c72c7cd37aa, Job ID: 16e48c28-a8c7-4841-bd81-1f2d370f345d, Call Stack: org.ovirt.engine.core.common.errors.EngineException: EngineException: org.ovirt.engine.core.vdsbroker.vdsbroker.VDSNetworkException: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues (Failed with error VDS_NETWORK_ERROR and code 5022) 2018-03-25 14:42:14,372Z WARN [org.ovirt.engine.core.bll.Con currentChildCommandsExecutionCallback] (DefaultQuartzScheduler5) [] Command 'CreateAllSnapshotsFromVm' id: 'bad4f5be-5306-413f-a86a-513b3cfd3c66' end method execution failed, as the command isn't marked for endAction() retries silently ignoring 2018-03-25 14:42:15,951Z WARN [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [5017c163] EVENT_ID: VDS_NO_SELINUX_ENFORCEMENT(25), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: Host v1.cluster does not enforce SELinux. Current status: DISABLED 2018-03-25 14:42:15,951Z WARN [org.ovirt.engine.core.vdsbroker.VdsManager] (DefaultQuartzScheduler5) [5017c163] Host 'v1.cluster' is running with SELinux in 'DISABLED' mode
As soon as the VM is unresponsive, the VM console that was already open freezes. I can resume the VM only by powering off and on.
I am using ovirt 4.1.9 with 3 nodes and self-hosted engine. I am running mostly Windows 10 and Windows 2016 server VMs. I have installed latest guest agents from:
http://resources.ovirt.org/pub/ovirt-4.2/iso/oVirt-toolsSetu p/4.2-1.el7.centos/
At the screen where one takes a snapshot I get a warning saying "Could not detect guest agent on the VM. Note that without guest agent the data on the created snapshot may be inconsistent". See attached. I have verified that ovirt guest tools are installed and shown at installed apps at engine GUI. Also Ovirt Guest Agent (32 bit) and qemu-ga are listed as running at the windows tasks manager. Shouldn't ovirt guest agent be 64 bit on Windows 64 bit?
No idea, but I do not think it's related to your problem of freezing while taking a snapshot.
This error was already discussed in the past, see e.g.:
http://lists.ovirt.org/pipermail/users/2017-June/082577.html
Best regards, -- Didi
Checking further the logs I see this error given from libvirt of the host that has the guest VM running: Apr 1 17:53:41 v0 libvirtd: 2018-04-01 17:53:41.298+0000: 1862: warning : qemuDomainObjBeginJobInternal:3847 : Cannot start job (query, none) for domain Data-Server; current job is (async nested, snapshot) owned by (1863 remoteDispatchDomainSnapshotCreateXML, 1863 remoteDispatchDomainSnapshotCreateXML) for (39s, 41s) Apr 1 17:53:41 v0 libvirtd: 2018-04-01 17:53:41.299+0000: 1862: error : qemuDomainObjBeginJobInternal:3859 : Timed out during operation: cannot acquire state change lock (held by remoteDispatchDomainSnapshotCreateXML) Apr 1 17:53:57 v0 journal: vdsm Executor WARN Worker blocked: <Worker name=jsonrpc/3 running <Task <JsonRpcTask {'params': {u'frozen': False, u'vmID': u'6bdb3d02-cc33-4019-97cd-7447aecc1e02', u'snapDrives': [{u'baseVolumeID': u'adfabed5-451b-4f46-b22a-45f720b06110', u'domainID': u'2c4b8d45-3d05-4619-9a36-1ecd199d3056', u'volumeID': u'cc0d0772-924c-46db-8ad6-a2b0897c313f', u'imageID': u'7eeadedc-f247-4a31-840d-4de622bf3541'}, {u'baseVolumeID': u'0d960c12-3bcf-4918-896d-bd8e68b5278b', u'domainID': u'2c4b8d45-3d05-4619-9a36-1ecd199d3056', u'volumeID': u'590a6bdd-a9e2-444e-87bc-721c5f8586eb', u'imageID': u'da0e4111-6bbe-43cb-bf59-db5fbf5c3e38'}]}, 'jsonrpc': '2.0', 'method': u'VM.snapshot', 'id': u'be7912e6-ba3d-4357-8ba1-abe40825acf1'} at 0x3bf84d0> timeout=60, duration=60 at 0x3bf8050> task#=416 at 0x20d7f90> Immediately after above the engine reports the VM as unresponsive. The SPM host does not log any issues. In the same time, the 3 hosts are fairly idle with only one running guest VM. The gluster traffic is dedicated to a separate Gbit NIC of the servers (dedicated VLAN) while the management network is on a separate network. The gluster traffic does not exceed 40 Mbps during the snapshot operation. Can't understand why libvirt is logging timeout. Alex On Thu, Mar 29, 2018 at 9:42 PM, Alex K <rightkicktech@gmail.com> wrote:
Any idea with this issue? I am still trying to understand what may be causing this issue.
Many thanx for any assistance.
Alex
On Wed, Mar 28, 2018 at 10:06 AM, Yedidyah Bar David <didi@redhat.com> wrote:
On Tue, Mar 27, 2018 at 3:38 PM, Sandro Bonazzola <sbonazzo@redhat.com> wrote:
2018-03-27 14:34 GMT+02:00 Alex K <rightkicktech@gmail.com>:
Hi All,
Any idea on the below?
I am using oVirt Guest Tools 4.2-1.el7.centos for the VM. The Window 2016 server VM (which it the one with the relatively big disks: 500 GB) it is consistently rendered unresponsive when trying to get a snapshot. I amy provide any other additional logs if needed.
Adding some people to the thread
Adding more people for this part.
Alex
On Sun, Mar 25, 2018 at 7:30 PM, Alex K <rightkicktech@gmail.com> wrote:
Hi folks,
I am facing frequently the following issue:
On some large VMs (Windows 2016 with two disk drives, 60GB and 500GB) when attempting to create a snapshot of the VM, the VM becomes unresponsive.
The errors that I managed to collect were:
vdsm error at host hosting the VM: 2018-03-25 14:40:13,442+0000 WARN (vdsm.Scheduler) [Executor] Worker blocked: <Worker name=jsonrpc/7 running <Task <JsonRpcTask {'params': {u'frozen': False, u'vmID': u'a5c761a2-41cd-40c2-b65f-f3819293e8a4', u'snapDrives': [{u'baseVolumeID': u'2a33e585-ece8-4f4d-b45d-5ecc9239200e', u'domainID': u'888e3aae-f49f-42f7-a7fa-76700befabea', u'volumeID': u'e9a01ebd-83dd-40c3-8c83-5302b0d15e04', u'imageID': u'c75b8e93-3067-4472-bf24-dafada224e4d'}, {u'baseVolumeID': u'3fb2278c-1b0d-4677-a529-99084e4b08af', u'domainID': u'888e3aae-f49f-42f7-a7fa-76700befabea', u'volumeID': u'78e6b6b1-2406-4393-8d92-831a6d4f1337', u'imageID': u'd4223744-bf5d-427b-bec2-f14b9bc2ef81'}]}, 'jsonrpc': '2.0', 'method': u'VM.snapshot', 'id': u'89555c87-9701-4260-9952-789965261e65'} at 0x7fca4004cc90> timeout=60, duration=60 at 0x39d8210> task#=155842 at 0x2240e10> (executor:351) 2018-03-25 14:40:15,261+0000 INFO (jsonrpc/3) [jsonrpc.JsonRpcServer] RPC call VM.getStats failed (error 1) in 0.01 seconds (__init__:539) 2018-03-25 14:40:17,471+0000 WARN (jsonrpc/5) [virt.vm] (vmId='a5c761a2-41cd-40c2-b65f-f3819293e8a4') monitor became unresponsive (command timeout, age=67.9100000001) (vm:5132)
engine.log: 2018-03-25 14:40:19,875Z WARN [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler2) [1d737df7] EVENT_ID: VM_NOT_RESPONDING(126), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: VM Data-Server is not responding.
