
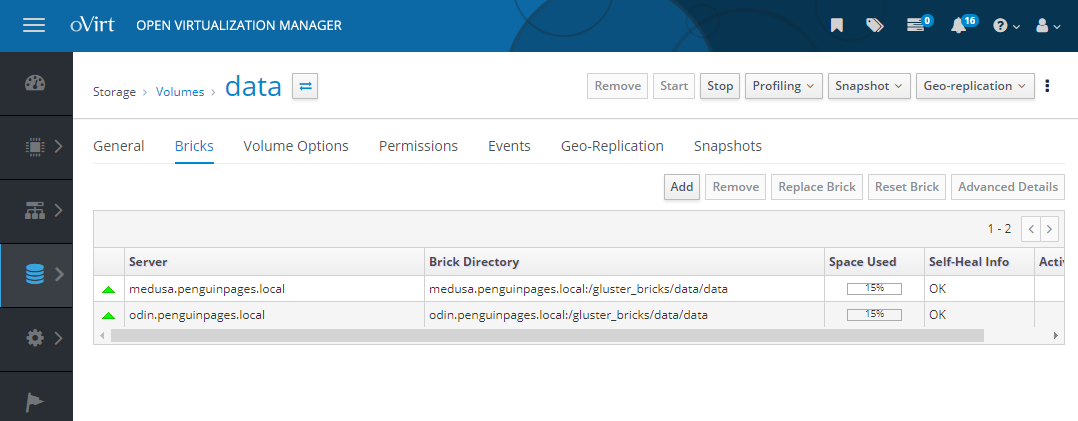
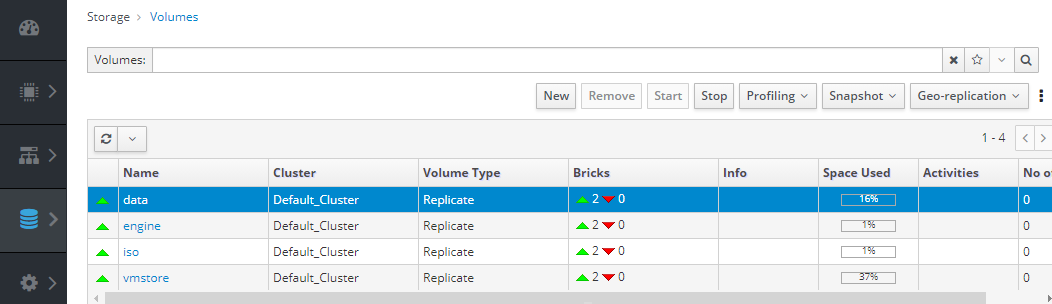
Its like oVirt thinks there are only two nodes in gluster replication [image: image.png] [image: image.png] # Yet it is clear the CLI shows three bricks. [root@medusa vms]# gluster volume status vmstore Status of volume: vmstore Gluster process TCP Port RDMA Port Online Pid ------------------------------------------------------------------------------ Brick thorst.penguinpages.local:/gluster_br icks/vmstore/vmstore 49154 0 Y 9444 Brick odinst.penguinpages.local:/gluster_br icks/vmstore/vmstore 49154 0 Y 3269 Brick medusast.penguinpages.local:/gluster_ bricks/vmstore/vmstore 49154 0 Y 7841 Self-heal Daemon on localhost N/A N/A Y 80152 Self-heal Daemon on odinst.penguinpages.loc al N/A N/A Y 141750 Self-heal Daemon on thorst.penguinpages.loc al N/A N/A Y 245870 Task Status of Volume vmstore ------------------------------------------------------------------------------ There are no active volume tasks How do I get oVirt to re-establish reality to what Gluster sees? On Tue, Sep 22, 2020 at 8:59 AM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Also in some rare cases, I have seen oVirt showing gluster as 2 out of 3 bricks up , but usually it was an UI issue and you go to UI and mark a "force start" which will try to start any bricks that were down (won't affect gluster) and will wake up the UI task to verify again brick status.
https://github.com/gluster/gstatus is a good one to verify your cluster health , yet human's touch is priceless in any kind of technology.
Best Regards, Strahil Nikolov
В вторник, 22 септември 2020 г., 15:50:35 Гринуич+3, Jeremey Wise < jeremey.wise@gmail.com> написа:
when I posted last.. in the tread I paste a roling restart. And... now it is replicating.
oVirt still showing wrong. BUT.. I did my normal test from each of the three nodes.
1) Mount Gluster file system with localhost as primary and other two as tertiary to local mount (like a client would do) 2) run test file create Ex: echo $HOSTNAME >> /media/glustervolume/test.out 3) repeat from each node then read back that all are in sync.
I REALLY hate reboot (restart) as a fix. I need to get better with root cause of gluster issues if I am going to trust it. Before when I manually made the volumes and it was simply (vdo + gluster) then worst case was that gluster would break... but I could always go into "brick" path and copy data out.
