
On Tue, Jul 12, 2022 at 9:02 AM David Johnson <djohnson@maxistechnology.com> wrote:
Good morning all,
I am trying to get the best performance out of my cluster possible,
Here are the details of what I have now:
Ovirt version: 4.4.10.7-1.el8 Bare metal for the ovirt engine two hosts TrueNAS cluster storage 1 NFS share 3 vdevs, 6 drives in raidz2 in each vdev 2 nvme drives for silog Storage network is 10 GBit all static IP addresses
Tonight, I built a new VM from a template. It had 5 attached disks totalling 100 GB. It took 30 minutes to deploy the new VM from the template.
Global utilization was 9%. The SPM has 50% of its memory free and never showed more than 12% network utilization
62 out of 65 TB are available on the newly created NFS backing store (no fragmentation). The TureNAS system is probably overprovisioned for our use.
There were peak throughputs of up to 4 GBytes/second (on a 10 GBit network), but overall throughput on the NAS and the network were low. ARC hits were 95 to 100% L2 hits were 0 to 70%
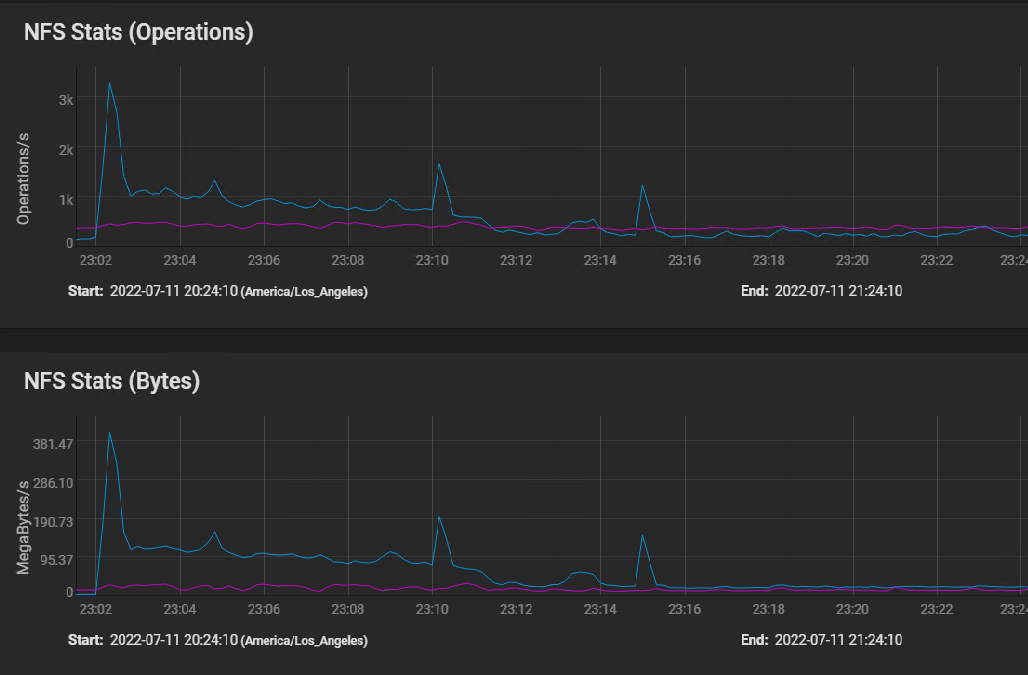
Here's the NFS usage stats: [image: image.png]
I believe the first peak is where the silog buffered the initial burst of instructions, followed by sustained IO as the VM volumes were built in parallel, and then finally tapering off to the one 50 GB volume that took 40 minutes to copy.
The indications of the NFS stats graph are that the network performance is just fine.