2018-03-25 14:42:13,708Z ERROR [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: VDS_BROKER_COMMAND_FAILURE(10,802), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: VDSM v1.cluster command SnapshotVDS failed: Message timeout which can be caused by communication issues 2018-03-25 14:42:13,708Z ERROR [org.ovirt.engine.core.vdsbrok er.vdsbroker.SnapshotVDSCommand] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] Command 'SnapshotVDSCommand(HostName = v1.cluster, SnapshotVDSCommandParameters:{runAsync='true', hostId='a713d988-ee03-4ff0-a0cd-dc4cde1507f4', vmId='a5c761a2-41cd-40c2-b65f-f3819293e8a4'})' execution failed: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues 2018-03-25 14:42:13,708Z WARN [org.ovirt.engine.core.bll.sna pshots.CreateAllSnapshotsFromVmCommand] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] Could not perform live snapshot due to error, VM will still be configured to the new created snapshot: EngineException: org.ovirt.engine.core.vdsbroke r.vdsbroker.VDSNetworkException: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues (Failed with error VDS_NETWORK_ERROR and code 5022) 2018-03-25 14:42:13,708Z WARN [org.ovirt.engine.core.vdsbroker.VdsManager] (org.ovirt.thread.pool-6-thread-15) [17789048-009a-454b-b8ad-2c72c7cd37aa] Host 'v1.cluster' is not responding. It will stay in Connecting state for a grace period of 61 seconds and after that an attempt to fence the host will be issued. 2018-03-25 14:42:13,725Z WARN [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (org.ovirt.thread.pool-6-thread-15) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: VDS_HOST_NOT_RESPONDING_CONNECTING(9,008), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: Host v1.cluster is not responding. It will stay in Connecting state for a grace period of 61 seconds and after that an attempt to fence the host will be issued. 2018-03-25 14:42:13,751Z WARN [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: USER_CREATE_LIVE_SNAPSHOT_FINISHED_FAILURE(170), Correlation ID: 17789048-009a-454b-b8ad-2c72c7cd37aa, Job ID: 16e48c28-a8c7-4841-bd81-1f2d370f345d, Call Stack: org.ovirt.engine.core.common.errors.EngineException: EngineException: org.ovirt.engine.core.vdsbroker.vdsbroker.VDSNetworkException: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues (Failed with error VDS_NETWORK_ERROR and code 5022) 2018-03-25 14:42:14,372Z ERROR [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [] EVENT_ID: USER_CREATE_SNAPSHOT_FINISHED_FAILURE(69), Correlation ID: 17789048-009a-454b-b8ad-2c72c7cd37aa, Job ID: 16e48c28-a8c7-4841-bd81-1f2d370f345d, Call Stack: org.ovirt.engine.core.common.errors.EngineException: EngineException: org.ovirt.engine.core.vdsbroker.vdsbroker.VDSNetworkException: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues (Failed with error VDS_NETWORK_ERROR and code 5022) 2018-03-25 14:42:14,372Z WARN [org.ovirt.engine.core.bll.Con currentChildCommandsExecutionCallback] (DefaultQuartzScheduler5) [] Command 'CreateAllSnapshotsFromVm' id: 'bad4f5be-5306-413f-a86a-513b3cfd3c66' end method execution failed, as the command isn't marked for endAction() retries silently ignoring 2018-03-25 14:42:15,951Z WARN [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [5017c163] EVENT_ID: VDS_NO_SELINUX_ENFORCEMENT(25), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: Host v1.cluster does not enforce SELinux. Current status: DISABLED 2018-03-25 14:42:15,951Z WARN [org.ovirt.engine.core.vdsbroker.VdsManager] (DefaultQuartzScheduler5) [5017c163] Host 'v1.cluster' is running with SELinux in 'DISABLED' mode
As soon as the VM is unresponsive, the VM console that was already open freezes. I can resume the VM only by powering off and on.
I am using ovirt 4.1.9 with 3 nodes and self-hosted engine. I am running mostly Windows 10 and Windows 2016 server VMs. I have installed latest guest agents from:
http://resources.ovirt.org/pub/ovirt-4.2/iso/oVirt-toolsSetu p/4.2-1.el7.centos/
At the screen where one takes a snapshot I get a warning saying "Could not detect guest agent on the VM. Note that without guest agent the data on the created snapshot may be inconsistent". See attached. I have verified that ovirt guest tools are installed and shown at installed apps at engine GUI. Also Ovirt Guest Agent (32 bit) and qemu-ga are listed as running at the windows tasks manager. Shouldn't ovirt guest agent be 64 bit on Windows 64 bit?
No idea, but I do not think it's related to your problem of freezing while taking a snapshot.
This error was already discussed in the past, see e.g.:
http://lists.ovirt.org/pipermail/users/2017-June/082577.html
Best regards, -- Didi
Hi All, Would appreciate for any ideas what to check further on the issue. Alex On Sun, Apr 1, 2018 at 9:04 PM, Alex K <rightkicktech@gmail.com> wrote:
Checking further the logs I see this error given from libvirt of the host that has the guest VM running:
Apr 1 17:53:41 v0 libvirtd: 2018-04-01 17:53:41.298+0000: 1862: warning : qemuDomainObjBeginJobInternal:3847 : Cannot start job (query, none) for domain Data-Server; current job is (async nested, snapshot) owned by (1863 remoteDispatchDomainSnapshotCreateXML, 1863 remoteDispatchDomainSnapshotCreateXML) for (39s, 41s) Apr 1 17:53:41 v0 libvirtd: 2018-04-01 17:53:41.299+0000: 1862: error : qemuDomainObjBeginJobInternal:3859 : Timed out during operation: cannot acquire state change lock (held by remoteDispatchDomainSnapshotCreateXML) Apr 1 17:53:57 v0 journal: vdsm Executor WARN Worker blocked: <Worker name=jsonrpc/3 running <Task <JsonRpcTask {'params': {u'frozen': False, u'vmID': u'6bdb3d02-cc33-4019-97cd-7447aecc1e02', u'snapDrives': [{u'baseVolumeID': u'adfabed5-451b-4f46-b22a-45f720b06110', u'domainID': u'2c4b8d45-3d05-4619-9a36-1ecd199d3056', u'volumeID': u'cc0d0772-924c-46db-8ad6-a2b0897c313f', u'imageID': u'7eeadedc-f247-4a31-840d-4de622bf3541'}, {u'baseVolumeID': u'0d960c12-3bcf-4918-896d-bd8e68b5278b', u'domainID': u'2c4b8d45-3d05-4619-9a36-1ecd199d3056', u'volumeID': u'590a6bdd-a9e2-444e-87bc-721c5f8586eb', u'imageID': u'da0e4111-6bbe-43cb-bf59-db5fbf5c3e38'}]}, 'jsonrpc': '2.0', 'method': u'VM.snapshot', 'id': u'be7912e6-ba3d-4357-8ba1-abe40825acf1'} at 0x3bf84d0> timeout=60, duration=60 at 0x3bf8050> task#=416 at 0x20d7f90>
Immediately after above the engine reports the VM as unresponsive. The SPM host does not log any issues.
In the same time, the 3 hosts are fairly idle with only one running guest VM. The gluster traffic is dedicated to a separate Gbit NIC of the servers (dedicated VLAN) while the management network is on a separate network. The gluster traffic does not exceed 40 Mbps during the snapshot operation. Can't understand why libvirt is logging timeout.