Now with oVirt.. .and LVM and thin provisioning etc.. I am abstracted from simple file recovery.. Without GLUSTER AND oVirt Engine up... all my environment and data is lost. This means nodes moved more to "pets" then cattle.
And with three nodes.. I can't afford to loose any pets.
I will post more when I get cluster settled and work on those wierd notes about quorum volumes noted on two nodes when glusterd is restarted.
Thanks,
Replication issue could mean that one of the client (FUSE mounts) is not attached to all bricks.
You can check the amount of clients via: gluster volume status all client-list
As a prevention , just do a rolling restart: - set a host in maintenance and mark it to stop glusterd service (I'm reffering to the UI) - Activate the host , once it was moved to maintenance
Wait for the host's HE score to recover (silver/gold crown in UI) and
On Tue, Sep 22, 2020 at 8:44 AM Strahil Nikolov <hunter86_bg@yahoo.com> wrote: then proceed with the next one.
Best Regards, Strahil Nikolov
В вторник, 22 септември 2020 г., 14:55:35 Гринуич+3, Jeremey Wise <
jeremey.wise@gmail.com> написа:
I did.
Here are all three nodes with restart. I find it odd ... their has been
a set of messages at end (see below) which I don't know enough about what oVirt laid out to know if it is bad.
####### [root@thor vmstore]# systemctl status glusterd ● glusterd.service - GlusterFS, a clustered file-system server Loaded: loaded (/usr/lib/systemd/system/glusterd.service; enabled;
vendor preset: disabled)
Drop-In: /etc/systemd/system/glusterd.service.d └─99-cpu.conf Active: active (running) since Mon 2020-09-21 20:32:26 EDT; 10h ago Docs: man:glusterd(8) Process: 2001 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS) Main PID: 2113 (glusterd) Tasks: 151 (limit: 1235410) Memory: 3.8G CPU: 6min 46.050s CGroup: /glusterfs.slice/glusterd.service ├─ 2113 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO ├─ 2914 /usr/sbin/glusterfs -s localhost --volfile-id shd/data -p /var/run/gluster/shd/data/data-shd.pid -l /var/log/glusterfs/glustershd.log -S /var/run/gluster/2f41374c2e36bf4d.socket --xlator-option *replicate*.node-uu> ├─ 9342 /usr/sbin/glusterfsd -s thorst.penguinpages.local --volfile-id data.thorst.penguinpages.local.gluster_bricks-data-data -p /var/run/gluster/vols/data/thorst.penguinpages.local-gluster_bricks-data-data.pid -S /var/r> ├─ 9433 /usr/sbin/glusterfsd -s thorst.penguinpages.local --volfile-id engine.thorst.penguinpages.local.gluster_bricks-engine-engine -p /var/run/gluster/vols/engine/thorst.penguinpages.local-gluster_bricks-engine-engine.p> ├─ 9444 /usr/sbin/glusterfsd -s thorst.penguinpages.local --volfile-id vmstore.thorst.penguinpages.local.gluster_bricks-vmstore-vmstore -p /var/run/gluster/vols/vmstore/thorst.penguinpages.local-gluster_bricks-vmstore-vms> └─35639 /usr/sbin/glusterfsd -s thorst.penguinpages.local --volfile-id iso.thorst.penguinpages.local.gluster_bricks-iso-iso -p /var/run/gluster/vols/iso/thorst.penguinpages.local-gluster_bricks-iso-iso.pid -S /var/run/glu>
Sep 21 20:32:24 thor.penguinpages.local systemd[1]: Starting GlusterFS, a clustered file-system server... Sep 21 20:32:26 thor.penguinpages.local systemd[1]: Started GlusterFS, a clustered file-system server. Sep 21 20:32:28 thor.penguinpages.local glusterd[2113]: [2020-09-22 00:32:28.605674] C [MSGID: 106003] [glusterd-server-quorum.c:348:glusterd_do_volume_quorum_action] 0-management: Server quorum regained for volume data. Starting lo> Sep 21 20:32:28 thor.penguinpages.local glusterd[2113]: [2020-09-22 00:32:28.639490] C [MSGID: 106003] [glusterd-server-quorum.c:348:glusterd_do_volume_quorum_action] 0-management: Server quorum regained for volume engine. Starting > Sep 21 20:32:28 thor.penguinpages.local glusterd[2113]: [2020-09-22 00:32:28.680665] C [MSGID: 106003] [glusterd-server-quorum.c:348:glusterd_do_volume_quorum_action] 0-management: Server quorum regained for volume vmstore. Starting> Sep 21 20:33:24 thor.penguinpages.local glustershd[2914]: [2020-09-22 00:33:24.813409] C [rpc-clnt-ping.c:155:rpc_clnt_ping_timer_expired] 0-data-client-0: server 172.16.101.101:24007 has not responded in the last 