
Hi everyone, I'm presenting here my proposal for the feature "Guest cloning" which is expected to be implemented for Kimchi 1.4. Description Cloning a guest means creating a new guest with a copy of the settings and data of the original guest. All data described by its XML will be copied completely, with the following exceptions: * name: the new guest will have an automatically generated name. We can append "-clone<n>" to the original guest's name, where <n> is related to the number of clones created from that guest. For example, cloning a guest named "myfedora" will create a new guest named "myfedora-clone1"; if another clone for that same guest is requested, it will be named "myfedora-clone2". * uuid: the new guest will have an automatically generated UUID. We can create a random UUID for every cloned guest. * devices/interface/mac: the new guest will have an automatically generated MAC address for every network interface. We can create random MAC addresses for every cloned guest. * devices/disk: the new guest will have copies of the original guest's disks. Depending on the storage pool type of each disk, a different procedure may be used to copy that disk: * DIR, NFS, Logical: the disk file will be copied to a new file with a modified name (e.g. "disk.img" -> "disk-clone1.img") on the same storage pool. * SCSI, iSCSI: the volume data will be copied as a new disk file on the storage pool "default". REST API Only one new REST command will be added. Syntax POST /vms/<vm-name>/clone Parameters: None. Return: An asynchronous Task with "target_uri" containing "/vms/<new-vm-name>". As expected with any Task, the cloning process can be tracked by checking the corresponding task's status. Discussion I think the most challenging part of this feature is how to deal with different types of disks while not prompting the user with any input. There are a lot of possibilities and a lot of things that can go wrong during the disks copy but we still need to do whatever is easier for the user. For example, do we really have to create the new disks in the same storage pool as the original disk's? If that's not possible (e.g. not available space), should we create them in another pool with available space? Should we ask any input from the user (e.g. "Would you like to create the new disk on the same storage pool or on a different one?")? What about the *SCSI pool types, is it OK to copy the volume data to a different storage pool (i.e. "default") like I'm proposing here? I couldn't think of a way to add a new volume in an existing pool of those types. How about making the *SCSI volumes shareable between the original and the new VMs? I don't like that approach because then both VMs will use the same disk, whatever is changed in one VM is also changed in the other one, and that's not a clone for me, that's a "hardlink". Any feedback is welcome! Best regards, Crístian.

At one point Adam had really suggested we look at how guests are defined and changed. In particular, straight copies of XML and or straight edits of XML could lead (after time) to the XML digressing into something libvirt might not understand at some point. To prevent this sort of problem, we thought that each time a guest is edited, the XML is created entirely anew but of course using the same values. This has the distinct advantage of making future additions of options easier to integrate. It is also the exact basis I think would be appropriate for any sort of cloning and dovetails nicely into your proposal. About a month ago I had a working version of this in draft form. Would anyone be interested in reviewing it and or adding to it prior to implementing the clone function? If so, ping me on IRC and I'll get you a copy of the patch. Brent On Thu, 2014-10-02 at 15:05 -0300, Crístian Viana wrote:
Hi everyone,
I'm presenting here my proposal for the feature "Guest cloning" which is expected to be implemented for Kimchi 1.4. Description Cloning a guest means creating a new guest with a copy of the settings and data of the original guest. All data described by its XML will be copied completely, with the following exceptions: * name: the new guest will have an automatically generated name. We can append "-clone<n>" to the original guest's name, where <n> is related to the number of clones created from that guest. For example, cloning a guest named "myfedora" will create a new guest named "myfedora-clone1"; if another clone for that same guest is requested, it will be named "myfedora-clone2". * uuid: the new guest will have an automatically generated UUID. We can create a random UUID for every cloned guest. * devices/interface/mac: the new guest will have an automatically generated MAC address for every network interface. We can create random MAC addresses for every cloned guest. * devices/disk: the new guest will have copies of the original guest's disks. Depending on the storage pool type of each disk, a different procedure may be used to copy that disk: * DIR, NFS, Logical: the disk file will be copied to a new file with a modified name (e.g. "disk.img" -> "disk-clone1.img") on the same storage pool. * SCSI, iSCSI: the volume data will be copied as a new disk file on the storage pool "default". REST API Only one new REST command will be added. Syntax POST /vms/<vm-name>/clone Parameters: None. Return: An asynchronous Task with "target_uri" containing "/vms/<new-vm-name>". As expected with any Task, the cloning process can be tracked by checking the corresponding task's status. Discussion I think the most challenging part of this feature is how to deal with different types of disks while not prompting the user with any input. There are a lot of possibilities and a lot of things that can go wrong during the disks copy but we still need to do whatever is easier for the user. For example, do we really have to create the new disks in the same storage pool as the original disk's? If that's not possible (e.g. not available space), should we create them in another pool with available space? Should we ask any input from the user (e.g. "Would you like to create the new disk on the same storage pool or on a different one?")? What about the *SCSI pool types, is it OK to copy the volume data to a different storage pool (i.e. "default") like I'm proposing here? I couldn't think of a way to add a new volume in an existing pool of those types. How about making the *SCSI volumes shareable between the original and the new VMs? I don't like that approach because then both VMs will use the same disk, whatever is changed in one VM is also changed in the other one, and that's not a clone for me, that's a "hardlink".
Any feedback is welcome!
Best regards, Crístian. _______________________________________________ Kimchi-devel mailing list Kimchi-devel@ovirt.org http://lists.ovirt.org/mailman/listinfo/kimchi-devel
On Sex, 2014-10-03 at 08:28 -0500, Brent Baude wrote:
At one point Adam had really suggested we look at how guests are defined and changed. In particular, straight copies of XML and or straight edits of XML could lead (after time) to the XML digressing into something libvirt might not understand at some point.
Do you remember exactly what in the XML file digressed like that? It would be very nice to know it.
To prevent this sort of problem, we thought that each time a guest is edited, the XML is created entirely anew but of course using the same values.
I first thought about doing that as well, but I'm afraid our own new XML does not have all the features the original VM had. For example, on Kimchi we don't have support to custom CPU flags yet (i.e. we don't add/change those values). What would happen if we clone an existing VM with "unsupported" (as of Kimchi) features like that one? If we don't know about them and we're creating a new XML from scratch, we're only going to add what we're aware of. And I think this could make our cloning feature very unrealiable. Reading an existing XML and redefining it will always propagate whatever there is in that VM. As long as the XML doesn't get digressed, of course. Here's one current scenario for me. I have a few VMs on my laptop which I use to test Kimchi on them. As they need to be a hypervisor in order to run Kimchi, I have to add a few CPU flags to their XML descriptors which allow them to be a hypervisor (i.e. those Intel/AMD virtualization parameters). I do that manually using "virsh edit". If I clone one of my VMs using the approach above and it recreates their XML files from the beginning, AFAIU, the CPU flags will not be copied along. And I'd be very unsatisfied because the clone feature dropped a few things of my original VM while cloning. If we know what are the problems you had with Adam while copying the XML files over and over, maybe it' easier to fix them than to try to create a new one with all the libvirt's features, including the ones Kimchi is still not aware of.