Alex
On Thu, Mar 29, 2018 at 9:42 PM, Alex K <rightkicktech@gmail.com> wrote:
Any idea with this issue? I am still trying to understand what may be causing this issue.
Many thanx for any assistance.
Alex
On Wed, Mar 28, 2018 at 10:06 AM, Yedidyah Bar David <didi@redhat.com> wrote:
On Tue, Mar 27, 2018 at 3:38 PM, Sandro Bonazzola <sbonazzo@redhat.com> wrote:
2018-03-27 14:34 GMT+02:00 Alex K <rightkicktech@gmail.com>:
Hi All,
Any idea on the below?
I am using oVirt Guest Tools 4.2-1.el7.centos for the VM. The Window 2016 server VM (which it the one with the relatively big disks: 500 GB) it is consistently rendered unresponsive when trying to get a snapshot. I amy provide any other additional logs if needed.
Adding some people to the thread
Adding more people for this part.
Alex
On Sun, Mar 25, 2018 at 7:30 PM, Alex K <rightkicktech@gmail.com> wrote:
Hi folks,
I am facing frequently the following issue:
On some large VMs (Windows 2016 with two disk drives, 60GB and 500GB) when attempting to create a snapshot of the VM, the VM becomes unresponsive.
The errors that I managed to collect were:
vdsm error at host hosting the VM: 2018-03-25 14:40:13,442+0000 WARN (vdsm.Scheduler) [Executor] Worker blocked: <Worker name=jsonrpc/7 running <Task <JsonRpcTask {'params': {u'frozen': False, u'vmID': u'a5c761a2-41cd-40c2-b65f-f3819293e8a4', u'snapDrives': [{u'baseVolumeID': u'2a33e585-ece8-4f4d-b45d-5ecc9239200e', u'domainID': u'888e3aae-f49f-42f7-a7fa-76700befabea', u'volumeID': u'e9a01ebd-83dd-40c3-8c83-5302b0d15e04', u'imageID': u'c75b8e93-3067-4472-bf24-dafada224e4d'}, {u'baseVolumeID': u'3fb2278c-1b0d-4677-a529-99084e4b08af', u'domainID': u'888e3aae-f49f-42f7-a7fa-76700befabea', u'volumeID': u'78e6b6b1-2406-4393-8d92-831a6d4f1337', u'imageID': u'd4223744-bf5d-427b-bec2-f14b9bc2ef81'}]}, 'jsonrpc': '2.0', 'method': u'VM.snapshot', 'id': u'89555c87-9701-4260-9952-789965261e65'} at 0x7fca4004cc90> timeout=60, duration=60 at 0x39d8210> task#=155842 at 0x2240e10> (executor:351) 2018-03-25 14:40:15,261+0000 INFO (jsonrpc/3) [jsonrpc.JsonRpcServer] RPC call VM.getStats failed (error 1) in 0.01 seconds (__init__:539) 2018-03-25 14:40:17,471+0000 WARN (jsonrpc/5) [virt.vm] (vmId='a5c761a2-41cd-40c2-b65f-f3819293e8a4') monitor became unresponsive (command timeout, age=67.9100000001) (vm:5132)
engine.log: 2018-03-25 14:40:19,875Z WARN [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler2) [1d737df7] EVENT_ID: VM_NOT_RESPONDING(126), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: VM Data-Server is not responding.
2018-03-25 14:42:13,708Z ERROR [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: VDS_BROKER_COMMAND_FAILURE(10,802), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: VDSM v1.cluster command SnapshotVDS failed: Message timeout which can be caused by communication issues 2018-03-25 14:42:13,708Z ERROR [org.ovirt.engine.core.vdsbrok er.vdsbroker.SnapshotVDSCommand] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] Command 'SnapshotVDSCommand(HostName = v1.cluster, SnapshotVDSCommandParameters:{runAsync='true', hostId='a713d988-ee03-4ff0-a0cd-dc4cde1507f4', vmId='a5c761a2-41cd-40c2-b65f-f3819293e8a4'})' execution failed: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues 2018-03-25 14:42:13,708Z WARN [org.ovirt.engine.core.bll.sna pshots.CreateAllSnapshotsFromVmCommand] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] Could not perform live snapshot due to error, VM will still be configured to the new created snapshot: EngineException: org.ovirt.engine.core.vdsbroke r.vdsbroker.VDSNetworkException: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues (Failed with error VDS_NETWORK_ERROR and code 5022) 2018-03-25 14:42:13,708Z WARN [org.ovirt.engine.core.vdsbroker.VdsManager] (org.ovirt.thread.pool-6-thread-15) [17789048-009a-454b-b8ad-2c72c7cd37aa] Host 'v1.cluster' is not responding. It will stay in Connecting state for a grace period of 61 seconds and after that an attempt to fence the host will be issued. 2018-03-25 14:42:13,725Z WARN [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (org.ovirt.thread.pool-6-thread-15) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: VDS_HOST_NOT_RESPONDING_CONNECTING(9,008), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: Host v1.cluster is not responding. It will stay in Connecting state for a grace period of 61 seconds and after that an attempt to fence the host will be issued. 2018-03-25 14:42:13,751Z WARN [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: USER_CREATE_LIVE_SNAPSHOT_FINISHED_FAILURE(170), Correlation ID: 17789048-009a-454b-b8ad-2c72c7cd37aa, Job ID: 16e48c28-a8c7-4841-bd81-1f2d370f345d, Call Stack: org.ovirt.engine.core.common.errors.EngineException: EngineException: org.ovirt.engine.core.vdsbroke r.vdsbroker.VDSNetworkException: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues (Failed with error VDS_NETWORK_ERROR and code 5022) 2018-03-25 14:42:14,372Z ERROR [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [] EVENT_ID: USER_CREATE_SNAPSHOT_FINISHED_FAILURE(69), Correlation ID: 17789048-009a-454b-b8ad-2c72c7cd37aa, Job ID: 16e48c28-a8c7-4841-bd81-1f2d370f345d, Call Stack: org.ovirt.engine.core.common.errors.EngineException: EngineException: org.ovirt.engine.core.vdsbroke r.vdsbroker.VDSNetworkException: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues (Failed with error VDS_NETWORK_ERROR and code 5022) 2018-03-25 14:42:14,372Z WARN [org.ovirt.engine.core.bll.Con currentChildCommandsExecutionCallback] (DefaultQuartzScheduler5) [] Command 'CreateAllSnapshotsFromVm' id: 'bad4f5be-5306-413f-a86a-513b3cfd3c66' end method execution failed, as the command isn't marked for endAction() retries silently ignoring 2018-03-25 14:42:15,951Z WARN [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [5017c163] EVENT_ID: VDS_NO_SELINUX_ENFORCEMENT(25), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: Host v1.cluster does not enforce SELinux. Current status: DISABLED 2018-03-25 14:42:15,951Z WARN [org.ovirt.engine.core.vdsbroker.VdsManager] (DefaultQuartzScheduler5) [5017c163] Host 'v1.cluster' is running with SELinux in 'DISABLED' mode
As soon as the VM is unresponsive, the VM console that was already open freezes. I can resume the VM only by powering off and on.