30 seconds, discon> Sep 21 20:33:24 thor.penguinpages.local glustershd[2914]: [2020-09-22 00:33:24.815147] C [rpc-clnt-ping.c:155:rpc_clnt_ping_timer_expired] 2-engine-client-0: server 172.16.101.101:24007 has not responded in the last 30 seconds, disc> Sep 21 20:33:24 thor.penguinpages.local glustershd[2914]: [2020-09-22 00:33:24.818735] C [rpc-clnt-ping.c:155:rpc_clnt_ping_timer_expired] 4-vmstore-client-0: server 172.16.101.101:24007 has not responded in the last 30 seconds, dis> Sep 21 20:33:36 thor.penguinpages.local glustershd[2914]: [2020-09-22 00:33:36.816978] C [rpc-clnt-ping.c:155:rpc_clnt_ping_timer_expired] 3-iso-client-0: server 172.16.101.101:24007 has not responded in the last 42 seconds, disconn> [root@thor vmstore]# [root@thor vmstore]# [root@thor vmstore]# [root@thor vmstore]# [root@thor vmstore]# [root@thor vmstore]# [root@thor vmstore]# [root@thor vmstore]# [root@thor vmstore]# [root@thor vmstore]# [root@thor vmstore]# [root@thor vmstore]# [root@thor vmstore]# [root@thor vmstore]# systemctl restart glusterd [root@thor vmstore]# systemctl status glusterd ● glusterd.service - GlusterFS, a clustered file-system server Loaded: loaded (/usr/lib/systemd/system/glusterd.service; enabled; vendor preset: disabled) Drop-In: /etc/systemd/system/glusterd.service.d └─99-cpu.conf Active: active (running) since Tue 2020-09-22 07:24:34 EDT; 2s ago Docs: man:glusterd(8) Process: 245831 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS) Main PID: 245832 (glusterd) Tasks: 151 (limit: 1235410) Memory: 3.8G CPU: 132ms CGroup: /glusterfs.slice/glusterd.service ├─ 2914 /usr/sbin/glusterfs -s localhost --volfile-id shd/data -p /var/run/gluster/shd/data/data-shd.pid -l /var/log/glusterfs/glustershd.log -S /var/run/gluster/2f41374c2e36bf4d.socket --xlator-option *replicate*.node-u> ├─ 9342 /usr/sbin/glusterfsd -s thorst.penguinpages.local --volfile-id data.thorst.penguinpages.local.gluster_bricks-data-data -p /var/run/gluster/vols/data/thorst.penguinpages.local-gluster_bricks-data-data.pid -S /var/> ├─ 9433 /usr/sbin/glusterfsd -s thorst.penguinpages.local --volfile-id engine.thorst.penguinpages.local.gluster_bricks-engine-engine -p /var/run/gluster/vols/engine/thorst.penguinpages.local-gluster_bricks-engine-engine.> ├─ 9444 /usr/sbin/glusterfsd -s thorst.penguinpages.local --volfile-id vmstore.thorst.penguinpages.local.gluster_bricks-vmstore-vmstore -p /var/run/gluster/vols/vmstore/thorst.penguinpages.local-gluster_bricks-vmstore-vm> ├─ 35639 /usr/sbin/glusterfsd -s thorst.penguinpages.local --volfile-id iso.thorst.penguinpages.local.gluster_bricks-iso-iso -p /var/run/gluster/vols/iso/thorst.penguinpages.local-gluster_bricks-iso-iso.pid -S /var/run/gl> └─245832 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO
Sep 22 07:24:34 thor.penguinpages.local systemd[1]: Starting GlusterFS, a clustered file-system server... Sep 22 07:24:34 thor.penguinpages.local systemd[1]: Started GlusterFS, a clustered file-system server. [root@thor vmstore]# gluster volume status Status of volume: data Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick thorst.penguinpages.local:/gluster_br icks/data/data 49152 0 Y 9342 Brick odinst.penguinpages.local:/gluster_br icks/data/data 49152 0 Y 3231 Brick medusast.penguinpages.local:/gluster_ bricks/data/data 49152 0 Y 7819 Self-heal Daemon on localhost N/A N/A Y 245870 Self-heal Daemon on odinst.penguinpages.loc al N/A N/A Y 2693 Self-heal Daemon on medusast.penguinpages.l ocal N/A N/A Y 7863
Task Status of Volume data
------------------------------------------------------------------------------
There are no active volume tasks
Status of volume: engine Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick thorst.penguinpages.local:/gluster_br icks/engine/engine 49153 0 Y 9433 Brick odinst.penguinpages.local:/gluster_br icks/engine/engine 49153 0 Y 3249 Brick medusast.penguinpages.local:/gluster_ bricks/engine/engine 49153 0 Y 7830 Self-heal Daemon on localhost N/A N/A Y 245870 Self-heal Daemon on odinst.penguinpages.loc al N/A N/A Y 2693 Self-heal Daemon on medusast.penguinpages.l ocal N/A N/A Y 7863
Task Status of Volume engine