About a month ago I had a working version of this in draft form. Would anyone be interested in reviewing it and or adding to it prior to implementing the clone function? If so, ping me on IRC and I'll get you a copy of the patch.
I am interested on it! I'll ping you then. -- Best regards, Crístian.

I'm guessing that Brent and Adam already discussed virt-clone, so I'm curious as to the reasons why that's not an option. I've found that virt-install (the package that includes it) has (on Fedora 20) a dependency on virt-manager-common. That, and maybe it's not available for all distros? Maybe it wouldn't copy disks into the right places? Thanks, - Christy On 10/06/2014 08:28 AM, Crístian Viana wrote:
On Sex, 2014-10-03 at 08:28 -0500, Brent Baude wrote:
At one point Adam had really suggested we look at how guests are defined and changed. In particular, straight copies of XML and or straight edits of XML could lead (after time) to the XML digressing into something libvirt might not understand at some point.
Do you remember exactly what in the XML file digressed like that? It would be very nice to know it.
To prevent this sort of problem, we thought that each time a guest is edited, the XML is created entirely anew but of course using the same values.
I first thought about doing that as well, but I'm afraid our own new XML does not have all the features the original VM had. For example, on Kimchi we don't have support to custom CPU flags yet (i.e. we don't add/change those values). What would happen if we clone an existing VM with "unsupported" (as of Kimchi) features like that one? If we don't know about them and we're creating a new XML from scratch, we're only going to add what we're aware of. And I think this could make our cloning feature very unrealiable. Reading an existing XML and redefining it will always propagate whatever there is in that VM. As long as the XML doesn't get digressed, of course.
Here's one current scenario for me. I have a few VMs on my laptop which I use to test Kimchi on them. As they need to be a hypervisor in order to run Kimchi, I have to add a few CPU flags to their XML descriptors which allow them to be a hypervisor (i.e. those Intel/AMD virtualization parameters). I do that manually using "virsh edit". If I clone one of my VMs using the approach above and it recreates their XML files from the beginning, AFAIU, the CPU flags will not be copied along. And I'd be very unsatisfied because the clone feature dropped a few things of my original VM while cloning.
If we know what are the problems you had with Adam while copying the XML files over and over, maybe it' easier to fix them than to try to create a new one with all the libvirt's features, including the ones Kimchi is still not aware of.
About a month ago I had a working version of this in draft form. Would anyone be interested in reviewing it and or adding to it prior to implementing the clone function? If so, ping me on IRC and I'll get you a copy of the patch.
I am interested on it! I'll ping you then.

On 10/07/2014 12:27 PM, Christy Perez wrote:
I'm guessing that Brent and Adam already discussed virt-clone, so I'm curious as to the reasons why that's not an option. I've found that virt-install (the package that includes it) has (on Fedora 20) a dependency on virt-manager-common. That, and maybe it's not available for all distros? Maybe it wouldn't copy disks into the right places?
It was what I had in mind. We could investigate on how virt-manager and virt-clone do it.
Thanks,
- Christy
On 10/06/2014 08:28 AM, Crístian Viana wrote:
On Sex, 2014-10-03 at 08:28 -0500, Brent Baude wrote:
At one point Adam had really suggested we look at how guests are defined and changed. In particular, straight copies of XML and or straight edits of XML could lead (after time) to the XML digressing into something libvirt might not understand at some point. Do you remember exactly what in the XML file digressed like that? It would be very nice to know it.
To prevent this sort of problem, we thought that each time a guest is edited, the XML is created entirely anew but of course using the same values. I first thought about doing that as well, but I'm afraid our own new XML does not have all the features the original VM had. For example, on Kimchi we don't have support to custom CPU flags yet (i.e. we don't add/change those values). What would happen if we clone an existing VM with "unsupported" (as of Kimchi) features like that one? If we don't know about them and we're creating a new XML from scratch, we're only going to add what we're aware of. And I think this could make our cloning feature very unrealiable. Reading an existing XML and redefining it will always propagate whatever there is in that VM. As long as the XML doesn't get digressed, of course.
Here's one current scenario for me. I have a few VMs on my laptop which I use to test Kimchi on them. As they need to be a hypervisor in order to run Kimchi, I have to add a few CPU flags to their XML descriptors which allow them to be a hypervisor (i.e. those Intel/AMD virtualization parameters). I do that manually using "virsh edit". If I clone one of my VMs using the approach above and it recreates their XML files from the beginning, AFAIU, the CPU flags will not be copied along. And I'd be very unsatisfied because the clone feature dropped a few things of my original VM while cloning.
If we know what are the problems you had with Adam while copying the XML files over and over, maybe it' easier to fix them than to try to create a new one with all the libvirt's features, including the ones Kimchi is still not aware of.
About a month ago I had a working version of this in draft form. Would anyone be interested in reviewing it and or adding to it prior to implementing the clone function? If so, ping me on IRC and I'll get you a copy of the patch. I am interested on it! I'll ping you then.
_______________________________________________ Kimchi-devel mailing list Kimchi-devel@ovirt.org http://lists.ovirt.org/mailman/listinfo/kimchi-devel
On 10/07/2014 11:29 AM, Aline Manera wrote:
On 10/07/2014 12:27 PM, Christy Perez wrote:
I'm guessing that Brent and Adam already discussed virt-clone, so I'm curious as to the reasons why that's not an option. I've found that virt-install (the package that includes it) has (on Fedora 20) a dependency on virt-manager-common. That, and maybe it's not available for all distros? Maybe it wouldn't copy disks into the right places?
It was what I had in mind. We could investigate on how virt-manager and virt-clone do it.
Also - FWIW, virt-install is available on PowerKVM as well as RHEL and Fedora.
Thanks,
- Christy
On 10/06/2014 08:28 AM, Crístian Viana wrote:
On Sex, 2014-10-03 at 08:28 -0500, Brent Baude wrote:
At one point Adam had really suggested we look at how guests are defined and changed. In particular, straight copies of XML and or straight edits of XML could lead (after time) to the XML digressing into something libvirt might not understand at some point. Do you remember exactly what in the XML file digressed like that? It would be very nice to know it.