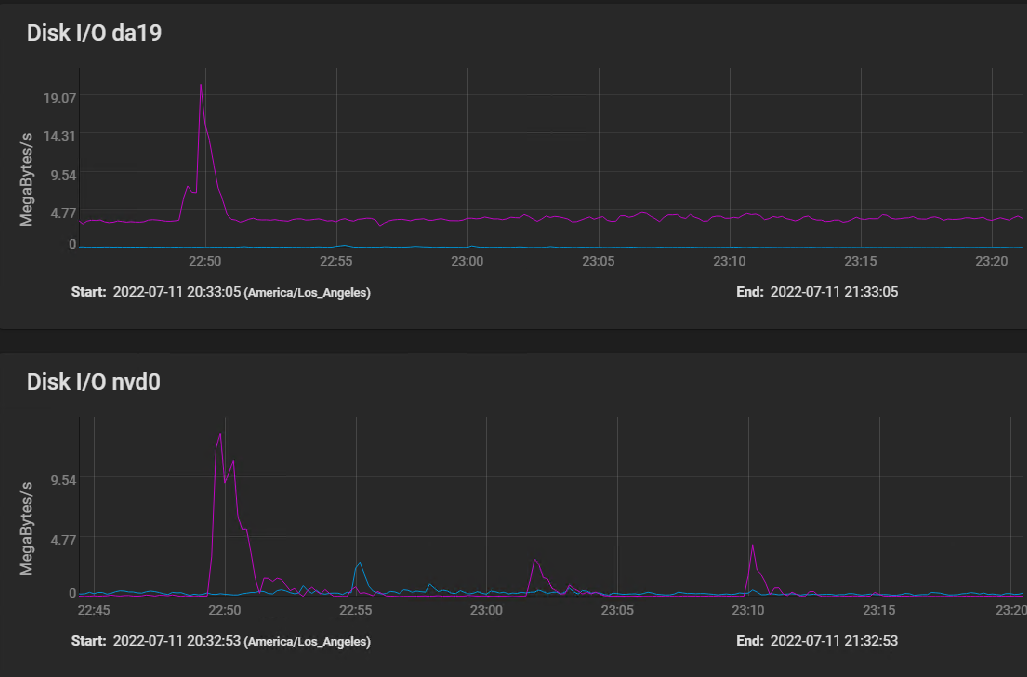
Here are the disk IO stats covering the same time frame, plus a bit before to show a spike IO:
[image: image.png] The spike at 2250 (10 minutes before I started building my VM) shows that the spinners actually hit write speed of almost 20 MBytes per second briefly, then settled in at a sustained 3 to 4 MBytes per second. The silog absorbs several spikes, but remains mostly idle, with activity measured in kilobytes per second.
The HGST HUS726060AL5210 drives boast a spike throughput of 12 GB/S, and sustained throughput of 227 Mbps.
------ Now to the questions: 1. Am I asking the on the right list? Does this look like something where tuning ovirt might make a difference, or is this more likely a configuration issue with my storage appliances?
2. Am I expecting too much? Is this well within the bounds of acceptable (expected) performance?
3. How would I go about identifying the bottleneck, should I need to dig deeper?
One thing that can be interesting to try to to apply this patch for vdsm: diff --git a/lib/vdsm/storage/sd.py b/lib/vdsm/storage/sd.py index 36c393b5a..9cb7486c0 100644 --- a/lib/vdsm/storage/sd.py +++ b/lib/vdsm/storage/sd.py @@ -401,7 +401,7 @@ class StorageDomainManifest(object): Unordered writes improve copy performance but are recommended only for preallocated devices and raw format. """ - return format == sc.RAW_FORMAT and not self.supportsSparseness + return True @property def oop(self): This enables unordered writes for qemu-img convert, which can be up to 6 times faster on block storage. When we tested it with file storage it did not give lot of improvement, but this was tested a long time ago, and since then we use unordered writes everywhere else in the system. Another thing to try is NFS 4.2, which can be much faster when coping images, since it supports sparseness. But I don't think TrueNAS supports NFS 4.2 yet (in 12.x they did not). If you must work with older NFS, using qcow2 disks will be much faster when copying disks (e.g. create vm from template). The way to get qcow2 disks is to check "enable incremental backup" when creating disks. Nir
{kind=link}
{kind=link}