------------------------------------------------------------------------------
There are no active volume tasks
Status of volume: iso Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick thorst.penguinpages.local:/gluster_br icks/iso/iso 49155 49156 Y 35639 Brick odinst.penguinpages.local:/gluster_br icks/iso/iso 49155 49156 Y 21735 Brick medusast.penguinpages.local:/gluster_ bricks/iso/iso 49155 49156 Y 21228 Self-heal Daemon on localhost N/A N/A Y 245870 Self-heal Daemon on odinst.penguinpages.loc al N/A N/A Y 2693 Self-heal Daemon on medusast.penguinpages.l ocal N/A N/A Y 7863
Task Status of Volume iso
------------------------------------------------------------------------------
There are no active volume tasks
Status of volume: vmstore Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick thorst.penguinpages.local:/gluster_br icks/vmstore/vmstore 49154 0 Y 9444 Brick odinst.penguinpages.local:/gluster_br icks/vmstore/vmstore 49154 0 Y 3269 Brick medusast.penguinpages.local:/gluster_ bricks/vmstore/vmstore 49154 0 Y 7841 Self-heal Daemon on localhost N/A N/A Y 245870 Self-heal Daemon on odinst.penguinpages.loc al N/A N/A Y 2693 Self-heal Daemon on medusast.penguinpages.l ocal N/A N/A Y 7863
Task Status of Volume vmstore
There are no active volume tasks
[root@thor vmstore]# ls /gluster_bricks/vmstore/vmstore/ example.log f118dcae-6162-4e9a-89e4-f30ffcfb9ccf ns02_20200910.tgz [root@thor vmstore]#
### VS nodes that are listed as "ok"
[root@odin vmstore]# systemctl status glusterd ● glusterd.service - GlusterFS, a clustered file-system server Loaded: loaded (/usr/lib/systemd/system/glusterd.service; enabled; vendor preset: disabled) Drop-In: /etc/systemd/system/glusterd.service.d └─99-cpu.conf Active: active (running) since Mon 2020-09-21 20:41:31 EDT; 11h ago Docs: man:glusterd(8) Process: 1792 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS) Main PID: 1818 (glusterd) Tasks: 149 (limit: 409666) Memory: 1.0G CPU: 7min 13.719s CGroup: /glusterfs.slice/glusterd.service ├─ 1818 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO ├─ 2693 /usr/sbin/glusterfs -s localhost --volfile-id shd/data -p /var/run/gluster/shd/data/data-shd.pid -l /var/log/glusterfs/glustershd.log -S /var/run/gluster/3971f0a4d5e2fd53.socket --xlator-option *replicate*.node-uu> ├─ 3231 /usr/sbin/glusterfsd -s odinst.penguinpages.local --volfile-id data.odinst.penguinpages.local.gluster_bricks-data-data -p /var/run/gluster/vols/data/odinst.penguinpages.local-gluster_bricks-data-data.pid -S /var/r> ├─ 3249 /usr/sbin/glusterfsd -s odinst.penguinpages.local --volfile-id engine.odinst.penguinpages.local.gluster_bricks-engine-engine -p /var/run/gluster/vols/engine/odinst.penguinpages.local-gluster_bricks-engine-engine.p> ├─ 3269 /usr/sbin/glusterfsd -s odinst.penguinpages.local --volfile-id vmstore.odinst.penguinpages.local.gluster_bricks-vmstore-vmstore -p /var/run/gluster/vols/vmstore/odinst.penguinpages.local-gluster_bricks-vmstore-vms> └─21735 /usr/sbin/glusterfsd -s odinst.penguinpages.local --volfile-id iso.odinst.penguinpages.local.gluster_bricks-iso-iso -p /var/run/gluster/vols/iso/odinst.penguinpages.local-gluster_bricks-iso-iso.pid -S /var/run/glu>
Sep 21 20:41:28 odin.penguinpages.local systemd[1]: Starting GlusterFS, a clustered file-system server... Sep 21 20:41:31 odin.penguinpages.local systemd[1]: Started GlusterFS, a clustered file-system server. Sep 21 20:41:34 odin.penguinpages.local glusterd[1818]: [2020-09-22 00:41:34.478890] C [MSGID: 106003] [glusterd-server-quorum.c:348:glusterd_do_volume_quorum_action] 0-management: Server quorum regained for volume data. Starting lo> Sep 21 20:41:34 odin.penguinpages.local glusterd[1818]: [2020-09-22 00:41:34.483375] C [MSGID: 106003] [glusterd-server-quorum.c:348:glusterd_do_volume_quorum_action] 0-management: Server quorum regained for volume engine. Starting > Sep 21 20:41:34 odin.penguinpages.local glusterd[1818]: [2020-09-22 00:41:34.487583] C [MSGID: 106003] [glusterd-server-quorum.c:348:glusterd_do_volume_quorum_action] 0-management: Server quorum regained for volume vmstore. Starting> [root@odin vmstore]# systemctl restart glusterd [root@odin vmstore]# systemctl