I am using ovirt 4.1.9 with 3 nodes and self-hosted engine. I am running mostly Windows 10 and Windows 2016 server VMs. I have installed latest guest agents from:
http://resources.ovirt.org/pub/ovirt-4.2/iso/oVirt-toolsSetu p/4.2-1.el7.centos/
At the screen where one takes a snapshot I get a warning saying "Could not detect guest agent on the VM. Note that without guest agent the data on the created snapshot may be inconsistent". See attached. I have verified that ovirt guest tools are installed and shown at installed apps at engine GUI. Also Ovirt Guest Agent (32 bit) and qemu-ga are listed as running at the windows tasks manager. Shouldn't ovirt guest agent be 64 bit on Windows 64 bit?
No idea, but I do not think it's related to your problem of freezing while taking a snapshot.
This error was already discussed in the past, see e.g.:
http://lists.ovirt.org/pipermail/users/2017-June/082577.html
Best regards, -- Didi

On Sun, Apr 1, 2018 at 9:04 PM, Alex K <rightkicktech@gmail.com> wrote:
Checking further the logs I see this error given from libvirt of the host that has the guest VM running:
Apr 1 17:53:41 v0 libvirtd: 2018-04-01 17:53:41.298+0000: 1862: warning : qemuDomainObjBeginJobInternal:3847 : Cannot start job (query, none) for domain Data-Server; current job is (async nested, snapshot) owned by (1863 remoteDispatchDomainSnapshotCreateXML, 1863 remoteDispatchDomainSnapshotCreateXML) for (39s, 41s) Apr 1 17:53:41 v0 libvirtd: 2018-04-01 17:53:41.299+0000: 1862: error : qemuDomainObjBeginJobInternal:3859 : Timed out during operation: cannot acquire state change lock (held by remoteDispatchDomainSnapshotCreateXML) Apr 1 17:53:57 v0 journal: vdsm Executor WARN Worker blocked: <Worker name=jsonrpc/3 running <Task <JsonRpcTask {'params': {u'frozen': False, u'vmID': u'6bdb3d02-cc33-4019-97cd-7447aecc1e02', u'snapDrives': [{u'baseVolumeID': u'adfabed5-451b-4f46-b22a-45f720b06110', u'domainID': u'2c4b8d45-3d05-4619-9a36-1ecd199d3056', u'volumeID': u'cc0d0772-924c-46db-8ad6-a2b0897c313f', u'imageID': u'7eeadedc-f247-4a31-840d-4de622bf3541'}, {u'baseVolumeID': u'0d960c12-3bcf-4918-896d-bd8e68b5278b', u'domainID': u'2c4b8d45-3d05-4619-9a36-1ecd199d3056', u'volumeID': u'590a6bdd-a9e2-444e-87bc-721c5f8586eb', u'imageID': u'da0e4111-6bbe-43cb-bf59-db5fbf5c3e38'}]}, 'jsonrpc': '2.0', 'method': u'VM.snapshot', 'id': u'be7912e6-ba3d-4357-8ba1-abe40825acf1'} at 0x3bf84d0> timeout=60, duration=60 at 0x3bf8050> task#=416 at 0x20d7f90>
Immediately after above the engine reports the VM as unresponsive.
If it's reproducible, it'd be great if you could: 1. Run libvirt with debug logs 2. Get a dump of libvirt when this happens (with gstack for example). 3. File a bug on libvirt. Thanks, Y.
The SPM host does not log any issues.
In the same time, the 3 hosts are fairly idle with only one running guest VM. The gluster traffic is dedicated to a separate Gbit NIC of the servers (dedicated VLAN) while the management network is on a separate network. The gluster traffic does not exceed 40 Mbps during the snapshot operation. Can't understand why libvirt is logging timeout.
Alex
On Thu, Mar 29, 2018 at 9:42 PM, Alex K <rightkicktech@gmail.com> wrote:
Any idea with this issue? I am still trying to understand what may be causing this issue.
Many thanx for any assistance.
Alex
On Wed, Mar 28, 2018 at 10:06 AM, Yedidyah Bar David <didi@redhat.com> wrote:
On Tue, Mar 27, 2018 at 3:38 PM, Sandro Bonazzola <sbonazzo@redhat.com> wrote:
2018-03-27 14:34 GMT+02:00 Alex K <rightkicktech@gmail.com>:
Hi All,
Any idea on the below?
I am using oVirt Guest Tools 4.2-1.el7.centos for the VM. The Window 2016 server VM (which it the one with the relatively big disks: 500 GB) it is consistently rendered unresponsive when trying to get a snapshot. I amy provide any other additional logs if needed.
Adding some people to the thread
Adding more people for this part.
Alex
On Sun, Mar 25, 2018 at 7:30 PM, Alex K <rightkicktech@gmail.com> wrote:
Hi folks,
I am facing frequently the following issue:
On some large VMs (Windows 2016 with two disk drives, 60GB and 500GB) when attempting to create a snapshot of the VM, the VM becomes unresponsive.
The errors that I managed to collect were:
vdsm error at host hosting the VM: 2018-03-25 14:40:13,442+0000 WARN (vdsm.Scheduler) [Executor] Worker blocked: <Worker name=jsonrpc/7 running <Task <JsonRpcTask {'params': {u'frozen': False, u'vmID': u'a5c761a2-41cd-40c2-b65f-f3819293e8a4', u'snapDrives': [{u'baseVolumeID': u'2a33e585-ece8-4f4d-b45d-5ecc9239200e', u'domainID': u'888e3aae-f49f-42f7-a7fa-76700befabea', u'volumeID': u'e9a01ebd-83dd-40c3-8c83-5302b0d15e04', u'imageID': u'c75b8e93-3067-4472-bf24-dafada224e4d'}, {u'baseVolumeID': u'3fb2278c-1b0d-4677-a529-99084e4b08af', u'domainID': u'888e3aae-f49f-42f7-a7fa-76700befabea', u'volumeID': u'78e6b6b1-2406-4393-8d92-831a6d4f1337', u'imageID': u'd4223744-bf5d-427b-bec2-f14b9bc2ef81'}]}, 'jsonrpc': '2.0', 'method': u'VM.snapshot', 'id': u'89555c87-9701-4260-9952-789965261e65'} at 0x7fca4004cc90> timeout=60, duration=60 at 0x39d8210> task#=155842 at 0x2240e10> (executor:351) 2018-03-25 14:40:15,261+0000 INFO (jsonrpc/3) [jsonrpc.JsonRpcServer] RPC call VM.getStats failed (error 1) in 0.01 seconds (__init__:539) 2018-03-25 14:40:17,471+0000 WARN (jsonrpc/5) [virt.vm] (vmId='a5c761a2-41cd-40c2-b65f-f3819293e8a4') monitor became unresponsive (command timeout, age=67.9100000001) (vm:5132)
engine.log: 2018-03-25 14:40:19,875Z WARN [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler2) [1d737df7] EVENT_ID: VM_NOT_RESPONDING(126), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: VM Data-Server is not responding.