To prevent this sort of problem, we thought that each time a guest is edited, the XML is created entirely anew but of course using the same values. I first thought about doing that as well, but I'm afraid our own new XML does not have all the features the original VM had. For example, on Kimchi we don't have support to custom CPU flags yet (i.e. we don't add/change those values). What would happen if we clone an existing VM with "unsupported" (as of Kimchi) features like that one? If we don't know about them and we're creating a new XML from scratch, we're only going to add what we're aware of. And I think this could make our cloning feature very unrealiable. Reading an existing XML and redefining it will always propagate whatever there is in that VM. As long as the XML doesn't get digressed, of course.
Here's one current scenario for me. I have a few VMs on my laptop which I use to test Kimchi on them. As they need to be a hypervisor in order to run Kimchi, I have to add a few CPU flags to their XML descriptors which allow them to be a hypervisor (i.e. those Intel/AMD virtualization parameters). I do that manually using "virsh edit". If I clone one of my VMs using the approach above and it recreates their XML files from the beginning, AFAIU, the CPU flags will not be copied along. And I'd be very unsatisfied because the clone feature dropped a few things of my original VM while cloning.
If we know what are the problems you had with Adam while copying the XML files over and over, maybe it' easier to fix them than to try to create a new one with all the libvirt's features, including the ones Kimchi is still not aware of.
About a month ago I had a working version of this in draft form. Would anyone be interested in reviewing it and or adding to it prior to implementing the clone function? If so, ping me on IRC and I'll get you a copy of the patch. I am interested on it! I'll ping you then.
_______________________________________________ Kimchi-devel mailing list Kimchi-devel@ovirt.org http://lists.ovirt.org/mailman/listinfo/kimchi-devel

On 2014年10月07日 23:27, Christy Perez wrote:
I'm guessing that Brent and Adam already discussed virt-clone, so I'm curious as to the reasons why that's not an option. I've found that virt-install (the package that includes it) has (on Fedora 20) a dependency on virt-manager-common. That, and maybe it's not available for all distros? Maybe it wouldn't copy disks into the right places?
Thanks,
- Christy This is a good idea, I haven't used virt-clone, is it copy image or just make a cow of the base one? For this scenario, we want a full copy or cow one?
On 10/06/2014 08:28 AM, Crístian Viana wrote:
On Sex, 2014-10-03 at 08:28 -0500, Brent Baude wrote:
At one point Adam had really suggested we look at how guests are defined and changed. In particular, straight copies of XML and or straight edits of XML could lead (after time) to the XML digressing into something libvirt might not understand at some point. Do you remember exactly what in the XML file digressed like that? It would be very nice to know it.
To prevent this sort of problem, we thought that each time a guest is edited, the XML is created entirely anew but of course using the same values. I first thought about doing that as well, but I'm afraid our own new XML does not have all the features the original VM had. For example, on Kimchi we don't have support to custom CPU flags yet (i.e. we don't add/change those values). What would happen if we clone an existing VM with "unsupported" (as of Kimchi) features like that one? If we don't know about them and we're creating a new XML from scratch, we're only going to add what we're aware of. And I think this could make our cloning feature very unrealiable. Reading an existing XML and redefining it will always propagate whatever there is in that VM. As long as the XML doesn't get digressed, of course.
Here's one current scenario for me. I have a few VMs on my laptop which I use to test Kimchi on them. As they need to be a hypervisor in order to run Kimchi, I have to add a few CPU flags to their XML descriptors which allow them to be a hypervisor (i.e. those Intel/AMD virtualization parameters). I do that manually using "virsh edit". If I clone one of my VMs using the approach above and it recreates their XML files from the beginning, AFAIU, the CPU flags will not be copied along. And I'd be very unsatisfied because the clone feature dropped a few things of my original VM while cloning.
If we know what are the problems you had with Adam while copying the XML files over and over, maybe it' easier to fix them than to try to create a new one with all the libvirt's features, including the ones Kimchi is still not aware of.
About a month ago I had a working version of this in draft form. Would anyone be interested in reviewing it and or adding to it prior to implementing the clone function? If so, ping me on IRC and I'll get you a copy of the patch. I am interested on it! I'll ping you then.
_______________________________________________ Kimchi-devel mailing list Kimchi-devel@ovirt.org http://lists.ovirt.org/mailman/listinfo/kimchi-devel
On 2014年10月03日 21:28, Brent Baude wrote:
At one point Adam had really suggested we look at how guests are defined and changed. In particular, straight copies of XML and or straight edits of XML could lead (after time) to the XML digressing into something libvirt might not understand at some point.
To prevent this sort of problem, we thought that each time a guest is edited, the XML is created entirely anew but of course using the same values. This has the distinct advantage of making future additions of options easier to integrate. It is also the exact basis I think would be appropriate for any sort of cloning and dovetails nicely into your proposal. About a month ago I had a working version of this in draft form.
Would anyone be interested in reviewing it and or adding to it prior to implementing the clone function? If so, ping me on IRC and I'll get you a copy of the patch. I would like to review.
Brent
On Thu, 2014-10-02 at 15:05 -0300, Crístian Viana wrote:
Hi everyone,
I'm presenting here my proposal for the feature "Guest cloning" which is expected to be implemented for Kimchi 1.4. Description Cloning a guest means creating a new guest with a copy of the settings and data of the original guest. All data described by its XML will be copied completely, with the following exceptions: * name: the new guest will have an automatically generated name. We can append "-clone<n>" to the original guest's name, where <n> is related to the number of clones created from that guest. For example, cloning a guest named "myfedora" will create a new guest named "myfedora-clone1"; if another clone for that same guest is requested, it will be named "myfedora-clone2". * uuid: the new guest will have an automatically generated UUID. We can create a random UUID for every cloned guest. * devices/interface/mac: the new guest will have an automatically generated MAC address for every network interface. We can create random MAC addresses for every cloned guest. * devices/disk: the new guest will have copies of the original guest's disks. Depending on the storage pool type of each disk, a different procedure may be used to copy that disk: * DIR, NFS, Logical: the disk file will be copied to a new file with a modified name (e.g. "disk.img" -> "disk-clone1.img") on the same storage pool. * SCSI, iSCSI: the volume data will be copied as a new disk file on the storage pool "default". REST API Only one new REST command will be added. Syntax POST /vms/<vm-name>/clone Parameters: None. Return: An asynchronous Task with "target_uri" containing "/vms/<new-vm-name>". As expected with any Task, the cloning process can be tracked by checking the corresponding task's status. Discussion I think the most challenging part of this feature is how to deal with different types of disks while not prompting the user with any input. There are a lot of possibilities and a lot of things that can go wrong during the disks copy but we still need to do whatever is easier for the user. For example, do we really have to create the new disks in the same storage pool as the original disk's? If that's not possible (e.g. not available space), should we create them in another pool with available space? Should we ask any input from the user (e.g. "Would you like to create the new disk on the same storage pool or on a different one?")? What about the *SCSI pool types, is it OK to copy the volume data to a different storage pool (i.e. "default") like I'm proposing here? I couldn't think of a way to add a new volume in an existing pool of those types. How about making the *SCSI volumes shareable between the original and the new VMs? I don't like that approach because then both VMs will use the same disk, whatever is changed in one VM is also changed in the other one, and that's not a clone for me, that's a "hardlink".