status glusterd ● glusterd.service - GlusterFS, a clustered file-system server Loaded: loaded (/usr/lib/systemd/system/glusterd.service; enabled; vendor preset: disabled) Drop-In: /etc/systemd/system/glusterd.service.d └─99-cpu.conf Active: active (running) since Tue 2020-09-22 07:50:52 EDT; 1s ago Docs: man:glusterd(8) Process: 141691 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS) Main PID: 141692 (glusterd) Tasks: 134 (limit: 409666) Memory: 1.0G CPU: 2.265s CGroup: /glusterfs.slice/glusterd.service ├─ 3231 /usr/sbin/glusterfsd -s odinst.penguinpages.local --volfile-id data.odinst.penguinpages.local.gluster_bricks-data-data -p /var/run/gluster/vols/data/odinst.penguinpages.local-gluster_bricks-data-data.pid -S /var/> ├─ 3249 /usr/sbin/glusterfsd -s odinst.penguinpages.local --volfile-id engine.odinst.penguinpages.local.gluster_bricks-engine-engine -p /var/run/gluster/vols/engine/odinst.penguinpages.local-gluster_bricks-engine-engine.> ├─ 3269 /usr/sbin/glusterfsd -s odinst.penguinpages.local --volfile-id vmstore.odinst.penguinpages.local.gluster_bricks-vmstore-vmstore -p /var/run/gluster/vols/vmstore/odinst.penguinpages.local-gluster_bricks-vmstore-vm> ├─ 21735 /usr/sbin/glusterfsd -s odinst.penguinpages.local --volfile-id iso.odinst.penguinpages.local.gluster_bricks-iso-iso -p /var/run/gluster/vols/iso/odinst.penguinpages.local-gluster_bricks-iso-iso.pid -S /var/run/gl> └─141692 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO
Sep 22 07:50:49 odin.penguinpages.local systemd[1]: Starting GlusterFS, a clustered file-system server... Sep 22 07:50:52 odin.penguinpages.local systemd[1]: Started GlusterFS, a clustered file-system server. Sep 22 07:50:52 odin.penguinpages.local glusterd[141692]: [2020-09-22 11:50:52.964585] C [MSGID: 106003] [glusterd-server-quorum.c:348:glusterd_do_volume_quorum_action] 0-management: Server quorum regained for volume data. Starting > Sep 22 07:50:52 odin.penguinpages.local glusterd[141692]: [2020-09-22 11:50:52.969084] C [MSGID: 106003] [glusterd-server-quorum.c:348:glusterd_do_volume_quorum_action] 0-management: Server quorum regained for volume engine. Startin> Sep 22 07:50:52 odin.penguinpages.local glusterd[141692]: [2020-09-22 11:50:52.973197] C [MSGID: 106003] [glusterd-server-quorum.c:348:glusterd_do_volume_quorum_action] 0-management: Server quorum regained for volume vmstore. Starti> lines 1-23/23 (END) [root@odin vmstore]# ls /gluster_bricks/vmstore/vmstore/ example.log f118dcae-6162-4e9a-89e4-f30ffcfb9ccf ns02_20200910.tgz ns02.qcow2 ns02_var.qcow2 [root@odin vmstore]# ################## [root@medusa sw2_usb_A2]# [root@medusa sw2_usb_A2]# systemctl status glusterd ● glusterd.service - GlusterFS, a clustered file-system server Loaded: loaded (/usr/lib/systemd/system/glusterd.service; enabled; vendor preset: disabled) Drop-In: /etc/systemd/system/glusterd.service.d └─99-cpu.conf Active: active (running) since Mon 2020-09-21 20:31:29 EDT; 11h ago Docs: man:glusterd(8) Process: 1713 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS) Main PID: 1718 (glusterd) Tasks: 153 (limit: 409064) Memory: 265.5M CPU: 10min 10.739s CGroup: /glusterfs.slice/glusterd.service ├─ 1718 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO ├─ 7819 /usr/sbin/glusterfsd -s medusast.penguinpages.local --volfile-id data.medusast.penguinpages.local.gluster_bricks-data-data -p /var/run/gluster/vols/data/medusast.penguinpages.local-gluster_bricks-data-data.pid -S > ├─ 7830 /usr/sbin/glusterfsd -s medusast.penguinpages.local --volfile-id engine.medusast.penguinpages.local.gluster_bricks-engine-engine -p /var/run/gluster/vols/engine/medusast.penguinpages.local-gluster_bricks-engine-en> ├─ 7841 /usr/sbin/glusterfsd -s medusast.penguinpages.local --volfile-id vmstore.medusast.penguinpages.local.gluster_bricks-vmstore-vmstore -p /var/run/gluster/vols/vmstore/medusast.penguinpages.local-gluster_bricks-vmsto> ├─ 7863 /usr/sbin/glusterfs -s localhost --volfile-id shd/data -p /var/run/gluster/shd/data/data-shd.pid -l /var/log/glusterfs/glustershd.log -S /var/run/gluster/709d753e1e04185a.socket --xlator-option *replicate*.node-uu> └─21228 /usr/sbin/glusterfsd -s medusast.penguinpages.local --volfile-id iso.medusast.penguinpages.local.gluster_bricks-iso-iso -p /var/run/gluster/vols/iso/medusast.penguinpages.local-gluster_bricks-iso-iso.pid -S /var/r>