2018-03-25 14:42:13,708Z ERROR [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: VDS_BROKER_COMMAND_FAILURE(10,802), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: VDSM v1.cluster command SnapshotVDS failed: Message timeout which can be caused by communication issues 2018-03-25 14:42:13,708Z ERROR [org.ovirt.engine.core.vdsbrok er.vdsbroker.SnapshotVDSCommand] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] Command 'SnapshotVDSCommand(HostName = v1.cluster, SnapshotVDSCommandParameters:{runAsync='true', hostId='a713d988-ee03-4ff0-a0cd-dc4cde1507f4', vmId='a5c761a2-41cd-40c2-b65f-f3819293e8a4'})' execution failed: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues 2018-03-25 14:42:13,708Z WARN [org.ovirt.engine.core.bll.sna pshots.CreateAllSnapshotsFromVmCommand] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] Could not perform live snapshot due to error, VM will still be configured to the new created snapshot: EngineException: org.ovirt.engine.core.vdsbroke r.vdsbroker.VDSNetworkException: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues (Failed with error VDS_NETWORK_ERROR and code 5022) 2018-03-25 14:42:13,708Z WARN [org.ovirt.engine.core.vdsbroker.VdsManager] (org.ovirt.thread.pool-6-thread-15) [17789048-009a-454b-b8ad-2c72c7cd37aa] Host 'v1.cluster' is not responding. It will stay in Connecting state for a grace period of 61 seconds and after that an attempt to fence the host will be issued. 2018-03-25 14:42:13,725Z WARN [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (org.ovirt.thread.pool-6-thread-15) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: VDS_HOST_NOT_RESPONDING_CONNECTING(9,008), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: Host v1.cluster is not responding. It will stay in Connecting state for a grace period of 61 seconds and after that an attempt to fence the host will be issued. 2018-03-25 14:42:13,751Z WARN [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: USER_CREATE_LIVE_SNAPSHOT_FINISHED_FAILURE(170), Correlation ID: 17789048-009a-454b-b8ad-2c72c7cd37aa, Job ID: 16e48c28-a8c7-4841-bd81-1f2d370f345d, Call Stack: org.ovirt.engine.core.common.errors.EngineException: EngineException: org.ovirt.engine.core.vdsbroke r.vdsbroker.VDSNetworkException: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues (Failed with error VDS_NETWORK_ERROR and code 5022) 2018-03-25 14:42:14,372Z ERROR [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [] EVENT_ID: USER_CREATE_SNAPSHOT_FINISHED_FAILURE(69), Correlation ID: 17789048-009a-454b-b8ad-2c72c7cd37aa, Job ID: 16e48c28-a8c7-4841-bd81-1f2d370f345d, Call Stack: org.ovirt.engine.core.common.errors.EngineException: EngineException: org.ovirt.engine.core.vdsbroke r.vdsbroker.VDSNetworkException: VDSGenericException: VDSNetworkException: Message timeout which can be caused by communication issues (Failed with error VDS_NETWORK_ERROR and code 5022) 2018-03-25 14:42:14,372Z WARN [org.ovirt.engine.core.bll.Con currentChildCommandsExecutionCallback] (DefaultQuartzScheduler5) [] Command 'CreateAllSnapshotsFromVm' id: 'bad4f5be-5306-413f-a86a-513b3cfd3c66' end method execution failed, as the command isn't marked for endAction() retries silently ignoring 2018-03-25 14:42:15,951Z WARN [org.ovirt.engine.core.dal.dbb roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) [5017c163] EVENT_ID: VDS_NO_SELINUX_ENFORCEMENT(25), Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: Host v1.cluster does not enforce SELinux. Current status: DISABLED 2018-03-25 14:42:15,951Z WARN [org.ovirt.engine.core.vdsbroker.VdsManager] (DefaultQuartzScheduler5) [5017c163] Host 'v1.cluster' is running with SELinux in 'DISABLED' mode
As soon as the VM is unresponsive, the VM console that was already open freezes. I can resume the VM only by powering off and on.
I am using ovirt 4.1.9 with 3 nodes and self-hosted engine. I am running mostly Windows 10 and Windows 2016 server VMs. I have installed latest guest agents from:
http://resources.ovirt.org/pub/ovirt-4.2/iso/oVirt-toolsSetu p/4.2-1.el7.centos/
At the screen where one takes a snapshot I get a warning saying "Could not detect guest agent on the VM. Note that without guest agent the data on the created snapshot may be inconsistent". See attached. I have verified that ovirt guest tools are installed and shown at installed apps at engine GUI. Also Ovirt Guest Agent (32 bit) and qemu-ga are listed as running at the windows tasks manager. Shouldn't ovirt guest agent be 64 bit on Windows 64 bit?
No idea, but I do not think it's related to your problem of freezing while taking a snapshot.
This error was already discussed in the past, see e.g.:
http://lists.ovirt.org/pipermail/users/2017-June/082577.html
Best regards, -- Didi
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
Thanx Yaniv, I will try to follow your advice. Alex On Tue, Apr 3, 2018 at 8:54 PM, Yaniv Kaul <ykaul@redhat.com> wrote:
On Sun, Apr 1, 2018 at 9:04 PM, Alex K <rightkicktech@gmail.com> wrote:
Checking further the logs I see this error given from libvirt of the host that has the guest VM running:
Apr 1 17:53:41 v0 libvirtd: 2018-04-01 17:53:41.298+0000: 1862: warning : qemuDomainObjBeginJobInternal:3847 : Cannot start job (query, none) for domain Data-Server; current job is (async nested, snapshot) owned by (1863 remoteDispatchDomainSnapshotCreateXML, 1863 remoteDispatchDomainSnapshotCreateXML) for (39s, 41s) Apr 1 17:53:41 v0 libvirtd: 2018-04-01 17:53:41.299+0000: 1862: error : qemuDomainObjBeginJobInternal:3859 : Timed out during operation: cannot acquire state change lock (held by remoteDispatchDomainSnapshotCreateXML) Apr 1 17:53:57 v0 journal: vdsm Executor WARN Worker blocked: <Worker name=jsonrpc/3 running <Task <JsonRpcTask {'params': {u'frozen': False, u'vmID': u'6bdb3d02-cc33-4019-97cd-7447aecc1e02', u'snapDrives': [{u'baseVolumeID': u'adfabed5-451b-4f46-b22a-45f720b06110', u'domainID': u'2c4b8d45-3d05-4619-9a36-1ecd199d3056', u'volumeID': u'cc0d0772-924c-46db-8ad6-a2b0897c313f', u'imageID': u'7eeadedc-f247-4a31-840d-4de622bf3541'}, {u'baseVolumeID': u'0d960c12-3bcf-4918-896d-bd8e68b5278b', u'domainID': u'2c4b8d45-3d05-4619-9a36-1ecd199d3056', u'volumeID': u'590a6bdd-a9e2-444e-87bc-721c5f8586eb', u'imageID': u'da0e4111-6bbe-43cb-bf59-db5fbf5c3e38'}]}, 'jsonrpc': '2.0', 'method': u'VM.snapshot', 'id': u'be7912e6-ba3d-4357-8ba1-abe40825acf1'} at 0x3bf84d0> timeout=60, duration=60 at 0x3bf8050> task#=416 at 0x20d7f90>
Immediately after above the engine reports the VM as unresponsive.
If it's reproducible, it'd be great if you could: 1. Run libvirt with debug logs 2. Get a dump of libvirt when this happens (with gstack for example). 3. File a bug on libvirt.
Thanks, Y.
The SPM host does not log any issues.
In the same time, the 3 hosts are fairly idle with only one running guest VM. The gluster traffic is dedicated to a separate Gbit NIC of the servers (dedicated VLAN) while the management network is on a separate network. The gluster traffic does not exceed 40 Mbps during the snapshot operation. Can't understand why libvirt is logging timeout.
Alex
On Thu, Mar 29, 2018 at 9:42 PM, Alex K <rightkicktech@gmail.com> wrote:
Any idea with this issue? I am still trying to understand what may be causing this issue.
Many thanx for any assistance.
Alex
On Wed, Mar 28, 2018 at 10:06 AM, Yedidyah Bar David <didi@redhat.com> wrote:
On Tue, Mar 27, 2018 at 3:38 PM, Sandro Bonazzola <sbonazzo@redhat.com> wrote:
2018-03-27 14:34 GMT+02:00 Alex K <rightkicktech@gmail.com>:
Hi All,
Any idea on the below?