Any feedback is welcome!
Best regards, Crístian. _______________________________________________ Kimchi-devel mailing list Kimchi-devel@ovirt.org http://lists.ovirt.org/mailman/listinfo/kimchi-devel
_______________________________________________ Kimchi-devel mailing list Kimchi-devel@ovirt.org http://lists.ovirt.org/mailman/listinfo/kimchi-devel
On 10/03/2014 10:28 AM, Brent Baude wrote:
At one point Adam had really suggested we look at how guests are defined and changed. In particular, straight copies of XML and or straight edits of XML could lead (after time) to the XML digressing into something libvirt might not understand at some point.
To prevent this sort of problem, we thought that each time a guest is edited, the XML is created entirely anew but of course using the same values. This has the distinct advantage of making future additions of options easier to integrate. It is also the exact basis I think would be appropriate for any sort of cloning and dovetails nicely into your proposal. About a month ago I had a working version of this in draft form.
Would anyone be interested in reviewing it and or adding to it prior to implementing the clone function? If so, ping me on IRC and I'll get you a copy of the patch.
Please, sent it to ML as RFC so we all can discuss on it.
Brent
On Thu, 2014-10-02 at 15:05 -0300, Crístian Viana wrote:
Hi everyone,
I'm presenting here my proposal for the feature "Guest cloning" which is expected to be implemented for Kimchi 1.4. Description Cloning a guest means creating a new guest with a copy of the settings and data of the original guest. All data described by its XML will be copied completely, with the following exceptions: * name: the new guest will have an automatically generated name. We can append "-clone<n>" to the original guest's name, where <n> is related to the number of clones created from that guest. For example, cloning a guest named "myfedora" will create a new guest named "myfedora-clone1"; if another clone for that same guest is requested, it will be named "myfedora-clone2". * uuid: the new guest will have an automatically generated UUID. We can create a random UUID for every cloned guest. * devices/interface/mac: the new guest will have an automatically generated MAC address for every network interface. We can create random MAC addresses for every cloned guest. * devices/disk: the new guest will have copies of the original guest's disks. Depending on the storage pool type of each disk, a different procedure may be used to copy that disk: * DIR, NFS, Logical: the disk file will be copied to a new file with a modified name (e.g. "disk.img" -> "disk-clone1.img") on the same storage pool. * SCSI, iSCSI: the volume data will be copied as a new disk file on the storage pool "default". REST API Only one new REST command will be added. Syntax POST /vms/<vm-name>/clone Parameters: None. Return: An asynchronous Task with "target_uri" containing "/vms/<new-vm-name>". As expected with any Task, the cloning process can be tracked by checking the corresponding task's status. Discussion I think the most challenging part of this feature is how to deal with different types of disks while not prompting the user with any input. There are a lot of possibilities and a lot of things that can go wrong during the disks copy but we still need to do whatever is easier for the user. For example, do we really have to create the new disks in the same storage pool as the original disk's? If that's not possible (e.g. not available space), should we create them in another pool with available space? Should we ask any input from the user (e.g. "Would you like to create the new disk on the same storage pool or on a different one?")? What about the *SCSI pool types, is it OK to copy the volume data to a different storage pool (i.e. "default") like I'm proposing here? I couldn't think of a way to add a new volume in an existing pool of those types. How about making the *SCSI volumes shareable between the original and the new VMs? I don't like that approach because then both VMs will use the same disk, whatever is changed in one VM is also changed in the other one, and that's not a clone for me, that's a "hardlink".
Any feedback is welcome!
Best regards, Crístian. _______________________________________________ Kimchi-devel mailing list Kimchi-devel@ovirt.org http://lists.ovirt.org/mailman/listinfo/kimchi-devel