Sep 21 20:31:29 medusa.penguinpages.local glusterd[1718]: [2020-09-22 00:31:29.352090] C [MSGID: 106002] [glusterd-server-quorum.c:355:glusterd_do_volume_quorum_action] 0-management: Server quorum lost for volume engine. Stopping lo> Sep 21 20:31:29 medusa.penguinpages.local systemd[1]: Started GlusterFS, a clustered file-system server. Sep 21 20:31:29 medusa.penguinpages.local glusterd[1718]: [2020-09-22 00:31:29.352297] C [MSGID: 106002] [glusterd-server-quorum.c:355:glusterd_do_volume_quorum_action] 0-management: Server quorum lost for volume vmstore. Stopping l> Sep 21 20:32:29 medusa.penguinpages.local glusterd[1718]: [2020-09-22 00:32:29.104708] C [MSGID: 106003] [glusterd-server-quorum.c:348:glusterd_do_volume_quorum_action] 0-management: Server quorum regained for volume data. Starting > Sep 21 20:32:29 medusa.penguinpages.local glusterd[1718]: [2020-09-22 00:32:29.125119] C [MSGID: 106003] [glusterd-server-quorum.c:348:glusterd_do_volume_quorum_action] 0-management: Server quorum regained for volume engine. Startin> Sep 21 20:32:29 medusa.penguinpages.local glusterd[1718]: [2020-09-22 00:32:29.145341] C [MSGID: 106003] [glusterd-server-quorum.c:348:glusterd_do_volume_quorum_action] 0-management: Server quorum regained for volume vmstore. Starti> Sep 21 20:33:24 medusa.penguinpages.local glustershd[7863]: [2020-09-22 00:33:24.815657] C [rpc-clnt-ping.c:155:rpc_clnt_ping_timer_expired] 0-data-client-0: server 172.16.101.101:24007 has not responded in the last 30 seconds, disc> Sep 21 20:33:24 medusa.penguinpages.local glustershd[7863]: [2020-09-22 00:33:24.817641] C [rpc-clnt-ping.c:155:rpc_clnt_ping_timer_expired] 2-engine-client-0: server 172.16.101.101:24007 has not responded in the last 30 seconds, di> Sep 21 20:33:24 medusa.penguinpages.local glustershd[7863]: [2020-09-22 00:33:24.821774] C [rpc-clnt-ping.c:155:rpc_clnt_ping_timer_expired] 4-vmstore-client-0: server 172.16.101.101:24007 has not responded in the last 30 seconds, d> Sep 21 20:33:36 medusa.penguinpages.local glustershd[7863]: [2020-09-22 00:33:36.819762] C [rpc-clnt-ping.c:155:rpc_clnt_ping_timer_expired] 3-iso-client-0: server 172.16.101.101:24007 has not responded in the last 42 seconds, disco> [root@medusa sw2_usb_A2]# systemctl restart glusterd [root@medusa sw2_usb_A2]# systemctl status glusterd ● glusterd.service - GlusterFS, a clustered file-system server Loaded: loaded (/usr/lib/systemd/system/glusterd.service; enabled; vendor preset: disabled) Drop-In: /etc/systemd/system/glusterd.service.d └─99-cpu.conf Active: active (running) since Tue 2020-09-22 07:51:46 EDT; 2s ago Docs: man:glusterd(8) Process: 80099 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS) Main PID: 80100 (glusterd) Tasks: 146 (limit: 409064) Memory: 207.7M CPU: 2.705s CGroup: /glusterfs.slice/glusterd.service ├─ 7819 /usr/sbin/glusterfsd -s medusast.penguinpages.local --volfile-id data.medusast.penguinpages.local.gluster_bricks-data-data -p /var/run/gluster/vols/data/medusast.penguinpages.local-gluster_bricks-data-data.pid -S > ├─ 7830 /usr/sbin/glusterfsd -s medusast.penguinpages.local --volfile-id engine.medusast.penguinpages.local.gluster_bricks-engine-engine -p /var/run/gluster/vols/engine/medusast.penguinpages.local-gluster_bricks-engine-en> ├─ 7841 /usr/sbin/glusterfsd -s medusast.penguinpages.local --volfile-id vmstore.medusast.penguinpages.local.gluster_bricks-vmstore-vmstore -p /var/run/gluster/vols/vmstore/medusast.penguinpages.local-gluster_bricks-vmsto> ├─21228 /usr/sbin/glusterfsd -s medusast.penguinpages.local --volfile-id iso.medusast.penguinpages.local.gluster_bricks-iso-iso -p /var/run/gluster/vols/iso/medusast.penguinpages.local-gluster_bricks-iso-iso.pid -S /var/r> ├─80100 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO └─80152 /usr/sbin/glusterfs -s localhost --volfile-id shd/data -p /var/run/gluster/shd/data/data-shd.pid -l /var/log/glusterfs/glustershd.log -S /var/run/gluster/709d753e1e04185a.socket --xlator-option *replicate*.node-uu>