I am using oVirt Guest Tools 4.2-1.el7.centos for the VM. The Window 2016 server VM (which it the one with the relatively big disks: 500 GB) it is consistently rendered unresponsive when trying to get a snapshot. I amy provide any other additional logs if needed.
Adding some people to the thread
Adding more people for this part.
Alex
On Sun, Mar 25, 2018 at 7:30 PM, Alex K <rightkicktech@gmail.com> wrote:
> Hi folks, > > I am facing frequently the following issue: > > On some large VMs (Windows 2016 with two disk drives, 60GB and > 500GB) when attempting to create a snapshot of the VM, the VM becomes > unresponsive. > > The errors that I managed to collect were: > > vdsm error at host hosting the VM: > 2018-03-25 14:40:13,442+0000 WARN (vdsm.Scheduler) [Executor] > Worker blocked: <Worker name=jsonrpc/7 running <Task <JsonRpcTask > {'params': {u'frozen': False, u'vmID': u'a5c761a2-41cd-40c2-b65f-f3819293e8a4', > u'snapDrives': [{u'baseVolumeID': u'2a33e585-ece8-4f4d-b45d-5ecc9239200e', > u'domainID': u'888e3aae-f49f-42f7-a7fa-76700befabea', u'volumeID': > u'e9a01ebd-83dd-40c3-8c83-5302b0d15e04', u'imageID': > u'c75b8e93-3067-4472-bf24-dafada224e4d'}, {u'baseVolumeID': > u'3fb2278c-1b0d-4677-a529-99084e4b08af', u'domainID': > u'888e3aae-f49f-42f7-a7fa-76700befabea', u'volumeID': > u'78e6b6b1-2406-4393-8d92-831a6d4f1337', u'imageID': > u'd4223744-bf5d-427b-bec2-f14b9bc2ef81'}]}, 'jsonrpc': '2.0', > 'method': u'VM.snapshot', 'id': u'89555c87-9701-4260-9952-789965261e65'} > at 0x7fca4004cc90> timeout=60, duration=60 at 0x39d8210> task#=155842 at > 0x2240e10> (executor:351) > 2018-03-25 14:40:15,261+0000 INFO (jsonrpc/3) > [jsonrpc.JsonRpcServer] RPC call VM.getStats failed (error 1) in 0.01 > seconds (__init__:539) > 2018-03-25 14:40:17,471+0000 WARN (jsonrpc/5) [virt.vm] > (vmId='a5c761a2-41cd-40c2-b65f-f3819293e8a4') monitor became > unresponsive (command timeout, age=67.9100000001) (vm:5132) > > engine.log: > 2018-03-25 14:40:19,875Z WARN [org.ovirt.engine.core.dal.dbb > roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler2) > [1d737df7] EVENT_ID: VM_NOT_RESPONDING(126), Correlation ID: null, Call > Stack: null, Custom ID: null, Custom Event ID: -1, Message: VM Data-Server > is not responding. > > 2018-03-25 14:42:13,708Z ERROR [org.ovirt.engine.core.dal.dbb > roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) > [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: > VDS_BROKER_COMMAND_FAILURE(10,802), Correlation ID: null, Call > Stack: null, Custom ID: null, Custom Event ID: -1, Message: VDSM v1.cluster > command SnapshotVDS failed: Message timeout which can be caused by > communication issues > 2018-03-25 14:42:13,708Z ERROR [org.ovirt.engine.core.vdsbrok > er.vdsbroker.SnapshotVDSCommand] (DefaultQuartzScheduler5) > [17789048-009a-454b-b8ad-2c72c7cd37aa] Command > 'SnapshotVDSCommand(HostName = v1.cluster, SnapshotVDSCommandParameters:{runAsync='true', > hostId='a713d988-ee03-4ff0-a0cd-dc4cde1507f4', > vmId='a5c761a2-41cd-40c2-b65f-f3819293e8a4'})' execution failed: > VDSGenericException: VDSNetworkException: Message timeout which can be > caused by communication issues > 2018-03-25 14:42:13,708Z WARN [org.ovirt.engine.core.bll.sna > pshots.CreateAllSnapshotsFromVmCommand] (DefaultQuartzScheduler5) > [17789048-009a-454b-b8ad-2c72c7cd37aa] Could not perform live > snapshot due to error, VM will still be configured to the new created > snapshot: EngineException: org.ovirt.engine.core.vdsbroke > r.vdsbroker.VDSNetworkException: VDSGenericException: > VDSNetworkException: Message timeout which can be caused by communication > issues (Failed with error VDS_NETWORK_ERROR and code 5022) > 2018-03-25 14:42:13,708Z WARN [org.ovirt.engine.core.vdsbroker.VdsManager] > (org.ovirt.thread.pool-6-thread-15) [17789048-009a-454b-b8ad-2c72c7cd37aa] > Host 'v1.cluster' is not responding. It will stay in Connecting state for a > grace period of 61 seconds and after that an attempt to fence the host will > be issued. > 2018-03-25 14:42:13,725Z WARN [org.ovirt.engine.core.dal.dbb > roker.auditloghandling.AuditLogDirector] > (org.ovirt.thread.pool-6-thread-15) [17789048-009a-454b-b8ad-2c72c7cd37aa] > EVENT_ID: VDS_HOST_NOT_RESPONDING_CONNECTING(9,008), Correlation > ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: > Host v1.cluster is not responding. It will stay in Connecting state for a > grace period of 61 seconds and after that an attempt to fence the host will > be issued. > 2018-03-25 14:42:13,751Z WARN [org.ovirt.engine.core.dal.dbb > roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) > [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: > USER_CREATE_LIVE_SNAPSHOT_FINISHED_FAILURE(170), Correlation ID: > 17789048-009a-454b-b8ad-2c72c7cd37aa, Job ID: > 16e48c28-a8c7-4841-bd81-1f2d370f345d, Call Stack: > org.ovirt.engine.core.common.errors.EngineException: > EngineException: org.ovirt.engine.core.vdsbroke > r.vdsbroker.VDSNetworkException: VDSGenericException: > VDSNetworkException: Message timeout which can be caused by communication > issues (Failed with error VDS_NETWORK_ERROR and code 5022) > 2018-03-25 14:42:14,372Z ERROR [org.ovirt.engine.core.dal.dbb > roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) > [] EVENT_ID: USER_CREATE_SNAPSHOT_FINISHED_FAILURE(69), Correlation > ID: 17789048-009a-454b-b8ad-2c72c7cd37aa, Job ID: > 16e48c28-a8c7-4841-bd81-1f2d370f345d, Call Stack: > org.ovirt.engine.core.common.errors.EngineException: > EngineException: org.ovirt.engine.core.vdsbroke > r.vdsbroker.VDSNetworkException: VDSGenericException: > VDSNetworkException: Message timeout which can be caused by communication > issues (Failed with error VDS_NETWORK_ERROR and code 5022) > 2018-03-25 14:42:14,372Z WARN [org.ovirt.engine.core.bll.Con > currentChildCommandsExecutionCallback] (DefaultQuartzScheduler5) [] > Command 'CreateAllSnapshotsFromVm' id: 'bad4f5be-5306-413f-a86a-513b3cfd3c66' > end method execution failed, as the command isn't marked for endAction() > retries silently ignoring > 2018-03-25 14:42:15,951Z WARN [org.ovirt.engine.core.dal.dbb > roker.auditloghandling.AuditLogDirector] (DefaultQuartzScheduler5) > [5017c163] EVENT_ID: VDS_NO_SELINUX_ENFORCEMENT(25), Correlation > ID: null, Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: > Host v1.cluster does not enforce SELinux. Current status: DISABLED > 2018-03-25 14:42:15,951Z WARN [org.ovirt.engine.core.vdsbroker.VdsManager] > (DefaultQuartzScheduler5) [5017c163] Host 'v1.cluster' is running with > SELinux in 'DISABLED' mode > > As soon as the VM is unresponsive, the VM console that was already > open freezes. I can resume the VM only by powering off and on. > > I am using ovirt 4.1.9 with 3 nodes and self-hosted engine. I am > running mostly Windows 10 and Windows 2016 server VMs. I have installed > latest guest agents from: > > http://resources.ovirt.org/pub/ovirt-4.2/iso/oVirt-toolsSetu > p/4.2-1.el7.centos/ > > At the screen where one takes a snapshot I get a warning saying > "Could not detect guest agent on the VM. Note that without guest agent the > data on the created snapshot may be inconsistent". See attached. I have > verified that ovirt guest tools are installed and shown at installed apps > at engine GUI. Also Ovirt Guest Agent (32 bit) and qemu-ga are listed as > running at the windows tasks manager. Shouldn't ovirt guest agent be 64 bit > on Windows 64 bit? >
No idea, but I do not think it's related to your problem of freezing while taking a snapshot.