_______________________________________________ Kimchi-devel mailing list Kimchi-devel@ovirt.org http://lists.ovirt.org/mailman/listinfo/kimchi-devel

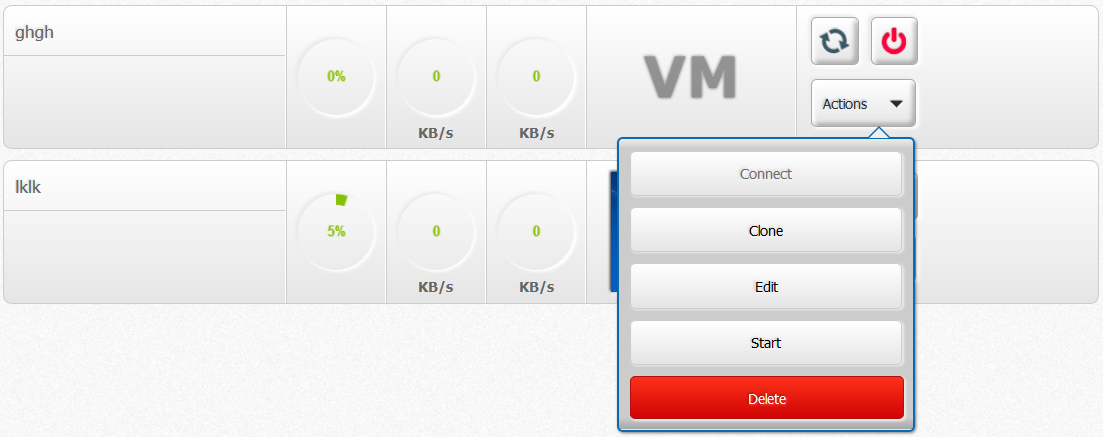
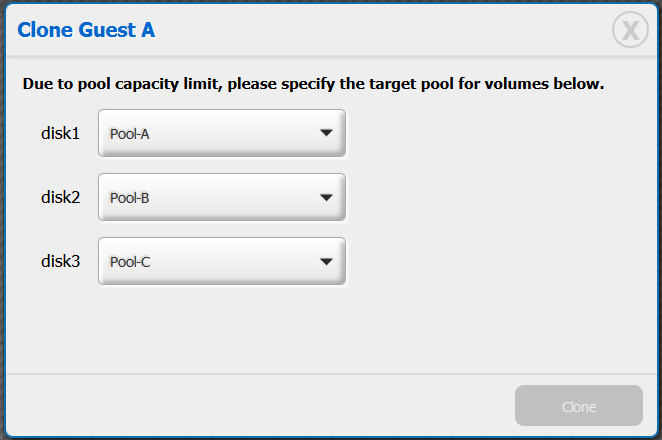
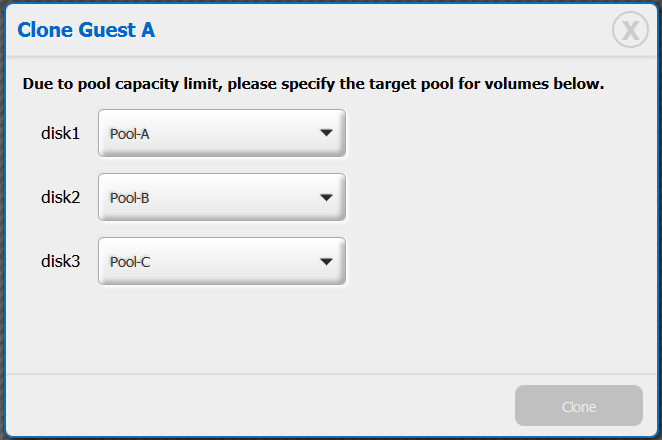
When user click on clone button below, a request is sent to server. Server should pre-check to see whether all relevant storage pools have enough space to copy vm volumes. If the pre-check fail, response a message indicate the vm volumes that need re-assign a pool. Then UI popup a dialog below. Once user selected the pool and click 'Clone' button, then re-send the request with [{disk1: Pool-A},{disk2: Pool-B},{disk3: Pool-C}] Once the cloning process is triggered. On 10/3/2014 2:05 AM, Crístian Viana wrote:
Hi everyone,
I'm presenting here my proposal for the feature "Guest cloning" which is expected to be implemented for Kimchi 1.4.
Description
Cloning a guest means creating a new guest with a copy of the settings and data of the original guest. All data described by its XML will be copied completely, with the following exceptions:
* name: the new guest will have an automatically generated name. We can append "-clone<n>" to the original guest's name, where <n> is related to the number of clones created from that guest. For example, cloning a guest named "myfedora" will create a new guest named "myfedora-clone1"; if another clone for that same guest is requested, it will be named "myfedora-clone2". * uuid: the new guest will have an automatically generated UUID. We can create a random UUID for every cloned guest. * devices/interface/mac: the new guest will have an automatically generated MAC address for every network interface. We can create random MAC addresses for every cloned guest. * devices/disk: the new guest will have copies of the original guest's disks. Depending on the storage pool type of each disk, a different procedure may be used to copy that disk:
* DIR, NFS, Logical: the disk file will be copied to a new file with a modified name (e.g. "disk.img" -> "disk-clone1.img") on the same storage pool. * SCSI, iSCSI: the volume data will be copied as a new disk file on the storage pool "default".
REST API
Only one new REST command will be added.
Syntax
POST /vms//<vm-name>//clone
Parameters:
None.
Return:
An asynchronous Task with "target_uri" containing "/vms/</new-vm-name/>". As expected with any Task, the cloning process can be tracked by checking the corresponding task's status.
Discussion
I think the most challenging part of this feature is how to deal with different types of disks while not prompting the user with any input. There are a lot of possibilities and a lot of things that can go wrong during the disks copy but we still need to do whatever is easier for the user. For example, do we really have to create the new disks in the same storage pool as the original disk's? If that's not possible (e.g. not available space), should we create them in another pool with available space? Should we ask any input from the user (e.g. "Would you like to create the new disk on the same storage pool or on a different one?")? What about the *SCSI pool types, is it OK to copy the volume data to a different storage pool (i.e. "default") like I'm proposing here? I couldn't think of a way to add a new volume in an existing pool of those types. How about making the *SCSI volumes shareable between the original and the new VMs? I don't like that approach because then both VMs will use the same disk, whatever is changed in one VM is also changed in the other one, and that's not a clone for me, that's a "hardlink".
Any feedback is welcome!
Best regards, Crístian.
_______________________________________________ Kimchi-devel mailing list Kimchi-devel@ovirt.org http://lists.ovirt.org/mailman/listinfo/kimchi-devel
{kind=link}
{kind=link}
{kind=link}
On 10/10/2014 06:34 AM, Yu Xin Huo wrote:
When user click on clone button below, a request is sent to server. Server should pre-check to see whether all relevant storage pools have enough space to copy vm volumes.
If the pre-check fail, response a message indicate the vm volumes that need re-assign a pool. Then UI popup a dialog below. Once user selected the pool and click 'Clone' button, then re-send the request with [{disk1: Pool-A},{disk2: Pool-B},{disk3: Pool-C}]
There may be a time between user clicks on "Clone" until get a response from pool capacity. In that time, what will be shown to user? A loading icon in somewhere?