Sep 22 07:51:43 medusa.penguinpages.local systemd[1]: This usually indicates unclean termination of a previous run, or service implementation deficiencies. Sep 22 07:51:43 medusa.penguinpages.local systemd[1]: glusterd.service: Found left-over process 7863 (glusterfs) in control group while starting unit. Ignoring. Sep 22 07:51:43 medusa.penguinpages.local systemd[1]: This usually indicates unclean termination of a previous run, or service implementation deficiencies. Sep 22 07:51:43 medusa.penguinpages.local systemd[1]: glusterd.service: Found left-over process 21228 (glusterfsd) in control group while starting unit. Ignoring. Sep 22 07:51:43 medusa.penguinpages.local systemd[1]: This usually indicates unclean termination of a previous run, or service implementation deficiencies. Sep 22 07:51:43 medusa.penguinpages.local systemd[1]: Starting GlusterFS, a clustered file-system server... Sep 22 07:51:46 medusa.penguinpages.local systemd[1]: Started GlusterFS, a clustered file-system server. Sep 22 07:51:46 medusa.penguinpages.local glusterd[80100]: [2020-09-22 11:51:46.789628] C [MSGID: 106003] [glusterd-server-quorum.c:348:glusterd_do_volume_quorum_action] 0-management: Server quorum regained for volume data. Starting> Sep 22 07:51:46 medusa.penguinpages.local glusterd[80100]: [2020-09-22 11:51:46.807618] C [MSGID: 106003] [glusterd-server-quorum.c:348:glusterd_do_volume_quorum_action] 0-management: Server quorum regained for volume engine. Starti> Sep 22 07:51:46 medusa.penguinpages.local glusterd[80100]: [2020-09-22 11:51:46.825589] C [MSGID: 106003] [glusterd-server-quorum.c:348:glusterd_do_volume_quorum_action] 0-management: Server quorum regained for volume vmstore. Start> [root@medusa sw2_usb_A2]# ls /gluster_bricks/vmstore/vmstore/ example.log f118dcae-6162-4e9a-89e4-f30ffcfb9ccf isos media ns01_20200910.tgz ns02_20200910.tgz ns02.qcow2 ns02_var.qcow2 qemu
As for files... there is replication issues. Not really sure how bricks show ok but it is not replicating
On Tue, Sep 22, 2020 at 2:38 AM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Have you restarted glusterd.service on the affected node. glusterd is just management layer and it won't affect the brick
Best Regards, Strahil Nikolov
В вторник, 22 септември 2020 г., 01:43:36 Гринуич+3, Jeremey Wise <
jeremey.wise@gmail.com> написа:
Start is not an option.
It notes two bricks. but command line denotes three bricks and all
------------------------------------------------------------------------------ processes. present
[root@odin thorst.penguinpages.local:_vmstore]# gluster volume status
data
Status of volume: data Gluster process TCP Port RDMA Port Online Pid
Brick thorst.penguinpages.local:/gluster_br icks/data/data 49152 0 Y 33123 Brick odinst.penguinpages.local:/gluster_br icks/data/data 49152 0 Y 2970 Brick medusast.penguinpages.local:/gluster_ bricks/data/data 49152 0 Y 2646 Self-heal Daemon on localhost N/A N/A Y 3004 Self-heal Daemon on thorst.penguinpages.loc al N/A N/A Y 33230 Self-heal Daemon on medusast.penguinpages.l ocal N/A N/A Y 2475
Task Status of Volume data
There are no active volume tasks
[root@odin thorst.penguinpages.local:_vmstore]# gluster peer status Number of Peers: 2
Hostname: thorst.penguinpages.local Uuid: 7726b514-e7c3-4705-bbc9-5a90c8a966c9 State: Peer in Cluster (Connected)
Hostname: medusast.penguinpages.local Uuid: 977b2c1d-36a8-4852-b953-f75850ac5031 State: Peer in Cluster (Connected) [root@odin thorst.penguinpages.local:_vmstore]#
On Mon, Sep 21, 2020 at 4:32 PM Strahil Nikolov <hunter86_bg@yahoo.com> wrote:
Just select the volume and press "start" . It will automatically mark "force start" and will fix itself.
Best Regards, Strahil Nikolov
В понеделник, 21 септември 2020 г., 20:53:15 Гринуич+3, Jeremey Wise < jeremey.wise@gmail.com> написа:
oVirt engine shows one of the gluster servers having an issue. I did a graceful shutdown of all three nodes over weekend as I have to move around some power connections in prep for UPS.
Came back up.. but....
And this is reflected in 2 bricks online (should be three for each volume)
Command line shows gluster should be happy.
