
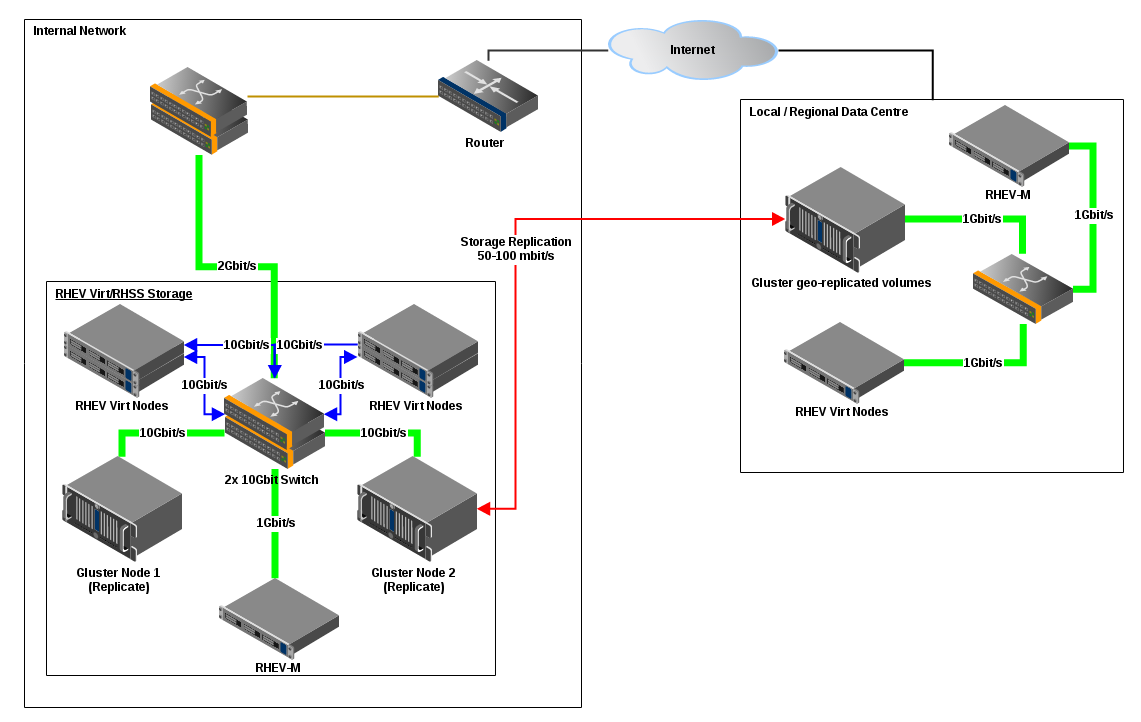
Hello all, I'm looking for some opinions on our current topology and how a disaster recovery plan would shake out in the real world on an ovirt/gluster clustered system. Please ignore the RH references in the attached diagram, we're still on the fence if we're going with support or not. [image: Inline image 1] The Plan At HQ site: Two Gluster nodes running as replica's. ~4 Virt notes 1 Manager node (likely running on as separate kvm HA VM) Offsite: 1 Gluster node acting as a geo-replication target 1 Virt node 1 Manager in standby (waiting to recover db backup) *Even better would be using both nodes at this site as one striped gluster volume, standby Manager, and Virt nodes to eliminate the standby Manager box, decrease costs and increase virt resources, but I'm not sure this is doable quite yet.* During regular operations we're replicating our gluster storage offsite with geo-replication. In the event of a disaster (for simplicity we'll say the server room becomes unusable) I would want to recover the Manager at the offsite location from a backup, add the geo-replicated gluster storage domain as the normal domain, then start spinning up the business critical VM's. With a router in-place and some external DNS changes we should be able to keep our VPN accessible and all our internal resources available to mobile/home workers, or in this simple case even from our normal office location (already have the site-to-site VPN active). I'm planning on using a vpls solution to extend the VM subnet and storage/virt subnet across both sites so we don't need to worry about dns/IP changes in the middle of recovery. I think the biggest question so far is can we smoothly replace the normal storage domain on ovirt with the geo-replicated storage domain in the DR situation off-site? I've tried to layout most of the high level stuff here so if anyone sees any flaws or potential gotcha's feel free to chime in. I can provide more detail if necessary. Thanks! *Steve *
{kind=link}