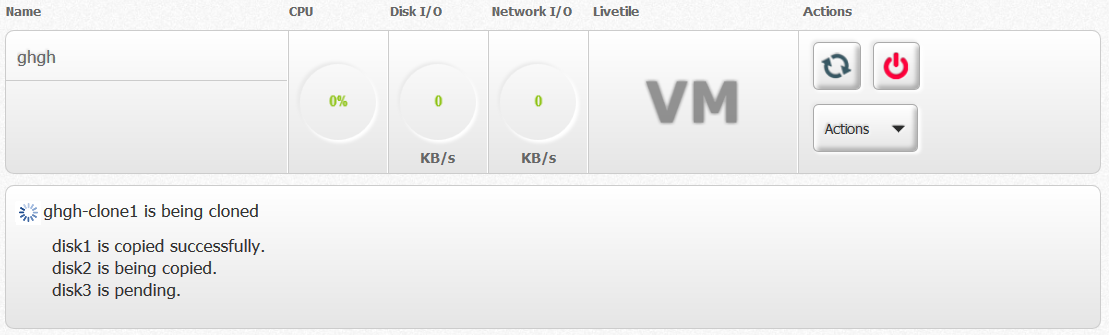
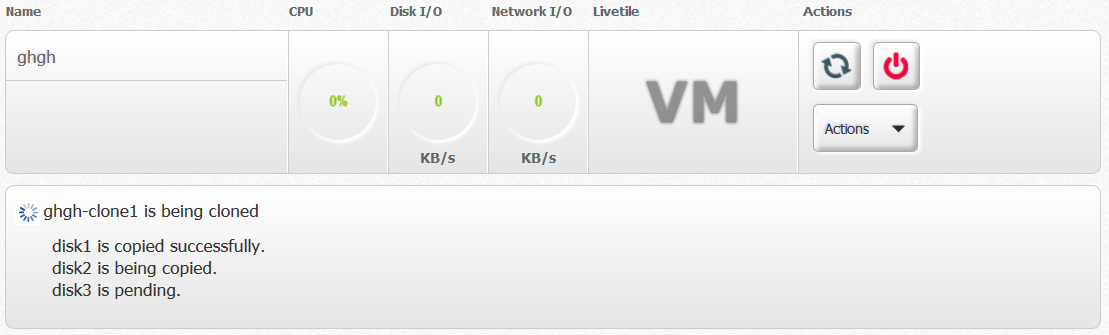
Once the cloning process is triggered.
I think we can display a new VM box with an loading icon on "Livetitle" with "Clone in progress..." or something like it. I don't think we need to display the progress messages to user. At least I would just care about new VM cloned.
On 10/3/2014 2:05 AM, Crístian Viana wrote:
Hi everyone,
I'm presenting here my proposal for the feature "Guest cloning" which is expected to be implemented for Kimchi 1.4.
Description
Cloning a guest means creating a new guest with a copy of the settings and data of the original guest. All data described by its XML will be copied completely, with the following exceptions:
* name: the new guest will have an automatically generated name. We can append "-clone<n>" to the original guest's name, where <n> is related to the number of clones created from that guest. For example, cloning a guest named "myfedora" will create a new guest named "myfedora-clone1"; if another clone for that same guest is requested, it will be named "myfedora-clone2". * uuid: the new guest will have an automatically generated UUID. We can create a random UUID for every cloned guest. * devices/interface/mac: the new guest will have an automatically generated MAC address for every network interface. We can create random MAC addresses for every cloned guest. * devices/disk: the new guest will have copies of the original guest's disks. Depending on the storage pool type of each disk, a different procedure may be used to copy that disk:
* DIR, NFS, Logical: the disk file will be copied to a new file with a modified name (e.g. "disk.img" -> "disk-clone1.img") on the same storage pool. * SCSI, iSCSI: the volume data will be copied as a new disk file on the storage pool "default".
REST API
Only one new REST command will be added.
Syntax
POST /vms//<vm-name>//clone
Parameters:
None.
Return:
An asynchronous Task with "target_uri" containing "/vms/</new-vm-name/>". As expected with any Task, the cloning process can be tracked by checking the corresponding task's status.
Discussion
I think the most challenging part of this feature is how to deal with different types of disks while not prompting the user with any input. There are a lot of possibilities and a lot of things that can go wrong during the disks copy but we still need to do whatever is easier for the user. For example, do we really have to create the new disks in the same storage pool as the original disk's? If that's not possible (e.g. not available space), should we create them in another pool with available space? Should we ask any input from the user (e.g. "Would you like to create the new disk on the same storage pool or on a different one?")? What about the *SCSI pool types, is it OK to copy the volume data to a different storage pool (i.e. "default") like I'm proposing here? I couldn't think of a way to add a new volume in an existing pool of those types. How about making the *SCSI volumes shareable between the original and the new VMs? I don't like that approach because then both VMs will use the same disk, whatever is changed in one VM is also changed in the other one, and that's not a clone for me, that's a "hardlink".
Any feedback is welcome!
Best regards, Crístian.
_______________________________________________ Kimchi-devel mailing list Kimchi-devel@ovirt.org http://lists.ovirt.org/mailman/listinfo/kimchi-devel
_______________________________________________ Kimchi-devel mailing list Kimchi-devel@ovirt.org http://lists.ovirt.org/mailman/listinfo/kimchi-devel
{kind=link}
{kind=link}
{kind=link}
On 10-10-2014 06:34, Yu Xin Huo wrote:
If the pre-check fail, response a message indicate the vm volumes that need re-assign a pool. Then UI popup a dialog below. Once user selected the pool and click 'Clone' button, then re-send the request with [{disk1: Pool-A},{disk2: Pool-B},{disk3: Pool-C}]
AFAIU, there should be no input from the user in order to clone a VM. This adds complexity to the operation, which I think it's Kimchi's opposite goal. IMO, the clone operation should work entirely without user input.
On 10/13/2014 03:07 PM, Crístian Viana wrote:
On 10-10-2014 06:34, Yu Xin Huo wrote:
If the pre-check fail, response a message indicate the vm volumes that need re-assign a pool. Then UI popup a dialog below. Once user selected the pool and click 'Clone' button, then re-send the request with [{disk1: Pool-A},{disk2: Pool-B},{disk3: Pool-C}]
AFAIU, there should be no input from the user in order to clone a VM. This adds complexity to the operation, which I think it's Kimchi's opposite goal. IMO, the clone operation should work entirely without user input.
Yeap, I think we have an agreement on it. On those UI mockups, Yu Xin proposed to display a new dialog only when user needs to change the storage pool to do the clone - for example when the target pool is full or if it is iSCSI or SCSI. I've just re-read this mail thread and noticed we haven't decided how to proceed in those cases. I agree with you, we should require as less as possible input from user. IMO We could always fallback to the default pool in those cases and if the default pool is full we raise an error.
_______________________________________________ Kimchi-devel mailing list Kimchi-devel@ovirt.org http://lists.ovirt.org/mailman/listinfo/kimchi-devel
On 13-10-2014 16:12, Aline Manera wrote:
On those UI mockups, Yu Xin proposed to display a new dialog only when user needs to change the storage pool to do the clone - for example when the target pool is full or if it is iSCSI or SCSI.
And how would we use that input? When we do POST /vms/<vm-name>/clone, we don't have the chance to specify a different storage pool.
I am also thinking to add a centralized area in header to hold all asynchronous tasks. On 10/3/2014 2:05 AM, Crístian Viana wrote:
Hi everyone,
I'm presenting here my proposal for the feature "Guest cloning" which is expected to be implemented for Kimchi 1.4.