[root@thor engine]# gluster peer status Number of Peers: 2
Hostname: odinst.penguinpages.local Uuid: 83c772aa-33cd-430f-9614-30a99534d10e State: Peer in Cluster (Connected)
Hostname: medusast.penguinpages.local Uuid: 977b2c1d-36a8-4852-b953-f75850ac5031 State: Peer in Cluster (Connected) [root@thor engine]#
# All bricks showing online [root@thor engine]# gluster volume status Status of volume: data Gluster process TCP Port RDMA Port Online Pid
Brick thorst.penguinpages.local:/gluster_br icks/data/data 49152 0 Y 11001 Brick odinst.penguinpages.local:/gluster_br icks/data/data 49152 0 Y 2970 Brick medusast.penguinpages.local:/gluster_ bricks/data/data 49152 0 Y 2646 Self-heal Daemon on localhost N/A N/A Y 50560 Self-heal Daemon on odinst.penguinpages.loc al N/A N/A Y 3004 Self-heal Daemon on medusast.penguinpages.l ocal N/A N/A Y 2475
Task Status of Volume data
There are no active volume tasks
Status of volume: engine Gluster process TCP Port RDMA Port Online Pid
Brick thorst.penguinpages.local:/gluster_br icks/engine/engine 49153 0 Y 11012 Brick odinst.penguinpages.local:/gluster_br icks/engine/engine 49153 0 Y 2982 Brick medusast.penguinpages.local:/gluster_ bricks/engine/engine 49153 0 Y 2657 Self-heal Daemon on localhost N/A N/A Y 50560 Self-heal Daemon on odinst.penguinpages.loc al N/A N/A Y 3004 Self-heal Daemon on medusast.penguinpages.l ocal N/A N/A Y 2475
Task Status of Volume engine
There are no active volume tasks
Status of volume: iso Gluster process TCP Port RDMA Port Online Pid
Brick thorst.penguinpages.local:/gluster_br icks/iso/iso 49156 49157 Y 151426 Brick odinst.penguinpages.local:/gluster_br icks/iso/iso 49156 49157 Y 69225 Brick medusast.penguinpages.local:/gluster_ bricks/iso/iso 49156 49157 Y 45018 Self-heal Daemon on localhost N/A N/A Y 50560 Self-heal Daemon on odinst.penguinpages.loc al N/A N/A Y 3004 Self-heal Daemon on medusast.penguinpages.l ocal N/A N/A Y 2475
Task Status of Volume iso
There are no active volume tasks
Status of volume: vmstore Gluster process TCP Port RDMA Port Online Pid
Brick thorst.penguinpages.local:/gluster_br icks/vmstore/vmstore 49154 0 Y 11023 Brick odinst.penguinpages.local:/gluster_br icks/vmstore/vmstore 49154 0 Y 2993 Brick medusast.penguinpages.local:/gluster_ bricks/vmstore/vmstore 49154 0 Y 2668 Self-heal Daemon on localhost N/A N/A Y 50560 Self-heal Daemon on medusast.penguinpages.l ocal N/A N/A Y 2475 Self-heal Daemon on odinst.penguinpages.loc al N/A N/A Y 3004
Task Status of Volume vmstore
There are no active volume tasks
[root@thor engine]# gluster volume heal data engine iso vmstore [root@thor engine]# gluster volume heal data info Brick thorst.penguinpages.local:/gluster_bricks/data/data Status: Connected Number of entries: 0
Brick odinst.penguinpages.local:/gluster_bricks/data/data Status: Connected Number of entries: 0
Brick medusast.penguinpages.local:/gluster_bricks/data/data Status: Connected Number of entries: 0
[root@thor engine]# gluster volume heal engine Launching heal operation to perform index self heal on volume engine has been successful Use heal info commands to check status. [root@thor engine]# gluster volume heal engine info Brick thorst.penguinpages.local:/gluster_bricks/engine/engine Status: Connected Number of entries: 0
Brick odinst.penguinpages.local:/gluster_bricks/engine/engine Status: Connected Number of entries: 0
Brick medusast.penguinpages.local:/gluster_bricks/engine/engine Status: Connected Number of entries: 0
[root@thor engine]# gluster volume heal vmwatore info Volume vmwatore does not exist Volume heal failed. [root@thor engine]#
So not sure what to do with oVirt Engine to make it happy again.
-- penguinpages _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/RRHEVF2STA5EVJ...
-- jeremey.wise@gmail.com _______________________________________________ Users mailing list -- users@ovirt.org To unsubscribe send an email to users-leave@ovirt.org Privacy Statement: https://www.ovirt.org/privacy-policy.html oVirt Code of Conduct: https://www.ovirt.org/community/about/community-guidelines/ List Archives: https://lists.ovirt.org/archives/list/users@ovirt.org/message/ZFVGMWRMELRGEE...
-- jeremey.wise@gmail.com
-- jeremey.wise@gmail.com
-- jeremey.wise@gmail.com
{kind=link}
{kind=link}