This error was already discussed in the past, see e.g.:
http://lists.ovirt.org/pipermail/users/2017-June/082577.html
Best regards, -- Didi
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
Interestingly enough this happens only to a Windows VM with two disks (60GB, 500GB). This is reproducible every time a snapshot is taken. If I snapshot only one disk, regardless if it is the small or the big one, the snapshot completes fairly quickly and the VM is not rendered unresponsive. Seems to be a race issue with libvirtd. Alex On Wed, Apr 11, 2018 at 6:57 PM, Alex K <rightkicktech@gmail.com> wrote:
Thanx Yaniv,
I will try to follow your advice.
Alex
On Tue, Apr 3, 2018 at 8:54 PM, Yaniv Kaul <ykaul@redhat.com> wrote:
On Sun, Apr 1, 2018 at 9:04 PM, Alex K <rightkicktech@gmail.com> wrote:
Checking further the logs I see this error given from libvirt of the host that has the guest VM running:
Apr 1 17:53:41 v0 libvirtd: 2018-04-01 17:53:41.298+0000: 1862: warning : qemuDomainObjBeginJobInternal:3847 : Cannot start job (query, none) for domain Data-Server; current job is (async nested, snapshot) owned by (1863 remoteDispatchDomainSnapshotCreateXML, 1863 remoteDispatchDomainSnapshotCreateXML) for (39s, 41s) Apr 1 17:53:41 v0 libvirtd: 2018-04-01 17:53:41.299+0000: 1862: error : qemuDomainObjBeginJobInternal:3859 : Timed out during operation: cannot acquire state change lock (held by remoteDispatchDomainSnapshotCreateXML) Apr 1 17:53:57 v0 journal: vdsm Executor WARN Worker blocked: <Worker name=jsonrpc/3 running <Task <JsonRpcTask {'params': {u'frozen': False, u'vmID': u'6bdb3d02-cc33-4019-97cd-7447aecc1e02', u'snapDrives': [{u'baseVolumeID': u'adfabed5-451b-4f46-b22a-45f720b06110', u'domainID': u'2c4b8d45-3d05-4619-9a36-1ecd199d3056', u'volumeID': u'cc0d0772-924c-46db-8ad6-a2b0897c313f', u'imageID': u'7eeadedc-f247-4a31-840d-4de622bf3541'}, {u'baseVolumeID': u'0d960c12-3bcf-4918-896d-bd8e68b5278b', u'domainID': u'2c4b8d45-3d05-4619-9a36-1ecd199d3056', u'volumeID': u'590a6bdd-a9e2-444e-87bc-721c5f8586eb', u'imageID': u'da0e4111-6bbe-43cb-bf59-db5fbf5c3e38'}]}, 'jsonrpc': '2.0', 'method': u'VM.snapshot', 'id': u'be7912e6-ba3d-4357-8ba1-abe40825acf1'} at 0x3bf84d0> timeout=60, duration=60 at 0x3bf8050> task#=416 at 0x20d7f90>
Immediately after above the engine reports the VM as unresponsive.
If it's reproducible, it'd be great if you could: 1. Run libvirt with debug logs 2. Get a dump of libvirt when this happens (with gstack for example). 3. File a bug on libvirt.
Thanks, Y.
The SPM host does not log any issues.
In the same time, the 3 hosts are fairly idle with only one running guest VM. The gluster traffic is dedicated to a separate Gbit NIC of the servers (dedicated VLAN) while the management network is on a separate network. The gluster traffic does not exceed 40 Mbps during the snapshot operation. Can't understand why libvirt is logging timeout.
Alex
On Thu, Mar 29, 2018 at 9:42 PM, Alex K <rightkicktech@gmail.com> wrote:
Any idea with this issue? I am still trying to understand what may be causing this issue.
Many thanx for any assistance.
Alex
On Wed, Mar 28, 2018 at 10:06 AM, Yedidyah Bar David <didi@redhat.com> wrote:
On Tue, Mar 27, 2018 at 3:38 PM, Sandro Bonazzola <sbonazzo@redhat.com
wrote:
2018-03-27 14:34 GMT+02:00 Alex K <rightkicktech@gmail.com>:
> Hi All, > > Any idea on the below? > > I am using oVirt Guest Tools 4.2-1.el7.centos for the VM. > The Window 2016 server VM (which it the one with the relatively big > disks: 500 GB) it is consistently rendered unresponsive when trying to get > a snapshot. > I amy provide any other additional logs if needed. >
Adding some people to the thread
Adding more people for this part.