Description
Cloning a guest means creating a new guest with a copy of the settings and data of the original guest. All data described by its XML will be copied completely, with the following exceptions:
* name: the new guest will have an automatically generated name. We can append "-clone<n>" to the original guest's name, where <n> is related to the number of clones created from that guest. For example, cloning a guest named "myfedora" will create a new guest named "myfedora-clone1"; if another clone for that same guest is requested, it will be named "myfedora-clone2". * uuid: the new guest will have an automatically generated UUID. We can create a random UUID for every cloned guest. * devices/interface/mac: the new guest will have an automatically generated MAC address for every network interface. We can create random MAC addresses for every cloned guest. * devices/disk: the new guest will have copies of the original guest's disks. Depending on the storage pool type of each disk, a different procedure may be used to copy that disk:
* DIR, NFS, Logical: the disk file will be copied to a new file with a modified name (e.g. "disk.img" -> "disk-clone1.img") on the same storage pool. * SCSI, iSCSI: the volume data will be copied as a new disk file on the storage pool "default".
REST API
Only one new REST command will be added.
Syntax
POST /vms//<vm-name>//clone
Parameters:
None.
Return:
An asynchronous Task with "target_uri" containing "/vms/</new-vm-name/>". As expected with any Task, the cloning process can be tracked by checking the corresponding task's status.
Discussion
I think the most challenging part of this feature is how to deal with different types of disks while not prompting the user with any input. There are a lot of possibilities and a lot of things that can go wrong during the disks copy but we still need to do whatever is easier for the user. For example, do we really have to create the new disks in the same storage pool as the original disk's? If that's not possible (e.g. not available space), should we create them in another pool with available space? Should we ask any input from the user (e.g. "Would you like to create the new disk on the same storage pool or on a different one?")? What about the *SCSI pool types, is it OK to copy the volume data to a different storage pool (i.e. "default") like I'm proposing here? I couldn't think of a way to add a new volume in an existing pool of those types. How about making the *SCSI volumes shareable between the original and the new VMs? I don't like that approach because then both VMs will use the same disk, whatever is changed in one VM is also changed in the other one, and that's not a clone for me, that's a "hardlink".
Any feedback is welcome!
Best regards, Crístian.
_______________________________________________ Kimchi-devel mailing list Kimchi-devel@ovirt.org http://lists.ovirt.org/mailman/listinfo/kimchi-devel
{kind=link}
On 10/10/2014 07:25 AM, Yu Xin Huo wrote:
I am also thinking to add a centralized area in header to hold all asynchronous tasks.
Hrm... Tasks are an internal concept (from development view). The user doesn't know what they are.
On 10/3/2014 2:05 AM, Crístian Viana wrote:
Hi everyone,
I'm presenting here my proposal for the feature "Guest cloning" which is expected to be implemented for Kimchi 1.4.
Description
Cloning a guest means creating a new guest with a copy of the settings and data of the original guest. All data described by its XML will be copied completely, with the following exceptions:
* name: the new guest will have an automatically generated name. We can append "-clone<n>" to the original guest's name, where <n> is related to the number of clones created from that guest. For example, cloning a guest named "myfedora" will create a new guest named "myfedora-clone1"; if another clone for that same guest is requested, it will be named "myfedora-clone2". * uuid: the new guest will have an automatically generated UUID. We can create a random UUID for every cloned guest. * devices/interface/mac: the new guest will have an automatically generated MAC address for every network interface. We can create random MAC addresses for every cloned guest. * devices/disk: the new guest will have copies of the original guest's disks. Depending on the storage pool type of each disk, a different procedure may be used to copy that disk:
* DIR, NFS, Logical: the disk file will be copied to a new file with a modified name (e.g. "disk.img" -> "disk-clone1.img") on the same storage pool. * SCSI, iSCSI: the volume data will be copied as a new disk file on the storage pool "default".
REST API
Only one new REST command will be added.
Syntax
POST /vms//<vm-name>//clone
Parameters:
None.
Return:
An asynchronous Task with "target_uri" containing "/vms/</new-vm-name/>". As expected with any Task, the cloning process can be tracked by checking the corresponding task's status.
Discussion
I think the most challenging part of this feature is how to deal with different types of disks while not prompting the user with any input. There are a lot of possibilities and a lot of things that can go wrong during the disks copy but we still need to do whatever is easier for the user. For example, do we really have to create the new disks in the same storage pool as the original disk's? If that's not possible (e.g. not available space), should we create them in another pool with available space? Should we ask any input from the user (e.g. "Would you like to create the new disk on the same storage pool or on a different one?")? What about the *SCSI pool types, is it OK to copy the volume data to a different storage pool (i.e. "default") like I'm proposing here? I couldn't think of a way to add a new volume in an existing pool of those types. How about making the *SCSI volumes shareable between the original and the new VMs? I don't like that approach because then both VMs will use the same disk, whatever is changed in one VM is also changed in the other one, and that's not a clone for me, that's a "hardlink".
Any feedback is welcome!
Best regards, Crístian.
_______________________________________________ Kimchi-devel mailing list Kimchi-devel@ovirt.org http://lists.ovirt.org/mailman/listinfo/kimchi-devel
_______________________________________________ Kimchi-devel mailing list Kimchi-devel@ovirt.org http://lists.ovirt.org/mailman/listinfo/kimchi-devel
{kind=link}

On 10/14/2014 12:15 AM, Aline Manera wrote:
On 10/10/2014 07:25 AM, Yu Xin Huo wrote:
I am also thinking to add a centralized area in header to hold all asynchronous tasks.
Hrm... Tasks are an internal concept (from development view). The user doesn't know what they are.
It'd be good to have this feature to let user know what's going on in the kimchi and even more it'd be better to have a progress bar(UI) for each under task like guest clone/migrate. -Simon
On 10/3/2014 2:05 AM, Crístian Viana wrote:
Hi everyone,
I'm presenting here my proposal for the feature "Guest cloning" which is expected to be implemented for Kimchi 1.4.
Description
Cloning a guest means creating a new guest with a copy of the settings and data of the original guest. All data described by its XML will be copied completely, with the following exceptions:
* name: the new guest will have an automatically generated name. We can append "-clone<n>" to the original guest's name, where <n> is related to the number of clones created from that guest. For example, cloning a guest named "myfedora" will create a new guest named "myfedora-clone1"; if another clone for that same guest is requested, it will be named "myfedora-clone2". * uuid: the new guest will have an automatically generated UUID. We can create a random UUID for every cloned guest. * devices/interface/mac: the new guest will have an automatically generated MAC address for every network interface. We can create random MAC addresses for every cloned guest. * devices/disk: the new guest will have copies of the original guest's disks. Depending on the storage pool type of each disk, a different procedure may be used to copy that disk:
* DIR, NFS, Logical: the disk file will be copied to a new file with a modified name (e.g. "disk.img" -> "disk-clone1.img") on the same storage pool. * SCSI, iSCSI: the volume data will be copied as a new disk file on the storage pool "default".
REST API
Only one new REST command will be added.
Syntax
POST /vms//<vm-name>//clone
Parameters:
None.
Return:
An asynchronous Task with "target_uri" containing "/vms/</new-vm-name/>". As expected with any Task, the cloning process can be tracked by checking the corresponding task's status.
Discussion
I think the most challenging part of this feature is how to deal with different types of disks while not prompting the user with any input. There are a lot of possibilities and a lot of things that can go wrong during the disks copy but we still need to do whatever is easier for the user. For example, do we really have to create the new disks in the same storage pool as the original disk's? If that's not possible (e.g. not available space), should we create them in another pool with available space? Should we ask any input from the user (e.g. "Would you like to create the new disk on the same storage pool or on a different one?")? What about the *SCSI pool types, is it OK to copy the volume data to a different storage pool (i.e. "default") like I'm proposing here? I couldn't think of a way to add a new volume in an existing pool of those types. How about making the *SCSI volumes shareable between the original and the new VMs? I don't like that approach because then both VMs will use the same disk, whatever is changed in one VM is also changed in the other one, and that's not a clone for me, that's a "hardlink".
Any feedback is welcome!
Best regards, Crístian.
_______________________________________________ Kimchi-devel mailing list Kimchi-devel@ovirt.org http://lists.ovirt.org/mailman/listinfo/kimchi-devel
_______________________________________________ Kimchi-devel mailing list Kimchi-devel@ovirt.org http://lists.ovirt.org/mailman/listinfo/kimchi-devel
_______________________________________________ Kimchi-devel mailing list Kimchi-devel@ovirt.org http://lists.ovirt.org/mailman/listinfo/kimchi-devel
-- Yun Tong Jin, Simon Linux Technology Center, Open Virtualization project IBM Systems& Technology Group jinyt@cn.ibm.com, Phone: 824549654
{kind=link}
Eclipse can run long task in background. 'Run in Background' is just like kimchi's async tasks. It use a centralized task manager to manage those tasks. Currently, kimchi's long tasks are distributed along with each feature. The problem is that if the user is not waiting on the original location, user need to assume that if no error occur, the task is completed and he need to remember the object he is operating on. On 10/14/2014 2:47 PM, simonjin wrote:
On 10/14/2014 12:15 AM, Aline Manera wrote:
On 10/10/2014 07:25 AM, Yu Xin Huo wrote:
I am also thinking to add a centralized area in header to hold all asynchronous tasks.
Hrm... Tasks are an internal concept (from development view). The user doesn't know what they are.
It'd be good to have this feature to let user know what's going on in the kimchi and even more it'd be better to have a progress bar(UI) for each under task like guest clone/migrate.
-Simon
On 10/3/2014 2:05 AM, Crístian Viana wrote:
Hi everyone,
I'm presenting here my proposal for the feature "Guest cloning" which is expected to be implemented for Kimchi 1.4.
Description
Cloning a guest means creating a new guest with a copy of the settings and data of the original guest. All data described by its XML will be copied completely, with the following exceptions:
* name: the new guest will have an automatically generated name. We can append "-clone<n>" to the original guest's name, where <n> is related to the number of clones created from that guest. For example, cloning a guest named "myfedora" will create a new guest named "myfedora-clone1"; if another clone for that same guest is requested, it will be named "myfedora-clone2". * uuid: the new guest will have an automatically generated UUID. We can create a random UUID for every cloned guest. * devices/interface/mac: the new guest will have an automatically generated MAC address for every network interface. We can create random MAC addresses for every cloned guest. * devices/disk: the new guest will have copies of the original guest's disks. Depending on the storage pool type of each disk, a different procedure may be used to copy that disk:
* DIR, NFS, Logical: the disk file will be copied to a new file with a modified name (e.g. "disk.img" -> "disk-clone1.img") on the same storage pool. * SCSI, iSCSI: the volume data will be copied as a new disk file on the storage pool "default".
REST API
Only one new REST command will be added.
Syntax
POST /vms//<vm-name>//clone
Parameters:
None.
Return:
An asynchronous Task with "target_uri" containing "/vms/</new-vm-name/>". As expected with any Task, the cloning process can be tracked by checking the corresponding task's status.
Discussion
I think the most challenging part of this feature is how to deal with different types of disks while not prompting the user with any input. There are a lot of possibilities and a lot of things that can go wrong during the disks copy but we still need to do whatever is easier for the user. For example, do we really have to create the new disks in the same storage pool as the original disk's? If that's not possible (e.g. not available space), should we create them in another pool with available space? Should we ask any input from the user (e.g. "Would you like to create the new disk on the same storage pool or on a different one?")? What about the *SCSI pool types, is it OK to copy the volume data to a different storage pool (i.e. "default") like I'm proposing here? I couldn't think of a way to add a new volume in an existing pool of those types. How about making the *SCSI volumes shareable between the original and the new VMs? I don't like that approach because then both VMs will use the same disk, whatever is changed in one VM is also changed in the other one, and that's not a clone for me, that's a "hardlink".
Any feedback is welcome!
Best regards, Crístian.
_______________________________________________ Kimchi-devel mailing list Kimchi-devel@ovirt.org http://lists.ovirt.org/mailman/listinfo/kimchi-devel
_______________________________________________ Kimchi-devel mailing list Kimchi-devel@ovirt.org http://lists.ovirt.org/mailman/listinfo/kimchi-devel
_______________________________________________ Kimchi-devel mailing list Kimchi-devel@ovirt.org http://lists.ovirt.org/mailman/listinfo/kimchi-devel
-- Yun Tong Jin, Simon Linux Technology Center, Open Virtualization project IBM Systems & Technology Group jinyt@cn.ibm.com, Phone: 824549654
{kind=link}
{kind=link}
participants (7)
-
 Aline Manera
Aline Manera -
 Brent Baude
Brent Baude -
 Christy Perez
Christy Perez -
 Crístian Viana
Crístian Viana -
 Royce Lv
Royce Lv -
 simonjin
simonjin -
 Yu Xin Huo
Yu Xin Huo