> > Alex > > On Sun, Mar 25, 2018 at 7:30 PM, Alex K <rightkicktech@gmail.com> > wrote: > >> Hi folks, >> >> I am facing frequently the following issue: >> >> On some large VMs (Windows 2016 with two disk drives, 60GB and >> 500GB) when attempting to create a snapshot of the VM, the VM becomes >> unresponsive. >> >> The errors that I managed to collect were: >> >> vdsm error at host hosting the VM: >> 2018-03-25 14:40:13,442+0000 WARN (vdsm.Scheduler) [Executor] >> Worker blocked: <Worker name=jsonrpc/7 running <Task <JsonRpcTask >> {'params': {u'frozen': False, u'vmID': >> u'a5c761a2-41cd-40c2-b65f-f3819293e8a4', u'snapDrives': [{u'baseVolumeID': >> u'2a33e585-ece8-4f4d-b45d-5ecc9239200e', u'domainID': >> u'888e3aae-f49f-42f7-a7fa-76700befabea', u'volumeID': >> u'e9a01ebd-83dd-40c3-8c83-5302b0d15e04', u'imageID': >> u'c75b8e93-3067-4472-bf24-dafada224e4d'}, {u'baseVolumeID': >> u'3fb2278c-1b0d-4677-a529-99084e4b08af', u'domainID': >> u'888e3aae-f49f-42f7-a7fa-76700befabea', u'volumeID': >> u'78e6b6b1-2406-4393-8d92-831a6d4f1337', u'imageID': >> u'd4223744-bf5d-427b-bec2-f14b9bc2ef81'}]}, 'jsonrpc': '2.0', 'method': >> u'VM.snapshot', 'id': u'89555c87-9701-4260-9952-789965261e65'} at >> 0x7fca4004cc90> timeout=60, duration=60 at 0x39d8210> task#=155842 at >> 0x2240e10> (executor:351) >> 2018-03-25 14:40:15,261+0000 INFO (jsonrpc/3) >> [jsonrpc.JsonRpcServer] RPC call VM.getStats failed (error 1) in 0.01 >> seconds (__init__:539) >> 2018-03-25 14:40:17,471+0000 WARN (jsonrpc/5) [virt.vm] >> (vmId='a5c761a2-41cd-40c2-b65f-f3819293e8a4') monitor became unresponsive >> (command timeout, age=67.9100000001) (vm:5132) >> >> engine.log: >> 2018-03-25 14:40:19,875Z WARN >> [org.ovirt.engine.core.dal.dbbroker.auditloghandling.AuditLogDirector] >> (DefaultQuartzScheduler2) [1d737df7] EVENT_ID: VM_NOT_RESPONDING(126), >> Correlation ID: null, Call Stack: null, Custom ID: null, Custom Event ID: >> -1, Message: VM Data-Server is not responding. >> >> 2018-03-25 14:42:13,708Z ERROR >> [org.ovirt.engine.core.dal.dbbroker.auditloghandling.AuditLogDirector] >> (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: >> VDS_BROKER_COMMAND_FAILURE(10,802), Correlation ID: null, Call Stack: null, >> Custom ID: null, Custom Event ID: -1, Message: VDSM v1.cluster command >> SnapshotVDS failed: Message timeout which can be caused by communication >> issues >> 2018-03-25 14:42:13,708Z ERROR >> [org.ovirt.engine.core.vdsbroker.vdsbroker.SnapshotVDSCommand] >> (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] Command >> 'SnapshotVDSCommand(HostName = v1.cluster, >> SnapshotVDSCommandParameters:{runAsync='true', >> hostId='a713d988-ee03-4ff0-a0cd-dc4cde1507f4', >> vmId='a5c761a2-41cd-40c2-b65f-f3819293e8a4'})' execution failed: >> VDSGenericException: VDSNetworkException: Message timeout which can be >> caused by communication issues >> 2018-03-25 14:42:13,708Z WARN >> [org.ovirt.engine.core.bll.snapshots.CreateAllSnapshotsFromVmCommand] >> (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] Could not >> perform live snapshot due to error, VM will still be configured to the new >> created snapshot: EngineException: >> org.ovirt.engine.core.vdsbroker.vdsbroker.VDSNetworkException: >> VDSGenericException: VDSNetworkException: Message timeout which can be >> caused by communication issues (Failed with error VDS_NETWORK_ERROR and >> code 5022) >> 2018-03-25 14:42:13,708Z WARN >> [org.ovirt.engine.core.vdsbroker.VdsManager] >> (org.ovirt.thread.pool-6-thread-15) [17789048-009a-454b-b8ad-2c72c7cd37aa] >> Host 'v1.cluster' is not responding. It will stay in Connecting state for a >> grace period of 61 seconds and after that an attempt to fence the host will >> be issued. >> 2018-03-25 14:42:13,725Z WARN >> [org.ovirt.engine.core.dal.dbbroker.auditloghandling.AuditLogDirector] >> (org.ovirt.thread.pool-6-thread-15) [17789048-009a-454b-b8ad-2c72c7cd37aa] >> EVENT_ID: VDS_HOST_NOT_RESPONDING_CONNECTING(9,008), Correlation ID: null, >> Call Stack: null, Custom ID: null, Custom Event ID: -1, Message: Host >> v1.cluster is not responding. It will stay in Connecting state for a grace >> period of 61 seconds and after that an attempt to fence the host will be >> issued. >> 2018-03-25 14:42:13,751Z WARN >> [org.ovirt.engine.core.dal.dbbroker.auditloghandling.AuditLogDirector] >> (DefaultQuartzScheduler5) [17789048-009a-454b-b8ad-2c72c7cd37aa] EVENT_ID: >> USER_CREATE_LIVE_SNAPSHOT_FINISHED_FAILURE(170), Correlation ID: >> 17789048-009a-454b-b8ad-2c72c7cd37aa, Job ID: >> 16e48c28-a8c7-4841-bd81-1f2d370f345d, Call Stack: >> org.ovirt.engine.core.common.errors.EngineException: EngineException: >> org.ovirt.engine.core.vdsbroker.vdsbroker.VDSNetworkException: >> VDSGenericException: VDSNetworkException: Message timeout which can be >> caused by communication issues (Failed with error VDS_NETWORK_ERROR and >> code 5022) >> 2018-03-25 14:42:14,372Z ERROR >> [org.ovirt.engine.core.dal.dbbroker.auditloghandling.AuditLogDirector] >> (DefaultQuartzScheduler5) [] EVENT_ID: >> USER_CREATE_SNAPSHOT_FINISHED_FAILURE(69), Correlation ID: >> 17789048-009a-454b-b8ad-2c72c7cd37aa, Job ID: >> 16e48c28-a8c7-4841-bd81-1f2d370f345d, Call Stack: >> org.ovirt.engine.core.common.errors.EngineException: EngineException: >> org.ovirt.engine.core.vdsbroker.vdsbroker.VDSNetworkException: >> VDSGenericException: VDSNetworkException: Message timeout which can be >> caused by communication issues (Failed with error VDS_NETWORK_ERROR and >> code 5022) >> 2018-03-25 14:42:14,372Z WARN >> [org.ovirt.engine.core.bll.ConcurrentChildCommandsExecutionCallback] >> (DefaultQuartzScheduler5) [] Command 'CreateAllSnapshotsFromVm' id: >> 'bad4f5be-5306-413f-a86a-513b3cfd3c66' end method execution failed, as the >> command isn't marked for endAction() retries silently ignoring >> 2018-03-25 14:42:15,951Z WARN >> [org.ovirt.engine.core.dal.dbbroker.auditloghandling.AuditLogDirector] >> (DefaultQuartzScheduler5) [5017c163] EVENT_ID: >> VDS_NO_SELINUX_ENFORCEMENT(25), Correlation ID: null, Call Stack: null, >> Custom ID: null, Custom Event ID: -1, Message: Host v1.cluster does not >> enforce SELinux. Current status: DISABLED >> 2018-03-25 14:42:15,951Z WARN >> [org.ovirt.engine.core.vdsbroker.VdsManager] (DefaultQuartzScheduler5) >> [5017c163] Host 'v1.cluster' is running with SELinux in 'DISABLED' mode >> >> As soon as the VM is unresponsive, the VM console that was already >> open freezes. I can resume the VM only by powering off and on. >> >> I am using ovirt 4.1.9 with 3 nodes and self-hosted engine. I am >> running mostly Windows 10 and Windows 2016 server VMs. I have installed >> latest guest agents from: >> >> >> http://resources.ovirt.org/pub/ovirt-4.2/iso/oVirt-toolsSetup/4.2-1.el7.cent... >> >> At the screen where one takes a snapshot I get a warning saying >> "Could not detect guest agent on the VM. Note that without guest agent the >> data on the created snapshot may be inconsistent". See attached. I have >> verified that ovirt guest tools are installed and shown at installed apps >> at engine GUI. Also Ovirt Guest Agent (32 bit) and qemu-ga are listed as >> running at the windows tasks manager. Shouldn't ovirt guest agent be 64 bit >> on Windows 64 bit? >> >
No idea, but I do not think it's related to your problem of freezing while taking a snapshot.
This error was already discussed in the past, see e.g.:
http://lists.ovirt.org/pipermail/users/2017-June/082577.html
Best regards, -- Didi
_______________________________________________ Users mailing list Users@ovirt.org http://lists.ovirt.org/mailman/listinfo/users
participants (4)
-
 Alex K
Alex K -
 Sandro Bonazzola
Sandro Bonazzola -
 Yaniv Kaul
Yaniv Kaul -
 Yedidyah Bar David
Yedidyah Bar David